МОСКОВСКИЙИНСТИТУТ НАЦИОНАЛЬНЫХ И РЕГИОНАЛЬНЫХ ОТНОШЕНИЙ
Реферат
Статистика
Сводка статистических данных
Москва 2005г.
Содержание
Сводка статистических данных
Ошибки выборки
Список литературы
Сводка статистических данных
В результате первой стадии статистического исследования (статистического наблюдения) получают статистическую информацию,
представляющую собой большое количество первичных, разрозненных сведений об отдельных единицах объекта исследования (записи о каждом гражданине страны при переписи населения: пол, национальность, возраст, образование, род занятий и многие другие признаки). Дальнейшая задача статистики заключается в том, чтобы привести эти материалы в определенный порядок, систематизировать и на этой основе дать сводную характеристику всей совокупности фактов при помощи обобщающих статистических показателей, отражающих сущность социально-экономических явлений и определенные статистические закономерности. Это достигается в результате сводки
— второй стадии статистического исследования.
Статистическая сводка
— это научно организованная обработка материалов наблюдения, включающая в себя систематизацию, группировку данных, составление таблиц, подсчет групповых и общих итогов, расчет производных показателей (средних, относительных величин). Она позволяет перейти к обобщающим показателям совокупности в целом и отдельных ее частей, осуществлять анализ и прогнозирование изучаемых процессов.
Если производится только подсчет общих итогов по изучаемой совокупности единиц наблюдения, то сводка называется простой.
Например, для получения общей численности студентов высших учебных заведений России достаточно сложить данные о численности студентов всех высших учебных заведений (на конец 1998 г. — 3,6 млн. чел.).
По технике или способу выполнения сводка может быть ручной
либо механизированной
(с помощью ЭВМ).
Статистическая сводка проводится по определенной программе и плану.
Программа статистической сводки
устанавливает следующие этапы:
•выбор группировочных признаков;
•определение порядка формирования групп;
•разработка системы статистических показателей для характеристики групп и объекта в целом;
•разработка макетов статистических таблиц для представления результатов сводки.
План статистической сводки
содержит указания о последовательности и сроках выполнения отдельных частей сводки, ее исполнителях и о порядке изложения и представления результатов.
В сводке статистического материала отдельные единицы статистической совокупности объединяются в группы при помощи метода группировок.
Статистическая группировка
— это процесс образования однородных групп на основе расчленения статистической совокупности на части или объединения изучаемых единиц в частные совокупности по существенным
для них признакам, каждая из которых характеризуется системой статистических показателей. Например, группировка промышленных предприятий по формам собственности, группировка населения по размеру среднедушевого дохода, группировка коммерческих банков по сумме активов баланса и т.д.
Особым видом группировок является классификация,
представляющая собой устойчивую номенклатуру классов и групп, образованных на основе сходства и различия единиц изучаемого объекта. Классификация выступает в роли своеобразного статистического стандарта, устанавливаемого на определенный промежуток времени, например, ЕГРПО. Общероссийский классификатор видов экономической деятельности, продукции и услуг (ОКПД), классификация основных фондов в промышленности, строительстве, капитальных вложений, затрат на производство и т.д.
Метод статистических группировок позволяет разрабатывать первичный статистический материал. На основе группировки рассчитываются сводные показатели по группам, появляется возможность их сравнения, анализа причин различий между группами, изучения взаимосвязей между признаками. Расчет сводных показателей в целом по совокупности позволяет изучить ее структуру.
Кроме того, группировка создает основу для последующей сводки и анализа данных. Этим определяется роль группировок как научной основы сводки.
Большие достижения в области применения метода группировок имеет современная отечественная статистика. Введение группировочных таблиц, содержащих показатели международной системы национальных счетов
(СНС), превращает группировки (классификации) в эффективный метод анализа и вскрытия резервов в экономике.
Ошибки выборки
При выборочном наблюдении должна быть обеспечена случайность
отбора единиц. Каждая единица должна иметь равную с другими возможность быть отобранной. Именно на этом основывается собственно-случайная выборка.
