Государственное общеобразовательное учреждение высшего
профессионального образования
Московской области
«Международный университет природы общества и человека "Дубна»
Филиал «Котельники»
Кафедра естественных и гуманитарных наук
Курсовая работа
По дисциплине
«Теория вероятности, математическая статистика и случайные процессы»
Тема работы:
«Статистическое изучение выборочных данных экономических показателей »
Выполнила:
студентка 2-го курса
очной формы обучения гр. ПОВТ-21
___________________ И.И.Власова
Проверил:
доцент
___________________ Е.Ю.Орлова
Котельники-2010
Оглавление
Введение
1. Распределение вероятностей
1) Распределение Вейбулла
2) Задача
2. Исследование методами математической статистики
1) Общие методы математической статистики
2) Исследование выборочных статистических данных
3. Корреляция величин
1) Корреляция величин
2) Задача
Заключение
Список использованной литературы
Введение
Математическая статистика
, раздел математики, посвященный математическим методам систематизации, обработки и использования статистических данных для научных и практических выводов. При этом статистическими данными называются сведения о числе объектов в какой-либо более или менее обширной совокупности, обладающих теми или иными признаками.
Предмет и метод математической статистики. Статистическое описание совокупности объектов занимает промежуточное положение между индивидуальным описанием каждого из объектов совокупности, с одной стороны, и описанием совокупности по её общим свойствам, совсем не требующим её расчленения на отдельные объекты, — с другой. По сравнению с первым способом статистические данные всегда в большей или меньшей степени обезличены и имеют лишь ограниченную ценность в случаях, когда существенны именно индивидуальные данные (например, учитель, знакомясь с классом, получит лишь весьма предварительную ориентировку о положении дела из одной статистики числа выставленных его предшественником отличных, хороших, удовлетворительных и неудовлетворительных оценок). С другой стороны, по сравнению с данными о наблюдаемых извне суммарных свойствах совокупности статистические данные позволяют глубже проникнуть в существо дела. Например, данные гранулометрического анализа породы (то есть данные о распределении образующих породу частиц по размерам) дают ценную дополнительную информацию по сравнению с испытанием нерасчленённых образцов породы, позволяя в некоторой мере объяснить свойства породы, условия её образования и прочее.
Метод исследования, опирающийся на рассмотрение статистических данных о тех или иных совокупностях объектов, называется статистическим. Статистический метод применяется в самых различных областях знания. Однако черты статистического метода в применении к объектам различной природы столь своеобразны, что было бы бессмысленно объединять, например, социально-экономическую статистику, физическую статистику.
Цель работы
: исследование эмпирических данных методами теории вероятности и математической статистики.
Поставленные задачи
:
1. Подробное изучение распределения непрерывной случайной величины с точки зрения теории вероятности на примере логарифмически-нормального распределения
2. Исследование статистических данных методом математической статистики
3. Изучение корреляции величин и нахождение с помощью коэффициента корреляции линейной зависимости случайных величин
1. Распределение вероятностей
1)
Распределение Вейбулла
Распределение Ве́йбулла в теории вероятностей — двухпараметрическое семейство абсолютно непрерывных распределений.
Пусть распределение случайной величины Х задаётся плотностью
 , имеющей вид: , имеющей вид:
 , ,
где λ и k параметры распределения
Тогда говорят, что X имеет распределение Вейбулла.
Функция распределения
F(x)=1-
Математическое ожидание
M(x)=λГ
Дисперсия
D(x)=
2)
Задача
Пассажир может уехать на любом из двух маршрутов автобусов.Закон времени ожидания прихода этих автобусов задается графикомплотности распределения вероятности случайной величины X.
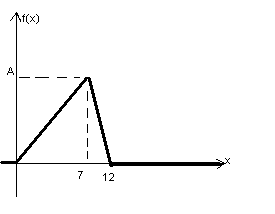
Требуется найти:
1) параметр А,
2) плотность распределенияf(x),
3) функцию распределения F(x) (найти аналитическую формулу и построить график),
4) числовые характеристики: математическое ожидание M(x), дисперсию D(x) и среднее квадратическое отклонение  (х), (х),
5) вероятность того, что во время ожидания пассажиром автобуса составит от 3,5 до 6 (вероятность попадания величины в интервал (3,5;6))
Решение
1)
f(x)=
Найдем А по условию нормировки:

