Реферат
Записка
: 68 стр., 7 рис., 1 табл., 1 додаток, 41 джерел.Об’єкт дослідження
– система розпізнавання рукописних символів.
Мета роботи
– розробити інформаційне та програмне забезпечення системи розпізнавання рукописних символів.
Методи дослідження
– інформаційно–екстремальна інтелектуальна технологія.
Результати
– розроблено алгоритм та програмне забезпечення системи розпізнавання символів, що навчається в рамках інформаційно-екстремальної інтелектуальної технології.
Зміст
ВСТУП.. 4
1 АНАЛІЗ ПРОБЛЕМИ ТА ПОСТАНОВКА ЗАДАЧІ5
1.1 Огляд методів розпізнавання образів. 5
1.2 Методи оброблення та розпізнавання рукописних символів. 8
1.3 Постановка задачі та формування завдань дослідження. 16
2 ОПИС МЕТОДУ РОЗПІЗНАВАННЯ РУКОПИСНИХ СИМВОЛІВ.. 19
2.1 Основні ідеї інформаційно-екстремального методу розпізнавання рукописних символів. 19
2.2 Математична модель системи розпізнавання рукописних символів. 23
2.3 Критерій оптимізації параметрів функціонування системи розпізнавання. 25
2.4 Базовий алгоритм навчання. 26
2.5 Алгоритм екзамену. 30
3 ІНФОРМАЦІЙНЕ ТА ПРОГРАМНЕ ЗАБЕЗПЕЧЕННЯ СИСТЕМИ РОЗПІЗНАВАННЯ РУКОПИСНИХ СИМВОЛІВ.. 32
3.1 Оброблення рукописних символів. 32
3.2 Оптимізація контрольних допусків на ознаки розпізнавання системи розпізнавання. 34
3.4 Короткий опис програми. 36
3.5 Результати фізичного моделювання. 37
4 ОХОРОНА ПРАЦІ42
4.1 Характеристика приміщення. 43
4.2 Аналіз стану охорони праці в приміщенні45
4.3 Висновки. 55
ВИСНОВКИ.. 57
СПИСОК ЛІТЕРАТУРИ.. 58
Додаток. 61
Незважаючи на те, що електронні методи знайшли широке впровадження при автоматизації документообігу і діловиробництва, але існує велика кількість підприємств та організацій, в котрих надходження інформації ззовні неможливе без участі паперових документів. Ця проблема особливо актуальна в банках, податкових інспекціях та інших подібних закладах. У зв’язку з цим загострилась проблема автоматичного введення і розпізнавання рукописної інформації.
У теперішній час технічно не складно перетворити паперовий документ в цифровий формат. Для цього можна скористатися сканером, цифровою фото або відео камерою. Якщо перетворення паперових документів в цифровий вигляд можна вважати вирішеною проблемою, то розпізнавання введеного документа все ще залишається актуальним. Хоч і створені програми розпізнавання друкованих документів з прийнятною якістю розпізнавання, але більшість розроблених систем дають великі похибки при обробці текста низької якості, чи текста з різним рівнем яскравості. Якщо ж говорити про розпізнавання рукописних документів, то можна сказати, що результатів, задовільних на практиці, ще не отримано.
Тема дипломної роботи є актуальною, оскільки вона присвячена розпізнаванню рукописних символів, що до теперішнього часу залишається невирішеною проблемою. У дипломній роботі розглядається задача підвищення функціональної ефективності системи розпізнавання рукописних символів, що дозволяє з більшою достовірністю і оперативністю приймати управлінські рішення, обробляти великі масиви текстової інформації, здійснювати факсимільну передачу оригіналів підписів і фінансових документів.
1.1 Огляд методів розпізнавання образів
Найбільш ефективними методами виведення нових знань є методи розпізнавання образів на основі навчання (самонавчання) [1, 2, 3].
Виділяють такі способи відображення знань:
1. Інтенсіональне відображення – у вигляді схеми зв’язків між атрибутами (ознаками).
2. Екстенціональне відображення – за допомогою конкретних фактів (об’єкти, приклади).
Інтенсіональне відображення фіксує закономірності і зв’язки, якими пояснюється структура даних. Відповідно до діагностичних задач така фіксація полягає у визначенні операцій над атрибутами (ознаками) об’єктів, що призводять до потрібного діагностичного результату. Інтенсіональне зображення реалізуються за допомогою операцій над значенням атрибутів і не припускають операцій над відповідними інформаційними фактами (об’єктами).
У свою чергу, екстенціональне відображення знань пов’язане з описом і фіксацією конкретних об’єктів з предметної галузі і реалізоване в операціях, елементами котрих являються об’єкти як цілісні системи.
Описані вище два фундаментальні способи зображення знань дозволяють запропонувати таку класифікацію методів розпізнавання образів (табл. 1.1):
Таблиця 1.1 Класифікація методів розпізнавання
| Класифікація методів розпізнавання |
Область застосування |
Обмеження (недоліки) |
Методи розпізнавання
|
Інтенсіональні методи |
Методи, основані на оцінках плотності розподілу значень ознак (або подібність і розбіжність об’єктів) |
Задачі з відомим розподілом , як правило нормальним, необхідна наявність великої кількості статистичних даних |
Відсутність ототожнення. Необхідність в переборі всієї навчальної вибірки при розпізнаванні, висока чутливість до непредставницької навчальної вибірки та артефактів. |
| Методи, основані на припущеннях про клас вирішальних функцій |
Класи повинні бути добре роздільними, система ознак - ортонормованою |
Відсутність ототожнення. Повинен бути попередньо відомий вид вирішальної функції. Неможливість врахування нових знань про кореляцію серед ознак |
| Логічні методи |
Задачі невеликої розмірності простору ознак |
Відсутність ототожнення. При відборі логічних вирішальних правил (кон’юнкцій) необхідний повний перебір. Висока обчислювальна робота |
| Лінгвістичні (структурні) методи |
Задачі невеликої розмірності простору ознак |
Відсутність ототожнення. Задача відновлення(визначення)граматики по певній множині висловлювань (опису об’єктів), являється важкою для формалізації. Невирішеність теоретичних проблем. |
| Методи порівняння з прототипом |
Задачі невеликої розмірності простору ознак |
Відсутність ототожнення. Висока залежність результатів класифікації від міри відстані (метрики) |
| Метод k-найближчих сусідів |
Задачі невеликої розмірності по кількості класів та ознак |
Відсутність ототожнення. Висока залежність результатів класифікації від міри відстані (метрики).
Необхідність повного перебору навчальної вибірки при розпізнаванні. Трудоємність при обчисленні.
|
| Алгоритм обчислення оцінок (голосування) АОО |
Задачі невеликої розмірності по кількості класів та ознак |
Відсутність ототожнення. Залежність результатів класифікації від міри відстані (метрики). Необхідність повного перебору навчальної вибірки при розпізнаванні. Висока технічна складність методу. |
| Колективи вирішальних правил |
Задачі невеликої розмірності по кількості класів та ознак |
Відсутність ототожнення. Висока технічна складність методу,невирішеність ряду теоретичних проблем, як при виділенні області компетенції часткових методів, так і самих часткових методах |
Аналіз перспективних напрямів розвитку методів розпізнавання показує, що для успішного досягнення мети дослідження необхідно вирішити (або обійти) такі проблеми:
1) комбінаторного вибуху;
2) досягнення незалежності часу розпізнавання від обсягу навчальної вибірки;
3) корекція зниження розмірності простору ознак без відчутної втрати значимої інформації;
4) досягнення високої валідності результатів аналізу;
1.2.1 Двовимірне дискретне косинусне перетворення
Надійність розпізнавання значною мірою залежить від якості зображення символів, яке визначається формою символів або стилем написання і способом виконання.
Алгоритм двомірного дискретного косинусного перетворення [4, 5, 7] реалізується наступним виразом:
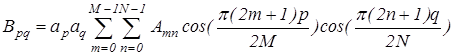 , ,
де  , ,  ; ;
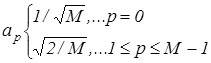 ; ; 
ФункціяB
=
dct
2
(
A
)
повертає результат двомірного дискретного косинусного перетворення для матриці А. Матриця В
має той же розмір, що і матриця А
, і відображає коефіцієнти дискретного косинусного перетворення.
Функція B
=
dct
2
(
A
,
m
,
n
)
повертає результат двомірного дискретного косинусного перетворення для матриці А
розміром m
х
n
. Якщо розмір матриці А
менший, вона доповнюється нульовими елементами до заданого розміру.
МатрицяА
може включати елементи класу double
або любого класу integer
. МатрицяВ
має елементі класу double
.
Алгоритм зворотного дискретного косинусного перетворення [4, 5, 8] реалізується наступним виразом:
 , ,
де 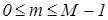 , , 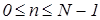 , ,
,
Функція B
=
idct
2
(
A
)
повертає результат двомірного зворотного дискретного косинусного перетворення для матриці А
. Результат повертає у вигляді матриці В
.
Функція B
=
idct
2
(
A
,
m
,
n
)
повертає результат двомірного зворотного дискретного косинусного перетворення з розміром матриць А
і В
m
х
n
. Якщо розмір матриціА
менший, вона доповнюється нульовими елементами до заданого розміру.
Матриця А
може включати елементи класу double
або любого класу integer
. МатрицяВ
має елементі класу double
.
1.2.3 Пряме перетворення Радона
Пряме перетворення Радона [4, 6, 8] використовується для полутонового зображення, представленого матрицею І
. У результаті перетворення отримаємо матрицю проекцій R
. Дане перетворення зводиться до обчислення проекцій зображення на осі, що задаються кутом відносно горизонталі по часовій стрілці.
Матриця І
повинна мати елементи, що відносяться до класу double
або любому іншому класу integer
. Алгоритм прямого перетворення Радона заключається в обчисленні проекцій зображення відносно конкретних напрямків. Так, проекція функцій двох змінних f
(
x
,
y
)
на вісь 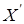 задається лінійним інтегралом: задається лінійним інтегралом:
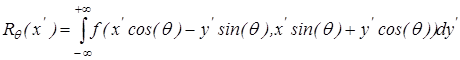 , ,
де осі та  задаються поворотом проти часової стрілки на кут задаються поворотом проти часової стрілки на кут 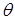 з використанням наступного виразу: з використанням наступного виразу:
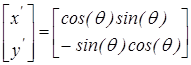 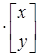 . .
Базове полутонове зображення І розглядається як функція двох змінних з початком в координатах 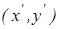 в місті центрального піксела зображення в піксельній системі координат. в місті центрального піксела зображення в піксельній системі координат.
1.2.4 Зворотнє перетворення Радона
Функція І =
irandom
(
P
,
theta
)
здійснює зворотне перетворення Радона [4, 8] і реконструює зображення І по його матриці проекцій Р
. Якщо theta
– вектор, то він повинен містити кути в градусах, що монотонно збільшуються з однаковим кроком d
_
theta
і задають напрямок осей, проекції яких знаходяться в матриці Р
. Якщо theta
– скаляр, що задається як d
_
theta
, то кути проекцій розраховуються як theta
=
m
*
d
_
theta
, де
m
=0,1,2,…,
size
(
P
,2)-1
.
Функція І =
irandom
(
P
,
theta
,
interp
,
filter
,
d
,
n
)
дозволяє задати чотири додаткових параметри:
1) interp
– задає тип інтерполяції(лінійна, сплайнова, по найближчому відліку):
2) filter
– задає тип фільтра:
3) d
– число в діапазоні [0,1], що задає нормалізовану частоту;
4) n
– кількість стовпчиків і рядків у відновленому зображенні;
Всі вхідні і вихідні параметри повинні бути класу double
.
Методи розпізнавання рукописних символів, що розглядатимуться далі, історично являються ранніми. Вони передбачають попередню детальну обробку зображень, що розпізнаються. На основі такої обробки виділяють найбільш характерні особливості зображень для їх класифікації. Потім ці особливості перетворюються в коди, зручні для введення в систему розпізнавання.
Так як опис зображень формується з врахуванням конкретної задачі, системи розпізнавання такого типу є непридатні, коли якісно змінюється множина зображень, які необхідно класифікувати, а також коли класифікація набуває новий зміст. В такого типу системах практично відсутнє навчання, так як всі її параметри відразу жорстко задаються конструктором.