К собственно-случайной выборке
относится отбор единиц из всей генеральной совокупности (без предварительного расчленения ее на какие-либо группы) посредством жеребьевки (преимущественно) или какого-либо иного подобного способа, например, с помощью таблицы случайных чисел. Случайный отбор
— это отбор не беспорядочный. Принцип случайности предполагает, что на включение или исключение объекта из выборки не может повлиять какой-либо фактор, кроме случая. Примером собственно-случайного
отбора могут служить тиражи выигрышей: из общего количества выпущенных билетов наугад отбирается определенная часть номеров, на которые приходятся выигрыши. Причем всем номерам обеспечивается равная возможность попадания в выборку. При этом количество отобранных в выборочную совокупность единиц обычно определяется исходя из принятой доли выборки.
Долявыборки
есть отношение числа единиц выборочной совокупности к числу единиц генеральной совокупности:
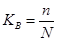
Так, при 5%-ной выборке из партии деталей в 1000 ед. объём выборки п
составляет 50 ед., а при 10%-ной выборке — 100 ед. и т.д. При правильной научной организации выборки ошибки репрезентативности можно свести к минимальным значениям, в результате — выборочное наблюдение становится достаточно точным.
Собственно-случайный отбор «в чистом виде» применяется в практике выборочного наблюдения редко, но он является исходным среди всех других видов отбора, в нем заключаются и реализуются основные принципы выборочного наблюдения.
Рассмотрим некоторые вопросы теории выборочного метода и формулы ошибок для простой случайной выборки.
Применяя выборочный метод в статистике, обычно используют два основных вида обобщающих показателей: среднюю величину количественного признака
и относительную величину альтернативного признака
(долю или удельный вес единиц в статистической совокупности, которые отличаются от всех других единиц этой совокупности только наличием изучаемого признака).
Выборочная доля
(
w
),
или частость, определяется отношением числа единиц, обладающих изучаемым признаком т,
к общему числу единиц выборочной совокупности п:
w
=
m
/
n
.
Например, если из 100 деталей выборки (n
=100), 95 деталей оказались стандартными (т
=95), то выборочная доля
w
=95/100=0,95 .
Для характеристики надежности выборочных показателей различают среднюю
и предельную ошибки выборки.
Ошибка выборки
ε или, иначе говоря, ошибка репрезентативности представляет собой разность соответствующих выборочных и генеральных характеристик:
• для средней количественного признака
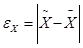 ; (форм. 1) ; (форм. 1)
• для доли (альтернативного признака)
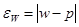 ; (форм. 2) ; (форм. 2)
Ошибка выборки свойственна только выборочным наблюдениям. Чем больше значение этой ошибки, тем в большей степени выборочные показатели отличаются от соответствующих генеральных показателей.
Выборочная средняя и выборочная доля по своей сути являются случайными величинами,
которые могут принимать различные значения в зависимости от того, какие единицы совокупности попали в выборку. Следовательно, ошибки выборки также являются случайными величинами и могут принимать различные значения. Поэтому определяют среднюю из возможных ошибок — среднюю ошибку выборки.
От чего зависит средняя ошибка выборки?
При соблюдении принципа случайного отбора средняя ошибка выборки определяется прежде всего объемом выборки:
чем больше численность при прочих равных условиях, тем меньше величина средней ошибки выборки. Охватывая выборочным обследованием все большее количество единиц генеральной совокупности, всё более точно характеризуем всю генеральную совокупность.
Средняя ошибка выборки также зависит от степени варьирования
изучаемого признака. Степень варьирования, как известно, характеризуется дисперсией σ2
или w
(1-
w
)
—
для альтернативного признака. Чем меньше вариация признака, а следовательно, и дисперсия, тем меньше средняя ошибка выборки, и наоборот. При нулевой дисперсии (признак не варьирует) средняя ошибка выборки равна нулю, т. е. любая единица генеральной совокупности будет совершенно точно характеризовать всю совокупность по этому признаку.
Зависимость средней ошибки выборки от ее объема и степени варьирования признака отражена в формулах, с помощью которых можно рассчитать среднюю ошибку выборки в условиях выборочного наблюдения, когда генеральные характеристики (х ,
p
)
неизвестны, и следовательно, не представляется возможным нахождение реальной ошибки выборки непосредственно по формулам (форм. 1), (форм. 2).
- При случайном повторном отборе
средние ошибки
теоретически рассчитывают по следующим формулам:
• для средней количественного признака
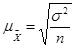 ; (форм. 3) ; (форм. 3)
• для доли (альтернативного признака)
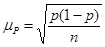 ; (форм. 4) ; (форм. 4)
Поскольку практически дисперсия признака в генеральной совокупности σ2
точно неизвестна, на практике пользуются значением дисперсии S2
, рассчитанным для выборочной совокупности на основании закона больших чисел, согласно которому выборочная совокупность при достаточно большом объеме выборки достаточно точно воспроизводит характеристики генеральной совокупности.
