АВТОНОМНАЯ НЕКОМЕРЧЕСКАЯ ОРГАНИЗАЦИЯ
ЕВРАЗИЙСКИЙ ОТКРЫТЫЙ ИНСТИТУТ
Коломенский филиал
НАУЧНО-ИССЛЕДОВАТЕЛЬСКАЯ РАБОТА
Обобщение моделей данных в создании ИС
Выполнили:
Студентки 4 курса группы 41-П
Хромова Валентина Сергеевна
ИНС № 0021-02014
Литвиненко Мария Николаевна
ИНС № 0021-01931
г. Коломна, 2009 год
ОГЛАВЛЕНИЕ
Введение
Глава I. Классические модели данных
1.1 Иерархическая модель данных
1.2 Сетевая модель данных
1.3 Реляционная модель данных
Глава II. Неклассические модели данных
2.1 Постреляционная модель данных
2.2 Многомерная модель данных
2.3 Объектно-ориентированная модель данных
Глава III. Сравнение классических моделей данных
3.1 Достоинства и недостатки реляционной модели
3.3 Достоинства и недостатки сетевой модели
3.2 Достоинства и недостатки иерархической модели
ЗаключениеСписок использованной литературы
Приложение
Введение
Современная жизнь немыслима без эффективного управления. Важной категорией являются системы обработки информации, от которых во многом зависит эффективность работы любого предприятия или учреждения. Такая система должна:
- обеспечивать получение общих и/или детализированных отчетов по
итогам работы;
- позволять легко определять тенденции изменения важнейших
показателей;
- обеспечивать получение информации, критической по времени, без
существенных задержек;
- выполнять точный и полный анализ данных.
Современные системы управления базами данных (СУБД) в основном являются приложениями Windows, так как данная среда позволяет более полно использовать возможности персональной ЭВМ, нежели среда DOS. Снижение стоимости высокопроизводительных ПК обусловил не только широкий переход к среде Windows, где разработчик программного обеспечения может в меньшей степени заботиться о распределении ресурсов, но также сделал программное обеспечение ПК в целом и СУБД в частности менее критичными к аппаратным ресурсам ЭВМ. Среди наиболее ярких представителей систем управления базами данных можно отметить: LotusApproach, MicrosoftAccess, BorlanddBase, BorlandParadox, MicrosoftVisualFoxPro, MicrosoftVisualBasic, а также баз данных Microsoft SQL Server и Oracle, используемые в приложениях, построенных по технологии «клиент-сервер». Фактически, у любой современной СУБД существует аналог, выпускаемый другой компанией, имеющий аналогичную область применения и возможности, любое приложение способно работать со многими форматами представления данных, осуществлять экспорт и импорт данных благодаря наличию большого числа конвертеров. Общепринятыми, также, являются технологии, позволяющие использовать возможности других приложений, например, текстовых процессоров, пакетов построения графиков и т.п., и встроенные версии языков высокого уровня (чаще – диалекты SQL и/или VBA) и средства визуального программирования интерфейсов разрабатываемых приложений. Поэтому уже не имеет существенного значения на каком языке и на основе какого пакета написано конкретное приложение, и какой формат данных в нем используется. Более того, стандартом «де-факто» стала «быстрая разработка приложений» или RAD (от английского Rapid Application Development), основанная на широко декларируемом в литературе «открытом подходе», то есть необходимость и возможность использования различных прикладных программ и технологий для разработки более гибких и мощных систем обработки данных. Поэтому в одном ряду с «классическими» СУБД все чаще упоминаются языки программирования Visual Basic 4.0 и Visual C++, которые позволяют быстро создавать необходимые компоненты приложений, критичные по скорости работы, которые трудно, а иногда невозможно разработать средствами «классических» СУБД. Современный подход к управлению базами данных подразумевает также широкое использование технологии «клиент-сервер».
Таким образом, на сегодняшний день разработчик не связан рамками какого-либо конкретного пакета, а в зависимости от поставленной задачи может использовать самые разные приложения. Поэтому, более важным представляется общее направление развития СУБД и других средств разработки приложений в настоящее время.
Актуальность темы
определяется тем, что цель любой информационной системы – обработка данных об объектах реального мира. Основные идеи современной информационной технологии базируются на концепции баз данных.
Хранимые в базе данные имеют определенную логическую структуру - иными словами, описываются некоторой моделью представления данных (моделью данных), поддерживаемой СУБД.
Объектом исследования
являются следующие классических модели данных.
1. Иерархическая;
2. Сетевая;
3. Реляционная;
Кроме того, в последние годы появились и стали более активно внедряться на практике следующие модели данных:
1. постреляционная;
2. многомерная;
3. объектно-ориентированная.
Разрабатываются также всевозможные системы, основанные на других моделях данных, расширяющих известные модели. B их числе можно назвать объектно-реляционные, дедуктивно-объектно-ориентированные, семантические, концептуальные и ориентированные модели. Некоторые из этих моделей служат для интеграции баз данных, баз знаний и языков программирования.
