ЗМІСТ
ВСТУП.. 2
1БАГАТОЯДЕРНІ АМД ПРОЦЕСОРИ.. 5
1.1 АМД ПРОЦЕСОРИ.. 5
1.2AMD Opteron/Athlon64. 7
1.3 AMD Phenom.. 8
1.4 AMD Turion. 13
2ЗАСОБИ МОВ С#, ADA ДЛЯ ПРОГРАМУВАННЯ ПОТОКІВ.. 16
2.1 Вирішення завдання синхронізації в мові С#. 16
2.2 Засоби синхронізації в мові С#. 20
2.3 ВИРІШЕННЯ ЗАВДАННЯ СИНХРОНІЗАЦІЇ В МОВІ АДА.. 29
3АПАРАТНИЙ КОМПЛЕКС.. 34
3.1 Компютерна система. 34
3.2 Процесор. 34
3.4 Оперативна память. 36
3.4 Жорсткий диск. 36
3.5 Корпус. 37
4РОЗРОБКА ПРОГРАМ.. 38
4.1 Задача  ...................... 38 ...................... 38
4.2 Задача  ...................................... 41 ...................................... 41
4.2 Задача  ............................... 44
C:\www\doc2html\work\bestreferat-232132-13965101163743\input\Бакалаврська Вайнагій Олександр.docx - _Toc263737444 ............................... 44
C:\www\doc2html\work\bestreferat-232132-13965101163743\input\Бакалаврська Вайнагій Олександр.docx - _Toc263737444
4.4 Тестування програм. 47
ВИСНОВКИ.. 51
СПИСОК ВИКОРИСТАНОЇ ЛІТЕРАТУРИ.. 52
Сьогодні все більше комп'ютерів оснащується багатоядерними процесорами. Такі чіпи – наприклад Core| Duo| корпорації Intel| або Athlon| 64 X2| від AMD| – містять|утримують| два (Dual| Core|) або навіть чотири (Quad| Core|) процесори.
Довгий час виробники процесорів – для підвищення продуктивності процесорів підвищували їх тактову частоту. Проте|однак| при тактовій частоті більше 3,8 ГГц чіпи просто перегріваються, відповідно, про вигоду можна забути.
Було потрібно нові ідеї і технології, одній з яких і стала ідея створення|створіння| багатоядерних чіпів. У такому чіпі паралельно працюють два і більше процесорів, які при меншій тактовій частоті забезпечують велику продуктивність. Виконувана в даний момент програма ділить завдання|задачі| по обробці даних на обоє|обидва| ядра. Це дає максимальний ефект, коли і операційна система, і прикладні програми розраховані на паралельну роботу.|із||застосуваннями| «Багатоядерність» впливає і на одночасну роботу стандартних застосувань. Так, наприклад, одне ядро процесора може відповідати за програму, що працює у фоновому режимі, тоді як антивірусна програма займає|позичає| ресурси другого ядра.
Та все ж управління паралельними завданнями|задачами| теж|також| вимагає часу і задіює ресурси ПК, крім того, часом для вирішення однієї з них доводиться чекати результату виконання інший. Тому на практиці двоядерні процесори не виробляють|справляють| обчислення|підрахунку| в два рази швидше одноядерних: хоча приріст швидкодії і виявляється|опиняється| значним, але|та| при цьому він залежить від типа|типу| додатка|застосування|. В|у| ігор, які поки що зовсім не використовують нову технологію, швидкодію, на жаль, збільшується всього на 5% при однаковій тактовій частоті. А ось|от| оптимізовані під багатоядерні процесори програми для обробки музики і відео працюють швидше вже на 50%.
Наявність декількох ядер дозволяє розподіляти фонові завдання|задачі| операційної системи по декількох ядрах процесорів, всі процеси, що вимагають інтенсивних обчислень|підрахунків|, протікають швидше:
Обробка відео: стискування|стиснення| і обробка відеофайлів відбуваються|походять| помітно швидше.
Відтворення відео: якісне відтворення фільмів з|із| високим дозволом, наприклад з дисків Blu-ray| або HD-DVD| можливо лише з|із| багатоядерними процесорами. Адже при декомпресії такого відео, що містить|утримує| великі об'єми|обсяги| даних, процесор повинен виробляти|справляти| величезну кількість обчислень|підрахунків|;
ігри: перевага за швидкістю в|у| ігор поки|поки| невелика, вони дістали користь лише від великого розміру кеша процесора, встановленого|установленого| у вашому ПК. Пройде ще деякий час, поки|доки| з'являться|появлятимуться| ігри, які на багатоядерних процесорах працюватимуть помітно швидше;
Використання|споживання| електроенергії: понижене|знизити| енергоспоживання давно стало актуальним для процесорів мобільних систем – це дозволяє продовжити автономну роботу ноутбука від акумуляторів. Багатоядерні чіпи, в яких реалізовані всі сучасні технології енергозбереження, швидше звичайних|звичних| справляються з|із| поставленими завданнями|задачами| і тому швидше можуть перейти в режим з|із| меншою тактовою частотою і, відповідно, з|із| меншим енергоспоживанням.
Розробники корпорацій Intel| і AMD| постійно розробляють нові ідеї, як зробити процесори продуктивнішими і, як наслідок, більш конкурентоздатними|конкурентоспроможними|. Так, новітнє|найновіше| покоління багатоядерних процесорів, окрім іншого, використовує наступні|слідуючі| прийоми:
інтегрований кеш: оскільки|тому що| прочитування і запис даних в оперативній пам'яті триває набагато довше, ніж вимагається процесору для обчислень|підрахунків|, ці чіпи використовують особливо швидкий кеш, який, на відміну від старих рішень|вирішень|, разом з електронікою (так званим кеш-контроллером), що управляє, вбудований в той же чіп, що і ядра. Це дозволяє процесору дуже швидко звертатися|обертатися| до вбудованої кеш-пам'яті, що в черговий раз|у черговий раз| підвищує швидкодію. У багатоядерних процесорах від AMD| кожне ядро має свій власний кеш, завдяки чому досягається певна перевага: коди, що зберігаються в кеші, і дані одночасно виконуваних програм не заважають|мішають| один одному;
покращування|поліпшувати| схеми: з|із| кожним поколінням процесорів розробники оптимізують електронні схеми, зменшуючи кількість елементів. За рахунок цього нові чіпи виконують операції набагато швидше своїх попередників;
вузькі струмопровідні доріжки: ширина робочих елементів найсучасніших мікропроцесорів складає всього 65 нанометрів. Завдяки цьому на одній і тій же площі|майдані| уміщається більше схем, а відстані між ними стають коротшими, що дозволяє значно прискорити виконання операцій;
багатоступінчасті|багатоступінчаті| енергозбережні функції: новітні|найновіші| процесори набагато економніше витрачають електроенергію, що подовжує|продовжує| термін служби і безперервної роботи акумуляторів в ноутбуках. Залежно від міри|ступеня| завантаженості окремі ділянки чіпа можуть поетапно відключатися, витримуючи таким чином різні «фази сну». Наприклад, використовується динамічна кеш-пам'ять: якщо вся буферна пам'ять в даний момент не використовується, сучасні багатоядерні процесори можуть відключати її фрагменти.
1.1
АМД ПРОЦЕСОРИ
Перехід до багатоядерних процесорів стає основним напрямом|направленням| підвищення продуктивності. Такими є сучасні багатоядерні процесори |AMD.| Ці процесори по більшості показників продуктивності випереджають своїх х86-конкурентов| від Intel|, будучи лідерами цілочисельної продуктивності серед серверних процесорів, лише трохи поступаючись IBM| Power5| і Intel| Itanium| 2
Розробка досконалішої|довершеної| мікроархітектури, що містить|утримує| більше число функціональних виконавчих пристроїв|устроїв|, з метою підвищення кількості команд, що одночасно виконуються за один такт, — традиційний альтернативний зростанню|зросту| тактової частоти метод|колія| підвищення продуктивності. Але|та| такі розробки дуже складні і дорогі; складність розробки зростає із|із| складністю логіки експоненціально.
Ще один підхід до вирішення даної проблеми був реалізований в VLIW/EPIC-архітектурі IA-64|, де частина|частка| проблем перекладена з апаратури на компілятор; проте|однак| сьогодні розробники визнають, що для високої продуктивності мікроархітектура важливіша.
Крім того, при великому числі функціональних блоків мікросхеми і великому її розмірі виникає фундаментальна проблема обмеженості швидкості поширення|розповсюдження| сигналу: за один такт сигнал не встигає|устигає| добратися у всі необхідні блоки. Як можливий вихід в мікропроцесорах Alpha| були введені|запроваджувати| так звані «кластери», де пристрої|устрої| частково дублювалися, та зате усередині|всередині| кластерів відстані були менше.
Можна сказати, що ідея побудови|шикування| багатоядерних мікропроцесорів є розвитком ідеї кластерів, але|та| в даному випадку дублюється цілком процесорне ядро. Іншим попередником багатоядерного підходу можна вважати|лічити| технології Intel| HyperThreading|, де також є невелике дублювання апаратури.
Про випуск двоядерних процесорів з|із| архітектурою х86| в AMD| і Intel| оголосили майже одночасно.
AMD| пропонує 64-розрядні двоядерні процесори Opteron| для серверних систем і робочих станцій і 64-розрядні двоядерні Athlon64| — для настільних систем. Intel| використовує аналогічну 64-розрядну архітектуру EM64T| в своїх серверних процесорах Xeon| і «настільних» Pentium| 4.
Процесори Opteron| і до появи двоядерних версій випереджали своїх х86-конкурентов| від Intel| по продуктивності на більшості додатків|застосувань|. Opteron| взагалі є лідером серед всіх серверних процесорів по цілочисельній продуктивності, хоча на тестах SPECint2000| і поступається «настільному» Pentium| 4/3,8 ГГц. На тестах SPECfp2000| він поступається IBM| Power5| і Intel| Itanium| 2. Проте|однак| останні процесори досягають настільки|так| високих показників у тому числі і за рахунок дуже великої ємкості|місткості| кеша. Можна порівняти дані SPECfp2000| для Itanium| 2/1,4 ГГц з|із| 1,5-мегабайтним| кешем третього рівня (порівнянно з|із| 1 Мбайт в|у| Opteron|) і для Itanium| 2 з|із| тією ж частотою і кешем в 3 Мбайт. При такому збільшенні ємкості|місткості| кеша продуктивність Itanium| 2 зростає на 15% (дані для SGI| Altix| 350), а Opteron| відстає від Itanium| 2 з|із| кешем на 9 Мбайт всього на 30% (таблиця. 1).
Таблиця 1. Продуктивність серверних процесорів на тестах SPECcpu2000| (пиковое/базовое значення)

