Введение
В практике моделирования систем наиболее часто приходится иметь дело с объектами, которые в процессе своего функционирования содержат элементы случайности событий внешней среды. К примерам систем, характеризующихся случайными параметрами, можно отнести системы связи, у которых характеристики канала связи меняются случайным образом, а также локационные системы обнаружения отражений от целей на фоне случайных помех. Широкие возможности для моделирования с использованием современных вычислительных систем открывают датчики случайных чисел.
Датчики случайных чисел применяются для имитации реальных условий функционирования систем автоматического управления, для решения задач методом статистических испытаний, для моделирования случайных изменений параметров производства в автоматизированных системах управления и т. д. Кроме непосредственного использования в статистических моделях, равномерно распределённые случайные числа, вырабатываемые датчиком случайныхчисел, являются основой для формирования числовых последовательностей с заданным законом распределения.
Цель работы - овладение навыками алгоритмизации и программирования задач с использованием датчиков случайных чисел, способами получения случайных чисел с различными законами распределения, навыками оценки качества псевдослучайных чисел и их соответствия их выполняемым задачам.
Для чего нужны случайные числа?
Для чего нужны «случайно выбранные» числа? Они, оказывается полезны для самых различных целей. Вот некоторые примеры:
1. Моделирование. Когда с помощью вычислительной машины моделируются природные явления, случайные числа позволяют приблизить модель к реальности.
2. Выборка. Часто бывает, что проверка всех возможных вариантов практически не осуществима, тогда на некоторые вопросы позволяет получить ответы случайная выборка.
3. Численный анализ. Для решения сложных задач вычислительной математики была разработана остроумная техника, использующая случайные числа.
4. Программирование для вычислительных машин. Случайные значения служат хорошим источником данных при испытании эффективности различных алгоритмов для вычислительных машин.
5. Принятие решений.
6. Развлечения.
И все-таки, что же такое «случайность»? в некотором смысле такого объекта, как случайное число, просто нет. Скажем, двойка – это случайное число? Скорее это последовательность независимых случайных чисел с определенным законом распределения, и это означает, грубо говоря, что каждое число было получено самым произвольным образом, без всякой связи с другими членами последовательности, и что у него есть определенная вероятность оказаться в любом заданном интервале.
Равномерным называется такое распределение, при котором каждое возможное число равновероятно. Каждая из десяти цифр от 0 до 9 составляют примерно одну десятую часть всех цифр во всякой случайной (равномерной) последовательности цифр. Любая заданная пара двух соседних цифр должна составлять примерно одну сотую часть всех пар, встречающихся в последовательности и т. д. Тем не менее, если мы рассмотрим какую-нибудь конкретную случайную последовательность из миллиона цифр, в ней совсем не обязательно окажется ровно 100 000 нулей, 100 000 единиц и т. д. В действительности вероятность такого события очень мала. Закономерность же выполняется в среднем для последовательности таких последовательностей.
Любая заданная последовательность столь же вероятна, как и последовательность, состоящая из одних нулей. Более того, допустим, что мы выбираем случайным образом последовательность из миллиона цифр. Пусть оказалось, что первые 999 999 из них равны нулю. И в этом случае вероятность того, что последняя цифра будет нулем, все еще в точности равна одной десятой, если выборка действительно случайная.
Немного истории
Раньше ученые, нуждавшиеся для своей работы в случайных числах, раскладывали карты, бросали кости или вытаскивали шары из урны, которую предварительно «как следует трясли». В 1927 году Л. Типпет опубликовал таблицы, содержащие свыше 40 000 случайных цифр, «произвольно взятых из отчетов о переписи». Позже были сконструированы специальные машины, механически вырабатывающие случайные числа. Первую такую машину в 1939 году использовали М. Дж. Кендалл и Б. Бэбингтон-Смит при создании таблиц, включающих 100 тысяч случайных цифр. В 1935 году компания RAND Corporation опубликовала хорошо известные таблицы с миллионом случайных цифр, полученных другой такой машиной. Известная машина ERNIE, вырабатывающая случайные числа, определяет выигравшие номера в Британской лотерее. Вскоре после создания вычислительных машин начались поиски эффективных методов получения случайных чисел, пригодных для использования в программах. В принципе можно работать и с таблицами, однако этот метод имеет ограничения, связанные с конечным объемом памяти машин и затратами времени для ввода чисел в машину в том случае, когда таблица оказывается слишком короткой. Кроме того, довольно неприятно готовить таблицы заранее, да и вообще иметь с ними дело. Можно присоединить к ЭВМ машину типа ERNIE, но и этот путь оказывается неудовлетворительным, потому что при отладке программы невозможно воспроизвести вторично вычисления, сделанные ранее.
