Министерство образования и науки Украины
Сумский государственный университет
Кафедра Информатики
Курсовая работа
по дисциплине
“Теория алгоритмов и математическая логика”
на тему:
“Алгоритмы поиска остовного дерева Прима и Крускала”
Сумы 2006
Содержание
Задание
Вступление
1.
Теоретическаячасть
2.
Практическаяреализация
Вывод
Программный код
Литература
Задание
Разработать программную реализацию решения задачи о минимальном покрывающем дереве (построение минимального остова). Для нахождения минимального покрывающего дерева использовать алгоритмы Прима и Крускала.
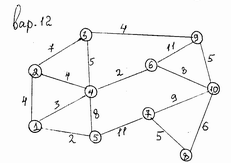
Исходная информация о ребрах графа находится в текстовом файле dan.txt.
Вступление
Пусть имеется связный неориентированный граф G = (V, Е), в котором V— множество контактов, а E — множество их возможных попарных соединений. Для каждого ребра графа (u, v) задан вес w(u, v) (длина провода, необходимого для соединения uи v). Задача состоит в нахождении подмножества Т  Е, связывающего все вершины, для которого суммарный вес минимален. Е, связывающего все вершины, для которого суммарный вес минимален.
w(T) =  w(u,v) w(u,v)
Такое подмножество Т будет деревом (поскольку не имеет циклов: в любом цикле один из проводов можно удалить, не нарушая связности). Связный подграф графа G, являющийся деревом и содержащий все его вершины, называют покрывающим деревом этого графа. (Иногда используют термин "остовное дерево"; для краткости мы будем говорить просто "остов".)
Далее мы рассмотрим задачу о минимальном покрывающем дереве. (Здесь слово "минимальное" означает "имеющее минимально возможный вес".)
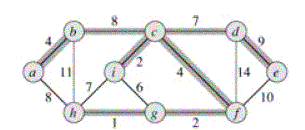
Рис
1
На Рис 1
показано на примере минимальное покрывающее дерево. На каждом ребре графа указан вес. Выделены ребра минимального покрывающего дерева (суммарный вес 37). Такое дерево не единственно: заменяя ребро (Ь, с) ребром (а,h), получаем другое дерево того же веса 37.
Мы рассмотрим два способа решения задачи о минимальном покрывающем дереве: алгоритмы Крускала и Прима. Каждый их них легко реализовать со временем работы O(ElogV), используя обычные двоичные кучи. Применив фибоначчиевы кучи, можно сократить время работы алгоритма Прима до O(E+VlogV) (что меньше Е logV, если |V| много меньше \Е\).
Оба алгоритма следуют "жадной" стратегии: на каждом шаге выбирается "локально наилучший" вариант. Не для всех задач такой выбор приведёт к оптимальному решению, но для задачи о покрывающем дереве это так. Здесь будет описана общая схема алгоритма построения минимального остова (добавление рёбер одного за другим). В дальнейшем будут указаны две конкретных реализации общей схемы.
Итак, пусть дан связный неориентированный граф G = (V, Е) и весовая функция w: Е . Мы хотим найти минимальное покрывающее дерево (остов), следуя жадной стратегии. . Мы хотим найти минимальное покрывающее дерево (остов), следуя жадной стратегии.
Общая схема всех наших алгоритмов будет такова. Искомый остов строится постепенно: к изначально пустому множеству А на каждом шаге добавляется одно ребро. Множество А всегда является подмножеством некоторого минимального остова. Ребро (u, v), добавляемое на очередном шаге, выбирается так, чтобы не нарушить этого свойства: А {(u, v)} тоже должно быть подмножеством минимального остова. Мы называем такое ребро безопасным ребром для А. {(u, v)} тоже должно быть подмножеством минимального остова. Мы называем такое ребро безопасным ребром для А.
Generic-MST(G,w)
1 А
2 whileA не является остовом
3 do найти безопасное ребро (u,v) для А
4 А  A{(u,v)} A{(u,v)}
5 return A
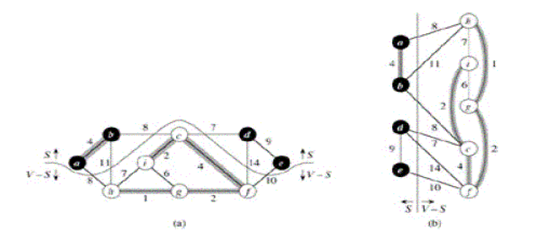
Рис. 2. Два изображения одного и того же разреза графа с Рис 1.
