Полтавський Військовий Інститут Зв’язку
Кафедра схемотехніки радіоелектронних систем
ЗАТВЕРДЖУЮ
Начальник кафедри № 3
полковник ____________О.І. Тиртишніков
“___” _______________2006 р.
ЛЕКЦІЯ
з навчальної дисципліни
ОБЧИСЛЮВАЛЬНА ТЕХНІКА ТА МІКРОПРОЦЕСОРИ
напрям підготовки 0924 «Телекомунікації»
Розділ № 2.
Мікропроцесорні системи.
Змістовий модуль № 7
Підвищення продуктивності
мікропроцесорних систем.
Тема № 10.
Підвищення продуктивності мікропроцесорних систем.
Заняття: № 1
.
Багатоядерні МП та багатопроцесорні МПС.
Лекція обговорена і схвалена на засіданні
предметно-методичної комісії
Протокол № ____ від ________
Полтава – 2006
Навчальна література.
1. Мікропроцесорна техніка: Підручник/ Ю.І. Якименко та інш. – К.: ІВЦ Політехніка; Кондор, 2004. с. 235-240.
2. Кравчук С.О., Шохін В.О. Основи комп’ютерної техніки: Компоненти, системи, мережі: Навч. Посіб. – К.: ІВЦ Політехніка; Каравела, 2005. с. 85-86, 287-290.
ВСТУП
Цілком зрозуміло, що постійне розширення та ускладнення кола задач, що вирішуються за допомогою засобів обчислювальної техніки – як універсальних, так і спеціалізованих – потребує постійного підвищення продуктивності (швидкодії) МП і МПС різноманітного призначення. До основних напрямків підвищення продуктивності МП та МПС можна віднести наступне:
1. Вдосконалення існуючих архітектур МП та МПС, сучасної елементної бази обчислювальної техніки.
2. Розробка принципово нових архітектур МП та МПС, що базуються на нетрадиційних методах організації обчислень та використанні нової елементної бази.
В даної лекції розглядаються методи та способи підвищення продуктивності МП та МПС, що можуть бути віднесені до першого напрямку. Загальні відомості про принципово нові архітектури МП та МПС, що базуються на нетрадиційних методах організації обчислень та використанні нової елементної бази, будуть розглянути на наступної лекції.
Вдосконалення сучасної кремній-напівпровідникової елементної бази обчислювальної техніки відбувається, головним чином, у напрямку зменшення розмірів базових транзисторних ключів, що надає можливість підвищення ступеню інтеграції мікросхем та підвищення тактової частоти вузлів МП та МПС.
1.
Основні напрями вдосконалення архітектури сучасних
обчислювальних систем
Для виділення напрямків розвитку існуючих архітектур МП та МПС, нагадаємо їх узагальнену класифікацію.
Узагальнена класифікація обчислювальних систем за архітектурними ознаками. базується на поняттях потоку команд – I
та потоку даних – D
в обчислювальній структурі. При цьому розрізняють: одинарний потік – S;
множинний потік - M
.
SISD
-- одинарний потік команд і одинарний потік даних
.
Управління здійснює одинарна послідовність команд, кожна з яких забезпечує виконання однієї операції і далі передає управління наступній команді.
MISD
-- множинний потік команд і одинарний потік даних.
Має також назву конвеєра обробки даних. Вона становить ланцюжок послідовно сполучених процесорів (мікропроцесорів), що управляються паралельним потоком команд. На вхід конвеєра з пам’яті подається одинарний потік даних.
SIMD -- одинарний потік команд і множинний потік даних
. Процесор таких машин має матричну структуру, в вузлах якої включена велика кількість порівняно простих швидкодіючих процесорних елементів. Одинарний потік команд виробляє один загальний пристрій управління. При цьому всі процесорні елементи виконують одночасно одну і ту ж команду, але над різними операндами, які доставляються з пам’яті множинним потоком.
МIMD
-- множинні потоки команд і даних
. До таких структур відносяться багатопроцесорні і багатомашинні обчислювальні системи. Гнучкість MIMD
структур дозволяє організувати сумісну роботу ЕОМ або процесорів за розпаралеленою програмою при рішенні одного складного завдання або роздільну роботу всіх ЕОМ при одночасному рішенні безлічі завдань поза незалежним програмам.
Як розглядалося раніше, гарвардська архітектура, порівняно з нейманівською, має більші потенціальні можливості з точки зору підвищення продуктивності, тому і стала базовою для побудови МП і МПС, що працюють у реальному масштабі часу – мікроконтролерів та процесорів цифрових сигналів. Але нейманівська, або класична, архітектура є більш гнучкою, тому універсальні МП та ПЕОМ будуються переважно на її основі.