Таким образом, расчетные формулы
средней
ошибки выборки
при случайном повторном отборе будут следующие:
• для средней количественного признака
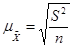 ; (форм. 5) ; (форм. 5)
• для доли (альтернативного признака)
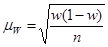 . (форм. 6) . (форм. 6)
Однако дисперсия выборочной совокупности не равна дисперсии генеральной совокупности, и следовательно, средние ошибки выборки, рассчитанные по формулам (форм. 5) и (форм. 6), будут приближенными. Но в теории вероятностей доказано, что генеральная дисперсия выражается через выборную следующим соотношением:
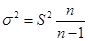 . (форм. 7) . (форм. 7)
Так как п/
(n
-1) при достаточно больших п —
величина, близкая к единице, то можно принять, что 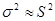 , а следовательно, в практических расчетах средних ошибок выборки можно использовать формулы (форм. 5) и (форм. 6). И только в случаях малой выборки (когда объем выборки не превышает 30) необходимо учитывать коэффициент п
/(n
-1) иисчислять среднюю ошибку малой выборки
по формуле: , а следовательно, в практических расчетах средних ошибок выборки можно использовать формулы (форм. 5) и (форм. 6). И только в случаях малой выборки (когда объем выборки не превышает 30) необходимо учитывать коэффициент п
/(n
-1) иисчислять среднюю ошибку малой выборки
по формуле:
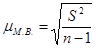 . (форм. 8) . (форм. 8)
- XПри случайном бесповторном отборе
в приведенные выше формулы расчета средних ошибок выборки необходимо подкоренное выражение умножить на 1-(n/N), поскольку в процессе бесповторной выборки сокращается численность единиц генеральной совокупности. Следовательно, для бесповторной выборки расчетные формулы
средней ошибки выборки
примут такой вид:
• для средней количественного признака
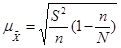 ; (форм. 9) ; (форм. 9)
 • для доли (альтернативного признака) • для доли (альтернативного признака)
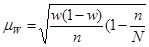 . (форм. 10) . (форм. 10)
Так как п
всегда меньше N
, то дополнительный множитель 1-(n
/
N
)всегда будет меньше единицы. Отсюда следует, что средняя ошибка при бесповторном отборе всегда будет меньше, чем при повторном. В то же время при сравнительно небольшом проценте выборки этот множитель близок к единице (например, при 5%-ной выборке он равен 0,95; при 2%-ной — 0,98 и т.д.). Поэтому иногда на практике пользуются для определения средней ошибки выборки формулами (форм. 5) и (форм. 6) без указанного множителя, хотя выборку и организуют как бесповторную. Это имеет место в тех случаях, когда число единиц генеральной совокупности N неизвестно или безгранично, или когда п
очень мало по сравнению с N
, и по существу, введение дополнительного множителя, близкого по значению к единице, практически не повлияет на значение средней ошибки выборки.
Механическая выборка
состоит в том, что отбор единиц в выборочную совокупность из генеральной, разбитой по нейтральному признаку на равные интервалы (группы), производится таким образом, что из каждой такой группы в выборку отбирается лишь одна единица. Чтобы избежать систематической ошибки, отбираться должна единица, которая находится в середине каждой группы.
При организации механического отбора единицы совокупности предварительно располагают (обычно в списке) в определенном порядке (например, по алфавиту, местоположению, в порядке возрастания или убывания значений какого-либо показателя, не связанного с изучаемым свойством, и т.д.), после чего отбирают заданное число единиц механически, через определенный интервал. При этом размер интервала в генеральной совокупности равен обратному значению доли выборки. Так, при 2%-ной выборке отбирается и проверяется каждая 50-я единица (1 : 0,02), при 5%-ной выборке — каждая 20-я единица (1 : 0,05), например, сходящая со станка деталь.
При достаточно большой совокупности механический отбор по точности результатов близок к собственно-случайному. Поэтому для определения средней ошибки механической выборки используют формулы собственно-случайной бесповторной выборки (форм. 9), (форм. 10).
