Введення
Рішення деяких задач комп'ютерної безпеки засноване на обмеженні доступу програмного коду до різного роду ресурсів, зокрема, мережевих ресурсів і файлової системи. Надавши доступ до цих ресурсів лише окремим довіреною програмами, можна гарантувати (при додатковому контролі цілісності цих програм) виконання важливих вимог з безпеки, серед яких слід зазначити запобігання витоку критично важливої інформації через різні канали передачі даних: мережеве з'єднання, переносні (USB) накопичувачі та ін.
Сучасні операційні системи (ОС) надають широкі можливості з управління доступом процесів до ресурсів комп'ютера. Однак недостатня надійність масових ОС (таких як Windows, Linux та ін.) [1] робить актуальним завдання розробки незалежних від ОС (ортогональних до неї) програмних засобів захисту інформації. Такі засоби захисту можуть бути реалізовані з використанням технології апаратної віртуалізації, коли захищається система виконується в апаратній віртуальній машині (ВМ), а система захисту розміщується в тілі монітора віртуальних машин (також званого гіпервізор) [2,4]. Функціонування гіпервізора на більш високому апаратному рівні привілеїв дозволяє повністю контролювати виконання як коду ОС, так і призначених для користувача програм, залишаючись при цьому апаратно захищеним від шкідливого впливу з боку коду в ВМ, у тому числі, коду, що виконується в привілейованому режимі.
Користувальницький процес в сучасних ОС не має прямого доступу до апаратних ресурсів; операційна система являє процесу деяку абстрактну модель апаратного забезпечення, взаємодія з якою здійснюється за допомогою набору операцій – системних викликів (СВ). Зокрема, для встановлення мережевого з'єднання з віддаленим комп'ютером і передачі йому даних процесу необхідно виконати в заданому порядку кілька цілком певних системних викликів (socket, connect, send і т. п.).
У наших роботах [2,3] було показано, як за допомогою поділу повноважень з обслуговування ресурсів між віртуальними машинами і делегування обслуговування системних викликів від однієї віртуальної машини іншої можуть бути вирішені деякі задачі комп'ютерної безпеки. Запропоновані рішення в цілому базуються на схемі, зображеній на рисунку 1. Гіпервізор забезпечує одночасне виконання двох ізольованих один від одного віртуальних машин. Обидві ВМ працюють під управлінням однієї і тієї ж операційної системи. Перша ВМ – обчислювальна – є основною. Користувач може працювати з нею в діалоговому режимі.
Обладнання, через яке здійснюється доступ до контрольованих ресурсів (ресурси мережі Інтернет на рис. 1), фізично відключається гіпервізор від обчислювальної ВМ. Це обладнання управляється другий – сервісної – віртуальною машиною, яка, взагалі кажучи, може виконуватися прихованим для користувача чином у фоновому режимі. Системні виклики окремих (довірених) процесів перехоплюються гіпервізор, і ті з них, які відносяться до контрольованих ресурсів, передаються на обслуговування (обслуговуються віддалено) в сервісну ВМ. Зауважимо, що обслуговування цих викликів всередині обчислювальної ВМ неминуче призведе до помилки через відсутність у неї можливостей (обладнання) здійснити доступ до відповідних ресурсів. Решта системні виклики довірених процесів, а також всі системні виклики інших процесів, обслуговуються засобами ОС в обчислювальній ВМ.

Рисунок 1. Делегування системних викликів другий віртуальній машині
При перехопленні системного виклику гіпервізор може проконтролювати допустимість контексту, з якого виконується запит на системний виклик, тобто чи дозволений даному процесу доступ до такої категорії ресурсів, і виконувати віддалене обслуговування виклику тільки у випадку успішного проходження перевірки. Аналізуючи параметри виклику, гіпервізор може також здійснювати більш тонкий контроль доступу до ресурсу, наприклад, дозволяти мережевий доступ тільки до обмеженого числа комп'ютерів в мережі, що мають задані адреси.
У даній роботі описується архітектура і деталі реалізації механізму віддаленого виконання системних викликів, що використовується в системі безпеки, яка представлена в роботі [3]. У ній контрольованими ресурсами є виключно ресурси мережі Інтернет. Як наслідок, реалізація, що розглядається в даній роботі, допускає віддалене обслуговування тільки тих системних викликів, які можуть бути використані при мережевому взаємодії через сокети. Однак, враховуючи спільність подання сокетів і файлів для користувацького процесу у вигляді дескрипторів файлів і, як наслідок, спільність багатьох системних викликів, аналізований механізм в цілому придатний також для тих сценаріїв, коли контрольованим ресурсом є файлова система.
Окремі компоненти системи, що розглядається у даній роботі, можуть також використовуватися для ефективного вирішення тих завдань, в яких потрібно виконувати трасування системних викликів. Справа в тому, що штатні механізми трасування в ОС Linux (ptrace) базуються на сигналах, що посилаються ядром ОС процесу-монітора (відладчик) при виконанні відлагоджує процесом системного виклику, що призводить до частого перемикання контексту процесів (монітора і трасуванню процесу). Крім того, читання даних з адресного простору трасуванню процесу можливе тільки порціями по 4 байти. Розміщення монітора процесів на рівні гіпервізора дозволяє усунути вказані обмеження.
Завдання віддаленого виконання системних викликів розглядається також в рамках проекту VirtualSquare [6]. Відмінність запропонованого нами підходу полягає у використанні технології апаратної віртуалізації для перехоплення системних викликів. Крім того, в роботі [6] підмножина системних викликів, виконуваних віддалено, задається жорстко, у той час як у нашому підході рішення про віддалений виконання системного виклику приймається, виходячи з дескриптора ресурсу, до якого звертається процес. У ряді випадків системний виклик треба одночасно виконувати в обох системах (локальної та дистанційної) з наступним об'єднанням результатів, і це питання також розглянуто в даній роботі.