Метод суміщення з еталонами [9, 10] є одинм з перших найпростіших методів розпізнавання образів. Основна ідея методу полягає в співставленні зображення, що розпізнається, з набором ідеальних еталонів, попередньо сформованих конструктором. Належність зображення до певного образу визначається по мірі його збіжності з еталонами. Системи розпізнавання, побудовані за даним методом, можна класифікувати за способом зберігання еталонних наборів:
1) системи, що використовують фотографічні маски;
2) системи, що використовують електричні моделі еталонів;
В системах розпізнавання з фотомасками застосовують безпосередньо оптичне накладання зображення на еталонну маску. Такі системи використовуються для розпізнавання зорових образів. Зображення, що розпізнається, проектується на еталонні маски, набір котрих включає всю множину образів. Степінь збіжності цього зображення з кожним із еталонів фіксується за допомогою еталонного множника, що розміщується за еталонною маскою, за мінімумом світлового потоку, що пройшов скрізь маску. Якщо еталонні маски представленні негативним зображенням знаків, що розпізнаються, то при повній збіжності знака з еталоном вихідний сигнал фотомножника дорівнює нулю. Вхідне зображення відноситься до того образу, з еталоном котрого виявлена найбільша збіжність.
В системах розпізнавання, що використовують для зберігання еталона його електричну модель, зображення попередньо перетворюється в послідовність дискретних за рівнем і часом електричних сигналів. Кожен сигнал з певною точністю відповідає коефіцієнту відображення однієї клітини рецепторного поля. В даній ситуації накладання зображення на еталон відбувається шляхом сумування сигналів від клітин рецепторного поля на еталонних матрицях опору або феритових сердечників. Значення сумарного сигналу відображає степінь збіжності зображення і еталона.
Область застосування методу обмежена в силу необхідності створення для кожного образу точно відтвореного еталону. При цьому зображення, що розпізнаються, повинні мати строго фіксоване положення відносно еталона. Такі системи не можуть перенавчитися для розпізнавання інших образів. Для цього потрібно формувати нові еталони, які б відповідали тим образам, яуі необхідно розпізнати в нових умовах.
Серед відомих методів розпізнавання букв і символів метод зондів [9, 10, 11] виділяється своєю простотою. Даний метод базується на аналізі певних ознак, суттєвих для даного зображення, і дає можливість класифікувати рукописні знаки, написані з певними невеликими відмінностями в розмірі і стилі написання.
Система розпізнавання потребує написання знаків, що розпізнаються, спеціальними струмопровідними чорнилами. Листок паперу повинен бути розмічений на клітинки, всередині кожної із яких ставляться дві точки. Знак, що розпізнається, повинен розміщуватися певним чином відносно цих двох точок і не виходити за межі клітинки. На знак накладається спеціально підібрана система електронів-зондів, а по чорнилам пропускається струм. Кожний зонд являється ознакою зображення, що розпізнається. Сигнали від електродів, що торкаються ліній знаку, подаються на дешифратор, котрий в залежності від того, які електроди перетнулися, видає код, відповідний певному знаку розпізнавання.
На рецепторному полі знаходяться декілька доріжок-зондів, які можна розглядати як групи або ланцюги одиничних фоторецепторів. Зонди можна розглядати в якості координат простору ознак. У цьому випадку кожне зображення може бути представлене у вигляді вектора 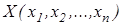 , складові котрого приймають значення 0 або 1. Для того, щоб система розпізнавання могла безпомилково класифікувати зображення, необхідно підібрати відповідну систему зондів. При виборі зондів необхідно врахувати можливі зсуви зображення по рецепторному полю, а також їх невелику деформацію. Вплив викривлень, які не перевищують певного значення, може бути відображено в записах кодів зондів. , складові котрого приймають значення 0 або 1. Для того, щоб система розпізнавання могла безпомилково класифікувати зображення, необхідно підібрати відповідну систему зондів. При виборі зондів необхідно врахувати можливі зсуви зображення по рецепторному полю, а також їх невелику деформацію. Вплив викривлень, які не перевищують певного значення, може бути відображено в записах кодів зондів.
При побудові системи зондів необхідно врахувати два основні факти: ліміт допустимих перетворень зображень і належність в зображеннях частин, що включають найбільшу для розпізнавання інформацію. Враховуючи ці фактори, потрібно вибирати зонди так, щоб, по-перше, при будь-яких допустимих перетвореннях зображення даного образу система зондів видавала одну і ту саму реакцію, по-друге, при представлені зображень різних образів реакція системи зондів в значній мірі змінювались.
Метод маркування зображень [9, 11, 12] полягає в тому, що зображенню штучно надаються ознаки, що визначають його в процесі розпізнавання. В натуральних зображеннях дуже важко автоматично виділити ознаки для якісного розпізнавання любого зображення. Разом з тим присутня можливість промаркувати кожне із зображень, що розпізнається.
Припустимо, що при друкуванні цифр біля кожної з них буде надрукована група точок з різним для кожної точки інтервалом. Тоді система розпізнавання може аналізувати не самі зображення, а супроводжуючі їх групи точок. Поява кожної точки фіксується, наприклад, одиничним фоторецептором, а вся група перетворюється в послідовність імпульсів. Цю послідовність подають на дешифратор, котрій видає сигнал, що характеризує дану цифру. На формування сигналу не впливають ні якість надрукованої літери, ні зміна її положення в рядку, ні зміна стилю написання. Задача розпізнавання зображень зводиться до задачі розпізнавання кодів, подібних азбуці Морзе.
Основний недолік методу заключається в тому, що кожне зображення, яке необхідно розпізнати, повинно до представлення системі пройти спеціальну обробку в маркувальному приладі. Тому даний метод не знайшов широкого застосування на практиці.
Основна складність розпізнавання полягає в тому, що один і той же образ може бути представлений зображеннями, що суттєво відрізняються між собою. Наприклад, для одного і того ж алфавіту існує велика кількість написання одних і тих же знаків. Не дивлячись на це, система розпізнавання повинна завжди ототожнювати всі написання однієї літери в один образ. Для цього необхідно скласти таке описання зображення, яке було б інваріантним до вказаних змін.
Для аналізу зображень можна використати математичний апарат топології. Так як проекційні перетворення, що розглядаються в топології, дуже широкі, то використовується лише одна математична категорія – графи. Граф – це множина, що складається з підмножини елементів, що називаються ребрами, і підмножини елементів, що називаються вершинами. Кожному кінцю ребра відповідає одна вершина, а кожному ребру відповідає дві вершини. Якщо є можливим взаємно неперервне і взаємно однозначне відображення графа на граф на граф 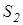 , то таке відображення називається гомеоморфним. , то таке відображення називається гомеоморфним.
Такі зображення, як літери латинського алфавіту, можна розглядати як плоскі графи, а різні написання однієї і тієї ж літери – як гомеоморфні перетворення деякого ідеального знаку.
Гомеоморфність двох графів встановлюється за допомогою топологічних інваріантів, тобто ознак, які не змінюються при гомеоморфних перетвореннях. Простіше всього користуватися інваріантами, котрі можуть бути виражені за допомогою чисел. Для цього необхідно встановити правило, за яким кожному графу ставиться у відповідність деяке число, що залишається незмінним при гомеоморфних перетвореннях. Частіше всього в якості топологічного інваріанту використовують індекс вершини, котрий визначається як кількість ребер, що входять у вершину. Індекс вершин встановлюється при послідовному обході графа за певним правилом. Це правило може бути сформоване так: обхід відбувається по ребрам, при чому напрям обходу змінюється на протилежний у випадку попадання на вершину з індексом 1; у випадку, якщо індекс вершини більше 2, далі рух з цієї вершини необхідно продовжувати по першому ребру, розміщеного за годинниковою стрілкою відносно ребра, по якому рухома точка потрапила в цю вершину. Таке правило дозволяє проводити послідовний обхід любого графа по зовнішнім ребрам при умові, що обхід почався з випадкової точки будь-якого зовнішнього ребра.
Метод квазітопологічного розпізнавання [9, 13] може бути реалізований за допомогою слідкуючої розгортки, коли обхід відбувається по зовнішньому контуру зображення. До слідкуючої розгортки повинен бути добавлений пристрій, який визначає індекси вершин в місцях згину зовнішнього контуру. Далі схема логіки повинна проводити декодування отриманих кодових комбінацій. Крім цього, повинен бути присутній або пристрій для фіксації початку обходу, або пристрій, який би забезпечував декодування кодових комбінацій в циклічних перестановках.
Таким чином квазітопологічний метод можна успішно застосовувати для побудови читаючих автоматів. Але використання цього методу не може принципово забезпечити повного розподілу літер алфавіту, так як деякі зображення літер є гомеоморфними одному і тому ж еталонному графу. Це стосується літер П, С, Г. Вони є гомеоморфними відрізку прямої. Крім того, метод не може забезпечити якісного розпізнавання при наявності нечіткого зображення літери, що розпізнається, та потребує багато часу.
Виходячи з аналізу методів розпізнавання образів (табл. 1.1), та перспектив розвитку методів розпізнавання [14, 17], в даній роботі запропоновано розробляти систему розпізнавання рукописних символів у рамках інформаційно екстремальної інтелектуальної технології (ІЕІТ), що ґрунтується на максимізації інформаційної спроможності системи, шляхом оптимізації її параметрів функціонування за умов апріорної невизначеності інформаційних і ресурсних обмежень. В рамках ІЕІТ, завдяки самонавчанню системи та шляхом оптимізації просторово-часових параметрів функціонування системи розпізнавання, можна побудувати безпомилкові вирішальні правила.
Розглянемо постановку задачі загального синтезу систами розпізнавання. Нехай ефективність навчання розпізнаванню реалізацій класу 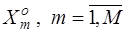 , характеризується значенням , характеризується значенням 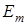 критерію функціональної ефективності. Відома навчальна матриця критерію функціональної ефективності. Відома навчальна матриця 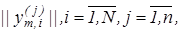 де де 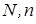 - кількість ознак розпізнавання і випробувань відповідно. Рядок матриці - кількість ознак розпізнавання і випробувань відповідно. Рядок матриці 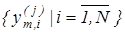 утворює утворює  -ту реалізацію образу, а стовпець -ту реалізацію образу, а стовпець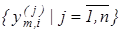 - навчальну вибірку з генеральної сукупності значень - навчальну вибірку з генеральної сукупності значень 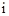 -ї ознаки розпізнавання. Треба для структурованого вектора параметрів функціонування системи розпізнавання -ї ознаки розпізнавання. Треба для структурованого вектора параметрів функціонування системи розпізнавання 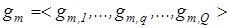 , які будемо називати параметрами навчання і для яких відомі обмеження , які будемо називати параметрами навчання і для яких відомі обмеження 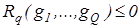 , шляхом організації послідовних ітераційних процедур знайти екстремальні значення координат вектора , шляхом організації послідовних ітераційних процедур знайти екстремальні значення координат вектора 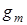 , що забезпечують максимум КФЕ навчання системи розпізнавання: , що забезпечують максимум КФЕ навчання системи розпізнавання:
 , ,
де 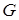 - область допустимих значень параметрів навчання. - область допустимих значень параметрів навчання.
Треба на етапі екзамену визначити з наближеною до асимптотичної повної достовірності належність зображення, що розпізнається до одного з класів розпізнавання із сформованого на етапі навчання алфавіту класів 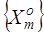 . .
Об’єктом дослідження є слабо формалізований процес розпізнавання зображень.
Предметом дослідження є метод розпізнавання зображень у рамках МФСВ.
Метою роботи є підвищення достовірності та оперативності розпізнавання рукописних символів у рамках ІЕІТ.
