УДК 621.391
Рассмотрены
современныэ
тенденции
развития систем
автоматического
распознавания
и синтеза речевых
сигналов. Освещены
проблемы построения
алгоритмов
распознавания
в неадаптивных
системах речевого
управления.
Описаны эксперименты
по созданию
систем автоматического
речевого запроса
экономической
информации
с элементами
автоматического
обучения.
Книга рассчитана
на научных
работников,
инженеров и
студентов,
специализирующихся
по технической
кибернетике
и теории информации.
Работу рецензировали
и рекомендовали
к изданию:
академик
АН СССР А.А.Дородницын
кандидат
физико-математических
наук М.Н.Маричук©
Издательство
"Штиинца",1985 г.
О I5Q3000000 - 62
39-85 M755(I2) - 85
ВВЕДЕНИЕ
Проблема
реализации
речевого диалога
человека и
технических
средств - актуальная
задача современной
кибернетики.
В настоящее
время пользователями
вычислительных
машин и средств,
оснащенных
вычислительными
машинами, становятся
люди, не являющиеся
специалистами
в области
программирования.
Особенно актуальной
стала задача
общения человека
и ЭВМ с появлением
микропроцессоров
и больших
интегральных
схем. Новая
технология
оказала прогрессивное
влияние на
психологию
как разработчиков
современных
многопроцессорных
ЭВМ .так и
неспециалистов-пользователей,не
подготовленных
к тому, чтобы
пользоваться
сложной функциональной
клавиатурой,
языком программирования,
комплексными
средствами
управления
техникой. Проблема
речевого управления
возникла, кроме
того,в связи
с тем, что в
некоторых
областях применения
речь стада
единственно
возможным
средством
оощения с техникой
(в условиях
перегрузок,
темноты или
резкого изменения
освещенности,при
занятости
рук, чрезвычайной
сосредоточенности
внимания на
объекте, который
не позволяет
отвлечься ни
на секунду, и
т.д.).
Массовое
внедрение
различных
бытовых технических
средств, содержащих
микропроцессоры
и другие большие
интегральные
схемы, в частности,
сложных микрокалькуляторов,
пег-зональных
ЭВМ, также требует
упрощения,
"демократизации"
систем управления
такими средствами.
Мы должны
пользоваться
новой сложной
техникой так
же, как
пользуемся
часами,
радиоприемником,
стиральной
машиной.Приближается
время, когда
будут созданы
"механические
слуги" человека
- роботы, помогающие
в быту, выполняющие
работу по уборке
помещения,
оказывающие
помощь в
сельскохозяйственных
и строительных
работах и т.д.
Безусловно,
человек будет
заинтересован
в голосовом
управлении
сложной бытовой
техникой и в
конечном счете
такими роботами.
Ближайшие
перспективы
развития
вычислительной
техники, создание
высокопроизводительных
ЭВМ пятого
поколения,
надеденных
способностью
анализировать
зрительные
и звуковые
образы, также
3
требуют того,
чтобы задачи
автоматического
распознавания
и синтеза речевых
сигналов не
оставались
без внимания.
Невозможно
предположить,
чтобы вычислительные
системы обладали
производительностью
в десятки и
сотни миллионов
операций в
секунду и в
качестве вводных
устройств
использовали
традиционную
клавиатуру
дисплея, перфоленты
или перфокарты.
В первой главе
рассматривается
современное
состояние
автоматического
распознавания
и синтеза речевых
сигналов (по
публикациям
до 1981 г. включительно).
Отмечается
возрастающий
поток публикаций
по этим проблемам,
причем многие
работы посвящены
вопросам
практического
построения
систем распознавания
и синтеза речи
на специализированных
микроЭВМ. В
настоящей
монографии
не нашли отражение
работы, опубликованные
после 1981 г., так
как материалы
к публикации
готовились
в основном до
бтого времени.
(южно лишь отметить,
что за 1982 и 1983 гг.
практическое
направление
работ в области
автоматического
распознавания
и синтеза речи
интенсифицировалось.
В нашей стране
появились
первые промышленные
системы автоматического
ввода/вывода
речевой информации
- "ИКАР", разработанная
в НИИСчетмаше
(г.Москва),
СРД-1,изготовленная
в ОКБ Института
кибернетики
АН УССР им.
В.М.Глушко-ва,
и Марс, созданная
Минским отделением
ЦНИИС. Эти
системы,широко
демонстрировавшиеся
на ВДНХ и других
промышленных
выставках,
обладают примерно
сходными техническими
характеристиками
-они обучаются,
настраиваются
на голос конкретного
пользователя
и словарь,
достигающий
йОО слов, и
обеспечивают
точность
распознавания
около 95& и реальное
время распознавания.
В качестве
метода, обеспечивающего
нелинейное
сравнение
входных реализации
и эталонов,
используется
динамическое
программирование.
Большие успехи
в области создания
систем такого
рода достигнуты
также в QUA и Японии.
В США с 1982 г. начал
выходить специальный
журнал Speech Technology
(Речевая технология),
в котором
описываются
области применения
промыиленных
систем распознавания
и синтеза речи,
их тестирование,
технические
характеристики
и технологические
особенности.
В монографии
основное внимание
уделяется
описанию систем
распознавания
речи, работающих
без предварительной
настройки на
диктора. Авторы
в течение ряда
лет совместно
работали над
этой проблемой
в Вычислительном
центре Академии
наук СССР.Идеология
неадаптивных
систем распознавания
сложилась еще
в 60-е гг.-в совместных
разработках
Вычислительного
центра и Института
проблем передачи
информации
АН СССР. Но основные
результаты,
описанные в
книге, получены
авторами в
конце 70-х - начале
80-х гг.
Глава 1
СОВРЕМЕННЫЕ
ТЕНДЕНЦИИ
РАЗВИТИЯ ПРОБЛЕМЫ
РЕЧЕВОГО
ВЗАИМОДЕЙСТВИЯ
«ЧЕЛС ВЕК - ЭВМ»
§ I.I. Некоторые
аспекты исследования
речевых сигналов
на современном
этапе
В 70-х гг. повысился
интерес к проблемам
исследования
речи. Это связано
с возросшими
успехами дискретной
обработки
сигналов на
современной
микроэлектронной
технике и широким
распространением
микроЭВМ и
мультимикроцессорньк
систем, появление
которых означало
революцию в
информатике.
Научные достижения
в области
автоматического
распознавания
и синтеза речи
поставили
вопрос о практическом
общении человека
с миром мощных
по своей производительности
и возможностям
микроЭВМ
на языке,
близком к
естественному.
Сложнейшая
техника приблизилась
к пользователю-неспециалисту,
и пользователь
"потребовал",
чтобы общение
о ЭВМ (в частности,
с информационными
и управляющими
ЭВМ) производилось
на более привычном
ему естественном
языке.
В связи с
этим привлекли
внимание работы
по созданию
первых промышленных
устройств
ограниченного
речевого ввода
и вывода информации,
а также достаточно
широко разрекламированных
систем автоматического
понимания
естественной,
слитной речи,
над которыми
работали в
ОДА в течение
I972-I976 гг. по проекту
айра.
Следует
отметить, что
автоматическое
распознавание
и синтез речи
- не единственное
в речевых
исследованиях,
что привлекает
внимание специалистов
и возможных
потребителей.
Наряду с
автоматическим
распознаванием
смысла сообщения
и синтезом
речи (проблемами,
которым в основном
и посвящена
настоящая
монография),
исследователи
речевых сигналов
успешно решают
задачи: автоматического
распознавания
личности говорящего
(т.е. решают задачу,
кто это сказал),
автоматической
верификации
говорящего
(подтверждение,
тот ли конкретный
человек произнес
эту фразу), оценки
по голосу
эмоционального
состояния
оператора,распознавания
речи, произносимой
в другой воздушной
среде (гелиевая
речь), определения
по речевому
сигналу патологии
органов речеобразования,
разработки
более совершенных
методов преподавания
иностранных
языков (выработка
правильного
акцента и интонации
по картине
"эталонных"
параметров
речевого сигнала
), помощи лицам
с дефектами
органов слуха
и речеобразования,
очистки и анализа
затупленной
речи, создания
систем узкополосной
помехоустойчивой
связи, а также
ряд других
задач. Рассмотрение
всех этих проблем
не входило в
планы авторов,
которые ограничиваются
здесь простым
их перечислением.
В данной
главе кратко
рассматриваются
основные публикации
по проблемам
автоматического
распознавания
и синтеза речи,
появившиеся
в I976-I98I гг. Сведения
о более ранних
работах в этой
области можно
получить из
[58,79,8б].
В СЮ9] приводятся
основные лаборатории
США, Великобритании,
Франции и Западной
Германии, тематика
которых связана
с автоматическим
распознаванием
и синтезом
речи. В [127] сообщается,
что проблема
построения
машин, способных
воспринимать
речь человека
(желательно
с использованием
пра' л естественного
языка), остается
главным направлением
речевых исследований,
одной из ключевых
проблем кибернетики.
В [144] отмечается
возрастающий
интерес к этой
проблеме, связанный
с увеличением
спроса
на малые
устройства
распознавания
слов и появлением
новых компаний,
активно участвующих
в создании
промышленных
систем автоматического
распознавания
речи на новой
технологической
базе.
В нашей стране
наблюдается
широкий интерес
к проблеме
исследования
речевых сигналов.
Регулярно
проводятся
всесоюзные
школы-семинары
по проблеме
автоматического
распознавания
слуховых образов
(APGO). В каждой союзной
республике
существуют
лаборатории
или группы,
решающие эти
задачи.
Стало традиционным
классифицировать
системы автоматического
распознавания
речи на адаптивные,
работающие
с подстройкой
под диктора
и словарь, и
неадаптивные,
обеспечивающие
работу с произвольным
диктором-носителем
нормы произношения
данного языка.
К практическим
системам первого
типа относятся
vip- юо, WRS и ИКАР,
СРД-1, МАРС, к
неадаптивным
- экспериментальные
системы лаборатории
Bell, ВЦ и ИППИ АН
СССР, устройство
фирмы Dialog Systems . Следует
отметить, что
системы автоматического
распознавания
речи пока не
получили широкого
распространения,
хотя и выпускаются
с 1973 г. серийно.
Более доведенными
до уровня
коммерческих
образцов являются
системы автоматического
речевого ответа,
т.е. системы,
основанные
на автоматическом
синтезе речи.
Промышленность
США и Японии
выпускает
большими партиями
синтезаторы
речи, ориэнтированные
на самое разнообразное
применение,
- от детских
игрушек,оснащенных
голосовым
выводом, до
мощных информационных
систем, отвечающих
голосом по
речевому запросу
пользователя.
В основе современных
б
коммерческих
систем речевого
ответа лежат
три основных
способа синтеза
- непосредственное
кодирование
речевой волны
(дискретизация
и сжатие), формантный
синтез и синтез,
основанный
на линейном
предсказании
[5]. (Подробное
описание достижений
науки и промышленности
в области
автоматического
синтеза речи
дано
в § 1.4).
В пятой главе
подробно
рассматриваются
особенности
разработанной
авторами
экспериментальной
запросной
системы речевого
ввода, работающей
с проблемно-ориентированным
языком, словарный
запас которого
составляет
120 слов. Система
базируется
на аппаратурно-программном
методе распознавания,
использующем
информативные
признаки речевых
отрезков ^23,13,9?].
§ I.
В середине
70~х гг. получили
распространение
системы распознавания
речи, предназначенные
для промышленного
использования.
Важнейшие
требования
к таким системам
- высокая точность
и реальное
время распознавания
высказывания.
Постепенно
стал накапливаться
опыт эксплуатации
подобных систем,
который определил
их дальнейшее
развитие. Первые
практические
системы автоматического
речевого ввода
информации
обладали рядом
положительных
свойств, необходимых
для пользователей.
Мартин [&8] отмечает,
что к таким
свойствам можно
отнести мобильность
и возможность
совмещения
работ оператора,
гибкость словаря,
100% точность
распознавания
(при использовании
обратной связи),
стабильность
эталонных
данных и уверенность
оператора,
контактирующего
с системой,
обладающей
высокой точностью
распознавания.
Главными
недостатками
первых систем
можно считать
длительную
подстройку
под диктора
и словарь, малый
объем словаря,
отсутствие
помехозащищенности
от слов, не входящих
в рабочий словарь,
проблемы фонового
шума и шумов
дыхания, высокую
стоимость и
т.д.
Первым широко
внедренным
устройством
систем автоматического
речевого ввода
данных можно
считать vip-ioo, подробно
описанное в
[58,134] .
В [13б] отмечается
использование
VXP-100 в конфигурации
Threshold -500, которая
дает возможность
вводить информацию
голосом в ЭВМ
одновременно
трем операторам.
Указывается,что
средняя точность
распознавания
слов в этих
системах
колеблется
от 96,5 (для словаря
из 35 слов и высокого
уровня шумов)
до 99,5%
(для словаря
из 15 слов и тихого
помещения). В
[136] рассматривается
использование
vip - 100 для речевого
ввода информации
в ЭВМ станков
с программным
управлением.
Отмечается,
что для этих
целей разработаны
три специальные
систейн: vw - 50, vno- 100
и virc - 200 с использованием
соответственно
31 слова и слитного
словосочетания,
4Ь и 65 слов.
Системы VHC
-200 применяются
для управления
четырехшиин-дельными
сверлильными
станками и
лазерами,
iопользующимися
для обработки
полупроводников
и сверхтвердых
материалов,
а также для
управления
токарными
станками. Кроме
того, эта система
применяется
для взаимодействуя
с системой
искусственного
интеллекта
и управления
голосом.
Данная система
используется
для технической
диагностики
компрессоров
холодильных
установок и
при распределении
посылок.про-ходящих
по конвейеру
[П9].
й[П7] описывается
использование
одной из систем
фирмы Threshold Technology для
автоматического
ввода голосом
по телефону
гидрографических
данных исследования
морских акваторий.
Еще одной
американской
промышленной
системой
автоматического
распознавания
изолированных
слов является
v/RS [l40] . Система
предназначена
для практического
использования
в армии и обеспечивает
прямую двустороннюю
связь между
персоналом
на передней
линии фронта
и армейскими
информационными
системами,
использующими
автоматическое
распознавание
слов, идентификацию
диктора и его
верификацию
(подтверждение,
тот ли человек
разговаривает
с системой).
Мини-ЭВМ этой
армейской
системы полностью
обеспечивает
автоматизированную
обработку
сигналов в
реальном времени,
трансляцию
(т.е. автоматическое
распознавание)
сообщения и
синтезированный
речевой ответ
на три сети
связи одновременно
для любых трех
из 64 пользователей.
Рабочий словарь
системы 250 слов.
Полевой оператор-разведчик
оснащ'ен переносным
блоком записи
донесений для
точной записи
тактических
данных и возможного
ввода их по
радио или телефонным
линиям в армейскую
тактическую
информационную
систему. Для
удаленного
оператора
используются
передатчики
с частотной
модуляцией.
Система распознавания
слов таз, воспринимая
дискретные
речевые сообщения
(фразы, произносимые
в жестком формате
пословно),
"подсказывает"
оператору на
каждом шаге,
какого рода
информацию
ждет она от
него далее,
предварительно
подтвердив
правильную
запись предыцущего
донесения.
Жесткий формат
фраз определяется
специализированным
языком точного
описания тактических
условий в поле
деятельности
оператора и
управления
артиллерийским
огнем.
Для голосового
ответа в «'/КЗ
используется
программно-управляемый
звуковой синтезатор
фирмы Vocal Interf;ice Division,
который позволяет
получать цепочки
фонем и фонемоподобных
звуков в соответствии
со смыслом
речевого ответа;
при этом обеспечивается
необходимая
модуляция
основного тона
для большей
естественности
звучания. Если
какой-либо
оператор хочет
ввести в армейскую
тактическую
информационную
систему донесение
после того,
как
wrs обучалась
его речевьм
характеристикам,
он должен
обнаружить
канал связи,
а затем ввести
шесть слов,
представляющих'
шифр (код) используемой
сети, код пользователя
и слова завершения.
Хотя система
распознавания
способна работать
автоматически,
на стороне v/RS
всегда присутствует
оператор. Он
следит за экраном
буквенно-цифрового
дисплея, где
отражаются
донесения,поступающие
с трех линий
связи. По мере
распознавания
донесений
появляется
их буквенный
текст. Если
донесения
полностью
удовлетворяют
оператора, он
передает их
для исполнения
(и для получения
"твердой копии"
на бумаге), нажимая
на пульте
соответствующую
клавишу. Оператор
может с пульта
отредактировать
любое . донесение,
прежде чем
выдать его
для исполнения.
Оператор может
также с пульта
управления
в тобой момент
связаться по
радио или телефонному
каналу с каждым
разведчиком-пользователем
(или со всеми
сразу). Если
при распознавании
донесения,
поступающего
от пользователя,
возникают
трудности, то
оператор должен
сделать вое.
чтобы донесение
было принято.
Для этого он
может,например,переучить
систему на
голос этого
пользователя.
Автономный
блок системы,
предназначенный
для связи с
пользователями,
возбуждается
без вмешательства
оператора при
одном из трех
"условий":
а) распознано
слово "оператор";
б) последовательно
прошло неверное
распознание
двух слов подряд;
в) во время
трансляции
шифра диктор
идентифицирован
как злоумышленник
.
Точность
распознавания
слов превышает
95% при передаче
речи по несекретной
радиолинии
с отношением
сигнад/шум,
равным 10 дБ. При
использовании
более совершенной
радиолинии
точность,трансляции
донесения
достигала 9'?%.
Зак.480
В 1977г. Оыло
выпущено устройство
Heuristics $299 Speuchlab, требующее
ддя реализации
системы распознавания
дополнительной
ЭВМ. Точность
распознавания
слов в системах,
использующих
это устройство,
была относительно
низкой (около
90%), однако из-за
невысокой
стоимости оно
оказалось в
настоящее
время наиболее
распространенным.
В 19УО г. этой же
фирмой была
выпущена система
7000, соединенная
со стандартными
видеотерминальными
RS -232 [903 • Система,
выпускаемая
в автономном
корпусе, включает
цифровой
спектроанализатор
и блок распознавания.
Она может быть
обучена распознаванию
64 слов или фраз,
длительность
аву-чания
каждой из которых
до 3 с.
Система 7000
дает возможность
вводить информацию
голосом в ЭВМ,
не набирая ее
на клавиатуре
видеотерминала,
однако позволяет
также пользоваться
клавиатурой
(по очереди или
одновременно).
В [69J сообщается,
что фирмой
Interstate Electronics Inc. выпускается
сходный по
техническим
характеристикам
с системой
7000 одноплатный
модуль распознавания
речи VRK - Voice recognition module,
реализованный
на базе микропроцессора
и представляющий
"интеллектуальным"
терминалам
и небольшим
вычислительным
системам средства
автоматического
речевого ввода.
Отмечается,
что 'это устройство
обеспечивает
распознавания
более 99% при
вариантах с
объемом словаря
в 40, 70 или 100 слов.
На входе устройства
используется
16-канальный
аналоговый
спектроанализатор,
информация
с которого
далее преобразуется
в цифровую
форму и уплотняется
до размера
эталонов, хранящихся
в памяти van .В
настоящее время
фирма выпускает
одноплатное
устройство
распознавания
слов vrt-зоо, которое
полностью
позволяет
дублировать
клавишную
систему управления
видеоматериалом.
В [45J рассматриваются
вопросы использования
устройств
автоматического
распознавания
и синтеза речи
в системах
военного назначения.
Указывается,
что в настоящее
время автоматический
анализ и синтез
речи испытывается
в тренажерах
для подготовки
специалистов
(например, летчиков
или диспетчеров
управления
воздушным
движением), а
также в устройствах
ддя автоматизации
ввода данных
в ЭВМ при дешифрации
аэрофотоснимков
в процессе
составления
карт местности.
Предполагается,
что в перспективе
устройства
распознавания
речи будут
использоваться
для ввода команд
в систему оружия
или в систему
управления
полетом.О
необходимости
заполнить
пробел между
относительно
простыми,,
настраивающимися
на диктора и
словарь, промышленными
устройствами
автоматического
распознавания
речи и громоздкими
экспериментальными
сис-
10
темами понимания
речи, основанными
на моделях
естественных
языков, Ли и
Шоуп писали
еще в [ 144] .
Одной из
самых совершенных
коммерческих
систем автоматического
распознавания
речи является
система распознавания
изолированных
слов и слитной
речи CSRS японской
фирмы NEC [47] . Технологической
базой этой
системы служит
микропроцессорная
техника. (В системе
используются
пять микропроцессоров.)
CSRS обеспечивает
надежное
автоматическое
распознавание
в действительно
шумных
средах ^до 90 дБ)
с 0,2% ошибок и
0,7^, отказов
на материале
120 слов. Система
csrs , как и vip -100 и wrs,
является адаптивной,
настраиваемой
на диктора и
словарь. При
распознавании
слитно произносимых
словосочетаний
(до пяти слов
одновре-* менно)
система использует
методику
распознавания,
основанную
на так называемом
двухступенчатом
согласовании
эталонных
реализации
и входной
последовательности
словосочетаний
с использованием
аи-г 'итмов
динамического
программирования.
Блок автоматического
распознавания
включает цифровой
анализатор
спектра, преобразующий
входной сигнал,
который поступает
с АЦП в 46-мерные
векторы через
каждые 18 мс, память
эталонных
реализации,позволяющих
хранить до 120
эталонов слов,
процессор
динамического
программирования
, представляющий
собой мультимикропроцессорную
ЭВМ, и интерфейсную
микроЭВМ,
обеспечивающую
управление
всей системой.gsrs
осуществляет
распознавание
практически
в реальном
масштабе времени.
Систему можно
приспособить,
несколько
изменив программу
динамического
согласования
эталонов и
выходного
высказывания,
для распознавания
1000 слов, произносимых
изолированно.
На выставке
в Москве (декабрь
1976 г.) демонстрировалась
система gsrs ,
позволяющая
подключать
к одному блоку
двух пользователей,
работающих
одновременно
в режиме диалога
с csrs [29]» За счет
более совершенного
распознавания
система обеспечивает
более простое
обучение, допуская
одно- или двукратное
произнесение
каждого слова.
В [16] рассматривается
отечественная
система,предназначенная
для распознавания
набора слов,
число которых
около 400.Сяо-варь
представлен
в памяти фонемными
кодами, что
позволяет после
этапа подстройки
системы -юд
диктора (сводящейся
к однократному
произнесению
специального
словаря, содержащего
фонемы русского
языка в различных
словосочетаниях)
заменять,корректировать
и пополнять
словарь без
участия диктора.
В системе
используется'пять
параметров
речевого сигнала,
которые служат
цля распознавания
слов - логарифм
полной энергии
сигнала и логарифмы
отношения •
Полной энергии
сигнала к энергиям
сигнала в четырех
полосах.
II
Из-за использования
относительно
медленной
машины и чисто
программной
реализации
алгоритмов
анализа сигнала
время обработки
около I мин
на слово, время
принятия решения
~ W/8 с, где И - объем
словаря.
В более поздней
работе этого
же коллектива
рассматриваются
системы признаков,
основанные
на модеси линейного
предсказания
С 17] и психоакустическом
эффекте маскировки
более схабых
составляющих
речевого сигнала
более сильными.При
использовании
данного подхода
точность
распознавания
изолированных
слов для одного
диктора составила
при лексиконе
из 100 слов - 97%,а при
лексиконе из
300 первых слов
русского частотного
словаря - 94^.
В Институте
кибернетики
АН УССР в 1977 г.
разработана
адаптивная
система распознавания
слов, работающая
в реальном
масштабе времени
[1б] . Система
создана на
основе ЭВМ
БЭСМ-6, но может
быть реализована
на других ЭВМ
или в специализированном
устройстве
на микропроцессорах.
В процессе
предварительной
обработки
речевого сигнала
вычисляется
последовательность
48-разрядных
двоичных кодов,
каждый из которых
определяет
знак производной
по частоте
амплитудного
спектра речи,
вычисленных
на участках
в 15 мс. Обработка
введенного
речевого сигнала
длительностью
I с происходит
за 0,3 с, время
распознавания
одного слова
для словаря
из 100 слов - не
более I с. Точность
распознавания
словаря из
500 слов - 98%. Методика
принятия решения
в системе более
подробно рассмотрена
в С20].
В [21] описывается
разработанная
в ИК АН УССР
система распознавания
речи, настроенная
на голос нескольких
дикторов и
обеспечивающая
надежность
распознавания
изолированных
слов около
98^ для словаря
из 500 слов.
Интересная
адаптивная
система распознавания
изолированных
слов, использующая
параметры
клиппироваяного
речевого сигнала,
разработана
Н.П.Бусленко,
В.В. Деевым и
Г.Д.Фроловым
[8].В этой системе
для формирования
эталонов и
автоматического
распознавания
предложен
оригинальный
математический
подход к анализу
последовательности
чисел, соответствующей
интервалам
между нулевыми
перечислениями
сигнала. Обобщенные
эталоны формируются
после нескольких
for 2 до Ь) произнесений
слова. При
распознавании
происходит
сравнение
поступившего
на вход слова
с этими эталонами.
В системе реализован
речевой ответ,
также основанный
на
формировании
клиппированного
речевого сигнала.
Ццеи,рассмотренные
в [в] , нашли свое
дальнейшее
развитие в
системе, реализованной
на мини-ЭВМ.
12
В ряде кибернетических
систем массового
пользования
целесообразно
использовать
автоматический
речевой ввод
без предварительной
настройки на
голос оператора.
В таких системах
распознавание
должно базироваться
на универсальных
фонологических
правилах, а в
дальнейшем
- на использовании
синтаксиса
и семантики
естественных
языков. Другой
путь построения
неадаптивных
систем распознавания
речи - сбор
эталонных
реализации
от большого
(до 500) числа дикторов,
кластеризация
эталонов и
использование
того факта,
что каждый
новый диктор
произносит
слова так, как
этр делал один
из тех дикторов,
который участвовал
в обучении
системы распознавания.
В настоящее
время не достигнуто
высокой точности
распознавания
слов в неадаптивных
системах (кроме
системы Dialog Systems ,
где весьма
небольшой
словарь и
используются
эталоны, полученные
от 500 дикторов).
Однако исследования,
проведенные
в этой области,
а также феномен
человека,
воспринимающего
слитную речь
произвольного
диктора без
предварительной
настройки на
его голос,
доказывают,
что технические
средства,направленные
на распознавание
речи любого
пользователя,
несомненно,
будут созданы.
Первой системой
автоматического
распознавания
речи, выпускаемой
нашей промышленностью,
стала адаптивная
микропроцессорная
система распознавания
изолированных
слов,разработанная
в НШЮчетмаше.Система
содержит блок
аналоговой
обработки
сигнала - предпроцессор
(он включает
микрофонный
усилитель,
16-канальный
спектроанализа-тор
с рабочей полосой
до Ь кГц, индикаторы
уровня основного
тона и огибающей,
блоки клиппирования,
наличия устной
команды, вторичной
обработки и
управления),
микропроцессор
К580ИК80, специализированную
подсистему
для вычисления
меры сходства
между входной
и эталонной
реализациями
слов, оперативное
запоминающее
устройство,
интерфейсный
блок и пульт
инженера-оператора
.Поток информации
о речевом сигнаде
(1250 байт в секунду)
поступает с
процессора
для последующей
обработки в
микроЭВМ, которая
одновременно
управляет
отдельными
узламг и блоками
всэй системы.
Следует отметить,
что система
[72J по своей структуре
и возможностям
занимает
промежуточное
положение между
коммерческими
системами V
IP-100 (США) и dp фирмы
яёс (Япония).От
VIP-IOO наши разработчики
позаимствовали
бинарное
представление
информации
о слове на уровне
вторичной
обработки
сигнала, а от
системы нес
- использование
динамического
программирования
при нелинейном
сравнении
входной и эталонной
реализации.
Такой подход
позволил производить
распознавание
в реальном
масштабе времени
и с высокой
надежностью,
используя
отечественную
элементную
13
базу. Для
обучения новому
словарю требуется
однократное
произнесение
каждого слова.
Надежность
распознавания
для группы из
четырех дикторов,
каждый из которых
работал со
своим словарем,превысила
96%; время распознавания
для словаря
из 200 слов - близкое
к реальному
(не превышающее
1с).
В [б33 описано
автономное
адаптивное
устройство
распознавания
ограниченного
набора слов,
разработанное
во Всесоюзном
сельскохозяйственном
институте
заочного образования.
Устройство
выполнено на
базе микросхем
155-й серии и состоит
из 16 плат размером
140 х 150 мм. На вход
устройства
с аппаратуры
первичного
анализа подаются
16 бинарных
признаков,
один аналоговый,
представленный
четырехразряд
очным двоичным
кодом, и признак
конца речевого
сигнала. Память
устройства
вмещает до 256
отсчетов эталонов
сигнала. Речевая
информация
поступает для
последующей
обработки с
частотой 100 Гц,
но в дальнейшем
сжимается (в
среднем до
16 отсчетов на
слово) так, что
в память можно
записать лишь
16 эталонов.
Нелинейное
сравнение с
эталоном
осуществляется
методом динамического
программирования.
Устройство
[вз] может работать
в двух режимах
- обучения и
распознавания.Точность
распознавания
(для одного
диктора) зависит
от словаря,
объем которого
не превышает
16 слов, и колеблется
в пределах
96-99%.
Система [l] ,
разработанная
в МВТУ им. Н.Э.Баумана
и ориентированная
на речевое
управление
движущимися
объектами,
была испытана
десятью дикторами
на словарях
иг 32 слов и слитных
словосочетаний
на русском,
английском
и немецком
языках ( каждый
диктор имел
свои эталоны).На
материале 3200
реализации
было получено
9Ё% правильных
ответов, 1%
отказов от
распознавания
и 1% ошибок.
Система позволяла
работать в
трех режимах
- обучения,
распознавания
и управления.
В режиме речевого
управления
словарь включал
всего 14 слов;
надежность
распознавания
команд управления
составила при
этом 99,5№.
Интересная
адаптивная
система распознавания
и синтеза речи
была разработана
на устройстве
аналогового
типа и ЭВМ ЕС-1030
М.Г.Демковым
[35] . Словарь системы,
работающей
в близком к
реальному
времени, составлял
300 слов и словосочетаний.
В результате
аппаратной
и программной
обработки три
обучающие
реализации
каждого слова
преобразовались
в эталонную
последовательность
длиной в 10 - 20 символов.
Эксперименты
по определению
надежности
системы проводились
в условиях
акустических
шумов 75 -60 дБ на
голосе одного
оператора. При
однократном
произнесении
словаря в объеме
300 слов точность
распознавания
составляла
97,2%,при одном
повторении
- 98,6%, при двух
повторениях
ошибочно
распознанного
слова - 99,3%.
14
В [2b] сообщается,
что фирма Dialog
Systems (США) подготовила
к коммерческому
производству
первую неадаптивную
систему распознавания
слов, построенную
на бсль'"их
интегральных
схемах. Особенностью
этой системы
является метод
сравнения,
основанный
на анализе
большого
статистического
материала.
Эталонные
реализации
формировались
после изучения
500 образцов
произнесения
мужчинами и
женщинами
каждого словаря:
статистика
собиралась
по всей территории
США. Из каждого
слова берется
12 выборок;на
каждом отчете
измеряется
общая амплитуда
сигнала и вычисляется
спектр сигнала
в диапазоне
телефонного
канала(300 - 3400 Гц)
в 31 точке. Таким
образом, каидому
слову соответствует
384 числа. Обучающая
выборка включала
обработанные
реализации
500 слов. Неизвестное
слово, поступающее
на вход системы,
подвергается
такой же обработке
и сравнивается
с эталонами.
Система использует
речевой ответ.
Базовый словарь
состоит из
12, слов
- 10 цифр и слов
"да" и "нет".
Система позволяет
добавлять
специализированные
словари. Например,
для банковских
работников
предусмотрено
включение 30
дополнительных
слов, включая
такие, как
"баланс","итог",
"взнос". В [52]
сообщается,
что эта фирма
разработала
систему продажи
билетов на
самодеты,
откликающуюся
на голос любого
диктора. Однако
для нее возможны
и другие применения.
С ее помощью
служащий, находящийся
в другом городе,
легко может
вызвать любого
абонента внутренней
сети. Для этого
он набирает
номер коммутатора
фирмы, называет
свой идентификационный
номер и телефонный
номер, который
он хочет вызвать.
Система обрабатывает
устные команды
с точностью,
превышающей
95№.
В [102, 147, 146, 150, I6b - 168] описана
экспериментальная
система автоматического
распознавания
127 слов, произносимых
несколькими
дикторами.
Проблема особенностей
произношения
решается таким
образом, что
каждый диктор
имеет набор
своих эталонов,
поэтому в строгом
смысле слова
систему Bell Laboratories
нельзя считать
неадаптивной.
Словарь был
выбран с учетом
того, чтобы
произвольный
пользователь
мог заказывать
по телефону
билеты на
авиарейсы,
используя ЭВМ
с речевым вводом.
Отмечается,
что использование
синтаксиса
языка понижает
ошибки распознавания
слов с 11,7 до 0,4%/
В [170,172] рассматривается
распознавание
словаря, включающего
название английских
букв, цифры и
три служебных
слова редактирования
("стоп", "ошибк^.",
"повторяю").
Словарь позволяет
произносить
произвольные
слова, в частности
фамилии,по
буквам. При
испытаниях
системы, в которых
участвовали
шесть мужчин
и четыре женщины,
при средней
точности
распознавания
слов словаря
в
15
60% средняя
точность
распознавания
слов, произносимых
по буквам (50
случайных
фамилий сотрудников
Bell Laboratories ), составила
96%. Каждый диктор,
как и в [25] , имел
собственные
эталоны. В
[166,167] используется
около 12 эталонов
на каждое слово
словаря, причем
каждый эталон
характеризует
особенности
некоторой
группы дикторов.
Эталоны получаются
методом кластерного
анализа;
при этом
используется
100 обучающих
реализации
на каждое слово.
Точность
распознавания
10 цифр приближается
к точности их
распознавания
в адаптивных
системах и
колеблется
(для различных
дикторов) от
97,5 до 100%.
В [125] предлагается
для повышения
точности
распознавания
слов ввести
дополнительный
уровень
распознавания,
который автоматически
определяет
пол диктора
и уже дальнейшее
распознавание
производит
с учетом этого.
Введение
предварительного
автоматического
распознавания
пола диктора
повысило точность
распознавания
цифр.
В СССР проблеме
построения
неадаптивных
систем автоматического
распознавания
речи также
уделяется
большое внимание
[10,13,33, 38, 57, 66, 76, 77, 87, йб] . Как
правило, системы
работают с
проблемно-ориентированными
языками, словарный
запас которых
составляет
несколько
десятков словоформ
[40] . В [1.0,12] описана
опытная эксплуатация
одной из таких
систем. Сейчас
существуют
некоторые
промежуточные
экспериментальные
системы распознавания,
работающие
со множеством
дикторов, часть
из которых
можно отнести
к адаптивным,
например систему
МВТУ [l] .которая
по своей
идеологии
и принципам
близка к типичным
настраивающимся
на диктора
системам - лишь
память ЭВМ
ограничивает
число дикторов,
каждый из которых
имеет свою
систему эталонов.
Рассматриваемые
же ниже системы
обладают рядом
особенностей,
характеризующих
именно неадаптивные
системы: попытка
пользоваться
универсальными
признаками
фонем, использование
синтаксиса
и семантики
рабочего языка,
верификация
диктора до
того, как система
обратилась
к его эталонам,
и т.д. В этом смысле
к неадаптивным
системам
распознавания
речи можно
отнести две
интересные
системы распознавания
фраз, произносимых
с паузами между
словами. Эти
систрмы были
созданы в Институте
систем управления
АН ГрузССР.
Одна из этих
систем [ 77] была
предназначена
для оперативного
управления
объектами путем
распознавания
фраз-команд,
произносимых
предварительно
верифицированными
дикторами.
Ьможество фраз,
составленных
из 134 слов,включало
75 типовых синтаксических
конструкций.
Каждая фраза
содержала не
более 14 слов
и произносилась
полным стилем
с паузами между
словами. Параметрами
16
первичного
описания были:
энергия с 6 полосовых
фчльтров, дедек-торы
плотности
нулевых пересечений
сигнала, общая
энергия сигнала
и признак звонкости
- гдухости.
(Параметры
измерялись
и вводились
в память ЭВМ
каждые 20 мс.) На
первом этапе
анализа определялась
(по динамике
параметров
первичного
описания)
макро-временная
структура фразы
и слов. Полученная
грубая структура
кодировалась
и вместе с данными
о положении
локальных
максимумов
скорости изменения
значений параметров
первичного
описания служила
основой для
получения
посегментного
(кваэифонетичес-кого)
описания слов
во фразе. В
результате
каждое слово
фразы представлялось
в виде матрицы
чисел Ц3'17! > W
l•/•л-номера
соответственно
признака, сегмента
в слове и слова
во фразе.
Процесс
распознавания
слов начинался
с выбора эталонов
-претендентов,
идентичных
входной реализации,
и кодов макровре-ненной
структуры и
отличных от
нее числом
квазифонетичвских
сегментов на
величину не
более заданного
порога. Наиболее
вероятные пары
гипотез о слове
принимались
методом динамического
программирования.
При этом учитывались
лексические
ограничения
на место слова
во фразе. Далее
блок семантико-синтаксического
анализа принимал
решение об
истинной
последовательности
слов во фразе.
При работе с
шестью операторами
и обучении
системы на
каждом из них
надежность
распознавания
слов составила
8836,а надежность
распознавания
фраз за счет
блока лингвистического
анализа - 95%. Точность
верификации
диктора по
произвольной
фразе - 96%. Система
устойчива к
внешним шумам
до 65 дБ.
Другая система,
разработанная
в Институте
систем управления
АН ГрузССР,способна
работать при
более высоком
урочне шумов
(до 100 дБ и выше)
СЗб]. Основной
особенностью
этой системы
распознавания
фраз, произносимых
с паузами между
словами, было
наличие комплекса
помехозащищенных
датчиков, который
обеспечил
приемлемое
отношение
сигнал/шум на
входе системы
распознавания.
В качестве
приемника
речевой информации
применялся
ларингофон
ЛЭМ-3, а также
дополнительные
помехозащитные
признаки устной
речи, в качестве
которых использовались
артикуляционные
характеристики
ре-чеобразования.
Бесконтактные
датчики позволяли
выделять:
- признак,
отражающий
изменение
величины раствора
ротовой щели
во время произнесения
неогубя°нных
звуков;
- признак
степени огубяения;
- признак
скорости воздушного
потока у потового
отверстия
[42].
Зак.480
17
Изучение
свойств речевого
сигнала в
пространстве
выбранных
признаков
позволило
разработать
процедуру
описания слов,
обеспечивающую
восстановление
как макровременной
(имеется в виду
пос-хедовательность
звонких и глухих
участков, а
также пауз),так
и квазифонемной
структуры речи.
При испытании
систем [ЗЬ,??]
выявилась
высокая точность
распознавания
фраз. К сожалению,обе
системы реализованы
на ЭВМ Ы-200, обладающей
малым объемом
оперативной
памяти и слабым
быстродействием,
из-за чего время
распознавания
фраз было в 30
- 50 раз больше
реального.
В ранках
традиционного
аппаратурно-программного
направления
автоматического
распознавания
речи ведутся
работы в ВЦ и
Институте
проблем передачи
информации
АН СССР [13,67,6?] .В
основе метода
лежит алгоритмическая
обработка
выделяемых
специальной
аппаратурой
информативных
параметров
коротких отрезков
речевого сигнала
(сегментов
длительностью
10-20 мс). Последовательность
этих отрезков
и составляет
высказывание,
которое требуется
дешифрировать.
Параметры
(признаки) сегментов
характеризуют
(в большей или
меньшей степени)
параметры
речеобразующего
тракта человека,
определяющие
особенности
порождаемых
звуков.
В Cl3] рассмотрены
алгоритмы
распознавания
названий чисел
от нуля до ста,
причем система
предусматривает
реальное время
распознавания
и произвольного
диктора. Алгоритм
распознавания
двухступенчатый
и состоит из
блоков распознавания
и подтверждения
фонетической
структуры
(верификации).
Если гипотезируемое
слово не подтверждается
(блоком верификации),
то входная
реализация
сравнивается
с другими словами,
близкими к ней
в пространстве
признаков, или
подается сигнал
переспроса.
При распознавании
двухсловных
сочетаний
второе слово
анализируется
с конца в направлении
к его началу.
Варианты
произношения,
на основании
которых создавался
алгоритм,
исследовались
на материале
около 2200 реализации
названий чисел,
произносимых
20 дикторами. В
результате
анализа получены
варианты произношения
двузначных
чисел. Многие
из них произносятся
сравнительно
единообразно
и различаются
степенью редукции
безударных
гласных, степенью
аффрицирова-ния
мягких взрывных,
наличием или
отсутствием
смычек перед
аффрикатами
и т.д. В других
числах может
существенно
нарушаться
фонетическая
структура,
пропуски отдельных
согласных.В
условиях, когда
возможно множество
вариантов
произнесения,
алгоритм должен
использовать
лишь наиболее
употребительные
варианты, в
которых сохраняются
"оперные" звуки
- ударные гласные,
щелевые, взрывные,
а также начальные
и конечные
звуки.
I&
В OS?] рассмотрено
использование
речевого Управления
в подсистеме
АСУП на базе
мини-ЭВМ.
Аппаратурно-программная
система, разработанная
в Львовском
ордена Ленина
государственном
университете
им. И.Франко,
уже эксплуатируется.
Система использует
мини-ЭВМ ЕС-1010
в режиме реального
времени и
параллельной
работы около
90 производственных
задач. Это налагает
жесткие условия
на объем оперативной
памяти, используемой
для программ
обработки
речевого сигнала
(всего 10 Кбайт).
Словарь системы
40 слов, которые
могут быть
организованы
в командные
фразы (5 слов
во фразе). Используется
девять типов
запроса, примерами
которых могут
быть: "оперативная
сводка выпуска",
"ресурсы смены",
"выходные
характеристики
участка первой
настройки"
и т.п. Из-за жест-'
ких ресурсов
памяти система
ориентирована
на работу с
одним диктором,
сформировавшим
свои эталоны
и имеющим свой
пароль. Работа
системы в помещении
машинного зала
с уровнем шумов
68-75 дБ показала
надежность
распознавания
фраз, превышающую
У0%, а после переспроса
- более 9Ь%.
Недостаточная
надежность
распознавания
с первого
^^произнесения
обусловлена
в основном
упрощениями
алгоритма
распознавания,
на которые
пришлось пойти
ради экономии'места
и оперативной
памяти.
Аппаратурно-программное
направление
представлено
также системой
[33] , которая на
первом уровне
распознавания
обнаруживала
в словах сегменты
и классифицировала
их по способу
образования
звуков на гласные,
щелевые, аффрикаты,
дрожащие , а
также глухие
и звонкие. На
втором этапе
некоторые звуки
классифицировались
внутри данной
группы по месту
их образования.
В результате
каждому сегменту
присваивалась
Кодовая
последовательность,занимающая
I байт. Четыре
старших разряда
этого кода
указывали
групповую
принадлежность
данного звука,
четыре младших
разряда определяли
тип звука внутри
данной группы.
Для распознавания
слов образуется
элементарная
последовательность
псевдослогов,
сравнивающаяся
с эталонами
последовательности.
При экспериментальной
проверке работы
система распознавания
на материале
50 и 200 слов с участием
трех дикторов
она показала
93 и 84% точности
распознавания
соответственно.Анализ
ошибок показал,
что в большей
части они вызвали
неправильными
формированиями
сегментов
контрольной
реализации
или эталонов,
возникающими
при срабатывании
системы до
начала произнесения
от посторонних
шумов или шумов
дыхания.
Интерес к
построении
систем распознавания
речи, работающих
с множеством
дикторов,стали
проявяять и
исследователи,
тради-
19
ционно работавшие
с одним диктором.
Т.К.Винцюк и
соавторы [21]
показали, что
в рамках существующей
однодикторной
системы фонемного
распознавания
речи может быть
создана многодикторная
система распознавания,
которую авторы
назвали
кооперативной,поскольку
система предварительно
обучается по
выборке кооператива
дикторов. Основные
результаты
экспериментов:
при индивидуальном
обучении системы
распознавания
речи средняя
надежность
распознавания
по чужим дикторам
не превышает
80% (на
словаре из 100
слов);
- при кооперативном
обучении средняя
надежность
распознавания
для четырех
членов кооператива
составляем
98^, что вполне
приемлемо для
практического
использования;
- кооперативное
обучение способствует
существенному
превышению
надежности
распознавания
речи лиц, не
участвовавших
в получении
обучающей
выборки (для
двух новых
дикторов средняя
надежность
распознавания
97 и 92%).
S 1.3. Развитие
систем распознавания/понимания
слитной речи
Задача общения
человека и
ЭВМ с помощью
естественной,слитной
речи оказалась
гораздо более
сложной, чем
построение
систем распознавания
изолированных
слов. Одной из
первых практических
систем распознавания
последовательности
слитных словосочетаний
(пять слов исходного
словаря) явилась
система фирмы
KdC .описанная
ранее.
В дальнейшем
будем различать
системы распознавания
*и системы
понимания
слитной речи.
В первых, как
правило, рассматриваются
фразы, составленные
из последовательности
слов, между
которыми
синтаксическая
и семантическая
связь либо
отсутствует,либо
слишком жесткая
(используется
автономная
грамматика).Системы
понимания, в
отличие от
систем распознавания,
при декодировании
входного высказывания
используют
высшие лингвистические
уровни языков,
близкие к
естественным,
работая с фразами,
в которых
допустимы
стилистические
ошибки, бессмысленные
звуковые сочетания,
произвольные
паузы и междометия.
При построении
систем понимания
речи необходимо
в большей степени,
чем при создании
систем распознавания
слитной речи,
использовать
опыт специалистов
по искусственному
интеллекту,
а также привлекать
специальные
знания о синтаксисе,
семантике и
прагматике
языка общения.
В то же время
отметим, что
деление на
системы автоматического
распознавания
и понимания
является 20
достаточно
условным и
фактически
определяется
коэффициентом
ветвления,
который показывает,
сколько возможных
слов допускается
после каждого
слова высказывания.
В современных
системах
распознавания
слитной речи
средний коэффициент
не превышает,как
правило, 30 (в
системе Nac-ISQ), а
в системах
понимания
этот коэффициент
достигает
200-300 (бессмысленные
звукосочетания
типа цмм
... , эээ ... и
т.д., а также паузы
и междометия
можно рассматривать
в СПР как возможные
варианты слов).
Так как
автоматическое
распознавание
300 - 300 слов в непрерывном
речевом потоке
- сложная задача,
веди использовать
обычные математические
методы распознавания,
то для ее решения
и привлекаются
высшие уровни
знания о языке
(синтаксис,
сематика и
прагматика),
а также другие
способы, обеспечивающие
сужение числа
альтернатив
на каждом шаге
принятия решения
о слове, используемые
обычно в задачах
искусственного
интеллекта
(ИИ). В связи с
этим в системах
понимания
говорят о
семантической
точности
распознавания
смысла фразы,
когда не все
составляющие
(слова) могут
быть распознаны
правильно.
Перейдем
к рассмотрению
систем распознавания
слитной речи.
Как правило,
такие системы
работают по
принципу фонемного
распознавания,
от точности
которого зависит
общая надежность
работы системы.
Одной из наиболее
интересных
отечественных
систем с обучением
на конкретного
диктора и словарь
является система,
построенная
в Институте
кибернетики
АН УССР им.
В.М.Гяуи-кова
[l9,20] , развитием
которой стала
кооперативная
система распознавания
рвчи[213.
В основу этой
системы положена
математическая
модель речевого
сигнала, в которой
каждой фонеме
соответствует
полученный
алгоритмически
(на основе анализа
текущей автокорреляции
сигнала, параметров
линейного
предсказания
и текущего
энергетического
спектра) определенный
набор бинарных
признаков (
двоичный код).
Модель учитывает
коартикуляционныв
эффекты, изменение
длительности
фонем и динамику
интенсивности
сигнала. Модель
автоматического
распознавания
Института
кибернетики
АН СССР использует
анализ сигнала
посредством
синтеза.
Некоторый
процеср порождает
из элементарных
эталонных
сигналов по
определенным
правилам эталонную
слитную речь
(общий для всех
слов алфавит
эталонных
элементов
содержит около
80 элементов
кодов). Распознавание
слитной рччи
сводится к
необходимости
нахождения
наиболее
правдоподобного
эталонного
сигнала слитной
речи.
21
В этой модели
автоматически
находятся
границы отдельных
фонем, паузы,
тип и общее
количество
фонем в распознаваемой
последовательности
о учетом априорной
вероятности
частоты встречаемости
фонем. Эталонный
сигнал слитной
речи формируется
из эталонных
сигналов отдельных
слов путем
нелинейного
преобразования
исходных словесных
эталонов. При
этом эталонные
сигналы слов
складывались
в эталонную
слитную речь
так, что паузы
между словами
имели различную
длительность
(в том чис/ie и
нулевую),а
длительность
элементов фразы
изменялась
плавно. Параметрами
грамматики,
порождающей
эталонные
фразы, являлись:
алфавит эталонных
элементов,
акустике-фонетические
транскрипции
слов, правила
стыковки слов
во фразе, правила
нелинейной
деформации
сигналов вдоль
оси времени
и некоторые
другие параметры.
Для экспериментов
по распознаванию
слитной речи
( словарь включал
200 слов) были
получены 1000
реализации
этих слов,
произнесенных
одним диктором
(обучающая
выборка). При
испытаниях
система дала
0,5% ошибок и 3% отказов
при распознавании
слов в слитном
потоке. Расширение
словаря до 300
слов увеличило
количество
ошибок до 1%,
причем отказов
было 3,5%. При
экспериментах
со словарем
из 100 слов удалось
получить время
распознавания
(на ЭВМ БЭСМ-6),
равное I с на
I слово [193 • Отметим,
что близкий
к этому метод
используется
в системах
распознавания
слитной речи
(СРСР), разработанных
в Отделе вычислительной
науки исследовательского
центра фирмы
1УЫ. В связи с
тем, что данная
фирна (так же,
как и фирма
Sperry Univac ) активно
занимается
исследованиями
по распознаванию
слитной речи
после завершения
проекта arpa , рассмотрим
эти работы
более подробно.
В С39] описана
СРСР, в основе
которой лежит
модель акустического
канала, обеспечивающая
автоматическое
порождение
всех возможных
поверхностных
форм предполагаемого
высказывания
совместно с
вероятностями
их порождения.
Это порождение
осуществляется
с помощью
акустико-фонологических
правил (АФП).приложенных
к базовой цепочке
высказывания.
АФП учитывают
в слитной речи
такие фонологические
явления, как
пропуски, вставки
и замены отдельных
фонем внутри
слов, повышенный
тон речи, диалектные
особенности,
изменения на
стыках слов
и т.д.
Удобной
структурой
для выражения
поверхностных
форд высказывания
явился направленный
граф, дуги которого
помечены возможными
звуками. Каждому
узлу графа
соответствует
распределение
вероятностей,
указанных на
выходящих
дугах. Дуги на
концах графа,
соответствующего
совокупности
всех поверхностных
форм произнесен-
22
ного слова,
имеют связанные
с начальными
и конечными
состояни-яни
условия соединения,
определяемые
фонологическими
явлениями на
стыках слов.
Язык системы
определяется
автоматной
грамматикой,
представленной
графом и включающей
250 слов. Для распознавания
использовался
лингвистический
декодер-алгоритм
последовательного
декодирования,
обеспечивающий
нахождение
предложения
о максимальной
апостериорной
вероятностью
по последовательности
цепочки фонем,
поступающих
с выхода специального
акустического
процессора.
Точность
декодирования
высказываний
на контрольной
выборке составила
(по данным на
август 1977 г.) 95% при
6% ошибочной
интерпретации,
которые были
вызваны 0,6% ошибок
неправильного
распознавания
слов. Следует
отметить, что
рассматриваемая
система была
сияьно модифицирована
за последние
три года: упрощен
акустический
процессор, с
которого быви
сняты функции
фонемной сегментации
и маркировки.
Сказалось
возможным,
используя
алфавит из 33
фонем, маркировать
ими десятимиллисвкундные
отрезки речевого
сигнала непосредственно
по акустическим
данным.Преимущество
такого представления
авторы работы
[Ю5Д видят в том,
что, во-первых,
информация
о звуке,распределенная
по длине фонем,
оказывается
более полезной
для распознавания,
так как при
этом возрастает
количество
информации,
поступающей
от акустического
процессора
к лингвистическоу
декодеру. Во-вторых,
сегментация
и маркировка
(принятие решения
о звуке) разнесены
во времени, и
лингвистический
декодер может,
основываясь
на структуре
отдельных слов,
во время сравнения
решить, представляет
ли короткая
маркированная
цепочка
десятимиллисекунцных
сегментов
истинный звук
или же это -
ошибочная
ложная ставка.
Дальнейшее
совершенствование
сантисенундного
акустического
процессора
( asAJ ) за счет использования
45 эталонных
фонетических
меток вместо
33 позволило
повысить точность
классификации
(на языке со
словарем из
250 слов) до 98,8% на
контрольном
материале 100
предложений
[l07] . Следует отметить,
что еще более
совершенный
процессор (
wbap ), на котором
получены наилучшие
результаты
распознавания
(0% ошибок), использует
лишь пять
параметров,
один из котррых
- кратковременные
изменения общей
энергии сигнала,
а четыре - отражают
параметры
гласных и описаны
ранее в [l4l] . Этот
процессор
осуществляет
акустическое
сравнение
непосредственно,
используч
величины акустических
параметров,
а не фонетические
метки, связанные
с сантисекундными
отрезками. Для
каждого слова
используется
модель с конечным
числом состояний,
которая порождается
алгоритмически
из отображенного
23
произношения.
Число состояний
модели равно
длине этого
произнесения
в сантисекундах.
В модели обеспечиваются
переходы из
состояния к
этому же состоянию,
к соседнему
и через одно.С
каждым переходом
связано пятимерное
гауссовское
распределение
в пространстве
первичных
параметров.
Средние значения
и дисперсии
выходных
распределений,
а также переходные
вероятности
формируются
автоматически
при обучении
на дополнительных
реализациях
слов при формировании
обобщенных
эталонов с
помощью алгоритма
Вктер-би [39].
В процессоре
wbap используемая
статистика
основана скорее
на
особенности
слов, чем на
особенности
звуков.
Следует
отметить, что
за I976-I978 гг. предпринимались
попытки увеличить
объем используемого
в СРСР фирмы
IBh словаря до
1000 слов (тезаурус
лазерных патентов).
Предварительные
результаты
испытаний этой
системы описаны
в [106} . На
тестовом
множестве фраз,
куда входило
486 слов, ошибка
распознавания
слов составила
33,1%, причем ни
одна из й0 контрольных
фраз не была
определена
правильно -
программа
распознавания
делала ошибку
хотя бы в одном
слове каждой
фразы. Развитие
этой системы
[107] позволило
за счет увеличения
числа фонетических
меток до 52 снизить
ошибки в распознавании
слов до 20%.
В [108,109] рассмотрены
дальнейшие
улучшения этой
системы, позволившие
уменьшить число
ошибок при
распознавании
слов за счет
использования
более совершенного
сантисекундного
акустического
процессора
сзар-зоо, в
котором число
эталонных
фонетических
меток было
расширено до
двухсот. При
распознавании
50 п"едл°жений,
включающих
980 слов, неверно
распознано
87 слов, в числе
которых 34 слова,
составившие
односложные
слова типа
"of", " а ", " are ","as"
и др. Переход
к работе этой
системы с множеством
дикторов описан
в [l59]. Работа с
новыми дикторами
реализована
за счет использования
автоматической
селекции
акустических
эталонов,
выполняющейся
двумя различными
способами.Один
из методов,
в основе которого
лежит процедура
Витерби С 39],
реализован
с помощью
сантисекундного
акустического
процессора
TPIVIAI [l07], а другой,
основанный
на алгоритме
кластеризации,
использует
акустический
процессор
autociust. (В первом методе
использовалось
85 эталонов, во
втором - 20D.) Точность
распознавания
слов составила
при использовании
первого алгоритма
65%, а второго -
90%. В 1983 г. была публикация
одной фирмы
о распознавании
словаря деловой
переписки общим
объемом 5000 слов.
Над проблемами
распознавания
слитной речи
продолжает
работать фирма
Sperry Univas, участвовавшая
в проекте АЙРА.
Эта
24
фирма разработала
с"стему автоматического
распозньвания
слов,словосочетаний
и естественных
предложений
{l74] . На основе
спектрального
анализа и линейного
предсказания
в спектральной
об-дасти звуки
классифицировались
по способу и
месту образования.
Система была
испытана на
словаре из 31
слова двумя
дикторами.
Точность
распознавания
изолированных
слов при использовании
синтаксиса
задачи составила
95%. Предварительные
результаты
по распознаванию
слитной последовательности
слов, произносимые
тремя дикторами,
составили от
54 до 74% для задачи
с ограничечным
порядком следования
слов. Предполагалось,
что в дальнейшем
будут использованы
акустико-фонетичзские
и фонологические
правила, нормализация
дикторских
произношений,
просодические
характеристики
речи. Предполагалось
также, что будут
использованы
более сложные
процедуры для
синтаксического
и семантического
анализа. В
1977 г. система
работала с
двумя словарями
- из 36 (алфавит-но-цифровой
словарь) и 64 слов
(словарь речевого
управления)
[123, 153] . Для обоих
словарей точность
распознавания
составила
95^, а средней
точности
распознавания
слитялс словосочетаний
- 88%.Дальнейшие
разработки
включали расширение
словарного
состава системы,
числа типов
предложений,
использование
правил фонетической
и словесной
верификации.
В [l54] сообщается,
что система
Sperry Univac. была модернизирована
для поиска и
верификации
ключевых слов
в потоке слитной
речи. В этой
системе использовались
измеряемые
на деся-тимиллисекундных
интервалах
параметры
речевого сигнала,
проведшего
через телефонный
канал. Исследователями
был выбран
достаточно
мощный набор
параметров-
Непосредственно
по речевой
волне определилась
частота основного
тона. Спектральный
анализ с помощью
быстрого
преобраэозания
Фурье (БПД) позволял
получить следующие
признаки речевых
отрезков: общую
энергию в полосе
100 -8600 Гц, энергию
сонорных (100 - 3000
Гц), высокочастотную
энергию сонорных
(650 - 3000 Гц), низкочастотную
энергию (JOO - 600 Гц),
разность энергий
низких и высоких
частот <100 - 900 Гц)
- (3000 - 3600 Гц), частоту
максимума
спектральной
амплитуды в
полосе 100 - 3600 Гц,
спектральную
производную
на этой частоте
и энергии в
15 полосах частот
телефонного
канала. Кроме
того, линейное
предсказание
в спектрадьной
области давило
возможность
получить и
использовать
коэффициенты
линейного
предсказания
и частоты первой
и третьей формант.
Система
содержит компоненты
просодического
и фонетического
анализа, которые
обеспечивают
последующее
сегментное
структурирование
высказывания
(получение
цепочки кваэифонетическюс
сегментов)
Зак.480 26
для лексического
сравнения.
Сравнение
осуществляется
с помощью блоков
словесного
гипотезирования
и верификации.
Верификация
слов производится
методом динамического
программирования.
При построении
системы обнаружения
ключевых слов
была использована
обучающая
выборка - разговорная
речь, продолжительностью
13 мин. Предложения
произносили
8 дикторов.
Контрольная
выборка составляла
II мин разговорной
речи 10 дикторов
(из которых
двое участвовали
в обучении).
При контрольном
эксперименте
точность обнаружения
10 ключевых слов
была невысока,
но все же испытания
следует считать
обнадеживающими.
В [124] отмечается,
что в течение
1978 г. отдел речевой
связи Jperry nnivac работал
над созданием
более совершенного
блока фонетического
анализа, который
фактически
стал лексически-управляемым
фонетическим
верификатором
(а не автономным
фонетическим
анализатором,
как раньше
),что лучше учитывает
коартакуля-циокные
эффекты внутри
слова. Модернизация
счстемы позволила
[I55J получить более
удовлетворительные
результаты
по обнаружению
и верификации
ключевых слов
в потоке слитной
речи. На тестовых
предложениях
(16,7 мин разговорной
речи 14 дикторов,
не принимавших
участия в обучении
системы) ключевые
слова были
обнаружены
в 30% случаев.
В [l87] описана
система распознавания
слитно произносимых
цифр, разработанная
фирмой Bell laboratories.
Систэма состоит
из двух взаимодействующих
блоков. Первый
осуществляет
пословную
сегментацию
всего высказывания
на отдельные
цифры, а второй
производит
распознавание
этих цифр по
результатам
сегментации.
При распознавании
использовались
признаки сеп/^нтов
речевого сигнала:
р - параметр,
логарифм анергии,
кооффициенты
линейного
предсказания
и ошибка предсказания
.и коэффициента
автокорреляции.Для
пословной
сегментации
слитных словосочетаний
учитывалось
то обстоятельство,
что для этого
конкретного
словаря (английские
названия цифр)
шумные участки
и паузы (глухие
смычки) могли
находиться
только в начале
или конце слов.
&ти участки
и являлись в
основном опорными
границами между
словами. Точность
пословной
сегментации
составляла
99% (при произнесении
словосочетаний
как в тихой
комнате, так
и в условиях
машинного
зала). Точность
распознавания
словосочетаний
(названий семизначных
телефонных
номеров) составила
91% для
10 дикторов (5 мужчин
и 5 женщин), произносивших
фразы в тихой
комнате, и QT%
для тех же дикторов,
находившихся
а машинной
зале. В [149] отмечается,
что получены
обнадеживающие
результаты
по распознаванию
слитной речи,
использующей
словарь в 1й*7
слов, аналогичный
словарю [ 147,148] .
Дальнейшее
развитие этих
систем описано
в [156,1693.
26
Система
Hearsay-П создавалась
на базе разработанных
ранее систем
распознавания
слитной речи
Dragon и Hearsay-I.Аналогично
Hearsay-I главным
принципом
Hearsay-д было выдвижение
гипотезы (о
звуке, слове,
фразе) и
ее подтверждение
с помощью всех
возможных
источников
знаний (ИЗ) о
речевом сигнале
.
Описания
высказываний,
которые должны
анализироваться
в этой системе
понимания речи,
имеют унифицированную
трехмерную
структуру,
причем размерностями
являются: уровни
представления
(акустический,
фонетический,
слоговой,
лексический,
синтаксический
и семантический),
время и вероятностные
альтернативы
(на каждом уровне
для каждого
временного
отрезка). Ьта
структура
содержится
в памяти системы
как единая
информационная
база (ВИБ),подвергающаяся
исследованиям
и модификациям
с помощью
различных
программ, реализующих
ввод в систему
необходимых
источников
знаний.
Работа комплекса
программы на
единой информационной
базе (которую
называют "классной
доской") и есть
интерпретация
слитно произнесенного
высказывания
на различных
лингвистических
уровнях - от
фонетического
до семантического.
Общая информационная
память, построенная
как единая
многоуровневая
информационная
структура с
внутренними
связями, представлена
в системе
Hearsay-П в виде графа.
Основная единица
этой информационной
структуры -
узел графа,
являющийся
гипотезой о
существовании
в высказывании
некоего частичного
элемента. Структурные
отношения
между узлами
графа (гипотезами)
представляются
дугами графа,
обозначающего
связи. Существует
два наиболее
важных типа
структурных
отношений -
"последовательность
элементов"
и "выбор элементов".
Последовательность
- это структурное
отношение,
означающее,
что гипотеза
верхнего уровня
поддерживается
"юследовательныы
рядом гипотез
на нижнем уровне
(например, слово
представляется
последовательностью
непересекающихся
во время звуков
речи). Выбор
- отношение,
определяющее
гипотезой
альтернативную
поддержку от
двух и более
гипотез , причем
каждая от них
существенно
перекрывает
тот же временной
отрезок (т.е.,
например, гипотезой,
допускающей
на данном временном
интервале
несколько
различных слов
примерно одинаковой
фонетической
структуры).
Распространение
идеи "выдвижение
гипотезы - ее
подтверждение"
на все уровни
знаний о речевом
сигнале требует
организации
системы передачи
информации
между уровнями.
В связи б двумя
видами, структурных
отношений между
узлами графа
можно рассматривать
и два типа гипотез
- горизонтальные
и вертикальные,
подт-
27
верхдаемые
соответствующими
источниками
знаний. Гипотеза
считается
горизонтальной,
если источник
знаний использует
контекстуальную
информацию
на данном уровне
для подтверждения
гипотезы того
хе уровня.
Вертикальная
гипотеза определяется
как гипотеза,требующая
для своего
подтверждения
информации,
получаемой
источниками
знаний на
других уровнях.
Основная
функция источников
знаний - устранить
ошибки, возникающие
при обработке
слитной речи.
При этом источники
знаний должны
вовремя добавить
какую-то новую
информацию,
внести что-то
полезное для
более надежного
распознавания.
Источники
знаний должны
уметь распределять
эти знания
через механизм
выработки
гипотез, оценивать
цобавку от
других источников
знаний,т.е.
подтверждать
иди отвергать
гипотезы, сделанные
другими источниками
знаний. Источники
знаний необходимо
создавать таким
образом, чтобы
их можно
было приспособить
к новым участкам
анализа высказывания
и вообще к новым
задачам автоматического
понимания
слитной речи.
Для нормальной
работы СПР
Нвагаау-11 необходимо
реализовать:
1) достаточно
общую, структурно-полную
информационную
базу, анализируя
которую, источники
знаний могут
вводить новые
гипотезы,' проверять
и изменять
гипотезы, размещенные
в этой базе
другими источниками
знаний;
2) средства
для описания
разнообразных
источников
знаний и обеспечения
их внутренней
обрабатывающей
способности;
3) возможность
управлять
действиями
источников
знаний
ин-фовмационко-направленным
способом (необходим
способ, с помощью
которого определяется
ряд предварительных
условий, запускающих
необходимый
источник знаний);.
4) признаки,
по которым
обнаруживается
удовлетворение
этих условий
и локализуется
часть информационной
базы, в которой
заинтересованы
соответствующие
источники
знаний.
Для реализации
п.4 необходимы
два механизма:
мониторный
руководящий
механизм,
обнаруживающий
изменение общей
информационной
базы и оценивающий
природу этих
изменений, и
ассоциативный
механизм повторных
испытаний и
восстановления
частей информационной
базы, когда это
необходимо.
Таковы самые
общие сведения
о Hearsay-П. Переедем
к более детальному
рассмотрению
этой системы.
Параметрическое
представление
высказывания
в Неагвау-П
сводится к
использованию
двухступенчатой
системы признаков.
Несмотря
на то, что
в последнее
время большое
внимание уделяется
28
точным методам
нахождения
параметров
речеобраэующего
тракта (в частности,
с помощью линейного
предсказания),
неапау-11 используется
лишь на втором
этапе. Но прежде
чем использовать
коэффициенты
линейного
предсказания,
авторы Неагвау-П
получают гораздо
более простые
и дешевые обобщенные
параметры,которые
назвали параметрами
zapbash (Zero Orosetng and PeaHs at
Differenced and Smooth Vaweform). Эти параметры
обеспечивают
грубую сегментацию
речевого потока
по способу
образования
звуков, т.е.
обеспечивают
сегментацию
и маркировку
I уровня. После
локализации
в высказывании
фонетических
элементов
применяют
сегментацию
и маркировку
П уровня, основанную
на использовании
коэффициентов
линейного
предсказания,
обеспечивающего
более точную
идентификацию
сегментов.
zapdash - параметры
речевого сигнала,
определяющие
интегральные
характеристики
звуков в низкочастотном
(< I кГц) и высокочастотном
( >1 кГц) диапазонах.
Эти параметры
выделяются
в реальном
масштабе времени
из сигнале,
поступающего
с АЦП в мини-ЭВМ,
которая обладает
средним быстродействием
600 тыс. операций
в I с. Параметры
(число нулевых
пересечений
и амплитудное
значение сигнала
на интервале
анализа для
каждого из
диапазонов)
формируются
программно,
и их значения
дают возможность
грубо классифицировать
сегменты на
10 различных
типов - пауэы
(глухая смычка),
наличие звонкой
смычки, характеризующие
звонкие взрывные
б, д,г, сонорный
согласный,
глухой фрикативный
(переднеязычный
или заднеязычный),
носовой, свистящий,
гласный высокого
иди низкого
подъема. В дальнейшем
производится
пере классификация
сегментов на
59 классов, некоторые
из них
пересекаются
в пространстве
признаков.
На второй
стадии к среднему
участку сегментов
применяют
сравнение с
эталонами (этих
эталонов для
каждого класса
сегментов
может быть до
100). При сравнении
средний участок
сегмента по-ступившей
на вход реализации
сравнивается
с множеством
эталонов, которые
подучены от
специально
обученных
дикторов.
Использование
сегментации
I уровня позволяет,
как отмечается
в [l79], ускорить
общую сегментацию
в пять раз по
сравнению с
унифицированной,
основанной
.исключительно
на коэффициентах
линейного
предсказания.
Как уже отмечалось,
ключевой проблемой
систем понимания
Речи является
верификация
сдоврсиьк
гипотез.подожданных
различ-иыми
источниками
знаний. Блок
словесной
верификации
должен оце-нвдь,
насколько
акустические
данные входной
реализации
соответствуют
фонетической
транскрипции
гипотезируеного
слова.
2S
В соответствии
с оценкой,
словесный
верификатор
отбрасывает
большее числе
гипотезированных
слов, сохраняя
возможные пра~
вильные, чтобы
впоследствии
отобрать единственное
с помощью инфор~
мации высших
уровней.
В Hearsay -П слова
порождаются
либо словесным
гипотезато-ром
снизу вверх
(блоком POMOW), либо
преде называются
сверху вниз
семантико-синтаксическим
блоком sass . Блок
словесной
верификации
wizard обрабатывает
гипотезы о
словах снизу
вверх, используя
акустическую
информацию
и результаты
автоматической
сегментации.
Каждый сегмент
высказывания
представлен
вектором фонемных
вероятностей
(т.е. с каждым
отрезком высказывания
связываются
определенные
звуки, которым
присваиваются
некие веса),
Каждое слово
словаря записывается
эталонным
графом возможных
фонетических
произнесений,
учитывающим
все альтернативные
варианты
произнесений.
Однородная
модель, используемая
блоком словесной
верификации,
дает возможность
найти оптимальное
совпадение
одного из эталонов
(соответствующее
пути на одном
из эталонных
графов) и участка
входной реализации,
соответствующего
слову.
В системе
Hearsay-П при словесной
верификации
стыки между
словами не
рассматриваются,
делается лишь
их внутренняя
обработка.
wizard пытается
верифицировать
слова, как будто
они находятся
в изоляции.
При верификации
слова обрабатываются
снизу вверх
следующим
образом: предсказанные
моменты начала
и конца слова
связываются
с соответствующими
сегментами
высказывания
bseg и eseg. Исследуются
все пути в эталонных
графах возможных
слов, которые
совпадают с
отрезками и
входной реализацией.
Сравниваются
с эталонами
отрезки, которые
начинаются
в (baeg-I: beeg +I ) и заканчиваются
в jeseg -I I eeeg +I(, т.е. параллельно
рассматриваются
девять возможных
участков
высказывания,
что приводит
к девяти оптимальным
путям на эталонных
графах, из
которых выбирается
тот. оценки
которого наибольшие,
или наиболее
соответствуют
рассматриваемому
участку. Сдвиг
на один сегмент
вправо или
влево позволяет
избегать ошибок
при представлении
входного,
высказывания
(акустических
данных) различными
источниками
знаний. В результате
блок словесной
верификации
может изменять
время словесных
гипотез, а также
их оценки. Следует
отметить, что
если в проектах
ВШ (Speechlis и HWIM) идет
непосредственный
переход от
фонетического
описания к
словесному,
то в Hearsay-П используется
еще промежуточный,
слоговый уровень
между словами
и звуковыми
сегментами.
Для поддержки
словесных
гипотез используются
так называемые
типовые слоги,
слоготипы
(syltypes).
Ццея слоготипов
сводится к
тому, что слоги,
имеющие похожие
сегменты (например
"та", " па"), относятся
к одному типу.
Никаких попыток
различать слова
с одинаковыми
слогами в Нвагвау-П
не делается.
Каждый слоготип
характеризуется
слоговым ядром,
определяемым
эвристически
присвоенными
сегментными
метками и положением
максимума
энергии на
отрезке. Для
каждого слоготипа
гипотези-руются
слова, в которых
встречается
данный слог;
многосложные
слова отбрасываются,
если плохо
согласовываются
о последовательностью
слоготипов.
Подробное
описание слогового
гипотезатора
pokow содержится
в С 1783.
В Неагаау-П
содержится
еще один гипотезатор
- гипотеза-тор
словесных
последовательностей
wozeq. В сравнении
со стратегией
однословных
"островков
надежности"
многословная
последовательность
желательна
по двум причинам:
1) доверие к
гипотезе о
последовательности
сдов более
высоко, чем в
однословной
гипотезе;
<;) правильность
оценки (в очках)
для последовательности
слов выие, чем
для одного
слова. (Последовательность
слов использует
избыточность
языка, йероятность
того, что гилотияируемая
последовательность
правильна,
может превосходить
вероятность
того, что правильно
одно слово.
Сравнение
оценок, основанных
на средних
оценках нескольких
составляющих,
статистически
более надежно,
чем сравнение,
основанное
на оценке одной
составляющей.)
Синтаксический
и семантический
источники
знаний в
Неагвау-п
представляются
блоком sass . Этот
блок имеет дело
с гипотезами,
представляющими
слова, словосочетания
или фразы,
воспринятые
или предложенные.
Задача sass - найти
наиболее
правдоподобное
предложение
по последовательности
смежных слов.
Правдоподобие
определяется
достоверностью
словесных
гипотез и
грамматической
правильностью
и осмысленностью
предложения.
Как уже отмечалось,
в и«эаг-aay-il многочисленные
альтернативы
представляются
в общей информационной
базе и обрабатываются
параллельно
независимыми
информационно
направляемыми
программными
блоками - модулями
источников
знаний, которые
создают, проверяют
и переписывают
гипотезы о
высказывании,
запоминая их
на доске. Одна
размерность
доски - уровень
представления,
другая - время,
третья - вероятность
правильности
гипотезы, оцениваемая
в очках. С точки
зрения sass общую
информационную
базу ("классную
доску") можно
рассматривать
как схему
гипотезированных
слов, порождаемых
различными
источниками
знаний. Вертикальные
измерения - это
очки (в диапазоне
- 100 * -» +100), оценивающие
достоверность
словесных
гипотез.
31
30
Проблемы,
стоящие перед
семантико-синтаксическиы
блоком -неопределенный
комбинаторный
поиск, слабое
(например,
предложение
заполнить
пробелы на
временной оси
гипотезами
о словах) и сильное
(например, совсем
отвергнуть
какую-либо
гипотезу)
вмешательство,
необходимость
использовать
частичную
информацию
(частичные
грамматические
конструкции),
способность
динамически
менять свои
критерии
достоверности
- общие проблемы
многих больших
систем,основанных
на информационном
управлении.
Уффективное
решение этих
проблем,
по-видимому,потребует
построения
такой системы,
в которой
последовательность
процедур
заключительной
обработки
чувствительна
к различным
сотрудничающим
и конкурирующим
отношениям
между гипотезами,
ато означает,
что семантико-синтаксическая
обработка
облегчается
на гипотезах,
поддержанных
одновременно
несколькими
источниками
знаний, и задерживается
на гипотезах,
которые конкурируют,
не согласуются
с очень надежной
гипотезой.
Задержка гипотезы
должна быть
достаточно
гибкой, недетерминистской,
неокончательной,
так как и слабая
гипотеза при
интерпретации
высказывания
может оказаться
верной. Гибкая
задержка
осуществляется
в Hearsay- П механизмом
фокусировки
внимания,
который распределяет
ресурсы так,
чтобы в первую
очередь рассмотреть
наиболее обещающие
гипотезы.
Синтаксические
и семантические
знания о
проблемно-ориентированном
языке Hearsay-П выражаются
в компактной,
легко читаемой
грамматике»
которая задается
параметрическими
структурными
представлениями
(PSR), являющимися
множеством
пар типа "определение
- объект". psr используются
для определения
класса слов
и фраз, которые
могут выполнять
синтаксические
и семантические
функции
проблемно-ориентированного
языка, состоящего
для Hearsays И из простых
вопросов. Например,
psr:
($СЪА35: $QUEPY, $HAME: "PAPSED
QUEPY", 6 : $QinME + $flfHAT,
El ТЕ L Ь
+'$ ME + $ПЕ + ФТОПСЗ,
6 » WHAT + HAPPENED + $ АЮТ AY, e s
WHAT + ф BE + THE + $N EWS+tRE + ^TOPICS
ЦСТЮМ t PASS, $LEV EL !
300)
определяет
класс возможных
вопросов в
терминах
их альтернативных
синтаксических
реализации,
аначок ® обозначает
принадлежность
к классу. Каждая
член класса
- это последовательность
эталонов,
составляющие
которых, разделенные
знаком "+", слова
или фразы. «разовые
сосгааяяшеи»
помечаются
значком $ и
определяются
в
32
свою очередь
другими psr. faction pass
означает, что
реакция блока
ЗАЗЗна распознавание
люоого из пяти
эталонов в
классе должна
трактоваться
как признак
вопроса ( $query ) .»level
оценивает
относительную
завершенность
частичного
грамматического
разбора, лежащего
в основе гипотезируемой
фразы PSR:
6 : $CL ASS ! $TOPICS,
ЈPL АСЕ,
$FOOD,
$TECHNOL ОСУ,
$ С OVER NT.IE:IT,
ФР01Т1Т1С,
$PEOPL E,
e ; $TOPICS + SCONJUN CTICOT + 3>TOPIG
S, 6 :
CACTIOH : PASS, LEVEL : 40)
и определяет
класс возможных
предметов
разговора
(.Topice) в терминах
их семантических
подклассов.
Как уже упоминалось,
sass имеет набор
сильных и слабых
средств, представляющих
различные виды
обработки
информации
на синтаксическом
и семантическом
уровнях.
1.Правило
распознавания
порождает
гипотезу о
фразе по достаточно
надежным гипотезам
о составляющих
фразы. sass рассматривает
слова распознанными,
если их оценки
(в очках), определенные
другими источниками
знанчй, превышают
некий порог.
Составляющие
фразы должны
также удовлетворять
некоторым
структурным
требованиям
- например, таким,
как временная
смежность
между составляющими.
Правила распознавания
ведут обработку
снизу вверх,
двигаясь от
частичного
грамматического
разбора к полному.
Они представляют
собой сильные
средства обработки
(сила оценивается
вероятностью
того, что
последовательность
распознанных
составгчющих
может как-то
осмысленно
интерпретироваться)
.
2. Правила
предсказания
гипотезируют
сио-во или фразу
в зависимости
от вероятности
контекста,
определенного
на предыдущих
этапах распознавания
высказывания.
Правила предсказания
выполняют
обработку,
перекрывая
временной
ин-Тврвая "островками
надежности".
Эти правила
необходимы
потому, что
не все слова
в произнесенном
высказывании
могут быть
рас-чознаны
снизу вверх,
т.е. источниками
знаний нижних
уровней. ^ияа
правила предсказания
определяется
условной вероятностью
того, что предсказанные
составляющие
могут быть в
высказывании
при
Денном (распознанном
ранее) контексте,
ата сила обратно
пропор-'тонаяьна
числу составляющих,которые
могут появиться
в этом контексте.
Зак.480
3. Правила
повторного
разбора ( res-pelling rules
) производят
обработка7
сверху вниз
и численно
оценивают
составляющие
предскапанной
фразы, разбивая
гипотезируемое
предложение
на гипотезы
для последовательных
составляющих
или же "расщепляя"
гипотезируемый
класс на альтернативные
гипотезы для
различных
составляющих
высказывания.
Правила повторного
разбора (прочтения)
проводят обработку,
возвращаясь
к словесному
уров. ню, так
что предсказание
(о фразе) верхнего
уровня может
быть подвергнуто
испытанию
(слово за словом)
источниками
знаний нижнего
уровня, если
на верхнем
уровне что-то
не сходится.
4. Правила
постдикции
несЭходимы
для того, чтобы
уже после
сформирования
понятия подтвердить
его большим
числом "очков
доверия", дать
ему более высокую
оценку, подтвердив
существующую
гипотезу о
фразе другими
гипотезами.
Правила постдикции
как более сильные
включают правила
предсказания
и повторного
прочтения,
которуе слишком
слабы, чтобы
подтвердить
создание гипотезы,
но могут внести
полезный вклад,
когда гипотеза
уже существует.
Правила постдикц^и
выполняют три
функции:
а) позволяют
объединять
выводы, поддерживающие
оцениваемую
гипотезу на
основе различных
источников
знаний;
б) дают воамсвность
гилотеэирсвать
слова и фразы
с низкими
первоначальными
оценками за
счет их
распознавания
на основе контекста»
в) способствуют
фокусированию
внимания на
главных направлениях,
определяемых
возрастанием
очков гипотез
тех слов, которые
контекстуально
возможны (и
таким ооразом
могут считаться
правильными),
так что обработка
высказывания
в этих направлениях
происходит
по списку приоритетов
в первую очередь.
Автоматическое
превращение
описательной
информации
о грамматике
языка -Hearsay- П , заданной
параметрическими
структурными
представлениями
( psr), в процедурную
форму осуществляет
ком-пиллятор
суытет , который
транслирует
эти представления
в правила
распознавания,
предсказания,
повторного
прочтения и
постдикции.
cvshet разбивает
последовательности
слов, составляющих
высказывания
и представленных
PSR, на пары последовательных
эталонов, формируя
новые подпоследовательности
и порождая для
них
соответствующие
правила [ 13Й 3 .
Одна из самых
интересных
систем автоматического
распознавания
слитной речи
- система harfy,
разработанная
по проекту arpa
(США, Питсбург).
Эта система
по сравнению
с другими
разработками,
проводившимися
по этому проекту
[l5lj,наиболее близка
к практическому
использованию.
Словарь harpy составляет
ЮН словоформ
- слов телефонной
информацион-
34
но-справочной
службы о новостях.
При испытаниях
harpy была получена
точность
распознавания
фраз, равная
95% на обучающей
выборке и 92^ на
контрольной.
Система воспринимает
слитную речь,
не содержащую
стилистических
ошибок. В harpy информация
о языке представлена
фонетическим
графом - интегральной
сетью переходов
с конечным
числом состояний,
не учитывающей
априорные
вероятности
переходов.
Распознавание
осуществляется
сравнением
входной реализации,
представленной
маркированными
сегментами,
с этой сетью.
Система
содержит несколько
эвристических
процедур для
улучшения ее
характеристик:
выделение
подсетей и
сжатие их
для уменьшения
общего объема
сети, автоматическое
составление
описания
коартикуляционных
явлений
на стыках
слов и т.д. Время
распознавания
системы в период
испытания
составляло
2D с на 1 с речи
(есть сведения,
что в настоящее
время оно снижено
до Зс на I с речи).
Синтаксические
значения в
hahpy однозначно
определяются
независимым
от контекста
рядом выработанных
правил, формализующих
проолемно-ориентированный
язык. Лексические
знания представлены
словарем, который
содержит
символическую
фонемную транскрипцию
всех альтернативных
произнесений.
Правила стыков,
как и в системах
IBM, учитывают
фонетические
явления при
соединении
слов в слитно
произносимое
словосочетание.
В качестве
первичных
параметров
используются
коэффициенты
автокорреляции
и линейного
предсказания.
У системе Нлару
в процессе
работы осуществляется
адаптивная
подстройка
под диктора
с помощью десяти
обобщенных
эталонов,
характеризующих
усредненный
вокальный тракт
группы дикторов.
На базе harp? был
разработан
голосовой ввод
в картографическую
систему ( vigs),
позволяющий
дублировать
клавиатуру
при вводе
картографической
информации
[l3l].B настоящее
время система
harpy переводится
на мультимикропроцессорную
базу [36].
перейдем
к краткому
описанию систем
"понимания"
речи. Их разработка
началась после
появления
отчета [161] , в котором
известные
американские
специалисты
в области
искусственного
интеллекта,
распознавания
речи, системного
программирования,
математической
лингвистики
изложили взгляды
на проблему
построения
систем, воспринимающих
слитную речь,
произносимую
на естественном
языке. Основные
положения
отчета [161] легли
в основу пятилетней
программы arpa.
Достаточно
подробные
обзоры по начальному
этапу работ
над системами
понимания речи
содержатся
в [79,85] . Поэтому
здесь рассмотрим
лишь итоги
проекта arpa в
области построения
35
конкретных
СПР. Можно считать
законченными
(в большей или
меньшей степени)
системы понимания
речи трех
американских
организаций
-ОЫП, 3RI и ввн [179, 162,
187, 189].
Основные
усилия c:,?J были
направлены
на построение
системы понимания
речи Неагаау-1
"^основанной
на принципе:
"Выдвижение
гипотезы и ее
подтверждение
различными
независимыми
источниками
знаний о языке".
Отдельные
элементы этой
системы подробно
освещены в
[79, 85, 8b, I2U, 179].
Система
Псагвву-п была
испытана на
IOU предложениях,
составленных
из IUH словоформ,
аналогичных
словарю системы
harpy, описанной
ранее (система
HARPY имела грамматику
с гораздо более
простым синтаксисом).
Ошибки при
распознавании
фраз в Неагаау-п
составляди
16%, а время распознавания
превышало время
распознавания
системы harfx в 2 -
33 раз.
В фирме вен
на I этапе разрабатывалась
система понимания
речи
Speeohlis, в качестве
языка которой
использовался
упрощенный
вариант языка
ИПС lunar; система
Ь^-паг давала
возможность
анализировать
образцы лунных
пород[?9,Уб1В
дальнейшем
была усовершенствована
этой же фирмой
новая система
понимания речи
нули (Hear what I mean ) С учетом
недостатков
Speechlia.
.Язык системь.
hwim относится
^ области бухгалтерских
расчетов. Вместо
раздельных
синтаксического
и семантического
блоков системы
Speechlis , нздш имеет
единый, семантико-синтакси-ческий
модуль, реализующий
так называемый
блок "прагматической
грамматики".
Эта грамматика
представлена
здесь в виде
сети и основывается
не на таких
синтаксических
категориях,
как подлежащее,
сказуемое,
определение,а
на семантических
- "поездка","ли
ад", "расстояние".
Словарь itvim включает
1100 словоформ
[185, I8yJ
Прагматическая
грамматика,
хотя и жестко
связана с
проблемно-ориентированным
языком, очень
удобна длк
обеспеченля
простых принципов
использования
синтаксических,
семантических
и прагматических
ограничений
языка, которые
необходимо
делать для
повышения
точности
интерпретации
высказывания.
По-видимому,на
перво» этапе
построения
автоматических
систем понимания
речи целесообразно
так и поступать,
т.е. разделить
задачи использования
словарями
(например, при
автоматическом
машинном переводе
текстов) и
использованием
синтаксиса
и семантики
для построения
СПР. dc ьтором
случае задача
несколько иная
- и более сложная,
и боле( простая.
С одной стороны,
нет уверенности
в правильном
распоэ навании
всех составляющих
высказывания;
неясно, существуют
я'
36
вообще пробелы
(паузы, междометия
и т.д.) на временной
оси,где искать
ключевые слова
и пр. Но с другой
стороны, мы
ограничиваемся
достаточно
простым
проблемно-ориентированным
языком с относительно
небольшим
словарем и
упрощенными
грамматическими
конструкциями.
В системе
нто,1 акустическая
информация
используется
блоками
акустико-фонетического
распознавания
( apr) и
периметри-чеокой
верификации
слов ( ?та ). Результатом
работы APR является
фонетическая
транскрипция
"снизу-вверх".
Блок pvw осуществляет
верификацию
"сверху-вниз",
води словесная
гипотеза
поддерживается
акустическим
уровнем. Основной
программный
модуль верификатора
- программа
синтеза слов
по правилам.
Отдичие
системы h.'.'im от
Speechlia заключается
также и в характере
акустико-фонетического
распознавания
- в наличии у
системы HWIM блока
селективной
модификации
( зМ), дающего
возможность
реализовать
двухступенчатую
сегментацию
и маркировку.
Программа SM
на выходе порождает
решетку сегментов,
представляющую
возможные
альтернативы
фонам. Каждый
из сегментов
первоначально
маркируется
одной меткой.
Затем в зависимости
от этой предварительной
классификации
вычисляются
некоторые
величины
аку-отичаских
параметров
и модифицируются
оценки данных
фонем. Функции
пяотности
вероятностей,
используемые
блоком сеяективной
модификации
sM, поступают
в бяок агер (
Acoustic Rionetic Experiments Facility ), который
содержит модули,
позволяющие
моделировать
звуки речи и
проверять
параметрические
многомерные
распределения
вероятностей
для ряда фонетических
классов, что
дает возможность
полнее использовать
многие независимые
параметры
одновременно.
Программа
ан? выделяет
не только грубые
классы фонем,
но и производит
идентификацию
внутри классов.
Характеристики
фонам в слитной
речи сильно
зависят от
контекста, т.е.
наблюдается
наличие нескольких
аллофонов, для
которых оценки
сильно перекрываются.
Поэтому в hv/im для
каждого класса
фонем устанавливается
ряд фонетических
признаков и
используется
таблица, в которой
показано ранжирование
этих признаков
для аллофонов
каждого класса.
После сегментации
высказывания
и построения
сегментной
решетки, перекрывающей
высказывайте
отрезками,
соответствующими
фонемам, блок
управления
вызывает процедуру
лексического
поиска для
сканирования
вдоль всей
сегментной
решетки и поиска
Ib наиболее
подходящих
слов. Из-за большой
неопределенности
на стыках
37
слов эту
процедуру
проделывают
слева направо
и справа налево.
Сяова, отобранные
процедурой
лексического
поиска, образуют
словесную
решетку, где
они используются
при последующей
обработке. Блок
управления,
выбрав из УО
отобранных
при сканировании
слов одно с
наибольшим
весом (получившее
наибольшую
оценку).пытается,
основываясь
на прагматической
грамматике,
строить гипотезу
о большем отрезке
сигнала. Если
расширение
гипотезы не
получается,
блок управления
берет следующее
(по вес^) слово
словесной
решетки; если
это слово подходит,
то расширяют
двухсловную
гипотезу, если
же нет, то подбирают
новое ключевое
слово.так продолжают
до тех пор, пока
не будет построена
гипотеза обо
всем высказывании.
Если система
не в состоянии
сформировать
правильную
гипотезу о
фразе или если
исчерпаны
ресурсы, то
считается,что
система не
смогла интерпретировать
высказывание.
При расширении
гипотезы блок
управления
вызывает
синтаксическую
компоненту,
которая дает
возможность
оценить гипотезу
и предсказать
новые слова.
Синтаксическая
компонента
помечает каждое
слово словесной
решетки, которое
можно использовать
для расширения
гипотезь', и
устанавливает,
какие еще слова
требуются для
подтверждения
этой гипотезы
("подсказка"
сверху). В связи
с последним
могут быть
произведены
дополнительные
сравнения с
эталонами для
проверки, нет
ли в текущей
реализации
высказывания
необходимых
слов.
После того,
как синтаксическая
компонента
("прагматическая
грамматика")
сделала свои
предположения
слов слева
направо, она
вызывает процедуру
лексического
поиска для
проверки новых
гипотез о словах.
Оценки слов,
оценки гипотез
об отрезках
фразы и оценки
фраз ("событий",
как их называют
разработчики
Wi'iu ) влияют на
общую стратегию
интерпретации
высказывания.
Событиям
присваиваются
очки, приблизительно
равные сумме
очков слов
подтвержденной
гипотезы и
слов, требуемых
для расширения
этой гипотезы,
Попробуем
рассмотреть
пример, из которого
станет ясно,
как работает
механизм
анализа предположения,
основанный
на так называемой
"островковой
стратегии".
Пусть на вход
системы поступила
фраза:
"What Is the total budget figure ?"(Какова
общая сумма
бюджета?). При
просмотре фразы
справа налево
процедура
лексического
поиска формирует
таблицу:
17 17
24
22 11
182
178 174
-38
-10
-R
-d
-R
1. FIGURE
2. FIGURE
3. TOTAL
38
4. FIGURE1723169-535. YEAR2023107-23б.
УСУ2022100-317. IS3596-318. ABOVE10149409.
BUDGET111781-1610. IT6880-1611. IS2576-3112, ТО7973-4613^
WOULD0372-3114. -34572015, FIGURE172169-38Слева
направо16. TOTAL -
ED71?1971017. FIGURE1724182018. WHAT03178019. PIOURE1722178-3820.
TOTAL711174-1021, FIGURE1723169-5322. HJDGET1117154-1623.
VKAH2023107-2324. YOU2022100-3125. IS3596-3126. FIGURE -
ED172389-3827. FIGURE172883028. BUDGET111781-1629. IT6880-1630.
HIS2576-31
Список представляет
30 возможных
слов при сканировании
справа и слева,
позиции правой
и левой конечных
сегментов
слова, очков,
которые получило
данное слово
при сравнении
эталонов с
участками
входной реализации
на местах между
начальной и
конечной точками
гипотезируемого
слова, логарифма
вероятности
произнесения
данного слова.
Список может
описывать некие
специфические
свойства, связанные
с произношением
(здесь всюду
пропуски - -), а
также показывать,
справа или
слева производилось
сравнение с
эталоном (здесь
показатели
R и L).
Анализ списка
гипотезируемых
слов показывает,
что больше
всего очков
набрало слово
totaled (при сканировании
слева направо).
Бто слово занимает
в словесной
решетке позицию
от сегмента
7 до сегмента
12 и имеет вес
197. Для этого слова
соа-
39
дается однословная
гипотеза, которую
должна расширить
синтаксическая
процедура. Но
прагматическая
грамматика
не позволяет
формировать
фразу с этим
словом в прошедшем
времени. Следовательно,
никакого предсказания
о возможном
контексте с
этим словом
сделано Сыть
не может. Следует
перейти к следующему
(по оцен. не в
очках) слову
figure . Отметим, что
существует
семь различных
сравнений с
этим словом
примерно в гом
же месте высказывания,
немного отличающихся
очками.(Это
объясняется
различными
фонологическими
эффектами на
концах слова,
возможностями
различной
сегментации
в сегментной
решетке и
различными
возможными
произнесениями
этого слова,
отраженными
в эталонном
фонетическом
графе; в кашем
случае все
связано с
неопределенностями
сегментации
этого слова
в конце.) Вообще
говоря, то, что
одно слово
встречается
в списке вероятных
кандидатов
несколько
раз, является
хорошим признаком
того, что это
слово действительно
присутствует
в высказывании,
Чтобы избежать
избыточной
обработки,
авторы вводят
понятие "нечеткого
словесного
сравнения",
которое обобщает
сравнение с
эталоном одного
и того же слова,
появившегося
примерно в том
же месте. Всегда,
когда слово-кандидат
подобно figure встречалось
несколько раз,
при расширении
гипотезы используются
нечеткие границы.
Итак, для слова
figure предлагается
расширить
гипотезу.
При обработке
предложенного
слова (с примерно
известными
границами)
процедура
Syntax подбирает
слово виос-зт,
заканчивающееся
позицией 17. В
прагматической
грамматике
hwim слово budget может
использоваться
лишь в словосочетании
budget figure и, так как
это словосочетание
находится в
конце предложения,
никаких слов
справа больше
не будет. Блок
управления
использует
далее найденное
словосочетание
в качестве
расширенного
"островка
надежности"
для поиска слов
от позиции II
до начала
высказывания.
Обращаясь
к синтаксической
процедуре, блок
управления
обнаруживает,
что прагматическая
грамматика
допускает еще
несколько слов,
кроме слов из
списка, рассмотренного
ранее, для
расширения
этой гипотезы.
9то связано с
тем, что служебные
слова,которые
могут стоять
перед словосочетанием
budget. figure , имеют слишком
небольшой вес
(очки). В результате
сравнения
сегментов,
расположенных
слева от слова
budget , и эталонов
слов, допускаемых
прагматической
грамматикой,
получают новый
список, расширяющий
предыдущий
(в списке остаются
лишь слова,
оценки которых
превышают
40
33. OF 10
11 4 , - 16 - - Н
34. А
10 11 4 - 16 - - R
35. THE 911 -105 - 16 - -
R
36. THE 9
11 -105 - 16 - - R
37. OUR 10 11 -123 - 31 -
- R 3°. THE 9 11 -135 - 16 -
- R
39. - S 10 11 -140 0 -
- R
40. ANO 9 11 -163 - 26 -
- R
41. OUR 911 -169 - 46 - -
R
42. ME 9 11 -189 - 46 -
- R
Каждое из
этих слов может
расширить
гипотезу budget
figure слева. Посмотрим,
что выберет
блок управления.
Наиболее подходящим
(см. позиции 3
и ЯО) оказывается
слово total ,которое
используется
лишь с определенным
артиклем THE. Таким
образом, -удалось
объединить
уже четыре
слова THE TOTAL budget figure, для
которых синтаксическая
процедура в
словесной
решетке отмечает
слова "is" и "
s ", найденные
при первоначальном
сканировании
( - s- укороченный
глагол-связка,
допускаемый
правилами
произношения).
Синтаксис также
предлагает
и некоторые
другие слова,
но их оценки
(очки) меньше
100, тогда как is
имеет вео 96 (см.
позицию 7). Поэтому
переходим к
новой гипотезе
IS the total budget figure и пытаемся
ее расширить.
При расширении
гипотезы
синтаксическая
процедура
"подсказывает"
слова what и но'.'?
ыасн. Процедура
лексического
поиска выбирает
для начального
участка высказывания
слово v/hat с оценкой
176 очков и формирует
окончательную
гипотезу what IS the
total budget figure. Процедура
"синтаксис"
производит
в заключение
полный грамматический
разбор этой
фразы.
Описанная
"островковая"
стратегия
интерпретации
высказывания
одна из нескольких,
реализованных
в системе hwim .
Другие стратегии
используют
словесную
верификацию
на параметрическом
Уровне, предсказание
слов на уровне
диалога, просодическую
информацию
и т.д.
Испытание
системы hwim производилось
на двух словарях:
из 409 и 1097 словоформ,
124 предложения
произносили
трое дикторов"
"ужчин. Точность
интерпретации
высказывания
составила 52% в
первом случае
и 44% во втором.
Процент высказываний,
близких к
пра-видьным,
составил 23 и
20% соответственно.
Основное
отличие системы
VDMS (Voioe-Controlled Date Manage-roent Sis.) от ранее
рассмотренных
СПР Speeohlis.HWIM и Неаг-^-И
заключается
в тим, что в ее
основе лежит
синтаксис спон-
Зак.480
41
тайного
английского
диалога [182] ; это
позволяет
использовать
при общении
с системой
сильно "усеченные"
эллиптические
выражения СПР.
Система vdms использует
проблемно-ориентированный
язщ доступа
к информационно-поисковой
системе данных
о подводном
фаоте США,
Великобритании
и СССР. Общий
словарь языка
составлял 450
слое. Система
имела возможность
запонинать
информацию
о ранее произнесенных
фразах и декодировать
текущие, имея
результаты
рас познавания
предыдущих
высказываний.
В системе vdms при
интерпретации
предложений
наиболее полно
использована
идеология
искусственного
интеллекта.
Общая структура
vdms включает три
основь-ле компоненты:
1) акустико-фонетический
процессор, в
результате
работы которого
формируется
массив данных,
содержащих
информацию
о фонетическом
строении высказывания
(А-матрица);
2) процедуру
лексического
сравнения,
которая производит
сравнения
предсказываемых
слов, опираясь
на слоговой
уровень и используя
акустико-фонологические
правила;
3) лингвистический
процессор,
который содержит
блок грамматического
разбора (парсер)
и управляющий
блок диалогового
уровня (discourse level
controller )> вктоочающий
модель пользова-теяя
и семантическую
память.
Эксперименты
с vdms показали,
что речевой
сигнал ограничивается
по полосе на
частоте 9 кГц
и поступает
на 12-разрядный
аналого-цифровой
преобразователь,
где квантуется
с частотой 30
кГц. Затеи
оцифрованная
речь проходит
через ЦАП и
результирую
щая аналоговая
речь поступает
на три полосовых
фильтра, имеющих
полосы пропускания
I&0 - 190, 990 - 2200 и 8000 - 5000 Гц. Через
интервалы в
10 мс с фильтров
снимались два
параметра -
максимальная
амплитуда и
число нулевых
пересечений.
Полученные
шесть параметров
использовались
для грубой
акустической
маркировки
каждого
десятимиллисекувдного
отрезка.
Как только
слово поступает
в систему,
формируется
и хранится в
памяти информахцж
о нем, в частности,
отмечается,
сколько высказываний
тому назад это
слово было
произнесено
и былс ли оно
использовано,
насколько
вероятно, что
это слово
повторится
еще раз. В системе
учтено, что
различные
контекстные
слова предсказанные
тематической
памятью, "стареют"
от высказывания
ч высказывании
и вероятности
их использования
уменьшаются.
Вел* вероятность
предсказанного
слова Падает
ниже заданного
нaпepe^ порога,
то это слово
какое-то время
не рассматривается.Все
эт' в vdms выполняет
блок диалогового
уровня Discourse , являющийся
наиболее оригинальным
блоком системы.
Процедуры,
которые
42
реализует
Discourse, основаны
на изучении,диаюга
между двумя
людьми, совместно
выполняющими
некоторую
работу. Ьыло
найдено и
Досмаяизовано
влияние контекста
на характер
диалога,причем
рассматриваются
два вида контекстного
влияния. Глобальный
контекст обеспечивает
один вид ограничений
при интерпретации
высказывания.
Эти ограничения
используются
при идентификации
группы существительных.
Второй вид
ограничений
связан с текущим
контекстом
соседних
высказываний.
Они используются
при интерпретации
сокращенных,
эллиптических
выражений и,
в частности,
добавляют
дополнительные
фрагменты к
сокращенному
высказыванию.
В качестве
примера высказывания,
которое может
воспринять
система VDl'iS , ыож"
но привести
такое: "Напечатайте
типы подводных
лодок, на которых
больше семи
ракет".
СПР vdms - spi построена
на базе
проблемно-ориентированного
языка,доступного
информационно-поисковой
системе данных
о подводном
флоте США,
Великобритании
и СССР. Общий
словарь системы
составляет
450 слов [ 182] , Система
использует
синтаксис
спонтанного
английского
диалога, что
позволяет
запоминать
информацию
о ранее произнесенных
фразах и декодировать
текущие, используя
предыдущие
высказывания.
Система vdms-sri наиболее
полно использует
идеологию
искусственного
интеллекта
при интерпретации
устных высказываний,
которые могут
быть сильно
"усеченными".
Для испытания
системы была
проделана серия
опытов, которые
должны были
определять
наилучшую
структуру СПР
подобного
типа. Было испытано
16 экспериментальных
систем, которые
дали точность
интерпретации
высказываний
от 46,7 до 73,3%, причем
если итерировать
несущественные
оаибки распознавания,
то точность
(для наилучшей
конфигурации
системы) возрастает
до 81,7%. В [1в2~\
отмечается,
что наиболее
эффективной
помощью при
реализации
речевого диалога
оказались
использование
и проверка
контекста.
Начиная с
1976 г. начали появляться
работы о построении
СПР в Западной
Европе (Франция,
Италия, ФРГ),
Японии и СССР.Уровень
исследований
по СПР в этих
странах (объем
словаря,сложность
языка) пока
ниже, чем работ,
выполненных
в США по проекту
arpa. Сяедует, впрочем,
отметить, что
разработка
"малых" СПР
производится
в соответствии
с тенденцией
[145] , которая заклта-в»оя
в том, чтобы
"заполнить
пропасть" между
практическими
сис-^мами распознавания
слов и относительно
громоздкими
СПР, выполнившимися
по проекту
arpa.
В С142]приведена
таблица, которая,
по мнению автора,
характеризует
действительное
состояние и
будущее развитие
коммерческих
систем распознавания/
понимания речи
до 3000 г.:
431982 -
БИС для системы
распознавания
речи.
1985 -
Высокоточные
системы распознавания
изолированных
слов с большими
словарями.
1990 - Системы
автоматической
диктовки с
ограниченным
словарем,
управляемые
синтаксисом
языка.
I&95
- Системы
понимания речи
с неограниченным
словарем, но
с ограничениями
на синтаксис.
2000 - Системы
распознавания
слитной речи
с неограниченным
словарем и без
ограничений
на синтаксис.
§
1.4. Системы
автоматического
речевого ответа
1.4.1.
Коммерческие
системы автоматического
синтеза речи.
В системах
автоматического
речевого общения
"человек-ЭВМ"
важную роль
играет автоматический
речевой вывод,
позволяющий
человеку получать
необходимую
ему информацию
в привычной
форме речевого
сигнала. Проблема
автоматического
речевого вывода
считается более
простой, чем
автоматическое
распознавание
речи (в первом
случае речь
воспринимает
человеческий
мозг, -;
а во втором
- автомат).
Поэтому работы
по построению
систем автоматического
речевого ответа
(САРО) промышленность
получила раньше,
чем работы по
автоматическому
распознаванию/
пониманию речи.
Синтезаторы
речи,являющиеся
главными узлами
таких систем,
уже изготовляются
промышленностью
США, Японии и
некоторых
других стран
[30, 46, 51, 52, 100, 142] .
В саязи с появлением
микропроцессоров
и специализированных
БИС, а также в
связи с тем,
что пользователи
потребовали,
чтобы информационные,
управляющие
и другие подобные
системы, основанные
.на использовании
ЭВМ, "говорили",
фирмы, выпускающие
ЭВМ или отдельные
узлы ЭВМ, начали
выпуск оборудования
дея систем
речевого ответа.
Построены
первые промышленные
системы, который
обеспечивают
одновременное
автоматическое
распознавание
(автоматический
речеэой запрос"
с использованием
ограниченного
лексикона) и
речевой ответ.
Первое применение
такие системы
нашли в "интеллектуальных"
терминалах
больших ЭВМ
(или сетей ЭВМ),
в некоторых
системах военного
назначения,
в приборах
бытовой электроники
[52, 60, I40t
.
Следует
отметить также,
что продолжают
развиваться
научные исследования
в области создания
систем автоматического
синтеза. Эти
работы, направленные
в основном на
повышение
качества
(разборчивости
и естественности)
синтезируемой
речи (без существенного
повышения
объема информации,
требуемой для
управления
син-
44
двзатором),
проводятся
в США [103,
112, 129, 133, I??]
, СССР f48,
63, 54] , Японии
[l3b,I62] ,
Великобритании
[l64] ,
Канаде [167]
, Франции
[146 171] , Италии
[l60,JSl] ,
Мексике
[ill],Западной
Германии
[122, 184] , Норвегии
[137] и других
странах.
В
[142] отмечается,
что ЭВМ пятого
поколения
(мультиыикро-процессорные
машины) будут
гораздо шире,
чем современные
ЭЗУ, использовать
ввод и вывод
информации
в речевой форме.
Предполагается,
что уже в ближайшее
время ЭВМ,
оборудованные
системами
речевого вывода,
настолько
проникнут в
нашу жизнь, что
совершенно
изменят взаимоотношения
человека и
техники.
В основе
систем автоматического
речевого ответа,
поступающих
в настоящее
время на рынок,
лежат три основных
способа синтеза
рэчи -
непосредственное
кодирование
речевой волны
(дискрети-аация
и сжатие), форматный
синтез и синтез,
основанный
на линейном
предиктивном
кодировании
(линейном
предсказании).
В [б] приводятся
системы автоматического
речевого вывода
- наиболее
распространенные
в настоящее
время в США
системы такого
рода. Так, в сис-томч
Votrax процесс
формирования
устного высказывания
по тексту,
поступившему
из ЭВМ или с
клавиатуры
в закодированном
виде,начинается
о разбивки
текста на основные
звуковые влементы
- фонемы.
Так как фонемная
цепочка, соответствующая
тексту, не
обеспечивает
высокочастотной
речи, то эта
цепочка программно
преобразуется
в цепочку аллофонных
кодов (аллофоны
- это варианты
произнесения
фонем в зависимости
от контекста;
разные исследователи
называют различное
число аллофонов
для каждого
языка;в системе
Votrax используется
12Ь аллофонов,
что позволяет
получать более
естественную
речь). Для порождения
слитной речи
аллофоны Должны
плавно переходить
друг в друга.
Каждому
аллофону
соответствует
управляющее
слово, воздействующее
на аппаратный
синтезатор
звуков, который
в два этапа
перерабатывает
цепочку 12-разрядных
управляющих
слов. На первом
этапе Управляющее
слово декодируется
и перерабатывается
в аналоговые
управляющие
сигналы, задающие
частоту основного
тона, длительность
изменения во
времени амплитуды
и гармоник,
связанных с
каждым ал-Яофоном.
На втором этапе
реализуется
собственно
синтез. При
этом параметрические
сигналы, воздействуя
на генераторы
звука и прог-Рачмируемые
фильтры, преобразуются
в звуки речи.
Звонкие звуки
°оздаются с
помощью генератора
регулируемой
высоты тона,
а глухие
- с помощью
генератора
бел го шума.
В приборах
Texas Instruments три
большие интегральные
сис-^ы (БИС) моделируют
голосовой тракт
человека. В
основе модели
•вяит метод
линейного
предсказания
(или линейного
предиктивного
ко-
45
дирования
- ЛПК). При
ЛПК на
кристалл синтезатора
подаются значения
коэффициентов
для цифрового
фильтра второго
порядка,который
моделирует
динамику форматных
частот. Вычисление
коэффициентов
фильтра производит
другая БИС
- микропроцессор
тыз -1000. Третья
БИС хранит
отдельные части
слов в параметрическом
виде. Воссоздание
речи по этим
параметрам
осуществляет
сложный программный
алгоритм.
Преимущество
метода ЛПК
заключается
в тс-л, что он
позволяет
воспользоваться
тем фактом, что
голосовой тракт
человека
относительно
медленно меняет
свои параметры
при речеобразовании.Это
свойство ограничивает
диапазон изменения
форматных
параметров,
которые могут
следовать за
форматами уже
с генерированных
отрезков
звуков речи.
Такое прогнозирование
уменьшает
требования
к объему памяти
системы, а также
к скорости
обмена данными;
с описываемой
системой она
равна
1200 бит/с.
Синтезатор
National Semiconduoton Inc. способен
осуществлять
анаяого-цифровое
преобразование
речевых сигналов
и сохранять
их в памяти
для дальнейшего
восстановления.
Такой метод
предполагает
огромный объем
информации,
которая должна
храниться в
памяти, что
делает его
малопривлекательным.
Однако в рассматриваемой
системе эта
трудность
обходится за
счет использования
различных
методов сжатия
данных. Это
позволило
реализовать
качественный
синтез речи
во временной
области на
уровне &1С.
Дискретизацию
и сжатие исходной
речи, записанной
на магнитной
ленте, осуществляет
мини-ЭВМ. Результирующие
данные сохраняются
в постоянном
запоминающем
устройстве
(ПЗУ) для последующего
восстановления,
осуществляемого
БИС процессора
речи. Благодаря
применению
Трех методов
сжатия (подстройки
фазового угла,
дельта-модуляции
и полупериодного
обнуления)
скорость поступления
данных, по которым
восстанавливается
нормальная
речь, снижается
примерно до
1000 бит/с речи,
так что по ПЗУ
емкостью
10 кбит можно
хранить примерно
10 слов.
Процесс
сяатия начинается
с дискретизации
аналогового
речевого Сигнала
и разделения
цифрового
массива на
участки, в каждом
из которых
128 оГсчетов;
эти участки
в какой-то степени
характеризуют
периоды основного
тона. Для получения
набора цифровых
выборок, аналогичных
формируемому
предложению,
подстраиваются
фазовые углы
этих отрезков.
Дальнейшее
сжатие осуществляется
с помощью
дельта-модуляции,
в результате
чего вместо
хранения
абсолютной
амплитуды
каждой выборки
в память записываются
только знаки
приращения
амплитуд относительно
предшествующего
значения.
46
рассмотрим
далее более
подробно несколько
современных
систем параметрического
синтеза.
В ГЮО]
описана разработанная
фирмой
Texas Instrument a программа,
позволяющая
преобразовывать
произвольный
текст в речь.
Программа
совместно с
интегральным
синтезатором
речи типа
tms-5й00
позволяет
читать вслух
информацию,
отражаемую
на экране дисплея
домашнего
компьютера
9S14. В отличив
от Speak and Spell
система
не иоподозувт
записанные
ранее в ПЗУ
слова и фразы,
а синтезирует
слова из
128 аллофонов
(аналогично
системе
Votrax описанной
ранее), которые
объединяются
системой для
образования
слитной речи.
Программа
преобразования
текста в цепочку
аллофонов
выбирает аллофоны
из библиотеки
и определяет
их ударение
и интонацию.
Затем эта информация
поступает в
блок синтеза
речи, который
формирует
звуки, используя
кодирование,
основанное
на линейном
предсказании.
Блок-схема
преобразования
текста в речь,
реализованного
Texas Instruments,
представлена
на рис.I.I.
Аллофоны
имеют переменную
длительность
от 50
до 200
мс и кодируются
в соответствии
с параметрами,
необходимыми
для организации
синтеза, основанного
на линейном
предсказании.
Библиотека
аллофонов,
включающая
длинные и короткие
паузы, кодируется
по энергиям
и коэффициентам,
необходимым
для установки
характеристик
фильтра ЛПК-синтезатора.
Библиотека
аллофонных
кодов занимает
3 кбайта
памяти.
Для
преобразования
текста, поступающего
на вход в
пооледова-тедьность
аллофонов,
используется
набор из
650 правил,
который в процессе
испытаний
обеспечивал
правильный
выбор
97^ фонем и
92% аллофонов.
Правила занимают
7 кбайт
памяти. Программа
конструиро-
Синтез речи
Конструирование
речи (программное
формирование
кодовой аллофонной
цепочки)
| Входное |
Правила
преобразования
текста в аллофоны |
|
Преобразование
аллофонов
в данные для
синтезатора |
1 + 1 |
Центральный
Процессор |
| текст |
|

