Огляд архітектури IBM PC-сумісного комп’ютера
(курсова робота)
Перелік скорочень
AGP – AcceleratedGraphicPort, прискорений графічний порт;
ATA – AT Attachment for Disk Drives, підключення дискових пристроїв до AT;
BIOS –BasicInput/OutputMemory, базова система введення/виведення;
CD – Compact Disc, компакт-диск;
CMOS – ComplimentaryMetalOxideSemiconductor, компліментарна структура (метал-оксид-напівпровідник (КМОП);
COM – Communications Port, комунікаційний порт;
CPU – CentralProcessor Unit, центральний процесор;
DMA – Direct Memory Access, прямий доступ до пам’яті;
ESCD – Extended System Configuration Data, розширені дані системної конфігурації;
FDC – FloppyDriveController, контролер накопичувачів на гнучких дисках;
FDD – FloppyDiskDrive, накопичувач на гнучких дисках;
FSB – Front Side Bus, системна шина;
HDD – HardDiskDrive, накопичувач на жорстких дисках;
ISA – IndustryStandardArchitecture, стандартна промислова архітектура – шина розширення IBMPC;
KBC – Keyboard Controller, контролер клавіатури;
LPT – LinePrinter, порядковий принтер;
PCI – PeripheralComponentInterconnect, з’єднання периферійних компонентів, шина розширення;
NMI – Non-Maskable Interrupt, немасковане переривання;
PIC – ProgrammableInterruption Controller, програмований контролер переривань;
RAM – RandomAccessMemory, пам’ять з довільним доступом, ОЗП;
ROM - ReadOnlyMemory, постійний запам’ятовуючий пристрій (тільки для читання);
RTC – RealTimeClock, таймер реального часу;
SMI – SystemManagementInterrupt, переривання системного рівня;
USB – UniversalSerial Bus, універсальна послідовна шина.
Вступ
Структурна схема сучасного IBM PC представлена на рисунку:
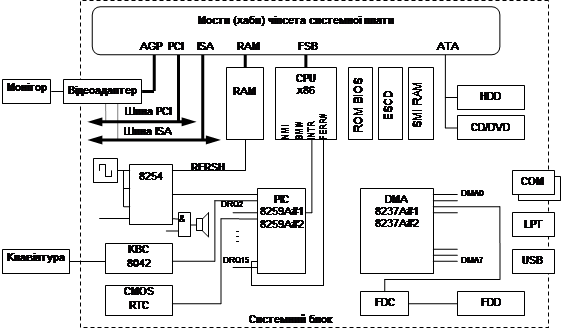
Ядром комп’ютера є процесор (CPU), ОЗП (RAM); ПЗП з BIOS (ROM BIOS) та інтерфейсні засоби, які зв’язують їх між собою та рештою компонентів. Стандартна архітектура PC визначає набір обов’язкових засобів введення-виведення і підтримки периферії – системи апаратних переривань (PIC 8259A), системи прямого доступу до пам’яті (DMA 8237A), трьох-канальний лічильник (8254), інтерфейс клавіатури і керування (KBC 8042), канал керування звуком, пам’ять і годинник (CMOSRTC). Інтерфейсні засоби разом із засобами введення-виведення і підтримки периферії реалізуються чіпсетом системної плати.
Будь-який PC-сумісний комп’ютер володіє такими характерними рисами:
· процесор, програмно сумісний із сімейством Intel x86;
· специфічна система розподілу простору адрес пам’яті;
· традиційний розподіл адрес простору введення-виведення з фіксованим положення обов’язкових портів і сумісністю їх програмної моделі;
· система апаратних переривань, яка дозволяє периферійним пристроям сигналізувати процесору про необхідність виконання деяких обслуговуючих процедур;
· система прямого доступу до пам’яті, яка дозволяє периферійним пристроям обмінюватися масивами даних з оперативною пам’яттю, не відволікаючи для цього процесор;
· набір системних пристроїв та інтерфейсів введення-виведення;
· уніфіковані по конструктиву та інтерфейсу шини розширення (ISA, EISA, MCA, VLB, PCI, PCCard, CardBus), склад яких може варіюватися в залежності від призначення і моделі комп’ютера;
· базова система введення-виведення (BIOS), що виконує початкове тестування і завантаження операційної системи, а також володіє набором функцій по обслуговуванню системних пристроїв введення-виведення.
Основні визначення
Під архітектурою процесора розуміється його програмна модель, тобто властивості, які є доступними програмно. Під мікроархітектурою розуміється внутрішня реалізація цієї програмної моделі. Для однієї і тієї ж архітектури (IntelArchitecture 32 bit, IA-32) різними фірмами і у різних поколіннях застосовуються принципово різні мікроархітектурні реалізації.
У мікроархітектурі процесорів 5-го і 6-го поколінь – Pentium, PentiumPro, PentiumMMX, PentiumII – суттєве значення має реалізація різних способів конвеєризації і розпаралелювання обчислювальних процесів, а також інших технологій, не притаманних процесорам попередніх поколінь.
Конвеєризація (pipelining) – передбачає розбиття виконання кожної інструкції на декілька етапів, при цьому кожний етап виконується на своїй ступені конвеєра процесора. Під час виконання інструкція пересувається по конвеєру по мірі звільнення наступних ступіней.
Скалярним називають процесор з єдиним конвеєром (усі процесори Intel до 486 включно). Суперскалярний процесор має більше одного конвеєра (Pentium – 2, PentiumPro – 3), здатних обробляти інструкції паралельно.
Перейменування регістрів (register renaming) дозволяє обійти архітектурне обмеження на можливість паралельного виконання інструкцій (доступно усього 8 загальних регістрів). Процесори з перейменуванням регістрів фактично мають більше 8 загальних регістрів, і при запису проміжних результатів встановлюється відповідність логічних імен і фізичних регістрів.
Переміщення даних (data forwarding) передбачає початок виконання інструкції до готовності усіх операндів.
Передбачення переходів (branch prediction) дозволяє продовжувати вибірку і декодування потоку інструкцій після вибірки інструкції розгалуження (умовного переходу), не чекаючи перевірки умови переходу.
Виконання по припущенню, або спекулятивне виконання (speculative execution) – передбачені після переходу інструкції не тільки декодуються, але й по можливості виконуються до перевірки умови переходу.
Виконання зі зміною послідовності інструкцій (out-of-orderexecution) – змінюється порядок внутрішнього маніпулювання даними, а зовнішні (шинні) операції введення-виведення і запису в пам’ять виконуються, звичайно, у порядку передбаченому програмним кодом.
Існуючі на даний час процесорні архітектури поділяються на 2 глобальні категорії – RISC і CISC.
Покоління процесорів x86
Сімейство x86 нараховує 7 поколінь процесорів:
Перше покоління (процесори 8086, 8080 і математичний сопроцесор 8087) заклало архітектурну основу – набір нерівноправних 16-розрядних регістрів, сегментну систему адресації пам’яті у межах 1Мбайт з великим різноманіттям режимів, систему команд, систему переривань та ін. В процесорах застосовувалась „мала" конвеєризація – поки одні вузли виконували поточну інструкцію, блок попередньої вибірки вибирав з пам’яті наступну. На виконання інструкції було потрібно в середньому 12 тактів процесорного ядра.
Друге покоління (80286 із сопроцесором 80287) принесло захищений режим, що дозволяє задіяти віртуальну пам’ять розміром до 1Гбайт для кожної задачі, користуючись адресованою фізичною пам’яттю у межах 16Мбайт. Захищений режим є основою для побудови багатозадачних операційних систем, в яких жорстко регламентуються взаємовідношення задач з пам’яттю. На виконання інструкції – в середньому 4,5 тактів.