 +A +A
6А=1
А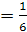
2)
f(x)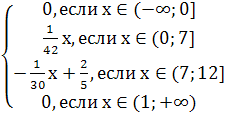
3) Используем формулу:
F(x)=
1.x
F(x)=
2. x

3. x
F(x)= + +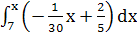 = = + +
-
4. х
F(x)=+ + + =+ =+
F(x)=
График функции распределения

4) Найдем математическое ожидание по формуле
M(x)=
M(x)=
С помощью формулы D(x)= найдем дисперсию: D(x)=( найдем дисперсию: D(x)=( = = 46.09 46.09
 =6.78 =6.78
5) P(3.5<X<6)=F(6)-F(3.5)=
2. Исследование методами математической статистики
1)
Общие методы математической статистики
Во многих своих разделах математическая статистика опирается на теорию вероятностей, позволяющую оценить надёжность и точность выводов, делаемых на основании ограниченного статистического материала (напр., оценить необходимый объём выборки для получения результатов требуемой точности при выборочном обследовании).
Математическая статистика — раздел математики, разрабатывающий методы регистрации, описания и анализа данных наблюдений и экспериментов с целью построения вероятностных моделей массовых случайных явлений[1]. В зависимости от математической природы конкретных результатов наблюдений статистика математическая делится на статистику чисел, многомерный статистический анализ, анализ функций (процессов) и временных рядов, статистику объектов нечисловой природы.
Выделяют описательную статистику, теорию оценивания и теорию проверки гипотез. Описательная статистика есть совокупность эмпирических методов, используемых для визуализации и интерпретации данных (расчет выборочных характеристик, таблицы, диаграммы, графики и т. д.), как правило, не требующих предположений о вероятностной природе данных. Некоторые методы описательной статистики предполагают использование возможностей современных компьютеров. К ним относятся, в частности, кластерный анализ, нацеленный на выделение групп объектов, похожих друг на друга, и многомерное шкалирование, позволяющее наглядно представить объекты на плоскости.
Методы оценивания и проверки гипотез опираются на вероятностные модели происхождения данных. Эти модели делятся на параметрические и непараметрические. В параметрических моделях предполагается, что характеристики изучаемых объектов описываются посредством распределений, зависящих от (одного или нескольких) числовых параметров. Непараметрические модели не связаны со спецификацией параметрического семейства для распределения изучаемых характеристик. В математической статистике оценивают параметры и функции от них, представляющие важные характеристики распределений (например, математическое ожидание, медиана, стандартное отклонение, квантили и др.), плотности и функции распределения и пр. Используют точечные и интервальные оценки.
Большой раздел современной математической статистики — статистический последовательный анализ, фундаментальный вклад в создание и развитие которого внес А. Вальд во время Второй мировой войны. В отличие от традиционных (непоследовательных) методов статистического анализа, основанных на случайной выборке фиксированного объема, в последовательном анализе допускается формирование массива наблюдений по одному (или, более общим образом, группами), при этом решение об проведении следующего наблюдения (группы наблюдений) принимается на основе уже накопленного массива наблюдений. Ввиду этого, теория последовательного статистического анализа тесно связана с теорией оптимальной остановки.
В математической статистике есть общая теория проверки гипотез и большое число методов, посвящённых проверке конкретных гипотез. Рассматривают гипотезы о значениях параметров и характеристик, о проверке однородности (то есть о совпадении характеристик или функций распределения в двух выборках), о согласии эмпирической функции распределения с заданной функцией распределения или с параметрическим семейством таких функций, о симметрии распределения и др.
Большое значение имеет раздел математической статистики, связанный с проведением выборочных обследований, со свойствами различных схем организации выборок и построением адекватных методов оценивания и проверки гипотез.
Задачи восстановления зависимостей активно изучаются более 200 лет, с момента разработки К. Гауссом в 1794 г. метода наименьших квадратов.
Разработка методов аппроксимации данных и сокращения размерности описания была начата более 100 лет назад, когда К. Пирсон создал метод главных компонент. Позднее были разработаны факторный анализ[2] и многочисленные нелинейные обобщения[3].
Различные методы построения (кластер-анализ), анализа и использования (дискриминантный анализ) классификаций (типологий) именуют также методами распознавания образов (с учителем и без), автоматической классификации и др.
В настоящее время компьютеры играют большую роль в математической статистике. Они используются как для расчётов, так и для имитационного моделирования (в частности, в методах размножения выборок и при изучении пригодности асимптотических результатов).
2)
Исследование выборочных статистических данных
Объем продаж компьютерной техники в магазине «Горбушкин двор» изменяется в зависимости от времени года, ассортимента товаров, цен производителя и т.д. Известны статистические данные этого показателя в течение некоторого времени.
1) Необходимо сгруппировать данные, образовав 8-10 интервалов. Найти распределение частот и относительных частот .
2) Найти и построить эмпирическую функцию распределения
Найдем эмпирическую функцию распределения по формуле:
3) Построить полигон распределения. Построить гистограмму частот и относительных частот распределения. Объяснить основное свойство гистограммы
4) Выдвинуть гипотезу о вероятном распределении показателя. Найти точечные оценки числовых характеристик распределения
5) Методом моментов найти оценку параметров распределения, считая его равномерным на заданном интервале значений
6) Оценить истинные значения параметров выборочного распределения с помощью доверительного интервала с надежностью 0.95,считая распределение нормальным
7) Использовать критерий Пирсона, при уровне значимости 0.05 проверить согласуется ли гипотеза о
а) нормальном распределении выборки
б) показательном распределении выборки
в) равномерном распределении выборки
1. Сгруппировав данные получим 8 интервалов:
 |
[3;5) |
[5;7) |
[7;9) |
[9;11) |
[11;13) |
[13;15) |
[15;17) |
[17;19] |
 |
1 |
1 |
4 |
9 |
17 |
12 |
4 |
1 |
Найдем распределение частот:
 |
4 |
6 |
8 |
10 |
12 |
14 |
16 |
18 |
|
1 |
1 |
4 |
9 |
17 |
12 |
4 |
1 |
Найдем распределение относительных частот
n= 1+1+4+9+17+12+4+1=49
|
4 |
6 |
8 |
10 |
12 |
14 |
16 |
18 |
 |
0.02 |
0.02 |
0.08 |
0.18 |
0.35 |
0.24 |
0.082 |
0.02 |
2.