Механізм віддаленого виконання системних викликів близька механізму віддаленого виконання процедур [7], широко вживаному в розподілених програмних системах, зокрема, в мережевої файлової системи NFS [8]. Принципова відмінність пропонованого нами рішення полягає у відсутності необхідності модифікації (в тому числі, перекомпіляції) коду програми і операційної системи для обслуговування системних викликів в іншій системі.
Стаття організована наступним чином. У розділі 2 представлено короткий огляд технології апаратної віртуалізації і викладена загальна архітектура системи та її компонент. У розділі 3 детально розглянуті принципи роботи системи і обробка різних сценаріїв доступу до ресурсів. У розділі 4 представлені результати аналізу продуктивності системи як на синтетичних тестах, так і на реальних додатках. У розділі 5 підводяться підсумки роботи.
1
. Архітектура системи
Технологія віртуалізації дозволяє виконувати ОС в апаратній віртуальній машині (ВМ) під управлінням порівняно невеликий за розміром системної програми – монітора віртуальних машин (гіпервізора) [5]. Апаратна віртуальна машина є ефективний ізольований дублікат реальної машини, і виконання в ній операційної системи не вимагає внесення будь-яких змін в код ОС. Гіпервізор повністю контролює взаємодію ОС в ВМ з устаткуванням і може забезпечити надійну ізоляцію ВМ, спираючись на апаратні механізми захисту.
Функціонування гіпервізора та організація виконання віртуальної машини багато в чому схожі з тим, як операційна система керує виконанням користувацьких процесів. Гіпервізор ініціалізує системні структури даних, необхідні обладнанню, і виконує спеціальну інструкцію VMRUN, що реалізовує запуск ВМ і передачу управління відповідної інструкції коду ОС. При виникненні апаратного події (переривання) або при виконанні операційною системою привілейованої інструкції (у тому числі, системного виклику) виконання ВМ переривається, і управління передається гіпервізор на наступну інструкцію після VMRUN. Після обробки перехопленого події гіпервізор відновлює виконання ВМ.
Архітектура системи виглядає наступним чином. Гіпервізор реалізує одночасне виконання двох віртуальних машин (мал. 1), що працюють під управлінням операційної системи Linux однаковою. Відзначимо, що операційні системи у віртуальних машинах можуть бути різними, якщо гіпервізор при цьому забезпечує необхідне перетворення системних викликів між вихідної та цільової операційними системами. У обчислювальної ВМ виконуються процеси користувача, серед яких виділено набір довірених процесів. Гіпервізор надає довіреною процесам привілей доступу до ресурсів, що обслуговується ОС в сервісній ВМ (контрольованим ресурсів); інші процеси доступу до цих ресурсів не мають. Доступ довірених процесів до контрольованих ресурсів проводиться за допомогою перехоплення їх системних викликів і, при необхідності, їх перенаправлення для обслуговування в сервісну ВМ.
Обидві віртуальні машини виконуються асинхронно, і обчислювальна ВМ не блокується на час віддаленого обслуговування системного виклику. У цей час процес, який ініціював системний виклик, знаходиться в стані очікування, а всі інші процеси в обчислювальній ВМ продовжують виконуватися нормальним чином. Більш того, система допускає одночасне обслуговування декількох віддалених системних викликів, що надходять від різних довірених процесів.
При перехопленні запиту процесу на виконання системного виклику гіпервізор копіює всі вхідні параметри виклику у власну область пам'яті і передає запит на обслуговування виклику в сервісну ВМ. Системний виклик може бути блокуючим (наприклад, read), і час його виконання в загальному випадку не обмежена. Для уникнення блокування всієї обчислювальної ВМ на час обслуговування виклику процес, який ініціював системний виклик, переводиться в стан очікування, дозволяючи іншим процесам продовжити своє виконання. При надходженні з сервісної ВМ результатів обслуговування виклику гіпервізор перериває виконання обчислювальної ВМ, виводить процес зі стану очікування і копіює результати в його адресний простір. Перебування процесу в стані очікування реалізується штатними засобами ОС в ВМ без вмешівательства в роботу механізму управління процесами в операційній системі.
Всередині сервісної ВМ виконується набір процесів – делегатів, які є екземплярами спеціалізованої програми. Кожен із делегатів обслуговує запити на системні виклики окремого довіреної процесу з обчислювальної ВМ, причому ієрархія делегатів в сервісній ВМ відповідає ієрархії довірених процесів в обчислювальній ВМ. Новий делегат породжується кожного разу при створенні нового довіреної процесу і знищується при завершенні роботи цього процесу.
Виконання делегата полягає в циклічному виконанні системних викликів, що надійшли від відповідного довіреної процесу, і сповіщення гіпервізора про результати (делегат, на відміну від довіреної процесу, знає про існування гіпервізора). Делегати отримують запит на виконання системного виклику від спеціалізованого процесу – диспетчера – через механізм взаємодії між процесами (черга повідомлень). Всі запити, що надходять від гіпервізора, проходять через процес-диспетчер. Диспетчер відстежує відповідності між ідентифікаторами довірених процесів і ідентифікаторами делегатів і, отримавши запит від гіпервізора на обслуговування системного виклику деякого довіреної процесу, перенаправляє його відповідного делегату. Подальше обслуговування запиту цілком проводиться делегатом без участі диспетчера. Зокрема, делегат самостійно виконує доступ до сховища, сповіщає гіпервізор про результати системного виклику і т.д.
Ієрархія кожного довіреної процесу сходить до службового процесу, що є екземпляром спеціальної користувацької програми – монітора. Перший довірений процес завжди породжується монітором. Монітор, у свою чергу, не є надійною програмою. Завдання монітора складається у запуску нового (в тому числі, першого) довіреної процесу та відстеження його стану, а також стану всіх його дочірніх процесів, частина з яких можуть бути довіреними, а частина – ні.