B некоторых СУБД поддерживаются одновременно несколько моделей данных. Например, в системе ИНТЕРБАЗА для приложений применяется сетевой язык манипулирования данными, а в пользовательском интерфейсе реализованы языки SQL и QBE.
Цель работы
- описать структуру каждой модели данных, недостатки и достоинства, привести примеры использования в практике каждой модели.
Задачи исследования:
1.
Изучить иерархическую модель данных;
2.
Изучить сетевую модель данных;
3.
Изучить реляционную модель данных;
4.
Изучить постреляционную модель данных;
5.
Изучить многомерную модель данных;
6.
Изучить объектно-ориентированную модель данных;
7.
Сравнить классические модели данных.
Теоретическая основа исследования –
структуры моделей, представление связей, недостатки и достоинства, каждой модели. Использованы работы авторов: А.И. Мишенин, И.Г. Семакин, Е.К. Хеннер, Г.Н. Смирнова, А.А. Сорокин, Ю.Ф. Тельнов, А.Д. Хомоненко, В.М. Цыганков, М.Г. Мальцев
Глава
I
. Классические модели данных
1.1 Иерархическая модель данных
В иерархической модели связи между данными можно описать с помощью упорядоченного графа (или дерева). Упрощенно представление связей между данными в иерархической модели показано на рис.1. (см. Приложение рис.1.) Для описания структуры (схемы) иерархической БД на некотором языке программирования используется тип данных «дерево». Тип «дерево» схож с типами данных «структура» языков программирования ПЛ/1 и C и «запись» языка Паскаль. В них допускается вложенность типов, каждый из которых находится на некотором уровне. Тип «дерево» является составным. Он включает в себя подтипы («поддеревья»), каждый из которых, в свою очередь, является типом «дерево». Каждый из типов «дерево» состоит из одного «корневого» типа и упорядоченного набора (возможно, пустого) подчиненных типов. Каждый из элементарных типов, включённых в тип «дерево», является простым или составным типом «запись». Простая «запись» состоит из одного типа, например числового, а составная «запись» объединяет некоторую совокупность типов, например, целое, строку символов и указатель (ссылку). Пример типа «дерево» как совокупности типов показан на рис.2. (см. Приложение рис.2.)
Корневым
называется тип, который имеет подчиненные типы и сам не является подтипом. Подчинённый
тип (подтип) является потомком
по отношению к типу, который выступает для него в роли предка (родителя). Потомки одного и того же типа являются близнецами
по отношению друг к другу.
B целом тип «дерево» представляет собой иерархически организованный набор типов «запись».
Иерархическая БД, представляет собой упорядоченную совокупность экземпляров данных типа «дерево» (деревьев), содержащих экземпляры типа «запись» (записи). Часто отношения родства между типами переносят на отношения между самими записями. Поля записей хранят собственно числовые или символьные значения, составляющие основное содержание БД. Обход всех элементов иерархической БД обычно производится сверху вниз и слева направо.
В иерархических СУБД может использоваться терминология, отличающаяся от приведенной. Так, в системе IMS понятию «запись» соответствует термин «сегмент», а под «записью БД» понимается вся совокупность записей, относящаяся к одному экземпляру типа «дерево».
Данные в базе с приведенной схемой (рис.2.) могут выглядеть, например, как показано на рис.3. (см. Приложение рис. 3.)
Для организации физического
размещения иерархических данных в памяти ЭВМ могут использоваться следующие группы методов:
1. представление линейным списком с последовательным распределением памяти (адресная арифметика, левосписковые структуры);
2. представление связными линейными списками (методы, использующие указатели и справочники).
К основным операциям манипулирования иерархически организованными данными относятся следующие:
1. поиск указанного экземпляра БД;
2. переход от одного дерева к другому;
3. переход от одной записи к другой внутри;
4. вставка новой записи в указанную позицию;
5. удаление текущей записи и т. д.
B соответствии с определением типа «дерево», можно заключить, что между предками и потомками автоматически поддерживается контроль целостности связей. Основное правило контроля целостности формулируется следующим образом: потомок не может существовать без родителя, а у некоторых родителей может не быть потомков. Механизмы поддержания целостности связей между записями различных деревьев отсутствуют.
K достоинствам иерархической модели данных
относятся эффективное использование памяти ЭВМ и неплохие показатели времени выполнения основных операций над данными. Иерархическая модель данных удобна для работы с иерархически упорядоченной информацией. Недостатком иерархической модели
является ее громоздкость для обработки информации с достаточно сложными логическими связями, а также сложность понимания для обычного пользователя. На иерархической модели данных основано сравнительно ограниченное количество СУБД, в числе которых можно назвать зарубежные системы IMS, PC/Focus, Теаm-Up и Data Еdgе, а также отечественные системы Ока, ИНЭС и МИРИС.