Третє покоління (386/387 DX і SX) – перехід до 32-розрядної архітектури IA-32. Збільшився об’єм адресованої пам’яті (до 4Гбайт реальної, 64Тбайт віртуальної). В систему команд введено можливість переключення розрядності адресації і даних. На виконання інструкції – ті самі 4,5 тактів, але тактова частота досягла 40МГц.
Четверте покоління (486 DX і SX) у видиму архітектурну модель великих змін не внесло, але було прийнято ряд заходів для збільшення продуктивності. Значно ускладнений виконавчий конвеєр – основні операції виконує RISC-ядро, „завдання" для якого готуються з вхідних CISC-інструкцій. На виконання інструкції – в середньому 2 такти. Введено швидкодіючий первинний кеш об’ємом 8-16Кбайт. Відмовились від зовнішнього математичного сопроцесора: тепер він розміщується на одному кристалі з центральним (FPU – Floating-PointUnit), або відсутній взагалі. Тактова частота досягла 100МГц (Intel) і 133МГц (AMD).
П’яте покоління (IntelPentium, AMDK5) привнесло суперскалярну архітектуру. Після блоків попередньої вибірки і першої стадії декодування інструкцій є два конвеєра, U-конвеєр і V-конвеєр. Кожен з них має ступіні кінцевого декодування, виконання інструкцій і буфер запису результатів. На виконання інструкції – в середньому 1 такт. Застосовується блок передбачення розгалужень. Для швидкого забезпечення конвеєрів інструкціями і даними з пам’яті шина даних процесорів є 64-розрядною. З’являється розширення MMX (MultimediaExtensions), яке застосовує принцип SIMD: одна інструкція виконує дії одразу з декількома (2, 4 або 8) комплектами операндів.
Шосте покоління процесорів Intel (мікроархітектура P6: PentiumPro, PentiumII, PentiumIII, Celeron, Xeon). Характерна риса – динамічне виконання, під котрим розуміється виконання інструкцій не в тому порядку (outoforder), як передбачено програмним кодом, а в тому, як „зручно" процесору. Інструкції, які поступають на конвеєр, розбиваються на мікрооперації μ-ops, які надалі виконуються суперскалярним процесорним ядром у порядку, зручному процесору. Результати „невпорядкованого" виконання операції збираються в упорядкувальному буфері та в коректному порядку записуються в пам’ять (і порти в/в). Застосовується апаратне перейменування регістрів. Реалізовано виконання по припущенню. Середня кількість тактів на інструкцію (PentiumPro) скоротилося до 0,5. Введено подвійну незалежну шину (DIB), яка зв’язує процесор із вторинним кешем, що знаходиться в одній упаковці з процесором. AMD у своїх процесорах 6-го покоління (K6) реалізувала невпорядковане виконання, а подвійна шина з’явилася лише в K6-III. Шосте покоління отримало потокове розширення 3DNow! (AMD) і SSE – StreamingSIMDExtension (Intel).
Сьоме покоління (у AMD) почалося з процесора Athlon, в якому суперскалярність і суперконвеєрність охопили блок FPU. Intel розпочала 7 покоління процесором Pentium4.
1.1 Архітектура системи команд. Класифікація процесорів (CISC та RISC)
Термін "архітектура систем" часто вживається як в загальному, так і в конкретному значенні. У конкретному значенні під архітектурою розуміють архітектуру набору команд. Архітектура набору команд служить межею між апаратною та програмною частинами системи та представляє ту частину системи, що є доступною для програміста або розроблювача компіляторів. У загальному значенні термін архітектура охоплює поняття організації системи, включаючи такі високорівневі аспекти розробки комп‘ютера як систему пам‘яті, структуру системної шини, організацію в/в і т.д.
Двома основними архітектурами набору команд, що використовуються сучасною комп‘ютерною промисловістю є архітектури CISC та RISC. Винахідником архітектури CISC можна вважати компанію IBM з її серією /360, ядро якої використовується з 60-х років і у теперішній час у машинах серії ES/9000.
Лідером в розробці мікропроцесорів з повним набором команд (CISC – Complete Instruction Set Computer) вважається компанія Intel із серією Pentium. Ця архітектура практично є стандартною для ринку мікрокомп‘ютерів. Характерні ознаки CISC-процесорів: невелика кількість регістрів загального призначення; велика кількість машинних інструкцій, деякі з них навантажені семантичним значенням подібним до операторів високорівневих мов програмування, які виконуються за декілька тактів; велика кількість методів адресації; велика кількість форматів команд різної розрядності; перевага двоадресного формату команд; наявність команд обробки типу регістр-пам‘ять.
Основою архітектури сучасних робочих станцій та серверів є архітектура із скороченим набором команд (RISC – Reduced Instruction Set Computer). Ця архітектура базується на комп‘ютерах серії CDC6600, розробники якої (Торнтон, Крей та інші) вважали за доцільне спростити набір команд процесора для підвищення швидкодії. Кінцеве формування поняття RISC архітектури сформувалось на базі 3 проектів: процесора 801 компанії IBM, процесора RISC університету Берклі, процесора MIPS Стенфордського університету.
Розробка експериментального проекту почалася компанією IBM в кінці 70-х років, але його результати опубліковано не було і комп‘ютер на його основі в промислових масштабах не використовувався. У 1980 р. Д. Паттерсон зі своїми колегами з Берклі почали свій проект і виготовили 2 машини, які мали назву RISC-I та RISC-II. Головною ідеєю цих машин було відокремлення повільної пам‘яті від швидких регістрів та використання регістрових вікон. У 1980 р. Дж. Хеннессі зі своїми колегами опублікував опис стенфордської машини MIPS, основним аспектом розробки якої була ефективна реалізація конвеєрної обробки за допомогою планування команд компілятором.
Ці три машини мали багато спільного. Усі вони дотримувались архітектури, що відокремлювала команди обробки від команд роботи з пам’яттю та робили акцент на ефективну конвеєрну обробку. Система команд була реалізована таким чином, що виконання кожної команди займало невелику кількість машинних тактів. Логіка виконання команд з метою підвищення швидкодії базувалась на апаратній, а не на мікропрограмній реалізації. Щоб спростити декодування, використовувались команди фіксованої довжини та фіксованого формату.
Інші особливості архітектури RISC: великий об‘єм регістрового файлу (у сучасних процесорах по 32 регістра цілочисельних та математичних), що спрощує роботу компілятора по розміщенню даних в регістрах. Для обробки як правило використовуються трьоадресний формат команд.
Під час закінчення університетських проектів (1983-1984 рр.) намітився технологічний прорив у виготовленні надвеликих інтегральних мікросхем. Простота архітектури та її ефективність викликали велику зацікавленість у комп‘ютерній індустрії і починаючи з 1986р. RISC системи почали розроблятися промислово. У теперішній час ця архітектура переважає у робочих станцій та серверів.
Розвиток архітектури RISC у значному ступеню визначався розвитком технології оптимізації компіляторів. Саме сучасна техніка оптимізації дозволяє використати оптимально регістровий файл процесора. Сучасні компілятори також використовують технологію затриманих переходів, що дозволяє в один момент часу виконувати декілька команд.
Слід зауважити, що у останніх розробках компанії Intel а також у її конкурентів (AMD, Cyrix, NexGen) широко використовуються ідеї RISC-процесорів, таким чином різниця між цими двома архітектурами поступово зникає.