(а) Вершины множества S изображены чёрными, его дополнения V\S — белым. Рёбра, пересекающие разрез, соединяют белые вершины с черными. Единственное лёгкое ребро, пересекающее разрез — ребро (d, с). Множество А состоит из серых ребер. Разрез (s, V \S) согласован с А (ни одно ребро из А не пересекает разрез).
(Ь) Вершины множества S изображены слева, вершины V \ S — справа. Ребро пересекает разрез, если оно пересекает вертикальную прямую.
По определению безопасного ребра свойство "А является подмножеством некоторого минимального остова" (для пустого множества это свойство, очевидно, выполнено) остаётся истинным для любого числа итераций цикла, так что в строке 5 алгоритм выдаёт минимальный остов. Конечно, главный вопрос в том, как искать безопасное ребро в строке 3. Такое ребро существует (если А является подмножеством минимального остова, то любое ребро этого остова, не входящее в А, является безопасным). Заметим, что множество А не может содержать циклов (поскольку является частью минимального остова). Поэтому добавляемое в строке 4 ребро соединяет различные компоненты графа Ga
= (V,A), и с каждой итерацией цикла число компонент уменьшается на 1. Вначале каждая точка представляет собой отдельную компоненту; в конце весь остов — одна компонента, так что цикл повторяется |V| — 1 раз.
Теоретическая часть
Алгоритм Крускала
В любой момент работы алгоритма Крускала множество А выбранных рёбер (часть будущего остова) не содержит циклов. Оно соединяет вершины графа в несколько связных компонент, каждая из которых является деревом. Среди всех рёбер, соединяющих вершины из разных компонент, берётся ребро наименьшего веса. Надо проверить, что оно является безопасным.
Пусть (u, v) — такое ребро, соединяющее вершины из компонент С1
и C2
- Это ребро является лёгким ребром для разреза (С1
, V\C1
).
Реализация алгоритма Крускала использует структуры данных для непересекающихся множеств. Элементами множеств являются вершины графа. Напомним, что Find-Set(u) возвращает представителя множества, содержащего элемент u. Две вершины uи vпринадлежат одному множеству (компоненте), если Find-Set(u) = Find-Set(v). Объединение деревьев выполняется процедурой Union. (Строго говоря, процедурам Find-Set и Union должны передаваться указатели на uи v)
MST-Kruskal(G,w)
1 A
2 for каждой вершины v V[G] V[G]
3 doMake-Set(v)
4 упорядочить рёбра Е по весам
5 for(u,v)E (в порядке возрастания веса)
6do ifFind-Set(u)  Find-Set(v) Find-Set(v)
7then A := A{(u,v)}
8Union(u,v)
9 returnA
Сначала (строки 1-3) множество А пусто, и есть |V| деревьев, каждое из которых содержит по одной вершине. В строке 4 рёбра из Е упорядочиваются по неубыванию веса. В цикле (строки 5-8) мы проверяем, лежат ли концы ребра в одном дереве. Если да, то ребро нельзя добавить к лесу (не создавая цикла), и оно отбрасывается. Если нет, то ребро добавляется к А (строка 7), и два соединённых им дерева объединяются в одно (строка 8).
Подсчитаем время работы алгоритма Крускала. Будем считать, что для хранения непересекающихся множеств используется метод с объединением по рангу и сжатием путей — самый быстрый из известных. Инициализация занимает время O(V), упорядочение рёбер в строке 4 — O(ElogE). Далее производится O(Е) операций, в совокупности занимающих время О(Е (Е, V)). (основное время уходит на сортировку). (Е, V)). (основное время уходит на сортировку).
Алгоритм Прима
Как и алгоритм Крускала, алгоритм Прима следует общей схеме алгоритма построения минимального остова. В этом алгоритме растущая часть остова представляет собой дерево (множество рёбер которого есть А). Формирование дерева начинается с произвольной корневой вершины r. На каждом шаге добавляется ребро наименьшего веса среди рёбер соединяющих вершины этого дерева с вершинами не из дерева. По следствию такие рёбра являются безопасными для А, так что в результате получается минимальный остов.