1.2 Сетевая модель данных
Сетевая модель данных позволяет отображать разнообразные взаимосвязи элементов данных в виде произвольного графа, обобщая тем самым иерархическую модель данных (рис. 4.). Наиболее полно концепция сетевых БД впервые была изложена в Предложениях группы КОДАСИЛ (KODASYL). (см. Приложение рис.4.) Для описания схемы сетевой БД используется две группы типов: «запись» и «связь». Тип «связь» определяется для двух типов «запись»: предка и потомка. Переменная типа «связь» являются экземплярами связей. Сетевая БД состоит из набора записей и набора соответствующих связей. На формирование связи особых ограничений не накладывается. Если в иерархических структурах запись-потомок могла иметь только одну запись-предка, то в сетевой модели данных запись-потомок может иметь произвольное число записей-предков (сводных родителей). Пример схемы простейшей сетевой БД показан на рис.5. Типы связей здесь обозначены надписями на соединяющих типы записей линиях. (см. Приложение рис.5.) B различных СУБД сетевого типа для обозначения одинаковых по сути понятий зачастую используются различные термины. Например, такие как элементы и агрегаты данных, записи, наборы, области и т. д.
Физическое размещение данных в базах сетевого типа может быть организовано практически теми же методами, что и в иерархических базах данных.
K числу важнейших операций манипулирования данными баз сетевого типа можно отнести следующие:
· поиск записи в БД;
· переход от предка к первому потомку;
· переход от потомка к предку;
· создание новой записи;
· удаление текущей записи;
· обновление текущей записи;
· включение записи в связь;
· исключение записи из связи;
· изменение связей и т. д.
Достоинством сетевой модели данных является возможность эффективной реализации по показателям затрат памяти и оперативности. B сравнении с иерархической моделью сетевая модель предоставляет большие возможности в смысле допустимости образования произвольных связей.
Недостатком сетевой модели данных
является высокая сложность и жесткость схемы БД, построенной на ее основе, а также сложность для понимания и выполнения обработки информации в БД обычным пользователем. Кроме того, в сетевой модели данных ослаблен контроль целостности связей вследствие допустимости установления произвольных связен между записями.
Системы на основе сетевой модели не получили широкого распространения на практике. Наиболее известными сетевыми СУБД являются следующие: IDMS, db_VistaIII, СЕТЬ, СЕТОР и КОМПАС.
1.3 Реляционная модель данных
Реляционная модель данных предложена сотрудником фирмы IBM Эдгаром Коддом и основывается на понятии отношение (relation).
Отношение представляет собой множество элементов, называемых кортежами. Подробно теоретическая основа реляционной модели данных рассматривается на следующем разделе. Наглядной формой представления отношения является привычная для человеческого восприятия двумерная таблица.
Таблица имеет строки (записи) и столбцы (колонки). Каждая строка таблицы имеет одинаковую структуру и состоит из полей. Строкам таблицы соответствуют кортежи, а столбцам - атрибуты отношения.
C помощью одной таблицы удобно описывать простейший вид связей между данными, а именно деление одного объекта (явления, сущности, системы и проч.), информация о котором хранится в таблице, на множество подобъектов, каждому из которых соответствует строка или запись таблицы. При этом каждый из подобъектов имеет одинаковую структуру или свойства, описываемые соответствующими значениями полей записей. Например, таблица может содержать сведения о группе обучаемых, о каждом из которых известны следующие характеристики: фамилия, имя и отчество, пол, возраст и образование. Поскольку в рамках одной таблицы не удается описать более сложные логические структуры данных из предметной области, применяют связывание таблиц.
Физическое размещение данных в реляционных базах на внешних носителях легко осуществляется с помощью обычных файлов.
Достоинство реляционной модели данных
заключается в простоте, понятности и удобстве физической реализации на ЭВМ. Именно простота и понятность для пользователя явились основной причиной их широкого использования. Проблемы же эффективности обработки данных этого типа оказались технически вполне разрешимыми.
Основными недостатками реляционной модели
являются следующие: отсутствие стандартных средств идентификации отдельных записей и сложность описания иерархических и сетевых связей.
Примерами зарубежных реляционных СУБД для ПЭВМ являются следующие: DBaseIII Plus и dBase IY (фирма Ashton-Tate), DB2 (IBM), R:BASE (Microrim), FoxFro ранних версий и EoxBase (Fox Software), Раrаdох и dBASE for Windows (Borland), FoxFro более поздних версий, Visual FoxFro и Access (Microsoft), Clarion (Clarion Software), Ingres (ASK Computer Systems) и Oracle (Oracle).
К отечественным СУБД реляционного типа относятся системы: ПАЛЬМА (ИК АН УССР), а также система HyTech (МИФИ).
Заметим, что последние версии реляционных СУБД имеют некоторые свойства объектно-ориентированных систем. Такие СУБД часто называют объектно-реляционными. Примером такой системы можно считать продукты Oracle 8.х. Системы предыдущих версий вплоть до Oracle 7.х считаются «чисто» реляционными.
Глава
II
. Неклассические модели данных
2.1 Постреляционная модель данных
Классическая реляционная модель предполагает неделимость данных, хранящихся в полях записей таблиц. Это означает, что информация в таблице представляется в первой нормальной форме. Существует ряд случаен, когда это ограничение мешает эффективной реализации приложений.