Розроблювачі архітектури комп‘ютерів завжди вживали методи, відомі під загальною назвою "суміщення операцій", при якому апаратура комп‘ютера у будь-який момент часу виконує більше ніж 1 базову операцію. Цей загальний метод включає два поняття: паралелізм та конвеєризацію. При паралелізмі суміщення операцій досягається за рахунок одночасного виконання операцій у декількох копіях апаратної структури.
Конвеєризація (або конвеєрна обробка) у загальному випадку основана на розділенні функції на дрібні частини, що називаються етапами та виділенні для кожної з них окремого блока апаратури. При цьому дані передаються від попереднього етапу до наступного. При цьому конвеєрну обробку можна використовувати для суміщеної обробки етапів різних команд. Швидкодія зростає за рахунок того, що одночасно виконуються декілька етапів різних команд. Така обробка застосовується у всіх типах сучасних швидкодіючих процесорів.
Далі для ілюстрації принципів роботи процесорів будемо розглядати найпростішу архітектуру: 32 цілочисельних регістра R0 – R31, 32 регістра для роботи з плаваючою комою F0 – F31 та вказівник команд РС. Будемо вважати, що набір команд такого процесора включає арифметичні та логічні операції, операції з плаваючою комою, операції пересилки даних, операції керування потоком команд та системні операції. У арифметичних командах використовується троьхадресний формат, типовий для RISC-процесорів, а для звернення до пам‘яті використовуються операції завантаження та запису вмісту регістру в пам‘ять.
Виконання типової команди можна розділити на такі етапи:
- вибір команди (IF) з адреси, на яку вказує вказівник команд;
- декодування команди / вибір операндів з регістрів (ID);
- виконання операції / обчислення ефективної адреси у пам‘яті (EX);
- звернення до пам‘яті (MEM);
- запис результату (WB).
Розглянемо схему виконання команд на найпростішому процесорі без використання конвеєра (нехай на виконання команди потрібно 5 тактів):
| Номер команди |
Номер такту |
| 1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
| I |
х |
х |
х |
х |
х |
| I + 1 |
х |
х |
х |
х |
х |
Як бачимо, для виконання двох команд знадобилось 10 тактів, тобто загальна кількість тактів необхідна для виконання фрагменту з N машинних команд буде N*M, де М – кількість тактів, необхідних для виконання однієї команди. Для того, щоб застосувати конвеєризацію, потрібно розділити виконання команд на означені етапи. Хоча у такому випадку час обробки однієї команди все рівно буде складати 5 тактів, апаратура процесора одночасно буде виконувати 5 команд:
| Номер команди |
Номер такту |
| 1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
| I |
IF |
ID |
EX |
MEM |
WB |
| I + 1 |
IF |
ID |
EX |
MEM |
WB |
| I + 2 |
IF |
ID |
EX |
MEM |
WB |
| I + 3 |
IF |
ID |
EX |
MEM |
WB |
| I + 5 |
IF |
ID |
EX |
MEM |
WB |
Як бачимо, конвеєризація збільшує пропускну здатність процесора (кількість виконаних команд за одиницю часу), не зменшуючи час виконання однієї команди. Але збільшення пропускної здатності означає, що програма буде виконуватись швидше, ніж при використанні простої неконвеєрної схеми.
Той факт, що час виконання однієї команди не зменшується накладає деякі обмеження на практичну довжину конвеєра. Частота синхронізації не може бути вища, а звідси такт синхронізації не може бути менше, ніж час, необхідний для роботи найповільнішого етапу конвеєра. Накладні витрати при організації конвеєра виникають внаслідок затримки сигналів в конвеєрних регістрах. Конвеєрні регістри до довжини такту додають час встановлення та затримку розповсюдження сигналів.
При реалізації конвеєрної архітектури виникають ситуації, які перешкоджають виконанню наступної команди:
1.Структурні конфлікти, які виникають внаслідок конфліктів по ресурсах, коли апаратні засоби не можуть підтримувати всі комбінації команд у режимі одночасного виконання із суміщенням;
2.Конфлікти по даних, що виникають у випадку, коли виконання наступної команди залежить від результатів виконання попередньої;
3.Конфлікти по керуванню, які виникають при конвеєризації команд переходів які змінюють значення вказівника команд.
Конфлікти у конвеєрі призводять до необхідності призупинки виконання команд (pipeline stall). У найпростіших конвеєрах якщо зупиняється виконання однієї з команд, зупиняється виконання всіх наступних команд. Команди, які слідують перед командою, що викликала призупинку, продовжують виконуватися, але під час зупинки жодна нова команда не вибирається.
Суміщений режим виконання команд потребує конвеєризації функціональних пристроїв та дублювання ресурсів для дозволу всіх можливих комбінацій команд в конвеєрі. Якщо деяка команда не може бути прийнята внаслідок конфлікту по ресурсах, то кажуть, що в машині присутній структурний конфлікт. Найбільш типовим прикладом машин, в яких можлива поява структурних конфліктів є машини з не повністю конвеєрною архітектурою. В цьому випадку команди, які використовують вказаний функціональний пристрій, не можуть поступати до нього у кожному такті. Час роботи такого пристрою може складати декілька тактів синхронізації конвеєра. Інша можливість появи структурних конфліктів пов‘язана з недостатнім дублюванням деяких ресурсів, що не дозволяє виконання довільної послідовності команд в процесорі без його затримки. Коли послідовність команд призводить до такого конфлікту, процесор зупиняє обробку однієї з команд доти, доки пристрій не звільниться.
Структурні конфлікти можуть виникати, наприклад у машинах, які мають єдиний конвеєр пам‘яті для команд та даних. У цьому випадку коли команда буде містити звернення до пам‘яті за даними, воно буде конфліктувати з вибіркою наступної команди з пам‘яті. Щоб вирішити таку проблему, достатньо просто призупинити конвеєр на один такт, коли відбувається звернення до пам‘яті за даними. Подібна зупинка називається "конвеєрною бульбашкою" оскільки бульбашка проходить по конвеєру, займаючи місце, але не виконуючи ніякої корисної роботи:
| Команда |
Номер такту |
| 1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
| Команда завантаження |
IF |
ID |
EX |
MEM |
WB |
| Команда 1 |
IF |
ID |
EX |
MEM |
WB |
| Команда 2 |
IF |
ID |
EX |
MEM |
WB |
| Команда 3 |
Stall |
IF |
ID |
EX |
MEM |
WB |
| Команда 4 |
IF |
ID |
EX |
MEM |
WB |
| Команда 5 |
IF |
ID |
EX |
MEM |
| Команда 6 |
IF |
ID |
EX |
В загальному випадку, машина без структурних конфліктів буде мати менший CPI (середня кількість тактів на виконання однієї інструкції). Виникає питання: чому розроблювачі процесорів допускають появу структурних конфліктів? Є дві причини для цього: зменшення ціни на процесор та зменшення затримок пристрою. Конвеєризація всіх функціональних пристроїв може бути дуже коштовною. Машини, що мають можливість одночасного звернення до пам‘яті, мають подвоєну пропускну здатність пам‘яті наприклад шляхом розділення кешей для даних та для команд. Як правило, можливо спроектувати не конвеєрний або не повністю конвеєрний пристрій, який би мав менший CPI ніж повністю конвеєрний пристрій. Наприклад, розроблювачі машин CDC7600 та MIPS R2010 віддали перевагу меншій затримці виконання конвеєрних операцій замість повної конвеєризації.
