Завдання № 1
Визначення необхідного числа спостережень
Постановка завдання
1. Запропонуйте й опишіть приклад досліджень шляхом проведення експериментів, спостережень або вимірювань з метою встановлення середньоарифметичного значення будь-якого техніко-економічного показника діяльності організації (підприємства, виробничого підрозділу, механізму тощо).
2. Викладіть методику встановлення необхідного обсягу статистичної вибірки (кількості спостережень).
3. Обґрунтуйте вихідні дані, потрібні для встановлення обсягу вибірки.
4. Встановіть необхідну кількість спостережень техніко-економічного показника, що досліджується.
5. Сформулюйте висновок стосовно отриманого обсягу статистичної вибірки.
Виконання завдання:
1. Досліджується попит одягу в мережі супермаркетів. Для цього встановлюється необхідний обсяг статистичної вибірки.
2. Методика вирішення:
1) Розраховується ймовірність появи випадкового відхилення за відношенням:
3. ε = , ,
де ∆x – припустима величина випадкового відхилення вибірки;
S – середньоквадратичне відхилення вибірки.
2) Приймається коефіцієнт надійності експерименту (α), виходячи з умов задачі та призначення експериментальних даних. Як-правило, для задач економічного характеру α приймається рівним 0,9.
3) За табл.1 знаходиться, згідно зі значеннямиε та α, число мінімально необхідних спостережень досліджуваної ознаки.
4) Формулюється висновок стосовно отриманого обсягу статистичної вибірки.
3. Приймаємо середньоквадратичне відхилення даних вибірки, таким, що дорівнює 7,5%. Випадкове відхилення представлених значень, згідно з метою дослідження, дорівнює 1,5%. Коефіцієнт надійності експерименту (α) прийнято рівним 0,9. Коефіцієнт вірогідності появи випадкового відхилення Е = 1,5/7,5= 0,2.
4. Визначаємо необхідну кількість спостережень за витратами на маркетингові дослідження згідно з наступними даними: E = 0,2, α = 0,95. За табл.1 число необхідних спостережень дорівнює 70.
5. Висновок: Таким чином, вибірковасукупність повинна мати не менше 70 спостережень. Цей обсяг даних дозволить розрахувати таку середньоквадратичну величину, відносно якої в інтервалі припустимого випадкового відхилення ± 1,5 % будь-який результат спостереження буде потрапляти з вірогідністю α = 0,95.
статистичний вибірка детермінація кореляція
Таблиця 1
Необхідне число вимірів для отримання випадкової похибки ε з надійністю α
ε =
|
α |
| 0,5 |
0,7 |
0,9 |
0,95 |
0,99 |
0,999 |
| 1,0 |
2 |
3 |
5 |
7 |
11 |
17 |
| 0,5 |
3 |
6 |
13 |
18 |
31 |
50 |
| 0,4 |
4 |
8 |
19 |
27 |
46 |
74 |
| 0,3 |
6 |
13 |
32 |
46 |
78 |
127 |
| 0,2 |
13 |
29 |
70 |
99 |
171 |
277 |
| 0,1 |
47 |
169 |
273 |
387 |
668 |
1089 |
| 0,05 |
183 |
431 |
1084 |
1540 |
2659 |
4338 |
| 0,02 |
4543 |
10732 |
27161 |
38416 |
66358 |
108307 |
Завдання № 2
Перевірка на нормальність розподілу вибіркової сукупності
1. Запропонуйте й опишіть приклад досліджень шляхом проведення експериментів, спостережень або вимірювань.
2. Складіть статистичну вибірку для перевірки на нормальність розподілу будь-якого техніко-економічного показника діяльності організації (підприємства, виробничого підрозділу, механізму тощо). Обсяг статистичної вибірки – не менш 40 спостережень (вимірювань).
3. Викладіть методику перевірки статистичної вибірки на розподіл за нормальним законом.
4. Здійсніть перевірку складеної вибірки за поз. 2 на нормальність розподілу.
5. Сформулюйте висновок стосовно одержаного результату перевірки.
Виконання завдання:
Досліджується попит одягу в мережі супермаркетів, що має достатній обсяг спостережень, але розподіл випадкової величини є невідомим. Необхідно перевірити вибірку на нормальність розподілу.
2. Впорядкуємо розміщення даних у зростаючому порядку за допомогою програми Майстер функцій (п. 2).