Рис1.1 Продуктивність серверних процесорів на тестах SPECcpu2000| (пікове/базове значення)
1.2
AMD Opteron/Athlon64
«Opteron» (укр. Оптерон; кодова назва під час розробки Sledgehammer або K8) — перший мікропроцесор фірми AMD, заснований на 64-бітовій технології AMD64 (також званою x86-64). AMD створила цей процесор в основному для застосування на ринку серверів, тому існують варіанти Opteron для використання в системах з 1—16 процесорами.
Загальну|спільну| архітектуру серверів на базі Opteron| [1] в AMD| називають «архітектурою з|із| прямим з'єднанням|сполукою|», оскільки процесори «безпосередньо|напряму|» сполучені|з'єднані| з|із| оперативною пам'яттю за допомогою вбудованого контроллера пам'яті. В даний час|нині| Opteron| підтримує пам'ять DDR400|, що забезпечує пропускну спроможність 6,4 Гбайт/с на процесор. Із|із| зростанням|зростом| числа процесорів пропускна спроможність пам'яті зростає|росте| лінійно.
У двоядерному процесорі Athlon64| пропускна спроможність пам'яті з розрахунку на|розраховуючи на| ядро стає удвічі|вдвічі| менше|. У двоядерних Opteron| вона ділиться лише|тільки| між двома ядрами кожного процесора.
Крім того, Opteron і Athlon64 використовуть для підтримки когерентності кеша досконаліший|довершений| протокол MOESI|, що дає переваги в масштабуванні при роботі з|із| пам'яттю. Пов'язаний з роботою протоколу MOESI| трафік в двоядерних процесорах Athlon64| не зачіпає комутатор, що не блокується, а використовує SRQ|, чергу системних запитів, що відповідає за управління ядрами і визначення їх пріоритету, і контроллер пам'яті. При цьому також зменшуються затримки, оскільки не додаються|добавляють| затримки на комутаторі.
Для багатопроцесорних серверів перевага|вищість| двоядерних процесорів Opteron| представляється важливішою|поважною|: частина|частка| трафіку, що викликається|спричиняє| підтримкою когерентності кеша, доводиться|припадає| на SRQ| і контроллері пам'яті, і не дає навантаження на комутатор. Крім того, використання високошвидкісного інтерфейсу HyperTransport| в Opteron і Athlon64 передбачає|припускає| як з'єднання|сполуку| процесорів через HyperTransport| з|із| підтримкою когерентності кеша в багатопроцесорних серверах, так і пряме — без північного і південного мостів — під'єднування через HyperTransport| мостів шин PCI-X/PCI-Express, що також підвищує продуктивність. Сумарна пропускна спроможність вводу/виводу для 8-процесорних систем на базі Opteron| 8xx| досягає 30,4 Гбайт/с, для двопроцесорних систем на базі Opteron| 2xx| — 22,4 Гбайт/с. З точки зору|з погляду| архітектури пам'яті побудова|шикування| серверів з|із| Opteron| відповідає архітектурі ccNUMA|, хоч доки|поки| і з|із| невеликим, до 8, числом процесорів.
Інші переваги Opteron|, наприклад, низькі величини затримок при роботі з|із| ієрархією пам'яті. Так, затримка Opteron| при вибірці з|із| кеша даних першого рівня дорівнює трьом тактам, і є|наявний| два порти читання, що дають можливість|спроможність| двох одночасних операцій. У Xeon| DP| ця затримка дорівнює 4 тактам, а порт читання лише|тільки| один.
1.3
AMD Phenom
AMD Phenom (скорочено від слова phenomenon (феномен, незвичне явище) - багатоядерний центральний процесор від компанії AMD. Створений для персональних комп'ютерів. Має: два, три або чотири ядра. Базується на архітектурі К10. Триядерні версії (кодова назва Toliman) Phenom відносяться до серії 8000 і чотирьохядерні (кодова назва Agena) до AMD Phenom X4 9000.
AMD вважають, що чотирьохядерні Phenom-и були першими «істинними» чотирьохядерними процесорами, тому що саме вони, по суті, являються монолітним багатоядерним чіпом (всі ядра розташовані на тій же підложці кремнію), на відміну від серії процесорівIntel Core 2 Quad, які за дизайном являються мультикристально-модульними процесорами. Процесори розроблені для платформи Socket AM2+.[2]
Ці процесори покоління AMD| K10|, на жаль, не здобули популярності серед користувачів із-за проблем, що мали місце при їх появі.Перед офіційним випуском Phenom, була виявлена помилка в буфер асоціативної трансляції (TLB), яка могла спричинити блокування системи в різних випадках. Процесори Phenom аж до степінгу «B2» і «BA» схильні до цієї помилки. Якщо в BIOS і в програмному забезпеченні відключч\ити TLB, то це, як правило, призводить до втрати швидкодії порядку 10%. Процесори Phenom степінгу «В3» (моделі з номерами «xx50») були представлені 27 березня 2008 року, і були позбавлені помилки TLB
З технічної точки зору архітектура процесорів AMD| Phenom| X4/X3 (кодове ім'я Agena/Toliman) стала логічним продовженням ідей, закладених в дуже успішні Athlon| 64 і Athlon| 64 X2|.
Серед ключових|джерельних| особливостей виділимо наступні|такі| пункти.
Шина HyperTransport| була розроблена для Athlon| 64 і благополучно перекочувала до нового покоління - HyperTransport| 3.0. Вона використовується для обміну даними процесора зі|із| всією останньою периферією. Для Phenom| X3| її частота складає 1800 Мгц (для порівняння: у попередньому поколінні це значення було 1000 Мгц, а максимальна для топовых| моделей Phenom| X4| – 2000 Мгц). Хоча це поліпшення|покращання| має сенс лише|тільки| для серверних версій процесорів, призначених для багатопроцесорних конфігурацій. Настільним комп'ютерам з лишком вистачає частоти HT| в 1 ГГц.
Вбудований | контроллер пам'яті, по суті, кардинальним чином не змінився, оскільки|тому що| повністю|цілком| виправдовує себе. За швидкістю доступу до оперативної пам'яті процесори AMD| випереджали Intel| Pentium4| і навіть Core| 2 Duo|. Інженери компанії лише допрацювали|доопрацьовували| контроллер, зменшили затримки звернення до модулів ОЗУ, додали|добавляли| новий режим роботи – Unganged| (так званий "розпарений" режим), який, на відміну від звичайного|звичного| режиму Ganged| ("спареного"), має два як би незалежних 64-бітових каналу пам'яті. Тоді як класична двухканальність| – це один канал, але|та| подвоєної ширини - 128 біт. Підтримується пам'ять з|із| швидкістю аж до DDR2-1066|. Додана|добавляти| також підтримка пам'яті DDR3|, правда, вона не задіяна до цих пір, і практичну реалізацію знайде лише|тільки| в нових процесорах - Phenom| II.
Внутрішня кеш-пам'ять L1| і L2| за логікою роботи залишилася колишньою: вона ексклюзивна, тобто дані з|із| L1| не дублюються в L2|, і їх об'єм|обсяг| можна підсумовувати. Розміри цих кешів складають 128 і 512 KB| відповідно, як і у більшості процесорів попереднього покоління. З|із| удосконалень відзначимо розширення шини обміну ядра процесора з|із| обома|обидва| кешами з 64 до 128 біт.
Проте|однак| найзначнішим нововведенням слід вважати|лічити| появу внутрішньої кеш-пам'яті L3| розміром 2 MB|, також ексклюзивною, що є|з'являється|, по відношенню до L1| і L2|. Ця кеш-пам'ять загальна|спільна| для всіх трьох ядер Phenom| X3| (або чотири – для Phenom| X4|), а L1| і L2| є|наявний| в кожному окремому ядрі. Таким чином, сумарний об'єм|обсяг| кеша другого і третього рівнів для всіх процесорів Phenom| X4| складає 4 MB| і 3.5 MB| – для AMD| Phenom| X3|.
Виконавчі блоки ядра процесора для роботи з|із| дійсними числами залишилися в тій же кількості, що і в|у| Athlon| 64, але|та| збільшили свою розрядність удвічі|вдвічі| – до 128 біт.
Набор інструкцій SSE4A| для швидкого виконання певних операцій, що використовуються для прискорення або кодування відео і інших завдань|задач|, тепер несумісний з|із| аналогічними інструкціями Intel|. Це може створити певні труднощі для програмістів і привести до появи неоптимізованого ПО для однієї з платформ (із зрозумілих причин їй швидше|скоріше| стане AMD|).
Інші оптимізації. Серед них можна виділити вдосконалену технологію енергозбереження Cool’n’Quiet| 2.0, що тепер управляє окремо і незалежно всіма ядрами процесора і шиною HyperTransport|, знижуючи частоту і напругу|напруження| живлення|харчування| кожного з названих|накликати| компонентів в разі|у разі| їх простою або навіть повністю|цілком| відключаючи незадіяні блоки ядра процесора. Сюди додамо|добавлятимемо| і покращувану|поліпшувати| технологію віртуалізації AMD| Virtualization| (AMD-V|).
Всі перераховані і деякі інші нововведення забезпечують, за словами представників AMD|, підвищення продуктивності кожного ядра Phenom| на 20 -25% в порівнянні з поколінням Athlon| 64 при рівних тактових частотах. Що ж, в цьому у нас ще буде можливість|спроможність| переконатися.
Основним і, мабуть, єдиною відмінністю|відзнакою| процесора Phenom| X3| від Phenom| X4| є кількість задіяних ядер. Блок-схеми цих двох процесорів представлені на
Рис. 1.2 і Рис. 1.3