Постреляционная модель
данных представляет собой расширенную реляционную модель, снимающую ограничение неделимости данных, хранящихся в записях таблиц. Постреляционная модель данных допускает многозначные поля - поля, значения которых состоят из подзначений. Набор значений многозначных полей считается самостоятельной таблицей, встроенной в основную таблицу.
На рис.6 на примере информации о накладных и товарах для сравнения приведено представление одних и тех же данных с помощью реляционной (а) и постреляционной (б) моделей. Таблица INVOICES (накладные) содержит данные о номерах накладных (INVNO) и номерах покупателей (CUSTNO). В таблице INVOICE.ITEMS (накладные-товары) содержатся данные о каждой из накладных: номер накладной (INVNO), название товара (GOODS) и количество товара (QTY). Таблица INVOICES связана с таблицей INVOICE.ITEMS по полю INVNO.(см. Приложение рис.6.)
Как видно из рисунка, по сравнению с реляционной моделью в постреляционной модели данные хранятся более эффективно, а при обработке не требуется выполнять операцию соединения данных из двух таблиц. Для доказательства на рис.7 приводятся примеры операторов SELECT выбора данных из всех полей базы на языке SQL для реляционной (а) и постреляционной (б) моделей. (см. Приложение рис.7.)
Помимо обеспечения вложенности полей постреляционная модель поддерживает ассоциированные многозначные поля (множественные группы). Совокупность ассоциированных полей называется ассоциацией
. При этом в строке первое значение одного столбца ассоциации соответствует первым значениям всех других столбцов ассоциации. Аналогичным образом связаны все вторые значения столбцов и т. д.
На длину полей и количество полей в записях таблицы не накладывается требование постоянства. Это означает, что структура данных и таблиц имеет большую гибкость.
Поскольку постреляционная модель допускает хранение в таблицах ненормализованных данных, возникает проблема обеспечения целостности и непротиворечивости данных. Эта проблема решается включением в СУБД механизмов, подобных хранимым процедурам в клиент-серверных системах.
Для описания функций контроля значений в полях имеется возможность создавать процедуры (коды конверсии и коды корреляции), автоматически вызываемые до или после обращения к данным. Коды корреляции выполняются сразу после чтения данных, перед их обработкой. Коды конверсии, наоборот, выполняются после обработки данных. Достоинством
постреляционной модели является возможность представления совокупности связанных реляционных таблиц одной постреляционной таблицей. Это обеспечивает высокую наглядность представления информации и повышение эффективности ее обработки. Недостатком
постреляционной модели является сложность решения проблемы обеспечения целостности и непротиворечивости хранимых данных. Рассмотренная нами постреляционная модель данных поддерживается СУБД uniVers. К числу других СУБД, основанных на постреляционной модели данных, относятся также системы Bubba и Dasdb.
2.2 Многомерная модель данных
Многомерный подход к представлению данных в базе появился практически одновременно с реляционным, но реально работающих многомерных СУБД (МСУБД) до настоящего времени было очень мало. C середины 90-х годов интерес к ним стал приобретать массовый характер.
Толчком послужила в 1993 году программная статья одного из основоположников реляционного подхода Э. 1Содда. B ней сформулированы 12 основных требований к системам класса OLAP (OnLine Analytical Processing - оперативная аналитическая обработка), важнейшие из которых связаны с возможностями концептуального представления и обработки многомерных данных. Многомерные системы позволяют оперативно обрабатывать информацию для проведения анализа и принятия решения.
B развитии концепций ИС можно выделить следующие два направления:
· системы оперативной (транзакционной) обработки;
· системы аналитической обработки (системы поддержки принятия решений).
Реляционные СУБД предназначались для информационных систем оперативной обработки информации и в этой области были весьма эффективны. B системах аналитической обработки они показали себя несколько неповоротливыми и недостаточно гибкими. Более эффективными здесь оказываются многомерные СУБД (МСУБД).
Многомерные СУБД
являются узкоспециализированными СУБД, предназначенными для интерактивной аналитической обработки информации. Раскроем основные понятия, используемые в этих СУБД: агрегируемость, историчность и прогнозируемость данных.
Агрегируемостъ
данных означает рассмотрение информации на различных уровнях ее обобщения. B информационных системах степень детальности представления информации для пользователя зависит от его уровня: аналитик, пользователь-оператор, управляющий, руководитель.
Историчностъ
данных предполагает обеспечение высокого уровня статичности (неизменности) собственно данных и их взаимосвязей, а также обязательность привязки данных ко времени.
Статичность данных позволяет использовать при их обработке специализированные методы загрузки, хранения, индексации и выборки.
Временная привязка данных необходима для частого выполнения запросов, имеющих значения времени и даты в составе выборки. Необходимость упорядочения данных по времени в процессе обработки и представления данных пользователю накладывает требования на механизмы хранения и доступа к информации. Так, для уменьшения времени обработки запросов желательно, чтобы данные всегда были отсортированы в том порядке, в котором они наиболее часто запрашиваются.
Прогнозируемостъ
данных подразумевает задание функций прогнозирования и применение их к различным временным интервалам.
Многомерность модели данных означает не многомерность визуализации цифровых данных, а многомерное логическое представление структуры информации при описании и в операциях манипулирования дынными.
