Содержание
1. Введение. 5
1.1. Предмет и задачи курса. 5
1.2. Рекомендации по литературе. 5
1.3. Краткий очерк истории ОС.. 6
1.4. Классификация ОС.. 10
1.5. Критерии оценки ОС.. 11
1.6. Основные функции и структура ОС.. 14
1.7. ОС, используемые в дальнейшем изложении. 14
2. Управление устройствами. 14
2.1. Основные задачи управления устройствами. 14
2.2. Классификация периферийных устройств и их архитектура. 14
2.3. Прерывания. 14
2.4. Архитектура подсистемы ввода/вывода. 14
2.5. Способы организации ввода/вывода. 14
2.6. Буферизация и кэширование. 14
2.7. Драйверы устройств. 14
2.8. Управление устройствами в MS-DOS. 14
2.9. Управление устройствами в Windows. 14
2.10. Управление устройствами в UNIX.. 14
3. Управление данными. 14
3.1. Основные задачи управления данными. 14
3.2. Характеристики файлов и архитектура файловых систем.. 14
3.3. Размещение файлов. 14
3.4. Защита данных. 14
3.5. Разделение файлов между процессами. 14
3.6. Файловая система FAT и управление данными в MS-DOS. 14
3.7. Файловые системы и управление данными в UNIX.. 14
3.8. Файловая система NTFS и управление данными в Windows. 14
4. УПРАВЛЕНИЕ ПРОЦЕССАМИ.. 14
4.1. Основные задачи управления процессами. 14
4.2. Реализация многозадачного режима. 14
4.3. Проблемы взаимодействия процессов. 14
4.4. Управление процессами в MS-DOS. 14
4.5. Управление процессами в Windows. 14
4.6. Управление процессами в UNIX.. 14
5. УПРАВЛЕНИЕ ПАМЯТЬЮ... 14
5.1. Основные задачи управления памятью.. 14
5.2. Виртуальные и физические адреса. 14
5.3. Распределение памяти без использования виртуальных адресов. 14
5.4. Сегментная организация памяти. 14
5.5. Страничная организация памяти. 14
5.6. Сравнение сегментной и страничной организации. 14
5.7. Управление памятью в MS-DOS. 14
5.8. Управление памятью в Windows. 14
5.9. Управление памятью в UNIX.. 14
6. Литература. 14
Предметом изучения в данном курсе являются операционные системы
(ОС) современных компьютеров.
В первом приближении ОС можно определить как комплекс программ, обеспечивающих интерфейс между аппаратурой компьютера, прикладными программами и пользователем компьютера. Соответственно этому определению, все функции, выполняемые ОС, подчинены решению двух основных задач:
· организации эффективной работы аппаратуры компьютера;
· обеспечению удобного использования ресурсов компьютера как прикладными программами, так и пользователем, работающим с компьютером.
Основной целью курса является изучение устройства и функционирования современных ОС. При этом будут рассматриваться два круга вопросов:
· основные принципы построения ОС, наиболее распространенные алгоритмы выполнения различных функций ОС, типовые структуры данных, используемые для обеспечения работы ОС;
· практическое воплощение этих принципов, алгоритмов, структур в наиболее распространенных современных ОС.
В задачи курса не входит обучение практическим приемам работы с конкретными ОС. Это гораздо лучше делать самостоятельно. С другой стороны, не ставится и задача научить слушателей разрабатывать новые ОС. Операционные системы не являются массовыми изделиями, и участвовать в их разработке доводится лишь меньшей части программистов. Уровень знаний, которого хотелось бы достичь при изучении данного предмета, можно сравнить с тем уровнем знаний об устройстве автомобиля, который полезен хорошему водителю. Он не обязательно должен быть автомехаником, однако должен в основных чертах понимать, что находится под капотом и как оно там крутится.
Содержание лекционного курса не обязательно на 100% совпадет с данным конспектом, поэтому надежнее всего ходить на лекции и иметь к экзамену собственный конспект.
Из книг общего характера учебник /1/ более всего соответствует данному курсу, как по содержанию, так и в еще большей степени по общему взгляду на предмет. Эту книгу можно найти и в Сети, а также в локальной сети кафедры.
Похвалы и уважения заслуживает книга /2/ - огромный по объему и достаточно простой по изложению обзор всего важного об ОС.
Достаточно хороша также книга /3/, используемая как основной учебник по ОС во многих американских университетах.
Лентяям пригодится книга /4/, в которой, наряду с другими вопросами системного программирования, кратко и довольно толково изложены основные проблемы ОС. Правда, книга старовата.
Книги /5/ и /6/ содержат много полезного по практическим вопросам проектирования ОС, а /7/ остается хорошим источником по теоретическим и алгоритмическим вопросам.
Из литературы по Windows следует прежде всего рекомендовать классическую книгу /8/, которая делает понятными многие вопросы, трудно перевариваемые по официальной документации. Более глубокий разбор того, «как это сделано в Windows», можно найти в книге /9/. К сожалению, эта книга заметно уступает замечательной, но устаревшей по материалу книге того же автора /10/, которую, тем не менее, полезно прочесть тем, кого интересуют вопросы практической реализации ОС.
На фоне неисчислимых и неотличимых друг от друга пользовательских руководств по UNIX следует выделить достаточно серьезную работу /11/. Не потеряла интереса старенькая, тонкая книжка /12/, в которой содержится много полезного об основных структурах данных и алгоритмах UNIX. Намного подробнее те же вопросы рассмотрены в другой старой книге, которая давно приобрела известность в электронном варианте /13/. Бумажное издание этой книги на русском языке существует только в пиратском варианте, без указания имени автора.
Для тех, кого еще интересует MS-DOS, можно порекомендовать /14/, это одна из лучших книг на данную тему.
Некоторые алгоритмы, используемые при реализации различных ОС, хорошо изложены в классической книге /15/.
Большие коллекции литературы и документации по ОС имеются в Интернете. Среди русскоязычных сайтов можно рекомендовать, например, /16, 17, 18, 19, 20/.
Знание английского языка открывает доступ к морю свежей информации в Интернете. Огромная куча сведений по Windows содержится в /21/. На сайте /22/ можно найти интересные статьи по отдельным вопросам архитектуры Windows, а также скачать ряд полезных утилит. Из большого числа сайтов, посвященных UNIX и Linux, можно назвать, например, /23/ и /24/. На сайте /25/ можно найти много статей и книг по актуальным вопросам программирования, в том числе по ОС.
Изучение истории развития ОС показывает, что все существенные продвижения в области архитектуры ОС связаны с влиянием двух основных факторов:
· прогресс технологии, приводящий к быстрому возрастанию характеристик аппаратуры ЭВМ и к появлению принципиально новых типов аппаратуры;
· принципиально новые идеи, возникающие у проектировщиков.
Не ввязываясь в давний спор материалистов с идеалистами, в данном частном случае приходится признать, что первый, материальный фактор определял развитие ОС на 80 – 90%. Такие технологические прорывы, как изобретение магнитных дисков, микропроцессоров, создание высококачественных видеомониторов, настоятельно требовали радикальных изменений в технологии работы с компьютером, и вследствие этого обуславливали создание принципиально новых типов ОС или их отдельных подсистем. С другой стороны, некоторые идеи в области организации вычислительного процесса и интерфейса дали серьезный толчок совершенствованию архитектуры компьютеров.
Не зная хотя бы в общих чертах основных этапов развития аппаратного и программного обеспечения, трудно понять многие особенности современных ОС.
Дополнительный аргумент в пользу знания истории заключается в том, что многие технические решения, которые, казалось, навсегда ушли в прошлое вместе с конкретными системами, неожиданно вновь оказываются актуальными на новом витке развития. Некоторые примеры такого рода будут рассмотрены в курсе.
1.3.1. Предыстория ОС
Вскоре после того, как в конце 40-х годов XX века были созданы первые электронные компьютеры, очень остро встала проблема повышения эффективности использования оборудования, и прежде всего центрального процессора.
Типичный компьютер первого – второго поколений представлял собой большую комнату, уставленную шкафами и увитую кабелями. Каждое из основных устройств – центральный процессор, оперативная память, накопители на магнитных лентах, устройства ввода с перфокарт, принтер – занимало один или несколько «шкафов» или «тумб», наполненных радиолампами и механическими частями.
Все это стоило больших денег, потребляло бешеное количество электроэнергии[1]
и регулярно ломалось.
В таких условиях машинное время стоило очень дорого. Тем не менее, обычная практика использования ЭВМ не способствовала экономии. Как правило, программист, разрабатывающий программу, заказывал ежедневно несколько часов машинного времени и в течение этого времени монопольно использовал машину. Выполнив очередной запуск отлаживаемой программы (которую надо было каждый раз вводить либо с клавиатуры, либо, в лучшем случае, с перфокарт), пользователь получал распечатку (чаще всего в виде массива цифр), анализировал результаты, вносил изменения в программу и снова запускал ее. Таким образом, в ходе сеанса отладки дорогостоящее оборудование простаивало 99% времени, пока программист осмысливал результаты и работал с устройствами ввода/вывода. Кроме того, сбой при вводе одной перфокарты мог потребовать начать сначала всю работу программы.
Возникла великая идея – использовать сам компьютер для повышения эффективности работы с ним же.
Одно из ответвлений этой идеи – создание языков и систем программирования – рассматривается в отдельных курсах. Другим важным шагом стало возложение на специальную компьютерную программу части тех функций, которые до этого выполнял оператор или сам программист.
Программы такого рода назывались обычно мониторами
(не путать с монитором как устройством вывода, который в то время был редчайшей экзотикой!). Монитор принимал команды, состоящие, как правило, из 1-2 букв названия и 1-3 аргументов, заданных 8-ричными или 16-ричными числами. Типичными командами были, например:
· загрузка данных с перфокарт по указанному адресу памяти;
· просмотр и корректировка (с пишущей машинки) значений в указанном диапазоне адресов;
· пошаговое выполнение программы с выдачей результатов каждой команды на пишущую машинку;
· запуск программы с указанного адреса с заданием адресов контрольных точек остановки.
Несмотря на убогость, по нынешним меркам, подобных средств, они в свое время значительно повысили производительность работы программистов. Однако кардинального повышения загрузки процессора не произошло.
Временем широкого распространения мониторов в мире были 50-е годы прошлого века (в СССР – 60-е годы). В настоящее время нечто подобное можно встретить на самых примитивных микропроцессорных контроллерах.
1.3.2. Пакетные ОС
Историю собственно ОС можно начать с появления в конце 50-х годов первых систем, организующих работу по пакетному принципу.
Важнейшим организационным изменением, происшедшим на этом этапе развития, стало массовое изгнание программистов из машинных залов, как фактора, лишь вносящего сумятицу в работу.
Теперь от программиста требовалось собрать пакет перфокарт, содержащий его программу, данные к ней, а также управляющие перфокарты. Эти карты на специально разработанном языке управления заданиями
(JCL, JobControlLanguage) объясняли операционной системе, чье это задание, что нужно сделать с программой (например, передать ее транслятору с Фортрана), что предпринять в случае успешной трансляции (вероятно, пустить на решение), что – при наличии ошибок (например, перейти к другой программе), откуда взять исходные данные (например, с такого-то цилиндра магнитного диска). Кроме того, там могли быть даже указания на то, сколько метров бумаги можно выделить на распечатку и какое максимальное время может занять работа программы.
Обойтись без столь подробных инструкций было нельзя, потому что программист не присутствовал при запуске задания и не мог вмешаться лично.
Подготовленный пакет передавался, вместе с другими подобными пакетами, оператору ЭВМ, перед которым стояли две основные задачи: чтобы в устройстве ввода не переводились пакеты заданий и чтобы в принтере не кончилась бумага. Когда процессор заканчивал обработку задания и печать его результатов, он вводил следующий пакет и приступал к его обработке. Так достигалась основная цель пакетного режима – исключить простои процессора из-за нерасторопности людей.
В скором времени разработчики ОС осознали, что вычерпаны далеко не все резервы повышения загрузки процессора. Операции ввода и печати требовали лишь очень небольшой доли от полной производительности процессора. Кроме того, в ходе работы программы случались обращения к периферийным устройствам (например, к магнитным лентам и, позднее, дискам), при выполнении которых процессор опять простаивал. Целесообразно было найти способ, чтобы в эти периоды ожидания загрузить процессор другой работой. Но для этого необходимо, чтобы в памяти процессора находились сразу несколько программ, тогда ОС смогла бы переключать процессор на выполнение той программы, которая в данный момент может работать.
Такая организация работы, когда в памяти находятся несколько программ и система в определенные моменты переключает выполнение с одной программы на другую, была названа мультипрограммированием
. Эта важная идея в разных воплощениях пережила те пакетные системы, в которых она впервые была реализована, и является основой для функционирования практически всех современных ОС.
Среди наиболее развитых пакетных ОС с мультипрограммированием нельзя не назвать OS/360, основную ОС знаменитого в 60-70 гг. семейства ЭВМ IBM 360/370.
1.3.3. ОС с разделением времени
На рубеже 60-70 гг. распространенным и не слишком дорогим периферийным устройством становятся мониторы (сначала монохромные и работающие только в текстовом режиме). При этом процессор и ОЗУ остаются самыми дорогими и громоздкими устройствами вычислительной системы. В этих условиях возникает и быстро приобретает популярность принципиально новый тип ОС – системы с разделением времени
.
К одной ЭВМ подключается несколько десятков рабочих мест, оборудованных дисплеем (монитор + клавиатура) и совместно использующих вычислительные ресурсы ЭВМ. Процессорное время делится на кванты длительностью в несколько десятков миллисекунд и по истечении каждого кванта процессор может быть переключен на обслуживание другого процесса, другого дисплея. Поскольку теперь подготовку текстов программ выполняют сами программисты за дисплеями, а работа по редактированию текста требует очень малых затрат процессорного времени, процессор успевает обслужить все рабочие места практически без ощутимой задержки. Большая часть времени процессора уделяется небольшому числу рабочих мест, где в данный момент запущены на выполнение программы. При этом, разумеется, средняя скорость работы каждой программы уменьшается, по крайней мере во столько раз, сколько программ выполняется одновременно.
Режим разделения времени стал огромным облегчением для программистов, которые вновь смогли в некоторой степени почувствовать себя «хозяевами» ЭВМ и получили возможность запускать программы на трансляцию и отладку хоть каждые 5 минут. Это позволило сократить сроки разработки и отладки программ.
Для трудоемких вычислительных заданий, предусматривающих счет по ранее отлаженным программам, режим разделения времени менее эффективен, чем пакетный, поскольку частое переключение процессора между выполняемыми программами требует дополнительных затрат времени.
Системы разделения времени используются в режиме диалога с пользователем, поэтому вместо громоздких, детализированных операторов JCL в них используются более простые команды, выполняющие элементарные действия – запуск программы, выдача на экран файла или каталога, копирование или удаление файла и т.п. Пользователю не нужно предвидеть заранее все возможные исходы выполнения команды, гораздо проще увидеть результат выполнения на экране и после этого принять решение, какую команду выполнять следующей. В то же время, некоторые часто повторяющиеся последовательности команд удобно описать один раз в виде «пакетного задания» и затем использовать при необходимости. В этом плане системы разделения времени сохраняют те удобные возможности, которые предоставляли пакетные системы.
Первоначально в качестве аппаратной основы систем разделения времени должны были использоваться «большие» ЭВМ, которые позднее стало принято называть «мейнфреймами» (mainframes). Позднее, по мере прогресса вычислительной техники, это стало по плечу даже миниЭВМ (так назывался в те годы класс компьютеров, занимавших всего лишь один-два небольших шкафчика). Следует особо упомянуть серию миниЭВМ PDP-11, имевшую широчайшее распространение во всем мире в течение полутора десятков лет.
Этот период (70-е годы в мире, 80-е в СССР) характерен глубоким развитием теории и практики создания мощных ОС, содержащих развитые средства управления процессами и памятью, реализующих многопользовательский режим работы. Из большого числа подобных систем особого упоминания заслуживает UNIX – единственная система, благополучно дожившая до нашего времени.
1.3.4. Однозадачные ОС для ПЭВМ
В середине 70-х годов был изобретен микропроцессор, а к началу 80-х микропроцессоры стали догонять по функциональным характеристикам ранее использовавшиеся «большие» процессоры. Эта ситуация сделала почти бесполезным режим разделения времени: зачем делить один процессор между многими задачами и многими пользователями, если проще и дешевле дать отдельный микропроцессор каждому пользователю? Разделение времени осталось целесообразным разве что в отношении суперкомпьютеров.
Появление и бурное распространение персональных компьютеров (ПК) вызвало к жизни новое поколение ОС, которые оказались во много раз проще своих предшественниц. Ненужной оказалась многопользовательская защита. На первых порах показалась ненужной и многозадачность. Все это можно было расценить как явный регресс в развитии ОС.
Наиболее популярной ОС для ранних восьмиразрядных ПК была система CP/M известной тогда фирмы DigitalResearch, однако с появлением в начале 80-х знаменитой машины IBMPC лидерство было прочно перехвачено системой MS-DOS фирмы Microsoft.
1.3.5. Многозадачные ОС для ПК с графическим интерфейсом
Быстрое развитие технологии привело к тому, что к концу 80-х годов ПК оказались в состоянии решать значительно более сложные и трудоемкие задачи, чем раньше. При этом многие из достижений прежних этапов развития ОС оказались вновь востребованными, но теперь уже в новых условиях, среди которых надо назвать резкое повышение мощности процессоров и объема памяти, появление высококачественных графических мониторов и развитие сетевых технологий.
Стала реальной такая вещь, как многозадачная ОС для ПК. Надо сказать, что первоначально идея системы, в которой один пользователь запускает одновременно несколько приложений, большинству специалистов казалась пустым пижонством и вызывала насмешки: «Почему бы не выполнить несколько программ по очереди?». Сейчас с таким взглядом смешно даже спорить.
А все же, как бы вы обосновали пользу многозадачности для современных ОС типа Windows?
На смену ОС, которые выполняли текстовые команды, вводимые пользователем с клавиатуры, пришли системы, в которых взаимодействие с пользователем основано на использовании GUI (GraphicalUserInterface, графический интерфейс пользователя).
Значительная часть ПК работает в составе локальных вычислительных сетей. Это привело к тому, что вопросы защиты данных пользователя вновь приобрели первостепенное значение.
Существуют различные виды классификации ОС по тем или иным признакам, отражающие разные существенные характеристики систем.
· По назначению.
- Системы общего назначения. Это достаточно расплывчатое название подразумевает ОС, предназначенные для решения широкого круга задач, включая запуск различных приложений, разработку и отладку программ, работу с сетью и с мультимедиа.
- Системы реального времени
. Этот важный класс систем предназначен для работы в контуре управления объектами (такими, как летательные аппараты, технологические установки, автомобили, сложная бытовая техника и т.п.). Из подобного назначения вытекают жесткие требования к надежности и эффективности системы. Должно быть обеспечено точное планирование действий системы во времени (управляющие сигналы должны выдаваться в заданные моменты времени, а не просто «по возможности быстро»). Особый подкласс составляют системы, встроенные
в оборудование. Такие системы годами могут выполнять фиксированный набор программ, не требуя вмешательства человека-оператора на более глубоком уровне, чем нажатие кнопки «Вкл.».
Иногда выделяют также такой класс ОС, как системы с «нежестким» реальным временем. Это такие системы, которые не могут гарантировать точное соблюдение временных соотношений, но «очень стараются», т.е. содержат средства для приоритетного выполнения заданий, критичных по времени. Такой системе нельзя доверить управление ракетой, но она вполне справится с демонстрацией видеофильма. Выделение подобных систем в отдельный класс имеет скорее рекламное значение, позволяя таким системам, как WindowsNT и некоторые версии UNIX, тоже называть себя «системами реального времени».
- Прочие специализированные системы. Это различные ОС, ориентированные прежде всего на эффективное решение задач определенного класса, с большим или меньшим ущербом для прочих задач. Можно выделить, например, сетевые системы (такие, как NovellNetware), обеспечивающие надежное и высокоэффективное функционирование локальных сетей.
· По характеру взаимодействия с пользователем.
- Пакетные ОС, обрабатывающие заранее подготовленные задания.
- Диалоговые ОС, выполняющие команды пользователя в интерактивном режиме. Красивое слово «интерактивный» означает постоянное взаимодействие системы с пользователем.
- ОС с графическим интерфейсом. В принципе, их также можно отнести к диалоговым системам, однако использование мыши и всего, что с ней связано (меню, кнопки и т.п.) вносит свою специфику.
- Встроенные ОС, не взаимодействующие с пользователем.
· По числу одновременно выполняемых задач.
- Однозадачные ОС. В таких системах в каждый момент времени может существовать не более чем один активный пользовательский процесс. Следует заметить, что одновременно с ним могут работать системные процессы (например, выполняющие запросы на ввод/вывод).
- Многозадачные ОС. Они обеспечивают параллельное выполнение нескольких пользовательских процессов. Реализация многозадачности требует значительного усложнения алгоритмов и структур данных, используемых в системе.
· По числу пользователей.
- Однопользовательские ОС. Для них характерен полный доступ пользователя к ресурсам системы. Подобные системы приемлемы в основном для изолированных компьютеров, не допускающих доступа к ресурсам данного компьютера по сети или с удаленных терминалов.
- Многопользовательские ОС. Их важной компонентой являются средства защиты данных и процессов каждого пользователя, основанные на понятии владельца ресурса и на точном указании прав доступа, предоставленных каждому пользователю системы.
· По аппаратурной основе.
- Однопроцессорные ОС. В данном курсе будут рассматриваться только они.
- Многопроцессорные ОС. В задачи такой системы входит, помимо прочего, эффективное распределение выполняемых заданий по процессорам и организация согласованной работы всех процессоров.
- Сетевые ОС. Они включают возможность доступа к другим компьютерам локальной сети, работы с файловыми и другими серверами.
- Распределенные ОС. Их отличие от сетевых заключается в том, что распределенная система, используя ресурсы локальной сети, представляет их пользователю как единую систему, не разделенную на отдельные машины.
При сравнительном рассмотрении различных ОС в целом или их отдельных подсистем возникает вечный вопрос – какая из них лучше и почему, какая архитектура системы предпочтительнее, какой из алгоритмов эффективнее, какая структура данных удобнее и т.п.
Очень редко можно дать однозначный ответ на подобные вопросы, если речь идет о практически используемых системах. Система или ее часть, которая хуже других систем во всех отношениях, просто не имела бы права на существование. На самом деле имеет место типичная многокритериальная задача: имеется несколько важных критериев качества, и система, опережающая прочие по одному критерию, обычно уступает по другому. Сравнительная важность критериев зависит от назначения системы и условий ее работы.
1.5.1. Надежность
Этот критерий вообще принято считать самым важным при оценке программного обеспечения, и в отношении ОС его действительно принимают во внимание в первую очередь.
Что понимается под надежностью ОС?
Прежде всего, ее живучесть
, т.е. способность сохранять хотя бы минимальную работоспособность в условиях аппаратных сбоев и программных ошибок. Высокая живучесть особенно важна для ОС компьютеров, встроенных в аппаратуру, когда вмешательство человека затруднено, а отказ компьютерной системы может иметь тяжелые последствия.
Во-вторых, способность, как минимум, диагностировать, а как максимум, компенсировать хотя бы некоторые типы аппаратных сбоев. Для этого обычно вводится избыточность хранения наиболее важных данных системы.
В-третьих, ОС не должна содержать собственных (внутренних) ошибок. Это требование редко бывает выполнимо в полном объеме (программисты давно сумели доказать своим заказчикам, что в любой большой программе всегда есть ошибки, и это в порядке вещей), однако следует хотя бы добиться, чтобы основные, часто используемые или наиболее ответственные части ОС были свободны от ошибок.
Наконец, к надежности системы следует отнести ее способность противодействовать явно неразумным действиям пользователя. Обычный пользователь должен иметь доступ только к тем возможностям системы, которые необходимы для его работы. Если же пользователь, даже действуя в рамках своих полномочий, пытается сделать что-то очень странное (например, отформатировать системный диск), то самое малое, что должна сделать ОС, это переспросить пользователя, уверен ли он в правильности своих действий.
1.5.2. Эффективность
Как известно, эффективность любой программы определяется двумя группами показателей, которые можно обобщенно назвать «время» и «память». При разработке системы приходится принимать много непростых решений, связанных с оптимальным балансом этих показателей.
Важнейшим показателем временнóй эффективности является производительность
системы, т.е. усредненное количество полезной вычислительной работы, выполняемой в единицу времени. С другой стороны, для диалоговых ОС не менее важно время реакции
системы на действия пользователя. Эти показатели могут в некоторой степени противоречить друг другу. Например, в системах разделения времени увеличение кванта времени повышает производительность (за счет сокращения числа переключений процессов), но ухудшает время реакции.
В программировании известна аксиома: выигрыш во времени достигается за счет проигрыша в памяти, и наоборот. Это в полной мере относится к ОС, разработчикам которых постоянно приходится искать баланс между затратами времени и памяти.
Забота от эффективности долгое время стояла не первом месте при разработке программного обеспечения, и особенно ОС. К сожалению, оборотной стороной стремительного увеличения мощности компьютеров стало ослабление интереса к эффективности программ. В настоящее время эффективность является первостепенным требованием разве что в отношении систем реального времени.
1.5.3. Удобство
Этот критерий наиболее субъективен. Можно предложить, например, такой подход: система или ее часть удобна, если она позволяет легко и просто решать те задачи, которые встречаются наиболее часто, но в то же время содержит средства для решения широкого круга менее стандартных задач (пусть даже эти средства не столь просты). Пример: такое частое действие, как копирование файла, должно выполняться при помощи одной простой команды или легкого движения мыши; в то же время для изменения разделов диска не грех почитать руководство, поскольку это может понадобиться даже не каждый год.
Разработчики каждой ОС имеют собственные представления об удобстве, и каждая ОС имеет своих приверженцев, считающих именно ее идеалом удобства.
1.5.4. Масштабируемость
Довольно странный термин «масштабируемость» (scalability) означает возможность настройки системы для использования в разных вариантах, в зависимости от мощности вычислительной системы, от набора конкретных периферийных устройств, от роли, которую играет конкретный компьютер (сервер, рабочая станция или изолированный компьютер) от назначения компьютера (домашний, офисный, исследовательский и т.п.).
Гарантией масштабируемости служит продуманная модульная структура системы, позволяющая в ходе установки системы собирать и настраивать нужную конфигурацию. Возможен и другой подход, когда под общим названием объединяются, по сути, разные системы, обеспечивающие в разумных пределах программную совместимость. Примером могут служить версии WindowsNT/2000/XP, Windows 95/98 и WindowsCE.
В некоторых случаях фирмы, производящие программное обеспечение, искусственно отключают в более дешевых версиях системы те возможности, которые на самом деле реализованы, но становятся доступны, только если пользователь покупает лицензию на более дорогую версию. Но это уже вопрос, связанный не с технической стороной дела, а с маркетинговой политикой.
1.5.5. Способность к развитию
Чтобы сложная программа имела шансы просуществовать долго, в нее изначально должны быть заложены возможности для будущего развития.
Одним из главных условий способности системы к развитию является хорошо продуманная модульная структура, в которой четко определены функции каждого модуля и его взаимосвязи с другими модулями. При этом создается возможность совершенствования отдельных модулей с минимальным риском вызвать нежелательные последствия для других частей системы.
Важным требованием к развитию ОС является совместимость версий снизу вверх
, означающая возможность безболезненного перехода от старой версии к новой, без потери ранее наработанных прикладных программ и без необходимости резкой смены всех навыков пользователя. Обратная совместимость – сверху вниз – как правило, не гарантируется, поскольку в ходе развития система приобретает новые возможности, не реализованные в старых версиях. Программа из Windows3.1 будет нормально работать и в WindowsXP; наоборот – вряд ли.
Фирмы-производители ОС прилагают максимум усилий для обеспечения совместимости снизу вверх, чтобы не отпугнуть пользователей. Но при этом фирмы стараются в каждую новую версию заложить какую-нибудь новую конфетку, которая побудила бы пользователей как можно скорее купить ее.
Совместимость версий – благо для пользователя, однако на практике она часто приводит к консервации давно отживших свой век особенностей или же просто неудачных решений, принятых в ранней версии системы. В документации подобные архаизмы помечаются как «устаревшие» (obsolete), но полного отказа от них, как правило, не происходит (а вдруг где-то еще работает прикладная программа, написанная двадцать лет назад с использованием именно этих средств?).
Как правило, наиболее консервативной стороной любой ОС являются не алгоритмы, а структуры системных данных, поэтому дальновидные разработчики заранее строят структуры «на вырост»: закладывают в них резервные поля, используют переменные вместо некоторых констант, устанавливают количественные ограничения с большим запасом и т.п.
1.5.6. Мобильность
Под мобильностью
(portability) понимается возможность переноса программы (в данном случае ОС) на другую аппаратную платформу, т.е. на другой тип процессора и другую архитектуру компьютера. Здесь имеется в виду перенос с умеренными трудозатратами, не требующий полной переработки системы.
Свойство мобильности не столь однозначно положительно, как может показаться. Чтобы программа была мобильна, при ее разработке следует отказаться от глубокого использования особенностей конкретной архитектуры (таких, как количество и функциональные возможности регистров процессора, нестандартные команды и т.п.). Мобильная программа должна быть написана на языке достаточно высокого уровня (часто используется язык C), который можно реализовать на компьютерах любой архитектуры. Платой за мобильность всегда является некоторая потеря эффективности, поэтому немобильные системы распространены достаточно широко.
С другой стороны, история системного программирования усеяна останками замечательных, эффективных и удобных, но немобильных ОС, которые вымерли вместе с процессорами, для которых они предназначались. В то же время мобильная система UNIX продолжает процветать четвертый десяток лет, намного пережив те компьютеры, для которых она первоначально создавалась. Примерно 5-10% исходных текстов UNIX написаны на языка ассемблера и должны переписываться заново при переносе на новую архитектуру. Остальная часть системы написана на C и практически не требует изменений при переносе.
Некоторым компромиссом являются многоплатформенные
ОС (например, WindowsNT), изначально спроектированные для использования на нескольких аппаратных платформах, но не гарантирующие возможность переноса на новые, не предусмотренные заранее архитектуры.
Согласно многолетней традиции, при рассмотрении основ функционирования ОС принято выделять четыре основных группы функций, выполняемых системой.
· Управление устройствами
. Имеются в виду все периферийные устройства, подключаемые к компьютеру, – клавиатура, монитор, принтеры, диски и т.п.
· Управление данными
. Под этим старинным термином сейчас понимается работа с файлами, хотя были времена, когда обращение к данным на магнитных носителях выполнялось путем указания адреса размещения данных на устройстве, а понятия файла не существовало.
· Управление процессами
. Эта сторона работы ОС связана с запуском и завершением работы программ, обработкой ошибок, обеспечением параллельной работы нескольких программ на одном компьютере.
· Управление памятью
. Оперативная память компьютера – это такой ресурс, которого всегда не хватает. В этих условиях разумное планирование использования памяти является важнейшим фактором эффективной работы.
Имеется еще несколько важных обязанностей, ложащихся на ОС, которые трудно втиснуть в рамки традиционной классификации функций. К ним, прежде всего, относятся следующие.
· Организация интерфейса с пользователем
. Формы интерфейса могут быть разнообразными, в зависимости от типа и назначения ОС: язык управления пакетами заданий, набор диалоговых команд, средства графического интерфейса.
· Защита данных
. Как только система перестает быть достоянием одного изолированного от внешнего мира пользователя, вопросы защиты данных от несанкционированного доступа приобретают первостепенную важность. ОС, обеспечивающая работу в сети или в системе разделения времени, должна соответствовать имеющимся стандартам безопасности.
· Ведение статистики
. В ходе работы ОС должна собираться, храниться и анализироваться разнообразная информация: о количестве времени, затраченном различными программами и пользователями, об интенсивности использования ресурсов, о попытках некорректных действий пользователей, о сбоях оборудования и т.п. Собранная информация хранится в системных журналах и в учетных записях пользователей.
Для понимания работы ОС необходимо уметь выделять основные части системы и их связи, т.е. описывать структуру системы. Для разных ОС их структурное деление может быть весьма различным. Наиболее общими видами структуризации можно считать два. С одной стороны, можно считать, что ОС разделена на подсистемы, соответствующие перечисленным выше группам функций. Такое деление достаточно обосновано, программные модули ОС действительно в основном можно отнести к одной из этих подсистем. Другое важное структурное деление связано с понятием ядра
системы.
Ядро, как можно понять из названия, это основная, «самая системная» часть операционной системы. Имеются разные определения ядра. Согласно одному из них, ядро – это резидентная
часть системы, т.е. к ядру относится тот программный код, который постоянно находится в памяти в течение всей работы системы. Остальные модули ОС являются транзитными
, т.е. подгружаются в память с диска по мере необходимости на время своей работы. К транзитным частям системы относятся:
· утилиты
(utilities) – отдельные системные программы, решающие частные задачи, такие как форматирование и проверку диска, поиск данных в файлах, мониторинг (отслеживание) работы системы и многое другое;
· системные библиотеки подпрограмм
, позволяющие прикладным программам использовать различные специальные возможности, поддерживаемые системой (например, библиотеки для графического вывода, для работы с мультимедиа и т.п.);
· интерпретатор команд
– программа, выполняющая ввод команд пользователя, их анализ и вызов других модулей для выполнения команд;
· системный загрузчик
– программа, которая при запуске ОС (например, при включении питания) обеспечивает загрузку системы с диска, ее инициализацию и старт;
· другие виды программ, в зависимости от конкретной системы.
Не менее важным является определение ядра, основанное на различении режимов работы компьютера. Все современные процессоры поддерживают, как минимум, два режима: привилегированный
режим (он же режим ядра, kernelmode) и непривилегированный
(режим задачи, режим пользователя, usermode). Программы, работающие в режиме ядра, имеют полный, неограниченный доступ ко всем ресурсам компьютера: его командам, адресам, портам ввода/вывода и т.п. В режиме задачи возможности программы ограничены, она, в частности, не может выполнить некоторые специальные команды. Аппаратное разграничение возможностей является абсолютно необходимым условием реализации надежной защиты данных в многопользовательской системе. Отсюда вытекает и определение ядра как части ОС, работающей в режиме ядра. Все остальные программы, как системные утилиты, так и программы пользователей, работают в режиме пользователя и должны обращаться к ядру для выполнения многих системных действий.
Следует сказать, что переходы из режима пользователя в режим ядра и обратно – это действия, требующие определенного времени, и слишком частое их выполнение может привести к заметному снижению скорости работы программ. В связи с этим определение того, какие функции должны поддерживаться ядром, а какие лучше выполнять в режиме пользователя – это непростая и важная задача, которую должны решить разработчики ОС.
Особую роль в структуре системы играют драйверы устройств
. Эти программы, предназначенные для обслуживания конкретных периферийных устройств, несомненно, можно отнести к ядру системы: они почти всегда являются резидентными и работают в режиме ядра. Но в отличие от самого ядра, которое изменяется только при появлении новой версии ОС, набор используемых драйверов весьма мобилен и зависит от набора устройств, подключенных к данному компьютеру. В некоторых системах (например, в ранних версиях UNIX) для подключения нового драйвера требовалось перекомпилировать все ядро. В большинстве современных ОС драйверы подключаются к ядру в процессе загрузки системы, а иногда разрешается даже загрузка и выгрузка драйверов в ходе работы системы.
В качестве программного интерфейса системы, т.е. средств для обращения прикладных программ к услугам ОС, используется документированный набор системных вызовов
или функций API
(AppliedProgrammingInterface). Между этими двумя терминами есть некоторая разница. Под системными вызовами понимаются функции, реализуемые непосредственно программами ядра системы. При их выполнении происходит переход из режима пользователя в режим ядра, а затем обратно. В отличие от этого, API-функции определяются как функции, описанные в документации ОС, независимо от того, выполняются ли они ядром или же системными библиотеками, работающими в режиме пользователя. В Windows часто несколько разных API-функций обращаются к одному и тому же недокументированному системному вызову, но имеют различные обрамляющие части, работающие в режиме пользователя.
Там, где различие между двумя этими понятиями несущественно, можно использовать нейтральный термин «системные функции
».
В следующих разделах курса будут рассматриваться основные функции ОС и способы их реализации. Изложение общих подходов будет дополняться примерами, относящимися главным образом к трем широко известным ОС:
· MS-DOS – пример простой однозадачной системы;
· Windows – сложная современная система, выросшая на базе MS-DOS;
· UNIX – система, по возможностям сопоставимая с Windows, однако разительно отличающая по набору основных концепций и методам реализации.
1.7.1. MS-DOS
Система MS-DOS была разработана в 1981 г. специально для только что появившейся первой 16-разрядной ПЭВМ IBMPC на базе процессора i86. Первая версия системы была ужасна, но работоспособна. В последующие годы фирме Microsoft удалось значительно улучшить свою систему, хотя некоторые пережитки первой версии оказались неистребимы. Альянс с фирмой IBM позволил Microsoft добиться фантастического финансового успеха.
MS-DOS представляет собой однозадачную, однопользовательскую, диалоговую ОС. Она ведет диалог с пользователем в текстовом режиме и в большей степени рассчитана на обслуживание прикладных программ текстового режима, хотя допускает и графику. Работа с мышью должна обеспечиваться самими прикладными программами при минимальной поддержке со стороны ОС. Для размещения программы пользователя и для своих собственных нужд MS-DOS позволяет использовать 640 Кбайт памяти, что казалось огромной величиной в те незапамятные времена аккуратного программирования и полного отсутствия файлов AVI и MP3. Позднее были добавлены средства, позволяющие с некоторым усилием использовать до 4 Мб памяти.
Интерфейс MS-DOS с прикладными программами основан на вызовах программных прерываний, обрабатываемых системой. Бóльшую часть этих прерываний принято называть функциями
DOS
.
Система MS-DOS явилась стартовой площадкой для создания Windows. В настоящее время MS-DOS тихо отмирает, хотя все версии Windows стараются обеспечить выполнение большей части программ, разработанных для их предшественницы.
В данном курсе MS-DOS рассматривается как наиболее жизненный пример простой и хорошо изученной однозадачной системы для сравнения с более мощными многозадачными системами.
1.7.2. Windows
Система Windows была первоначально разработана фирмой Microsoft как графическая оболочка, загружаемая поверх MS-DOS. Идеи GUI (GraphicUserInterface – графический интерфейс пользователя) были впервые разработаны для экспериментальной машины XeroxPARC еще в 70-х гг., затем подхвачены в MacOS – операционной системе компьютера Macintosh, откуда и были с некоторыми ухудшениями позаимствованы в Windows. Версию Windows 1.0, вышедшую в 1985 г. и работавшую на 1 Мб памяти с неперекрывающимися окнами, принято рассматривать как интересную игрушку. Версия 2.0 (1987 г.) была более серьезна, а версии 3.0 и 3.1 (1990-1992 гг.), предназначенные для процессоров i386 и использующие до 16 Мб памяти, уже имели большой успех.
Все перечисленные версии продолжали оставаться надстройками над MS-DOS, использующими имеющуюся файловую систему, но добавляющие свое собственное управление процессами, памятью и устройствами. За счет этого комбинацию DOS + Windows можно было назвать многозадачной однопользовательской ОС с графическим интерфейсом пользователя.
В 1993 г. Microsoft выпустила WindowsNT – полноценную многозадачную и многопользовательскую ОС, уже не основанную на MS-DOS. Однако, поскольку NT предъявляла повышенные требования к мощности процессора и объему памяти, в 1995 г. была выпущена компромиссная система Windows 95, предназначавшаяся для замены Windows 3.x у массового пользователя. Повышение скорости работы по сравнению с версией NT было достигнуто ценой отказа от многопользовательской защиты и ослабления надежности системы. В Windows 95 неаккуратно написанная прикладная программа может привести к краху системы, а в WindowsNT система лучше изолирована от программ пользователя. В то же время, практически все корректно написанные программы могут переноситься из Windows 95 в WindowsNT и наоборот.
Некоторое время две линии Windows развивались параллельно. Очередные версии WindowsNT получили название Windows 2000, WindowsXP, Windows 2003. Линия Windows 95 была продолжена непринципиально отличающимися от нее версиями Windows 98 и WindowsME, но дальше, видимо, развиваться не будет. Microsoft считает, что современный уровень производительности ПЭВМ снимает необходимость в облегченной версии системы.
Windows предоставляет в распоряжение прикладных программ несколько тысяч документированных API-функций на все случаи жизни.
Современная Windows– весьма мощная и чересчур сложная система, имеющая множество достоинств и недостатков, которые невозможно обсудить коротко. Отметим, что широкому распространению Windows, помимо особого положения фирмы Microsoft на рынке, способствует простота установки системы, позволяющая рядовому пользователю обойтись без помощи специалистов.
В дальнейшем изложении описание возможностей Windows будет в основном ориентировано на линию Windows NT/2000/XP.
1.7.3. UNIX
ОС UNIX была первоначально разработана в 1969 г. сотрудниками фирмы BellLaboratories Кеном Томпсоном и Деннисом Ритчи. В 1971 г. система была перенесена на машины чрезвычайно распространенной в 70-е годы серии PDP-11, а в 1973 г. Ритчи переписал систему на языке C, оставив лишь минимум текста на языке ассемблера. В первое десятилетие существования UNIX и сама система, и ее исходные тексты распространялись свободно, что привело к чрезвычайной популярности системы в научных кругах и университетах. Усовершенствования системы могли вноситься каждым желающим и обсуждались «всем миром». Оборотной стороной такой открытости стала трудность стандартизации UNIX. Однако в 1988-1990 гг. был разработан набор стандартов, получивший название POSIX (PortableOS, а окончание IX – как намек на UNIX). Эти стандарты фиксировали современные требования к системам типа UNIX с учетом теоретических и практических достижений за прошедшие годы.
Начиная с первых версий, UNIX представляет собой многозадачную, многопользовательскую систему разделения времени. Основными достоинствами UNIX являются ее высокая мобильность, хорошо продуманный программный и пользовательский интерфейс. Общепризнанной особенностью UNIX является внутренняя красота, элегантность основных архитектурных решений. Как известно, красота программы является верным признаком ее удачной конструкции и дает основания надеяться, что программа способна к совершенствованию и будет служить долго. Многолетняя история UNIX подтверждает это правило.
К недостаткам UNIX можно отнести более низкую эффективность и надежность работы, что в значительной мере является платой за мобильность. Традиционная модель безопасности UNIX не соответствует современным требованиям, поэтому в различные коммерческие версии приходится включать дополнительные средства защиты данных. Широкому распространению UNIX мешает также то, что процедуры установки и настройки системы не так просты, как у Windows, и при их выполнении желательно участие программиста.
В 80-е годы были попытки превратить UNIX в коммерческую систему. Однако в 1991-1994 гг. Линус Торвальдс, в то время студент-программист из Хельсинки, заново написал систему, соответствующую стандартам POSIX, но отличающуюся от традиционной UNIX большей надежностью и эффективностью. Эта система получила название Linux. Исходные тексты Linux свободно распространяются, что позволяет, как во времена молодости UNIX, развивать систему общими усилиями огромного сообщества заинтересованных программистов. Эффективной координации этих усилий очень способствует Интернет. Несколько позднее был открыт свободный доступ к текстам известной версии UNIXFreeBSD.
Архитектура UNIX, первоначально предназначенная для систем разделения времени с одним процессором, впоследствии оказалась вполне подходящей для поддержки сетевых систем. Значительная часть серверов Интернета работает под управлением той или иной версии UNIX.
В настоящее время происходит ощутимое сближение разных типов ОС, предназначенных для поддержки одних и тех же типов вычислительных систем. Современные версии UNIX и Windows предоставляют весьма близкие функциональные возможности, хотя зачастую в совершенно разной форме. Выравниваются также характеристики надежности и производительности систем.
Существенным отличием UNIX от Windows остается место, занимаемое в системе средствами графического интерфейса. Если в Windows окна и все, что с ними связано, являются неотъемлемой частью архитектуры системы, то для UNIX по традиции основным средством интерфейса с пользователем является текстовая консоль. Те или иные средства оконного интерфейса, конечно, присутствуют в современных UNIX-системах, но как дополнительная, необязательная надстройка скорее прикладного, чем системного характера.
Очень интересной особенностью UNIX является развитый язык команд shell, который позволяет не только вести элементарный диалог с системой, но и писать своеобразные программы (скрипты), с помощью которых часто удается решить требуемую задачу, не прибегая к разработке новой программы на одном из традиционных языков программирования.
Понятие периферийных устройств (ПУ) объединяет, по сути, все основные аппаратурные блоки компьютера, за исключением процессора и основной памяти. Характерными чертами современных вычислительных систем являются широкое разнообразие типов и моделей ПУ, а также быстрый прогресс технологий, приводящий к постоянному увеличению производительности устройств и к появлению дополнительных возможностей аппаратуры.
Важнейшими задачами любой ОС являются обеспечение надежной работы ПУ, эффективное использование всех возможностей устройств.
Для повышения надежности могут использоваться различные аппаратно-программные методы, такие как дублирование данных, использование помехозащищенных кодов, контрольных сумм данных и т.п. Процедуры выполнения операций с устройствами должны обеспечивать, как минимум, выявление аппаратных ошибок и сбоев, а как максимум – их компенсацию за счет избыточности данных и повторного выполнения операций.
Эффективность использования устройств означает прежде всего сокращение времени, затрачиваемого на обмен данными. Помимо повышения скорости обмена, сокращение времени может достигаться за счет распараллеливания работы ПУ и процессора. Мощным фактором повышения производительности системы является сокращение количества операций ввода/вывода за счет сохранения данных в памяти для последующего использования.
Большое разнообразие используемых устройств и постоянное появление новых моделей диктуют необходимость такой структуры системы, которая позволяла бы легкое подключение новых устройств. Широкое распространение получает технология «Plug & Play», т.е. возможность оперативного подсоединения устройств без выключения компьютера.
При всем разнообразии ОС должна обеспечивать максимально возможную стандартизацию работы с ними, чтобы изменения аппаратуры не приводили к необходимости постоянно модифицировать прикладное программное обеспечение.
К числу дополнительных задач, решаемых подсистемами управления устройствами современных ОС, можно отнести хранение данных в сжатом виде, шифрование данных и т.п.
Под программной архитектурой
(или просто – архитектурой
) устройства мы будем понимать совокупность тех структурных особенностей, которые влияют на работу программ с устройством. Например, форма разъема для подключения устройства не входит в его архитектуру, но количество и назначение линий в этом разъеме может в нее входить (если эти линии могут программно управляться).
Как правило, вместе с устройством поставляется его контроллер
(адаптер), содержащий электронные схемы управления устройством. Конструктивно контроллер может представлять собой плату, вставляемую в разъем шины компьютера, либо может быть расположен в корпусе устройства. В любом случае программы работают с устройством через посредство его контроллера, а поэтому с точки зрения архитектуры нет различия между понятиями «устройство» и «контроллер устройства».
Классификация периферийных устройств может быть выполнена по различным признакам.
· Устройства последовательного доступа
(sequentialaccess) и устройства произвольного доступа
(randomaccess). Для последовательных устройств характерно наличие определенного естественного порядка данных, при этом обработка данных в ином порядке либо невозможна, либо крайне затруднена. Классическим примером являются магнитные ленты, для которых чтение и запись данных ведутся от начала ленты к концу, а попытка доступа в ином порядке потребует постоянной перемотки ленты, резко снижающей скорость работы. К устройствам последовательного доступа можно отнести также клавиатуру, мышь, принтер, модем.
Для устройств произвольного доступа возможно обращение к различным порциям данных в любом порядке, причем эффективность работы не зависит (или слабо зависит) от порядка обращения. Для таких устройств характерно наличие адресации данных и операции поиска нужного адреса. Наиболее известный пример – магнитные диски и другие дисковые устройства. Кроме того, к устройствам произвольного доступа можно отнести монитор ПК (там есть адресация точек-пикселов, хотя операция поиска не нужна).
· Символьные (байтовые
) и блочные
устройства. Для символьных устройств наименьшей порцией вводимых и выводимых данных является один байт. Для некоторых символьных устройств можно за одну операцию выполнить ввод или вывод любого (в разумных пределах) требуемого количества байт.
Для блочных устройств наименьшей порцией ввода/вывода, выполняемого за одно обращение к устройству, является один блок, равный, как правило, 2k
байт. Типичным размером блока может быть 512 байт, 1K байт, 4K байт и т.п., в зависимости от конкретного устройства. Наиболее известные примеры блочных устройств – магнитные диски и магнитные ленты. Для диска понятие блока обычно совпадает с понятием сектора. В частности, для IBM-совместимых ПК сектор (блок) диска равен 512 байт.
Блочная архитектура обусловлена особенностями используемой среды и, кроме того, блочный ввод/вывод более эффективен для высокоскоростных устройств, поскольку при этом уменьшается относительная доля времени, расходуемая на подготовительные и заключительные операции при каждом обращении к устройству.
· Физические
, логические
и виртуальные
устройства. Под физическим устройством обычно понимается некоторый реально существующий прибор, «железка». На самом деле, с точки зрения программной архитектуры для наличия физического устройства достаточно знать набор адресов, команд, прерываний и других сигналов, позволяющих выполнять операции с данными. Куда идут или откуда приходят эти сигналы – это вопрос, не касающийся программиста.
Логическое устройство – это понятие, характеризующее специальное назначение устройства в данной ОС. Например, «загрузочный диск» (т.е. тот, с которого была выполнена загрузка ОС). Наиболее важными логическими устройствами во многих ОС являются устройство стандартного ввода
и устройство стандартного вывода
. Их можно упрощенно определить как устройства, используемые для ввода и, соответственно, вывода «по умолчанию», т.е. когда в программе явно не указано другое устройство или файл для ввода/вывода. Как правило, для современных компьютеров устройству стандартного ввода соответствует физическое устройство – клавиатура, а устройству стандартного вывода – монитор. Важно, однако, понимать, что это соответствие может быть изменено: стандартный вывод может быть переназначен, например, на принтер или в файл, стандартный ввод – на удаленный терминал, на файл и т.п.
Понятие «виртуальный» в программировании, вообще говоря, означает примерно следующее: «нечто, на самом деле не существующее, но ведущее себя так, как если бы оно существовало». С этой точки зрения, виртуальное устройство – это программно реализованный объект, который ведет себя подобно некоторому физическому устройству, хотя на самом деле использует ресурсы совсем других устройств (или даже никаких устройств). Примеры виртуальных устройств весьма разнообразны:
- виртуальные диски, расположенные на самом деле в оперативной памяти (такие устройства были популярны в конце 80-х годов);
- виртуальная память, расположенная на самом деле на диске;
- виртуальные CD и DVD – программы, имитирующие поведение соответствующих устройств;
- виртуальный экран, предоставляемый DOS-программе, работающей в режиме окна Windows (программа работает так, как если бы ей был предоставлен весь экран, но на самом деле система направляет вывод программы в отведенное ей окно);
- самый забавный (но очень полезный) пример – пустое устройство, которому не соответствует никакая аппаратура. Почему его вообще можно назвать устройством? Потому что соответствующая системная программа (драйвер пустого устройства) корректно выполняет все действия, которые обязан выполнять драйвер устройства. Такое устройство безотказно принимает выходной поток символов (и тут же выбрасывает принятые данные), а также может использоваться для ввода, но при этом тут же сообщает – дескать, достигнут конец файла. Пустое устройство полезно в тех случаях, когда некоторая программа требует непременно указать файл или устройство для вывода объемных и не очень нужных данных. Кроме того, копирование файла на пустое устройство – это простой способ убедиться, что файл читается без ошибок.
Прерывания (аппаратные) – это сигналы, при поступлении которых нормальная последовательность выполнения программы может быть прервана, при этом система запоминает информацию, необходимую для возобновления работы прерванной программы, и передает управление подпрограмме обработки прерывания
(ISR, InterruptServiceRoutine). По завершению обработки, как правило, управление возвращается прерванной программе.
Все прерывания можно разделить на три основных типа:
· аппаратные прерывания от периферийных устройств;
· внутренние аппаратные прерывания (называемые также исключениями
, exceptions);
· программные прерывания.
В подавляющем большинстве ОС обработку всех прерываний берет на себя сама система, поскольку это слишком «интимная» часть работы, способная повлиять на функционирование всех системных и прикладных программ.
Поскольку типы и разновидности прерываний весьма многообразны и каждый из них требует особой обработки, большинство процессоров поддерживает векторные прерывания
. Это означает, что каждая разновидность прерывания имеет свой номер, и этот номер используется как индекс в массиве, хранящем адреса ISR для всех прерываний. При возникновении прерывания аппаратура компьютера по номеру прерывания определяет адрес подпрограммы обработки и вызывает ее.
Для того чтобы некоторые наиболее ответственные участки системных программ выполнялись без прерываний, система имеет возможность временно запретить прием большинства прерываний. Такой запрет должен устанавливаться лишь на короткие интервалы времени, не более нескольких миллисекунд.
Программные прерывания вызываются выполнением специальной команды, но обрабатываются точно так же, как остальные типы прерываний. По сути, команда программного прерывания представляет собой особый случай вызова подпрограммы, но при этом вместо адреса подпрограммы указывается номер прерывания, обработчик которого должен быть вызван. В большинстве современных ОС программные прерывания используются для перехода из режима пользователя в режим ядра при вызове системных функций из прикладной программы.
Одним из важнейших источников прерываний являются периферийные устройства. Как правило, устройство генерирует сигнал прерывания в одном из двух случаев:
· при переходе в состояние готовности;
· при возникновении ошибки выполнения операции.
Состояние готовности – это такое состояние устройства, в котором оно готово принять и выполнить команды от процессора. Для устройства ввода готовность означает наличие в устройстве данных, которые могут быть переданы в процессор (например, клавиатура переходит в состояние «Готово» при нажатии клавиши и возвращается в состояние «Не готово», когда код нажатой клавиши считан в процессор). Для устройства вывода готовность – это возможность принять от процессора данные, которые следует вывести. Например, матричный принтер принимает символы, которые нужно напечатать, в свой внутренний буфер. Если буфер полон, принтер переходит в состояние «Не готово» до тех пор, пока часть символов будет напечатана и в буфере освободится место. Дисковый накопитель при начале выполнения новой операции чтения или записи на диск переходит в состояние «Не готово», а после завершения операции возвращается в состояние «Готово». В любом из этих случаев переход в состояние «Готово» – это повод для устройства напомнить о себе процессору: обратите на меня внимание, я к вашим услугам! Для этого и служит сигнал прерывания.
Ошибка операции также требует вмешательства системы или пользователя. Например, при ошибке отсутствия бумаги в лотке принтера система должна оповестить об этом пользователя; при ошибке чтения с диска либо система, либо пользователь должен решить, что делать: повторить операцию, завершить программу или продолжить выполнение.
Не каждое устройство генерирует прерывания. Например, монитор ПК не выдает прерываний: он «всегда готов», т.е. всегда может принять данные для отображения, и он «никогда не ошибается», точнее сказать, его неисправность обнаруживается «на глаз».
С программной точки зрения, устройство (или его контроллер) обычно представлено одним или несколькими регистрами
. Регистр устройства – это адресуемое машинное слово, используемое для обмена данными или сигналами между устройством и процессором. Можно выделить два основных типа регистров.
· Регистр данных
служит для обмена данными. Запись данных в такой регистр (если она возможна) означает вывод данных на устройство, чтение данных из регистра – ввод с устройства.
· Регистр управления и состояния
содержит два типа двоичных разрядов (битов). Биты состояния служат для передачи процессору информации о текущем состоянии устройства (например, флагов готовности и ошибки, сигналов прерывания). Биты управления служат для передачи на устройство команд, позволяющих задать выполняемую операцию, запустить выполнение операции, установить режимы работы устройства и т.п.
В различных компьютерах используется один из двух способов адресации регистров устройств.
· Отображение регистров устройств на память. При этом способе для устройств отводится определенная часть адресного пространства памяти, а для работы с устройствами можно использовать те же команды, что и для работы с основной памятью (например, команду MOV).
· Адресация регистров через порты ввода/вывода. Для портов отводится отдельное адресное пространство, и для работы с ними имеются специальные команды (например, IN и OUT).
Первый способ удобнее для программирования, поскольку позволяет использовать более широкий набор команд. Однако этот способ труднее реализовать на аппаратном уровне, поскольку аппаратура должна определять, относится ли конкретный адрес к памяти или к устройству, и по-разному обрабатывать эти два случая.
Среди различных возможных конфигураций однопроцессорной вычислительной системы принято выделять два основных типа: системы с магистральной и с радиальной архитектурой (рис. 2‑1).