1.4
Конфлікти по даних, реалізація механізмів обходів
Одним з факторів, які мають суттєвий вплив на швидкодію процесора, є міжкомандні логічні залежності. Такі залежності суттєво скорочують ступінь паралелізму, якого можна було б досягти. Ступінь впливу цих залежностей залежить як від архітектури процесора, так і від характеристик набору команд.
Конфлікти по даних виникають у тому випадку, коли застосування конвеєрної обробки може змінити порядок звернення за операндами таким чином, що порядок виконання команд буде відрізнятись від порядку команд, що виконувались би на неконвеєрній машині. Розглянемо конвеєрне виконання команд:
| ADD R1,R2,R3 |
IF |
ID |
EX |
MEM |
WB |
| SUB R4,R1,R5 |
IF |
ID |
EX |
MEM |
WB |
| AND R6,R1,R7 |
IF |
ID |
EX |
MEM |
WB |
| OR R8,R1,R9 |
IF |
ID |
EX |
MEM |
WB |
| XOR R10,R1,R11 |
IF |
ID |
EX |
MEM |
WB |
У цьому прикладі всі команди, що слідують за командою ADD, використовують результат її виконання. Команда ADD записує результат у R1, а команда SUB читає його значення. Якщо не вживати ніяких заходів, команда SUB може прочитати невірне значення і використати його. Ця проблема може бути вирішена за допомогою достатньо простої апаратної техніки, яка називається пересилкою або переміщенням даних (data forwarding). Ця апаратура працює наступним чином: Результат операції АЛП з вихідного регістра завжди пересилається назад на входи АЛП. Якщо апаратура з‘ясовує, що попередня операція записує результат у регістр, який є одним з операндів наступної, читається значення передане на вхід АЛП, а не значення регістрового файлу.
Така техніка "обходу" може бути узагальнена для того, щоб включити передачу результату прямо в той функціональний пристрій, який його потребує.
Нажаль, не всі потенційні конфлікти по даних можуть оброблятися за допомогою механізмів "обходу". Розглянемо послідовність команд:
| Команда |
| LW R1,32(R6) |
IF |
ID |
EX |
MEM |
WB |
| ADD R4,R1,R7 |
IF |
ID |
STALL |
EX |
MEM |
WB |
| SUB R5,R1,R8 |
IF |
STALL |
ID |
EX |
MEM |
WB |
| AND R6,R1,R7 |
STALL |
IF |
ID |
EX |
MEM |
WB |
Команда завантаження R1 з пам‘яті має затримку, яка не може бути ліквідована звичайною "пересилкою". Замість цього нам потрібна додаткова апаратура, що називається апаратурою внутрішнього блокування конвеєра для того, щоб забезпечити коректне виконання прикладу. Взагалі така апаратура виявляє конфлікт і призупиняє конвеєр доки конфлікт не буде ліквідовано.
Багато типів зупинок конвеєра можуть траплятися досить часто. Наприклад, для оператора A = B + C компілятор генерує таку послідовність команд:
| LW R1,B |
IF |
ID |
EX |
MEM |
WB |
| LW R2,C |
IF |
ID |
EX |
MEM |
WB |
| ADD R3,R1,R2 |
IF |
ID |
Stall |
EX |
MEM |
WB |
| SW A,R3 |
IF |
Stall |
ID |
EX |
MEM |
WB |
Зрозуміло, виконання команди ADD має бути зупинено до тих пір, доки не стане доступним операнд С.
Для даного простого прикладу компілятор ніяк не може покращити ситуацію, але у багатьох інших випадках компілятор може досить суттєво впливати на ситуацію за допомогою перестановок команд. Ця техніка називається плануванням завантаження конвеєра (pipeline scheduling) або плануванням потоку команд (instruction scheduling), використовується з 60-х років і розвинулась у окрему галузь у 80-х коли з‘явилась велика кількість конвеєрних машин.
Наприклад, маємо 2 оператора на мові програмування С: a = b + c; d = e – f; Яким чином можна згенерувати послідовність команд для зменшення конфліктів по даних?
| Неоптимізована послідовність команд |
Оптимізована послідовність команд |
LW Rb,b
LW Rc,c
ADD Ra,Rb,Rc
SW a,Ra
LW Re,e
LW Rf,f
SUB Rd,Re,Rf
SW d,Rd
|
LW Rb,b
LW Rc,c
LW Re,e
ADD Ra,Rb,Rc
LW Rf,f
SW a,Ra
SUB Rd,Re,Rf
SW d,Rd
|
В результаті ліквідовано блокування (командою LW Rc,c команди ADD Ra,Rb,Rc та командою LW Rf,f команди SUB Rd,Re,Rf). Мається залежність між операцією АЛП та операцією запису до пам‘яті, але структура конвеєру дозволяє запис результатів за допомогою ланцюгів обходу. Використання різних регістрів для першого та другого операторів було критичним для реалізації правильного планування. В загальному випадку планування може потребувати великої кількості регістрів. Це особливо суттєво для машин, які можуть одночасно виконувати декілька команд за один такт.
Всі сучасні компілятори використовують техніку планування завантаженості конвеєра для підвищення швидкодії згенерованих програм. У найпростішому випадку компілятор просто планує виконання команд в одному базовому блоці. Базовий блок представляє собою фрагмент програми без переходів. Планування такої послідовності відбувається досить просто, оскільки компілятор знає, що всі команди в блоці будуть виконуватись, якщо виконується перша команда блоку. У цьому випадку достатньо побудувати граф залежностей цих команд та розташувати їх таким чином, щоб мінімізувати зупинки конвеєра. Для простих конвеєрів такий алгоритм дає добрі результати, але коли конвеєризація стає більш інтенсивною, виникає потреба у більш складних алгоритмах.
Існують апаратні методи зміни порядку виконання команд для того, щоб мінімізувати зупинки конвеєра. Ці методи отримали загальну назву методів динамічної оптимізації.
Основними засобами динамічної оптимізації є
1.Розміщення схеми виявлення конфліктів у найнижчій точці конвеєра команд таким чином, щоб дозволити команді пересуватись по конвеєру до тих пір, поки їй реально не знадобиться операнд, що є також результатом логічно більш ранньої але ще не завершеної команди. Альтернативним підходом є централізоване виявлення конфліктів на ранній стадії конвеєра;
2.Буферизація команд, що очікують вирішення конфлікту, та видача наступних, логічно не зв‘язаних команд в "обхід" буфера;
3.Відповідна організація комутуючих магістралей, що забезпечує безпосередню передачу результату операції в буфер, що зберігає логічно залежну команду що було затримано внаслідок конфлікту або безпосередньо на вхід функціонального пристрою до того, як результат буде записаний у регістровий файл або в пам‘ять.
Ще одним апаратним методом мінімізації конфліктів по даних є метод перейменування регістрів (register renaming). Він отримав свою назву від широковживаного в компіляторах методу перейменування – метода розміщення даних, що сприяє скороченню залежностей між даними і тим самим підвищенню швидкодії при відображенні об‘єктів програми (змінні) на апаратні ресурси комп‘ютера (пам‘ять, регістри).
При апаратній реалізації методу перейменування регістрів виділяються логічні регістри, звернення до яких виконується за допомогою відповідного поля команди, та фізичні регістри, що знаходяться в апаратному регістровому файлі процесора. Номери логічних регістрів динамічно відображаються на номери фізичних регістрів за допомогою таблиць відображення, що відновлюються після декодування кожної команди. Кожний новий результат записується у новий фізичний регістр. Але попереднє значення логічного регістра зберігається і може бути встановлено у випадку переривання чи неправильно передбаченого умовного переходу.