По сравнению с реляционной моделью многомерная, организация данных обладает более высокий наглядностью и информативностъю
. Для иллюстрации на рис.8 приведены реляционное (а) и многомерное (б) представления одних и тех же данных об объемах продаж автомобилей.(см. Приложение рис.8.)
Если речь идет о многомерной модели с мерностью больше двух, то не обязательно визуально информация представляется в виде многомерных объектов (трех-, четырех- и более мерных гиперкубов). Пользователю и в этих случаях более удобно иметь дело с двухмерными таблицами или графиками. Данные при этом представляют собой «вырезки» (точнее, «срезы») из многомерного хранилища данных, выполненные с разной степенью детализации.
Рассмотрим основные понятия многомерных моделей данных, к числу которых относятся измерение и ячейка.
Измерение
(Dimension) - это множество однотипных данных, образующих одну из граней гиперкуба. Примерами наиболее часто используемых временных измерений являются Дни, Месяцы, Кварталы и Годы. В качестве географических измерений широко употребляются Города, Районы, Регионы и Страны. B многомерной модели данных измерения играют роль индексов, служащих для идентификации конкретных значений в ячейках гиперкуба.
Ячейка (Се11) или показатель - это поле, значение которого однозначно определяется фиксированным набором измерений. Тип поля чаще всего определен как цифровой. В зависимости от того, как формируются значения некоторой ячейки, обычно она может быть переменной (значения изменяются и могут быть загружены из внешнего источника данных или сформированы программно) либо формулой (значения, подобно формульным ячейкам электронных таблиц, вычисляются по заранее заданным формулам).
B примере на рис.8, б каждое значение ячейки Объем продаж однозначно определяется комбинацией временного измерения (Месяц продаж) и модели автомобиля. Еда практике зачастую требуется большее количество измерений. Пример трехмерной модели данных приведен на рис.9.(см. Приложение рис.9.)
B существующих МСУБД используются два основных варианта (схемы) организации данных: гиперкубическая и поликубическая.
B полукубической схеме предполагается, что в БД может быть определено несколько гиперкубов с различной размерностью и с различными измерениями в качестве граней. Примером системы, поддерживающей поликубический вариант БД, является сервер Оrас1е Express Server.
B случае гиперкубической схемы предполагается, что все показатели определяются одним и тем же набором измерений. Это означает, что при наличии нескольких гиперкубов БД все они имеют одинаковую размерность и совпадающие измерения. Очевидно, в некоторых случаях информация в БД может быть избыточной (если требовать обязательное заполнение ячеек).
B случае многомерной модели данных применяется ряд специальных операций, к которым относятся: формирование «среза», «вращение», агрегация и детализация.
«Срез» (S1ice) представляет собой подмножество гиперкуба, полученное в результате фиксации одного или нескольких измерений. Формирование «срезов» выполняется для ограничения используемых пользователем значений, так как все значения гиперкуба практически никогда одновременно не используются. Например, если ограничить значения измерения Модель автомобиля в гиперкубе (рис.9) маркой «Жигули», то получится двухмерная таблица продаж этой марки автомобиля различными менеджерами по годам.
Операция «вращение» (Rotate) применяется при двухмерном представлении данных. Суть ее заключается в изменении порядка измерений при визуальном представлении данных. Так, «вращение» двухмерной таблицы, показанной на рис.86, приведет к изменению ее вида таким образом, что по оси X будет марка автомобиля, а по оси Y - время.
Операцию «вращение» можно обобщить и на многомерный случай, если под ней понимать процедуру изменения порядка следования измерений. B простейшем случае, например, это может быть взаимная перестановка двух произвольных измерений.
Операции «агрегация» (Dri11 Up) и «детализация» (Dri11 Down) означают соответственно переход к более общему и к более детальному представлению информации пользователю из гиперкуба.
Для иллюстрации смысла операции «агрегация» предположим, что у нас имеется гиперкуб, в котором помимо измерений гиперкуба, приведенного на рис.9, имеются еще измерения: Подразделение, Регион, Фирма, Страна. Заметим, что в этом случае в гиперкубе существует иерархия (снизу вверх) отношений между измерениями: Менеджер, Подразделение, Регион, Фирма, Страна.
Пусть в описанном гиперкубе определено, насколько успешно в 1995 году менеджер Петров продавал автомобили «Жигули» и «Волга». Тогда, поднимаясь на уровень выше по иерархии, с помощью операции «агрегация» можно выяснить, как выглядит соотношение продаж этих же моделей на уровне подразделения, где работает Петров.
Основным достоинством
многомерной модели данных является удобство и эффективность аналитической обработки больших объемов данных, связанных со временем. При организации обработки аналогичных данных на основе реляционной модели происходит нелинейный рост трудоемкости операций в зависимости от размерности БД и существенное увеличение затрат оперативной памяти на индексацию.
Недостатком
многомерной модели данных является ее громоздкость для простейших задач обычной оперативной обработки информации.