Рис.
2‑1
· Магистральная
архитектура основана на подключении всех имеющихся устройств, включая процессор и память, к единой системной магистрали (шине), которая объединяет в себе линии передачи данных, адресов и управляющих сигналов. Совместное использование магистрали различными устройствами подчиняется специальным правилам (протоколу), обеспечивающему корректность работы магистрали.
· Радиальная
архитектура предполагает, что каждое из устройств, включая память, подключается к процессору отдельно, независимо от других устройств, и взаимодействует с процессором по собственным правилам.
Для программиста понятия магистральной и радиальной архитектуры имеют несколько иное содержание, чем для инженера-системотехника. С точки зрения программной архитектуры, неважно, подсоединено ли устройство к процессору напрямую или через посредство системной магистрали. Важно то, какие сигналы должна посылать и принимать программа, работающая с устройством, и какие команды могут для этого использоваться.
Основная особенность магистральной архитектуры – единообразный способ подключения всех устройств. Структура регистров устройства стандартизуется, при этом определяется, какими сигналами любое устройство может обмениваться с процессором и каким разрядам регистра должны соответствовать эти сигналы. Конечно, не всякое устройство нуждается в использовании всего набора стандартных сигналов. Некоторые типы устройств могут, например, не генерировать прерываний, не сообщать об ошибках. Но те сигналы, которые устройство использует, должны соответствовать стандарту данной магистрали.
Преимуществом магистральной архитектуры является простота подключения новых типов устройств, поэтому такая архитектура особенно удобна для открытых вычислительных систем, т.е. таких, которые рассчитаны на расширяемый набор периферийных устройств.
Напротив, для радиальной архитектуры характерен индивидуальный выбор способа подключения, наиболее удобного для каждого типа устройств. При этом в принципе можно достичь экономии аппаратных ресурсов и более высокой эффективности. Случается даже, что в одном порту объединяются управляющие сигналы от нескольких разных устройств. Очевидно, подобная архитектура удобна только в том случае, когда она рассчитана на постоянный набор устройств. Расширение радиальной системы всегда вызывает затруднения.
Исходя их этих определений, не так уж легко точно охарактеризовать современные IBM-совместимые ПК. Исходная модель IBMPC имела довольно четко выраженную радиальную архитектуру и небольшой набор стандартных устройств. В последующих моделях были сделаны значительные шаги по стандартизации подключения новых устройств. Однако и сегодня эти компьютеры не тянут на магистральную архитектуру в полном смысле слова: у них для этого слишком много разных шин.
Важной деталью архитектуры современных компьютеров является такое устройство, как контроллер прямого доступа к памяти
(ПДП, англ. DMA – Direct Memory Access). Если обычно весь обмен данными идет через регистры процессора, то ПДП подразумевает прямой перенос данных с устройства в память или обратно. Роль процессора в данном случае только в том, чтобы инициировать операцию ввода/вывода блока данных, послав соответствующие команды контроллеру ПДП. Далее процессор не участвует в выполнении обмена данными. Завершив операцию, контроллер ПДП посылает сигнал прерывания, извещая об этом процессор. Это позволяет повысить производительность системы за счет частичной разгрузки процессора и магистрали.
2.5.1. Ввод/вывод по опросу и по прерываниям
Рассмотрим более подробно работу программы, непосредственно выполняющей ввод или вывод данных на конкретное устройство. (На самом деле, этой работой обычно занимается драйвер устройства, так что мы фактически рассматриваем логику работы драйвера.)
Для определенности положим, что программа должна выдать N байт данных из массива A на символьное устройство X. Для операции ввода могут использоваться те же подходы, которые будут рассмотрены здесь для операции вывода.
Пусть архитектура устройства представлена регистром данных X.DATA и флагом готовности X.READY. Когда X.READY = TRUE, в регистр X.DATA можно выдавать очередной байт данных. Запишем на псевдокоде, близком к языку Паскаль, варианты организации соответствующей программы.
а) Ввод/вывод без проверки готовности
i := 1;
while i <= N do begin
X.DATA := A[i];
i := i + 1;
end;
Этот «наглый» способ вывода вполне работоспособен, если используется «всегда готовое» устройство (например, монитор), т.е. флаг X.READY всегда истинен и потому вообще не нужен. При попытке использовать тот же подход для вывода на принтер мы убедились бы, что напечатаны будут лишь некоторые символы, которым посчастливилось быть выданными в редкие моменты готовности принтера.
б) Ввод/вывод по опросу готовности
i := 1;
while i <= N do begin
while not X.READY do
;
X.DATA := A[i];
i := i + 1;
end;
Здесь добавлен цикл ожидания, в котором не делается ничего, кроме постоянной циклической проверки готовности устройства. Передача данных происходит только тогда, когда устройство готово. Поскольку после выдачи одного байта устройство вполне может опять перейти в состояние неготовности, следует опять выполнять цикл ожидания, пока выданный символ не будет обработан устройством.
Такая организация ввода/вывода позволяет корректно работать с любыми устройствами. Этот способ действительно применяется в некоторых однозадачных системах. Недостатком данного способа является непроизводительная трата времени на постоянное «долбление» флага готовности. При современном соотношении скоростей работы процессора и периферии, цикл ожидания может повторяться миллионы раз перед выдачей каждого байта. Более того, если по каким-то причинам устройство вообще не перейдет в состояние готовности, то работа всей системы может быть парализована бесконечным циклом ожидания.
в) Ввод/вывод по прерываниям
i := 1;
while i <= N do begin
X_INT: if not X.READY
return;
X.DATA := A[i];
i := i + 1;
end;
Здесь исчез цикл ожидания, вместо него – однократная проверка готовности и оператор возврата, если не готово.
Куда, собственно, происходит возврат? Чтобы это понять, надо вспомнить, что данный фрагмент – явно не единственная программа, работающая в данный момент на ЭВМ. Очевидно, операция вывода была начата операционной системой по запросу какой-то программы. Данный фрагмент был вызван как подпрограмма ОС, и возврат означает передачу управления ОС. Как система распорядится полученным временем? Это уже совсем другой вопрос, не связанный с вводом/выводом. Например, ОС может переключиться на другой процесс. Или, от нечего делать, запустить экранную заставку либо программу самотестирования.
Но как же быть с брошенной на полпути операцией вывода? Для ее возобновления будет использовано аппаратное прерывание, которое должно выдать устройство X при переходе в состояние готовности. Системный обработчик прерывания должен будет передать управление по адресу, обозначенному меткой X_INT. После нелишней дополнительной проверки готовности программа вывода передаст очередной байт на устройство, затем снова проверит готовность и, возможно, вновь вернет управление системе. Таким образом, выполнение ввода/вывода разбивается на отдельные интервалы работы при готовности устройства, перемежающиеся работой системы, пока устройство не готово.
Для устройств, использующих контроллер ПДП, возможные варианты организации работы остаются, по сути, теми же, но только используются гораздо более крупные операции: вместо ввода или вывода одного элемента данных выполняется ввод/вывод целого блока данных, и только после этого контроллер переходит в состояние готовности и генерирует прерывание.
2.5.2. Активное и пассивное ожидание
Поговорим подробнее об одном важном различии между способами ввода/вывода по опросу готовности и по прерываниям.
Основной особенностью ввода/вывода по опросу готовности является цикл ожидания. Если выполняется ввод или вывод на медленное устройство (например, матричный принтер), то этот скромно выглядящий цикл будет занимать, мягко говоря, 99% всего времени работы процессора. Если происходит ожидание ввода с клавиатуры, то процессор вообще не будет делать ничего полезного, пока пользователь не удосужится нажать клавишу.
Такое абсурдное использование процессора может быть оправдано разве что в том случае, если для него нет никакой более полезной работы. Это возможно в случае однозадачной ОС, когда работающая прикладная программа не может продвигаться дальше, пока не завершена операция ввода/вывода. В этом случае ввод/вывод по опросу не лишен определенных достоинств: он не связан с обработкой прерываний, которая требует некоторого времени, а потому замедляет реакцию на переход устройства в состояние готовности.
Способ ожидания программой некоторого события, основанный на постоянной циклической проверке ожидаемого условия, называется активным ожиданием
(busywaiting). Это понятие применяется не только по отношению к вводу/выводу, но и во многих других ситуациях, возникающих при работе системных и прикладных программ.
Если рассматривается многозадачная ОС, в которой может быть несколько активных задач одновременно, то активное ожидание становится совершенно неприемлемым. В этом случае расход процессорного времени на выполнение циклического опроса наносит прямой ущерб другим программам, которые могли бы использовать это время более осмысленно. Поэтому при разработке многозадачных систем, как при вводе/выводе, так и в некоторых других ситуациях, обязательно реализуется пассивное ожидание
, т.е. такая реализация ожидания, при которой ожидающая программа не затрачивает процессорного времени. Для реализации пассивного ожидания всегда в той или иной форме используются аппаратные прерывания. Частным примером пассивного ожидания является рассмотренный выше ввод/вывод по прерываниям.
2.5.3. Синхронный и асинхронный ввод/вывод
Программист, разрабатывающий прикладные программы, не должен думать о таких вещах, как способ работы системных программ с регистрами устройств. Система скрывает от приложений детали низкоуровневой работы с устройствами. Однако различие между организацией ввода/вывода по опросу и по прерываниям находит определенное отражение и на уровне системных функций, в виде функций для синхронного и асинхронного ввода/вывода.
Выполнение функции синхронного ввода/вывода
включает в себя запуск операции ввода/вывода и ожидание завершения этой операции. Только после завершения ввода/вывода функция возвращает управление вызвавшей программе.
Синхронный ввод/вывод – это наиболее привычный для программистов способ работы с устройствами. Стандартные процедуры ввода/вывода языков программирования работают именно таким способом.
Вызов функции асинхронного ввода/вывода
означает только запуск соответствующей операции. После этого функция сразу возвращает управление вызвавшей программе, не дожидаясь завершения операции.
Рассмотрим, например, асинхронный ввод данных. Понятно, что программа не может обращаться к данным, пока нет уверенности, что их ввод завершен. Но вполне возможно, что программа может пока что заняться другой работой, а не простаивать в ожидании.
Рано или поздно программа все-таки должна приступить к работе с введенными данными, но предварительно убедиться, что асинхронная операция уже завершилась. Для этого различные ОС предоставляют средства, которые можно разбить на три группы.
· Ожидание завершения операции. Это как бы «вторая половина синхронной операции». Программа сначала запустила операцию, потом выполнила какие-то посторонние действия, а теперь ждет окончания операции, как при синхронном вводе/выводе.
· Проверка завершения операции. При этом программа не ожидает, а только проверяет состояние асинхронной операции. Если ввод/вывод еще не завершен, то программа имеет возможность еще какое-то время погулять.
· Назначение процедуры завершения. В этом случае, запуская асинхронную операцию, программа пользователя указывает системе адрес пользовательской процедуры или функции, которая должна быть вызвана системой после завершения операции. Сама программа может больше не интересоваться ходом ввода/вывода, система напомнит ей об этом в нужный момент, вызвав указанную функцию. Этот способ наиболее гибкий, поскольку в процедуре завершения пользователь может предусмотреть любые действия.
В Windows прикладной программе доступны все три способа завершения асинхронных операций. В UNIX асинхронных функций ввода/вывода нет, однако тот же эффект асинхронности может быть достигнут иначе, путем запуска дополнительного процесса.
Асинхронное выполнение ввода/вывода позволяет в некоторых случаях повысить производительность работы и обеспечить дополнительные функциональные возможности. Без такой простейшей формы асинхронного ввода, как «ввод с клавиатуры без ожидания», были бы невозможны многочисленные компьютерные игры и тренажеры. В то же время логика программы, использующей асинхронные операции, сложнее, чем при синхронных операциях.
А в чем заключается упомянутая выше связь между синхронными/асинхронными операциями и способами организации ввода/вывода, рассмотренными в предыдущем пункте? Ответьте сами на этот вопрос.
2.6.1. Понятие буферизации
Буферизацию
в самом широком смысле можно определить как такую организацию ввода/вывода, при которой данные не передаются непосредственно с устройства в заданную область памяти (или из области памяти на устройство), а предварительно направляются во вспомогательную область памяти, называемую буфером
. Как правило, организуемые системой буферы невидимы для прикладного программиста, он получает данные как готовый результат. Нередко данные «по дороге» проходят через несколько буферов разного назначения.
Существует несколько причин для использования буферизации, важнейшие из которых рассмотрены ниже.
2.6.2. Сглаживание неравномерности скоростей процессов
Достаточно часто в работе ОС встречается ситуация, когда один процесс порождает данные, которые должны оперативно обрабатываться другим процессом. В качестве примера можно привести прием по сети данных, которые должны обрабатываться браузером или другой прикладной программой.
Скорость приема данных очень неравномерна: интервалы времени интенсивного поступления данных перемежаются с интервалами простоя. Обработка данных прикладной программой тоже не обязательно идет с постоянной скоростью. В результате, хотя средняя скорость обработки может быть вполне достаточной, не исключено, что в некоторые моменты обрабатывающая программа будет «захлебываться» данными. Это может привести к потере части данных, не успевших пройти обработку.
Стандартным решением в этой ситуации является использование буфера, размер которого достаточно велик, чтобы вместить все данные, ожидающие обработки. Чем больше буфер, тем меньше вероятность потери данных из-за его переполнения.
2.6.3. Распараллеливание ввода и обработки
Во многих вычислительных системах имеются аппаратные возможности совместить во времени выполнение операций ввода/вывода и обработку данных процессором. Чтобы использовать эти возможности, данные при вводе направляются в буфер. После заполнения буфера его данные пересылаются в обрабатывающую программу, а их обработка выполняется параллельно с накоплением следующей порции данных в буфере.
Еще более эффективна схема работы с двумя переключаемыми буферами. Пока в первом буфере накапливаются вводимые данные, предыдущая порция данных обрабатывается во втором буфере, без потери времени на пересылку. Затем буфера меняются ролями: в первом буфере обрабатывается следующая введенная порция данных, а второй буфер используется для ввода, и т.д.
Аналогичным образом буферизация может использоваться и при выводе данных.
В некоторых случаях оказывается выгодно выполнять ввод «с опережением», т.е. вводить те данные, которые пока не запрошены обрабатывающим процессом, но по всей вероятности скоро понадобятся.
2.6.4. Согласование размеров логической и физической записи
Логической записью называют порцию данных, указанную в операторе ввода/вывода. Размер логической записи определяется логикой работы программы или, например, логической структурой базы данных.
При фактическом выполнении чтения или записи на блочное устройство обрабатывается порция данных, называемая физической записью или блоком. Размер физической записи определяется особенностями устройства (для диска это один сектор) и никак не связан с логикой программы.
На рис. 2‑2 показана ситуация, когда логическая запись содержит 100 байт, а физическая – 512 байт.

Рис.
2‑2
Предположим, что логические записи в последовательном порядке записываются в файл на диске. Если каждый оператор вывода логической записи будет вызывать немедленную запись на диск, то выдача первых пяти логических записей потребует пять раз выполнить последовательность операций: «чтение физической записи с диска – изменение 100 байт – запись измененной записи на диск». На шестой раз получится еще хуже, поскольку придется читать – изменять – записывать не одну, а две физических записи.
Использование буфера для накопления данных до размера физической записи позволяет резко сократить количество операций записи на диск и почти полностью исключить чтение с диска.
2.6.5. Редактирование при интерактивном вводе
Несколько особняком от других форм буферизации стоит использование буфера строки при вводе с клавиатуры.
Для пользователя привычно, что в процессе ввода числовых или строковых значений он может легко откорректировать ошибки ввода: «забить» неверный символ, вернуться в любое место вводимой строки и внести там изменения и т.п. При этом прикладная программа «не видит» процесса редактирования строки, она получает всю строку целиком после нажатия, например, клавиши Enter. Чтобы обеспечить возможность редактирования вводимой строки, используется буфер строки, выделяемый либо ОС, либо библиотекой времени выполнения конкретной системы программирования. Все редактирование выполняется над символами, которые помещаются в этот буфер подпрограммами ввода с клавиатуры. После нажатия Enter происходит либо копирование символов из буфера в массив, выделенный прикладной программой, либо передача этой программе указателя на буфер.
2.6.6. Кэширование дисков
Очень важной, специфической формой буферизации является кэширование[2]
. Этот термин означает использование сравнительно небольшой по объему, но быстродействующей памяти для того, чтобы уменьшить количество обращений к более медленной памяти большого объема.
Идея кэширования основывается на так называемой гипотезе о локальности ссылок
. Эта гипотеза заключается в следующем. Если в какой-то момент времени произошло обращение к определенному участку данных, то в ближайшее время можно с высокой вероятностью ожидать повторения обращений к тем же самым данным или же к соседним участкам данных. Конечно, локальность ссылок нельзя считать законом, однако практика показывает, что эта гипотеза оправдывается для подавляющего большинства программ.
В современных вычислительных системах может использоваться несколько уровней кэширования. В данном курсе не рассматривается аппаратный кэш процессора, позволяющий сократить число обращений к основной памяти за счет использования быстродействующих регистров. К работе ОС более прямое отношение имеет программное кэширование устройств произвольного доступа (дисковых накопителей). В этом случае гипотезу о локальности ссылок можно переформулировать более конкретно: если программа выполнила чтение или запись данных из некоторого блока диска, то весьма вероятно, что в скором будущем последуют еще операции чтения или записи данных из того же блока.
В роли быстродействующей памяти (кэша) здесь выступает массив буферов, размещенный в системной памяти. Каждый буфер состоит из заголовка и блока данных, соответствующего по размеру блоку (сектору) диска. Заголовок буфера содержит адрес блока диска, копия которого в данный момент содержится в буфере, и несколько флагов, характеризующих состояние буфера.
Когда система получает запрос на чтение или запись определенного блока данных диска, она прежде всего проверяет, не содержится ли в данный момент копия этого блока в одном из буферов кэша. Для этого требуется выполнить поиск по заголовкам буферов. Если блок найден в кэше, то обращение к диску выполняться не будет. Вместо этого данные читаются из буфера или, соответственно, записываются в буфер. В случае записи данных следует также в заголовке буфера отметить с помощью специального флага, что буфер стал «грязным
», т.е. его содержимое не соответствует данным на диске.
Если требуемый блок диска не найден в кэше, то для него должен быть выделен буфер. Проблема в том, что общее количество буферов кэша ограничено. Чтобы отдать один из них под требуемый блок, надо «вытеснить» из кэша один из блоков, которые там хранились. При этом, если вытесняемый блок «грязный», то он должен быть «очищен», т.е. записан на диск. При вытеснении «чистого» блока никаких операций с диском выполнять не надо.
Какой из блоков, хранящихся в кэше, следует выбрать для вытеснения, чтобы сократить общее количество обращений к диску? Это крайне важный вопрос, и если он будет решаться неправильно, то вся работа системы может затормозиться из-за постоянных обращений к диску.
Имеется теоретически оптимальное решение данной задачи, которое заключается в следующем. Число обращений к диску будет минимально, если каждый раз выбирать для вытеснения тот блок данных, к которому в будущем дольше всего не будет обращений. К сожалению, воспользоваться этим правилом на практике невозможно, так как последовательность обращений к блокам диска непредсказуема. Данный теоретический результат полезен только как недостижимый идеал, с которым можно сравнивать результаты применения более реалистичных алгоритмов выбора.
Среди алгоритмов, используемых на практике, лучшим считается алгоритм LRU
(LeastRecentlyUsed, в вольном переводе «давно не использовавшийся»). Он заключается в следующем: выбирать для вытеснения следует тот блок, к которому дольше всего не было обращений. Здесь как раз используется принцип локальности ссылок: раз обращений давно не было, то, вероятно, их и не будет в ближайшее время.
Как на практике реализуется выбор блока по правилу LRU? Очевидное решение – при каждом обращении к буферу записывать в его заголовке текущее время, а при выборе для вытеснения искать самую раннюю запись – слишком громоздко и медленно. Есть гораздо лучшая возможность.
Все буферы кэша связываются в линейный список. В заголовке каждого буфера хранится ссылка на следующий по порядку списка буфер (фактически хранится индекс этого буфера в массиве буферов). При каждом обращении к блоку данных для чтения или записи выполняется также перемещение соответствующего буфера в конец списка. Это не означает перемещения данных, хранящихся в буфере, изменяются только несколько ссылок в заголовках.
В результате постоянного перемещения использованных блоков в конец списка буферов этот список оказывается отсортированным по возрастанию времени последнего обращения. В начале списка оказывается тот буфер, к данным которого дольше всего не было обращений. Он-то нам и нужен как кандидат на вытеснение.
На рис. 2‑3 показан массив буферов, связанный в список.

Рис.
2‑3
Теперь о «грязных» буферах. В каких случаях должна выполняться их «очистка», т.е. запись блока данных из кэш-буфера на диск? Можно назвать три таких случая.
· Выбор блока для вытеснения из кэша.
· Закрытие файла, к которому относятся «грязные» блоки. Общепринято, что при закрытии файла должно выполняться его сохранение на диске.
· Операция принудительной очистки всех буферов либо только буферов, относящихся к определенному файлу. Подобная операция может выполняться для повышения надежности хранения данных, как страховка от возможных сбоев. В ОС UNIX, например, очистка всех буферов традиционно выполняется каждые 30 с.
Следует признать, что кэширование операций записи на диск, в отличие от кэширования чтения, всегда создает определенную опасность потери данных. В случае случайного сбоя системы, отключения питания и т.п. может оказаться, что важная информация, которую следовало записать на диск, застряла в грязных буферах кэша и была поэтому потеряна.[3]
Это неизбежная плата за значительное повышение производительности системы. Программы, требующие высокой надежности работы с данными (например, банковские программы), обычно записывают данные прямо на диск. При этом кэш либо не используется вообще, либо в кэш-буфер заносится копия данных, которая может пригодиться при последующих операциях чтения.
«Узким местом» кэширования дисков является поиск требуемого блока данных в кэше. Как было описано выше, для этого система просматривает заголовки буферов. Если кэш состоит из нескольких сотен буферов, время поиска будет ощутимо. Один из возможных приемов ускорения поиска, используемый в UNIX, показан на рис. 2‑4.

Рис.
2‑4
В UNIX каждый кэш-буфер может входить одновременно в два линейных списка. Один из них, называемый «списком свободных блоков», это знакомый нам LRU-список, используемый для определения блока, подлежащего вытеснению. Слово «свободный» не значит «пустой»; в данном случае это слово означает блок, не занятый в текущий момент в операции чтения/записи, выполняемой каким-нибудь процессом. Другой список называется «хеш-цепочкой» и используется для ускорения поиска нужного блока.
При записи в буфер данных, соответствующих некоторому блоку диска, номер хеш-цепочки, в которую будет помещен этот буфер, определяется как остаток от деления номера блока на N – количество хеш-цепочек. Для наглядности на рисунке принято значение N = 10. Таким образом, блоки с номерами 120, 40, 90 попадают в цепочку 0, блоки 91, 1, 71 – в цепочку 1 и т.д. Когда система ищет в кэше блок с определенным номером, она прежде всего по номеру блока определяет, в какой из хеш-цепочек этот блок должен находиться. Если блока нет в этой цепочке, то его вообще нет в кэше. Таким способом удается сократить поиск в лучшем случае в N раз (это если все цепочки окажутся одинаковой длины).
Перемещение буфера из одной хеш-цепочки в другую, как и его перемещение в конец списка свободных блоков, не требует перезаписи всего блока данных в памяти и выполняется путем изменения ссылок в заголовках блоков.
Еще одна особенность кэширования дисков в UNIX состоит в том, что при обнаружении в начале списка свободных блоков «грязных» буферов система запускает процессы их очистки, но не дожидается завершения этих процессов, а выбирает для вытеснения первый по списку чистый блок. После завершения очистки блоки возвращаются в начало списка свободных блоков, оставаясь первыми кандидатами на вытеснение.
2.6.7. Опережающее чтение.
В том случае, если обработка данных ведется последовательным образом (от начала файла к концу), кэширование не дает значительного эффекта. После того, как обработаны данные из одного блока, дальнейшее пребывание этого блока в кэш-буфере бесполезно. Значительно более полезной в этом случае может оказаться другая специальная форма буферизации, известная как опережающее чтение
. Она заключается в том, что при обращении к некоторому блоку диска система, выполнив чтение требуемого блока, считывает затем еще несколько следующих за ним блоков. Если аппаратура позволяет выполнять операцию чтения одновременно с обработкой ранее прочитанных данных, то велика вероятность, что к моменту, когда следующий блок данных будет запрошен для обработки, этот блок уже окажется прочитанным.
Как правило, системе неизвестно, будет ли обработка файла вестись в режиме последовательного или произвольного доступа, поэтому часто используется та или иная комбинация кэширования с опережающим чтением. В Windows программа, открывающая файл, может указать системе, для какого способа доступа желательно оптимизировать механизм буферизации.
Идея опережающего чтения получила интересное развитие в WindowsXP. В этой системе введен механизм опережающей загрузки данных (prefetch), который основан на автоматическом сборе и хранении статистики о том, какие файлы и каталоги используются в ходе загрузки ОС и при запуске конкретных приложений, а также какие данные читаются из этих файлов в первые минуты работы. При последующих загрузках ОС и запусках приложений система выполняет ожидаемые операции чтения еще до того, как они будут в действительности запрошены загружаемыми компонентами ОС или приложением. При этом система планирует порядок операций таким образом, чтобы сократить перемещения читающих головок и тем самым ускорить загрузку данных.
Драйвер устройства
– это системная программа, которая под управлением ОС выполняет все операции с конкретным периферийным устройством. Драйвер является как бы посредником между ОС и устройством. Перед драйверами стоят две одинаково важные, но трудно совместимые задачи:
· обеспечить возможность стандартного обращения к любому устройству, скрывая от остальных частей ОС специфические особенности отдельных устройств;
· добиться максимально эффективного использования всех функциональных возможностей и особенностей конкретных устройств.
Возможность стандартными средствами работать с разными устройствами очень желательна с точки зрения архитектуры ОС и удобства программирования. Было бы крайне противно, если бы при написании прикладной программы нужно было заранее учитывать, какая модель принтера будет использоваться для выдачи результатов. Наоборот, в большинстве случаев прикладной программист даже не должен знать, будет ли это принтер или плоттер-графопостроитель, или же результаты будут отображаться на экране. Большие проблемы могли бы возникнуть и при замене одной модели принтера, диска, монитора на другую, если бы такая замена потребовала переписывать заново все программы, работающие с этим устройством. Другое дело, если все особенности устройства учитываются в одном-единственном месте, а именно – в драйвере этого устройства.
Разумеется, полностью скрыть все различия между устройствами невозможно. Никаким образом нельзя приравнять, скажем, диск к клавиатуре, и даже разные типы дисков похожи, но не совсем. Например, для дискет можно выполнить такую операцию, как проверка смены носителя (фактически при этом проверяется, открывался ли карман дисковода). Для жестких дисков эта операция не имеет смысла.
В большинстве ОС различаются, как минимум, два разных типа драйверов: для символьных и для блочных устройств.
Обращаясь к драйверу, ОС указывает функцию, которую требуется выполнить. Список этих функций общий для драйверов различных устройств, при этом каждый драйвер может реализовать только те функции, которые имеют смысл для данного устройства. Наиболее общими являются функции чтения данных, записи данных, инициализации устройства (эта функция вызывается системой один раз, сразу после загрузки), открытия и закрытия устройства (используются, когда символьное устройство открывается как файл). Для блочных устройств имеют смысл функции форматирования, поиска сектора. Для символьных устройств ввода – функция «неразрушающего ввода», т.е. проверки очередного символа без его изъятия из входного потока.
Для того, чтобы учесть все разнообразие возможных операций, в число функций драйвера вводят такую, как «выполнение специальных функций», и здесь уже для каждого устройства определен свой набор этих специальных функций.
Типичный драйвер устройства содержит, как минимум, три основных блока:
· заголовок драйвера;
· блок стратегии;
· блок прерываний.
Заголовок
содержит различную информацию о данном драйвере и об управляемом устройстве. Сюда может включаться имя устройства, тип устройства, число однотипных устройств, обслуживаемых одним драйвером, объем памяти на устройстве и т.п. Заголовок содержит также адреса блока стратегии и блока прерываний.
В обязанность блока стратегии
входит прием заявок на выполнение операции, ведение очереди заявок (в многозадачных системах, а также при асинхронных операциях, выполнения могут дожидаться несколько заявок), а также запуск операции и ее завершение.
Заявка на выполнение операции представляет собой стандартную запись, формируемую системой перед обращением к драйверу. Заявка содержит код требуемой функции драйвера и сведения об адресе данных в памяти и на устройстве, о количестве передаваемых данных. Заявка также содержит поле, в которое драйвер должен будет записать код завершения операции (обычно 0 – нормально выполненная операция, другие значения – коды ошибок).
Блок прерываний
выполняет примерно тот алгоритм, который в п. 2.5.1 назывался вводом/выводом по прерываниям. Система вызывает этот блок, когда получает сигнал прерывания от устройства, обслуживаемого драйвером. Закончив выполнение заявки, блок прерываний возвращает управление блоку стратегии для завершения операции.
Помимо трех основных блоков, в разных ОС драйверы могут содержать, например, блок инициализации (он используется один раз при загрузке ОС, а затем может быть выгружен из памяти), блок изменения параметров драйвера и др.
В последние годы возрастающее усложнение периферийных устройств и самих ОС сделало популярной многоуровневую схему использования драйверов. По этой схеме, помимо описанных выше низкоуровневых драйверов аппаратуры, допускается еще создание высокоуровневых драйверов, лежащих между драйверами аппаратуры и остальной частью ОС. Высокоуровневый драйвер не содержит блока прерываний, он принимает заявки от системы, преобразует данные тем или иным образом, а затем вызывает низкоуровневый драйвер для работы с устройством. Например, высокоуровневый графический драйвер может преобразовывать команды рисования фигур, заливок, текста в набор команд конкретной модели принтера, а связанный с ним драйвер параллельного порта отвечает за передачу этих команд принтеру. Для диска можно реализовать в виде отдельного драйвера алгоритм шифрации данных, которые потом передаются обычному драйверу диска.
2.8.1. Уровни доступа к устройствам
Система MS-DOS предоставляет пользователю возможности доступа к устройствам на нескольких уровнях, отличающихся степенью близости к аппаратуре. Нижние уровни позволяют более полно использовать тонкие особенности устройств, но за это приходится платить сложностью программирования. Верхние уровни более удобны для решения стандартных задач ввода/вывода.
Уровни доступа к устройствам показаны на рис. 2‑5.

Рис.
2‑5
Самый нижний уровень предполагает, что программа пользователя работает непосредственно с портами ввода/вывода, а также, если это необходимо, частично или полностью берет на себя обработку аппаратных прерываний, поступающих от устройства. В принципе, программа пользователя может вообще не использовать средства MS-DOS для работы с устройствами, но при этом ей придется взять на себя много скучной работы.
В работе MS-DOS широко используются возможности, предоставляемые BIOS (BasicInput/OutputSystem, базовая система ввода/вывода) – набором программных модулей, записанных в постоянной памяти (ПЗУ) компьютера. BIOS по умолчанию выполняет обработку всех аппаратных прерываний, если эту работу не берет на себя DOS или прикладная программа. Кроме того, BIOS содержит процедуры обработки ряда программных прерываний ввода/вывода.
Программные прерывания BIOS представляют собой подпрограммы, выполняющие операции ввода/вывода и управления конкретными устройствами. Для каждого из стандартных устройств зарезервирован свой номер прерывания, а для указания требуемой операции используется номер функции, который заносится в один из регистров процессора перед вызовом прерывания.
Драйверы устройств не вызываются непосредственно из программы пользователя. Они вызываются из функций DOS и выполняют заданную операцию, обычно используя для этого программные прерывания BIOS, хотя возможна и прямая работа драйвера с портами и аппаратными прерываниями.
Функции DOS, в отличие от прерываний BIOS, работают не с конкретной аппаратурой, а с именованными устройствами. Имена устройств задаются в заголовках соответствующих драйверов. Например, для DOS клавиатура и экран объединяются драйвером консольного устройства CON.
Процедуры ввода/вывода, используемые в языках программирования (например, Read и Write в Паскале, scanf и printf в C), при компиляции реализуются как подходящие вызовы функций DOS или, в особых случаях, программных прерываний BIOS.
2.8.2. Драйверы устройств в MS-DOS
Драйвер устройства в MS-DOS состоит из трех блоков с известными нам названиями: заголовок драйвера, блок стратегии и блок прерываний. При близком рассмотрении оказывается, однако, что сходство ограничивается в основном названиями блоков.
Заголовок драйвера содержит основную информацию об устройстве: символьное или блочное устройство; для символьных устройств – имя устройства; для блочных – количество однотипных устройств, обслуживаемых данным драйвером; не является ли данное устройство системной консолью, системными часами или пустым устройством; какие специальные операции поддерживает устройство.
В заголовке содержатся адреса блока стратегии и блока прерываний, а также адрес заголовка следующего драйвера в списке. Когда система должна выполнить запрос на ввод/вывод, она просматривает список всех драйверов, пока не найдет устройство с нужным именем (если задано символьное устройство) или, для блочного устройства, не определит, какой по счету драйвер соответствует указанному номеру (букве) диска. Затем система вызывает блок стратегии найденного драйвера, передавая ему адрес заявки на выполнение операции. Затем вызывается блок прерываний.
Если в файле конфигурации CONFIG.SYS указаны имена файлов дополнительных (загружаемых) драйверов, то эти драйверы помещаются в списке впереди стандартных системных драйверов. Поэтому, если имя устройства для загружаемого драйвера совпадает с именем стандартного устройства MS-DOS, то будет вызван загружаемый драйвер, а не стандартный.
Блок стратегии драйвера MS-DOS не делает практически ничего, только запоминает адрес заявки. Блок прерываний выполняет всю работу по обработке заявки, причем у всех стандартных драйверов этот блок работает вовсе не по прерываниям, а по опросу готовности. По-видимому, разработчики первой версии MS-DOS предполагали когда-нибудь в будущем реализовать нормальную структуру драйвера, да так и не собрались.
Заявка на выполнение операции содержит код операции, поле для записи результата операции, номер диска (для блочных устройств) и другие данные (например, адрес выводимых данных в памяти и адрес сектора на диске). Код операции определяет требуемую операцию – например, чтение, запись, запись с проверкой, открытие или закрытие устройства, проверка смены дискеты, опрос состояния устройства и т.п. Закончив выполнение операции, драйвер записывает в поле результата, была ли операция выполнена успешно или с ошибкой, и с какой именно (ошибка чтения, ошибка записи, нет бумаги в принтере, не найден сектор на диске, недопустимая операция для данного устройства и т.п.).
2.8.3. Управление символьными устройствами
Работу MS-DOS с символьными устройствами интереснее всего рассмотреть на примере клавиатуры. Путь, который проходят при этом вводимые данные, схематично показан на рис. 2‑6.