Рис. 1.2AMD| Phenom| X4|

Рис. 1.3 AMD| Phenom| X3|
Як бачимо, обоє|обидва| процесора дуже схожі. Окрім|крім| загального|спільного| числа обчислювальних ядер (і, відповідно, внутрішніх L1-| і L2-кэшей|, оскільки|тому що| вони фізично і логічно є внутрішньою частиною|часткою| кожного обчислювального ядра), відмінностей|відзнак| немає. Адже об'єднання відразу чотирьох ядер на одному кристалі, на відміну від Intel| Core| 2 Quad|, об'єднуючих в одному процесорі два окремі двоядерні кристали, одночасно є і його недоліком|нестачею|. Кристал з|із| чотирма ядрами в рамках|у рамках| 65-нм| технології виявився занадто складним і великим. Поза сумнівом|безсумнівно|, вірогідність|ймовірність| виробничого браку|шлюбу| в одному з обчислювальних ядер при виготовленні такого кристала набагато вище, ніж у конкурента. Тим більше що AMD| все ж |все же таки|помітно відстає в технологічному плані від Intel|. Тому поява Phenom| X3| багато в чому обумовлена необхідністю якось використовувати кристали Phenom| X4| з|із| технологічним браком|шлюбом| в одному з обчислювальних ядер. Тобто|цебто| Phenom| X3| – це не що інше, як Phenom| X4| з|із| одним відключеним ядром.
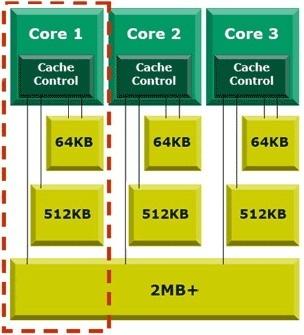
Рис. 1.4 Структура процессораAMD| Phenom| X3
Поважно відмітити|помітити|, що при відключенні четвертого ядра об'єм|обсяг| кеш-пам'яті третього рівня L3| залишився таким же, як і в|у| Phenom| X4|, і складає 2 MB|. У деяких умовах ця особливість може навіть дати перевагу Phenom| X3| над його старшим "братом" при однакових тактових частотах. Допустимо, процесор працює з|із| додатком|застосуванням|, що ефективно використовує лише|тільки| три ядра. В цьому випадку одне ядро Phenom| X4| простоюватиме, тоді як всі ядра Phenom| X3| задіяні. Все б добре, але|та| на одне ядро Phenom| X4| доводиться|припадає| лише чверть|четвертина| 2 MB| кеш-пам'яті L3|, а Phenom| X3| – третина, тобто|цебто| трохи більше. Це і може трохи збільшити продуктивність останнього.
1.4
AMD Turion
TurionX2 Ultra (кодове ім'я Griffin) є першим із сімейства процесорів AMD виключно для мобільної платформи, заснованої на Athlon 64 (K8 Редакція G) архітектури з деякими конкретними архітектурних удосконалень за аналогією з нинішньою Phenom процесорів, спрямованих на зниження споживання потужності і збільшення терміну служби батарей . Ultra процесор Turion була випущена як частина " Пума "мобільної платформи в червні 2008 року.
TurionX2 Ultra є двоядерний процесор для виготовлених на 65-нм технології з використанням 300 мм пластин КНІ. Вона підтримує DDR2-800 SO-DIMM і можливості DRAMPrefetcher для підвищення продуктивності і мобільних підвищеної північний міст (контролер пам'яті, контролер HyperTransport і координатний комутатор). Кожне ядро процесора входить 1 Мб кеша L2 на загальну суму 2 Мбайт кешу L2 на весь процесор. Кеш L2 знаходиться на поточному Turion 64 X2. Тактова частота коливається від 2,0 ГГц до 2,4 ГГц, а теплової енергії дизайн (TDP) в діапазоні від 32 Вт до 35 Вт.]
Нова функція X2 Ultra процесор Turion є те, що він реалізує три напруги площинах: одна для північного мосту і один для кожного ядра. Це, поряд з кількома фазами петлі (PLL), дозволяє змінювати основні напруги, і частоту незалежно від інших основних і незалежно від північного мосту. Дійсно, протягом декількох мікросекунд, процесор може переключитися на один з 8 рівнів частоти і один з 5 рівнів напруги. Змінюючи частоту і напругу під час роботи, процесор може адаптуватися до різних навантаження і знизити споживання енергії. Він може працювати як низький, як 250 МГц, для збереження контролю в енерговикористанні.
Він також реалізує теплові датчики на основі комплексного SMBUS (SB-TSI) інтерфейс (замінює і виключає теплової схеми чіп монітор через SMBUS в його попередники) з додатковим сигналом, посланим з вбудованих контролера до процессора і пам'яті для зниження температури.
TurionX2 Ultra процесор буде ділитися на той же сокет S1, як і його попередник ( Turion 64 X2 ), але не буде мати ту ж розкладку.
Зважаючи на вищевказані заходи по архітектурі ядра були мінімально змінені і засновані на K8, а не K10 мікроархітектури. Це робить більш імовірним, що TurionUltra будуть уникати труднощі масштабування тактової частоти, присутньої в продукції AMD K10.
TurionIIUltra (кодове ім'я Каспію) є мобільною версією архітектури K10.5, відомий також своїм настільним варіантом Regor. Це двоядерний процесор, з тактовою частотою 2,4 ГГц до 2,6 ГГц, 2 Мб кеша L2 (1 МБ на кожне ядро), HyperTransport на 3,6 GT / с і 128-бітний FPU. Він підтримує TDP 35W від від свого попередника TurionX2 Ultra (кодове ім'я Griffin).
TurionII збігається з TurionUltraII, за винятком того TurionII кошти лише 1 МБ кешу L2 (512 КБ на кожне ядро), і більш низькі тактові частоти від 2,2 ГГц до 2,3 ГГц.
| Характеристики |
AMD Turion 64 X2 |
| Кодове названня |
Taylor, Trinidad |
| Архітектура |
AMD64 |
| Сокет |
S1, 638 контактов |
| Інтерфейс |
HyperTransport (HT800) |
| Техпроцесс |
90 нм SOI |
| Контролер памяті |
Двохканальний DDR2-667 |
| Число ядер |
2 |
| Кеш L1 |
64 кбайт даних, 64 кбайт інструкції на ядро |
| Кеш L2 |
512 кбайт на ядро |
| Тактова частота |
1,6 - 2,0 ГГц |
| Площа ядра |
183 мм² |
| Число транзисторів |
154 млн. |
| Рабоча напруга |
0,8 - 1,1 В |
| Тепловой пакет (TDP) |
31, 33, 35 Вт |
| Функції енергозбереження |
PowerNow! |
| Набір інструкцій |
MMX, E3DNow!, SSE, SSE2, SSE3, NX-Bit, Pacifica VT |
Таблиця 1. Характеристики AMD Turion
2 ЗАСОБ
И МОВ С#, ADA ДЛЯ ПРОГРАМУВАННЯПОТОКІВ
2.1
Вирішення завдання синхронізації в мові С#
C#| підтримує паралельне виконання коду через багатопоточність. Потік – це незалежний шлях|колія| виконання, здатний|здібна| виконуватися одночасно з іншими потоками.
Програма на C#| запускається як єдиний потік, автоматично створюваний CLR| і операційною системою (“головний|чільний|” потік), і стає багатопотоковою за допомогою створення|створіння| додаткових потоків. Наприклад:
using| System|;
using System.Threading;
clas|s ThreadTes|t
{
static| void| Main|()
{
Thread| t = new| Thread|(WRITEY|);
t.Start();
while| (true|)
Console|.Write("x"); |
}
static| void| WRITEY|()
{
while| (true|)
Console|.Write("y|у|");
}
У головному потоці створюється новий потік t, виконуючий метод, який безперервно друкує символ ‘ y’. Одночасно головний потік безперервно друкує символ ‘ x’.
CLR призначає кожному потоку свій стек, так що локальні змінні зберігаються окремо. У наступному прикладі ми визначаємо метод із локальною змінною, а потім виконуємо його одночасно в головномуі cтвореному потоках:
static| void| Main|()
{
new| Thread|(Go|).Start();
Go|(); }
static| void| Go|()
{
// Визначаємо і використовуємо локальну змінну 'cycles|'
for| (int| cycles| = 0; cycles| < 5; cycles++|)
Console|.Write('?');
}
Управління багатопоточністю здійснює планувальник потоків, цю функцію CLR| зазвичай|звично| делегує операційній системі. Планувальник потоків гарантує, що активним потокам виділяється відповідний час на виконання, а потоки, чекаючі або блоковані, наприклад|приміром|, на чеканні|очікуванні| ексклюзивного блокування, або призначеного для користувача введення – не споживають часу CPU|.
На однопроцесорних комп'ютерах планувальник потоків використовує квантування часу – швидке перемикання між виконанням кожного з активних потоків. Це наводить до непередбачуваної поведінки, як в найпершому прикладі, де кожна послідовність символів ‘ X’ і ‘ Y’ відповідає кванту часу, виділеному потоку. У WindowsXP типове значення кванта часу – десятки мілісекунд – вибрано як набагато більше, ніж витрати CPU на перемикання контексту між потоками (декілька мікросекунд).
На багатопроцесорних комп'ютерах багатопоточність реалізована як суміш квантування часу і справжнього паралелізму, коли різні потоки виконують код на різних CPU|. Необхідність квантування часу все одно залишається, оскільки|тому що| операційна система повинна обслуговувати як свої власні потоки, так і потоки інших застосувань.
Говорять, що потік витісняється,
коли його виконання припиняється із-за зовнішніх чинників типа квантування часу. В більшості випадків потік не може контролювати, коли і де він буде витиснений.
Всі потоки одного застосування логічно містяться|утримуються| в межах процесу – модуля операційної системи, в якому виконується додаток|застосування|.
У деяких аспектах потоки і процеси схожі – наприклад, час розділяється між процесами, що виконуються на одному комп'ютері, так само, як між потоками одного C#-додатком|. Ключова|джерельна| відмінність полягає в тому, що процеси повністю|цілком| ізольовані один від одного. Потоки розділяють пам'ять з|із| іншими потоками цього ж застосування. Завдяки цьому один потік може поставляти дані у фоновому режимі, а інший – показувати ці дані у міру їх вступу|надходження|.
Типове застосування з багатопоточністю виконує тривалі обчислення у фоновому режимі. Головний потік продовжує виконання, тоді як робочий потік виконує фонове завдання. У додатках WindowsForms, коли головний потік зайнятий тривалими обчисленнями, він не може обробляти повідомлення клавіатури і миші, і додаток перестає відгукуватися. З цієї причини слід запускати що віднімають багато часу завдання в робочому потоці, навіть якщо головний потік в цей час демонструє користувачеві модальний діалог з написом “Працюю... Будь ласка, чекайте”
, оскільки програма не може перейти до наступної операції, поки не закінчена поточна. Таке рішення гарантує, що додаток не буде помічений операційною системою як що “Не відповідає”. В разі|у разі| додатків|застосувань| без UI|, наприклад, служб Windows|, багатопоточність має сенс, якщо виконуване завдання|задача| може зайняти|позичати| багато часу, оскільки|тому що| потрібне чекання|очікування| відповіді від іншого комп'ютера (сервера додатків|застосувань|, сервера баз даних або клієнта). Запуск такого завдання|задачі| в окремому робочому потоці означає, що головний|чільний| потік негайно звільняється|визволяє| для інших завдань|задач|.
Інше вживання багатопоточність знаходить в методах, що виконують інтенсивні обчислення. Такі методи можуть виконуватися швидше на багатопроцесорних комп'ютерах, якщо робоче навантаження рознесене по декількох потоках (кількість процесорів можна отримати через властивість Environment
.ProcessorCount
).
C#-додаток можна зробити багатопотоковим двома способами: або явно створюючи додаткові потоки і управляючи ними, або використовуючи можливості неявного створення потоків .NET Framework – BackgroundWorker
,
пул потоків, потоковий таймер, Remoting-сервер, Web-службы або додаток ASP.NET. У двох останніх випадках альтернативи багатопоточності не існує. Однопоточний web-сервер не просто поганий, він просто неможливий. На щастя, в разі серверів додатків, що не зберігають стан (stateless), багатопоточність реалізується зазвичай досить просто, складнощі можливі хіба що в синхронізації доступу до даних в статичних змінних.
Багатопоточність разом з|поряд з| перевагами має і свої недоліки|нестачі|. Саме головний|чільний| з|із| них – значне збільшення складності програм. Складність збільшують не додаткові потоки самі по собі, а необхідність організації їх взаємодії. Від того, наскільки ця взаємодія є навмисною|умисною|, залежить тривалість циклу розробки, а також кількість помилок, що спорадично виявляються і важковловимих, в програмі. Таким чином, потрібно або підтримувати дизайн взаємодії потоків простим, або не використовувати багатопоточність взагалі, якщо лише|тільки| ви не маєте протиприродної схильності до переписування і відладки коди.
Крім того, надмірне використання багатопоточності віднімає ресурси і час CPU на створення потоків і перемикання між потоками. Зокрема, коли використовуються операції чтения/записи на диск, швидшим може виявитися послідовне виконання завдань в одному або двох потоках, чим одночасне їх виконання в декількох потоках.
Створення|створіння| і запуск потоків С#
Для створення потоків використовується конструктор класу Thread
, що приймає як параметр делегат типа ThreadStart
, вказуючий метод, який потрібно виконати. Делегат ThreadStart
визначається так:
public delegate void ThreadStart();
Виклик методу Start
починає виконання потоку. Потік триває до виходу з виконуваного методу. Ось приклад, що використовує повний синтаксис C# для створення делегата ThreadStart
:
class| ThreadTest|
{
static| void| Main|()
{
Thread| t = new| Thread|(new| ThreadStart|(Go|));
t.Start(); // Виконати Go|() у новому потоці.
Go|(); // Одночасно запустити Go|() у головному|чільному| потоці.
}
static void Go() { Console.WriteLine("hello!"); }
В даному прикладі потік виконує метод Go
()
одночасно з головним потоком. Результат – два майже одночасних «hello»:
hello|! hello|!
2.2 Засоби|кошти| синхронізації в мові С#
У наступних|таких| таблицях приведена інформація про інструменти С# для координації (синхронізації) потоків:
Конструкція
|
Призначення
|
Sleep
|
Блокування на вказаний час
|
Join
|
Чекання закінчення іншого потоку
|
Табл. 2.1 Прості методи блокування
Конструкція
|
Призначення
|
Доступна з інших процесів?
|
Швидкість
|
Lock
|
Гарантує, що лише один потік може дістати доступ до ресурсу або секції коди.
|
немає
|
швидко
|
Mutex
|
Гарантує, що лише один потік може дістати доступ до ресурсу або секції коди. Може використовуватися для запобігання запуску декількох екземплярів додатка.
|
так
|
середня
|
Semaphore
|
Гарантує, що не більш заданого числа потоків може дістати доступ до ресурсу або секції коди.
|
так
|
середня
|
Табл. 2.2 Блокувальні конструкції
Конструкція
|
Призначення
|
Доступна з інших процесів
|
Швидкість
|
EventWaitHandle
|
Дозволяє потоку чекати сигналу від іншого потоку.
|
так
|
середньо
|
Wait and Pulse
|
Дозволяє потоку чекати, поки не виконається задана умова блокування.
|
немає
|
середньо
|
Табл. 2.3 Сигнальні конструкції
Конструкція
|
Призначення
|
Доступна з інших процесів
|
Швидкість
|
Interlocked
|
Виконання простих не блокуючих атомарних операцій.
|
Так – через пам'ять, що розділяється
|
дуже швидко
|
volatile
|
Для безпечного не блокуючого доступу до полів.
|
Так – через пам'ять, що розділяється
|
дуже швидко
|
Табл. 2.4 Не блокуючі конструкції синхронізації
Блокування
Коли потік зупинений в результаті використання конструкцій, перерахованих в наведених вище таблицях, говорять, що він блокований. Будучи блокованим, потік негайно перестає отримувати час CPU, встановлює властивість ThreadState
в WaitSleepJoin
і залишається в такому стані, поки не розблоковується. Розблокування може статися в наступних чотирьох випадках (кнопка виключення живлення не вважається!):
- виконається умова розблокування;
- витече|закінчуватиметься| таймаут операції (якщо він був заданий);
- по перериванню через Thread
.Interrupt;
- по аварійному завершенню через Thread
.Abort.
Потік не вважається блокованим, якщо його виконання припинене методом Suspend
, що не рекомендується.
Виклик Thread
.Sleep
блокує поточний потік на вказаний час (або до переривання):
static| void| Main|()
{
Thread|.Sleep(0); |
Thread|.Sleep(1000);
Thread|.Sleep(TimeSpan|.FromHours(1));
Thread|.Sleep(Timeout|.Infinite);
}
Якщо бути точнішим, Thread
.Sleep
відпускає CPU і повідомляє, що потоку не повинен виділятися час у вказаний період. Thread
.Sleep(0)
відпускає CPU для виділення одного кванта часу наступному потоку в черзі на виконання.
Унікальність Thread
.Sleep
серед інших методів блокування в тому, що він припиняє прокачування повідомлень Windows в додатках WindowsForms або COM-окружении потоку в однопоточному апартаменті. Через це тривале блокування головного (UI) потоку додатка WindowsForms наводить до того що додаток перестає відгукуватися – і отже, використання Thread
.Sleep
потрібно уникати незалежно від того, чи дійсно прокачування черги повідомлень технічно припинене. У старому COM-среде ситуація складніша, там інколи може бути бажане блокування за допомогою Sleep
з одночасним прокачуванням черги повідомлень.
Клас Thread
також надає метод SpinWait
, який не відмовляється від часу CPU, а навпаки, завантажує процесор в циклі на задану кількість ітерацій. 50 ітерацій еквівалентні паузі приблизно в мікросекунду, хоча це залежить від швидкості і завантаження CPU. Технічно SpinWait
– не блокуючий метод: ThreadState
такого потоку не встановлюється в WaitSleepJoin
,
і потік не може бути перерваний з іншого потоку. SpinWait
рідко використовується – його головне вживання це чекання ресурсу, який повинен звільниться дуже скоро (у перебігу мікросекунд) без виклику Sleep
і витрати процесорного часу на перемикання потоку. Проте ця методика вигідна лише на багатопроцесорних комп'ютерах, на однопроцесорному комп'ютері в ресурсу немає жодного шансу звільнитися, поки чекаючий на SpinWait
потік не розтратить залишок кванта часу, а значить, необхідний результат недосяжний спочатку. А часті або тривалі виклики SpinWait
даремно розтрачує час CPU.
Чекання|очікування| завершення потоку
Потік можна заблокувати до завершення іншого потоку викликом методу Join
:
class| JoinDemo|
{
static| void| Main|()
{
Thread| t = new| Thread|(delegate|() { Console|.ReadLine(); });
t.Start();
t.Join(); // чекати, поки|доки| потік не завершиться
Console|.WriteLine("Thread| t's| ReadLine| complete|!");
}
}
Метод Join
може також приймати як аргумент timeout
- в мілісекундах або як TimeSpan
.
Якщо вказаний час витік, а потік не завершився, Join
повертає false. Join
з timeout
функціонує як Sleep
– фактично наступні два рядки коди наводять до однакового результату:
Thread|.Sleep(1000);
Thread.CurrentThread.Join(1000);
Блокування і потокова безпека
Блокування забезпечує монопольний доступ і використовується, аби|щоб| забезпечити виконання однієї секції коди лише|тільки| одним потоком одночасно. Для прикладу|зразка| розглянемо|розглядуватимемо| наступний|слідуючий| клас:
class| ThreadUnsafe|
{
static| int| val1|, val2|;
static| void| Go|()
{
if| (val2| != 0)
Console|.WriteLine(val1| / val2|);
val2| = 0;
}
}
Він не є потокобезпечним: якби метод Go
викликався двома потоками одночасно, можна було б отримати помилку ділення на 0, оскільки змінна val2
могла бути встановлена в 0 в одному потоці, у той час коли інший потік знаходився б між if
і Console
.WriteLine.
От як за допомогою блокування можна вирішити цю проблему:
class| ThreadSafe|
{
static| object| locker| = new| object|();
static| int| val1|, val2|;
static| void| Go|()
{
lock| (locker|)
{
if| (val2| != 0)
Console|.WriteLine(val1| / val2|);
val2| = 0;
}
}
}
Лише один потік може одноразово заблокувати об'єкт синхронізації (в даному випадку locker
), а всі інші конкуруючі потоки будуть припинені, поки блокування не буде знято. Якщо за блокування борються декілька потоків, вони ставляться в чергу чекання – "Readyqueue" – і обслуговуються, як тільки це стає можливим, за принципом “першим прийшов – першим обслужений”. Ексклюзивне блокування, як вже говорилося, забезпечує послідовний доступ до того, що вона захищає, так що виконувані потоки вже не можуть накластися один на одного. В даному випадку ми захистили логіку усередині методу Go
, так само, як і поля val1
і val2
.
Потік, заблокований на час чекання звільнення блокування, має властивість ThreadState
,
встановлену в WaitSleepJoin
. Пізніше ми обговоримо, як потік, заблокований в такому стані, може бути примусово звільнений з іншого потоку викликом методів Interrupt