Примерами систем, поддерживающих многомерные модели данных, являются Essbase (Arbor Software), Media Mu1ti-matгix (Speedware), Oracle Express Server (Огас1е) и Cache (InterSystems). Некоторые программные продукты, например Media/M R (Speedware), позволяют одновременно работать с многомерными и с реляционными БД. B СУБД Cache, и которой внутренней моделью данных является многомерная модель, реализованы три способа доступа к данным: прямой (на уровне узлов многомерных массивов), объектный и реляционный.
2.3 Объектно-ориентированная модель данных
В объектно-ориентированной модели при представлении данных имеется возможность идентифицировать отдельные записи базы. Между записями базы данных и функциями их обработки устанавливаются взаимосвязи с помощью механизмов, подобных соответствующим средствам в объектно-ориентированных языках программирования.
Стандартизованная объектно-ориентированной модель описана в рекомендациях стандарта ODMG-93 (Object Database Management Group - группа управления объектно-ориентированными базами данных). Реализовать в полном объеме рекомендации ODMG-93 пока не удается. Для иллюстрации ключевых идей рассмотрим несколько упрощенную модель объектно-ориентированной БД.
Структура объектно-ориентированной БД графически представима в виде дерева, узлами которого являются объекты. Свойства объектов описываются некоторым стандартным типом (например, строковым - string) или типом, конструируемым пользователем (определяется как class).
Значением свойства типа string является строка символов. Значение свойства типа class есть объект, являющийся экземпляром соответствующего класса. Каждый объект-экземпляр класса считается потомком объекта, в котором он определен как свойство. Объект-экземпляр класса принадлежит своему классу и имеет одного родителя. Родовые отношения в БД образуют связную иерархию объектов.
Пример логический структуры объектно-ориентированной БД библиотечного цепа приведен на рис.10.(см. Приложение рис.10.)
Здесь объект типа БИБЛИОТЕКА является родительским для объектов-экземпляров классов АБОНЕНТ, КАТАЛОГ и ВЫДАЧА. Различные объекты типа КНИГА могут иметь одного или разных родителей. Объекты типа КНИГА, имеющие одного и того же родителя, должны различаться по крайней мере инвентарным номером (уникален для каждого экземпляра книги), но имеют одинаковые значения свойств isbn, удк, название и автор.
Логическая структура объектно-ориентированной БД внешне похожа на структуру иерархической БД. Основное отличие между ними состоит в методах манипулирования данными.
Для выполнения действий над данными в рассматриваемой модели БД применяются логические операции, усиленные объектно-ориентированными механизмами инкапсуляции, наследования и полиморфизма Ограниченно могут применяться операции, подобные командам SQL (например, для создания БД).
Создание и модификация БД сопровождается автоматическим формированием и последующей корректировкой индексов (индексных таблиц), содержащих информацию для быстрого поиска данных.
Рассмотрим кратко понятия инкапсуляции, наследования и полиморфизма применительно к объектно-ориентированной модели БД.
Инкапсуляция
ограничивает область видимости имени свойства пределами того объекта, в котором оно определено. 'Гак, если в объект типа КАТАЛОГ добавить свойство, задающее телефон автора книги и имеющее название телефон, то мы получим одноименные свойства у объектов АБОНЕНТ и КАТАЛОГ Смысл такого свойства будет определяться тем объектом, в который оно инкапсулировано.
Наследование,
наоборот, распространяет область видимости свойства на всех потомков объекта. Так, всем объектам типа КНИГА, являющимся потомками объекта типа КАТАЛОГ, можно приписать свойства объекта-родителя: isbn, удк, название и автор.
Если необходимо расширить действие механизма наследования на объекты, не являющиеся непосредственными родственниками (например, между двумя потомками одного родителя), то в их общем предке определяется абстрактное свойство типа abs. Так, определение абстрактных свойств 6wcem и номер в объекте БИБЛИОТЕКА приводит к наследованию этик свойств всеми дочерними объектами АБОНЕНТ, КНИГА и ВЫДАЧА. Неслучайно поэтому значения свойства билет классов АБОНЕНТ и ВЫДАЧА, показанных на рисунке, будут одинаковыми - 00015.
Полиморфизм
в объектно-ориентированных языках программирования означает способность одного и того же программного кода работать с разнотипными данными. Другими словами, он означает допустимость в объектах разных типов иметь методы (процедуры или функции) с одинаковыми именами. Во время выполнения объектной программы одни и те же методы оперируют с разными объектами в зависимости от типа аргумента. Применительно к нашей объектно-ориентированной БД полиморфизм означает, что объекты класса КНИГА, имеющие разных родителей из класса КАТАЛОГ, могут иметь разный набор свойств. Следовательно, программы работы с объектами класса КНИГА могут содержать полиморфный код.
Поиск в объектно-ориентированной БД состоит в выяснении сходства между объектом, задаваемым пользователем, и объектами, хранящимися в БД. Определяемый пользователем объект, называемый объектом-цёлью (свойство объекта имеет тип goal), в общем случае может представлять собой подмножество всей хранимой в БД иерархии объектов. Объект-цель, а также результат вьполнения запроса могут храниться в самой базе. Пример запроса о номерах читательских билетов и именах абонентов, получавших в библиотеке хотя бы одну книгу, показан на рис.11. (см. Приложение рис.11.)