|
Управление
Память
|
|
Синтезатор
речи
тае-
5200
|
Речь |
|
|
.
1 { |
| Речевое
постоянное
запоминающее
устройство
tm S-6100 |
Р и с.
I.I. Блок-схема
преобразователя
"текст
- речь'
47
вания связывает
и сглаживав!
переходы между
ними. В результате
формируется
кодовая управляющая
цепочка аллофонов,
у которых
согласованы
энергетические
уровни и достигнута
плавность
огибающей, а
сглаживание
коэффициентов
фильтра делает
более плавными
переходы между
звуками.
После объединения
аллофонов и
сглаживания
переходов
между ними в
аллофонной
цепочке должны
быть расставлены
ударения и
указана интонация
в соответствии
с метками
пользователя
при кодировании
входного текста.
Алгоритм
конструирования
речи устанавливает
частоту основного
тона только
для отмеченных
слогов.Управление
интонацией
основано на
градиентном
управлении
частотой основного
тона в ударных
слогах. В нейтральных
интонациях
безударным
слогам соответствует
среднее значение
частоты основного
тона, тогда как
ударные будут
располагаться
несколько выше
средней линии
тона. Наклон
создается
программой,
а пользователь
только помечает
ударные слоги.
Как уже отмечалось,
синтез речи
в системе
преобразования
"текст
- речь"
системы
Texas instruments основан
на линейном
пред-сказуемостном
кодировании,
являющемся
математической
моделью голосового
тракта, реализованной
в виде фильтра.
Коэффициенты
линейных
уравнений
фильтра, определяемые
путем анализа
естественной
речи, используются
в модели для
управления
"конфигурацией"
голосового
тракта при
формировании
речевого сигнала.
В системе
запоминаются
соответствующие
различным
аллофонам
коэффициенты
фильтра, коэффициент
передачи фильтра,
частота сигнала
возбуждения,используемого
для управления
фильтром. Система
Texas Instruments обеспечивает
[100] хорошее
качество речи
при использовании
ЛПК со скоростью
передачи информации
от 1200
до 2400
бит/с.
В Cl40]
отмечалось,
что разработанная
в 1976
г. система
дискретного
распознавания
слов
was, предназначенная
для ввода речевых
команд в ЭВМ
управления
огнем тактической
артиллерии,
использовала
систему речевого
ответа (обратной
связи)
YS фирмы
Vo-fcrax.
Блок речевс"
о ответа повторял
слова устного
донесения,
которые по
радио или
телефонному
каналу поступали
к корректировщику
стрельбы. В
случае, если
устная команда
распознавалась
машиной
верно,корректировщик
произносил
ключевое слово,
означающее,
что команда
может поступить
в систему управления
огнем.
В [30,129]
рассматриваются
новая интегральная
схема синтезатора
речи
sc-OI и система
для проектирования
словаря
cds-ii. Речевой
интегральный
синтезатор
sg-oi
реализует
фонемный синтез.
Для преобразования
фонем в параметры
речи используется
фо-
48
немный
контроллер.Синтезатор
работает с
внешней памятью,
где хранятся
6-разрядные
коды фонем. В
отличие от
системы
Texas Inntru-ments синтезатор
sc-OI использует
для моделирования
голосового
тракта человека
не кодирование,
основанное
на линейном
предсказании,
а более традиционный
метод, основанный
на применении
аналоговых
полосовых
фильтров, на
вход которых
поступают
сигналы возбуждения
от генератора
с регулируемой
частотой,
моделирующего
работу голосовых
связок, и от
генератора
псевдослучайных
сигналов,
моделирующего
шумовой источник.
На входе
синтезатора
SC-OI стоит
фонемный контроллер,
который преобразует
код фонемы (их
64) в матрицу
спектральных
параметров.
Контроллер
же может изменять
частоту основного
тона;
что позволяет
устранять
монотонность
звучания
синтезированной
речи. Управление
синтезатором
осуществляет
генератор
синхронизирующих
импульсов,
находящийся
в интегральной
схеме. Управление
час-'тотой
основного тона
производите"!
внешним воздействием
на источник
тонального
сигнала.
После поступления
кода фонем на
фонемный контроллер
последний
в соответствии
с тем, какой
звук должен
быть порожден,управляет
моделью голосового
тракта, воздействуя
на цепи с
переключаемыми
емкостями.
Длительность
каждой фонемы
устанавливается
в пределах
50 - 250 мс.
Фонемная
информация,
поступающая
на вход, создается
программой
преобразования,
которая анализирует
тексг, вводимый
в память из
ведущей ЭВМ
или с клавиатуры.
В кодах фонетических
сим-всдов,
формируемых
этой программой,
содержатся
числа, означающие
длительность
генерируемого
звука, которая
зависит от
ударения.
Информация
для синтезатора
sc-OI вырабатывается
системой для
проектирования
словаря типа
cds
-II,
на входной
клавиатуре
которой набираются
слова или фразы,
подлежащие
синтезу. Система
базируется
на микропроцессоре
типа 6У08 фирмы
Motorola.Дд-горитм
преобразования
"текст-речь"
и операционная
система занимают
24 кбайта
ПЯУ и рабочую
часть оперативной
памяти емкостью
2
кбайта. Выходная
информация
ciis-11 используется
для программирования
памяти стираемого
ПСУ, где хранятся
данные для ИС
синтезатора.
Для программирования
ПЗУ информация
из cds-ii
передается
последовательным
кодом в ведущую
ЭВМ (которую
можно использовать
для перевода
слов в фонемы),
ленточный
перфоратор
или другое
устройство
с целью последующей
записи в ПЗУ.
В систему
проектирования
словаря входят
также печатающее
устройство,
позволяющей
печатать речевую
информацию
в шестнадцатиричном
коде (исполь-
зaк.480
49
ауя, как отмечено,
6 бит на
фонему), а затем
вручную вводить
в программатор
ПЗУ.
Наряду с
системой
cDy-II ^той же
фирмой выпускается
универсальный
речевой модуль
fYHtl), не обладающий
возможностью
преобразования
текста в речь.
В памяти этого
устройства
в табличном
виде записаны
коды 1300
слов, а также
25 суффиксов
и префиксов.
Как и система
проектирования
словаря
cds-ii,
УРЫ включает
в свой состав
микропроцессор
типа 6806.
Он также содержит
синтезатор
типа ас-01,
операционную
систему, хранящуюся
в ПЗУ емкостью
2 кбайта,
таблицу слов,
записанную
в перепрограммируемом
ПЗУ емкостью
2 кбайта,
и I
кбайт рабочей
области оперативного
запоминающего
устройства.
УРМ можно
использовать
в качестве
рабочего модуля
а различной
аппаратуре.
При этом модуль
может управляться
внешним процессором
или ведущей
ЭВМ.
Некоторые
сведения о
других синтезаторах
содержатся
в [51, 52, 55, 142].
1.4.2.
Повышение
качества
синтезируемой
речи. Несмотря
на появление
коммерческих
систем автоматического
речевого
ответа,синтетическая
речь еще ке
качественна.
Поэтому в
лабораториях
мира продолжают
энергично
работать над
проблемой
синтеза речи.
В трудах ежегодных
международных
конференций
по акустике
речи и обработке
сигналов, которые
проводятся
Институтом
инженеров по
электротехнике
и радиоэлектронике
США с 1976
г., большинство
докладов посвящено
автоматическому
синтезу. Работы
относятся к
самым различным
языкам.
В С 115]
описана разрабатываемая
для шведского
языка система
"текст-речь",
базирующаяся
на правилах
перевода буквенной
информации
в фонетическую.
Система синтеза
состоит из
последовательности
преобразований,
каждое из которых
отражает часть
знаний о речевое
процессе. Отмечается,
что для получения
качественной
речи целесообразно
математизировать
использование
таких просодических
параметров,
как длительность
звуков и интонация.
При формализации
правил преобразования
был использован
опыт работ
по созданию
систем "текст-речь",
проводимых
в США, и учтен
тот факт, что
фонетическое
представление
высказываний
в шведском
языке бо-яее
простое, чем
в английском.
Наибольшие
трудности
вызывает поиск
в неразмеченном
знаками ударения
тексте ударных
слогов, а также
слогов вторичного
ударения
( aecondary stressed
syllable ).
Во время этого
поиска следует
использовать
различные
ключевые индикаторы,
такие как сдвоенные
гласные, некоторые
окончания и
комбинации
гласных с
согласными,
образующими
ударные слоги.
50
разработаны
основные правила
преобразования
фонетической
цепочки в
синтезированную
акустическую
волну.Эти правила,
для формализации
которых создан
специальный
язык, работают
на сегментном
уровне. Например,
правило, определяющее
длительность
сегмента,
запювется<"segment>—<
DURATION -
Т *
ЙХР (-ЬОО(В)*
0,12 - LOG(A>*
«
0,35)> ,
где Т
- номинальная
длительность;
А,В,С, -
переменные,
зависящие от
позиции и
длительности
слова или фразы.
В [Иб] сообщается
о системе речевого
синтеза, разработанной
для английского
языка в
Bell Laboratories. Система
обеспечивает
более высокое
качество
синтезируемой
речи за счет»
I) более
точных правил
определения
длительности
звуков речи,
основанных
на измерениях,
которые продесаны
на участках
естественной
речи; 2)
расширяющихся
правил учета
аллофонических
изменений как
функции словесных
и других границ;
3) введения
большого числа
правил просодии
нижнего уровня,
учитывающих
особенности
речеобра-эования
(ассимиляцию
звуков, изменения
внутри звукосочетания
согласных,
контекстную
зависимость
гласных и т.д.);
4) правил,
учитывающих
медленные
изменения
параметров
модели голосовых
связок и шумового
источника
возбуждения.
Многие особенности
системы синтеза
речи
Bell Laboratories рассмотрены
также в С75,Ь9].В
[69], в частности,
довольно подробно
описаны свойства
просодии
английского
языка.Предполагается
различать
просодию высшего
(собственна
Просодические
функции) и просодию
низшего уровней
(их акустические
компоненты)
и использовать
правила просодии
для повышения
качества
синтезируемой
речи.
При исследовании
слитной речи
выявилось, что
в английском
языке:
- главный
фактор, определяющий
длительность
гласных,
- позиция
гласной в слове,
а слова
- в предложении
(или в синтагме);
гяасная имеет
наибольшую
длительность,
если она находится
в последнем
слоге перед
паузой; это
объясняется
особенностями
контура основного
тона перед
паузой, что
значительно
удлиняет гласный;
различие длительности
гласных в
предпауэальной
и непредпау-эальной
позициях
приблизительно
находится в
соотношении
2:1;
- последующие
согласные
укорачивают
длительность
гласного Ьо
сравнению с
некоторым
средним значением),
если за гласным
следует глухой
взрывной
(характеризуемый
смычкой), и удлиняют,
если за
гласным следует
звонкий фрикативный;
наибольшее
влияние на
длительность
гласных согласные
оказывают в
предпаузальной
позиции;
-.длительность
безударных
гласных, если
они не находятся
в конце слова,
составпяет
около
40 мс; в конечных
позициях они
Содее длительны;
51
- дифтонгизация
сильно удлиняет
гласную;
- на
длительность
согласных
основное влияние
оказывают
2 фактора:
положение
согласной
относительно
ударного сдога
и границ слова
или предложения
и консонантность
окружения;
- длительности
консонантных
согласных (а
именно глухих
фрикативных
f,s,S)
подчинены
точному аддитивному
правилу, ударение
и границы слова
действуют как
факторы приращения,
а согласные
, смежные
с фрикативными,
действуют как
фактор укорачивания;
- наибольшее
непостоянство
длительностей
в зависимости
от ударения
и позиции проявляют
переднеязычные
согласные
t , d, n
',
-
звонкие Фрикативные
в середине и
конце счов
значительно
короче глухих
фрикативных,
находящихся
в такой же позиции;
- влияние
окружающих
согласных на
длительность
конкретной
согласной
зависит от
способа и места
их артикуляции;
длительность
согласной
зависит также
от степени
консонантности
ее окружения;
- в связи
с этим комбинации
двух последовательных
согласных,
характеризующихся
одним и тем
же местом
артикуляции,
проявляют
тенденцию к
уменьшению
длительности
обеих, например,
пй и
nt;
звонкие
фрикативные
обычно удлиняют
соседнкж. согласную;
- длительность
плавных и
носовых,согласных
сильнее других
подвергается
воздействию
смежных согласных
с ослыпей степенью
консонантности,
влияние которых
проявляется
даже через
границы слов;
- начальная
согласная
функциональных
слов (артикля
и предлогов)
значительно
короче, чем в
случаях значимых
слов;
- легко
предсказуемые
слова обычно
состоят из
более коротких
гласных и согласных,
чем непредсказуемые;
- в
английском
языке согласные
в начале слова
могут обладать
другими акустическими
характеристиками,
чем те же согласные
в конце слова
(это явление
называют селективной
аллофонией
в отличие от
позиционно
обусловленной
адлофонии,
связанной с
явлением
коартикуляции);
- начальные
аллофоны (по
сравнению с
конечными и
средними) имеют
более сильные
консонантные
признаки
- большую
прерывность,
четкость
интонационных
составляющих
(основного тона
и гармонической
структуры) в
потоке рачи,
более интенсивную
шумовую составляющую
фрикативных,
более сильный
взрыв с явным
участком аспирации
в глухих взрывных
и т.п.; эти свойства
начальных
аллофонов
нвняются признаками
начала сообщения,
обычно слова.
В С89] рассмотрены
и некоторые
другие свойства
просодии, положенные
в о&нову правил
преобразования
"текст
- речь" и
обеспечивающие
высокую разборчивость
и естественность
синтетической
речи.
52
вГ2]
подробно описана
лингвистическая
и фонетическая
сторона паботы,
которую необходимо
выполнить при
реализации
качественного
синтеза
речи по произвольному
тексту. Важнейшими
этапами иссяедований
здесь являются:
-
создание более
совершенной
модели речевого
тракта;
-
определение
более полного
набора абстрактных
правил лингвистического
описания текста;
-
разработка
полного свода
правил, позволяющих
вывести фонетические
описания по
правилам
лингвистического
описания текста
(дравид преобразования
букв в звуки);
-
формализация
морфофонематичаских
правил и правил
лексического
ударения, которые
дают на уровне
слов окончательную
коррекцию
цепочки фонем
(аллофонов);
-
грамматический
анализ предложений,
раскрывающий
иерархическую
природу
их построения
для определения
правильности
интонационного
контура;
-
более тщательное
иосдедование
просодических
коррелят
лингвистических
структур.
Отметим
особую важность
создания хорошей
модели речевого
тракта, параметры
которой изменяются
в соответствии
с правилами
ре-чвобразования.
Хорошая модель
позволяет
существенно
онизить объем
информации,
описывающей
форму речевого
сигнала (вырабатываемого
на Мходе модели
из небольшого
числа параметров),
а также более
глубоко и еотеотвенно
описать речевые
явления. При
параметрическом
синтезе информация
о фонемах (аллофонах)
запоминается
в виде комплекса
параметров
и правил модификации
отих параметров
под влиянием
различных
ограничений.
В связи о этим
для повышения
качества синтеза
необходимы
структурные
модели, отражающие
ащ
ограничения
на различных
уровнях
- артикуляторном,
дистрибутивом,
словообразовательном,
синтаксическом
и семантическом.
Эти иодеди
должны координироваться
гибкой структурой
управления,обео-почивающей
их взаимодействие.
Для
повышения
естественности
и разборчивости
речи, генерируе-"ой
форматными
синтезаторами,
в [176 ]
предлагается
использовать
вычисление
форматных
параметров
на более коротких
интервалах,
что позволяет
улучшило синхронный
с основным
тоном анализ.
1домен-т^
смыкания голосовых
связок характеризуются
импульсным
воабужде" нием.
На первом этапе
анализа оцифрованной
волны такие
точки воз-°Й<дения
легко выделяются
(со средней
точностью)
процедурой
пи-Чового
детектирования.
(Во время шумового
возбуждения
эти точки
^определяются
случайно, тогда
как при возбуждении
речевого сиг-
53
нала импульсами
голосовых
связок большинство
таких точек
соответствует
моментам смыкания
связок.) Даяее,
для каждого
отрезка волны
длительностью
10 мс с помощью
ДПФ вычисляется
33-точечный
логарифмированный
энергетический
спектр. Временные
отсчеты для
получения
спектра берутся,
начиная с момента,
соответствующего
найденной точке
возбуждения.
Если десятимиллисекундный
сегмент содержит
одну точку
возбуждения,
то логарифмы
энергетического
спектра вычисляются
по формуле
^
=
'°
Чю \ Ц, ^
ехр
(-^тп/32
\
'•
где п
= 0 - 32;
Л„, -
отсчеты речевой
волны, следующие
за моментом
возбуждения;
У -
оценка (в дБ)
логарифма
энергетического
спектра на
частотах
156, 25 х п
(в Гц).
Итеративный
анализ составляющих
этого спектра
и позволяет
оценить все
требуемые для
синтезатора
формантные
параметры.
Процедура
итеративного
анали-а посредством
синтеза (когда
спектр, синтезированный
по приближенным
формантным
параметрам
речи, сравнивается
с реальным
спектром входной
речевой волны,
и если расхождения
велики, производится
уточнение
формант) позволяет
получать параметры
качественной
синтетической
речи.
В ряде работ
подчеркивается,
что для повышения
естественности
синтезированной
речи целесообразно
разработать
хорошие правила
корректировки
микро- и макровариаций
частоты основного
тона, длительности
звуков и интенсивности.
Полная модель
генерации
частоты основного
тона, его микро-
и макровариаций
рассмотрена
в Ll04]
, где исследовались
различные
синтетические
структуры,
позволившие
выявить, в частности,
влияние модальности
на контур
основного тона
в вопросо-ответных
системах при
перемещении
центрального
слова фразы
(слово, на которое
делается акцент
при вопросе).
(Формирование
контура
ochobhofj
тона будет
более подробно
рассмотрено
в п.1.4.4).
В [113']
предлагается
для повышения
качества
синтезированной
речи (полученной
методом линейного
предсказания),
поступающей
на наушники,
использовать
эффект бинауральной
реверберации
который можно
смоделировать,
подав синтезированную
речь на громкоговоритель
и записав
(в условиях
реальной комнаты)
прошедшув
через громкоговоритель
речь в два канала
через разнесенные
микрофоны.
Полученные
таким способом
сигналы поступают
на правый и
левый наушники,
создавая у
слушателя
впечатление
более естест'
венной речи.
54
для
повышения
натуральности
речи в
[162] предлагается
про-записывать
на магнитный
диск больший
емкости сообщения
в Siawe
параметров,
представляющих
собой набор
раноон
-коэффициентов.
Требуемые фразы
считываются
в буферную
память. На
стомегабайтном
диске можно
таким образом
записать
5000 сообщений
яжительностыо
по 15
с каждое. Время
выборки сообщения
0,1 с,мак-симвльное
число возможных
каналов, по
которым может
поступать
информация,
- 128.
Ряд
работ, появившихся
в последние
годы, посвящен
повыше-шф качества
синтезированной
речи за счет
модернизации
модели источников
возбуждения.
Модель смешанного
источника
возбуждения
рассмотрена
в [1523 .
Смешение достигается
делением речевого
спектра на две
области
- низкочастотную,
возбуждаемую
импульс-нк«
источником,
и высокочастотную,
которая возбуждается
шумовым источником.
Для определения
степени оэвончения
вводится параметр
fc
•
показывающий
частоту отсечки
между звонкой
и глухой областями.
Для компрессии
речи
Fp может
выцеляться
автоматически
из речевого
спектра и
передаваться
в управляющие
цепи. Эксперименты,
при которых
использовалась
новая модель,
показали ее
эффективность
при синтезе
звонких фрикативных
и помогли ис-кяючить
характерное
"жужжание"
вокодерной
речи.
8 [166
3 описана
новая функция
возбуждения
для синтеза,использующего
коэффициенты
линейного
предсказания.
Эта функция
за счет соответствующего
сглаживания,
инверсной
фильтрации
и усечения
верхушки сохраняет
фазовые характеристики
импульсов
возбуждения,
Поступающих
из голосовой
щели. Отмечается,
что качество
речи
при этом существенно
улучшается,
а между тем до
последнего
времени в
lpg-синтезаторах
слишком мало
усилий было
направлено
на поиск более
соответствующих
реальным функций
возбуждения
рачаобразующего
тракта из-за
того, что не
были установлены
четкие соотношения
между остатком
линейного
предсказания
и формой возбуждающей
волны.
В
[137] описан
LPU-синтеэатор
речи, разработанный
в Норвегии.
По мнении авторов,
он обеспечивает
высококачественную
речь (при высокой
компрессии)
за счет использования
более совер-аенной
модели смешанного
возбуждения.
В модели предусмотрено
использование:
-
фильтра импульсов
основного тона
- двухполюсного
фильтра, Делающего
импульсы возбуждения
более похожими
на реальные
импуль-^i
поступающие
с голосовых
связок в полоогя
речеобрааующего
тракта;
55
Орфограф^еский
текст
I
Трансляция
"графема-фонема"
фонетическая
цепочка
-
фильтра, моделирующего
влияние излучения
речевого потока
с губ
(liP -
radiation filter)!
-
дополнительного
фрикативного
источника,
который автоматически
подключается
при формировании
звонких взрывных
и фрикативных.
Ряд работ,
связанных с
повышением
качества
синтезированной
речи, относится
к проблеме
формализации
правил наложения
на фонетическую
цепочку интонационного
контура. Они
-Зудут подробно
рассмотрены
в п. 1.4.4.
1.4.3.
Дифонный синтез
речи. Одним
из направлений,
обеспечивших
синтез более
высококачественной
речи, стало
направление,
связанное с
выбором иной,
чем фонема (или
аллофон) структурной
единицы, лежащей
в основе формирования
высказывания.Выяснилось,
что основные
неприятности,
приводящие
к ухудшению
естественности
и разборчивости
речи, связаны
с явлениями
на стыках звуков.
Поэтому в ряде
последних работ
по автоматическому
синтезу речи
в качестве
опорного элемента
выбирается
участок речевого
сигнала, включающий
переход между
звуками. Такие
элементы называют
"диадами",
"дифонами",
"транземами",
парами фонем,
машинными
слогами...
В Ll433
описан диадный
синтез французской
речи. В памяти
хранятся эталоны
1000 дифонов
(пар фонем),
представленных
спектром,
полученным
с гребенки
фильтров (отсчеты
спектра брались
каждые
13,3 мс) и частотой
основного тона.
Система предусматривает
использование
довольно простой
грамматики
для сцепления
диад и автоматического
определения
просодии фразы.
При обработке
цепочки диад,
соответствующей
тексту для
генерации
синтезируемой
волны, корректируются
длительности
звуков, микро-
и макровариации
частоты основного
тона, контур
интенсивности.
Дифонный
синтез рассматривается
и в [.1463 .
Блок-схема этой
системы "текст
- речь"
приводится
на рис.
1.2.
Система
юорвомйз
(рис."1.2
) превращает
орфографическую
запись предложения
в звучащую
речь. Скорость
преобразования
0,1 с на предложение,
состоящее из
70 символов.
Система, включающая
мини-компьютер,
является полностью
автономной.
Преобразование
"текст
- речь" в
первом приближении
не требует
синтаксического
анализа структуры
предложения
(во французском
языке). Основным
графическим
понятием при
преобразованиях
является в
этой системе
слово, представляющее
собой субцепочку
графем между
пробелами или
знаками пунктуации.
Слова сравниваются
со списком
предварительно
записанных
слов -
исключений,
произношение
которых
не соответствует
стандартам.
Если слова в
спис-'
Ь6
Последовательность
дифснов Словарь
дифонов
Буфер
Синтезатор
речи из
44 синусо-
|___гт1
гх,.,. ___идальных
колебаний____
UJ -
рис.
1.2. Блок-схема
системы "текст
- речь"
основанной
на использовании
дифонов
ке исключений
нет, оно разделяется
на множество
буквенных
символов,
которые обрабатываются
элементарными
правилами типа
Р—[Р]/Н;
P—[f]/H,
т.е. р
произносится
как [/?] ,
если за ней не
следует Н,
и как [/З.всли
следует Н
.
Числа,
встречающиеся
в тексте, также
преобразуются
в фонетическую
цепочку по
соответствующим
правилам. Последняя
гласная перед
знаком пунктуации
удваивает
длительность.
Общий объем
памяти,
которую использует
этот алгоритм,
6 кбайт.
В память
словаря должно
быть записано
для французской
речи 627
дифонов. Однако
если учесть,
что для некоторых
дифонов некоторые
спектры в первом
приближении
можно считать
симметричными,
обв(ее число
хранящихся
в памяти дифонов
уменьшается
до 425
(при использовании
параметров
8 временных
отрезков каждого
дифона). Ойций
объем памяти
после сильного
сжатия информации
о дифонах составил
около
8 Кбайт.
Средняя разборчивость
слов в предложениях
была около
96%. Система
автоматически
находила по
тексту просодические
характеристики.
Для управления
просодическими
параметрами
использовались
различные
уровни языка:
акустический,
фонетический,
лексический,
синтаксический
и семантический.
Несколько
Дикторов читали
один и тот же
текст; при этом
сравнивались
кон-'Уры основного
тона и длительности,
полученные
после нормализации.
Несмотря на
различие' в
индивидуальных
просодических
характери.-^чках,
удалось выявить
общие закономерности,
позволяющие
форма-
Зак.480
57
дизовать
просодику по
фонетической
цепочке. Так,
для выявления
динамики основного
тона на всем
высказывании
учитывалось,что
од, повременно
накладываются
друг на друга
три явления.
Первое обусловлено
изменением
основного тона
на всем предложении,
второе -контуром
основного тона
на двух соседних
словах ( "элементарный
контур") и третье
- ыикроваризции
основного тона
на отдельных
звуках.
Структура
системы синтеза,
основанного
на объединении
ди-фонов, рассмотрена
также и для
итальянского
языка [160, 181].Ди-фоны
представлены
кодами
lpc.
Система
проектируется
с ориентацией
на многоканальность
и ответ в реально».'
времени. Для
каждого выходного
канала этой
системы автоматического
речевого ответа
выполняются
действия:
предварительная
обработка
входной цепочки
символов, трансляция
в соответствующую
последовательность
дифонов, порождение
просодического
контура и управление
в реальном
времени аппаратурой
синтезатора.
Блокл
речевого ответа,
подключенные
к телефонным
линиям, могут
обеспечивать
пользователям
получение
информации
в речевом виде.
Основное применение
такого оборудования
- информационно-поисковые
системы, читающие
текст автоматические
устройства
для слепых,
в связи с чем
к системе
предъявляются
требования:
неограниченный
словарь, хорошее
качество и
естественность
речи, возможность
подключения
систем речевого
ответа к разным
каналам.Матобе
с-печение выполняет
все действия,
необходимые
для преобразования
входного текста
в последовательность
команд, необходимых
для управления
аппаратурой
синтезатора,
описанного
в [160].
Система
синтеза основывается
на объединении
коротких речевых
элемэнтов
(дифонов), которые
включают переходный
участок от
согласного
к последующему
гласному
CV
,
квазистационарный
участок гласного
V2
и начальный
участок гласного
звука в начале
слова VI.
Элементарные
дифоны, извлекаемые
из естественной
речи, кодировались
в соответствии
с акустической
моделью речеобразова
ния. Математическая
модель состоит
только из полюсного
фильтра, представляющего
вокальный
тракт, и источника
возбуждения.
Параметры,
описывающие
вокальный
тракт, - это
коэффициенты
отражения
неоднородной
акустической
трубы, подученные
использованием
методе линейного
предсказания.
При
записи информации
о дифонах в
память используется
следующая
схема. Первый
байт каждого
дифона показывает
число сре' зов,
Используемых
для кодирования
втого дифона.
После атог»
каждый фрейм,
кодирующий
срез дифона,
описывается
13 байтами;
56
представляющими
коэ^ициент
усиления
G
,10 ко-^ициентов
отражения
К,
. параметр
озвонченности
V/UV
и длину
D
этого фрейма.
В среднем для
кодирования
дифонов приходится
около
7-6 фреймов.
Общий объем
памяти для
запоминания
150 дифонов
- около
15 кбайт.
Наиболее
важным преимуществом
дифонного
синтеза, обеспечивающим
довольно высокую
естественность
синтетической
речи, является
возможность
отгэсительно
легкой модификации
просодических
параметров.
Просодический
контур порождается
правилами,
которые используют
знание фонетической
природы дифонов
и символы, вводимые
модулями
предварительной
обработки.
В [I77J
рассмотрен
разработанный
в США фирмой
ВВЫ дифон" ный
синтез для
фонетического
вокодера, работающего
со скоростью
100
бит/с. С каждой
финемой вокодер
передает ее
длительность
и значение
одного периода
основного тона.
Для синтеза
необходимой
фонемной цепочки
использовался
большой список
дифонов. (Список
дифонов отбирался
таким образом,
чтобы можно
было различить
предвокальные
и пьствокзльные
аллофоны сонорных
согласных.)
ду-фоны
извлекались
ис тщательно
сконструированных
бессмысленных
коротких предложений
и запоминались
как последовательность
LK3-параметров.
Во время синтеза
участки дифонов
деформировались
во времени,
смыкались и
сглаживались,
формируя
последовательную
цепочку
LPC- параметре
в, которая
использовалась
при синтезе.
Дифон определялся
как область
от середины
одной фонемы
до середины
следующей, что
учитывает
коартикучяционное
влияние фонем,
простирающееся,
как правило,
не более чем
на половину
следующей
фонемы. Для
получения
высококачественной
речи потребовалось
около
2000 дифонов.
В некоторых
случаях были
записаны
необходимые
Трифоны (дифоны
в контексте).
Общий объем
памяти, используемый
при синтезе,
менее
50 килобайт.
В Японии
разработан
кепстральный
синтез речи
из параметров
слогов "согласный
- гласный",
которых в японском
языке около
100
Cl38j . Каждый
слог анализируется
и запоминается
в виде кепстра,
соответствующего
истинной (сглаженной)
логарифмической
спектральной
огибающей
(a true log spectral envelope
).Система
речевого синтеза
превращает
цепочки символов
в кепстральные
параметры
с плавным и
динамическим
переходом от
одного слога
к следующему
и порождает
плавную картину
изменения
частоты основного
тона. Основным
узлом модели
преобразования
кепстральных
параметров
в акустическую
волну является
специальный
фильтр, порождающий
акустическую
волну из кепстра
в реальном
времечи.Экспериментальное
матобеспечение
для реализации
автоматического
син-
59
теза
речи, основанного
на подусдогах,
описано в [184] . Ддя
синтеза произвольного
текста на немецком
языке используется
около 1300 подуслогов,
включающих
часть гласного
и примыкающие
кусочки согласного.
Описаны эксперименты,
которые помогли
выбрать правила
соединения
полуслогов.
Синтез выполнялся
с помощью
LPO-вокодера,
использовавшего
parcor-
коэффициенты.
Отмечается,что
в немецком
языке используется
47 начальных и
153 конечных
звукосочетания
согласных с
16 типами гласных.
Уменьшение
словаря подуслогов
было осуществлено
за счет уменьшения
числа гласных
(до 10) и конечных
звукосочетаний
с согласными
(до 53). Программа
синтеза автоматически
контролирует
амплитуду и
длительность
полуслогов,
формируя безударные
слоги из эталонных
ударных.
1.4.4.
Просодика
синтезированной
речи.
В [184] рассмотрено
управление
просодическими
параметрами
для форматного
синтезатора,
основанного
на соединении
дифонов и
разработанного
для немецкого
языка. Синтезатор
используется
в системе речевого
ответа
sam',
позволяющей
формировать
фразы, составленные
из словарей
большого объема.
Используются
параллельные
форматные
фильтры, которые
возбуждаются
независимо
источниками
тона или шума.
Параметры
управления
фильтрами
вырабатываются
специальным
блоком pcu
,
который является
частью системы
samt
•
Тексты, которые
должны быть
синтезированы,
вводятся в
pcu
как
звуковая
последовательность;
каждый звук
кодируется
восьмью битами.
Дальнейшая
обработка в
рои базируется
на дифонах,
чтобы наилучшим
образом учесть
влияние коартикуляций.
Для управления
просодическими
параметрами
синтезируемой
речи необходимо,
чтобы звуковая
последовательность
включала коды
управления
просодией. (Эти
коды должны
влиять на частоту
основного тона,
длительность
звуков и интенсивность.)
В
[122] отмечается,
что интонационная
модель для
немецкого
языка уже
разработана.
В соответствии
с этой моделью
каждое предложение
разделяется
на две или более
синтетические
группы (фразы),
такие, как фраза
существительного
(не всегда
совпадающая
с группой
подлежащего),
глагольная
фраза и т.д.
Изменение
частоты основного
тона первых
г»-1 фраз завершается
повышением
тона (нарастающей
каденцией
ffC
), а завершающая
предложение
фразе - снижением
частоты основного
тона (финальная
каденция
FC
).
Дня каждого
слова фразы
можно найти
один ритмозадающий
ударный слог,
а для каждой
фразы - одно
слово, которое
несет главное,
смысловое
ударение
Ml
.
Позиция гласного
в ударном слоге
этого саова
1^,, , определяющем
ударение, дает
начальную
точку двух
различных типов
частоты основного
тона /д . Характер
60
affix Jfl
к&чаственн0
определяется
типом каденции
( /ус-тип
или pC-isW)
1 количественно
- другими
факторами,
такими, как
длина г«всного
или позиция
главного ударения
во фраае.
В доподнение
к каденции, на
изменение /^
влияют основное
И вторичное
ударения
( S
и SS
). Во фразах
слитной речи
ударе-ijgg
появляются
тогда, когда
необходимо
выделить некоторые
олова (дроиэнести
их бояее выразительно)
или когда в
беглой речи
о^вдиняютоя
две последовательные
фразы с нарастающей
каденцией. Яде
обоих типов
ударений находится
характер изменения
основного
тона (
S-vw f^
) на участках,
начальные точки
которых определяются
позицией гласных
ударных слогов.
Естественная
речь большинства
дикторов
характеризуется
постепенным
снижением
частоты основного
тона (примерно,
на полтона
lie)
от начала к
концу фразы.
(При формировании
синтетической
речи это следует
учитывать, так
как речь с постоянной
f, неприятна
на слух, монотонна.)
На этот основной
тип /д
нак-хддюаются
НС-,
FC- и Я-тилы
основного тона.
Нарастающая
ка-данция
характеризует
возрастание
f
в конце гласного
V^,
, не-суцего
основное ритмическое
ударение
( the main )
• Для точной
идентификации
типа /д необходимо
различать два
случая)
а) V^i
- последний
звонкий звук
фразы;
б)
наличие других
звонких между
Ущ
и концом
фразы.
Исследования
показали, что
в обоих случаях
частота основного
тона нарастает
по синусоидальному
закону, но ъ
одучае а) время
нарастания
120 мо, а в случае
б) - 190
мо.
Частота
fy
возрастает
от двух до четырех
полутонов.
Поо-ае того,
как f,
достигнет
верхней границы
(по синусоиде),
она продолжает
медленно возрастать
по линейному
закону оо скоростью
оолтона в
I о. Абсолютные
отклонения
частоты
Af
естественной
речи сильно
меняются от
диктора к диктору.
Ддя синтетической
рв«р| однако
эти отклонения
не должны быть
слишком велики.
Если -ажду главным
ритмическим
ударением и
концом фрааы
содержится
ЧНогосложное
слово, то часто
(например, в
одучае ударения
на червой части
длинного составного
слова) возникает
вторичная
каден-4W
SC
в ритмическом
ударении последнего
олова или части
слова э»ов
фразы. Начало
и- длительность
вторичной
каденции
соответот-вуеэ
этим параметрам
главной каденции,
но отклонение
частоты Никогда
не превышает
полутона.
При
объединении
фраз, име'"'аих
нарастающую
каденцию, частота
7» яосле
возрастания
на конце первой
фразы начинает
оинусоидадь-"0
уменьшаться
на границах
между фразами.
Сяад частоты
начина-
1)Ййу«Моп80
мс
ifiP
начала
второй фразы
и имеет общую
длительность,
«-""ую
190 мс. Далее
f
продолжает
уменьшаться
ооТторосгыо
пол-
'°на
в I
с. ^
В
конечных фразах
синтезируемого
высказывания,
где существует
каденция типа
FC,
в
начале фраз
fg
соответствует
частоте основного
тона, которая
определяется
предшествующей
• нарастающей
каденцией.
Однако за 80 мс
до начала гласного
^.определяющего
главное ритмическое
ударение, /д
начинает
синусоидально
уменьшаться
в течение 190 мс
до величины,
равной двум
полутонам по
отношению к
основному тону
в начале предложения.
Далее
f
продолжает
уменьшаться
со скоростью
полтона в I с,
пока не закончится
предложение.
Изменение
основного тона
на ударных
слогах зависит
от того, какой
гласный содержит
ударный слог:
короткий или
длинный. В обоих
случаях 5-тип
основного тона
состоит из
нарастающего
и падающего
участков. Это
нарастание
начинается
за 80 мс до начала
гласного и
продолжается
для коротких
слогов 160 мс,для
длинных - 240 мс.
Такое же время
продолжается
и синусоидальный
спад для слогов
первого и второго
типа. В зависимости
от силы ударения
подъем частоты
основного тона
лежит в пределах
от двух до пяти
полутонов, а
спад - от полутона
до двух полутонов.
Исследования
по управлению
просодическими
параметрами
описаны в
[122] . В [2, 103, 104, 163] приводятся
исследования
различных
синтаксических
структур и
их
влияние на
микро- и макровариации
частоты основного
тона в английской
речи.Результатом
исследований
был алгоритм,
определяющий
динамику основного
тона синтезированной
английской
речи. Алгоритм
рассматривается
как последовательность
двух уровней
единой системы,
формирующей
контур основного
тона. На первом
(высшем) уровне
учитывается
влияние синтаксической
и семантической
информации,
на втором (низшем)
-информации
о фонемной
цепочке и лексическом
ударении (рис.1.3).
| оинтаксическая |
Система
верхнего уровня |
Просодические |
Система
нижнего уровня |
УР
в- |
| информация
Семантическая |
| индикаторы |
| информация |
|
Фонетическая |
J
• |
• \ Конт
осно ного
|
| информация
Информация |
Рис.
1.3. Структура
алгоритма,
определяющего
динамику основного
тона синтезированной
речи
62
рассмотрим
далее алгоритм,
реализующий
формирование
контура основного
тона для высказывания,
в общем случав
содержащего
несколько
предложений,
каждое из которых
разбивается
на фразы, состоящие
из нескольких
слов. Для формирования
контура основного
тона на вход
системы высшего
уровня поступает
информация
о типе высказывания,
границах и
типах предложений,
границах и
типах фраз, а
также о том,
какой частью
речи является
каждое сдово.
Слова упорядочены
по степени
важности, причем
к словам, не
входящим в
список важных,
относятся
артикли, союзы,
относительные
местоимения,
предлоги,
вспомогательные
глаголы и личные
1|еетоимения.
Для каждого
высказывания
формализована
его синтаксическая
структура, т.е.
для ввода
производится
идентификация
синтаксических
единиц: выделяются
независимые
или зависимые
пред-яожения,
внутри которых
локализуются
и маркируются
фразы существительного,
фразы глагола,
предложные
фразы, фразы,
связанные с
прияагательным
или употребляющиеся
в качестве
прилагательных,
фразы, соответствующие
наречиям. В
системы вводится
также информация
о специальных
фразах и пунктуации,
определяющая
тип мамровариаций
основного тона:
а) обычные
вопросительные
и звательные
фразы, характеризующиеся
повышением
частоты основного
тона;
б) знаки цитирования
и восклицания,
усиливающие
изменения
частоты основного
тона внутри
своих областей;
в) "ответвления"
фраз (куски
высказываний
со скобками
или тире), уменьшающие
динамику основного
тона;
г) знак вопроса
в конце предложения,
дающий тон типа
В для
каждого независимого
предложения,
не содержащего
вопросительного
слова; остальные
предложения,
дающие тон типа
А.
Влияние
семантики на
контур основного
тона учитывается
ак-центацией
слов, их ранжированием
по степени
важности, а
также временной
близостью
одинаковых
слов. Каждое
существительное,
глагол или
прилагательное
высказывания
запоминаются
в буферной
магазинной
памяти, способной
хранить до
50 слов. Новые
слова сравниваются
с содержимым
буфера. Для
каждого сравнения
характер изменения
/д коррелируется
с тем, на каком
месте буфера
находится
слово, с который
сравнивается
вновь поступившее.
Чем ближе
находится
слово, аналогичное
входному, тем
более высокая
степень редукции
/д .
Типы тона
А и В характеризуются
следующим: тон
типа А вызывает
снижение /д на
всем предложении,
а также резкое
падение его
на последнем
важном (значащем)
слове и после
этого.
63
Тип
В означает
относитеяьно
пологую /д с
резким подъемом
в конце предложения.
Эти типы тонов
характеризуют
глобальный
уровень иерархии
в рассматриваемой
системе.
Предложения,
не являющиеся
конечными (т.е.
уже не связанные
с типом тона),
характеризуются
подъемом
fy
на первом значащем
слове и его
падением на
последнем
значащем слове
(падении меньшем,
чем при тоне
типа А), после
чего начинается
новый последовательный
подъем. Размах
"понижение
- нарастание"
частоты основного
тона
fy
зависит от
идентичности
предыдущему
следующего
предложения:
если за предвдущим
следует независимое
предложение,
то изменение
основного тона
на стыке больше,
чем в случае,
когда второе
предложение
является зависимым.
Более того,
если в высказывании
остается единственное
зависимое
предложение,
то подъем основного
тона после
завершения
независимого
пред. ложения
пропадает
вообще. Весь
участок "падение
- подъем" основного
тона может не
выявиться, если
границы независимого
предложения
включают начало
ограниченного
вводного предложения
(в зависимости
от числа слов,
предшествующих
границе: чем
меньше слов,
тем меньше
Провал "падение
- подъем
fg
").
Внутри
каждого предяожения
в дополнение
к изменению
на границах
предложений
происходят
изменения /д
и на границах
фраз в зависимости
от числа "важных"
слов в каждом
предложении.
Каждая фраэа
с двумя и болев
такими словами
выделяется
таким образом,
что ее начало
совпадает с
нарастанием
частоты основного
тона, а завершение
- со снижением
и последующим
подъемом. Изменение
частоты основного
тона на границах
фраз зависят
от числа "важных"
слов фразы,
т.е. фразам с
большим числом
таких слов
соответствует
больший "провал"
частоты основного
тона; увеличивают
этот провал
также границы,
помеченные
знаками пунктуации.
Внутри фраз
начальный
подъем
fy
продолжается
на первом важном
слове, а падение
заканчивается
на последнем
важном слове
этой фразы с
неким подъемом
к концу фразы.
Все остальные
важные слова
"получают"
подъем и снижение
/д примерно
одинаковой
величины.
Ранее
уже отмечалось,
что каждому
слову синтезируемого
высказывания
приписывается
некое значение
акцента в
соответствии
с его рангом
по порядку
важности. Контур
изменения
f.
(подъем и падение)
тем резче, чем
важнее слово.
Акцентирование
слова снижается,
если оно обнаруживается
в магазинном
запоминающем
устройстве,
т.е. оно уже недавно
произнесено.
Система
верхнего уровня
снабжает каждое
слово входного
высказывания
просодическими
индикаторами
(рис. 1.3), обеспечивающими
получение
просодического
контура на
нижнем уровне
анализа.К таким
64
индикаторам
относятся
связанные с
каждым словом
числа, определяющие
а) акцент, б)
границу, указывающую
позицию слова
внутри йразы
/ предложения
(положительное
число определяет
позицию относительно
начала фразы,
отрицательное
- относительно
конца; при этом
большие числа
соответствуют
словам на границах,
отмеченных
знаком препинания,
и на границах
между большими
и /
иди важ-щдаи
фразами);
в) продолжительный
подъем
fg
, т.е. число,
показывающее
величину подъема
на границе
слова, что отражает
важность
синтаксической
границы, предшествующей
этому слову;
г) тип тона (А,
В или нулевой^,
показывающий,
относится
данное слово
и конечному
участку фразы
с нарастанием
или падением
fg
или не относится
(при типе А падение
Уд идет до более
низкого уровня,
чем в других
случаях, а при
типе В подъем
fg
продолжает
расти после
лексически
ударного слога,
что не характерно
для других
случаев).
Наряду с
просодическими
индикаторами
каждого слова,
система верхнего
уровня вводит
в систему низшего
уровня число
слогов, место
лексически
ударного слога,
фонемную структуру,
которая для
каждого слога
дополнительно
указывает,
начинается
ли он или заканчивается
взрывным звуком
и не является
ли этот взрывной
глухим.
Рассмотрим
далее работу
системы нижнего
уровня, формирующей
контур основного
тона. Алгоритм
устанавливает
на лексически
ударных слогах
каждого важного
слова сначала
пиковые уровни
/д,
после чего
вокруг каждого
пика строятся
акцентированные
подъемы и падения
частоты основного
тона. Затем
добавляются
участки общего
контура, соответствующие
участкам постепенного
нарастания
и конечным
типам тона.
Наконец, заполняются
по соответствующим
правилам и
остальные
участки; контур
основного тона
высказывания
сформулирован.
Пики основного
тона устанавливаются
пропорционально
величине акцента
для каждого
важного слова,
однако по отношению
к начальным
словам высказывания
пики имеют
некую тенденцию
к уменьшению.
К ним добавляется
наклонная
линия, такая,
что для слов
равного .акцента
каждое последующее
значение частоты
/„ на пике
•^УДет уменьшаться
пропорционально
наклону этой
кривой. Величина
этого наклона
для предложений,
заканчивающихся
тыом тона В,
более полога
по сравнению
с другими
предложениями.
Каждое пред-^«ение
получает свою
линию наклона
в зависимости
от того,в ка-^ом
месте общего
высказывания
находится
предложение
(и, естествен-н0»
в зависимости
от пда тона,
которым заканчивается
предложение)
. Пики каждого
предложения
уменьшаются
от начала к
концу
Зак.480
65
всего
высказывания,
но при этом
соблюдается
тенденция.что
начальный
пик каждого
предложения
более высокий,
чем последний
пик частоты
основного тона
предыдущего
предложения,
но более низкий
чем первый пик
этого предыдущего
предложения.
Такие линии
нак-жона являются
в какой-то степени
опорными при
формировании
контура, так
что более длинные
предложения
начинаются
с более высоких
пиков
fg
.
Каждый
лексически
ударный слог
значимого слова
приобретает
контур /о ,
характеризующийся
подъемом и
спадом» отношения
меж. ду которыми
определяются
числами, характеризующими
границы. Большие
положительные
числа ведут
к значительному
подъему, а большие
отрицательные
- к значительному
спаду. Величины
подъемов и
спа-доа пропорциональны
акценту, но
зависят также
и от числа
соседних
неакцентированных
слогов. Большое
временное
разделение
между акцентированными
слогами ведет
к большему
отношению на
этом участке,
характеризующему
провал.
Информация
о продолжительных
подъемах /
кодируется
в числе, стоящем
после последнего
слога каждого
слова; это число
характеризует
и высоту подъема,
и его длительность.Формирование
контура /д на
неакцентированных
участках высказывания
основано на
том, что в высказываниях
частота /д имеет
тенденцию к
понижению.
Учет фонемической
структуры
слогов приводит
к тому, что на
участках
высказываний,
соответствующих
глухим взрывным,
контур основного
тона отсутствует,
а акцентированные
слоги с начальными
взрывными имеют
более высокие
пики
f
,
чем слоги,
начинающиеся
со звонких.
Изменение
длительностей
звуков синтетической
речи рассмотрено
ранее в п. 1.4.2. Не
представляет
особых проблем
формирование
контура интенсивности,
в какой-то степени
коррелированного
с контуром
основного тона;
имеются известные
соотношения
между средней
интенсивности
ударных и безударных
гласных, сонорных
согласных,фрикативных
и смычных согласных
(включающих
участки смычек),
что позволяет
автоматически
формировать
контур интенсивности
по фонетической
цепочке.
1.4.5.
Алгоритмическое
и программное
обеспечение
синтеза речи.
Создание
алгоритмического
и программного
обеспечения
синтеза речи
рассматривается
в ряде публикаций.
Разрабатываются
его циализированные
языки для перевода
графем в фонемы
CI26]
, 8 также системы
программных
модулей, обеспечивающих
автоматический
анализ текста
и синтеза речи
[103, 133] . Системный
подход к созданию
программного
обеспечения
синтеза речи
становится
все более
определяющим.
66
В CI26]
рассматривается
разработанный
в0 Франции
специализированный
язык программирования
ТОР, предназначенный
для перевода
гоафем французского
текста в соответствующие
фонемы. Язык
ТОР (
Transcription Orthographlque Phonetique
) - это язык
правил описания,
применение
которых зависит
от контекста.
Программы,
написанные
на языке ТОР,
содержат три
части:
1) описание
используемых
кодов;
2) описанир
классов (необязательное);
3)
правила.
Система правил
основана на
частичном
упорядоченном
множестве
фонологических
правил французского
языка. Левая
часть каждого
правила указывает
на графему,
которую необходимо
перекодировать
в фонему (указанную
в правой части)
при условии,
что известен
буквенный
контекст, в
котором находится
перекодируемая
графема.
В С.ЮЗ] описана
модульная
система речевого
ответа, представляющая
собой большое
количество
программных
модулей (по
одному ^ля каждой
структурной
области),
связанных между
собой множеством
информационных
структур. Каждая
структурная
область (т.е.
морфология,
синтаксис,
семантика,
фонология)
делает свой
вклад в общую
систему, но
взаимоотношения
этих областей
с лингвистической
структурой
высказывания
не всегда однозначны
из-за индивидуальных
акустических
особенностей
синтезируемой
волны. Различные
структурные
области должны
1ыть представлены
так, чтобы можно
было обеспечить
их оптимальное
взаимодействие.
Лишь таким
образом можно
установить
сложные отношения
между поверхностной
речевой волной
и лежащей в ее
основе абстрактной
лингвистической
структурой,
которая должна
быть смоделирована
глубоко и
всесторонне
.
При
создании модульной
системы предусматривалось:
а) получить
такую полную
модель в алгоритмической
форме, чтобы
процесс был
представлен
с исчерпывающей
полнотой;
б) обеспечить
работу системы
для моделей
переменной
сложности,
например, чтобы
система работала
с фиксированным
словарем иди
без учета
просодических
параметров;
в) обеспечить
развитие и
достаточную
гибкость
системы,чтобы
изменения,
которые должны
быть внесены
в один структурный
Уровень, не
требовали
изменения
других уровней;
г) реализовать
эффективную
работу отдельных
частей алгоритма»
ориентируясь
на специфику
применения
систем речевого
' ответа;
^и этом доляно
учитываться
использование
специального
оборудования,
обеспечивающего
минимальные
габариты
системы,время
формирования
фразы, мощность
и стоимость
системы. 67
Модульное
матобеспечение,
реализующее
эти требования,
произ-водит
анализ текста
и синтез речи.
На стадии анализа
создается
некая
абстрактная
лингвистическая
структура,
общая как для
вход-ного текста,
так и для речевого
вывода. Основными
программными
модулями при
создании такой
структуры
являются:
1. Модуль
"Формат",
обеспечивающий
предварительную
обработку
входного текста
в форм;', удобную
для морфологического
анализа и
порождения
соответствующей
фонемной цепочки.
2.
Модуль "Декомпозиция1',
осуществляющий
морфологический
ана-диз и находящий
каждое слово
в лексиконе
морфем, представляет
последовательность
морфем, составляющих
входной текст,
кодами, учитывающими
их особенности
произнесения
(в сочетании
с другими
морфемами) и
грамматические
функции.
3. Модуль
"Парсер"
(грамматический
разбор) работает
с цепочкой
морфем и определяет,
к какой части
речи принадлежит
каждое слово;
этот модуль
строит грамматические
сети и формирует
фразы, объединяя
слова в словосочетания,
на которые
далее будет
накладываться
соответствующий
интонационный
контур; основная
роль этого
модуля - разрешать
фонемные
неопределенности
(что-то убрать,
что-то добавить)
и производить
лингвистические
описания,
необходимые
для временных
процедур, и
процедуры
наложения
контура основного
тона.
4. Модуль
"Звук-1", в котором
морфофонетические
правила (множественного
числа, прошедшего
времени, палаталлэации)
применяются
к словам,
анализировавшимся
модулем "Декомпозиция";
эти правила
очищают фонетическую
цепочку и позволяют
объединять
два иди более
смежных корня
в составное
слово , а также
построить для
слова соответствующий
контур ударения.
5.
Модуль "Звук-2"
использует
правила перевода
букв (графем)
в звуки для
порождения
фонетической
последовательности,
если модуль
"Декомпозиция"
не смог полностью
превратить
слова в последовательность
лексических
морфем. После
превращения
последовательности
букв в последовательность
фонетических
символов этот
модуль использует
полный набор
правил лексического
ударения,
определяющих
контур ударности
для этого слова
(эти правила,
например,
определяют
Правильность
произношения
аффикса
ate
в словах eyatematio
и
eyetemeUze).
При
синтезе речи
используется
набор модулей,
обеспечивающих
порождение
входной речевой
водны:
- модуль
"Просодика"»
определяющий
для каждой
фонемы формируемого
предложения
частоту основного
тона, длительность
и интенсивность
(ударность);
68
- модуль
"Синтез", используя
фонетические
метки и
проводи-ивокую
ш«формацию,
каждые б мо
порождает
параметры,
достаточные
•ля управления
цифровой модель»
речевого тракта,
формирующей
от-очеты речевой
волны. Модуль
"Синтез"
- ато большая
программа,
мализуккцая
алгоритм
фонетического
синтеза речи
по правилам
с дополнительным
наложением
просодического
контура;
-
модуль "Речь"
превращает
полученную
последовательность
десантных
отсчетов в
речевую волну,
используя
цифроаналоговый
Преобразователь.
В
[133] рассмотрена
интерактивная
система исследования
речи
tiK; ,
чозвояяищая
в диалоговом
режиме изучать
и модернн-ащювать
правила преобразования
"текст
- фонема",
что дает возможность
получать более
качественную
синтетическую
речь. Система
spy
использует
три вида правил
преобразования
(рис.1.4):
1)
правила модификации
текста, модифицирующие
начальную
тек-стоьуь
строку и связанные
с ней признаки;
2)
правила конверсии,
формирующие
цепочку фонем
и связанную
в ней матрицу
признаков на
основе информации,
имеющейся в
модифицированной
текстовой
строке;
3)
правила модификации
признаков,
которые изменяют
матрицу признаков,
формируемую
правилами
конверсии.
Рассмотрим
алгоритм
преобразования
"текст-фонема",реализованный
в [I33J
, на примере
преобразования
слова.
На вход программы
преобразования
поступает
слово, каждой
букве которого
соответствует
присоединенный
признак, определяющий
глаонке или
согласные
звуки, соответствующие
етим буквам:
с буква
согл..
(символы)
(присоединенные)
признаки
a r L п д
буква буква букяа буква буква
глад. оогл. глао. согл. глас.
На аерьом
уровне текстовая
цепочка и связанная
о ней матрица
Признаков
модифицируются
множеством
правил модификации
текста. б»н
аравиле могут
устранять,
добамнгь и
заменять символы,а
так-*•
делать соответствуххцие
ыодифхнации
матрицы признаков.
Правила ч^дифинации
•мжста, например,
вводят символ
е*' после гласного,
»»
которым следует
один или два
согласных, и
перед суффиксами
Ing
.
69
Текст и признаки
Правила
модификации
текста (ТМ-правила)
Модифицированный
текст и признаки
Правила
конверсии
(С-правила)
Фонемы
и признаки
(
W-правила)
Правила
модификации
признаков
Модифицированные
признаки
Рис.
1.4. Три уровня
правил преобразования
"текст-фонема1'
системы
SRS
sharing
+s/?are+.
ing+
Ce] [C]
Правила
модификации
текста I.
0---e+/l/c[?,2L{ed|^}
Пракиха
конверсии
И.
а—р/_с[*
соп}е^
Правила
модификации
признаков
3.
[\tfns\—-[-tens']
/_ [+ ret]
Применение
ТМ-оравмя к
сяоэу
carlna
дает:
< с
а г е
+ i
n (f буква
буква букм
буква буква
буква буква
соги. глас.
согя. гяас. пас.
согя. согд.
Таким обозом,
эти аравияа
вводят новую
букву е
, а также
опредедяшт
границу модемы
"+" и суффикса
" •". (Введенные
си»»-воям служ*»т
важной частью
иравия контекста,
которые исоояьауются
С- и /
М-правияами.)
Модифицированный
текст и связанные
с ним признаки
далее обрабатываются
С-оравмяаыи,
которые формируют
фонетическую
цепочку из
последовательности
буке, полученных
на предыдущем
ваге. С-иравияо
(рис. 1.Ь
), например,
показывает,
что буква "а"
произносится,
как "е", когда
она предшествует
одиночной
согяас-ной,
за которой
сявдует эаканчиваиаая
морфему буква
"е". (Это
70
Оравию
применяется
к "а" в
w»e
Bathing,гд,»
звуки
" th
" проиэ.
косятся как
один согяасный,
но не к "а" в
слове
taxina
, где •х'1
произносится
как два согласных.)
Результат
применения
всех оравил
конверсии к
сдову
carinq
позвояяет
пожучить ояедующгю
вались:
подъема,
альвеолярный
велярный, передний
звонкий
+ А-
е г
-+. I n
согл.
гдас. согя.
глас.
con. взрывной,
среднего ретро-
верхнего
назальный,
велярный, пид-ьеыа,
Фявчсный подъема,
гяухой передний
Если правила
модификации
текста изменяют
текстовую
цепочку непосредственно,
то С-правила
формируют ноаую
цепочку (фонем)
на основе
tm{iupuaiyiH.
заключенной
в текстовой
цепочке,
F/И-пра-
•ила модифицируют
фонетическую
цепочку, применяя
прарила контекстной
зависимости
х матрице признаков
и включая или
устраняя соот
катет йущяв
сегменты. Так.
ГМ
-правило устанавливает,
что напряженный
гласный становится
напряженным
перед ретрофлексными
звуками. Другии
/^"дравидом
яуяяетая правило
объединения
п и д
, когда
произносится
п
. Все эти
правила использовались
совместно
с английскими
правилами
порождения
параметров,
соответствующих
фонемам, для
похучения
речевой волны.
В [%]
рассматривается
математическое
обеспечение
однокристальной
микроЭВМ модели
<»20, преднааначенной
для обработки
сигналов. Благодаря
наличию аналоговых
входных и выходных
схем М высокому
быстродействию
она легко может
быть перестроена
для синтеза
речи. На атой
микроЭВМ можно
реализовывать
различий способы
синтеза речи.
Описаны программы,
моделирующие
работу генератора
голосовых
импульсов
(программа
формирует ряд
асимметричных
треугольных
импульсов), а
также генератор
шумового сигнала,
который моделируется
при помощи
генератора
псевдослучайных
чи~ Св*.
Для моделирования
передаточных
функций речеобразумаего
тра-«»а разработаны
программы
модификации
выходных значений
сигна-
*ов, поступающих
с выхода генератора
голосовых
импульсов и
гене-Р»тора
шумовых сигналов.
Для втого применяют
моделирование
рекурсивных
фильтров с
переменными
временными
параметрами
и ыиогоавен-чах.
В [96]
приведена
типичная программа
для одного
звена ччогозввнного
фнютра, управляемого
параметром,
который иивет
раз-чые значения
для различных
звеньев. Отмечается,
что для пос-•Ровния
типичного
синтезатора
речи требуется
два микропроцессора
®20; первый обеспечивает
работу генератора
воабуадаицих
сигна-
71
лов
и моделирование
нескольких
первых звеньев
многозвенного
фидьтра, а второй
- для остальных
звеньев этого
фильтра. Для
построения
форматного
синтезатор»»
достаточно
воспользоваться
одним микропроцессором
2920. Речевой тракт
моделируется
здесь последовательностью
рекурсивных
фильтров второго
порядка (в [96] при»
водится программа
такого фильтра).
Для удовлетворительного
синтеза
последовательно
включают не
менее трех
звеньев,моделирующих
три форманта.
1.4.6.
Отечественные
системы автоматического
речевого вывода.
Основные
работы по
автоматическому
синтезу речи
связаны с
построением
параметрических
синтезаторов
[6,43, 48-50, 53, 70, 75]. Некоторые
из систем речевого
вывода информации
из ЭВМ внедрены
в опытную
эксплуатацию
[43,48] , другие - близки
к внедрению
[6, 70,78] , третьи -
используются
в экспериментальных
установках
[50, 56] .
Развитие
работ по построению
систем автоматического
речевого вывода
ведется в нашей
стране в широком
диапазоне - от
фо" немных
синтезаторов
до словесных
и даже фразовых
временных
компиляторов.
Если
в работах первого
направления,
при которых
фонема рассматривается
как набор заданной
последовательности
движения
артикулятороа
в артикулчторной
программе,
стремятся к
компактности
представления
генерируемого
речевого сообщения
и универсальности,
обеспечивающей
речевое отображение
произвольной
текстовой
информации,
то в компилятивных
временных
синтезаторах
второго направления
делается упор
на разборчивость
и естественность
скомпилированных
высказываний
(в ущерб универсальности
и компактности
представления
сигнала).
Одним
из наиболее
типичных синтезаторов
параметрического
типа является
ортогональный
синтезатор
речи [48] . Синтезатор
предназначен
для выцачи
голосом из ЭВЫ
в телефонный
канал счетов-справок
о стоимости
состоявшихся
междугородных
переговоров
городской
телефонной
сети. Речевой
сигнал (слово
ограниченного
по объему словаря)
представлен
временными
изменениями
параметров
сигнала - логарифмов
огибающей
амплитудных
спектров. Речевые
ответы (фразы)
вначале формируются
в виде списков
номеров слоя,
речевые эквиваленты
которых затем
посегментно
объединяются
и выводятся
на синтезатор.
Отмечается,
что разборчивость
синтезируемых
фраз близка
к 100%, скорость
вывода речевого
сигнала на
синтезатор
равна 12 бит/с.
При
артикуяяторно-форматном
синтезе речи
по печатному
тексту
L6.^]
в качестве
минимального
артикуяяторного
компдйкса
72
используется
элементарный
слог, представленный
набором артикуля-торных
команд способа
и места образования
входящих в него
фонем. Процесс
реализации
слога делится
на три основные
фазы: переходная
фаза от предыдущего
слога к данному,
фаза реализации
согласной
фонемы и фаза
реализации
гласной. Синтезатор
учитывает
просодические
характеристики
естественной
речи, а также
то обстоятельство.
что в ней могут
встретиться
сочетания
согласных и
гласных фон-эы.
Система синтеза
в последнем
случае вводит
фиктивные
согласные и
гласные, разбивая
речевой поток
не слоги,причем
фиктивным
звукам приписывается
длительность,
равная нулю.
Для автоматического
задания интонационных
характеристик
фраз в синтезируемой
текстовой
информации
выделяются
ранжированные
единицы:
фраза, синтагма,
фонетическое
слово, слог.
При автоматической
обработке
синтезируемого
текста определяется
число единиц
ранга К в единице
ранга
K-I,
номер логически
выцеденной
единицы ранга
К, а также тип
интонации.
Для моделирования
алгоритмов
синтеза использовалась
универсальная
мини-ЭВМ, обдацаищая
быстродействием
200 тыс. операций
в I
с и оперативной
памятью
16 кбайт.
Объем программ
нодедм синтеза
речи составляет
1200 32-разрядных
команд. В настоящее
время принципы
технической
реализации
артикуляционного
синтезатора
легли в основу
разработки
стандартного
устройства
речевого вывода
с микропроцессорным
управлением
для ЕС ЭВМ [б]
. Появились
первые синтезаторы,
основанные
на параметрах
линейного
предсказания
[55,78].
В нашей стране
и за рубежом
появляется
также интерес
к устройствам
речевого вывода,
основанным
на компиляции
речевого сигнала,
соответствующего
фразам, из более
мелких отрезков
речевой волны:
слов, слогов,
аллофонов
['44,96]. Подобные
синтеза-Юры
предназначены
для информирования
пользователей
ограниченным
количеством
типов фраз,
часто вполне
достаточным.
Большие же
затраты памяти
для хранения
в цифровом виде
элементов,
из которых
формируются
фразы, не
так страшны,
потому что
новые виды
запоминающих
устройств
(например, на
цилиндрических
магнитных
до-хенах) позволят
хранить в малых
объемах десятки
мегабайт. В
СССР работы
по компиаятивному
выводу ориентированы
на использование
в качестве
основного
элемента синтеза
как слов,
так и схо-^в.
Предполагается,
что такой синтезатор
компилятивного
типа ^УДет
изготовлен
серийно.
Зак.480
ГОВОРЯЩИЕ и
понимающие
речь машины
строятся сейчас
на основе ЭВМ,
которые включают,
как правило,
микропроцессоры
и другие большие
интегральные
схемы. А ЭВМ
работают с
числами, перерабатывают
цифровую информацию.
Лучше сказать
так: все, что
перерабатывает
вычислительная
машина, должно
быть представлено
в виде чисел.
В понятие «все»
входят, в частности,
сигналы, получаемые
с датчиков.
Сюда относят
сигналы, получаемые
медиками
(кардиограммы,
энцефаллограммы),
и различные
технические
шумы, например
шумы двигателя,
по которым ЭВМ
может определить
причину его
неисправности,
геофизические
(шумы подземных
недр и моря),
биологические
шумы (разговоры
дельфинов,
пение птиц,
мяуканье кошек
и лай собак,
кваканье лягушек),
различные
двумерные
сигналы (изображения).
Сюда же относят
и человеческую
речь. В этом
разделе рассмотрим,
как речь (речевой
сигнал) превращается
в набор чисел
и какие превращения
с этими числами
происходят
до того, как
«умная» машина
произнесет
нужную фразу
или поймет
с'!ысл высказывания.
Но мы должны
помнить, что
основные приборы
и способы обработки
сигналов,
превращенных
в набор чисел,
можно использовать
и для работы
с любыми сигналами,
поступающими
с соответствующих
датчиков информации,
сигналами не
обязательно
речевой природы.
Цифровые методы
анализа открывают
поистине
безграничные
возможности
вычислительной
техники. Ученые
показали, что
если у непрерывно
изменяющегося
во времени
сигнала брать
достаточно
близко расположенные
друг к другу
цифровые отсчеты,
то последовательность
этих отсчетов
будет почти
полностью
отражать все
свойства этих
сигналов. При
обратном
преобразовании
этих цифр в
речь она будет
слышна без
искажений. Это
значит, что
достаточно
представить
речевой сигнал
в цифровом
виде, в виде,
64
удобном для
машинной обработки,
и можно применять
всю мощь программных
средств ЭВМ
для расшифровки
смысла речевого
сообщения
в системах,
понимающих
речь. В говорящих
же машинах
используют
обратное
преобразование:
«цифры —
речевой сигнал».
Полученную
программно
в виде последовательности
чисел речь
пропускают
через специальные
преобразователи
«цифровая
последовательность—электрическое
напряжение»
(«цифра—аналог»).
Далее речевой
сигнал можно
подавать на
наушники или
динамический
громкоговоритель,
преобразующие
электрический
сигнал в колебание
мембраны, или
рупоры (диффузора)
динамика, которые
колеблют воздух
в соответствии
с электрическим
сигналом,
поступающим
на вход.
Напомним, что
сам речевой
сигнал изменяется
во времени
достаточно
быстро. Это
объясняется
особенностями
его образования
— фильтрацией
сигналов возбуждения
импульсов
воздушного
давления, толчков
воздуха, поступающих
с голосовых
связок при их
колебании, т.
е. через открытые
голосовые
связки из легких
при выдохе
через резонансную
систему (артикуляторные
органы —
гортань. язык,
полости рта
и носа). Свойства
же речеобразующего
тракта из-за
его инерционности
меняются медленно.
И в вычислительной
машине в цифровой
форме крайне
желательно
получать и
хранить медленно
меняющиеся
параметры
голосового
тракта и источника
— частоты
основного тона,
формантные
частоты, определяющие
характер самого
речевого сигнала.
Поэтому здесь
рассмотрим
и способы получения
параметров
речеобразующего
тракта —
формант и
различных
связанных с
ними характеристик,
которые иногда
будем называть
информативными
параметрами.
Изменение
главного параметра
голосового
источника
— частоты
основного
тона—относится
к просодическим
характеристикам
речи, некоторые
методы его
получения уже
были рассмотрены.
Если по информативным
параметрам
и их изменениям
во времени
(используя
модели речеобразования)
можно восстановить
речевую волну
или распознать
ее смысл (на
основе модели
речевос-приятия),
то, кроме как
с параметрами,
вроде бы ни с
чем и работать
не надо. Параметры
эти очень удобны,
слабо меняются
во времени,
поэтому их
гораздо меньше,
чем цифровых
отсчетов са-'
мого сигнала.
Значит, меньший
объем памяти
можно занять
под высказывание,
которое анализируется
или генерируется.
Значит, меньше
времени потребует
машинная обработка
при распознавании.
Значит, меньшими
машинными
ресурсами можно
снабдить систему
автоматического
распознавания
или синтеза
речи и тем сильно
снизить ее
стоимость. Но
как автоматически
получить эти
параметры
(признаки, лежащие
в основе машинных
моделей распознавания
и синтеза речи)?
Ведь при построении
понимающих
речь машин,
например, мы
имеем на входе
машины лишь
речевой сигнал.
Как от него
перейти к параметрам?
Только создав
аппаратуру,
которая их
выделяет и
позволяет
вводить в ЭВМ
в цифровой
форме, или разработав
алгоритмы и
соответствующие
программы,
которые по
оцифрованному
речевому сигналу
или по спектру
позволяют
получать эти
параметры
программным
способом. В
связи с этим
вводить в ЭВМ
информацию
о речевом сигнале
в цифровой
форме можно
тремя способами.
Первый способ
осуществляется
с помощью
универсального
прибора-преобразователя
«аналог—цифра»,
который дает
возможность
вводить в память
ЭВМ отдельные
отсчеты речевого
сигнала в виде
последовательности
чисел.
Второй способ
включает сложный
преобразователь,
позволяющий
вводить в ЭВМ
информацию
о спектре сигнала
за относительно
короткие временные
интервалы.
Обычно такая
информация
вводится с
гребенки аналоговых
полосовых
фильтров, каждый
из которых
пропускает
лишь ограниченный
диапазон частот.
Вместе же фильтры
гребенки перекрывают
весь частотный
диапазон речевого
сигнала, прошедшего
через технические
устройства
(микрофон и
микрофонный
усилитель).
Использование
устройств
речевого ввода
этого типа
позволяет
получать в
памяти ЭВМ в
цифровом виде
картинку так
называемой
«видимой речи»,
динамическую
спектрограмму,
которая раньше
создавалась
с помощью
спектроанали-заторов,
сонографов-приборов,
сыгравших
большую роль
в изучении
речи и ее параметров
лингвистами.
В настоящее
время информация
о кратковременном
спектре может
быть получена
с помощью
специализированных
БИС и СБИС цифровой
обработки
66
сигналов, которые
реализуют
гребенку фильтров
цифровыми
методами.
И, наконец, третий
способ —
это устройства
ввода в ЭВМ
выделяемых
аналоговым
способом
непосредственно
из речевой
волны главных
параметров
речеобразующего
тракта, а также
просодических
параметров
— формантных
частот, усредненной
мгновенной
частоты, усредненной
интенсивности
сигнала, частоты
основного тона
и некоторых
других признаков.
Все эти параметры
или их эквиваленты,
вообще говоря,
можно получить
программно
по оцифрованной
речи аналого-цифровым
преобразователем
или по спектру
сигнала. Устройства
ввода третьего
типа позволяют
получать эти
параметры
аналоговым
способом в
процессе произнесения
предложения.
В связи с широким
распространением
микропроцессоров
и микроЭВМ,
которые становятся
основным инструментом
анализа речи,
и появлением
микропроцессорных
систем, обеспечивающих
обработку
оцифрованных
речевых сигналов
(введенных с
универсальных
аналого-цифровых
преобразователей)
с огромной
скоростью,
достигающей
сотен миллионов
операций в
секунду, далее
будут рассмотрены
методы первичной
цифровой обработки
речи. Эти методы
лежат в основе
современных
систем автоматического
распознавания
и синтеза речи
и связаны с
получением
текущей автокорреляции
сигнала,
энергетического
спектра, параметров
линейного
предсказания,
гомоморфной
обработки, а
также клиппированной
речи. Будет
обращено
внимание на
использование
специализированных
устройств ввода
в ЭВМ информации
об информативных
признаках
речевого сигнала.
2.1.
УСТРОЙСТВА
ВВОДА РЕЧЕВОЙ
ИНФОРМАЦИИ
В ЭВМ
Аналого-цифровое
преобразование.
Преобразователь
типа «аналог—цифра»
— это устройство,
дающее возможность
вводить в ЭВМ
дискретные
отсчеты речевого
Сигнала, представлять
непрерывную
речевую волну
последовательностью
чисел, сохраняя
все основные
свойства сигнала.
Как правило,
такой ввод
применяется,
когда не хотят
пользоваться
аналоговой
аппаратурой
выделения
речевых параметров
и когда анализ
сигнала не
обязательно
осуществлять
в реальном
масштабе времени.
Работа с оцифрованным
речевым сигналом,
вводимым
непосредственно
с аналого-цифрового
преобразователя,
обеспечивает
более гибкую
последующую
обработку
речи в ЭВМ
программными
методами.
Теорема отсчетов,
связывающая
дискретные
отсчеты аналогового
сигнала и сохранение
частотных
составляющих
сигнала, была
предложена
еще в 1933 году
В. А. Котельниковым:
если сигнал
x(t) не содержит
частотных
составляющих
выше Fc
Гц, то его можно
полностью
определить
собственными
значениями
в моменты, отстающие
друг от друга
на 1/2 Fc секунд.
Интуитивное
подтверждение
этой теоремы
состоит в том,
что если сигнал
x(t) не содержит
частот выше
критической
частоты Fc,
то он не может
существенно
изменить свое
значение за
время, меньше
половины периода
наивысшей
частоты. Согласно
теореме отсчетов,
таким образом,
сигнал как
функцию времени
можно восстановить
по значениям
в точках отсчета
х(кТ), если частота
отсчета Ро==1/Г
не меньше удвоенной
критической
частоты Fc.
Предположение
теоремы отсчетов
о существовании
критической
частоты не
является сильным
ограничением,
так как все
физические
устройства
в принципе не
допускают
произвольно
высоких частот,
не пропуская
их, обрезая. Во
всех реальных
технических
приложениях
всегда исходят
из того, что
существует
некая Fc
для любых аналоговых
сигналов.
При вводе в ЭВМ
дискретных
отсчетов речевого
сигнала пользуются,
как правило,
стандартными
преобразователями
«аналог—
код». Действия
аналого-цифровых
преобразователей
основаны на
электрическом
преобразовании
дискретизированных
аналоговых
сигналов в
соответствующую
последовательность
двоичных чисел.
Это преобразование
выполняется
различными
способами,
включая линейную
импульсно-кодовую
модуляцию,
дифференциальную
им-пульсно-кодовую
модуляцию,
дельта-модуляцию,
адаптивную
дельта-модуляцию
и другие методы,
о чем можно
прочесть в
специальных
книгах по
аналого-цифровым
преобразователям.
Наиболее
распространенными
в настоящее
время аналого-циф-ровыми
преобразователями
являются
преобразователи,
использую
68