або Abort
.
Це досить потужна можливість, використовувана зазвичай для завершення робочого потоку.
Оператор lock
мови C# фактично є синтаксичним скороченням для викликів методів Monitor
.Enter
і Monitor
.Exit
в рамках блоків try-finally
. Ось в що фактично розвертається реалізація методу Go з попереднього прикладу:
Monitor|.Enter(locker|);
try|
{
if| (val2| != 0)
Console|.WriteLine(val1| / val2|);
val2| = 0;
}
finally { Monitor.Exit(locker); }
Виклик Monitor
.Exit
без попереднього виклику Monitor
.Enter
для того ж об'єкту синхронізації викличе виключення.
Monitor
також надає метод TryEnter
,
що дозволяє задати час чекання в мілісекундах або у вигляді TimeSpan
. Метод повертає true
, якщо блокування було отримане, і false
, якщо блокування не було отримане за заданий час. TryEnter
може також бути викликаний без параметрів і в цьому випадку повертає управління негайно.
При неправильному використанні в блокування можуть бути і негативні наслідки – зменшення можливості паралельного виконання потоків, взаимоблокировки, гонки блокувань. Можливості для паралельного виконання зменшуються, коли надто багато коди поміщено в конструкцію lock
, заставляючи інші потоки простоювати весь час, поки цей код виконується. Взаємоблокування настає, коли кожен з двох потоків чекає на блокуванні іншого потоку і, таким чином, ні той, ні інший не може рушити далі. Гонкою блокувань називається ситуація, коли будь-який з двох потоків може першим отримати блокування, проте програма ламається, якщо першим це зробить “неправильний” потік.
Взаємоблокування – загальний|спільний| синдром багатьох об'єктів синхронізації. Хороше|добре| правило, що допомагає уникати взаємоблокуваннь |, полягає в тому, аби|щоб| починати з блокування мінімальної кількості об'єктів, і збільшувати міру|ступінь| деталізації блокувань, коли розмір коди в блокуванні надмірно збільшується.
Заблокований потік може бути передчасно розблокований двома шляхами:
- За допомогою Thread
.Interrupt.
- За допомогою Thread
.Abort.
Це повинно бути зроблено з|із| іншого потоку; чекаючий потік безсилий що-небудь зробити в блокованому стані|статку|.
Interrupt|
Виклик Interrupt
для блокованого потоку примусово звільняє його з генерацією виключення ThreadInterruptedException
, як показано в наступному прикладі:
class| Program|
{
static| void| Main|()
{
Thread| t = new| Thread|(delegate|()
{
try|
{
Thread|.Sleep(Timeout|.Infinite);
}
catch|(ThreadInterruptedException|)
{
Console|.Write("Forcibly| ");
}
Console|.WriteLine("Woken|!");
});
t.Start();
t.Interrupt();
}
}
Wait| Handles|
Оператор lock
– один з прикладів конструкцій синхронізації потоків. Lock
є самим відповідним засобом для організації монопольного доступу до ресурсу або секції коди, але є завдання синхронізації (типа подачі сигналу початку роботи чекаючому потоку), для яких lock
буде не найадекватнішим і зручнішим засобом.
У Win32 API є багатий набір конструкцій синхронізації, і вони доступні в .NET Framework у вигляді класів EventWaitHandle
, Mutex
і Semaphore
.
Деякі з них практичний за інших: Mutex
, наприклад, здебільше дублює можливості lock
, тоді як EventWaitHandle
надає унікальні можливості сигналізації.
Всі три класи засновано на абстрактному класі WaitHandle
, але вельми відрізняються по поведінці. Одна із загальних особливостей – це здатність іменування, що робить можливою роботу з потоками не лише одного, але і різних процесів.
EventWaitHandle
має два похідних класу – AutoResetEvent
і ManualResetEvent
(що не мають жодного відношення до подій і делегатів C#). Обом класам доступні всі функціональні можливості базового класу, єдина відмінність полягає у виклику конструктора базового класу з різними параметрами.
У частині продуктивності, все WaitHandle
зазвичай виконуються в районі декількох мікросекунд. Це рідко має значення з врахуванням контексту, в якому вони застосовуються.
AutoResetEvent
дуже схожий на турнікет – один квиток дозволяє пройти одній людині. Приставка “auto” в назві відноситься до того факту, що відкритий турнікет автоматично закривається або “скидається” після того, як дозволяє кому-небудь пройти. Потік блокується в турнікета викликом WaitOne
(чекати (wait
) в даного (one
) турнікета, поки він не відкриється), а квиток вставляється викликом методу Set
. Якщо декілька потоків викликають WaitOne
, за турнікетом утворюється черга. Квиток може “вставити” будь-який потік – іншими словами, будь-який (неблокований) потік, що має доступ до об'єкту AutoResetEvent
,
може викликати Set
,
аби пропустити один блокований потік.
Якщо Set
викликається, коли немає чекаючих потоків, хэндл знаходитиметься у відкритому стані, поки який-небудь потік не викличе WaitOne
.
Ця особливість допомагає уникнути гонок між потоком, відповідним до турнікета, і потоком, що вставляє квиток (“опа, квиток вставлений на мікросекунду раніше, дуже шкода, але вам доведеться почекати ще скільки-небудь!”). Проте багатократний виклик Set
для вільного турнікета не дозволяє пропустити за раз цілий натовп – зможе пройти лише один людина, всі останні квитки будуть витрачені даремно.
WaitOne
приймає необов'язковий параметр timeout
– метод повертає false
, якщо чекання закінчується по таймауту, а не по здобуттю сигналу. WaitOne
також можна виучити виходити з поточного контексту синхронізації для продовження чекання (якщо використовується режим з автоматичним блокуванням) щоб уникнути надмірного блокування.
Метод Reset
забезпечує закриття відкритого турнікета, без всяких чекань і блокувань.
Мьютекс забезпечує ті ж самі функціональні можливості, що і оператор lock
в C#, що робить його таким, що не дуже зажадався. Єдина перевага полягає в тому, що Mutex
доступний з різних процесів, забезпечуючи блокування на рівні комп'ютера, у відмінності від оператора lock
, який діє лише на рівні додатка. Mutex
відносно швидкий, але lock
швидше в сотні разів. Здобуття мьютекса займає декілька мікросекунд, виклик lock
– десятки Наносекунди (якщо не відбувається власне блокування). Метод WaitOne
для Mutex
отримує виняткове блокування, блокуючи потік, якщо це необхідно. Виняткове блокування може бути зняте викликом методу ReleaseMutex
. Точно також як оператор lock
в C#, Mutex
може бути звільнений лише з того ж потоку, що його захопив.
Типове використання мьютекса| для взаємодії процесів – забезпечення можливості|спроможності| запуску лише|тільки| одного екземпляра|примірника| програми одноразово. Приклад:
class| OneAtATimePlease|
{
static| Mutex| mutex| = new| Mutex|(false|, "oreilly|.com OneAtATimeDemo|");
static| void| Main|()
{
if| (!mutex.WaitOne(TimeSpan|.FromSeconds(5), false|))
{
Console|.WriteLine("У системі запущений інший екземпляр|примірник| програми!");
return|;
}
try|
{
Console|.WriteLine("Працюємо - натискуйте|натискайте| Enter| для виходу...");
Console|.ReadLine();
}
finally| { mutex|.ReleaseMutex(); }
}
}
Корисна властивість Mutex
– якщо додаток завершується без виклику ReleaseMutex
, CLR звільняє мьютекс автоматично.
Semaphore
з ємкістю, рівній одиниці, подібний Mutex
або lock
, за винятком того, що він не має потоку-господаря. Будь-який потік може викликати Release
для Semaphore
, тоді як у випадку з Mutex
або lock
лише потік, що захопив ресурс, може його звільнити.
У наступному прикладі по черзі запускаються десять потоків, що виконують виклик Sleep
. Semaphore
гарантує, що не більше трьох потоків можуть викликати Sleep
одночасно:
class| SemaphoreTest|
{
static| Semaphore| s = new| Semaphore|(3, 3); // Available=3|; Capacity=3|
static| void| Main|()
{
for| (int| i = 0; i < 10; i++|)
new| Thread|(Go|).Start();
}
static| void| Go|()
{
while| (true|)
{
s.WaitOne();
// Лише|тільки| 3 потоки можуть знаходитися|перебувати| тут одночасно
Thread|.Sleep(100);
s.Release();
}
}
}
2.3
ВИРІШЕННЯ ЗАВДАННЯ СИНХРОНІЗАЦІЇ В МОВІ АДА
Завдання синхронізації двох процесів полягає в тому, що в одному процесі, наприклад Б, у визначеній точці (точці події) виконується подія (обчислення даних, уведення або виведення даних і т. ін.), а другий процес А у визначеній точці (точці очікування події) блокується доти, доки ця подія не відбудеться і він зможе продовжити своє виконання. Точка події і точка очікування - це точки синхронізації Якщо процес А вийшов на точку синхронізації, коли подія вже відбулася, то він не блокується і продовжує виконуватись.
Існує декілька схем синхронізації процесів :
• один процес очікує на подію в одному процесі (а);
• декілька процесів очікують на подію в одному процесі (b);
• один процес очікує на події в кількох процесах (с).
Для вирішення завдання синхронізації, яке іноді називають синхронізацією за подіями (eventsynchronization), можна використовувати різні механізми синхронізації процесів, таки як семафори, події, монітори.
Для вирішення завдання синхронізації в мові Ада95 можна застосувати механізм семафорів, а також захищені модулі.
Застосування семафорів. Розглянемо приклад, у якому задача А чекає на подію, яку мають містити задачі В, наприклад, введення даних (змінної х). Для синхронізації процесів з уведення використовуємо семафор СігналПроПодію з початковим значенням false, яке встановлюється автоматично під час створювання семафора. Очікування події в процесі А реалізовано за допомогою операції Suspend__Until_True (СігналПроПодію), а посилання сиггалу про подію в задачі В реалізовано за допомогою операції SetTrue(СігналПроПодію) .
procedureСинхронізація is
X: integer; -- глобальна змінна
СігналПроПодію: Suspension_Object; -- семафор
— задача, що чекає на подію
taskA;
task body A is
begin
точка очікування події
Suspend_Until_True(СігналПроПодію);
end A;
-- задача, де пройде подія
task В;
task body В is
begin
get(X); -- введення даних(подія, наяку чекає А)
Set_True(СігналПроПодію); -- сигнал задачі А
end В; begin
null ;
end Синхронізація;
Механізм семафорів запропонував математик Е.Дейкстра. У класичній інтерпретації механізм семафорів - це спеціальний захищений тип Semaphore та дві неподільні операції над змінною цього типу: P(S)
і V(S).Неподільність операції означає, що її не можна переривати, поки не завершиться її виконання.
У мови Ада механізм семафорів подано у вигляді пакета Synchronous_Task_Control в додатку Annex D: Real-Time Systems. Пакет реалізує механізм семафорів таким чином. Семафорний тип забезпечується приватним типом Suspension_object, операції P(S)
і V(S)
реалізовані за допомогою процедур Suspend_Until_True () і SetJTrue (). Використовується бінарний логічний семафор, тобто семафорні змінні типу Suspension_Object набувають значень false і true. Крім указаних процедур, в пакеті реалізовані допоміжні процедури SetFalseOдля встановлення значення семафора в false і Currentstate () для зчитування поточного значення семафора. Специфікація пакета:
package
Ada.Synchronous_Task_Control is
type
Suspension_Object limited private
;
rocedure
Set_True(S : in out
3uspension_Object);
procedure
Set_False(S : in out
Suspension_Object);
function
Current_State(S : Suspension_Object) return Boolean
;
procedure
Suspend_Until_True(3:in out
Suspension_Object); private
end
Ada.
Synchronous_Task_Control;
Ідея монітора, яку запропонував Б. Хансен і розвинув С. Хо ґрунтується на об'єднанні змінних, що описують спільний ресуpc, і дій, які визначають засоби доступу до спільного ресурсу. Монітор - програмний модуль, що містить змінні та процедури роботи над ними, причому доступ до змінних можливий тільки
в процедурі.
Монітор - засіб розподілу ресурсів і взаємодії процесів Це назначення монітора реалізується за допомогою властивостей, якими наділені процедури монітора. Характерна особливість процедур монітора - взаємне виключення ними одне одного. У будь-який момент часу може виконуватися тільки одна процедура монітора. Якщо будь-який процес викликав і виконуй процедуру монітора. то жоден процес не може виконувати будь-які процедури цього монітора. За спроби виклику іншим процесом процедури, що виконується, або іншої процедури монітора цей процес блокується і розміщується в черзі блокованих процесів доти, доки активний процес не закінчить виконання процедури монітора. Тобто в моніторі не може "знаходитись" більше одного процесу. Така властивість процедур монітора забезпечує взаємне виключення процесів. які працюють з монітором.
Загальна структура монітора:
monitor
ім'я Монітора;
-- Опис локальних даних
-- Опис процедур для доступу до даних begin
-- Ініціалізація локальних даних end
ім'я Монітора;
У моніторі декларуються локальні змінні (спільні змінні), які захищені монітором, і процедури монітора. Значення локальних змінних можуть бути встановлені під час створення монітора. Далі значення цих змінних можуть бути прочитані або змінені процесами тільки за допомогою процедур, визначених у моніторі.
Концепцію моніторів у новому стандарті мови Ада95 реалізовано у вигляді спеціальних програмних модулів - захищених модулів (protected units). їх призначення - розширення можливості мови для програмування паралельних процесів. зокрема, для вирішення проблеми доступу до спільних ресурсів і синхронізації процесів. Крім того, захищені модулі забезпечують підтримку різних парадигм систем реального часу, для розроблення яких мову Ада використовують в першу чергу.
Спільні дані і операції над ними (захищені операції) об'єднуються в захищеному модулі, аналої ічно тому, як це робиться в інших модулях мови Ада- пакетах. Доступ до спільних ресурсів можливий тільки через захищені операції, які мають властивості, що дозволяють вирішити завдання взаємного виключення під час роботи зі спільними ресурсами.
Як і всі модулі в мові, захищені модулі складаються зі специфікації і тіла.
PROTECTED [TYPE] імя _Захшценого_Модуля
[Дискримінант] IS
Опис_Захищених_Операцій
[PRIVATE]
Опис_Захищених_Елемєнтів
END імя_Захищєного_Модуля;
Захищені операції - це:
• захищені функції.
• захищені процедури,
• захищені входи.
Захищені функції забезпечують доступ тільки до читання захищених і елементів. Але дозволяють робити це одночасно всім процесам автоматичним копіюванням елементів, які зчитуються.
Це порушує головну властивість процедур монітора, яка дозволяє знаходитися в моніторі тільки одному процесу, але це ''порушення" дозволяє скоротити час доступу до захищених елементів і не має будь-яких наслідків, оскільки зміна даних заборонена і не виконується.
Захищені процедури забезпечують ексклюзивний доступ до захищених елементів через читання і запис.
Захищені входи забезпечують ті самі функції, що й захищені процедури, додатково реалізуючі за допомогою бар 'єрів ексклюзивний (умовний) доступ до тіла захищеного входу. Це Дозволяє реалізувати за допомогою входів вирішення завдання синхронізації.
\\
3 А
ПАРАТНИЙ КОМПЛЕКС
Табл 3.1 Структура комп’ютерної системи.
Процесор:
|
AMD PHENOM II X4 945(3.00GHz,AM3)
|
1213.00 Грн.
|
Материнська плата:
|
AMD 780V
|
559 грн.
|
Оперативна пам'ять:
|
DDR II 4GB PC6400 KINGSTONE(HYNIX)
|
1 115,80 грн.
|
Жорсткий диск:
|
500GB SATA II 16MB(WD,SEAGATE)
|
470.82 грн.
|
Відеокарта:
|
onboard VGA(DVI) up to 512MB
|
CD:
|
DVD-RW
|
184 грн.
|
Звук:
|
6-Channel HD Audio
|
| Корпус |
ATX 400W FSP(CHIEFTEC) 4U 701 |
624,1 |
4166,72
|
AMD PHENOM II X4 945(3.00GHz,AM3)
| Лінійка |
Phenom II X4 |
| Сокет |
AM3 |
| Тактова частота |
3000 Мгц |
| Частота шини |
HT |
| Коефіцієнт множення |
15 |
| Напруга на ядрі |
0.875 B |
| Інструкції |
MMX, SSE, SSE2, SSE3, SSE4, 3DNow! |
| Підтримка AMD64/EM64T |
є |
| Підтримка NX Bit |
є |
| Підтримка Virtualization Technology |
є |
| Ядро |
Deneb |
| Кількість ядер |
4 |
| Техпроцесс |
45 нм |
| Об'єм кеша L1 |
128 Кб |
| Об'єм кеша L2 |
2048 |
| Об'єм кеша L3 |
6144 |
| Типове тепловиділення |
125 Вт |
| Максимальна робоча температура |
62 °C |
| Додаткова інформація |
напруга на ядрі 0.875-1.5В |
Табл 3.2 Характеристика процесора.
3.3
Системна плата ASUS| M3A78-CM| 6xSATA
| Socket |
AM2+ |
| Кількість сокетів для процесора |
1 |
| Системна шина |
HyperTransport |
| Підтримка багатоядерних процесорів |
Є
|
Підтримувані процесори
|
AMD PhenomFX/Phenom/Athlon64 FX/Athlon64 X2/Athlon64/Sempron |
| Пам'ять |
DDR2 DIMM, 533 - 1066 Мгц |
| Кількість слотів пам'яті |
4 |
| Максимальний об'єм пам'яті |
8 Гб |
| Підтримка двоканального режиму |
є |
| Слоти розширення |
1xPCI-E 16x, 1xPCI-E 1x, 2xPCI |
| Підтримка PCI Express 2.0 |
є |
| Ethernet |
1000 Мбіт/с |
| S-ATA |
кількість слотів: 6, S-ATA II, RAID: 0, 1, 10 |
| IDE |
кількість слотів: 1, ULTRADMA 133 |
| Звук |
7.1CH, HDA |
| Вбудований відеоадаптер |
Є |
| Роз'єм живлення процесора |
4-pin |
Наявність інтерфейсів
|
12xUSB 2.0, вихід S/PDIF, 1xCOM, LPT, D-Sub, DVI, Ethernet, PS/2 (клавіатура) |
Роз'єми на задній панелі
|
6xUSB 2.0, D-Sub, DVI, Ethernet, PS/2 (клавіатура) |
| Основний роз'єм живлення |
24-pin |
| Форм-фактор |
mATX |
| Чіпсет |
AMD 780V |
| Підтримка SLI/CrossFire |
Hybrid CrossFireX |
| BIOS |
AMI з можливістю аварійного відновлення |
Табл 3.2 Характеристика системної плати.
Hynix DDR2-800 4096MB PC6400 (HMP351U6AFR8C-S6)
| Об'єм пам'яті |
4 ГБ |
| Тип пам'яті |
DDR2 SDRAM |
| Частота пам'яті |
800 Мгц |
| Ефективна пропускна спроможність |
6400 Mб/с |
| Схема таймінгів пам'яті |
CL6 |
Табл 3.3 Характеристика оперативної памяті.
3.4
Жорсткий диск
Вінчестер SATA 500 GB WD WD5000AAKS 16MB 7200rpmА
| Ємкість |
500 Гб |
| Час включення |
11 сек |
| Тип підшипників |
Гідродинамічний (FDB). |
Інтерфейс
|
SATA-II (Сумісно з SATA-I або SATA150 контроллерами) |
| Буфер |
16 Мб |
| Швидкість обертання шпинделя |
7200 оборотов/хв. |
| Середній час доступу |
8.9 мс (читання), 10.9 мс (запис) |
| Час переходу з доріжки на доріжку |
2 мс |
| Швидкість обміну між носієм і контроллером |
до 972 Мбіт/сек
|
Рівень шуму
|
28 дБ (А) в режимі чекання, 33 дБ (А) - Seek Mode, 29 дБ (А) - Seek Mode 3 |
Максимальні перевантаження
|
65G тривалістю 2 мс при роботі; 300G тривалістю 2 мс у вимкненому стані |
| Пропускна спроможність інтерфейсу |
300 Мб/сек
|
| Живлення |
Від SATA коннектора живлення. |
Вжиток енергії
|
8.77 Вт (чтение/запись), 8.4 Вт (у режимі чекання) |
Табл 3.4 Характеристика вінчестера.
Корпус ATX 400W FSP(CHIEFTEC) 4U 701
| 5.25" |
4 шт |
| 3.5" зовнішні (для FDD,CardReader) |
1шт |
| 3.5" внутрішні (для HDD) |
5шт |
| Додатково |
| USB 2.0 виходів - |
2шт |
| Audio роз`єм(мікрофон, навушники) |
2шт |
| Блок живлення |
ATX 450 Вт кулер 120мм (SATA) |
| Розміри: |
| высота*глубина*ширина (мм) |
430*480*200 |
Табл 3.5 Характеристика корпусу
4
РОЗРОБКА ПРОГРАМ
Реалізація множення матриці на матрицю у чотирьох процесорній системі із спільною пам’яттю (рис. 4.1) з використання захищеного модуля мови Ада.
Вхідні дані:
комп’ютерна система зі спільною пам’яттю, яка включає чотири процесори і два пристрої введення-виведення (рис. 2.1);
математичне завдання: реалізації множення матриці на матрицю і вектора на матрицю  ; ;
де MА, М
B
, М
C
– вектори розмірності N
.
введення вектора M
В
виконується в процесорі Т2, введення матриці МС
виконується в процесорі Т1, виведення результату – матриці МА
– у процесі Т1.
Етап 1. Побудова паралельного алгоритму.
Паралельний алгоритм можна подати у вигляді
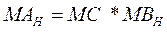 (4.1) (4.1)
де 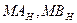 - Н
елементів матриці MB
, MA
. - Н
елементів матриці MB
, MA
.
Співвідношення (4.1) визначає дії у кожному процесорі системи під час виконання обчислень.
Спільним ресурсом у рівнянні (4.1) є MC
.