У процесі виконання програми генеруються багато тимчасових регістрових результатів. Ці тимчасові результати записуються у регістровий файл разом з постійними значеннями. Тимчасове значення стає постійним коли завершується виконання команди (фіксується її результат). В свою чергу, завершення команди відбувається коли всі попередні команди успішно завершились у заданому програмою порядку.
Програміст має справу тільки з логічними регістрами. Кожен новий результат записується у фізичні регістри. Але до тих пір, доки не завершено команду, значення в фізичному регістрі вважаються за тимчасові.
Метод перейменування регістрів спрощує контроль залежностей по даних. В машині, яка може виконувати команди не в порядку їх розташування у програмі, номери логічних регістрів можуть стати неоднозначними, оскільки один і той самий регістр може бути використаний для збереження послідовних двох значень. Але оскільки номери всіх фізичних регістрів унікально ідентифікують кожне значення, неоднозначності ліквідуються.
Конфлікти по керуванню можуть викликати навіть більші втрати, ніж конфлікти по даних. Коли виконується команда умовного переходу, вона може змінити або не змінити значення вказівника команд. Коли команда заміняє вказівник команд на адресу, що було обчислено у команді, перехід називається виконаним, інакше – невиконаним.
Найпростіший метод роботи з переходами полягає у зупинці конвеєра при появі команди переходу до того, як буда з‘ясована адреса переходу. Такі зупинки повинні реалізовуватись інакше, ніж зупинки конфліктів по даних. Вибір команди після команди умовного переходу має статись якомога швидше після з‘ясування адреси переходу:
| Команда переходу |
IF |
ID |
EX |
MEM |
WB |
| I |
IF |
Stall |
Stall |
IF |
ID |
EX |
MEM |
WB |
| I + 1 |
Stall |
Stall |
Stall |
IF |
ID |
EX |
MEM |
WB |
| I + 2 |
Stall |
Stall |
Stall |
IF |
ID |
EX |
MEM |
| I + 3 |
Stall |
Stall |
Stall |
IF |
ID |
EX |
| I + 4 |
Stall |
Stall |
Stall |
IF |
ID |
| I + 5 |
Stall |
Stall |
Stall |
IF |
Наприклад, якщо конвеєр буде зупинено на 3 такти на кожної стадії умовного переходу, то це може суттєво вплинути на швидкодію процесора. При частоті команд умовного переходу 30% та ідеальному CPI = 1 машина буде мати тільки половину прискорення конвеєрної обробки. Таким чином, зниження втрат від команд умовного переходу є критичним питанням. Число тактів, що втрачаються у зупинках викликаних переходами може бути зменшено двома шляхами:
1.Виявлення виконуваності чи невиконуваності переходу на ранніх стадіях обробки;
2.Обчислення адреси переходу для виконуваного переходу на ранніх стадіях.
Найпростіша схема обробки команд умовного переходу полягає в зупинці операцій в конвеєрі шляхом блокування будь-якої операції, що знаходиться в конвеєрі після операції умовного переходу до точного з‘ясування цільової адреси умовного переходу. Перевагою цього рішення є його простота
Більш досконала і не небагато складніша схема полягає у тому, щоб прогнозувати умовний перехід як той що не виконується. При цьому апаратура повинна просто продовжувати виконання програми як у випадку, що умовний перехід не виконується. При цьому необхідна додаткова апаратура для того, щоб не змінювати стан машини до того, як буде з‘ясовано напрямок переходу. Якщо ж з‘ясується, що перехід є виконуваний, то необхідно просто очистити конвеєр від команд, що йшли після команди умовного переходу та почати вибірку нових команд після виконання переходу:
| Невиконуваний перехід |
IF |
ID |
EX |
MEM |
WB |
| І + 1 |
IF |
ID |
EX |
MEM |
WB |
| І + 2 |
IF |
ID |
EX |
MEM |
WB |
| І + 3 |
IF |
ID |
EX |
MEM |
WB |
| І + 4 |
IF |
ID |
EX |
MEM |
WB |
| Виконуваний перехід |
IF |
ID |
EX |
MEM |
WB |
| І + 1 / Цільова команда |
IF |
IF |
ID |
EX |
MEM |
WB |
| Ц.К. + 1 |
Stall |
IF |
ID |
EX |
MEM |
WB |
| Ц.К. + 2 |
Stall |
IF |
ID |
EX |
MEM |
WB |
| Ц.К. + 3 |
Stall |
IF |
ID |
EX |
MEM |
Альтернативна схема прогнозує перехід як виконуваний. Як тільки команду умовного переходу декодовано та обчислена цільова адреса переходу, робиться припущення що перехід виконуваний і вибираються команди з цільової адреси переходу. Якщо не можливо виявлення цільової адреси переходу до того як буде виявлено виконуваний це перехід чи ні, такий підхід не дає ніяких переваг. Якщо б умова переходу залежала від безпосередньо попередньої команди, то виникла б зупинка конвеєра завдяки конфлікту по даним. У таких випадках прогнозування переходу як виконуваного невигідно.
Четверта схема, яка використовується у деяких машинах має назву "затриманих переходів". У затриманому переході такт виконання із затримкою переходу довжиною в n є:
Команда умовного переходу
Наступна команда 1
Наступна команда 2
……………………..
Наступна команда n
Цільова адреса при виконуваному переході
Команди 1 – n знаходяться в слотах (часових інтервалах) затриманого переходу. Задача програмного забезпечення полягає у тому, щоб зробити команди, що слідують за командою умовного переходу, дійсними та корисними. Апаратура гарантує реальне виконання цих команд перед командою переходу. Тут використовуються декілька методів оптимізації.
Планування затриманих переходів ускладнюється:
1.Наявністю обмежень на команди, розміщення яких планується в слотах затримки
2.Необхідністю передбачати під час компіляції, чи буде перехід виконуваним.
Практика свідчить, що біля 50% всіх слотів є заповненими, і 80% їх є корисними. Це може здатися дивним, оскільки 53% умовних переходів не практиці виконуються. Але високий відсоток поясняється тим, що приблизно половина слотів заповнюється командами, виконання яких необхідно без залежності від переходу.
Обробка переривань в конвеєрній машині виявляється більш складною завдяки тому, що суміщене виконання команд ускладнює визначення можливості безпечної зміни стана машини довільною командою. В конвеєрній машині команда виконується по етапам, і її виконання завершується через декілька тактів після її видачі. Ще в процесі виконання окремих її етапів команда може змінити стан машини. Тим часом переривання може змусити процесор перервати виконання ще не завершених команд.
Як і в безконвеєрних машинах двома основними проблемами реалізації переривань є:
1.переривання виникає у процесі виконання деякої команди;
2.необхідний механізм повернення з переривання для продовження виконання програми.
Наприклад, для найпростішого конвеєра переривання по відсутності сторінки віртуальної пам‘яті може виникнути до етапу вибірки з пам‘яті (MEM). На момент виникнення цього переривання в конвеєрі будуть знаходитися декілька команд. Оскільки подібне переривання повинно забезпечити повернення та потребує переключення на інший процес (операційну систему) необхідно надійно очистити конвеєр та зберегти стан машини. Часто це реалізується збереженням регістру РС для команди, що викликала переривання. Якщо команда, що виконала переривання не є командою умовного переходу, зберігається звичайний порядок виконання команд. Якщо ж це є команда переходу, треба оцінити умову та почати вибірку команд з певної адреси.
Коли відбувається переривання, для коректного збереження стану машини необхідно виконати такі дії:
1.У послідовність команд що поступають на обробку в конвеєр, треба вставити команду переходу на підпрограму обробки переривання;
2.Доки виконується команда переходу на переривання, задовольнити всі потреби запису команди, що викликала переривання, а також всіма командами що слідують в конвеєрі за нею;
3.Після передачі керування підпрограмі обробки, вона повинна зберегти адресу повернення для наступного повернення з переривання.