Монітор реалізований на базі стандартного інтерфейсу налагодження ptrace. Монітор перехоплює події породження та завершення процесів, в тому числі, аварійного, наприклад, при отриманні сигналу процесом, для якого у нього не зареєстрований обробник. При виконанні одним з дочірніх процесів системного виклику fork або exec монітор визначає, чи треба даному процесу виконання у довіреному режимі (тобто чи буде новий процес довіреною), і, у разі необхідності, може вимагати гіпервізор про його включення для процесу. При завершенні довіреної процесу монітор також сповіщає про це гіпервізор.

Рисунок 2. Паспорт довіреної завдання.
Монітор визначає, для яких процесів слід запитувати довірений режим виконання, ґрунтуючись на спеціальному файлі конфігурації – паспорті завдання (рис. 2). Паспорт містить ім'я спочатку завантажується програми (не обов'язково довіреної) і список переданих їй параметрів командного рядка. Основна частина паспорта складається з набору шаблонів для ідентифікації нових процесів, для яких слід запитувати включення довіреної режиму. Для кожного шаблона вказується унікальний ідентифікатор довіреної програми, зареєстрованої в гіпервізора. У гіпервізора для кожної зареєстрованої програми перерахований набір хеш-кодів, що дозволяють перевірити, що запускається програма дійсно є однією з довірених [1].
При виконанні дочірнім процесом системного виклику exec монітор проводить пошук шаблону, який може бути зіставлений імені запускається програми, і, у разі успіху, робить запит гіпервізор на включення довіреної режиму, повідомляючи йому ідентифікатор процесу (PID) і ідентифікатор відповідної довіреної програми (наприклад, 444 на рис. 2). Гіпервізор перевіряє допустимість включення довіреної режиму для процесу в даній точці виконання і, в разі дотримання контекстних умов безпеки [1], активує довірений режим. При перехопленні системного виклику fork монітор активує довірений режим для дочірнього процесу лише в тому випадку, якщо батьківський процес виконується в довіреному режимі. Слід зазначити, що гіпервізор контролює коректність виконання запиту, тобто що батьківський процес виконується в довіреному режимі і дійсно виконав системний виклик fork.
Паспорт задачі також містить адресу довільній інструкції RET в коді довіреної програми. Монітор за допомогою модуля (розширення) ядра в обчислювальній ВМ реєструє для довіреної процесу за цією адресою обробник сигналу, не використовуваного процесом. Здійснення такого сигналу довіреній процесу призведе просто до виконання інструкції RET. Цей сигнал використовується для скасування виконання системного виклику в обчислювальній ВМ у тих випадках, коли для коректного обслуговування системного виклику його потрібно виконувати в обох віртуальних машинах (див. розділ 3.1).
1.1 Компоненти системи та їх взаємодія
Віддалене обслуговування системних викликів реалізується гіпервізор спільно з іншими компонентами системи, що функціонують в обох ВМ – обчислювальної і сервісною. Компоненти функціонує як у просторі користувача (монітор, диспетчер, делегати), так і в просторі ядра ОС (завантажувані модулі ядра ОС).
У ході ініціалізації системи в ядро ОС в обчислювальній та сервісної ВМ динамічно завантажуються модулі ядра. Кожен модуль виділяє безперервне простір фізичної пам'яті (за замовчуванням 1 сторінку розміром 4Кб) для організації кільцевого буфера, реєструє кілька обробників переривань, за допомогою яких гіпервізор сповіщає віртуальну машину про події, що вимагають обробки і повідомляє цю інформацію (адреса буфера та номери переривань) гіпервізор за допомогою гіпервизова. У сервісній ВМ також запускається користувальницький процес – диспетчер.
У ході віддаленого обслуговування системного виклику компоненти системи взаємодіють між собою, причому механізми взаємодії реалізовані по-різному (рис. 3). Реалізація механізму взаємодії деякої пари компонент визначається рівнями привілеїв, на яких вони виконуються. Будь-яка компонента може звернутися до гіпервізор допомогою гіпервизова. Виконання ВМ при цьому переривається, і управління передається гіпервізора. Синхронний характер цього звернення дозволяє передавати параметри гіпервизова аналогічно тому, як користувальницький процес передає параметри ядру ОС при виконанні системного виклику: числові параметри та адреси областей пам'яті передаються через регістри, при необхідності гіпервізор читає область пам'яті віртуальної машини за вказаними адресами і витягує з неї (або записує в неї) додаткову інформацію.
Користувальницький процес (диспетчер або монітор) звертається за сервісом до модуля ядра за допомогою системних викликів. Модуль ядра реєструє в ОС спеціальне логічний пристрій, видиме на рівні файлової системи як файл. Операції доступу до цього файлу (системні виклики read / write / ioctl) викликають відповідні функції в драйвері логічного пристрою. Драйвер обробляє запит процесу і повертає управління йому. Якщо операція блокуюча, то драйвер може призупинити виконання процесу до тих пір, поки він не зможе обслужити запит. Модуль ядра звертається до призначеного для користувача процесу за допомогою посилки сигналів.

Взаємодія користувальницьких процесів один з одним (наприклад, диспетчера з делегатами) здійснюється за допомогою стандартних механізмів взаємодії між процесами (IPC) ОС Linux – поділюваної пам'яті, черги повідомлень і пр. Всі делегати в сервісній ВМ є членами однієї ієрархії процесів, висхідній до диспетчера, що полегшує контроль створення поділюваних між процесами ресурсів: ресурс, який створюється з батьків, доступний нащадку, а ресурс, який створюється нащадком, не доступний батьку.
Найбільш складною є ситуація, в якій гіпервізор потрібно сповістити компоненти у віртуальній машині про деяке подію. Для цього гіпервізор використовує можливість, що надається апаратурою віртуалізації, вкидати переривання і виняткові ситуації у віртуальну машину за допомогою відповідних полів в керуючій структурі VMCB ВМ. Тоді після відновлення ВМ апаратура забезпечує їй доставку переривання безпосередньо перед виконанням першої інструкції в ВМ. У результаті вкидання переривання ОС передає управління на обробник (вектор) даного переривання, зареєстрований модулем ядра в таблиці обробників переривань в процесі ініціалізації системи.