3. Методика складається з наступних етапів:
а) вибірку розбивають на рівні інтервали, величина яких визначається за виразом:
h = , (2.1) , (2.1)
де Х – максимальне значення вибірки; – максимальне значення вибірки;
Х – мінімальне значення вибірки; – мінімальне значення вибірки;
n – число спостережень.
Нижньою границею початкового інтервалу буде мінімальне значення вибірки, верхньою – мінімальне, збільшене на величину (крок) інтервалу. Останнє, в свою чергу, буде нижньою границею наступного інтервалу, а верхня – визначатиметься кроком інтервалу. Останній інтервал має вміщувати максимальне значення вибіркової сукупності даних.
б) за кожним інтервалом знаходять його середнє значення  як суму верхньої та нижньої границь відповідного інтервалу, поділену навпіл. Виділивши поле, що дорівнює числу інтервалів, та скориставшись командою Вставка / Функция / Статистические / Частота вбудованих функцій Еxcel знаходять частоту появи значень кожного інтервалу m як суму верхньої та нижньої границь відповідного інтервалу, поділену навпіл. Виділивши поле, що дорівнює числу інтервалів, та скориставшись командою Вставка / Функция / Статистические / Частота вбудованих функцій Еxcel знаходять частоту появи значень кожного інтервалу m , зазначивши у діалоговому вікні ‚‚ Аргументы функции ’’ у полі ‚‚Массив данных’’ массив даних вибірки, а у полі ‚‚Массив интервалов’’ – верхні границі інтервалів сукупності даних. Для виконання команди одночасно натискають клавіши <Ctrl> + <Shift> + <Enter>. , зазначивши у діалоговому вікні ‚‚ Аргументы функции ’’ у полі ‚‚Массив данных’’ массив даних вибірки, а у полі ‚‚Массив интервалов’’ – верхні границі інтервалів сукупності даних. Для виконання команди одночасно натискають клавіши <Ctrl> + <Shift> + <Enter>.
в)
розраховують середнє значення всієї сукупності даних x та її середньоквадратичне відхилення δ за допомогою команд, відповідно, Вставка / Функция / Статистические / СРЗНАЧ та Вставка / Функція / Статистические / СТАНДОТКЛП, де у полі діалогових вікон програми зазначають весь діапазон даних вибірки; та її середньоквадратичне відхилення δ за допомогою команд, відповідно, Вставка / Функция / Статистические / СРЗНАЧ та Вставка / Функція / Статистические / СТАНДОТКЛП, де у полі діалогових вікон програми зазначають весь діапазон даних вибірки;
г) для кожного інтервалу значень визначають теоретичну (вирівнюючу) частоту за виразом:
m = = , (2.2) , (2.2)
де φ(t) – табличне значення функції φ(x)= вірогідності появи теоретичного значення вибірки (середнього значення і - го інтервалу). вірогідності появи теоретичного значення вибірки (середнього значення і - го інтервалу).
Параметр t як кількісне вираження вірогідності появи середнього значен-ня xвиділеного і - го інтервалу визначають за формулою:
t = =  . (2.3) . (2.3)
д) встановлюють відносні емпіричні частості за виразом:
m′ = , (2.4) , (2.4)
де m′– емпірична частота і - го інтервалу;
n – число спостережень; – число спостережень;
е) визначимо відносні теоретичні частості за виразом:
m′= , (2.5) , (2.5)
де m – теоретична частота і - го інтервалу; – теоретична частота і - го інтервалу;
 – сума теоретичних частот; – сума теоретичних частот;
ж) розраховують накопичені емпіричні F(m ′) та теоретичні F(m ′) та теоретичні F(m ′) частості як суму відповідної відносної частості і -го інтервалу та відносних частостей попередніх інтервалів; ′) частості як суму відповідної відносної частості і -го інтервалу та відносних частостей попередніх інтервалів;
з) визначають різницю між накопиченими емпіричними та теоретичними частостями за кожним інтервалом та встановлюють серед них максимальне відхилення D;
і) встановлюють фактичний критерій відхилення емпіричного розподілу від теоретичного за наступної формулою:
λ = D∙ = D∙ . (2.6) . (2.6)
к) визначають граничне значення відхилення λ емпіричної функції від теоретичної за накопиченими частостями згідно з критерієм Колмогорова за табл. 2.1, виходячи з рівня значущості результатів розрахунків k. емпіричної функції від теоретичної за накопиченими частостями згідно з критерієм Колмогорова за табл. 2.1, виходячи з рівня значущості результатів розрахунків k.
