Вступ до анал
і
зу асоціативних правил
Останнім часом задачі пошуку нових знань у великих базах сирих даних стають все більш популярними та актуальними. Одним із популярних методів виявлення знань став алгоритм пошуку так званих асоціативних правил (Association Rules). Суть задачі полягає в знаходження наборів об’єктів, які зустрічаються найчастіше серед всієї множини ймовірних наборів об’єктів. Першим застосуванням такої задачі був аналіз тенденцій в поведінці покупців у супермаркетах. При цьому аналізувались дані про всі здійснені покупки, які кожен покупець кладе у свій кошик, та одержувалась інформація про те, які товари переважно купуються разом, в якій послідовності, якими категоріями покупців, в які періоди часу, тощо. Такого роду знання дозволяють ефективно планувати закупку товарів у магазин, розробляти ефективні рекламні кампанії та розкладати товар таким чином, щоб провокувати покупців на різноманітні покупки.
Наприклад, з набору товарів, які купуються в магазинах, можна виділити такі набори товарів, що переважно купуються одночасно:
- {чіпси, пиво};
- {вода, горіхи};
- {чай, печиво};
- Тощо.
Таким чином, можна зробити висновок про те, що якщо купуються чіпси чи горіхи, то, як правило, купуються, пиво чи вода, відповідно. Отже, можна розмістити ці товари поруч на прилавках, об’єднати їх в один пакет зі знижкою чи здійснити інші дії.
Задача пошуку асоціативних правил є актуальною не лише у сфері торгівлі. Наприклад, в сфері обслуговування цікавою є інформація про те, якими послугами клієнти користуються в сукупності. Для одержання цієї інформації вирішується задача аналізу даних про послуги, якими користується один клієнт протягом певного часу. Це допомагає визначити, наприклад, як найбільш вигідно сформувати пакети послуг для клієнтів.
В медицині аналізуватись можуть симптоми та хвороби пацієнтів. В цьому випадку знання про те, які поєднання хворів та симптомів зустрічаються найчастіше, дозволяють в майбутньому ставити правильні діагнози.
Визначення
Щоб дати означення асоціативного правила, будемо вважати, що існує база даних, якій містяться записи про всі здійснені покупки в супермаркеті. Кожен запис називається транзакцією і включає дані про набір товарів, куплених одним покупцем за один візит. Таку транзакцію ще називаю ринковим кошиком.
Нехай  – це вся множина товарів з супермаркету, що називаються елементами. – це вся множина товарів з супермаркету, що називаються елементами.
Приклад[1]
:
| Ідентифікатор |
Найменування товару |
Ціна |
| 0 |
Шоколад |
30.00 |
| 1 |
Чіпси |
12.00 |
| 2 |
Кокоси |
10.00 |
| 3 |
Вода |
4.00 |
| 4 |
Пиво |
14.00 |
| 5 |
Горіхи |
15.00 |
Тобто вся множина елементів (їх загальна кількість рівна  ) )  буде: буде:
 . .
Кожна транзакція  описується як: описується як:  . Приклади транзакцій: . Приклади транзакцій:


Набір усіх відомих транзакцій (загальна їх кількість нехай рівна  ) позначаємо як ) позначаємо як  : :  . .
Нехай для нашого прикладу:

Тоді множину  можемо представити у вигляді: можемо представити у вигляді:
| № транзакції |
Ідентифікатор товару |
Найменування товару |
Ціна |
| 0 |
1 |
Чіпси |
12.00 |
| 0 |
3 |
Вода |
4.00 |
| 0 |
4 |
Пиво |
14.00 |
| 1 |
2 |
Кокоси |
10.00 |
| 1 |
3 |
Вода |
4.00 |
| 1 |
5 |
Горіхи |
15.00 |
| 2 |
5 |
Горіхи |
15.00 |
| 2 |
2 |
Кокоси |
10.00 |
| 2 |
1 |
Чіпси |
12.00 |
| 2 |
2 |
Кокоси |
10.00 |
| 2 |
3 |
Вода |
4.00 |
| 3 |
2 |
Кокоси |
10.00 |
| 3 |
5 |
Горіхи |
15.00 |
| 3 |
2 |
Кокоси |
10.00 |
Множину транзакцій, в яку входить об’єкт  позначимо як: позначимо як:
 . .
