| ФЕДЕРАЛЬНОЕ АГЕНТСТВО ПО ОБРАЗОВАНИЮ
РОССИЙСКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ
ИМЕНИ ИММАНУИЛА КАНТА
кафедра управления хозяйством
|
КОНТРОЛЬНАЯ РАБОТА
по дисциплине «Статистика»
вариант № 6
КАЛИНИНГРАД
2006
Содержание
Задание………………………………………………………………………….…3
1. Виды средних величин. Функции средних в статистике……………………4
2. Уравнение тренда на основе линейной зависимости………………..……..13
Задача 1…………………………………………………………………………..20
Задача 2…………………………………………………………………………..24
Список использованных источников…………………………………………..25
Задание:
Теоретические вопросы:
1. Виды средних величин. Функции средних в статистике.
2. Уравнение тренда на основе линейной зависимости.
Практические задачи:
1. Десять человек различного возраста имеют следующие параметры:
| Возраст, лет
|
18
|
20
|
21
|
22
|
22
|
24
|
25
|
26
|
31
|
39
|
| Рост, см
|
174
|
183
|
182
|
180
|
178
|
179
|
185
|
185
|
184
|
182
|
| Вес, кг
|
65
|
73
|
69
|
74
|
77
|
75
|
78
|
84
|
79
|
79
|
1. Определить результативный признак.
2. Рассчитать парные и частные коэффициенты корреляции. Сделать выводы.
2. При контрольной выборочной проверке процента влажности почвы фермерских хозяйств региона получены следующие данные:
| 3.8
|
3.9
|
4.0
|
3.6
|
4.5
|
4.1
|
4.0
|
3.2
|
1. С вероятностью 0.95 и 0.99 установить предел, в котором находится средний процент содержания влаги.
2. Сделать выводы.
1. Средние величины
1.1. Понятие средней величины и значение метода средних величин.
Значения, отображающие размер признака общественного явления, различаются между собой. Это называют вариацией явления. С другой стороны, различные элементы принадлежат одному и тому же явлению, оказывают влияние друг на друга, поэтому значения признаков у таких элементов сближаются, что дает возможность рассматривать их как единую совокупность. Для исследования совокупности, обладающей различными значениями признака у отдельных ее единиц, необходимо иметь единую типическую для совокупности величину признака, позволяющую анализировать совокупность и сравнивать динамические изменения в совокупности. Для этого применяется средняя величина. Средняя величина рассчитывается только по количественным признакам.
Средняя величина это:
1) наиболее типичное для совокупности значение признака;
2) объем признака совокупности, распределенный поровну между единицами совокупности.
Средняя величина является показателем, рассчитываемым путем сопоставления абсолютных или относительных величин. Для получения требуемой средней величины необходимо корректно определить те показатели, которые следует соотнести, т.е. построить исходное соотношение средней. Исходное соотношение отражает сущность рассчитываемой средней величины. Для каждой средней величины может быть только одно исходное соотношение. Средняя величина имеет двойственный характер: с одной стороны она характеризует совокупность в целом, а с другой стороны, она относится к единице совокупности, и также является характеристикой единицы совокупности. Средняя величина может принимать такие значения, которые не присущи непосредственно ни одному из элементов изучаемой совокупности, кроме того, на практике часто средняя величина для дискретного признака выражается как для непрерывного.
Средняя величина являются равнодействующей всех факторов, оказывающих влияние на изучаемое явление. То есть, при расчете средних величин взаимопогашаются влияние случайных (пертурбационных, индивидуальных) факторов и, таким образом, возможно определение закономерности, присущей исследуемому явлению. Значения исследуемого признака принимают различные размеры, находящиеся в определенном интервале. То есть существует возможность говорить о распределении размеров признака, подверженном влиянию целого ряда факторов. Тогда средняя величина является показателем центра распределения. Необходимо подчеркнуть важность понимания средней величины как центра распределения, так как на этом основывается дальнейший статистический анализ.
1.2. Условия применения средних величин в анализе.
Обязательным условием расчета средних величин для исследуемой совокупности является ее однородность. Действительно, допустим, что отдельные элементы совокупности, вследствие подверженности влиянию некоторого случайного фактора, имеют слишком большие (или слишком малые) величины изучаемого признака, существенно отличающиеся от остальных. Такие элементы повлияют на размер средней для данной совокупности, поэтому средняя не будет выражать наиболее характерную для совокупности величину признака.