щие линейную
импульсно-кодовую
модуляцию. На
входе системы
(рис. 2.1) стоит
фильтр нижних
частот /,
ослабляющий
высокочастотные
компоненты
сигнала, лежащие
выше критической
частоты Fc.
Аналого-цифровое
преобразование
сигнала включает
два этапа. На
первом этапе
значение аналогового
напряжения
в момент измерения
запоминается
на некоем
«аналоговом»
запоминающем
элементе, в
качестве которого
используется
обычный электрический
конденсатор.
На втором этапе
напряжение,
«запоминаемое»
на конденсаторе,
измеряется
с определенной
точностью, и
двоичный код
числа, наиболее
близкий напряжению
на конденсаторе,
передается
в память ЭВМ.
Сигнал, пройдя
через низкочастотный
фильтр ./, в
определенный
момент запоминания
сигнала поступает
на электрический
конденсатор
2. который
быстро заряжается
до величины
напряжения,
равного значению
напряжения
на выходе фильтра.
Далее заряженный
конденсатор
отключается
от питающей,
входной цепи
на время измерения
«запоминаемого»
на емкости
напряжения
и хранит его
в течение всего
времени измерения,
не разряжаясь.
Аналоговая
схема 3
сравнивает
напряжение
сигнала, хранящееся
на емкости, с
калибровочным,
«компенсирующим»
напряжением.
Это напряжение
автоматически
получается
на выходе схемы
4, которая
преобразует
некий код, двоичное
число на входе
в аналоговое
напряжение,
являясь таким
образом цифроаналоговым
преобразователем.
В формировании
двоичного кода
на входе схемы
4 основную
роль играет
схема 5,
которая называется
регистром
запоминания
последовательных
аппроксимаций.
Попытаемся
разобраться,
что это
69
за схема. В
вычислительной
технике понятие
«регистр»
является одним
из основных
понятий. Регистр
— это узел
ЭВМ, состоящий
из нескольких
параллельно
соединенных
двоичных электронных
запоминающих
элементов
— триггеров.
Каждый из триггеров
хранит только
один разряд
двоичного
числа. Если
регистр состоит
из 10 триггеров,
то можно сказать,
что он может
запоминать
только десятиразрядное
двоичное число.
Различают
старший разряд
запоминающего
регистра, где
хранится старший
разряд кода,
соответствующего
двоичному
числу, и последующие
младшие разряды.
Вес каждого
разряда в два
раза меньше
веса соседнего,
стоящего слева
разряда регистра.
Аналого-цифровой
преобразователь
устроен так,
что на запоминающем
регистре вначале
(во время цикла
измерения
напряжения
на емкости)
старший разряд
триггера
устанавливается
принудительно
в единичное
состояние. Это
означает, что
значение
«компенсирующего»
напряжения,
вырабатываемого
схемами 4
и 5, в два раза
меньше, чем
возможное
напряжение
на емкости.
Если напряжение
на емкости
выше, чем напряжение
на выходе
цифроаналогового
преобразователя,
то схема сравнения
3 вырабатывает
такой сигнал,
что в единичное
состояние
устанавливается
соседний, стоящий
рядом со старшим
разряд регистра
5. А это уже
означает, что
на следующем
шаге сравнения
двоичного числа
с напряжением
на емкости
/ компенсирующее
напряжение
будет составлять
3/4 от максимально
возможного
напряжения
на запоминающей
емкости. Если
же при первом
сравнении
напряжение
на емкости
ниже, чем компенсирующее
напряжение,
поступающее
с выхода схемы
4, то старший
разряд регистра
5 обнуляется,
а соседний
все равно
устанавливается
в единичное
состояние,
означающее,
что на втором
шаге сравнения
компенсирующее
напряжение
будет составлять
1/4 от максимального
значения, которое
может запоминать
емкость /.
Такое сравнение
продолжается
до тех пор, пока
не будут опрошены
все разряды
регистра
5, до самого
младшего.
Понятно поэтому,
почему регистр
5 называется
регистром
последовательных
аппроксимаций,—мы
последовательно
приближаемся
ко все более
точному измерению
напряжения
на емкости.
После того, как
произошла
проверка самого
младшего разряда,
на
70
регистре хранится
число, наиболее
точно аппроксимирующее
сигнал, хранящийся
на емкости
./. Этот двоичный
код и пересылается
в ЭВМ, после
чего переходим
к измерению
следующего
отсчета сигнала,
поступающего
на емкость с
выхода фильтра
/ в момент
подключения
его к запоминающему
конденсатору
2. Такой
способ ана-лого-цифрового
преобразования
называют поразрядным
взвешиванием.
Отметим, что
большие перспективы
в использовании
универсальных
аналого-цифровых
преобразователей
открываются
в связи с
мультипроцессорной
реализацией
различных
методов цифровой
обработки
сигналов
— дискретного
преобразования
Фурье, линейного
предсказания,
цифровой фильтрации
и др. Для исследовательских
целей этот тип
ввода речевых
сигналов в ЭВМ
наиболее применим
и в настоящее
время, так как
он достаточно
гибок и позволяет
сохранять все
частотные
составляющие
речевых сигналов.
Применяют
аналого-цифровые
преобразователи
и в тех случаях,
когда необходимо
использовать
фильтры с такими
характеристиками,
которые трудно
реализовать
на реальных
физических
элементах, а
также в случаях,
когда требуется
частое изменение
параметров
фильтра, используемого
при анализе
сигнала, или
подбор характеристик
фильтра и когда
реальный масштаб
времени анализа
не обязателен.
Кроме того,
ввод с аналого-цифрового
преобразователя
может оказаться
целесообразным
(и единственно
возможным),
когда ставится
задача поиска
информативных
речевых параметров
(не обязательно
чисто спектральных)
на значительном
статистическом
материале,
собираемом
в архиве речевых
произнесений
в цифровой
форме.
Ввод сигнала
с гребенки
аналоговых
фильтров. Второй
тип ввода речевых
сигналов в ЭВМ
— это ввод
сигналов с
гребенки аналоговых
полосовых
фильтров,
перекрывающих
частотный
диапазон речи,
прошедшей через
технические
устройства
(микрофон—микрофонный
усилитель—
(возможно) канал
передачи). Информация
с гребенки
фильтров о
медленно меняющихся
огибающих
сигнала с каждого
фильтра поступает
на электронный
коммутатор
(переключатель),
который обеспечивает
последовательное
подключение
напряжения
с выхода каждого
фильтра к
аналого-цифровому
преобра-
71