Етап2. Розроблення алгоритмів роботи кожного процесу.
Цей етап включає розроблення детального алгоритму роботи кожного процесу. Такий алгоритм має включати всі дії процесу, які, крім безпосередніх обчислень за формулою (2.1), будуть включати введення даних і виведення результату, а також дії, що пов’язані з організацією взаємодії процесів (розв’язування задач взаємного виключення та синхронізації).
| Т1 |
Т2 |
Т3 |
Т4 |
| 1.Ввід MC
.
|
1.Введення М
B
.
|
1. Чекати сигнал від Т1,Т2. |
1.Чекати сигнал від Т1,Т2. |
| 2.СигналT1,Т2,Т3,Т4 про закінчення введення MC.
|
2.СигналТ1,T2,T3,Т4 про закінчення введення М
B
.
|
2. Копія
 = = . .
|
2. Копія
 =. =.
|
| 3.Чекати сигнал від Т1,Т2. |
3.Чекати сигнал від Т1,Т2. |
3.Обчислення
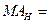 * *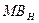
|
3.Обчислення
*
|
4. Kопія =. =. |
4. Копія
 =. =.
|
4. Сигнал про завершення обчислення Т1 |
4.Сигнал від Т1, про завершення обчислення |
5.Обчислення
*
|
5.Обчислення
*
|
| 6.Чекатисигналвід T1,Т2,Т3,Т4 про завершення обчислення. |
6.Сигнал про завершення обчислення Т1. |
| 7.Виведення MА
. |
Табл.3.1. Структурна таблиця розроблення алгоритмів роботи кожного процесу.
Етап 3. Розробка структурної схеми взаємодії задач.
Цей етап пов'язаний із розробкою структури захищеного модуля, за допомогою якого реалізується взаємодія задач. Захищений модуль Керування
(рис 2.2) включає чотири захищені елементи: В, МС,
F
1,
F
2,
а також набір захищених операцій:
· вхід Чекати 1
для синхронізації з введенням в задачах Т1, Т2;
· вхід Чекати 2
для синхронізації після завершення обчислень у задачі Т1;
· функцію Копія МС
для копіювання спільного ресурсу МС;
· процедуру Ввід МС
для запису значення МС у захищений модуль;
· процедуру Сигнал 1
для сигналу про завершення обчислень у задачі Т1, Т2, Т3,T4;
· процедуру Сигнал 2
для сигналу про завершення введення даних у задачах Т2 і Т4.
Захищені змінні F1 F2 використовуються в бар’єрах входів Чекати 1
і Чекати 2.
Схема захищеного модуля представлена в Додатку А
Етап 4.
Лістинг програми
Лістинг програми представлено в Додатку Б
4.2
Задача 
Реалізація множення матриці на матрицю у чотирьох процесорній системі із спільною пам’яттю (рис. 4.2) з використання захищеного модуля мови Ада.
Вхідні дані:
· комп’ютерна система зі спільною пам’яттю, яка включає чотири процесори ітри пристрої введення-виведення (рис. 2.1);
· математичне завдання: реалізації множення матриці на матрицю і на
· ще одну матрицю  ; ;
де MА, М
B
, М
C
, МЕ
– матриці розмірності N
.
· введення матриціM
В
виконується в процесорі Т2, введення матриці МС
виконується в процесорі Т1, введення матриці М
E
виконується в процесорі Т3, виведення результату – матриці МА
– у процесі Т4.
Етап 1. Побудова паралельного алгоритму.
Паралельний алгоритм можна подати у вигляді

