Министерство образования и науки РФ
Федеральное агентство по образованию
Тверской колледж имени А. Н. Коняева
Расчетно-графическая письменная работа
по практике получения первичных навыков на ПЭВМ
на теме: «Базы и банки данных»
Миньковец Марии Александровны
Студентки группы 2НнСК2
Тверь
2010
Содержание
Введение
Глава 1 «Введение в базы и банки данных»
1.1 Понятия базы и банка данных
1.2 Компоненты базы данных
1.3 Типология моделей
1.4 Пользователи баз данных
Глава 2 «Модели и структуры данных
2.1 Многоуровневые модели предметной области
Введение
Сегодня трудно себе представить сколько-нибудь значимую информационную систему, которая не имела бы в качестве основы или важной составляющей базу данных. Концепции и технологии баз данных складывались постепенно и всегда были тесно связанны с развитием систем автоматизированной обработки информации. Создание баз данных после появления реляционного подхода превратилось из искусства в науку, но, как показала практика последних лет, все, же окончательно его не исключившая. Тем не менее, сейчас это вполне сложившаяся дисциплина (хотя являющаяся скорее инженерной, чем чисто научной), основанная на достаточно формализованных подходах и включающая широкий спектр приемов и методов создания баз данных.
Соответственно назначение систем управления базами данных – обеспечение в течение длительного времени их сохранности, а также возможности выборки и актуализации. Данные существуют всегда , пока есть потребность в их использовании, хотя характер использования, как и пути извлечения практической пользы могут быть самыми разными: от их использования для совершенствования сложных систем управления до формирования «чемоданов компромата».
Базы данных в стремительно, а в какой-то степени и сумбурно развивающихся информационных технологиях – это сравнительно консервативное направление, где СУБД и сами базы представляют собой «долговременные сооружения». Элементарная база ЭВМ и парадигмы программирования меняются быстрее, чем хранимые данные теряют актуальность. В таких условиях, в отличие от прикладных программистов, создатели баз данных должны постоянно помнить о проблеме «наследственности»- о том, как интегрировать в создаваемую систему наследуемые данные, находящиеся под управлением устаревшей СУБД , и о том, как построить систему, чтобы вновь создаваемые данные могли быть, в свою очередь, наследованы следующим поколением систем и разработчиков.
Широкое использование баз данных различными категориями пользователей привело, с одной стороны, к созданию интерфейсов, требующих минимум времени на освоение средств управления системой, а с другой - к построению мощных, гибких СУБД, имеющих в том числе развитые средства защиты данных от случайного или намеренного разрушения. Появились и средства автоматизации разработки, позволяющие создать базу данных любому пользователю, даже не владеющему основами теории БД. Базы данных – это уже достаточно хорошо проработанная научная дисциплина.
Глава 1 Введение в базы и банки данных
1.1 Понятие базы и банка данных
Развитие вычислительной техники и появление емких запоминающих устройств прямого доступа предопределило интенсивное развитие автоматических и автоматизированных систем разного назначения и масштаба, в первую очередь заметное в области бизнес-приложений. Такие системы работают с большими объемами информации. (Рис. 1)
Рисунок 1 - Схема «Автоматизированной системы»
Другими направлениями стали, с одной стороны, системы управления физическими экспериментами, обеспечивающими сверхоперативную обработку в реальном масштабе времени огромных потоков данных от датчиков, а с другой – автоматизированные библиотечные информационно-поисковые системы. Это и привело к появлению новой информационной технологии интегрированного хранения и обработки данных – концепции баз данных, в основе которой лежит механизм предоставления обрабатывающей программе из всех хранимых данных только тех, которые ей необходимы, и в форме, требуемой именно этой программе.
Банк данных (БнД) - это система специально организованных данных, программных, языковых, организационных и технических средств, предназначенных для централизованного накопления и коллективного многоцелевого использования данных.