Если исследуемое явление не является однородным, то его разбивают на группы, содержащие только однородные элементы. Для такого явления рассчитываются сначала средние по группам, которые называются групповые средние, – они будут выражать наиболее типичную величину явления в каждой группе. Затем рассчитывается для всех элементов общая средняя величина, характеризующая явление в целом, – она рассчитывается как средняя из групповых средних, взвешенных по числу элементов совокупности, включенных в каждую группу.
Еще одним важным условием применения средних величин в анализе является достаточное количество единиц в совокупности, по которой рассчитывается среднее значение признака. Достаточность анализируемых единиц обеспечивается корректным определением границ исследуемой совокупности, т.е. закладывается еще на начальном этапе статистического исследования.
Определение максимального и минимального значения признака в изучаемой совокупности также является условием применения средней величины в анализе. В случае больших отклонений между крайними значениями и средней, необходимо проверить принадлежность экстремумов к исследуемой совокупности. Если сильная изменчивость признака вызвана случайными, кратковременными факторами, то, возможно, крайние значения не характерны для совокупности. Следовательно, их следует исключить из анализа, т.к. они оказывают влияние на размер средней величины.
1.3. Виды средних величин, способы их вычисления.
В статистике выделяют несколько видов средних величин:
1. По наличию признака-веса:
а) невзвешенная средняя величина;
б) взвешенная средняя величина.
2. По форме расчета:
а) средняя арифметическая величина;
б) средняя гармоническая величина;
в) средняя геометрическая величина;
г) средняя квадратическая, кубическая и т.д. величины.
3. По охвату совокупности:
а) групповая средняя величина;
б) общая средняя величина.
Средние величины различаются в зависимости от учета признаков, влияющих на осредняемую величину: Если средняя величина рассчитывается для признака, без учета влияния на него каких-либо других признаков, то такая средняя величина называется средней невзвешенной или простой средней. Если имеются сведения о влиянии на осредняемый признак некоторого признака или нескольких признаков, которые необходимо учесть при расчете для корректного расчета средней величины, то рассчитывается средняя взвешенная.
При выборе вида средней величины исходят из логической сущности осредняемого признака и его взаимосвязи с итоговым (определяющим) показателем. Величина итогового показателя не должна изменяться при замене индивидуальных значений признака средней величиной. Способность средних величин сохранять свойства статистических совокупностей называют определяющим свойством.
Общая формула степенной средней выглядит следующим образом:
.
`x = k
Ö x
1
k
+ x
2
k
+ ...
+
x
n
k
.
n
С изменением показателя степени k выражение данной функции меняется, и в каждом отдельном случае приходит к определённому виду средней.
Виды степенных средних величин.
| k
|
Вид средней
|
Простая
|
Взвешенная
|
| -1
|
Средняя гармоническая
|
`x = n .
å 1/xi
|
`x = å
f
i
.
å(1/xi
)*fi
|
| 0
|
Средняя геометрическая
|
.
`x = n
Ö x1
*x2
* ... *xn
|
.
``x = å
fi
Ö x1
f1
*x2
f2
* ... *xn
fn
|
| 1
|
Средняя арифметическая
|
`x = å
x
i
.
n
|
`x = å
x
i
*f
i
.
åfi
|
| 2
|
Средняя квадратическая
|
.
`x = Ö å
x
i
2
*f
i
.
åfi
|
.
`x = Ö å
x
i
2
n
|
1.3.1. Средняя арифметическая величина.
1). Средняя арифметическая не взвешенная величина – наиболее характерная форма средней, на примере которой можно выявить все свойства средней. Если показатель степени равен 1, то получаем следующую форму средней. Такая средняя величина называется средней арифметической простой (невзвешенной).
`x = å
x
i
n
xi
– значение изучаемого признака для i-того элемента совокупности;
n – число наблюдений (число единиц совокупности).
Данная форма средней величины является наиболее распространенной. Она получается путем соотношения суммарного объема индивидуальных значений признака каждого элемента совокупности и числа элементов совокупности. Средняя арифметическая невзвешенная применяется в том случае, если имеются сведения об объеме осредняемого признака.
2) Средняя арифметическая взвешенная величина.
Если имеются сведения о количестве или доле единиц совокупности с тем или иным значением осредняемого признака, то рассчитывается средняя арифметическая взвешенная:
`x = å
x
i
*f
i
åfi
xi
– индивидуальные значения осредняемого признака у отдельных единиц совокупности;
fi
– значения признака-веса для каждой единицы совокупности.