Якщо використовуються механізми затриманих переходів, стан машини відновити за допомогою тільки РС неможливо, оскільки в конвеєрі команди можуть бути не послідовними. Тому треба зберігати для кожної в слоті затримки свій РС.
Підтримка точних переривань в багатьох системах є обов‘язковою. Як мінімум в машинах зі сторінковою організацією пам‘яті повинна бути підтримка точних переривань або за допомогою тільки апаратних засобів, або з деякою участю програмного забезпечення.
1.9
Основи планування завантаження конвеєра та розгортання циклів
Для підтримання максимальної завантаженості конвеєра повинен використовуватись паралелізм рівня команд, оснований на виявлені послідовності незв‘язаних команд, які можуть виконуватися в конвеєрі із суміщенням. Щоб уникнути зупинки конвеєра залежна команда повинна бути відокремлена від вихідної команди на відстань у тактах, не меншу ніж затримка конвеєра для цієї команди. Для прикладів будемо вважати, що умовні переходи мають затримку в 1 такт. Затримки для інших типів команд:
| Вихідна команда |
Команда, що використовує результат |
Затримка в тактах |
| Операція АЛП з ПК |
Операція АЛП з ПК |
3 |
| Операція АЛП з ПК |
Завантаження подвійного слова |
2 |
| Завантаження подвійного слова |
Операція АЛП з ПК |
1 |
| Завантаження подвійного слова |
Завантаження подвійного слова |
0 |
У даному розділі ми розглянемо яким чином компілятор може збільшити ступінь паралелізму за допомогою розгортання циклу. Для прикладу будемо розглядати простий цикл, який додає до вектора в пам‘яті скалярну величину. Такий цикл є повністю паралельним, оскільки залежність між його ітераціями відсутня. Припускаємо, що R1 містить адресу останнього
елементу вектора, а F2 – скаляр, який потрібно додати до вектора. Програма яка не використовує переваги конвеєризації буде виглядати таким чином:
Loop:LDF0,0(R1)
ADDF4,F0,F2
SD0(R1),F4
SUBR1,R1,#8
BNEZR1,Loop
Для спрощення вважаємо, що масив починається з адреси 0. Якщо б він знаходився у іншому місці, цикл вимагав би наявності ще однієї додаткової цілочисельної команди для виконання порівняння з R1.
Розглянемо роботу цього циклу при виконанні на простому конвеєрі із вищевказаними затримками. Якщо не робити ніякого планування, робота циклу буде виглядати наступним чином:
Такт видачі
Loop:LDF0,0(R1)1
Зупинка2
ADDF4,F0,F23
Зупинка4
Зупинка5
SD0(R1),F46
SUBR1,R1,#87
BNEZR1,Loop8
Зупинка9
Для виконання потрібно 9 тактів на ітерацію: одна зупинка для команди LD, дві для команди ADD, та одна для затриманого переходу. Але можна спланувати цикл таким чином:
Такт видачі
Loop:LDF0,0(R1)1
Зупинка2
ADDF4,F0,F23
SUBR1,R1,#84
BNEZR1,Loop5Затриманий перехід
SD0(R1),F46
Час виконання зменшився з 9 до 6 тактів. Зауважимо, що для планування затриманого переходу компілятор повинен з‘ясувати, що він може поміняти місцями команди SUB та SD шляхом зміни адреси в команді запису SD: адреса була 0(R1), а тепер 8(R1). Це не тривіальна задача, оскільки більшість компіляторів будуть бачити що команда SD залежить від команди SUB, і відмовляться від їх перестановок. Ланцюжок залежностей від команд LD до команди ADD та далі до команди SD визначає кількість тактів, необхідних для даного циклу.
У наведеному прикладі ми завершуємо одну ітерацію циклу та виконуємо запис одного елемента вектора кожні 6 тактів, але дійсна робота по обробці елемента вектора займає 3 такти (завантаження, додавання, запис). Решта 3 такти складають накладні витрати для організації циклу. Для того щоб зменшити накладні витрати потрібно збільшити кількість операцій в кожному циклі. Для цього служить метод розгортання циклів. Він не зменшує абсолютну кількість тактів на накладні витрати, але робить витрати відносно меншими. Таке розгортання здійснюється шляхом чисельної реплікації (повторення) тіла циклу.
Розгортання циклу може також використовуватись для покращання планування. У цьому випадку ми можемо збільшити паралелізм шляхом створення багатьох незалежних команд в тілі циклу. Потім компілятор може використовувати ці команди для розміщення в слот затримки. Якщо при розгортанні просто дублювати тіло циклу, результуючі залежності по іменах можуть завадити ефективно спланувати цикл. Таким чином для різних ітерацій потрібно використовувати різні регістри, що збільшує потрібну кількість регістрів.
Розгорнемо цикл на 4 ітерації:
Loop:LDFO,0(R1)
ADDF4,F0,F2
SD0(R1),F4
LDF6,-8(R1)
ADDF8,F6,F2
SD-8(R1),F8
LDF10,-16(R1)
ADDF12,F10,F2
SD-16(R1),F14
LDF14,-24(R1)
ADDF16,F14,F2
SD-24(R1),F16
SUBR1,R1,#32
BNEZR1,Loop
Ми ліквідували 3 умовних переходи та 3 операції декременту R1. Адреси команд завантаження та запису були скоректовані таким чином, що з‘явилась можливість користуватись R1 для всіх звернень до пам‘яті. При відсутності планування за кожною командою буде йти залежна команда, що приведе до затримок. Цей цикл буде виконуватись за 27 тактів, або по 6.8 тактів на кожний елемент масиву.
В реальних програмах верхня межа циклу невідома. Припустимо, що вона рівна n і ми хотіли б розгорнути цикл таким чином щоб мати k копій тіла циклу. Замість одного розгорнутого циклу ми генеруємо 2: один виконується n mod k раз, другий – n div k, причому він охоплює перший цикл.
У цьому прикладі розгортання циклу збільшує швидкодію за рахунок усунення команд, пов‘язаних з накладними витратами циклу, хоча це суттєво збільшує розмір коду. Як покращиться швидкодія, якщо цикл буде оптимізований?
Нижче представлений розгорнутий цикл з попереднього прикладу після оптимізації:
Loop:LDF0,0(R1)
LDF6,-8(R1)
LDF10,-16(R1)
LDF14,-24(R1)
ADDF4,F0,F2
ADDF8,F6,F2
ADDF12,F10,F2
ADDF16,F14,F2
SD0(R1),F4
SD-8(R1),F8
SD-16(R1),F12
SUBR1,R1,#32
BNEZLoop
SD8(R1),F16
Час виконання зменшився до 14 тактів, або до 3.5 тактів на елемент масиву.
Виграш від оптимізації розгорнутого циклу навіть більший ніж від оптимізації нерозгорнутого тому що розгортання циклу виявило більшу кількість команд котрі не залежать одна від іншої.
Розгортання циклу представляє собою простий але дуже корисний метод підвищення розміру лінійного кодового сегменту, який може ефективно оптимізуватися.