Базы данных (БД) - это именованная совокупность данных, отображающая состояние объектов и их отношения в рассматриваемой предметной области. Характерной чертой баз данных является постоянство: данные постоянно накапливаются и используются; состав и структура данных, необходимы для решения тех или иных прикладных задач, обычно постоянны и стабильны во времени; отдельные или даже все элементы данных могут меняться – но и это есть проявления постоянства – постоянная актуальность.
Система управления базами данных (СУБД) – это совокупность языковых и программных средств, предназначенных для создания, ведения и совместного использования БД многими пользователями.
Иногда в составе банка данных выделяют архивы. Основанием для этого является особый режим использования данных, когда только часть данных находится под оперативным управлением СУБД. Все остальные данные обычно располагаются на носителях, оперативно не управляемых СУБД. Одни и те же данные в разные моменты времени могут входить как в базы данных, так и в архивы. Банки данных могут не иметь архивов, но если они есть, то состав банка данных может входить и система управления архивами.
Эффективное управление внешней памятью являются основной функцией СУБД. Эти обычно специализированные средства настолько важны с точки зрения эффективности, что при их отсутствии система просто не сможет выполнять некоторые задачи уже по тому, что их выполнение будет занимать слишком много времени. При этом ни одна из таких специализированных функций, как построение индексов, буферизация данных, организация доступа и оптимизация запросов, не является видимой для пользователя и обеспечивает независимость между логическим и физическим уровнями системы: прикладной программист не должен писать программы индексирования, распределять память на диске и т. д.
Развитие теории и практики создания информационных систем, основанных на концепции баз данных, создание унифицированных методов и средств организации и поиска данных позволяют хранить и обрабатывать информацию о все более сложных объектах и их взаимосвязях, обеспечивая многоаспектные информационные потребности разных пользователей. Основные требования, предъявляемые к банкам данных, можно сформулировать так:
Многократное использование данных: пользователи должны иметь возможность использовать данные различным образом.
Простота: пользователи должны иметь возможность легко узнать и понять, какие данные имеются в их распоряжении.
Легкость использования: пользователи должны иметь возможность осуществлять (процедурно) простой доступ к данным, при этом все сложности доступа к данным должны быть скрыты в самой системе управления базами данных.
Гибкость использования: обращение к данным или их поиск должны осуществляться с помощью различных методов доступа.
Быстрая обработка запросов на данные: запросы на данные, должны обрабатываться с помощью высокоуровневого языка запросов, а не только прикладными программами, написанными с целью обработки конкретных запросов.
Язык взаимодействия конечных пользователей с системой должен обеспечивать конечным пользователям возможность получения данных без использования прикладных программ.
База данных – это основа для будущего наращивания прикладных программ: базы данных должны обеспечивать возможность быстрой и дешевой разработки новых приложений.
Сохранение затрат умственного труда: существующие программы и логические структуры данных не должны переделываться при внесении изменений в базу данных.
Наличие интерфейса прикладного программирования: прикладные программы должны иметь возможность просто и эффективно выполнять запросы на данные; программы должны быть изолированными от расположения файлов и способов адресации данных.
Распределенная обработка данных: система должна функционировать в условиях вычислительных сетей и обеспечивать эффективный доступ пользователей к любым данным распределенной БД, размещенным в любой точке сети.
Адаптивность и расширяемость: база данных должна быть настраиваемой, причем настройка не должна вызывать перезаписи прикладных программ. Кроме того, поставляемый с СУБД набор предопределенных типов данных должен быть расширяемым – в системе должны иметься средства для определения новых типов и не должно быть различий в использовании системных и определенных пользователем типов.
Контроль за целостностью данных: система должна осуществлять контроль ошибок в данных и выполнять проверку взаимного логического соответствия данных.
Восстановление данных после сбоев: автоматическое восстановление без потери данных транзакции. В случае аппаратных или программных сбоев система должна возвращаться к некоторому согласованному состоянию данных.
