Министерство Образования Республики Таджикистан
Таджикский Технический Университет
имени М.С. Осими
Кафедра «АСОИиУ»
Лабораторная работа №1
На тему:Моделирование датчиков случайных чисел с заданным законом распределения
Выполнила:
ст-т. 3-го курса гр. 2202 Б2
Принял: преподаватель кафедры
Ли И.Р.
Душанбе-2010
Лабораторная работа № 2
Моделирование датчиков случайных чисел с заданным законом распределения
I
Цель работы
Целью работы является:
1.
Практическое освоение методов моделирования случайных чисел с заданным законом распределения
2.
Разработка и моделирование на ПЭВМ датчика случайных чисел с конкретным законом распределения
3.
Проверка адекватности полученного датчика
II
Теоретические сведения
1. Основные методы моделирования случайных последовательностей с заданным законом распределения
При исследовании и моделировании различных сложных систем в условиях действия помех возникает необходимость в использовании датчиков случайных чисел с заданным законом распределения. Исходным материалом для этого является последовательность x
1,
x
2….
xn
с равномерным законом распределения в интервале [0,1]
. Обозначим случайную величину, распределенную равномерно через ζ(кси).
Тогда равномерно-распределенные случайные числа будут представлять собой независимые реализации случайной величины ζ, которые можно получить с помощью стандартной функции RND
(ζ)– программно реализованной на ПЭВМ в виде генератора случайных чисел с равномерным законом распределения в интервале [0,1]
. Требуется получить последовательность y
1,
y
2,..
yn
независимых реализаций случайной величины η, распределенных по заданному закону распределения. При этом закон распределения непрерывной случайной величины может быть задан интегральной функцией распределения:
F
(
y
)=
P
(
ksi y
) (1) y
) (1)
или плотностью вероятности
f
(
y
)=
F
’(
y
) (2)
Функцииf
(
y
)
и F
(
y
)
могут быть заданы графически или аналитически.
Для получения случайной величины η с функцией распределения F
(
y
)
из случайной величины ζ, равномерно-распределенной в интервале [0,1]
, используются различные методы. К основным методам моделирования случайных чисел с заданным законом распределения относятся:
- метод обратной функции
- метод отбора или исключения
- метод композиции.
2. Метод обратной функции
Если ζ- равномерно-распределенная на интервале [0,1]
случайная величина, то искомая случайная величина может быть получена с помощью преобразования:
η=F-1
(
ζ) (3)
Где F-1
(
ζ)
-
обратная функция по отношению к функции распределения F(
ζ)
 F
(
y
) F
(
y
)
   1 1
  ζ ζ
 0 η
y 0 η
y
Рис 1 Функция распределения
F
(ζ)
Действительно, при таком определении случайной величины η имеем:
P
(η
y
)=
P
{
F
-1
(ζ)
y
}=
P
{ ζ
F
(
y
) }=
F
(
y
) (4)
В данной цепочке равенств первое равенство следует из (3)
, второе из неубывающего характера функций F(
ζ)
и F-1
(
ζ)
и третье из равномерного в интервале [0,1]
распределения величин ζ.
Таким образом, если задана функция распределения F(
y
)
, то для получения случайной последовательности с таким распределением необходимо найти ее обратную функцию.
Для нахождения обратной функции можно использовать два метода: аналитический
и графический
.
3.Метод отбора или исключения
Данный метод удобнее использовать, если требуемый закон распределения задан плотностью вероятности f
(
y
).
В отличии от метода обратной функции метод отбора или исключения для получения одного требуемого случайного числа требует не одного равномерно- распределенного случайного числа, а двух, четырех, шести или более случайных чисел. В этом случае область возможных значений η
представляет конечный отрезок (
a
,
b
),
а плотность вероятности f
(
y
) ограничена сверху значением fmax
(Рис.7).
Тогда область значений η*
и ζ*
можно ограничить ступенчатой кривой:
 0,
если
y<a 0,
если
y<a
g(y)= fmax,
если
a y b (25)
0, если
y
>
b
Затем берутся с помощью генератора случайных чисел (
RND
(ζ))
два равномерно-распределенных числа ζ1 и
ζ2
, по которым определяются равномерные на интервале [
a
,
b
]
независимые величины:
η
’
=a + (b-a)*
ζ
1
ζ
’=fmax*
ζ
2
(26)
Где a
,
b
– границы возможных значений случайной величины η
,
fmax
- максимальное значение функции f
(
y
)
(Рис.7)
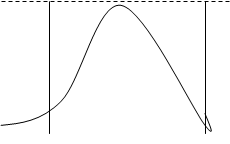
 f(y) f(y)
  g(y) g(y)
fmax
f(y)
ζ
 
 a
η
’
b a
η
’
b
Рис.7 Заданная плотность вероятности
Если ζ’
f
(η
’)
, то η
’
принимается в качестве очередной реализации случайной величиныη
. В противном случае η
’
отбрасывается и берется следующая пара равномерно- распределенных случайных чисел ζ1
и ζ2
. Такая процедура повторяется до тех пор, пока мы не получим требуемого количества случайных чисел с заданной плотностью вероятности.