При реализации важно быстро выбирать лёгкое ребро. Алгоритм получает на вход связный граф Gи корень r минимального покрывающего дерева. В ходе алгоритма все вершины, ещё не попавшие в дерево, хранятся в очереди с приоритетами. Приоритет вершины vопределяется значением key[u], которое равно минимальному весу рёбер, соединяющих vс вершинами дерева А. (Если таких рёбер нет, полагаем key[V] =  ). Поле ). Поле  [v] для вершин дерева указывает на родителя, а для вершины vQуказывает на вершину дерева, в которую ведёт ребро веса key[v] (одно из таких рёбер, если их несколько). Мы не храним множество А вершин строимого дерева явно; его можно восстановить как [v] для вершин дерева указывает на родителя, а для вершины vQуказывает на вершину дерева, в которую ведёт ребро веса key[v] (одно из таких рёбер, если их несколько). Мы не храним множество А вершин строимого дерева явно; его можно восстановить как
A = {(v,[v]):vV\{r} \Q}.
В конец работы алгоритма очередь Qпуста, и множество
A = {(v,[v]):vV\{r}}.
есть множество ребер покрывающего дерева.
MST-Prim(G,W,r)
1 QV[G]
2 for для каждой вершины uQ
3 do key[u]
4 key[r] 0
5 [r] nil
6 while Q
7do u Extract-Min(Q)
8for для каждой вершины vAdj[u]
9 do if vQ и w(u,v)<key[v]
10 then [v] u
11 key(v) w(u,v)
После исполнения строк 1-5 и первого прохода цикла в строках 6 ‑ 11 дерево состоит из единственной вершины r, все остальные вершины находятся в очереди, и значение key[v] для них равно длине ребра из r в vили , если такого ребра нет (в первом случае [v] = r). Таким образом, выполнен описанный выше инвариант (дерево есть часть некоторого остова, для вершин дерева поле указывает на родителя, а для остальных вершин на "ближайшую" вершину дерева — вес ребра до неё хранится в key[v].
Время работы алгоритма Прима зависит от того, как реализована очередь Q. Если использовать двоичную кучу (7), инициализацию в строках 1-4 можно выполнить с помощью процедуры Build-Heapза время O(V). Далее цикл выполняется \V\ раз, и каждая операция Extract-Minзанимает время O(logV), всего O(VlogV). Цикл for в строках 8-11 выполняется в общей сложности О(Е) раз, поскольку сумма степеней вершин графа равна 2\Е\. Проверку принадлежности в строке 9 внутри цикла for можно реализовать за время O(1), если хранить состояние очереди ещё и как битовый вектор размера |V|. Присваивание в строке 11 подразумевает выполнение операции уменьшения ключа (Decrease-Key), которая для двоичной кучи может быть выполнена за время O(logV). Таким образом, всего получаем O(VlogV+ ElogV) = O(ElogV) — та же самая оценка, что была для алгоритма Крускала.
Однако эта оценка может быть улучшена, если использовать в алгоритме Прима фибоначчиевы кучи, с помощью неё можно выполнять операцию Extract-Minза учётное время O(logV), а операцию Decrease-Key— за (учётное) время O(1). (Нас интересует именно суммарное время выполнения последовательности операций, так что амортизированный анализ тут в самый раз.) Поэтому при использовании фибоначчиевых куч для реализации очереди время работы алгоритма Прима составит O(Е + VlogV).
Программная реализация
Реализуем вышеописанные алгоритмы на практике с помощьюDelphi 7.
Данный скрин является подтверждением выполненной работы.

Вывод
Сравнивать будем по количеству затраченного времени поиска дерева, по суммарному весу дерева, по количеству сравнений и присвоений для каждого из алгоритмов. Время вычисляется как среднее время выполнения алгоритмов.
Для алгоритма Прима количество сравнений и присваиваний больше, так как нужно сортировать данные два раза (в алгоритме Крускала 1 раз).
Можно сделать вывод, что для нахождения остова для графов с большим количеством вершин, алгоритм Прима будет затрачивать больше времени. Также для разреженных графов более применителен алгоритм Крускала.