Вспомогательные средства должны позволять разработчику или администратору базы данных предсказать и оптимизировать производительность системы.
Автоматическая реорганизация и перемещение: система должна обеспечивать возможность перемещения данных или автоматическую реорганизацию физической структуры.
1.2 Компоненты банка данных
Определение банка данных предполагает, что с функционально-организационной точки зрения банк данных является сложной человеко-машинной системой, включающей в себя все подсистемы, необходимые для надежного, эффективного и продолжительного во времени функционирования.
В структуре банка данных выделяют следующие компоненты:
· Информационная база;
· Лингвистические средства;
· Программные средства;
· Технические средства;
· Организационно-административные подсистемы и нормативно-методическое обеспечение.
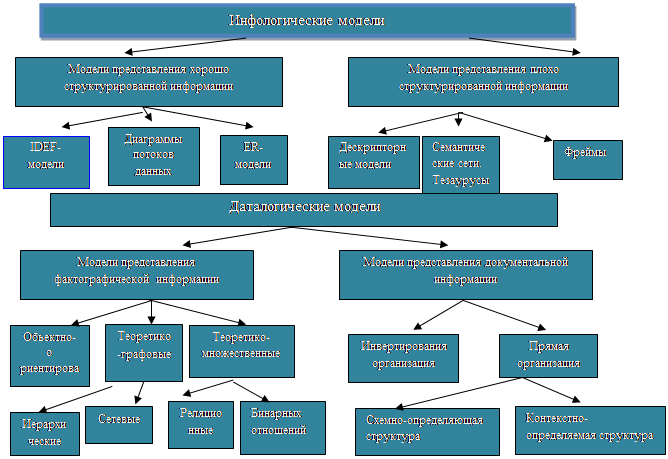
1.3 Типология моделей
1.4 Пользователи баз данных
В информационных системах, создаваемых на основе СУБД, способы организации данных и методы доступа к ним перестали играть решающую роль, поскольку оказались скрытыми внутри СУБД. Массовый, так называемый конечный пользователь, как правило, имеет дело только с внешним интерфейсом, поддерживаемым СУБД.
Эти преимущества, как уже понятно, не могут быть реализованы путем механического объединения данных в БД. Предполагается, что в системе обязательно существует специальное должностное лицо (группа лиц) — администратор базы данных (АБД), который несет ответственность за проектирование и общее управление базой данных. АБД определяет информационное содержание БД. С этой целью он идентифицирует объекты БД и моделирует базу, используя язык описания данных. Получаемая модель служит в дальнейшем справочникомадминистраторов приложений и пользователей. Администратор решает также все вопросы, связанные с размещением БД в памяти, выбором стратегии и ограничений доступа к данным. В функции АБД входят также организация загрузки, ведения и восстановления БД и многие другие действия, которые не могут быть полностью формализованы и автоматизированы.
Администратор приложений (или, если таковой специально не выделяется — администратор БД) определяет для приложений подмодели данных. Тем самым разные приложения обеспечиваются собственным «взглядом», но не на всю БД, а только на требуемую для конкретного приложения («видимую») ее часть. Вся остальная часть БД для данного приложения будет «прозрачна».
Прикладные программисты имеют, как правило, в своем распоряжении один или несколько языков программирования, с помощью которых генерируются прикладным документом.
Глава 2. Модели и структуры данных
Рассматриваемые в контексте понятия «информационная система» элементы реального мира, информацию о которых мы сохраняем и обрабатываем, будем называть объектами. Объект может быть материальным (например, служащий, изделие или населенный пункт) и нематериальным (например, имя, понятие, абстрактная идея). Будем называть набором объектов совокупность объектов, однородных с некоторой точки зрения (например, объектов нашего внимания, пусть даже и разнородных по своей внутренней природе).