Несовершенство всех этих методов пробудило интерес к получению случайных чисел с помощью арифметических операций вычислительной машины. Первым такой подход в 1946 году предложил Джон фон Нейман, использовавший метод «середины квадрата». Идея заключается в том, что предыдущее число возводится в квадрат, а затем из результата извлекаются средние цифры. Пусть, например, мы вырабатываем десятизначные числа и допустим, что предыдущее число было равно 5772156649; возведя его в квадрат, получим 33317792380594909201, и поэтому следующее число равно 7923805949.
Метод вызывает довольно очевидное возражение. Как может быть случайной выработанная таким способом последовательность, если каждый ее член полностью определен своим предшественником? Ответ заключается в том, что эта последовательность не случайна, но выглядит как случайная. В типичных приложениях обычно не имеет значения, как связаны друг с другом два последующих числа последовательности; таким образом, неслучайный характер последовательности не является нежелательным. Интуитивно метод середины квадрата должен довольно хорошо «перемешивать» предыдущее число.
Однако первоначальный «метод середины квадрата» фон Неймана оказался сравнительно скудным источником случайных чисел. Недостаток его заключается в том, что последовательности имеют тенденцию превращаться в короткие циклы повторяющихся элементов. Например, если какой-нибудь член последовательности окажется равным нулю, все последующие члены также будут нулями. В начале пятидесятых годов некоторые ученые проводили эксперименты с методом середины квадрата. Дж. Э. Форсайт, работавший с четырехзначными (а не с десятичными) числами, проверил 16 чисел в качестве начальных значений последовательностей. Оказалось, что 12 из них порождали последовательности, оканчивающиеся циклом 6100, 2100, 4100, 8100, 6100, …, а две последовательности выродились в нуль. Обширные эксперименты по исследованию метода середины квадрата провел Н. Метрополис, оперировавший главным образом двоичными числами. Работая с 20-разрядными числами, он показал, что существует тринадцать различных циклов, в которые могут выродиться последовательности; длина периода самого большого из них равна 142. Как только последовательность вырождается в нуль, довольно легко начать выработку случайных чисел заново. Гораздо трудней бороться с длинными циклами. Все же Р. Флойд предложил остроумный метод, позволяющий зарегистрировать возникновение цикла в последовательности.
Метод Флойда требует небольшой памяти машины, увеличивает время выработки случайного числа всего в три раза и сразу же сигнализирует, как только в последовательности появляется встречавшееся ранее число.
С другой стороны, отметим, что, работая с 38-разрядными двоичными числами, Н. Метрополис обнаружил последовательность, состоящую из 750 000 членов, отличающихся друг от друга. Статистические тесты подтвердили случайный характер полученной последовательности из 750 000 × 38 битов. Это подтверждает, что, применяя метод середины квадрата, можно получить полезные результаты.
Тем не менее без предварительных трудоемких вычислений ему не стоит излишне доверять.
Многие датчики случайных чисел, популярные сейчас, недостаточно хороши. Среди пользователей наметилась тенденция избегать их изучения. Довольно часто какой-нибудь старый сравнительно неудовлетворительный метод передается от одного программиста к другому в слепую, и сегодняшний пользователь уже ничего не знает об его недостатках.
Получения последовательности
Так как в вычислительной машине действительное число всегда представляется с ограниченной точностью, фактически мы будем генерировать целые числа Xn
в интервале от 0 до некоторого m. Тогда дробь Un
=Xn
/m, где Un
случайные действительные числа, попадает в интервал от 0 до 1. Обычно m на единицу больше максимального числа, которое можно записать в машинном слове. Поэтому Xn
можно интерпретировать как целое содержимое машинного слова с десятичной запятой, расположенной справа, а Un
можно считать дробью, содержащейся в том же слове, с запятой в крайней левой позиции.