зователю. Коды
с аналого-цифрового
преобразователя
(информация
на выходе гребенки)
с более низкой,
чем при первом
типе скоростью
ввода, определяемой
частотой опроса
гребенки (частотой
квантования),
поступают в
ЭВМ (рис. 2.2).
Достоинство
этого способа
заключается
в том, что в памяти
ЭВМ после ввода
сигнала находится
уже непосредственно
динамическая
спектрограмма
речевого сигнала
(картина «видимой
речи»), и нет
необходимости
тратить машинное
время на цифровое
моделирование
фильтров. Современные
практические
системы автоматического
распознавания
речи широко
используют
этот способ
ввода информации
о речевом сигнале,
позволяющий
автоматически
анализировать
полученные
аналоговым
способом медленно
меняющиеся
параметры
тракта речеобразования.
72
. Этот тип
устройств ввода
речи обладает
рядом недостатков.
Что во-первых,
то, что в них
трудно изменить
характеристики
(Ьильтров (их
средние частоты
и полосы пропускания)—если
они однажды
вычислены и
реализованы
«в железе», то
перейти к (Ьильтрам
с другими
характеристиками
весьма непросто.
Во-вторых, с
гребёнки полосовых
фильтров поступает
много избыточной
информации,
что не только
чрезмерно
загружает
память ЭВМ, но
и приводит
к тому, что программы
надежного
выделения
основных параметров
речеобразующего
тракта, а также
просодических
параметров
.достаточно
сложны. Иногда
формантные
параметры
мгновенную
частоту основного
тона, среднюю
интенсивность
(громкость)
относят к
наиболее
информативным
параметрам
в отличие от
параметров,
представляющих
просто энергию
в полосах частот
общего спектра
сигнала. Гребёнка
фильтров дает
слишком много
информации,
так как энергия
в полосах частот
характеризует
не только звуки
речи, но и индивидуальные
особенности
речеобразующего
тракта, эмоциональное
состояние
человека и т.
д.
В связи с этим
гребёнку фильтров
используют,
как правило,
в дикторозависимых
системах
автоматического
распознавания
речи, работающих
с предварительной
настройкой
на голос диктора
и набор слов—рабочий
словарь. Иногда
такие системы
называют
адаптивными.
В системах,
работающих
без предварительной
настройки на
голос конкретного
диктора, которые
иногда называют
неадаптивными,
используют
гребенку для
получения
параметров
следующего
уровня распознавания
речи, более
независимых
от дикторского
произношения.
Однако для
систем автоматической
диагностики
заболеваний
органов речеобразования,
распознавания
эмоционального
состояния
диктора и его
индивидуальности
использование
гребёнки полосовых
фильтров как
первичного
анализатора
оказывается
весьма эффективным.
Для неадаптивных
же систем
автоматического'
распознавания
смысла сообщения,
работающих
от голоса
произвольного
диктора, полосовые
фильтры, как
правило, являются
вспомогательными
средствами
первичного
анализа.
Еще раз отметим,
что алгоритмы
автоматического
распознавания
смысла произнесенного
только по картине
видимой речи
оказываются
достаточно
сложными. К
тому же использование
только
73.