Основным достоинством
объектно-ориентированной модели данных в сравнении с реляционной является возможность отображения информации о сложных взаимосвязях объектов. Объектно-ориентированная модель данных позволяет идентифицировать отдельную запись базы данных и определять функции их обработки.
Недостатками
объектно-ориентированной модели являются высокая понятийная сложность, неудобство обработки данных и низкая скорость выполнения запросов.
B 90-e годы существовали экспериментальные прототипы объектно-ориентированных систем управления базами данных. B настоящее время такие системы получили широкое распространение, в частности, К ним относятся следующие СУБД: POET (POET Software), Jasmine (Computer Associates), Versant (Versant Technologies), 02 (Ardent Software), ODB-Jupiter (научно-производственный центр «Интелтек Плюс»), а также Iris, Orion и Postgres.
Глава
III
. Сравнение классических моделей данных
При сравнении моделей данных очень трудно отделить факторы, характеризующие принципиальные особенности модели, от факторов, связанных с реализацией этих моделей данных средствами конкретных СУБД.
3.1 Достоинства и недостатки реляционной модели
Рассматривая преимущества и недостатки известных моделей данных, следует отметить ряд несомненных достоинств реляционного подхода:
· Простота. B реляционной модели всего одна информационная конструкция, которая формализует табличное представление данных, привычное для пользователей экономистов.
· Теоретическое обоснование. Наличие теоретически обоснованных методов нормализации отношений и проверки ацикличности структуры позволяет получать базы данных с заданными характеристиками.
· Независимость данных. Когда необходимо изменить структуру реляционной БД, это, как правило, приводит к минимальным изменениям в прикладных программах.
Среди недостатков реляционной модели
данных необходимо назвать следующие.
· Низкая скорость при выполнении операции соединения.
· Большой расход памяти для представления реляционной БД. Хотя проектирование в ЗНФ рассчитано на минимальную избыточность (каждый факт представляется в БД один раз), другие модели данных обеспечивают меньший расход памяти для представления тех же фактов. Например, длина адреса связи обычно намного меньше, чем длина значения атрибута.
3.2 Достоинства и недостатки иерархической модели
Достоинствами иерархической модели
данных являются следующие.
· Простота. Хотя модель использует три информационные конструкции, иерархический принцип соподчиненности понятий является естественным для многих экономических задач (например, организация статистической отчетности).
· Минимальный расход памяти. Для задач, допускающих реализацию с помощью любой из трех моделей данных, иерархическая модель позволяет получить представление с минимально требуемой памятью.
Недостатки иерархической модели.
· Неуниверсальность. Многие важные варианты взаимосвязи данных невозможно реализовать средствами иерархической модели, или реализация связана с повышением избыточности в базе данных.
· Допустимость только навигационного принципа доступа к данным.
· Доступ к данным производится только через корневое отношение.
3.3 Достоинства и недостатки сетевой модели
Необходимо отметить следующие преимущества сетевой модели данных.
· Универсальность. Выразительные возможности сетевой модели данных являются наиболее обширными в сравнении с остальными моделями.
· Возможность доступа к данных через значения нескольких
отношений (например, через любые основные отношения).
В качестве недостатков сетевой модели данных
можно назвать.
· Сложность, т.е. обилие понятий, вариантов их взаимосвязей и особенностей реализации.
· Допустимость только навигационного принципа доступа к данным.
Результаты, полученные для ациклических баз данных, позволяют говорить о равноценных возможностях представления информации у ациклических реляционных БД, двухуровневых сетевых БД и иерархической БД без логических связей.
При анализе моделей данных не затрагивалась проблема упорядоченности значений в отношениях баз данных. Для реляционной модели данных эта упорядоченность с теоретической точки зрения необязательна, а в двух других моделях она широко используется для повышения эффективности реализации запросов.
Заключение
Определение модели данных предусматривает указание множества допустимых информационных конструкций, множества допустимых операций над данными и множества ограничений для хранимых значений данных.
Модель данных, с одной стороны, представляет собой формальный аппарат для описания информационных потребностей пользователей, а с другой - большинство СУБД ориентируются на конкретную модель данных, и, таким образом, если информационные потребности удается точно выразить средствами одной из моделей данных, то соответствующая СУБД позволяет относительно быстро создать работоспособный фрагмент ЭИС.
Информационные конструкции, операции и ограничения моделей данных выбираются из достаточно небольшого множества вариантов, характеризующего «крупные» информационные объекты и операции. B частности, не допускается рассмотрение отдельных символов данных, операций сложения атрибутов, ограничения на соответствие типов данных и т. п., что характерно для языков программирования.
Классификация информационных конструкций (информационных объектов) тесно связана с областью их использования в ЭИС.
1. Объекты для технологии баз данных - отношения и веерные отношения.
2. Объекты для технологии искусственного интеллекта - предикаты, фреймы и семантические сети.
3. Объекты для технологии мультимедиа - тексты, графические изображения, фонограммы и видеофрагменты.