Таблиця 2.1
Граничний критерій відхилення емпіричного розподілу від теоретичного
| k |
10 |
5 |
2 |
1 |
0,5 |
0,1
|
| λ |
1,224 |
1,358 |
1,517 |
1,627 |
1,731 |
1,950 |
л) порівнюють значення λ з λ. Якщо λ ≤ λ, то роблять висновок, що емпіричний розподіл даних не суперечить нормальному розподілу.
4. Здійснюється перевірка вибірки на нормальність розподілу:
а) розіб’ємо вибірку на інтервали, визначивши їх крок за формулою (2.1):
h = 15,3. Результат розрахунків представимо у табл. 2.3, гр. 1 та на рис. 2.1.
Таблиця 2.2
Вихідні дані перевірки на нормальність розподілу
| День дослідження |
Попит одягу |
День дослідження |
Попит одягу |
День дослідження |
Попит одягу |
День дослідження |
Попит одягу |
| 1 |
306 |
11 |
336 |
21 |
357 |
31 |
377 |
| 2 |
308 |
12 |
338 |
22 |
358 |
32 |
381 |
| 3 |
311 |
13 |
339 |
23 |
360 |
33 |
381 |
| 4 |
313 |
14 |
343 |
24 |
361 |
34 |
382 |
| 5 |
317 |
15 |
344 |
25 |
362 |
35 |
392 |
| 6 |
320 |
16 |
344 |
26 |
366 |
36 |
392 |
| 7 |
323 |
17 |
346 |
27 |
372 |
37 |
396 |
| 8 |
325 |
18 |
354 |
28 |
374 |
38 |
399 |
| 9 |
326 |
19 |
355 |
29 |
374 |
39 |
399 |
| 10 |
326 |
20 |
355 |
30 |
375 |
40 |
400 |
б) знаходимо середню частку маркетингових досліджень xта частоту появи значень кожного інтервалу mзгідно з викладеною вище методикою. Результати розрахунків представимо у табл. 2.3, гр. 2 та 3.
Таблиця 2.3
Розрахунок накопичених частостей
Інтервал
|
Середнє
значення,x
|
Частота
|
Відносна
частість
|
Відносна
накопичена
частість
|
Різниця
|
| m |
m |
m′ |
m′ |
F(m′) |
F(m′) |
(гр.7- гр.8) |
| 1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
| 306-321,3 |
| 321,4-336,7 |
| 336,8-352,1 |
| 352,2-367,5 |
| 367,6-382,9 |
| 383-400 |
|
| 313,7 |
| 329,1 |
| 344,5 |
| 359,9 |
37
,3
|
| 392 |
|
|
| 7,15 |
| 4,46 |
| 5,64 |
| 8,13 |
| 9,12 |
| 5,08 |
|
| 0,150 |
| 0,125 |
| 0,150 |
| 0,225 |
| 0,200 |
| 0,150 |
|
| 0,18 |
| 0,11 |
| 0,14 |
| 0,21 |
| 0,23 |
| 0,13 |
|
| 0,150 |
| 0,275 |
| 0,425 |
| 0,650 |
| 0,850 |
| 1,000 |
|
| 0,18 |
| 0,29 |
| 0,44 |
| 0,64 |
| 0,87 |
| 1,00 |
|
| -0,03 |
| -0,02 |
| -0,01 |
| 0,01 |
| -0,02 |
| 0,00 |
|
| Σ |
 40 40 |
39,58 |
1 |
1 |
в) знаходимо середнє значення вибіркової сукупності  та середньо-квадратичне відхилення вибірки δ за допомогою програми Майстер функцій: та середньо-квадратичне відхилення вибірки δ за допомогою програми Майстер функцій:
=354,7, δ= 28;
г) для кожного інтервалу часток маркетинговихдосліджень встановлюємо теоретичні частоти за формулою (2.2), (табл. 2.3, гр. 4) з попередньо визначеним параметром tзгідно з формулою (2.3);
д) визначимо відносні емпіричні частості m′ за формулою (2.4) ( табл. 2.3, гр. 5):
е) визначимо відносні теоретичні частості m′ за формулою 2.5 ( табл. 2.3, гр. 6);
ж) розрахуємо, відповідно, накопичені відносні емпіричні F(m′) та теоретичні частості F(m′) (табл. 2.3, гр. 7 - 8) згідно з пунктом ж методики;
з) визначимо різницю накопичених емпіричних та теоретичних частостей часток маркетингових досліджень за кожним інтервалом та встановимо їх максимальне відхилення D(табл. 2.3, гр. 9): D= 0,03;
і) встановимо фактичний критерій відхилення емпіричного розподілу від теоретичного за Колмогоровим згідно з формулою (2.6): λ=0,19;
к) за табл. 2.1 визначаємо граничний критерій Колмогорова відповідності емпіричних даних нормальному розподілу. За рівнем значущості 5%, що відповідає умові задачі, λ = 1,358;
л) порівнюємо розрахункове та табличне значення критерію Колмогорова: λ= 0,19 < λ= 1,358.