Наилучшие из известных сегодня датчиков случайных чисел представляют собой частные случаи следующей схемы, предложенной Д. Х. Лемером в 1948 году. Выбираем четыре «магических числа»:
x0
- начальное значение; x0
≥0;
a - множитель; a≥0;
c - приращение; c≥0;
m - модуль; m>x0
, m>a, m>c.
Тогда искомая последовательность случайных чисел <Xn
> получается из соотношения Xn
+1
=(aXn
+c) modm, n≥0. Она называется линейной конгруэнтной последовательностью. Например, при Xn
= a= c=7, m=10 последовательность выглядит так: 7, 6, 9, 0, 7, 6, 9, 0, … .
Как видно из приведенного примера, последовательность не всегда оказывается «случайной», если выбирать x0
, a, c, m произвольно. Этот пример иллюстрирует тот факт, что конгруэнтные последовательности всегда «зацикливаются», т.е. в конце концов числа образуют цикл, который повторяется бесконечное число раз. Это свойство присуще всем последовательностям, имеющим общий вид Xn
+1
=f(Xn
). Повторяющийся цикл называется периодом. Длина периода у данного примера равна 4.
Специального рассмотрения требует частный случай с=0, когда процесс выработки случайных чисел происходит несколько быстрее. Ограничение с=0 уменьшает длину периода последовательности, но при этом все еще можно получить относительно большой период. В первоначальном методе Лемера было принято с=0, хотя автор и упомянул возможность использования с≠0. Идея получения более длинных последовательностей за счет обобщения с≠0 принадлежит Томсону и независимо Ротенбергу.
Чтобы хоть немного упростить формулы, можно определить b=a-1. Можно сразу отбросить случай а=1, так как при этом Xn
=(X0
+nc) modm, и очевидно, что последовательность не случайная. Вариант а=0 еще хуже. Следовательно, для практических целей мы можем предположить, что а≥2, b≥1.
случайный число моделирование программирование
Выбор модуля
Как правильно выбрать число m? Оно должно быть достаточно большим, так как длина периода не может быть больше m. Другой фактор влияющий на выбор m, - это скорость выработки чисел: мы должны выбрать такое значение m, чтобы быстро вычислять (aXn
+c) modm.
Выбор множителя и длины.
Как выбрать множитель a, чтобы получился период максимальной длины? Для любой последовательности, предназначенной для использования в качестве источника случайных чисел, важен большой период. Действительно, хотелось бы, чтобы период содержал значительно больше чисел, чем это необходимо для решения какой-либо одной задачи. Однако, большой период – это только один из необходимых признаков случайной последовательности. Вполне возможны абсолютно неслучайные последовательности с очень большим периодом. Например, при a=c=1 последовательность сводится к Xn
+1
=(Xn
+1) modm. Очевидно, что ее период равен m, тем не менее ее никак нельзя назвать случайной.
Так как возможны только m различных значений, длина периода не может превышать m. Исследуем все возможные способы выбора a и c, которые дают период длины m.
Замечание! Когда период имеет длину m, каждое число от 0 до (m-1) встречается за период ровно один раз. Поэтому в этом случае выбор X0
не влияет на длину периода.
Теорема.
Длина периода линейной конгруэнтной последовательности равна m тогда и только тогда, когда
1) c и m взаимно простые числа;
2) b=a-1 кратно p для любого простого p, являющегося делителем m;
3) b кратно 4, если m кратно 4.
Теорема.
Если m=10e
, e≥5, c=0 и X0
не кратно 2 или 5, период линейной конгруэнтной последовательности равен 5×10e
-2
в том и только том случае, когда amod 200 принимает одно из следующих 32 значений:
3, 11, 13, 19, 21, 27, 29, 37, 53, 59, 61, 67, 69, 77, 83, 91, 109, 117, 123, 131, 133, 139, 141, 147, 163, 171, 173, 179, 181, 187, 189, 197.