Найпростішою схемою динамічного прогнозування напрямку умовних переходів є буфер прогнозування умовних переходів (branch prediction buffer) або таблиця "історії" переходів. Буфер прогнозування умовних переходів представляє собою невелику пам‘ять, що адресується молодшими розрядами адреси команди умовного переходу. Кожна комірка цієї пам‘яті містить 1 біт, який містить інформацію про те, був попередній перехід виконаний чи ні. Це найпростіший тип такого буфера, в ньому відсутні теги, і він корисний тільки для скорочення затримки переходу у тому випадку, коли ця затримка більша, ніж час потрібний для обчислення цільового значення умовного переходу. Ми не знаємо, чи є цей прогноз коректним (значення у відповідну комірку буфера могла занести зовсім інша команда). Але це не має значення. Прогноз – це тільки передбачення, яке розглядається як коректне, і вибірка команд починається із спрогнозованої адреси. Якщо прогноз виявився невірним, відповідний біт інвертується.
Але проста однобітова схема має недостатню ефективність. Розглянемо, наприклад, команду умовного переходу в циклі яка 9 разів виконувалась, а на 10 раз не виконалась. Напрямок переходу буде невірно спрогнозовано на 1 та на останній ітерації. Невірний прогноз останньої ітерації неминучий, оскільки перехід виконувався 9 разів підряд. Таким чином точність прогнозу була 80% (8 правильних та 2 неправильних прогнози).
Для виправлення цього стану часто використовується схема двобітового прогнозу. У двобітовій схемі прогноз має 2 рази бути неправильний, щоб напрямок прогнозування змінився на протилежний. Двобітова схема є частковим випадком більш загальної схеми, яка в кожній строчці буфера прогнозування має n-бітовий регістр. Цей регістр може приймати значення від 0 до 2n
-1. Тоді схема прогнозування буде такою:
- якщо значення регістра буде більше або рівне 2n-1
то напрямок прогнозується як виконуваний. Якщо напрямок було передбачено вірно, до значення додається 1 (якщо значення не досягло максимального значення), інакше віднімається 1.
- якщо значення регістра буде меншим ніж 2n-1
то напрямок прогнозується як невиконуваний. Якщо напрямок було передбачено вірно, від значення віднімається 1 (якщо значення не досягло 0), інакше додається 1.
Дослідження n-бітових схем прогнозування показали, що вони працюють не набагато краще ніж 2-бітові.
Буфер прогнозування може бути реалізований як невелика кеш-пам‘ять, доступ до якої відбувається за допомогою адреси команди під час стадії IF. Якщо команду декодовано як команду переходу, і якщо перехід спрогнозовано як виконуваний, вибір команд починається з цільової адреси як тільки ця адреса стане відомою.
Точність прогнозу залежить від того, наскільки часто прогноз є виконуваним або невиконуваним. Якщо строка в буфері ідентифікована невірно (прогноз зовсім іншої команди переходу), прогнозування все рівно виконується, оскільки така ситуація не може бути розпізнана процесором на ранніх стадіях обробки команди, але навіть у цьому випадку прогноз може бути вірним.
Як показують практичні тести, 2-бітовий буфер розміром 4096 комірок дає точність прогнозування від 99% до 82% в залежності від типу програмного забезпечення.
Але одного знання про точність прогнозування недостатньо для того, щоб з‘ясувати вплив переходів на швидкодію машини, навіть якщо відомі час виконання переходу та втрати часу при невдалому прогнозі. Необхідно враховувати частоту переходів в програмі, оскільки важливість точного прогнозу більша в програмах з великим числом переходів. Наприклад, цілочисельні програми li, eqntott, expresso та gcc мають більшу частоту переходів, ніж значно простіші для прогнозування програми розрахунку nasa7, matrix300 та tomcatv. Оскільки головною метою є використання якомога більшого паралелізму програми, точність прогнозу напрямку переходів стає дуже важливою.
1.11 Схеми корельованого прогнозування переходів
Схеми з 2-бітовою структурою розглядають попередні результати переходів для прогнозування наступних. Можливо, вдасться підвищити точність прогнозу, якщо розглядати не тільки одну команду переходу, як і інші пов‘язані з нею. Розглянемо, наприклад фрагмент програми:
If(aa == 2)
aa = 0;
if(bb == 2)
bb = 0;
if(aa != bb) { ………
Нижче наведений лістінг команд згенерованих компілятором з цього фрагменту (aa знаходиться в R1, bb знаходиться в R2):
SUBR3,R1,#2
BNEZR3,L1
SUBR1,R0,R0
L1:SUBR3,R2,#2
BNEZR3,L2
SUBR2,R0,R0
L2:SUBR3,R1,R2
BEQZR3,L3
Позначимо команди переходу як п1, п2, п3. Можна помітити, що команда переходу п3 корелює з командами п1 та п2. Якщо обидва переходи п1 та п2 будуть виконуваними, то перехід п3 буде виконуваним, оскільки значення змінних рівні. Розглянута схема прогнозування, яка розглядає тільки історію поведінки тільки одного переходу, ніколи це не врахує.
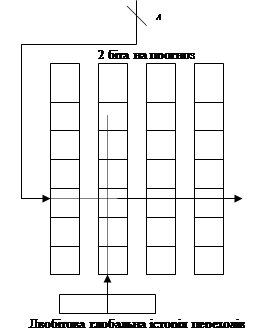
Схеми прогнозування, які для передбачення переходу використовують поведінку інших команд переходу, називаються корельованими або дворівневими схемами прогнозування. Схема прогнозування називається прогнозом (1,1) якщо вона використовує поведінку одного останнього переходу для вибору з пари однобітових схем прогнозування на кожний перехід. В загальному випадку схема прогнозування (m,n) використовує поведінку останніх m переходів для вибору з 2m
схем прогнозування, кожна з якої представляє собою n-бітову схему прогнозування для кожного окремого переходу. Перевага такого типу корельованих схем полягає в тому, що вони можуть давати більший відсоток правильних прогнозів, ніж проста схема та потребують невеликого ускладнення апаратних засобів. Простота апаратних засобів пояснюється тим, що історія останніх m переходів може бути записана в регістр зсуву розрядності m, у кожний розряд якого заноситься інформація, був цей перехід виконаний чи ні. Тоді буфер прогнозування переходів може адресуватись конкатенацією регістру зсуву та молодших бітів адреси команди переходу. На малюнку зображена схема прогнозування (2,2):
1.12 Одночасна видача декількох команд для виконання та динамічне планування
Методи мінімізації зупинок у роботі конвеєра, пов‘язаних із логічною залежністю команд, були націлені на досягнення ідеального СРІ рівного 1. Щоб ще більше підвищити швидкодію машини треба цей коефіцієнт зробити меншим ніж 1. Зрозуміло, що цього не можна досягти якщо у одному такті обробляється максимум одна команда. Тобто необхідна паралельна обробка декількох команд за один такт. Існує два типа таких машин, що можуть виконувати більше ніж одну команду за такт: суперскалярні машини та VLIW-машини. Суперскалярні машини можуть виконувати за один такт змінне число команд, а робота їх конвеєрів може плануватись як програмно за допомогою компілятора, так і апаратно засобами процесора. На відміну від суперскалярних машин, VLIW-машини видають на виконання фіксоване число команд та планування виконання відбувається тільки статично за допомогою компілятора.
Суперскалярні машини використовують паралелізм на рівні команд шляхом обробки декількох команд з потоку у декількох пристроях. Додатково, щоб зняти обмеження послідовного виконання команд, ці машини використовують механізми позачергової видачі та позачергового завершення команд, прогнозування переходів, кеші цільових адрес переходів та умовне виконання команд. Збільшена складність створює проблему точного переривання.