4.
Метод композиции
Метод композиции основывается на представлении плотности вероятности fη (
x
)
по формуле полной вероятности:
f
η (
x
)= (27) (27)
Где H
(
z
)=
P
(ζ
z
)–
интегральная функция распределения случайной величины ζ
;
P(x
/
z
)- условная плотность вероятности.
Переходя к дискретной форме, интеграл заменяется на сумму и тогда получаем
f
η
(x
)=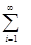 Pj
*fj
(x
) (28) Pj
*fj
(x
) (28)
где Pj
=1(29)
fj
(
x
) -условная плотность вероятности
Таким образом, для любой заданной плотности вероятности ее фигура единичной площади, ограниченной осью x
и кривой f
η
(x), разбивается на произвольное число простых не пересекающихся частей gj
(
i
=1,
k
),
с площадями Pj
(
j
=1,
k
), (Рис.8)
Рис.8Разбивка плотности вероятности на отдельном участке
 f
η
(x) f
η
(x)
  g1
(Р1
) g1
(Р1
)
g2
(Р2
)
g3
(Р3
)
 x x
g1
(Р1
)

 x x
Рис. 9 Условные плотности
вероятности
g2
(Р2
)
 x x
g3
(Р3
)
x
Условные плотности вероятности имеют вид (Рис.9)
Для полученных условных плотностей вероятности одним из предыдущих методов определяются случайные последовательности, которые в сумме дадут требуемую случайную последовательность с заданной плотностью вероятности.
5. Оценка закона распределения
Для полученной случайной последовательности y
1,
y
2,…
,
yn
с заданным законом распределения необходимо провести оценку соответствия заданного закона распределения, который реализует смоделированный датчик случайных чисел. Поэтому для последовательности y
1,
y
2,…
,
yn
строится статистическая функция распределения
F
* (
y
)
(Рис. 10).
На этом же графике строится интегральная функция распределения F
(
y
)
для заданного закона распределения и производится сопоставление F
*(
y
)
и F
(
y
).
Согласие закона проверяется по критерию Колмогорова
. Для этого вычисляется статистика:
Ди=
max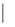 F
*(
y
)
- F
(
y
) F
*(
y
)
- F
(
y
) (30)
(30)
Для конечных решений и распределения статистики Ди получены пороговые значения в форме таблиц (Таблица 1.).
По этой таблице для заданных объемов последовательности и
и значению статистики Ди
определяется уровень значимости 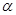 . .
Если гипотеза верна то статистика Ди*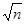 имеет в пределе при n
имеет в пределе при n  распределение Колмогорова
и квантили уровня P
= (1-2)
близки к 1. Это значит, что полученный генератор случайных чисел вырабатывает последовательность с заданным законом распределения. Если значения статистики Ди
не попадают в пороговые значения, то такой генератор не годится для пользования.
распределение Колмогорова
и квантили уровня P
= (1-2)
близки к 1. Это значит, что полученный генератор случайных чисел вырабатывает последовательность с заданным законом распределения. Если значения статистики Ди
не попадают в пороговые значения, то такой генератор не годится для пользования.
 F(y) F(y)
 F(y) 1 F(y) 1

   F*(y) F*(y)
 
0.5 Dn
{
 y y
y1
y2
y3
y4
…….yn-1
yn
Рис.10Оценка распределения
III
Содержание исследования
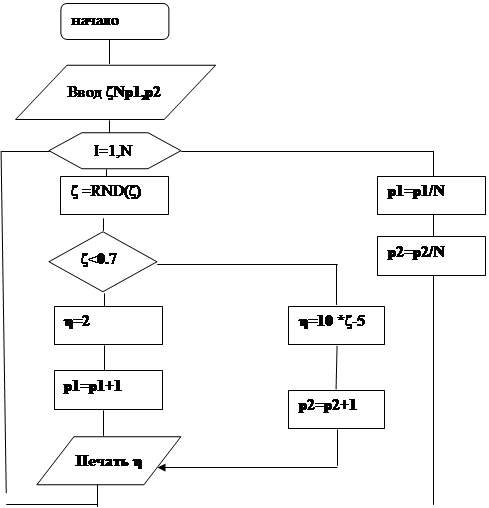
Исследование, проводимое в данной работе, заключается в получении программного датчика случайных чисел, пригодного для моделирования случайной последовательности с заданным законом распределения. При этом необходимо разработать алгоритм и программу датчика, а затем исследовать свойства выработанной им последовательности. При проведении исследований необходимо:
1
.По двадцати числам (n
=20
) выведенным на печать построить статистическую функцию распределения F
*(
y
)(рис.10)
На этом же графике построить интегральную функцию распределения F
(
y
)
для заданного преподавателем закона распределения. Сопоставив значения F
*(
y
)и F
(
y
), вычислить статистику Ди (30).