Другие методы
Конечно, линейные конгруэнтные последовательности – не единственный из предложенных для вычислительных машин источников случайных чисел.
Одно из общепринятых заблуждений, когда речь идет о получении случайных чисел, заключается в том, что достаточно взять хороший датчик и слегка его изменить, чтобы выработать «еще более случайную» последовательность. Довольно часто это неверно. Например, мы знаем, что по формуле Xn
+1
=(aXn
+c) modm можно получить довольно хорошие случайные числа. Не будет ли последовательность Xn
+1
=((aXn
+c) mod (m+1)+c) modm еще более случайной? Ответ таков, что новая последовательность с большей вероятностью менее случайна.
Например, простейший пример зависимости Xn
+1
от более чем одного из предыдущих значений реализуется в последовательность Фибоначчи Xn
+1
=(Xn
+Xn
-1
) modm. Этот датчик рассматривали в начале пятидесятых годов. Он дает обычно длину периода, большую, чем m. Однако тесты с определенностью показали, что числа, получаемые из соотношения Фибоначчи, являются недостаточно случайными. Поэтому в настоящее время эта формула интересна главным образом как прекрасный «плохой пример».
Можно также рассмотреть датчики вида Xn
+1
=(Xn
+Xn
-
k
) modm, где k – достаточно большое число, предложенные Грином, Смитом и Клемом. При соответствующем выборе X0
, X1
, … , Xk
эта формула обещает стать источником хороших случайных чисел. Этот датчик работает обычно быстрее, чем датчики, реализующие предыдущие методы, так как здесь не требуется никакого умножения. В статье Грина, Смита и Клема говорится, что при k≤15 последовательность не удовлетворяет тесту «проверка интервалов», хотя при k=16 тест проходит нормально.
Статистические тесты
Основная задача состоит в получении последовательностей, которые похожи на случайные. Мы уже видели, как добиться большого периода последовательности. Хотя это и важно, но большой период еще вовсе не означает, что последовательность хороша для работы. Как же решить, достаточно ли случайна последовательность?
Если дать любому человеку карандаш и бумагу и попросить его написать 100 случайных десятичных цифр, очень мало шансов на то, что он достаточно хорошо сможет с этим справиться. Люди стремятся избегать комбинаций, кажущихся им неслучайными, таких, как пары одинаковых соседних цифр (хотя примерно каждая из 10 цифр должна совпадать с предыдущей). Поэтому увидев таблицу действительно случайных чисел, любой человек скорее всего скажет, что они совсем не случайные, его глаз сразу же отметит некоторые видимые закономерности.
Все мы выделяем особенности телефонных номеров, номерных знаков машин и т.д., чтобы легче их запомнить. Главная мысль всего сказанного заключается в том, что мы не можем доверять себе в оценке, случайна или нет данная последовательность чисел. Необходимо использовать какие-то непредвзятые механические тесты.
Статистическая теория дает нам некоторые количественные критерии случайности. Возможным же тестам буквально нет конца.
Если последовательность ведет себя удовлетворительно относительно тестов Т1
, Т2
, … , Тn
, мы не можем быть уверены в том, что она выдержит и следующее испытание Тn
+1
. Однако каждый тест дает нам все больше и больше уверенности в случайности последовательности. Обычно последовательность проверяется с помощью полудюжины разных тестов. Если их результаты оказываются удовлетворительными, мы считаем ее случайной.
Различают два сорта тестов: эмпирические тесты, когда машина манипулирует с группами чисел последовательности и производит оценку с помощью определенных статистических критериев, и теоретические тесты.
Критерий χ2
Критерий χ2
(«хи-квадрат»), вероятно, самый распространенный из всех статистических критериев. Он используется не только сам по себе, но и как составная часть многих других тестов. Прежде чем приступить к общему описанию критерия χ2
, рассмотрим сначала в качестве примера, как можно было бы применить этот критерий для анализа игры в кости. Пусть каждый раз бросаются независимо две «правильные» кости, причем бросание каждой из них приводит с равной вероятностью к выпадению одного из чисел 1, 2, 3, 4, 5 и 6. Вероятности выпадения любой суммы s при одном бросании представлены в таблице:
Сумма s= 2 3 4 5 6 7 8 9 10 11 12
Вероятность ps
=  . .