В зависимости от осредняемых данных выделяют несколько случаев применения средней арифметической взвешенной величины:
- расчет средней арифметической взвешенной в случае, если осредняемый признак выражен в абсолютных величинах, а признак-вес представлен первичным показателем;
- расчет средней арифметической взвешенной в случае, если осредняемый признак представлен в интервальном виде, т.е. когда данные, находящиеся в числителе исходного соотношения, рассчитываются следующим образом: сначала определяются середины интервалов (xi
); затем серединное значение для каждого интервала умножается на значение признака-веса для этого интервала (fi
); полученные произведения суммируются (åxi
*fi
). Полученный таким образом числитель соотносится с суммой значений признака-веса.
- расчет средней арифметической взвешенной, если в качестве осредняемого признака принимается удельный вес (т.е. когда совокупность поделена на подгруппы, в каждой из которых определено количество единиц, обладающих изучаемым признаком, доля таких единиц в общей численности подгруппы, и необходимо рассчитать среднее значение доли во всех подгруппах.
1.3.2. Средняя гармоническая величина.
1) Средняя гармоническая невзвешенная величина.
Если показатель степени равен (-1), то образуется следующая форма средней:
`x = n .
å(1/xi
)
xi
– индивидуальные значения осредняемого признака у отдельных единиц совокупности.
Такая средняя величина называется средней гармонической простой (невзвешенной). Она взаимосвязана со средней арифметической невзвешенной как величина, обратная средней арифметической, рассчитанная из обратных значений признака. Средняя гармоническая невзвешенная величина применяется в том случае, если согласно исходному соотношению средней необходимо, чтобы в знаменателе располагались обратные значения осредняемого признака. Данный вид средней применяется также, если значения признаков-весов одинаковы, следовательно, образуется тождество между средней гармонической взвешенной и средней гармонической невзвешенной.
2) Средняя гармоническая взвешенная величина.
Средняя гармоническая взвешенная величина имеет следующий вид:
`x = å
f
i
.
å(1/xi
)*fi
хi
– осредняемый признак;
Средняя гармоническая взвешенная величина рассчитывается в том случае, если имеющиеся данные предоставляют сведения об объеме определяющего показателя, рассчитываемого как произведение осредняемого признака и признака-веса. И если имеются также сведения об индивидуальных значениях осредняемого признака, а данные об отдельных значениях признака веса отсутствуют.
Такая форма средней применяется, когда необходимо рассчитать:
- общую среднюю из групповых средних величин; - среднюю относительную величину, если не известна величина, находящаяся в знаменателе осредняемого признака.
1.3.3. Средняя геометрическая величина.
1) Средняя геометрическая невзвешенная величина.
Если показатель степени равен 0, то получаем следующую форму средней:
.
x = n
Ö x
1
* x
2
* ...
*
x
n
.
n
xi
– индивидуальные значения признака у отдельных единиц совокупности;
Пxi
– произведение индивидуальных значений осредняемого признака;
n – число элементов совокупности.
Такая средняя величина называется средней геометрической простой (невзвешенной).
Данная форма средней отличается от остальных форм, описанных выше, в той же мере, как арифметическая прогрессия от геометрической. То есть, в случае расчета средних арифметической и гармонической элементы совокупности представляли собой либо:
- абсолютные величины, которые могли быть просуммированы между собой;
- относительные величины, которые путем дополнительных расчетов переводились в абсолютные, и затем суммировались.
В данной форме средней элементами исследуемой совокупности являются:
- относительные величины, объединенные в ряд динамики, т.е. с учетом фактора времени. Например, темпы роста, или относительные величины планового задания и выполнения плана, или относительные величины сравнения, рассчитанные для нескольких периодов. То есть, в качестве единиц совокупности выступают величины, полученные путем соотнесения различных признаков, поэтому для таких величин средняя рассчитывается через их произведение. Кроме того, как уже указывалось выше, вторичные показатели, которыми являются относительные величины динамики, не могут суммироваться.
- максимальная и минимальная величины признака. То есть, в случае если известны лишь экстремальные значения признака (хmin и хmax), то средняя рассчитывается как корень квадратный произведения между ними.
2) Средняя геометрическая взвешенная величина.
Данная форма средней применяется когда темпы роста остаются неизменными в течение нескольких периодов. Формула средней геометрической взвешенной определяется следующим образом:
.
