Раздел 1. ТЕОРИЯ ПРОЕКТИРОВАНИЯ УДАЛЕННЫХ БАЗ ДАННЫХ
Тема 1.1. Архитектуры удаленных баз данных
1.1.1 Основные понятия
Аббревиатура ЛВС (она же LAN - Local Area Network) расшифровывается как локальная вычислительная сеть. Первые сети появились в 50 годы. Бурное развитие началось с появлением ПК (персонального компьютера).
Локальная вычислительная сеть
- это группа компьютеров, которые соединены между собой при помощи специальной аппаратуры, обеспечивающей обмен данными. Компьютеры могут соединяться друг с другом непосредственно либо через узлы связи. Внутри здания или в пределах небольшой территории ЛВС позволяет соединить между собой группу ПК для совместного использования информации.
ЛВС предоставляет пользователям возможность разделять ресурсы компьютера и информацию, находясь далеко друг от друга, они могут совместно работать над проектами и задачами, которые требуют тесной координации и взаимодействия. К тому же, даже если компьютерная сеть выйдет из строя, вы все же сможете продолжить работу на вашем ПК. Ниже перечислены семь задач, которые решаются с помощью ПК, работающего в составе ЛВС, и которые достаточно трудно решить с помощью отдельного ПК.
Разделение файлов.
ЛВС позволяет многим пользователям одновременно работать с одним файлом, хранящимся на центральном файл-сервере. К примеру, в офисе адвоката может иметься набор документов, к которому необходим одновременный доступ нескольких секретарей.
Передача файлов.
ЛВС позволяет быстро копировать файлы любого размера с одной машины на другую без использования дискет.
Доступ к информации и файлам.
ЛВС позволяет запускать прикладные программы с любой из рабочих станций, где бы она ни была расположена.
Разделение прикладных программ.
ЛВС позволяет двум пользователям использовать одну и ту же копию программы, например, текстового процессора MS Word. При этом, конечно, два пользователя не могут одновременно редактировать один и тот же документ.
Одновременный ввод данных в прикладные программы.
Сетевые прикладные программы позволяют нескольким пользователям одновременно вводить данные, необходимые для работы этих программ. Например, вести записи в бухгалтерской книге так, что они не будут мешать друг другу. Однако только специальные сетевые версии программ позволяют одновременный ввод информации. Обычные компьютерные программы позволяют работать с набором файлов только одному пользователю.
Разделение принтера.
ЛВС позволяет нескольким пользователям на различных рабочих станциях совместно использовать один или несколько дорогостоящих лазерных принтеров.
Электронная почта и Интернет.
Вы можете использовать ЛВС как почтовую службу и рассылать служебные записки, доклады, сообщения другим пользователям. Телефон, конечно, быстрее и более удобен, но электронная почта передаст ваше сообщение даже в том случае, если в данный момент абонент отсутствует на своем рабочем месте, и для этого ей не требуется бумаги.
Основное назначение любой компьютерной
сети
- предоставление информационных и вычислительных ресурсов подключенным к ней пользователям. С этой точки зрения локальную вычислительную сеть можно рассматривать как совокупность серверов и рабочих станций.
Сервер
- компьютер, подключенный к сети и обеспечивающий ее пользователей определенными услугами. Серверы могут осуществлять хранение данных, управление базами данных, доступ к всемирной сети Интернет, удаленную обработку заданий, печать заданий и ряд других функций, потребность в которых может возникнуть у пользователей сети. Сервер - источник ресурсов сети.
Рабочая станция
- персональный компьютер, подключенный к сети, через который пользователь получает доступ к ее ресурсам. Рабочая станция сети функционирует как в сетевом, так и в локальном режиме. Она оснащена собственной операционной системой (Windows, Unix, MAC OS и т.д.), обеспечивает пользователя всеми необходимыми инструментами для решения прикладных задач.
Клиент
- Рабочая станция для одного пользователя, обеспечивающая режим регистрации и др. необходимые на его рабочем месте функции вычисления, коммуникацию, доступ к базам данных и др.
Обработка Клиент - Сервер
- среда, в которой обработка приложений распределена между клиентом и сервером. Нередко в обработке участвуют машины разных типов, причем клиент и сервер общаются между собой с помощью фиксированного множества стандартных протоколов обмена и процедур обращения к удаленным платформам.
Одноранговая сеть
. В такой сети нет единого центра управления взаимодействием рабочих станций и нет единого устройства для хранения данных. Сетевая операционная система распределена по всем рабочим станциям. Каждая станция сети может выполнять функции как клиента, так и сервера. Она может обслуживать запросы от других рабочих станций и направлять свои запросы на обслуживание в сеть.
Достоинства одноранговых сетей
: низкая стоимость и высокая надежность.
Недостатки одноранговых сетей:
- зависимость эффективности работы сети от количества станций;
- сложность управления сетью;
- сложность обеспечения защиты информации;
- трудности обновления и изменения программного обеспечения станций.
Сеть с выделенным сервером.
В сети с выделенным сервером один из компьютеров выполняет функции хранения данных, предназначенных для использования всеми рабочими станциями, управления взаимодействием между рабочими станциями и ряд сервисных функций.
Взаимодействие между рабочими станциями в сети, как правило, осуществляется через сервер. Логическая организация такой сети может быть представлена топологией звезда. Роль центрального устройства выполняет сервер.
Достоинства сети с выделенным сервером:
- надежная система защиты информации;
- высокое быстродействие;
- отсутствие ограничений на число рабочих станций;
- простота управления по сравнению с одноранговыми сетями,
Недостатки сети:
- высокая стоимость из-за выделения одного компьютера под сервер;
- зависимость быстродействия и надежности сети от сервера;
- меньшая гибкость по сравнению с одноранговой сетью.
- В подавляющем большинстве случаев локальная сеть используется для коллективного доступа к базам данных.
1.1.2 Основные тенденции развития средств удаленного управления
Общие положения. Удаленный доступ — очень широкое понятие, которое включает в себя различные типы и варианты взаимодействия компьютеров, сетей и приложений. Существует огромное количество схем взаимодействия, которые можно назвать удаленным доступом, но их объединяет использование глобальных каналов или глобальных сетей при взаимодействии. Кроме того, для удаленного доступа, как правило, характерна несимметричность взаимодействия, то есть с одной стороны имеется центральная крупная сеть или центральный компьютер, а с другой — отдельный удаленный терминал, компьютер или небольшая сеть, которые должны получить доступ к информационным ресурсам центральной сети. За последние год-два количество предприятий, имеющих территориально распределенные корпоративные сети, значительно возросло.
Поэтому для современных средств удаленного доступа очень важны хорошая масштабируемость и поддержка большого количества удаленных клиентов.
Отличия между удаленным доступом и удаленным управлением
Существует два типа удаленных вычислений; вы должны выбрать то, что более подходит к вашим требованиям.
Удаленное управление
ПО удаленного управления используется уже несколько лет. Начиная с небольших пакетов, типа PCAnywhere, и заканчивая большими приложениями масштаба предприятия, как SMS. Оно дает пользователям или администратору возможность управлять удаленной машиной и выполнять разнообразные функции. При использовании удаленного управления, от удаленной машины на локальную машину посылаются коды нажатых клавиш. Локальная машина посылает на удаленную изменения экрана. Обработка и передача файлов, как правило, делаются на локальной машине. На рисунке 1.4 показана схема сеанса удаленного управления:

Преимущества удаленного управления
ПО удаленного управления стало очень популярным. Используя централизованные инструменты, персонал службы поддержки может решать проблемы, возникающие на удаленном компьютере. Это улучшает поддержку пользователей. Кроме того, администратор может собирать информацию с большого числа машин и вести записи о их конфигурации и установленном программном обеспечении. Это помогает следить за использованием лицензий.
Удаленное управление может использоваться и как средство дистанционного обучения. Администратор может работать за другим ПК, подключенным к ПК пользователя, видеть экран пользователя, и помогать пользователю освоить программу в режиме демонстрации.
Программы удаленного управления, как правило, предусматривают защиту. В компаниях, хранящих важную информацию, часто запрещается хранить на своих ПК секретную информацию, чтобы удаленные пользователи не могли получить к ней доступ. При удаленном доступе администратор может ограничить пользователя в загрузке информации на свой домашний ПК.
Недостатки удаленного управления
Программы удаленного управления имеют ряд ограничений. Большинство пакетов ограничены разрешением экрана, которое они могут воспроизвести. Клиенты Terminal Services поддерживают максимум 256 цветов. Кроме того, программы, использующие графику, сильно загружают каналы связи и могут свести на нет все преимущества удаленного управления. Citrix MetaFrame недавно выпустила Feature Release 1, дополнительный пакет для MetaFrame 1.8, который позволяет пользователям использовать 24-битный цвет.
Клиент Citrix может масштабировать графику сессии в зависимости от пропускной способности канала связи. Чем больше разрешение, тем больше загружается канал. Из-за этого некоторые программы, например, системы автоматизированного проектирования, не подходят для использования с Terminal Services или MetaFrame. Однако, приложения Windows Office - такие как Word и Excel, - идеально подходят для сеансов удаленного доступа.
Feature Release 1 доступен для обладателей Subscription Advantage. Он включает Service Pack 2 for MetaFrame 1.8, а также набор новых возможностей, таких как поддержка нескольких мониторов, большая глубина цвета, SecureICA.
Еще одна потенциальная опасность удаленного управления состоит в том, что возникает опасность несанкционированного доступа в сеть. Если некто за пределами сети получает доступ к локальному ПК, он может выполнять на нем любые команды, как если бы он находился в локальной сети. Поэтому многие администраторы предпочитают не оставлять постоянно включенными компьютеры с установленными на них программами удаленного доступа, и тщательно настраивают механизмы аутентификации и ограничения прав пользователей.
Последний недостаток удаленного управления состоит в том, что скорость передачи файлов между локальным и удаленным ПК ограничена скоростью соединения. Большинство пользователей используют обычную телефонную сеть, позволяющую скорость максимум 56Кbps. Хотя MetaFrame неплохо работает и на модемном соединении 28.8 Kbps, рекомендуются высокоскоростные соединения типа ADSL или кабельные модемы.
Удаленный узел
Удаленный ПК, оборудованный модемом или сетевой платой, выполняет соединение через глобальную сеть к локальному серверу. Этот удаленный ПК теперь рассматривается как локальный узел сети, способный получать доступ к сетевым ресурсам, например, к другим ПК. Сервер отвечает за предоставление всей сетевой информации, за передачу файлов, и даже за некоторые приложения на удаленном узле.
Удаленный узел отвечает за обработку, выполнение, изменение информации, с которой он работает. Все это выполняется с той скоростью, с которой может работать клиент.
Из-за этих ограничений вычисления на удаленном узле предъявляют высокие требования к пропускной способности канала связи. Это следует учитывать при проектировании. Как видно на рисунке, между клиентом на локальном ПК и клиентом удаленного узла есть небольшое различие. Сервер будет одинаково обрабатывать запросы от любой машины. Но если локальный клиент запрашивает 2Мб данных, сервер передаст их по локальной сети. Для удаленного клиента, по каналу 56К эта передача займет около 6 минут. Кроме того, после внесения изменений клиент должен отправить эти 2Мб обратно.

Зачем использовать удаленный доступ?
Почему же компании предпочитают использовать удаленный доступ, а не удаленное управление, несмотря на все эти проблемы, вытекающие из скорости соединения? Для начинающих удаленный доступ проще настроить. Все, что требуется - это способ подключиться к серверу. Для этого обычно используется RAS или соединение через Интернет.
Другая важная особенность состоит в том, что для соединения с центральным сервером можно использовать разные операционные системы. Это может быть важно для компаний, использующих различные платформы. Сервисы могут отличаться в разных ОС, но пользователи могут получать доступ к сетевым ресурсам, по крайней мере, на базовом уровне.
Удаленный доступ более безопасен, чем удаленное управление. Для клиентов, использующих Интернет, существуют много программ, реализующих защищенное соединение между клиентом и сервером. В последнее время стали очень популярны виртуальные частные сети (VPN).