Для досягнення поставленої мети необхідно вирішити такі завдання:
- розробити базовий алгоритм навчання та екзамену за ІЕІТ;
- сформувати навчальну матрицю для зображень в декартових і полярних координатах;
- розробити та програмно реалізувати алгоритм навчання системи розпізнавання рукописних символів за ІЕІТ з оптимізацією контрольних допусків на ознаки розпізнавання;
- програмно реалізувати алгоритм екзамену та оцінити достовірність результатів;
2
ОПИС
МЕТОДУ РОЗПІЗНАВАННЯ РУКОПИСНИХ СИМВОЛІВ
2.1 Основні
ідеї інформаційно-екстремального методу розпізнавання рукописних символів
Базовим методом ІЕІТ є метод функціонально-статистичних випробувань (МФСВ) [18, 19, 20] – непараметричний інформаційно-екстремальний метод аналізу та синтезу здатної навчатися системи керування, який ґрунтується на прямій оцінці інформаційної здатності системи за умов нечіткої компактності реалізацій образу, та обмеження навчальної вибірки, яка є прийнятною для задач контролю і керування. Метод призначено для розв’язання практичних задач контролю та управління слабо формалізованими системами і процесами шляхом автоматичної класифікації їх функціональних станів за умови невизначеності.
МФСВ окрім системних та специфічних принципів ґрунтується також на 2-х дистанційних принципах:
- максимально-дистанційному, який вимагає максимальної міжцентрової відстані між класами;
- мінімально-дистанційному, вимагає мінімальної середньої відстані реалізацій від центру свого класу:
Класом розпізнавання (образом)  називається відбиття властивостей m-го функціонального стану системи розпізнавання і відношень між елементами системи. Клас розпізнавання - топологічна категорія, яка задається в просторі ознак розпізнавання областю ÌWБ
. називається відбиття властивостей m-го функціонального стану системи розпізнавання і відношень між елементами системи. Клас розпізнавання - топологічна категорія, яка задається в просторі ознак розпізнавання областю ÌWБ
.
Детерміновано-статистичний підхід [21, 22] до моделювання систем вимагає завдання систем нормованих (експлуатаційних) і контрольних допусків на ОР. Нехай - базовий клас, який характеризує максимальну функціональну ефективність, тобто є найбільш бажаним для розробника інформаційного забезпечення системи. Нормованим називається поле допусків 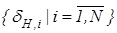 , в якому значення і–ї ОР знаходиться з імовірністю , в якому значення і–ї ОР знаходиться з імовірністю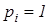 або або 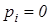 , за умови, що функціональний стан відноситься до класу , за умови, що функціональний стан відноситься до класу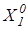 . Контрольним називається поле допусків . Контрольним називається поле допусків , в якому значення і-ї ОР знаходиться з імовірністю , в якому значення і-ї ОР знаходиться з імовірністю 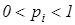 за умови, що функціональний стан відноситься до класу. за умови, що функціональний стан відноситься до класу.
В ІЕІТ система контрольних допусків вводиться з метою рандомізації процесу прийняття рішень, оскільки для повного дослідження об’єкту контролю та управління необхідно використовувати як детерміновані, так і статистичні характеристики. Зрозуміло, що 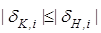 і базова (відносно класу) СКД є сталою для всієї абетки класів розпізнавання. і базова (відносно класу) СКД є сталою для всієї абетки класів розпізнавання.
Реалізацією образу  називається випадковий структурований бінарний вектор називається випадковий структурований бінарний вектор 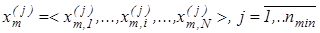 , де , де 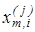 - і-та координата вектора, яка приймає одиничне значення, якщо значення і-ї ОР знаходиться в полі допусків - і-та координата вектора, яка приймає одиничне значення, якщо значення і-ї ОР знаходиться в полі допусків 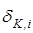 , і нульове значення, якщо не знаходиться; , і нульове значення, якщо не знаходиться; 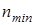 - мінімальна кількість випробувань, яка забезпечує репрезентативність реалізацій образу. - мінімальна кількість випробувань, яка забезпечує репрезентативність реалізацій образу.
При обґрунтуванні гіпотези компактності (чіткої, або нечіткої) реалізацій образу за геометричний центр класу приймається вершина бінарного еталонного вектору хm
.
Еталонний вектор xm
- це математичне сподівання реалізацій класу.
Він подається у вигляді детермінованого структурованого бінарного вектора 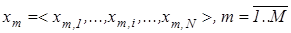 , де хm,і
- і-та координата вектора, яка приймає одиничне значення, якщо значення і-ї ОР знаходиться в нормованому полі допусків , де хm,і
- і-та координата вектора, яка приймає одиничне значення, якщо значення і-ї ОР знаходиться в нормованому полі допусків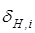 , і нульове значення, якщо не знаходиться. , і нульове значення, якщо не знаходиться.
Основною задачею етапу навчання за МФСВ є розбиття простору ознак розпызнавання за поданою навчальною матрицею на області класів розпізнавання деяким оптимальним в інформаційному сенсі способом, який забезпечує на етапі екзамену прийняття рішень з достовірністю, наближеною до максимальної асимптотичної достовірності.
Параметром функціонування називається характеристика інформаційного забезпечення, яка прямо або непрямо впливає на функціональну ефективність системи. Такими параметрами можуть бути параметри навчання, перетворення образу, впливу середовища та інші, які безпосередньо впливають на асимптотичну достовірність.
Як критерій оптимізації процесу навчання системи прийняттю рішень в рамках МФСВ застосовується статистичний інформаційний КФЕ, який є природною мірою різноманітності (або схожості) класів розпізнавання і одночасно функціоналом асимптотичних точнісних характеристик СР. При цьому важливо, щоб параметри навчання були оптимальними в інформаційному розумінні, тобто забезпечували максимальну функціональну ефективність СР, яка визначається достовірністю прийняття рішень на екзамені.
Достовірність класифікатора залежить від геометричних параметрів роздільних гіперповерхонь класів розпізнавання.
У загальному випадку, коли класи розпізнавання перетинаються, розглянемо відносний коефіцієнт нечіткої компактності реалізації образу для класу
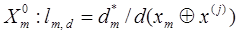 (2.1.1) (2.1.1)
Процес навчання полягає в мінімізації цього виразу.
В МФСВ, який ґрунтується на допущенні гіпотези компактності (чіткої або нечіткої) реалізацій образу, як наближення ²точної² роздільної гіперповерхні для класу розглядається гіперсфера, центром якої є еталонний вектор 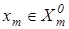 , а радіусом , а радіусом  - кодова відстань, яка у просторі Хеммінга визначається як - кодова відстань, яка у просторі Хеммінга визначається як
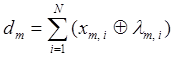 (2.1.2) (2.1.2)
де 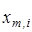 - і-та координата вектора - і-та координата вектора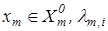 - i-тa координата деякого вектора lm, вершина якого знаходиться на роздільні гіперповерхні класу ; - i-тa координата деякого вектора lm, вершина якого знаходиться на роздільні гіперповерхні класу ; 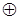 - операція складання за модулем два. - операція складання за модулем два.
Оптимальною кодовою відстанню (радіусом) між вектором 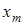 і контейнером і контейнером 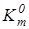 називається екстремальне значення називається екстремальне значення 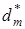 , яке визначає максимум інформаційного КФЕ , яке визначає максимум інформаційного КФЕ 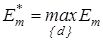 , де {d}
– послідовність збільшень радіуса контейнера , де {d}
– послідовність збільшень радіуса контейнера 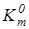 . .
Побудова оптимальної в інформаційному сенсі РГП у вигляді гіперсфери за МФСВ зводиться до оптимізації радіуса роздільної гіперсфери dm
, яка відбувається за ітераційним алгоритмом
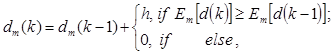 (2.1.3) (2.1.3)
де k
- змінна числа збільшень радіуса РГП; h
- крок збільшення.
Процедура закінчується при знаходженні екстремального значення критерію , де 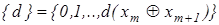 - множина радіусів концентрованих гіперсфер, центр яких визначається вершиною еталонного вектора - множина радіусів концентрованих гіперсфер, центр яких визначається вершиною еталонного вектора 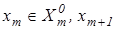 - еталонний вектор найближчого (до - еталонний вектор найближчого (до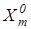 ) класу ) класу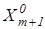 . .
2.2
Математична модель системи розпізнавання рукописних символів
Категоріальну модель процесу навчання системи розпізнавання символів [19] при нечіткому розбитті за МФСВ подамо у вигляді діаграми відображень множин:
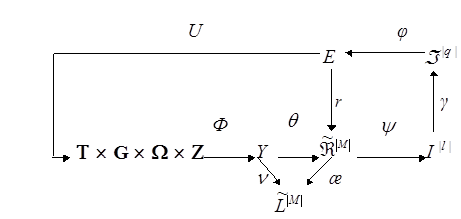 (2.2.1) (2.2.1)
де
- 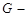 множина сигналів на вході СР множина сигналів на вході СР
- 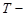 множина моментів зчитування інформації з рецепторів; множина моментів зчитування інформації з рецепторів;
-  множина можливих станів СР; множина можливих станів СР;
- 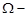 простір ОР; простір ОР;
- 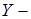 множина сигналів після первинної обробки інформації; множина сигналів після первинної обробки інформації;
- 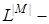 покриття, що визначає абетку класів розпізнавання; покриття, що визначає абетку класів розпізнавання;
- 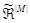 - нечітке розбиття; - нечітке розбиття;
- 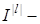 множина гіпотез; множина гіпотез;
- 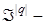 множина точнісних характеристик; множина точнісних характеристик;
- 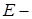 множина значень КФЕ; множина значень КФЕ;
За діаграмою (2.2.1) оператори контуру

реалізують базовий алгоритм начання, який безпосередньо визначає екстремальні значення геометричних параметрів контейнерів шляхом пошуку максимуму критерію 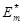 . .
Оператор 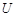 регламентує процес навчання і дозволяє оптимізувати параметри плану навчання. регламентує процес навчання і дозволяє оптимізувати параметри плану навчання.
Діаграма відображень множин на екзамені має такі відмінності від діаграм оптимізаційного навчання за МФСВ:
· зворотний зв’язок у діаграмі не містить контурів оптимізації параметрів функціонування СР, а призначенням оператора UЕ
є регламентація екзамену;
· замість оператора q
вводиться оператор Р
відображення вибіркової множини X
Ì
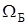 ,
щорозпізнається, на побудоване на етапі навчання розбиття
,
щорозпізнається, на побудоване на етапі навчання розбиття 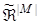 ; ;
· комутативне кільце утворюється між розбиттям , множиною гіпотез I
|
M
+1|
і покриттям  ; ;
· оператор класифікації Y
утворює композицію двох операторів: Y1
:
®
F
, де F
– множина функцій належності, і оператор дефазіфікації Y
2
: F
®
I
|
M
+1|
, який вибирає гіпотезу за максимальним значенням функції належності.
З урахуванням наведених відмінностей діаграма відображень множинна екзамені набуває вигляду
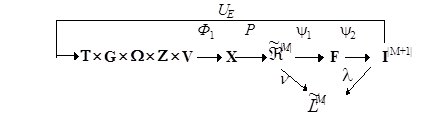 (2.2.2) (2.2.2)
У діаграмі (2.2.2) оператор Ф1
відображає універсум випробувань на вибіркову множину Х, яка утворює екзаменаційну матрицю 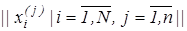 , аналогічну за структурою, процедурою та параметрами формування навчальній матриці. , аналогічну за структурою, процедурою та параметрами формування навчальній матриці.