Наприклад, множина транзакцій, в які входить елемент «вода»:

Деякий довільний набір елементів позначимо так:  . Набір, що складається з . Набір, що складається з  об’єктів називається -елементним набором. Приклад 2-елементного набору: об’єктів називається -елементним набором. Приклад 2-елементного набору:  . .
Множину транзакцій, в яку входить набір  , позначимо , позначимо  : :  . .
В даному прикладі:
 . .
Відношення кількості транзакцій, в які входить , до загальної кількості транзакцій називається підтримкою (
support
)
набору та позначається  : :
 . .
Можна підтримку рахувати у відсотках (тоді треба помножити на 100%).
Для набору підтримка рівна 0.5 або 50%, так як цей набір входить у дві транзакції (з номерами 1 та 2), а всього транзакцій є 4.
При пошуку аналітик може вказати мінімальне значення підтримки для наборів, що його цікавлять –  . .
Набір називається частим, якщо значення його підтримки є більшим за вказане мінімальне значення, задане користувачем:  . .
Таким чином, при пошуку асоціативних правил необхідно знайти множину всіх частих наборів:
 . .
В даному прикладі частими наборами при  є такі: є такі:

З іншого боку, важливо не лише знайти часті набори, але виявити правила «якщо....., то...». Наприклад, в даному прикладі можна досліджувати, наскільки правдивим є правило: якщо «кокоси», то «вода»
. Тобто важливо не просто знати. Що ці ва елементи часто знаходяться в одному наборі, але й вміти прогнозувати, що при покупці «кокосів» ймовірно буде покупка «води» або навпаки.
Розіб’ємо наш досліджуваний наборі на два піднабори:  та та  . Наприклад, набір будемо розглядати як: . Наприклад, набір будемо розглядати як:  та та  , тобто , тобто  . Тоді асоціативним правилом можна назвати імплікацію[2]
: . Тоді асоціативним правилом можна назвати імплікацію[2]
:  , де , де  . Правило має підтримку: . Правило має підтримку:
 , , 
тобто  – це відсоток зі всіх транзакцій , що містять і набір , і набір (тобто містять набір ). – це відсоток зі всіх транзакцій , що містять і набір , і набір (тобто містять набір ).

Бо, як було вже згадано вище, з чотирьох транзакцій дві містять і «Кокоси» і «Воду».
Достовірністю
правила називається ймовірність того, що саме з випливає . Правило має достовірність (confidence):
 , ,
що показує, який відсоток з усіх транзакцій , що містить , також містить і .
 . .
Отже, підтримка правила  рівна 50% (50% зі всіх транзакцій містять і «Кокоси», і «Воду»), а достовірність цього правила рівна 66.7% (66.7% зі всіх транзакцій, що містять «Кокоси», також містять і «Воду»). рівна 50% (50% зі всіх транзакцій містять і «Кокоси», і «Воду»), а достовірність цього правила рівна 66.7% (66.7% зі всіх транзакцій, що містять «Кокоси», також містять і «Воду»).
Іншими словами, метою аналізу є встановлення наступних залежностей: якщо в транзакції зустрівся деякий набір елементів , то на підставі цього можна зробити висновок про те, що інший набір елементів також повинен з'явитися в цій транзакції. Алгоритми пошуку асоціативних правил призначені для знаходження всіх правил , причому підтримка і достовірність цих правил повинні бути вищими за деякі наперед задані пороги, що називаються відповідно мінімальною підтримкою () та мінімальною достовірністю ( ). ).
Деякі видозміни асоціативних правил
Узагальнені асоціативні правила (Generalized Association Rules)
При пошуку асоціативних правил вище припускалось, що всі аналізовані елементи є однорідними. Проте, повертаючись до аналізу ринкової корзини, не складе великих труднощів доповнити транзакцію інформацією про те, до якої товарної групи входить товар і побудувати ієрархію товарів. Приведемо приклад такого групування (таксономії) у вигляді ієрархічної моделі.

Нехай дана база транзакцій та відомо, в які групи (таксони) входять елементи. Тоді з даних можна одержувати правила, що пов'язують групи з групами, окремі елементи з групами і т.д. Наприклад, якщо покупець купив товар з групи «Безалкогольні напої», то він купить і товар з групи «Молочні продукти»: правило  . Ці правила носять назву узагальнених асоціативних правил. . Ці правила носять назву узагальнених асоціативних правил.