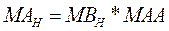 (4.2) (4.2)
де  - Н
елементів матриціМА
,MB,MC,MAA
. - Н
елементів матриціМА
,MB,MC,MAA
.
Співвідношення (4.2) визначає дії у кожному процесорі системи під час виконання обчислень.
Спільним ресурсом у рівнянні (4.2) є матрицяMC
іпотім створена матриця M
АА
.
Етап2. Розроблення алгоритмів роботи кожного процесу.
Цей етап включає розроблення детального алгоритму роботи кожного процесу. Такий алгоритм має включати всі дії процесу, які, крім безпосередніх
обчислень за формулою (4.2), будуть включати введення даних і виведення результату, а також дії, що пов’язані з організацією взаємодії процесів (розв’язування задач взаємного виключення та синхронізації).
| Т1 |
Т2 |
Т3 |
Т4 |
| 1. Введення MC
.
|
1.Введення М
B
.
|
1. Введення М
E
.
|
1.Чекати сигнал від Т1,Т2,Т3. |
| 2.Сигнал T1,Т2,Т3,Т4 про закінчення введення MC
.
|
2.Сигнал Т1,Т3,Т4 про закінчення введення М
B
.
|
2.Сигнал Т1,Т2,Т4 про закінчення введення ME
.
|
2.Копія  |
| 3.Чекати сигнал від T1,Т2,Т3. |
3.Чекати сигнал від Т1,T2,Т3. |
3.Чекати сигнал від Т1,Т2,T3. |
3.Обчислення
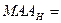 
|
4.Копія 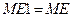 |
4.Копія  |
4.Копія  |
4.Сигнал від Т1, Т2, Т3, Т4
про завершення обчислення.
|
5.Обчислення

|
5.Обчислення
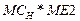
|
5. Обчислення

|
5. Чекати сигнал від Т1,Т2,T3,Т |
6. Сигнал від Т1, Т2, Т3, Т4
про завершення обчислення.
|
6. Сигнал від Т1, Т2, Т3, Т4
про завершення обчислення.
|
6. Сигнал від Т1, Т2, Т3, Т4
про завершення обчислення.
|
6.Копія  |
| 7. Чекати сигнал від Т1,Т2,T3,Т4. |
7. Чекати сигнал від Т1,Т2,T3,Т4. |
7. Чекати сигнал від Т1,Т2,T3,Т4. |
7.Обчислення
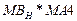
|
8.Копія  |
8.Копія  |
8.Копія  |
8. Сигнал Т4
про завершення обчислення.
|
9. Сигнал Т4
про завершення обчислення
|
9. Сигнал Т4
про завершення обчислення
|
8. Сигнал Т4
про завершення обчислення
|
9. Вивід MA
|
Табл. 4.2 Структурна таблиця розроблення алгоритмів роботи кожного процесу.
Етап 3. Розробка структурної схеми взаємодії задач.
Цей етап пов'язаний із розробкою структури захищеного модуля, за допомогою якого реалізується взаємодія задач. Захищений модуль Керування
(рис 2.2) включає чотири захищені елементи: МE,
F
1,
F
2,
F3
а також набір захищених операцій:
· вхід Чекати 1
для синхронізації з введенням в задачах Т1, Т2, Т3;
· вхід Чекати
2
для синхронізації після завершення обчислень у задачі Т1, Т2, Т3,Т4;
· вхід Чекати
3
для синхронізації після завершення обчислень у задачі Т4;
· функцію Копія
MAA
,
Kopija ME
для копіювання спільного ресурсу MAA,МС;
· процедуру Ввід М
E
для запису значення МE у захищений модуль;
· процедуру Сигнал 1
для сигналу про завершення обчислень у задачі Т1, Т2, Т3;
· процедуру Сигнал 2
для сигналу про завершення введення даних у задачах Т1, Т2, Т3,Т4;
· процедуру Сигнал
3
для сигналу про завершення введення даних у задачах Т1, Т2, Т3,Т4;
Захищені змінні F1, F2, F3 використовуються в бар’єрах входів Чекати 1
, Чекати 2, Чекати 3.
Схема захищеного модуля представлена в Додатку В
Етап 4.
Лістинг програми
Лістинг програми представлено в Додатку Г
4.2
Задача 
Реалізація cуми двох добутків матриці на матрицю у чотирьох процесорній системі із спільною пам’яттю (рис. 4.3) з використання захищеного модуля мови Ада.
Вхідні дані:
· комп’ютерна система зі спільною пам’яттю, яка включає чотири процесори і чотири пристрої введення-виведення (рис. 2.1);
· математичне завдання: реалізації множення матриці на матрицю і вектора на матрицю 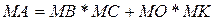 ; ;
де MА, М
B
, М
C,MO,MK
– матриці розмірності N
.
· введення вектора M
В
виконується в процесорі Т2, введення матриці МС
виконується в процесорі Т1, введення матриці М
O
виконується в процесорі Т3, введення матриці МK
виконується в процесорі Т4, виведення результату – матриці МА
– у процесі Т3.
Етап 1. Побудова паралельного алгоритму.
Паралельний алгоритм можна подати у вигляді
 (4.3) (4.3)
де 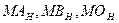 - Н
елементів матриці M
A
. - Н
елементів матриці M
A
.
Співвідношення (4.3) визначає дії у кожному процесорі системи під час виконання обчислень.
Спільним ресурсом у рівнянні (4.3) є MC
і MK
.