Як критерій оптимізації параметрів навчання системи розпізнавання може розглядатися будь-яка статистична інформаційна міра, яка є функціоналом від точнісних характеристик. Так, широкого використання в алгоритмах навчання за МФСВ набула модифікація інформаційної міри Кульбака [19], в якій розглядається відношення правдоподібності у вигляді логарифмічного відношення повної ймовірності правильного прийняття рішень  до повної ймовірності помилкового прийняття рішень до повної ймовірності помилкового прийняття рішень 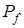 : :
 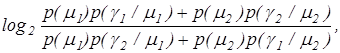
де 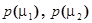 -безумовні ймовірності появи реалізацій класів -безумовні ймовірності появи реалізацій класів 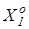 і і 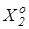 відповідно, а умовні ймовірності - точнісні характеристики: перша достовірність відповідно, а умовні ймовірності - точнісні характеристики: перша достовірність  , помилка першого роду , помилка першого роду 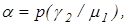 помилка другого
помилка другого  роду роду 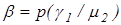 і друга достовірність і друга достовірність 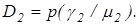 Для рівноймовірних гіпотез, що характеризує найбільш важкий у статистичному розумінні випадок прийняття рішень, міру Кульбака подамо у вигляді Для рівноймовірних гіпотез, що характеризує найбільш важкий у статистичному розумінні випадок прийняття рішень, міру Кульбака подамо у вигляді
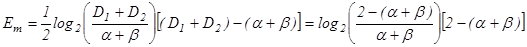 (2.3.1) (2.3.1)
Отже, критерій (2.3.1) є нелінійним функціоналом від точнісних характеристик процесу навчання. Крім того він є неоднозначним, що потребує знання робочої області його визначення. Оскільки навчальна вибірка є обмеженою за обсягом, то замість, наприклад, помилок першого та другого роду розглянемо їх оцінки: 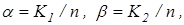 де де 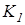 - кількість реалізацій класу , які не належать контейнеру - кількість реалізацій класу , які не належать контейнеру 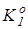 ; ; 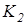 - кількість реалізацій класу , які належать контейнеру . Після підстановки цих оцінок у (2.3.1) отримаємо робочу формулу КФЕ за Кульбаком: - кількість реалізацій класу , які належать контейнеру . Після підстановки цих оцінок у (2.3.1) отримаємо робочу формулу КФЕ за Кульбаком:
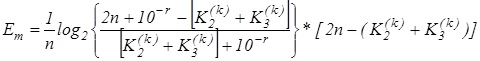 (2.3.2) (2.3.2)
де 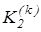 - кількість реалізацій класу - кількість реалізацій класу 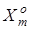 , які не знаходяться в k
-му контейнері цього класу; , які не знаходяться в k
-му контейнері цього класу; 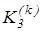 -кількість “чужих” реалізацій, які знаходяться в k
-му контейнері. У виразі (2.3.2) -кількість “чужих” реалізацій, які знаходяться в k
-му контейнері. У виразі (2.3.2) 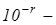 любе мале позитивне число, яке дозволяє уникнути появи нуля в знаменнику дробу. На практиці доцільно брати любе мале позитивне число, яке дозволяє уникнути появи нуля в знаменнику дробу. На практиці доцільно брати 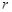 рівним кількості знаків у мантисі значення критерію. Нормований критерійКульбака можна подати у вигляді рівним кількості знаків у мантисі значення критерію. Нормований критерійКульбака можна подати у вигляді 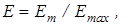 де де 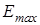 - максимальне значення критерію при - максимальне значення критерію при  і і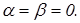
Вхідною інформацією для навчання за базовим алгоритмом є дійсний, в загальному випадку, масив реалізацій образу 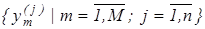 ; система полів контрольних допусків ; система полів контрольних допусків 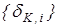 і рівні селекції і рівні селекції 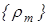 , які за умовчанням дорівнюють 0,5 для всіх класів розпізнавання. , які за умовчанням дорівнюють 0,5 для всіх класів розпізнавання.
Розглянемо етапи реалізації алгоритму:
1.Формування бінарної навчальної матриці  , елементи якої дорівнюють , елементи якої дорівнюють
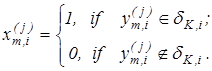 (2.4.1) (2.4.1)
2.Формування масиву еталонних двійкових векторів 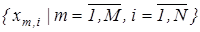 , елементи якого визначаються за правилом: , елементи якого визначаються за правилом:
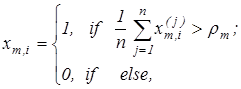 (2.4.2) (2.4.2)
де 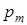 - рівень селекції координат вектору . - рівень селекції координат вектору .
3. Розбиття множини еталонних векторів на пари найближчих ²сусідів²: 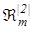 =<xm
, xl
>
, де xl
- еталонний вектор сусіднього класу =<xm
, xl
>
, де xl
- еталонний вектор сусіднього класу 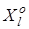 , за таким алгоритмом: , за таким алгоритмом:
а) структурується множина еталонних векторів, починаючи з вектора x
1
базового класу , який характеризує найбільшу функціональну ефективність системи розпізнавання;
б) будується матриця кодових відстаней між еталонними векторами розмірності M
´
M
;
в) для кожної строки матриці кодових відстаней знаходиться мінімальний елемент, який належить стовпчику вектора - найближчого до вектора, що визначає строку. При наявності декількох однакових мінімальних елементів вибирається з них будь-який, оскільки вони є рівноправними;
г) формується структурована множина елементів попарного розбиття 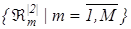 , яка задає план навчання. , яка задає план навчання.
4. Оптимізація кодової відстані dm відбувається за рекурентною процедурою. При цьому приймається 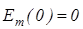 . .
5.Процедура закінчується при знаходженні максимуму КФЕ в робочій області його визначення: 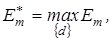 де де 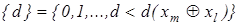 - множина радіусів концентрованих гіперсфер, центр яких визначається вершиною . - множина радіусів концентрованих гіперсфер, центр яких визначається вершиною .
Таким чином, базовий алгоритм навчання :
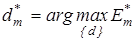 (2.4.3) (2.4.3)
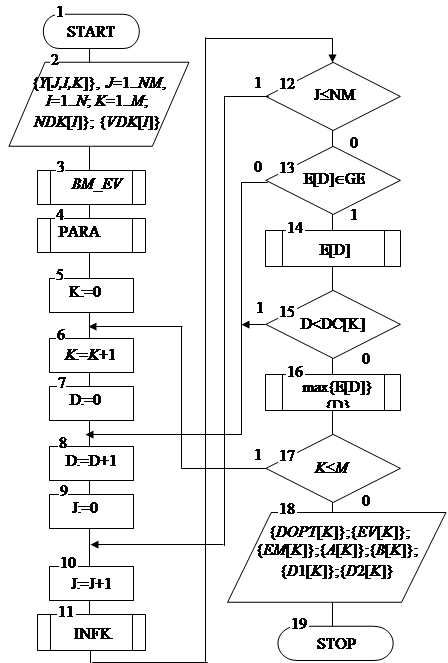
На рис.2.4.1 наведено структурну схему базового алгоритму навчання. Тут показано такі вхідні дані: {Y[J,I,K]} - масив навчальних вибірок, J=1..NM - змінна кількості випробувань, де NM - мінімальний обсяг репрезентативної навчальної вибірки, I=1..N - змінна кількості ознак розпізнавання, K=1..M - змінна кількості класів розпізнавання; {NDK[I]}, {VDK[I]} - масиви нижніх і верхніх контрольних допусків на ознаки відповідно. Результатом реалізації алгоритму є: {DOPT[K]} - цілий масив оптимальних значень радіусів контейнерів класів розпізнавання у кодовій відстані Хеммінга; {EV[K]} - масив еталонних двійкових векторів класів розпізнавання; {EM[K]} - дійсний масив максимальних значень інформаційного КФЕ процесу навчання; {D1[K]}, {A[K]}, {B[K]}, {D2[K]} - дійсні масиви оцінок екстремальних значень точнісних характеристик процесу навчання для відповідних класів розпізнавання: перша вірогідність, помилки першого та другого роду і друга вірогідність відповідно.
Змінна D є робочою змінною кроків навчання, на яких послідовно збільшується значення радіуса контейнера. У структурній схемі алгоритму (рис. 2.4.1) блок 3 формує масив навчальних двійкових вибірок {X[J,I,K]} шляхом порівняння значень елементів масиву {Y[J,I,K]} з відповідними контрольними допусками за правилом (1) і формує масив еталонних двійкових векторів {EV[K]} шляхом статистичного усереднення стовпців масиву {X[J,I,K]} за правилом (2) при відповідному рівні селекції, який за умовчанням дорівнює 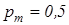 . Блок 4 здійснює розбиття множини еталонних векторів на пари “найближчих сусідів”. Блок 11 обчислює на кожному кроці навчання значен . Блок 4 здійснює розбиття множини еталонних векторів на пари “найближчих сусідів”. Блок 11 обчислює на кожному кроці навчання значен
Рисунок 2.4.1 - Структурна схема базового алгоритму навчання
ня інформаційного КФЕ і оцінки точнісних характеристик процесу навчання. При невиконанні умови блоку порівняння 12 блок 13 оцінює належність поточного значення критерію 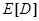 робочій області робочій області 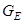 визначення його функції і при позитивному рішенні блоку 13 це значення запам’ятовується блоком 14. При негативному рішенні блока порівняння 15, в якому величина визначення його функції і при позитивному рішенні блоку 13 це значення запам’ятовується блоком 14. При негативному рішенні блока порівняння 15, в якому величина 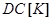 дорівнює кодовій відстані між парою сусідніх еталонних векторів, блок 16 здійснює у робочій області пошук глобального максимуму КФЕ – EM
[K
] і визначає для нього екстремальне значення радіуса гіперсфери – DOPT
[K
]. Аналогічно будуються оптимальні контейнери для інших класів. Якщо параметри навчання {DOPT
[K
]} і {EV
[K
]} є вхідними даними для екзамену, то значення КФЕ та екстремальних оцінок точнісних характеристик використовуються для аналізу ефективності процесу навчання. Таким чином, основною процедурою базового алгоритму навчання за МФСВ є обчислення на кожному кроці навчання статистичного інформаційного КФЕ і організація пошуку його глобального максимуму в робочій області визначення функції критерію. дорівнює кодовій відстані між парою сусідніх еталонних векторів, блок 16 здійснює у робочій області пошук глобального максимуму КФЕ – EM
[K
] і визначає для нього екстремальне значення радіуса гіперсфери – DOPT
[K
]. Аналогічно будуються оптимальні контейнери для інших класів. Якщо параметри навчання {DOPT
[K
]} і {EV
[K
]} є вхідними даними для екзамену, то значення КФЕ та екстремальних оцінок точнісних характеристик використовуються для аналізу ефективності процесу навчання. Таким чином, основною процедурою базового алгоритму навчання за МФСВ є обчислення на кожному кроці навчання статистичного інформаційного КФЕ і організація пошуку його глобального максимуму в робочій області визначення функції критерію.
Алгоритми екзамену за МФСВ можуть мати різну структуру залежно від розподілу реалізацій образу, що розпізнаються. Обов’язковою умовою їх реалізації є забезпечення однакових структурованості і параметрів формування як для навчальної, так і для екзаменаційної матриць.
Для нечіткого розбиття алгоритм екзамену за МФСВ ґрунтується на аналізі значень функції належності, яка має вигляд (2.5.1) і обчислюється для кожної реалізації, що розпізнається. Розглянемо кроки реалізації алгоритму екзамену при нечіткому розбитті:
1. Формування лічильника 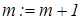 класів розпізнавання. класів розпізнавання.
2. Формування лічильника числа реалізацій, що розпізнаються: 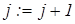 . .
3. Обчислення кодової відстані  . .
4. Обчислення функції належності за виразом:
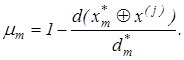 (2.5.1) (2.5.1)
5. Порівняння: якщо j
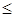 n
, то виконується крок 2, інакще – крок 6.
n
, то виконується крок 2, інакще – крок 6.
6. Порівняння: якщо m
M
, то виконується крок 1, інакще – крок 7.
7. Визначення класу 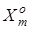 , до якого належить екзаменаційна реалізація, наприклад, за умови , до якого належить екзаменаційна реалізація, наприклад, за умови 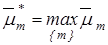 , де , де  - усереднене значення функцій належності для реалізацій класу , або видача повідомлення: «Клас не визначено», якщо - усереднене значення функцій належності для реалізацій класу , або видача повідомлення: «Клас не визначено», якщо 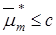 . Тут с- порогове значення. . Тут с- порогове значення.
Для перетворення зображення в полярних координатах [23] сформуємо матрицю яскравості 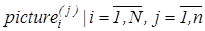 , де N
,
n
– відповідні розміри зображення. При перетворенні зображення попередньо виконана процедура пошуку геометричного центру літери: , де N
,
n
– відповідні розміри зображення. При перетворенні зображення попередньо виконана процедура пошуку геометричного центру літери:
1. За допомогою матриці яскравості знаходимо прямокутник, в який вписано рукописну літеру, наприклад, А (рис.3.1).
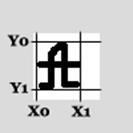
Рисунок 3.1 – Пошук геометричного центру літери
2. Із розмірів прямокутника знаходимо значення координат на рецепторному полі, що відповідають центру кола, в яке вписано літеру (центр кола знаходиться на перетині діагоналей прямокутника; довжину діагоналі знаходимо, використовуючи теорему Піфагора).