Программный код
program Project1;
uses
Forms,
Unit1 in 'Unit1.pas' {Main},
Unit2 in 'Unit2.pas' {AboutBox};
{$R *.res}
begin
Application.Initialize;
Application.CreateForm(TMain, Main);
Application.CreateForm(TAboutBox, AboutBox);
Application.Run;
end.
unit Unit1;
interface
uses
Windows, Messages, SysUtils, Variants, Classes, Graphics, Controls, Forms,
Dialogs, StdCtrls, Unit2, Menus;
type
TRebro = record
Fst,Lst,Vs:byte;
end;
Gr = array[1..256] of TRebro;
TVect = array[1..256] of byte;
TMain = class(TForm)
Label1: TLabel;
Label2: TLabel;
Button2: TButton;
Label3: TLabel;
Label4: TLabel;
Button3: TButton;
Label5: TLabel;
Label6: TLabel;
Label7: TLabel;
Label8: TLabel;
Label9: TLabel;
Label10: TLabel;
Label11: TLabel;
Label12: TLabel;
Label13: TLabel;
Label14: TLabel;
Label15: TLabel;
Label16: TLabel;
Label17: TLabel;
MainMenu1: TMainMenu;
N1: TMenuItem;
N2: TMenuItem;
N3: TMenuItem;
N4: TMenuItem;
Label18: TLabel;
Label19: TLabel;
procedure FormCreate(Sender: TObject);
procedure Button2Click(Sender: TObject);
procedure Button3Click(Sender: TObject);
procedure N2Click(Sender: TObject);
procedure N4Click(Sender: TObject);
private
{ Private declarations }
public
{ Public declarations }
end;
var
Main: TMain;
X:GR;
Mark:TVect;
R,V:byte;//кол-во ребер и вершин соответственно
procedure LoadGraph;
implementation
{$R *.dfm}
Function Timer:longint;
const c60:longint=60;
var h,m,s,s100:word;
begin
decodetime(now,h,m,s,s100);
timer:=((h*c60+m)*c60+s)*100+s100;
end;
procedure LoadGraph;
var f:textfile;
i:byte;
begin
i:=1;
Assignfile(f,'dan.txt');
Reset(f);
R:=0;
V:=0;
Readln(f,R,V);
while not eof(f) do
begin
Readln(f,X[i].Fst,X[i].Lst,X[i].Vs);
Main.Label2.Caption:=Main.Label2.Caption+IntToStr(X[i].Fst)+' '+IntToStr(X[i].Lst)+
' '+IntToStr(X[i].Vs)+#13;
inc(i);
end;
end;
procedure TMain.FormCreate(Sender: TObject);
begin
LoadGraph;
end;
//АлгоритмКрускала
procedure TMain.Button2Click(Sender: TObject);
var j,k,v2,Ves_gr:byte;
t1,t2,t,Sr,Pr:longint;
Tk:real; Y:Gr;
procedure UniteComponents(a,b:byte);
var i:byte;
begin
If a>b then begin inc(sr);Pr:=Pr+3;i:=a; a:=b; b:=i; end else inc(sr);
for i:=1 to V do
If Mark[i] = b then begin Mark[i]:=a;inc(pr);end;
Sr:=Sr+V;
end;
procedure SortRebr(var X:Gr);
var i,n,j,numb:integer; Mx:TRebro;
begin
N:=R;
for i:=1 to R-1 do
begin
Mx:=X[1];
numb:=1;
Pr:=Pr+2;
For j:=2 to N do
If X[j].Vs>Mx.Vs then
begin
inc(Sr);
Pr:=Pr+2;
Mx:=X[j];
numb:=j;
end
else inc(sr);
X[numb]:=X[N];
X[N]:=Mx;
N:=N-1;
pr:=Pr+3;
end;
end;
begin
Y:=X;
t:=0;
for k:=1 to 100 do
begin
Sr:=0; //кол-во сравнений
Pr:=0; //кол-во присваиваний
Ves_gr:=0;
SortRebr(X);
Label3.Caption:='';
t1:=timer;
for v2:=1 to V do
Mark[v2]:=v2;
for j:=1 to R do
If Mark[X[j].Fst]<>Mark[X[j].Lst] Then
Begin
Label3.Caption:=Label3.Caption+IntToStr(X[j].Fst)+' '+IntToStr(X[j].Lst)+
' '+IntToStr(X[j].Vs)+#13;
inc(sr);
Ves_gr:=Ves_gr+X[j].Vs;