Объект имеет различные свойства (например, цвет, вес, имя), которые важны для нас в то время, когда мы обращаемся к объекту (например, выбираем среди множества других) с какой-либо целью его использования. Причем свойства могут быть заданы как отдельными однозначно интерпретируемыми количественными показателями, так и словесными нечеткими описаниями, допускающими разную трактовку, иногда зависящую от точки зрения и наличных знаний воспринимающего субъекта.
Однако во всех случаях человек, работая с информацией, имеет дело с абстракцией, представляющей интересующий его фрагмент реального мира — той совокупностью характеристических свойств (атрибутов), которые важны для решения его прикладной задачи! Абстрагирование — это способ упрощения совокупности фактов, относящихся к реальному объекту (по своей сути бесконечно сложному и разнообразному при изучении его человеком). При этом некоторые свойства объекта игнорируются, поскольку считается, что для решения данной прикладной задачи (или совокупности задач) они не являются определяющими и не влияют на конечный результат! действий при решении.
Цель такого абстрагирования — построение конструктивного операбельного описания (рабочей модели), удобного в обработке как для человека, так и для машины, позволяющего организовать эффективную обработку больших объемов информации, причем высокопроизводительной должна быть работа не только вычислительной системы, но и взаимодействующего с ней человека.
2.1Многоуровневые модели предметной области
Обычно отдельная база данных содержит (отражает) информацию о некоторой предметной области — наборе объектов, представляющих интерес для актуальных или предполагаемых пользователей. То есть,реальный мир отображается совокупностью конкретных и абстрактных понятий, между которыми существуют (и соответственно, фиксируются) определенные связи. Выбор для описания предметной области существенных понятий и связей является предпосылкой того, что пользователь будет иметь практически все необходимые ему в рамках задачи знания об объектах предметной области. Однако следует отметить, что пользователь, который хочет работать с базой данных, должен владеть основными понятиями, представляющими предметную область.
И в этом смысле абстрагирование позволяет построить такое описание (модель предметной области), которое другой человек сможет не только воспринять, но и безошибочно использовать для работы с описаниями экземпляров объектов, хранимых в базе данных. Модель предметной области соотносится с реальными объектами и связями так же, как схема маршрутов городского Пассажирского транспорта с фактической траекторией движения автобуса. Схема адекватно отражает действительность на уровне Основных понятий — маршрутов и остановок: выбрав по схеме маршрут, пассажир достигнет цели (прибудет на нужную остановку) независимо от того, в каком транспортном ряду будет двигаться автобус.
Наиболее простой способ представления предметных областей в БД реализуется поэтапно: 1) фиксацией логической точки зрения на данные (т. е. данные рассматриваются независимо от особенностей ИХ хранения и поиска в конкретной вычислительной среде); 2) определением физического представления данных с учетом выбранных структур хранения данных и архитектуры ЭВМ.
Абстрагированное описание предметной области с фиксированной (логической) точки зрения будем называть концептуальной схемой. Соответственно, систематизация понятий и связей предметной Области называется логическим или концептуальным проектированием Модель (представление логической точки зрения), используемая при абстрагировании — совокупность функциональных характеристик объектов и особенностей представления информации (например, в числовой или текстовой форме), будем называть моделью донных.
Отображение концептуальной схемы на физический уровень будем называть внутренней схемой.
Отражение взгляда (точки зрения) отдельного пользователя на концептуальную схему (как вариант восприятия предметной области) будем называть внешней схемой. Внешняя схема использует те же абстрактные категории, что и концептуальная, а на практике соответствует логической организации данных в прикладной программе.
Теоретически вопрос о многообразии уровней абстракции был решен еще в 60—70-х гг. Основой для его решения является концепция многоуровневой архитектуры системы базы данных. Например, в отчете предусматривался архитектурный уровень подсхемы, который позволял для каждого конкретного приложения строить свое собственное «видение» используемого подмножества базы данных путем определения его «персональной» подсхемы базы данных.