Введення додаткової інформації про угрупування елементів у вигляді ієрархії має свої переваги, зокрема, допомагає встановити асоціативні правила не тільки між окремими елементами, але й між різними рівнями ієрархії (групами). Проте з додаванням до транзакції понять груп збільшується кількість атрибутів і, відповідно, розмірність вхідного простору. Це ускладнює завдання, а також призводить до генерації більшої кількості правил. Для знаходження узагальнених асоціативних правил бажано використання спеціалізованого алгоритму, який усуває вищеописані проблеми.
Групувати елементи можна не тільки по входу до певної товарної групи, але й за іншими характеристиками, наприклад за ціною (дешево, дорого), брендом і т.д.
Чисельні асоціативні правила (Quantitative Association Rules)
При пошуку асоціативних правил все зводилося до того, чи присутній в транзакції елемент чи ні. Тобто, якщо розглядати випадок ринкової корзини, то розглядаємо два стани: куплено товар чи ні. При цьому ігнорується, наприклад, інформація про те, скільки чого було куплено, хто саме купив, тощо. Тобто було розглянуто "булеві" асоціативні правила. Проте можна аналізувати дані різних типів: числові, категоріальні і т.д.
Приклад чисельного асоціативного правила:
Якщо «[Вік: 30-35]» і «[Сімейний стан: одружений]», то «[Місячний дохід: 1000-1500 гривень]».
Ознайомлення з аналітичною платформою
Deductor
Deductor Studio – аналітичне ядро платформи Deductor, що містить повний набір механізмів імпорту, обробки, візуалізації й експорту даних для швидкого й ефективного аналізу інформації. У ньому зосереджені найсучасніші методи видобутку, очищення, маніпулювання та візуалізації даних, а також доступні методи моделювання, прогнозування, кластеризації, пошуку закономірностей та багато інших технологій видобутку знань (Knowledge Discovery in Databases) і видобутку даних (Data Mining).
В Deductor Studio включений повний набір механізмів, що дозволяє одержати інформацію з будь-якого джерела даних, провести весь цикл обробки (очищення, трансформацію даних, побудову моделей), відобразити одержані результати у найбільш зручний спосіб (OLAP, таблиці, діаграми, дерева рішень...) і експортувати результати.
Вся робота з аналізу даних в Deductor Studio базується на виконанні наступних дій:
-  Імпорт даних; Імпорт даних;
-  Ообробка даних; Ообробка даних;
-  Візуалізація; Візуалізація;
-  Експорт даних. Експорт даних.
Відправною точкою для аналізу завжди є процедура імпорту даних. Одержаний набір даних може бути опрацьований будь-яким доступним способом. Результатом опрацювання також є набір даних, що може опрацьовуватись при потребі і далі. Результати опрацювання можна звізуалізувати різними способами та експортувати в найбільш популярні формати. Послідовність дій, які проводяться при аналізі даних, називаються сценарієм
, який можна автоматично виконувати на будь-яких даних.
Deductor Studio підтримує багато різних джерел даних: промислові СУБД (Oracle, MS SQL...), текстові файли, офісні ужитки (Excel, Access), ADO і ODBC джерела. Очевидно, що Deductor Studio є також повністю інтегрований з багатомірним сховищем даних Deductor Warehouse.
Під обробкою чи опрацюванням даних мається на увазі будь-яка дія, пов'язана із перетворенням даних, наприклад, побудова моделей, очищення від шумів чи аномальних значень. При цьому механізми обробки можна комбінувати довільним чином так, щоб досягти найкращого результату.
Візуалізація – це відображення імпортованих та опрацьованих даних. Візуалізувати можна будь-який об'єкт у сценарії обробки. Програма самостійно аналізує, яким чином можна відобразити інформацію, а користувач повинен лише вибрати потрібний варіант.
Майстер імпорту даних
Майстер імпорту допоможе в інтерактивному покроковому режимі вибрати тип джерела даних і налаштувати відповідні параметри. На першому кроці відкривається список всіх передбачених у системі типів джерел даних, згрупованих за способом доступу до даних. Список доступних джерел може змінюватися залежно від налаштувань на панелі підключень, а також індивідуальних налаштувань доступних дій і доступних джерел даних. Підключенням
називається налаштоване і назване певним чином під’єднання до зовнішньої системи, що дозволяє обмінюватись із нею даними (приймати чи передавати). на панелі підключень, а також індивідуальних налаштувань доступних дій і доступних джерел даних. Підключенням
називається налаштоване і назване певним чином під’єднання до зовнішньої системи, що дозволяє обмінюватись із нею даними (приймати чи передавати).