Рис.
2‑6
Когда пользователь нажимает клавишу, клавиатура переходит в состояние готовности и по этому поводу посылает сигнал аппаратного прерывания Int 09h. Одновременно в порт, к которому подключена клавиатура, посылается скан-код нажатия
клавиши. Этот код представляет собой однобайтовое число, означающее порядковый номер нажатой клавиши. Если клавиша долго удерживается нажатой, то через некоторое время начинается «автоповтор» – сигнал прерывания и скан-код посылаются многократно. Наконец, когда клавиша отпускается, генерируется еще одно прерывание и посылается скан-код отпускания
клавиши, который отличается от кода нажатия единичным значением старшего бита. Этим практически исчерпываются аппаратные события, связанные с клавиатурой. Все остальное делается программно.
На самом деле, все происходило именно так со старой, 83-клавишной клавиатурой компьютеров IBMPCXT. Современные клавиатуры за одно нажатие умудряются послать от 1 до 4 скан-кодов подряд. Причины этого объяснять долго и не очень интересно.
Подпрограмма BIOS, обрабатывающая аппаратное прерывание от клавиатуры, должна, во-первых, запоминать текущее состояние клавиатуры: нажаты или нет «сдвиговые» клавиши Shift, Ctrl, Alt, включены или нет режимы Caps Lock, Num Lock. Во-вторых, обработчик должен с учетом этого состояния определить, какой символ хотел ввести пользователь. Одна и та же клавиша может, например, означать букву ‘Z’ прописную или строчную, русскую букву ‘Я’ прописную или строчную, а также быть частью комбинаций Ctrl+Z, Alt+Z. Соответствующий символ будет помещаться в буфер клавиатуры в виде двух байт: скан-код нажатой клавиши и ASCII-код символа. Для некоторых клавиш и комбинаций, которым не соответствует никакой ASCII-код (например, F1, Insert, Ctrl+Home, Alt+буква, -), фирма IBM разработала собственный набор «расширенных» кодов.
Буфер клавиатуры может вместить до 15 введенных символов, а при переполнении начинает противно пищать.
Программное прерывание Int 16h также обрабатывается BIOS’ом. Его назначение – удовлетворять запросы программ, обращающихся к клавиатуре. Наиболее часто используются следующие три функции этого прерывания.
· Ввод символа с ожиданием. Эта функция возвращает значение кодов очередного символа из буфера клавиатуры и удаляет этот символ из буфера. Если буфер был пуст, функция выполняет активное ожидание до тех пор, пока при обработке очередного нажатия клавиши в буфере не появится введенный символ.
· Ввод символа без ожидания. Он отличается тем, что при пустом буфере не происходит ожидания, а возвращается соответствующий признак. Без этой функции было бы невозможно запрограммировать большую часть игр.
· Опрос состояния клавиатуры. Возвращает информацию о текущем состоянии «сдвиговых» клавиш.
Прикладные программы могут вызывать либо прерывание Int 16h, либо одну из функций DOS, предназначенных для ввода символов с консоли. Следует подчеркнуть, что эти функции работают не с клавиатурой, а с устройством CON (консолью оператора), через драйвер этого устройства. Конечно, практически всегда устройство CON – это и есть клавиатура (плюс еще и экран монитора, который используется при выводе символов на консоль). Однако теоретически есть возможность написать нестандартный драйвер устройства CON, который будет брать вводимые символы, например, с удаленного терминала, через модем. Или в качестве консольного устройства можно использовать пишущую машинку, как это и делалось раньше, до широкого распространения мониторов.
Набор функций DOS для ввода с консоли довольно разнообразен. Однако ни одна из этих функций не использует особенностей клавиатуры как устройства. В частности, функции DOS не знают понятия «состояние клавиатуры». Зато набор функций включает ввод с «эхо-отображением» введенного символа на устройстве CON (т.е. на экране) или без отображения, с ожиданием или без ожидания, ввод одного символа или сразу строки (завершающейся нажатием Enter), а также ввод с предварительной очисткой буфера (чтобы давно завалявшиеся там символы не были случайно введены как ответ на задаваемый программой вопрос).
Кратко рассмотрим работу с другими символьными устройствами.
Монитор не посылает сигналов прерываний и вывод на него выполняется не через порт, а путем записи данных в область видеопамяти. Имеющееся программное прерывание BIOS практически используется для переключения видеорежима (текстовый или графический, число цветов, число точек на экране) и для изменения вида и положения курсора текстового режима. Вывод символов через BIOS достаточно медленный и используется в основном для небольших текстовых сообщений. В графических режимах BIOS работает неприемлемо медленно, ибо он за каждый вызов прерывания может вывести только одну точку. Серьезные программы работают с видеопамятью напрямую. Функции DOS для вывода на консоль не имеют даже права использовать такую специфику монитора, как управление курсором и выбор цвета, ведь они работают с устройством CON, которое может оказаться и пишущей машинкой.
Для принтера BIOS предлагает возможность проверки состояния устройства (в частности, находится ли принтер в состоянии готовности) и вывода одного символа с опросом готовности. В то же время, DOS, кроме убогой функции вывода одного символа с ожиданием на устройство PRN, позволяет использовать системную программу PRINT, которая умеет выводить файлы в фоновом режиме, не мешая одновременно выполнять другие программы. Эта программа работает с аппаратными прерываниями в обход BIOS.
Про работу с последовательным портом можно сказать почти то же самое, что про работу с принтером. Отличие в том, что порт может работать и на ввод данных. Один из самых верных способов «подвесить» систему навечно – запросить ввод символа из COM-порта с ожиданием через BIOS или DOS, если на вход порта не поступают никакие данные. Практически всегда работа с COM-портом ведется с помощью нестандартных драйверов, работающих по прерываниям.
Мышь вообще не является стандартным устройством для компьютеров – потомков IBMPC. BIOS ничего не знает о существовании мышей. Драйверы мыши мало похожи на другие драйверы MS-DOS. Они позволяют опрашивать текущее положение мыши и состояние кнопок, однако более удобной для приложений является возможность задать с помощью драйвера собственную процедуру обработки прерываний от мыши. Эта процедура должна определять, в каком месте экрана был курсор при нажатии кнопки мыши, какой элемент управления (кнопка, пункт меню, полоса прокрутки и т.п.) находится в этой точке, и только потом – какое действие следует предпринять при щелчке мыши на этом элементе. Слишком много черновой работы, которую более современные ОС (например, Windows) берут на себя.
2.8.4. Управление блочными устройствами
2.8.4.1. Структура диска
Основным видом блочных устройств являются магнитные и другие диски, поэтому начнем с рассмотрения структуры диска (рис. 2‑7).

Рис.
2‑7
Поверхность нового магнитного диска покрыта однородным слоем магнитного материала. У дискеты используется либо одна поверхность, либо (чаще) обе поверхности. Число поверхностей жесткого дискового тома определяется количеством дисков, из которых собран том.
Первой операцией, которая должна быть проделана с диском, является низкоуровневое форматирование
. Оно заключается в разметке поверхности на дорожки
магнитной записи, разделенные на секторы
. Расстояние между дорожками определяется шагом перемещения головок чтения/записи, а разбиение на секторы выполняется программно, путем записи данных на дорожки в моменты, рассчитанные на основании известной скорости вращения диска. Для всех операций с диском, кроме низкоуровневого форматирования, сектор является минимальной единицей чтения или записи данных.
Совокупность дорожек одинакового радиуса на всех поверхностях диска называется цилиндром
.
Структура сектора показана на рис. 2‑8.

Рис.
2‑8
Сектор состоит из заголовка, блока данных и контрольной информации (контрольной суммы), которая служит для проверки правильности считывания сектора.
Заголовок сектора содержит физический адрес
сектора и его размер. Физический адрес состоит из трех чисел: номер цилиндра, номер поверхности и номер сектора на дорожке. Самый первый сектор диска имеет адрес (0, 0, 1). Размер сектора на IBM-совместимых компьютерах всегда равен 512 байт.
Одно время было модно использовать нестандартный размер отдельных секторов на дискете (например, 1024 байта) для затруднения несанкционированного копирования. Дискету, содержащую нестандартный сектор, могла правильно прочитать только программа, которой было точно известно о наличии такого сектора.
Между секторами и внутри секторов имеются промежутки, которые используются аппаратурой при поиске заданного сектора.
Нумерация секторов не обязательно ведется в порядке их размещения на дорожке. Если скорость имеющейся аппаратуры недостаточна для того, чтобы успеть прочесть и передать в память данные со всей дорожки за время одного оборота диска, то система при форматировании нумерует секторы «через один» или даже «через два». Например, при 9 секторах на дорожке они могут быть пронумерованы «через один» в таком порядке: 1, 6, 2, 7, 3, 8, 4, 9, 5. После чтения сектора 1 у контроллера диска есть время передать прочитанные данные, пока к головке чтения не подойдет сектор 2. В результате вся дорожка может быть прочитана за два оборота диска.
2.8.4.2. Разделы и логические тома
Общая структура дискет и жестких дисков различаются между собой. Эти структуры показаны на рис. 2‑9.

Рис.
2‑9
Начальный сектор дискеты (рис. 2‑9, а) принято называть BOOT-сектором
. Он содержит количественные данные о дискете (размер секторов, количество секторов на каждой дорожке и на всей дискете, число поверхностей и т.п.), метку (название) и серийный номер дискеты, а также данные о файловой системе. Кроме того, если дискета содержит системные файлы ОС, то в BOOT-секторе находится также небольшая программа начальной загрузки, которая считывает один сектор ОС и передает ему управление для продолжения загрузки. Все остальные секторы дискеты могут использоваться ОС для хранения ее файлов и других данных. Общее количество секторов на дискете не может превышать 216
(на самом деле, их значительно меньше).
Скажите быстро, сколько примерно секторов содержит стандартная трехдюймовая дискета?
Для жесткого диска (рис. 2‑9, б) начальный сектор называется MBR (MasterBootRecord, главная загрузочная запись). Он тоже может содержать программу начальной загрузки, но, кроме того, содержит таблицу разделов
(partitiontable), которая описывает разбиение жесткого диска на разделы
.
Таблица может содержать от 1 до 4 записей о разделах. Каждая запись содержит тип раздела, число секторов в нем, физические адреса начала и конца раздела.
Возможны следующие типы разделов.
· Обычный
раздел. Его структура точно такая же, как у дискеты, т.е. такой раздел начинается с BOOT-сектора, а общее число секторов не превышает 216
. Таким образом, общий размер раздела не может превышать 32 Мб.
· Большой
раздел. Он отличается от обычного тем, что число секторов может достигать 232
. Это позволяет описывать большие разделы размером до 2048 Гб.
· Расширенный
раздел. Его структура аналогична структуре всего жесткого диска, т.е. начальный сектор раздела – не BOOT, а MBR-сектор. Аналогия не совсем полная, поскольку таблица разделов в MBR расширенного раздела может содержать не более двух записей, причем первая из них должна описывать либо обычный, либо большой раздел, а вторая запись, если она имеется, описывает еще один расширенный раздел.
· Разделы других ОС (например, UNIX).
Обычные и большие разделы называются также логическими томами
или логическими дисками
, в отличие от физических дисков. Обычная буквенная нумерация дисков A, B, C, D и т.д. относится именно к логическим томам. Для дискет понятия физического и логического тома совпадают.
Изначально MS-DOS поддерживала только обычные разделы на жестком диске. В 80-е годы казалось, что 32 Мб – это очень большой объем диска. Когда появились диски объемом в несколько сотен мегабайт, была придумана матрешечная структура расширенных разделов, что позволило на одном физическом томе разместить сколько угодно логических томов по 32 Мб. Затем были реализованы большие разделы, что потребовало от разработчиков MS-DOS внести существенные изменения в программный интерфейс и реализацию средств работы с дисками. После этого использование расширенных разделов стало необязательным, если пользователю достаточно иметь не более четырех логических томов на одном физическом диске.
2.8.4.3. Средства доступа к дискам
На уровне архитектуры системы контроллер диска представлен несколькими регистрами, доступными через порты компьютера. В эти порты перед выполнением операций заносятся такие данные, как номер диска, количество секторов, участвующих в операции и физический адрес начального сектора, записываемые данные. Один из портов служит для посылки команды на выполнение операции (чтение, запись, запись с проверкой, поиск цилиндра, форматирование дорожки и др.). Когда операция завершена, контроллер посылает сигнал прерывания.
Прикладные программы могут работать с дисками либо средствами BIOS (программное прерывание int 13h), либо средствами DOS (программные прерывания int 25h – чтение и int 26h – запись). При этом BIOS работает только с физическими дисками, используя физическую нумерацию секторов, в то время как MS-DOS работает только с логическими томами, а секторы при этом нумеруются числами от 0 (что соответствует BOOT-сектору) до максимального номера сектора на томе. На практике то и другое используется достаточно редко. Большинство прикладных программ не работают с дисками как с устройствами, вместо этого работа ведется на уровне файлового ввода/вывода, а отображение файлов на секторы диска является обязанностью ОС.
Для повышения эффективности работы с дисками в MS-DOS используются кэширование дисков и опережающее чтение, описанные в пп. 2.6.6 и 2.6.7. Дисковый кэш в MS-DOS устроен проще, чем в UNIX. Во-первых, в однозадачной системе нет необходимости в списке свободных блоков (когда процесс обращается к диску, нет других процессов, которые могли бы в это время работать с буферами). Во-вторых, размер кэша редко превышает 30 – 40 буферов, поэтому не нужны и хеш-цепочки, все буфера объединены в едином LRU-списке.
Почему в MS-DOS не нужен такой большой кэш, как в UNIX?
2.9.1.1. Драйверы устройств в Windows
Поскольку Windows – многозадачная система, она исключает для прикладных программ такие вольности, как прямое обращение к портам ввода/вывода или обработка аппаратных прерываний. Взаимодействие с аппаратурой на низком уровне может выполняться только системными программами, работающими в привилегированном режиме. Основную роль здесь играют драйверы устройств.
В Windows используется многоуровневая структура драйверов, в которой высокоуровневые драйверы могут играть роль фильтров, выполняющих специальную обработку данных, полученных от драйвера низкого уровня или передаваемых такому драйверу. В качестве примера можно привести отделение драйвера, управляющего шиной, от драйверов конкретных устройств, подключенных к шине. Еще один пример – драйвер, выполняющий шифрацию/дешифрацию данных при работе с файловой системой NTFS. Структура драйверов всех уровней подчинена единым стандартам, известным как WDM (WindowsDiverModel), однако высокоуровневые драйверы, в отличие от низкоуровневых, не занимаются обработкой аппаратных прерываний.
Как ни странно, в WindowsNT низкоуровневые драйверы – это еще не самый нижний уровень управления устройствами. Еще ближе к аппаратуре лежит так называемый уровень HAL (HardwareAbstractionsLevel, уровень аппаратных абстракций). Его роль – скрыть от остальных модулей ОС, в том числе и от драйверов, некоторые детали работы с аппаратурой, зависящие от конкретных шин, типа материнской платы, способа подключения. Например, HAL предоставляет драйверам возможность обращаться к регистрам устройств по их логическим номерам, не зная при этом, подключен ли регистр к порту процессора или отображен на память.
Несмотря на стандартизацию структуры, можно выделить несколько специальных типов драйверов, отличающихся функциональным назначением.
· Драйверы GDI (GraphicDeviceInterface) представляют собой высокоуровневые драйверы графических устройств (мониторов, принтеров, плоттеров). Эти драйверы выполняют трансляцию графических вызовов Windows (таких, как «провести линию», «залить область», «выдать текст», «выбрать текущий шрифт, текущее перо, текущую заливку») в команды, выполняющие соответствующие действия на конкретном устройстве. Выдача этих команд на устройство выполняется уже другим, низкоуровневым драйвером. Благодаря наличию драйверов GDI одна и та же программа может выдавать графическое изображение на разные устройства. Яркий пример этого – имеющийся в различных редакторах режим предварительного просмотра, который отображает страницы на экране точно в том виде, как они будут напечатаны.
· Драйверы клавиатуры и мыши, помимо стандартных для драйвера операций, выполняют дополнительную нагрузку. Они генерируют сообщения о событиях на соответствующем устройстве (нажатие и отпускание клавиши, перемещение мыши, нажатие и отпускание кнопок мыши) и помещают их в системную очередь сообщений. Затем система переправляет каждое сообщение процессу, которому оно было предназначено, для дальнейшей обработки.
· Драйверы виртуализации устройств (VxD-драйверы) служат для того, чтобы разделять устройства между процессами, создавая иллюзию, что процесс монопольно владеет устройством. На самом деле драйвер организует очередь заявок от процессов, переключает устройство в нужный для очередного процесса режим и т.п. Примером может служить драйвер виртуализации монитора. Консольное приложение (например, программа MS-DOS) работает со всем экраном в текстовом режиме. Но если такое приложение запущено в окне Windows, то VxD-драйвер имитирует текстовый режим в графике. Для этого драйвер должен перехватывать попытки программы обратиться напрямую к адресам видеопамяти и преобразовывать координаты знакомест текстового режима в координаты соответствующих позиций в окне.
2.9.1.2. Доступ к устройствам
В большинстве случаев программы не работают непосредственно с устройствами. Вместо этого для выполнения требуемых операций используются API-функции более высокого уровня, а обращения к устройствам выполняются системой по мере надобности. Например, файловые функции обращаются в конечном счете к дисковым устройствам, а функции GDI работают с монитором или с принтером, в зависимости от указанного контекста устройства.
В ряде случаев программист все же может предпочесть непосредственную работу с устройством. Чтобы получить доступ к устройству, программа должна открыть это устройство вызовом той же API-функции CreateFile, которая используется и для открытия файлов. В данном случае вместо имени файла следует указать имя драйвера открываемого устройства. Для дисковых устройств можно вместо имени драйвера указать имя самого устройства. Например, имя «\\.\C:» означает логический диск C, а имя «\\.\PHYSICALDRIVE0» – первый физический диск компьютера.
Открыв устройство, программа может либо читать или записывать данные, используя функции файлового ввода/вывода, либо выдавать команды управления устройством с помощью функции DeviceIoControl. С помощью этих команд можно, например, отформатировать диск и разбить его на разделы, загрузить или извлечь CD-ROM диск, изменить некоторые параметры работы модема и т.п..
2.10.1. Драйверы устройств в
UNIX
Драйверы в ОС UNIX довольно точно соответствуют стандартной схеме драйвера, приведенной в п. 2.7. Тем не менее, ввиду существенных различий в работе с символьными и с блочными устройствами, в UNIX различаются два основных типа драйверов: символьные и блочные.
Для символьных устройств используются только символьные драйверы. Для каждого блочного устройства обычно имеется два разных драйвера: блочный и символьный. Блочный драйвер позволяет выполнять операции только с целым числом блоков, как и положено работать с блочными устройствами. Символьный драйвер блочного устройства является более высокоуровневой программой, которая имитирует выполнение операций чтения и записи произвольного количества байт, на самом деле используя обращения к блочному драйверу.
Помимо драйверов реальных физических устройств, система может включать драйверы «псевдоустройств». Примером может служить драйвер, обеспечивающий обращение программ к содержимому системной памяти.
При загрузке системы формируются две таблицы, для символьных и для блочных драйверов. Строки таблицы соответствуют конкретным драйверам, а столбцы – функциям, которые должен уметь выполнять драйвер, так что в ячейках таблицы содержатся адреса, по которым вызываются функции драйвера. Набор функций для символьных и для блочных драйверов слегка разнится, поэтому используются две разных таблицы.
К наиболее важным функциям драйвера относятся следующие.
· Открытие устройства. Как минимум, при этом увеличивается счетчик текущих обращений к устройству, что позволяет ставить обращения в очередь, если устройство занято. Некоторые устройства при открытии могут выполнять еще какие-то начальные действия.
· Закрытие устройства – операция, противоположная открытию.
· Обработка прерывания – выполняет ввод или вывод очередной порции данных, когда устройство переходит в состояние готовности.
· Опрос устройства – эта функция выполняется для тех устройств, которые не генерируют прерываний, или если при разработке драйвера почему-либо решено не использовать прерывания от устройств. Опрос выполняется не постоянно, а с некоторым периодом, по прерыванию от таймера.
· Чтение данных с устройства.
· Запись данных на устройство.
· Вызов стратегии. Это способ выполнения операций ввода/вывода, характерный для блочных устройств. При этом запрос может быть поставлен в очередь. Запрос в ряде случаев может быть удовлетворен путем обращения к дисковому кэшу (см. п. 2.6.6), без выполнения чтения или записи на устройство.
· Выполнение специальных функций. Набор этих функций зависит от конкретного устройства. Это может быть, например, опрос или установка текущего режима работы устройства, форматирование дорожек диска, перемотка ленты и т.п.
2.10.2. Устройство как специальный файл
Интересной отличительной особенностью UNIX является то, что для работы с периферийными устройствами прикладные программы могут и должны использовать те же средства, что для работы с файлами. Вообще, устройства в UNIX представлены как специальные файлы
, вписанные в каталог файловой системы наравне с обычными файлами. Каждому драйверу устройства соответствует отдельный специальный файл, символьный или блочный, в зависимости от типа драйвера. Как правило, все специальные файлы размещаются в каталоге /dev. Чтобы начать работу с устройством, программа должна вызвать функцию открытия файла, указав ей имя специального файла. При этом происходит обращение к функции открытия из драйвера соответствующего устройства.
С каждым специальным файлом связаны два числа, называемые старшим и младшим номерами устройства. Старший номер определяет номер строки в таблице символьных либо блочных драйверов. Младший номер передается драйверу как дополнительный параметр. Он может означать, например, номер конкретного дискового устройства.
Старинный термин «управление данными» в настоящее время всегда понимается как управление файлами.
Файл
есть набор данных, хранящийся на периферийном устройстве и доступный по имени. При этом конкретное расположение данных на устройстве не интересует пользователя и полностью передоверяется системе. До изобретения файлов пользователь должен был обращаться к своим данным, указывая их адреса на диске или на магнитной ленте.
Понятие «файловая система
» означает стандартизованную совокупность структур данных, алгоритмов и программ, обеспечивающих хранение файлов и выполнение операций с ними. Мощная современная ОС обычно поддерживает возможность использования нескольких разных файловых систем. И наоборот, одна и та же файловая система может поддерживаться различными ОС.
Среди задач, решаемых подсистемой управления данными, можно назвать следующие:
· выполнение операций создания, удаления, переименования, поиска файлов, чтения и записи данных в файлы, а также ряда вспомогательных операций;
· обеспечение эффективного использования дискового пространства и высокой скорости доступа к данным;
· обеспечение надежности хранения данных и их восстановления в случае сбоев;
· защита данных пользователя от несанкционированного доступа;
· управление одновременным совместным использованием данных со стороны нескольких процессов.
С каждым файлом связан набор атрибутов
(характеристик
), т.е. набор сведений о файле. Состав атрибутов может сильно различаться для разных файловых систем. Приведем примерный список возможных атрибутов, не привязываясь к какой-либо конкретной системе.
· Имя файла
. В старых ОС длина имени была жестко ограничена 6 – 8 символами с целью экономии места для хранения имени и ускорения работы. В настоящее время максимальная длина имени составляет обычно около 250 символов, что позволяет при желании включить в имя файла подробное описание его содержимого.
· Расширение имени
. По традиции, так принято называть правую часть имени, отделенную точкой. В MS-DOS, как и в некоторых более ранних системах, этот атрибут не является частью имени, он хранится отдельно и ограничивается по длине 3 символами. Однако сейчас возобладал подход, принятый в UNIX, где расширение – это чисто условно выделяемая часть имени после последней точки. Расширение обычно указывает тип данных в файле.
· Тип файла
. Некоторые ОС выделяют несколько существенно различных типов файлов, например, символьные и двоичные, файлы данных и файлы программ и т.п. Ниже будут рассмотрены типы файлов, различаемые UNIX.
· Размер файла
. Обычно указывается в байтах, хотя раньше часто задавался в блоках.
· Временн
ые штампы
. Под этим термином понимаются различные отметки даты и, может быть, времени дня. Важнейшим из временных штампов является время последней модификации, позволяющее определить наиболее свежую версию файла. Полезными могут быть также время последнего доступа (т.е. открытия файла), время последней модификации атрибутов.
· Номер версии
. В некоторых ОС при всяком изменении файла создавалась его новая версия, причем система могла хранить либо все версии, либо только несколько последних. Это давало немаловажное преимущество – возможность вернуться к старой версии файла, если изменения оказались неудачными. Тем не менее, этот атрибут не привился из-за большой избыточной траты дисковой памяти. При необходимости разработчики могут использовать специальные программные системы управления проектами, обеспечивающие в том числе и хранение старых версий файлов.
· Владелец файла
. Этот атрибут необходим в многопользовательских системах для организации защиты данных. Как правило, владельцем является пользователь, который создал файл. Иногда, кроме индивидуального владельца, указывается еще и группа пользователей как коллективный владелец файла.
· Атрибуты защиты
. Они указывают, какие именно права доступа к файлу имеют различные пользователи, в том числе и владелец файла.
· Тип доступа
. В некоторых ОС (например, в OS/360) для каждого файла должен был храниться допустимый тип доступа: последовательный, произвольный или один из индексных типов, обеспечивающих быстрый поиск данных в файле. В настоящее время более распространен подход, при котором для всех файлов поддерживаются одни и те же типы доступа (последовательный и произвольный), а ускорение поиска должно обеспечиваться, например, системой управления базами данных.
· Размер записи
. Если эта величина указана, то адресация нужных данных выполняется с помощью номера записи. Другой подход заключается в том, что данные адресуются их смещением (в байтах) от начала файла, а разбиение файла на записи возлагается на прикладные программы, работающие с файлом.
· Флаги
(битовые атрибуты
). Их разнообразие ограничивается лишь фантазией разработчиков системы, но наиболее распространенным и важным является флаг «только для чтения» (readonly), защищающий файл от случайного изменения или удаления. В зависимости от возможностей конкретной файловой системы, файл может быть отмечен как «сжатый», «шифрованный» и т.п.
· Данные о размещении файла на диске
. Пользователь, как правило, не знает и не хочет ничего знать о размещении файла (именно для этого и существует понятие файла). Для системы эти данные необходимы, чтобы найти файл.
Записи, в которых содержатся атрибуты каждого файла, собраны в каталоги
(они же папки, директории). В ранних ОС (и даже в первой версии MS-DOS) на каждом дисковом томе имелся единственный каталог, содержащий полный список всех файлов этого тома. Такое решение было вполне естественным, пока количество файлов не превышало двух – трех десятков. Однако при увеличении объема дисков и, как следствие, числа файлов на них такой одноуровневый каталог становился все менее удобным. В некоторых ОС использовалась двухуровневая организация каталогов. При этом главный каталог содержал список каталогов второго уровня, закрепленных за отдельными пользователями или проектами. Однако позднее стала общепринятой иерархическая структура каталогов
, при которой каждый каталог может, помимо файлов, содержать вложенные подкаталоги, причем глубина вложения не ограничивается.
Все хранящиеся в файловой системе служебные данные, описывающие атрибуты и размещение файлов, структуру каталогов, общую структуру дискового тома и т.п., принято называть метаданными
, в отличие от «просто данных», хранящихся в файлах.
Помимо устройств произвольного доступа (дисков), файлы могут храниться и на таких устройствах последовательного доступа, как магнитные ленты. Однако для лент ведение каталогов затруднительно и польза от них невелика. Как правило, имя и прочие атрибуты файла записываются на ленту непосредственно перед данными этого файла.
Область данных диска, отведенную для хранения файлов, можно представить как линейную последовательность адресуемых блоков (секторов). Размещая файлы в этой области, ОС должна отвести для каждого файла необходимое количество блоков и сохранить информацию о том, в каких именно блоках размещен данный файл. Существуют два основных способа использования дискового пространства для размещения файлов.
· Непрерывное размещение
характеризуется тем, что каждый файл занимает непрерывную последовательность блоков.
· Сегментированное размещение
означает, что файлы могут размещаться «по кусочкам», т.е. один файл может занимать несколько несмежных сегментов разной длины. Оба способа размещения показаны на рис. 3‑1.

Рис.
3‑1
Непрерывное размещение имеет два серьезных достоинства.
· Информация о размещении файла очень проста и занимает мало места. Фактически достаточно хранить два числа: номер начального блока файла и число занимаемых блоков (или размер файла в байтах, по которому легко вычислить число блоков).
· Доступ к любой позиции в файле выполняется быстро, поскольку, зная смещение от начала файла, легко можно вычислить номер требуемого блока и прочитать сразу этот блок, не читая предыдущие блоки.
К сожалению, недостатки непрерывного распределения еще более весомы.
· При создании файла требуется заранее знать его размер, чтобы найти и зарезервировать на диске область достаточной величины. Последующее возможное увеличение файла весьма затруднено, т.к. после конца файла может не оказаться достаточно свободного места. Фактически вместо увеличения файла обычно приходится заново создавать файл большего размера в другом месте, переписывать в него данные и удалять старый файл. Но такое решение требует много времени на чтение и запись данных и, кроме того, снижает надежность хранения данных, поскольку ошибка при чтении или записи гораздо более вероятна, чем порча данных, «спокойно лежащих» на диске.
· В ходе обычной эксплуатации файловой системы, после многократного создания и удаления файлов разной длины, свободное пространство на диске оказывается разбитым на небольшие кусочки. Суммарный объем свободного места на диске может быть достаточно большим, но создать файл приличного размера не удается, для него нет непрерывной области нужной длины. Это явление носит название фрагментации диска
. Для борьбы с ним приходится использовать специальную процедуру дефрагментации, которая перемещает все файлы, размещая их впритык друг к другу от начала области данных диска. Но такая процедура требует много времени, снижает, как сказано выше, надежность и усугубляет проблемы в случае, если позднее потребуется увеличить файл.
Сегментированное размещение лишено первого из недостатков непрерывного: при создании файла ему обычно вообще не выделяют память, а потом, по мере возрастания размера файла, ему могут быть выделены любые свободные сегменты на диске, независимо от их длины.
Не так просто с фрагментацией. Конечно, в отличие от непрерывного размещения, при сегментированном никакая фрагментация не помешает системе использовать все блоки, имеющиеся на диске. Однако последовательное чтение из сегментированного файла может выполняться существенно медленнее за счет необходимости переходить от сегмента к сегменту. Замедление особенно заметно, если файл оказался разбросан маленькими кусочками по нескольким цилиндрам диска. В результате, время от времени целесообразно выполнять дефрагментацию диска, чтобы повысить скорость доступа к данным. При сегментированном размещении дефрагментация означает не только объединение всех свободных участков диска, но и, главным образом, объединение сегментов каждого файла. Эта процедура выполняется значительно сложнее, чем дефрагментация при непрерывном размещении.
Можете ли вы предложить хороший алгоритм дефрагментации? Учтите, что он должен эффективно работать, даже если на диске осталось всего несколько свободных блоков.
Недостатком сегментированного размещения является то, что информация о размещении файла в этом случае намного сложнее, чем для непрерывного случая и, что наиболее неприятно, объем этой информации переменный: чем большее число сегментов занимает файл, тем больше нужно информации, ибо надо перечислить все сегменты. Имеется почти столько же способов решения этой проблемы, сколько вообще придумано разных файловых систем.
Чтобы уменьшить влияние сегментации на скорость доступа к данным файла, в ОС, использующих сегментированное размещение, применяются различные алгоритмы выбора места для файла. Их целью является разместить файл по возможности в одном сегменте, и только в крайнем случае разбивать файл на несколько сегментов.
В современных ОС для файловых систем на магнитных дисках практически всегда используют сегментированное размещение. Иное дело файловые системы на дисках, предназначенных только для чтения (например, CDROM). Нетрудно понять, что в этом случае недостатки непрерывного размещения не имеют никакого значения, а его достоинства сохраняются.
Еще одной важной характеристикой размещения файлов является степень его «дробности». До сих пор мы предполагали, что файл может занимать любое целое число блоков, а под блоком фактически понимали сектор диска. Проблема в том, что для дисков большого объема число блоков может быть слишком большим. Допустим, в некоторой файловой системе размер блока равен 512 байт, а для хранения номеров блоков файла используются 16-разрядные числа. В этом случае размер области данных диска не сможет превысить 512 * 216
= 32 Мб, что нынче смешно. Конечно, можно перейти к использованию 32-разрядных номеров блоков, но тогда суммарный размер информации о размещении всех файлов на диске становится чересчур большим. Обычный выход из этого затруднения заключается в том, что минимальной единицей размещения файлов считают кластер
(называемый в некоторых системах блоком
или логическим блоком
), который принимается равным 2k
секторов, т.е., например, 1, 2, 4, 8, 16, 32 сектора, редко больше. Каждому файлу отводится целое число кластеров, и в информации о размещении файла хранятся номера кластеров, а не секторов. Увеличение размера кластеров позволяет сократить количество данных о размещении файлов «и в длину и в ширину»: во-первых, для каждого файла нужно хранить информацию о меньшем числе кластеров, а во-вторых, уменьшается число двоичных разрядов, используемых для задания номера кластера (либо при той же разрядности можно использовать больший диск). Так, при кластере размером 32 сектора и 16-разрядных номерах можно адресовать до 1 Гб дисковой памяти.
Использование больших кластеров имеет свою плохую сторону. Поскольку размер файла можно считать случайной величиной (по крайней мере, этот размер никак не связан с размером кластера), то можно приближенно считать, что в среднем половина последнего кластера каждого файла остается незанятой. Это явление иногда называют внутренней фрагментацией
(в отличие от описанной выше фрагментации свободного пространства диска, которую называют также внешней
фрагментацией). Кроме того, если хотя бы один из секторов, входящих в кластер, отмечен как дефектный, то и весь кластер считается дефектным, т.е. не может быть использован. Очевидно, что при увеличении размера кластера возрастает и число неиспользуемых секторов диска.
Оптимальный размер кластера либо вычисляется автоматически при форматировании диска, либо задается вручную.
Для нормальной работы файловой системы требуется, чтобы, кроме информации о размещении файлов, система хранила в удобном для использования виде информацию об имеющихся свободных кластерах диска. Эта информация необходима при создании новых или увеличении существующих файлов. Используются различные способы представления информации о свободном месте, некоторые из них перечислены ниже.
· Можно хранить все свободные кластеры как связанный линейный список, т.е. в начале каждого свободного кластера хранить номер следующего по списку. Недостаток такого способа в том, что затрудняется поиск свободного непрерывного фрагмента нужного размера, поэтому сложнее оптимизировать размещение файлов.
· Названный недостаток можно преодолеть, если хранить список не из отдельных кластеров, а из непрерывных свободных фрагментов диска. Правда, работать с таким списком несколько сложнее.
· В системах с непрерывным размещением часто каждый непрерывный фрагмент диска описывают так же, как файл, но отмечают его флажком «свободен».
· Удобный и простой способ заключается в использовании битовой карты
(bitmap) свободных кластеров. Она представляет собой массив, содержащий по одному биту на каждый кластер, причем значение 1 означает «кластер занят», а 0 – «кластер свободен». Для поиска свободного непрерывного фрагмента нужного размера система должна будет просмотреть весь массив.
В многопользовательских ОС первостепенное значение приобретает задача защиты данных пользователя от случайного или намеренного доступа со стороны других пользователей. Вопросы защиты данных и стандартизации требований к безопасности ОС заслуживают изучения в отдельном курсе, поэтому здесь они будут рассмотрены очень кратко.
Как отмечалось в п. 1.6, для реализации многопользовательской защиты данных необходимо наличие аппаратных средств, таких как привилегированный режим работы процессора. В противном случае любая чисто программная система защиты могла бы быть нарушена с помощью достаточно изощренной программы взлома.
Для любой системы защиты характерно наличие, по крайней мере, трех компонент.
· Список пользователей системы, содержащий имена, пароли и привилегии, присвоенные пользователям.
· Наличие атрибутов защиты у файлов и других защищаемых объектов. Эти атрибуты указывают, кто из пользователей имеет право доступа к данному объекту и какие именно операции ему разрешены.
· Процедура аутентификации пользователя
, т.е. установление его личности при входе в систему. Такие процедуры чаще всего основаны на вводе пароля, хотя могут использоваться и более экзотические средства (отпечатки пальцев, специальные карточки и т.п.).
Помимо отдельных пользователей, определенными правами доступа к объектам могут обладать группы пользователей
. Понятие группы облегчает администрирование прав доступа. Вместо того, чтобы индивидуально указывать набор прав для каждого пользователя, достаточно зачислить его в одну или несколько групп, права которых определены заранее.
Нормальное обслуживание системы защиты невозможно без наличия администратора системы
(он же в различных системах именуется привилегированным пользователем
или суперпользователем
) или же группы пользователей, обладающих правами администратора. Администратор назначает права прочим пользователям, а также имеет возможность в чрезвычайных случаях получить доступ к объектам любого владельца. Однако при этом желательно, чтобы действия администратора, как минимум, фиксировались системой с целью выявления возможных злоупотреблений с его стороны.
В многозадачных ОС, а также в сетевых системах, возможна ситуация, когда два или более процессов пытаются одновременно использовать один и тот же файл. Например, два пользователя могут одновременно работать с одной базой данных. Будем предполагать, что с правами доступа все в порядке, каждый процесс в отдельности имеет право читать и записывать файл. Вопрос в том, можно ли разрешить одновременную работу, не приведет ли это к нарушению целостности данных.
Может привести. Если один процесс обновляет данные в файле, а другой в это время пытается читать эти же данные, то он может прочесть частично обновленные данные. Еще опаснее, когда два процесса пытаются одновременно изменить одни и те же данные. В этом случае трудно даже предсказать, что в результате будет сохранено в файле.
В принципе, всегда безопасными являются лишь два крайних случая:
· только один процесс работает с файлом, выполняя чтение и запись;
· с файлом работает произвольное число процессов, но все они выполняют только чтение.
ОС могла бы обеспечить безопасный доступ, разрешая процессу открывать файл только в этих двух случаях, т.е. если файл не открыт еще ни одним другим процессом либо если файл открыт кем-то только для чтения и данный процесс тоже открывает его для чтения. Однако такая суровость в ряде случаев существенно снизила бы производительность системы. Скажем, много пользователей хотели бы одновременно работать с одной базой данных. И в этом нет ничего плохого, пока они работают с разными записями базы. Опасность возникает только при одновременной работе с одной и той же записью. Но ОС не может сама отследить ситуацию так подробно, это может сделать программа, управляющая базой данных. Ввиду подобных ситуаций, большинство ОС позволяют программам процессов самим определять, допустим ли совместный доступ в различных конкретных ситуациях.
Типичное решение заключается в следующем. Прикладная программа, вызывая системную функцию открытия файла, указывает два дополнительных параметра: режим доступа и режим разделения.
Режим доступа
определяет, какие операции сам процесс собирается выполнять с файлом. Обычно различают доступ «только для чтения», «только для записи», «для чтения и записи».
Режим разделения
определяет, какие операции данный процесс готов разрешить другим процессам, которые захотят открыть тот же файл. Примерный набор режимов разделения – «запрет записи», «запрет чтения», «запрет чтения и записи» и «без запретов».
Первый процесс, открывающий файл, устанавливает по своему усмотрению режимы доступа и разделения. Когда второй процесс пытается открыть тот же файл, ОС проверяет два условия:
· режим доступа второго процесса не должен противоречить режиму разделения, установленному первым процессом;
· режим разделения, запрашиваемый вторым процессом, не должен запрещать тот режим доступа, который уже установил для себя первый процесс.
В случае нарушения одного из этих условий система не открывает файл для второго процесса, функция открытия файла возвращает ошибку. Если же условия соблюдены, система открывает файл для второго процесса, как бы снимая с себя ответственность за последствия: вы этого хотели – получите.
До сих пор речь шла только о поведении процессов и системы при открытии файла. Однако это не полностью решает проблему. Вернемся к примеру с базой данных. Пусть соответствующий файл открыт несколькими процессами. Когда один из процессов приступает к работе с конкретной записью, он должен иметь возможность временно запретить или ограничить доступ других процессов к этой же записи. Для этой цели служит блокировка
процессом фрагментов файла.
Для установления блокировки процесс вызывает соответствующую системную функцию, указывая начало блокируемого фрагмента и его размер. Если другой процесс после этого попытается прочитать или записать данные, хотя бы частично попадающие в заблокированный фрагмент, то либо функция чтения (записи) выдаст ошибку, либо процессу придется ждать снятия блокировки. Как правило, блокировка устанавливается на как можно меньший интервал времени, чтобы не снижать производительность системы.
Описанный выше тип блокировки называется эксклюзивной
или исключительной блокировкой: процесс разрешает себе и чтение, и запись, а другим процессам временно запрещает то и другое. Некоторые системы допускают также кооперативную
(не исключительную) блокировку: устанавливая ее, процесс запрещает только запись всем процессам, в том числе и себе самому, в то время как чтение остается разрешенным для всех.
3.6.1. Общая характеристика системы FAT
Система FAT была разработана для ОС MS-DOS. Это простая файловая система с сегментированным размещением, без многопользовательской защиты. Структура каталогов – древовидная, причем на каждом дисковом томе создается отдельное дерево. Для указания местоположения файла может использоваться его полное имя
, содержащее букву диска, путь по дереву каталогов и собственно имя файла, например: «C:\UTILS\ARCH\RAR.EXE».
В ОС Windows также возможно использование FAT, особенно оправданное для дискет. Для жестких дисков большого объема система FAT становится малоэффективной и постепенно вытесняется более мощной системой NTFS.
3.6.2. Структуры данных на диске
При форматировании дискеты или раздела жесткого диска в системе FAT все дисковое пространство разбивается на следующие области, показанные на рис. 3‑2.