Очевидно, що з точки зору узагальненої класифікації, і нейманівська, і гарвардська архітектури, що розглядалися у попередніх темах – це різновиди найпростішої SISD
- архітектури.
Неважко помітити, що всі інші, більш складні архітектури, так чи інакше, базуються на конвеєризації та розпаралелюванні
обчислень – як на рівні МП, та к і на рівні МПС. Це – основні напрями підвищення продуктивності всіх сучасних обчислювальних систем.
Крім конвеєризації та розпаралелювання обчислень, у сучасних МП та МПС застосовується ще велика кількість архітектурних (та технологічних) рішень, що сприяють підвищенню їх швидкодії:
1. Поступовий перехід від паралельних системних та зовнішніх інтерфейсів до послідовних
(наприклад, шини PCI
Express
та USB
у ПК). Як вже розглядалося раніше, це пов’язано с тим, що зі збільшенням тактової частоти порушується синхронізація сигналів, що передаються по окремим лініям паралельної шини.
2. Застосування
RISK
- ядра у універсальних МП.
Нагадаємо, що CISC-
архітектура (повна система команд -- Complicated Instruction Set Computer
) більш підходить для побудови універсальних МП, але RISC
-архітектура (скорочена система команд -- Reduced Instruction Set Computer
) забезпечує, у багатьох випадках, більшу швидкодію МП за рахунок можливості більш глибокої конвеєризації обчислень. Тому сучасні універсальні МП, залишаючись для користувача CISC
– процесорами, часто мають RISC
–ядро.
3. Інтеграція більшості контролерів периферійних та комунікаційних пристроїв безпосередньо у складі системних плат ПК
(аудіо, відео, мережеві контролері, модеми та ін.). Така інтеграція зменшує час проходження сигналів між окремими компонентами обчислювальної системи, що позитивно впливає на загальну швидкодію системи.
4. Збільшення розрядності МП
(внутрішньої та зовнішньої шин даних). Зрозуміло, що збільшення розрядності ШД, наприклад, з 32 до 64 розрядів, дозволяє передавати удвічі більший обсяг інформації за той самий інтервал часу.
5. Широке застосування багаторівневої кеш- пам’яті.
Збільшення ємності пам'яті МПС зумовлює зниження швидкодії операцій обміну інформацією між процесором та модулем пам'яті. Навіть за час звернення до пам'яті, що дорівнює 70 нс, неможливо отримати потрібну інформацію за один тактовий цикл шини. Це призводить до потреби виконання тактів очікування у процесі роботи процесора для того, щоб час звернення до пам'яті був узгоджений із часом виконання команди у процесорі. Підвищення швидкодії обміну інформацією можливе через реалізацію додаткової пам'яті порівняно невеликої ємності, звернення до якої відбувається на тактовій частоті процесора. Така пам'ять отримала назву кеш-пам 'яті
або буферної пам 'яті.
Кеш-пам'ять реалізується на основі ВІС ОЗП статичного типу. Інформаційна ємність та принцип організації кеш-пам'яті є одними з основних чинників, що визначають продуктивність роботи МПС.
Кеш-пам'ять використовують не тільки для обміну даними між МП і ОЗП, але й для обміну між ОЗП і зовнішніми накопичувачами. В основу роботи кеш-пам'яті покладено принципи часової і просторової локальностей програм.
Принцип часової локальності
полягає в тому, що під час зчитування будь-яких даних із пам'яті існує висока ймовірність звернення програми протягом деякого невеликого проміжку часу знову до них.
Принцип просторової локальності
ґрунтується на високій імовірності того, що програма через деякий невеликий проміжок часу звернеться до комірки пам'яті, наступної за тією, до якої вона зверталася перед цим.
Згідно з принципом часової локальності інформацію у кеш-пам'яті доцільно зберігати протягом деякого часу, а принцип просторової локальності вказує на доцільність розміщення у кеш-пам'яті вмісту декількох сусідніх комірок, тобто певного блоку інформації. Лінійні ділянки програм (без переходів) у більшості випадків не перевищують 3-5 команд, тому недоцільно використовувати блоки інформації, ємність яких перевищує ємність пам'яті, потрібну для зберігання 3-5 команд. Як правило, інформація з основної пам'яті завантажується у кеш-пам'ять блоками по 2-4слова і зберігається там деякий час.