Сеансы удаленного доступа не ограничены в графике. Если клиентский ПК настроен на 24-битный цвет, то именно такое качество он и попытается показать. Однако, в случае больших изображений может потребоваться значительное время для их отображения. Если ваше приложение выводит много графики, это сильно снизит производительность.
Однако, самым большим преимуществом удаленного доступа над удаленным управлением является требование к аппаратному обеспечению. При удаленном доступе, небольшое число локальных машин могут обрабатывать большое число пользовательских сеансов. Следовательно, нет необходимости держать для каждого пользователя отдельный ПК. Пользователи могут работать на удаленных компьютерах, а потом подключаться к локальной сети и выгружать свои изменения. Это также локализует источники ошибок и облегчает их поиск и устранение.
Недостатки вычисления на удаленном узле
Как было сказано выше, скорость является ключевым аспектом, поскольку передается намного больше данных, чем при удаленном управлении. Частично проблему можно решить использованием кабельных модемов и ADSL, но даже в этом случае скорость будет составлять лишь 1/5 от скорости в ЛВС, если только пользователь не платит ежемесячно $1,000 за персональный канал T1.
Поскольку удаленный доступ требует, чтобы удаленный ПК мог осуществлять обработку информации, требования к его аппаратному обеспечению также могут стать важным фактором. Это может означать частую замену ПК, модернизацию программного обеспечения. Удаленный ПК также более уязвим для вирусных атак, чем при удаленном управлении. Еще один недостаток удаленного доступа - это выдача клиенту лицензии. Если клиенту запрещено индивидуально устанавливать на своем ПК копию программы, слежение за лицензиями становится еще одной головной болью системных администраторов.
И последнее замечание по поводу удаленного доступа касается совместимости аппаратных платформ. Заранее не зная конфигурации ПК клиента, часто приходится строго ограничивать список поддерживаемых конфигураций. Это часто ограничивает пользователя
1.1.3 Архитектуры прикладных систем
В составе прикладной системы удобно выделить прикладное программное обеспечение и платформу. Формирующие (наряду с аппаратурой) платформу операционную систему, СУБД и программное обеспечение промежуточного слоя [1-4] вместе называют системным ПО.
Большинство прикладных программ можно разделить на три части: логику (алгоритмы) представления, бизнес-логику (расчетные алгоритмы и правила) и логику (алгоритмы) доступа к данным. Каждая часть вовсе не должна полностью соответствовать отдельному модулю, типу отдельной программы, нити, функции или процедуре — такое разделение весьма полезно, но не необходимо. Очень простые приложения часто способны собрать все три части в единственную программу, и подобное разделение соответствует функциональным границам.
Пользователи взаимодействуют с частью, называемой логикой представления, которая управляет доступом к приложению. Независимо от конкретных характеристик этой части системы (интерфейс командной строки, сложные графические пользовательские интерфейсы, интерфейсы через посредника) ее задача состоит в том, чтобы обеспечить средства для наиболее эффективного обмена информацией между пользователем и системой. Вот почему на стадии проектирования приложения так много внимания уделяют этому компоненту, видимому со стороны внешнего мира.
Бизнес-логика определяет, для чего, собственно, предназначено приложение. В зависимости от конкретных функциональных требований и сложности задач может быть полезным подразделить эту часть на несколько компонентов. В этом случае конкретная реализация каждого компонента может быть представлена в виде набора процедур (библиотеки), класса или классов объектов, отдельных программ. Разделение приложения по границам между программами обеспечивает естественную основу для распределения приложения на нескольких компьютерах.
Алгоритмы доступа к данным исторически рассматривались как специфический для конкретного приложения интерфейс к механизму постоянного хранения данных наподобие файловой системы или СУБД. Так, при помощи этой части программы приложение управляет соединениями с базой данных и запросами к ней (перевод специфических для конкретного приложения запросов на язык SQL, получение результатов и перевод этих результатов обратно в специфические для конкретного приложения структуры данных). К этой части относят только специфический для приложения интерфейс к СУБД, но не ее саму.
Иногда три указанные части называют слоями — от теоретической модели, которая рассматривает каждую часть приложения в терминах ее положения относительно пользователя, от «переднего слоя» (front-end, логика представления) до «заднего слоя» — (back-end, логика доступа к данным). Одна из функций «среднего слоя» (бизнес-логика) состоит в обеспечении двунаправленного преобразования между структурами данных высокого уровня переднего слоя и низкоуровневыми структурами заднего слоя. В этой модели положение каждого слоя (относительно пользователя) непосредственно связано с различными уровнями абстракции.
Рассмотрим приложение, которое производит поиск в базе данных согласно определенным пользователем критериям (рис. 1
). Пользователь заполняет формы и нажимает кнопку «Поиск». Эта информация передается блоку бизнес-логики для формирования одного или более запросов. Эти запросы один за другим передаются блоку логики доступа к данным, который преобразует данные и запросы в формат, совместимый с СУБД, выполняет каждый запрос, получает результат и преобразует его в формат приложения. Наконец, он возвращает результат блоку бизнес-логики, который объединяет результаты нескольких запросов в порцию информации, передаваемую блоку логики представления; тот помещает эти данные в удобочитаемую форму и показывает ее пользователю.
Как правило, преобразования данных выполняются несколько раз. В некоторых приложениях избегают этого, используя структуры, подобные структурам СУБД, в качестве внутреннего формата представления данных. Тогда в рассматриваемом примере блок бизнес-логики может сразу же брать данные пользователя по мере получения их от блока логики представления и преобразовывать в SQL-запросы. После этого блок бизнес-логики может обращаться к базе данных непосредственно, без вовлечения специфической для приложения логики доступа к данным.
Проблема такого подхода состоит в том, что он привязывает приложение к определенному формату данных. Если приложение необходимо перенести на другую СУБД, внутренние структуры данных придется изменить. (Эта зависимость находится вне связи со специфической моделью базы данных, например, с различиями между иерархической и реляционной базами.)
Проблема обостряется еще, когда используется несколько различных по структуре представлений. В этом случае блок бизнес-логики вынужден поддерживать несколько внутренних представлений для, возможно, одних и тех же данных. Поэтому разумнее иметь один «родной» для приложения формат внутреннего представления данных. Преобразование в другой формат может выполняться, когда оно становится неизбежным (в блоке логики доступа к данным при взаимодействии с конкретной базой данных, в слое представления при взаимодействии с пользователем и т.д.).
Разделение функциональных алгоритмов на логику представления, бизнес-логику и логику доступа к данным предполагает разные уровни абстракции в различных частях приложения. Разложение же приложения на части согласно различным уровням абстракции представляет иерархию, которую можно использовать, чтобы разделить одну программу на несколько одновременно исполняемых модулей. Процесс, реализующий один или несколько уровней в этой иерархии, не должен ничего знать об уровнях, расположенных выше или ниже. Поэтому за исключением обмена информацией между процессами в различных слоях (рис. 1
) каждый процесс независим и самодостаточен. Процесс на одном уровне не нуждается в прямом доступе к структурам данных, расположенным на другом уровне; следовательно, он может быть легко выделен в отдельно исполняемую программу.
Такое разделение минимизирует взаимодействие между составными элементами, уменьшая объем передаваемой информации и упрощая алгоритмы, отвечающие за связь между процессами, и потому служит основой для выделения компонентов, которые могут быть распределены на нескольких компьютерах.
Архитектуры прикладных систем
В таблице 1
перечислены наиболее часто встречающиеся архитектуры прикладных систем. Колонка «максимальное число пользователей» может рассматриваться как некоторая мера масштабируемости. Все архитектуры, кроме первой, являются архитектурами распределенных систем.
Как можно заметить, самая «древняя», централизованная архитектура обеспечивает намного более масштабируемое решение, чем две следующих. Потребовалось три поколения, прежде чем эти распределенные архитектуры смогли эффективно конкурировать с решением, ориентированным на универсальный компьютер: построить распределенную систему гораздо труднее.
Централизованная архитектура
Одна мощная универсальная ЭВМ была единственной платформой, выполняющей все алгоритмы логики приложения (рис. 2). У централизованной архитектуры множество достоинств: простая разработка приложений, легкость обслуживания и управления. Именно они и обеспечили столь долгую жизнь «унаследованных» систем. Смерть универсальных ЭВМ неоднократно провозглашалась после появления четырех- и восьмиразрядных ПК в начале 80-х годов (компьютеры PET и VIC-20 компании Commodore, TRS-80 компании Radio Shack и множество других машин на базе процессоров Z-80, а также 6502 и 6800 производства Motorola). Однако они продолжали работать, переваривая десятки миллионов транзакций в день, приспосабливаясь к постоянно увеличивающимся нагрузкам.
Разделение файлов
Особое внимание следует уделить одному из типов серверов - файловому серверу (File Server). В распространенной терминологии для него принято сокращенное название - файл-сервер
.
Файл-сервер хранит данные пользователей сети и обеспечивает им доступ к этим данным. Это компьютер с большой емкостью оперативной памяти, жесткими дисками большой емкости и дополнительными накопителями.
Он работает под управлением специальной операционной системы, которая обеспечивает одновременный доступ пользователей сети к расположенным на нем данным.
Файл-сервер выполняет следующие функции: хранение данных, архивирование данных, синхронизацию изменений данных различными пользователями, передачу данных.
Едва появившись, ПК принесли ожидание того, что большое число маленьких машин может заменить, а, в некоторых случаях, и превзойти по производительности универсальную ЭВМ. Архитектура разделения файлов, ставшая первым шагом к реализации этого притязания, включает множество настольных ПК и файловый сервер, связанных сетью (рис. 3). Файловый сервер загружает файлы из разделяемого местоположения, а прикладные программы исполняются полностью на настольных ПК.
Подобная архитектура была особенно популярна при использовании продуктов наподобие dBASE, FoxPro и Clipper. Первоначально сети персональных компьютеров были основаны на метафоре совместного использования файлов, потому что это было просто. Однако она хорошо работала лишь в некоторых случаях. Во-первых, все приложения должны вписаться в единственный ПК. Во-вторых, совместное использование и конфликты обновления чрезвычайно снижают производительность. Наконец, учитывая пропускную способность сети, объем данных, которые могут передаваться, также невелик. Все эти факторы крайне ограничивают число параллельных пользователей, которое способна поддерживать архитектура разделения файлов [6-8].
Клиент-сервер
Стремление исправить архитектуру разделения файлов привело к замене файлового сервера сервером баз данных (рис. 4). Вместо передачи файлов целиком он пересылает только ответы на запросы клиентов, уменьшая нагрузку на сеть. Эта стратегия вызвала появление архитектуры клиент-сервер. Появившись в 80-х годах, она ввела понятие «клиента» (сторона, запрашивающая функции/обслуживание) и «сервера» (сторона, предоставляющая функции/обслуживание). На уровне программного обеспечения разделение на клиента и сервер является логическим: процессы клиента и сервера могут физически размещаться как на одной, так и на разных машинах. Под общим концептуальным названием скрываются три варианта архитектуры: двухзвенная, трехзвенная и многозвенная.
Самая старая — двухзвенная (рис. 5). Она разделяет приложение на две части, клиентскую и серверную. Сторона клиента содержит логику представления, а логика доступа к данным, СУБД и сама база находятся на стороне сервера.
Остаются алгоритмы бизнес-логики, которые могут быть размещены как на машине клиента вместе с логикой представления (конфигурация «толстый клиент»), так и на стороне сервера (конфигурация «тонкий клиент»), или даже могут быть разделены между ними. Конфигурация «толстый клиент» более распространена: суммарная вычислительная мощность клиентов, по крайней мере, в теории, предполагается большей, чем мощность единственного сервера. Подобный ход рассуждений привел некоторых из разработчиков к созданию приложений, где даже логика доступа к данным размещается на клиенте, оставляя серверу только поддержание самой базы данных.
Двухзвенная архитектура, особенно конфигурация «толстый клиент», имеет ряд недостатков. Например, как и в архитектуре разделения файлов, — это ограничение, вытекающее из вычислительной мощности отдельных машин клиентов.