Рис.
3‑2
· BOOT-сектор
содержит основные количественные параметры дискового тома и файловой системы, а также может содержать программу начальной загрузки ОС.
· таблица FAT
(FileAllocationTable) – содержит информацию о размещении файлов и свободного места на диске. Ввиду критической важности этой таблицы она всегда хранится в двух экземплярах, которые должны быть идентичны[4]
. Каждая операция, изменяющая содержимое FAT, должна одинаковым образом изменять оба экземпляра.
· ROOT
– корневой каталог системы, содержащий данные о файлах и о подкаталогах верхнего уровня, каждый из которых в свою очередь может содержать файлы и подкаталоги.
· Область данных
– массив кластеров, содержащий все файлы и все каталоги (кроме корневого).
Рассмотрим подробно, как хранится вся информация о файле, имеющаяся в системе FAT.
При создании файла в одном из каталогов файловой системы создается запись, хранящая основной объем информации об этом файле. Каждый каталог, кроме корневого, также является файлом особого вида, и запись о нем содержится в родительском каталоге. Каталожная запись всегда занимает 32 байта, ее структура показана в табл. 3.1.
Таблица 3.1
Структура записи каталога файловой системы FAT
| Поле записи |
Размер поля (в байтах) |
| Имя файла |
8 |
| Расширение имени (тип файла) |
3 |
| Атрибуты (флаги) |
1 |
| Размер файла (в байтах) |
4 |
| Дата последнего изменения |
2 |
| Время последнего изменения |
2 |
| Резерв (не используется) |
10 |
| Номер первого кластера файла |
2 |
Как видно из таблицы, имя файла может занимать не более 8 символов плюс еще 3 символа расширения. В начале 80-х годов казалось, что этого вполне достаточно. Позднее это ограничение окрестили «проклятием 8 + 3», и избавить от него файловую систему FAT удалось только в Windows 95.
Байт атрибутов содержит набор битов, характеризующих свойства файла. Наряду с практически бесполезными атрибутами «скрытый», «системный» и «архивный», там содержатся и важные: «только для чтения», «каталог» и «метка тома». Атрибут «только для чтения» запрещает системе удалять файл или открывать его для записи. Атрибут «каталог» означает, что данная запись описывает не обычный файл, а каталог. Атрибут «метка тома» может содержаться только в корневом каталоге, такая запись не описывает никакой файл, а вместо этого содержит в полях имени и расширения 11-символьную метку (имя), присвоенную данному дисковому тому.
В целом, запись каталога содержит почти все, что системе известно о файле, а если размер файла не превышает одного кластера, то полностью все. Если же файл содержит более одного кластера, то номера остальных можно найти в таблице FAT.
Таблица FAT состоит из записей, количество которых равно количеству кластеров в области данных, а размер одной записи может быть равен 12, 16 или 32 битам. Соответственно говорят о разновидностях файловой системы FAT-12, FAT-16 или FAT-32. Размер записи должен быть таким, чтобы в ней можно было записать максимальный номер кластера. Например, для стандартной трехдюймовой дискеты емкостью 1.44 Мб достаточно использовать FAT-12, поскольку это позволяет иметь 212
= 4096 кластеров (на самом деле, чуть меньше), и даже при кластерах размером в 1 сектор (512 байт) этого более чем достаточно: 4096 ´ 512 = 2 Мб.
Записи FAT «по историческим причинам» нумеруются, начиная с 2 и кончая максимальным номером кластера, каждая запись FAT описывает соответствующий кластер с тем же номером. Запись может принимать следующие значения:
· если кластер принадлежит некоторому файлу (или каталогу) и является последним (или единственным) в этом файле, то запись FAT содержит специальное значение – все единицы (FFF16
для FAT-12 или FFFF16
для FAT-16);
· если кластер принадлежит некоторому файлу (или каталогу), но не является последним в файле, то запись FAT содержит номер следующего кластера того же файла;
· если кластер свободен, то запись содержит все нули;
· если кластер дефектный (т.е. при проверке диска выяснилось, что данный кластер содержит хотя бы один дефектный сектор), то запись содержит специальное значение FF716
для FAT-12 или FFF716
для FAT-16.
Теперь мы знаем, каким образом в системе FAT хранится информация о размещении сегментированного файла. Номер первого кластера файла хранится в записи каталога, а остальные кластеры можно последовательно определить по записям таблицы FAT.
В каждом каталоге, кроме корневого, первые две записи содержат специальные имена: имя «.» означает сам данный каталог, имя «..» – родительский каталог.
3.6.3. Создание и удаление файла
Чтобы завершить изучение структур данных системы FAT, рассмотрим, как изменяются эти структуры при операциях создания и удаления файла.
Когда ОС выполняет функцию создания файла с заданным именем в заданном каталоге, то она, прежде всего, находит данный каталог в дереве каталогов файловой системы. (Как она его находит – опустим для краткости. Попробуйте разобраться сами.) Прочитав каталог, система проверяет, нет ли в нем уже записи с заданным именем (т.е. нет ли уже такого файла). Если есть, то не установлен ли у этого файла атрибут «только для чтения»? Если установлен, то новый файл создан быть не может, предварительно надо снять атрибут. Если не установлен, то старый файл удаляется. Затем система находит в каталоге свободную запись. Если в каталоге нет свободного места, то он может быть увеличен еще на один кластер, этот факт отражается в таблице FAT. Наконец, найдя свободное место, система заполняет поля записи о новом файле: его имя и расширение, дату и время последнего изменения, атрибуты. Размер и номер первого кластера устанавливаются нулевыми, т.к. файл пока что не содержит данных.
В дальнейшем, при выполнении первой операции записи в файл, система найдет любой свободный кластер по таблице FAT, отметит его в FAT как последний кластер файла, заполнит номер первого кластера в каталожной записи, выполнит запись и занесет количество записанных байт в поле размера файла в каталоге.
При удалении файла прежде всего по каталожной записи проверяется, можно ли его удалить (не установлен ли атрибут «только для чтения»), а затем делаются две вещи:
· первый байт имени удаляемого файла заменяется на специальный символ с кодом E516
(он отображается как русская буква «х»; вероятно, разработчики системы FAT считали, что этот код не может встретиться в имени файла);
· все записи таблицы FAT, соответствующие кластерам удаляемого файла, заполняются нулями, т.е. кластеры объявляются свободными.
Как видно из описанной процедуры, в момент удаления файла его данные не стираются с диска, однако информация о размещении файла портится. Если размер файла превышал один кластер, то нет гарантии, что его удастся восстановить в случае нечаянного удаления, даже если пользователь спохватится сразу же.
3.6.4. Работа с файлами в MS-DOS
3.6.4.1. Системные функции
Для работы с файлами и каталогами системы FAT в MS-DOS предусмотрен достаточно богатый набор функций. Все они вызываются с помощью команды программного прерывания int 21h, а конкретная функция определяется числом, занесенным в регистр AH. Эти функции позволяют, в частности:
· создавать файл, указывая его полное имя;
· удалять файл;
· изменять атрибуты файла;
· переименовывать файл или перемещать его в другой каталог того же диска[5]
;
· искать в заданном каталоге все файлы, имена которых соответствуют заданному шаблону (например, шаблону «XYZ??.C*» соответствуют все файлы, имена которых начинаются с «XYZ» и содержат ровно 5 символов, а расширение начинается с буквы «C»);
· создавать и удалять каталоги;
· задавать текущий диск и текущий каталог;
· открывать файл, получая доступ к его данным, и закрывать файл.
3.6.4.2. Доступ к данным
В MS-DOS существует два различных набора функций, позволяющих работать с данными файлов. Один из них, основанный на использовании блока управления файлом (FCB), вряд ли кем-то использовался в последние 20 лет, однако сохраняется из соображений совместимости с версией MS-DOS 1.0. Общепринятый метод работы с файлами основан на использовании хэндлов[6]
.
Чтобы открыть существующий файл, следует вызвать соответствующую функцию, указав в качестве параметров имя файла и желаемый режим доступа (один из трех: только чтение, только запись, чтение и запись). В более поздних версиях MS-DOS появилась также возможность указывать режим разделения, как рассмотрено в п.3.5. Любой файл рассматривается как последовательность байт, а если программа предпочитает рассматривать файл как набор записей, то она должна сама вести пересчет номера записи в смещение (в байтах) от начала файла. Операции чтения и записи всегда выполняются от текущей позиции, которая называется указателем чтения/записи, и приводят к смещению указателя вперед на прочитанное или записанное количество байт. Возможность произвольного доступа к данным обеспечивается операциями перемещения указателя.
Хэндл
– это некоторое число, которое система возвращает пользовательской программе при удачном выполнении операции открытия или создания файла. Значение этого числа не играет роли для программы. Важно лишь то, что при последующих обращениях к открытому файлу программа должна передавать этот хэндл системе как указатель на этот файл.
MS-DOS предоставляет вполне достаточный набор функций для работы с открытыми файлами. Сюда включаются функции чтения и записи произвольного числа байт, функция перемещения указателя в произвольную точку файла, функции установки и снятия блокировки фрагментов файла, принудительной очистки кэш-буферов файла (обычно очистка выполняется только при закрытии файла или при нехватке буферов, см. п.2.6.6; принудительная очистка гарантирует немедленное сохранение изменений на диске).
При вызове функции открытия файла можно вместо имени файла указать имя любого символьного устройства, например, «PRN:». При этом также возвращается хэндл, с которым можно выполнять операции записи так же, как если бы этот хэндл указывал на дисковый файл. Разумеется, нельзя открыть принтер для чтения, а также нельзя выполнять перемещение указателя назад.
При запуске любой программы она получает «в подарок» от MS-DOS пять уже открытых хэндлов с номерами от 0 до 4. Из них наиболее важными являются хэндл 0, который по определению указывает на стандартный ввод программы, и хэндл 1 – стандартный вывод. Хэндл 2 означает стандартное устройство для вывода сообщений об ошибках, хэндл 3 – стандартное устройство последовательного ввода/вывода (COM-порт), хэндл 4 – стандартный принтер.
Выше, в п. 2.2, давалось иное определение стандартного ввода и вывода, как устройств, используемых «по умолчанию». Здесь нет противоречия. Компиляторы языков программирования, встречая вызовы процедур ввода/вывода без указания файла, транслируют их в вызовы системных функций MS-DOS с хэндлами, соответственно, 0 или 1.
Если программа запускается из командной строки MS-DOS, то обычно хэндл 0 указывает на клавиатуру (точнее, на устройство CON:), а хэндл 1 – на экран монитора (тоже устройство CON:, но работающее на вывод). Однако пользователь может использовать символы перенаправления стандартного ввода (знак «<») и вывода (знаки «>» и «>>»). Например, программа, запущенная при помощи команды «MY_PROG <INFILE.TXT >PRN» будет использовать в качестве стандартного ввода файл INFILE.TXT, а стандартный вывод направит на принтер. Знак «>>» означает добавление данных в конец файла стандартного вывода, знак «>» – перезапись файла заново. Чтобы выполнить указанное пользователем перенаправление стандартного ввода или вывода, система открывает заданный файл или устройство (а при знаке «>>» еще и выполняет перемещение указателя в конец файла) и обеспечивает доступ к нему из запускаемой программы через стандартный хэндл 0 или 1. Таким образом, работающая программа вообще не знает, какие именно устройства или файлы являются ее стандартным вводом и выводом.
Перенаправление стандартного ввода и вывода может быть выполнено и программой пользователя. Обычно это делается перед тем, как данная программа запускает какую-либо другую программу, передавая ей перенаправленные стандартные хэндлы.
Для обеспечения доступа к открытым файлам MS-DOS использует системные таблицы двух типов.
Таблица SFT (SystemFileTable) содержит записи о всех файлах, в данный момент открытых программами пользователя и самой ОС. Эта таблица хранится в системной памяти, число записей в ней определяется параметром FILES в файле конфигурации CONFIG.SYS, но не может превышать 255.
Если один и тот же файл был открыт несколько раз (неважно, одной и той же программ ой или разными программами), то для него будет несколько записей в SFT.
Каждая запись содержит подробную информацию о файле, достаточную для выполнения операций с ним. В частности, в записи SFT содержатся:
· копия каталожной информации о файле;
· адрес каталожной записи (сектор и номер записи в секторе);
· текущее положение указателя чтения/записи;
· номер последнего записанного или прочитанного кластера файла;
· адрес в памяти программы, открывшей файл;
· режим доступа, заданный при открытии.
Кроме того, в записи SFT содержится значение счетчика ссылок на данную запись из всех таблиц JFT, речь о которых пойдет ниже. Когда этот счетчик становится равным нулю, запись SFT становится свободной, поскольку файл закрыт.
В отличие от единственной SFT, таблицы JFT (JobFileTable) создаются для каждой запускаемой программы, поэтому одновременно может существовать несколько таких таблиц. (А откуда в однозадачной MS-DOS могут взяться одновременно несколько программ? Простейший ответ: когда одна программа запускает другую, то в памяти присутствуют обе. Подробнее см. п. 4.4.3.) Таблица JFT имеет простейшую структуру: она состоит из однобайтовых записей, причем значение каждой записи представляет собой индекс (номер записи) в таблице SFT. Неиспользуемые записи содержат значение FF16
. Размер таблицы по умолчанию составляет 20 записей (байт), но может быть увеличен до 255.
Теперь о хэндлах. Прикладная программа использует хэндлы как некоторые условные номера открытых файлов, конкретное значение хэндла при этом не играет никакой роли (за понятным исключением стандартных хэндлов с 0 по 4). На самом же деле значение хэндла представляет собой не что иное, как индекс записи в таблице JFT данной программы. Первая запись таблицы соответствует хэндлу 0.
На рис. 3‑3 показана связь между хэндлами, таблицами JFT, таблицей SFT и открытыми файлами/устройствами.

Рис.
3‑3
В примере, показанном на рисунке, стандартные хэндлы процесса A используются так, как это по умолчанию делает MS-DOS: хэндлы 0, 1 и 2 указывают на запись SFT, соответствующую консольному устройству CON, хэндл 3 – на запись об устройстве COM1, хэндл 4 –на запись о принтере. У процесса B стандартный вывод перенаправлен на принтер, что отражено в значении элемента 1 из JFT этого процесса. Хэндлы 3 и 4 для процесса B не показаны, чтобы не захламлять рисунок. Остальные показанные на рисунке элементы JFT обоих процессов указывают на записи SFT, описывающие открытые файлы на дисках.
Заметим, что с файлом PICTURE.BMP связаны две записи в таблице SFT. Это означает, что данный файл был открыт в каждом процессе отдельно (но, очевидно, с использованием одного из режимов разделения файла).
Когда программа вызывает какую-либо из системных функций и передает ей значение хэндла одного из открытых файлов, то система находит адрес таблицы JFT вызвавшей программы, читает указанную хэндлом запись этой таблицы, определяет соответствующий индекс в таблице SFT и получает таким образом доступ к информации, необходимой для выполнения операции с файлом.
В чем смысл такой двухступенчатой схемы? Не проще ли было, чтобы хэндл указывал непосредственно на запись SFT? Можно привести, по крайней мере, два очевидных аргумента в пользу применения JFT.
· Что происходит с файлами при завершении программы, которая их открыла? Правила хорошего программистского тона требуют, чтобы программа перед окончанием работы закрыла за собой все файлы. Однако программист может и не выполнить это требование, или программа может завершиться аварийно. В любом случае ОС должна при завершении программы закрыть все ее файлы. Как ОС узнает, какие файлы следует закрыть? Ответ очень простой: достаточно просмотреть таблицу JFT завершаемой программы и найти там все записи, отличные от FF16
.
· Использование JFT дает возможность отделить логическое понятие стандартного устройства (в частности, стандартный ввод – хэндл 0 и стандартный вывод – хэндл 1) от конкретных устройств. Перенаправление стандартных устройств выполняется путем изменения значений соответствующих элементов JFT.
3.6.5. Новые версии системы FAT
Структуры данных файловой системы являются одной из наиболее консервативных, плохо поддающихся изменениям характеристик ОС. Проблема заключается в том, что при изменениях структур данных трудно сохранить совместимость с более ранними версиями. Было бы катастрофой, если бы все множество накопленных в мире файлов в системе FAT вдруг перестало читаться в новой версии системы. Тем не менее, некоторые интересные изменения все же удалось ввести при выпуске версий Windows 95 и 98.
В Windows 95 было преодолено досадное ограничение длины имени файла – знаменитое правило «8 + 3». Казалось бы, при размере записи каталога в 32 байта трудно надеяться на длинные имена файлов. Тем не менее, было найдено забавное решение этой проблемы.
Разработчики из Microsoft обратили внимание, что те записи каталога, в которых встречается бессмысленная комбинация битовых атрибутов «скрытый + системный + только чтение + метка тома», просто-напросто игнорируются как системными программами MS-DOS, так и распространенными утилитами других разработчиков. Это дало возможность использовать записи с такой комбинацией для хранения длинного имени файла. По-прежнему для каждого файла в каталоге имеется основная запись в обычном, старом формате, содержащая атрибуты файла, номер первого кластера и обязательное «короткое» имя. Однако если пользователь при создании файла указывает имя, не укладывающееся в стандарт «8 + 3» или содержащее строчные буквы, то перед основной записью будет вставлено нужное количество дополнительных записей с разбитым на кусочки «длинным именем» в кодировке UNICODE (по 2 байта на символ, что позволяет использовать любой известный алфавит). Длина имени, согласно документации, может достигать 255 символов (на самом деле, чуть меньше).
Начиная с Windows 98, появилась возможность использовать новую разновидность файловой системы – FAT-32. Ее отличие от FAT-12 и FAT-16 заключается не только в большей разрядности номера кластера (хотя и это очень важно для больших дисков), но и в том, что Microsoft наконец-то решилась использовать 10-байтовый резерв, который неизвестно для каких целей сохранялся незанятым в каждой записи каталога. Благодаря этому появилась возможность добавить к дате/времени последней модификации файла еще два временных штампа: дату/время создания (на самом деле, это дата/время последнего изменения каталожной записи) и дату последнего доступа к файлу.
3.7.1. Архитектура файловой системы UNIX
Здесь рассматривается классическая файловая система UNIX, называемая иногда системой s5fs
и поддерживаемая всеми версиями UNIX. Современные усовершенствования файловой системы будут рассмотрены в п. 3.7.4.
3.7.1.1. Жесткие и символические связи
Структуру каталогов файловой системы UNIX называют иногда сетевой, чтобы подчеркнуть ее отличие от строго иерархической (древесной) структуры каталогов таких систем, как, например, FAT. Отличие это заключается в понятиях жестких и символических связей
файла.
Жесткая связь означает связь между именем файла и самим файлом. Особенность UNIX в том, что любой файл может иметь несколько (точнее, неограниченное количество) жестких связей, т.е. неограниченное количество имен. Это могут быть разные имена в одном каталоге или даже имена, хранящиеся в разных каталогах одного дискового тома.
Есть ли какая-нибудь польза от нескольких имен одного файла? Безусловно, есть. Предположим, пользователь часто использует какую-либо системную программу или файл данных, лежащий где-то глубоко в одной из ветвей дерева каталогов. Вместо того, чтобы каждый раз указывать длинный путь к нужному файлу, пользователь может просто создать новую жесткую связь, т.е. дать файлу удобное имя и поместить это имя в свой личный каталог. UNIX предоставляет для этого команду link, которая создает новое имя для указанного файла.
Что произойдет, если один из пользователей удалит имя файла из каталога? Произойдет только обрыв одной из жестких связей. Пока у данного файла остаются другие имена, файл продолжает существовать. Только после того, как удалены все имена файла, система понимает, что файл перестал быть доступен кому-либо, и удаляет сам файл.
Все жесткие связи (имена) одного файла абсолютно равноправны, среди них нельзя выделить какое-то «основное» имя.
Несколько иным образом работает символическая связь. Такая связь представляет собой файл, который содержит только полное имя другого файла. Важно при этом то, что файл помечен в системе именно как символическая связь, а не просто текстовый файл, случайно хранящий имя файла. Когда файл символической связи используется как аргумент системной команды или функции, UNIX автоматически подставляет вместо него тот файл, на который указывает связь.
Можно кратко сказать, что жесткая связь указывает на сам файл, а символическая – на имя файла. Оба типа связей проиллюстрированы на рис. 3‑4.

Рис.
3‑4
В примере на рисунке показан файл данных, для которого имеются три жесткие связи, т.е. три имени в каталогах системы, обозначенные как «Имя 1», «Имя 2» и «Имя 3». Кроме того, в системе имеется файл типа «символическая связь», который содержит одно из имен файла данных. Файл символической связи, как и любой другой файл, доступен по имени и в данном случае имеет два имени (две жестких связи): «Имя 4» и «Имя 5». Таким образом, использование любого из пяти имен в качестве, например, имени открываемого файла приведет к открытию одного и того же файла.
Предположим, администратор системы решил заменить некоторый файл его более свежей версией, оставив то же самое имя файла. Если некоторые пользователи хранили жесткие связи на прежнюю версию, то они так и будут ею пользоваться, пока явно не удалят ее имя и не создадут связи на новую версию. Если же пользователь хранил символическую связь, то она теперь будет указывать на новую версию.
В Windows используется некоторый аналог понятия символической связи – ярлык файла (shortcut). Отличие в том, что с точки зрения файловой системы Windows ярлык не является каким-то особым типом файла, это обычный текстовый файл с расширением LNK. Ярлык распознается не файловой системой, а такими программами, как Проводник (Explorer).
3.7.1.2. Монтируемые тома
В UNIX нет понятия «буква диска», подобно буквам A:, C: и т.д., используемым в MS-DOS и в Windows. В системе может быть несколько дисковых томов, но, прежде чем получить доступ к файловой системе любого диска, кроме основного, пользователь должен выполнить операцию монтирования диска
. Она заключается в том, что данный диск отображается на какой-либо из каталогов основного тома. Как правило, для этого используются пустые подкаталоги каталога /mount или /mnt.
Если представить файловую систему на дисковом томе в виде дерева, то монтирование тома – это как бы «прививка» одного дерева к какому-либо месту на другом, основном дереве. В отличие от этого, MS-DOS и Windows допускают использование нескольких отдельных деревьев.
3.7.1.3. Типы и атрибуты файлов
Для каждого файла в UNIX хранится его тип, который при выдаче каталога обозначается одним из следующих символов:
| - – |
обычный файл, т.е. файл, содержащий данные; |
| d – |
каталог; |
| c – |
символьный специальный файл, т.е., на самом деле, символьное устройство; |
| b – |
блочный специальный файл; |
| l – |
символическая связь; |
| p – |
именованный канал (будет рассмотрен в п. 4.6.3); |
| s – |
сокет – объект, используемый для передачи данных по сети. |
Особенностью UNIX является то, что работа с разными типами объектов, перечисленными выше (файлами, устройствами, каналами, сокетами) организуется с использованием одного и того же набора функций файлового ввода/вывода.
К числу атрибутов, описывающих файл, относятся его размер в байтах, число жестких связей и три «временных штампа»: дата/время последнего доступа к файлу, последней модификации файла, последней модификации атрибутов файла. Эту последнюю величину часто называют неточно «датой создания файла».
Для специальных файлов вместо размера хранятся старший и младший номера устройства, см. п. 2.10.1.
Кроме того, для каждого файла хранятся атрибуты управления доступом, описанные в следующем пункте, а также информация о размещении файла на диске, описанная в п. 3.7.2.
3.7.1.4. Управление доступом
Для каждого файла (в том числе каталога, специального файла) определены такие понятия, как владелец
(один из пользователей системы) и группа-владелец
. Их числовые идентификаторы (называемые, соответственно, UID и GID) хранятся вместе с другими атрибутами файла. Полные имена, пароли и другие характеристики пользователей и групп хранятся в отдельном системном файле. Владельцем файла обычно является тот пользователь, который создал этот файл.
Кроме того, для файла задаются атрибуты защиты
, хранящиеся в виде 9 бит, которые определяют допустимость трех основных видов доступа – на чтение, на запись и на исполнение – для владельца, для членов группы-владельца и для прочих пользователей.
При отображении каталога с помощью команды ls –l эти атрибуты показываются в виде 9 букв или прочерков, например:
r w x r – x - - x
В приведенном примере показано, что сам владелец файла имеет все права (r – чтение, w – запись, x – исполнение), члены группы-владельца могут читать файл и запускать на исполнение (если этот файл содержит программу), всем прочим разрешено только исполнение.
Привилегированный пользователь (администратор системы) всегда имеет полный доступ ко всем файлам.
В том случае, если файл является каталогом, права доступа на чтение и на исполнение понимаются несколько иначе. Право на чтение каталога позволяет получить имена файлов, хранящиеся в данном каталоге. Право на исполнение каталога означает возможность читать атрибуты файлов каталога, использовать эти файлы, а также право сделать данный каталог текущим. Возможны интересные ситуации: если текущий пользователь не имеет права на чтение каталога, но имеет право на его «исполнение», то он не может узнать имена файлов, хранящихся в каталоге; однако, если он все же каким-то образом узнал имя одного из файлов, то может открыть этот файл или запустить на исполнение (если этому не препятствуют атрибуты доступа самого файла).
Чтобы удалить файл, не нужно иметь никаких прав доступа к самому файлу, но необходимо право на запись в соответствующий каталог (потому что удаление файла есть изменение не файла, а каталога). Впрочем, в современных версиях UNIX добавлен еще один битовый атрибут, при установке которого удаление разрешено только владельцу файла или пользователю, имеющему право записи в файл.
Изменение атрибутов защиты, а также смена владельца файла, могут быть выполнены только самим владельцем либо привилегированным пользователем.
Еще два битовых атрибута, имеющих отношение к защите данных, называются SUID и SGID. Они определяют, какие права (а точнее сказать, чьи идентификаторы владельца и группы) унаследует при запуске программа, хранящаяся в данном файле. Оба бита по умолчанию сброшены, при этом программа использует идентификаторы UID и GID того пользователя, который ее запустил. Программа как бы «действует от имени этого пользователя», и использует его права доступа к файлам. Если же для установлены атрибуты SUID и/или SGID, то запущенная программа будет использовать идентификаторы UID и/или GID своего владельца.
Для чего такие тонкости? Представим себе, что пользователь хочет сменить свой пароль. С одной стороны – нормальное желание, которое следует удовлетворить. С другой стороны, пароль данного пользователя хранится в одном файле с паролями других пользователей, и доступ к этому файлу должен быть, очевидно, закрыт для всех рядовых пользователей. Можно подобрать и другие примеры ситуаций, когда обычному пользователю необходим ограниченный доступ к данным, которые система должна защищать.
Решение, которое предлагает UNIX, заключается в следующем. Для работы с паролями имеется специальная программа, владельцем которой является администратор системы. Программа доступна для исполнения всем пользователям, но у нее установлен бит SUID. В результате этого запущенная программа работает от имени администратора, т.е. получает неограниченный доступ к файлам. Таким образом, ответственность за защиту системных данных перекладывается на работающую программу.
Следует отметить, что в UNIX нет особых средств защиты для периферийных устройств. Как было описано выше, устройства (а также именованные каналы и сокеты) считаются особыми типами файлов, поэтому для них определены те же атрибуты защиты, что и для файлов.
3.7.2. Структуры данных файловой системы
UNIX
Дисковый том UNIX состоит из следующих основных областей, показанных (не в масштабе) на рис. 3‑5:

Рис.
3‑5
· блок начальной загрузки (BOOT-сектор); его структура определяется не UNIX, а архитектурой используемого компьютера;
· суперблок – содержит основные сведения о дисковом томе в целом (размер логического блока и количество блоков, размеры основных областей, тип файловой системы, возможные режимы доступа), а также данные о свободном месте на диске;
· массив индексных дескрипторов, каждый из которых содержит полные сведения об одном из файлов, хранящихся на диске (кроме имени этого файла);
· область данных, состоящая из логических блоков (кластеров), которые используются для хранения файлов и каталогов (в UNIX используется сегментированное размещение файлов).
В отличие от системы FAT, где основные сведения о файле содержались в каталожной записи, UNIX использует более изощренную схему.
Запись каталога не содержит никаких данных о файле, кроме только имени файла и номера индексного дескриптора этого файла.
В ранних версиях UNIX каждая запись имела фиксированную длину 16 байт, из которых 14 использовались для имени и 2 для номера. В более современных версиях запись имеет переменный размер, что позволяет использовать длинные имена файлов.
Как и в системе FAT, в каждом каталоге первые две записи содержат специальные имена «..» (ссылка на родительский каталог) и «.» (ссылка на данный каталог).
Точнее, это в FAT сделано по примеру UNIX.
Нулевое значение номера соответствует удаленной записи каталога.
Все сведения о файле, кроме имени, содержатся в его индексном дескрипторе
(inode
). Такая схема делает возможными жесткие связи, описанные выше: любое количество записей из одного каталога или из разных каталогов может относиться к одному и тому же файлу. Для этого надо только, чтобы эти записи содержали один и тот же номер inode.
Индексные дескрипторы хранятся в массиве, занимающем отдельную область диска. Размер этого массива задается при форматировании, этот размер определяет максимальное количество файлов, которое можно разместить на данном томе.
Дескриптор содержит, прежде всего, счетчик жестких связей файла, т.е. число каталожных записей, ссылающихся на данный дескриптор. Этот счетчик изменяется при создании и удалении связей, его нулевое значение говорит о том, что файл перестал быть доступным и должен быть удален.
В дескрипторе содержатся тип и атрибуты файла, описанные выше. Наконец, здесь же содержатся данные о размещении файла, имеющие весьма оригинальную структуру (см. рис. 3‑6).

Рис.
3‑6
Размещение блоков файла задается массивом из 13 (в некоторых версиях 14) элементов, каждый из которых может содержать номер блока в области данных. Пусть, для определенности, блок равен 1 Кб, а его номер занимает 4 байта (обе эти величины зависят от версии файловой системы). Первые 10 элементов массива содержат номера первых 10 блоков от начала файла. Если размер файла превышает 10 Кб, то в ход идет 11-й элемент массива. Он содержит номер косвенного блока
– такого блока в области данных, который содержит номера следующих 256 блоков файла. Таким образом, использование косвенного блока позволяет работать с файлами размером до 266 Кб, используя для этого один дополнительный блок. Если файл превышает 266 Кб, то в 12-ом элементе массива содержится номер вторичного
косвенного блока
, который содержит до 256 номеров косвенных блоков, каждый из которых… Ну, вы поняли. Наконец, для очень больших файлов будет задействован 13-й элемент массива, содержащий номер третичного косвенного блока
, указывающего на 256 вторичных косвенных.
Подсчитайте, какой максимальный размер файла может быть достигнут при такой схеме адресации блоков.
Недостатком описанной схемы является то, что доступ к большим файлам требует значительно больше времени, чем к маленьким. Если расположение первых 10 Кб данных файла записано непосредственно в индексном дескрипторе, то для того, чтобы прочитать данные, отстоящие, скажем, на 50 Мб от начала файла, придется сперва прочитать третичный, вторичный и обычный косвенные блоки.
Еще один важный вопрос для любой файловой системы – способ хранения данных о свободном месте. Для UNIX следует различать два вида свободных мест – свободные блоки в области данных и свободные индексные дескрипторы, которые бывают нужны при создании новых файлов. Количество тех и других может быть очень большим. В суперблоке UNIX имеются массивы для хранения некоторого количества номеров свободных блоков и свободных дескрипторов. Если исчерпаны номера свободных дескрипторов в суперблоке, то UNIX просматривает массив дескрипторов, находит в нем свободные и выписывает их номера в суперблок.
Сложнее обстоит дело со свободными блоками данных. Первый элемент размещенного в суперблоке массива номеров свободных блоков указывает на блок в области данных, который содержит продолжение этого массива и, в первом элементе, указатель на следующий блок продолжения. Когда системе нужны блоки дисковой памяти, она берет их из основного массива в суперблоке, а при исчерпании массива читает его продолжение в суперблок. При освобождении блоков происходит обратный процесс: их номера записываются в массив, а при переполнении массива все его содержимое переписывается в один из свободных блоков, номер которого заносится в первый элемент массива как адрес продолжения списка. На рис. 3‑7 показана структура списка свободных блоков.

Рис.
3‑7
Как нетрудно понять, из сказанного вытекает, что блоки диска распределяются «по стековому принципу»: блок, освобожденный последним, будет первым снова задействован.
3.7.3. Доступ к данным в UNIX
UNIX предоставляет в распоряжение прикладных программ набор системных вызовов, позволяющих выполнять основные операции с файлами и каталогами в целом (создание, удаление, поиск, изменение владельца и прав доступа), а также с данными, хранящимися в файлах (открытие и закрытие файла, чтение и запись данных, перемещение указателя в файле).
В основе работы с данными, как и для MS-DOS, лежит понятие хэндла открытого файла. Программа получает значение хэндла при открытии или создании файла, а затем использует хэндл для ссылки на открытый файл при обращении к функциям чтения, записи, перемещения указателя и т.п.
UNIX не имеет средств управления разделением доступа при открытии файла, т.е. всегда позволяет нескольким процессам открывать один и тот же файл. Для обеспечения корректной работы процессы могут использовать блокирование фрагментов файла. Можно установить блокировку для записи (эксклюзивную блокировку, см. п. 3.5) или для чтения (кооперативную блокировку). По умолчанию в UNIX используются рекомендательные
блокировки. Это означает, что система не препятствует процессу обращаться к заблокированному фрагменту файла. Процесс должен сам запрашивать (если считает нужным), не заблокирован ли данный фрагмент. В более поздних версиях UNIX стало возможным и обязательное
блокирование, при котором попытка обращения к заблокированному фрагменту приводит к ошибке.
Для реализации доступа к файлу по значению хэндла в UNIX используются таблицы, аналогичные таблицам JFT и SFT в MS-DOS (см. п. 3.6.4.3). Однако, в отличие от MS-DOS, запись SFT не содержит копии всех атрибутов файла. Вместо этого UNIX хранит в памяти отдельную таблицу копий индексных дескрипторов (inode) всех открытых файлов. Запись SFT содержит ссылку на запись таблицы индексных дескрипторов, а сверх того – те параметры, которых нет в inode: режим доступа к открытому файлу, положение указателя в файле, количество хэндлов, указывающих на данную запись SFT. Если один и тот же файл был открыт несколько раз, то создается несколько записей SFT, указывающих на один и тот же inode.
3.7.4. Развитие файловых систем
UNIX
Описанная выше классическая файловая система UNIX является по-своему весьма стройной и мощной, способной удовлетворить разнообразные требования пользователей. В то же время эта система давно уже подвергалась критике за два существенных недостатка, определяемых выбором описанных выше структур данных. Эти недостатки следующие:
· ненадежность;
· низкая производительность.
Поговорим сначала о ненадежности. Можно назвать следующие опасные места в структуре файловой системы UNIX.
· Широкое использование сцепленных списковых структур для хранения жизненно важной информации о размещении файлов и свободных блоков. Программистам известен основной недостаток сцепленных списков: при минимальном искажении хотя бы одного из указателей теряется, в лучшем случае, вся последующая часть списка. Возможна и потеря данных, не входящих в поврежденный список. Попробуйте представить себе, что произойдет на диске, если в качестве номера косвенного блока вследствие аппаратного сбоя будет записан номер ни в чем не повинного блока данных из совсем другого файла…
· Интенсивное использование суперблока для хранения часто изменяющейся информации. Поскольку каждая операция записи связана с возможностью искажения данных, под угрозой оказываются жизненно важные параметры файловой системы, которые тоже хранятся в суперблоке, но не требуют частых изменений: размеры всей файловой системы и ее частей, размер блока и т.п.
· Компактное размещение в начале дискового тома наиболее важных метаданных (суперблок, массив дескрипторов) приводит к тому, что при механическом повреждении начальных дорожек диска теряется возможность доступа ко всем данным на диске.
Давно известны и факторы, влияющие на снижение производительности работы:
· использование косвенных блоков приводит к тому, что для поиска нужного места в большом файле могут потребоваться дополнительные операции чтения с диска.
· используемые алгоритмы выделения и освобождения дисковых блоков по принципу «последним освободился – первым занят» способствуют фрагментации дискового пространства, а это, как нам известно, приводит к снижению скорости доступа.
Неудивительно, что в качестве замены системы s5fs были предложены различные более надежные и производительные файловые системы. К их числу относятся, например, система FFS, используемая в версии UNIX 4BSD, а также система ext2, поставляемая с Linux. Все эти системы поддерживают привычную архитектуру UNIX, включая структуру каталогов, жесткие и символические связи, типы файлов, набор атрибутов. Различия заключаются в реализующих эту архитектуру структурах дисковых данных и в алгоритмах работы с ними.
Постараемся дать общее представление о направлениях усовершенствования файловых систем UNIX, не вдаваясь в детали конкретных систем.
· Дисковый том разбивается на несколько групп цилиндров. Каждая группа содержит копию общего суперблока, а также отдельный массив дескрипторов и блоки данных. В случае повреждения основного экземпляра суперблока его содержимое может быть восстановлено по сохранившейся копии. Повреждение метаданных в одной из групп цилиндров не ведет к потере информации в остальных группах.
· Данные о количестве и местонахождении свободных блоков вынесены из суперблока и хранятся отдельно в каждой группе цилиндров.
· Для хранения данных о свободных блоках используется не списковая структура, а битовая карта, в которой каждый блок из группы цилиндров помечается как свободный или занятый. Это уменьшает тяжесть последствий в случае повреждения данных.
· Алгоритм размещения файлов старается по возможности размещать все файлы одного каталога, а также их дескрипторы, в пределах одной группы цилиндров. Напротив, подкаталоги по возможности не размещаются в той же группе цилиндров, что родительский каталог. Таким способом обычно удается уменьшить количество перемещений головок при работе программы с файлами.
Нужно отметить, что в современных версиях UNIX, как и в других современных ОС, поддерживается одновременное использование разных файловых систем на разных дисковых томах. Этой цели служит понятие виртуальной файловой системы
(VFS). Она позволяет подключать к единому дереву каталогов файловые системы различных типов, в том числе такие чужеродные для UNIX, как FAT или NTFS. Для работы с файлами используется единый набор файловых функций, однако при их вызове, в зависимости от того, к какой файловой системе принадлежит данный файл, будут вызываться различные подпрограммы.
3.8.1. Особенности файловой системы NTFS
Файловая система NTFS была разработана специально для использования в ОС WindowsNT как замена для устаревшей системы FAT. NTFS является основной системой и для новых версий – Windows 2000/XP.
Система NTFS спроектирована как очень мощная многопользовательская файловая система с большим количеством возможностей. Тем не менее, как утверждают разработчики, NTFS обеспечивает более быстрый доступ к данным, чем предельно простая система FAT, если объем диска превышает 600 Мб.
Среди возможностей, отсутствующих в FAT, но реализованных в NTFS, можно назвать следующие.
· Развитые средства защиты данных, предотвращающие возможность несанкционированного доступа к данным и при этом позволяющие весьма детально разграничить права доступа для различных пользователей и групп пользователей.
· Быстрый поиск файлов в больших каталогах.
· Обеспечение целостности данных в случае сбоев или отключения питания, основанное на механизме транзакций. Это означает, что любая операция с файлом рассматривается как неделимое действие (транзакция), которое должно быть либо выполнено до конца, либо не выполнено вовсе. В ходе операции система протоколирует в специальном журнале ход выполнения отдельных этапов транзакции: запись данных, внесение изменений в каталог и т.п. Если транзакция будет прервана на промежуточном этапе, то при следующей загрузке системы информация из журнала позволит «откатить» недовыполненную транзакцию, т.е. отменить выполненные этапы.
· Возможность сжатия данных на уровне отдельных файлов (т.е. на одном дисковом томе могут храниться файлы как в сжатом, так и в несжатом формате).
· Возможность хранения файлов в зашифрованном виде.
· Механизм точек повторного анализа (reparsepoints), позволяющий для отдельных каталогов задать действия, которые должны выполняться всякий раз, когда система обращается к данному каталогу. В частности, этот механизм позволяет реализовать такие UNIX-подобные возможности, как символические связи и монтирование файловых систем.
· Возможность протоколирования всех изменений, происходящих в файловой системе, таких как создание, изменение и удаление файлов и каталогов.
· Расширяемость системы. Учтя трудный опыт, связанный с попытками модернизации FAT, разработчики NTFS заранее заложили в систему возможность добавления новых, не предусмотренных в настоящее время атрибутов файлов.
Некоторые возможности, заложенные в файловую систему NTFS, даже опережают развитие ОС Windows и пока не могут быть использованы в этой системе.
3.8.2. Структуры дисковых данных
Общую структуру хранения данных на диске в системе NTFS часто характеризуют двумя короткими фразами:
На диске нет ничего, кроме файлов.
В файле нет ничего, кроме атрибутов.
Поговорим подробнее об этих загадочных утверждениях.
3.8.2.1. Главная таблица файлов
Наиболее важной частью файловой системы на диске является главная таблица файлов
(MFT, MasterFileTable). Эта таблица содержит записи обо всех файлах и каталогах, расположенных на данном томе. Размер записи составляет один кластер, но не менее 1 Кб. Если метаданные о файле не помещаются в одной записи, то могут быть использованы дополнительные записи (не обязательно соседние).
После форматирования дискового тома, когда на нем еще нет пользовательских файлов, MFT содержит 16 записей, из которых 11 содержат описания файлов метаданных, а 5 зарезервированы как дополнительные. Список файлов метаданных достаточно интересен.
· Первая запись MFT описывает саму MFT, которая тоже считается файлом. Это отнюдь не формальность, поскольку MFT может, как и прочие файлы, состоять из нескольких сегментов, размещение которых задается в этой записи.
· Копия первых 16 записей MFT, которая хранится как файл где-нибудь в середине диска. Это позволяет восстановить метаданные в случае повреждения основного экземпляра MFT.
· Журнал протоколирования транзакций.
· Файл информации о томе: имя тома, серийный номер, дата форматирования и т.п.
· Файл с перечислением всех атрибутов, используемых для описания файлов на данном томе. Таким образом, список атрибутов не является жестко фиксированным и может быть расширен в последующих версиях NTFS.
· Корневой каталог тома.
· Битовая карта занятости кластеров тома.
· BOOT-сектор. Он по-прежнему является первым сектором тома, но тоже считается файлом.
· Файл, состоящий из всех дефектных кластеров на данном томе. Это дает основания пометить в битовой карте все дефектные кластеры как занятые.
· Файл, содержащий все различные дескрипторы защиты, используемые для файлов и каталогов данного тома (см. п. 3.8.4.2).
· Файл, задающий пары прописных / строчных букв для всех языков, поддерживаемых Windows. Такие данные необходимы, поскольку имена файлов могут содержать буквы обоих типов, но в Windows по традиции регистр букв в именах файлов не различается (в отличие, например, от UNIX).
· Каталог, содержащий еще 4 файла метаданных, добавленных в Windows 2000. К ним относятся:
- файл уникальных 16-байтовых идентификаторов, создаваемых Windows для каждого файла, на который имеется ярлык или OLE-связь; это позволяет автоматически исправить ярлык, если исходный файл был перемещен в другой каталог или даже на другой компьютер в пределах домена сети;
- файл квот дискового пространства, выделяемых каждому пользователю;
- файл точек повторного анализа, установленных для каталогов данного тома;
- файл журнала изменений, происходящих на томе.
Далее, начиная с 17-й позиции MFT, хранятся записи метаданных о файлах и каталогах, размещенных на данном томе.
Система пытается сохранить MFT непрерывной, поскольку это ускоряет обращение ко всем описанным в ней файлам. Для этого система старается по возможности не занимать некоторую область в начале диска под размещение файлов, сохраняя свободное место для роста MFT.
3.8.2.2. Атрибуты файла
Каждая запись MFT содержит набор атрибутов, который может различаться для разных файлов и каталогов.
Атрибут в NTFS состоит из заголовка и значения, а заголовок, в свою очередь, содержит тип атрибута, его имя, длину и данные о размещении атрибута. Имя атрибута может отсутствовать, остальные поля обязательны. Заголовок атрибута всегда хранится в самой записи MFT, а значение – либо тоже в самой записи (при этом атрибут называется резидентным
), либо в кластере области данных (нерезидентный
атрибут). Некоторые типы атрибутов обязаны быть резидентными, для других типов выбор размещения зависит от наличия достаточного свободного места в записи MFT. Если атрибут нерезидентный, то в заголовке указываются сведения о размещении его значения на диске.
Рассмотрим наиболее важные типы атрибутов, используемых в записи о файле.
· Имя файла
. Этот атрибут всегда резидентен. Допускается несколько атрибутов этого типа, например, «длинное» имя (до 255 символов, включая буквы любого языка) и имя «8 + 3» для того же файла.
· Стандартная информация
. Это примерно та информация о файле, которая хранилась в записи каталога FAT: размер файла, временные штампы и битовые флаги.
· Дескриптор защиты
. Он служит для задания прав доступа к данному файлу для различных пользователей и групп, подробнее см. п. 3.8.4.2. В новых версиях NTFS запись MFT содержит не сам дескриптор, а ссылку на его место в системном файле. Так получается компактнее, поскольку обычно на диске имеется много файлов с одинаковыми дескрипторами защиты и лучше хранить каждый дескриптор один раз, в специально отведенном для этого файле метаданных.
· Данные
. Это самое неожиданное при первом знакомстве с NTFS: сами данные файла рассматриваются как один из типов атрибутов этого файла. Следующая неожиданность состоит в том, что атрибут данных небольшого файла может храниться резидентно в составе записи MFT. Напомним, что размер этой записи – от 1 Кб и больше, так что место для данных маленького файла может найтись. Безусловно, резидентное хранение данных позволяет ускорить доступ к ним, поскольку запись MFT так или иначе всегда читается при открытии файла.
Еще одна интересная особенность NTFS заключается в том, что один файл может иметь несколько атрибутов данных, определяющих несколько потоков данных
(streams). Один из потоков безымянный, остальные должны иметь имена. Получается как бы целый каталог файлов внутри одного файла. Безусловно, для этой возможности можно придумать интересные применения, однако ни в одной версии Windows, включая XP, пока не предусмотрены API-функции, работающие с потоками данных.
Если запись MFT описывает не файл, а каталог, то вместо атрибута данных в ней содержится другой атрибут, содержащий либо весь каталог, либо его часть. Если каталог слишком велик, то другие его части хранятся в нерезидентных атрибутах еще одного типа. Здесь мы не будем рассматривать этот вопрос детально, однако следует отметить, что атрибуты, описывающие большой каталог, образуют структуру данных, известную как Б-дерево (B-tree). Эта структура позволяет ускорить поиск файла в каталоге.
Запись каталога содержит лишь имя файла, номер записи об этом файле в MFT и копию атрибута «стандартная информация». Эта копия позволяет отображать содержимое каталога без чтения записей MFT о каждом файле.
При сравнении структуры NTFS с ранее рассмотренной структурой s5fs можно найти некоторую аналогию между таблицей MFT и массивом индексных дескрипторов, содержащих всю информацию о файле в s5fs. При этом NTFS имеет значительно более сложную структуру и предоставляет много дополнительных возможностей.
3.8.3. Доступ к данным
Windows предоставляет прикладным программам API-функцию CreateFile, которая может использоваться как для создания нового файла, так и для открытия существующего. В любом случае эта функция создает в системной памяти объект типа «открытый файл», именно потому название функции начинается со слова «Create».
Функция CreateFile может использоваться для работы с файлами любой файловой системы, поддерживаемой Windows (в частности, FAT и NTFS).
Параметры этой функции многочисленны и дают достаточно хорошее представление о возможностях работы с файлами в Windows. Некоторые параметры имеют смысл только для NTFS (но не для FAT) или только для WindowsNT (но не для Windows 95). Список параметров включает в себя следующие параметры.
· Имя файла (включая путь к каталогу, если файл расположен не в текущем каталоге). Вместо имени файла может также быть указано специальное имя устройства, в том числе даже имя физического или логического диска.
· Режим доступа. Может быть указан доступ для чтения, для записи или их комбинация.
· Режим разделения. Он может включать в себя разрешение другим процессам читать файл, записывать данные в файл, удалять файл или любую комбинацию этих разрешений, в том числе, разумеется, и отсутствие всех разрешений.
· Атрибуты защиты. Их использование будет описано в п. 3.8.4.2.
· Режим создания. Определяет действия функции в случаях, когда файл с заданным именем уже существует и когда не существует. Определены следующие режимы.
- CREATE_NEW – Создается новый файл. Если файл уже существует, выдается ошибка.
- CREATE_ALWAYS – Создается новый файл в любом случае, даже если файл с таким именем уже существует.
- OPEN_EXISTING – Открывается существующий файл. Выдает ошибку, если файл не существует.
- OPEN_ALWAYS – Если файл существует, то он открывается, если не существует – создается новый файл.
- TRUNCATE_EXISTING – Открывается существующий файл, но все его содержимое удаляется. Если файл не существует, выдается ошибка.
· Большой набор атрибутов и флагов, который следует рассмотреть подробнее. В данном случае атрибутами называются признаки файла, которые устанавливаются при его создании, а флагами – признаки, уточняющие режим работы с открытым файлом.
К атрибутам файла относятся все те, которые Windows унаследовала от MS-DOS (только для чтения, скрытый, системный, архивный), а также атрибут «сжатый» (т.е. файл, создаваемый в NTFS, будет храниться в сжатом виде) и атрибут «временный». Этот атрибут означает, что файл, вероятно, будет скоро удален, а поэтому система должна попытаться удержать его данные в памяти, не тратя зря время на запись файла на диск.
Флаги функции предоставляют, в частности, следующие возможности:
· при операциях записи немедленно выполнять запись на диск (очищать кэш-буфера файла);
· вообще исключить использование кэша для данного файла, всегда записывать и читать секторы данных непосредственно с диска;
· указать системе желательность оптимальной буферизации для последовательного доступа или, наоборот, для произвольного доступа;
· открыть файл для выполнения асинхронных операций;
· указать системе, что файл должен быть автоматически удален сразу же, как только он будет закрыт.
Функция
CreateFile возвращает хэндл открытого файла. Этот хэндл может затем использоваться при обращении к функциям чтения, записи, перемещения указателя, очистки буферов, блокирования фрагментов, закрытия фала и др.
Чтение и запись данных при синхронных операциях начинается с текущей позиции указателя и сопровождается смещением указателя чтения/записи вперед на количество прочитанных/записанных байт. Однако если при открытии файла был указан флаг асинхронных операций, то указатель не используется. Вместо этого при каждом вызове функции чтения или записи должен задаваться дополнительный параметр – смещение от начала файла тех данных, которые следует прочитать или записать.
Как вы думаете, почему при асинхронных операциях не используется указатель чтения/записи?
Процесс, запустивший асинхронную операцию чтения/записи, может затем проверить ее результат с помощью вызова системной функции, которая, в зависимости от параметров, либо ожидает завершения операции, либо просто проверяет, завершилась ли она. Кроме того, есть возможность связать с завершением асинхронной операции либо событие (event), либо функцию завершения, которая будет вызвана, если операция завершена, а нить процесса, начавшая операцию, вызвала функцию ожидания (см. пп.4.5.5.2, 4.5.5.3 о событиях и функциях ожидания).
Некоторые файловые функции не требуют хэндла, т.е. выполняются над закрытыми файлами. Сюда относятся удаление файла, копирование, переименование, перемещение файла, поиск файла по заданному пути и шаблону имени и т.п. В качестве интересных особенностей файловых операций Windows можно отметить следующие.
· Операции копирования файла или перемещения его на другой диск можно выполнить вызовом одной системной функции, даже не открывая файл. В других ОС подобные операции требуют написания целой процедуры.
· Специально для замены версий системных программ предусмотрен вариант переименования/перемещения файла с откладыванием фактического выполнения до перезагрузки системы. Иным способом невозможно было бы, например, установить новые версии системных библиотек, поскольку существующие версии постоянно открыты и потому не могут быть удалены иначе как при старте системы.
3.8.4. Защита данных
Средства безопасности в WindowsNT/2000/XP представляют собой отдельную подсистему, которая обеспечивает защиту не только файлов, но и других типов системных объектов. Файлы и каталоги NTFS представляют собой наиболее типичные примеры защищаемых объектов.
Как известно, Windows позволяет использовать различные файловые системы, при этом возможности защиты данных определяются архитектурой конкретной файловой системы. Например, если на дисковом томе используется система FAT (где, как нам известно, никаких средств защиты не предусмотрено), то Windows может разве что ограничить доступ ко всему тому, но не к отдельным файлам и каталогам.
Важным элементом любой системы защиты данных является процедура входа в систему, при которой выполняется аутентификация пользователя. В WindowsNT для вызова диалога входа в систему используется известная «комбинация из трех пальцев» – Ctrl+Alt+Del. Как утверждают разработчики, никакая «троянская» программа не может перехватить обработку этой комбинации и использовать ее с целью коллекционирования паролей.
Не хочет ли кто-нибудь попробовать?
Система ищет введенное имя пользователя сначала в списке пользователей данного компьютера, а затем и на других компьютерах текущего домена локальной сети. В случае, если имя найдено и пароль совпал, система получает доступ к учетной записи
(account) данного пользователя.
На основании сведений из учетной записи пользователя система формирует структуру данных, которая называется маркером доступа
(accesstoken). Маркер содержит идентификатор пользователя (SID, SecurityIDentifier), идентификаторы всех групп, в которые включен данный пользователь, а также набор привилегий
, которыми обладает пользователь.
Привилегиями называются права общего характера, не связанные с конкретными объектами. К числу привилегий, доступных только администратору, относятся, например, права на установку системного времени, на создание новых пользователей, на присвоение чужих файлов. Некоторые скромные привилегии обычно предоставляются всем пользователям (например, такие, как право отлаживать процессы, право получать уведомления об изменениях в файловой системе).
В дальнейшей работе, когда пользователю должен быть предоставлен доступ к каким-либо защищаемым ресурсам, решение о доступе принимается на основании информации из маркера доступа.
Для любого защищаемого объекта Windows (файла, каталога, диска, устройства, семафора, процесса и т.п.) может быть задана специальная структура данных – атрибуты защиты.
Основным содержанием атрибутов защиты является другая структура – дескриптор защиты
. Этот дескриптор содержит следующие данные:
· идентификатор защиты (SID) владельца объекта;
· идентификатор защиты первичной группы владельца объекта;
· пользовательский («дискреционный», «разграничительный») список управления доступом (DACL, DiscretionaryAccessControlList);
· системный список управления доступом (SACL, SystemAccessControlList).
Пользовательский список управляет разрешениями
и запретами
доступа к данному объекту. Изменять этот список может только владелец объекта.
Системный список управляет только аудитом
доступа данному объекту, т.е. задает, какие действия пользователей по отношению к данному объекту должны быть запротоколированы в системном журнале. Изменять этот список может только пользователь, имеющий права администратора системы.
В Windows, в отличие от многих других ОС, администратор не всесилен. Он не может запретить или разрешить кому бы то ни было, даже самому себе, доступ к чужому файлу. Другое дело, что администратор имеет право объявить себя владельцем любого файла, но потом он не сможет вернуть файл прежнему хозяину. Подобные ограничения вытекают из понимания, что администратор тоже не всегда ангел и, хотя он должен иметь в системе большие права, его действия следует хоть как-то контролировать.
Оба списка управления доступом имеют одинаковую структуру, их основной частью является массив записей управления доступом
(ACE, AccessControlEntity).
Рассмотрим структуру записи ACE. Она содержит:
· тип ACE, который может быть одним из следующих: разрешение, запрет, аудит;
· флаги, уточняющие особенности действия данной ACE;
· битовая маска видов доступа, указывающая, какие именно действия следует разрешить, запретить или подвергнуть аудиту;
· идентификатор (SID) пользователя или группы, чьи права определяет данная ACE.
Более интересен пользовательский список. Он может содержать только записи разрешения и запрета. В начале списка всегда идут запрещающие записи, затем разрешающие.
Когда пользователь запрашивает доступ к объекту (т.е., например, программа, запущенная этим пользователем, вызывает функцию открытия файла), происходит проверка прав доступа. Она выполняется на основе сравнения маркера доступа пользователя со списком DACL. Система просматривает по порядку все записи ACE из DACL, для каждой ACE определяет записанный в ней SID и сверяет, не является ли он идентификатором текущего пользователя или одной из групп, куда входит этот пользователь. Если нет, то данная ACE не имеет к нему отношения и не учитывается. Если да, то выполняется сравнение прав, необходимых пользователю для выполнения запрошенной операции с маской видов доступа из ACE. При этом права анализируются весьма детально: например, открытие файла на чтение подразумевает наличие прав на чтение данных, на чтение атрибутов (в том числе владельца и атрибутов защиты), на использование файла как объекта синхронизации (см. п. 4.5.5.2).
Если в запрещающейACE найдется хотя бы один единичный бит в позиции, соответствующей одному из запрошенных видов доступа, то вся операция, начатая пользователем, считается запрещенной и дальнейшие проверки не производятся.
Если такие биты будут найдены в разрешающейACE, то проверка следующих ACE выполняется до тех пор, пока не будут разрешены и все остальные запрошенные виды доступа.
Как выдумаете, почему в списке DACL сначала идут запрещающие ACE, а только потом разрешающие?
Таким образом, говоря кратко, пользователь получит доступ к объекту только в том случае, если все запрошенные им виды доступа явным образом разрешены и ни один их них не запрещен.
В годы перестройки много писалось о двух противоположных принципах: «запрещено все, что не разрешено» или «разрешено все, что не запрещено». В Windows все гораздо строже: запрещено все, что запрещено, и все, что не разрешено.
Список DACL со всеми необходимыми разрешениями и запретами может быть установлен программно при создании файла, а впоследствии программно же может быть изменен владельцем. Можно также изменять разрешения в диалоге, воспользовавшись окном свойств файла.
Имеются также два крайних случая. Список DACL может совсем отсутствовать (для этого достаточно, например, при создании файла указать NULL вместо атрибутов защиты), при этом права доступа не проверяются, все действия разрешены всем пользователям. Список DACL может присутствовать, но иметь нулевую длину (нет ни одной ACE). Как следует из общих правил, в этом случае в доступе будет отказано всем, в том числе и хозяину файла.
Под управлением процессами понимаются процедуры ОС, обеспечивающие запуск системных и прикладных программ, их выполнение и завершение.
В однозадачных ОС управление процессами решает следующие задачи:
· загрузка программы в память, подготовка ее к запуску и запуск на выполнение;
· выполнение системных вызовов процесса;
· обработка ошибок, возникших в ходе выполнения;
· нормальное завершение процесса;
· прекращение процесса в случае ошибки или вмешательства пользователя.
Все эти задачи решаются сравнительно просто.
В многозадачном режиме добавляются значительно более серьезные задачи:
· эффективная реализация параллельного выполнения процессов на единственном процессоре, переключение процессора между процессами;
· выбор очередного процесса для выполнения с учетом заданных приоритетов процессов и статистики использования процессора;
· исключение возможности несанкционированного вмешательства одного процесса в выполнение другого;
· предотвращение или устранение тупиковых ситуаций, возникающих при конкуренции процессов за системные ресурсы;
· обеспечение синхронизации процессов и обмена данными между ними.
4.2.1. Понятия процесса и ресурса
Согласно определению, данному в /7/, «последовательный процесс (иногда называемый «задача») есть работа, производимая последовательным процессором при выполнении программы с ее данными».
Проанализируем это определение. Оно подчеркивает последовательный характер процесса, т.е. выполнение команд в определенном порядке. Термин «задача» мы будем понимать как синоним термина «процесс» (в некоторых ОС эти термины различаются). Далее, процесс – понятие динамическое. Программа – это текст, процесс – выполнение этого текста. Конечно, на практике мы часто говорим: «программа вызывает функцию», «программа ждет ввода» и т.п., однако, строго говоря, правильнее было бы «процесс, выполняющий программу, вызывает…».
Еще один важный момент в определении – упоминание данных. В многозадачных системах зачастую одна и та же программа может запускаться несколько раз (например, можно несколько раз открыть текстовый редактор Notepad для разных файлов). Это означает, что несколько процессов могут использовать одну и ту же программу, но с разными данными.
При описании работы многозадачных систем основное внимание уделяется вопросам, связанным с параллельным выполнением, т.е. с одновременной работой нескольких процессов. Однако общий термин «параллельное выполнение» объединяет два существенно различных способа организации выполнения процессов – синхронный и асинхронный параллелизм.
Синхронный параллелизм предполагает наличие общей тактовой последовательности, управляющей шагами выполнения параллельно работающих процессов. Синхронная организация используется в некоторых типах многопроцессорных вычислительных систем.
При асинхронном параллелизме никакого общего такта нет. Процессы выполняются независимо друг от друга, при этом не делается никаких предположений об их сравнительной скорости, о соотношении времени выполнения различных фрагментов программ и т.п. Сопоставить продвижение разных процессов можно только в явно заданных точках программы процессов, называемых точками синхронизации. Синхронизация обычно означает ожидание одним процессом какого-либо события, связанного с другим процессом. Например, после разветвления выполнения на две параллельные ветви и выполнения ветвями определенных задач может понадобиться свести ветви воедино: та ветвь, которая закончила свое выполнение раньше, должна дождаться завершения другой ветви. Другой пример: процесс, выполняющий обработку введенных строк, может ждать, пока другой процесс не прочтет очередную строку из файла или с клавиатуры.
Точка синхронизации может быть связана также с обменом данными между процессами. Когда процесс-приемник завершает прием данных, то можно быть, по крайней мере, уверенным, что процесс-источник достиг того места в программе, где он должен был передать данные.
В дальнейшем всюду будет рассматриваться только асинхронный параллелизм, поскольку он характерен для работы ОС.
Другим основополагающим понятием, тесно связанным с управлением процессами, является понятие ресурса
. Под ресурсом понимается любой аппаратный или программный объект, который может понадобиться для работы процессов и доступ к которому может при этом вызвать конкуренцию процессов. Говоря упрощенно, ресурс – это нечто дефицитное в вычислительной системе. К важнейшим ресурсам любой системы относятся процессор (точнее сказать, процессорное время), основная память, периферийные устройства, файлы. В зависимости от конкретной ОС, к дефицитным ресурсам могут относиться места в таблице процессов или в таблице открытых файлов, буферы кэша, блоки в файле подкачки и другие системные структуры данных.
Если два процесса никак не связаны логикой своей работы, то никакой синхронизации или обмена данными между ними нет, однако такие процессы все же могут оказывать косвенное влияние друг на друга вследствие конкуренции за ресурсы. Многозадачная ОС управляет доступом процессов к ресурсам. В некоторых случаях система временно закрепляет ресурс за одним процессом, отказывая другим процессам в доступе или заставляя их ждать освобождения ресурса. В других случаях оказывается возможным совместный доступ нескольких процессов к одному ресурсу.
4.2.2. Квазипараллельное выполнение процессов
С точки зрения внешнего наблюдателя, в хорошей многозадачной ОС происходит одновременная, параллельная работа нескольких процессов. Однако понятно, что эта одновременность кажущаяся. На самом деле, если в системе работает лишь один процессор, то в каждый момент времени он выполняет команды, относящиеся только к одному из имеющихся процессов. Иллюзия параллельности создается за счет того, что процессы сменяют друг друга через малые интервалы времени, которые человек-наблюдатель не в силах отследить. Подобная организация работы называется квазипараллельным выполнением процессов.
Разумеется, если в системе имеется несколько процессоров, то может быть организовано настоящее параллельное выполнение процессов, количество которых не превышает количества процессоров. При большем числе процессов может использоваться смешанная организация, сочетающая истинную параллельность и квазипараллельность.
Важно отметить, что для большинства задач взаимодействия процессов нет разницы, какого рода параллельность используется в данной ОС. Вообще, основные проблемы управления процессами можно разбить на два уровня:
· проблемы корректной и эффективной реализации параллельного (т.е. обычно квазипараллельного) выполнения процессов – это проблемы нижнего уровня;
· проблемы корректного взаимодействия параллельных процессов – это проблемы верхнего уровня, при рассмотрении которых считается, что низкоуровневые проблемы реализации процессов так или иначе решены.
Такое разбиение облегчает проектирование и отладку систем, а также позволяет лучше понять существо рассматриваемых проблем.
4.2.3. Состояния процесса
Любой процесс в многозадачной ОС многократно испытывает переход из одного состояния в другое.
Основных состояний всего три.
· Работа (running) – в этом состоянии находится процесс, программу которого в данный момент выполняет процессор. Работающий процесс иногда удобно называть также текущим процессом.
· Готовность (ready) – состояние, их которого процесс может быть переведен в состояние работы, как только это сочтет нужным сделать ОС.
· Блокировка или, что то же самое, сон (sleeping, waiting) – состояние, в котором процесс не может продолжать выполнение, пока не произойдет некоторое внешнее по отношению к процессу событие.
Первые два состояния часто объединяют понятием активного состояния процесса.
Для состояний готовности и сна общее то, что процесс не работает. В чем разница между этими двумя «способами не работать»?
Готовый к выполнению процесс не выполняется только потому, что есть другие не менее готовые процессы, по мнению системы более достойные занимать сейчас процессорное время. В каждый момент времени выбор одного из готовых процессов на роль работающего определяется логикой работы ОС. Этот выбор должен обеспечивать эффективную квазипараллельную работу готовых процессов. Как решается эта задача – будет рассмотрено ниже.
В отличие от этого, спящий процесс – это всегда процесс, ожидающий некоторого конкретного события. Спящий процесс не сможет заработать, даже если процессор вдруг окажется свободным. Такой процесс, в соответствии со своей собственной логикой, ждет чего-то, что должно произойти.
Чего он может ждать? Ну, например:
· завершения начатой операции синхронного ввода/вывода (т.е., например, процесс ждет нажатия клавиши Enter или окончания записи на диск);
· освобождения запрошенного у системы ресурса (например, дополнительной области памяти или открытого файла);
· истечения заданного интервала времени («посплю-ка я минут десять!») или достижения заданного момента времени («разбудите меня ровно в полночь!») (в обоих случаях процесс ждет сигнала от запрограммированного таймера);
· сигнала на продолжение действий от другого, взаимосвязанного процесса;
· сообщения от системы о необходимости выполнить определенные действия (например, перерисовать содержимое окна).
В любом из названных (и многих неназванных) случаев должно произойти некоторое событие, источник которого лежит вне данного процесса.
Чисто условно можно сказать, что если бы в вычислительную систему вдруг было добавлено еще несколько процессоров, то «готовые» процессы могли бы сразу перейти в состояние «работа», но «спящие» продолжили бы свой сон.
Разумеется, как мы видели в п. 2.5, процесс может выполнять ожидание путем циклической проверки ожидаемого условия. При этом он формально будет оставаться активным, растрачивая драгоценное процессорное время на то, что в п. 2.5.2 было названо активным ожиданием. Однако такое решение будет говорить лишь о вопиющей неквалифицированности программиста. Любая многозадачная ОС предоставляет в распоряжение прикладных программ набор функций, переводящих вызвавший их процесс в состояние сна, в котором процесс не пытается использовать процессорное время (другими словами, состояние сна есть состояние пассивного ожидания). Такие системные функции называются блокирующими. К их числу относятся функции синхронного ввода/вывода, запроса ресурсов, приостановки до заданного времени, получения сообщений и многие другие.
Поскольку ОС берет на себя блокировку, «усыпление» процесса, она должна обеспечить и его разблокировку, «пробуждение». Чтобы это стало возможным, система должна для каждого спящего процесса помнить, «чего он ждет», т.е. помнить условия пробуждения процесса. Система отслеживает все события, способные разблокировать какой-либо процесс (во многих случаях используя для этого аппаратные прерывания) и, когда для одного или сразу нескольких процессов наступает ожидаемое событие, переводит эти события из состояния сна в состояние готовности.
На рис. 4‑1 показаны основные состояния процесса и переходы между ними. Этот рисунок кочует из книги в книгу, поскольку он действительно наглядно отражает самую суть работы многозадачных систем.