Параметри події передаються через кільцевої буфер. Буфер фізично розташований в області пам'яті ВМ і розділяється між гіпервізор та ВМ за схемою «постачальник – споживач». Буфер являє собою замкнутий в кільце масив структур даних (фіксованого розміру), голова якого зрушується в міру виїмки запитів з буфера, а хвіст – в міру приміщення запитів в буфер. Якщо буфер переповнений, то доставка запиту відкладається до тих пір, поки в буфері не звільниться місце, тобто поки ОС не обробить хоча б одне з раніше згенерованих подій. Запити, які очікують доставки в ВМ, накопичуються в черзі в пам'яті гіпервізора.
Структура даних, що представляє собою елемент кільцевого буфера, єдина для всіх подій і включає поля для всіх можливих параметрів фіксованої довжини. Параметри змінної довжини передаються через окремий буфер змінного розміру, розташований в пам'яті гіпервізора – сховище. Координати параметра змінної довжини – зміщення від початку сховища і довжина – специфікується в структурі даних кільцевого буфера. Наприклад, для системного виклику write структура включає 3 поля: ідентифікатор файлового дескриптора, початок (зміщення) буфера в сховище і довжина буфера. Для кожного довіреної процесу гіпервізор підтримує окремий екземпляр сховища.
При отриманні запиту, що містить параметри змінної довжини, код за ВМ, якому призначається цей запит (наприклад, делегат), виконує гіпервизов на доступ до сховища, передаючи координати запитуваної параметра і адреса буфера у власній пам'яті, в який повинні бути записані дані зі сховища. Гіпервізор обслуговує запит і відновлює виконання ВМ. При цьому він контролює, що кордони запитуваної блоку даних не виходять за межі сховища. Доступ до сховища можливий як з читання, так і по запису.
При необхідності передати запит однієї з компонент всередині ВМ гіпервізор очікує, коли виконання ВМ буде перерване за тієї чи іншої події (наприклад, за таймером), і аналізує, чи може він послати запит в даній точці. Для цього в кільцевому буфері має бути вільне місце, а переривання не повинні бути маскуватися в ВМ. Якщо це так, то гіпервізор (при необхідності) заповнює сховище параметрами змінної довжини, формує структуру даних для кільцевого буфера, вказуючи в ній координати параметрів у сховище, записує сформований запит в буфер і вкидає переривання. Вкидання переривання передає управління оброблювачеві переривання, який аналізує вміст буфера і або обслуговує його самостійно, або передає запит другий компоненті, що відповідає за його обслуговування (наприклад, диспетчеру).
Якщо одержувачем запиту гіпервізора є користувальницький процес (наприклад, диспетчер), то доставка такого запиту здійснюється транзитом через драйвер логічного пристрою. Користувальницький процес звертається до файлу устрою і, у разі відсутності запиту на даний момент, переходить в стан очікування. Під час отримання запиту від гіпервізора обробник переривання сповіщає про це драйвер пристрою. Той, у свою чергу, читає запит з кільцевого буфера, копіює його в пам'ять процесу і виводить його зі стану очікування. Якщо запит містить параметри змінної довжини, то доступ до сховища здійснюється тим користувальницьким процесом, який безпосередньо обслуговує запит.
2. Прозоре обслуговування системних викликів
Механізм системних викликів в процесорах сімейства x86 може бути реалізований різними способами. Історично для цього використовувалися програмні переривання (інструкція INTn), зокрема, в ОС Linux для виконання системного виклику використовується вектор 128. Повернення з системного виклику проводився за допомогою інструкції IRET. При виконанні інструкцій INTn і IRET процесор проводить ряд перевірок контексту виконання інструкції і його параметрів. Часте виконання процесом системних викликів може справити значний вплив на продуктивність системи. Як рішення, виробники процесорів запропонували додаткову пару інструкцій, спеціально призначених для швидкого переходу в режим ядра на задану адресу і назад: SYENTER / SYSEXIT від Intel і SYSCALL / SYSRET від AMD. Використання цих інструкцій є переважним, однак оригінальний механізм виконання системних викликів на базі програмних переривань, як і раніше підтримується з міркувань зворотної сумісності додатків.
У розглянутій у цій роботі системі віддаленого обслуговування системних викликів потрібно, щоб довірені програми використовували для виконання системних викликів механізм програмних переривань. Це зумовлено можливістю перехоплення інструкції програмного переривання і повернення з переривання безпосередньо за допомогою апаратури віртуалізації. Решта процеси в обчислювальній ВМ можуть використовувати довільні механізми системних викликів. З міркувань підвищення продуктивності перехоплення програмного переривання (інструкція INTn) встановлюється, тільки коли управління передається довіреній процесу, що дозволяє запобігти виходу з ВМ, якщо ця інструкція виконувалася будь-яким іншим (недоверенним) процесом.
Прапор перехоплення інструкції IRET, у свою чергу, встановлюється при кожному поверненні управління ВМ, якщо в системі виконується хоча б один довірений процес. Лише перехоплюючи всі такі інструкції, гіпервізор може відстежити момент, коли ОС передає управління довіреній процесу. Це необхідно для коректного відновлення процесу після отримання результатів з сервісної ВМ. Якщо результати готові, і повернення управління відбувається на наступну інструкцію після запиту на системний виклик, то гіпервізор записує результати, отримані з сервісної ВМ, на регістри і в пам'ять процесу, і процес продовжує виконання.