3. Формуємо вектор 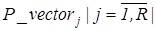 , де R
– радіус кола, описаного навколо літери. Елементи вектора дорівнюють , де R
– радіус кола, описаного навколо літери. Елементи вектора дорівнюють
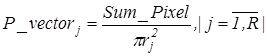
де 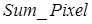 – сума значень яскравості пікселів, що потрапили в коло з радіусом – сума значень яскравості пікселів, що потрапили в коло з радіусом 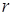 , ,  - площа кола з радіусом - площа кола з радіусом 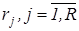 . .
На рис.3.2 наведено графік спектру зміни яскравостідля однієї з реалізацій літери А в полярних координатах.
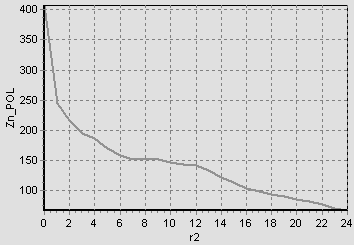
Рисунок 3.2 – Графік спектру зміни яскравості літери А в полярних координатах
Для перетворення зображення в декартових координатах, використано ідею дискретного перетворення Гільберта (ДПГ) [24].
Якщо зображення відобразити у вигляді матриці дискретних відрізків яскравості, тоді 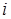 -й рядок зображення, що вміщує один об’єкт, можна представити наступним виразом: -й рядок зображення, що вміщує один об’єкт, можна представити наступним виразом:
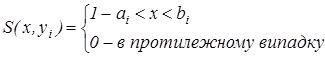
ДПГ такого сигналу характеризується виразом
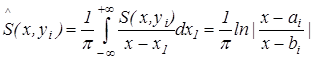
При перетворенні зображення в декартових координатах, спочатку формуємо матрицю яскравості , де N
,
n
– відповідні розміри зображення. Скануємо отриману матрицю по стовпчикам та сформуємо вектор сум різниць значень яскравості 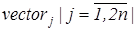 , де: , де:
4. елементи  приймають додатні значення суми різниць яскравості; приймають додатні значення суми різниць яскравості;
5. елементи 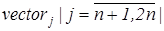 приймають від’ємні значення суми різниць яскравості; приймають від’ємні значення суми різниць яскравості;
6. якщо значення суми різниць яскравості приймає нульове значення, то відповідні елементи та також приймають нульові значення;
Таким чином, двомірний масив значень яскравості зображення ми переводимо в вектор сум різниць значень яскравості довжини вдвічі більшої, ніж ширина зображення.
3.
2 Оптимізація контрольних допусків на ознаки розпізнаваннясистеми розпізнавання
Категоріальну модель процесу навчання системи розпізнавання символів з оптимізацією контрольних допусків [19] на ознаки розпізнавання подамо у вигляді діаграми відображень множин:
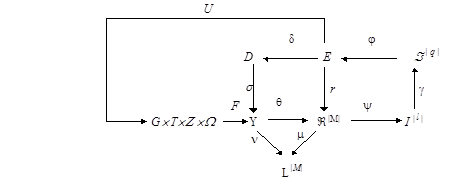 (3.3.1) (3.3.1)
де
- множина сигналів на вході системи розпізнавання;
- множина моментів зчитування інформації з рецепторів;
-  множина можливих станів системи розпізнавання; множина можливих станів системи розпізнавання;
- простір ознак розпізнавання;
- множина сигналів після первинної обробки інформації;
- покриття, що визначає абетку класів розпізнавання;
- - нечітке розбиття;
- множина гіпотез;
- множина точнісних характеристик;
- множина значень коефіцієнту функціональної ефективності;
За діаграмою (3.3.1) оператори контуру

здійснють оптимізацію СКД за ітераційною процедурою.
Алгоритми було реалізовано за допомогою середовища розробки Borland Delphi 7. Створена програма складається з трьох модулів:
- UnitMy.pas – модуль формування та попередньої обробки реалізацій зображень літер в полярних та декартових координатах;
- Unit1.pas – модуль реалізації алгоритмів навчання, оптимізації системи контрольних допусків та екзамену в полярних координатах;
- Unit2.pas – модуль реалізації алгоритмів навчання, оптимізації системи контрольних допусків та екзамену в декартових координатах;
Всі модулі об’єднані в один проект Project1.dpr.
Таблиця 3.1 Основні процедури модулів Unit1.pas
| №
|
Назва процедури
|
Короткий опис
|
| 1 |
function
INFK
(my_k:integer;
INFK_d:integer;
var INFK_D1:real;
var INFK_betta:real):real;
|
Обчислення значення інформаційного критерію та точносних характеристик INFK_D1
та INFK_betta
. |
| 2 |
Procedure
Make_D
(l:integer;my_k:integer);
|
Завдання системи допусків як відхилення від середнього по реалізаціях класу my_k
на кодову відстань sd
|
| 3 |
Procedure
Make_BM; |
Формування бінарної навчальної матриці |
| 4 |
Procedure
Make_EV; |
Формування еталонних векторів |
| 5 |
Procedure
Make_PARA; |
Розбиття еталонних векторів на пари сусідніх |
| 6 |
Function
Make_DO;
|
Побудова роздільних гіперповерхонь |
| 7 |
Procedure
Make_SK
(my_k:integer);
|
Заповнення масиву кодових відстаней від еталонного вектора до кожної реалізації класу my_k
|
| 8 |
Procedure
Make_Y |
Формування начальних матриць |
| 9 |
Procedure
optim_dk; |
Паралельна оптимізація СКД на ОР |
| 10 |
Procedure
optim_dk_ksam; |
Послідовна оптимізація СКД на ОР |
| 11 |
Procedure
examination_2() |
Проведення екзамену в полярних координатах |
| 12 |
Procedure
search_center_K() |
Пошук геометричного центру літери в полярних координатах |
| 13 |
Procedure
examination() |
Проведення екзамену в декартових координатах |
На рис.3.8 наведено графік зміни значення критерію функціональної ефективності від зміни  при паралельної оптимізації на ознаки розпізнавання в полярних координатах, коли за базових приймається клас при паралельної оптимізації на ознаки розпізнавання в полярних координатах, коли за базових приймається клас  . .
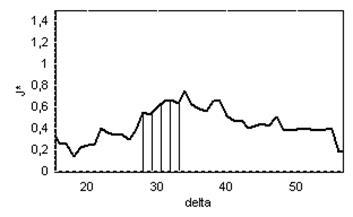
Рисунок 3.8 – Графік залежності КФЕ від при паралельній оптимізації в полярних координатах для базового класу
В табл. 3.2 наведені числові значення функціонування системи розпізнавання рукописних символів при паралельно – послідовної оптимізації для кожного з класів в полярних координатах.
Таблиця 3.2 Числові значення функціонування системи розпізнавання при паралельній та послідовній оптимізації для кожного з класів в полярних координатах
| Базовий класс |
Паралельна оптимізація |
Послідовна оптимізація |
| Середній КФЕ |
Delta |
Середній КФЕ |
Кількістьітерацій |
 |
0,653 |
47 |
0,886 |
4 |
|
0,743 |
34 |
1,155 |
4 |
 |
0,792 |
29 |
1,341 |
3 |
З табл. 3.2 робимо висновок, що найбільше середнє значення КФЕ для трьох класів досягається, коли за базовий приймається клас .
На рис.3.10 наведено графік зміни значення критерію функціональної ефективності від зміни при паралельної оптимізації на ознаки розпізнавання в декартових координатах, коли за базових приймається клас .
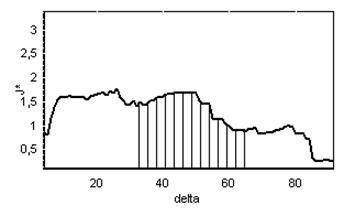
Рисунок 3.10 – Графік залежності КФЕ від при паралельній оптимізації в декартових координатах для базового класу
На рис.3.11 наведено графік зміни значення критерію функціональної ефективності на кроках ітерації при послідовній оптимізації на ознаки розпізнавання в декартових координатах, коли за базових приймається клас .
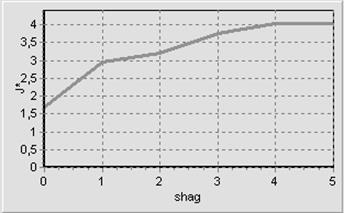
Рисунок 3.11 –Графік зміни значень КФЕ на кроках ітерації при послідовній оптимізації в декартових координатах для базового класу
В табл. 3.3 наведені числові значення функціонування системи розпізнавання при паралельно – послідовної оптимізації для кожного з класів в декартових координатах.
Таблиця 3.3 Числові значення функціонування системи розпізнавання при паралельно – послідовной оптимізації для кожного з класів в декартових координатах
| Базовий класс |
Паралельна оптимізація |
Послідовна оптимізація |
| Середній КФЕ |
Delta |
Середній КФЕ |
Кількістьітерацій |
|
1,450 |
36 |
3,695 |
5 |
|
1,016 |
8 |
3,925 |
3 |
|
1,691 |
47 |
4,017 |
5 |
Після проведення паралельно – послідовної оптимізації системи контрольних допусків на ознаки розпізнавання та вибору базового класу, проводимо етап навчання при перетворенні в полярних та декартових координатах.
Аналіз результатів етапу паралельно – послідовної оптимізації показав, що за базовий потрібно приймати клас , так як в цьому випадку досягається максимальне середнє значення КФЕ для трьох класів, що дає можливість на етапі екзамену з більшою достовірністю розпізнавати класи.
В табл. 3.4 наведені параметри функціонування системи розпізнавання на етапі навчання для кожного з класів в полярних та декартових координатах, коли за базовий почергово приймається клас , та .
Результати табл. 3.4 підтверджують, що найбільше середнє значення КФЕ для трьох класів досягається, коли за базовий приймається клас .
Таблиця 3.4 Параметри функціонування системи розпізнавання в полярних та декартових координатах, коли за базові приймаються класи , , .
| Кл.
|
Полярні координати
|
Декартові координати
|
| КФЕ |
R |
D1 |
betta |
КФЕ |
R |
D1 |
betta |
| базовий
|
|
1,1628 |
5 |
0,675 |
0,05 |
2,7421 |
5 |
0,875 |
0 |
|
0,3328 |
3 |
0,55 |
0,2 |
3,9518 |
4 |
0,975 |
0 |
|
1,1628 |
1 |
0,85 |
0,225 |
4,3923 |
2 |
1 |
0 |
|
0,4997 |
5 |
0,6 |
0,175 |
2,9897 |
7 |
0,9 |
0 |
| базовий
|
|
1,1628 |
7 |
0,625 |
0 |
4,3923 |
8 |
1 |
0 |
|
1,8017 |
9 |
0,9 |
0,15 |
4,3923 |
6 |
1 |
0 |
|
1,0559 |
9 |
0,75 |
0 |
3,2675 |
9 |
0,925 |
0 |
|
1,1628 |
4 |
0,65 |
0,025 |
4,3923 |
9 |
1 |
0 |
| базовий
|
|
1,8015 |
8 |
0,75 |
0 |
4,3923 |
8 |
1 |
0 |
Після етапу навчання, проведено етап екзамену.
4 ОХОРОНА ПРАЦІ
Питання підвищення продуктивності праці й збільшення економічної ефективності господарської діяльності пов'язані з автоматизацією процесів виробництва й керування, розвитком обчислювальної техніки, розробкою систем автоматизації проектних, дослідницьких і технологічних робіт. Тому широке поширення одержали електронно-обчислювальні машини (ЕОМ).
Широке поширення мікроелектроніки, комп'ютерів індивідуального користування, потужних засобів автоматизованої обробки тексту й графічної інформації, високо ефективних пристроїв її зберігання й пошуку дозволяють порушувати питання про вироблення техніки безпеки при роботі з комп'ютерними технологіями. Робота операторів, програмістів і просто користувачів безпосередньо зв'язана комп'ютерами, а відповідно, необхідно знати техніку безпеки при роботі з ними. Вивчення й рішення проблем, пов'язаних із забезпеченням здорових і безпечних умов, у яких протікає праця людини - одне з найбільше важливих завдань у розробці нових технологій і систем виробництва.