Но еще хуже имеющее фундаментальный характер ограничения на число одновременных соединений с сервером. Сервер поддерживает открытое соединение со всеми активными клиентами, даже если никакой работы нет. Это необходимо, чтобы сервер мог получать сигналы тактового импульса, что не так страшно, когда клиентов менее 100 [9-12]; однако сверх этого числа производительность начинает быстро деградировать до недопустимо низкого уровня. Хорошим примером возникновения подобной проблемы может служить работа прокси-сервера.
В некоторых прикладных системах бизнес-логику пытаются реализовать, используя хранимые процедуры. Идея состоит в том, чтобы в соответствии с «тонкой» конфигурацией клиента переместить алгоритмы бизнес-логики на серверную машину, ближе к данным, которые требуются им постоянно. Это выглядит как хорошая идея, однако только усугубляет главную проблему. Так как осуществляющие бизнес-правила процессы теперь управляются СУБД, число пользователей, которых может поддерживать такая система, ограничено максимумом возможных активных соединений с СУБД. Кроме того, от СУБД к СУБД механизмы хранимых процедур разнятся. Тем не менее, двухзвенная архитектура хорошо работает в маленьких рабочих группах [9-12]. С начала 90-х годов появилась масса инструментальных средств, упрощающих создание систем в такой архитектуре, в том числе Delphi и PowerBuilder.
 |
| Рис. 6. Трехзвенная архитектура
|
С середины 90-х годов признание специалистов получила трехзвенная архитектура, которая, как и двухзвенная, поддерживала концепцию клиент-сервер, но разделила систему по функциональным границам между тремя слоями: логикой представления, бизнес-логикой и логикой доступа к данным (рис. 6). В отличие от двухзвенной архитектуры появляется дополнительное звено — «сервер приложений», целиком, предназначенное для осуществления бизнес-логики.
Именно выделение бизнес-логики в отдельное звено позволяет преодолеть фундаментальные ограничения двухзвенной архитектуры. Клиенты не поддерживают постоянного соединения с базой данных, а обмениваются информацией со средним звеном только тогда, когда это необходимо. В то же время процесс среднего звена поддерживает всего несколько активных соединений с базой данных, но использует их многократно; поэтому процессы в среднем звене могут предоставлять обслуживание теоретически неограниченному числу клиентов. В сравнении со всеми другими моделями трехзвенная архитектура обладает столь многими преимуществами. Но преимущества не даются даром. Разработка прикладных программ, основанных на трехзвенной архитектуре, — более трудное дело, чем для двухзвенной архитектуры или при использовании централизованного подхода. Преодолеть возникающие проблемы помогает программное обеспечение промежуточного слоя [5-9].
Трехзвенная архитектура
Рассмотрим четыре варианта распределенных систем, основанных на трехзвенной архитектуре: с сервером приложений, с монитором обработки транзакций, с сервером передачи сообщений и с брокером объектных запросов.
Сервер приложений
 |
| Рис. 7. Трехзвенная архитектура с сервером приложений
|
Клиенты (рис. 7) содержат только слой логики представления прикладного ПО, а алгоритмы бизнес-логики и логики доступа к данным перемещены в среднее звено. В этом случае сервер приложений обеспечивает «общее хранилище» бизнес-правил и процедур. Клиенты соединяются с сервером приложений и предоставляют ему данные для обработки. Совместное использование алгоритмов бизнес-логики, общих для всего приложения, обладает важными достоинствами. Помимо «утоньшения» клиента, эта стратегия ведет к созданию системы, в которой будущие обновления прикладного ПО будут производиться, главным образом, на сервере приложений, что упрощает процесс модификаций.
Обычно сервер приложений поддерживает пул ограниченного числа открытых подключений к базам данных и вместо того чтобы делать каждое подключение к базе данных выделенным для определенного клиента (как в двухзвенной архитектуре), подключения многократно используются для выполнения запросов различных клиентов.
Есть и другие преимущества. Во-первых, так как вся «важная» часть прикладной логики теперь централизована в среднем звене, нет необходимости поддерживать сложные механизмы аутентификации на стороне клиентов.
Во-вторых, аппаратная платформа, на которой выполняется сервер приложений, может быть достаточно мощной; это дает дополнительную степень масштабируемости всей прикладной системы.
В-третьих, централизованный доступ к данным в серверах приложений делает всю прикладную систему менее зависящей от конкретной СУБД.
Наконец, сервер приложений обеспечивает эффективную стратегию для интеграции. Придерживаясь того же протокола коммуникации, что и клиент, другое «внешнее» приложение может легко взаимодействовать с «чужим» сервером приложений. Эта конфигурация допускает интеграцию приложений не только на уровне данных, но и на уровне правил бизнес-логики. Это чрезвычайно важно, потому что совместное использование данных разными прикладными программами может вести к логическим противоречиям в базе данных. Типичное решение состоит в том, чтобы копировать одни и те же правила и алгоритмы в несколько прикладных программ. Но тогда очень затрудняются их поддержка и обновление — любое изменение кода должно проводиться во всех прикладных программах, которые его используют. Если же бизнес-правила сосредоточены на сервере приложений и используются совместно, то такой проблемы нет.
Отличие «многозвенной» архитектуры от «двухзвенной».
Довольно распространена модель работы, когда клиент обращается не непосредственно к серверу БД, а к промежуточной программе
. Эта программа обычно называется сервером приложений
. Такую архитектуру называют «трехзвенной»
, в отличие от «двухзвенной»
архитектуры клиент-сервер.
Мониторы обработки транзакций
Мониторы обработки транзакций (transaction processing monitor, TPM) — самый старый тип технологии распределенных систем, которая появилась в 70-х годах в среде больших универсальных ЭВМ [9-12]. Одной из первых прикладных систем была интерактивная среда поддержки, созданная компанией Atlantic Power and Light для совместного использования прикладных служб и информационных ресурсов в режимах пакетной обработки и с применением среды с разделением времени. TPM (например, IBM CICS) стали главным инструментом построения высоко масштабируемых решений для сетевых прикладных систем. Однако в начале 90-х популярность TPM начала падать; причиной стало появление продуктов категории TPM «Lite» — мониторов обработки транзакций внутри СУБД. Их функциональные возможности были близки к обычным TPM, и с возрастающей тогда популярностью двухзвенной архитектуры они первоначально обеспечили хорошее решение для создания распределенных прикладных систем.
К концу десятилетия ситуация изменилась. Оказалось, что в то время как обычный монитор транзакций может легко поддерживать тысячи пользователей, их производительность становится недопустимо низкой, когда совокупность пользователей превышает 100. Сегодня TPM снова вернулись, но теперь это технология, которая воплощает среднее звено в трехзвенной архитектуре.
Клиенты связываются с мониторами, посылая запросы на транзакции. Так как коммуникации асинхронны, после того, как запрос послан, клиент может выполнять другие задачи. Каждый запрос ставится в очередь, и монитор может обработать его позднее. Поддерживая различные схемы приоритетов, можно определить, в каком порядке запросы принимаются из очереди на обработку. Мониторы постоянно поддерживают установленное число подключений к базам данных, поэтому непосредственного соответствия между клиентами и подключениями к базе данных нет. Вместо этого мониторы мультиплексируют запросы от различных клиентов по одному и тому же подключению — точно так же, как и серверы приложений.
Одно из достоинств процессора транзакций — способность обращаться к гетерогенным источникам данных (реляционные и сетевые базы данных, плоские файлы и т.д.). Поэтому каждый TPM содержит логику доступа к данным, которая выполняет соответствующее преобразование, связанное с различными источниками.
 |
| Рис. 8. Трехзвенная архитектура с монитором обработки транзакций
|
Самая простая конфигурация — клиент-A взаимодействует только с одним монитором TPM-A (рис. 8), который обеспечивает доступ к данным, расположенным на одном компьютере (Сервер Данных A). При помощи двухфазного протокола фиксации монитор может обеспечивать семантику транзакций и с несколькими базами данных. Таким образом, транзакция одного клиента будет фактически разбита между несколькими базами данных; эта ситуация показана в случае с TPM-B, который взаимодействует с источниками данных на нескольких машинах (Сервер Данных A, Сервер Данных B и Сервер Данных C). В этом случае, если подтранзакция терпит неудачу на одном из серверов, все другие подтранзакции также откатываются назад, а Клиент-B получает сообщение о таком событии.
Отношения между клиентами и мониторами, так же как и между мониторами и источниками данных, фактически являются отношениями «многие-ко-многим». Эта конфигурация часто используется, чтобы обеспечить балансировку нагрузки. Когда число пользователей увеличивается, система может запускать дополнительные экземпляры мониторов, обеспечивающих доступ к одним и тем же источникам данных.
В этой конфигурации мониторы могут также обеспечить инфраструктуру для разработки систем, способных обрабатывать ошибки. Например, как видно из рис. 8, Клиент-C и Клиент-D могут обращаться к одним и тем же источникам данных (Сервер Данных C и Сервер Данных D) либо через TPM-C, либо через TPM-D, причем каждый монитор выполняется на своем собственном компьютере. Если один из мониторов выходит из строя, то все клиенты могут переключаться на все еще работающий монитор. Система в этом случае замедлится, но будет способна обеспечить исходный набор функций.
Сервер сообщений
Вместо монитора транзакций приложение может использовать сервер сообщений. Он обладает большинством существенных преимуществ монитора транзакций. Клиенты взаимодействуют с сервером сообщения асинхронно, помещая в очередь сообщения, которые обрабатываются позднее. В свою очередь, сервер сообщений поддерживает пул доступных подключений к базе данных, которые он может использовать многократно. Но вместо предопределенных запросов, с которыми должен работать монитор, само сообщение содержит достаточно информации относительно того, что нужно с ним делать.
У каждого сообщения есть заголовок и тело. Заголовок определяет, что должно быть сделано с сообщением (скажем, выполнить бизнес-правило или хранимую процедуру, послать его в базу данных или передать его другому серверу сообщений). Последнее позволяет осуществлять коммуникации не только между клиентом и базой данных, но и между клиентами или между клиентом и базами данных, доступными через различные серверы сообщений (рис. 9).
 |
| Рис. 9. Трехзвенная архитектура с сервером сообщений
|
Используя механизмы передачи с промежуточным хранением, сообщения могут обходить точки отказов по альтернативным маршрутам и дополнительным серверам сообщений.
Это похоже на использование нескольких мониторов, обслуживающих одних и тех же клиентов и связанных с одними и теми же источниками данных. Но в отличие от мониторов, сообщение может быть пропущено через несколько серверов сообщений прежде чем оно, наконец, достигнет своего адресата.
Более того, «интеллект», который направляет сообщение по дополнительному пути, находится не на клиенте, а на сервере сообщений. Таким образом, отказы могут оставаться полностью скрытыми от клиента.
Большинство серверов сообщений поддерживает несколько протоколов связи и выполняется на различных платформах.
В результате прикладная система, построенная с серверами сообщений, может охватывать весьма сложные гетерогенные среды, состоящие из компьютеров разных платформ, различных операционных систем, сетей и протоколов коммуникаций.
Ясно, что помимо создания таких переносимых приложений, серверы сообщений играют очень важную роль в интеграции, позволяя совместно использовать сообщения, данные и бизнес-правила.
Брокер объектных запросов
Брокер объектных запросов (object request broker, ORB) обеспечивает инфраструктуру, поддерживающую распределенные объекты, которыми можно управлять, как и объектами, расположенными «рядом» с процессом, работающим с ними. По вызову метода (в смысле объектно-ориентированного программирования) на одном компьютере может фактически выполняться некоторый программный код другого, притом, что доступ к данным в пределах распределенного объекта может потребовать получения соответствующей информации из удаленной базы данных. Все эти детали остаются скрытыми от прикладной программы [15].