Для отбора единиц из неоднородной совокупности применяется, так называемая типическая выборка
,
которая используется в тех случаях, когда все единицы генеральной совокупности можно разбить на несколько качественно однородных, однотипных групп по признакам, влияющим на изучаемые показатели.
При обследовании предприятий такими группами могут быть, например, отрасль и подотрасль, формы собственности. Затем из каждой типической группы собственно-случайной или механической выборкой производится индивидуальный отбор единиц в выборочную совокупность.
Типическая выборка обычно применяется при изучении сложных статистических совокупностей. Например, при выборочном обследовании семейных бюджетов рабочих и служащих в отдельных отраслях экономики, производительности труда рабочих предприятия, представленных отдельными группами по квалификации.
Типическая выборка дает более точные результаты по сравнению с другими способами отбора единиц в выборочную совокупность. Типизация генеральной совокупности обеспечивает репрезентативность такой выборки, представительство в ней каждой типологической группы, что позволяет исключить влияние межгрупповой дисперсии на среднюю ошибку выборки.
При определении средней ошибки типической выборки
в качестве показателя вариации выступает средняя из внутригрупповых дисперсий.
Среднюю ошибку выборки
находят по формулам:
• для средней количественного признака
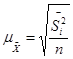 (повторный отбор); (форм. 11) (повторный отбор); (форм. 11)
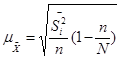 (бесповоротный отбор); (форм. 12) (бесповоротный отбор); (форм. 12)
• для доли (альтернативного признака)
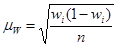 (повторный отбор); (форм.13) (повторный отбор); (форм.13)
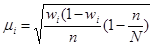 (бесповторный отбор), (форм. 14) (бесповторный отбор), (форм. 14)
где 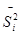 - средняя из внутригрупповых дисперсий по выборочной совокупности; - средняя из внутригрупповых дисперсий по выборочной совокупности;
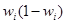 - средняя из внутригрупповых дисперсий доли (альтернативного признака) по выборочной совокупности. - средняя из внутригрупповых дисперсий доли (альтернативного признака) по выборочной совокупности.
Серийная выборка
предполагает случайный отбор из генеральной совокупности не отдельных единиц, а их равновеликих групп (гнезд, серий) с тем, чтобы в таких группах подвергать наблюдению все без исключения единицы.
Применение серийной выборки обусловлено тем, что многие товары для их транспортировки, хранения и продажи упаковываются в пачки, ящики и т.п. Поэтому при контроле качества упакованного товара рациональнее проверить несколько упаковок (серий), чем из всех упаковок отбирать необходимое количество товара.
Поскольку внутри групп (серий) обследуются все без исключения единицы, средняя ошибка выборки (при отборе равновеликих серий) зависит только от межгрупповой (межсерийной) дисперсии.
- Среднюю ошибку выборки для средней количественного признака
при серийном отборе находят по формулам:
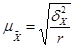 (повторный отбор); (форм.15) (повторный отбор); (форм.15)
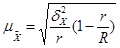 (бесповторный отбор), (форм. 16) (бесповторный отбор), (форм. 16)
где r
-
число отобранных серий; R
-
общее число серий.
Межгрупповую дисперсию серийной выборки вычисляют следующим образом:
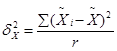 , ,
где 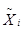 - средняя i
- й серии; - средняя i
- й серии; 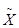 - общая средняя по всей выборочной совокупности. - общая средняя по всей выборочной совокупности.
- Средняя ошибка выборки для доли (альтернативного признака)
при серийном отборе:
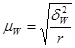 (повторный отбор); (форм. 17) (повторный отбор); (форм. 17)
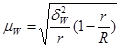 (бесповторный отбор). (
форм. 18) (бесповторный отбор). (
форм. 18)
Межгрупповую
(межсерийную) дисперсию доли серийной выборки
определяют по формуле:
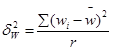 , (форм. 19) , (форм. 19)
где 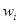 - доля признака в i
-й серии; - доля признака в i
-й серии; 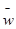 - общая доля признака во всей выборочной совокупности. - общая доля признака во всей выборочной совокупности.
Впрактике статистических обследований помимо рассмотренных ранее способов отбора применяется их комбинация (комбинированный отбор).
Список литературы
Гусаров В.М. Теория статистики: уч. М.: ЮНИТИ, Аудит, 1998
Колбачёв Е.Б. Основы статистики. Учебник. М.: Ростов-на-Дону, Феникс,1999
|