гребенки фильтров
не позволяет
эффективно
анализировать
такие звуки
речи, как глухие
взрывные,
длительность
которых сравнима
<: временем
нарастания
энергии на
фильтре.
Ввод в ЭВМ
информативных
речевых параметров.
Следствием
развития системы
ввода второго
типа — системы
анализа речевых
сигналов, основанной
на выделении
аналоговыми
средствами
некоторых
медленно меняющихся
параметров
речи и их последующей
программной
обработки,
являются системы,
использующие
третий тип
ввода сигналов
в ЭВМ. В таких
системах первичным
анализатором
речи служат
устройства
выделения
информативных
речевых параметров,
близких к параметрам
речеобразующего
тракта. Ввод
третьего типа
позволяет еще
сильнее сжать
информацию
о речевом сигнале,
поступающую
в ЭВМ.
Блок-схема
одного из устройств
выделения
речевых признаков
•представлена
на рис. 2.3. Общая
идеология таких
устройств и
обоснование
выбранных
признаков
речевого сигнала
разработаны
в Вычислительном
центре Академии
наук СССР и
Институте
проблем
74
передачи информации
Академии наук
СССР. Усиленный
речевой сигнал
подается на
16 каналов, из
которых 9
дают бинарный
выход сигнализирующий
о наличии или
отсутствии
соответствующего
признака. Эти
признаки названы
групповыми,
их комбинация
может дать
представление
лишь о способе
образования
звуков, т. е. о
принадлежности
к группе звуков,
сходных по
способу образования
— шумные, взрывные,
гласные, но не
о звуке в группе.
Остальные
7 каналов дают
количественные
характеристики
шумных звуков
речи и гласных,
т. е. позволяют
классифицировать
эти звуки по
месту их образования.
К признакам
места образования
шумных здесь
относят:
— число переходов
сигнала через
нулевой уровень
в положительном
направлении
No, т. е. общее
число положительных
импульсов
клиппированного,
или предельно
ограниченного
речевого сигнала,
при котором
он сохраняет
лишь два возможных
значения амплитуды
(уровня);
— число положительных
импульсов
клиппированной
речи, превышающих
длительности
в 100, 200 и 400
мкс;
— число положительных
импульсов
клиппированной
речи, не превышающих
50 мкс.
К признакам
места образования
гласных причисляют
значения первой
и второй формантных
частот. К групповым
двоичным признакам,
принимающим
только два
значения—О
и 1, относятся:
признак наличия
энергии сигнала,
превышающей
ранее заданный
уровень (порог)
в области низких
частот (если
пороговый
уровень энергии
не превзойден,
считается, что
данный групповой
признак отсутствует);
признак наличия
энергии, превышающей
пороговый
уровень в области
высоких частот;
трехуровневый
признак огибающей
сигнала. Трехуровневый
признак наличия
участков с
повышенным
числом перехода
сигнала через
нулевой уровень
характеризует
усредненную
мгновенную
частоту сигнала.
Кроме того, в
число двоичных
признаков
входит признак
повышенной
частоты основного
тона, определяющий
«высокочастотные»
женские и детские
голоса.
.Признаки вводятся
в машину каждые
10 мс в мультипрограммном
режиме на фоне
решения других
задач. Трехпороговый
признак плотности
нулей представляет
собой три одинаковых
канала
75
Таблица
2.1
| Звук |
—о |
/о |
Wl |
N,
|
Ns
|
К.
|
л^в |
N,
|
nh
|
/Л. |
N..
|
|
21
|
3900
|
11
|
3
|
2
|
1
|
1
|
— |
— |
— |
— |
|
24
|
3700
|
16
|
3
|
1
|
|
|
— |
— |
— |
8
|
|
22
|
5400
|
15
|
2
|
1
|
1
|
|
— |
— |
— |
14
|
|
С
|
24
|
4700
|
12
|
3
|
1
|
1
|
— |
— |
— |
— |
20
|
|
28
|
4900
|
8
|
4
|
|
|
— |
— |
— |
— |
16
|
|
29
|
4750
|
8
|
2
|
|
|
|
— |
— |
— |
23
|
|
36
|
1950
|
9
|
1
|
3
|
3
|
1
|
— |
— |
— |
10
|
|
40
|
850
|
3
|
4
|
2
|
2
|
3
|
1
|
— |
1
|
— |
|
48
|
300
|
|
|
|
|
|
1
|
ч
0
|
|
|
|
э
|
50
|
550
|
1
|
|
2
|
— |
1
|
2
|
1
|
1
|
— |
|
54
|
750
|
2
|
— |
1
|
1
|
— |
1
|
1
|
1
|
— |
|
60
|
600
|
1
|
— |
— |
— |
— |
5
|
2
|
— |
— |
|
58
|
650
|
5
|
— |
— |
— |
— |
5
|
1
|
— |
— |
|
57
|
500
|
2
|
|
— |
.—
|
— |
5
|
— |
— |
— |
|
57
|
600
|
2
|
1
|
2
|
— |
1
|
— |
1
|
— |
— |
|
42
|
650
|
1
|
5
|
1
|
1
|
1
|
— |
1
|
— |
— |
|
36
|
350
|
2
|
|
|
2
|
|
1
|
|
— |
— |
|
33
|
250
|
|
|
.
|
|
1
|
— |
— |
2
|
— |
|
м
|
26
|
250
|
—— |
— |
—— |
— |
— |
— |
1
|
2
|
— |
|
23
|
200
|
|
— |
|
— |
— |
— |
1
|
1
|
— |
|
22
|
250
|
|
„ |
|
1
|
— |
— |
— |
2
|
— |
|
20
|
200
|
|
|
|
|
|
|
1
|
1
|
|
|
|
|
|
|
|
|
|
|
|
|
|
с порогами на
частоте в
200, 3500 и 5000 Гц,
что позволяет
уже на уровне
аппаратуры
класс шумных
звуков разделить
на высоко-и
низкочастотные.
Аналогичным
образом построен
трехпороговый
признак огибающей.
Отметим, что
аналоговые
устройства
выделения
информативных
речевых признаков
могут дополняться
другими каналами,
видоизменять
общую структуру,
включать в свой
состав устройства
ввода второго
типа (гребёнки
полосовых
фильтров).
76
2.2.
ВЫЧИСЛЕНИЕ
ПРИЗНАКОВ
ПЕРВИЧНОГО
ОПИСАНИЯ РЕЧИ
ЦИФРОВЫМИ
МЕТОДАМИ
При анализе
речи цифровыми
методами в ЭВМ
с аналого-дифрового
преобразователя
поступают
дискретные
отсчеты речевого
сигнала, т. е.
речь представляется
.набором чисел.
Последовательность
этих чисел
подвергается
программной
обработке по
определенным
алгоритмам
цифровой обработки
сигналов для
того, чтобы
представлять
речь в более
простом виде—меньшим
набором чисел,
первичными
признаками
(признаками
первичного
описания), которые
дают достаточно
полное описание
речевого сигнала.
Признаки (параметры)
первичного
описания программно
вычисляются
за время, в течение
которого положение
речеобразующих
(артикуля-торных)
органов почти
не меняется,—за
0,01—0,02 с (10—20 мс).
На отрезках
такой длительности
аналого-цифровой
преобразователь,
«оцифровывающий»
речевой сигнал
с частотой
20 кГц, дает
200— 400 отсчетов.
Признаков же
первичного
описания на
отрезках такой
длительности
обычно 10—20,
а иногда и меньше,
поэтому уменьшается
объем памяти,,
которая отводится
в ЭВМ для -хранения
речи, и увеличивается
скорость
последующей
обработки
сигнала.
Первичные
признаки записываются
в запоминающем
устройстве
в виде таблицы
(матрицы) параметров.
Каждая строчка
такой таблицы—это
набор признаков,
вычисленных
при цифровой
обработке
речи за 10—20
мс, а каждый
столбец показывает
изменение
данного признака
во времени
(через 10—20
мс). Например,
несложная
табл. 2.1 соответствует
параметрическому
представлению
слова «семь».
При этом признаками
первичного
описания являются:
средняя энергия
сигнала Ац,
средняя частота
перехода сигнала
через нуль /о
(усредненная
мгновенная
частота) и числа
положительных
импульсов
клиппированной
речи. Иными
словами, речи,
представленной
прямоугольными
импульсами,
полученными
из первоначальной
речевой волны
после ее усиления
и предельного
ограничения
по амплитуде,
когда сигнал
принимает лишь
два значения,
одному из
которых может
соответствовать
0, а другому
1. Положительные
импульсы находятся
в диапазоне
длительностей
100—200
77
(Л';), 200—300 (ЛЛ;),
300—400 (Л^з), 400—600
(Л^), 600—800
(/Vg), 800—1200
(Ns), 1200—1800
мкс (Na),
свыше 1800 мкс
(Nis) и ме.
нее 50 мкс
{Ns). Все
признаки измерены
на интервалах
в 20 мс.
Данные для
такой таблицы
получаются
цифровыми
методами с
помощью очень
простых алгоритмов.
Средняя интенсивность
сигнала
Ay на отрезке
в 20 мс может
быть получена
сложением 400
отсчетов входного
сигнала, поступающих
с аналого-цифрового
преобразователя,
без учета их
знака и с последующим
делением на
400. Усредненная
за время анализа
«мгновенная»
частота сигнала
Го вычисляется
подсчетом
точек, где соседние
значения отсчетов
имеют разные
знаки. Число
точек, в которых
сигнал меняет
знак, деленное
пополам, определяет
среднее число
переходов
сигнала через
нуль в положительном
направлении.
Если среднее
число умножить
на 100, то получится
усредненная
мгновенная
частота
fo. Таким образом,
простейшей
формулой,
определяющей
алгоритм вычисления
усредненной
мгновенной
частоты сигнала,
является формула