UniteComponents(Mark[X[j].Fst],Mark[X[j].Lst]);
end
else inc(Sr);
t2:=timer;
T:=t+t2-t1;
label12.Caption:=inttostr(Ves_gr);
label14.Caption:=inttostr(Pr);
label16.Caption:=inttostr(Sr);
X:=Y;
end;
Tk:=abs(t/100);
label6.Caption:=FloatToStr(Tk)+'*0.01 c';
end;
//АлгоритмПрима
procedure TMain.Button3Click(Sender: TObject);
const MaxVes=255;
var Mark:array[1..10] of boolean;
D,Res:array[1..10] of byte;
i,j,imin,min,k:byte;
t1,t2,t,Sr,Pr,Ves_gr:longint; TP:real;
Function FindVes(i,j:byte):byte;
var k:byte;
begin
k:=0;
Repeat
inc(k);
Until (k>16) or
( (X[k].Fst=i) and (X[k].Lst=j) )
or( (X[k].Fst=j) and (X[k].Lst=i) );
if k>16 then FindVes:=255 else
FindVes:=X[k].Vs;
end;
Function Aps(i,j:byte; var Ves:byte):boolean;
var k:byte;
begin
k:=0; inc(pr);
Repeat
inc(k); inc(pr);
Until (k>R) or
( (X[k].Fst=i) and (X[k].Lst=j) )
or( (X[k].Fst=j) and (X[k].Lst=i) );
if k>R then begin inc(sr);Aps:=false; end else
begin inc(sr);pr:=pr+2;Ves:=X[k].Vs; Aps:=true end;
end;
Procedure Calc(i : byte);
Var j : byte;
Begin
For j := 1 To V Do
If Not Mark[j] Then
If Aps(i,j,D[j]) Then begin Res[j] := i; inc(pr);end;
inc(sr);
End;
begin
t:=0;
for k:=1 to 100 do
begin
Sr:=0;
Pr:=0;
Ves_gr:=0;
t1:=timer;
Label7.Caption:='';
For i := 1 To V Do begin
D[i] := MaxVes; Mark[i]:=false;end;
Pr:=2*V;
Mark[4] := True;
Calc(4);
For j := 1 To V-1 Do Begin { каркассостоитиз n-1 ребер }
min := MaxVes; inc(pr);
For i := 1 To V Do
If Not Mark[i] Then
If min > D[i] Then Begin
Sr:=Sr+2; Min := D[i]; imin := i; pr:=pr+2;
End
else sr:=Sr+2
else inc(sr);
Mark[imin] := True;
Calc(imin);
pr:=pr+2;
ves_gr:=ves_gr+FindVes(imin,Res[imin]);
label7.Caption:=Label7.Caption+IntToStr(imin)+' '+IntToStr(Res[imin])+
' '+IntToStr(FindVes(imin,Res[imin]))+#13;
end;
label13.Caption:=inttostr(Ves_gr);
label15.Caption:=inttostr(Sr);
label17.Caption:=inttostr(Pr);
t2:=timer;
t:=t+t2-t1;
end;
TP:=abs(t/100);
Label8.Caption:=floattostr(TP)+'*0.01 c';
end;
procedure TMain.N2Click(Sender: TObject);
begin
close;
end;
procedure TMain.N4Click(Sender: TObject);
begin
aboutbox.Show;
end;
end.
unit Unit2;
interface
uses Windows, SysUtils, Classes, Graphics, Forms, Controls, StdCtrls,
Buttons, ExtCtrls;
type
TAboutBox = class(TForm)
Panel1: TPanel;
ProgramIcon: TImage;
ProductName: TLabel;
Version: TLabel;
Copyright: TLabel;
Comments: TLabel;
OKButton: TButton;
procedure OKButtonClick(Sender: TObject);
private
{ Private declarations }
public
{ Public declarations }
end;
var
AboutBox: TAboutBox;
implementation
{$R *.dfm}
procedure TAboutBox.OKButtonClick(Sender: TObject);
begin
close;
end;
end.
Литература
1.
Ахо А., Хопкрофт Дж., Ульман Дж. Структуры данных и алгоритмы. — М.: Видавничий будинок «Вільямс», 2001.
2.
Кормен Т., Лейзерсон Ч., Ривест Р. Алгоритмы: построение и анализ. — М.: МЦНМО, 2001
3.
Теория графов Н. Кристофидес – «Мир» Москва, 1978
4.
Методические указания.
|