`x = å
fi
Ö x1
f1
*x2
f2
* ... *xn
fn
хi
– количество периодов, в течение которых темпы роста оставались неизменными;
По охвату совокупности выделяют групповую среднюю и общую среднюю. Такие виды средних применяются, когда существует необходимость разбить совокупность на группы для более полного изучения. Тогда одной из характеристик выделенных групп будет служить групповая средняя. Она рассчитывается по тем же принципам, что и общая средняя, т.е. объем группы исследуется как объем отдельной совокупности. Причем, среднее значение групповых средних, взвешенных по числу единиц или по суммарному значению признака-веса в группе будет равно общей средней.
2. Уравнение тренда на основе линейной зависимости.
2.1. Основные элементы временного ряда.
Можно построить эконометрическую модель, используя два типа исходных данных:
-данные, характеризующие совокупность различных объектов в определённый момент времени.
-данные, характеризующие один объект за ряд последовательных моментов времени.
Модели, построенные по данным первого типа, называются пространственными
. Модели, построенные на основе второго типа данных, называются временными рядами
.
Временной ряд
– это совокупность значений какого-либо показателя за несколько последовательных моментов или периодов времени. Каждый уровень временного ряда формируется под воздействием большого числа факторов, которые условно можно подразделить на три группы:
-факторы, формирующие тенденцию ряда.
-факторы, формирующие циклические колебания ряда.
-случайные факторы.
При различных сочетаниях в изучаемом явлении или процессе этих факторов зависимость уровней ряда от времени может принимать различные формы.
Во-первых, большинство временных рядов экономических показателей имеют тенденцию, характеризующую совокупное долговременное воздействие множества факторов на динамику изучаемого показателя. Очевидно, что эти факторы, взятые в отдельности, могут оказывать разнонаправленное воздействие на исследуемый показатель. Однако в совокупности они формируют его возрастающую или убывающую тенденцию. На рис. 1.
показан временной ряд, содержащий возрастающую тенденцию.
Во-вторых, изучаемый показатель может быть подвержен циклическим колебаниям. Эти колебания могут носить сезонный характер, поскольку экономическая деятельность ряда отраслей экономики зависит от времени года. При наличии больших массивов данных за длительные промежутки времени можно выявить циклические колебания, связанные с общей динамикой конъюнктуры рынка, а также с фазой бизнес цикла, в которой находится экономика страны. На рис. 2.
представлен временной ряд, содержащий только сезонную компоненту.
Некоторые временные ряды не содержат тенденции и циклической компоненты, а каждый следующий их уровень базируется как сумма среднего уровня ряда и некоторой случайной компоненты. Пример ряда, содержащего только случайную компоненту, приведён на рис. 3.
Очевидно, что реальные данные не следуют полностью из каких-либо описанных моделей. Чаще всего они содержат все три компоненты. Каждый их уровень формируется под воздействием тенденции, сезонных колебаний и случайной компоненты.
В большинстве случаев фактический уровень временного ряда можно представить как сумму или произведение трендовой, циклической и случайной компонент. Модель, в которой временной ряд представлен как сумма перечисленных компонент, называется аддитивной моделью
. Модель, в которой временной ряд представлен как произведение перечисленных компонент, называется мультипликативной моделью.
2.2. Автокорреляция уровней временного ряда.
При наличии во временном ряде тенденции и циклических колебаний значения каждого последующего уровня ряда зависят от предыдущих. Корреляционную зависимость между последовательными уровнями временного ряда называют автокорреляцией.
Количественно её можно измерить с помощью линейного коэффициента корреляции между уровнями исходного временного ряда и уровнями этого ряда, сдвинутыми во времени.
Одна из рабочих формул для расчёта коэффициента корреляции имеет вид:
rxy
= å
(
xj
-
`
x
) * (
yj
-
`
y
) .
Öå(xj
-`x)2
* å(yj
-`y)2
В качестве переменной x
мы рассмотрим ряд y2
, y3
, ... yt
; в качестве переменной y
рассмотрим ряд y1
, y2
, ... yt
-1
. Тогда данная формула примет вид:
r1
= å
(y
t
-
`
y
1
) * (y
t-1
-
`
y
2
)
; где `y1
= å
y
t
; `y2
= å
y
t-1
.
Öå(yt
-`y1
)2
* å(yt-1
-`y2
)2
n - 1 n - 1
Эту величину называют коэффициентом автокорреляции уровней ряда первого порядка. Число периодов, по которым рассчитывается коэффициент автокорреляции, называют лагом
. С увеличением лага число пар значений, по которым рассчитывается коэффициент автокорреляции, уменьшается.