Міністерство праці й соціальної політики України й Комітет з нагляду за охороною праці України затвердили наказом від 10 лютого 1999 року "Правила охорони праці при експлуатації електронно-обчислювальних машин". Ці правила встановлюють вимоги безпеки й санітарно-гігієнічні вимоги до встаткування робочих місць користувачів ЕОМ і працівників, що виконують обслуговування, ремонт, налагодження ЕОМ і роботи із застосуванням ЕОМ.
У даному розділі дипломного проекту аналізується приміщення на предмет виконання основних нормативних вимог до робочих приміщень, оснащених комп'ютерами.
У розглянутому приміщенні розташовано 3 робочих місця, кожне з яких обладнане комп'ютером.
План приміщення представлений на рис. 4.1. Приміщення розташоване в цегляному будинку на п’ятому поверсі, загальна площа приміщення 18 м2
, висота 3,2 м. Всі дані занесені до таблиці4.1.

Рисунок 4.1– Схема приміщення
Таблиця 4.1 Характеристики приміщення
| Довжина кімнати, м |
6 |
| Ширина кімнати, м |
3 |
| Висота приміщення, м |
3,2 |
| Ширина вікна, м |
2 |
| Висота вікна, м |
2 |
| Ширина дверей, м |
0,8 |
| Висота дверей, м |
2,1 |
Таким чином, на працівника доводиться 6 м2
робочої площі та 19,2 м об’єму, що задовольняє норми СНиП 2.09.04-87[14], згідно з яким на кожного працівника в комп'ютерному бюро й обчислювальних центрах повинно доводитися не менше 6 м2
робочої площі та 20 м об’єму. об’єму, що задовольняє норми СНиП 2.09.04-87[14], згідно з яким на кожного працівника в комп'ютерному бюро й обчислювальних центрах повинно доводитися не менше 6 м2
робочої площі та 20 м об’єму.
У приміщенні обладнання представлене 3 персональними комп’ютерами з джерелами безперебійного живлення та плотером.
Стіни, стеля, підлога приміщення, де розташована ЕОМ, виготовлені з матеріалів, дозволених для обробки приміщень органами державного санітарно-епідеміологічного нагляду.
Заземлені конструкції, що перебувають у приміщенні (батареї опалення, водопровідні труби, кабелі із заземленим відкритим екраном і т.п.), надійно захищені діелектричними щитками або сітками від випадкового дотику.
У приміщенні щодня проводиться вологе прибирання, є медичні аптечки першої допомоги.
У приміщенні знаходиться один вогнегасник. Відповідно до вимог Правил пожежної безпеки в Україні необхідно забезпечити 2 вогнегасники на кожні 20м2
площі приміщення з обліком гранично припустимих концентрацій вогнегасної рідини. Приміщення не оснащено системою автоматичної пожежної сигналізації. Відповідно до СНиП 2.04. 09-84 [32] необхідно встановити в приміщенні систему автоматичної пожежної сигналізації або теплові сповіщувачі. Підхід до засобів пожежогасіння вільний.
Природне світло проникає в приміщення через бічне вікно (1 вікно розміром 2м х 2м), орієнтовано на захід.
Вікна приміщення мають регулюючі пристосування для відкривання, а також штори й зовнішні козирки.
По небезпеці поразки робітників електричним струмом приміщення ставиться до категорії без підвищеної небезпеки — сухі, не запилені приміщення, з нормальною температурою повітря й ізолюючою підлогою; монтаж електричних установок можна робити, використовуючи проведення без підвищеної ізоляції з установкою вимикачів, штепсельних розеток і світильників, що відповідає нормам ОНТП 24-86.[26]
Згідно з "Гігієнічною класифікацією праці труда МОЗ N4137-86" праця оператора ЕОМ відноситься до I-П класу за гігієнічними умовами, її тяжкість не повинна перевищувати оптимальних, а напруженість – допустимих величин. На користувача персональних комп’ютерів потенційно впливають наступні фактори виробничого середовища:
1) небезпека ураження електричним струмом;
2) шум;
3) недостатня освітленість;
4) параметри мікроклімату;
5) небезпека виникнення пожежі;
6) електромагнітні поля й опромінення;
7) статична електрика;
8) психоемоційна напруга.
Робоче місце користувача ЕОМ повинно відповідати ГОСТ 12.2.032-78 [5].
Довжина столу (зліва направо) - 80см., ширина забезпечує місце перед клавіатурою (38см.) для розташування нотаток. Поверхня столу горизонтальна.
Ширина простору для ніг під столом 55см., глибина - 50см.
Рельєф спинки стільців, що знаходяться в кабінеті, повторює форму спини. Висота поверхні сидіння складає 45см., кут нахилу спинки - в межах 90-110 град. Ширина сидіння - 40см, глибина - не менше 38см. Висота опорної поверхні спинки - 40см., її ширина - 42см.
Поверхня сидіння й спинки напівм’яка, з нековзним покриттям, що не електризується.
Руки повинні розташовуватися так, щоб вони знаходились на відстані декількох десятків сантиметрів від тулуба. Передпліччя повинні спиратися на поверхню столу, знімаючи тим самим статичну напругу плечового поясу й рук.
Термінали розташовані екраном справа від вікна.
Стіна позаду комп’ютера повинна бути освітлена приблизно так, як і екран. Для зменшення поглинання світла стелю, верхні частини стін та віконні рами пофарбовано в білий колір (коефіцієнт відбивання 0,7), стіни й панелі – світло-жовті (коефіцієнт відбивання 0,5-0,6).
Характеристика вентиляції відповідає СНиП ІІ.04.05–91 [31]. В кабінеті повітрообмін відбувається внаслідок різниці температур повітря в приміщенні й зовнішнього повітря, а також в результаті дії вітру, отже, це природна вентиляція (необмежена), так як надходження й видалення повітря відбувається через вікно (провітрювання).
4.2.1 Аналіз фактичного значення природного освітлення
Приміщення розміром 3м х 6м і висотою 3,2м при бічному освітленні розташоване в 4-му поясі світлового клімату. Призначено для IV розряду зорових робіт.
Є одне вікно розміром 2м х 2м, розташоване вздовж меншої стіни приміщення й орієнтоване на захід. Висота від підлоги до підвіконня 0,8м, рівень робочої поверхні від підлоги дорівнює 0,8м, відстань від рівня робочої поверхні до верху вікна становить 2м. Відстань від вікна до розрахункової точки 4м (відповідно до схеми приміщення).
Необхідні розрахунки.
Нормоване значення коефіцієнта природного освітлення (КПО) для четвертого світлового пояса, у якому розміщається Україна 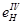 , визначається у відсотках по формулі: , визначається у відсотках по формулі:
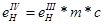
де 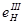 — нормоване значення КПО для III світлового пояса, що визначається по СНиП II- 4-79 [18] (з огляду на розряд зорової роботи, дорівнює 1,5 %). — нормоване значення КПО для III світлового пояса, що визначається по СНиП II- 4-79 [18] (з огляду на розряд зорової роботи, дорівнює 1,5 %).
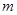 — коефіцієнт світлового клімату (для України - 0,9); — коефіцієнт світлового клімату (для України - 0,9);
с
— коефіцієнт сонячності клімату (з огляду на 4- й пояс світлового клімату й розташування вікон, дорівнює 0,8).
Нормоване значення КПО дорівнює:
=1,5*0,9*0,8=1,08 %.
Фактичне значення коефіцієнта природного освітлення для досліджуваного приміщення можна визначити по формулі:
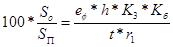
звідки
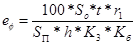
ДеS0
— площа всіх вікон у приміщенні, м2
, S0
=2*2*1=4м2
;
SП
— площа підлоги приміщення, м2; SП
= 6 * 3 = 18м2
;
t=t1
*t2
*t3
*t4
*t5
- загальний коефіцієнт світлопропускання віконного отвору (складається з коефіцієнтів світлопропускання матеріалу, що враховують втрати світла в рамі світлопрорізу, у несучих конструкціях і в сонцезахисних пристроях, а також втрати світла в захисній сітці, що встановлюється під ліхтарями й при бічному висвітленні — t3
=t4
=t5
1);
t1
= 0,5 — оскільки матеріал вікон — пустотілі світлопрозорі блоки;
t2
, = 0,9 — оскільки обрамлення сталеві, одинарні глухі;
t= 0,5*0,9*1*1*1=0,45;
1
— коефіцієнт, що враховує підвищення КПО при бічному висвітленні за рахунок світла, відбитого від поверхонь приміщення:
(глибина приміщення)/(відстань від рівня робочої поверхні до верху вікна)=6/2=3;
(відстань від розрахункової точки до вікна)/(глибина приміщення)= 4/6=0,66;
(довжина приміщення)/(глибина приміщення )=6/6=1;
з огляду на це, а також значення середньозваженого коефіцієнта відбиття r=0,4 [30] (для меблів середнього відтінку між темним і світлим тонами) r1
= 1,7[18];
h — світлова характеристика вікна, береться по таблиці, для розглянутого приміщення: h=18 [30]; Кб
— коефіцієнт, що враховує затемнення вікон іншими будинками, якщо будинків немає, то Кб
=1, що підходить і для даного приміщення; К3
— коефіцієнт запасу, з у межах 1,3 - 1,5[30], візьмемо значення 1,4. Отже, фактичне значення коефіцієнта природного освітлення для досліджуваного приміщення дорівнює:
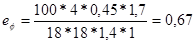 % %
Порівняємо значення нормованого коефіцієнта природного освітлення для даного приміщення (=1,08%)і фактичного (еф
= 0,67%) і звідси виходить, що потрібні додаткові міри для покращення природного освітлення приміщення, тобто необхідно передбачити систему комбінованого освітлення та використовувати систему вимикачів, котра дозволить регулювати інтенсивність штучного освітлення в залежності від інтенсивності природного, а також дозволить освічувати тільки необхідні для роботи зони приміщення.
4.2.2 Аналіз штучного освітлення
Приміщення обладнане системою загального рівномірного освітлення - світильниками з лампами накалювання. Світильники штучного освітлення розміщуються локально над робочими місцями. Їх кількість дорівнює 4. У кожному світильнику по 1 лампі накалювання потужністю 150 Вт.
Значення фактичного освітлення Еф, лк, у приміщенні можна обчислити за допомогою методу коефіцієнта використання світлового потоку по формулі
 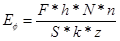
де F— світловий потік лампи, лм (приблизно лампа накалювання потужністю 100 Вт створює 1450 лм, 150Вт - 2000 лм, 60 Вт - 790 лм). У нашому випадку - 2000 лм;
h — коефіцієнт використання світлового потоку (у рамках 0,4-0,6, візьмемо середнє значення — 0,5)[30];
S — площа приміщення, м2(18);
k — коефіцієнт запасу, (у рамках 1,5-2, візьмемо значення -1,5)[30];
N - кількість світильників, шт.(у нашому випадку 4шт);
n — кількість ламп у світильнику, шт.;
z — коефіцієнт нерівномірності освітлення (для ламп накалювання -1,15).
Таким чином, фактичне значення штучного освітлення складе:
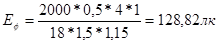
Порівнюючи нормоване значення штучного освітлення (при використанні люмінесцентних ламп по 200 Люкс) з фактичним, можна зробити висновок про те, що штучного освітлення не досить і є необхідність в додаткових заходах по його поліпшенню в досліджуваному приміщенні як мінімум до нормованого. Рішенням даної ситуації буде використання ламп більшої потужності або додавання до вже існуючої системи ламп такої ж потужності.
4.2.3 Аналіз достатності вентиляції в приміщенні
Згідно СНиП 2.09.04-87 [14] об’єм виробничого приміщення, з розрахунку на одного робітника у приміщеннях для обслуговування ЕОМ, повинен становити не менш 40 м3
.
Розміри досліджуваного приміщення: 6м х 3м х 3,2м.
Розмір кватирки: 0,5м х 0,7м.
Кількість кватирок: 1 шт.
Обсяг приміщення складе VП
= 6 * 3 * 3,2 = 57,6м3
.