В более общем виде этот вопрос решен в архитектурной модели! Здесь на внешнем уровне может поддерживаться совсем иная модель данных (или даже несколько моделей)! чем на концептуальном уровне. Поддержка разнообразных возможностейабстрагирования в такой системе достигается благодари средствам определения и поддержки межуровневого отображений моделей данных.
Помимо этого, для решения указанной проблемы может использоваться внутри модельная структура, например, механизмы представлений (view).). В объектных системах для этих целей может использоваться отношение наследования.
В общем случае концепция трехуровневого представления не требует более трех уровней, однако с практической точки зрения иногда удобно включать схемы дополнительных уровней, приведены некоторые варианты решений.
Рассмотренная трехуровневая архитектура обеспечивает выполнение основных требований, предъявляемых к системам баз данных:
• адекватность отображения предметной области;
• возможность взаимодействия с БД разных пользователей при решении разных прикладных задач;
• обеспечение независимости программ и данных;
• надежность функционирования БД и защита от несанкционированного доступа.
С точки зрения пользователей различных категорий трехуровневая архитектура имеет следующие достоинства:
• системный аналитик, создающий модель предметной области, не обязательно должен быть специалистом в области программирования и вычислительной техники;
• администратор баз данных, обеспечивающий отражение концептуальной схемы во внутреннюю, не должен беспокоиться о корректности представления предметной области;
• конечные пользователи, используя внешнюю схему, могут не] вдаваться полностью в предметную область, обращаясь только к необходимым составляющим. При этом исключается возможность несанкционированного обращения к данным объявленных внешней схемой, так как формирование ее находится в сфере деятельности администратора базы данных;
• системный аналитик, как и конечный пользователь, не вмешивается во внутреннее представление данных.
Это отражает распространенную практику специализации и разделения ответственности. Главное же заключается в том, что работу по проектированию и эксплуатации баз данных можно разделить на три достаточно самостоятельных этапа. Хотя надо отметить, что на практике создание концептуальной схемы не всегда предшествует построению внешней. Иногда трудно с самого начала полностью определить предметную область, но с другой стороны, уже известны требования пользователей (именно поэтому создание базы уже имеет смысл). И кроме того, адекватность модели предметной области, в конце концов, должна подтверждаться практикой пользовательских представлений.
2.2 Идентификация объектов и записей
В задачах обработки информации, и в первую очередь в алгоритмизации и программировании, атрибуты именуют (обозначают) и приписывают им значения.
При обработке информации мы, так или иначе, имеем дело с совокупностью объектов, информацию о свойствах каждого из котoрых надо сохранять (записывать) как данные, чтобы при решениизадач их можно было найти и выполнить необходимые преобразования.
Таким образом, любое состояние объекта характеризуется совокупностью актуализированных атрибутов (имеющих некоторое из значений в этот момент времени), которые фиксируются на некотором материальном носителе в виде записи — совокупности (группы) формализованных элементов данных (значений атрибутов, представленных в том или ином формате). Кроме того, в контексте задач хранения и поиска можно говорить, что значение атрибута идентифицирует объект: использование значения в качестве поискового признака позволяет реализовать простой критерий отбора по условию сравнения.
Так же как и в реальном мире, отдельный объект всегда уникален (уже хотя бы потому, что мы именно его выделяем среди других). Соответственно, запись, содержащая данные о нем, также должна быть узнаваема однозначно (по крайней мере, в рамках предметной области), т. е. иметь уникальный идентификатор, причем никакой другой объект не должен иметь такой же идентификатор. Поскольку идентификатор — суть значение элемента данных, в некоторых случаях для обеспечения уникальности требуется использовать более одного элемента. Например, для однозначной идентификации записей о дисциплинах учебного плана необходимо использовать элементы СЕМЕСТР и НАИМЕНОВАНИЕ ДИСЦИПЛИНЫ, так как возможно преподавание одной дисциплины в разных семестрах.