Для виклику Майстра імпорту можна скористатися кнопкою
«Майстер імпорту» на панелі інструментів  «Сценарії», вибрати відповідну команду з контекстного меню або натиснути <F6>. З доступних підключень клацанням миші виберіть потрібне: «Сценарії», вибрати відповідну команду з контекстного меню або натиснути <F6>. З доступних підключень клацанням миші виберіть потрібне:
- Сховища даних:
o  Virtual Warehouse – імпорт даних з Virual Warehouse; Virtual Warehouse – імпорт даних з Virual Warehouse;
o  Deductor Warehouse - імпорт даних з Deductor Warehouse. Deductor Warehouse - імпорт даних з Deductor Warehouse.
- Бізнес-програми:
o  1С: Підприємство 7.7 – імпорт даних з облікової системи 1С версії 7.7; 1С: Підприємство 7.7 – імпорт даних з облікової системи 1С версії 7.7;
o  1С:Підприємство 8.x – імпорт даних з облікової системи 1С 8.х. 1С:Підприємство 8.x – імпорт даних з облікової системи 1С 8.х.
- Бази даних:
o  База даних – імпорт даних з баз даних різних видів. База даних – імпорт даних з баз даних різних видів.
- Прямий доступ до файлів:
o  Текстовий файл із роздільниками – тобто у форматі, в якому стовпці даних розділені однотипними символами-роздільниками; Текстовий файл із роздільниками – тобто у форматі, в якому стовпці даних розділені однотипними символами-роздільниками;
o  Імпорт з DBF – прямий доступ до файлів плоских баз даних типу DBF, що підтримується такими ужитками, як dBase, FoxBase, FoxPro. Імпорт з DBF – прямий доступ до файлів плоских баз даних типу DBF, що підтримується такими ужитками, як dBase, FoxBase, FoxPro.
- Механізм MS ADO:
o  Microsoft Excel – книга Microsoft Excel (*.xls); Microsoft Excel – книга Microsoft Excel (*.xls);
o  Microsoft Access – файл СУБД Microsoft Access (*.mdb); Microsoft Access – файл СУБД Microsoft Access (*.mdb);
o Імпорт з DBF (ADO) – доступ через ADO[3]
до файлів плоских баз даних типу DBF, що підтримується такими ужитками, як dBase, FoxBase, FoxPro;
o  Текстовий файл з доступом через ADO – тобто текстовий файл із роздільниками, доступ до якого здійснюється через механізм ADO; Текстовий файл з доступом через ADO – тобто текстовий файл із роздільниками, доступ до якого здійснюється через механізм ADO;
o  ADO-джерело – імпорт даних безпосередньо за допомогою системних налаштувань механізму ADO. ADO-джерело – імпорт даних безпосередньо за допомогою системних налаштувань механізму ADO.
Кількості кроків Майстри імпорту та параметрів відрізянються для різних типів джерел. На кожному кроці Майстра імпорту доступні кнопки «Далі» та «Назад», які дозволяють перейти до наступного кроку або повернутися на попередній крок для внесення змін у раніше налаштовані параметри. Кнопка «Скасувати» дозволить відмовитися від використання Майстра імпорту.
Майстер опрацювання даних
Майстер опрацювання даних допоможе в інтерактивному покроковому режимі налаштувати всі необхідні етапи обробки даних. У вікні першого кроку Майстри наведені всі доступні в системі методи опрацювання даних, згруповані за типом. Для виклику Майстра опрацювання даних можна скористатися кнопкою «Майстер обробки» на панелі інструментів «Сценарії», попередньо виділивши потрібну гілку у сценарії або вибравши відповідну команду з контекстного меню (<F7>).
З доступних алгоритмів опрацювання даних потрібно вибрати один, скориставшись мишкою:
- Очищення даних:
o  Парціальна обробка – алгоритми відновлення, згладжування та редагування аномальних даних. Парціальна обробка – алгоритми відновлення, згладжування та редагування аномальних даних.
o  Факторний аналіз – для зниження розмірності вхідних факторів. Зниження розмірності необхідно у випадках, коли вхідні фактори є скорельованими один з одним, тобто взаємозалежні. У факторному аналізі мова йде про виділення з множини вимірюваних характеристик об'єкта нових факторів, що більш адекватно відображають властивості об'єкта. Факторний аналіз – для зниження розмірності вхідних факторів. Зниження розмірності необхідно у випадках, коли вхідні фактори є скорельованими один з одним, тобто взаємозалежні. У факторному аналізі мова йде про виділення з множини вимірюваних характеристик об'єкта нових факторів, що більш адекватно відображають властивості об'єкта.