Свойства коэффициента автокорреляции:
-во-первых, он строится по аналогии с линейным коэффициентом корреляции и таким образом характеризует тесноту только линейной связи текущего и предыдущего уровней ряда. Поэтому по коэффициенту автокорреляции можно судить о наличии линейной тенденции.
-во-вторых, по знаку коэффициента автокорреляции нельзя делать вывод о возрастающей или убывающей тенденции в уровнях ряда.
Последовательность коэффициентов автокорреляции уровней первого, второго, и т.д. порядков называют автокорреляционной функцией временного ряда. График зависимости её значений от величины лага называется коррелограммой. Анализ автокорреляционной функции и коррелограммы позволяет определить лаг, при котором автокорреляция наиболее высокая, а, следовательно, и лаг, при котором связь между текущим и предыдущим уровнями ряда наиболее тесная, т.е. при помощи анализа автокорреляционной функции и коррелограммы можно выявить структуру ряда.
Если наиболее высоким оказался коэффициент автокорреляции первого порядка, исследуемый ряд содержит только тенденцию. Если наиболее высоким оказался коэффициент автокорреляции порядка t
, ряд содержит циклические колебания с периодичностью в t
моментов времени. Если ни один из коэффициентов автокорреляции не является значимым, можно сделать вывод: либо ряд не содержит тенденции и циклических колебаний, либо ряд содержит сильную нелинейную тенденцию, для выявления которой нужно провести дополнительный анализ.
2.3. Моделирование тенденции временного ряда.
Одним из наиболее распространённых способов моделирования тенденции временного ряда является построение аналитической функции, характеризующей зависимость уровней ряда от времени, или тренда. Этот способ называют аналитическим выравниванием временного ряда.
Т.к. зависимость от времени может принимать разные формы, для её формализации можно использовать различные виды функции. Для построения трендов чаще всего применяются следующие функции:
-линейный тренд: `yt
= a + b*t ;
-гипербола:`yt
= a + b/t ;
-экспоненциальный тренд: `yt
= e a
+
b
*
t
;
-тренд в форме степенной функции: `yt
= a*tb
;
-парабола: `yt
= a + b1
*t + b2
*t2
+ ... + bk
*tk
;
Параметры каждого из этих трендов можно определить методом наименьших квадратов, используя в качестве независимой переменной время t
= 1, 2, ... ,n , а в качестве зависимой переменной – фактические уровни временного ряда yt
. Для нелинейных трендов предварительно проводят стандартную процедуру их линеаризации.
Существует несколько способов определения типа тенденции. К числу наиболее распространённых способов относятся качественный анализ изучаемого процесса, построение и визуальный анализ графика зависимости уровней ряда от времени, расчёт некоторых основных показателей динамики. В этих же целях можно использовать и коэффициенты автокорреляции уровней ряда. Тип тенденции можно определить путем сравнения коэффициентов автокорреляция первого порядка, рассчитанных по исходным и преобразованным уровням ряда. Если временной ряд имеет линейную тенденцию, то его соседние уровни yt
и yt
-1
тесно коррелируют. В этом случае коэффициент автокорреляции первого порядка уровней исходного ряда должен быть высоким. Если временной ряд содержит не6линейную тенденцию, например, в форме экспоненты, то коэффициент автокорреляции первого порядка по логарифмам уровней исходного ряда будет выше, чем соответствующий коэффициент, рассчитанный по уровням ряда. Чем сильнее выражена нелинейная тенденция в изучаемом временном ряде, тем в большей степени будут различаться значения указанных коэффициентов.
Выбор наилучшего уравнения в случае, если ряд содержит нелинейную тенденцию, можно осуществить путем перебора основных форм тренда, расчета по каждому уравнению скорректированного коэффициента детерминации R
и выбора уравнения тренда с максимальным значением скорректированного коэффициента детерминации.
Высокие значения коэффициентов автокорреляции первого, второго и третьего порядков свидетельствуют о том, что ряд содержит тенденцию. Приблизительно равные значения коэффициентов автокорреляции по уровням этого ряда и по логарифмам уровней позволяют сделать следующий вывод: если ряд содержит нелинейную тенденцию, то она выражена в неявной форме. Поэтому для моделирования его тенденции в равной мере целесообразно использовать и линейную, и нелинейную функции, например степенной или экспоненциальный тренд. Для выявления наилучшего уравнения тренда необходимо определить параметры основных видов трендов.