При перехопленні програмного переривання гіпервізор перевіряє, що воно було виконане з контексту довіреної процесу, і що вектор переривання відповідає вектору запитів на обслуговування системних викликів (128 в ОС Linux). Далі гіпервізор перевіряє, чи потрібне обслуговувати даний системний виклик віддалено в сервісній ВМ або локально в обчислювальній ВМ. Правила такого аналізу системних викликів будуть розглянуті в наступному розділі. Якщо виклик локальний, то гіпервізор просто відновлює управління ВМ, передаючи управління ядру ОС. Якщо виклик віддалений, то гіпервізор копіює параметри системного виклику з регістрів і, можливо, з адресного простору процесу у власну область пам'яті, формує запит і відправляє його в сервісну ВМ. Схема механізму прозорого обслуговування системних викликів наведена на рисунку 4.
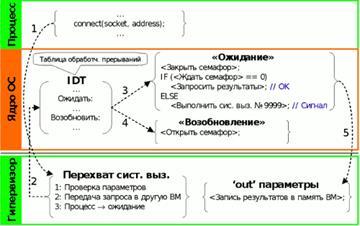
Рисунок 4. Прозоре обслуговування системного виклику в обчислювальній ВМ
Для визначення адреси параметрів системного виклику у фізичній пам'яті гіпервізор програмним чином обходить таблиці приписки процесу і обчислює умовно фізичну адресу в контексті ВМ. Далі, знаючи відображення пам'яті ВМ на машинну пам'ять, гіпервізор обчислює точне розміщення параметрів виклику у фізичній пам'яті. В процесі читання параметрів, розташованих у пам'яті процесу (наприклад, у разі системного виклику write), можлива ситуація, коли дані розташовані в сторінки пам'яті, відкачати ОС на зовнішній пристрій.
Гіпервізор, виявивши відкачаний сторінку, вкидає у ВМ виключення «помилка сторінки» з адресою, відповідним відсутньої сторінці, і поновлює управління ВМ. ОС підкачує сторінку в пам'ять і повертає керування процесу за адресою інструкції виконання системного виклику. Процес повторно виконує системний виклик, і гіпервізор заново починає копіювання параметрів. Такий процес буде повторюватися до тих пір, поки всі сторінки пам'яті, зайняті вхідними параметрами системного виклику, не опиняться в фізичної пам'яті.
Після копіювання вхідних параметрів системного виклику гіпервізор відновлює виконання обчислювальної ВМ і переводить процес в стан очікування. Для цього в точці виконання системного виклику він вкидає синхронне переривання, для якого модуль ядра в обчислювальній ВМ зареєстрував обробник. В результаті, замість переривання 128, відповідного системним викликам, апаратура доставляє інше переривання.
Отримавши управління, обробник здійснює доступ до закритого семафор, що переводить процес в стан очікування штатними засобами ОС. Процес чекає відкриття семафора в режимі, допускають обробку зовнішніх подій. У разі надходження сигналу для процесу ОС перериває очікування семафора. Модуль ядра при цьому імітує запит на виконання неіснуючого системного виклику (наприклад, з номером 9999). Ядро ОС, зрозуміло, не буде виконувати цей запит, однак до того, як повернути управління процесу, він виконає обробку надійшли сигналів.
Після обслуговування сигналу ОС повертає управління процесу на вихідну інструкцію системного виклику, і процес повторно виконує запит на системний виклик. Гіпервізор перехоплює його, визначає, що в даний час системний виклик знаходиться в процесі віддаленого обслуговування, знову підміняє переривання, і процес вдруге переходить в стан очікування. Такий циклічний процес буде повторюватися до тих пір, поки з сервісної ВМ не надійдуть результати виконання системного виклику.
При отриманні результатів з сервісної ВМ гіпервізор необхідно відновити виконання довіреної процесу з наступною інструкції, причому в регістр r / eax повинен бути записаний результат виконання виклику, а в пам'ять процесу (наприклад, у разі системного виклику read) за заданими адресами повинні бути записані вихідні дані, якщо вони є.
Гіпервізор виводить процес зі стану очікування за допомогою вкидання іншого синхронного переривання в обчислювальну ВМ, обробник якого звільняли семафор і, тим самим, відновлює виконання процесу. Процес далі виконує гіпервизов на запит результатів системного виклику. Зауважимо, що хоча гіпервизов проводиться з контексту ядра, в точці гіпервизова на апаратурі завантажені власні таблиці приписки довіреної процесу. Гіпервізор переглядає таблиці і перевіряє, що віртуальні адреси, за якими мають бути записані результати, відображені на фізичну пам'ять, і доступ до цих адресами відкрито по запису. Наявність доступу тільки з читання може означати, що дана область пам'яті є «копійований при операції запису». При наявності доступу по запису до всього необхідного діапазону адрес гіпервізор копіює результати виконання системного виклику зі сховища в адресний простір процесу і відновлює виконання ВМ. В іншому випадку гіпервізор для всіх необхідних віртуальних сторінок вкидає у ВМ виключення «помилка сторінки», що дає ОС вказівку виділити пам'ять для відповідної віртуальної сторінки і відобразити її на фізичну пам'ять.
При віддаленому обслуговуванні системного виклику делегат може отримати сигнал від ОС в сервісній ВМ, наприклад, сигнал SIGPIPE про розрив мережевого з'єднання. У цьому випадку делегат сповіщає гіпервізор про здобутий сигналі, і гіпервізор доставляє сигнал довіреній процесу. Для цього він інформує про сигнал модуль ядра ОС, який, у свою чергу, доставляє сигнал процесу засобами API ядра ОС Linux. Доставка процесу сигналу може привести до його аварійного завершення. У цьому випадку монітор повідомить гіпервізор про закінчення виконання процесу, і гіпервізор звільнить пам'ять, відведену під службові структури даних.
2.1 Точка обслуговування системного виклику
У переважній більшості випадків системний виклик може бути асоційований з ресурсами якої-небудь однієї з віртуальних машин або на підставі номера системного виклику, або на підставі його параметрів. Зокрема, системний виклик socket, що створює кінцеву точку для мережевої взаємодії і повертає файловий дескриптор для роботи з нею, повинен обслуговуватися в сервісній ВМ. Системний виклик write вимагає додаткового аналізу файлового дескриптора, що передається в параметрах дзвінка. Якщо дескриптор асоційований з сокетом, то він повинен обслуговуватися в сервісній ВМ, в іншому випадку – в обчислювальній ВМ.