o  Кореляційний аналіз – усунення факторів, що не сильно впливають на результат (вихідні поля): такі фактори можуть бути виключені з розгляду практично без втрати корисної інформації. Критерієм прийняття рішення про виключення фактора служить порог чутливості: якщо кореляція (ступінь взаємозалежності) між вхідним та вихідним факторами є нижчою за поріг чутливості, то відповідний вхідний фактор відкидається як незначний. Кореляційний аналіз – усунення факторів, що не сильно впливають на результат (вихідні поля): такі фактори можуть бути виключені з розгляду практично без втрати корисної інформації. Критерієм прийняття рішення про виключення фактора служить порог чутливості: якщо кореляція (ступінь взаємозалежності) між вхідним та вихідним факторами є нижчою за поріг чутливості, то відповідний вхідний фактор відкидається як незначний.
o  Дублікати та протиріччя – виявлення дублікатів та суперечливих записів у вхідному наборі даних. Дублікати та протиріччя – виявлення дублікатів та суперечливих записів у вхідному наборі даних.
o  Фільтрація – фільтрація записів вибірки за заданими умовами. Фільтрація – фільтрація записів вибірки за заданими умовами.
- Трансформація даних:
o  Налаштування набору даних – налаштування параметрів полів: можна змінити ім'я, мітку, тип, вид і призначення полів, а також налаштувати кешування проміжних даних. Налаштування набору даних – налаштування параметрів полів: можна змінити ім'я, мітку, тип, вид і призначення полів, а також налаштувати кешування проміжних даних.
o  Ковзаюче вікно – дозволяє здійснювати перетворення даних методом ковзаючого вікна. Ковзаюче вікно – дозволяє здійснювати перетворення даних методом ковзаючого вікна.
o  Дата і час – опрацювання даних у форматі «дата» і «час» (наприклад, перетворення вхідних даних у днях в дані по тижнях). Дата і час – опрацювання даних у форматі «дата» і «час» (наприклад, перетворення вхідних даних у днях в дані по тижнях).
o  Квантування значень вибірки – процес, в результаті якого відбувається розподілення значень неперервних даних між скінченною кількістю інтервалів заданої довжини. Квантування значень вибірки – процес, в результаті якого відбувається розподілення значень неперервних даних між скінченною кількістю інтервалів заданої довжини.
o  Сортування – сортування записів у вхідній вибірці даних. Сортування – сортування записів у вхідній вибірці даних.
o  Злиття – об'єднання даних із двох таблиць. Злиття – об'єднання даних із двох таблиць.
o  Заміна – заміна значень згідно таблиці підстановки. Заміна – заміна значень згідно таблиці підстановки.
o  Групування даних. Групування даних.
o  Разгрупування даних – відновлення вибірки, до якої була застосована операція групування. Разгрупування даних – відновлення вибірки, до якої була застосована операція групування.
- Data Mining:
o  Прогнозування часового ряду. Наприклад, методом ковзаючого вікна було одержано часовий ряд: Прогнозування часового ряду. Наприклад, методом ковзаючого вікна було одержано часовий ряд:  , а потрібно спрогнозувати наступне значення , а потрібно спрогнозувати наступне значення  на основі всіх попередніх значень. на основі всіх попередніх значень.
o  Автокореляція – автокореляційний аналіз даних, метою якого є з'ясування ступеня статистичної залежності між різними значеннями випадкової послідовності. У процесі автокореляційного аналізу розраховуються коефіцієнти кореляції (міра взаємної залежності) для двох значень вибірки, що перебувають один від одного на певній відстані (кількість проміжних значень між ними), яку називають також лагом. Сукупність коефіцієнтів кореляції по всіх лагах називається автокореляційною функцією ряду. За поведінкою цієї функції можна судити про характер аналізованої послідовності: ступеня її гладкості, наявності періодичності, тощо. Автокореляція – автокореляційний аналіз даних, метою якого є з'ясування ступеня статистичної залежності між різними значеннями випадкової послідовності. У процесі автокореляційного аналізу розраховуються коефіцієнти кореляції (міра взаємної залежності) для двох значень вибірки, що перебувають один від одного на певній відстані (кількість проміжних значень між ними), яку називають також лагом. Сукупність коефіцієнтів кореляції по всіх лагах називається автокореляційною функцією ряду. За поведінкою цієї функції можна судити про характер аналізованої послідовності: ступеня її гладкості, наявності періодичності, тощо.