2.
Составить блок- схему и программу для ПЭВМ
, в которой следует предусмотреть построение статистического ряда и вычисление статистики Ди
по критерию Колмогорова.
3
.По таблице пороговых значений статистики Ди
произвести оценку распределения.
4.
Для полученной последовательности произвести оценку математического ожидания, дисперсии, среднеквадратического отклонения.
Блок- схема генератора
 Интерфейс программы: Интерфейс программы:
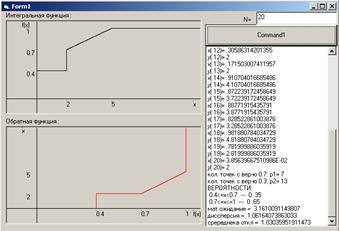
Листинг
программы
:
Private Sub Command1_Click()
Dim n As Integer
Dim p1, p2 As Integer
Dim Y() As Variant, X As Double
p1 = 0: p2 = 0: m = 0: d = 0
List1.Clear
Randomize
X = 0.5
n = Val(Text1.Text)
ReDim Y(n) As Variant
For i = 1 To n
X = Rnd(X)
List1.AddItem ("x(" + Str(i) + ")=" + Str(X))
If X < 0.7 Then
p1 = p1 + 1
Y(i) = 2
m = m + Y(i)
List1.AddItem ("y(" + Str(i) + ")=" + Str(Y(i)))
Else
p2 = p2 + 1
Y(i) = 10 * X - 5
m = m + Y(i)
List1.AddItem ("y(" + Str(i) + ")=" + Str(Y(i)))
End If
Next i
List1.AddItem ("кол. точек с вер-ю 0.7: p1=" + Str(p1))
List1.AddItem ("кол. точек с вер-ю 0.3: p2=" + Str(p2))
List1.AddItem ("ВЕРОЯТНОСТИ:")
List1.AddItem (" 0.4<=x<0.7 --- 0" + Str(p1 / n))
List1.AddItem (" 0.7<=x<=1 --- 0" + Str(p2 / n))
m = m / n
List1.AddItem ("мат ожидание = " + Str(m))
For i = 1 To n
d = d + (Y(i) - m) ^ 2
Next i
d = d / (n - 1)
b = Sqr(d)
List1.AddItem ("диссперсия = " + Str(d))
List1.AddItem ("сререднекв откл = " + Str(b))
'построение интегральной функции
Picture1.Scale (-2, 11)-(11, -2)
Picture1.Line (0, -2)-(0, 11)
Picture1.Line (-2, 0)-(11, 0)
Picture1.PSet (-1, 11)
Picture1.Print ("f(x)")
Picture1.PSet (10.5, -0.3)
Picture1.Print ("x")
Picture1.PSet (-0.7, 4)
Picture1.Print ("0.4")
Picture1.PSet (-0.7, 7)
Picture1.Print ("0.7")
Picture1.PSet (-0.7, 10)
Picture1.Print ("1")
Picture1.PSet (2, -0.3)
Picture1.Print ("2")
Picture1.PSet (5, -0.3)
Picture1.Print ("5")
For i = 0 To 11 Step 0.001
If i < 2 Then
l = 4
Else
If i < 5 Then
l = (0.1 * i + 0.5) * 10
Else
l = 10
End If
End If
Picture1.PSet (i, l)
Next i
Picture1.Line (2, 4)-(2, 7)
'построение обратной функции
Picture2.Scale (-2, 11)-(11, -2)
Picture2.Line (0, -2)-(0, 11)
Picture2.Line (-2, 0)-(11, 0)
Picture2.PSet (-1, 11)
Picture2.Print ("x")
Picture2.PSet (10.5, -0.3)
Picture2.Print ("f(x)")
Picture2.PSet (-0.7, 2)
Picture2.Print ("2")
Picture2.PSet (-0.7, 5)
Picture2.Print ("5")
Picture2.PSet (4, -0.3)
Picture2.Print ("0.4")
Picture2.PSet (7, -0.3)
Picture2.Print ("0.7")
Picture2.PSet (10, -0.3)
Picture2.Print ("1")
For i = 4 To 10 Step 0.001
If i < 7 Then
l = 2
Else
l = i - 5
End If
Picture2.PSet (i, l), vbRed
Next i
Picture2.Line (4, 0)-(4, 2), vbRed
Picture2.Line (10, 5)-(10, 11), vbRed
End Sub
|