1. x (- (-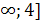
 0 0
2. x
 =0.02 =0.02
3. x
=0.02+0.02=0.04
4. x
=0.04+0.08=0.12
5. x 
=0.12+0.18=0.3
6. x
=0.3+0.35=0.65
7. x 
=0.65+0.24=0.89
8. x 
0.89+0.082=0.972
9. x
0.97+0.02=1
Итак, эмпирическая функция распределения будет выглядеть так
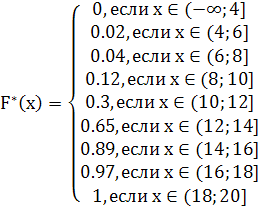
Построим эмпирическую функцию распределения
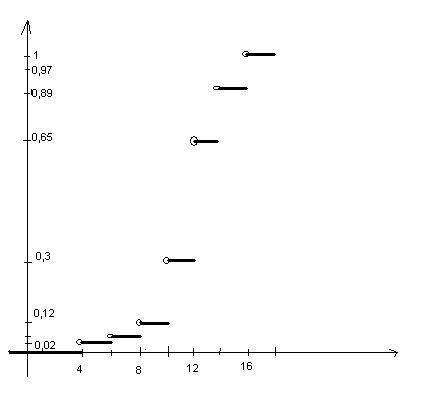
3.
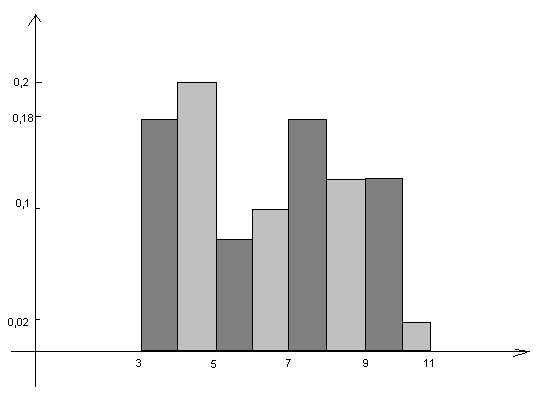
Полигон распределения
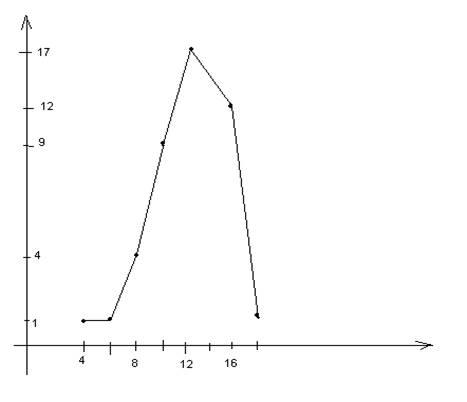
Гистограммой – называется фигура состоящая из прямоугольника . Основания прямоугольников – интервальные задания случайной величины, высота прямоугольников
- для гистограммы частот находится по формуле:
 = =
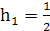 =0.5 =0.5
 =0.5 =0.5