Использование брокера объектных запросов в трехзвенной архитектуре очень похоже на использование сервера сообщений. Единственное различие состоит в том, что взаимодействие осуществляется на объектном уровне, а не на уровне отдельных сообщений. Эта парадигма, объединенная с мощью объектно-ориентированного программирования, делает распределенные объекты очень привлекательной стратегией для разработки распределенных систем.
 |
| Рис. 10. Трехзвенная архитектура с брокером объектных запросов
|
Пример использования двух брокеров объектных запросов показан на рис. 10. Как и в случае сервера сообщения, бизнес-логика разделена между клиентами и ORB. Однако доступ к процедурам, физически расположенным на брокере, остается скрытым от клиентов при помощи распределенных объектов. Через конкретное выполнение распределенных объектов в среднем звене можно мультиплексировать запросы клиентов на одном и том же пуле подключений к базам данных. В качестве источника данных можно использовать объектно-ориентированную СУБД, однако разного рода «упаковщики» могут обеспечивать доступ к другим источникам (базы данных других типов, плоские файлы и т. п.).
Точно так же распределенные объекты могут «упаковывать» другие прикладные программы. Поэтому интеграция приложений может осуществляться не просто на уровне бизнес-правил, но на уровне объектов. Эти два подхода, однако, очень похожи. Так как бизнес-правила скрыты в методах объекта, совместное использование объекта подразумевает совместное использование бизнес-правил. Но объект также содержит информацию о состоянии, поэтому он допускает интеграцию и на уровне данных.
Тема 1.2. Основные технологии доступа к данным и типовые элементы доступа
Во все времена одной из актуальнейших задач, стоящих перед разработчиками ПО, было обеспечение взаимодействия между отдельными программами. Для ее решения используется целый арсенал различных способов и приемов.
На заре существования Windows были внедрены разделяемые файлы, буфер обмена и технология динамического обмена данными
(DynamicDataExchange, DDE).
Для обеспечения обмена данными и предоставления служб был разработан первый вариант технологии связывания и внедрения объектов (ObjectLinkingandEmbedding – OLE 1). она предназначалась для создания составных документов – того, к чему мы все уже давно привыкли. Эта технология была во многом несовершенной, и на смену ей пришла технология OLE 2. Она представляет способ решения более общей проблемы – как научить разные программы предоставлять друг другу собственные функции (службы) и как научить их правильно использовать эти функции.
Для решения этой проблемы помимо OLE был разработан целый ряд технологий. В основе этих разработок лежит базовая технология ComponentObjectModel (COM) - Многокомпонентная Модель Объектов. Она часть ПО предоставляет для использования собственные службы, а другая получает к ним доступ. При этом совершенно не важно, где расположены эти части – в одном процессе, в разных процессах на одном компьютере или на разных компьютерах.
Дополнительные возможности разработчикам распределенных приложений на основе COM дает модификация базовой технологии – распределенная модель
COM
(DistributedCOM, DCOM).
В настоящее время COM используется в самых различных областях разработки ПО. На основе COM разработаны технологии автоматизации (Automation),ActiveX, ActiveFormMicrosoftTransactionServer. На базе COM создано большинство новейших продуктов (MS Office, MTS, …) и технологий Windows (Automation, Drag & Drop, ...).
В составе DELPHI работают две динамические библиотеки OLE32.DLLOLEAUT32.DLL, которые содержат базовые интерфейсы и общие функции COM.
1.2.1 Разработка приложений на основе COM
Во все времена одной из актуальнейших задач, стоящих перед разработчиками ПО, было обеспечение взаимодействия между отдельными программами. Для ее решения используется целый арсенал различных способов и приемов.
На заре существования Windows были внедрены разделяемые файлы, буфер обмена и технология динамического обмена данными (DynamicDataExchange, DDE).
Для обеспечения обмена данными и предоставления служб был разработан первый вариант технологии связывания и внедрения объектов ObjectLinkingandEmbedding – OLE 1. она предназначалась для создания составных документов – того, к чему мы все уже давно привыкли. Эта технология была во многом несовершенной, и на смену ей пришла технология OLE 2. Она предоставляет способ решения более общей проблемы – как научить разные программы предоставлять друг другу собственные функции (службы) и как научить их правильно использовать эти функции.
Для решения этой проблемы помимо OLE был разработан целый ряд технологий. В основе этих разработок лежит базовая технология ComponentObjectModel(COM) – Многокомпонентная Модель Объектов. Она описывает способ взаимодействия программ любого типа. Одна часть ПО предоставляет для использования собственные службы, а другая получает к ним доступ. При этом совершенно не важно, где расположены эти части – в одном процессе, в разных процессах на одном компьютере или на разных компьютерах.
Для созданных на основе спецификаций COM приложений также неважно, какой язык программирования использовался при их разработке – если стандарт COM соблюден, взаимодействие осуществляется без помех.
В настоящее время COM используется в самых различных областях разработки ПО. На основе COM разработаны технологии Автоматизации (Automation), ActiveX, ActiveFormMicrosoftTransactionServer.
В составе Delphi работают две динамические библиотеки OLE32.dllOLEAUT32.dll, которые содержат базовые интерфейсы и общие функции COM.
COM
– это технология, позволяющая объектам взаимодействовать, несмотря на границы процесса или машины, так же легко, как и объектам внутри одного процесса. COM обеспечивает такое взаимодействие, определяя, что единственный путь управления данными, ассоциированными с объектом, лежит через интерфейс объекта. Термин «интерфейс», о котором речь пойдет чуть ниже, означает реализацию в коде COM-совместимого двоичного интерфейса, ассоциированного с объектом.
СОМ
– общая технология взаимодействия объектов стандартизующая как сами объекты, так и методы их взаимодействия. Это спецификация, строящаяся на базе эталонных реализаций. COM является платформно-независимой, объектно-ориентированной технологией, позволяющей создавать бинарные компоненты. Эти компоненты можно использовать как локально, так и в распределенном сетевом окружении. COM служит основой для: OLE (технология составных документов), ActiveX-объектов и элементов управления ActiveX, DCOM, COM+.
DCOM
(Distributed COM) – это расширение COM, делающее эту модель распределенной, то есть позволяющей вызывать COM-объекты, находящиеся на другом компьютере в сети.
COM+
– это эволюция COM и MTS. COM+ полностью встроен в Windows 2000. Он существенно расширяет возможности своих предшественников. COM+ обратно совместим с DCOM, MTS и COM, и позволяет создавать распределенные приложения, клиентские части которых можно запускать на старых ОС (Windows 9x и Windows NT).
Напомним, что в модели COM все основано на интерфейсах. Интерфейс
- это контракт между реализующим данный интерфейс компонентом и клиентом, представленный набором определений методов (ничего кроме определений методов в интерфейс включать нельзя). Один и тот же интерфейс могут реализовать различные компоненты, написанные на разных языках, но любой компонент, реализующий данный интерфейс, гарантирует полную реализацию его семантики, т.е. определенный набор методов.
COM-объект
В технологии
COM приложение предоставляет для использования свои службы, применяя для этого объекты
COM. Одно приложение содержит как минимум один объект. Каждый объект имеет один или несколько интерфейсов
. Каждый интерфейс объединяет методы
объекта, которые обеспечивают доступ к свойствам
(данным) и выполнение операций. Обычно в интерфейсе объединяются все методы, выполняющие операции одного типа или работающие с однородными свойствами.
Клиент получает доступ к службам объекта только через интерфейс и его методы. Этот механизм является ключевым. Клиенту достаточно знать несколько базовых интерфейсов, чтобы получить исчерпывающую информацию о составе свойств и методов объекта. Поэтому любой клиент может работать с любым объектом, независимо от их среды разработки. Согласно спецификации COM, уже созданный интерфейс не может быть изменен ни при каких обстоятельствах. Это гарантирует постоянную работоспособность приложений на основе COM, невзирая на любые модернизации.
Объект всегда работает в составе сервера
COM. Сервер может быть динамической библиотекой или исполняемым файлом. Объект может иметь собственные свойства и методы или использовать данные и службы сервера.
Для доступа к методам объекта клиент должен получить указатель на соответствующий интерфейс. Для каждого интерфейса существует собственный указатель. После чего клиент может использовать службы объекта, просто вызывая его методы. Доступ к свойствам объектов осуществляется только через его методы.
Предположим, что объект COM встроен в электронную таблицу и обеспечивает доступ к математическим операциям. Будет логично разделить математические функции на группы по типам и создать для каждой группы собственный интерфейс. Например, можно выделить линейные, тригонометрические, агрегатные функции и т.д. На рис. 1. объект расположен внутри сервера – электронной таблицы. Интерфейсы обозначены кружками, связанными с объектом. Пусть интерфейс линейных функций называется ILinear, а интерфейс агрегатных функций –IAggregate.
Объект СОМ
– это некоторая сущность, имеющая состояние и методы доступа, позволяющие изменять это состояние. СОМ-объекты можно создавать прямым вызовом специальных функций, но напрямую уничтожить его невозможно. Вместо прямого уничтожения используется механизм самоуничтожения, основанный на подсчете ссылок. Самым близким аналогом в объектно-ориентированных языках программирования является понятие объекта в языке Java.
Так, в COM присутствует понятие класса. Класс в COM носит название CoClass.
Рис. 1. Сервер, объект и его интерфейсы
Согласно правилам обозначения объектов COM, базовый интерфейс IUnknown, который имеется у любого объекта, обозначается как кружок, примыкающий к верхней стороне прямоугольника объекта. Остальные интерфейсы обозначаются справа и слева.
Рис.2. Схема взаимодействия клиента и объекта COM
Чтобы получить доступ к агрегатной функции расчета среднего, клиент должен получить указатель на интерфейс IAgregate, а затем обратится к этой функции.
Взаимодействие между клиентом и объектом обеспечивается базовыми механизмами COM. При этом от клиента скрыто, где именно расположен объект: в адресном пространстве того же процесса, в другом процессе или на другом компьютере. Поэтому с точки зрения разработчика клиентского ПО использование функций электронной таблицы выглядит как обычное обращение к методу объекта. Механизм обеспечения взаимодействия между удаленными элементами COM называется маршалингом
(marshalling).
Возникает вопрос – как происходит создание и инициализация объекта COM при первом обращении клиента? Сомнительно, чтобы ОС самостоятельно создавала экземпляры всех зарегистрированных в ней классов в надежде, что один их них понадобится. А ведь для работы объекта требуются еще и серверы. Представьте, что каждый раз при загрузке Windows настойчиво запускает Word, excel, InternetExplorer и т.д.
Любой объект COM является обычным экземпляром некоторого класса, описывающего его свойства и методы. Информация обо всех зарегистрированных и доступных в данной ОС классах COM собрана в специальной библиотеке
COM, которая используется для запуска экземпляра класса – объекта.
Сначала объект обращается к библиотеке COM, передавая ей имя требуемого класса и необходимого в первую очередь интерфейса. Библиотека находит нужный класс и сначала запускает сервер, который затем создает объект – экземпляр класса. После этого библиотека возвращает клиенту указатели на объект и интерфейс. В последующей работе клиент может обращаться непосредственно к объекту и его интерфейсам.
После создания наступает очередь инициализации – объект должен загрузить необходимые данные, считать настройки из системного реестра и т.д. за это отвечают специальные объекты COM, которые называются моникерами
(monikers). Они работают скрытно от клиента. Обычно моникер создается вместе с классом.
Довольно реальной представляется ситуация, когда одновременно несколько клиентов обращаются к одному объекту. При соответствующих настройках для каждого клиента создается отдельный экземпляр класса. За выполнение этой операции отвечает специальный объект COM, который называется фабрикой класса
.
Наконец, остался не рассмотренным последний вопрос – как клиент может получить информацию об объекте. Например, разработчик клиентского ПО знает, что электронная таблица создана в соответствии со спецификацией COM, но не имеет понятия об объектах COM, которые предоставляют клиентам ее службы. Для разрешения подобных ситуаций разработчик объекта COM может распространять вместе с объектом информацию о типе. Она включает сведения об интерфейсах, их свойствах и методах, параметрах методов.
Эта информация содержится в библиотеке типов, которая создается при помощи специального языка описания интерфейса (InterfaceDefinitionLanguage, IDL).