Етап2. Розроблення алгоритмів роботи кожного процесу.
Цей етап включає розроблення детального алгоритму роботи кожного процесу. Такий алгоритм має включати всі дії процесу, які, крім безпосередніх обчислень за формулою (4.3), будуть включати введення даних і виведення результату, а також дії, що пов’язані з організацією взаємодії процесів (розв’язування задач взаємного виключення та синхронізації).
| Т1 |
Т2 |
Т3 |
Т4 |
| 1.Ввід MB
.
|
1.Введення М
B
.
|
1. Введення М
O
.
|
1. Введення М
K
.
|
| 2.Сигнал T1-T4про закінчення введення.
|
2.Сигнал T1-T4про закінчення введення.
|
2.Сигнал T1-T4про закінчення введення.
|
2. Сигнал T1-T4про закінчення введення.
|
| 3.Чекати сигнал від Т1-T4. |
3.Чекати сигнал від Т1-T4. |
3.Чекати сигнал від Т1-T4. |
3.Чекати сигнал від Т1-T4. |
4. Копія

 = = . .
|
4. Копія

 =. =.
|
4. Копія

 =. =.
|
4. Копія

 =. =.
|
5.Обчислення

|
5.Обчислення

|
5.Обчислення

|
5.Обчислення
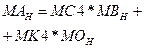
|
| 6.Чекати сигнал від Т1-T4 про завершення обчислення. |
6. Чекати сигнал від Т1-T4 про завершення обчислення. |
6. Чекати сигнал від Т1-T4 про завершення обчислення. |
6. Чекати сигнал від Т1-T4 про завершення обчислення. |
| 7.Виведення MА
. |
Табл. 4.3 Структурна таблиця розроблення алгоритмів роботи кожного процесу.
Етап 3. Розробка структурної схеми взаємодії задач.
Цей етап пов'язаний із розробкою структури захищеного модуля, за допомогою якого реалізується взаємодія задач. Захищений модуль Керування
(рис 2.2) включає чотири захищені елементи: МС,
MK,
F
1,
F
2,
а також набір захищених операцій:
· вхід Чекати 1
для синхронізації з введенням в задачах Т1-T4;
· вхід Чекати 2
для синхронізації після завершення обчислень у задачахТ1-T4;
· функцію Копія МС
для копіювання спільного ресурсу МС;
· функцію Копія М
K
для копіювання спільного ресурсу МС;
· процедуру Ввід МС
для запису значення МС у захищений модуль;
· процедуру Ввід М
K
для запису значення МK у захищений модуль;
· процедуру Сигнал 1
для сигналу про завершення обчислень у задачі Т1, Т2, Т3,T4;
· процедуру Сигнал 2
для сигналу про завершення введення даних у задачах Т1, Т2, Т3,T4;
Захищені змінні F1 F2 використовуються в бар’єрах входів Чекати 1
і Чекати 2.
Схема захищеного модуля представлена в Додатку Д
Етап 4.
Лістинг програми
Лістинг програми представлено в Додатку Е
Для визначення ефективності розроблених програм було проведено дослідження, де визначався час виконання програми паралельної обчислюваної системи. Для цього було визначено час виконання програми у паралельно обчислюваній системі із двома ядрами, а потім у паралельно обчислюваній системі, де одне ядро було відключено через диспетчер задач. Це було зроблено для кількох значень N- розміру матриць. N ,було рівне 100, 200, 400, 600, 800, 1000.
Результати часу в сек.  , ,  , ,  представлені в таблицях 4.4, 4.5, 4.6 представлені в таблицях 4.4, 4.5, 4.6
| 1 - ядро
|
2 - ядра
|
4 - ядра
|
| 100 |
3 |
2 |
1 |
| 200 |
10 |
6 |
3 |
| 400 |
43 |
25 |
13 |
| 600 |
97 |
55 |
30 |
| 800 |
177 |
100 |
58 |
| 1000 |
288 |
166 |
110 |
Табл. 4.4 Тестування 
Графік відношення часу до кількості елементів

Рис. 4.4 Графік відношення часу
| 1 - ядро |
2 - ядра |
4 - ядра |
| 100 |
7 |
4 |
1 |
| 200 |
23 |
12 |
6 |
| 400 |
160 |
98 |
56 |
| 600 |
227 |
129 |
89 |
| 800 |
396 |
207 |
156 |
| 1000 |
653 |
326 |
250 |
Табл. 4.5 Тестування
Графік відношення часу до кількості елементів

Рис. 4.5 Графік відношення часу
| 1 - ядро |
2 - ядра |
4 - ядра |
| 100 |
5 |
4 |
2 |
| 200 |
20 |
11 |
8 |
| 400 |
76 |
43 |
30 |
| 600 |
189 |
95 |
67 |
| 800 |
341 |
173 |
117 |
| 1000 |
523 |
268 |
177 |
Табл. 4.5 Тестування
Графік відношення часу до кількості елементів

Рис. 4.5 Графік відношення часу
Перехід до багатоядерних процесорів може дати помітний поштовх розвитку індустрії віртуалізації. Віртуалізація ресурсів процесорів дозволить здійснювати паралельну обробку різних застосувань і потоків даних |. Розділення|поділ| ресурсів (ядра і потоки) і їх динамічний перерозподіл для різних завдань|задач| і ІВМ за допомогою мікропрограмних засобів|коштів| роблять|чинять| віртуалізацію набагато надійнішою і ефективнішою. Багатоядерність, багатопоточність, віртуалізація і енергозбереження стають ключовими|джерельними| напрямами|направленнями| розвитку процесорній індустрії.
Метою бакалаврської роботи було розробити Програмно-апаратний комплекс на основі Амд-процесорів. В перших двох розділах описано AMD-багатоядерні процесори і засоби мов С# і ADA для програмування паралельних потоків.
У третьомурозділу розглядаєся апартна частина комплексу, визначено його складові і їхній кошторис
Метою четвертого розділу було визначення ефективності програми. Для визначення ефективності розробленої програми було проведено дослідження, де визначалося час виконання паралельної програми обчислюваної системи.
1. Жуков І.А., Корочкин О.В. Паралельні та розподілені обчислення. Навч. Посіб – К.: Корнійчук, 2005. – 226 с.
2. Корочкин А. В. Ада95: Введение в программирование- К.:
Свит, 1999.-260 с.
3. Корочкин А., Мустафа Акрам Параллеьные вычисления: Ада и Java. - Вісн. НТУУ "КГП", Інформап ка, управління та обчислювальна техніка, 1999, К.: - № 32, С 3-17.
4. Языки программирования: Ада, Паскаль, Си.Сравнение и оценка/ Под ред.Н. Джехани - М.: Радио и связь, 1989. - 386 с.
5.Русанова О.В. Программное обеспечение компьютерны систем. Особенности программирования и компиляции. - К.: Корійчук, 2003.-94 с
6. Троелсон Є. С# и платформа-NET. Библиотека программиста -СПб.: Питер, 2004. - 796 с.
7. Эндрюс Г. Основы многопоточного, параллельного и распреде -ленного програмирования.: Пер. с англ. - М.: Изд. Дом «Виль -ямс», 2003.-512 с.
8. Элементы параллельного программирования / В.А.Вальковский, В.Е.Котов, А.Г.Марчук/ Под ред. В. Е. Котова- М.: Радио и связь, 1983.-240 с.
9.Бар Р. Язык Ада в проектировании систем. - М.: Мир, 1988.-ЗІ 0 с
10. Богачев К.Ю. Основы параллельного программирования.- М.: БИНОМ. Лаб. знаний, 2003. - 342 с .
11. М. Кузьминский, «64-разрядные микропроцессоры AMD». Открытые системы, № 4, 2002.
12.Паралельне програмування для многопроцессорних обчислювальних систем автори: Немнюгин С., Стесик О.
ДОДАТКИ
Додаток А
Блок-схема роботи програми  
Рис. A.1 Захищений модуль операції 
\
Додаток Б
Лістинг
програми

-- Zaxushenuj modylj----
----------------------------------
with Ada.Text_IO,
Ada.Integer_Text_IO,Ada.Calendar;
use Ada.Text_IO,
Ada.Integer_Text_IO,Ada.Calendar;
Procedure Bakalawr1 is
P:integer:=4;
N:integer:=5000;
H:integer:=N/P;
t:time;
s1,s3:day_Duration;
s2,s4,s5:integer;
-----Tupu-----
type Vector is array (1..N) of integer;
type Matrix is array (1..N) of Vector;
-----Zminni------
MA,MC,MB:Matrix;
----Zaxuchenuj m-----
Protected Box is
procedure VvidMC(MCK: in Matrix);
function Kopija1 return Matrix;
procedure Signal1;
procedure Signal2;
entry Zdat1;
entry Zdat2;
private
F1:integer:=0;
F2:integer:=0;
end Box;
----------------------
protected body Box is
Procedure VvidMC(MCK: in Matrix) is
begin
MC:=MCK;
end VvidMC;
function Kopija1 return Matrix is
begin
return MC;
end Kopija1;
procedure Signal1 is
begin
F1:=F1+1;
end Signal1;
procedure Signal2 is
begin
F2:=F2+1;
end Signal2;
entry Zdat1
when F1=2 is
begin
null;
end Zdat1;
entry Zdat2
when F2=4 is
begin
null;
end Zdat2;
end Box;
----------------------
procedure start is
task T1;
task body T1 is
MCC,MC1:Matrix;
begin
put("T1 started");
new_line;
--vvid matruci MC-----
for i in 1..N loop
for j in 1..N loop
MCC(i)(j):=1;
end loop;
end loop;
Box.VvidMC(MCC);
--Signal pro zavershennja vvody--
Box.Signal1;
--Chekaje zavershennja vvody inshux danux--
Box.Zdat1;
--Kopija---
MC1:=Box.Kopija1;
--Obchuslennja--
for i in 1..H loop
for j in 1..N loop
for k in 1..N loop
MA(i)(j):=MA(i)(j)+MC1(k)(j);--MB(i)(k);--*MC1(k)(j);
end loop;
end loop;
end loop;
--Signal pro zavershennja obchuslennja--
Box.Signal2;
--Chekaje zavershennja obchuslennja inshux procesiv--
Box.Zdat2;
--vuvid--
for i in 1..N loop
for j in 1..N loop
put(MA(i)(j));
put(" ");
end loop;
new_line;
end loop;
put(" T1 Finished ");
end T1;
--------------------------------
task T2;
task body T2 is
MBB,MC2:Matrix;
begin
put(" T2 started ");
--vvid---------
for i in 1..N loop
for j in 1..N loop
MB(i)(j):=1;
end loop;
end loop;
--Signal pro zavershennja vvody---
Box.Signal1;
--Chekaje zavershennja vvody inshux danux--
Box.Zdat1;
--Kopija--
MC2:=Box.Kopija1;
---Obchuslennja--
for i in H+1..2*H loop
for j in 1..N loop
for k in 1..N loop
MA(i)(j):=MA(i)(j)+MB(i)(k)*MC2(k)(j);
end loop;
end loop;
end loop;
--Signal pro zavershennja obchuslennja--
Box.Signal2;
put(" T2 Finished ");
end T2;
-------------------------------------------
task T3;
task body T3 is
MC3:Matrix;
begin
put(" T3 started ");
--Chekaje zavershennja vvody inshux danux--
Box.Zdat1;
---Kopija---
MC3:=Box.Kopija1;
---Obchuslennja--
for i in 2*H+1..3*H loop
for j in 1..N loop
for k in 1..N loop
MA(i)(j):=MA(i)(j)+MB(i)(k)*MC3(k)(j);
end loop;
end loop;
end loop;
--Signal pro zavershennja obchuslennja--
Box.Signal2;
put(" T3 Finished ");
end T3;
-------------------------------------------
task T4;
task body T4 is
MC4:Matrix;
begin
put(" T4 started ");
--Chekaje zavershennja vvody inshux danux--
Box.Zdat1;
---Kopija---
MC4:=Box.Kopija1;
---Obchuslennja--
for i in 3*H+1..N loop
for j in 1..N loop
for k in 1..N loop
MA(i)(j):=MA(i)(j)+MB(i)(k)*MC4(k)(j);
end loop;
end loop;
end loop;
--Signal pro zavershennja obchuslennja--
Box.Signal2;
put(" T4 Finished ");
end T4;
begin Null;
end start;
begin
put_line("Main");
put("N=");
get(N);
t:=clock;
s1:=Seconds(t);
s2:=integer(s1);
start;
t:=clock;
s3:=Seconds(t);
s4:=integer(s3);
S5:=S4-S2;
new_line;
put("Càs programu=");
put(s5);
end Bakalawr1;
Додаток В
Блок-схема роботи програми
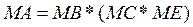