ОС в обох ВМ підтримують набори файлових дескрипторів для довіреної процесу і його делегати незалежно один від одного. Якщо гіпервізор після віддаленого обслуговування системного виклику поверне довіреній процесу ідентифікатор файлового дескриптора, отриманого від делегата, без будь-яких змін, то це може призвести до наявності в пам'яті довіреної процесу двох ідентичних дескрипторів, які насправді відповідають різним ресурсів в тій і іншій ВМ. У подальшому, при виконанні довіреною процесом системного виклику для такого дескриптора гіпервізор не зможе розрізнити, чи відноситься виклик до локального ресурсу в обчислювальній ВМ або віддаленого в сервісній ВМ.
Для вирішення цієї проблеми гіпервізор реалізує додатковий рівень абстракції файлових дескрипторів для довірених процесів. Файлові дескриптори, що зберігаються в пам'яті довіреної процесу (в якихось змінних), являють собою не реальні дескриптори, призначені ядром ОС в обчислювальній або сервісній ВМ, а індекси в таблиці віддалених ресурсів, підтримуваної гіпервізора. Гіпервізор перехоплює і обробляє всі системні виклики довіреної процесу, у яких вхідні або вихідні параметри містити файлові дескриптори. Якщо параметр вхідний, то гіпервізор витягує з таблиці віддалених ресурсів фактичний файловий дескриптор, модифікує параметри системного виклику і передає його на обслуговування тієї ВМ, яка є власником ресурсу з цим дескриптором. Якщо параметр вихідний, то гіпервізор створює новий запис у таблиці віддалених ресурсів, позначаючи, яка з віртуальних машин є власником ресурсу, і модифікує вихідні параметри процесу, підставляючи індекс створеної запису замість фактичного значення дескриптора. Компонента гіпервізора, що відповідає за обробку файлових дескрипторів, враховує особливості виділення вільних дескрипторів ОС Linux, включаючи нюанси роботи системних викликів dup2 і fcntl. Таким чином, за значенням, передається довіреною процесом, завжди можна визначити віртуальну машину – власника ресурсу та номер файлового дескриптора в її контексті.
У ряді випадків виконання системного виклику може задіяти ресурси обох ВМ. Зокрема, параметри системного виклику select і його аналогів, а саме, набори файлових дескрипторів, для яких процес очікує виникнення відповідних подій, можуть одночасно ставитися до ресурсів як обчислювальної, так і сервісної ВМ. Такий виклик повинен обслуговуватися одночасно в обох ВМ, інакше програма може перестати виконуватися коректно. При цьому системний виклик в кожній віртуальній машині повинен обслуговуватися тільки з тими параметрами (файловий дескриптор), які відносяться до ресурсів даної ВМ.
При перехопленні запиту на виконання системного виклику, що вимагає одночасного виконання в обох ВМ, гіпервізор, використовуючи таблицю віддалених ресурсів, розшивають фактичні параметри на два непересічних набору (по одному для кожної з ВМ) і виконує виклик одночасно в обох ВМ з відповідними наборами параметрів. Модифікований набір параметрів записується в пам'ять довіреної процесу поверх оригінального. Перед поверненням управління процесу (після обслуговування системного виклику) гіпервізор відновлює вихідний набір параметрів, можливо, коректуючи його з урахуванням результатів системного виклику, отриманих з сервісної ВМ. Підсумковим результатом виконання системного виклику є результат тієї ВМ, яка хронологічно першою закінчила виконання своєї частини виклику, результати другий ВМ відкидаються.
Після отримання результатів від однієї з ВМ гіпервізор виробляє скасування виконання системного виклику в іншій ВМ. Механізм скасування виконання системного виклику реалізований в обох віртуальних машинах по-різному. У разі обчислювальної ВМ модуль ядра посилає довіреній процесу певний сигнал (не використовується процесом). При цьому модуль системи захисту безпосередньо перед посилкою сигналу реєструє для процесу спеціальний «порожній» обробник сигналу, що представляє собою адресу RET інструкції в коді довіреної програми. Адреса інструкції вказується в паспорті завдання. Реєстрація обробника гарантує, що посилка сигналу не призведе до аварійного останову процесу. У сервісній ВМ всі системні виклики, які можуть виконуватися одночасно в обох ВМ, виконуються в окремому потоці (нитки) делегати. Скасування виконання системного виклику проводиться за допомогою примусового завершення цього потоку.
3
. Продуктивність системи
Описана в цій роботі система реалізована на базі монітора віртуальних машин KVM [9]. KVM включений в основну гілку розробки ядра ОС Linux і являє собою модуль, що динамічно завантажений в ядро базової (хост) операційної системи Linux. Управління виконанням ВМ реалізується спільно ядром хост системи, модулем KVM та користувацький програмою QEMU. QEMU віртуалізується периферійні пристрої та забезпечує спільний доступ віртуальних машин до обладнання, встановленого на комп'ютері і керованого базовою системою.
Реалізація, представлена в цій роботі, побудована на базової операційної системи Linux з ядром версії 2.6.31.6 і моніторі віртуальних машин KVM версії 88. Сумарний обсяг коду компонент системи складає близько 16 тис. рядків. Віртуальні машини виконуються під управлінням ОС Linux з дистрибутива Fedora версії 9 зі штатним ядром версії 2.6.27.12–78.2.8.fc9.i686. На комп'ютері встановлений чотирьохядерних процесор Phenom 9750 компанії AMD з тактовою частотою 2.4 Ггц і 2 Гбайта оперативної пам'яті. Даний процесор підтримує технологію апаратної віртуалізації, включаючи віртуалізацію пам'яті на базі вкладених (NPT) таблиць приписки віртуальної машини. Базова операційна система використовує всі чотири ядра процесора (ядро базової ОС зібрано в SMP-конфігурації). Кожній віртуальній машині виділяється по одному віртуальному процесору і по 512 Мбайт оперативної пам'яті.