где Ai
и Лц.1—соседние
отсчеты речевого
сигнала;
sign—произведение
двух чисел Л,
и Лг+i, равное
1, если одно
из чисел (неважно
какое) положительное,
а другое —
отрицательное.
Числа положительных
импульсов
клиппированной
речи, определяющих
интервалы между
нулями в возможных
интервалах
длительностей
(Ni—A^ia),
также вычисляются
очень просто.
Представьте
себе, что в массиве
чисел, которые
соответствуют
речевому сигналу
и получаются
с помощью
аналого-цифрового
преобразователя,
отмечены места,
где сигнал
меняет знак
с отрицательного
на положительный,
и наоборот.
Числа, представляющие
речь, идут,
например, так:
18, 13, 10, 7,3, —1, —8, —12, —20, —32,
—25, —19,
—13, —6, —2, 4, 12, 16, 29, 21, 25, 14, 17, 12, 6,
—2. —5, —11,
—18, —29, —29, —31, —21,
—13 и т. д. В этой
последовательности
соседние числа
трижды имеют
разные знаки.
Дважды сигнал
переходит из
области положительных
значений в
область отрица-
—ro-T^iii-.v г,
r>ni»u пяэ—ия
области отоицательных
в область положи-
тельных (эти
числа в массиве
подчеркнуты).
Если частота
квантования
аналого-цифрового
преобразователя
20 кГц, то временные
отрезки, которым
соответствует
интервал между
двумя соседними
яисламп —
50 мкс (за одну
секунду в память
ЭВМ вводится
20 тысяч отсчетов
речевого сигнала).
Значит, достаточно
подсчитать,
сколько чисел
прошло между
сменой знака
с отрицательного
на положительный,
и наоборот,
чтобы определить
длительность
одного положительного
прямоугольного
импульса
клиппированной
речевой волны.
В нашем случае
число интервалов
между второй
и третьей
сменами знаков
составляет
12, т. е. длительность
прямоугольного
импульса
12Х50—600 мкс. Можно
полагать, что
параметр
Ms должен увеличиваться
на единицу. Для
каждого из
параметров
^V,—,Vi6 имеются
ячейки-счетчики,
которые называются
счетчиками
селекции импульсов
по длительности
и куда программа
за время анализа
(10—20 мс) заносит
для суммирования
единицы, если
выполнено
условие записи
в соответствующую
ячейку памяти
после проверки
длительности
положительного
импульса. Это
делается сравнением
длительности
импульсов с
константами,
определяющими,
в какой из диапазонов
длительностей
попало данное
число.
Что дает такая
таблица признаков?
Рассмотрим
данные табл.
2.1 более
внимательно.
В ней даются
22 строки. Это
означает, что
длительность
слова «семь»
440 мс, так как
каждая строка
таблицы характеризует
отрезок сигнала
длительностью
в 20 мс. Столбцы
таблицы показывают,
как изменяются
признаки на
протяжении
слова. Слово
начинается
с фонемы, характеризующейся
высокой мгновенной
частотой:
4—5 кГц. Далее
следует участок,
на котором
самая высокая
громкость и
мгновенная
частота снижается
до 600— 700 Гц.
Затем следует
конечный участок
слова, на котором
и интенсивность
падает, и усредненная
мгновенная
частота снижается
до 200—250 Гц. Это
соответствует
последовательности
звуков с—э—м.
Особенно следует
сказать о признаках
Ni—A^g.
Для щелевого
с длительности
положительных
импульсов
фактически
лежат в пределах
До 200 мкс. Для
ударного гласного
э эти длительности
лежат в диапазоне
300—800 мкс, а для
носового м—в
пределах
1000 мкс и более.
79
Рассматривают
цифровой анализ
сигналов во
временной и
спектральной
областях. В
первом случае
признаки более
компактного
представления
речи получаются
непосредственно
из оцифрованного
речевого сигнала,
так, как в рассматриваемом
примере. Во
втором —
параметры
извлекаются
на основании
анализа динамической
спектрогрммы,
которая характеризует
изменяющийся
во времени
спектр звуков
речи. Спектральный
анализ (получение
динамической
спектрограммы)
на ЭВМ осуществляют
с помощью алгоритма
дискретного
преобразования
Фурье, который
кратко будет
рассмотрен
далее,

Отметим, что
к методам анализа
речевых сигналов
во временной
области относится
автокорреляционный
анализ. Это
метод обработки
сигналов, основанный
на временнной
задержке начального
сигнала с последующим
умножением
задержанного
сигнала на
исходный.
Автокорреляционная
функция —
это функция
времени, показывающая,
как зависят
последующие
значения речевого
сигнала от
предыдущих:
чем больше ее
значение, тем
большая зависимость
определения
последующего
отсчета сигнала
от предыдущего,
т. е. последующие
отсчеты более
коррелированы
с предыдущими.
На звонких
участках речи
автокорреляционная
функция квазипериодична,
на глухих, где
речевой сигнал
представляет
собой фрикативный
квазислучайный
шум, автокорреляционная
функция непернодична,
случайна. На
этом основано
выделение по
автокорреляционной
функции участков,
соответствующих
глухим и звонким
звукам речи,
а также определение
периода основного
тона. На рис.
1.14, г представлена
автокорреляционная
функция для
звонкого участка
речевого сигнала.
С помощью
автокорреляционной
функции можно
определить
некоторые
важные свойства
речевого сигнала,
в частности,
узнать, является
ли даяный сигнал
периодическим,
т. е. присутствует
ли в нем основной
тон. Автокорреляционная
функция для
дискретной
последовательности
х(п) вычисляется
по формуле
R(s)=-Zx(n)x(n—s),
s=0, I, 2, ..., N,
n=s
где х(п)—отсчет
речевого сигнала
в п-й момент
времени; п=0,
1, 2, ..., N;
N+l—количество
отсчетов в
интервале
анализа;
.V-4-1— количество
отсчетов
автокорреляционной
функции.
80
Автокорреляционная
функция является
четной функцией,
т. е. R(s)==R(—s),
и максимального
значения достигает
при s=0. Величина
R(o) равна
полной энергии
речевого сигнала
на интервале
анализа, что
весьма важно
для определения
энергии сигнала,
если известно
значение
автокорреляционной
функции
R(o).

Вычисление
отсчетов
автокорреляционной
функции можно
производить
в процессе
ввода речи с
аналого-цифрового
преобразователя,
уточняя с каждым
вновь принятым
отсчетом сигнала
значение отсчетов
автокорреляции
по рекуррентной
формуле
R»o»(s)=Rc-r!4?(s)+x(n)x(n—s),
s==0, I, 2, ...,
N.
В начале интервала
анализа принимаем
R(s)=0, s=0,
I, 2,..., ..., N,
а предыдущие
отсчеты сигнала
— равными
нулю. Отметим,
что в аналоговую
аппаратуру
выделения
информативных
признаков,
описанную
ранее, может
быть включен
канал, дающий
возможность
получить значения
автокорреляционной
функции на
интервале
анализа
— коррелометр.
2.3.
КРАТКИЕ СВЕДЕНИЯ
О СПЕКТРАЛЬНОМ
АНАЛИЗЕ РЕЧИ
Ранее упоминалось
о том, что речевой
сигнал можно
рассматривать
как реакцию
системы с медленно
меняющимися
параметрами
речеобразующего
тракта на
периодическое
или шумовое
возбуждающее
колебание.
Многообразие
звуков речи
определяется
многообразием
форм голосового
тракта. При
построении
модели речевого
сигнала, например
в говорящих
машинах —
синтезаторах
речи, принимают,
что на относительно
коротких временных
интервалах
(10—20 мс) формы
голосового
тракта при
произнесении
звуков речи
существенно
изменяться
не могут. На
таких коротких
интервалах
подобные формы
тракта считают
постоянными.
А это означает,
что электрический
фильтр с резонансными
свойствами,
отражающими
свойства голосового
тракта, тоже
можно рассматривать
на коротких
временных
интервалах
как систему
с постоянными
параметрами.
Это позволяет
моделировать
сложный процесс
ре-чеобразования
электрической
цепью или программно
на ЭВМ.