Объект
Центральным элементом COM является объект. Приложения, поддерживающие COM, имеют в своем составе один или несколько объектов COM. Каждый объект представляет собой экземпляр соответствующего класса и содержит один или несколько интерфейсов. Что же такое объект COM?
Любой объект является экземпляром некоторого класса, т.е. представляет собой переменную объектного типа. Поэтому объект обладает набором свойств и методов, которые работают с этими свойствами. К объектам применимы три основные характеристики: инкапсуляция, наследование и полиморфизм. Объекты COM всем этим требованиям удовлетворяют.
Применительно к объектам вообще понятие интерфейса объекта, как он был определен выше, не используется. В первом приближении можно считать, что все методы объекта составляют его единственный интерфейс, а указателем интерфейса является указатель на объект.
Объект COM может иметь любое число интерфейсов (если это число больше нуля), причем каждый интерфейс обладает собственным указателем. Это первое отличие объектов COM от обычных.
У объектов COM имеется особенность еще в одном объектом механизме – наследовании. Вообще различают два способа наследования. Наследование реализации
подразумевает передачу родителем потомку всего программного кода. Наследование интерфейса
означает передачу только объявления методов, их программный код потомок должен предоставить самостоятельно.
Объекты COM поддерживают только наследование интерфейса, избегая тем самым возможного нарушения инкапсуляции родителя. Тем не менее, просто так выбросить наследование реализации нельзя. Вместо нее объекты COM используют механизм включения
, т.е. при необходимости потомок вызывает нужный метод родителя. Также применяется механизм агрегирования, когда один или несколько интерфейсов одного объекта на время включаются в другой объект путем передачи указателей.
Интерфейс
Если объект COM является ключевым элементом реализации COM, то интерфейсы являются центральным звеном идеологии COM. Как двум принципиально разным объектам обеспечить взаимодействие друг с другом? Ответ прост: им необходимо заранее договорится о том, как они будут общаться.
Интерфейс как раз является тем средством, которое позволяет клиенту правильно обратиться к объекту COM, а объекту ответить так, чтобы клиент его понял.
Рассмотрим небольшой пример. На улице случайно встретились два человека: местный житель (объект COM) и заблудившийся иностранец (клиент). Предусмотрительный иностранец взял с собой словарь (библиотека типов или интерфейс IUnknown). Иностранцу нужны знания местного жителя о городе. Он достал ручку и бумагу и, заглянув в словарь, составил фразу и старательно перерисовал незнакомые слова на бумагу. Местный житель оказался не промах. Он прочитал фразу, отобрал у иностранца словарь, составил по нему собственную фразу и тоже написал ее на бумаге. И все закончилось хорошо: довольный клиент (иностранец) получил от объекта COM (местного жителя) результат работы службы (информацию о дороге), а местный житель ушел вместе со словарем.
Как вы уже догадались, в этом примере интерфейсом является бумага и ручка: иностранец не знает чужого языка, зато знает, как правильно спросить, чтобы ему ответили.
Для идентификации каждый интерфейс имеет два атрибута. Во-первых, это его имя, составленное из символов в соответствии с правилами используемого языка программирования. Каждое имя должно начинаться с символа «I». Это имя используется в программном коде. Во-вторых, это глобальный уникальный идентификатор
(GloballyUniqueIDentifer, GUID), который представляет собой гарантированно уникальное сочетание символов, практически не повторяемое ни на одном компьютере в мире. Для интерфейсов такой идентификатор носит название IID (Interface Identifier).
В общем случае клиент может не знать, какие интерфейсы имеются у объекта. Для получения их перечня используется базовый интерфейс IUnknown., который есть у любого объекта COM.
Затем клиенту необходимо знать, какие методы имеет выбранный им интерфейс. Для этого разработчик должен распространять описание методов интерфейсов вместе с объектом. Эту задачу помогает решать язык IDL (он также используется в библиотеках типов).
Теперь осталось сделать самое важное – правильно вызвать сам метод. Для этого в COM описана реализация интерфейса на основе стандартного двоичного формата. Это обеспечивает независимость от языка программирования.
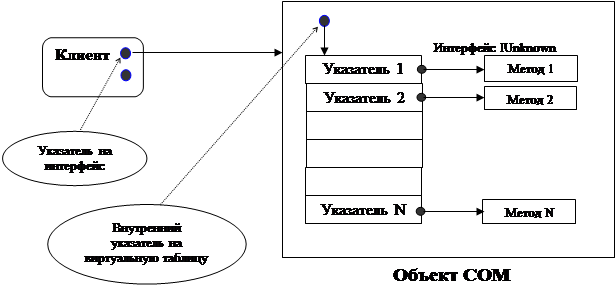
Рис.3. Формат интерфейса COM
Доступный клиенту указатель интерфейса ссылается на внутренний указатель объекта и, через него, на специальную виртуальную таблицу. Эта таблица содержит указатели на все методы интерфейса.
В результате, вызов метода клиентом проходит по цепочке указателей и получает указатель на конкретный метод, а затем исполняется соответствующий программный код.
Реализация интерфейса (interface implementation) – это код, который программист создает для выполнения действий, оговоренных в определении интерфейса. Реализации интерфейсов, помещенные в COM-библиотеки или exe-модули, могут использоваться при создании объектно-ориентированных приложений. Разумеется, программист может игнорировать эти реализации и создать собственные. Интерфейсы ассоциируются с CoClass’ами. Чтобы воспользоваться реализацией функциональности интерфейса, нужно создать экземпляр объекта соответствующего класса, и запросить у этого объекта ссылку на соответствующий интерфейс.
CoClass
CoClass – это класс, поддерживающий набор методов и свойств (один или более), с помощью которых можно взаимодействовать с объектами этого класса. Такой набор методов и свойств называется интерфейсом (Interface).
Каждый CoClass имеет два идентификатора – один из них, текстовый, называется ProgID и предназначен для человека, а второй, бинарный, называется CLSID.
CLSID является глобально уникальным идентификатором (GUID). GUID имеет размер 128 бит и уникален в пространстве и времени. Его уникальность достигается путем внедрения в него информации об уникальных частях компьютера, на котором он был создан, таких, как номер сетевой карты, и времени создания с точностью до миллисекунд. Эта технология, как и большинство других базовых концепций в СОМ, позаимствована из OSF DCE RPC. С помощью CLSID можно точно указать, какой именно объект требуется. Тип данных GUID применяется и для идентификации COM-интерфейсов. В этом случае он называется IID. Сгенерировать новое значение типа GUID можно с помощью API-функции Win32 CoCreateGuid. На практике использовать эту функцию приходится не часто, так как современные средства разработки полностью автоматизируют эту задачу, а VB вообще скрывает от программиста такие тонкости, как работу с CLSID и IID.
Для создания экземпляра объекта используется CLSID. Если имеется только ProgID CoClass’а или CLSID в строковом виде ("{XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX} ", где X – шестнадцатеричная цифра), то CLSID можно получить, вызвав функцию CLSIDFromString. Для случая с ProgID информация о CoClass’е должна содержаться в реестре машины, на которой производится вызов функции. В реестр информация заносится автоматически при регистрации объекта (во время процедуры инсталляции или при компиляции).
Перевести CLSID, IID или любой другой GUID в строку можно с помощью функции StringFromGUID2. Как уже говорилось выше, практически все необходимые GUID генерируются автоматически, но при необходимости можно сгенерировать GUID вручную, с помощью утилиты guidgen.
Программист никогда не взаимодействует с объектом и его данными напрямую. Для этого используются интерфейсы объектов.
Интерфейс
IUnknown
Каждый объект COM обязательно имеет интерфейс IUnknown. Этот интерфейс имеет всего три метода, но они играют ключевую роль в функционировании объекта.
Метод QueryInterface возвращает указатель на интерфейс объекта, идентификатор IID которого передается в параметре метода. Если такого интерфейса объект не имеет, метод возвращает null.
Обычно при первом обращении к объекту клиент получает указатель на интерфейс. Так как любой интерфейс является потомком IUnknown, то любой интерфейс имеет и метод QueryInterface. Поэтому в общем случае не важно, какой именно интерфейс может использовать клиент. При помощи метода QueryInterface он может получить доступ к любому интерфейсу объекта.
Интерфейс IUnknown обеспечивает работу еще одного важного механизма объекта COM – механизма учета ссылок. Объект должен существовать до тех пор, пока его использует хотя бы один клиент. При этом клиент не может самостоятельно уничтожить объект, ведь с ним могут работать и другие клиенты.
Поэтому при передаче наружу очередного указателя на интерфейс объект увеличивает специальный счетчик ссылок на единицу. Если один клиент передает другому указатель на интерфейс этого объекта, то клиент, получающий указатель, обязан еще раз инкрементировать счетчик ссылок. Для этого используется метод AddRef интерфейса IUnknown.
При завершении работы с интерфейсом клиент обязан вызвать метод Release интерфейса IUnknown. Этот метод уменьшает счетчик ссылок на единицу. После обнуления счетчика объект уничтожает себя.
Сервер
Сервер COM представляет собой исполняемый файл приложения или динамическую библиотеку, который содержит один или несколько объектов одного или разных классов. Различают три типа Сервер.
Внутренний сервер
(inprocessserver) реализуется динамическими библиотеками, которые подключаются к клиенту и работают в одном адресном пространстве.
Локальный сервер
(localserver) создается отдельным процессом, который работает на одном компьютере с клиентом.
Удаленный сервер
(remoteserver) создается процессом, который работает на друго компьютере по отношению к клиенту.
Рассмотрим локальный сервер. Получаемый клиентом указатель интерфейса в этом случае ссылается на специальный proxy
-объект
COM
(назовем его заместителем
, который функционирует внутри клиентского процесса). Заместитель предоставляет клиенту те же интерфейсы, что и вызываемый объект COM на локальном сервере. Получив вызов от клиента, заместитель упаковывает его параметры и при помощи служб ОС передает вызов в процесс сервера. В локальном сервере вызов передается еще одному специализированному объекту – заглушке
(stub), который распаковывает вызов и передает его требуемому объекту COM. Результат вызова возвращается клиенту в обратном порядке.
Рассмотрим удаленный сервер. Он функционирует так же, как и локальный сервер. Однако передача вызовов между двумя компьютерами осуществляется средствами DCOM – с помощью механизма вызова удаленных процедур
(RemoteProcedureCall, RPC).
Для обеспечения работы локальных и удаленных серверов используется механизм маршалинга и демершалинга. Маршалинг
реализует единый в рамках COM формат упаковки параметров запроса, демаршалинг
отвечает за распаковку. В описанных выше реализациях серверов за выполнение этих операций отвечают заместитель и заглушка. Эти типы объектов создаются совместно с основным объектом COM. Для этого применяется IDL.
Библиотека COM
Для обеспечения выполнения общих функций и базовых интерфейсов в ОС устанавливается специальная библиотека COM (конкретная реализация может быть различной). Доступ к функциям библиотеки осуществляется стандартным способом, а не через интерфейс.
Согласно спецификации, имена всех библиотечных функций начинаются с приставки «Со».
При установке использующего COM приложения в системный реестр записывается информация обо всех используемых им объектах COM:
- Идентификатор класса (ClassIdentifier, CLSID), который однозначно определяет класс объекта;
- Тип сервера объекта – внутренний, локальный или удаленный;
- Для локальных и внутренних серверов сохраняется полное имя динамической библиотеки или исполняемого файла;
- Для удаленных серверов записывается полный сетевой адрес.
Предположим, что клиент пытается использовать некоторый объект COM, который до этого момента не использовался.
Следовательно, клиент не может получить указатели на объект и интерфейс. В этом случае он обращается к библиотеке COM и вызывает метод CoCreateInstance, передавая ей в качестве параметра CLSID нужного класса, IID интерфейса и требуемый тип сервера.
Библиотека при помощи диспетчера управления службами (ServiceControlManager, SCM) обращается к системному реестру, по идентификатору класса – объект, и возвращает библиотеке указатель на запрошенный интерфейс.
Библиотека COM передает управление клиенту, который в последствии может обращаться непосредственно к объекту. Схема создания первого экземпляра объекта с помощью библиотеки COM и системного реестра приведена на рисунке.