Під час звернення процесора до пам'яті спочатку перевіряють наявність у кеш-пам'яті даних, які запитують, і якщо їх немає, здійснюють завантаження у кеш-пам'ять потрібної інформації. Правильна організація роботи кеш-пам'яті забезпечує підвищення швидкодії системи, оскільки у більшості випадків відбувається звернення процесора до кеш-пам'яті, а не до більш повільної основної оперативної пам'яті.
В сучасних МП кеш-пам'ять команд та даних розділені для попередження конфліктів при одночасної їх вибірки. Крім того, кеш-пам'ять будується за ієрархічним, багаторівневим принципом. Наприклад, МП Pentium
IV
і Xeon
кеш-пам'ять трьох рівнів.
Кеш-пам'ять першого рівня
L
1
називають також внутрішньою кеш-пам'яттю. Це найбільш швидкодіюча, але й найменша за ємністю кеш-пам'ять. Цю пам'ять розділено на два блоки: кеш-пам'ять даних і кеш-пам'ять команд (по 8... 16 кбайт).
Кеш-пам'ять команд
L
1,
названа в останніх моделях Pentium
IV
кеш-пам'яттю трасування виконання ETC
(
Execution
Trace
Cache
),
містить мікрокоманди, декодовані вузлом завантаження-дешифрування в блоці оброблення команд.
Кеш-пам 'ять даних
L
1
використовують для завантаження і зберігання всіх типів даних: цілих, із плаваючою точкою і мультимедійних. Звернення до цієї пам'яті виконується двічі протягом одного такту.
Якщо дані не знайдено в кеш-пам'яті L
1
, то виконується звернення до менш швидкодіючої, але більшої за ємністю (від 256 кбайт до 1 Мбайт) кеш-пам'яті другого рівня (
L
2).
Спочатку ця кеш-пам'ять розміщувалася на материнській платі, тому її інколи називають також зовнішньою кеш-пам'яттю. Кеш-пам'ять L
2
виконано у вигляді одного блоку. Кеш-пам'ять передає 32 байт протягом одного такту процесора і для процесора, тактова частота якого 3,4 ГГц; швидкість обміну досягає 108,8 Гбайт/с.
У свою чергу, якщо дані не знайдено в кеш-пам'яті L
2
, то за допомогою системної шини виконується звернення до оперативної пам'яті.
У блок кеш-пам'яті останніх моделей процесорів Pentium
IV
і Хеоп
між кеш-пам'яттю L
2
і системною шиною добавлено кеш-пам 'ять третього рівня
(
L
3)
.
Ця найменш швидкодіюча пам'ять має ємність від 512 кбайт до 2 Мбайт. Кеш-пам'ять L3
також виконано у вигляді одного блоку.
2. Конвеєризація обчислень та багатоядерні МП.
Конвеєрну (MISD)
архітектуру ЕОМ запропонував академік С.А. Лебедєв в 1956 році (рис.1).
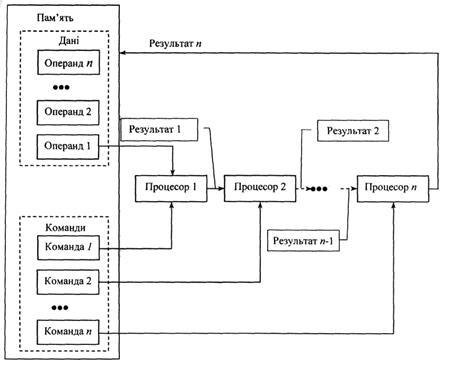
Рис. 1. Оброблення даних у обчислювальної системі конвеєрної (
MISD
) архітектури.
Ця структура реалізується у вигляді ланцюжка послідовно з'єднаних процесорів, тому інформація на виході одного процесора є вхідною інформацією для іншого процесора, тобто процесори утворюють процесорний конвеєр. В окремому потоці даних ланцюжка операнди з пам'яті спрямовуються на вхід конвеєра. Кожний процесор обробляє відповідну частину завдання, передаючи результати сусідньому процесору, що використовує їх як вихідні дані. Отже, розв'язання задач з деякими вихідними даними розгортається послідовно в конвеєрному ланцюжку. Це забезпечується підведенням до кожного процесора свого потоку команд, тобто формується множинний потік команд.
Як тільки конвеєр заповнюється, вихідний процесор видає результати для послідовності вхідних даних через дуже короткі інтервали часу, хоча дійсний час проходження команд через конвеєр може бути значно більшим (фактично це – паралельно-послідовний спосіб обчислень).
Слід зазначити, що розглянута схема (конвеєр з окремих процесорів, кожний з яких керується своїм потоком команд) характерна для так званих суперкомпьютерів
– багатопроцесорних обчислювальних систем надвеликої обчислювальної потужності.