Наиболее простую экономическую интерпретацию имеют параметры линейного и экспоненциального трендов. Параметры линейного тренда:
a
- начальный уровень временного ряда в момент времени t = 0;
b
- средний за период абсолютный прирост уровней ряда.
Расчётные по линейному тренду значения уровней временного ряда определяются двумя способами. Во-первых, можно последовательно подставлять в найденное уравнение тренда значения t
= 1, 2, ..., n. Во-вторых, в соответствии с интерпретацией параметров линейного тренда каждый последующий уровень ряда есть сумма предыдущего уровня и среднего цепного абсолютного прироста.
Задача №1
Десять человек различного возраста имеют следующие параметры:
| Возраст, лет
|
18
|
20
|
21
|
22
|
22
|
24
|
25
|
26
|
31
|
39
|
| Рост, см
|
174
|
183
|
182
|
180
|
178
|
179
|
185
|
185
|
184
|
182
|
| Вес, кг
|
65
|
73
|
69
|
74
|
77
|
75
|
78
|
84
|
79
|
79
|
1. Определить результативный признак.
2. Рассчитать парные и частные коэффициенты корреляции. Сделать выводы.
Рассчитаем зависимость роста от возраста:
Фактор (X): возраст.
Результативный признак (Y): рост.
| №
|
X
|
Y
|
X*Y
|
X2
|
Y2
|
Yx
|
Y-Yx
|
(Y-Yx)2
|
.
(X – X)2
|
| 1
|
18
|
174
|
3132
|
324
|
30276
|
179.50
|
-5.50
|
30.25
|
46.24
|
| 2
|
20
|
183
|
3660
|
400
|
33489
|
180.00
|
3.00
|
9.00
|
23.04
|
| 3
|
21
|
182
|
3822
|
441
|
33124
|
180.25
|
1.75
|
3.06
|
14.44
|
| 4
|
22
|
180
|
3960
|
484
|
32400
|
180.50
|
-0.50
|
0.25
|
7.84
|
| 5
|
22
|
178
|
3916
|
484
|
31684
|
180.50
|
-2.50
|
6.25
|
7.84
|
| 6
|
24
|
179
|
4296
|
576
|
32041
|
181.00
|
-2.00
|
4.00
|
0.64
|
| 7
|
25
|
185
|
4625
|
625
|
34225
|
181.25
|
3.75
|
14.06
|
0.04
|
| 8
|
26
|
185
|
4810
|
676
|
34225
|
181.50
|
3.50
|
12.25
|
1.44
|
| 9
|
31
|
184
|
5704
|
961
|
33856
|
182.75
|
1.25
|
1.56
|
38.44
|
| 10
|
39
|
182
|
7098
|
1521
|
33124
|
184.75
|
-2.75
|
7.56
|
201.64
|
| S
|
248
|
1812
|
45023
|
6492
|
328444
|
1812
|
0.00
|
88.24
|
341.6
|
Определим параметры линейной функции с помощью системы уравнений:
 n*a + b*åx = åy n*a + b*åx = åy
a*åx + b*åx2
= åx*y
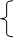 10*a + 248*b = 1812 10*a + 248*b = 1812
248*a + 6492*b = 45023
a = 1812 - 248*b
=> 1812 – 248*b
*248 + 6492*b = 45023
10 10
b = 0.25
a = 175
r = å
x*y – (
å
x*
å
y)/n
= 45023 – (248*1812)/10
=>
Ö(åx2
– (åx)2
/n)*(åy2
– (åy)2
/n) Ö(6492 – 2482
/10)*(328444 – 18122
/10)
r
= 0.44 -
прямая умеренная связь
r
2
= 0.19 -
рост на 19% зависит от возраста
Тест Фишера:
Fcp
= r
2
* (n – 2)
1 – r2
Fcp
= 0.19
* (10 – 2) = 1.78
1 – 0.19
Fтабл
= 5.32
Fcp
< Fтабл
=> нулевая гипотеза подтвердилась, уравнение статистически незначимо.
Рассчитаем зависимость веса от возраста:
Фактор (X): возраст.
Результативный признак (Y): вес.
| №
|
X
|
Y
|
X*Y
|
X2
|
Y2
|
Yx
|
Y-Yx
|
(Y-Yx)2
|
.