o  Лінійна регресія – будується модель даних у вигляді набору коефіцієнтів лінійного перетворення. Лінійна регресія – будується модель даних у вигляді набору коефіцієнтів лінійного перетворення.
o  Логістична регресія – будується бінарна логістична регресійна модель. Логістична регресія – будується бінарна логістична регресійна модель.
o  Нейромережа – опрацювання даних за допомогою багатошарової нейронної мережі. Нейромережа – опрацювання даних за допомогою багатошарової нейронної мережі.
o  Дерево рішень – опрацювання даних за допомогою дерев рішень. Дерево рішень – опрацювання даних за допомогою дерев рішень.
o  Самоорганізовані карти – виконується кластеризація даних. Самоорганізовані карти – виконується кластеризація даних.
o  Асоціативні правила – виявлення залежностей між взаємозв'язаними подіями. Асоціативні правила – виявлення залежностей між взаємозв'язаними подіями.
o  Користувацька модель – задання моделі вручну за формулами. Користувацька модель – задання моделі вручну за формулами.
- Інше:
o  Скрипт – застосування моделі до нових даних.Скрипти призначені для автоматизації процесу додавання в сценарій однотипних гілок обробки. По суті скрипт є динамічною копією вибраної ділянки сценарію. При зміні оригінальної гілки змінюється і скрипт, який посилається на неї. Наприклад, після імпорту даних з двох різних баз даних потрібно провести їх попередню обробку (очистити дані, згладити, поміняти назви стовпців, додати кілька однакових значень, тощо) та побудувати однакові моделі прогнозу, а потім експортувати отримані дані назад. Для першої гілки (першої БД) ці дії проводяться як звичайно: послідовними кроками будується ланцюжок обробників. Для другого джерела (другої БД) достатньо буде створити вузол імпорту, до якого потрібно приєднати скрипт, що базується на побудованій першій гілці. У цьому скрипті будуть виконані точно такі ж дії, як в оригінальній гілці. На виході скрипта ставиться вузол експорту, і друга гілка є готовою до використання. Аналогом скриптів є функції та процедури в мовах програмування: гілка обробки будується один раз, а потім за допомогою скриптів виконуються закладені в ній універсальні обробники. Скрипт – застосування моделі до нових даних.Скрипти призначені для автоматизації процесу додавання в сценарій однотипних гілок обробки. По суті скрипт є динамічною копією вибраної ділянки сценарію. При зміні оригінальної гілки змінюється і скрипт, який посилається на неї. Наприклад, після імпорту даних з двох різних баз даних потрібно провести їх попередню обробку (очистити дані, згладити, поміняти назви стовпців, додати кілька однакових значень, тощо) та побудувати однакові моделі прогнозу, а потім експортувати отримані дані назад. Для першої гілки (першої БД) ці дії проводяться як звичайно: послідовними кроками будується ланцюжок обробників. Для другого джерела (другої БД) достатньо буде створити вузол імпорту, до якого потрібно приєднати скрипт, що базується на побудованій першій гілці. У цьому скрипті будуть виконані точно такі ж дії, як в оригінальній гілці. На виході скрипта ставиться вузол експорту, і друга гілка є готовою до використання. Аналогом скриптів є функції та процедури в мовах програмування: гілка обробки будується один раз, а потім за допомогою скриптів виконуються закладені в ній універсальні обробники.
o  Калькулятор – дозволяє сформувати нове поле вибірки як результат обчислень над даними з інших полів. Калькулятор – дозволяє сформувати нове поле вибірки як результат обчислень над даними з інших полів.
o  Умова – дозволяє організувати умовне виконання сценарію обробки даних. Умова – дозволяє організувати умовне виконання сценарію обробки даних.
o  Команда OC – забезпечує формування й запуск різних команд операційної системи. Команда OC – забезпечує формування й запуск різних команд операційної системи.
Залежно від обраного методу Майстер обробки буде містити різне число кроків і набір параметрів, що надбудовуються на кожному кроці. На кожному кроці Майстра обробки доступні кнопки «Далі», «Назад» та «Скасувати».