Виходить, обсяг, що доводиться на робітника, становить V = 57,6/3 = 19,2м3
, що не відповідає нормам. В цьому випадку на кожного робітника повинно приходитись не менше L1
= 40 м3
/г (при постійній природній вентиляції), повний необхідний повітрообмін приміщення Lн
, м3
/г повинен бути рівний
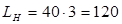 м3
/г м3
/г
Визначимо фактичний повітрообмін, що здійснюється в приміщенні за допомогою природної вентиляції як неорганізоване через різні нещільності віконних і дверних прорізів, так і організовано через кватирки у віконних прорізах або спеціальні вентиляційні канали. Будемо припускати, що вентиляція здійснюється за допомогою кватирки.
Фактичний повітрообмін Lф
м3
/год визначимо по формулі
Lф
=m*F*V*N*3600
де m — коефіцієнт витрати повітря, що приймає значення в рамках 0,3-0,8 (візьмемо середнє значення 0,55)[18];
F — площа кватирки, F = 0,7 * 0,5 = 0,35м2
;
V — швидкість виходу повітря через кватирку, м/с;
N — кількість кватирок, шт.
Швидкість виходу повітря визначається по формулі
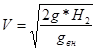
де g — прискорення вільного падіння, g=9,8 м/с2
;
H2
— тепловий напір, під дією якого буде вироблятися вихід повітря із кватирки, якому можна обчислити по формулі
Н2
= h2
* (gвнеш
– gвн
)
де h2
— висота від площини рівних тисків до центра кватирки; у нашому випадку 1,3 м;
gвнеш
, gвн
— відповідно об'ємна вага повітря зовні приміщення і усередині нього, кгс/м3
.
У загальному випадку об'ємна вага повітря визначається по формулі:
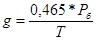
Рб
— барометричний тиск, мм. рт. ст. (приймається 750 мм рт.ст.);
Т — температура повітря, К. Для робочих приміщень, де виконуються легкі роботи, відповідно до ГОСТ 12.1. 005-88 для теплого періоду року температура не повинна перевищувати 280
С або Т=301К, для холодного періоду року відповідно Т=17С, або 290К. Для повітря поза приміщенням температура визначається згідно СНиП 2.04. 05-91:
— для теплого періоду року t=24С, Т=297К;
— для холодного періоду року t=-11 С, Т=262К;
Фактичний повітрообмін для теплого періоду року:
gвн
= 0,465 * 750/301 = 1,16 кгс/м3
;
gвнеш
= 0,465 * 750/297 = 1,17 кгс/м3
.
Тоді
Н2
=1,3* (1,17 - 1,16) = 0,013кгс/м2
;
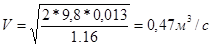
Lф
=0,55*0,35*0,47*3600=325,71 м3
/ч.
Фактичний повітрообмін для холодного періоду року:
gвн
= 0,465 * 750/290 = 1,2 кгс/м3
;
gвнеш
= 0,465 * 750/262 = 1,33 кгс/м3
.
Тоді
Н2
=1,3* (1,33 - 1,2) = 0,17кгс/м2
;
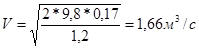
Lф
=0,55*0,35*1,66*3600=1150,38 м3
/ч.
Із розрахунків видно, що природна вентиляція для теплого періоду року є достатньою, а от в холодний період набагато перевищує норму. Тому для холодного періоду року необхідно заклеювати вікна, та інколи провітрювати приміщення, щоб уникати захворювання робітників.
4.2.4 Аналіз метеорологічних умов праці.
У відповідності до ГОСТ 12.1.005-88 [25] роботи, що проходять в даному приміщенні, відносяться до категорії робіт 1а (затрати енергії до 120 ккал/год). Для такої категорії робіт граничним значення мікроклімату є наступні дані (таблиця 4.1).
Таблиця 4.1 Показники мікроклімату повітря робочої зони
| Період року |
Температура
повітря, °С
|
Відносна вологість, % |
Швидкість руху повітря V, м/с |
| Параметри |
Оптим. |
Допуст. |
Оптим. |
Допуст. |
Оптим. |
Допуст. |
| Холодний |
21-24 |
20-25 |
40-60 |
не більшее 75 |
0,1 |
не більше 0,1 |
| Теплий |
22-25 |
21-28 |
40-60 |
55
(при 28°С)
|
не більше 0,1 |
0,1-0,3 |
Фактичне значення температури повітря в холодну пору року складає в середньому 19°С – 22°С, а в теплу 25°С – 27°С. Отже, фактичні значення температури в холодну і теплу пори року відповідають нормативним.
Відносна вологість в даному приміщенні складає 45% і 48% відповідно в холодну і теплу пори року. Ці значення відповідають нормативним.
4.2.5 Оцінка джерел шуму
Джерела шуму в приміщенні: комп’ютер, плотер.
Вимірювання рівня звуку в приміщенні проводились за допомогою шумоміру ИШМ-3. В результаті вимірів рівень звуку склав L = 50 дБА. Отримане значення не перевищує допустимі норми ГсанПиН 3.3.2 007 – 98 [12], 60дБА.
Таблиця 4.2 Параметри санітарно-гігієнічних умов праці в приміщенні
| Параметр |
Значення параметру |
Нормативний
документ
|
| Фактичне |
Нормоване |
Освітленність
штучна, лк
|
128,82 |
200 |
СНИП II-4-79 [18] |
| КПО, % |
0,75 |
1,08 |
СНИП II-4-79 [18] |
Температура повітря
в приміщенні, °С:
взимку
влітку
|
19-22
25-27
|
21-25
22-28
|
ГОСТ 12.1.005-88 [13] |
| Відносна вологість, % |
45 |
40-60 |
ГОСТ
12.1.005-88 [13]
|
| Швидкість руху повітря, м/с |
0,15 |
0,1-0,3 |
ГОСТ
12.1.005-88 [13]
|
| Шум, дБА |
50 |
не більше 60 |
ГсанПиН 3.3.2 007 – 98 [12] |
4.3 Висновки
Як об’єкт дослідження було взято приміщення, у якому проходила переддипломна практика у теплу пору року.
Виявлено, що на кожного працівника доводиться 6 м2
, що відповідає нормам СНиП 2.09.04-87 [14].
Природного освітлення не вистачає, тому необхідно передбачити систему комбінованого освітлення та використовувати систему вимикачів, котра дозволить регулювати інтенсивність штучного освітлення в залежності від інтенсивності природного, а також дозволить освічувати тільки необхідні для роботи зони приміщення. Штучного освітлення також не вистачає, оскільки його значення Еф
=128,82 лк не перевищує норму, яка згідно з СНиП ІІ-4-79 [30] становить 200 лк при використанні зазначених ламп, отже необхідно використовувати лампи більшої потужності або додати до вже існуючої системи ламп такої ж потужності. Тобто для нашого приміщення необхідно додати ще 3 лампи такої ж потужності, як видно з наступних розрахунків:

Виявлено, що на кожного працівника доводиться 19,2 м3
повітря, чого достатньо відповідно до норм СНиП 2.09.04-87 [14]. Для нормальної роботи в приміщенні забезпечується постійний повітрообмін за допомогою вентиляції, рівний в теплий період раку 325,71 м3
/ч, що є достатнім, а от в холодний період набагато перевищує норму. Тому для холодного періоду року необхідно заклеювати вікна, та інколи провітрювати приміщення, щоб уникати захворювання робітників.
В приміщенні не дотримується температурний режим взимку – температура знаходиться на межі допустимих значення. Тому взимку необхідно утеплювати вікна.
Здійснення такого роду заходів з покращення умов праці в приміщенні дозволить створити сприятливі умови праці для робітників, зокрема мікроклімату, що в свою чергу буде сприяти підвищенню активності робітників та їх продуктивність праці
1. Розроблено алгоритм навчання системи в рамках ІЕІТ – технології, що дозволило програмно реалізувати процес навчання системи розпізнавання символів.
2. Сформовано навчальні матриці для зображень в полярних і декартових координатах. При формуванні навчальної матриці в полярних координатах розв’язана задача центрування зображення, що підвищило значення КФЕ.
3. Оптимізація контрольних допусків на ознаки розпізнавання при обробленні літер в полярних координатах забезпечує в порівнянні з обробленням в декартових координатах підвищення асимптотичної достовірності розпізнавання та їх інваріантність до зсуву, повороту та зміні масштабу;
4. Розроблено та програмно реалізовано алгоритм навчання системи розпізнавання рукописних символів за ІЕІТ з оптимізацією СКД на ознаки розпізнавання, що якісно збільшило значення КФЕ, а це підвищило достовірність прийняття рішення на етапі екзамену;
5. Програмно реалізовано алгоритм екзамену, що дає можливість з певною достовірністю розпізнавати рукописні символи;
unit UnitMy;
interface
uses
Windows, Messages, SysUtils, Variants, Classes, Graphics, Controls, Forms,
Dialogs, ExtCtrls, StdCtrls, TeEngine, Series, TeeProcs, Chart, Grids,
ComCtrls;
type
TForm0 = class(TForm)
PageControl1: TPageControl;
TabSheet1: TTabSheet;
Panel1: TPanel;
GroupBox1: TGroupBox;
PaintBox1: TPaintBox;
Button2: TButton;
Button3: TButton;
Panel2: TPanel;
Panel3: TPanel;
Image1: TImage;
Button5: TButton;
Button1: TButton;
Panel4: TPanel;
Chart1: TChart;
Series1: TBarSeries;
Button10: TButton;
Chart2: TChart;
Series2: TFastLineSeries;
Button6: TButton;
Panel5: TPanel;
Label1: TLabel;
Label2: TLabel;
Panel7: TPanel;
Edit3: TEdit;
Button7: TButton;
Button8: TButton;
Label3: TLabel;
Label4: TLabel;
Label5: TLabel;
Panel6: TPanel;
Button4: TButton;
Button9: TButton;
Button11: TButton;
Button12: TButton;
Button13: TButton;
procedure PaintBox1MouseDown(Sender: TObject; Button: TMouseButton;
Shift: TShiftState; X, Y: Integer);
procedure PaintBox1MouseUp(Sender: TObject; Button: TMouseButton;
Shift: TShiftState; X, Y: Integer);
procedure PaintBox1Paint(Sender: TObject);
procedure PaintBox1MouseMove(Sender: TObject; Shift: TShiftState; X,
Y: Integer);
procedure Button1Click(Sender: TObject);
procedure Button2Click(Sender: TObject);
procedure Button3Click(Sender: TObject);
procedure FormCreate(Sender: TObject);
procedure Button5Click(Sender: TObject);
procedure Button10Click(Sender: TObject);
procedure Button6Click(Sender: TObject);
procedure Button8Click(Sender: TObject);
procedure Button7Click(Sender: TObject);
procedure Button4Click(Sender: TObject);
procedure Button9Click(Sender: TObject);
procedure Button11Click(Sender: TObject);
procedure Button12Click(Sender: TObject);
procedure Button13Click(Sender: TObject);
private
{ Private declarations }
public
{ Public declarations }