Рис.4. Создание первого экземпляра объекта с помощью библиотеки COM
Для неявной инициализации созданного объекта (установки значений свойств) может использоваться специальный объект самостоятельно, применив специальные интерфейсы (IPersistFile, IPersistStorage, IPersistStream).
Фабрика класса
Для запуска экземпляра класса используется специальный объект –фабрика класса. С его помощью можно создать как один объект, так и несколько его экземпляров. Для каждого класса должна существовать собственная фабрика класса.
Объект COM имеет право называться фабрикой класса, если он поддерживает интерфейс IClassFactory. В нем реализованы всего два метода:
- CoCreateInstance – создает новый экземпляр класса. Все необходимые параметры, кроме IID, метод получает от фабрики класса. В этом его отличие от одноименного общего метода библиотеки.
- LockServer –оставляет сервер функционировать после создания объекта.
Для вызова фабрики класса существует специальный общий метод CoClassObject. В качестве параметра ему передается CLSID нужного класса и IID интерфейса (IClassFactory). Метод ищет требуемую фабрику и возвращает указатель на интерфейс. С его помощью и используя метод CoCreateInstance, клиент заставляет фабрику класса создать объект.
Библиотека типов
Чтобы документировать интерфейсы объекта для пользователей, разработчик создает информацию о типах объекта. Для этого используется язык IDL.
Вся информация объединяется в специальной библиотеке типов. Она может описывать свойства и методы (а также их параметры) интерфейсов и содержать сведения о необходимых заглушках и заместителях. Информация об отдельном интерфейсе оформляется в виде отдельного объекта внутри библиотеки.
Для создания библиотеки типов, описанной при помощи операторов IDL, используются специальные компиляторы. Доступ к библиотеке осуществляется по CLSID класса объекта. Кроме того, библиотека имеет собственный GUID, который сохраняется в системном реестре при регистрации объекта.
Каждая библиотека типов имеет интерфейс ItypeLib, который работает с ней, как с единым объектом. Для доступа к информации об отдельном интерфейсе используется интерфейс ItypeInfo.
Для доступа к библиотеке по GUID используется общий метод LoadRegTypeLib. Если клиенту известно имя файла библиотеки, то можно воспользоваться методом LoadTypeLib.
1.2.2 Назначение и основные характеристики технологий ADO, MIDAS, MTS, CORBA
Общие понятия.
Отличие «тонкого» клиента от «толстого». «Тонким» клиентом обычно называют пользовательское приложение, не содержащее никакой функциональности, и предназначенное только для ввода/вывода информации. Вся обработка данных производится на сервере БД, либо на сервере приложений. Зачастую, такой клиент изначально не содержит вообще никаких возможностей, а подгружает дополнительные модули с сервера, по мере необходимости. Обычно, в качестве «тонкого» клиента, выступают Web броузер + HTML/ASP/Java. «Толстый» клиент содержит всю функциональность и интерфейсную часть в себе, и при любом изменении, требует замены у всех пользователей.
Технология ADO
ADO (Microsoft ActiveX Data Objects) это технология стандартного обращения к реляционным данным от Microsoft. ADO представляет собой высокоуровневый программный интерфейс для доступа к OLE DB-интерфейсам. Он позволяет манипулировать данными с помощью любых OLE DB-провайдеров, как входящих в состав MDAC(Microsoft Data Access Components) некоторых других продуктов Microsoft, так и произведенных сторонними производителями. ADO содержит набор объектов, используемых для соединения с источником данных, для чтения, добавления, удаления и модификации данных.
DAO, ADO, RDO... Все это похоже на какую-то игру слов, где присутствует два ключевых понятия: данные и объекты. (Data Access Objects — объекты доступа к данным, ActiveX Data Objects — ActiveX-объекты работы с данными, Remote Data Objects — объекты удаленных данных.) На самом же деле речь здесь идет о разных технологиях доступа к данным (см. врезку «Сравнение ADO, DAO и RDO»), которые имеют не только разные внутренние механизмы, но и, что, может быть, гораздо важнее для прикладного программиста, разные перспективы на будущее.
DAO и RDO известны уже достаточно давно, и появление двух разных механизмов было связано с необходимостью оптимизации решения двух отдельных задач: доступа к локальным и удаленным базам данных соответственно. Однако естественное развитие вычислительных систем привело к необходимости создания единого механизма, который обеспечил бы единый подход при работе с БД различных классов.
В результате несколько лет назад Microsoft предложила в качестве единого интерфейса для доступа к локальным и удаленным данным новую технологию ADO, которая сегодня является частью архитектуры Microsoft Universal Data Access (MUDA).
ADO Extension for DDL and Security
(ADOX)
применяется для решения различных задач, недоступных с помощью обычных объектов ADO. Например, используя объекты ADOX, можно извлекать метаданные из баз данных и, следовательно, переносить структуру данных из одной базы данных в другую (в том числе и иного типа). Вторая возможность, предоставляемая этим расширением, — манипулирование сведениями о безопасности. Например, с помощью ADOX можно получать информацию о пользователях базы данных и группах пользователей, а также создавать новых пользователей и группы. ADOX расширяет объектную модель ADO десятью новыми объектами, которые можно использовать как отдельно, так и вместе с другими объектами ADO, в частности можно применять объект ADO Connection
для соединения с источником данных и извлекать метаданные из него.
Прежде чем углубляться в детали объектов ADOX, поговорим о том, что такое метаданные. В общем случае метаданные
представляют собой описания объектов базы данных (таблиц, полей, индексов, ключей, представлений, хранимых процедур и прочих объектов). В подавляющем большинстве современных СУБД метаданные определяются с помощью языка SQL (Structured Query Language)
. До появления ADOX единственным программным способом извлечения метаданных из источников данных с помощью ADO был метод OpenSchema
объекта ADO Connection
. Для создания новых объектов в базе данных применялся язык Data Definition Language (DDL)
— подмножество языка SQL, а также объект ADO Command
.
Многоуровневые приложения
Разработка распределенных корпоративных систем доступа к данным – одна из наиболее высокотехнологических и динамично развивающихся областей современной индустрии ПО. Именно здесь сосредоточены усилия разработчиков прикладного ПО.
Мощные серверы должны обеспечивать бесперебойный доступ к данным сотен клиентов одновременно. При этом клиентское ПО установлено на разных аппаратных платформах и работает под управлением разных ОС. Пользователи могут находится в корпоративной сети, обращаться к серверу через Internet, intranet или по радиоканалу.
Для создания распределенных систем разработаны подходы на основе ряда технологических решений. Используютсятехнологии COM, OLEnterprise, сокеты TCP\IP, Microsoft Transaction Server, CORBA.
Для работы с корпоративными БД используются многоуровневые приложения, т.к. эффективное взаимодействие с БД многих пользователей может обеспечить только ПО промежуточного уровня. Серверы приложений решают задачи управления запросами клиентов и результатами запросов, разграничения доступа, сохранения целостности данных т.д. Причем и в этой сфере существуют готовые решения на основе вышеперечисленных технологий.
Создание средств разработки корпоративных систем доступа к данным является основным направлением деятельности фирмы Inprise.
В Delphi можно создавать приложения для распределенных систем на основе всех перечисленных подходов. Для этого предназначена специальная технология MIDAS (Multi-tiredDistributedApplicationService) – Службы многоуровневых распределенных приложений. Она обеспечивает создание приложений для распределенных систем баз данных на основе единого подхода.
Многоуровневые приложения
представляют собой распределенные системы удаленного доступа к данным, которые состоят как минимум их трех логических уровней.
1. Сервер БД
, который обеспечивает функционирование используемой приложением БД и непосредственную обработку запросов пользователей. Для создания серверов БД имеются готовые решения, предоставляемые целым рядом компаний. В зависимости от назначения БД, объема, решаемых задач всегда можно подобрать наиболее подходящий вариант.
2. сервер приложений,
который составляет так называемое ПО промежуточного слоя. Обычно это специально разработанная программа, которая обеспечивает взаимодействие клиентов с сервером БД. В этой области всегда найдутся проблемы, которые необходимо решать: конфликты доступа к данным, регистрация, управление транзакциями и т.д.поэтому сервер приложений предоставляет минимально необходимый промежуточный уровень. Обычно он называется брокером данных.
Серьезные многоуровневые приложения имеют несколько уровней ПО промежуточного слоя. Из наиболее распространенных решаемых задач можно выделить регистрацию пользователей и разграничение доступа, защита от несанкционированного доступа, управление блокировками. Часто промежуточный уровень должен обеспечить доступ к БД клиентов с разными программными и аппаратными платформами.
3. Совокупность клиентских программ или клиентский уровень приложения
. В рассматриваемом случае используются «тонкие
» (или «слабые») клиенты, которые, в отличие от аналогичных программ в архитектуре клиент/сервер, выполняют только минимальные функции по отображению данных и передаче запросов серверу, а результатов – обратно.

Рис.5. Структура многоуровнего приложения
Технология MIDAS позволила вынести BDE в отдельный уровень – сервер приложений, который обеспечивает взаимодействие множества клиентов с сервером БД. Это стало возможным за счет применения удаленных модулей данных.
Технология MIDAS
Таким образом, мы подошли к важнейшей особенности настоящих многоуровневых приложений – ПО, обеспечивающее взаимодействие клиентов с БД (в нашем случае это BDE), которое требует установки только на одном компьютере – компьютере сервера приложений (рис. 5). В результате клиентские программы избавляются от лишнего программного кода и становятся чрезвычайно простыми в установке (появился даже новый термин – нуль-конфигурация «тонкого» клиента).
MIDAS
- это технология Borland для создания многоуровневых приложений баз данных. Применение данной архитектуры позволяет быстро разрабатывать простые в сопровождении и установке, надежные, распределенные БД. Трехуровневое приложение баз данных содержит несколько компонентов (слоев):
а) Слой БД. Хранит данные. Выполняет функции хранения информации, обеспечения целостности и непротиворечивости данных. Пример -локальные (dBase, Paradox) и серверные БД (Oracle, Sybase, MS SQL), текстовые файлы и т.д.
б) Слой бизнес логики (сервер приложений) - это программа, обеспечивающая доступ клиентов к информации. На этом слое вводится понятие сервиса, как некоей услуги, поставляемой клиенту (например, получение данных об остатке денег на счете, как частный случай из реляционной БД). В этом слое реализуются правила и алгоритмы обработки информации, отражающие поведение реального моделируемого объекта (бизнес правила). Например, проверка остатка денег на не отрицательность, перевод денег со счета на счет.
в) Презентационный слой (тонкий клиент). Задача этого слоя, используя сервисы слоя бизнес логики, предоставлять пользователям запрошенную информацию в форме удобной и приятной во всех отношениях. Может быть выполнен в виде традиционного exe файла или в качестве тонкого клиента можно использовать Web броузер.
Применение данной схемы позволяет создать клиентское приложение, которое практически не требует настройки и сопровождения, вся логика работы с БД сосредоточена в среднем слое (сервере приложений). Соответственно при доработке алгоритмов доступа к БД необходимо лишь переустановить сервер приложений.
MIDAS
предназначен для обеспечения связи между слоем бизнес логики и презентационным слоем. Он позволяет организовать взаимодействие тонкого клиента с сервером приложений. При этом сервер приложений взаимодействует с реляционной БД (чаще всего данные хранятся именно в этой форме) как и обычные приложения работы с БД, разработанные в Delphi.
Тонкий клиент для конечного пользователя ничем не отличается от обычного (толстого) клиента БД. Разница в том, что толстый клиент через BDE, ADO, компоненты прямого доступа к серверам БД и другие библиотеки работает с БД, а тонкий клиент взаимодействует с сервером приложений, используя MIDAS. Сервер приложений скрывает от клиента детали доступа и обработки БД. На компьютере с тонким клиентом не нужно устанавливать и настраивать BDE, ADO, клиентскую часть сервера БД. Необходимо лишь иметь небольшие по объему dll, которые легко переносить вместе с exe файлом тонкого клиента. В качестве тонкого клиента может использоваться и Web браузер.