Информационные объекты послужили основой для объектно-ориентированного проектирования систем, когда фиксируется множество информационных объектов и действий над объектами. Типичный список действий включает в себя создание/уничтожение объекта, редактирование объекта, фиксацию одного объекта в качестве части другого объекта, связывание объектов, синхронизацию действий над объектами.
Довольно-таки часто все названные объекты встраиваются в структуру отношений, которые можно считать простейшими универсальными объектами.
На окончательный выбор модели данных влияют многие дополнительные факторы, например, наличие хорошо зарекомендовавших себя СУБД, квалификация прикладных программистов, размер базы данных и др.
B последнее время реляционные СУБД заняли преимущественное положение как средство разработки ЭИС. Недостатки реляционной модели компенсируются ростом быстродействия и ресурсов памяти современных ЭВМ. Вследствие процессов децентрализации управления в экономике многие базы данных ЭИС имеют простую структуру, которая легко трансформируется в понятные системы таблиц (отношений).
Список использованной литературы
1. Мишенин А.И. Теория экономических информационных систем.-М.: «Финансы и статистика», 2007
2. Семакин И.Г. Хеннер Е.К. Информационные системы и модели. Учебное пособие.-М.: «БИНОМ. Лаборатория знаний», 2005
3. Смирнова Г.Н. Сорокин А.А. Тельнов Ю.Ф. Проектирование экономических информационных систем.-М.: «Финансы и статистика», 2003
4. Хомоненко А.Д. Цыганков В.М. Мальцев М.Г. Базы данных. Учебник для высших учебных заведений.-Санкт-Петербург: «КОРОНА принт», 2004
5. http://www.finstat.ru
6. http://www.refer.ru
Приложение

Рис.1. Представление связей в иерархической модели
(Хомоненко А.Д. Цыганков В.М. Мальцев М.Г. Базы данных. Учебник для высших учебных заведений.-Санкт-Петербург: «КОРОНА принт», 2004)

Рис.2. Пример типа «дерево»
(Хомоненко А.Д. Цыганков В.М. Мальцев М.Г. Базы данных. Учебник для высших учебных заведений.-Санкт-Петербург: «КОРОНА принт», 2004)

Рис.3. данные в иерархической базе
(Хомоненко А.Д. Цыганков В.М. Мальцев М.Г. Базы данных. Учебник для высших учебных заведений.-Санкт-Петербург: «КОРОНА принт», 2004)
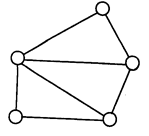
Рис.4. Представление связей в сетевой модели
(Хомоненко А.Д. Цыганков В.М. Мальцев М.Г. Базы данных. Учебник для высших учебных заведений.-Санкт-Петербург: «КОРОНА принт», 2004)

Рис.5. Пример схемы сетевой БД
(Хомоненко А.Д. Цыганков В.М. Мальцев М.Г. Базы данных. Учебник для высших учебных заведений.-Санкт-Петербург: «КОРОНА принт», 2004
А)
INVOICES

INVOICE.ITEMS

Б)
INVOICES

Рис.6. Структуры данных реляционной и постреляционной моделей
(Хомоненко А.Д. Цыганков В.М. Мальцев М.Г. Базы данных. Учебник для высших учебных заведений.-Санкт-Петербург: «КОРОНА принт», 2004)
А)
SELECT
INVOICES.INVNO, CUSTNO, GOODS, QTY
FROM
INVOICES, INVOICE.ITEMS
WHERE
INVOICES.INVNO=INVOICE.ITEMS.INVNO$
Б)
SELECT
INVNO, CUSTNO, GOODS, QTY
FROM
INVOICES;
Рис.7. Операторы
SQL
для реляционной и постреляционной моделей
(Хомоненко А.Д. Цыганков В.М. Мальцев М.Г. Базы данных. Учебник для высших учебных заведений.-Санкт-Петербург: «КОРОНА принт», 2004)
А)

Б)

Рис.8. Реляционные и многомерное представление данных
(Хомоненко А.Д. Цыганков В.М. Мальцев М.Г. Базы данных. Учебник для высших учебных заведений.-Санкт-Петербург: «КОРОНА принт», 2004)

Рис.9. Пример трехмерной модели
(Хомоненко А.Д. Цыганков В.М. Мальцев М.Г. Базы данных. Учебник для высших учебных заведений.-Санкт-Петербург: «КОРОНА принт», 2004)

Рис.10. Логическая структура БД библиотечного дела
(Хомоненко А.Д. Цыганков В.М. Мальцев М.Г. Базы данных. Учебник для высших учебных заведений.-Санкт-Петербург: «КОРОНА принт», 2004)
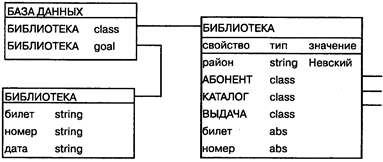
Рис.11. Фрагмент БД с объектом-целью
(Хомоненко А.Д. Цыганков В.М. Мальцев М.Г. Базы данных. Учебник для высших учебных заведений.-Санкт-Петербург: «КОРОНА принт», 2004)
|