Рис. В.1 Захищений модуль операції 
Додаток Г
Лістинг
програми

-- Zaxushenuj modylj----
----------------------------------
with Ada.Text_IO,
Ada.Integer_Text_IO,Ada.Calendar;
use Ada.Text_IO,
Ada.Integer_Text_IO,Ada.Calendar;
Procedure Bakalawr2 is
P:integer:=4;
N:integer:=5000;
H:integer:=N/P;
t:time;
s1,S3:day_Duration;
s2,S4,S5:integer;
-----Tupu-----
type Vector is array (1..N) of integer;
type Matrix is array (1..N) of Vector;
-----Zminni------
MA,MC,MB,ME,MAA:Matrix;
----Zaxuchenuj m-----
Protected Box is
procedure VvidME(MEK: in Matrix);
function Kopija1 return Matrix;
function Kopija2 return Matrix;
procedure Signal1;
procedure Signal2;
procedure Signal3;
entry Zdat1;
entry Zdat2;
entry Zdat3;
private
F1:integer:=0;
F2:integer:=0;
F3:integer:=0;
end Box;
----------------------
protected body Box is
Procedure VvidME(MEK: in Matrix) is
begin
ME:=MEK;
end VvidME;
function Kopija1 return Matrix is
begin
return ME;
end Kopija1;
function Kopija2 return Matrix is
begin
return MAA;
end Kopija2;
procedure Signal1 is
begin
F1:=F1+1;
end Signal1;
procedure Signal2 is
begin
F2:=F2+1;
end Signal2;
procedure Signal3 is
begin
F3:=F3+1;
end Signal3;
entry Zdat1
when F1=3 is
begin
null;
end Zdat1;
entry Zdat2
when F2=4 is
begin
null;
end Zdat2;
entry Zdat3
when F3=4 is
begin
null;
end Zdat3;
end Box;
----------------------
procedure start is
task T1;
task body T1 is
MCC,ME1,MA1:Matrix;
begin
put("T1 started");
new_line;
--vvid matruci MC-----
for i in 1..N loop
for j in 1..N loop
MC(i)(j):=1;
end loop;
end loop;
--Signal pro zavershennja vvody--
Box.Signal1;
--Chekaje zavershennja vvody inshux danux--
Box.Zdat1;
--Kopija---
ME1:=Box.Kopija1;
--Obchuslennja MC*ME--
for i in 1..H loop
for j in 1..N loop
for k in 1..N loop
MAA(i)(j):=MAA(i)(j)+MC(i)(k)*ME1(k)(j);
end loop;
end loop;
end loop;
--Signal pro zavershennja obchuslennja--
Box.Signal2;
--Chekaje zavershennja obchuslennja inshux procesiv--
Box.Zdat2;
--Kopija---
MA1:=Box.Kopija2;
--Obchuslennja MB*(MC*ME)--
for i in 1..H loop
for j in 1..N loop
for k in 1..N loop
MA(i)(j):=MA(i)(j)+MB(i)(k)*MA1(k)(j);
end loop;
end loop;
end loop;
--Signal pro zavershennja obchuslennja--
Box.Signal3;
put(" T1 Finished ");
end T1;
--------------------------------
task T2;
task body T2 is
MBB,ME2,MA2:Matrix;
begin
put(" T2 started ");
--vvid---------
for i in 1..N loop
for j in 1..N loop
MB(i)(j):=1;
end loop;
end loop;
--Signal pro zavershennja vvody---
Box.Signal1;
--Chekaje zavershennja vvody inshux danux--
Box.Zdat1;
--Kopija--
ME2:=Box.Kopija1;
--Obchuslennja MC*ME--
for i in H+1..2*H loop
for j in 1..N loop
for k in 1..N loop
MAA(i)(j):=MAA(i)(j)+MC(i)(k)*ME2(k)(j);
end loop;
end loop;
end loop;
--Signal pro zavershennja obchuslennja--
Box.Signal2;
--Chekaje zavershennja obchuslennja inshux procesiv--
Box.Zdat2;
--Kopija---
MA2:=Box.Kopija2;
--Obchuslennja MB*(MC*ME)--
for i in H+1..2*H loop
for j in 1..N loop
for k in 1..N loop
MA(i)(j):=MA(i)(j)+MB(i)(k)*MA2(k)(j);
end loop;
end loop;
end loop;
--Signal pro zavershennja obchuslennja--
Box.Signal3;
put(" T2 Finished ");
end T2;
-------------------------------------------
task T3;
task body T3 is
MEE,ME3,MA3:Matrix;
begin
put(" T3 started ");
--vvid---------
for i in 1..N loop
for j in 1..N loop
MEE(i)(j):=1;
end loop;
end loop;
Box.VvidME(MEE);
--Signal pro zavershennja vvody---
Box.Signal1;
--Chekaje zavershennja vvody inshux danux--
Box.Zdat1;
---Kopija---
ME3:=Box.Kopija1;
--Obchuslennja MC*ME--
for i in 2*H+1..3*H loop
for j in 1..N loop
for k in 1..N loop
MAA(i)(j):=MAA(i)(j)+MC(i)(k)*ME3(k)(j);
end loop;
end loop;
end loop;
--Signal pro zavershennja obchuslennja--
Box.Signal2;
--Chekaje zavershennja obchuslennja inshux procesiv--
Box.Zdat2;
--Kopija---
MA3:=Box.Kopija2;
--Obchuslennja MB*(MC*ME)--
for i in 2*H+1..3*H loop
for j in 1..N loop
for k in 1..N loop
MA(i)(j):=MA(i)(j)+MB(i)(k)*MA3(k)(j);
end loop;
end loop;
end loop;
--Signal pro zavershennja obchuslennja--
Box.Signal3;
put(" T3 Finished ");
end T3;
-------------------------------------------
task T4;
task body T4 is
ME4,MA4:Matrix;
begin
put(" T4 started ");
--Chekaje zavershennja vvody inshux danux--
Box.Zdat1;
---Kopija---
ME4:=Box.Kopija1;
--Obchuslennja MC*ME--
for i in 3*H+1..N loop
for j in 1..N loop
for k in 1..N loop
MAA(i)(j):=MAA(i)(j)+MC(i)(k)*ME4(k)(j);
end loop;
end loop;
end loop;
--Signal pro zavershennja obchuslennja--
Box.Signal2;
--Chekaje zavershennja obchuslennja inshux procesiv--
Box.Zdat2;
--Kopija---
MA4:=Box.Kopija2;
--Obchuslennja MB*(MC*ME)--
for i in 3*H+1..N loop
for j in 1..N loop
for k in 1..N loop
MA(i)(j):=MA(i)(j)+MB(i)(k)*MA4(k)(j);
end loop;
end loop;
end loop;
--Signal pro zavershennja obchuslennja—
Box.Signal3;
--Chekaje zavershennja obchuslennja inshux procesiv--
Box.Zdat3;
--vuvid--
for i in 1..N loop
for j in 1..N loop
put(MA(i)(j));
put(" ");
end loop;
new_line;
end loop;
put(" T4 Finished ");
end T4;
begin Null;
end start;
begin
put("N=");
get(N);
put_line("Main");
t:=clock;
s1:=Seconds(t);
s2:=integer(s1);
start;
t:=clock;
s3:=Seconds(t);
s4:=integer(s3);
S5:=S4-S2;
put(s5);
end Bakalawr2;
Додаток Д
Блок-схема роботи програми
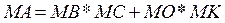
Рис. Д.1 Захищений модуль операції 
Додаток Е
Лістинг
програми
-- Zaxushenuj modylj----
----------------------------------
with Ada.Text_IO,
Ada.Integer_Text_IO,Ada.Calendar;
use Ada.Text_IO,
Ada.Integer_Text_IO,Ada.Calendar;
Procedure Bakalawr3 is
P:integer:=4;
N:integer:=4000;
H:integer:=N/P;
t:time;
s1,S3:day_Duration;
s2,S4,S5:integer;
-----Tupu-----
type Vector is array (1..N) of integer;
type Matrix is array (1..N) of Vector;
-----Zminni------
MA,MC,MB,MO,MK:Matrix;
----Zaxuchenuj m-----
Protected Box is
procedure VvidMC(MCK: in Matrix);
procedure VvidMK(MKK: in Matrix);
function Kopija1 return Matrix;
function Kopija2 return Matrix;
procedure Signal1;
procedure Signal2;
entry Zdat1;
entry Zdat2;
private
F1:integer:=0;
F2:integer:=0;
end Box;
----------------------
protected body Box is
Procedure VvidMC(MCK: in Matrix) is
begin
MC:=MCK;
end VvidMC;
Procedure VvidMK(MKK: in Matrix) is
begin
MK:=MKK;
end VvidMK;
function Kopija1 return Matrix is
begin
return MC;
end Kopija1;
function Kopija2 return Matrix is
begin
return MK;
end Kopija2;
procedure Signal1 is
begin
F1:=F1+1;
end Signal1;
procedure Signal2 is
begin
F2:=F2+1;
end Signal2;
entry Zdat1
when F1=4 is
begin
null;
end Zdat1;
entry Zdat2
when F2=4 is
begin
null;
end Zdat2;
end Box;
----------------------
Procedure start is
task T1;
task body T1 is
MCC,MC1,MK1:Matrix;
begin
put("T1 started");
new_line;
--vvid matruci MC-----
for i in 1..N loop
for j in 1..N loop
MCC(i)(j):=1;
end loop;
end loop;
Box.VvidMC(MCC);
--Signal pro zavershennja vvody--
Box.Signal1;
--Chekaje zavershennja vvody inshux danux--
Box.Zdat1;
--Kopija---
MC1:=Box.Kopija1;
MK1:=Box.Kopija2;
--Obchuslennja--
for i in 1..H loop
for j in 1..N loop
for k in 1..N loop
MA(i)(j):=MA(i)(j)+MB(i)(k)*MC1(k)(j)+MO(i)(k)*MK1(k)(j);
end loop;
end loop;
end loop;
--Signal pro zavershennja obchuslennja--
Box.Signal2;
put(" T1 Finished ");
end T1;
--------------------------------
task T2;
task body T2 is
MBB,MC2,MK2:Matrix;
begin
put(" T2 started ");
--vvid---------
for i in 1..N loop
for j in 1..N loop
MB(i)(j):=1;
end loop;
end loop;
--Signal pro zavershennja vvody---
Box.Signal1;
--Chekaje zavershennja vvody inshux danux--
Box.Zdat1;
--Kopija--
MC2:=Box.Kopija1;
MK2:=Box.Kopija2;
--Obchuslennja--
for i in H+1..2*H loop
for j in 1..N loop
for k in 1..N loop
MA(i)(j):=MA(i)(j)+MB(i)(k)*MC2(k)(j)+MO(i)(k)*MK2(k)(j);
end loop;
end loop;
end loop;
--Signal pro zavershennja obchuslennja--
Box.Signal2;
put(" T2 Finished ");
end T2;
-------------------------------------------
task T3;
task body T3 is
MOO,MC3,MK3:Matrix;
begin
put(" T3 started ");
--vvid---------
for i in 1..N loop
for j in 1..N loop
MO(i)(j):=1;
end loop;
end loop;
--Signal pro zavershennja vvody---
Box.Signal1;
--Chekaje zavershennja vvody inshux danux--
Box.Zdat1;
---Kopija---
MC3:=Box.Kopija1;
MK3:=Box.Kopija2;
--Obchuslennja--
for i in 2*H+1..3*H loop
for j in 1..N loop
for k in 1..N loop
MA(i)(j):=MA(i)(j)+MB(i)(k)*MC3(k)(j)+MO(i)(k)*MK3(k)(j);
end loop;
end loop;
end loop;
--Signal pro zavershennja obchuslennja--
Box.Signal2;
--Chekaje zavershennja obchuslennja inshux procesiv--
Box.Zdat2;
--vuvid--
for i in 1..N loop
for j in 1..N loop
put(MA(i)(j));
put(" ");
end loop;
new_line;
end loop;
put(" T3 Finished ");
end T3;
-------------------------------------------
task T4;
task body T4 is
MKK,MC4,MK4:Matrix;
begin
put(" T4 started ");
--vvid---------
for i in 1..N loop
for j in 1..N loop
MKK(i)(j):=1;
end loop;
end loop;
Box.VvidMK(MKK);
--Signal pro zavershennja vvody---
Box.Signal1;
--Chekaje zavershennja vvody inshux danux--
Box.Zdat1;
---Kopija---
MC4:=Box.Kopija1;
MK4:=Box.Kopija2;
--Obchuslennja--
for i in 3*H+1..N loop
for j in 1..N loop
for k in 1..N loop
MA(i)(j):=MA(i)(j)+MB(i)(k)*MC4(k)(j)+MO(i)(k)*MK4(k)(j);
end loop;
end loop;
end loop;
--Signal pro zavershennja obchuslennja--
Box.Signal2;
put(" T4 Finished ");
end T4;
begin Null;
end start;
begin
put("N=");
get(N);
t:=clock;
s1:=Seconds(t);
s2:=integer(s1);
start;
t:=clock;
s3:=Seconds(t);
s4:=integer(s3);
S5:=S4-S2;
put_line("Main");
new_line;
put("Cas=");
put(s5);
end Bakalawr3;
|