В основе MIDAS лежит использование использование объектной модели COM. MIDAS обеспечивает функционирование в рамках единой службы нескольких технологий удаленного доступа к данным, предоставляя единый стандарт обмена данными между сервером и клиентами.
· DCOM
– распределенный COM расширение базовой технологии COM, позволяющей клиенту использовать свойства и методы удаленных объектов на сервере. Элементы COM установлены в WindowsNT, Windows 98, Windows 95 требует специальной интсалляции допаолнительного ПО.
· Microsoft
Transaction
Server
(
MTS
)
– надстройка над базовой технологией COM, обеспечивающая дополнительные функции при взаимодействии клиента и сервера. Это управление транзакциями, обеспечение безопасности данных. MTS доступна в ОС WindowsNT, Windows 98.
· Сокеты
являются популярным программным интерфейсом доступа к стеку сетевых протоколов и позволяют создавать распределенные приложения для большинства современных систем, включая соединение через Internet.
· OLEnterprise
– разработанное фирмой Borlandрасширение объектной модели COM, обеспечивающее ряд дополнительных возможностей. С его помощью можно связывать объекты, созданные на разных языках программирования. Соответствующее ПО устанавливается на сервере и клиенте.
· CORBA
(CommonObjectRequestBrokerArhitecture – Архитектура Брокера Общих Объектных Запросов) представляет собой специально разработанный стандарт и ПО, обеспечивающее взаимодествие объектов, манипулирующих данными в разных ОС. Основу архитектура составляет ORB (ObjectRequestBroker – Брокер Объектных Запросов), обеспечивающий взаимодействие сервера приложений и клиентов.
В соответствии с технологией MIDAS, многоуровневое приложение должно иметь три составные части:
· Сервер приложений, который должен содержать в качестве основы удаленный модуль данных;
· Клиент, взаимодествие которого с сервером обеспечено спецмальными компонентами и динамической библиотекой DBClient.DLL.
· Брокер данных, который обеспечивает передачу пакетов данных на основе интерфейса IProvider.
Технология MTS
Создавая в Delphi многоуровневые приложения на основе DCOM, разработчики могут расширить их возможности за счет использования дополнительных функций, предоставляемых специализированной системной службой MicrosoftTransactionServer (MTS).
MTS может работать с ОС WindowsNT, Windows 98. MTS позволяет достаточно гибко управлять режимами выполнения транзакций в системе и поддерживает двухфазное завершение транзакций. Одним из существенных недостатков схемы управления транзакциями СОМ является необходимость явной передачи контекста транзакции в качестве -аргумента при вызове удаленных методов. Такая схема не является ни эффективной, ни гарантирующей от ошибок, особенно при вовлечении в транзакцию большого количества объектов.
Использование MTS дает серверу ряд дополнительных полезных функций:
· При выполнении запросов поддерживаются транзакции;
· Работая с сервером, несколько клиентов могут использовать для доступа к данным одно соединение. Так реализуется совместное использованиеи ресурсов БД.
· Обеспечивая дополнительное разграничение доступа клиентов к интерфейсам.
Для использования возможностей MTS необходимо только иметь установленные динамические библиотеки этой службы на компьютере сервера приложений.
COM+ является слиянием COM- и MTS- моделей программирования, таким образом справедлива формула:
COM + MTS = COM+
Базовая программная модель и того, и другого являются идентичными: разрабатываются компоненты "в процессе", в них выставляются интерфейсы, для обеспечения автоматизации реализуется IDispatch, реализуется код для регистрации, т.е. в рамках новой парадигмы нужно делать то же, что делалось и ранее.
Однако в дополнение к этому появились новые сервисы, значительно расширяющие возможности приложений.
COM был создан как компонентная технология уровня изолированной рабочей станции.
Потом, с реализацией распределенного COM в NT4 (DCOM), эта технология получила развитие в направлении поддержки удаленных обращений к компонентам. MTS создавался для обеспечения работы серверных компонент и устранения некоторых недостатков DCOM. COM+ появился для унификации и объединения COM, DCOM и MTS в согласованную технологию, понятную и удобную для реализации приложений корпоративного уровня.
Технология CORBA
CORBA (Common Request Broker Architecture) — архитектура для построения распределенных объектных приложений. Была предложена некоммерческой организацией — консорциумом OMG (Object Management Group), состоящей из нескольких сотен (!) ведущих компаний из отрасли разработки программного обеспечения (включая таких гигантов, как Microsoft и Borland/Inprise). Первая спецификация CORBA появилась еще в далеком 1991 году.
Целью разработчиков CORBA было создание механизмов межплатформенного взаимодействия приложений в распределенных системах. Можно поразиться дальновидности OMG — ведь в середине — конце 80-х годов XX века распределенные системы не играли той впечатляющей роли в компьютерной индустрии, как сейчас. Кроме того, расширение экспансии Intel и Microsoft ставило под угрозу само наличие разнообразия аппаратно-программных платформ. Тем не менее, в сложившейся обстановке работы были продолжены, причем результаты были настолько успешны, что даже всемогущий Microsoft счел нужным присоединиться к консорциуму разработчиков, чтобы держать руку на пульсе развития новой перспективной технологии.
Как и DCOM, CORBA основывается на коммуникации типа клиент-сервер. Запрашивая сервис, клиент вызывает метод, реализуемый удаленным объектом, действующим в роли сервера. Сервис, предоставляемый объектом, инкапсулируется с помощью интерфейса, определенного на языке IDL. Именно собственный язык IDL является одной из изюминок CORBA. Вообще, существуют три различных языка описаний под одним и тем же названием: OMG IDL (очевидно, используется в CORBA), Microsoft IDL (разработан для технологии DCOM, но в силу двоичного представления объектов не играет в этой технологии ключевой роли) и OSF IDL. Однако, по сравнению с DCOM, CORBA имеет ряд существенных отличий.
Технология CORBA изначально проектировалась для создания распределенных систем. В силу этого сервер объектов и клиентские программы, в отличие от COM/DCOM, в технологии CORBA, как правило, располагаются на разных машинах. Взаимодействие между клиентом и сервером происходит следующим образом. В процессе клиента имеется объект-посредник, именуемый stub (или Client-Side Stab). Он является полномочным представителем сервера и исполняет функции, во многом сходные с функциями объекта Proxy в технологии DCOM. Именно к stub при помощи интерфейса объекта обращается программа-клиент так, как будто stub и являет собой объект. Далее stub перенаправляет запрос клиента к особому объекту, который действует также на машине клиента. Этот объект называется ORB (Object Required Broker, брокер объектных запросов). Получив запрос, ORB формирует широковещательное сообщение во внешнюю сеть. На это сообщение откликается один из объектов Smart Agent, который функционирует на одном из компьютеров сетевого окружения (локальная сеть или Интернет). Smart Agent знает, где расположены соответствующие серверы объектов (фактически это как бы виртуальный сетевой каталог, где зарегистрированы некоторые серверы), и перенаправляет запрос на нужный сервер. На сервере пакет запроса принимает еще один объект ORB, который дешифрует запрос и пересылает его следующему объекту — BOA (Basic Object Adapter, базовый адаптер объектов). Роль объекта BOA заключается в фильтрации, кэшировании запросов и, соответственно, разграничении доступа к объекту сервера. Если запрос пропущен BOA, то он попадает в объект сервера skeleton. При этом в адресном пространстве сервера создается требуемый объект, skeleton помещает аргументы вызова в стек объекта и реализует собственно вызов. Используя объект BOA, skeleton также регистрирует созданный серверный CORBA-объект с помощью Smart Agent, а также сообщает о доступности, факте создания и о готовности объекта принимать запросы клиента. Далее следует обратная связь по описанной цепочке объектов (рис. 4.6).
 <> <>
Рис. 4.6.
Технология CORBA
Как видно из описания, CORBA реализует собой типичную многозвенную (здесь — трехзвенную) архитектуру. В роли Middleware — программного обеспечения промежуточного слоя — здесь выступает объект Smart Agent. Обычно при практической реализации программа, выполняющая Действия Smart Agent, устанавливается на выделенную машину в корпоративной сети или на несколько машин в сети Интернет. При создании серверов они регистрируются на ДОСТУПНЫХ Smart Agent.
ТЕМА 1.3. ВВЕДЕНИЕ В РАБОТУ С УДАЛЕННЫМИ БАЗАМИ ДАННЫХ
Основные понятия. СУБД — Система Управления Базами Данных (DBMS — DataBase Management System). Программа, либо комплекс программ, предназначенных для полнофункциональной работы с данными. Как правило, включает в себя инструменты для создания и изменения структуры хранения наборов данных, а также средства доступа к хранимым данным, с возможностью их чтения, добавления, изменения и удаления. При этом, у большинства СУБД имеется собственный встроенный язык (возможно не один) для работы с данными. Сама база данных (БД) обычно находится просто в файлах закрытого, либо открытого формата.
Отличие «серверной» и «настольной» СУБД. Под настольной (desktop) обычно подразумевается СУБД, которая всегда запускается на компьютере пользователя, хотя сама база данных может находиться в другом месте. В результате несколько копий СУБД могут обращаться к одной базе данных. Серверная (server) СУБД, как правило, запускается в на той же машине (сервере баз данных), где находятся файлы БД. Непосредственно к базе данных обращается лишь один экземпляр СУБД. Пользовательские приложения общаются только с этой СУБД через ее API, независимо от того, работают они на той же машине или на другой. Для многопользовательских баз данных более эффективным и надежным вариантом является серверная СУБД. В ней гораздо быстрее происходит доступ к данным, и значительно проще решаются конфликты между разными пользователями.
Понятие реляционной базы данных. Реляционная (relational) БД отличается способом представления информации, находящейся в ней. Данные в такой базе хранятся в плоских таблицах. Каждая таблица имеет собственный, заранее определенный набор именованных колонок (полей). Поля таблицы обычно соответствуют атрибутам сущностей, которые необходимо хранить в базе. Количество строк (записей) в таблице неограниченно, и каждая запись соответствует отдельной сущности. Каждая таблица должна иметь первичный ключ
(ПК) — поле или набор полей, содержимое которых однозначно определяет запись в таблице
и отличает ее от других. Связь между двумя таблицами
обычно образуется при добавлении в первую таблицу поля, содержащего значение первичного ключа второй таблицы. Реляционные СУБД (РСУБД) предоставляют средства для всевозможных пересечений и объединений
любых таблиц, отбора записей
по разнообразным условиям, группировки и сортировки
результатов.
Реляционная база данных сочетает наглядность представления информации с простотой (относительной) реализации своей концепции и является наиболее популярной структурой для хранения данных на сегодняшний день.
Хранение реляционной БД.
Данные в реляционной БД хранятся в плоских таблицах
. Каждая таблица имеет собственный, заранее определенный набор именованных колонок
(полей). Поля таблицы обычно соответствуют атрибутам сущностей, которые необходимо хранить в базе. Количество строк (записей) в таблице неограниченно, и каждая запись соответствует отдельной сущности.
Отличие записей от друг друга.
Записи в таблице отличаются только содержимым их полей. Две записи, в которых все поля одинаковы
, считаются идентичными
. Каждая таблица должна иметь первичный ключ
(ПК) — поле или набор полей, содержимое которых однозначно определяет запись в таблице
и отличает ее от других. Отсутствие первичного ключа
и наличие идентичных записей в таблице обычно возможно, но крайне нежелательно
.
Связывание таблиц между собой.
Простейшая связь между двумя таблицами
образуется при добавлении в первую таблицу поля, содержащего значение первичного ключа второй таблицы. В общем случае
, реляционные БД предоставляют очень гибкий механизм
для всевозможных пересечений и объединений любых таблиц, с разнообразными условиями. Для описания множеств, получающихся при пересечении и объединении
таблиц, используется специальный математический аппарат — реляционная алгебра
.
Понятие «нормализация».