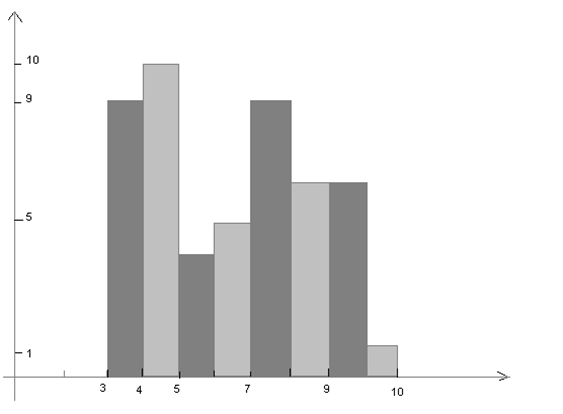
- для гистограммы относительных частот находится по формуле:

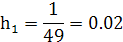

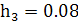





4.  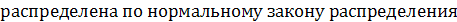 . .
5. Метод моментов применяется для оценки неизвестных параметров распределения, суть методов заключается в том, что приравниваются теоретические и эмпирические моменты. Если закон распределения содержит 1 параметр, то для оценки этого параметра составляется одно уравнение, в котором теоретический момент приравнивают к эмпирическому моменту. Если распределение случайной величины содержит 2 параметра, то составляют два уравнения и т.д.
Считая распределение равномерным на заданном интервале значений запишем дифференциальный закон:
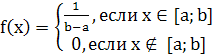 2 параметра распределения a и b 2 параметра распределения a и b
M(x)=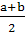
D(x)=
D(x) 
 (4+6+32+90+204+168+64+18)= (4+6+32+90+204+168+64+18)= =11.959 =11.959
=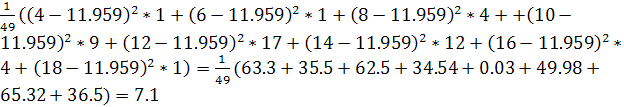




 
6. Доверительным называют интервал который с заданной надежностью  показывает заданный параметр. показывает заданный параметр.
Истинное значение измеряемой величины равно ее математическому ожиданию a. Поэтому задача сводится к оценке математического ожидания (при известном ) при помощи доверительного интервала

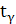 = 2.009 = 2.009
Все величины кроме S(среднеквадратического отклонения) известны. Для нахождения S сначала найдем  (исправленную дисперсию). (исправленную дисперсию).

 *175.4=3.58 *175.4=3.58
 =1.89 =1.89


7. а)
1.
2. Вычислим теоретические частоты, учитывая, что n=49, h=1,  =2.6, по формуле: =2.6, по формуле:

| i |
 |
 |
 |
 |
| 1 |
4 |
-3,06 |
0.0037 |
0,07 |
| 2 |
6 |
-2,29 |
0.0290 |
0,55 |
| 3 |
8 |
-1,52 |
0.1257 |
2,37 |
| 4 |
10 |
-0,75 |
0.3011 |
5,67 |
| 5 |
12 |
0,015 |
0.3989 |
7,52 |
| 6 |
14 |
0,78 |
0.2943 |
5,55 |
| 7 |
16 |
1,55 |
0.1200 |
2,26 |
| 8 |
18 |
2,32 |
0.0270 |
0,51 |
3. Сравним эмпирические и теоретические частоты
I) составим расчетную таблицу, из которой найдем наблюдаемое значение критерия
 |
 |
 |
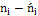 |
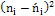 |
 |
| 1 |
1 |
0,07 |
0,93 |
0,86 |
12,2 |
| 2 |
1 |
0,55 |
0,45 |
0,2 |
0,36 |
| 3 |
4 |
2,37 |
1,63 |
2,66 |
1,12 |
| 4 |
9 |
5,67 |
3,33 |
11,09 |
1,95 |
| 5 |
17 |
7,52 |
9,48 |
89,87 |
11,95 |
| 6 |
12 |
5.55 |
6,45 |
61,15 |
11,02 |
| 7 |
4 |
2,26 |
1,74 |
3,03 |
1,1 |
| 8 |
1 |
0,51 |
0,49 |
0,24 |
0,47 |
Из таблицы найдем 
II) по таблице критических точек распределения  , по уровню значимости , по уровню значимости  k=s-3=8-3=5 k=s-3=8-3=5

Т.к.  - гипотезу о нормальном распределении генеральной совокупности отвергаем. Другими словами, эмпирические и теоретические частоты различаются значимо. - гипотезу о нормальном распределении генеральной совокупности отвергаем. Другими словами, эмпирические и теоретические частоты различаются значимо.
б)
 |
|
| 3-5 |
1 |
| 5-7 |
1 |
| 7-9 |
4 |
| 9-11 |
9 |
| 11-13 |
17 |
| 13-15 |
12 |
| 15-17 |
4 |
| 17-19 |
1 |
1.
2. Найдем оценку параметра предполагаемого показательного распределения

Т.о. плотность предполагаемого показательного распределения имеет вид:
 (x>0) (x>0)
3. Найдем вероятности попадания X в каждый из интервалов по формуле:

Например, для первого интервала:








⅀=0.89
4.  , где , где  -й интервал -й интервал
Например, для первого интервала
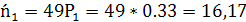





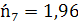

5. Сравним эмпирические и теоретические частоты с помощью критерия Пирсона. Для этого составим расчетную таблицу, причем объединим малочисленные частоты (4+6=10), (16+18=34) и соответствующие им теоретические частоты (16,17+5,88=22,05), (1,96+1,96=3,92)
 |
|
|
|
|
|
| 1 |
2 |
21,07 |
-19,07 |
363,6 |
17,2 |
| 2 |
4 |
3,92 |
-0,08 |
0,0064 |
0,0016 |
| 3 |
9 |
3,43 |
5,57 |
31,02 |
9,04 |
| 4 |
17 |
3,136 |
13,864 |
192,2 |
61,3 |
| 5 |
12 |
2,744 |
9,26 |
85,74 |
31,25 |
| 6 |
5 |
3,92 |
1,08 |
1,166 |
0,3 |
 |
49 |
По таблице найдем 

Т.к. 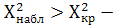 гипотеза о распределении X по показательному закону отвергается. гипотеза о распределении X по показательному закону отвергается.
в)
 |
|
| 3-7 |
2 |
| 7-9 |
4 |
| 9-11 |
9 |
| 11-13 |
17 |
| 13-15 |
12 |
| 15-19 |
5 |
1. 

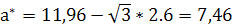

2. 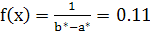
3. Найдем теоретические частоты:




4. Сравним эмпирические и теоретические частоты, используя критерий Пирсона приняв число степеней свободы k=s-3=8-3=5 для этого
Составим расчетную таблицу
|
|
|
|
|
|
| 1 |
2 |
2,91 |
-0,91 |
0,83 |
0,28 |
| 2 |
4 |
10,78 |
-6,78 |
45,96 |
4,27 |
| 3 |
9 |
10,78 |
-1,78 |
3,17 |
0,294 |
| 4 |
17 |
10,78 |
6,22 |
38,7 |
3,6 |
| 5 |
12 |
10,78 |
1,22 |
1,49 |
0,14 |
| 6 |
5 |
7,87 |
-2,87 |
8,24 |
1,04 |
| ⅀ |
50 |
9,62 |
Из расчетной таблицы получаем 
Найдем по таблице критических точек распределения по уровню значимости  критическую точку правосторонней критической области критическую точку правосторонней критической области 
Т.к.  гипотеза о равномерном распределении отвергается. гипотеза о равномерном распределении отвергается.
3. Корреляция величин
3.1 Корреляция величин
Корреляция — зависимость между случайными величинами, не имеющая, вообще говоря, строго функционального характера. В отличие от функциональной зависимости корреляции, как правило, рассматривается тогда, когда одна из величин зависит не только от данной другой, но и от ряда случайных факторов. Зависимость между двумя случайными событиями проявляется в том, что условная вероятность одного из них при наступлении другого отличается от безусловной вероятности. Аналогично, влияние одной случайной величины на другую характеризуется условными распределениями одной из них при фиксированных значениях другой.
Некоторые виды коэффициентов корреляции могут быть положительными или отрицательными (возможна также ситуация отсутствия статистической взаимосвязи — например, для независимых случайных величин). Если предполагается, что на значениях переменных задано отношение строгого порядка, то отрицательная корреляция — корреляция, при которой увеличение одной переменной связано с уменьшением другой переменной, при этом коэффициент корреляции может быть отрицательным; положительная корреляция в таких условиях — корреляция, при которой увеличение одной переменной связано с увеличением другой переменной, при этом коэффициент корреляции может быть положительным.
3.2 Задача
Совместный закон распределения суммы дивидендов, выплачиваемых по привилегированной и обыкновенной акциям некоторой компании, задается следующей таблицей
1) Построить маргинальные законы распределения случайных величин X и Y.
 ) = ) =
 )= )=

Проверка: 
X:  )= )=
 )= )=
Проверка: 
| X |
2 |
4 |
| p |
 |
 |
2) Вычислить числовые характеристики: математические ожидания  и и 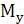 , дисперсии , дисперсии  и и  , среднеквадратические отклонения , среднеквадратические отклонения  и и 






3) Условные вероятности составляющих X и Y соответственно вычисляются по соответствующим формулам:
P(


| X |
2 |
4 |
 |
0,75 |
0.44 |



| X |
0 |
1 |
2 |
 |
0.3 |
0.325 |
0.375 |
4) Вычислить числовые характеристики: условное математическое ожидание  , дисперсию , дисперсию  и среднее квадратическое отклонение и среднее квадратическое отклонение 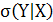
Условным математическим ожиданием дискретной случайной величины Y при X=x (x – определенное возможное значение X) называется произведение всех возможных значение y на их условные вероятности.


Условная дисперсия:


Условное среднеквадратическое значение:

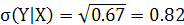
5) Рассчитать коэффициенты корреляции  и сделать выводы о линейной зависимости случайных величин X и Y. и сделать выводы о линейной зависимости случайных величин X и Y.
Коэффициент корреляции находится по формуле:










 связь знакоположительная связь знакоположительная
 связь средняя умеренная связь средняя умеренная
Заключение
В своей работе я постаралась наиболее кратким и наиболее понятным языком выразить основные положения и понятия о теории вероятности, математической статистике и случайных процессах.
В курсовой работе я изучила непрерывные случайные величины, исследование методами математической статистики и корреляцию величин.
Благодаря этой курсовой работе я многому научилась, узнала что многие очевидные для нас вещи основаны на теории вероятности и математической статистике.
В последнее время методы теории вероятностей все шире и шире проникают в различные области науки и техники, способствуя их прогрессу.
С помощью изучения экономических показателей мы можем понять происходящее в экономике. Они отражают текущее или будущее состояние экономики и могут помочь распознать приближение как положительных, так и отрицательных изменений в бизнесе и личных финансах.
Список использованной литературы
1. В.Е. Гмурман «Руководство к решению задач по теории вероятностей и математической статистике»
2. В.Е.Гмурман «Теория вероятностей и математическая статистика»
3. Булинский, А. В., Ширяев, А. Н. «Теория случайных процессов»
4. В.С.Кривошеева, С.Н.Поздеева «Методические указания и задания к курсовой работе по дисциплине «Теория вероятностей и математическая статистика»»
5. http://www.aup.ru/books/m155/4_13.htm
6. http://www.ecscada.ru/files/documents/agtu/fpe/Din7.doc
7. http://ru.wikipedia.org/wiki
|