Модель речевого
сигнала для
звонкого звука
представлена
на рис. 2.4.
Импульсы возбуждения,
т. с. электрические
сигналы, эквивалентны
толчкам воздуха
на выходе голосовых
связок (рис.
2.4, а); ^:o=2л/Гo—частота
импульсов
возбуждения,
или частота
основного
тона. В спектральной
области энергия
таких импульсов
представляется
гребенчатым
спектром (рис.
2.4,6). Это означает,
что квазипериодический
сигнал, соответствующий
импульсам
возбуждения,
имеет частотные
составляющие
лишь на гармониках,
кратных частоте
основного тона
на частотах
Fo, 2Fo,
3F„ и т. д. (точнее,
в областях
вблизи этих
гармоник).
Для аналоговых
электрических
сигналов выходное
напряжение
определяется
операцией
свертки функции
возбуждения
и отклика (реакции)
фильтра на
единичный
скачок напряжения
на его входе.
Иногда свертку
для аналоговых
сигналов называют
интегралом
Дюамеля. Операцию
свертки для
аналоговых
сигналов мы
рассматривать
здесь не будем
из-за се относительной
сложности.
Попытаемся
кратко описать,
что такое операция
свертки для
случая дискретных
сигналов.
Из теории фильтрации
следует, что
если возбуждающий
сигнал, поступающий
на фильтр,
представлять
последовательностью
его
82

отсчетов, то
сигнал на выходе
фильтра, который
моделирует
голосовой
тракт, можно
представить
операцией
дискретной
свертки, которая
учитывает
реакцию фильтра
на входные
(возбуждающие)
сигналы. Дискретный
сигнал на выходе
фильтра вычисляется
по сигналу на
входе Е(п) и
отклику (реакции)
h(n) фильтра
на единичный
импульс
6(ri), равный
единице в дискретные
моменты времени
п и нулю вне
этих дискретных
моментов. Дискретная
свертка вычисляется
S(n)=^ E(k)h(n—k)=E(n)* h(n),
k=—oa
где символ
* означает
свертку. Вычисление
этой громоздкой
суммы произведений
упрощается,
если учесть,
что большая
часть этих
произведений
равна нулю
из-за конечной
длительности
возбуждающего
сигнала Е(п).
Итак, если
S(n)—речевой
сигнал на входе
фильтра, моделирующего
голосовой
тракт, то значение
каждого отсчета
сигнала можно
представить
сверткой
S(n)=E(n)s h(n).
Переход к анализу
сигналов в
спектральной
области позволяет
достаточно
просто получить
спектр выходного
речевого сигнала,
если известен
спектр возбуждающего
сигнала и
передаточная
функция фильтра,
моделирующего
голосовой
тракт. Спектр
выходного
сигнала (звонкого
звука речи), т.
е. совокупность
значений амплитуд
всех частотных
составляющих,
образующих
данный звук
(рис. 2.4,6), можно
получить, перемножив
(а не произведя
сложную операцию
свертки) спектральные
составляющие
гребенчатого
спектра сигнала
возбуждения,
которые берутся
в точках, кратных
частоте основного
тона, на значения
передаточной
функции голосового
тракта. На этом
рисунке видны
подъемы спектра
на формант-ных
частотах
f[, /•2,
Fs, Ft-
Разработаны
математические
методы (аппарат
прямого и обратного
преобразования
Фурье), позволяющие
осуществлять
переход к
представлению
сигнала в
спектральной
области, если
известна временная
картина речевой
волны. И наоборот,
если известно
спектральное
представление
речевого сигнала
на последовательных
отрезках речевой
волны, то можно
получить временную
картину речи,
б* 83
т. е. увидеть
ее осциллограмму
и услышать
звучание
синтезированной
речи, когда
известны только
амплитуды ее
частотных
составляющих.
Спектральное
представление
оцифрованного
речевого сигнала
основывается
на кратковременном
дискретном
преобразовании
Фу- i рье,
учитывающем
обстоятельство,
о котором мы
уже упоминали:
на относительно
коротких временных
интервалах
(10—20 мс) свойства
голосового
тракта, а значит,
и передаточная
функция тракта,
определяющая
спектральные
свойства речевого
сигнала, существенно
не изменяются.
Хотя формула
дискретного
преобразования
Фурье строго
теоретически
представляет
бесконечное
суммирование
произведений
дискретных
отсчетов сигнала
и синусоид,
частоты которых
изменяются
дискретно от
некоей начальной
синусоиды до
бесконечности,
реальное
(кратковременное)
преобразование
Фурье использует
дополнительный
сомножитель.
Он называется
весовым окном,
или весовой
функцией, которая
имеет ненулевые
значения лишь
на окне (участке
сигнала длительностью
10—20 мс), где мы
принимаем
постоянными,
независимыми
от времени
частотные
составляющие
звука.
Формула кратковременного
преобразования
Фурье, которым
пользуются
при расчетах
дискретных
спектров звуков
речи, имеет вид

Кратковременное
преобразование
Фурье позволяет
представлять
речь динамической
спектрограммой,
или временной
последовательностью
спектральных
срезов, кратковременных
спектров, каждый
84
из которых
получен для
окна, короткого
отрезка речевого
сигнала, на
котором, как
мы считаем, не
изменяются
спектральные
свойства.
Динамическая
спектрограмма
(картина «видимой
речи», если ее
выводят на
печать в виде
рисунка) представляет
характеристики
речи в координатах
«время —
частота —
амплитуда».
Алгоритм дискретного
преобразования
Фурье позволяет
изобразить
спектр значениями
амплитуд частотных
составляющих
на равностоящих
частогах. По
спектральному
описанию
(кратковременному
спектру) можно
определить
— и довольно
несложными
математическими
методами
— основные
параметры
речеобразующего
тракта: частоту
основного тона,
формантные
характеристики,
энергии в полосах
частот.
В настоящее
время разработаны
алгоритмы
быстрого вычисления
значений спектральных
составляющих
по дискретным
отсчетам сигнала.
Такие алгоритмы
называются
алгоритмами
быстрого
преобразования
Фурье. В их основе
лежит разбиение
последовательности
Л" отсчетов
речевого сигнала
на составные
части (N
берется всегда
составным
числом), для
которых вычисления
осуществляются
значительно
быстрее. Обычно
N берется
как 2й, т. е. берутся
Л', равные
128, 256 или 512 (27,
28 или 29) в
зависимости
от частоты
квантования
сигнала и
длительности
окна анализа.
Отметим, что
разработаны
также ускоренные
методы для
вычисления
операции свертки.
2.4. НЕМНОГО
О ЛИНЕЙНОМ
ПРЕДСКАЗАНИИ
В последние
годы приобрел
широкое распространение
метод анализа
речевых сигналов
во временной
области, который
получил название
линейного
предсказания
или линейного
прогноза. В
развитие этого
метода анализа
речи большой
вклад внесли
советские
ученые А. А.
Харкевич, Н. Н.
Акинфиев, А. Н.
Собакин и др.
Линейное
предсказание—это
метод анализа,
основанный
на цифровой
фильтрации
оцифрованной
речи, при которой
текущий отсчет
сигнала может
быть «предсказан»
(например, при
автоматическом
синтезе речи)
линейной комбинацией
прошлых значений
выходной
последовательности
и настоящих,
а также прошлых
значе-
85
ний входной
последовательности.
Понятие «линейная
комбинация»
означает сумму
произведений
известных
дискретных
отсчетов сигнала
(входных и выходных),
умноженных
на соответствующие
коэффициенты
линейного
предсказания
для предсказания
(определения)
неизвестного
выходного
отсчета. При
линейном предсказании
основная задача
анализа речи
— найти коэффициенты
этой линейной
комбинации,
которые дают
минимальную
ошибку предсказания
на участке
анализа сигнала.
Модель сигнала,
наиболее часто
используемая
при линейном
предсказании,
сводится к
получению
неизвестного
отсчета х(п)
без учета предыдущих
входных воздействий
на выходе некоторой
системы
р
х(п)=^ dnx(n—k)+
Gu(n), k=i
где р —
число коэффициентов,
используемых
в модели; йк
— коэффициенты
линейного
предсказания;
G—коэффициент
усиления,
определяющий
вклад в линейную
комбинацию
входного отсчета;
и(п) — текущий
входной отсчет.
Задача анализа
оцифрованной
речи сводится
к определению
коэффициентов
Ок и G этой
модели. Метод
определения
величин, используемых
при расчетах,
называется
методом наименьших
квадратов.
Чтобы понять
его суть, пойдем
на некоторые
упрощения в
представлении
текущего выходного
отсчета. Будем
считать, что
входное воздействие
на вход системы,
моделирующей
формирование
речевых сигналов,
ненаблюдаемо,
что справедливо
для ряда прикладных
задач. Тогда
на интервале
анализа текущие
отсчеты речевого
сигнала приближенно
опишутся линейной
комбинацией
предыдущих
значений:


Коэффициенты
линейного
предсказания
а„ вычисляются
из условия
минимума
среднеквадратичного
значения ошибки
на интервале
анализа. На
этом интервале
полная среднеквадратичная
ошибка складывается
для каждого
отсчета сигнала,
представленного
линейной
комбинацией
р предыдущих
значений сигнала

Здесь п
— номер предыдущего
отсчета сигнала
на анализируемом
интервале;
k — номер
предыдущего
отсчета сигнала
при построении
линейной комбинации,
представляющей
текущий отсчет.

Коэффициенты
линейного
предсказания,
минимизирующие
полную ошибку
предсказания
Е, находятся
после того,
как выражение
для полной
ошибки продифференцировать
по всем коэффициентам
Он (полная ошибка
предсказания
может рассматриваться
как функция
параметров
ак) и приравнять
нулю все частные
производные:
дЕ/дс>к=0'Л<1г<р.
Частными
производными
называются
производные
сложной функции
по одной из
переменных
с учетом того,
что остальные
переменные
при таком
дифференцировании
считаются
константами.
Результатом
дифференцирования
по а,, является
система из
линейных уравнений
с неизвестными
коэффициентами
линейного
предсказания,
минимизирующими
ошибку линейного
предсказания
на отрезке
анализа сигнала,
где коэффициенты
йк считаются
постоянными.
Решение этой
системы линейных
уравнений, а
также другие
вопросы, связанные
с линейным
предсказанием
речи, подробно
рассмотрены
Маркелом и
Грэем в книге
«Линейное
предсказание
речи».
87
2.5. АНАЛИЗ
КЛИППИРОВАННОЙ
РЕЧИ
Клиппированным
речевым сигналом
называют предельно
ограниченный
«стриженый»
сигнал, сохраняющий
лишь два возможных
значения, которые
условно принимаются
за +1 и —1
(рис. 2.5).
В различных
работах отмечается,
что, несмотря
на недостаточную
естественность
звучания
клиппированной
речи, ее разборчивость
оказывается
достаточно
высокой, причем
разборчивость
речи повышается,
если до клиппирования
речевой сигнал
подвергнуть
дифференцированию.
Это явление
означает, что
информация
о распределении
интервалов
между нулевыми
пересечениями
сигнала может
быть использована
для построения
устройств
автоматического
распознавания
и синтеза речи.
Привлекательность
автоматического
анализа клиппированной
речи и использования
ее параметров
для целей построения
говорящих и
понимающих
речь машин
лежит в простоте
получения этих
параметров.
Если речевой
сигнал представлен
дискретной
последовательностью
его отсчетов
-J х(п)}
, то фиксирование
момента перехода
сигнала через
нуль происходит,
когда знаки
двух соседних
дискретных
отсчетов речевого
сигнала различны,
т. е.
sign[x(n)]-^s\gn[x(n—l)'\.
Информация
об общем числе
переходов
сигнала на
определенном
интервале и
различных
диапазонах
длительностей
участков между
нулями часто
используется
для грубой
оценки частотного
состава сигнала.
Существует
тесная связь
между числом
нулевых пересечений
и распределением
энергии по
частотам. Общее
число переходов
сигнала через
нуль, величину
Л'о, вычисляемую
для дискретной
последовательности
А" отсчетов,
можно представить
в виде

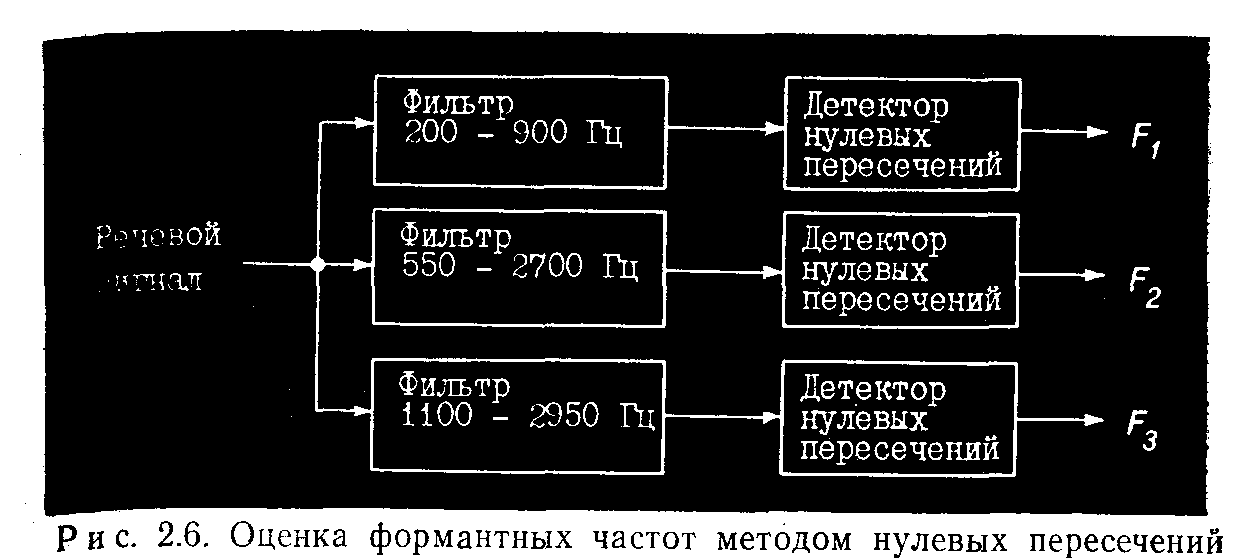


Существуют
системы автоматического
распознавания
речи, в которых,
как об этом
говорилось
ранее, нулевые
пересечения
используются
для приближенного
определения
формантных
частот. На рис.
2.6 показано,
как оцениваются
формантные
частоты с помощью
схемы анализа
нулевых пересечений
после прохождения
сигнала через
полосовые
фильтры, которые
перекрывают
диапазоны
частот, соответствующие
формантным
областям (первая
форманта Fi
лежит в диапазоне
200—900 Гц, вторая—550—2700
Гц и третья—
1100—2950Гц).
Иногда при
распознавании
речевых сигналов
используют
так называемую
гребенку временной
селекции, которая
позволяет
оценить ширину
импульсов
клиппированного
сигнала и тем
самым провести
более точный
анализ во временной
области, что
позволяет
относительно
простыми средствами
отличать одни
классы звуков
от Других. Так,
для фрикативных
согласных
селекторы
импульсов по
Длительности
дают возможность
отделить диффузные
(звуки с ши-
89
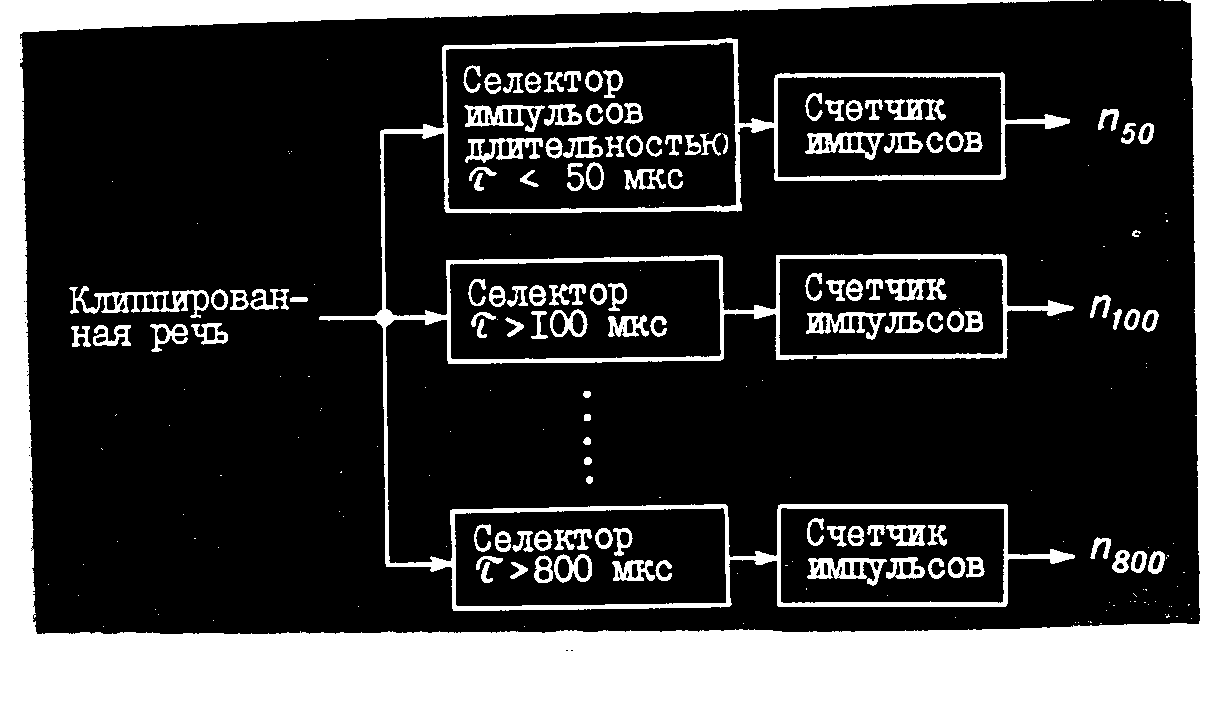
Рис. 2,7. Блок-схема
временной
селекции интервалов
между нулями
роким спектром
типа ф) от
компактных
(спектр которых
сосредоточен
в относительно
узкой области—с,
ш).
Блок-схема
селекции импульсов
клиппированного
речевого сигнала
по длительности
показана на
рис. 2.7.
Обычно с учетом
особенностей
клиппированных
согласных и
гласных выбирают
пороги временной
селекции, равные
50, 100, 200, 400, 600 и 800 мкс
(первый селектор
отбирает узкие
импульсы,
длительность
которых меньше
50 мкс). Поступающие
для дальнейшего
анализа числа
(со счетчиков
импульсов)
позволяют
получать
распределение
интервалов
между нулями
в диапазонах
длительностей
между пороговыми
значениями
селекторов
— узлов, пропускающих
на счетчики
импульсы,
превосходящие
(или не превосходящие)
по длительности
заданный порог.
Следует отметить,
что энергия
и переходы
сигнала через
нуль часто
совместно
используются
для разработки
алгоритмов
выделения
моментов начала
и конца речевой
реализации
(изолированного
слова фразы).
Такой алгоритм
применен, например,
в отечественной
промышленной
системе распознавания
изолированных
слов ИКАР.
90
Подобные алгоритмы
основываются
на тщательном
исследовании
статистических
параметров
функций среднего
значения сигнала
я числа нулевых
пересечений
для шумов различной
природы и различных
звуков фраз
и изолированных
слов.
2.6.
ГОМОМОРФНАЯ
ОБРАБОТКА
СИГНАЛОВ
Как было показано
ранее, речевой
сигнал на коротких
интервалах
можно рассматривать
как отклик
системы с медленно
меняющимися
параметрами
на периодическое
или шумовое
возбуждение.
Это означает,
что во временной
области дискретный
сигнал у(п)
представляется
результатом
свертки функции
возбуждения
х(п) с импульсной
реакцией голосового
тракта h(n).
Гомоморфная
обработка речи
сводится к
решению обратной
задачи — имея
речевой сигнал
у(п) =х(я)* h(n),
можно получить
параметры
сигналов, участвующих
в свертке. Эта
задача называется
иногда задачей
обратной свертки
или развертки.
Смысл гомоморфной
системы анализа
становится
более понятным,
если учесть,
что в частотной
области речевой
сигнал представляется
произведением
спектра сигнала
возбуждения
и передаточной
функции частотной
характеристики
голосового
тракта, учитывающего
спектральные
свойства излучателя
(произведением
P(f)=E(f) F(f), см. рис.
1.3). Это означает,
что в спектре
речевого сигнала
содержится
информация
о спектре сигнала
возбуждения
и передаточной
функции голосового
тракта. Гомоморфная
обработка
сигнала —
это способ
извлечь информацию
об основном
тоне и формантных
частотах на
основании
преобразований
сигнала, которые
будут описаны
далее.
Если произвести
кратковременное
дискретное
преобразование
Фурье (т. е. получить
динамический
спектр речевого
сигнала), а затем
прологарифмировать
спектральные
составляющие
динамического
спектра, то
каждый спектральный
отсчет можно
рассматривать
как сумму логарифмов
спектра сигнала
возбуждения
и частотной
характеристики
речевого тракта
(по свойству
логарифмической
функции логарифм
произведения
равен сумме
логарифмов
со-
91
преобразование
Фурье

множителей).
Обратное дискретное
преобразование
Фурье прологарифмированного
спектра позволяет
вновь перейти
к анализу сигнала
во временной
области. Сигнал,
полученный
в результате
обратного
дискретного
преобразования
Фурье прологарифмированного
спектра, называется
кепстром входного
сигнала, равного
сумме кеп-стров
сигналов возбуждения
и составляющих,
обусловленных
особенностями
речеобразующего
тракта. В результате
подобных
преобразований
дискретный
речевой сигнал,
представляющий
собой свертку
сигнала возбуждения
и импульсного
отклика фильтра,
моделирующего
голосовой
тракт, приближенно
преобразуется
в сложение
кепстров (рис.
2.8).
Логарифм
кратковременного
спектра вокализованных
звуков содержит
медленно меняющуюся
составляющую,
обусловленную
передаточными
свойствами
голосового
тракта, и быстро
меняющуюся
периодическую
составляющую,
которая вызывается
периодическим
сигналом возбуждения
(рис. 2.9, а). Для
невокализованной
речи прологарифмированный
спектр носит
характер, показанный
на рис. 2.9. б.
Спектр содержит
случайную
составляющую
с быстрыми
изменениями.
Кепстры отрезков
вокализованной
и невокализованной
речи (рис.
2.10) показывают,
что медленно
меняющаяся
часть прологарифмированных
значений
кратковременного
спектра представлена
составляющими
кепстра в области
малых времен.
Быстро меняющаяся
периодическая
составляющая
прологарифмированного
спек
92
р,.

тра, соответствующая
частоте основного
тона, в кепстре
вокализованной
речи проявляется
в виде резкого
пика, расположенного
от начала координат
на расстоянии,
равном периоду
основного тона.
Кепстр невокализованной
речи (рис.
2.10, б) таких пиков
не имеет.
Если кепстр
перемножить
на подходящую
функцию окна,
например на
прямоугольное
окно, пропускающее
только начальные
участки кепстра
(которые соответствуют
области малых
времен и отражают
относительно
медленно меняющиеся
параметры
голосового
тракта), а затем
вычислить
дискретное
преобразование
Фурье результирующего
взвешанного
кепстра, то
получим сглаженный
спектр сигнала
(см. рис. 2.8). Он
отражает резонансные
свойства тракта,
позволяя оценивать
частоты и полосы
формант. Наличие
или отсутствие
ярко выраженного
пика в области,
соответствующей
диапазону
изменений
периода основного
тона, указывает
на характер
возбуждения,
а местоположение
пика является
хорошим индикатором
периода основного
тона (рис.
2.10,0^).