Если бросать кости n раз, можно ожидать, что сумма s появится в среднем nps
раз. Например, при 144 бросаниях значение 4 должно появится около 12 раз. Следующая таблица показывает, какие результаты были в действительности получены при 144 бросаниях.
Сумма s= 2 3 4 5 6 7 8 9 10 11 12
Фактическое число выпадений Ys
= 2 4 10 12 22 29 21 15 14 9 6
Среднее число выпадений nps
= 4 8 12 16 20 24 20 16 12 8 4 .
Отметим, что фактическое число выпадений отличается от среднего во всех случаях. В этом нет ничего удивительного. Дело в том, что всего имеется 36144
возможных последовательностей исходов для 144 бросаний, и все они равновероятны. Каким же образом мы можем проверить, правильно ли изготовлена данная пара костей? Ответ заключается в том, что мы можем дать только вероятностный ответ, т.е. указать, насколько вероятно или невероятно данное событие.
Естественный путь решения нашей задачи состоит в следующем. Вычислим сумму квадратов разностей фактического числа выпадений Ys
и среднего числа выпадений nps
:
V=( Y2
- np2
)2
+( Y3
- np3
)2
+…+( Y12
- np12
)2
.
Для плохого комплекта костей должны получаться относительно высокие значения V.
Предположим, что все возможные результаты испытаний разделены на k категорий. Проводится n независимых испытаний: это означает, что исход каждого испытания абсолютно не влияет на исход остальных. Пусть ps
– вероятность того, что результат испытания попадает в категорию s, и пусть Ys
– число испытаний, которые действительно попали в категорию s. Сформируем статистику V= . Вернемся к вопросу о том, какие значения V можно считать разумными. Ответ на это дает табл. 1, в которой приведено «распределение χ2
с v степенями свободы» при разных значениях v. Следует пользоваться строкой таблицы с v=k-1; число «степеней свободы» равно k-1, т.е. на единицу меньше числа категорий. . Вернемся к вопросу о том, какие значения V можно считать разумными. Ответ на это дает табл. 1, в которой приведено «распределение χ2
с v степенями свободы» при разных значениях v. Следует пользоваться строкой таблицы с v=k-1; число «степеней свободы» равно k-1, т.е. на единицу меньше числа категорий.
Большим преимуществом рассматриваемого метода является то, что одни и те же табличные значения используются при любых n и любых вероятностях ps
. Единственной переменной является v=k-1. На самом деле приведенные в таблице значения не являются абсолютно точными во всех случаях: это приближенные значения, справедливые лишь при достаточно больших значениях n. Как велико должно быть n? Достаточно большими можно считать такие значения n, при которых любое из nps
не меньше 5; однако лучше брать n значительно большим, чтобы повысить надежность критерия.
На самом деле вопрос о выборе n не так прост. При больших значениях n могут сглаживаться локальные отклонения, такие, как следующие друг за другом блоки чисел с сильным систематическим смещением в противоположные стороны. При действительном бросании костей этого можно не опасаться, так как все время используются одни и те же кости, но если речь идет о последовательности чисел, полученных на ЭВМ, то такой тип отклонения от случайного поведения вполне возможен. В связи с этим желательно проводить проверку с помощью критерия χ2
при разных значениях n, но в любом случае эти значения должны быть довольно большими.
Итак, проверка с помощью критерия χ2
заключается в следующем. Проводится n независимых испытаний, где n – достаточно большое число. Подсчитывается число испытаний, результат которых относится к каждой из k категорий, и по формулам вычисляется значение V. Затем V сравнивается с числами из табл. 1 при v=k-1. Если V меньше значения, соответствующего p=99%, или больше значения, соответствующего p=1%, то результаты бракуются как недостаточно случайные. Если p лежит между 99 и 95% или между 5 и 1%, то результаты считаются «подозрительными»; при значениях p, полученных интерполяцией по таблице, заключенных между 95 и 90% или 10 и 5%, результаты «слегка подозрительны».