end;
const N=50;
const Pol=25;
const R=120;
const K=3;
const St=40;
var
Form0: TForm0;
down:boolean;
nachpic,pic:Tbitmap;
sch,kkproba,count:integer;
polmas:array[1..R,1..Pol] of integer;
polmassred:array[1..K,1..Pol] of real;
picmas:array [1..R,1..N,1..N] of integer;
evbin:array[1..R,1..2*N] of integer;
gilsred:array[1..K,1..2*N] of integer;
sred_s:array[1..K,1..N,1..N] of integer;
f1,f2,f3,temp,vrf:text;
center_x, center_y:array[0..1] of integer;
implementation
uses Unit1, Unit2;
{$R *.dfm}
procedure TForm0.PaintBox1MouseDown(Sender: TObject; Button: TMouseButton;
Shift: TShiftState; X, Y: Integer);
begin
down:=true;
nachpic.Canvas.MoveTo(X,Y);
paintbox1paint(nil);
end;
procedure TForm0.PaintBox1MouseUp(Sender: TObject; Button: TMouseButton;
Shift: TShiftState; X, Y: Integer);
begin
down:=false;
end;
procedure TForm0.PaintBox1Paint(Sender: TObject);
begin
PaintBox1.Canvas.Draw(0,0,nachpic);
end;
procedure TForm0.PaintBox1MouseMove(Sender: TObject; Shift: TShiftState; X,
Y: Integer);
begin
if down then
begin
nachpic.Canvas.LineTo(X,Y);
paintbox1paint(nil);
end;
end;
procedure TForm0.Button1Click(Sender: TObject);
begin
close;
end;
procedure TForm0.Button2Click(Sender: TObject);
var i,j,vspi,vspj:integer;
begin
vspi:=nachpic.Width;
vspj:=nachpic.Height;
for i:=1 to vspi do
for j:=1 to vspj do
nachpic.Canvas.Pixels[i,j]:=clWhite;
paintbox1paint(nil);
end;
procedure TForm0.Button3Click(Sender: TObject);
var i,j:integer;
color:boolean;
begin
color:=false;
pic:=Tbitmap.Create;
pic.Width:=N;
pic.Height:=N;
for i:=1 to N do
for j:=1 to N do
begin
if nachpic.Canvas.Pixels[i,j] <> clWhite then color:=true;
end;
if color then
begin
for i:=1 to N do
for j:=1 to N do
begin
pic.Canvas.Pixels[i,j]:=nachpic.Canvas.Pixels[i,j];
end;
sch:=sch+1;
pic.SaveToFile('image\'+inttostr(sch)+'.bmp');
end;
end;
procedure TForm0.FormCreate(Sender: TObject);
begin
nachpic:=Tbitmap.Create;
nachpic.Width:=PaintBox1.Width;
nachpic.Height:=PaintBox1.Height;
nachpic.Canvas.Pen.Color:=clBlack;
nachpic.Canvas.Pen.Width:=5;
down:=false;
sch:=0;
end;
procedure TForm0.Button5Click(Sender: TObject);
var ii,i,j,kk:integer;
begin
for kk:=1 to R do
begin
for ii:=1 to 2*N do evbin[kk,ii]:=0;
for i:=1 to N do
begin
for j:=1 to N do
begin
if i>1 then
begin
if (round((256-picmas[kk,i-1,j])-(256-picmas[kk,i,j])) > 0) then
begin
evbin[kk,j]:=evbin[kk,j]+(round((256-picmas[kk,i-1,j])-(256-picmas[kk,i,j])));
evbin[kk,50+j]:=evbin[kk,50+j]+0;
end
else if (round((256-picmas[kk,i-1,j])-(256-picmas[kk,i,j])) < 0) then
begin
evbin[kk,50+j]:=evbin[kk,50+j]+(round((256-picmas[kk,i-1,j])-(256-picmas[kk,i,j])));
evbin[kk,j]:=evbin[kk,j]+0;
end
else if (round((256-picmas[kk,i-1,j])-(256-picmas[kk,i,j])) = 0) then
begin
evbin[kk,j]:=evbin[kk,j]+0;
evbin[kk,50+j]:=evbin[kk,j+50]+0;
end;
end;
end;
end;
end;
for j:=1 to 2*N do
begin
gilsred[1,j]:=0;
gilsred[2,j]:=0;
gilsred[3,j]:=0;
end;
for kk:=1 to St do
for j:=1 to 2*N do
begin
gilsred[1,j]:=gilsred[1,j]+evbin[kk,j];
gilsred[2,j]:=gilsred[2,j]+evbin[40+kk,j];
gilsred[3,j]:=gilsred[3,j]+evbin[80+kk,j];
end;
for j:=1 to 2*N do
begin
gilsred[1,j]:=round(gilsred[1,j]/St);
gilsred[2,j]:=round(gilsred[2,j]/St);
gilsred[3,j]:=round(gilsred[3,j]/St);
end;
end;
{-----------Center search ...--------------------}
procedure search_center();
var i,j:byte;
vspS:integer;
begin
for i:=1 to N-1 do
begin
vspS:=0;
for j:=1 to N-1 do vspS:=vspS+(256-picmas[kkproba,i,j]);
if vspS > 0 then
begin
center_x[0]:=i;
break;
end;
end;
for i:=N-1 downto 1 do
begin
vspS:=0;
for j:=1 to N-1 do vspS:=vspS+(256-picmas[kkproba,i,j]);
if vspS > 0 then
begin
center_x[1]:=i;
break;
end;
end;
for j:=1 to N-1 do
begin
vspS:=0;
for i:=1 to N-1 do vspS:=vspS+(256-picmas[kkproba,i,j]);
if vspS > 0 then
begin
center_y[0]:=j;
break;
end;
end;
for j:=N-1 downto 1 do
begin
vspS:=0;
for i:=1 to N-1 do vspS:=vspS+(256-picmas[kkproba,i,j]);
if vspS > 0 then
begin
center_y[1]:=j;
break;
end;
end;
end;
{------------------------------------------------}
procedure TForm0.Button10Click(Sender: TObject);
var vspSum:integer;
i, j,kk,radius,radto:integer;
snosX,snosY,count0:integer;
vspmas:array[1..Pol] of integer;
begin
count:=0;
label3.Caption:='?';
Edit3.Text:=inttostr(count);
{----------------------------------------}
for kkproba:=1 to R do
begin
radto:=0;
snosX:=0;
snosY:=0;
for i:=1 to Pol do
begin
polmas[kkproba,i]:=0;
vspmas[i]:=0;
end;
search_center();
radto:=round((sqrt((center_y[1]-center_y[0])*(center_y[1]-center_y[0])+
(center_x[1]-center_x[0])*(center_x[1]-center_x[0])))/2);
snosX:=center_y[0]+round((abs(center_y[1]-center_y[0]))/2);
snosY:=center_x[0]+round((abs(center_x[1]-center_x[0]))/2);
for radius:=1 to Pol do
begin
vspSum:=0;
for i:=1 to N-1 do
for j:=1 to N-1 do
begin
if((i-snosX)*(i-snosX)+(j-snosY)*(j-snosY) <= (radius*radius))
then vspSum:=vspSum+(256-picmas[kkproba,i,j]);
end;
polmas[kkproba,radius]:=round(vspSum/(Pi*radius*radius));
end;
{
count0:=0;
for i:=Pol downto 1 do
if polmas[kkproba,i] = 0 then count0:=count0+1 else break;
if count0 > 1 then
begin
for i:=1 to round(count0/2) do vspmas[i]:=0;
for i:=1 to Pol-count0 do vspmas[i+round(count0/2)]:=polmas[kkproba,i];
for i:=1 to Pol do polmas[kkproba,i]:=vspmas[i];
end;}
end;
Assignfile(temp,'temp.txt');
rewrite(temp);
for j:=1 to R do
begin
for i:=1 to Pol do
begin
write(temp,' ',polmas[j,i]);
end;
writeln(temp);
writeln(temp);
writeln(temp);
end;
closefile(temp);
{----------------------------------------}
for i:=1 to Pol do
begin
polmassred[1,i]:=0;
polmassred[2,i]:=0;
polmassred[3,i]:=0;
end;
for kk:=1 to 40 do
for i:=1 to Pol do
begin
polmassred[1,i]:=polmassred[1,i]+polmas[kk,i];
end;
for kk:=41 to 80 do
for i:=1 to Pol do
begin
polmassred[2,i]:=polmassred[2,i]+polmas[kk,i];
end;
for kk:=81 to 120 do
for i:=1 to Pol do
begin
polmassred[3,i]:=polmassred[3,i]+polmas[kk,i];
end;
for i:=1 to Pol do
begin
polmassred[1,i]:=polmassred[1,i]/St;
polmassred[2,i]:=polmassred[2,i]/St;
polmassred[3,i]:=polmassred[3,i]/St;
end;
end;
procedure TForm0.Button6Click(Sender: TObject);
var i,j,kk:integer;
bit:Tbitmap;
begin
bit:=Tbitmap.Create;
bit.Width:=N;
bit.Height:=N;
for kk:=1 to 40 do
begin
bit.LoadFromFile('base\'+inttostr(kk)+'.bmp');
for i:=1 to N do
for j:=1 to N do
begin
picmas[kk,i,j]:=0;
picmas[kk,i,j]:=round(bit.Canvas.Pixels[i,j]/65536);
end;
end;
for kk:=41 to 80 do
begin
bit.LoadFromFile('base\'+inttostr(kk)+'.bmp');
for i:=1 to N do
for j:=1 to N do
begin
picmas[kk,i,j]:=0;
picmas[kk,i,j]:=round(bit.Canvas.Pixels[i,j]/65536);
end;
end;
for kk:=81 to 120 do
begin
bit.LoadFromFile('base\'+inttostr(kk)+'.bmp');
for i:=1 to N do
for j:=1 to N do
begin
picmas[kk,i,j]:=0;
picmas[kk,i,j]:=round(bit.Canvas.Pixels[i,j]/65536);
end;
end;
bit.Free;
//--------------------------------------------------------------
for kk:=1 to St do
begin
for i:=1 to N do
for j:=1 to N do
begin
sred_s[1,i,j]:=sred_s[1,i,j]+picmas[kk,i,j];
sred_s[2,i,j]:=sred_s[2,i,j]+picmas[40+kk,i,j];
sred_s[3,i,j]:=sred_s[3,i,j]+picmas[80+kk,i,j];
end;
end;
for i:=1 to N do
for j:=1 to N do
begin
sred_s[1,i,j]:=round(sred_s[1,i,j]/St);
sred_s[2,i,j]:=round(sred_s[2,i,j]/St);
sred_s[3,i,j]:=round(sred_s[3,i,j]/St);
end;
//--------------------------------------------------------------
end;
procedure TForm0.Button8Click(Sender: TObject);
var i,j:byte;
begin
if count < 120 then count:=count+1;
image1.Picture.LoadFromFile('base\'+inttostr(count)+'.bmp');
Edit3.Text:=inttostr(count);
if (count <= 40) then label3.Caption:='A'
else if ((count > 40) and (count <= 80)) then label3.Caption:='Б'
else if (count > 80) then label3.Caption:='B';
Series2.Clear;
Series1.Clear;
for i:=1 to Pol do Series2.Add(polmas[count,i]);
for j:=1 to 2*N do Series1.Add(round(evbin[count,j]/5));
end;
procedure TForm0.Button7Click(Sender: TObject);
var i,j:byte;
begin
if count > 1 then count:=count-1 else count:=1;
image1.Picture.LoadFromFile('base\'+inttostr(count)+'.bmp');
Edit3.Text:=inttostr(count);
if (count <= 40) then label3.Caption:='A'
else if ((count > 40) and (count <= 80)) then label3.Caption:='Б'
else if (count > 80) then label3.Caption:='B';
Series2.Clear;
Series1.Clear;
for i:=1 to Pol do Series2.Add(polmas[count,i]);
for j:=1 to 2*N do Series1.Add(round(evbin[count,j]/5));
end;
procedure TForm0.Button4Click(Sender: TObject);
var i,j:byte;
begin
Series2.Clear;
Series1.Clear;
for i:=1 to N do
for j:=1 to N do
image1.Canvas.Pixels[i,j]:=256-sred_s[1,i,j];
for i:=1 to Pol do Series2.Add(polmassred[1,i]);
for j:=1 to 2*N do Series1.Add(gilsred[1,j]);
end;
procedure TForm0.Button9Click(Sender: TObject);
var i,j:byte;
begin
Series2.Clear;
Series1.Clear;
for i:=1 to N do
for j:=1 to N do
image1.Canvas.Pixels[i,j]:=256-sred_s[2,i,j];
for i:=1 to Pol do Series2.Add(polmassred[2,i]);
for j:=1 to 2*N do Series1.Add(gilsred[2,j]);
end;
procedure TForm0.Button11Click(Sender: TObject);
var i,j:byte;
begin
Series2.Clear;
Series1.Clear;
for i:=1 to N do
for j:=1 to N do
image1.Canvas.Pixels[i,j]:=256-sred_s[3,i,j];
for i:=1 to Pol do Series2.Add(polmassred[3,i]);
for j:=1 to 2*N do Series1.Add(gilsred[3,j]);
end;
procedure TForm0.Button12Click(Sender: TObject);
begin
form0.Visible:=false;
form1.Show;
end;
procedure TForm0.Button13Click(Sender: TObject);
begin
form0.Visible:=false;
form11.Show;
end; end.
|