Предложенная выше схема представляет атрибутивный способ идентификации содержания объекта (рис. 3.3). Она является достаточно естественной для данных, имеющих фактографическую природу и описывающих обычно материальные объекты. Информацию, представляемую такого рода данными, называют хорошо 1
структурированной. Здесь важно отметить, что структурированность относится не только к форме представления данных (формат, способ хранения), но и к способу интерпретации значения пользователем', значение параметра не только представлено в предопределенной форме, но и обычно сопровождается указанием размерностивеличины, что позволяет пользователю понимать ее смысл без дополнительных комментариев. Таким образом, фактографические данные предполагают возможность их непосредственной интерпретации.
Однако атрибутивный способ практически не подходит для идентификации слабо структурированной информации, связанной d объектами, имеющими обычно идеальную (умозрительную) природу — категориями, понятиями, знаковыми системами. Такие объекты зачастую определяются логически и опосредованно — через другие объекты. Для описания таких объектов используются естественные или искусственные языки (например, язык алгебры)! Соответственно, для понимания смысла пользователю необходимо использовать соответствующие правила языка, и, более того, чаете! необходимо уже располагать некоторой информацией, позволяю щей идентифицировать и связать получаемую информацию с наличным знанием. То есть процесс интерпретации такого рода данных имеет опосредованный характер и требует использования дополнительной информации, причем такой, которая не обязательна присутствует в формализованном виде в базе данных.
Такое разделение нашло отражение в традиционном разделении баз данных на фактографические и документальные.
2.3 Поиск записей
Программисту или пользователю необходимо иметь возможности обращаться к отдельным, нужным ему записям или отдельным элементам данных. В зависимости от уровня программного обеспечения прикладной программист может использовать следующие способы.
• Задать машинный адрес данных и в соответствии с физическим форматом записи прочитать значение. Это случай, когда программист должен быть «навигатором».
• Сообщить системе имя записи или элемента данных, которые он хочет получить, и возможно, организацию набора данных. В этом случае система сама произведет выборку (по предыдущей схеме), но для этого она должна будет использовать вспомогательную информацию о структуре данных и организации набора. Такая информация по существу будет избыточной по отношению к объекту, однако общение с базой данных не будет требовать от пользователя знаний программиста и позволит переложить заботы о размещении данных на систему.
В качестве ключа, обеспечивающего доступ к записи, можно использовать идентификатор — отдельный элемент данных. Ключ, который идентифицирует запись единственным образом, называется первичным (главным).
В том случае, когда ключ идентифицирует некоторую группу записей, имеющих определенное общее свойство, ключ называется вторичным набором данных может иметь несколько вторичных ключей, необходимость введения которых определяется практической необходимостью — оптимизацией процессов нахождения записей по соответствующему ключу.
Иногда в качестве идентификатора используют составной сцепленный ключ — несколько элементов данных, которые в совокупности, например, обеспечат уникальность идентификации каждой записи набора данных.
При этом ключ может храниться в составе записи или отдельно. Например, ключ для записей, имеющих неуникальные значения атрибутов, для устранения избыточности целесообразно хранить отдельно. На рис. 3.4 приведены два таких способа хранения ключей и атрибутов для набора простейшей структуры.
Введенное понятие ключа является логическим и его не следует путать с физической реализацией ключа — индексом, обеспечивающим доступ к записям, соответствующим отдельным значениям ключа.
Один из способов использования вторичного ключа в качестве хода — организация инвертированного списка, каждый вход которого содержит значение ключа вместе со списком идентификаторовСоответствующихзаписей. Данные в индексе располагаются в возрастающем или убывающем порядке, поэтому алгоритм нахождениянужного значения довольно прост и эффективен, а после нахождения значения запись локализуется по указателю физического расположения. Недостатком индекса является то, что он занимает дополнительное пространство и его надо обновлять каждый раз, когда удаляется, обновляется или добавляется запись. На рис. 3.5 приведен инвертированный список для предыдущего примера.
В общем случае инвертированный список может быть построен для любого ключа, в том числе составного.
1) А(Е) = ? Каково значение атрибута А для объекта Е?