Критерий Колмогорова-Смирнова (КС-критерий)
Как мы видели, критерий χ2
применяется в тех случаях, когда результаты испытаний распадаются на конечное число k категорий. Однако нередко случайные величины могут принимать бесконечно много значений. В частности, бесконечно много значений принимают вещественные случайные числа в интервале между 0 и 1. Хотя множество значений случайных чисел, полученных в вычислительных машине, неизбежно ограничено, хотелось бы, чтобы это никак не сказывалось на результатах расчетов.
В теории вероятностей и статистике принято использовать одни и те же обозначения при описании дискретных и непрерывных распределений. Пусть требуется описать распределение значений случайной величины ξ. Это делается с помощью функций распределения F(x), где F(x) = вероятность того, что (ξ≤x).
На рис. 1 представлены три примера. Первый, – функция распределения случайного бита, т. е. случайной величины ξ, принимающей значения 0 или 1, каждое с вероятностью 12. На 1, b – функция распределения вещественной случайной величины, равномерно распределенной между нулем и единицей, так что вероятность того, что ξ≤x, просто равна x, если 0≤x≤1. Рисунок 1, c показывает предельное распределение значений V в критерии χ2
. Заметим, что F(x) всегда возрастает от 0 до 1 при увеличении x от -∞ до +∞.
Используя значения ξ1
, ξ2
, … , ξn
случайной величины ξ, полученные в результате независимых испытаний, можно построить эмпирическую функцию распределения Fn
(x):
Fn
(x)=(число таких , ξ1, ξ2, … , ξnкоторые ≤x)/n.
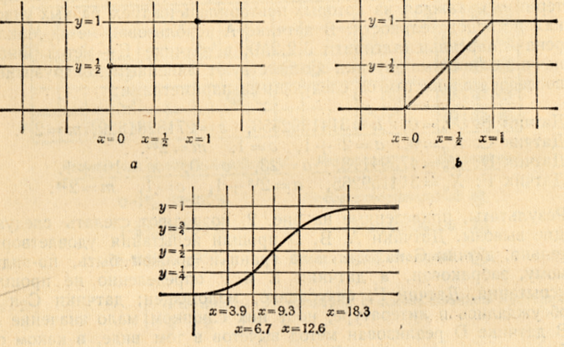
Рисунок 1 – Примеры функций распределения
На рис. 2 показаны три эмпирические функции распределения. Там же и изображены и истинные функции распределения F(x). При увеличении n функции Fn
(x) должны все более точно аппроксимировать F(x).
Критерий Колмогорова-Смирнова можно использовать в тех случаях, когда F(x) не имеет скачков. Он основан на разности между F(x) и Fn
(x). Плохой датчик случайных чисел будет давать эмпирические функции распределения, плохо F(x). На рис. 2, b приведен пример, когда значения ξi
слишком велики, так что кривая эмпирической функции распределения проходит слишком низко. На рис. 2, c представлен еще худший случай; ясно, что такие большие расхождения между Fn
(x) и F(x) крайне маловероятны; КС-критерий должен указать, насколько они маловероятны.
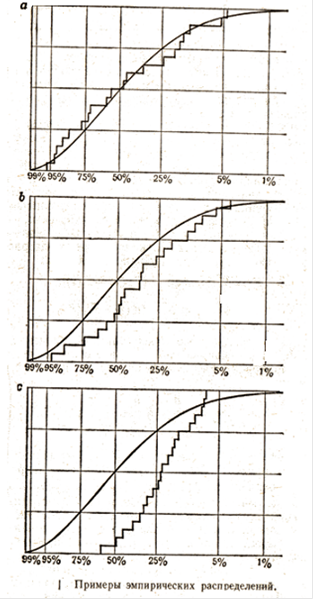
Рисунок 2 – примеры эмпирических распределений
Для этого формируются следующие статистики:
Kn
+
=n max (Fn
(x)- F(x));
Kn
-
=n max (F(x)- Fn
(x)), при -∞<x<+∞.
Здесь Kn
+
показывает, каково максимальное отклонение для случая Fn
>F, а Kn
-
- каково максимальное отклонение для случая Fn
<F.