5. Висновок: оскільки розрахункове значення критерію відповідності емпіричного розподілу 0,19 менше теоретичного критерію Колмогорова 1,358, то можна стверджувати, що сукупність часток маркетингових даних, яка досліджується, підкоряється нормальному закону розподілу, а результати обстежень (зазначені частки) є випадковими величинами й управління ними потребує спеціальних засобів.
Завдання № 3
Планування експериментів
Постановка завдання
1. Запропонуйте й опишіть приклад досліджень шляхом проведення експериментів, спостережень або вимірювань.
2. Розробіть рандомізований план проведення досліджень для встановлення кореляційної залежності будь-якого техніко-економічного показника діяльності організації (підприємства, виробничого підрозділу, механізму тощо) від однієї з керованих факторних перемінних, які впливають на цей показник. Виключіть при цьому вплив трьох зовнішніх незалежних перемінних. План має бути складений у вигляді двох квадратів 4х4.
3. Опишіть, яким чином слід проводити спостереження за Вашим планом експерименту.
4. Напишіть результати спостережень та розрахуйте середньо стати-стічні дані для визначення зазначеної вище залежності.
В
иконання завдання
1. Потрібно встановити залежність y= f (x), де y- обсяг перевезень руди від кар'єра до збагачувальної фабрики, а x- відстань транспортування, що дозволить визначити норму виробітку водія автомобіля для різної відстані перевезень. Вимірюється обсяг перевезень yпри різних відстанях (внутрішня регульована змінна x= 2,2; 2,8; 3,3; 4,0; 4,9; 5,4; 6,0 і 7,5 км), де як незалежні зовнішні змінні прийняті день тижня (ПН,ВТ,СР,ЧТ), водій (А,B,C,D) та автомобіль (Z,Y,X,W).
2. Кожна регульована змінна поєднується у рандомізованому плані з іншими незалежними факторами так, щоб в сукупності їх значень не було повторювань будь-якого фактору як по горизонталі, так і по вертикалі ( табл. 3.1). Таким чином кожний водій кожного дня працює на різній відстані перевезень та на іншому автомобілі і кожного дня ці умови не повторюються для інших водіїв.
Таблиця 3.1
Рандомізований план проведення спостережень за обсягами перевезень руди
| Блок 1 |
| Водії |
День тижня |
| ПН |
ВТ |
СР |
ЧТ |
| A |
2,2W |
2,8Y |
4W |
3,4Z |
| B |
3,4W |
4Z |
2,8X |
2,2Y |
| C |
4Y |
2,2X |
3,4X |
2,8W |
| D |
2,8Z |
3,4Z |
2,2Y |
4X |
| Блок 2 |
| Водії |
День тижня |
| ПН |
ВТ |
СР |
ЧТ |
| A |
4,9X |
5,4Y |
6W |
7,5X |
| B |
7,5Y |
4,9Z |
5,4X |
6Y |
| C |
6Z |
7,5W |
4,9Y |
5,4Z |
| D |
5,4W |
6X |
7,5Z |
4,9W |
Усереднення отриманих значень такого плану за регульованим фактором (відстань перевезення) дозволяє провести повну рандомізацію експерименту за всіма нерегульованими змінними (день тижня, водій, автомобіль), тим самим мінімізується випадковий вплив останніх на досліджувану ознаку.
3. Відтак, провівши спостереження, згідно зі складеним планом для кожної відстані перевезень отримаємо чотири значення обсягу перевезень (табл. 3.2), на підставі яких , відповідно, виводиться їх середнє значення.