Але конвеєрне оброблення команд на внутріпроцесорному рівні
реалізовано на всіх сучасних універсальних процесорах. Зрозуміло, що в цьому випадку обчислювальний конвеєр складається не з декількох МП, а з окремих функціональних вузлів (цифрових автоматів) того ж самого МП, кожний з яких виконує власну, спеціалізовану функцію.
Нагадаємо, що більшість сучасних універсальних МП є суперскалярними, тобто мають у своєму складі два обчислювальних конвеєра.
Крім того, останні моделі МП є двоядерними
, тобто мають у своєму складі два однакових процесорних ядра з загальною кеш- пам’яттю, що працюють з однаковою тактовою частотою.
3.
Багатопроцесорні МПС
Останнім часом набули поширення багатопроцесорні комп'ютери,
тобто комп'ютери, які містять кілька процесорів.
Функціонування багатопроцесорної системи потребує виконання таких умов:
- материнська плата має підтримувати кілька процесорів, тобто мати додаткові розніми для установлення процесорів і відповідний набір мікросхем;
- процесор має працювати в багатопроцесорній системі;
- операційна система має підтримувати декілька процесорів (такими операційними
системами є Windows NT/XP і Unix).
Багатопроцесорна система найбільш ефективна у випадках, коли вона використовується багатозадачними операційними системами і прикладними програмами, створеними за допомогою спеціальних засобів, що дозволяють виконувати паралельне оброблення даних.
У процесі одночасної роботи декількох процесорів операційна система розподіляє різні задачі між процесорами. Існують два режими роботи багатопроцесорних систем -- асиметричний і симетричний.
У режимі асиметричного оброблення
один процесор виконує тільки задачі операційної системи, а решта процесорів реалізовують прикладні програми.
У режимі симетричного мультиоброблення -- SMP (Symmetric Multi-Processing)
задачі операційної системи і прикладні задачі користувача може виконувати будь-який процесор залежно від його завантаження. Цей режим більш продуктивний і тому його використовують для більшості багатопроцесорних систем.
Сучасні універсальні МП можуть одночасно виконувати кілька команд. Оскільки звернення до оперативної пам'яті і пристроїв виконується значно повільніше, ніж команди, процесор може простоювати під час таких звернень. Однак усі сучасні операційні системи працюють у багатозадачному режимі, тому на процесор можна спрямовувати не один, а кілька потоків команд від різних розв'язуваних одночасно задач. Такий режим реалізовано в останніх процесорах Pentium IV, Xeon та Itanium фірми Intel
за допомогою гіперпотокової технології НТ (Hyper-Threading Technology).
Процесор, що підтримує цю технологію, виявляється для операційної системи як два віртуальні процесори і тому може обробляти два рівнобіжні потоки даних. У цьому разі, за оцінками фірми Intel,
продуктивність комп'ютера може підвищитися до 25 %. Реалізація гіперпотокової технології забезпечується не лише підтриманням цієї технології самим процесором, але й набором мікросхем і BIOS
материнської плати та операційною системою багатопроцесорного режиму роботи.
Поняття про с
уперкомп'ютери
С
уперкомп'ютери
зорієнтовано на досягнення надвисоких швидкостей оброблення інформації, підвищення надійності та живучості обчислювальних систем. Вони містять кілька десятків чи сотень порівняно простих (елементарних) процесорів.
Підвищення надійності, живучості та завадостійкості суперкомп'ютерів, а тепер і інших типів комп'ютерів, досягається введенням надлишкового устаткування і забезпеченням у разі відмов устаткування автоматичної реконфігурації системи для зберігання життєво важливих функцій (можливо ціною втрати другорядних).
Натепер існують дві структури побудови великих багатопроцесорних систем високої продуктивності: матрична структура (рис.2) і структура з конвеєрним обробленням команд (рис.1, була розглянута у попередньому навчальному питанні).
Комп'ютери, реалізовані з використанням матричної структури
, містять деяку кількість однакових порівняно простих швидкодіючих процесорів (трансп’ютерів
), з'єднаних між собою та пам'яттю так, що утворюється сітка (матриця), у вузлах якої розміщаються процесори. Система містить кілька потоків даних і один загальний потік команд, тобто всі процесори виконують одночасно одну й ту саму команду (допускається пропуск команд в окремих процесорах), але з різними операндами, що доставляються процесорам з пам'яті декількома потоками даних (SIMD –
архітектура).