(X – X)2
|
| 1
|
18
|
65
|
1170
|
324
|
4225
|
71.70
|
-6.70
|
44.89
|
46.24
|
| 2
|
20
|
73
|
1460
|
400
|
5329
|
72.76
|
0.24
|
0.058
|
23.04
|
| 3
|
21
|
69
|
1449
|
441
|
4761
|
73.29
|
-4.29
|
18.40
|
14.44
|
| 4
|
22
|
74
|
1628
|
484
|
5476
|
73.82
|
0.18
|
0.032
|
7.84
|
| 5
|
22
|
77
|
1694
|
484
|
5929
|
73.82
|
3.18
|
10.11
|
7.84
|
| 6
|
24
|
75
|
1800
|
576
|
5625
|
74.88
|
0.12
|
0.014
|
0.64
|
| 7
|
25
|
78
|
1950
|
625
|
6084
|
75.41
|
2.59
|
6.71
|
0.04
|
| 8
|
26
|
84
|
2184
|
676
|
7056
|
75.94
|
8.06
|
64.96
|
1.44
|
| 9
|
31
|
79
|
2449
|
961
|
6241
|
78.59
|
0.41
|
0.17
|
38.44
|
| 10
|
39
|
79
|
3081
|
1521
|
6241
|
82.83
|
-3.83
|
14.67
|
201.64
|
| S
|
248
|
753
|
18856
|
6492
|
56967
|
753.04
|
-0.04
|
160
|
341.6
|
Определим параметры линейной функции с помощью системы уравнений:
n*a + b*åx = åy
a*åx + b*åx2
= åx*y
10*a + 248*b = 753
248*a + 6492*b = 18856
a = 753 - 248*b
=> 1812 – 248*b
*248 + 6492*b = 18856
10 10
b = 0.53
a = 62
r = å
x*y – (
å
x*
å
y)/n
= 18856 – (248*753)/10
=>
Ö(åx2
– (åx)2
/n)*(åy2
– (åy)2
/n) Ö(6492 – 2482
/10)*(56967 – 7532
/10)
r
= 0.6 -
заметная прямая связь
r
2
= 0.36 -
вес на 36% зависит от возраста
Тест Фишера:
Fcp
= r
2
* (n – 2)
1 – r2
Fcp
= 0.36
* (10 – 2) = 4.5
1 – 0.36
Fтабл
= 5.32
Fcp
< Fтабл
=> нулевая гипотеза подтвердилась, уравнение статистически незначимо.
Рассчитаем зависимость веса от роста:
Фактор (X): рост.
Результативный признак (Y): вес.
| №
|
X
|
Y
|
X*Y
|
X2
|
Y2
|
Yx
|
Y-Yx
|
(Y-Yx)2
|
.
(X – X)2
|
| 1
|
174
|
65
|
11310
|
30276
|
4225
|
67.52
|
-2.52
|
6.35
|
51.84
|
| 2
|
183
|
73
|
13359
|
33489
|
5329
|
77.24
|
-4.24
|
17.98
|
3.24
|
| 3
|
182
|
69
|
12558
|
33124
|
4761
|
76.16
|
-7.16
|
51.26
|
0.64
|
| 4
|
180
|
74
|
13320
|
32400
|
5476
|
74.00
|
0
|
0
|
1.44
|
| 5
|
178
|
77
|
13706
|
31684
|
5929
|
71.84
|
5.16
|
26.63
|
10.24
|
| 6
|
179
|
75
|
13425
|
32041
|
5625
|
72.92
|
2.08
|
4.33
|
4.84
|
| 7
|
185
|
78
|
14430
|
34225
|
6084
|
79.40
|
-1.40
|
1.96
|
14.44
|
| 8
|
185
|
84
|
15540
|
34225
|
7056
|
79.40
|
4.60
|
21.16
|
14.44
|
| 9
|
184
|
79
|
14536
|
33856
|
6241
|
78.32
|
0.68
|
0.46
|
7.84
|
| 10
|
182
|
79
|
14378
|
33124
|
6241
|
76.16
|
2.84
|
8.06
|
0.64
|
| S
|
1812
|
753
|
136562
|
328444
|
56967
|
752.96
|
0.04
|
138.19
|
109.6
|
Определим параметры линейной функции с помощью системы уравнений:
 n*a + b*åx = åy n*a + b*åx = åy
 a*åx + b*åx2
= åx*y a*åx + b*åx2
= åx*y
10*a + 1812*b = 753
1812*a + 328444*b = 136562
a = 753 - 1812*b
=> 753 – 1812*b
*1812 + 328444*b = 136562
10 10
b = 1.08
a = -120
r = å
x*y – (
å
x*
å
y)/n
= 136562 – (1812*753)/10
=>
Ö(åx2
– (åx)2
/n)*(åy2
– (åy)2
/n) Ö(328444 – 18122
/10)*(56967 – 7532
/10)
r
= 0.69 -
заметная прямая связь
r
2
= 0.47 -
вес на 47% зависит от роста
`x = 1812/10 = 181.2
Тест Фишера:
Fcp
= r2
* (n – 2)
1 – r2
Fcp
= 0.47
* (10 – 2) = 7.1
1 – 0.47
Fтабл
= 5.32
Fcp
> Fтабл
=> нулевая гипотеза не подтвердилась, уравнение имеет экономический смысл.