Рис.
4‑1
Рассмотрим возможные переходы между состояниями процесса, показанные на рисунке стрелками.
Переход Работа - Сон представляет собой блокировку процесса, которая может произойти при вызове блокирующей системной функции.
Переход Сон - Готовность – это пробуждение процесса, оно выполняется системой при возникновении соответствующего условия.
Переход Работа - Готовность ранее не рассматривался. Он называется вытеснением процесса и выполняется системой, когда она принимает решение о смене текущего процесса.
Для обратного перехода Готовность - Работа нет общепринятого термина. Будем называть его выбором процесса для выполнения. Отметим, что этот переход почти всегда связан либо с блокировкой, либо с вытеснением прежнего текущего процесса.
Ответьте сами на вопрос: почему «почти всегда», а не «всегда»? Какие еще возможны варианты?
Двух стрелок нет на диаграмме. Прямой переход от сна к работе нелогичен, т.к. он совмещал бы два совершенно разных действия.
Каких именно?
Переход от готовности ко сну невозможен в принципе.
Кстати, почему?
Помимо трех основных состояний, в различных ОС могут использоваться и другие состояния.
Состояние старта означает, что процесс находится на этапе создания и пока не готов вступить в работу.
Состояние завершения (в UNIX оно почти официально называется «зомби») означает, что процесс завершил свою работу, но пока присутствует в системе в виде записи о результатах и причине завершения.
Состояние приостановки (suspended) означает, что выполнение процесса временно прервано оператором (или, может быть, другим процессом) и позднее должно быть им же возобновлено.
В некоторых системах (например, в UNIX) основные состояния раздроблены на ряд более мелких: работа в системном и в пользовательском режиме, готовность в памяти и готовность на диске и т.п. Необходимый набор состояний определяется алгоритмами работы конкретной ОС.
4.2.4. Вытесняющая и невытесняющая многозадачность
Все многозадачные ОС можно разделить на два класса, различающиеся по способам организации переключения процессов.
В системах с невытесняющей диспетчеризацией (non-preemptivemultitasking) работа любого процесса может быть прервана только «по инициативе самого процесса», а точнее – только когда процесс вызывает определенные системные функции. К ним относятся, в частности, описанные выше блокирующие функции. Может также иметься функция, специально предназначенная для добровольной уступки процессом очереди на выполнение (Yield). Вызов такой функции не приводит к блокировке, но может привести к вытеснению процесса[7]
. Если работающий процесс не вызывает системных функций, а занимается, например, долгими расчетами, то все остальные процессы вынуждены простаивать. Когда же системная функция, наконец, вызвана, то система, прежде всего, проверяет, может ли эта функция быть выполнена сразу или предполагает ожидание некоторого события (требуемый ресурс может быть занят другим процессом; операция ввода/вывода обычно требует определенного времени на свое выполнение; очередь сообщений, требующих обработки, может быть пуста). Если требуется ожидание, то система блокирует процесс, выбирая какой-либо другой из готовых процессов для выполнения. Не исключена ситуация, когда заблокированными по разным причинам оказываются все пользовательские процессы.
Но даже если действие, требуемое процессом, может быть выполнено без блокировки, система не обязательно спешит выполнить его и вернуть управление текущему процессу. На самом деле, момент вызова системной функции удобен для того, чтобы система могла решить, не пора ли процессу «отдохнуть», поскольку имеются другие процессы, давно претендующие на процессорное время или обладающие более высоким приоритетом. В этом случае система переводит процесс в состояние готовности к выполнению, а один из других готовых к выполнению процессов становится текущим. Что же касается вызванной системной функции, то ее выполнение будет завершено позднее, когда вызвавший процесс вновь станет текущим.
В предыдущем п. 4.2.3 смена текущего процесса, не связанная с его блокировкой, была названа вытеснением процесса.
Та часть ОС, которая по определенным в системе правилам выбирает, следует ли вытеснить текущий процесс и какой процесс должен стать следующим текущим, называется планировщиком (scheduler) или диспетчером процессов.
В системе с невытесняющей диспетчеризацией планировщик получает управление при вызове процессом одной из блокирующих или вытесняющих функций. Планировщик проверяет, не выполнены ли условия активизации одного из спящих процессов, а затем принимает решение о выборе одного из активных процессов для выполнения. Не исключено, что будет опять выбран тот же процесс (если только он не блокируется).
Использование невытесняющей диспетчеризации позволило разработать достаточно впечатляющие примеры ОС, из которых наиболее известной является Windows версий 1, 2 и 3. Обычно в таких системах большая часть процессов находится в спящем состоянии, ожидая, пока пользователь обратится к соответствующему приложению. Для пользователя это выглядит совершенно естественно.
Главный недостаток многозадачности невытесняющего типа заключается в том, что любой процесс в принципе имеет возможность полностью и надолго захватить процессор. Это «многозадачность на честном слове», основанная на предположении, что программы всех процессов написаны так, чтобы достаточно часто вызывать блокирующие функции. Даже если программист пишет программу для выполнения сложных многочасовых вычислений, он должен искусственно вставлять в некоторых местах вызов системных функций, передающих управление планировщику. Если же это не сделано, то система фактически теряет многозадачность и будет выполнять один процесс, не реагируя на действия пользователя, до тех пор, пока либо «нахальный» процесс завершится, либо рассвирепевший пользователь снимет его по Ctrl+Alt+Del.
Более сложным и совершенным типом многозадачных ОС являются системы с вытесняющей диспетчеризацией
процессов (preemptivemultitasking). Их отличие заключается в том, что планировщик вступает в работу не только (и не столько) при вызове системных функций, но и в следующих двух случаях (или хотя бы в одном из них):
· когда активизируется (т.е. пробуждается или запускается) процесс, обладающий более высоким приоритетом, чем текущий;
· когда истекает квант времени
, выделенный планировщиком для текущего процесса.
Понятие приоритета
процесса будет подробно рассмотрено чуть ниже. Приоритет характеризует относительную важность или срочность данного процесса. Надо отметить, что немедленный вызов планировщика при активизации высокоприоритетного процесса характерен не для всех систем с вытесняющей диспетчеризацией, а только для одного их подкласса – систем с абсолютными приоритетами
. В системах с относительными приоритетами
процесс с высоким приоритетом будет все же вынужден подождать истечения кванта времени.
Системы, в которых перепланировка процесса выполняется после истечения каждого кванта времени, называют системами с квантованием времени
[8]
(timeslicing). Если величина кванта достаточно мала, то для пользователя процесс периодической смены текущего процесса будет незаметен и создастся впечатление, что все активные процессы работают как бы одновременно. С другой стороны, чем меньше величина кванта, тем большую долю процессорного времени будет занимать процедура переключения текущего процесса.
Вызов планировщика не обязательно означает смену процесса. Если нет других активных процессов с таким же или более высоким приоритетом, то планировщик может продолжить выполнение того же процесса.
Принципиальной чертой систем с вытесняющей диспетчеризацией является то, что текущий процесс может быть прерван и вытеснен практически в любой точке своей программы. Это заметно усложняет реализацию таких систем по сравнению с невытесняющими системами, где смена текущего процесса может произойти только в момент вызова системной функции.
4.2.5. Дескриптор и контекст процесса
С каждым процессом связаны описывающие его данные в основной памяти, необходимые ОС для поддержки выполнения процесса. Все эти данные можно разбить на две большие структуры: дескриптор процесса и контекст процесса.
Дескриптор процесса
включает в себя все те данные о процессе, которые могут понадобиться ОС при различных состояниях процесса. В число элементов дескриптора могут входить, например, идентификатор процесса (некое условное число, обозначающее данный процесс); текущее состояние процесса; его приоритет; владелец процесса (т.е. идентификатор пользователя, запустившего процесс); статистика затраченного процессом общего и процессорного времени; указатель местоположения контекста процесса и др. Дескрипторы всех процессов, существующих в системе, собраны в таблицу процессов.
Контекст процесса
включает данные, необходимые только для текущего процесса. Суда относятся, прежде всего, значения всех регистров процессора, включая указатель текущей команды; таблица файлов, открытых процессом; указатели на области памяти, которые должен занимать процесс при его выполнении; значения системных переменных, используемых процессом (например, текущий диск и каталог, информация о последней ошибке при выполнении системных функций); другие системные флаги и режимы, которые могут иметь разные значения для разных процессов.
Точный состав дескриптора и контекста сильно зависят от конкретной ОС.
При переключении текущего процесса система должна каждый раз переключать и текущий контекст, т.е. сохранять в своей памяти или на диске контекст предыдущего выполнявшегося процесса и восстанавливать ранее сохраненный контекст того процесса, который будет выполняться.
4.2.6. Реентерабельность системных функций
В многозадачной системе нельзя исключить возможность того, что переключение процессов произойдет во время выполнения вытесняемым процессом какой-либо из системных функций. При этом выполнение функции не будет завершено, оно будет прервано на середине. Предполагается, что выполнение функции будет завершено позднее, когда прерванный процесс снова будет выбран на выполнение.
Проблема заключается в том, что новый текущий процесс может вызвать ту же самую системную функцию. Возникает вопрос: возможно ли корректное выполнение второго вызова функции, если к этому моменту не закончено выполнение первого вызова той же функции?
Простой пример подобной ситуации – запуск в ОС нескольких программ, каждая из которых блокируется на ожидании клавиатурного ввода, вызвав для этого одну и ту же системную функцию ввода.
Функция или процедура, для которой возможно корректное выполнение ее повторного вызова до завершения первого вызова, называется реентерабельной
или повторно-входимой
.
Проблема реентерабельности функций возникает в программировании и по совершенно другому поводу, не связанному с реализацией ОС. Речь идет о рекурсивных функциях, т.е. функциях, которые могут прямо или косвенно вызывать сами себя. Давно известна и основная причина нереентерабельности функций. Она заключается в использовании одних и тех же ячеек памяти для формальных параметров и локальных переменных при разных вызовах функции. Действительно, если при первом вызове функции в ячейку локальной переменной X будет занесено, например, число 10, а при втором – число 20, то после возобновления выполнения первого вызова значение X будет неверным.
Лекарство от этой формы нереентерабельности также давно известно и встроено во все уважающие себя языки программирования, начиная с C и Pascal. Оно заключается в том, что память для формальных параметров и локальных переменных должна выделяться в стеке программы, при этом каждый новый вложенный вызов получает свой набор ячеек для переменных.
Для случая многозадачной системы использование единого стека неприемлемо, поскольку вызовы функций не являются вложенными, т.е. первый вызов может завершиться раньше, чем второй, что привело бы к неверному использованию стека. Каждый процесс получает свой собственный стек, являющийся частью контекста процесса.
Еще одна причина нереентерабельности касается тех функций ввода/вывода, которые запускают операцию и затем дожидаются ее завершения. Повторное обращение к тому же устройству до завершения первого вызова может привести к ошибке. В данном случае система должна отслеживать состояние устройства и блокировать второй вызов до освобождения устройства.
Проблема реентерабельности системных функций значительно острее стоит для ОС с вытесняющей диспетчеризацией, поскольку переключение процесса может случиться при выполнении любой функции. При невытесняющей диспетчеризации достаточно обеспечить реентерабельную реализацию лишь небольшого числа блокирующих функций.
При переходе от невытесняющей Windows 3.x к вытесняющей Windows 95 одна из серьезных проблем состояла в сохранении кода большого количества нереентерабельных системных функций. Проблему «решили» путем введения семафора, блокирующего повторный вызов для большого числа функций. Неприятным следствием этого стало взаимное тормозящее влияние процессов. В WindowsNT этой проблемы нет, все функции реализованы реентерабельно.
4.2.7. Дисциплины диспетчеризации и приоритеты процессов
Когда планировщик процессов получает управление, его основной задачей является выбор следующего процесса, который должен получить управление. Алгоритмы, лежащие в основе этого выбора, определяют дисциплину диспетчеризации
, принятую в данной ОС.
Одной из самых очевидных дисциплин является простая круговая диспетчеризация
(roundrobinscheduling). Ее суть в следующем. Все активные процессы считаются равноправными и образуют круговую очередь. Каждый процесс получает от системы квант времени, по истечении которого планировщик выбирает для выполнения следующий процесс из очереди. Таким образом, если все процессы остаются активными, то система обеспечивает их равномерное продвижение, имитирующее параллельное выполнение всех процессов. Если текущий процесс блокируется, он выпадает из круга и попадает в список спящих процессов. Когда система активизирует один из спящих процессов, он включается в круговую очередь.
В некотором смысле противоположной дисциплиной является фоново-оперативная диспетчеризация
(foreground/backgroundscheduling) – одна из самых старых форм организации многозадачной работы. В простейшем случае она включает два процесса: фоновый процесс и оперативный процесс (процесс переднего плана). Фоновый процесс выполняется только тогда, когда спит оперативный процесс. При активизации оперативного процесса происходит немедленное вытеснение фонового, т.е. оперативный процесс имеет более высокий абсолютный приоритет. Обычно при такой дисциплине предполагается, что активизация оперативного процесса не потребует много процессорного времени, так что выполнение фонового процесса будет скоро возобновлено. Одним из примеров эффективного использования фоново-оперативной диспетчеризации является так называемая «фоновая печать», которую позволяет выполнить даже однозадачная MS-DOS. При этом процесс вывода файла на принтер рассматривается как процесс переднего плана, а обычная диалоговая работа с ОС – как фоновый процесс. Поскольку обслуживание прерываний от принтера занимает лишь доли процента процессорного времени, пользователь не ощущает никакого замедления работы.
Между описанными двумя крайностями лежит большое разнообразие дисциплин приоритетной диспетчеризации
. Все они основаны на приписывании каждому процессу при его создании некоторого числа – приоритета
. Более высокий приоритет должен давать процессу определенные преимущества перед низкоприоритетными процессами при работе планировщика.
Назначение приоритетов выполняется пользователем либо администратором системы, возможно также программное изменение приоритета процесса. На выбор оптимального уровня приоритета влияют в основном два соображения:
· важность, ответственность данного процесса либо привилегированное положение запускающего процесс пользователя;
· количество процессорного времени, на которое будет претендовать процесс (как мы видели в примере с фоновой печатью, высокий приоритет процесса, мало загружающего процессор, почти не приводит к замедлению работы остальных процессов).
Основной алгоритм приоритетного планирования напоминает простое круговое планирование, однако круговая очередь активных процессов формируется отдельно для каждого уровня приоритета. Пока есть хоть один активный процесс в очереди с самым высоким приоритетом, процессы с более низкими приоритетами не могут получить управление. Только когда все процессы с высшим приоритетом заблокированы либо завершены, планировщик выбирает процесс из очереди с более низким приоритетом.
Приоритет, присваиваемый процессу при создании, называется статическим
приоритетом. Дисциплина планирования, использующая только статические приоритеты, имеет один существенный недостаток: низкоприоритетные процессы могут надолго оказаться полностью отлученными от процессора. Иногда это приемлемо (если высокоприоритетные процессы несравнимо важнее, чем низкоприоритетные), однако чаще хотелось бы, чтобы и на низкие приоритеты хоть что-нибудь перепадало, пусть даже реже и в меньшем количестве, чем на высокие. Для решения этой задачи предложено множество разных алгоритмов планирования процессов, основанных на идее динамического
приоритета.
Динамический приоритет процесса – это величина, автоматически рассчитываемая системой на основе двух основных факторов: статического приоритета и степени предыдущего использования процессора данным процессом. Общая идея следующая: если процесс слишком долго не получал процессорного времени, то его приоритет следует повысить, чтобы дать процессу шанс на будущее. Наоборот, если процесс слишком часто и долго работал, есть смысл временно понизить его приоритет, чтобы пропустить вперед изголодавшихся конкурентов.
Могут учитываться и другие соображения, влияющие на динамический приоритет. Например, если процесс ведет диалог с пользователем, то имеет смысл повысить его приоритет, чтобы сократить время реакции и избежать досадных задержек при нажатии клавиш. Если процесс в последнее время часто блокировался, не использовав до конца выделенный ему квант времени, то это тоже основание для повышения приоритета: вполне возможно, процесс и впредь будет так же неприхотлив.
4.3.1. Изоляция процессов и их взаимодействие
Одна из важнейших целей, которые ставятся при разработке многозадачных систем, заключается в том, чтобы разные процессы, одновременно работающие в системе, были как можно лучше изолированы друг от друга. Это означает, что процессы (в идеале) не должны ничего знать даже о существовании друг друга. Для каждого процесса ОС предоставляет виртуальную машину
, т.е. полный набор ресурсов, имитирующий выполнение процесса на отдельном компьютере.
Изоляция процессов, во-первых, является необходимым условием надежности и безопасности многозадачной системы. Один процесс не должен иметь возможности вмешаться в работу другого или получить доступ к его данным, ни по случайной ошибке, ни намеренно.
Во-вторых, проектирование и отладка программ чрезвычайно усложнились бы, если бы программист должен был учитывать непредсказуемое влияние других процессов.
С другой стороны, есть ситуации, когда взаимодействие необходимо. Процессы могут совместно обрабатывать общие данные, обмениваться сообщениями, ждать ответа и т.п. Система должна предоставлять в распоряжение процессов средства взаимодействия. Это не противоречит тому, что выше было сказано об изоляции процессов. Чтобы взаимодействие не привело к полному хаосу, оно должно выполняться только с помощью тех хорошо продуманных средств, которые предоставляет процессам ОС. За пределами этих средств действует изоляция процессов.
Это как граница государств – пересекать ее в произвольных местах запрещено, но должна быть хорошо обустроенная система пропускных пунктов, где легко проконтролировать соблюдение правил пересечения границы.
Понятие взаимодействия процессов включает в себя несколько видов взаимодействия, основными из которых являются:
· синхронизация процессов, т.е., упрощенно говоря, ожидание одним процессом каких-либо событий, связанных с работой других процессов;
· обмен данными между процессами.
Набор средств, предназначенных для взаимодействия процессов, часто обозначают аббревиатурой IPC (InterProcessCommunication). Состав функций и методов обусловлен многолетним опытом как программистов-практиков, так и теоретиков, рассматривающих проблемы взаимодействия параллельных процессов.
Следует еще раз отметить, что проблемы взаимодействия процессов не зависят от способа реализации параллельной работы процессов в конкретной ОС. Большая часть этих проблем имеет место в равной степени и для квазипараллельной реализации, и для истинной параллельности с использованием нескольких процессоров. Средства решения проблем, правда, могут зависеть от реализации.
4.3.2. Проблема взаимного исключения процессов
Серьезная проблема возникает в ситуации, когда два (или более) процесса одновременно пытаются работать с общими для них данными, причем хотя бы один процесс изменяет значение этих данных.
Проблему часто поясняют на таком, немного условном, примере. Пусть имеется система резервирования авиабилетов, в которой одновременно работают два процесса. Процесс A обеспечивает продажу билетов, процесс B – возврат билетов. Не углубляясь в детали, будем считать, что оба процесса работают с переменной N – числом оставшихся билетов, причем соответствующие фрагменты программ на псевдокоде выглядят примерно так:
| Процесс A: |
Процесс B: |
. . .
R1 := N;
R1 := R1 - 1;
N := R1;
. . .
|
. . .
R2 := N;
R2 := R2 + 1;
N := R2;
. . .
|
Представим себе теперь, что при квазипараллельной реализации процессов в ходе выполнения этих трех операторов происходит переключение процессов. В результате, в зависимости от непредсказуемых случайностей, порядок выполнения операторов может оказаться различным, например:
1) R1 := N; R2 := N; R2 := R2 + 1; N := R2;
R1 := R1 - 1; N := R1;
2)R2 := N; R2 := R2 + 1;
R1 := N; R1 := R1 - 1; N := R1; N := R2;
3) R1 := N; R1 := R1 - 1; N := R1; R2 := N; R2 := R2 + 1; N := R2;
Ну и что? А то, что в случае 1 значение N в результате окажется уменьшенным на 1, в случае 2 – увеличенным на 1, и только в случае 3 значение N, как и положено, не изменится.
Можно привести менее экзотические примеры.
· Если два процесса одновременно пытаются отредактировать одну и ту же запись базы данных, то в результате разные поля одной записи могут оказаться несогласованными.
· Если один процесс добавляет сообщение в очередь, а другой в это время пытается взять сообщение из очереди для обработки, то он может прочесть не полностью сформированное сообщение.
· Если два процесса одновременно пытаются обратиться к диску, каждый со своим запросом, то что именно каждый из них в результате прочтет или запишет на диск – сказать трудно.
Ситуация понятна: нельзя разрешать двум процессам одновременно обращаться к одним и тем же данным, если при этом происходит изменение этих данных.
То, что мы рассматривали квазипараллельную реализацию процессов, не столь существенно. Для процессов, работающих на разных процессорах, но одновременно обращающихся к одним и тем же данным, ситуация примерно та же.
Задолго до создания многозадачных систем разработчики средств автоматики столкнулись с неприятным эффектом зависимости результата операции от случайного и непредсказуемого соотношения скоростей распространения разных сигналов в электронных схемах. Этот эффект они назвали «гонками». Мы здесь ведем речь, в сущности, о том же.
Для более четкого описания ситуации было введено понятие критической секции
.
Критической секцией процесса по отношению к некоторому ресурсу называется такой участок программы процесса, при прохождении которого необходимо, чтобы никакой другой процесс не находился в своей критической секции по отношению к тому же ресурсу.
В примере с билетами приведенные три оператора в каждом из процессов составляют критическую секцию этого процесса по отношению к общей переменной N. Алгоритм работы каждого процесса в отдельности правилен, но правильная работа двух процессов в совокупности может быть гарантирована, только если они не сунутся одновременно каждый в свою критическую секцию.
А как им это запретить?
На первый взгляд кажется, что эта проблема (ее называют проблемой взаимного исключения
процессов) решается просто. Например, можно ввести булеву переменную Free, доступную обоим процессам и имеющую смысл «критическая область свободна». Каждый процесс перед входом в свою критическую область должен ожидать, пока эта переменная не станет истинной, как показано ниже:
| Процесс A: |
Процесс B: |
. . .
while not Free do
;
Free := false;
(критическая секция A)
Free := true;
. . .
|
. . .
while not Free do
;
Free := false;
(критическая секция B)
Free := true;
. . .
|
В обоих процессах цикл while не делает ничего, кроме ожидания, пока другой процесс выйдет из своей критической секции.
А не нужно ли было что-нибудь сделать с переменной Free еще до запуска процессов A и B?
Прежде всего, отметим, что предложенное решение использует такую неприятную вещь, как активное ожидание: процессорное время растрачивается на многократную проверку переменной Free. Но это полбеды.
Беда в том, что такое решение ничего не решает. Если реализовать его на практике, то «неприятности» станут реже, но не исчезнут. В первом, бесхитростном варианте программы угрожаемыми участками были критические секции обоих процессов. Теперь же уязвимый участок сузился до одной точки, отмеченной в программе каждого процесса штриховой линией. Это точка между проверкой переменной Free и изменением этой переменной. Если переключение процессов произойдет, когда вытесняемый процесс будет находиться именно в этой точке, то сначала в критическую секцию войдет (с полным правом на это) другой процесс, а потом, когда управление вернется к первому процессу, он без дополнительной проверки тоже войдет в свою критическую секцию.
Разработчики первых программных систем, использующих взаимодействие параллельных процессов, не сразу осознали сложность проблемы взаимного исключения. Были испробованы различные программные решения, прежде чем удалось найти такое, которое удовлетворяло трем естественным условиям:
· в любой момент времени не более, чем один процесс может находиться в критической секции;
· если критическая секция свободна, то процесс может беспрепятственно войти в нее;
· все процессы равноправны.
Попробуйте сами найти такое решение. В книгах /3/ и /4/ можно найти несколько вариантов решения с анализом их ошибок.
В конце концов правильные алгоритмы решена задачи взаимного исключения предложили сначала Деккер (его алгоритм довольно запутанный, что часто случается с первыми решениями сложных задач), затем Питерсон, чей алгоритм проще и понятнее.
Для любознательных приводим решение Питерсона. В нем используются булевы переменные flagA, flagB, изначально равные false, и переменная перечисляемого типа turn: A..B.
| Процесс A: |
Процесс B: |
. . .
flagA := true;
turn := B;
while flagB and turn = B do
;
(критическая секция A)
flagA := false;
. . .
|
. . .
flagB := true;
turn := A;
while flagA and turn = A do
;
(критическая секция B)
flagB := false;
. . .
|
Приведенный алгоритм действительно решает проблему, однако у него есть два существенных недостатка. Во-первых, если в конкуренции за критическую секцию участвуют не два процесса, а три или более, то программа становится очень громоздкой. Во-вторых, решение Питерсона основано на использовании активного ожидания.
Еще одним направлением в реализации взаимного исключения стало включение специальных машинных команд в наборы команд новых процессоров. Поскольку опасность, как мы видели, связана с разделением по времени операций проверки и присваивания, то были предложены команды, выполняющие одновременно проверку и присваивание. Такие команды есть, например, у процессоров Pentium. С их помощью действительно можно проще реализовать взаимное исключение, но для этого все равно требуется активное ожидание.
4.3.3. Двоичные семафоры Дейкстры
Совершенно иным образом подошел к проблеме взаимного исключения великий голландский ученый Э.Дейкстра (E.Dijkstra, 1966). Он предложил использовать новый вид программных объектов – семафоры
. Здесь мы рассмотрим их простейший вариант – двоичные семафоры
, они же мьютексы
(mutex, от слов MUTualEXclusion – взаимное исключение).
Двоичным семафором называется переменная S, которая может принимать значения 0 и 1 и для которой определены только две операции.
· P(S) – операция занятия (закрытия) семафора. Она ожидает, пока значение S не станет равным 1, и, как только это случится, присваивает S значение 0 и завершает свое выполнение. Очень важно: операция Pпо определению неделима, т.е. между проверкой и присваиванием не может вклиниться другой процесс, который бы изменил значение S.
· V(S) – операция освобождения (открытия) семафора. Она просто присваивает S значение 0.
Чем переменная-семафор отличается от обычной булевой переменной? Тем, что для нее недопустимы никакие иные операции, кроме P и V. Нельзя написать в программе S:=1 или if(S)then ... , если S определена как семафор.
Чем операция P отличается от варианта с проверкой и присваиванием, который мы выше признали неудовлетворительным? Неделимостью. Но это «по определению», а как на практике добиться этой неделимости? Это отдельный, вполне решаемый вопрос.
Заслуга Дейкстры как раз в том, что он разделил проблему взаимного исключения на две независимые проблемы разных уровней:
· на уровне реализации: как обеспечить работу семафоров в соответствии с их определением;
· на уровне взаимодействия процессов: как написать корректно работающую программу, если в распоряжении программиста имеются семафоры.
Решать эти две задачи по отдельности легче, чем обе вместе, при этом решать их обычно должны разные люди: первую – разработчики ОС, а вторую – разработчики прикладной программы.
Рассмотрим сначала реализацию. Очевидно, функции P и V удобнее и надежнее один раз реализовать в ОС, чем каждый раз по-новому – в прикладных программах. (Названия этих функций могут в конкретных системах быть и иными, более выразительными.)
Системная функция P(S) должна проверить, свободен ли семафор S. Если свободен (S = 1), то система занимает его (S := 0) и на этом функция завершается. Если же семафор занят, то система блокирует процесс, вызвавший функцию P, и запоминает, что этот процесс блокирован по ожиданию освобождения семафора S. Таким образом, при реализации семафоров удается избежать активного ожидания.
Неделимость операции обеспечивается тем, что во время выполнения системой функции P переключение процессов запрещено. В крайнем случае, ОС имеет возможность для этого на короткое время запретить прерывания.
Системная функция V(S) – это, конечно, не просто присваивание S := 1. Кроме этого, система должна проверить, нет ли среди спящих процессов такого, который ожидает освобождения семафора S. Если такой процесс найдется, система разблокирует его, а переменная S в этом случае сохраняет значение 0 (семафор снова занят, теперь уже другим процессом).
Может ли случиться так, что несколько спящих процессов ждут освобождения одного и того же семафора? Да, так вполне может быть. Какой из этих процессов должен быть разбужен системой? С точки зрения корректности работы и соответствия определениям функций P и V – любой, но только один. С точки зрения эффективности работы – вероятно, надо разбудить самый приоритетный процесс, а в случае равенства приоритетов… ну, видимо, тот, который спит дольше.
Теперь, когда мы разобрались с реализацией семафоров, можно о ней забыть[9]
и помнить только, что семафоры существуют и могут быть использованы при необходимости.
Рассмотрим теперь вторую половину задачи – использование семафоров для управления взаимодействием процессов. Как можно реализовать корректную работу процессов с критическими секциями, если использовать двоичный семафор? Да очень просто.
| Процесс A: |
Процесс B: |
. . .
P(S);
(критическая секция A)
V(S);
. . .
|
. . .
P(S);
(критическая секция B)
V(S);
. . .
|
И все. Сложности ушли в реализацию семафоров. Надо только проследить, чтобы до начала работы процессов семафор S был открыт.
4.3.4. Средства взаимодействия процессов
Можно доказать, что использование двоичных семафоров позволяет корректно решить любые проблемы синхронизации процессов. Но вовсе не обязательно это решение окажется простым и удобным. В некоторых случаях использование семафоров должно все же сопровождаться нежелательным активным ожиданием.
За десятилетия, прошедшие после изобретения семафоров, были предложены различные средства синхронизации, более приспособленные для различных типовых задач. Рассмотрим некоторые из них.
4.3.4.1. Целочисленные семафоры
В упомянутой работе Дейкстры, помимо двоичных семафоров, принимающих значения 0 и 1, был рассмотрен также более общий тип семафоров со значениями на интервале от 0 до некоторого N. Функция P(S) уменьшает положительное значение семафора на 1, а при нулевом значении переходит в ожидание, как и в случае двоичного семафора. Функция V(S) увеличивает значение семафора на 1, но не более N.
Область применения целочисленных семафоров несколько иная, чем у двоичных. Целочисленные семафоры применяются в задачах выделения ресурсов из ограниченного запаса. Величина N характеризует общее количество имеющихся единиц ресурса, а текущее значение переменной – количество свободных единиц. При запросе ресурса процесс вызывает функцию V(S), при освобождении – P(S).
Для целочисленных семафоров иногда удобно использовать модифицированную функцию V(S, k), вторым параметром которой является число одновременно запрашиваемых единиц ресурса. Такая функция блокирует процесс, если значение семафора меньше k.
4.3.4.2. Семафоры с множественным ожиданием
Возможна ситуация, когда процесс может выбрать один из нескольких путей дальнейшей работы, но на каждом пути он может быть заблокирован закрытым семафором. Разумно было бы ждать освобождения любого из семафоров и только тогда выбрать свободный путь. Но как это сделать? Вызвав P(S) для одного из семафоров, процесс обречен ждать освобождения именно этого семафора, а не любого из имеющихся.
Житейская ситуация: покупатель в супермаркете, выбирающий, к какой из касс занять очередь. Хорошо бы угадать очередь, которая пройдет быстрее…
Функция множественного ожидания
P(S1
, S2
, … Sn
) позволяет указать в качестве параметров несколько двоичных семафоров (или массив семафоров). Если хотя бы один из семафоров свободен, функция занимает его, в противном случае она ждет освобождения любого из семафоров.
Другой, не менее полезный вариант множественного ожидания, это ожидание момента, когда все указанные семафоры окажутся свободны. Это означает, что процесс может работать дальше только в том случае, если одновременно выполнены несколько условий, каждое из которых задано в виде двоичного семафора.
4.3.4.3. Сигналы
Сигнал
– это нечто, что может быть послано процессу системой или другим процессом. С сигналом не связано никакой информации, кроме номера (кода), указывающего, какой именно тип сигнала посылается. При получении сигнала процесс прерывает свою текущую работу и переходит на выполнение функции, определенной как обработчик сигналов данного типа.
Таким образом, сигналы сильно похожи на прерывания, но только высокоуровневые, управляемые системой, а не аппаратурой.
Механизм сигналов позволяет решить, например, проблему критической секции иным способом, чем семафоры.
Подумайте самостоятельно, как это можно сделать.
4.3.4.4. Сообщения
Сообщения
также посылаются процессу системой или другим процессом, однако отличаются от сигналов в двух отношениях.
Во-первых, сообщения не прерывают работу процесса-получателя. Вместо этого они становятся в очередь сообщений. Процесс должен сам вызвать функцию приема сообщения. Если очередь пуста, эта функция блокирует процесс до получения какого-нибудь сообщения.
Во-вторых, с сообщением, в отличие от сигнала, может быть связана информация, передаваемая получателю. Таким образом, сообщения – это средство не только синхронизации, но и обмена данными между процессами.
4.3.4.5. Общая память
Поговорим теперь еще об обмене данными. Самым простым и естественным способом такого обмена представляется возможность совместного доступа двух или более процессов к общей области памяти. Но поскольку обычно ОС стремится, наоборот, надежно разделить память разных процессов, то для выделения обшей памяти нужны специальные системные средства.
Общая память служит только средством обмена данными, но никак не решает проблем синхронизации. Участки программы, где происходит работа с общей памятью, часто следует рассматривать как критические секции и защищать семафорами.
4.3.4.6. Программные каналы
Другое часто используемое средство обмена данными – программный канал (pipe; иногда переводится как «трубопровод»). В этом случае для выполнения обмена используются не команды чтения/записи в память, а функции чтения/записи в файл. Программный канал «притворяется файлом», для работы с ним используются те же операции, что для последовательного доступа к файлу: открытие, чтение, запись, закрытие. Однако источником читаемых данных служит не файл на диске, а процесс, выполняющий запись «в другой конец трубы». Данные, записанные одним процессом, но пока не прочитанные другим, хранятся в системном буфере. Если же процесс пытается прочесть данные, которые пока не записаны другим процессом, то процесс-читатель блокируется до получения данных.
4.3.5. Проблема тупиков
Согласно определению из /7/, тупик – это состояние, в котором «некоторые процессы заблокированы в результате таких запросов на ресурсы, которые никогда не могут быть удовлетворены, если не будут предприняты чрезвычайные системные меры».
Как это прикажете понимать?
Прежде всего, давайте отметим, что процессу, действующему в одиночку, не под силам загнать приличную ОС в тупик. Требования процесса не будут удовлетворены, только если они превышают то, что есть у системы. Скажем, процесс требует 500 Мб оперативной памяти, когда у системы есть всего-то 256 Мб. Ну, так в этом случае процесс будет не блокирован, а беспощадно убит системой.
Иное дело, если в деле замешаны два или более процессов. Согласно другому определению, данному в /2/, «Группа процессов находится в тупиковой ситуации, если каждый процесс из группы ожидает события, которое может вызвать только другой процесс из той же группы».
Рассмотрим такой пример. Пусть каждый из процессов A и B собирается работать с двумя файлами, F1 и F2, причем не намерен разделять эти файлы с другим процессом. Программы же процессов слегка различаются, а именно:
| Процесс A: |
Процесс B: |
. . .
Открыть(F1);
Открыть(F2);
(работа процесса A с файлами);
Закрыть(F1);
Закрыть(F2);
. . .
|
. . .
Открыть(F2);
Открыть(F1);
(работа процесса B с файлами);
Закрыть(F1);
Закрыть(F2);
. . .
|
В этой ситуации все может пройти благополучно. Пусть, например, процесс A успеет открыть оба файла к тому моменту, когда процесс B попытается открыть F2. Эта попытка не увенчается успехом: процесс B либо будет заблокирован до освобождения файлов, либо получит сообщение об ошибке при открытии файла и, если процесс умный, через какое-то время попытается еще раз. В конце концов оба процесса получат требуемые ресурсы (в данном случае открытые файлы), хотя и не оба сразу.
Совсем иное будет дело, если A успеет открыть только F1, после чего B откроет F2. Тут-то и получится тупик. Процесс A хочет открыть файл F2, но не сможет этого сделать раньше, чем B закроет этот файл. Но B не закроет F2 до того, как сумеет открыть файл F1, который занят процессом A. Каждый из процессов захватил один из ресурсов и не собирается его отдавать раньше, чем получит другой. Ситуация «двух баранов на мосту».
Подчеркнем: тупик – это не просто блокировка процесса, когда необходимый ему ресурс занят. Занят – ну и что, со временем, авось, освободится. Тупик – это взаимная блокировка
, из которой нет выхода.
Еще пример. Пусть в системе имеется 100 Мб памяти, доступной для процессов. Процесс A при своем старте занимает 40 Мб, но позднее на короткое время требует еще 30 Мб, после чего завершается, освобождая всю память. Процесс B ведет себя точно таким же образом.
Каждый из процессов по отдельности не требует у системы ничего невозможного. В то же время понятно: если оба процесса сумеют стартовать и начать параллельную работу, то ни один из них никогда не получит дополнительные 30 Мб. Тупик.
Совсем грубый пример. Процесс A на каком-то этапе работы ждет сообщения от процесса B, после чего собирается послать ответное сообщение. В то же время процесс B ждет сообщения от A, чтобы потом ответить на него. Тупик неизбежен. В данном случае, в отличие от предыдущих, возникновение тупика связано с явной ошибкой в логике программы.
Может ли помочь в борьбе с тупиками использование семафоров и других подобных средств? Вряд ли, разве что в редких случаях. Семафор – это, скорее, дополнительный тормоз для процесса. Вещь полезная, но не способствующая продвижению.
Все известные способы борьбы с тупиками можно разделить на три группы:
· исключение возможности тупиков путем анализа исходного текста программ;
· предотвращение возникновения тупиков при работе ОС;
· ликвидация возникших тупиков.
Что касается анализа текста – это, безусловно, нужная вещь, хотя и непростая. Определить по тексту программ процессов, могут ли они зайти в тупик – сложная задача. К тому же, если и могут, то совсем не обязательно зайдут, все может зависеть от конкретных исходных данных и от временных соотношений. Но главное – для анализа исходного текста программ нужно иметь в своем распоряжении этот текст. Реально ли это? Только в некоторых ситуациях. Например, при разработке встроенной системы исходные тексты всех прикладных программ обычно доступны разработчику ОС. Конечно, в этом случае анализ на возможность тупиков просто необходим. Другой пример – разработка сложного многопроцессного приложения, когда разработчик должен хотя бы выявить возможность взаимной блокировки между «своими» процессами.
Если тексты недоступны, то можно попытаться предотвращать тупики уже в ходе работы программ, отслеживая их запросы на ресурсы и блокируя либо прекращая те процессы, которые, по-видимому, «лезут в тупик».
Самый грубый из подобных подходов заключается в том, что каждый процесс должен захватывать все необходимые ему ресурсы сразу, при старте, после чего он может либо удерживать ресурсы в течение всего времени работы, либо освобождать ресурсы, которые больше не нужны. Такой подход, безусловно, в корне исключает возможность тупиков. К сожалению, на практике он почти исключает и многозадачную работу: многие ресурсы необходимы для работы большинства процессов (например, диски, принтер, системные файлы), поэтому пока один процесс удерживает все ресурсы, другие не смогут даже стартовать.
Чуть получше алгоритм нумерованных ресурсов
. Он заключается в том, что все ресурсы, имеющиеся в системе, нумеруются целыми числами в произвольном порядке (хотя, вероятно, для повышения эффективности лучше всего пронумеровать их в порядке возрастания дефицитности ресурса). Далее применяется простое правило: запрос процесса на выделение ему ресурса с номером K удовлетворяется только в том случае, если процесс в данный момент не владеет никаким другим ресурсом с номером N³K. Другими словами, запрос ресурсов следует выполнять только в порядке возрастания номеров. Нетрудно показать, что это правило является достаточным условием отсутствия тупиков. Но это условие слишком ограничивающее, оно отсекает много ситуаций, когда тупик на самом деле не возник бы.
Наиболее изящен алгоритм банкира
, предложенный тем же Дейкстрой. В нем предполагается, что каждый процесс при старте должен объявить системе, на какие ресурсы и в каком максимальном количестве он может в будущем претендовать. Далее, вводится понятие безопасного
(в отношении тупиков) состояния системы
. Текущее состояние, в котором имеется набор процессов, каждый из которых владеет некоторыми ресурсами, считается безопасным, если имеющихся в наличии свободных ресурсов достаточно для того, чтобы ОС смогла в определенной последовательности удовлетворить максимальные запросы каждого процесса.
Это определение проще понять, если рассмотреть, как проверяется безопасность заданного состояния. Согласно алгоритму, среди имеющихся процессов ищется такой, чьи максимальные заявленные запросы система может удовлетворить, используя имеющиеся свободные ресурсы. Если хотя бы один такой процесс найден, то он вычеркивается из общего списка и все ресурсы, которые он уже успел занять, считаются свободными (т.е. считается, что система смогла завершить этот процесс). Далее, при увеличившихся свободных ресурсах, ищется следующий процесс, чьи запросы система может удовлетворить, и т.д. Если в результате удается вычеркнуть все процессы, то анализируемое состояние системы является безопасным.
Сам же алгоритм банкира можно теперь сформулировать очень просто: любой запрос процесса на выделение ему дополнительных ресурсов должен удовлетворяться только в том случае, если состояние, в которое перейдет система после этого выделения, будет безопасным.
Название алгоритма навеяно, видимо, образом осторожного банкира, который выдает кредит только в том случае, если после этого сможет выполнить все свои обязательства даже в худшем случае. Явно не российский банкир.
Хотя данный алгоритм красив и логичен, у него есть, по меньшей мере, два недостатка. Во-первых, в современных ОС не принято требовать от процессов, чтобы те заранее объявляли свои будущие потребности в ресурсах. Во-вторых, выполнять проверку безопасности состояния при каждом запросе любого из процессов – слишком трудоемкое удовольствие.
Рассмотрим, наконец, третий подход – ликвидацию уже возникших тупиков, без попыток предотвратить их возникновение. В книге /2/ этот подход назван «алгоритмом страуса».
Здесь, прежде всего, возникает вопрос: как убедиться, что система действительно в тупике? Внешним признаком этого является длительное отсутствие какой-либо активности двух или более процессов. Но это недостоверный признак, процессы могли просто надолго задуматься над каким-нибудь трудоемким вычислением. Есть алгоритмы, которые анализируют текущее состояние процессов и ресурсов, наличие заблокированных запросов, и на этой основе ставят диагноз тупика. В принципе, такой алгоритм мог бы быть встроен в ОС. Однако в литературе нет сведений о том, чтобы это было осуществлено на практике. Обычно полагаются на волевое решение оператора или администратора системы.
Но пусть даже точно известно, что тупик есть. Как можно его устранить? Как «растащить баранов с моста»? Как правило, для этого применяется радикальное решение: принудительно прекратить один из тупиковых процессов (сбросить одного барана в реку). Если не помогло – утопить следующего барана. И т.д.
В литературе рассматриваются и более гуманные, но сложные способы. В принципе, можно регулярно запоминать состояние всех или только наиболее ответственных процессов в определенных контрольных точках или через определенные периоды времени. Тогда, вместо полного прекращения процесса, его можно вернуть к одной из последних контрольных точек и придержать там, пока другой баран не перейдет через реку.
Завершая рассмотрение проблемы тупиков, следует признать, что в настоящее время ее практическое значение значительно меньше, чем хотелось бы теоретикам. Во-первых, совсем не легко загнать в тупик современную ОС, работающую на компьютере с огромными ресурсами. В примере мы рассмотрели тупик, возникший из-за 100 Мб памяти, но если учесть еще несколько гигабайт, которые можно использовать в файле подкачки, то запросы процессов должны быть уж очень велики, чтобы привести к тупику. А, скажем, такое устройство, как принтер, в современных ОС вообще не может стать причиной тупика, т.к. система не отдает его во владение ни одному процессу даже на время.
Во-вторых, хотя тупик в принципе остается возможным, пользователь вряд ли даже заметит его. Скорее, он скажет «Опять Windows зависла!» и перезагрузит систему.
Предотвращение тупиков остается действительно важным, например, при разработке встроенной системы, которая должна длительное время безотказно работать без вмешательства человека.
4.4.1. Процессы в MS-DOS
Как говорилось выше, управление процессами в однозадачных ОС, к которым относится MS-DOS, является сравнительно тривиальной задачей.
Загрузка ОС завершается запуском программы командного интерпретатора COMMAND.COM, в задачи которого входит:
· чтение и анализ команд, вводимых пользователем с клавиатуры;
· выполнение внутренних команд системы, таких, как команда выдачи содержания каталога, команды копирования, удаления и переименования файлов и т.п.;
· запуск на выполнение системных и прикладных программ;
· обработка критических ошибок, происшедших в ходе выполнения системных функций MS-DOS;
· завершение работы программы с освобождением всех ресурсов, занимавшихся программой.
Запуская программу пользователя, COMMAND.COM не завершает собственную работу, а фактически переходит в состояние сна. После завершения запущенной программы COMMAND.COM возобновляет работу, выдавая приглашение к вводу следующей команды. Таким же образом программа пользователя может запустить другую программу и ожидать ее завершения. Количество одновременно присутствующих в системе процессов ограничено только размером памяти системы (не более 640 Кб на всех), однако только последняя запущенная программа может быть в активном (работающем) состоянии. Если же и эта программа блокируется на выполнении системной функции (например, ожидает ввода с клавиатуры), то в системе не остается активных процессов. Таким образом, термин «однозадачная ОС» в данном случае следует понимать как «ОС, допускающая не более одной активной задачи». Системе не приходится заниматься разделением процессорного времени и другими «многозадачными» проблемами, за исключением только сохранения и восстановления контекста родительской программы.
Некоторым исключением из правила «одна активная задача» являются резидентные программы MS-DOS, рассмотренные в п. 4.4.5.
4.4.2. Среда программы
Среда
программы (environment; другой перевод – «окружение») представляет собой текстовый массив, состоящий из строк вида:
"переменная=значение", 0
Здесь переменная и значение – любые (в разумных пределах) текстовые величины, байт 0 завершает каждую строку.
Понятие среды было введено в системе UNIX и позаимствовано оттуда в MS-DOS и Windows без особых изменений.
Имеется несколько стандартных (системных) переменных среды, из которых наиболее известны PATH (определяет пути к каталогам, в которых система ищет исполняемый файл) и PROMPT (задает вид подсказки при диалоге с ОС). Кроме того, многие прикладные программы требуют для правильной работы, чтобы были заданы специфические переменные среды, описывающие, например, размещение рабочих каталогов программы, способ работы с расширенной памятью или какие-то иные характеристики режима работы программы.
Можно рассматривать переменные среды как своего рода параметры, передаваемые программе при ее запуске, аналогично тому, как подпрограмма получает параметры при вызове. Интерпретатор команд COMMAND.COM также имеет свою среду, которую называют корневой средой. Для создания переменных корневой среды, их удаления и изменения значений может использоваться системная команда SET. Когда COMMAND.COM запускает программу пользователя или одна программа запускает другую, создается порожденный процесс, который получает собственный экземпляр блока среды, при этом по умолчанию создается точная копия среды родителя, однако можно создать совершенно иную среду.
4.4.3. Запуск программы
Одной из основных задач, которые должна решать система, является запуск программ на выполнение. Для этого предназначена системная функция Exec, которая может быть вызвана либо программой COMMAND.COM, выполняющей команду пользователя, либо непосредственно программой пользователя, через программное прерывание int 21h.
Функция Exec требует указания ряда параметров, из которых важны:
· Имя файла запускаемой программы. Если имя не содержит пути к каталогу, то файл ищется в текущем каталоге, а также в каталогах, перечисленных в переменной PATH.
· Командная строка. Так принято называть строку параметров, передаваемых программе. При запуске программы по команде пользователя командная строка задается после имени программы, она отделена от имени пробелом. Анализ содержимого командной строки полностью возлагается на запускаемую программу, система лишь передает эту строку программе.
· Адрес массива, содержащего параметры среды программы. Если он не задан, то для запускаемой программы создается копия среды программы-родителя.
В MS-DOS используются два формата выполняемых программ.
Файл формата COM содержит только коды позиционно-независимой программы, которая может быть без изменения загружена для исполнения по любому свободному адресу памяти. Все программа должна помещаться в единственном сегменте, поэтому размер файла ограничен 64 Кб.
Файл формата EXE представляет собой перемещаемую программу. Файл состоит из заголовка, словаря перемещений и собственно кода. Информация в заголовке позволяет указать размер части файла, которая должна загружаться в память при запуске программы, максимальный и минимальный размер памяти, дополнительно резервируемой для размещения данных, начальный адрес стека, адрес запуска программы. Размер файла практически не ограничен, но размер загружаемой части должен быть в пределах, предоставляемых DOS, т.е. примерно 500 – 550 Кб.
Первые два байта EXE-файла содержат сигнатуру (признак) файла формата EXE, в качестве которой используются две буквы 'MZ'[10]
. Считается, что это инициалы программиста Марка Збиковского, который участвовал в разработке MS-DOS.
При запуске программы система выполняет следующие действия:
· Выделяет два непрерывных блока памяти: для параметров среды (блок среды) и для самой программы (блок PSP). Для программы, как правило, выделяется максимально возможный непрерывный блок памяти, если только в заголовке EXE-файла не задан меньший размер.
· Определяет размер загружаемой части программы (для COM-файла это весь файл), и считывает из файла коды программы.
· Для EXE-файла выполняет настройку программы на адрес загрузки, прибавляя этот адрес к тем местам программы, которые перечислены в словаре перемещений.
· Формирует в начале блока программы массив, который называется PSP
(ProgramSegmentPrefix). В PSP содержатся, в частности, адрес блока среды, адрес возврата в родительскую программу, адрес и размер таблицы JFT, сама эта таблица, командная строка программы.
· Заполняет первые 5 элементов таблицы JFT (стандартные хэндлы), копируя их из JFT родительской программы.
· Заносит начальные значения в регистры процессора.
· Запоминает адрес PSP программы в качестве идентификатора текущего процесса (PID, ProcessIDentifier).
· Наконец, выполняет переход на адрес запуска программы. Для COM-файла этот адрес следует сразу за PSP, для EXE-файла в заголовке может быть указан любой адрес.
4.4.4. Завершение работы программы
Завершение программы обычно включает в себя следующие действия системы:
· Закрываются все файлы, открытые программой.
· Освобождаются все блоки памяти, отведенные для программы и ее среды.
· Восстанавливаются стандартные обработчики описанных ниже прерываний int 23h и int 24h, которые могли быть изменены отработавшей программой.
· Управление передается родительской программе.
В MS-DOS определены 4 возможные причины, которые могут вызвать завершение работы программы.
· Нормальное завершение
. Оно происходит, когда программа вызывает системную функцию Terminate. В качестве аргумента этой функции программа передает код завершения
– число, уточняющее причину завершения. Обычно код завершения 0 означает, что программа проработала благополучно, а ненулевые значения указывают на различные неприятности (отсутствие файла для обработки, неверный формат данных и т.п.).
· Завершение по запросу пользователя
. Оно происходит, если пользователь нажимает одну из комбинаций клавиш Ctrl+C или Ctrl+Break. Система не торопится прекращать работу программы, пока не вызовет программное прерывание int 23h. В зависимости от результата, возвращаемого обработчиком этого прерывания, программа либо будет завершена, либо продолжит работу. По умолчанию система сама обрабатывает прерывание и сама себе отвечает: «Завершить программу». Однако программа может взять обработку прерывания на себя и ответить системе: «Продолжаем работать». Так обычно и поступают все серьезные программы MS-DOS.
· Завершение по критической ошибке
. Критической считается ошибка, происшедшая в ходе выполнения какой-либо системной функции MS-DOS и имеющая аппаратный характер (точнее, обнаруженная драйвером устройства). Например, отсутствие файла не является критической ошибкой, а ошибка чтения с диска – является. Система вызывает программное прерывание int 24h, передавая как аргументы подробное описание ошибки (на каком устройстве, при какой операции и т.п.). В ответ система хочет получить от обработчика указание, как реагировать на ошибку. Имеется 4 вида реакции: Ignore – игнорировать ошибку; Retry – повторно выполнить операцию, вызвавшую ошибку; Abort – завершить программу; Fail – вернуть код ошибки программе пользователя. Системный обработчик прерывания запрашивает требуемую реакцию у пользователя. Однако программа и в данном случае может взять обработку прерывания на себя и попытаться автоматически выбрать желаемую реакцию на основании описания ошибки.
· Завершение с установкой резидента
. Оно похоже на нормальное завершение, но отличается двумя важными особенностями. Во-первых, файлы, открытые программой, не закрываются. Во-вторых, системе возвращается не вся память, занимаемая завершившейся программой. Некоторая часть памяти остается скрытой от системы и может быть использована для размещения резидентных программ, описанных в следующем пункте.
Имеется системная функция, с помощью которой родительская программа может проверить причину и код завершения программы-потомка.
4.4.5. Перехват прерываний и резидентные программы
Большая часть всех функциональных возможностей MS-DOS заключается в обработке разнообразных аппаратных и особенно программных прерываний. В частности, обращение к многочисленным системным функциям MS-DOS выполняется с помощью вызова программного прерывания int 21h.
Тем важнее оказывается тот факт, что в MS-DOS программа пользователя имеет возможность перехватить любое прерывание, т.е. установить свой обработчик этого прерывания. Фактически для этого достаточно записать адрес нового обработчика по соответствующему адресу памяти. Имеются системные функции для запоминания адреса прежнего обработчика и установки нового.
Перехват аппаратных прерываний позволяет программе оперативно реагировать на различные события. Особенно часто перехватываются прерывания от таймера, что позволяет выполнять некоторое действие регулярно, через заданный интервал времени, (скажем, отображать текущее время) или же выполнить его один раз в заранее запланированный момент, а также прерывания от клавиатуры, позволяющие выполнить действие при нажатии определенной комбинации клавиш. Например, одно время были популярны резидентные калькуляторы, которые появлялись на экране при нажатии заданных клавиш. Еще один пример такого рода – программы, переключающие русский/латинский регистры клавиатуры.
Перехват программных прерываний позволяет программе модифицировать выполнение любой функции MS-DOS. Выше говорилось об использовании перехвата прерываний для определения реакции программы на нажатие Ctrl+Break и на критические ошибки. Еще одним примером может служить системная программа SHARE.EXE, которая обеспечивает корректное разделение файлов между процессами. Эта программа перехватывает основные файловые функции MS-DOS, чтобы отследить все открытия и закрытия файлов и установку/снятие блокировок. На основании этой информации модифицированные функции открытия, чтения и записи файла определяют, разрешена ли запрошенная операция.
Программы, использующие перехват прерываний, можно разбить на два класса.
· Нерезидентные программы
, которые после завершения своей работы возвращают управление и всю занимаемую память системе. Такие программы перехватывают прерывания только на время своей работы и должны обязательно восстановить стандартную обработку прерываний при своем завершении. Это требование касается не только нормального завершения, но и завершения по Ctrl+Break и по критической ошибке. В противном случае при последующем возникновении прерывания управление будет передано по адресу уже не существующего в памяти обработчика, а это крах.
· Резидентные программы
представляют собой обработчики прерываний, остающиеся в памяти и после завершения загрузившего их процесса, вплоть до перезагрузки системы. Таким образом, резидентные программы могут оказывать влияние на работу MS-DOS и всех запускаемых программ.
К какому классу должна принадлежать упомянутая выше программа SHARE.EXE?
Не будет ошибкой сказать, что резидентные программы в некоторой степени превращают однозадачную MS-DOS в многозадачную систему. В данном случае реализуется примитивная форма фоново-оперативной диспетчеризации, в которой резидентные программы играют роль оперативных процессов, а обычная работа MS-DOS осуществляется в фоновом режиме.
К сожалению, в MS-DOS нет надежных, поддерживаемых системой средств для создания оперативных процессов. Вместо этого есть только возможность перехвата прерываний и еще некоторые полезные, но разрозненные функции, которые дают прикладному программисту возможность «вручную» реализовать многозадачность, но не гарантируют корректности результата.
Среди проблем, которые приходится решать разработчику резидентных программ, можно назвать несколько наиболее типичных.
· При установке резидентной программы следует проверить, не была ли она уже установлена, поскольку двукратный перехват прерываний одной и той же программой обычно приводит к неверной работе программы. Такую проверку можно выполнить различными способами. Чаще всего используют вызов определенного программного прерывания, которое должно вернуть характерный результат, если оно уже перехвачено.
· В MS-DOS нет понятия контекста программы и тем более нет средств переключения контекста. Если работа резидентной программы может привести к изменению таких системных данных, как текущие диск и каталог, информация о последней случившейся ошибке, идентификатор текущего процесса и т.п., то эта программа должна позаботиться о сохранении и восстановлении этих данных, чтобы не помешать нормальной работе фонового процесса.
· Почти все функции MS-DOS нереентерабельны, причем даже не по отдельности, а в совокупности, т.е. вызов одной из этих функций при незавершенном выполнении другой может привести к краху системы. Это не вызывает затруднений, пока MS-DOS работает как однозадачная система. Однако активизация резидентной программы может произойти во время выполнения функции DOS, вызванной из фоновой программы. Если резидентная программа также вызовет какую-либо системную функцию (а без этого невозможно, например, работать с файлами), то последствия будут плачевны. Способы обойти это затруднение существуют, но по своей запутанности они больше похожи на рецепты алхимиков.
В отличие от «полуторазадачной» MS-DOS, которая оставляет прикладному программисту всю работу (и весь риск) организации параллельного функционирования процессов, многозадачные ОС предоставляют программисту более или менее удобный и богатый набор системных функций, позволяющих запустить несколько параллельных процессов и организовать их взаимодействие (синхронизацию процессов, обмен данными, взаимное исключение и т.п.). При этом ОС обязана гарантировать корректную и эффективную организацию переключения процессов, разделения между ними процессорного времени, памяти и других ресурсов.
Сложность проблемы организации взаимодействия параллельных процессов существенно разная для систем, использующих вытесняющую и невытесняющую диспетчеризацию процессов. При вытесняющей диспетчеризации процесс может быть прерван диспетчером практически в любой момент. Помимо задачи сохранения и последующего восстановления контекста процесса (см. п. 4.2.5), которая должна решаться самой ОС, возникают еще и задачи обеспечения взаимного исключения при выполнении критических секций в многозадачных приложениях. Только разработчик программы может решить, какие части текста его программы являются критическими секциями и должны быть защищены семафорами.
В системе с невытесняющей диспетчеризацией программисту достаточно проверить, что критические секции не содержат вызовов блокирующих и вытесняющих функций. При этом можно гарантировать, что в ходе выполнения критической секции не произойдет переключения процессов.
Все версии Windows от 1.0 до 3.11 представляли собой достаточно мощные многозадачные системы с невытесняющей диспетчеризацией. Версии, начиная с WindowsNT и Windows 95, используют вытесняющую диспетчеризацию.
4.5.1. Понятие объекта в Windows
В ОС Windows широко используется понятие системного объекта
. По сути, любой объект представляет собой некоторую структуру данных, расположенную в адресном пространстве системы. Поскольку приложения не могут иметь доступа к этой памяти, то для работы с объектом приложение должно получить хэндл
объекта – некоторое условное число, которое будет представлять данный объект при обращении к API-функциям. Процесс получает хэндл, как правило, при вызове функции CreateXxx (здесь Xxx – название объекта), которая может либо создать новый объект, либо открыть существующий объект, созданный другим процессом. Функции вида OpenXxx позволяют только открыть существующий объект.
Объекты Windows делятся на объекты ядра (KERNEL), позволяющие управлять процессами, объекты USER, описывающие работу с окнами, и объекты GDI, задающие графические ресурсы Windows. В данном курсе рассматриваются только объекты ядра. Процессы, нити и открытые файлы являются примерами объектов ядра.
Одной из отличительных особенностей объектов ядра являются атрибуты защиты
, которые можно указать при создании объекта. Эти атрибуты определяют права доступа к объекту для различных пользователей и групп. Кроме того, при создании объекта ядра можно задать его имя, которое используется для того, чтобы другие процессы могли открыть тот же объект, зная его имя.
Хэндл объекта может быть использован только тем процессом, который создал или открыл этот объект. Нельзя просто переслать значение хэндла другому процессу, оно не будет действовать в другом контексте. Имеется, однако, функция DuplicateHandle, которая создает корректную копию хэндла, требуя указать для этого, какой процесс создает копию, какого именно хэндла и для какого процесса предназначена копия.
Если хэндл объекта больше не нужен данному процессу, его следует закрыть с помощью функции CloseHandle, общей для разных типов объектов.
Объект существует до тех пор, пока не будут закрыты все хэндлы, указывающие на него.
4.5.2. Процессы и нити
Общее понятие процесса, рассмотренное выше в п. 4.2.1, для ОС Windows как бы распадается на два понятия: собственно процесса и нити
(thread; в некоторых книгах используется термин поток
). При этом нить является единицей работы, она участвует в конкуренции за процессорное время, изменяет свое состояние и приоритет, как было описано выше для процесса. Что же касается процесса в Windows, то он может состоять из нескольких нитей, использующих общую память, открытые файлы и другие ресурсы, принадлежащие процессу. В двух словах: процесс – владеет (памятью, файлами), нити – работают, при этом совместно используя ресурсы своего процесса. Правда, нить тоже кое-чем владеет: окнами, очередью сообщений, стеком.
Процесс создается при запуске программы (EXE-файла). Одновременно создается одна нить процесса (должен же кто-то работать!). Создание процесса выполняется с помощью API-функции CreateProcess. Основными параметрами при вызове этой функции являются следующие.
· Имя файла запускаемой программы.
· Командная строка, передаваемая процессу при запуске.
· Атрибуты защиты для создаваемых процесса и нити. И процесс, и нить являются объектами ядра Windows и в этом качестве могут быть защищены от несанкционированного доступа (например, от попыток других процессов вмешаться в работу данного процесса).
· Различные флаги, уточняющие режим создания процесса. Среди них следует отметить класс приоритета процесса, флаг отладочного режима (при этом система будет уведомлять процесс-родитель о действиях порожденного процесса), а также флаг создания приостановленного процесса, который не начнет работать, пока не будет вызвана функция возобновления работы.
· Блок среды процесса.
· Текущий каталог процесса.
· Параметры первого окна, которое будет открыто при запуске процесса.
· Адрес блока информации, через который функция возвращает родительскому процессу четыре числа: идентификатор созданного процесса, идентификатор нити, хэндл процесса и хэндл нити.
Если процесс успешно создан, функция CreateProcess возвращает ненулевое значение.
Класс приоритета процесса используется при определении приоритетов его нитей. Подробнее об этом в п. 4.5.3.
Хэндл объекта ядра Windows (в данном случае процесса или нити) позволяет выполнять различные операции с этим объектом. Подробнее о хэндлах и идентификаторах см. п. 4.5.4.
После создания процесса его единственная нить начинает выполнять программу процесса, работая параллельно с нитями других запущенных процессов. Если логика работы программы предполагает параллельное выполнение каких-либо действий в рамках одного процесса, то могут быть созданы дополнительные нити. Для этого используется функция CreateThread. Ее основные параметры следующие:
· атрибуты защиты для создаваемой нити;
· размер стека нити;
· стартовый адрес нити (обычно нить связывается с выполнением одной из функций, описанных в программе процесса, при этом в качестве стартового адреса указывается имя функции);
· параметр-указатель, позволяющий передать нити при запуске некоторое значение в качестве аргумента;
· флаг создания нити в приостановленном состоянии;
· указатель на переменную, в которой функция должна возвратить идентификатор созданной нити.
Возвращаемым значением функции CreateThread является хэндл созданной нити либо NULL, если создать нить не удалось.
Прекрасным примером многонитевой программы является MicrosoftWord. В то время как основная нить обрабатывает ввод с клавиатуры, отдельная нить может динамически рассчитывать разбиение текста на страницы, еще одна нить может в это же время выполнять печать документа или его сохранение.
Для завершения работы нити используется вызов функции ExitThread. Для завершения работы всего процесса любая из его нитей может вызвать функцию ExitProcess. Единственным параметром каждой из этих функций является код завершения нити или процесса.
Завершение процесса приводит к освобождению всех ресурсов, которыми владел процесс: памяти, открытых файлов и т.п.
При завершении процесса завершаются все его нити. И наоборот, при завершении последней нити процесса завершается и сам процесс.
Не слишком широко известно, что нить не является самой мелкой единицей организации вычислений. На самом деле Windows позволяет создать внутри нити несколько волокон
(fiber), которые в обычной терминологии могут быть описаны как сопрограммы или как задачи с невытесняющей диспетчеризацией, работающие в рамках одной и той же задачи с вытесняющей диспетчеризацией. Переключение волокон выполняется только явно, с помощью функции SwitchToFiber. Об использовании сопрограмм см. /15/.
4.5.3. Планировщик
Windows
Задачей планировщика является выбор очередной нити для выполнения. Планировщик вызывается в трех случаях:
· если истекает квант времени, выделенный текущей нити;
· если текущая нить вызвала блокирующую функцию (например, WaitForMultipleObjects или ReadFile) и перешла в состояние ожидания;
· если нить с более высоким приоритетом пробудилась от ожидания или была только что запущена.
Для выбора нити используется алгоритм приоритетной очереди. Для каждого уровня приоритета система ведет очередь активных нитей (т.е. нитей, находящихся в состоянии готовности). Для выполнения выбирается очередная нить из непустой очереди с самым высоким приоритетом.
Очереди активных нитей пополняются за счет нитей, проснувшихся после состояния ожидания и нитей, вытесненных планировщиком. Как правило, нить помещается в конец очереди. Исключение делается для нити, вытесненной до истечения ее кванта времени более приоритетной нитью. Такая «обиженная» нить ставится в голову очереди.
Значение кванта времени для серверных установок Windows равно обычно 120 мс, для рабочих станций – 20 мс.
Как вы думаете, почему для серверов квант времени больше?
Теперь подробнее о приоритетах. Хотя общая схема их назначения одинакова для всех версий Windows, детали могут разниться. Дальнейшее изложение ориентировано на WindowsNT 4.0.
Все уровни приоритета нитей пронумерованы от 0 (самый низкий приоритет) до 31 (самый высокий). Уровни от 16 до 31 называются приоритетами реального времени
, они предназначены для выполнения критичных по времени системных операций. Только сама система или пользователь с правами администратора могут использовать приоритеты из этой группы. Уровни от 0 до 15 называются динамическими приоритетами
.
В Windows используется двухступенчатая схема назначения приоритетов. При создании процесса ему назначается (а впоследствии может быть изменен самой программой или пользователем) один из четырех классов приоритета
, с каждым из которых связано базовое значение приоритета:
· Realtime
(базовый приоритет 24) – высший класс приоритета, допустимый только для системных процессов, занимающих процессор на очень короткое время;
· High
(базовый приоритет 13) – класс высокоприоритетных процессов;
· Normal
(базовый приоритет 8) – обычный класс приоритета, к которому относится большая часть запускаемых прикладных процессов;
· Idle
(базовый приоритет 4) – низший (буквально – «холостой» или «простаивающий») класс приоритета, характерный для экранных заставок, мониторов производительности и других программ, которые не должны мешать жить более важным программам.
Собственно приоритет связывается не с процессом, а с каждой его нитью. Приоритет нити определяется базовым приоритетом процесса, к которому прибавляется относительный приоритет нити – величина от –2 до +2. Относительный приоритет назначается нити при ее создании и может при необходимости изменяться. Имеется также возможность назначить нити критический приоритет (31 для процессов реального времени, 15 для остальных) или холостой приоритет (16 для процессов реального времени, 0 для остальных).
Для нитей процессов реального времени приоритеты являются статическими в том смысле, что система не пытается их изменять по своему усмотрению. Предполагается, что для этой группы процессов соотношение приоритетов должно быть именно таким, как задумал программист.
Для процессов трех низших классов их приоритеты не случайно называются динамическими. Планировщик может изменять приоритеты, а заодно и кванты времени для нитей в ходе их выполнения, чтобы достичь более справедливого распределения процессорного времени. Правила изменения динамических приоритетов следующие.
· Когда заблокированная нить дождалась нужного ей события, к приоритету нити прибавляется величина, зависящая от причины ожидания. Эта прибавка может достигать 6 единиц (но приоритет не должен превысить 15), если нить разблокирована вследствие нажатия клавиши или кнопки мыши. Таким способом система стремится уменьшить время реакции на действия пользователя. Всякий раз, когда нить полностью использует свой квант времени, прибавка уменьшается на 1, пока приоритет нити не вернется к своему заданному значению.
· Если нить владеет окном переднего плана (т.е. тем, с которым работает пользователь), то ради уменьшения времени реакции планировщик может увеличить квант времени для этой нити с 20 мс до 40 или 60 мс, в зависимости от настроек системы.
· Если планировщик обнаруживает, что некоторая нить пребывает в очереди более 3 с, то он повышает ее приоритет аж до 15 и удваивает ее квант. Но эта благотворительность разовая: когда Золушка-нить израсходует увеличенный квант или заблокируется, ее приоритет и квант возвращаются к прежним значениям. Смысл акции понятен: система пытается обеспечить хоть какое-то продвижение даже для низкоприоритетных нитей.
4.5.4. Процесс и нить как объекты
Подсистема управления процессами в Windows позволяет рассматривать процессы и нити как объекты, над которыми нити различных процессов могут выполнить целый ряд действий. Для этого требуется иметь хэндл процесса или нити. Как нам известно, такие хэндлы возвращаются как побочные результаты работы функций CreateProcess и CreateThread. Это позволяет процессу, запустившему другой процесс или нить, выполнять с ними необходимые действия. Однако в некоторых случаях желательно дать возможность управлять процессом не процессу-«родителю», а другому, совершенно постороннему процессу (например, программе администрирования системы). Проблема при этом в том, что, как уже отмечалось, хэндл в Windows имеет смысл только в пределах того процесса, который вызвал функцию Create и не может быть просто передан другому процессу.
Функция OpenProcess позволяет одному процессу получить хэндл любого другого процесса, указав для этого два параметра: идентификатор интересующего процесса и маску, задающую набор запрашиваемых прав по отношению к этому процессу. Если подсистема безопасности Windows, сверив маркер доступа запрашивающего процесса с дескриптором безопасности процесса-объекта (см. п. 3.8.4.1), сочтет запрос законным, то функция вернет требуемый хэндл.
А о каких, собственно, правах идет речь? Что именно один процесс может сделать с другим процессом? Основные права следующие:
· запускать новую нить процесса;
· запрашивать и изменять класс приоритета процесса;
· читать и записывать данные в памяти процесса;
· использовать процесс в качестве объекта синхронизации;
· принудительно прекращать выполнение процесса;
· запрашивать код завершения процесса.
Все перечисленные действия выполняются с помощью соответствующих API-функций (например, для прекращения процесса вызывается функция TerminateProcess), одним из параметров которых указывается хэндл открытого процесса-объекта.
4.5.5. Синхронизация нитей
4.5.5.1. Способы синхронизации
Windows предоставляет разнообразные возможности для синхронизации работы нитей, т.е., иначе говоря, для организации пассивного ожидания нитью некоторых событий, связанных с работой других нитей того же процесса или других процессов.
· Традиционной для Windows формой синхронизации является обмен сообщениями
(messages). При этом, механизм сообщений предназначен не только для синхронизации, но и для обмена данными. Далее работа с сообщениями будет рассмотрена подробно.
· Разнообразные условия ожидания могут быть реализованы с помощью объектов синхронизации
и функций ожидания
, которые позволяют заблокировать нить до момента перехода указанного объекта в сигнальное состояние.
· Использование переменных типа CRITICAL_SECTION, в отличие от предыдущих способов, возможно только для синхронизации нитей одного и того же процесса, но зато реализуется более эффективно по времени и памяти.
Объекты синхронизации представляют собой частный случай объектов ядра Windows. Отличительной особенностью объектов синхронизации является возможность использовать в качестве аргументов функций ожидания.
Для создания объекта нужно вызвать функцию CreateXxx, где вместо Xxx указывается название конкретного типа объектов, например, CreateMutex или CreateEvent.
Общей чертой всех объектов синхронизации является наличие двух состояний, одно из которых называется сигнальным
(signaled), а другое, соответственно, несигнальным. Смысл сигнального состояния различен для разных типов объектов, общим же является то, что состояние ожидания для нити заканчивается тогда, когда объект переходит в сигнальное состояние.
Для конкретных типов объектов вместо термина «сигнальное состояние» может быть удобно использовать как синонимы «свободно», «включено», «имеется», «произошло» и т.п., а для несигнального, соответственно, «занято», «выключено», «нет» и т.п.
Поскольку объекты существуют в системной памяти, процессы могут получить к ним доступ только с помощью хэндлов. Это требует затрат времени на переключение контекста памяти при работе с объектами, но зато дает возможность синхронизации нитей, принадлежащих разным процессам. Для этого при создании объектов ядра одним из параметров функции CreateXxx может указываться имя этого объекта. Если после этого другой процесс попытается создать объект того же типа и с тем же именем, то он получит хэндл уже существующего объекта. В результате оба процесса будут работать с одним и тем же объектом синхронизации.
К функциям ожидания относятся WaitForSingleObject (ожидание одного объекта) и WaitForMultipleObjects (ожидание нескольких объектов). Рассмотрим сначала первую из них.
Функция WaitForSingleObject имеет два аргумента:
· хэндл какого-либо объекта синхронизации;
· тайм-аут ожидания, т.е. максимальное время ожидания (в миллисекундах).
Эта функция – блокирующая: если в момент ее вызова указанный объект находится в несигнальном состоянии, то вызвавшая нить переводится в состояние ожидания (разумеется, пассивного!). Ожидание, как правило, завершается в одном из двух случаев: либо объект переходит в сигнальное состояние, либо истекает заданный тайм-аут. Третий, особый случай завершения связан с понятием «заброшенный мьютекс», которое будет пояснено ниже. Значение, возвращаемое функцией, позволяет узнать, какая из трех причин пробуждения нити имела место.
Если в момент вызова функции указанный объект уже находился в сигнальном состоянии, то ожидания не происходит, функция сразу же возвращает результат.
Если задана нулевая величина тайм-аута, то выполнение функции сводится к проверке, находится ли в данный момент объект в сигнальном состоянии.
Если значение тайм-аута равно константе INFINITE, то время ожидания не ограничено, т.е. нить может пробудиться только по сигнальному состоянию объекта.
Функция WaitForMultipleObjects отличается тем, что вместо единственного хэндла принимает в качестве аргументов адрес массива, содержащего несколько хэндлов, и количество этих хэндлов (размер массива). Как и в предыдущем случае, задается величина тайм-аута. Дополнительный, четвертый аргумент – булевский флаг режима ожидания. Значение FALSE означает ожидание любого объекта (достаточно, чтобы хоть один из них перешел в сигнальное состояние), TRUE – ожидание всех объектов (ожидание завершится, только когда все объекты окажутся в сигнальном состоянии).
Возвращаемое значение позволяет определить причину пробуждения:
· переход одного из заданных объектов в сигнальное состояние, и какого именно объекта;
· переход одного из объектов-мьютексов в «заброшенное» состояние (будет пояснено ниже), и какого именно объекта;
· истечение тайм-аута ожидания.
Кроме двух названных, имеется еще ряд функций ожидания. Функции WaitForSingleObjectEx и WaitForMultipleObjectsEx позволяют также дожидаться завершения асинхронных операций ввода/вывода для указанного файла. Функция MsgWaitForMultipleObjects позволяет, наряду с объектами синхронизации, использовать для пробуждения появление сообщений, ожидающих обработки. Функция SignalObjectAndWait выполняет редкостный трюк: она переводит один объект в сигнальное состояние и тут же начинает дожидаться другого объекта.
Список объектов синхронизации включает следующие типы объектов:
· процессы;
· нити;
· события (в узком смысле);
· мьютексы (двоичные семафоры);
· семафоры (недвоичные);
· таймеры;
· уведомления об изменениях в каталоге;
· консольный ввод.
Рассмотрение объектов синхронизации проще всего начать с процессов и нитей. Для тех и других сигнальным состоянием является только состояние завершения работы. Другими словами, можно заставить нить одного процесса ожидать завершения работы другой нити или процесса.
Простейшим из объектов, предназначенных только для синхронизации, является событие
(event). Он создается при помощи функции CreateEvent, которая требует указать вид события (с автосбросом или с ручным сбросом), а также его начальное состояние – сигнальное или несигнальное. Переход в сигнальное состояние выполняется функцией SetEvent, а в несигнальное – ResetEvent. Функция PulseEvent как бы совмещает обе предыдущие: сигнальное состояние включается, функция ожидания, если она была вызвана ранее, завершается, но сигнальное состояние тут же сбрасывается.
Событие с автосбросом
означает, что функция ожидания при завершении ожидания сбрасывает то событие (или события), которого (которых) она дождалась. Если несколько нитей ждут одного и того же события с автосбросом, то разблокирована будет только одна из них (Windows не гарантирует, какая именно), поскольку остальным «события не достанется». Напротив, событие с ручным сбросом
остается в сигнальном состоянии и может быть сброшено только функцией ResetEvent, а до тех пор оно может «накормить» сколько угодно ожидающих нитей. Можно сказать, что событие с ручным сбросом больше похоже не на событие, а на состояние.
Следующий тип объектов – мьютекс
(mutex). Это почти в чистом виде двоичный семафор в смысле Дейкстры. Мьютекс может быть либо свободен (это его сигнальное состояние), либо захвачен какой-либо нитью. При создании мьютекса в функции CreateMutex указывается его начальное состояние. Допускается многократный захват мьютекса одной и той же нитью, но после этого нить должна столько же раз освободить мьютекс, чтобы он вернулся в свободное состояние.
Для освобождения мьютекса нить, владеющая им, вызывает функцию ReleaseMutex, которая является аналогом дейкстровской V(S). Никакая другая нить, кроме владельца, не может освободить «чужой» мьютекс.
В специальной функции для захвата мьютекса нет необходимости, поскольку работу примитива P(S) с успехом выполняют функции ожидания.
Если нить, владеющая мьютексом, завершает свою работу, не освободив мьютекс, то он переходит в «заброшенное» состояние: теперь уже никто не может его освободить. Такую ситуацию следует считать признаком неаккуратного программирования, и она может быть признаком наличия в программе более серьезных ошибок синхронизации.
Объект типа семафор
(semaphore) представляет собой недвоичный семафор, используемый обычно для управления распределением ограниченного числа единиц ресурса. В функции CreateSemaphore указываются два числа: максимальное значение счетчика, связанного с семафором (сколько всего имеется единиц ресурса), и начальное значение этого счетчика (сколько единиц свободно). Сигнальным является состояние семафора со счетчиком больше нуля. Функция ожидания уменьшает счетчик на 1, а функция ReleaseSemaphore увеличивает его на заданное количество единиц, но так, чтобы результат не превышал максимального значения.
В отличие от мьютекса, семафор не имеет владельца, т.е. возможна и вполне обычна ситуация, когда одна нить захватывает единицы ресурса, а другая освобождает их.
Таймер «для ожидания»
(waitabletimer) создается с помощью функции CreateWaitableTimer, после чего должен еще быть установлен функцией SetWaitableTimer. При создании таймера указывается его вид: с ручным сбросом или с автосбросом, аналогично объекту «событие». При вызове SetWaitableTimer указывается время до перехода в сигнальное состояние, в единицах по 100 нс. Время можно указать либо абсолютно (когда «зазвонить»), либо относительно текущего момента (как долго ждать). Можно также указать период (в миллисекундах), через который должен повторяться сигнал.
Таймер с ручным сбросом, перейдя в сигнальное состояние, остается в нем до вызова функции CancelWaitableTimer или повторного вызова SetWaitableTimer. Таймер с автосбросом может быть также сброшен функциями ожидания.
Полезно напомнить, что в Windows широко используется и другой тип таймеров «для сообщений», создаваемый функцией SetTimer, но эти таймеры не могут взаимодействовать с функциями ожидания и даже не являются объектами.
Объект типа уведомление об изменениях
создается при помощи функции FindFirstChangeNotification. При этом указываются следующие аргументы:
· каталог файловой системы, изменения в котором должны отслеживаться;
· флаг, указывающий, должны ли отслеживаться изменения только в заданном каталоге или также во всех вложенных подкаталогах;
· фильтр отслеживаемых изменений.
Фильтр изменений представляет собой маску, в которой отдельные биты задают такие события, как изменение списка имен файлов и каталогов (это включает их создание, удаление и переименование), изменение атрибутов файла, размера, даты изменения и атрибутов защиты.
Функция возвращает хэндл объекта, который переходит в сигнальное состояние один раз, при первом появлении одного из включенных в фильтр изменений. Если требуется повторять отслеживание, следует вызывать функцию FindNextChangeNotification, передавая ей хэндл. Для удаления объекта нужно вызвать функцию с диким именем FindCloseChangeNotification.
Уведомления об изменениях позволяют избежать активного ожидания для программ, которые должны отслеживать и отображать состояние каталогов в динамике (как это делают, например, Проводник или Far Manager). При этом характер происшедшего изменения программа может выяснить, только перечитав каталог, но зато достоверно известно, что какое-то изменение было.
Хэндл объекта типа консольный ввод
возвращается функцией CreateFile, у которой вместо имени открываемого файла указано устройство консольного ввода (CONIN$). Объект в сигнальном состоянии, когда в буфере ввода есть непрочитанные символы.
4.5.5.4. Критические секции
Еще одним средством синхронизации потоков служат переменные типа CRITICAL_SECTION. По назначению они совпадают с рассмотренными выше мьютексами, однако реализация двоичного семафора в этом случае совершенно иная. Если мьютексы – это один из типов объектов ядра, то критические секции – просто переменные. В чем здесь принципиальная разница? В том, что объекты существуют в памяти системы, поэтому прикладная программа не может напрямую обратиться к объекту, прочитать или записать его значение. Программа может только получить хэндл объекта, а затем она поручает системе выполнить то или иное действие с объектом, на который указывает данный хэндл. Такое решение позволяет использовать один объект для связи нескольких процессов, сохраняя при этом изоляцию памяти процесса от памяти системы и других процессов.
Недостаток использования объектов ядра в том, что обращение к ним всякий раз требует переключения контекста с пользовательского на системный и обратно, а это требует времени. Такова цена изоляции процессов.
Если требуется синхронизировать работу нитей одного и того же процесса, то более «дешевым» решением может быть использование переменных CRITICAL_SECTION. Программист должен описать переменную этого типа в программе процесса, при этом для всех нитей процесса будет доступен адрес этой переменной. Перед началом работы с критической секцией одна из нитей процесса должна вызвать функцию InitializeCriticalSection, передав ей адрес переменной. Затем он может использовать функцию EnterCriticalSection, чтобы занять двоичный семафор, и функцию LeaveCriticalSection, чтобы освободить его. Как и для мьютекса, один и тот же поток может несколько раз занять критическую секцию, но потом должен столько же раз освободить ее. Имеется еще удобная функция TryEnterCriticalSection, которая позволяет избежать блокировки и занимает критическую секцию, только если та была свободна в момент обращения. По истечении необходимости в синхронизации нитей следует вызвать функцию DeleteCriticalSection.
Вызов всех перечисленных функций выполняется системой гораздо быстрее, чем вызов функций, работающих с хэндлами объектов, поскольку вся работа выполняется в памяти вызывающего процесса, без переключения контекста памяти. Но зато невозможно использовать критические секции для синхронизации нитей разных потоков, для этого нужны мьютексы.
4.5.6. Сообщения
Огромную роль в организации работы прикладных программ и самой системы Windows играют сообщения
(messages). На обработке сообщений, посылаемых системой, основана вся работа с графическим интерфейсом программ. Процессы также могут обмениваться сообщениями с целью синхронизации действий и обмена данными.
Сообщение представляет собой структуру данных, содержащую тип сообщения, адресат сообщения (конкретное окно, все окна или нить процесса), время посылки сообщения, координаты курсора (для сообщений от мыши), а также два параметра, смысл которых зависит от типа сообщения.
Система посылает сообщения приложениям по самым разным поводам: при нажатии клавиш и кнопок мыши, создании и закрытии окон, изменении размеров и положения окна, выборе объекта в каком-либо списке, выборе команды в меню и т.п. Часто одно и то же действие пользователя (например, щелчок левой кнопкой мыши на пункте меню) вызывает посылку нескольких разных сообщений.
Большая часть посылаемых сообщений может обрабатываться самой системой по умолчанию. Прикладная программа может взять обработку некоторых сообщений на себя, чтобы обеспечить требуемую логикой работы реакцию на определенные события (например, при изменении размеров окна перераспределить его площадь между отдельными панелями; при попытке закрыть окно запросить подтверждение и т.п.). Программа должна также обрабатывать сообщения о посылаемых ей командах (при использовании меню, кнопок и т.п.) и сообщение о необходимости перерисовать содержимое окна.
При создании любого нового окна Windows требует задать оконную функцию
, которая должна обрабатывать сообщения, направленные этому окну. Нить, получившая сообщение, либо вызывает оконную функцию одного из своих окон (для выбора окна используется функция DispatchMessage), либо обрабатывает сообщение сама (если оно не связано с конкретным окном).
Имеется два принципиально разных способа посылки сообщения. Посылая сообщение синхронно
, отправитель дожидается окончания его обработки, прежде чем продолжить работу. Асинхронная
посылка напоминает опускание письма в почтовый ящик, она не оказывает влияния на дальнейшую работу отправителя. Прикладная программа может посылать любые сообщения синхронным или асинхронным способом, как сочтет нужным разработчик. Для этого могут использоваться, соответственно, функция SendMessage (синхронная посылка) или функция PostMessage (асинхронная посылка).
Нить процесса получает сообщения, адресованные принадлежащим ей окнам или самой нити. Для выборки сообщений из очереди используется функция GetMessage. В случае отсутствия сообщений нить блокируется до их поступления. При желании программист может использовать функцию PeekMessage, которая проверяет наличие сообщения, не блокируя вызывающую нить.
Реализация асинхронного способа посылки достаточно проста: система просто помещает сообщение в очередь нити-получателя. Синхронная посылка в ранних, невытесняющих версиях Windows также реализовалась очень просто: как непосредственный вызов оконной функции окна-получателя, минуя всякие очереди. После окончания обработки управление возвращалось отправителю. В современных версиях Windows все так и происходит, если нить посылает сообщение своему собственному окну. В остальных случаях такое решение невозможно. Во-первых, если сообщение пересылается между нитями разных процессов, то изоляция процессов в памяти не дает возможности одной нити вызвать другую как подпрограмму. Во-вторых, даже для нитей одного процесса такой вызов мог бы привести к непредсказуемым последствиям в случае переключения нитей по кванту времени.
В результате этого системе приходится действовать очень аккуратно. Нить, пославшая синхронное сообщение окну другой нити, блокируется. Сообщение помещается в отдельную очередь синхронных сообщений к нити-получателю. Эта нить продолжает свою нормальную работу до момента, когда она обратится за очередным сообщением, т.е. вызовет GetMessage или PeekMessage. Тогда система вызывает оконные функции нити для обработки каждого из ожидающих синхронных сообщений. Только когда все они обработаны, выполняется вызванная функция GetMessage или PeekMessage, проверяющая наличие асинхронных сообщений в очереди.
В процессе обработки синхронного сообщения оконная функция не должна вызывать функции, которые могут вызвать переключение системы на выполнение другой нити.
4.6.1. Жизненный цикл процесса
Понятие процесса в UNIX существенно отличается от аналогичного понятия в других популярных ОС. Если в MS-DOS, Windows и других системах новый процесс создается только при запуске программы, то в UNIX создание процесса и запуск программы – это два совершенно разных действия. При этом процесс в некотором роде «более первичен», чем программа. Если по стандартному определению (см. п. 4.2.1) процесс есть работа по выполнению программы, то в UNIX будет более уместно сказать, что программа – это один из ресурсов, используемых процессом.
Существует единственный способ создания процесса в UNIX, и этот способ заключается в вызове функции без параметров fork(). Эта функция создает новый процесс, который является точной копией процесса-родителя: выполняет ту же программу, наследует такие же хэндлы открытых файлов и т.д. При этом содержимое областей памяти процесса копируется. Единственным различием является идентификатор процесса (pid) – целое число, уникальное для каждого процесса в системе. После завершения создания оба процесса, и родитель, и потомок, будут выполнять одну и ту же команду, следующую в программе после вызова fork. Однако при этом функция fork возвращает процессу-родителю значение pid порожденного потомка, а потомку возвращает значение 0. Проверка возвращенного значения – простейший способ для процесса определить, «кто он такой» – родитель или потомок.
Типовой фрагмент программы на C может выглядеть примерно так:
pid = fork(); // Создание нового процесса
if (pid == -1) // Процесс не создан
{ обработка ошибки создания процесса}
elseif (pid == 0) // Это порожденный процесс
{ операторы, выполняемые процессом-потомком }
else // Это процесс-родитель
{ операторы, выполняемые процессом-родителем }
В принципе, оба процесса могут в дальнейшем выполнять команды из одного и того же файла программы. Чаще, однако, процесс вскоре после создания начинает выполнять другую программу. Для этого используется одна из функций семейства exec. Несколько функций, имена которых начинаются с exec, различаются деталями – в каком формате передаются параметры командной строки, следует ли использовать поиск файла программы по переменной PATH и т.п. Каждая из этих функций запускает указанный файл программы, однако при этом не порождается новый процесс, просто текущий процесс меняет выполняемую программу. При этом полностью перестраивается заново контекст процесса.
Механизм создания новых процессов один и тот же как для процессов пользователя, так и для системных процессов. Единственным исключением является самый первый процесс, имеющий идентификатор 0. Он порождает второй системный процесс, который называется INIT и имеет идентификатор 1. Все остальные процессы в системе являются потомками INIT.
Для нормального завершения процесса используется функция exit(status). Целое число status означает код завершения, заданный программистом, при этом значение 0 означает успешное завершение, а ненулевые значения – разного рода ошибки и нестандартные случаи.
Процесс-потомок полностью независим от родителя, и завершаются эти процессы независимо друг от друга. Тем не менее, процесс-родитель имеет возможность синхронизироваться с моментом завершения потомка (проще говоря, подождать этого завершения). Для этого родитель выполняет вызов функции wait:
pid = wait(&status);
Эта блокирующая функция переводит вызывающий процесс в ожидание до момента завершения любого из потомков, порожденных этим процессов. Так работает, например, интерпретатор команд UNIX, который запускает команду, введенную с консоли, и ожидает ее завершения. Функция wait возвращает pid завершившегося потомка, а в переменной status передает код завершения.
Если процесс-потомок завершает свое выполнение до того, как родитель вызвал функцию wait, то завершившийся процесс переходит в состояние, которое принято называть «зомби
». Фактически от процесса остается лишь запись в таблице процессов, содержащая код завершения и информацию о затраченном процессорном времени. Все ресурсы, занимавшиеся процессом, освобождаются. Если в дальнейшем родитель все же вызовет wait, то после передачи кода завершения «зомби» будет вычеркнут из таблицы, на чем и закончится жизненный цикл процесса.
Возможна также ситуация, когда процесс-родитель завершается до того, как будет завершен его потомок. Поскольку процесс не должен оставаться без родителя, «сирота» будет «усыновлен» системным процессом INIT.
Создание нового процесса в системе UNIX является обычным способом решения самых разнообразных проблем. В частности, в UNIX отсутствуют функции асинхронного ввода/вывода, они просто не нужны. Если программист хочет, чтобы операция ввода/вывода выполнялась параллельно с работой основной программы, ему достаточно запустить новый процесс и поручить ему эту операцию. Вместо асинхронного ввода/вывода используется асинхронный параллелизм процессов.
4.6.2. Группы процессов
При входе пользователя в систему для него создается процесс-оболочка, являющийся предком всех других процессов этого пользователя. Этот процесс становится лидером группы
порожденных им процессов. В качестве идентификатора группы принимается идентификатор (pid) ее лидера. Тот терминал, с которого пользователь вошел в систему, становится управляющим терминалом
группы. Это может быть как локальный терминал компьютера, на котором работает система, так и удаленный терминал, с которого был выполнен вход в систему по сети.
Любой процесс может покинуть свою группу и объявить себя лидером новой группы, к которой будут относиться его потомки. Одна из групп является текущей
(foreground), остальные группы – фоновыми
(background). Процессы текущей группы могут получать ввод с управляющего терминала.
Понятие группы процессов играет важную роль в ряде ситуаций при работе системы. Например, если пользователь нажимает Ctrl+C, то всем процессам текущей группы посылается сигнал о необходимости завершения. При разрыве соединения с терминалом подобный сигнал посылается всем процессам, для которых этот терминал являлся управляющим.
Процесс может, создав собственную группу, затем «открепиться» от управляющего терминала. Такой процесс, называемый в UNIX «демоном
», теряет возможность вести диалог с пользователем, но зато он не будет завершаться, когда пользователь закончит сеанс работы с системой. Демоны в UNIX выполняют обычно общесистемные задачи, такие, как управление печатью, получение и отправка почты, автоматический запуск процессов в заранее заданные моменты времени и т.п.
4.6.3. Программные каналы
Одним из «фирменных» изобретений UNIX, впоследствии позаимствованных другими ОС, является понятие программного канала
или «трубопровода» (pipe), позволяющего выполнять обмен данными между процессами с помощью тех же системных вызовов, которые используются для чтения/записи данных при работе с файлами и с периферийными устройствами.
Программные каналы могут быть безымянными или именованными. Для создания безымянного канала
процесс должен использовать системный вызов pipe, которая возвращает массив из двух элементов, содержащих хэндл для чтения из канала и хэндл для записи в канал. После этого для работы с каналом можно использовать обычные функции чтения из файла и записи в файл, указывая соответствующие хэндлы канала. Как правило, процесс, создавший канал, затем порождает двух потомков, из которых один будет выполнять запись в канал, а другой – чтение (напомним, что при создании процесса он получает копии всех хэндлов, открытых родителем). Не исключена также возможность использования канала несколькими процессами, каждый из которых может, в принципе, как записывать, так и читать данные.
Данные, записываемые в канал, буферизуются системой в памяти и затем могут быть прочитаны функциями чтения из канала. Если в канале нет данных, то функция чтения блокирует вызвавший ее процесс, пока другой процесс не запишет данные в канал.
Если все процессы закрыли хэндлы записи в канал (то есть, нет шансов, что в канал будут помещены еще какие-нибудь данные), то процесс-читатель, выбрав все данные, которые еще оставались в канале, прочтет затем признак конца файла.
Хуже, если закрыты все хэндлы чтения, а какой-нибудь процесс пытается выполнить запись данных, которые некому будет прочитать. В этом случае система посылает процессу сигнал об ошибке работы с каналом.
Использование безымянных каналов имеет одно ограничение: все процессы, работающие с каналом, должны быть потомками процесса, создавшего канал. Для передачи данных между неродственными процессами можно использовать именованные каналы
, называемые также каналами
FIFO
. Такой канал создается системным вызовом mknod, при этом указывается путь и имя канала, как при создании файла. Имена каналов хранятся в каталогах файловой системы UNIX наравне с именами обычных и специальных файлов. Чтобы открыть канал для чтения или для записи, используется обычный системный вызов open с указанием требуемого режима доступа, как при открытии файла.
4.6.4. Сигналы
Сигнал представляет собой уведомление процесса о некотором событии, посылаемое системой или другим процессом.
Основными характеристиками сигнала являются его номер и адресат сигнала. В разных версиях UNIX используется от 16 до 32 сигналов. Номер сигнала означает причину его посылки. В программах номер сигнала обычно задается одной из стандартных констант. Отметим следующие сигналы:
· SIGKILL – процесс должен быть немедленно прекращен;
· SIGTERM – более «вежливая» форма: система предлагает процессу прекратиться, но он может и не послушаться;
· SIGILL – процесс выполнил недопустимую команду;
· SIGSEGV – процесс обратился к неверному адресу памяти;
· SIGHUP – разорвана связь процесса с управляющим терминалом (например, модем «повесил трубку»);
· SIGPIPE – процесс попытался записать данные в канал, к другому концу которого не присоединен ни один процесс;
· SIGSTOP – процесс должен быть немедленно приостановлен;
· SIGCONT – приостановленный процесс возобновляет работу;
· SIGINT – пользователь нажал Ctrl+C, чтобы прервать процесс;
· SIGALRM – поступил сигнал от ранее запущенного таймера;
· SIGCHLD – завершился один из потомков процесса;
· SIGPWR – возникла угроза потери электропитания, компьютер переключился на автономный источник (т.е. пора срочно спасать данные);
· SIGUSR1, SIGUSR2 – номера сигналов, предоставленные в распоряжение прикладных программ для использования в произвольных целях.
При возникновении соответствующего события система посылает сигнал процессу или группе процессов (например, SIGHUP посылается всем процессам, связанным с данным терминалом).
Любой процесс также может послать любой сигнал другому процессу или группе процессов. Для этого используется системный вызов со страшным именем kill. Параметрами функции служат номер посылаемого сигнала и получатель сигнала. Сигнал может быть послан конкретному процессу (указывается pid получателя), а также всем процессам группы отправителя или другой указанной группы, или всем процессам, запущенным данным пользователем. Привилегированный пользователь может даже послать сигнал всем процессам в системе, за исключением корневых системных процессов 0 и 1.
Для каждого процесса система хранит маску, задающую его реакцию на каждый из сигналов. Всего возможно три вида реакции.
· По умолчанию
– выполняются действия, предусмотренные системой для данного номера сигнала. Для большинства сигналов действия по умолчанию предусматривают завершение процесса.
· Игнорировать
– процесс никак не реагирует на получение сигнала.
· Обработать
– в этом случае процесс должен задать адрес функции, которая будет вызвана при получении сигнала.
Для сигналов SIGKILL и SIGSTOP всегда используется реакция по умолчанию. Для остальных сигналов процесс может установить требуемую реакцию. Традиционным средством для этого является системный вызов signal. Одним из параметров этой функции указывается номер сигнала, другим – либо адрес функции, обрабатывающей сигнал, либо одно из специальных значений, означающих «По умолчанию» и «Игнорировать».
Установка функции-обработчика для сигнала действует только на первый полученный сигнал с данным номером, сразу же при вызове этой функции система автоматически восстанавливает обработку по умолчанию. Вероятно, это было сделано для того, чтобы избежать повторного вызова обработчика, если следующий сигнал будет получен до завершения обработки первого. Однако в результате может случиться другая неприятность: если процесс не успеет снова установить обработчик сигнала, то при получении следующего сигнала процесс может быть прекращен в порядке обработки сигнала по умолчанию.
Еще один недостаток традиционной модели обработки сигналов является невозможность временно заблокировать обработку сигналов на период выполнения каких-либо критически важных действий. Приходится выбирать: либо сигнал должен быть обработан немедленно при получении, либо он будет проигнорирован и потерян.
В современных версиях UNIX, наряду с традиционными средствами обработки сигналов, может также использоваться аппарат «надежных сигналов», позволяющий преодолеть названные трудности.
4.6.5. Средства взаимодействия процессов в стандарте POSIX
Десятилетия успешного использования UNIX выявили, тем не менее, ряд недостатков в исходной архитектуре этой системы. Одним из самых заметных пробелов была явная слабость механизма синхронизации процессов, основанного фактически лишь на сигналах и на функции wait. На практике в большинстве реализаций UNIX вводились дополнительные, более удобные средства межпроцессного взаимодействия, однако возникала проблема несовместимости таких средств для разных версий UNIX. Разнобой был пресечен в начале 90-х годов с выработкой стандарта POSIX, объединившего все лучшее, что к тому времени было предложено в разных версиях UNIX.
К средствам, которые, согласно POSIX, должна поддерживать любая современная реализация UNIX, относятся, в частности:
· сигналы;
· безымянные и именованные каналы;
· очереди сообщений;
· семафоры;
· совместно используемые (разделяемые) области памяти.
Сигналы и каналы были рассмотрены выше. Использование семафоров, очередей сообщений и разделяемой памяти дает примерно те же функциональные возможности, что аналогичные средства Windows, хотя и содержит много интересных особенностей, которые придется, к сожалению, оставить за рамками данного курса.
4.6.6. Планирование процессов
4.6.6.1. Состояния процессов в UNIX
UNIX является многозадачной системой с вытесняющей приоритетной диспетчеризацией.
Диаграмма основных состояний процесса, показанная на рис. 4‑1, в случае UNIX может быть уточнена так, как показано на рис. 4‑2.