Таблиця 3.2
Обсяги перевезень руди
Відстань
перевезення
x, км
|
Обсяг перевезення
y, т/зміну
|
Норма виробітку
yзм, т/зміну
|
| 2,2 |
26 |
27,5 |
26 |
24,5 |
26,00 |
| 2,8 |
23,7 |
25,3 |
22,3 |
22,3 |
23,40 |
| 3,4 |
21,6 |
22,8 |
21,2 |
20,8 |
21,60 |
| 4 |
19,8 |
20,6 |
20,1 |
19,4 |
20,00 |
| 4,9 |
18,1 |
19,9 |
19 |
18 |
18,75 |
| 5,4 |
16,6 |
18,1 |
18,1 |
16,8 |
17,40 |
| 6 |
15,2 |
16,4 |
17,2 |
15,7 |
16,00 |
| 7,5 |
14 |
14,9 |
16,3 |
14,7 |
15,00 |
4. Отримані норми виробітки є результатом збалансування умов експерименту і можуть бути використані для управління випадковими параметрами процесу транспортування через їх відповідність закономірності розподілу випадкових величин.
Завдання № 4
Регресійна модель. Коефіцієнти детермінації і кореляції
З використанням середньостатистичних даних, отриманих у результаті виконання завдання 3, встановіть кореляційну залежність будь-якого техніко-економічного показника діяльності організації (підприємства, виробничого підрозділу, механізму тощо) від однієї з керованих факторних перемінних (ознак), які впливають на цей показник. З цією метою виконайте наступне:
1) побудуйте графічну залежність;
2) виберіть форму рівняння зв’язку для описання вказаної залежності;
3) встановить коефіцієнти рівняння кореляції та напишіть це рівняння;
4) оцініть тісноту зв’язку між ознаками, що корелюють, для чого розрахуйте коефіцієнт кореляції, його похибку та надійність;
5) сформулюйте висновок стосовно можливості використання одержаного рівняння кореляції для прогнозування показника, який розглядається у цьому завданні.
Виконання завдання
У результаті проведення дослідження були отримані результати спостережень за обсягом перевезень руди автомобілями на різну відстань (табл.4.1). Необхідно встановити залежність між обсягом виробітку автомобіля (y) та відстанню перевезень (x) і перевірити отриману залежність показників на адекватність.
1. Будується графічна залежність за результатами спостережень у вигляді графіку функції y = f (x), що проходить через точки перетину всіх наявних даних досліджуваних ознак (рис. 4.1).
Таблиця 4.1
Обсяги перевезень на різну відстань
| Відстань перевезення, x, км |
Норма виробітку
yзм, т/зміну
|
| 2,2 |
26 |
| 2,8 |
23,4 |
| 3,4 |
21,6 |
| 4 |
20 |
| 4,9 |
18,75 |
| 5,4 |
17,4 |
| 6 |
16 |
| 7,5 |
15 |

Рис. 4.1. Залежність обсягу виробітку від відстані перевезення
2. Виходячи з рис. 4.1 є очевидним, що між показниками існує лінійна залежність типу y = а + bx: поступове збільшення відстані перевезення обумовлює відповідне зменшення обсягу виробітку.
3. Визначаються коефіцієнти регресії а та b за формулами (4.1) і (4.2). Отримано: b = - 1,5, a = 26,6. Отже, рівняння регресії має наступний вигляд: y = -1,5x + 26,6.
4. Розраховується коефіцієнт кореляції ознак, що досліджуються, за формулою (4.3). Для встановленого рівняння регресії r = 0,98, що свідчить про дуже тісний зв’язок між факторним та результативним показниками.
Встановлюється погрішність коефіцієнту кореляції та його надійність за виразами відповідно (4.4) та (4.5). Ці характеристики дорівнюють: S = 0,08, М = 12,25. = 0,08, М = 12,25.
5. Отриманий коефіцієнт кореляції, а також його погрішність та надійність свідчать про стійкий зв’язок між корельованими ознаками, що робить модель парної кореляції придатною для використання у практичних розрахунках норми виробітку.
Завдання № 5
Виявлення грубих помилок
1. Введіть у сукупність середньостатистичних даних, отриманих у результаті виконання завдання 4, один результат спостережень, що за величиною дуже відрізняється від загальної закономірності зміни даних, яку відображає сукупність.
2. З урахуванням цього результату (грубої помилки чи промаху), встановіть кореляційну залежність техніко-економічного показника від факторної перемінної у порядку, визначеному в завданні 4:
а) побудуйте графічну залежність;
б) виберіть форму рівняння зв’язку для описання вказаної залежності;
в) встановіть коефіцієнти рівняння кореляції та напишіть це рівняння;
г) оцініть тісноту зв’язку між ознаками, що корелюють, для чого розрахуйте коефіцієнт кореляції, його похибку та надійність;
3. Оцініть, наскільки змінилися показники тісноти зв’язку між ознаками, що досліджуються, при наявності в статистичній залежності грубих помилок, для чого отримані показники порівняйте з відповідними показниками в завданні 4 ;
4. Викладіть методику виявлення грубих помилок;
5. Здійсніть перевірку можливості вилучення результату спостережень, який дуже відрізняється від загальної закономірності зміни даних, із статистичної сукупності даних.