Для проведення ряду тестів використовується другий комп'ютер такої ж конфігурації. В обох комп'ютерах встановлені 100 Мбіт-ві мережеві адаптери, пов'язані один з одним через мережевий концентратор (хаб). До концентратора підключені тільки дані дві машини.
Доступ віртуальної машини до мережі здійснюється за допомогою створення в базовій ОС штатними засобами ядра ОС програмного мережевого інтерфейсу (TAP0). Цей інтерфейс є образом мережевого інтерфейсу (ETH0) віртуальної машини в базовій системі. Прив'язка інтерфейсу TAP0 до фізичної середовищі здійснюється через програмний Ethernet-міст (bridge) в ядрі базової ОС, також організовуваний штатними засобами ОС Linux. Така конфігурація (мал. 1) дозволяє відкрити ВМ для інших машин в мережі, на відміну від конфігурації QEMU за замовчуванням, що приховує ВМ від інших машин в мережі за допомогою механізму трансляції мережевих адрес (NAT) і роздільної лише вихідні з'єднання в ВМ.
Для тестування продуктивності ми використовували чотири спеціально розроблених синтетичних тесту, моделюючих «важкі» для системи сценарії використання, і три типових програми: утиліту тестування продуктивності мережі TTCP, програму віддаленого доступу SSH і веб-сервер Apache.
Синтетичні тести засновані на виконанні системного виклику select () з одним або двома файловий дескриптор. Один з дескрипторів (локальний), позначимо його LocalFD, являє собою файл, відкритий в контексті обчислювальної ВМ, другий (віддалений), позначимо його RemoteFD, – сокет, створений в сервісній ВМ. У всіх тестах, крім першого, виконання системного виклику вимагає взаємодії між ВМ. Тести запускаються з контексту обчислювальної ВМ.

Рисунок 5. Конфігурація мережі для тестування продуктивності.
Обрамлення дескриптора квадратними дужками означає, що запитувана операція не може бути виконана для даного ресурсу, і системний виклик заблокує виконання відповідного користувацького процесу в одній з ВМ. Відсутність квадратних дужок означає можливість виконання операції і негайне повернення управління для користувача процесу. Тоді синтетичні тести перевіряють наступні сценарії виконання системного виклику:
· select (LocalFD);
· select (RemoteFD);
· select (LocalFD, [RemoteFD]);
· select ([LocalFD], RemoteFD).
Виконання системного виклику select (LocalFD) не вимагає взаємодії між віртуальними машинами і характеризує «обчислювальні» накладні витрати усередині обчислювальної ВМ на перехоплення системних викликів, аналіз фактичних параметрів та ін Виконання системного виклику select (RemoteFD) показує сумарний час, необхідне на доставку запиту делегату в сервісну ВМ, виконання системного виклику в ній і повернення результатів процесу, яка перебуває весь цей час у стані очікування.
Виконання системного виклику select з двома дескрипторах включає в себе взаємодію між віртуальними машинами і, крім того, вимагає виконання скасування системного виклику в тій ВМ, в якій процес був заблокований, а саме, в тій ВМ, дескриптор ресурсу якої обрамлений квадратними дужками. Слід відзначити принципову відмінність третього і четвертого тесту. У тесті select (LocalFD, [RemoteFD]) скасування системного виклику, виконуваного делегатом в сервісній ВМ, проводиться асинхронно для процесу в обчислювальній ВМ, і він може продовжити своє виконання, не чекаючи підтвердження від мережевої ВМ. Така оптимізація можлива, оскільки для нормального продовження виконання процесу досить результатів, одержуваних локально від ядра обчислювальної ВМ. У свою чергу, в тесті select ([LocalFD], RemoteFD) процес не може продовжити виконання, поки виконання системного виклику не буде перервано, що призводить до додаткових накладних витрат.
У таблиці 1 вказано час виконання тестів (у секундах) у циклі з 100 тисяч ітерацій. Перший рядок таблиці характеризують виконання тесту select (LocalFD) в базовій системі. Другий рядок показує час виконання тесту select (LocalFD) у ВМ із включеним механізмом відстеження виконання процесу. Зростання часу виконання на один порядок обумовлено витратами на перехоплення інструкції INTn, що ініціює системний виклик і, головне, інструкції IRET, що реалізує повернення в призначений для користувача режим як з системного виклику, так з обробників переривань. Ми очікуємо, що за рахунок адаптації пропонованої системи під механізм швидкого виконання системних викликів (SYSCALL / SYSRET), підтримуваний сучасними процесорами сімейства x86, даний показник може бути покращено.
Показник у третьому рядку таблиці говорить про те, що власне обчислювальні витрати системи (за винятком перехоплення двох інструкцій) складають близько 20%. Четвертий рядок характеризує накладних витрати на асинхронну скасування частини системного виклику, виконуваної делегатом в сервісній ВМ. Відзначимо, що кілька послідовних операцій скасування також виконуються асинхронно, і синхронізація здійснюється тільки при наступному виконанні «істотного» (не скасовується) віддаленого системного виклику. Крім того, делегат не буде виконувати системний виклик, якщо виявить, що для нього вже надійшла команда на скасування. Таке можливо в силу асинхронності виконання віртуальних машин.
У тесті select (LocalFD, [RemoteFD]) синхронізація здійснюється тільки після вихід з циклу при закритті «віддаленого» сокета (системний виклик close). При наявності великої кількості послідовно скасованих системних викликів (100 тисяч в даному випадку) така операція синхронізації може займати тривалий час, що й відбито в таблиці. Безпосередньо при виході з основного циклу час виконання тесту складає всього 15 секунд. Подальша операція закриття сокета, що вимагає синхронізації операцій скасування, вимагає додаткових 16 секунд.