2) А(?) В V Какие объекты имеют значение атрибута, равное VI
3) ?(Е) = V Какие атрибуты объекта Е имеют значение, равное V|
4) ?(Е) = ? Какие значения атрибутов имеет объект Е?
5) А(?) = ? Какие значения имеет атрибут А в наборе?
6)?(?) В V Какие атрибуты объектов набора имеют значение, равное V?
Здесь в запросах типов 2, 3, 6 вместо оператора равенства может быть использован другой оператор сравнения (больше, меньше, не равно или другие).
Запросы типа 1 выполняются поиском по «прямому» массиву: доступ к записи производится по первичному ключу. Запросы типа 2 выполняются поиском по инвертированному списку: доступ к записном) производится по указателю, выбираемому из списка по значению вторичного ключа. Ответом в этих случаях будет значение атрибута или идентификатора. Запросы типа 3 имеют ответом имя атрибута. Запросы типа 2, 5, 6 относятся к нескольким атрибутам, и в этом случае могут быть построены несколько индексов, облегчающих поиск по этим ключам.
Составные условия поиска могут использовать несколько простых условий, обычно связанных логическими (булевыми) операторами.
Следует отметить, что в контексте обработки запросов 2-го типа «Какие объекты имеют заданное значение атрибута?» можно выделить три следующих типа архитектур доступа.
1. Системы с вторичными индексами. В этих системах последовательность расположения записей соответствует последовательности Значений первичного ключа. Как правило, используется один первичный индекс и несколько вторичных.
2. Системы частично инвертированных файлов. В этих системах записи могут располагаться в произвольной последовательности. В отличие от систем первого типа первичный индекс отсутствует. Вторичные индексы применяются для прямой адресации записей, Что существенно облегчает включение в файл новых записей, так Как допускается их размещение в любом свободном участке файла.
3. Системы полностью инвертированных файлов. В этих системах Предусмотрено наличие файлов, содержащих значения отдельных элементов данных, входящих в состав записей, — допускается раздельное хранение элементов данных записи. Значения элементов данных, составляющих конкретную запись или кортеж, в общем случае могут размещаться в памяти произвольно. Для ускорения Процесса поиска в системе используют два набора индексов: индекс экземпляров (значений ключей) и индекс данных (инвертированный список). С помощью индекса экземпляров можно найти в файле элементы данных, имеющих заданное значение. С помощью индекса данных можно найти записи, связанные с заданными значениями элементов. Такая организация характерна для организации данных документальных информационных систем.
2.4 Представление предметной области и модели данных
Если бы назначением базы данных было только хранение и поиск данных в массивах записей, то структура системы и самой базы была бы простой. Причина сложности в том, что практически любой объект характеризуется не только параметрами-величинами, но и взаимосвязями частей или состояний. Есть различия и в характере взаимосвязей между объектами предметной области: одни объекты могут использоваться только как характеристики остальных объектов, другие — независимы и имеют самостоятельное значение
Кроме того, сам по себе отдельный элемент данных (его значение) ничего не представляет. Он приобретает смысл только тогда, когда связан с атрибутом (природой значения, что позволит интерпретировать значение) и другими элементами данных.
Поэтому физическому размещению данных (и, соответственно, определению структуры физической записи) должно предшествовать описание логической структуры предметной области — построение модели соответствующего фрагмента реального мира, выделяющей только те объекты, которые будут интересны будущим пользователям, и представленные только теми параметрами, которые будут значимы при решении прикладных задач.
2.5 Структуры данных
При любом методе отображения предметной области в машинных базах данных в основе отображения лежит фиксация (кодирование) Понятий и отношений между понятиями. Абстрактное понятие структуры ближе всего к так называемой концептуальной модели Предметной среды и часто лежит в основе последней.