Основні принципи побудови завадостійких комп'ютерів такі:
—багато однотипних пристроїв
(система має містити декілька примірників однотипних пристроїв: процесорів, модулів оперативної пам'яті, контролерів і т. ін.);
—загальні поля
процесорів, оперативної пам'яті, каналів (шин) і периферійних пристроїв;
—динамічний розподіл функцій
між однотипними пристроями (заздалегідь не відомо, який з однотипних пристроїв буде виконувати цю функцію і, більше того, роботу можна почати на одному, продовжувати на другому і закінчувати на третьому пристрої);
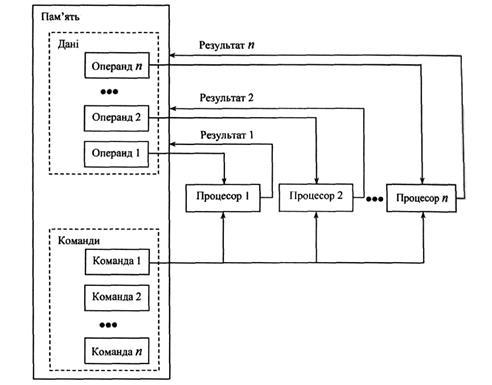
Рис. 2. Оброблення даних у обчислювальної системі матричної (
SIMD
) архітектури.
—автоматичний контроль правильності виконання операцій
(усі операції, наприкладобчислення в процесорі, виконуються на двох чи декількох пристроях і в разі розбіжності результатів операція повторюється і (чи) викликається програма автоматичної діагностики);
—динамічна реконфігурація
(можливість замінювати устаткування чи модулі програмного забезпечення, що відмовили, без перерви в роботі справної частини устаткування і програмного забезпечення).
Наявність загальних полів пристроїв і динамічного розподілу функцій дозволяє комплексу зберігати працездатність доти, доки залишається хоча б один справний пристрій кожного типу.
Суперкомп'ютери використовуються для розв'язання особливо складних науково-технічних задач, оброблення великих обсягів даних у реальному масштабі часу, моделювання складних систем, автоматизованого проектування складних об'єктів, а також у системах керування (промислових і військових).
Макет найпотужнішого суперкомп'ютера ES (Earth Simulator)
Центра моделювання Землі (Earth Simulator Center)
у Йокогамі (Японія) показаний рис. 3.
Цей суперкомп'ютер містить такі основні компоненти:
- 640 процесорних вузлів (PN -- Processor Node),
кожний з яких містить 8 суперскалярних процесорів NEC
, частота яких 500 МГц. Процесор містить векторний блок з 72 векторних регістрів (кожний з регістрів має 256 векторних елементів) і використовується для виконання конвеєрних операцій для чисел із плаваючою комою;
- систему дискової пам'яті загальною ємністю 250 000 Гбайт (250 Тбайт) (до кожного процесорного вузла підключено 16 Гбайт розподіленої дискової пам'яті);
- 64 вузли мережі зв'язку (IN -
- Interconnection Node)
між процесорами зі швидкістю обміну 12,3 Гбайт/с;
- архівну бібліотеку стрічкових картриджів (CTL -
- Cartridge Type Library)
загальною ємністю 1,5 Пбайт (1 500 Тбайт).
Швидкість оброблення даних під час тестування протягом 6 год - 35,6 1012
операцій/с.
Суперкомп'ютер ES
використовують для моделювання глобальних і регіональних процесів в атмосфері, океанах та земній корі (зокрема, для моделювання землетрусів).
ВИСНОВОК
До основних напрямків підвищення продуктивності МП та МПС можна віднести наступне:
1. Вдосконалення існуючих архітектур МП та МПС, сучасної елементної бази обчислювальної техніки.
2. Розробка принципово нових архітектур МП та МПС, що базуються на нетрадиційних методах організації обчислень та використанні нової елементної бази.
Основними напрямками підвищення продуктивності сучасних обчислювальних систем є конвеєризації та розпаралелюванні обчислень – як на рівні МП, та к і на рівні МПС.
Крім конвеєризації та розпаралелювання обчислень, у сучасних МП та МПС застосовується ще велика кількість архітектурних (та технологічних) рішень, що сприяють підвищенню їх швидкодії:
1. Поступовий перехід від паралельних системних та зовнішніх інтерфейсів до послідовних.
2. Застосування RISK- ядра у універсальних МП.
3. Інтеграція більшості контролерів периферійних та комунікаційних пристроїв безпосередньо у складі системних плат ПК.
4. Збільшення розрядності МП.
5. Широке застосування багаторівневої кеш-пам’яті.
В дійсний час існують дві основні структури побудови великих багатопроцесорних систем високої продуктивності: матрична структура і структура з конвеєрним обробленням команд.
|