РЗ
nOCIPOFHHE
СИСТЕМ ДИСКРЕТНОГО
РАСПОЗНАВАНИЯ
РЕЧИ, РАБОТАЮЩИХ
БЕЗ ПОДСТРОЙКИ
ПОД ДИКТОРА
§ 2.1. Общие
проблемы
автоматической
подстройки
неадаптивных
систем распознавания
речи
Ьеадаптивные
системы дискретного
распознавания
речи, рассматриваемые
в настоящей
главе, позволяют
произвольному
диктору-ногитедю
нормы произношения
данного языка
производить
автоматический
речевой ввод
изолированными
словами или
короткими
спиво-сочетанияуи.
Такие системы
являются, как
правило, аппаратурно-ц
рог равным и
и основываются
на выделении
некоторых
устойчивых
фонетических
признаков,
проявляццихся
у множества
дикторов-носителей
нормы данного
языка для различных
классов звуков,и
на дальнейшем
использовании
этих признаков
(представленных
гистограммами
их распределения)
для декодирования
высказывания.
Однако фактически
и в этих системах
осуществляется
некая подстройка
под множество
дикторов (обучение)
во время сбора
статистики,
построения
гистограмм
параметров
для различных
звуков и при
выборе решающих
правил. Поэтому,
строго говоря,
такие системы
не следовало
бы называть
неадаптивными,
т.е. термином,
достаточно
широко распространенным
в настоящее
время. Кроме
того,автоматическое
разбиение всего
множества
дикторов-пользователей
на группы
(кластеры) и
формирование
обобщенных
эталонов слов
дяя каждой
группы само
по себе есть
обучение на
диктора, адаптация
универсальной
системы к этому
множеству
пользователей,что
также заставляет
быть осторожным
в применении
Термина-"неада^тивные",
Если же говорить
об использовании
этого термина
в смысле отсутствия
адаптации к
новому словарю
и языку системы,
го, действительно,
все известные
невдаптивные
системы [10,
16,25, 166, 167] практически
не обеспечивав
автоматическое
изменение этих
основных
характеристик.
Попытка универсальной
сегментации
слов, яв-хякхцейся
основой подстройки
иод словарь,
рассмотрена
в [133 • Задача
настоящей главы
- исследовать
более широкие
аспекты проблемы
перестройки
к новым условиям
не адаптивных
систем, ориентированных
на работу с
произвольным
диктором. Под
адаптацией
будем здесь
понимать расширение,
развитие неадаптивной
системы автоматического
распознавания
фраз, составленных
мэ изолирований
74
йдов, эа счет
некоторого
изменения языка
этой системы
и его словарного
состава. Как
правило, в конкретных
задачах речевого
управления
возникают
Проблемы, связанные
с обогащением
языка, добавлением
новых слов и
понятий. В отдельных
случаях требуется
медиком заменить
словарный
состав языка,
приспособить
системы к
совершенно
новой задаче.
При этом желательно
сохранить
основные структурные
(синтаксические)
свойства языка,
связи между
лингвистическими
уровнями, соотношения
между понятиями
внутри уровня,
т.е. придать
свойствам языка
универсальный
характер,
формализовать
язык речевого
запроса таким
образом, чтобы
он напоминал
язык опи-оанйя
баз данных
- сетевой,
иерархической
или реляционной.
Основными
лингвистическими
вопросами,
возникгшцими
при этом, явжявтся:
1) как оценить
сложность языка
речевого общения
и попытаться,
используя
синонимию,
свести трудности
распознавания
сдов, вызванные
фонетическими
неопределенностями,
до минимума;
2) каким образом
ограничить
гибкость
проблемно-ориентнрова!:-иого
языка, не слыпком
сдерживая
желания и возможности
человека общаться
с информационной
системой
естественными
фразами; какие
задачи позволяют
нам практически
использовать
относительно
простой синтаксис
языка;
3) как автоматически
расширять
словарный запас
языка;
4) как при
этом корректировать
язык, на базе
которого создана
неадаптивная
система автоматического
распознавания.
(Вопросы о расширении
круга пользователей,
включая пользователей,
говорящих с
акцентом иди
дефектом речи,
а также проблемы
поиска новых
информативных
признаков,
использования
телефонного
канала опускаем,
относя их к
техническим
вопросам,которые
• работе
не рассматривается.)
Некоторые из
перечисленных
лингвистических
проблем возникают
и для адаптивных
систем, работающих
с подстройкой
под дик-Юра и
словарь. 3
известных
работах по
аравтическому
использованию
адаптивных
систем [134,140]
нет сведений
об адаптации
систем к новому
изменяемому
языку речевого
общения (если
не считать
замену словаря
в системах типа
vir-юо подстройкой
под язык).
йервой мз проблем
посвящен
§ 2.2, где выбор
словаря обус-яовлен
точностью
распознавания
слоя и связанной
с ней вероятностной
оценкой неопределенности
распознавания
При заданной
совокупности
фонетические
признаков.
Оценка граю-атнческой
сложности
яэыка, используемого
в неадаптивных
системах
распознавания
ре-11^^
(языка, древовидной
структуры без
сложных внутренних
связей)
76
(си.
§ 2.3), позволяет
подойти к решению
вышеуказанной
проблемы
2). Задаче автоматического
расширения
словарного
состава посвящена
четвертая
глава, тесно
связанная с
пятой главой,
где описаны
эксперименты
по построению
системы распознавания
понятийных
фраз конкретного
языка описания
данных информационной
системы, для
которого строилась
модель. Кратко
о проблеме
3 говорится
в п. 2.3.3 , в котором
рассматривается
автоматическая
подстройка
"под язык",
изменяющийся
с изменением
словарного
состава.
Рассматривающиеся
далее вопросы,на
наш взгляд,имеют
весьма важное
значение как
идеологическая
основа будущих
систем автоматического
речевого запроса
информации,
ориент грованных
на произвольного
пользователя.
Если первые
практические
неадаптивные
системы распознавания
речи (СРР) могут
и отличаться
от аппаратурно-программных,
аналогичных
нашей (скажем,
основываться
на мультимик-ропроцессорных
системах, в
которые речевой
сигнал поступает
с АЦП), то
общие лингвистические
проблемы, указанные
здесь, неизменно
будут возникать
при любой структуре
системы и любом
подходе к
первичному
описанию сигнала.
Не следует
забывать, что
неадаптивные
системы автоматического
распознавания
являются основными
системами
будущего
- при общении-,
с роботами и
информационными
системами
общего назначения.
Вопросы, рассматриваемые
далее, будут
относиться
к неадаптивным
системам,
ориентированным
на пословный
ввод речевой
информации,
а также на ввод
информации
короткими
словосочетаниями,
которые можно
рассматривать
как одно слово.
Это связано
с тем, что лишь
на изолированных
словах и коротких
словосочетаниях
параметры
звуков (выцеляемые
алпаратурно)
являются относительно
устойчивыми
(обладают малой
дисперсией),
и можно говорить
о возможном
использовании
характеристик,
определяемых
гистограммами
параметров,
для автоматического
распознавания
.
При
распознавании
изолированных
слов представляется
целесообразным
разработать
алгоритм, который
обеспечивал
бы устойчивое
сегментирование
поступающих
на вход реализации
слов на участки,
соответствующие
различи™ способам
образования
звуков, т.е. на
тональные
отрезки речи,
шумные и участки,
соответствующие
гиухии смычковым
(коротким паузам
внутри слова).
Звонкие фрикативные
звуки можно
было бы отнести
к шумным. Существуют
различные
методы такой
классификации
в зависимости
от первичного
описания речевых
сигналов. Для
аппаратурно-программного
метода достаточно
высокую точность
классификации
отрезков речи
на участки "тон
- иум ' Пауза"
для произвольного
диктора дают
бинарные признаки
способа образования
звуков, выделяемые
аппаратурно
[97] .
76
Динамика участков
"тон - шум
- пауза" является
хорошим признаком
распознавания
слов для небольших
специально
подобранных
„доварей. Не
представляет
труда перейти
к небольшому
новому словарю,
используя лишь
признаки
классификации
отрезков речи
на вти трч
класса и динамику
типов участков
в слове. Вакно
правильно
выбрать фонетическую
структуру слов
этого словаря.
В зависгзло-стИ
от возможностей
надежной
классификации
отрезков речи
на этапе анализа
сигнадоч (первичная
сегментация
и маркировка)
mosko использовать
большее число
классов сегментов
(классов фонетической
структуры
слова), динамика
которых позволит
надекно классифицировать
большее число
слов словаря.
(В наших работах
на начальной
уровне анализа
речи использовалось
как семь типов
сегментов (ей.
Я, 2.2.2), так
и три типа
- тональный-шумный-сауза
(см. § 5.5).)
В связи с этим
Ж.Дрейфу о-Граф
для распознавания
словарного
состава разработал
специализированный
язык речевого
общения sotina
, состоящий
из бессмысленных
слов, которым
условно придается
некое смысловое
значение, и
включал лишь
"контрастные"
в Пространстве
используемых
признаков
звуки, поэтому
легко различаемые
автоматически
[127] . Словарный
состав языка
sotina включал
бессмысленные
слова, на базе
которых предлагалось
создать искусственный
язык для речевого
общения человека
и 5ВУ.
§ 2.2. Оценка
сложности
распознавания
словаря речевого
общения
2.2.1.Связь
точности
распознавания
с особенностями
фонетики
слов.Сравнивать
качество
распознавания
существующих
СРР и СПР только
по точности
распознавания
или объему
словаря недостаточно
по нескольким
причинам.
Во-первых,разные
задачи, естественно,
требуют различных
языков общения,словарный
состав которых
включает слова,
имеющие различные
акустические
(фонетические)
характеристики.Источники
информации
о таких высших
уровнях знаний
языка, как синтаксис,
семантика,
прагматика,
накладывают
различные
ограничения
на возможные
альтернативы,
поэтому задача
распознавания
упрощается
для различных
языков по-разному;
даже для словаря
с высокой
степенью фонетической
неопределенности
можно получить
(за счет
семантико-синтаксических
ограничений)
высокую точность
иитер-Чрета11ии
высказывания.
Во-вторых, СРР
используют
разнообразные
методы первичной
обработки и
представления
речевых сигналов
на ниж-них
уровнях. С этим
связана различная
точность фонетической
классификации
, являющейся
основой распознавания.
Рассмотрим,
как раз-
77
лишаются
речевые сигналы
на разных уровнях
знания и как
они используются
при распознавании
слов. Известно,
что наибольшие
оаибхи дают
слова и фразы
с близкой
фонетической
структурой,
входящие в
общий словарь
распознавания.
При этих условиях
задача распознавания
как изолированных
слов, так и слитной
речи усложняется,
но синтаксис
и другие высшие
источники
знаний о языке
накладывают
ограничения,
которые сокращают
неопределенности,
тем самкл повкаая
точность
распознавания
слов.
При
выборе словаря
СРР важно, как
уже отмечалось,
знать не только
размер словаря,
но и степень
различимости
слов. Для частных
применений
и малых словарей
необходимо
предварительно
провести отбор
и разумную
замену слов,
если позволяет
задача, с целью
увеличения
различимости
слов словаря.
Поэтому целесообразно
исследовать
неопределенности,
ограничения
и сложности,
встречаемые
при использовании
различных
языков практических
СРР.
Дзя
того, чтобы
показать влияние
фонетической
структуры слов
словаря на
сложность
распознавания,
рассмотрим,
в качестве
примера. три
словаря: I)
"А", "Б", "В";
2) "ОДИН", "ДВА","ТРИ";
3) "А", "П", "Г".
Сравнивая
словари I
и 2, нетрудно
заметить, какой
словарь легче
распознавать.
В данном случае
интуитивно
можно утверждать,
что словарь
2)легче распознавать
из-за более
сложной фонетической
структуры
слов, так как
можно привлечь
больше дополнительной
информации
о последовательности
звуков, составляющих
слова.Сравнивая
словари I)
и 3)по сложности
распознавания,
трудно дать
однозначный
ответ, какой
словарь легче
распознавать
объективными
ме-тздами. Точность
автоматической
классификации
слов словарями
"А", "Б", "В" и
"А", "П", "Г"
сильно зависит
от объективно
регистрируемой
степени акустического
сходства элементов
калиюто словаря,
относящихся
к различным
классам, т.е.
от методов
первичной
обработки и
представления
речевых сигналов,
соответствующих
этим словам,
от порогов
срабатывания
устройств,
преобразующих
аналоговый
сигнал в цифровой,
и правил принятия
решения.
Существующие
системы распознавания
изолированных
слов показывают,
что количество
слов словаря
(при одинаковой
точности
распознавания)
не может быть,
вообще говоря,
мерой качества
системы распознавания.
В [139] исследуются
два словаря:
алфавитно-цифровой,
содержащий
26 букв и 10
цифр, и словарь
географических
названий, состоящий
из 250 слов.
В результате
была получена
точность
распознавания
первого словаря
88,6% и второго
97,356. Хотя объем
второго словаря
почти на порядок
больше, точность
распознавания
слов, входящих
в этот словарь,
выше. Можно
предполо
жить,
что это объясняется
более сложной
фонетической
структурой
слов второго
словаря, которая
и обеспечивает
меньшие трудности
при автоматическом
распознавании.
В
системах,
работающих
без подстройки
под диктора,
наиболее
груднокдассифицируемыми
звуками русской
речи являются,
как показано
в С4, 26, 62, 97] , носовые
и боковые сонорные
согласниэ,
звонкие взрывные
и безударные
гласные. Кроме
того, следует
отметить, что
в опоеделенном
фонетическим
окружении даже
звуки, относительно
хорошо классифицируемые,
в другом фонетическом
контексте
могут вызвать
определенные
трудности при
автоматическом
распознавании
из-за аллофонных
изменений,
связанных с
коар-уикуляцией.
Все это следует
учитывать при
оценке сложности
распознавания
словаря в
"неадаптивных"
системах
автоматического
распознавания
речи. Отметим,
что на точность
распознавания
речи влияют
также синтаксические
ограничения,
так как синтаксис
языка определяет
грамматические
изменения
словоформ и
порядок следования
слов.
Далее
рассмотрим
некоторые
подходы, позволяющие,
по нашему мнению,
осуществлять
относительное
сравнение
сложности
распознавания
словарей, и
введем определения,
связанные с
оценкой качества
автоматического
распознавания
слов проблемно-ориентированного
языка.
2.2.2.
Информационный
критерий оценки
фонетической
неопределенности.
При распознавании
устной речи
необходимо
стремиться
к тому, чтобы
все фонемы
классифицировались
правильно,
поэтому нас
интересует
распознавание
полной последовательности
фонетических
единиц, составляющих
высказывание.
При этом основным
источником
неопределенности
при распознавании
речи является
сам акустический
сигнал. Еще
большую неопределенность
представляет
параметрическое
описание речевой
волны. Рассмотрим
неопределенности
акустического
сигнала и приведем
меру оценки
фонетической
неопределенности.
Используя эти
мерь, можно
оценить лексическую
и фразеологическую
неопределенности.
Слитная речь
расчленяется
на последовательность
сегментов по
признакам
способа образования
звуков. К этим
признакам
добавляются
признаки места
образования,которые
изменяются
непрерывно
как внутри
сегментов, так
и через их Границы
С 91,97]. С некоторыми
дискретными
единицами-звуками
речи - фонемами
или квааифонемами
сегменты связаны
таким образом,что
смысловые
единицы речи
(слова) представляются
цепочкой фонем.
Большинство
систем автоматического
распознавания
речи [79] преобразует
речевой сигнал
в такую фонемную
цепочку, которая
затем сравнивается
с ожидаемыми
в слове звуками.
Процесс преоб-
79
разования
речевого сигнала
в последовательность
фонем включает
нахождение
признаков,
сегментацию
и маркировку
сегментов.
Опишем
модель фонетической
неопределенности,
позволяющую
оценивать
результаты
неправильного
распознавания
фонем. Далее
будем использовать
матрицу ошибок
распознавания
фонем и фонетическую
структуру слов
словаря при
оценке лексической
неопределенности.
Лексическая
неопределенность
будет иметь
место тогда,
когда слова
неверно классифицируются
из-за близости
их фонетической
структуры, т.е.
последовательности
параметров,
определяющих
эту структуру,
на конкурирующих
словах. Например,
в словах "слезать"
и "срезать"
первичные
параметры
звуков, входящих
в эти слова,
сходны. Когда
оба эти слова
входят в один
и тот же словарь,их
точная классификация
затруднена,
поэтому их
можно считать
лексически
неопределенными.
В реальных
системах, если
позволяет
задача, следует
подбирать
слова,чтобы
такой ситуации
не возникло.Приведем
критерии сложности
словаря для
того, чтобы
можно было
оценить степень
различимости
словарей
[63].
рассмотрим
распознавание
речи как процесс
передачи речевой
информации
через канал
с шумом и оценим
информацию,
теряющуюся
в канале. Потерянная
информация
является мерой
неопределенности
или сложности
распознавания
фонем. В идеальном
канале числи
входных идеальных,
полученных
после сегментации
высказывания
экспертами-фонетистами,
и выходных
фонетических
единиц должно
быть одинаковым,
а последовательность
фонем на выходе
должна соответствовать
входной последовательности.
Если же это
условие не
соблюдается,
в канале теряется
информация,
и в зависимости
от вели-vwi
потерь можно
говорить о
большей или
меньшей неопределенности
классификации
фонем. При
практической
оценке фонетической
неопределенности
в данной работе
использовались
система признаков
[73] и алгоритм
сегментации
речи на семь
типов сегментов:
V
- гласный, Т
- переходный,
М - сонорный,
L -
низкочастотный,
Н - высокочастотный,
/? - шумный, П
- пауза. Затем
алгоритм маркировки
ставил в соответствие
каждому сегменту
некоторый
фонетический
символ, используя
априорно полученные
гистограммы
параметров.
От надежности
маркировки
сегментов во
многом зависит
точность работы
GPP.
Так
как СРР рассматривается
здесь как канал
передачи
информации,
предположим,
что имеются
г возможных
входных символов
алфавита А
и s возможных
выходов алфавита
В . Таким
образом, СРР
описывается
канальной
матрицей. На
рис. 2.1 приводится
схема канала
передачи информации
и канальной
матрицы.
60
|
|
|
|
|
а,
"г
|
'и Рг,
|
Р„
• • Р„
••
|
• • • P,s
•
• •
Р„
|
|
*
|
|
|
|
| • |
|
|
|
|
'.
|
|
|
|
|
"г
|
^
|
Рг,
• •
|
• • Prs
|
рис. 2.1. Блок-схема
канала передачи
иниормации
и канальной
матрицы
Канал передачи
информации,
используемой
для описания
системы
распознавания
речи, представленной
цепочкой фонем,
преобразует
незашумденную
последовательность
звуков в выходную
последовательность
"машинных
" фонем, содержащую
ошибки пропуска,
вставки слияния
и замены звуков.
Символами
Ar'l{a•|.}
и ^s={Ц'}
обозначены
соответственно
входной и выходной
алфавиты фонем.
Дхя простоты
предполагается,
что канал
представляет
собой независимый
дискретный
канал без
памяти. Если
р {Ь. /а^)
- вероятность
символа Ь- на
выходе канала
при подаче
символа а^
, то этот канал
передачи информации
можно описать
матрицей условных
вероятностей
Р = =
[^(6//o,)J . Очевидно,
Ј p(
&/•/i=f~r.
На рис. 2.2
приводится
пример матрицы
условных вероятностей
при распознавании
изолированных
звуков.
Пусть элемента
входного
фонетического
алфавита {аЛ
появляются
на входе с некоторой
априорной
вероятностью
р(а ),р(а ),-..
••.,/?(а^), а элементы
алфавита [Ь.\
на виходв
- с вероятностью
P(ti,),
p(by),...,
р(.Ьу) •
Как отмечено
ранее, работу
канала передачи
входного ад^евита
{а^} кластеризует
канальная
ма'грипа,поэт<аду
Апостериорная
вероятность
того, '•то, если
в результате
распознавания
Получили фонеыу
Ь, , то на
вход поступила
фонема а^
, определяется
по Формуле
Байеса
Зак.480
у
0,15
0,75 0,10
0,01
0,10
0,89
Рис. 2.2.
Ilptttcap мктрицы
условных
вероятностей
распознавания
изолированных
звуков
(2.2)
Ииормацня
7(а^;
Ь ),
получаемая
от канала, когда
на его вход
потупила фонема
а.^
, а на выходе
распозналась
как 6, ,
опредедется
[91]
.
, p^Jbj)
l^i\b^lo
(2.3)
С]»дняя информация,
получаемая
на выходи канаха
с потерями при
жредаче (распознавании)
входного алфавита
фонем
A:={a•^,
которШ
распознается
как алфавит
в = {
^ } ,
будет
UA,B)=^p(a„^)Ha^^)=
^^,6,)^^/^-а,в'
L
J
у?
р(а,)
=-ip(a„b-)lo^p(ai)^p(a^b,)io^p(a,/^)^
^,0 /1,0
=-ip(a,)log,p(a^lp(a,^toy^p(a,/
6,);
л, в
I
(А
,В)
=
Н
W^P^,
^}to^f){a,
/Ь,).
(2.4)
л,
в
С»метим, чтоН(Л)-
энтропия,
характеризующая
степень неоп-редвдедости
входного алфавита
А-=-{а^] . Из
(2.4) подучаем,что
H(A)-I(A,S)=-^p(a,,b..)iw,p(ai/b^=
Л,
о
=-рР(^/Ь/)р(Ь,)1о^р(а,/6,)-
Д,В
=-^р(^-)^/?1'а,/^-)^/)(^./^.)=
Н(А/В);
(2.5)
Н(А^)-
апостериорная
ентропия входного
алфавита фонем,
которая 82
характеризует
меру информации,
теряемой в
системе распознавания
дрй передаче
входного алфавита
{ я^}
. Апостериорная
внтропия и
является мерой,
оценивающей
сложность
входного словаря
для автоматического
распознавания
при фиксированном
параметрическом
описании.
При наличии
значений энтропии
входного алфавита
фонем можно
вычислить
размер (объем),
равный У'"',
а значения
2 vw
характеризуют
среднее количество
возможных
альтернативных
(конкурентных)
элементов
алфавита {о
I на входе
СРР после того,
как на выходе
получили множество
{ 6 } , т.е. меру
сложности
распознавания
входного алфавита
фонем. Назовем
эту меру эквивалентным
размером алфавита
фонем. Значение
у"^0'
можно назвать
энтропийным
критерием
оценки фонетической
неопределенности,
который является
обобщенной
характеристикой
сложности
распознавания
алфавита фонем
< а^ \
данной системы
распознавания.
Если СРР работает
без ошибок,
условная энтропия
Н(А/В)вО и эквивалентный
размер алфавита
фонем 2"("/°'
= i.
Естественно,
что если Н(А/В)»0,
то Z"^^!,
а в случае, когда
СРР не распознает
Н(А/В)=Н(А), то
эквивалентный
размер алфавита
фонем равен
Z"^
Эквивалентный
размер алфавита
фонем дает
возможность
количественно
оценить среднее
число возможных
конкурентных
фонем (имеющие
близкие параметрические
описания), и
для его определения
необходимо
знать апостериорные
вероятности
p(a^/b-)
входного
алфавита.
Для решения
конкретных
проблем автоматического
распознавания
ограниченных
наборов слов
взе многообразие
фонем можно
свести к двум-трем
рабочим фонетическим
единицам
(например,к
классам длительных
шумных, звонких
и смычных звуков),
которые При
использовании
простой системы
признаков к
несложных
алгоритмов
распознавания
дают нулевую
апостериорную
энтропию. Однако
ври решении
задачи распознавания
относительно
сложных словарей
и/иди требование
надежной фонетической
верификаций
произнесенного
слова такого
количества
рабочих фонем
сказывается
явно недостаточно.
Работать Же
с полным набором
фоней "ложно
из-за ошибок
их автоматического
распознавания.
Поэтому к приходится
идти на
компромиссные
решения
- искать
какой-то оптимуи
при фонетическом
описании рабочих
словоформ.
Эти проблемы
будут частично
рас-емотрены
в а. 2.2.3.
Условные
вероятности
распознавания
фонем
^(6,/д.), определяющие
эквивалентный
размер фонетического
алфавита, можно
опре-•
Делить несколькими
методами.
83
Статистический
мегод позволяет
получать вероятности
распознавания
фонем, используя
реальную СРР.
ото осуществляется
путем сравнения
результата
распознавания
системы с точной
ручной сег~
ментацией и
маркировкой
речевого сигнала
(иди его параме-гричес-кого
представления),
поступающего
на вход системы
распознавания.
В результате
получается
классическая
матрица правильной
и оаибочной
классификации
входного алфавита
фонем.
Акустико-параметрический
метод, когда
матрица ошибок
классификации
фонем получается
путем прямого
сравнения их
параметрического
описания. При
этом эталон
фонемы выбирается
из множества
реализации
данной фонемы.
Расстояние
между фонемами
используется
для оценки
условных вероятностей
ошибочной
классификации
фонем. Точность
этого метода
зависит от
выбранного
эталона и объема
исследовательского
материала.
Кроме этих
методов, оценку
вероятности
ошибочной
классификации
фонем можно
произвести
на основе
моделирования
речеобразующе-го
тракта человека
[73.
^.2.3. Оценка
сложности
распознавания
слов по их
фонетичес-кой
структуре.
Рассмотрим
неадаптивную
систему распознавания
слов как канал
передачи информации.
Слова входного
словаря
V= ^Я.,У„,... ..., V.,...,
v„} можно
представить
последовательностью
фонетичес-
'•
f
Г Г
/* 1
~
" /•> ' *
о JiHftBa
п^гуппылрп
^ЛП—
НИХ
СИМВОЛОВ
V
\ а^ ,
af , . . . , af \
, а слова выходного
сло-11 г
"- 1
варя канала
W= {
'I
2 "
^ "1 ^,,^,..
.
W -.^}
цепочками
_^.. „_.....
квазифонетических
эталонов
iff, --
i bj ,
bj , . . . ,
bj } ,
где Q^ e А
, Ъ, f- В
- соответственно
входной и выходной
алфавиты фонем
канала; г= /,
R ;
s= /, 5 ; л= п(г)
; 1= l(s).
Тогда оценку
сложности
распознавания
слов, производимого
сравнением
входной реализации
с цепочками
квааифонетических
эталонов, можно
осуществить
на основании
анализа матрицы
ошибок, подученной
при представлении
эталонов слов
Wy ё.
W поверхностными
формами й^
f Wg , k^ f,Ky каждого
выходного
слова. Фактически
сложность
распознавания
входного словаря
V определяется
наличием сходных
эталонных
поверхностных
форы U^ выходного
словаря W
и частотой
встречаемости
зтих поверхностных
форм р
(w). Основная
проблема При
построении
матрицы ошибок
для каждого
словаря заключается
в формировании
эталонов
поверхностных
форм г^ е
w, для реализация
каждого слова
и получения
квазй-фонвтического
графа /Т г^), учитывающего
все поверхностные
формы в вероятностями
их появления.
Все множество
квазифоиетических
поверхностных
форм слова
w, записать
в виде эталонного
графа трудно,
так как ори
аппаратурно-програмыном
методе распознавания
появляются
не только
поверхностные
формы слова,
обусловленные
В4
особенностями
произношения,
но и формы,
включающие
случайные
сегменты,
маркированные
квазифонетическими
метками, появление
которых связано
с неидеальностью
автоматической
фонетической
сегментации
и маркировки
нашим алпаратурно-програмыным
методом, вызванной,
например, изменением
интенсивности
речевого сигнала.
В
дальнейшем
будем рассматривать
влияние двух
обстоятельств
на формирование
эталонных
поверхностных
форм слов рабочего
словаря, учитывая,
что поверхностные
формы, связанные
о особенностями
произношения
и матрицей
ошибок квазифонемной
классификации,
можно построить
вручную (или
автоматически,исполь-ауя
таблицу
акустико-фонодогических
правил, хранящуюся
в памяти, и
прилагаемых
к базовой
квазифонетической
цепочке), а
поверхностные
формы w
. , обусловленные
особенностями
аппаратуры
выделения
информативных
признаков,
можно получить,
анализируя
статистику
реализации
квазифояетических
цепочек слов
рабочего словаря,
полученных
с помощью ЭВМ.
Получение этой
статистики
не всегда
обязательно,
особенно если
рассматриваются
слова,контраст-ные
по своим акустическим
свойствам.
Предварительную
оценку сложности
распознавания
слов можно
сделать аналогично
оценке сложности
фонетического
алфавита
- по фонетической
структуре слов,
вычисляя
апостериорную
словесную
неопределенность
и не исследуя
статистики
реализации.
Все
эталоны слов
и^у б W
рабочих словарей
должны быть
представлены
последовательностью
маркированных
фонетическими
метками отрезков,
где квазифонемы
должны делиться
на опорные,
обязательные
для данного
слова (определяющие
базовую форму
и, как Правило,
присутствующие
во всех поверхностях),
и "вспомогательные",
трудноклассифицируемые.
Трудноклаосифицируемые
сегменты должны
быть расчленены
(хотя бы грубо)
на несколько
квазифонетических
элементов, если
длина этих
сегментов выше
пороговой (это
делает на первом
этапе человек
на основании
знаний фонетической
структуры
возможных форм
каждого слова).
Опорными сегментами
слова следует
считать маркированные
отрезки которые
при их маркировке
квазифонетичаскими
метками допускают
суммарную
ошибку ниже
ввристически
определенного
порога.
При
автоматическом
распознавании
выбор эталонов
(из словаря
эталонов) должен
быть в первую
очередь обусловлен
наличием в
Поступившей
на вход реализации
опорных, обязательных
маркированных
сегментов о.
с учетом того,
что за счет
иеидеадьности
сегментации
общее число
сегментов
входной реализации
может не совпадать
с возможным
числом сегментов
эталонного
графа,за счет
Неопорных
сегментов,
образующихся
или выпадающих
случайно.
У5
Сшибки
классификации
дают появление
"путающихся"
поверхностных
форм (представленных
последовательностью
квазифонеы)
дяя различных
слов словаря.
Будем считать,
что матрица
ошибок при
распознавании
слов априори
формируется
таким образом,
что (при сходстве
поверхностных
форм различных
слов словаря)
более часто
встречающиеся
поверхностные
формы слов
одного класса
(при заданном
алфавите
квазифонем)
считаются
относящимися
к словам только
этого класса,
а редко встречающиеся
сходные поверхностные
формы для других
слов словаря
дают ошибки
распознавания.
Впрочем, используя
синонимию или
семантико-синтаксические
ограничения
при распознавании
пословно произносимых
фраз. Всегда
следует добиваться
того, чтобы
подобные случаи
не происходили
(трудности
представляют
слова, входящие
в одну семантико-сиитаксическую
группу,которые
нельзя заменить
синонимами,
например, названия
цифр).
Следует
отметить, что
принятые решения
о принадлежности
поступившей
на вход реализации
к тому или иному
классу следует
делать но эталонам
с одинаковым
числом опорных
сегментов и
с учетом верификации
сяова, всякий
раз используя
эвристически
выбранные
пороги достоверности,
в общем случае
разные для
различных
слов. Так, для
принятия
окончательного
решения о
принадлежности
входной реализации
Уд. к классу
Wy необходимо
выбрать
и
w, ,
который ооответ-
два
наиболее вероятных
кандидата
— —— - .
^ ствуют
вероятности
p(v,/u7y]
и ^(i^/г^
), и проверить,удовлетворяются
ли условия:
WM,)>^,;
Р^/^-Р^/^,)^^
где А^
- пороговое
значение вероятности
того, что входная
реализация
соответствует
олову у/,
; Ay,
- пороговые
значения разности
условных вероятностей
принадлежности
входной реализации
г1д. классам и
vf. ,
при которых
принимается
решение о клас-
сификации
у^ .
Пороговые
значения /Зд,/!,,
выбираются
экспериментально
по заданной
системе используемых
фонетических
признаков,а
также требуемых
точности
распознавания
и вероятности
отказов от
распознавания.
В случае, если
подбором порогов
заданные требования
к системе
распознавания
не удается
выполнить,
следует провести
более детальный
анализ неопорных
сегментов, иди
попытаться
улучшить систему
признаков. В
ряде случаев
дяя удовлетворения
заданных в
системе требований
следует использовать
синонимию.
66
Рассмотрим
далее более
конкретно, как
оценить лексическую
неопределенность
словаря
V языка
речевого общения
неадаптивной
системы автоматического
распознавания.
Аналогично
тому, как оценивалась
неопределенность
алфавита фонем,
можно определить
сложность
распознавания
входного словаря
V ,
состоящего
из R
слов, и вычислить
эквивалентный
размер входного
словаря. При
этом необходимо
получить вероятности
p(v^/w,)
одиэости областей
призна-хового
описания слов
i^, « V,
ur, б
W, г= /7Д.
3s
/75. которые
представляются
в виде последовательности
фонетических
единиц (фонетической
транскрипции
слов). Далее
оценим вероятности
p(ff^/v7y).
Как уже отмечалось,
на основе
лингвистических
знаний, эта-жоны
слов
Wy (.
W представляются
в вида фонетических
( вернее,
квазифонетических)
цепочек,совокупность
которых описывается
графом с конечным
числом состояния,
а каждая фонема
- признаками
способа и места
образования.
Слову
VT,
соответствует
одна или
несколько
траекторий
(цепочек поверхностных
форм) на графе
(количество
траекторий
зависит от
метода произношения
и характеристики
диктора). Направленный
граф f
(W,) представляет
все фонемы
этахона сяова
иг, б
W , который
имеет
uf,
поверхностных
форм,
k=
!, 2, . . ., А-з
;
uly =
U'1Л
; каждая
поверхностная
форма
^ e w,
содержит
,.^,-...^
Пусть р
(
иГу)
ur, e 1=
l(3.k) опорных
квааифонем,
т.е. иг,
), } I-- /,2,...,
1(з, k).
априорная
вероятность
появления
слова
u^eW на
выходе блока
лексического
распознавания,
а априорная
вероят-
р
(vfs„
) • При
ность иГу
поверхностной
формы этого
же оаова этом
выполняются
условия
л,
« Р(Щ,)=
Z: Р(^)
;
Ј/?(ur,)=/.
Необходимо
отметить, что
количество
опорных сегментов
в поверхностных
формах слов
выходного
словаря различно,
т.е. предел
изменения
индекса I
зависит как
от номера слова,
так и от его
поверхностной
формы I
= I (.з,
k}.
Для того,чтобы
осуществить
оценку неверной
классификации
слов словаря
на стадии
лексического
распознавания
по фонетической
структуре этих
слов, выполним
операцию разбиения
всех поверхностных
форм эталонов
слов на М
фонетических
групп с одинаковым
количеством
опорных сегментов
1= I (з)
. При этом
слова, поверхностные
формы которых
принадлежат
разным группам,
не будут Путаться
между собой,
поскольку их
легко классифицировать
по числу "опорных"
фонем, составляющих
слова.
8?
Вообще говоря,
можно представить
себе фонетические
группы эталонных
поверхностных
форм, отличающиеся
не только числом
опорных фонем,
но и их характером,
а также порядком
следования.Если
учесть все три
фактора, позволяющие
разбить эталоны
на существенно
большее число
фонетических
групп, то дальнейшие
рассуждения
можно отнести
к каждой из
этих групп. Для
простоты,однако,
будем считать,
что мы имеем
М фонетических
групп, в каждой
из которых
одинаковое
число опорных
сегментов. В
практических
задачах при
разбиении на
группы следует
учитывать все
эти факторы,
однако необходимо
строго ограничивать
число различных
опорных сегментов,
выбирая лишь
те, которые не
путаются между
собой и характеризуются
групповыми
признаками
места образования
- ударные гласные,
смычные, фрикативные
[81,60] .
Итак, допустим,
что существует
М фонетических
групп слов
W, ,
W^, . . . ,
W^ , . ..,
W^ ,
в каждой из
которых^ одинаковое
число опорных
квазифонем.
Общее число
эталонов И/=
U W^ ,
а количество
фонем, составляющих:
слова (длина
фонетической
цепочки) каждой
группы, об означим
через I
; т= /,/И.
Представляя
таким образом
слова словаря
на входе СРР
и используя
матрицы ошибочной
классификации
фонем, составляющих
слова
/Кй/&)-[Ру],
(2.5) можно оценить
вероятности
p^(v /Wy) спутывания
поверхностных
форм слов внутри
каждой группы
слов следующим
образом:
где
t = t, 2, .
. . , t^
- длина фонетической
цепочки группы
слов ^ , а^ е
^ , Ь„ е иг,.
В общем случае
одно и ъо же
слово Wy
может иметь
К, поверхностных
форм, имеющих
разное число
фонетических
элементов и
попадающих
в разные группы
слов W^,
. Поэтому
общую условную
вероятность
"спутывания"
слов словаря
определим
(2.8)
P(v^/w,l=
Г P(w^)
р^ (
^ /г^-)
.
Для определения
потери информации
в СРР, которая
рассматривается
как канал перэдачи
информации,
в случае распознавания
слов используем
выражение
86
(2.9)
KV/W)--
-Z p(w,)i p(v^/ w^ locj^ p( v^ /v/,).
/
(V/W)
Тогда
2 определяет
эквивалентный
размер словаря
—
число
альтернативных
слов на входе
системы распознавания,
а
2й
v)
- фактический
объем входного
словаря, где
Эти выражения,
аналогичные
формулам
(2.4), (2.5), оценивающим
фонетическую
неопределенность,
являются критерием
оценки лексической
неопределенности.
Они определяют
сложность
распознавания
словаря и позволяют
судить о качестве
СРР. При автоматической
маркировке,
наряду с ошибками
неверной
кдассификации
фонем, существуют,
как уже отмечалось,
ошибки неверной
сегментации,
приводящие
к слиянию отрезков,
соответствующих
смежным фонемам,
в один сегмент
или расчленению
отрезка, соответсвувщего
одной фонеме,
на несколько
смежных фонем
разных классов.
При выборе
альтернативных
слов словаря
надо следить
за тем, чтобы
неприятности
такого рода
не вызывали
подобия
последовательностей
фонетических
единиц, соответствующих
разным словам.
Для этого
необходимо
использовать
матрицы, отражающие
возможные
варианты
сегментации
слов словаря
и частоты
встречаемости
тех или иных
вариантов
сегментации,
соответствующих
различит
поверхностным
фориам слов.
Так как информация
о словах, содержащихся
в фонемах,избыточна,
то часто при
оценке различимости
слов словаря
вполне достаточно
использовать
опорные фонемы,
допускающие
минимум ошибок
расчленения
и слияния. Поэтому
в формуле
(
§
2.3. О языке описания
данных в системе
автоматического
речевого запроса
информации
2.3.1.
Понятийный
язык и двухступенчатое
иерархическое
построение
его грамматического
представления.
Информационные
системы, стояь
распространившиеся
в настоящее
время, требувФ
общения с
ними с помощью
устной речи
на языяв, близком
к естественному.
Необходимая
нам информация
должна быть
выдана по запросу
последовательности
понятийных
дескрипторов,
которую человек
может произнести,
не используя
жесткого порядка
следования
этих дескрипторов.
Такое представление
совокупности
дескрипторов
- понятийного
поля не только
обеспечивает
естественность
запроса информации
из базы данных,
но и фактически
не увеличивает
времени поиска
релевантной
информации,
так как при
этом учитываются
отношения
между понятиями
и используется
иерархический
принцип с ыниыой
иерархией,
обеспечиваемой
перестраиваемой
структурой
дорического
дерева. В связи
с этим можно
представить
общую грамматику
6 формирования
понятийного
поля, включающего
посведо-вательность
предложений,
которые дают
информацию
о структуре
дег.криптов,
в виде иерархически
связанных
граыиатик
верхнего и
нижнего уровней.
(Процесс формирования
свободных от
ошибок словесных
цепочек, полученных
в результате
автоматического
распознавания
слов и устного
редактирования,
рассматривать
здесь не будем
.) Грамматика
верхнего уровня
G" определяет
общую структуру
понятийного
поля, а языки,
обусловленные
грамматиками
нижних уровней
б[ , конкретизируют
порождение
предложений
на уровне
формирования
понятийных
фраз. Грамматика
G" допускает
появление
понятий (они
выражены запросными
фразами
S^ ),
формирующих
смысл запроса,
в произвольном
чередовании.
Иными словами,
порождающая
грамматика
последовательности
понятий -
есть простей-вая
грамматика
типа 0 (по
Хомскому), в
которой нетерминальными
символами
vh являются
обобщенный
дескриптор
понятийного
поля (поисковый
образ запроса)
и понятийный
уровень, а
терминальными
V - конкретное
наименование
понятий (названия
уровней) ^ .
Нетерминальный
символ {
обобщенный
дескриптор
понятийного
поля j
является
начальным
символом
S в грамматике
в", а правила
вывода р
сводятся к
допустимости
перестановок
терминальных
символов
s.—^s-.такчто для
понятий
s,,Sg,...,5^ язык, обусловленный
этой грамматикой,
допускает К
' предложений
длины К ,
в каждом из
которых все
понятия различны:
S,
, S, , . . . , S„
; ^ ,
s,
, • • • , ^ ; 5,.
S,, S, ,. .., 5^ .
Вообще говоря,
грамматики
типа 0 допускают
бесконечное
количество
словесных
цепочек (предложений)
различной
длины, составленных
из терминальных
символов. Если
считать, что
нас интересуют
словесные
цепочки с
неповторяющимися
терминальными
символами,
и представлять
обобщенный
дескриптор
понятийного
поля цепочками
переменной
длины J
= f -L
К , то число
N возможных
предложений,
используемых
для работы и
допускаемых
языком этой
гр^матикм,
^^., ^^
90
Каждый из
терминальных
символов грамматики
в° в свою очередь
является начальным
(и нетерминальным)
символом порождающей
грамматики
второго уровня
(7, , накладывающей
или не нак-
ограничения
на формирование
предложений
в t'-ru понятийного
уровня (рис.2.3).
ладывающей
ограничения
на формирование
предложений
в рамках каждого
t-ru понятийного
ур

Рис. 2.3. Порождения
тийных полей
Отметим, что
в зависимости
от особенностей
терминального
словаря каждого
уровня и привычки
пользователей
к произношению
фраз этого
уровня на
естественном
языке порождающая
грамматика
с начальным
(нетерминальным)
символом,
полученным
на предыдущем
уровне, может
быть нулевого,
первого, второго
иди третьего
типа, определяемого
соответствующими
правилами
вывода.
Далее мы рассмотрим
оценку грамматической
сложности
языка (с точки
зрения автоматического
распознавания
речи) на уровне
формирования
предложений
с учетом произношения
слов, являющихся
Go терминальными
символами
грамматики
, и покажем,
что означает
"подстройка
под словарь
и язык" в неадаптивных
системах
автоматического
распознавания
слов. Языки,
определяемые
грамматиками
б", (7/, G',...,(?/,...,
G^ (рис.
2.3), будем называть
языками системы
распознавания
речи, подразумевая,
что с точки
зрения автоматического
распознавания
слова, являющиеся
терминальньгми
символами
грамматики
высшего уровня,
также конкурируют
между собой
и определяют
начальный
символ сети
(графа), которой
представляется
языком СРР.
2.2.2. Оценка
сложности
языка с точки
зрения автоматичес-кого
распознавания
пословно
произносимых
предложений.
Синтаксис и
семантика
языка СРР,
определяемых
грамматилаки
{G^} ,
накладывают
ограничения
на порядок
следования
слов в предложении
в характер
возможных
словосочетаний.
Эти ограничения
существенно
облегчают
задачу распознавания
речи вследствие
сокращения
общего поискового
пространства
признаков.
Для приближенной
оценки грамматической
сложности
языка СРР
рассмотрим
грамматику
автоматического
языка как
наиболее простого
и наиболее
поддающегося
количественному
анализу.Грамматики
Нулевого, первого
и второго типов,
как было указано
ранее, также
можно использовать
для формирования
предложений
в СРР, однако
их количественные
характеристики
подучить сложнее.
и тому же ряд
закономерностей,
характерных
дяя языков,
оаисываяицихся
грамматиками
91
большей сложности,
можно выявить
и на самом простом
языке, относящееся
к частным случаям
языков нулевого,
первого и второго
типов и наиболее
используемом
при формировании
предложений
в современных
системах
распознавания
речи.
Правила подстановки
в грамматиках
третьего типа
(автоматных)
имеют вид А
= а В или А
—- В , где
А, В с
1^ и а, Ь
(. \'i . Для
языка СРР А и
В характеризуют
названия смысловых
групп, а а
, Ь - названия
слов в смысловых
группах -
подсдоварях.
Грамматика
автономного
языка определяется
множеством
внутренних
состояний
s„3 ,.
. .,s^,...,
ss и правилом
перехода в
следующее
состояние
.
Следовательно,
после слова
с номером
i(n) из группы
слов s с
S может следовать
слово из подсловаря
s^, с s
. Кроме того,
заданы S
и S -
состояния,
которыми
соответствен
KG)
но начинаются
и кончаются
фразы. Например,
предложение
имеет структуру
l.(G)=S„v,
v. ,.
где
veS,, v, e S,,
. т
= /, 2, . . . , I
Оценим синтаксическую
сложность
автоматного
языка средним
коэффициентом
ветвления К^р
, который
определяется
средним числом
возможных слов
в каждой точке
дерева ветвления:
К,
ср
i м -—Z
К,
N l-i
(2.К)
количест-
^десь К^
- коэффициент
ветвления в
точке i
; N во точек
ветвления.
Средний коэффициент
ветвления
удовлетворительно
описывает
синтаксическую
сложность
языка тогда,
когда появления
слов в предложении
равновероятны.
Если средняя
длина предложения
/^д , то произведениями
Z^„ «/<- можно
оценивать
грамматическую
сложность
рассматриваемых
языков речевого
запроса и даже
в какой-то мере
(очень приближенно)
сравнивать
точность
автоматического
распознавания
пословно
произносимых
фраз. Но эта
оценка не учитывает
фонетических
особенностей
подсловарей.
К тому же в реальных
условиях различные
слов8 словаря
речевого общения
имеют разные
вероятности
при формировании
фраа. Для учета
этих факторов
будут использованы
квазифонетическое
представление
поверхностных
форм слов
(см.п.2.2.2) и
стохастическая
порождающая
грамматика,
у которой задано
вероятностное
распредеаенме
правил образований
предложений
рц из слов
в
i/
92
»аждой точке
ветвления
1= 1,п нкя выполняется
условие
При этом для
всех точек ветвле-
где К- -
количество
возможных слов
в точке I
(коэффициент
ветвления).
Тогда вероятность
получения
фразы l(G)6i(G)
в результате
применения
t правил
подстановок
равно произведению
вероятностей
примененных
при этом выводе
правил образования.
Отметим, «то
число слов,
составляющих
предложения,
может быть
различное И
зависит от
количества
правил,примененных
при формировании
данного предложения.
Определим
энтропию Н(/-}
языка /(0) .Для
этого обозначим
через L^
множество
всех фраз длины
п слов, допускаемых
грамматикой
G:
|
через
ЮЛИЯ
|
р(^)
|
/ -и1^
^п-\Ч '•••'
|
f(n)
|
Лп) '-г '• •
•
|
| - вероятность |
•s • •
• • ' получения
|
фразы /(0) |
|
HU
|
)
|
языка речевого
общения |
(2.14)
if/)) f(n)
•} ^
• • • • • '-г
' • • •)•
Тогда эн-
г(л)
н^-^, ^ ^О^/^О,
(2.15) где Т
- максимальная
длина предложения.
Естественно,
что
(2.16)
г
z pa^)=f.
/,.,
iyki, г
В
случае, когда
различные
предложения,
порождаемые
грамматикой
G , имеют
разные смысловые
интерпретации,
тогда энтропия
Языка характеризует
его возможность
передавать
информации.
В соответствии
с теорией
кодирования
информации
число возможных
фраз языка с
энтропией
H(Z) будет
2н(t),
и это значение
определяет
размер входного
языка.
Для
определения
сложности
(неопределенности)
распознавания
языка речевого
обшения рассмотрим
процесс распознавания
предложения
в виде последовательности
распознавания
слов из подсловарей
данного уровня,
размеры которых
определяются
коэффициентами
ветвления
К^ . Тогда
для оценки
сложности
распознавания
языка необходимо
оценить сложность
распознавания
всех N
подсловарей
93
этого
уровня, где
вероятностью
P(Vf,
} применения'
в
подсловаре
i- определяется
/с.-го правила
подстановки
в
каждом
узле дерева
стохастической
автоматной
грамматики.
Имея условные
вероятности
р. (v^/Шс)
ошибочного
распознавания
слов каждого
из подсловарей
и рассматривая
CPF как канал
передачи информации,
определяем
потери информации
/„ду в случае
распознавания
предложений,
произносимых
пословно, следующим
образом:
к к;
Ј
с?
Обычно
интересуются,
как распределены
потери информации
по различным
понятийным
уровням
S^ и различным
узлам графа,
представлякщего
автоматную
грамматику
уровня. Важно
знать,в каком
узле языка
общения "тонкое
место" и как
его устранить.
Для
общей оценки
сложности
распознавания
предложений,
которые произносятся
пословно в
соответствии
с заданной
грамматикой
G ,
можно пользоваться
выражением
2 "" , которое
определяет
среднее число
возможных
альтернативных
фраз на входе
в СРР. В случае,
если СРР работает
баз ошибок, при
пословном
произношении
фразы на выходе
системы всегда
одно предложение.
Формула
(2.17) оценивает
сложность
распознавания
фраз языка
речевого общения
СРР. При этом
отметим, что
эта мера зависит
как от фонетической
структуры слов
словаря, так
и от грамматических
правил образования
предложений.
В практических
СРР при
распознавании
языка необходимо,
чтобы /„ была
близка к нулю
^пот
< ] порог
• (РВД11118 ошибки
при распознавании
слов можно
устранить
словами устного
автоматического
редактирования
.) Если это
условие не
удовлетворяется,
то возникает
проблема изменения
языка, которая
сводится к
изменению
словаря системы
и/ияи грам-иатики
языка с целью
увеличения
точности
распознавания.Для
этого можно
либо использовать
синонимию в
подсловарях,
имеющих наибольшую
неопределенность,
либо изменить
грамматическую
структуру
предложения
путем изменения
грамматики
G , которая
используется
как механизм
сокращения
области поиска,
ограничивающей
число приемлемых
альтернатив.
94
г.3.3.
Изменение
языка в неадаптивных
системах
автоматического
речевого
запроса.Описанный
во. 2.3.1
в общем видепоня-тийный
язык речевого
общения "человек
- информационная
систеыа" допускает
его развитие
на основе некоторого
ядре или создание
-не
базе общих
представлений
о структуре
языка. Суть
развития этого
языка ("подстройка
под язык") сводится:
к замене или
увеличению
числа терминальных
символов грамматики
в",
определяющей
появление,
замену или
уничтожение
целых понятийных
уровней, язык
которых определяется
грамматиками
^ ; к
замене, уменьшению
или
увеличении
числа терминальных
символов грамматик
G^
без изменения
числа понятийных
уровней.
Понятийный
язык речевого
запроса информации
рассматривается
как лингвистический
процессор,
который представяен
комплексом
Программ,
обеспечивающим
автоматический
перевод устного
текста в заданный
момент для
того, чтобы
информационная
система могла
воспринимать
(понимать) фразы,
относящиеся
к рассматриваемой
пред-иетной
области. Тогда
задача "подстройки
под язык" сводится
к модификации
(иди вообще
построению)
этого лингвистического
процессора,
который допускает
только правильные,
осмысленные
пред-жижения,
обусловяенные
грамматики
6°, G,',
В соответствии
с п. 2.3.1,
задача построения
такого лингвистического
процессора,
если заданы
множества слов
{ у,
,
г^, . . . ....
Уд,}
словаря
V
описания данных
информационной
системы, формально
сводится к
построению
некоторой
функции
/
=
(v,,
^ ,
. . ..
1^ ),
где
i v, , Vy
, . . . , гГд.
} б
V ,
полностью
определяющей
работу «Ннгвистичесного
процессора
(семантико-синтаксического
анализатора),
который допускает
только слова,
являющиеся
грамматически
правильными
в данном контексте.
Дяя этой цели
фразы языка
речевого общения
представим
в виде направленного
графа с конечным
числом состояний
без циклов
(2.18)
Весь
словарь (узлы
графа) разобьем
на I
непересекающихся
понятийных
уровней, т.е.
V
П V^ П .
.. П V =
О
(2.19)
Для указания
связи между
словами (узлами)
понятийного
графа строим
матрицу смежности
2)= [и';,], которая
распадается
на
9Ь
D, ,Д,, . . .
,Д„, . . . ,^_, подматриц,
где Д„ =(о^ б {О,/})
указывает
смежность
п-го и п+1 уровней
графа 6(1/,
Г). Тогда задача
подстройки
"под язык"
заключается
в задании
и/или изменении
словаря языка
речевого общения
и матрицы смежности
D >
указывающей
связь между
словами понятийного
графа.
Иными словами,
частичная иди
полная замена
словари в
неадаптивных
системах
распознавания
фраз, составленных
из изолированных
слов и коротких
словосочетаний
на основе понятийных
языков, описываемых
грамматиками
{ 6°,
G\, CJ, . . . ,
G^ } ,
приводит к
изменению
грамматик, к
приспособлению
понятийного
графа к новым
требованиям,
Замена терминальных
символов
{V- ^ грамматик
{С/} производится
записью в
соответствующий
массив, где
хранятся эталоны
старых слов,
новых слов и
квазифонетических
поверхностных
форм, представляющих
эталоны нового
терминального
символа. Если
используются
программы
автоматического
порождения
множества
поверхностных
форм по базовой
форме слов
(слова), определяющих
новый терминальный
символ, то дл.-:
замены терминального
символа (получения
множества
эталонов) требуется
ввести лишь
информацию
о последовательности
квазифонетических
символов; запись
новых символов
можно производить
аналогично
описанному.
Эталоны названий
новых понятийных
уровней вводятся
так же,потому
что они являются
терминальными
символами
грамматики
верхнего уровня
G"•
При введении
нового уровня
необходимо
описать грамматику
языка этого
уровня и включить
эталоны новых
терминальных
символов. Изменение
матрицы смежности
производится
в зависимости
от требований
измененного
языка, от новых
понятий и новых
взаимоотношений
между словами
понятийного
графа. Если
необходима
замена правильных
слов словами-синонимами,
то никаких
изменений
матрицы смежности
не производится.
Оысл введения
слов-синонимов
сводится лишь
в уменьшению
1^, (2.17).
|