Тест Стьюдента:
Рассчитаем случайные ошибки:
.
ma =
Ö å
(y – yx
)2
* å
x2
.
n – 2 n*å(x –`x)2
.
mb =
Ö å
(y - yx
)2
/ (n – 2)
å(x –`x)2
.
mr
= Ö 1 – r2
n – 2
.
ma =
Ö 138.19
* 328444
= 72
8 10*109.6
.
mb =
Ö 138.19 / (10 – 2)
= 1
109.6
.
mr
= Ö 1 – 0.47
= 0.26
10 – 2
ta
= a/ma
= 120/72 = 1.67
tb
= b/mb
= 1.08/1 = 1.08
tr
= r/mr
= 0.69/0.26 = 2.65
tтабл
= 2.3
Для расчёта доверительного интервала рассчитаем предельную ошибку:
Da
= tтабл
– ta
= 2.3 – 1.67 = 0.63
Db
= tтабл
- tb
= 2.3 – 1.08 = 1.22
Dr
= tтабл
– tr
= 2.3 – 2.65 = -0.35
Рассчитаем доверительные интервалы:
ga
= a ± Da
= -121.03 ¸ 119.77
gb
= b ± Db
= -0.14 ¸ 2.3
gr
= r ± Dr
= 0.34 ¸ 1.04
Задача №2
При контрольной выборочной проверке процента влажности почвы фермерских хозяйств региона получены следующие данные:
| 3.8
|
3.9
|
4.0
|
3.6
|
4.5
|
4.1
|
4.0
|
3.2
|
1. С вероятностью 0.95 и 0.99 установить предел, в котором находится средний процент содержания влаги.
2. Сделать выводы.
| №
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
å
|
| x
|
3.8
|
3.9
|
4.0
|
3.6
|
4.5
|
4.1
|
4.0
|
3.2
|
31.1
|
| (x -`x)
|
-0.09
|
0.01
|
0.11
|
-0.29
|
0.61
|
0.21
|
0.11
|
-0.69
|
0.00
|
| (x -`x)2
|
0.0081
|
0.0001
|
0.0121
|
0.0841
|
0.3721
|
0.0441
|
0.0121
|
0.4761
|
1.0088
|
Генеральная средняя: `x = å
x
= 31.1
= 3.8875
n 8
Генеральная дисперсия: d2
= å
(
x
-
`
x
)2
= 1.8875
= 0.1261
n 8 .
Средняя квадратическая стандартная ошибка: m`
x
= Ö d
2
= Ö 0.1261
= 0.126
n 8
Предельная ошибка выборки: D`
x
= t*m`
x
Из таблицы значений t–критерия Стьюдента:
t0.95
= 2.4469
t0.99
= 3.7074
Для вероятности 0.95, предельная ошибка выборки:
D`
x
= 2.4469*0.126 = 0.308
Для вероятности 0.99, предельная ошибка выборки:
D`
x
= 3.7074*0.126 = 0.467
Доверительные интервалы:
`x - D`
x
£`x ³`x + D`
x
Предел среднего процента содержания влаги с вероятностью 0.95:
3.5795
¸
4.1955
Предел среднего процента содержания влаги с вероятностью 0.99:
3.4205
¸
4.3545
Из полученных значений видно, что при увеличении ширины доверительного интервала, вероятность попадания в него среднего значения изучаемого параметра повышается.
Список использованных источников:
1. Ефимова М. Р., Петрова Е. В., Румянцев В. Н. ”Общая теория статистики”, - М.: Инфра-М, 2000г.
2. Шмойлова Р. А. “Теория статистики”, - М.: Финансы и статистика, 1996г.
3. Пасхавер И.С. “Средние величины в статистике”, - М.: Статистика, 1979г.
4. Елисеева Н.В. “Эконометрика”, - М.: Инфра-М, 1998г.
|