Замечание. Наличие множителя n в формуле может показаться странным. Эти формулы не годятся для машинных расчетов, так как требуется отыскать максимальное среди бесконечного множества чисел. однако тот факт, что F(x) – неубывающая функция, а Fn
(x) имеет конечное число скачков, позволяет определить статистики Kn
+
и Kn
-
с помощью следующего простого алгоритма:
Шаг 1. Определяются выборочные значения ξ1
, ξ2
, … , ξn
.
Шаг 2. Значения ξi
располагаются в порядке возрастания так, чтобы ξ1
≤ ξ2
≤…≤ξn
.
Шаг 3. Нужные статистики вычисляются по формулам
Kn
+
= max ( max ( - F(xj
)); - F(xj
));
Kn
- -
= max (F(xj
) -  ), при 1≤j≤n. ), при 1≤j≤n.
Заключение
В данной курсовой работе рассмотрены вопросы применения случайных чисел для прикладных задач математики и информатики, рассмотрены методы получения случайных чисел, начиная от самых ранних методов с использованием первых вычислительных машин по настоящее время.
После проведения обзора используемых в настоящее время датчиков случайных чисел, можно сделать вывод, что многие из них, несмотря на свою популярность, недостаточно хороши. Довольно часто какой-нибудь старый сравнительно неудовлетворительный метод передается от одного программиста к другому в слепую, и сегодняшний пользователь уже ничего не знает об его недостатках. Поэтому, при моделировании процессов и систем, в которых нужно учитывать случайные параметры, необходимо оценочно подходить к выбору подходящего датчика случайных чисел.
Один из акцентов курсовой работы был сделан на способы получения последовательностей как источника случайных чисел для ЭФМ. Рассмотрен вариант построения линейной конгруэнтные последовательности случайных чисел. Вообще, получение последовательностей псевдослучайных чисел сводится к задаче получения последовательностей, которые похожи на случайные, и определения, достаточно ли хороша генерируемая последовательность случайных чисел для выполняемой задачи. В работе рассмотрен вопрос использования критерия χ2 и КС-критерия для определения «случайности» чисел генерируемых числовых последовательностей, и показано, как могут соотноситься истинные и эмпирические функции распределения.
В качестве практической части приводится пример создания датчика случайных чисел, с последующей разработкой программы на языке Pascal.
Список литературы
1. Д. Кнут Искусство программирования для ЭВМ. т. 2, Получисленные алгоритмы. – М.: Издательство «Мир», 1977 – с. 5-98
2. Полляк Ю.Г. Вероятностное моделирование на электронных вычислительных машинах. - М.: Сов. Радио, 1971 — 386 с.
3. Вентцель Е.С., Овчаров Л.А. Теория вероятностей и её инженерные приложения, М: Наука, 1988 — 301 с.
4. Советов Б.Я. Моделирование систем: Курсовое проектирование: Учеб. пособие для вузов по спец. АСУ.- М: Высш. шк., 1988. – 135с.: ил
Приложение
1. program g1;
const n=100;
var x0, a, c, m, i: byte; x: array[0..n] of integer;
begin
writeln ('vvedite x0>=0:');
readln (x0);
writeln ('vvedite a>=2:');
readln (a);
writeln ('vvedite c>=0:');
readln (c);
writeln ('vvedite m>(x0 and a and c):');
readln (m);
if (x0>=0) and (a>=0) and (c>=0) then
if (m>x0) and (m>a) and (m>c) then
for i:=0 to n do x[i+1]:=(a*x[i]+c) mod m;
writeln ('chisla: ');
for i:=1 to n do write(x[i], ' ');
writeln;
end.
2. Program g2;
var I, l: integer;
begin
for I:=l to 10 do
write(random(200):4)
end.
3. program number(input, output);
var a, b, n, s, i : integer;
begin
writeln ('poluchenie sluchainih chisel iz intervala [a,b]');
write ('vvedite a');
readln (a);
write ('vvedite b');
readln (b);
writeln ('vvedite n');
readln (n);
for i:=1 to n do
begin
s:=trunc(random(b-a)+a);
writeln (i:2,'-e sluchainoe chislo:',s:4);
end;
readln;
end.
|