Рис.
4‑2
Поставим следующий вопрос: в каком состоянии находится процесс, когда он вызвал системную функцию и ядро системы выполняет эту функцию? При описании работы большинства ОС этот вопрос обходят молчанием. В UNIX дается четкий ответ: процесс продолжает работать, но он переходит в режим ядра и выполняет системный код. Системные подпрограммы, работающие в режиме ядра, могут использовать все ресурсы системы. При этом контекст процесса остается доступен, что позволяет при выполнении системной функции использовать память и другие ресурсы процесса.
Возможно, что в ходе выполнения системной функции процесс будет заблокирован и перейдет в состояние сна. После пробуждения он перейдет в состояние готовности. Затем процесс будет выбран для выполнения и перейдет в режим ядра, чтобы завершить выполнение той системной функции, на которой он был заблокирован. После этого процесс должен вернуться в режим задачи, однако сразу после выхода из режима ядра процесс может быть вытеснен, если имеется активный процесс с более высоким приоритетом.
Еще один путь изменения состояния процесса связан с обработкой аппаратного прерывания. При этом обработка прерываний всегда выполняется в режиме ядра. После завершения обработки процессу следовало бы вернуться в режим задачи и продолжить выполнение прорванной программы. Однако и здесь возможны варианты. Если в результате прерывания пробудился более приоритетный процесс или если при обработке прерывания от таймера планировщик выбрал другой процесс для выполнения, то текущий процесс будет вытеснен в момент возврата из режима ядра в режим задачи.
Из сказанного можно сделать два важных вывода.
· Процесс, работающий в режиме ядра, не может быть вытеснен ни по истечению кванта времени, ни при активизации более приоритетного процесса. Вытеснение процесса возможно только в момент возврата из режима ядра в режим задачи.
· Переход в состояние сна всегда происходит из выполнения в режиме ядра. После пробуждения процесс возвращается в режим ядра через состояние готовности.
В диаграмме на рис. 4‑2 не учтены еще некоторые состояния, в которых может находиться процесс в UNIX. К их числу относятся состояние старта (процесс только что создан, но еще не готов к выполнению), состояние зомби (см. п. 4.6.1) и состояние приостановки, в которое переходит процесс, получивший сигнал SIGSTOP (см. п. 4.6.4).
4.6.6.2. Приоритеты процессов
В большинстве версий UNIX используются уровни приоритета от 0 до 127. Будем для определенности считать, что 0 соответствует высшему приоритету, хотя в некоторых версиях дело обстоит наоборот.
Весь диапазон приоритетов разделяется на верхнюю часть (приоритеты режима ядра) и нижнюю часть (приоритеты режима задачи). Это деление показано на рис. 4‑3.
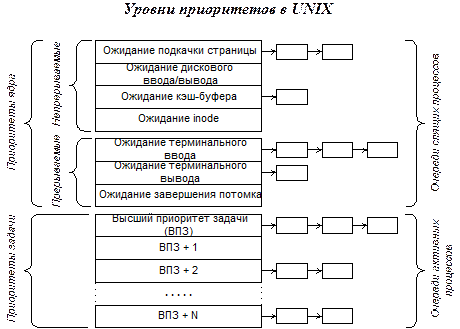
Рис.
4‑3
Текущий (динамический) приоритет процесса, работающего в режиме задачи, определяется суммой трех слагаемых: базового значения, относительного приоритета данного процесса и «штрафа» за интенсивное использование процессорного времени.
Базовое значение приоритета – это то значение, которое система по умолчанию присваивает новому процессу при его создании. Во многих версиях UNIX базовое значение равно высшему приоритету задачи + 20.
Относительный приоритет
, который почему-то называется в UNIX «nice number
»[11]
, присваивается процессу при его создании. По умолчанию система устанавливает для процесса нулевое значение относительного приоритета. Обычный пользователь может только увеличить это значение (т.е. понизить приоритет процесса), а привилегированный пользователь может и уменьшить вплоть до высшего приоритета задачи (для самых приоритетных процессов). При создании нового процесса он наследует относительный приоритет родителя.
Штраф за использование процессорного времени увеличивается для работающего процесса с каждым прерыванием от таймера. Вследствие этого, высокоприоритетный процесс не сможет монополизировать использование процессора и время от времени должен будет уступать квант времени низкоприоритетным процессам. Однако система «не злопамятна»: через каждую секунду происходит уменьшение накопленных процессами штрафов наполовину. Таким образом, процесс, отлученный от процессора, через некоторое время восстановит свой исходный приоритет.
Для выполнения всегда выбирается активная задача с наивысшим приоритетом, а если таких несколько, то они получают кванты времени в порядке круговой очереди.
Совершенно иной смысл имеют приоритеты ядра. Как нам известно, процессы, работающие в режиме ядра, не могут быть вытеснены, а поэтому приоритеты не имеют для них никакого значения. Приоритеты ядра устанавливаются только для спящих процессов и зависят только от причины сна. В некоторых случаях одно и то же событие приводит к пробуждению сразу нескольких процессов. В этом случае первым начинает работать тот, чей приоритет ядра выше. Распределение приоритетов ядра продумано таким образом, чтобы первыми завершались те системные вызовы, которые в наибольшей степени блокируют использование дефицитных ресурсов.
Диапазон приоритетов ядра разделен на две части в зависимости от того, как реагируют спящие процессы на получение сигнала. В состоянии «высокоприоритетного» сна, обычно связанного с выполнением дисковых операций, процесс игнорирует поступающие сигналы, поскольку их обработка могла бы задержать реакцию на ожидаемое важное событие. Если же процесс «спит с низким приоритетом», ожидая события несрочного и, возможно, нескорого (например, нажатия клавиши пользователем), то он может проснуться при получении сигнала и обработать этот сигнал.
4.6.7. Интерпретатор команд shell
Организация интерфейса с пользователем обычно не пользуется особым вниманием в курсах ОС. Причина этого в том, что вопросы интерфейса достаточно далеки от круга проблем, касающихся других основных подсистем ОС.
Однако при изучении UNIX нельзя обойти стороной такую интересную и развитую часть системы, как интерпретатор команд, чаще называемый просто шелл
(shell).
Шелл не является частью ядра UNIX, по своему статусу это обычная прикладная программа, выделяющаяся только своим назначением, которое заключается в выполнении команд пользователя, задаваемых либо в интерактивном (диалоговом) режиме, либо в виде командных файлов, называемых также шелл-скриптами. Существуют различные варианты шелла, которые, совпадая в основном, предлагают несколько разные дополнительные возможности.
Набор возможностей, предоставляемых любым интерпретатором команд UNIX, настолько широк, что может быть предметом изучения в отдельном курсе. Здесь будет дано только минимальное представление о принципах работы шелла. Более подходящей формой изучения шелла являются лабораторные работы.
Шелл можно рассматривать как своеобразный язык программирования, позволяющий создавать новые программы с достаточно сложными функциями, используя в качестве основных операций вызовы других, более простых программ. При этом конструкции языка шелла имеют прямую связь с описанными выше средствами управления процессами UNIX.
Базовой конструкцией языка команд UNIX (языка shell) является простая команда. Она состоит из имени команды и, возможно, параметров, разделенных пробелами. Имя команды – это обычно имя исполняемого файла (либо двоичной программы, либо шелл-скрипта).
Большинство команд UNIX выводят результат своей работы в текстовом виде на стандартный вывод. Как и в MS-DOS, это фактически означает вывод в файл или устройство, чей хэндл равен 1. По умолчанию это означает, что результаты выводятся на управляющий терминал пользователя. Однако стандартный вывод легко может быть перенаправлен в файл или на устройство. Для этого в команде используются символы ‘>’ и ‘>>’.
Многие команды используют также стандартный ввод (хэндл 0), который по умолчанию означает данные, вводимые с клавиатуры терминала. Признаком конца ввода служит комбинация Ctrl+D. Стандартный ввод также может быть перенаправлен для чтения данных из файла или с устройства (с помощью символа ‘<’), или даже непосредственно из текста команды.
Как правило, стандартный вывод команд UNIX имеет как можно более регулярную структуру. Например, команда просмотра каталога ls -l выдает в каждой строке информацию об одном файле, без общего заголовка и без итоговых данных. Очень часто вывод команды выглядит как таблица, столбцы которой разделены знаками табуляции. Это облегчает последующую обработку выведенных данных следующими командами. Из тех же соображений команды не выдают лишних сообщений типа «Команда успешно выполнена», хотя могут выдавать сообщения об ошибках.
Для выполнения команды шелл запускает отдельный процесс. В результате выполнения команды вырабатывается код завершения процесса, который может затем быть проанализирован. Нулевое значение кода обычно означает нормальное завершение, значение, большее нуля – ошибку.
Составная команда состоит из простых команд, соединенных в виде конвейера или списка.
Конвейер означает параллельное выполнение нескольких команд с передачей данных по мере их обработки от одной команды к следующей, как на заводском конвейере. Запись конвейера состоит из нескольких команд, разделенных знаками ‘|’. Для выполнения конвейера шелл запускает одновременно работающие процессы для каждой команды, при этом стандартный вывод каждой команды перенаправляется на стандартный ввод следующей. Фактически для такого перенаправления используется механизм программных каналов, описанный в п. 4.6.3. Перед запуском конвейера шелл создает необходимое количество каналов, а при запуске каждого процесса связывает его стандартные хэндлы 0 и 1 с соответствующими каналами, как показано на рис. 4‑4.