Понятие структуры используется на всех уровнях представления Предметной области и реализуется как:
• структура информации — схематичная форма представления сложных композиционных объектов и связей реальной предметной области, выделяемых как актуально необходимые для решения прикладных задач;
• структура данных — атрибутивная форма представления свойств и связей предметной области, ориентированная на выражение описания данных средствами формальных языков (т. е. учитывающая возможности и ограничения конкретных средств с целью сведения описаний к стандартным типам и регулярным связям);
структура записей — целесообразная (учитывающая особенности физической среды) реализация способов хранения данных и организации доступа к ним как на уровне отдельных записей,так и их элементов (с целью определения основных и вспомогательных функциональных массивов, а также совокупности унифицированных процедур манипулирования данными). Структура является общепринятым и удобным инструментом, одинаково эффективно используемым как на уровне сознания человека при работе с абстрактными понятиями, так и на уровне логики машинных алгоритмов. Структура позволяет простыми способами свести многомерность содержательного описания к линейной последовательности записей. Именно это позволяет формализовать на общей понятийной основе взаимосвязь представлений информации в разных средах: обеспечить контролируемое сведение бесконечного разнообразия объектов и видов взаимосвязей реального мира к жестко детерминированному описанию — совокупности двоичных данных и машинно-ориентированных алгоритмов их обработки.
Выделение трех видов структур, относящихся к представлению объектов предметной области, имеет, в некотором смысле, принципиальный характер.
Структура информации — это неотъемлемое свойство информации (сведений, сигналов, воспринимаемых субъектом) о некоторой совокупности объектов предметной области в контексте практической задачи (решаемой субъектом), в общем случае без учета того, будут ли для ее решения использованы средства программирования и вычислительные машины. Структурирование информации осуществляется системным аналитиком и сводится к выделению операционных объектов и определению их характеристических свойств и взаимосвязей.
Структура данных — это определение информационных массивов (состава и взаимосвязей данных на логическом уровне, соответствующих характеру информации и видам соответствующих преoбразований). При определении структур данных необходимо не только установить состав массива, но и определить оптимальную взаимосвязь (и, соответственно, определить критерии и методы оценки эффективности), например, выделение групп или агрегатовjимеющих иерархическую идентификацию. Эффективность в этом, случае связывается с процессом построения программы («решателя» прикладной задачи) и, в каком-то смысле — с эффективностью работы программиста. Например, при функциональной обработке массива необходимо обращаться к отдельным элементам, в то время? как в операциях присваивания или при записи массива в файл элементное обращение приведет к увеличению размера текста программы, а в ряде случаев — к увеличению времени выполнения.
Структура записи — это определение структуры физической памяти: выделение, освобождение и защита областей физического носителя, способы адресации и пересылки. Эффективность в этом случае связывается с процессами обмена между устройствами оперативной и внешней памяти, искусственно вводимой для обеспечения функциональной эффективностиотдельных операций (например, поиска по ключам) посредством избыточности данных.
Рассмотрим разновидности и типологию «компьютерных» логических структур данных с точки зрения особенности их организации. Структура здесь в первую очередь определяет алгоритм выборки отдельных элементов данных, но в то же время необходимо отметить, что она отражает и особенности «технологии» организации и обработки информации, свойственные человеку в его повседневной деятельности.
Физически понятию структура соответствует запись данных. Запись — это упорядоченная в соответствии с характером взаимосвязей совокупность полей (элементов) данных, размещаемых в памяти в соответствии с их типом. Поле представляет собой минимальную адресуемую (идентифицируемую) часть памяти — единицу данных, на которую можно ссылаться при обращении к данным.
Таким образом, структура данных — это способ отображения значений в памяти: размер области и порядок ее выделения (который и определит характер процедуры адресации/выборки). Зачастую именно успешность структурирования данных определяет сложность процедур их обработки [2].
Классификация структур данных должна проводиться с двух точек зрения.
1. По характеру взаимосвязи элементов структуры (с точки зрения порядка их размещения/выборки) виды структур можно разделить на линейные и нелинейные.
|