Майстер
візуалізації
даних
Майстер візуалізації допоможе в інтерактивному покроковому режимі вибрати та налаштувати найбільш зручний спосіб подання даних. В залежності від обраного способу візуалізації будуть налаштовуватись різні параметри, а Майстер, відповідно, буде містити різне число кроків.
Для виклику Майстра візуалізації можна скористатися кнопкою «Майстер візуалізації» на панелі інструментів «Сценарії», попередньо виділивши потрібну гілку у сценарії опрацювання або вибравши відповідну команду з контекстного меню для даної гілки сценарію.
Виконання аналізу асоціативних правил
На першому кроці необхідно імпортувати дані в Deductor.Використовуючи кнопку , вказуємо шлях до текстового файлу з роздільниками. Для прикладу, можна вибрати один із готових прикладів у папці «Samples» –Supermarket.txt:
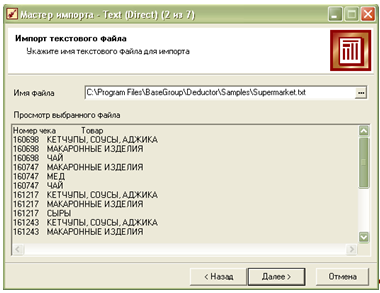
Пілся натискування кнопки «Далі» вказуємо тип роздільника та інші параметри імпорту. Наступним кроком є вказання параметрів стопвпців:
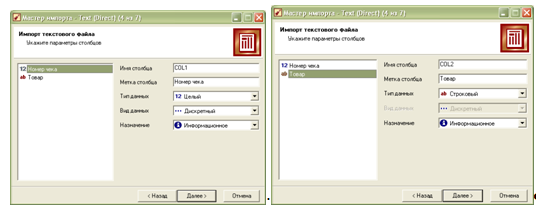
Після цього натискаємо кнопку «Далі», а потім – «Пуск». Після виконання процесу імпорту даних з текстового файлу потрібно вибрати спосіб їх відображення (за замовчуванням – таблиця). Після цього маємо дані, готові для опрацювання:
асоціативний правило аналітичний

Стаємо на відповідну гілку в сценарії та натискаємо кнопку Майстра обробки даних:

Серед методів опрацювання даних вибираємо  Асоціативні правила, після чого потрібно вказати, який стовпець відповідає за номер чи ідентифікатор транзакції, а який містить самі елементи (в даному випадку – покупки): Асоціативні правила, після чого потрібно вказати, який стовпець відповідає за номер чи ідентифікатор транзакції, а який містить самі елементи (в даному випадку – покупки):

Наступне вікно дозволяє вказати значення мінімальних та максимальних підтримки та достовірності правил:

В наступному вікні натискаємо кнопку «Пуск», після чого здійснюється аналіз згідно вказаних значень:

Далі знову пропонуються різні способи візуалізації даних. Вибираємо всі способи відображення, що знаходяться в групі «DataMining». В результаті одержуємо:
- Набір асоціативних правил з вказанням їх підтримки, достовірності та кількості.
- Популярні набори елементів (в даному випадку – покупок).
- Дерево правил за наслідком, наприклад:
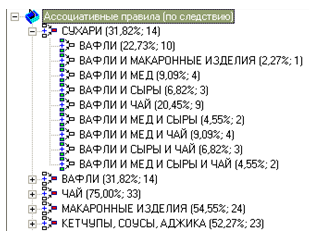
що буде показувати, після покупки яких продуктів далі ймовірно будуть куплені сухарі.
- Можливість розрахувати умову «якщо... то...»: наприклад, можна вказати умову «вафлі», а потім натиснути кнопку «Розрахувати правила» або Ctrl+Enter. Після цього внизу в області наслідку з’являться відповідні записи «чай», «сухарі», «сухарі і чай» з вказанням всіх параметрів.
[1]
Приклад з підручника: Методы и модели анализа данных: OLAP и Data Mining / А. А. Барсегян, М. С. Куприянов, В. В. Сепаненко, И. И. Холод.
[2]
Імплікація — логічний оператор «якщо …, то …».
[3]
ADO (від англ. ActiveX Data Objects — «об'єкти даних ActiveХ») — інтерфейспрограмування ужитків для доступу до даних, розроблений компанією Microsoft (MS Access, MS SQL Server), що базується на технології компонентів ActiveX. ADO дозволяє представляти дані з різноманітних джерел (реляційних баз даних, текстових файлів і т.д.) в объектно-орієнтованому вигляді.
|