Рис.
4‑4
Список означает последовательное выполнение команд. Он состоит из нескольких команд, разделенных знаками ‘;’, ‘&&’ или ‘||’. Если две команды разделены знаком ‘;’, то следующая команда запускается после завершения предыдущей. Если команды разделены знаком ‘&&’, то следующая будет выполняться только в том случае, если код завершения предыдущей равен 0 (нормальное завершение). Напротив, знак ‘||’ означает, что следующая команда будет выполняться только в том случае, если код завершения предыдущей не равен 0 (завершение с ошибкой).
Если запись команды заканчивается символом ‘&’, то шелл запускает процесс ее выполнения в фоновом режиме, т.е. не дожидается завершения процесса, а переходит к следующей команде. При этом фоновый процесс продолжает работать параллельно с шеллом и запускаемыми им другими командами. Фоновый процесс не имеет доступа к терминалу.
Как при интерактивной работе, так и при выполнении скриптов могут определяться и использоваться переменные, имеющие строковые значения. Ряд переменных определяется системой, например, PATH содержит список каталогов, в которых шелл ищет команды, а HOME – «домашний» каталог текущего пользователя. Для получения значения переменной перед ее именем записывается символ ‘$’. В скриптах можно также использовать значения параметров, с которыми был вызван скрипт, от $1 до $9.
Шелл, как и любой язык программирования, содержит набор операторов управления порядком выполнения команд, таких как if, case, while, until, for, break и некоторые другие. Логические выражения, используемые в операторах управления, строятся на основе кодов завершения команд, при этом специальная команда test позволяет проверить разнообразные условия, такие, как существование и тип указанного файла, равенство или неравенство строковых и числовых выражений и т.п.
Скорость выполнения шелл-скриптов во много раз меньше, чем скорость компилированной программы на C или на другом языке, однако шелл позволяет резко упростить решение многих практических задач, связанных с управлением операционной системой, обработкой текстовых файлов и т.п. Это достигается за счет того, что шелл-скрипты позволяют использовать «крупные блоки»: составлять новые программы путем изощренного комбинирования уже имеющихся программ-утилит, набор которых в любой современной версии UNIX весьма обширен.
Основная память (она же ОЗУ) является важнейшим ресурсом, эффективное использование которого решающим образом влияет на общую производительность системы.
Для однозадачных ОС управление памятью не является серьезной проблемой, поскольку вся память, не занятая системой под собственные нужды, может быть отдана в распоряжение единственного пользовательского процесса. Процедуры управления памятью решают следующие задачи:
· выделение памяти для процесса пользователя при его запуске и освобождение этой памяти при завершении процесса;
· обеспечение настройки запускаемой программы на выделенные адреса памяти;
· управление выделенными областями памяти по запросам программы пользователя (например, освобождение части памяти перед запуском порожденного процесса).
Совершенно иначе обстоят дела в многозадачных ОС. Суммарные требования к объему памяти всех одновременно работающих в системе программ, как правило, превышают имеющийся в наличии объем основной памяти. В этих условиях ОС не имеет другого выхода, кроме поочередного вытеснения процессов или их частей на диск, чтобы использовать освободившуюся память на нужды других процессов. Неудачная реализация такого вытеснения может почти полностью застопорить работу ОС, которая большую часть времени будет заниматься записью и чтением с диска.
К основным задачам, которые должна решать подсистема управления памятью многозадачной ОС, добавляются следующие.
· предоставление процессам возможностей получения и освобождения дополнительных областей памяти в ходе работы;
· эффективное использование ограниченного объема основной памяти для удовлетворения нужд всех работающих процессов, в том числе с использованием дисков как расширения памяти;
· изоляция памяти процессов, исключающая случайное или намеренное несанкционированное обращение одного процесса к областям памяти, занимаемым другим процессом;
· предоставление процессам возможности обмена данными через общие области памяти.
Понятие «адрес памяти» может рассматриваться с двух точек зрения. С одной стороны, при написании любой программы ее автор либо явно указывает, по каким адресам должны размещаться переменные и команды (так бывает при программировании на языке ассемблера), либо присвоение конкретных адресов доверяется системе программирования. Те адреса памяти, которые записаны в программе, принято называть виртуальными адресами
.
С другой стороны, каждой ячейке памяти компьютера соответствует ее адрес, который должен помещаться на шину адреса при каждом обращении к ячейке. Эти адреса называются физическими
.
В ЭВМ первого поколения не делалось различия между виртуальными и физическими адресами: в программе требовалось указывать физические адреса. Это означало, что такая программа могла правильно работать, только если сама программа и все ее данные при каждом запуске (и на любом компьютере) должны были размещаться по одним и тем же физическим адресам. Такой подход стал крайне неудобным, как только была поставлена задача передать распределение памяти под управление ОС.
В настоящее время программирование в физических адресах может использоваться лишь в очень специальных случаях. Как правило, ни программист, пишущий программу, ни компилятор, транслирующий ее в машинные коды, не должны рассчитывать на использование конкретных физических адресов.
Но тогда возникает вопрос, когда и каким образом должен происходить переход от виртуальных адресов к физическим.
Есть два принципиально разных ответа на этот вопрос.
В системах, не рассчитанных на использование специальных аппаратных средств преобразования адресов, замена виртуальных адресов на физические может быть выполнена только программным путем. Это должно быть сделано до начала работы программы, либо на этапе компоновки программы, либо (в более поздних системах) при загрузке программы из файла в память.
В современных системах, предназначенных для работы на процессорах с сегментной или страничной организацией памяти (см. об этом ниже), программа даже после загрузки в память содержит виртуальные адреса. Преобразование в физические адреса выполняется при выборке каждой команды из памяти, при обращении к ячейкам данных – т.е. при каждом использовании адреса. Конечно, это возможно только в том случае, если имеется специальная аппаратура, позволяющая преобразовывать адреса практически без потери времени.
5.3.1. Настройка адресов
Если в программе используются значения физических адресов, то правильность ее работы зависит от того, по каким адресам загружена в память сама программа. Это особенно очевидно для команд перехода: если в программе есть команда «Перейти по адресу 1000», то сдвиг этой программы в памяти приведет к тому, что переход будет выполнен на совсем другую команду, хотя и по тому же адресу.
В то же время трудно рассчитывать, что при каждом запуске программы ОС сможет загрузить ее по одним и тем же адресам. Если это еще в принципе возможно для однозадачной ОС, то в случае нескольких задач их программы могут претендовать на одни и те же адреса.
Для решения этой проблемы в составе файла программы приходится хранить словарь перемещений
– список всех тех мест в программе, которые содержат адреса, требующие настройки на адрес загрузки программы. Такая настройка в большинстве случаев представляет собой просто сложение адреса загрузки с адресом, хранящимся в файле программы, и выполняется при загрузке программы в память. Выполнение настройки приводит к некоторой задержке при запуске программ.
Более поздние архитектуры ЭВМ позволили в значительной мере упростить дело за счет использования относительной адресации – указания адреса как смещения относительно значения в некотором базовом регистре. Теперь настройка требовалась лишь для нескольких команд, загружающих значения в базовые регистры. Более того, для многих не слишком сложных программ стало возможно обойтись вообще без словаря перемещений (например, если все адреса указаны только как смещения относительно начала программы). Подобные программы, способные без изменений правильно работать при загрузке по любому адресу, называются позиционно-независимыми
, в отличие от перемещаемых
программ, требующих настройки адресов.
В системе MS-DOS все файлы типа COM содержат позиционно-независимые программы, а файлы EXE – перемещаемые.
5.3.2. Распределение с фиксированными разделами
При этом способе распределения памяти администратор системы заранее, при установке ОС, выполняет разбиение всей имеющейся памяти на несколько разделов. Как правило, формируются разделы разных размеров. Допускается также определение большого раздела как суммы нескольких примыкающих друг к другу меньших разделов, как показано на рис. 5‑1.
Рис.
5‑1
Возможны два варианта организации работы с фиксированными разделами.
· В более примитивных системах уже на этапе компоновки программы определяется, для какого из разделов она предназначена. В этом выборе учитывается размер программы, а также, если это возможно предсказать, набор других программ, которые будут работать одновременно с данной. В идеале, параллельно работающие программы должны быть скомпонованы для разных разделов. При запуске программы она загружается в соответствующий раздел, а если он занят, программа должна ожидать его освобождения, т.е. полного завершения работы программы, занимающей раздел.
· В более развитых системах программа хранится в перемещаемом формате, а при ее запуске система выбирает наиболее подходящий по размеру свободный раздел. При отсутствии такового программа ожидает.
Очевидно, что в обоих вариантах память используется не слишком эффективно. Вполне возможна ситуация, когда к некоторым разделам выстроилась очередь программ, а другие разделы в это время пустуют. В первом варианте, кроме того, невозможен перенос скомпонованных программ на другую ЭВМ (с другими разделами).
В описанных вариантах распределения памяти количество одновременно загруженных программ не может превышать числа разделов. Если желательно обеспечить большее задач, то можно разрешить разделение одного раздела между несколькими программами. При этом программа, которая в данный момент находится в спящем или готовом состоянии, может быть вытеснена из памяти на диск, в отведенный для этого файл подкачки
(swapfile). В освободившийся раздел из того же файла подкачки загружается программа, которую планировщик процессов выбрал для выполнения.
Использование подкачки позволяет неограниченно увеличивать количество загруженных программ (т.е. число процессов в системе). Однако подкачка – это достаточно опасное решение, злоупотребление ею может в десятки раз снизить производительность системы, поскольку большая часть времени будет уходить не на полезную работу, а на перекачку программ из памяти на диск и обратно. Чтобы избежать этой опасности, в систему должны быть заложены тщательно подобранные, проверенные алгоритмы планирования процессов и памяти.
Предельно простым случаем распределения с фиксированными разделами можно считать организацию памяти в однозадачных системах, где существует единственный раздел для программ пользователя, включающий всю память, не занятую системой.
5.3.3. Распределение с динамическими разделами
При такой организации памяти никакого предварительного разбиения не делается. Вся имеющаяся память рассматривается как единое пространство, в котором размещаются загруженные программы. Когда возникает необходимость запустить еще одну программу, система выбирает свободный фрагмент памяти достаточного размера и выделяет его в качестве «динамического раздела» для данной программы. Если не удается найти достаточно большой непрерывный участок памяти, то самым простым решением будет подождать с запуском новой программы, пока не завершится одна из работающих программ. В принципе, можно использовать подкачку, но ее организация в данном случае сложнее, чем в случае фиксированных разделов, поскольку нужно прежде всего выбрать, какая именно из загруженных программ должна быть вытеснена на диск.
Вообще говоря, распределение с динамическими разделами позволяет более эффективно использовать память, чем при использовании фиксированных разделов. Однако при этом возникает проблема, которая уже встречалась нам совсем в другой ситуации, в связи с непрерывным размещением файлов на диске (см. п. 3.3). Речь идет о фрагментации
, т.е. о разбиении свободной памяти на большое число маленьких фрагментов, которые не удается использовать для загрузки крупной программы, хотя суммарный объем свободной памяти остается достаточно большим. Фрагментация является неизбежным следствием того, что память выделяется и освобождается разделами различной длины, причем в произвольном порядке. Но если для файлов можно было время от времени выполнять дефрагментацию, перемещая все файлы ближе к началу диска, то для работающих программ это весьма затруднительно, поскольку перемещение программы нарушило бы настройку адресов, выполненную при ее загрузке.
Перейдем теперь к рассмотрению способов организации памяти, которые базируются на использовании виртуальных адресов, аппаратно преобразуемых в физические при выполнении команд. Два основных вида организации виртуальной памяти – сегментная и страничная организация
.
При сегментной организации вся виртуальная память, используемая программой, разбивается на части, называемые сегментами
. Это разбиение выполняется либо самим программистом (если он программирует на языке ассемблера), либо компилятором используемого языка программирования. Размеры сегментов могут быть различными, но в пределах максимального размера, используемого в данной архитектуре. Разбиение обычно производится на логически осмысленные части, такие, как сегмент данных, сегмент кода, сегмент стека и т.п. Большая программа может содержать несколько сегментов одного типа, например, несколько сегментов кода или данных.
Таким образом, при сегментной организации у программы нет единого линейного адресного пространства. Виртуальный адрес состоит из двух частей: селектора сегмента
и смещения
от начала сегмента.
Селектор сегмента представляет некоторое число, которое обычно является индексом в таблице сегментов данного процесса. Такая таблица содержит для каждого сегмента его размер, режим доступа (только чтение или возможна запись), флаг присутствия сегмента в памяти. Если сегмент находится в памяти, то в таблице хранится его базовый адрес (адрес физической памяти, соответствующий началу сегмента). Отсутствие сегмента означает, что его данные временно вытеснены на диск и хранятся в файле подкачки
(swapfile).
В кодах программы селектор сегмента может либо явно присутствовать как часть адреса, либо подразумеваться в зависимости от смысла конкретного адреса. Например, для адресов выполняемых команд используется селектор текущего сегмента команд, а для адресов операндов – селектор текущего сегмента данных.
При каждом обращении к виртуальному адресу аппаратными средствами выполняется преобразование пары «сегмент : смещение» в физический адрес. Упрощенная схема такого преобразования показана на рис. 5‑2.
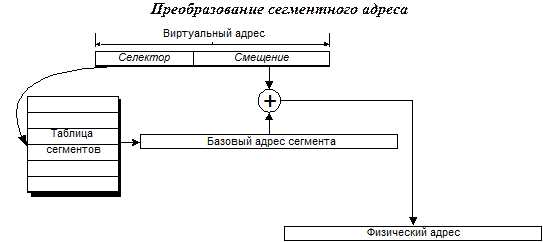
Рис.
5‑2
Селектор сегмента используется для доступа к соответствующей записи таблицы сегментов. Если данный сегмент присутствует в памяти, то его базовый адрес, прочитанный в таблице, складывается со смещением из виртуального адреса. Результат сложения представляет собой физический адрес, по которому и происходит обращение к памяти.
Если сегмент отсутствует в памяти, то происходит прерывание. Обрабатывая его, система должна подгрузить сегмент с диска на свободное место в памяти, записать его базовый адрес в таблицу сегментов и затем повторить команду, вызвавшую прерывание.
Но откуда возьмется свободное место в памяти? По всей вероятности, системе придется для этого убрать из памяти какой-то другой сегмент, принадлежащий либо к этому же, либо к иному процессу. Копия вытесняемого сегмента должна остаться в файле подкачки. Чтобы избежать лишней работы, в каждой записи таблицы хранится флаг, отмечающий, является ли сегмент в памяти «чистым» или «грязным», т.е. совпадает ли его содержимое с дисковой копией или же оно было изменено в памяти после последней загрузки с диска. «Грязный» сегмент должен быть сохранен на диске, для «чистого» сохранение не требуется. Если сегмент определен как доступный только для чтения, то он заведомо «чистый».
Поскольку сегменты имеют различные размеры, то в ходе работы системы, сопровождающейся многократной загрузкой и выгрузкой сегментов, возникает эффект фрагментации памяти, описанный выше в п. 3.3 и в п. 5.3.3. Во всех случаях причиной фрагментации является многократное занятие и освобождение областей различного размера.
Для борьбы с фрагментацией можно время от времени производить дефрагментацию, т.е. перемещение всех сегментов, находящихся в памяти, на новые места, без «дырок» в памяти между сегментами. При этом, однако, требуется, чтобы система откорректировала таблицы сегментов всех тех процессов, сегменты которых переместились в физической памяти. Кроме того, перемещение сегментов занимает ощутимое время, поэтому оно недопустимо для сегментов, содержащих, например, обработчики прерываний, которые должны срабатывать очень быстро. Чтобы избежать этих проблем, в некоторых системах сегменты могут находиться в одном из двух состояний:
· фиксированный
сегмент не должен перемещаться в памяти;
· перемещаемый
сегмент может перемещаться системой, однако программа не может обращаться к адресам в таком сегменте, поскольку его местоположение не определено.
Чтобы работать с данными в перемещаемом сегменте, программа должна предварительно временно зафиксировать его вызовом специальной системной функции. При этом ОС определяет текущее местоположение сегмента и корректирует его базовый адрес в таблице сегментов процесса. Если же программа в течение некоторого времени не планирует обращаться к данному сегменту, то его следует расфиксировать, поскольку чем больше фиксированных сегментов в системе, тем менее эффективна будет дефрагментация.
При переключении текущего процесса все, что должна сделать система в отношении памяти, заключается в замене таблицы сегментов. Для этого либо в специальный системный регистр записывается адрес таблицы сегментов текущего процесса, либо, если аппаратура допускает только одну таблицу сегментов, ее содержимое должно быть перезаписано так, чтобы соответствовать новому работающему процессу.
Эта форма организации виртуальной памяти во многом похожа на сегментную. Основные различия заключаются в том, что все страницы, в отличие от сегментов, имеют одинаковые размеры, а разбиение виртуального адресного пространства процесса на страницы выполняется системой автоматически. Типичный размер страницы – несколько килобайт. Для процессоров Pentium, например, страница равна 4 Кб.
Все виртуальные адреса одного процесса относятся к единому линейному пространству, Проще сказать, виртуальный адрес выражается одним числом, от 0 до некоторого максимума. Старшие разряды двоичного представления этого адреса определяют номер виртуальной страницы, а младшие разряды – смещение от начала страницы. Например, для страниц по 4 Кб смещение занимает 12 младших разрядов адреса.
Физическая память также считается разбитой на части, размеры которых совпадают с размером виртуальной страницы. Эти части называются физическими страницами
или страничными кадрами
(pageframes). Таблица страниц процесса по структуре похожа на таблицу сегментов. Для каждой виртуальной страницы она содержит режим доступа, флаг присутствия страницы в памяти, номер страничного кадра, флаг чистоты. Если страница отсутствует в памяти, ее данные сохраняются в файле подкачки, который в этом случае чаще называют страничным файлом
(pagefile).
Простейший вариант схемы преобразования виртуального страничного адреса в физический адрес показан на рис. 5‑3.