Останні два рядки таблиці характеризують повноцінне віддалене обслуговування системного виклику. Шостий рядок таблиці показує накладні витрати на скасування локальної частини системного виклику в обчислювальній ВМ, яка завжди виконується синхронно для процесу.
Таблиця 1. Час виконання синтетичних тестів
| Тест |
Час (сек.) |
| Базова система |
1 |
| Віртуальна машина |
9 |
| select(LocalFD) |
11 |
| select (LocalFD, [RemoteFD]) |
15 (31) |
| select(RemoteFD) |
189 |
| select([LocalFD], RemoteFD) |
253 |
Синтетичні тести показують, що при найгіршому сценарії час виконання системного виклику може зростати до 250 разів. Однак на практиці це не робить істотного впливу на час виконання програми в цілому. По-перше, більшість системних викликів, що вимагають видаленого виконання, включає в себе передачу даних через периферійний пристрій (зокрема, через мережу). По-друге, додаток, як правило, виконує також інші дії, які нівелюють дані накладні витрати, наприклад, воно може часто перебуває у стані очікування відкриття семафора.
На малюнку 6 наведено результати тестування системи на утиліті TTCP, що виконує в циклі передачу пакетів між двома машинами в мережі. Перша діаграма відповідає оригінальній TTCP утиліті, друга – модифікованої, в яку ми додали виконання системного виклику select перед кожною посилкою пакета. Системний виклик select в даному випадку виконується віддалено, тобто відповідає синтетичному тесту select (RemoteFD). При виконанні оригінальної утиліти накладні витрати на віддалене обслуговування системних викликів склали всього 2% від сумарного часу виконання програми. Додавання системного виклику select збільшило накладні витрати до 31%, однак навіть у цьому випадку вони значно менше витрат в синтетичному тесті select (RemoteFD), де час виконання збільшилося в 189 разів.
Ми також тестували пропоновану систему на утиліті віддаленого доступу SSH за допомогою копіювання файлу між двома машинами в мережі, а також на веб-сервері Apache, запускаючи для нього пакет тестів навантажувального тестування Flood. В обох випадках час виконання тестів варіювалося в межах 1% від їх виконання на базовій системі. Таким чином, ми вважаємо, що пропонований механізм віддаленого обслуговування системних викликів є досить ефективним для його використання в промислових завданнях.
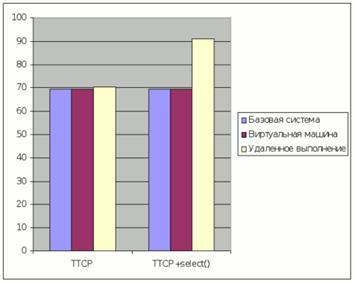
Рисунок 6. Час виконання утиліти TTCP (сек)
Висновок
У даній роботі представлено підхід до віддаленого виконання системних викликів користувацького процесу, що не вимагає внесення будь-яких змін (у тому числі, перекомпіляції) ні в код процесу, ні в код операційної системи. Особливістю розглянутого підходу є те, що процесу може бути наданий контрольований доступ до таких ресурсів, до яких операційна система, під управлінням якої виконується процес, ні прямої, ні опосередкованої доступу не має. Це дозволяє надавати селективний доступ до ресурсів, що вимагає контролю (наприклад, мережі Інтернет), окремим довіреною користувальницьким процесам, залишаючи в той же час ці ресурси недоступними іншим процесам і навіть ядру операційної системи.
Пропонований підхід заснований на виконанні операційної системи (і керованих нею процесів) всередині апаратної віртуальної машини. Монітор віртуальних машин (гіпервізор) перехоплює системні виклики окремих довірених процесів і при необхідності передає їх на обслуговування сервісної машині. Сервісна машина може бути інший віртуальною машиною, виконується паралельно, або іншої фізичної машиною, з якою у гіпервізора є канал зв'язку.
Розглянутий підхід реалізовано на базі монітора віртуальних машин KVM. В якості сервісної машини використовувалася паралельно виконує віртуальна машина, а в якості контрольованих ресурсів було вибрані мережеві ресурси (у т.ч. ресурси Інтернету). Тестування продуктивності системи показало, що на реальних додатках накладні витрати на віддалене обслуговування системних викликів укладаються в межі 3 відсотків.
Література
1.Tanenbaum, A.S., Herder, J.N., Bos, H. Can We Make Operating Systems Reliable and Secure?. Computer 39, 5 (May 2006), pp. 44–51.
2.Burdonov, I., Kosachev, A., Iakovenko, P. Virtualization-based separation of privilege: working with sensitive data in untrusted environment. In Proceedings of the 1st Eurosys Workshop on Virtualization Technology for Dependable Systems, New York, NY, USA, 2009, ACM, pp. 1–6.
3.Яковенко П.М. Контроль доступу процесів до мережевих ресурсів на базі апаратної віртуалізації. Методи і засоби обробки інформації. Праці Третьої Всеросійської наукової конференції, М, 2009, стор 355–360.
4.Chen, X., Garfinkel, T., Lewis, E.C., Subrahmanyam, P., Waldspurger, C.A., Boneh, D., Dwoskin, J., Ports, D.R. Overshadow: a virtualization-based approach to retrofitting protection in commodity operating systems. In Proceedings of the 13th international Conference on Architectural Support For Programming Languages and Operating Systems, ACM, 2008, pp. 2–13.
5.Adams, K., Agesen, O. A comparison of software and hardware techniques for x86 virtualization. In Proceedings of the 12th international Conference on Architectural Support For Programming Languages and Operating Systems, ACM, 2006, pp. 2–13.
6.VirtualSquare: Remote System Call.
7.Sun Microsystems, Inc. RPC: Remote Procedure Call. Protocol Specification. Version 2. Network working group. RFC 1057. 1988.
8.Sun Microsystems, Inc. NFS: Network File System Protocol Specification. Network working group. RFC 1094. 1989.
9.Shah. A. Deep Virtue: Kernel-based virtualization with KVM. Linux Magazine (86), 2008, pp. 37–39.
|