6. Сформулюйте висновок стосовно одержаного результату перевірки.
Виконання завдання
1. Підставимо замість одного показника статистичної сукупності, отриманої у завд. 3, інший показник, з метою його перевірки на відповідність закономірності розподілу даних, а саме, замість значення обсягу виробітку 16 т/зміну (табл. 4.1), яка відповідає відстані транспортування 6 км, обсяг виробітку, рівний 25 т/зміну (табл. 5.2).
Таблиця 5.2
Обсяги перевезень на різну відстань
| Відстань перевезення, x, км |
Норма виробітку
yзм, т/зміну
|
| 2,2 |
| 2,8 |
23,4 |
| 3,4 |
21,6 |
| 4 |
20 |
| 4,9 |
18,75 |
| 5,4 |
17,4 |
| 6 |
25 |
| 7,5 |
15 |
2-3. Встановлюємо кореляційну залежність між ознаками, що дослід-жуються, та порівнюємо її показники з аналогічними показниками, отриманими у завд. 4:
а) побудуємо графік функції залежності досліджуваних ознак:
Виходячи з рис. 5.1 видно, що значення 25 т/зміну, яке перевіряється, порушує загальну тенденцію зміни функції. Отже, його треба перевірити на достовірність;
б) припускається, що побудований графік функції описує лінійну залежність типу у= а + bx;
в)визначаються коефіцієнти регресії а та b за формулами (4.1) та (4.2), приведеними у п. 3 завд. 4: b = - 1, a = 25,3. Отже, рівняння регресії має наступний вигляд: y = -x + 25,3. У той же час, рівняння регресії до заміни одного результату спостережень мало вигляд: y = -x + 25,3. Отже, цей показник спричинив суттєве порушення зв’язку досліджуваних ознак;
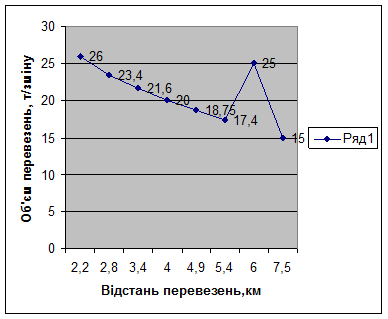
Рис. 5.1. Залежність обсягу виробітку від відстані перевезення
г) розраховується коефіцієнт кореляції ознак, що досліджуються за формулою (4.3):r =0,4 , що свідчить про послаблення зв’язку між факторним та результативним показниками проти r =0,98 за попереднього розрахунку.
Встановлюється погрішність коефіцієнту кореляції S= 0,4 та його надійність М = 1, відповідно, за формулами (4.4) та (4.5). Відтак, погрішність коефіцієнту кореляції проти S= 0,08 зросла, а надійність проти М =12,25 – зменшилась, що вказує на необхідність перевірки зазначеного результату спостережень на його адекватність встановленої раніше закономірності розподілу даних.
4. Описується, яким чином необхідно перевірити статистичну сукупність на наявність грубої помилки.
5. Здійснюється перевірка статистичної сукупності на наявність помилкового значення, згідно з методикою:
а) розраховується критичне значення критерію Шовене для наявної сукупності усереднених даних:
Pш
=1/(2∙8) = 0,0625.
б) визначається ймовірне відхилення сукупності даних за формулою (5.2):
ν =2,75.
в) обраховується показник точності даних вибірки за формулою (5.3):
η = 0,17.
г) встановлюється за формулою (5.4) величина відхилення показника, що перевіряється, від середнього значення статистичної сукупності: y = 9,5 ; = 9,5 ;
д) встановлюється за табл. 5.1 вірогідність Pη
y
потрапляння відхилення у інтервал від + 0,17∙9,5 до – 0,17∙9,5:
Pη
y
= 0,966;
е) визначається вірогідність непотрапляння Py
відхилення у заданий інтервал за формулою (5.5):
Py
= 1- 0,952 = 0,034.
6. Висновок: Так-як вірогідність непотрапляння заданого відхилення ознаки 0,048 є меншою критичного значення Шовене, яке для даної сукупності обсягів перевезення дорівнює 0,0625, то показник обсягу перевезення 25,0 т/зміну повинен бути виключеним із статистичної вибірки.
|