Рис.
5‑3
В отличие от случая сегментной организации, вместо сложения базового адреса со смещением в данном случае можно просто собрать вместе номер физической страницы и смещение.
При переключении текущего процесса система просто изменяет адрес используемой таблицы страниц, тем самым полностью изменяя отображение виртуальных адресов на физические.
Страничная организация памяти не может привести к фрагментации, поскольку все страницы одинаковы по размеру, а потому каждая высвобожденная физическая страница может быть затем использована для любой понадобившейся виртуальной страницы.
Размер пространства виртуальных адресов каждого процесса может быть огромным, ибо он определяется только разрядностью адреса. Для 32-разрядных процессоров этот размер равен 232
= 4 Гб. В настоящее время трудно представить программу, которой может всерьез понадобиться столько памяти, да и компьютер с таким объемом памяти – вещь не рядовая[12]
. На самом деле, программа обычно использует лишь небольшую часть своего адресного пространства, не более нескольких десятков или, в крайнем случае, сотен мегабайт. Только эти используемые страницы и должны быть отображены на физическую память. Тем не менее, суммарный объем страниц, используемых всеми процессами в системе, обычно превосходит объем имеющейся физической памяти, поэтому использование страничного файла становится неизбежным.
Управление замещением страниц в физической памяти в современных РС строится по принципу загрузки по требованию
(demandpaging). Это означает следующее. Когда программа только лишь планирует использование определенной области виртуальной памяти (например, для хранения массива переменных, описанного в программе), соответствующие виртуальные страницы помечаются в таблице страниц как существующие, но находящиеся в данный момент на диске. В некоторых системах при этом за виртуальной страницей действительно закрепляются конкретные блоки в страничном файле, хотя из соображений экономии дисковой памяти это можно сделать позже, когда реально потребуется записать страницу на диск. Выделение страниц физической памяти не выполняется до тех пор, пока программа не обратится к одной из ячеек виртуальной страницы. При этом происходит аппаратное прерывание по отсутствию страницы в памяти. Это прерывание обрабатывает часть ОС, которая называется менеджером памяти. Менеджер должен выполнить следующие действия:
· найти свободную физическую страницу;
· если свободной страницы нет (а ее чаще всего нет), то по определенному алгоритму выбрать занятую страницу, которая будет вытеснена на диск;
· если выбранная страница «грязная», т.е. ее содержимое изменялось после того, как она последний раз была прочитана с диска, то «очистить» страницу, т.е. записать ее в соответствующий блок страничного файла;
· на освободившуюся физическую страницу прочитать блок страничного файла, закрепленный за запрошенной виртуальной страницей;
· откорректировать таблицу страниц, пометив вытесненную страницу как отсутствующую в физической памяти, а прочитанную – как присутствующую и при этом «чистую»;
· повторить обращение к запрошенному виртуальному адресу, теперь уже присутствующему в физической памяти.
Последующие обращения к виртуальным адресам той же страницы будут успешно выполняться, пока страница не будет, в свою очередь, вытеснена на диск.
Приведенная схема работы менеджера памяти с загрузкой страниц по требованию очень похожа на кэширование диска, рассмотренное в п. 2.6.6. Эффективность работы системы базируется на том же самом эффекте локальности ссылок, но только примененном не к блокам диска, а к страницам памяти.
Однако есть и очень существенное отличие. Обращение программы к дисковому кэшу происходит только при запросе на выполнение операции чтения с диска или записи на диск, что происходит не столь часто. Поэтому система может позволить себе затратить некоторое время на выполнение операций по поддержанию кэша в должном порядке. Например, если для выбора вытесняемого блока используется алгоритм LRU, то при каждом обращении к кэш-буферу этот буфер должен переставляться в конец очереди.
Менеджер памяти работает в иной ситуации. Обращения к памяти происходят с огромной частотой, при выполнении почти каждой команды процессора. Абсолютно нереально при каждом обращении предпринимать какие-то программные действия. Из этого следует, что алгоритм выбора вытесняемой страницы должен опираться на аппаратную поддержку. Поскольку алгоритм LRU не так просто реализовать аппаратно, вместо него часто используют алгоритмы, более простые в реализации, пусть даже они менее эффективны.
Недостатком страничной организации является то, что при большом объеме виртуального адресного пространства сама таблица страниц должна быть очень большой. При размере страницы 4 Кб и адресном пространстве 4 Гб таблица должна содержать миллион записей! Однако вряд ли программа процесса постоянно использует весь огромный диапазон адресов. Как правило, на каждом интервале времени интенсивно используются только некоторые части таблицы страниц (это еще одно проявление локальности ссылок). Желательно иметь возможность вытеснять на диск временно неиспользуемые части таблицы страниц. Такая возможность в современных процессорах обеспечивается использованием более сложной, двухуровневой схемы страничной адресации. В этой схеме все адресное пространство делится на разделы равной величины, каждый из которых описывается отдельной небольшой таблицей страниц. Имеется также каталог таблиц страниц, который описывает текущее состояние каждой таблицы точно так же, как сама таблица страниц описывает состояние страниц памяти. Те таблицы страниц, которые долго не используются, вытесняются на диск и соответствующим образом помечаются в каталоге. Виртуальный адрес делится не на две, а на три части. Старшие разряды адреса указывают позицию таблицы в каталоге, средние разряды – позицию страницы в таблице, младшие – смещение адреса от начала страницы.
Оба рассмотренных способа организации виртуальной памяти имеют свои достоинства и недостатки.
К преимуществам сегментной организации в литературе обычно относят следующие.
· Легко можно указать режим доступа к сегменту в зависимости от смысла его данных. Например, сегмент кода программы обычно должен быть доступен только для чтения, а сегмент данных может быть доступен и для записи.
· В том случае, если программа работает с двумя или более структурами данных, каждая из которых может увеличиваться в размерах независимо от других, выделение отдельного сегмента для каждой структуры позволяет освободить программиста от забот, связанных с размещением структур в имеющейся памяти (эти проблемы перекладываются на ОС, которая обязана будет найти место в физической памяти для увеличивающихся сегментов).
· Гораздо реже называется еще одна, более прозаическая причина использования сегментов, которая на самом деле в определенный период являлась очень веской. Если в используемой архитектуре компьютера разрядность адреса в командах слишком мала (например, 16 разрядов, как у процессоров i286, что позволяет адресовать всего лишь 64 Кб), а размер программы и ее данных достигает многих мегабайт, то единственное решение – использовать много сегментов по 64 Кб.
Для современных процессоров разрядность адреса составляет 32 или даже 64 бита, что снимает необходимость возиться с большим количеством мелких сегментов. При этом на первый план выходят достоинства страничной организации:
· программист не должен вообще думать о разбиении программы и ее данных на части ограниченного размера (сегменты), в его распоряжении единое пространство виртуальных адресов;
· исключается возможность фрагментации физической памяти и связанные с этим проблемы;
· как правило, уменьшается обмен данными с диском, поскольку в него включаются только отдельные страницы, а не целые сегменты.
Для сравнительной оценки сегментной и страничной организации полезно также вспомнить историю развития версий Windows. Версия Windows 2.0 была ориентирована на процессор i286, имевший сегментную организацию памяти с 16-разрядным смещением в сегменте. В эти годы фирмы Intel и Microsoft активно защищали сегментную модель, подчеркивая ее достоинства. Однако в Windows 3.0 были уже частично использованы новые возможности процессора i386, а именно, страничная организация памяти. Поскольку эта версия по-прежнему была основана на 16-разрядных адресах, использование сегментов оставалось необходимым, что привело к сложной сегментно-страничной модели памяти. Зато переход к 32-разрядным версиям WindowsNT и Windows 95 сопровождался фактическим отказом от использования сегментного механизма в пользу чисто страничной организации памяти. Формально же теперь все адресное пространство пользователя укладывается в один очень большой сегмент размером 4 Гб.
Большим преимуществом использования виртуальной памяти, как в сегментном, так и в страничном варианте, является возможность легко и просто изолировать процессы в памяти. Для этого достаточно, чтобы система не отображала никакие виртуальные страницы двух разных процессов на одну и ту же физическую страницу. Тогда процессы просто «не будут видеть» друг друга в памяти и не смогут повредить друг другу.
С другой стороны, в некоторых ситуациях желательно, чтобы два или более процессов имели доступ к общей области памяти. Это дает, например, возможность хранить в памяти единственный экземпляр системных библиотек, которым могут пользоваться несколько процессов. Для создания общей памяти достаточно, чтобы виртуальные страницы всех заинтересованных процессов отображались на одни и те же страницы физической памяти.
MS-DOS – это ОС, работающая в реальном режиме процессора i86, что предполагает использование адресного пространства размером всего лишь 1 Мб. На самом деле, в компьютерах IBM гарантируется наличие лишь 640 Кб основной памяти, старшие же адреса памяти заняты под BIOS и видеопамять, хотя среди них попадаются разрозненные куски оперативной памяти, называемые UMB (верхний блок памяти).
Адрес в реальном режиме записывается в формате [сегмент : смещение], однако здесь сегмент – это не селектор, адресующий строку таблицы сегментов, как описывалось в п. 5.4, а просто номер параграфа памяти (1 параграф = 16 байт). Поэтому можно считать, что в MS-DOS используются только физические адреса.
В принципе, программы, работающие в MS-DOS, могут получить доступ к памяти за пределами 1 Мб, но для этого требуется специальный драйвер расширенной памяти.
Поскольку делить имеющуюся память между несколькими процессами не приходится, распределение получается бесхитростное. Основные области памяти показаны на рис. 5‑4.

Рис.
5‑4
Нижнюю часть памяти занимают модули ОС: обработчики прерываний, резидентная чисть интерпретатора команд, драйверы устройств. Некоторые системные программы могут быть ради экономии загружены в верхний блок памяти (выше 640 Кб). Все, что остается в середине, может быть предоставлено процессу пользователя.
Для пущей экономии памяти некоторые нерезидентные модули DOS могут занимать верхнюю часть области пользователя, но только до тех пор, пока не будут затерты пользовательской программой, которой потребуется вся имеющаяся память.
Часть системной памяти и вся область пользователя разбита на прилегающие друг к другу блоки, размер которых кратен параграфу. Перед началом каждого блока памяти размещается блок управления памятью (MCB, MemoryControlBlock), который занимает один параграф и содержит следующие данные:
· признак, определяющий, последний ли это блок памяти или за ним будут еще блоки (соответственно буква ‘Z’ или ‘M’, это, видимо, опять Марк Збиковский отметился);
· адрес PSP программы, владеющей этим блоком (0 означает свободный блок);
· размер блока в параграфах;
· имя программы-владельца (до 8 символов); это поле избыточно (зная PSP программы, можно найти имя ее файла), оно было добавлено, вероятно, чтобы хоть как-то занять пустующие байты параграфа MCB.
Когда система должна выделить блок памяти для собственных нужд или по запросу программы пользователя, она просматривает список блоков от начала, перемещаясь от одного MCB к следующему. Найдя свободный блок достаточного размера, система отмечает его как занятый соответствующим владельцем. Если выделяется не весь свободный блок, то после выделенного блока система записывает еще один MCB, описывающий свободный остаток блока.
При освобождении блока система записывает 0 в поле владельца MCB. Если с одной или с двух сторон от освобождаемого блока лежат свободные блоки, то два или три свободных блока сливаются в один.
При запуске программы система выделяет ей два блока памяти: сначала небольшой блок для переменных среды, затем самый большой среди оставшихся свободных блоков для самой программы (блок PSP, см. п. 4.4.3). Обычно этот блок занимает всю свободную память. Такое решение приемлемо, поскольку других претендентов на память нет.
Почему блок среды выделяется раньше, чем блок PSP?
При завершении программы система просматривает все блоки памяти и освобождает те из них, владельцем которых указана завершаемая программа. Исключением является случай завершения с установкой резидента (п. 4.4.4), при этом блок PSP не освобождается, но уменьшается до указанного размера. В дальнейшем этот блок остается занятым до перезагрузки системы.
MS-DOS предоставляет в распоряжение пользователя функции, позволяющие выполнять основные действия с блоками памяти.
· Выделение блока указанного размера. Если свободного блока достаточной величины не имеется, то система возвращает максимальный размер, который может быть выделен.
· Освобождение ранее выделенного блока.
· Изменение размера блока. Уменьшение блока возможно всегда, увеличение – только в том случае, если после данного блока расположен свободный блок достаточного размера.
Одним из немногих случаев, когда эти функции оказываются полезны, является запуск порожденного процесса. Система должна иметь достаточно свободного места, чтобы разместить блок среды и блок PSP загружаемой программы. Однако, как было сказано выше, вся свободная память обычно отдается под блок PSP текущей программы. Поэтому прежде чем запускать порожденный процесс, программа должна уменьшить свой собственный блок PSP, оставив себе необходимый минимум.
5.8.1. Структура адресного пространства
Принято считать, что каждый процесс, запущенный в Windows, получает в свое распоряжение виртуальное адресное пространство размером 4 Гб. Это число определяется разрядностью адресов в командах: 232
байт = 4 Гб.
Конечно, трудно рассчитывать, что для каждого процесса найдется такое количество физической памяти, речь идет только о диапазоне возможных адресов.
Но даже и в этом смысле процессу доступно лишь около 2 Гб младших адресов виртуальной памяти. В частности, для WindowsNT старшие 2 Гб с адресами от 8000000016
до FFFFFFFF16
доступны только системе. Такое решение позволило уменьшить время, затрачиваемое при вызове системных функций, поскольку отпадает необходимость изменять при этом отображение страниц, нужно только разрешить их использование. Однако, чтобы сам вызов API-функций был возможен, системные библиотеки, которые содержат эти функции, размещаются в младшей, пользовательской половине виртуального пространства.
В Windows 95 принято хулиганское решение: система и здесь располагается в старшей половине памяти, но эта половина доступна процессу пользователя и для чтения, и для записи. При этом вызов системы становится еще проще, но зато система становится беззащитной перед любой некорректной программой, лезущей куда не надо.
Кроме старших 2 Гб, процессу недоступны еще некоторые небольшие области в начале и в конце виртуального пространства. В WindowsNT недоступны адреса с 0000000016
по 0000FFFF16
и с 7FFF000016
по 7FFFFFFF16
, т.е. два кусочка по 64 Кб. Это сделано с целью выявления такой типичной ошибки программирования, как использование неинициализированных указателей, которые обычно попадают в запретные диапазоны адресов.
Для 64-разрядных процессоров размер виртуального адресного пространства возрастает до трудно представимых 264
байт (17 миллиардов гигабайт, если угодно), однако WindowsXP выделяет в распоряжение каждого процесса «всего лишь» 7152 гигабайта с адресами от 0 до 6FBFFFFFFFF16
, а остальное адресное пространство может использоваться только системой.
5.8.2. Регионы
Рассмотрим теперь, каким образом программа процесса может использовать свое адресное пространство.
Попытка просто-напросто использовать в программе произвольно выбранный адрес в пределах адресного пространства процесса, скорее всего, приведет к выдаче сообщения об ошибке защиты памяти. На самом деле, использовать виртуальный адрес можно только после того, как ему поставлен в соответствие адрес физический. Такое сопоставление выполняется путем выделения регионов виртуальной памяти
.
Регион памяти всегда имеет размеры, кратные 4 Кб (т.е. он содержит целое число страниц), а его начальный адрес кратен 64 Кб.
Для выделения региона используется функция VirtualAlloc. Она требует указания следующих параметров.
· Начальный виртуальный адрес региона. Если указана константа NULL, то система сама выбирает адрес. Если указан адрес, не кратный 64 К, то система округляет его вниз.
· Размер региона. При необходимости система округляет его до величины, кратной 4 Кб.
· Тип выделения. Здесь указывается одна из констант MEM_RESERVE (резервирование памяти) или MEM_COMMIT (передача физической памяти), смысл которых будет подробно рассмотрен ниже, или комбинация обеих констант.
· Тип доступа. Он определяет, какие операции могут выполняться со страницами выделенной памяти. Наиболее важны следующие типы доступа.
- PAGE_READONLY – доступ только для чтения, попытка записи в память приводит к ошибке.
- PAGE_READWRITE – доступ для чтения и записи.
- PAGE_GUARD – дополнительный флаг «охраны страниц», который должен комбинироваться с одним из предыдущих. При первой же попытке доступа к охраняемой странице генерируется прерывание, извещающее об этом систему. При этом флаг охраны автоматически снимается, так что дальнейшая работа со страницей выполняется без проблем.
Самое важное, что следует понять про выделение регионов, это смысл операций резервирования и передачи памяти.
Резервирование
региона памяти (MEM_RESERVE) означает всего лишь то, что диапазон виртуальных адресов, соответствующих данному региону, не будет использован ни под какие другие цели, система считает его занятым. Это как резервирование авиабилета: вы пока что не владеете билетом, но и никому другому его не продадут.
Попытка программы обратиться к адресу в зарезервированном, но не переданном регионе приведет к ошибке.
Передача
физической памяти (MEM_COMMIT) означает, что за каждой страницей виртуальной памяти региона система закрепляет… нет, вовсе не страницу физической памяти, как можно подумать. Закрепляется блок размером 4 Кб в страничном файле. В таблице страниц процесса переданные страницы помечаются как отсутствующие в памяти.
Теперь попытка обращения к адресу в регионе приведет уже к совсем другому результату. Поскольку страница отсутствует в памяти, произойдет прерывание. Однако это не будет рассматриваться как ошибка в программе. Система, обрабатывая прерывание, выполнит операцию чтения страницы с диска, из страничного файла, в основную память и занесет в таблицу страниц физический адрес, который теперь соответствует виртуальной странице. После этого команда, вызвавшая прерывание, будет повторена, но теперь уже с успехом, поскольку требуемая страница находится в памяти. Дальнейшие обращения к той же виртуальной странице будут выполняться без проблем, пока страница находится в памяти.
Резервирование и передача памяти могут выполняться одновременно, при одном обращении к функции VirtualAlloc, которой для этого нужно передать комбинацию обеих констант: MEM_RESERVE + MEM_COMMIT. Есть и другой вариант: сначала зарезервировать регион памяти, а затем, по мере необходимости, передавать физическую память либо всему региону сразу, либо его отдельным частям (субрегионам). Для этого в первый раз функция VirtualAlloc вызывается с константой MEM_RESERVE и, как правило, без указания конкретного адреса. Затем вызывается VirtualAlloc с константой MEM_COMMIT и с указанием адреса ранее зарезервированного региона или соответствующего субрегиона.
Все описанное полностью соответствует понятию загрузки страниц по требованию, описанному в п. 5.5. В качестве особенностей реализации замещения страниц в Windows следует отметить следующее.
· Для каждого процесса в системе определены максимальный и минимальный размер его рабочего множества
. При выборе вытесняемой страницы система пытается добиться, чтобы за каждым процессом сохранялось не менее минимального, но не более максимального количества памяти. Это позволяет избежать ситуации, когда один процесс, расточительно использующий память, вытесняет из нее почти все страницы других процессов. Процесс может изменить размеры своего рабочего множества, но при этом суммарные требования всех процессов ограничиваются реальным размером имеющейся памяти.
· Процесс может запереть в памяти
некоторый диапазон адресов, чтобы воспрепятствовать вытеснению соответствующих страниц на диск. Суммарный размер памяти, запертой одним процессом, по умолчанию не должен превосходить 30 страниц. Длительное удержание одним процессом большого числа страниц запертыми в памяти привело бы к уменьшению объема памяти, доступного для других процессов (да и для незапертых страниц того же процесса).
5.8.3. Отображение исполняемых файлов
При запуске нового процесса Windows использует практически тот же механизм выделения регионов памяти, который был описан в предыдущем пункте. Отличие в том, что выделение памяти выполняет сама система. Кроме того, нет необходимости в использовании страничного файла, поскольку для хранения страниц, вытесненных на диск, как нельзя лучше подходит сам EXE-файл (или DLL-файл, содержащий разделяемую библиотеку функций). При запуске программы Windows резервирует достаточное количество виртуальных страниц и закрепляет за ними блоки EXE-файла. При этом нет необходимости выполнять такое действие, как «загрузка» программы в традиционном смысле. Чтение кодов программы выполняется по мере необходимости, согласно общему принципу загрузки страниц по требованию.
Как правило, текст программы не подвергается изменениям в ходе ее выполнения. Это означает, что соответствующие виртуальные страницы остаются «чистыми» и при их вытеснении нет необходимости в записи на диск. Если один и тот же исполняемый файл используется одновременно несколькими процессами (что вполне возможно для EXE-файла в случае запуска нескольких экземпляров программы, а для DLL-файлов является правилом), то на один и тот же файл отображаются виртуальные страницы каждого из этих процессов. При этом вполне возможно, что в таблицах страниц разных процессов один и тот же исполняемый файл будет соответствовать разным диапазонам виртуальных адресов.
Проблема возникает в том случае, если по логике работы программы должна выполняться запись в некоторые страницы памяти, соответствующие исполняемому файлу. Это нормальное явление, поскольку в состав EXE-файла могут входить области памяти, отведенные для статических переменных программы. Очевидно, нельзя позволить программе изменять свой собственный файл только потому, что изменились значения переменных. Тем более, если файл используется сразу в нескольких процессах и в каждом из них переменные принимают разные значения. Выход, используемый WindowsNT в этой ситуации, заключается в следующем. Все виртуальные страницы, соответствующие выполняемому файлу, выделяются со специальным атрибутом доступа PAGE_WRITECOPY, т.е. «копирование при записи». Пока процессы только читают данные из этих страниц, все происходит, как описано выше. Если же процесс пытается выполнить запись на страницу с таким атрибутом, то происходит прерывание, которое система обрабатывает следующим образом. В страничном файле выделяется блок, в который копируется содержимое данной страницы из EXE-файла. В таблице страниц помечается, что эта виртуальная страница теперь закреплена не за EXE-файлом, а за блоком, выделенным из страничного файла. После этого операция записи успешно выполняется, а при вытеснении страницы она будет сохранена в страничном файле. Таким образом, страничный файл все-таки используется, но только для тех страниц программы, которые изменяются в ходе работы.
Если запускаемый EXE-файл находится на дискете, то система сразу копирует его в страничный файл, поскольку использовать для подкачки страниц такое медленное и ненадежное устройство, как дискетный накопитель, было бы крайне неэффективно.
5.8.4. Файлы, отображаемые на память
Нетрудно понять, что те же средства, которые используются для отображения исполняемого файла на виртуальную память, могут быть применены и к любому другому файлу. В Windows программистам предоставляется возможность создавать и использовать объекты типа «отображение файла» (filemapping).
Работа с таким объектом требует предварительной подготовки. Сначала программа должна создать объект, вызвав функцию CreateFileMapping. Среди параметров этой функции можно отметить:
· хэндл предварительно открытого файла, который будет отображаться на память;
· тип доступа к объекту (только для чтения или и для записи);
· размер объекта;
· имя объекта, которое может использоваться для того, чтобы разные процессы могли работать с одним и тем же объектом «отображение файла».
Функция возвращает хэндл созданного или открытого объекта.
Не втором этапе процесс вызывает функцию MapViewOfFile, передавая ей как параметры хэндл объекта «отображение файла», а также размер участка файла, который должен быть отображен, и смещение начала этого участка от начала файла.
Эта функция возвращает виртуальный адрес, соответствующий началу отображенного участка файла в памяти процесса. Другими словами, оказывается, что заданный участок файла каким-то образом уже очутился в памяти, хотя функция чтения из файла не вызывалась.
На самом деле, конечно, данные из файла еще не находятся в памяти. Просто в таблице страниц отмечено, что за такими-то страницами виртуальной памяти закреплены блоки файла. На сей раз не страничного файла и не EXE-файла программы, а того файла, который использовался при создании объекта «отображение файла». Далее начинает действовать все тот же стандартный механизм загрузки страниц по требованию, т.е. реальное чтение из файла произойдет тогда, когда программа обратится к виртуальным адресам, соответствующим отображенному участку файла.
Из сказанного вытекает, что отображение файла на память представляет собой оригинальный способ работы с файлами, при котором вместо явного чтения и записи данных программа ведет себя так, как если бы файл уже находился в памяти. Это действительно так, но это еще не все.
Если два процесса работают с одним и тем же объектом «отображение файла» и участки файла, которые они отображают в свою память, хотя бы частично пересекаются, то Windows гарантирует, что любые изменения данных, сделанные на этом участке одним процессом, сейчас же становятся доступными другому процессу. Таким образом, два процесса фактически работают с общей областью памяти, как показано на рис. 5‑5.
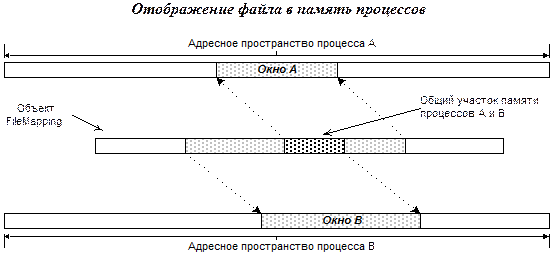
Рис.
5‑5
С этой точки зрения, отображение файлов можно рассматривать как одно из средств взаимодействия процессов, позволяющее под контролем системы преодолеть изоляцию памяти процессов.
Самое забавное, что файл-то здесь и не обязателен. Если при создании объекта «отображение файла» в качестве хэндла файла указано специальное значение FFFFFFFF16
, то Windows связывает страницы памяти с блоками страничного файла. В этом случае объект может использоваться только как средство обмена данными между процессами, без привязки к конкретному файлу. При закрытии объекта «отображение файла» его данные в этом случае не сохраняются.
5.8.5. Стеки и кучи
Описанные выше средства управления памятью, основанные на выделении регионов, представляют собой мощный и красивый инструмент для работы с большими массивами памяти. Однако в практике программирования чаще встречаются прозаические задачи, связанные с использованием небольших участков памяти: вызов функций с передачей им параметров и выделением локальных переменных, создание и освобождение переменных в динамической памяти и т.п. Но зато эти мелкие операции могут выполняться очень много раз. Использовать выделение отдельного региона ради того, чтобы получить 10 – 20 байт памяти, это примерно то же самое, что применять ракетное оружие в борьбе с тараканами. Напомним, что минимальный размер региона равен 4 Кб.
Программисты привыкли, что для размещения параметров и локальных переменных функций используется стек, а выделение участков динамической памяти происходит из «кучи» – специально предназначенной для этого области памяти, управляемой исполняющей системой языка программирования. Оба этих механизма получают поддержку со стороны Windows.
При создании новой нити она получает свой собственный стек, размер которого, если он не указан явно, принимается равным 1 Мб. Эта величина может показаться явно избыточной для большинства программ. Стоит ли системе так швыряться памятью?
На самом деле, выделяется 1 Мб резервированной памяти. Реального расходования ресурсов памяти при этом не происходит, разве что от 2 Гб адресного пространства процесса отщипывается сравнительно небольшой кусочек. Размер «настоящей» памяти, закрепленной за стеком в страничном файле, равен поначалу двум страницам, размещенным в самом конце зарезервированного региона, как показано на рис. 5‑6.

Рис.
5‑6
Стек по своему обыкновению растет в направлении убывания адресов, поэтому, начиная рост с самого старшего адреса, он постепенно заполняет одну страницу, а затем переходит ко второй, с меньшими адресами. Эта страница выделяется с атрибутом PAGE_GUARD, который, напомним, означает, что при первом обращении к странице генерируется прерывание, оповещающее об этом систему. Для Windows это сигнал, что пора передать стеку еще одну страницу памяти про запас, причем эта страница опять получает атрибут PAGE_GUARD, чтобы потом оповестить систему, что стек снова вырос. Так может продолжаться до тех пор, пока память не будет передана всем страницам региона стека, кроме самой младшей. Эта страница всегда остается зарезервированной и попытка записи на нее рассматривается как переполнение стека. Таким образом, младшая страница региона стека служит барьером, не позволяющим стеку выйти за начало региона.
А почему необходим такой барьер?
Для размещения динамических переменных удобно использовать объект «куча» (heap). Windows предоставляет каждому процессу собственную кучу, хэндл которой можно получить вызовом функции GetProcessHeap. После этого нити процесса могут запрашивать блоки памяти из кучи, вызывая функцию HeapAlloc. Параметры этой функции включают в себя хэндл кучи, размер запрашиваемого блока и некоторые флаги. По истечении надобности в выделенном блоке он может быть возвращен в кучу вызовом функции HeapFree.
Небольшая проблема возникает в связи с тем, что к одной и той же куче могут обращаться разные нити одного процесса. Не исключено их одновременное обращение к функциям, работающим с кучей. Возникает проблема взаимного исключения, и Windows решает ее, используя встроенный мьютекс. Это называется сериализацией
доступа к куче, т.е. последовательным выполнением запросов (от «serial» – последовательный). Для программы пользователя этот мьютекс не виден и можно не обращать на него внимания. Однако в том случае, если программист уверен, что нити не могут помешать друг другу, он может отключить сериализацию, указав соответствующий флаг или при открытии кучи, или при запросе блока. Это несколько повышает производительность.
В некоторых случаях оказывается выгодно использовать не одну, а несколько куч для одного и того же процесса. Можно назвать, по крайней мере, две подобных ситуации.
· Если с кучей работают две или более нитей процесса, то выделение отдельной кучи для каждой нити позволяет обойтись без сериализации, повысив таким образом производительность.
· Если программа запрашивает из кучи блоки различного размера, то неизбежно такое знакомое нам явление, как фрагментация памяти. В данном случае она приведет к излишнему росту кучи и к замедлению работы. Иногда удается избежать фрагментации, выделив отдельную кучу для каждого используемого размера блоков. Например, из одной кучи будут запрашиваться блоки только размером 105 байт, а из другой – размером 72 байта. При выделении блоков одного размера фрагментации не возникает.
Windows позволяет процессу создать любое количество дополнительных куч. Для этого нужно вызвать функцию HeapCreate, передав ей два числа: начальный размер физической памяти, передаваемой куче при создании, и максимальный размер кучи, задающий размер региона зарезервированной памяти для кучи. Если максимальный размер задан равным 0, то куча может расти неограниченно.
Когда дополнительная куча перестает быть нужна, можно освободить занимаемую память, передав хэндл кучи функции HeapDestroy.
Дать общую характеристику управления памятью в UNIX затруднительно, поскольку эта часть системы претерпела наибольшие изменения за долгий период существования UNIX, пройдя путь от управления динамическими разделами физической памяти до современной схемы замещения страниц по требованию, подобной той, которая используется в Windows.
Каждый процесс в UNIX имеет собственное виртуальное адресное пространство, разделяющееся на области программы, данных и стека. В зависимости от архитектуры памяти компьютера, область памяти UNIX может быть реализована как один или несколько сегментов памяти, как набор виртуальных страниц или просто как область в физической памяти. Адреса и размеры областей хранятся как часть контекста процесса.
Область программы, как правило, доступна только для чтения и имеет фиксированный размер. Область данных доступна для чтения и записи, ее размер может изменяться в ходе работы с помощью системного вызова brk. Область стека автоматически увеличивается системой по мере заполнения стека. При запуске нескольких процессов, выполняющих одну и ту же программу, они разделяют общую область программы, но каждый из процессов получает собственные области данных и стека.
Когда процесс выполняет системный вызов exec (т.е. начинает выполнять другую программу), все его области памяти освобождаются и затем выделяются заново.
Ядро системы имеет собственные области памяти. При выполнении системных вызовов ядро работает в контексте вызвавшего процесса, т.е. оно имеет доступ как к собственной памяти, так и к областям памяти процесса.
Эффективное использование ограниченного объема физической памяти обеспечивается работой системных процессов-«демонов», управляющих перемещением информации между памятью и файлом подкачки. В ранних реализациях UNIX, не использовавших механизм виртуальных страниц, была возможна только подкачка и вытеснение целых процессов. Демон подкачки (системный процесс с идентификатором 0) периодически отслеживал состояние процессов и принимал решение о вытеснении отдельных процессов на диск и подкачке в освободившуюся память одного из ранее вытесненных процессов. При этом во внимание принималась длительность пребывания процесса в памяти или на диске, текущее состояние процесса (спящие процессы – более подходящие кандидаты на вытеснение, чем готовые) и его размер (часто таскать туда-сюда большие процессы невыгодно).
В современных реализациях, основанных на страничной организации памяти, значительную роль играет понятие списка свободных страниц, которые могут быть немедленно выделены, если какой-либо процесс обратится к виртуальной странице, отсутствующей в памяти. В этот список заносятся страницы, к которым долго не было обращения со стороны процессов. Поскольку в отношении страниц памяти трудно реализовать алгоритм LRU, обычно используется более простой алгоритм «второго шанса» (его другое название – «алгоритм часов»). Идея заключается в следующем. Для каждой физической страницы в таблице страниц хранятся бит использования и бит модификации. Эти биты устанавливаются аппаратно: бит использования – при каждом обращении к странице, а бит модификации – при записи на страницу. Системный процесс, называемый демоном замещения страниц, активизируется периодически (по таймеру) и следит, не слишком ли мал размер списка свободных страниц. Обычно порог устанавливается равным ¼ общего объема физической памяти. Если число свободных страниц ниже этого порога, демон начинает циклически проверять все физические страницы. Если у страницы установлен бит использования, то этот бит сбрасывается. Если же бит уже был сброшен, то страница включается в список свободных. Таким образом, страница попадает в список свободных, если после последнего обращения к ней страничный демон успел дважды ее опросить. Если у страницы установлен бит модификации (в другой терминологии, если страница «грязная»), то перед ее зачислением в список свободных система сохраняет данные в страничном файле. Зачисление в список свободных страниц не означает немедленной потери данных, и если процесс успеет обратиться к странице до того, как она будет отдана другому процессу, эта страница будет исключена из числа свободных.
Демон подкачки процессов тоже не дремлет. Если страничный демон слишком часто выполняет запись страниц на диск, а число свободных страниц тем не менее остается низким, то демон подкачки выбирает один из процессов и отправляет его целиком на диск, чтобы уменьшить конкуренцию за память.
Здесь описан (весьма приблизительно) лишь один из вариантов управления памятью, реализованных в различных версиях UNIX и в Linux. Поскольку алгоритмы управления физической памятью являются «внутренним делом» системы и не регламентируются никакими стандартами, соответствующие алгоритмы, используемые в разных версиях системы, могут значительно отличаться.
В.Г., Олифер Н.А. Сетевые операционные системы. СПб.: Питер, 2001. 544 с.
Э. Современные операционные системы. СПб.: Питер, 2002. 1040 с.
В. Операционные системы. М.: Вильямс, 2002. 848 с.
Л. Введение в системное программирование. М.: Мир, 1988. 448 с.
С. Основы организации и функционирования ОС ЭВМ. М.: Мир, 1988. 480 с.
С. Проектирование операционных систем для малых ЭВМ. М.: Мир, 1986. 680 с.
А. Логическое проектирование операционных систем. М.: Мир, 1981. 360 с.
Дж. Windows для профессионалов. М.: Издательский отдел «Русская редакция» ТОО “ChannelTradingLtd.”, 1995. 720 с.
М. Секреты системного программирования в Windows 95. Киев, Диалектика, 1996. 448 с.
10. Питрек
М. Внутренний мир Windows. Киев, «ДиаСофт Лтд.», 1995. 416 с.
11. Робачевский
А.М. Операционная система UNIX. СПб.: БХВ, 1999. 528 с.
12. Дансмур М., Дейвис
Г. Операционная система UNIX и программирование на языке Си. М.: Радио и связь, 1989. 192 с.
13. Бах
М. Архитектура операционной системы UNIX.
14. Финогенов
К.Г. Самоучитель по системным функциям MS-DOS. М.: Радио и связь, Энтроп, 1995. 382 с.
15. Кнут Д. Искусство программирования. Т.1, Основные алгоритмы.
М.: Вильямс, 2002. 720 с.
16. http://www.citforum.ru
17. http://www.rsdn.ru
18. http://www.emanual.ru
19. http://www.infocity.kiev.ua
20.
http://www.helloworld.ru
21. http://
www.msdn.microsoft.com
22. http://
www.sysinternals.com
23. http://
www.bcd.org
24. http://
www.linux.org
25. http://
www.informit.com
[1]
Как вспоминает один из разработчиков первого советского компьютера МЭСМ (Малая(!) Электронная Счетная Машина), когда этого монстра включали, то приходилось в январе месяце открывать все окна, чтобы удержать температуру в машинном зале в пределах 30°.
[2]
Источник термина не совсем понятен. Среди значений английского слова «cash» наиболее подходящим кажется «наличные деньги» - та мелочь в кошельке, которая позволяет не обращаться каждый раз в банк ради мелких покупок.
[3]
Вспомните, как поступает Windows при очередной загрузке после некорректного выключения компьютера.
[4]
Теоретически можно задать число копий FAT, отличное от двух. Это число хранится как один из параметров в BOOT-секторе. На практике всегда используются две копии FAT.
[5]
Как вы думаете, в чем разница между перемещением файла в пределах одного диска и перемещением с диска на диск?
[6]
Придумано около десятка неудачных вариантов русского эквивалента для термина «handle», среди них – дескриптор, ссылка, логический номер, ключ, манипулятор, описатель, индекс... Выразительнее всего был бы прямой перевод – «рукоятка», но ни у кого не хватает смелости, чтобы ввести такой «несерьезный» термин. Так что давайте удовольствуемся честной транслитерацией «хэндл».
[7]
Налицо некоторый разнобой в общепринятой терминологии: в системе с невытесняющей диспетчеризацией вытеснение процесса все-таки возможно, но только по инициативе самого процесса.
[8]
Иногда используют также термин «разделение времени» (timesharing). Однако этот термин лучше оставить для обозначения многотерминальных ОС, описанных в п. 1.3.3. К системам с квантованием времени относятся также ОС реального времени, заметно отличающиеся от систем разделения времени.
[9]
Но к экзамену вспомнить!
[10]
Одно и то же расширение EXE означает различные форматы программ для MS-DOS и для Windows разных версий. Каждый из этих форматов имеет собственную сигнатуру. Например, для EXE-файлов современной Windows используется сигнатура 'PE'.
[11]
Использование слова «nice» – «приятный, любезный, благовоспитанный, изящный» в данном контексте обычно объясняют так: этот процесс настолько любезен, что уступает всем дорогу.
[12]
Опыт подсказывает, что как только компьютеры с памятью в несколько гигабайт станут обычными, появятся и программы, способные найти более или менее полезное употребление всей этой памяти.
|