Упорядочивание модели БД. Грубо говоря, нормализацией
называют процесс выявления отдельных независимых сущностей
и вынесения их в отдельные таблицы. При этом, связи с такими таблицами, обычно организуют по их первичному ключу. В результате нормализации, увеличивается гибкость
работы с БД. Также, уменьшается содержание дублирующей информации
в БД, а это сильно понижает вероятность возникновения ошибок
.
Имеет ли значение порядковый номер записи в таблице. Нет
. Реляционная алгебра оперирует множествами
, в которых порядковый номер элемента не несет никакой смысловой нагрузки. Записи отличатся только содержимым их полей
. Две записи, в которых все поля одинаковы
, будут абсолютно идентичны
в реляционной БД.
Понятие SQL-сервер. Сервер для управления реляционными БД
обычно называют SQL-сервером. SQL
(Structured Query Language — язык структурированных запросов) является стандартным языком
для работы с реляционными БД. Кроме стандартных реляционных операций, этот язык предоставляет возможности для изменений структуры таблиц
. Различные варианты SQL используются во всех, как серверных, так и в настольных реляционных СУБД.
Понятие пост-реляционной базы данных. Пост-реляционными
, часто называют многомерные базы данных
. Данные в многомерных базах, представляются в виде разреженных многомерных массивов
, а не плоских таблиц, как в реляционных базах. Для определенных задач, многомерные базы могут давать значительный выигрыш в быстродействии, по сравнению с реляционными. Наиболее известные многомерные СУБД:
· Cache
· Teradata
Разновидности СУБД.
Кроме реляционных
, объектно-ориентированных
и многомерных
СУБД, также давно известны иерархические
и сетевые
базы данных. Данные и связи между ними, в иерархических
БД представлены в виде деревьев. Для некоторых задач, такая форма представления данных может оказаться гораздо более эффективной, чем любая другая. В сетевых
базах, данные могут быть связаны произвольным образом, но эти связи должны создаваться предварительно, вместе со структурой данных. По сравнению с реляционными БД, сетевая модель может давать выигрыш в быстродействии
, при некоторой потере гибкости
.
Понятие «сервер баз данных».
Под сервером БД
обычно подразумевается СУБД, запущенная на той же машине, где находятся файлы БД, и монопольно
распоряжающаяся этими файлами. При этом, все пользовательские приложения
должны работать с базой только через эту СУБД
, используя ее язык запросов.
Понятие «Клиент».
Клиентом к БД
, обычно называют пользовательское приложение
, которое общается с сервером БД. Модель работы, в которой клиент общается непосредственно с сервером
, не используя промежуточных приложений, называется архитектурой клиент-сервер
.
Как клиент общается с сервером.
На пользовательских машинах
, обычно устанавливаются специальные программы-шлюзы
, которые, через сетевой протокол, обеспечивают связь с сервером БД. Через эти шлюзы, приложения передают запросы серверу и получают результаты. Часто, дополнительно устанавливается библиотека (ODBC, OLE DB и т.п.), предоставляющая приложениям API для работы с сервером БД
.
Назначение сервера приложений.
Сервер приложений может использоваться для многих целей. Как правило, сервер приложений находится на отдельной машине
. На него можно переложить всю функциональность программы
, оставив клиенту только интерфейсную часть. Это разгрузит клиента и сервер БД от вычислений. Также, при большом количестве пользователей, можно использовать несколько серверов приложений для распределения нагрузки
. А для ускорения доступа к часто используемым таблицам, их обычно кэшируют
на сервере приложений.
Объектно-ориентированная СУБД.
В объектно-ориентированных БД
(ООБД), данные представлены в виде объектов различных классов
. Как правило, имеются возможности создавать новые классы, наследовать их от уже имеющихся, задавать произвольные атрибуты и методы для классов. Для доступа к объектам, в каждой ООБД обычно предусматривается свой собственный язык, либо расширение другого языка. Пока еще ООБД недостаточно развиты
и не представляют серьезной конкуренции SQL-серверам, хотя и выглядят более предпочтительными для разработчиков. Производители SQL-серверов тоже, в свою очередь, иногда делают попытки соорудить над реляционным ядром сервера объектно-ориентированную надстройку
.
ДостаточнораспространеныследующиеООБД: Cache, FastObjects, GemStone/S, Jasmine,
ObjectStore,
Objectivity/DB, Versant.
Что можно делать при помощи SQL. SQL
(Structured Query Language — язык структурированных запросов) является стандартным языком
для работы с реляционными БД. Разделяется на две основные части:DDL
(Data Definition Language — язык определения данных) и DML
(Data Manipulation Language — язык обработки данных). DDL
предоставляет средства для создания и изменения структуры хранения данных
(БД, таблиц, процедур, типов данных и т.п.). DML
предназначен для чтения и изменения данных
. Основные операторы DML: select
— выборка, insert
— вставка, update
— изменение, delete
— удаление. Также, с помощью SQL
, часто реализован доступ к служебным функциям SQL-сервера (заведение пользователей, создание резервных копий БД и т.д.).
Зачем нужны транзакции.
Во многих случаях, необходимо проведение группы операций по изменению данных
таким образом, чтобы эта группа обладала свойством атомарности
(либо вся целиком выполняется, либо вся целиком не выполняется). Такая группа операций называется транзакцией
. В SQL-серверах существуют операторы, позволяющие обозначить начало транзакции
(begin transaction), ее успешное завершение
(commit transaction), либо откат транзакции
(rollback transaction).
Журнал транзакций.
Любые изменения данных, проведенные внутри транзакции, записываются в специальный журнал транзакций
(transaction log). При откате транзакции
, данные восстанавливаются в прежнем виде, а записи об изменениях удаляются из журнала транзакций.
Блокировки.
При изменении данных внутри транзакции, модифицируемые записи блокируются
сервером до окончания этой транзакции. Если какая-нибудь другая транзакция пытается изменить заблокированные записи, то ее выполнение останавливается
, пока не будет снята блокировка, то есть, пока не завершится первая транзакция. Некоторые сервера имеют неприятную особенность блокировать данные не отдельными записями, а целыми страницами
, которые могут содержать довольно много записей.
Отличие «версионников» от «блокировочников».
Классические «блокировочники»
не дают возможности разным транзакциям одновременно изменять одни и те же записи, блокируя их на время транзакции
. В результате, при попытке изменить заблокированную запись, другая транзакция будет простаивать, пока не завершиться первая. В свою очередь, «версионники»
позволяют одновременно модифицировать одни и те же записи, создавая при этом разные версии одной записи
.
Почему возникает deadlock. Перекрестная блокировка
(deadlock) двух транзакций возникает при изменении одних и тех же записей в разном порядке
. Последовательность действий, приводящая к перекрестной блокировке:
1. Транзакция A изменяет запись X. Заблокирована X.
2. Транзакция B изменяет запись Y. Заблокирована Y.
3. Транзакция A пытается изменить запись Y. Остановлена A.
4. Транзакция B пытается изменить запись X. Остановлена B.
Сервер определяет перекрестную блокировку и откатывает одну из транзакций, возвращая ошибку соответствующему соединению. Аминь. Чтобы не выводить ошибку пользователю, обломанное соединение должно молча повторить транзакцию.
Понятие «индексы».
Для ускорения операций выборки
данных. При поиске полей с определенным значением, сервер вынужден перебирать все записи в таблице. В этом случае, время поиска линейно зависит от размера таблицы
. Индекс по полю, обычно представляющий собой бинарное дерево
, дает возможность резко сократить время поиска
, превратив эту зависимость в логарифмическую
. Однако, наличие индексов в таблице, замедляет операции модификации
данных.
Необходимость первичного ключа в таблице. Первичный ключ
(ПК) — поле или набор полей, содержимое которых однозначно определяет запись в таблице
и отличает ее от других. Служит для однозначной идентификации записей и в таблице может быть только один. Обычно, при определении первичного ключа, по нему автоматически создается уникальный индекс.
Что такое триггер. Триггер
— процедура, выполняемая сервером автоматически
при модификации данных в таблице. В основном, триггеры используются для поддержания целостности дублирующей информации в денормализованной БД.
Можно ли использовать свою функцию в SQL-запросе.
Можно, практически во всех современных SQL-серверах. Различия только в синтаксисе определения и вызова функции. Кроме того, некоторые сервера позволяют использовать функции, написанные на других языках
(не SQL).
Представление
(view) — это запрос на выборку
, хранящийся на сервере, как отдельный объект. Так как, результат этого запроса можно рассматривать в качестве таблицы, представление допускается использовать в других запросах, также как любую обычную таблицу.
Материализованное представление
хранится на сервере в виде таблицы
, которая автоматически обновляется
при изменении данных, имеющих отношение к этому представлению.
Хранимые процедуры
(SP — Stored Procedure) представляют собой последовательность команд на расширениях SQL, либо на других языках, поддерживаемых сервером. Могут принимать параметры и возвращать значение заданного типа. Часто используются для выполнения операций, напрямую связанных с логикой задачи
, для которой проектировалась БД. Иногда, используются вместе с представлениями, для обеспечения безопасности БД
(все изменения через SP, все выборки через view).
Типы данных есть в SQL-сервере.
Обычно, для полей в таблицах могут использоваться только самые простые типы: числа
(целые и дробные), строки
(сильно ограниченные по длине), дата
(и время), бинарные
данные большого размера (для текста, графики и т.п.). В некоторых серверах допускается использование массивов и самодельных структур.
Необходимость внешнего ключа. Внешний ключ
(FK — Foreign Key) используется для создания жесткой связи
(многие к одному) между двумя таблицами. Внешний ключ задается только в том случае, если в первой таблице есть поле, содержащее значение первичного ключа
из второй таблицы. При изменении значения
первичного ключа во второй таблице, могут быть изменены все соответствующие значения
связанного поля в первой таблице. При удалении записи
с определенным первичным ключом из второй таблице, могут быть удалены все записи с соответствующим значением
связанного поля в первой таблице. Обычно, при определении внешнего ключа, по нему автоматически создается индекс, который используется в запросах при объединении этих двух таблиц.
Репликацией
обычно называют процесс синхронизации
данных между несколькими БД. Наиболее развитые SQL-сервера содержат встроенные
средства репликации. Для остальных могут быть использованы продукты сторонних фирм. Одностороняя
репликация подразумевает изменение данных только в одной базе, с последующей передачей изменений на остальные. Соответственно, довольно проста
в реализации и надежна
в работе. Двустороняя
репликация предоставляет гораздо более мощный инструмент распределенной работы между SQL-серверами. Плата за это — сложность и большая вероятность конфликтов при работе.
Типы SQL серверов и их особенности
Какой тип сервера лучше выбрать? На какой хватит денег.:) Вообще-то это может сильно зависеть от постановки задачи, количества пользователей и прихотей заказчика. Ниже приведена таблица самых распространенных SQL-серверов
в порядке (примерно) убывания их возможностей:
| Сервер
|
Достоинства
|
Недостатки
|
| IBM DB2 Universal Database
|
Самый навороченный язык запросов, лучший оптимизатор, возможность писать функции на других языках. |
Высокая стоимость. |
| Oracle Database
|
Великое множество дополнительных возможностей. Версионный сервер. |
Очень высокая стоимость сервера и поддержки. |
| Microsoft SQL Server
|
Быстро развивающийся продукт, уже вплотную приближающийся к своим более развитым конкурентам. Средняя стоимость. |
Существует только для одной платформы (Win32). |
| IBM Informix Dynamic Server
|
Довольно развитый быстрый сервер. |
— |
| Sybase Adaptive Server Enterprise
|
Достаточно развитый сервер. Средняя стоимость. |
— |
| Sybase Adaptive Server Anywhere
|
Существует под множество платформ, включая самые экзотичные. Низкая стоимость. |
— |
| Borland InterBase
|
Приличный набор возможностей. Версионный сервер. Бесплатный. |
Относительно медленно работает. |
| PostgreSQL
|
Поддерживает историческую модель. Возможность создавать свои типы данных. Бесплатный. |
— |
| MySQL
|
Быстро работает на простых запросах. Бесплатный. |
Очень бедный язык запросов. Мало дополнительных возможностей. |
|