У типовій суперскалярній машині процесор може виконувати від 1 до 8 команд за один такт. Ці команди повинні бути незалежними та задовольняти деяким вимогам, наприклад що в одному такті не може оброблятись більш ніж 1 команда звернення до пам‘яті. Якщо будь-яка команда у потоці пам‘яті є логічно залежною або не задовольняє критеріям видачі, на виконання будуть видані тільки команди, що передують їй. Тому швидкість обробки команд у суперскалярній машині є змінною. Це є основною відміною суперскалярної від VLIW архітектури. У VLIW архітектурі паралельні команди формує у пакети компілятор, і апаратура процесора не приймає ніяких рішень щодо розпаралелення команд.
У простих процесорах використовується підхід, коли може бути одночасно виконані дві команди: команда із плаваючою комою та цілочисельна команда. У реальних моделей процесорів може бути виконано одночасно дві довільні команди, якщо вони не є логічно залежні одна від іншої (Pentium, PA7100, HyperSPARC). У більшості потужних моделей процесорів реалізовано видачу до 4 команд в одному такті (MIPS R10000, UltraSPARC, PowerPC 620).
Видача двох команд в одному такті потребує одночасної вибірки та декодування як мінімум 64 біт. Щоб спростити декодування, можна припустити що команди розташовані парами та вирівняні по границі 64 біт. У противному випадку необхідно аналізувати команди у процесі вибірки та можливо міняти їх місцями при пересилці у цілочисельний АЛП та АЛП з плаваючою комою. При цьому постають додаткові вимоги до схем виявлення конфліктів. У будь якому випадку друга команда може видаватись, якщо може видаватись перша команда. На діаграмі представлена робота двох конвеєрів у ідеальному випадку, коли пари команд можуть виконуватись одночасно:
| Тип команди |
Фаза конвеєра |
| Цілочисельна |
IF |
ID |
EX |
MEM |
WB |
| ПК |
IF |
ID |
EX |
MEM |
WB |
| Ц |
IF |
ID |
EX |
MEM |
WB |
| ПК |
IF |
ID |
EX |
MEM |
WB |
| Ц |
IF |
ID |
EX |
MEM |
WB |
| ПК |
IF |
ID |
EX |
MEM |
WB |
| Ц |
IF |
ID |
EX |
MEM |
WB |
| ПК |
IF |
ID |
EX |
MEM |
WB |
Такий конвеєр дозволяє суттєво збільшити швидкість видачі команд. Але для того щоб він працював, необхідно мати або повністю конвеєризовані пристрої роботи з плаваючою комою, або відповідну кількість незалежних функціональних пристроїв. У противному випадку пристрій ПК стане вузьким місцем і ефект паралельної видачі команд зведеться до мінімуму.
При паралельній видачі двох операцій (цілочисельної та ПТ) потреба в додатковій апаратурі мінімальна: цілочисельні та пристрої ПК використовують різні функціональні пристрої та різні набори регістрів. Єдина складність виникає, тільки якщо команди представляють собою команди завантаження, запису або пересилки даних з ПК. Ці команди створюють конфлікти по регістрових портах регістрів з плаваючою комою.
Проблема регістрових портів може бути вирішена, наприклад, шляхом реалізації окремої видачі команд завантаження, запису та пересилки команд з ПК. У випадку складання пари зі звичайною операцією з ПК ситуацію можна розглядати як структурний конфлікт. Таку схему легко реалізувати, але вона буде мати суттєвий вплив на загальну швидкодію. Конфлікт такого типу може бути усунений реалізацією у регістровому файлі двох додаткових портів (для читання та запису).
Якщо пара команд складається із команди завантаження ПК та операції з ПК, яка від неї залежить, необхідно виявити подібний конфлікт та блокувати видачу команди операції з ПК. За виключенням цього випадку, всі інші конфлікти можуть виникати як у машині, що забезпечує видачу однієї команди за такт. Для запобігання зупинок можуть знадобитись додаткові ланцюги обходу.
Іншою проблемою, яка може обмежити ефективність суперскалярної обробки, є затримка завантаження даних з пам‘яті. У нашому прикладі простого конвеєра команди завантаження мали затримку в один такт, що не дозволяло наступній команді скористатись результатами завантаження без зупинки. У суперскалярному конвеєрі результат завантаження не може бути використаний у тому ж самому або у наступному такті. Це значить, що наступні три команди не можуть використовувати результат завантаження без зупинки. Затримка переходу також складає 3 такти, оскільки команда переходу повинна бути першою у парі команд. Щоб більш ефективно використовувати паралелізм, доступний на суперскалярній машині, треба використовувати більш складні методи планування потоку команд, що використовуються компілятором та апаратними засобами, та складніші схеми декодування команд.
Розглянемо наприклад, який ефект дає розгортання циклів та планування потоку команд для суперскалярного конвеєра:
Loop:LDF0,0(R1)
ADDF4,F0,F2
SD0(R1),F4
SUBR1,R1,#8
BNEZR1,Loop
Щоб спланувати цей цикл для роботи без затримок, необхідно його розгорнути та зробити 5 копій тіла циклу. Після такого розгортання цикл буде мати по п‘ять команд LD, ADD, SD, а також одну команду SUB та один умовний перехід BNEZ. Розгорнута та оптимізована програма для цього циклу може виглядати так:
| Цілочисельна команда |
Команда ПК |
Номер такту |
| Loop:LDF0,0(R1) |
1 |
| LDF8,-8(R1) |
2 |
| LDF10,-16(R1) |
3 |
| LDF14,-24(R1) |
4 |
| LDF18,-32(R1) |
ADDF4,F0,F2 |
5 |
| SD0(R1),F4 |
ADDF8,F6,F2 |
6 |
| SD-8(R1),F8 |
ADDF12,F10,F2 |
7 |
| SD-16(R1),F12 |
ADDF16,F14,F2 |
8 |
| SD-24(R1),F16 |
ADDF20,F18,F2 |
9 |
| SUBR1,R1,#40 |
10 |
| BNEZR1,Loop |
11 |
| SD-32(R1),F20 |
12 |
Цей розгорнутий суперскалярний цикл тепер працює із швидкістю 12 тактів на ітерацію, або 2.4 такти на один елемент – у порівнянні з 3.5 тактами у несуперскалярній архітектурі. У цьому прикладі прирощення швидкодії обмежене невеликою кількістю операцій з ПК.
У кращому випадку такий конвеєр дозволить виконувати одночасно дві команди якщо перша з них є цілочисельною, а друга – командою з ПК. Якщо ця умова не забезпечується, команди виконуються послідовно. Це показує 2 головні переваги суперскалярної архітектури над архітектурою VLIW. По-перше, малий вплив на щільність коду, оскільки машина сама з‘ясовує, чи може бути виконана наступна команда і нема потреби слідкувати за тим, щоб команди відповідали можливостям видачі. По-друге, на таких машинах можуть працювати неоптимізовані програми, тобто програми відкомпільовані для старої моделі процесора. Зрозуміло, ці програми не будуть працювати дуже швидко, але можна застосувати засоби динамічної оптимізації.
В загальному випадку у суперскалярній системі команди можуть виконуватись паралельно і не в тому порядку, в якому вони знаходяться у програмі. Якщо не вживати ніяких додаткових заходів, таке невпорядковане виконання команд та наявність багатьох функціональних пристроїв з різним часом виконання операцій може привести до додаткових труднощів. Наприклад, при виконанні деякої довгої команди з ПК (обчислення квадратного кореня) може виникнути помилка вже після того, як закінчилась більш швидка операція яка йшла після цієї операції. Для того, щоб гарантувати модель точних переривань, апаратура повинна гарантувати коректний стан процесора на момент виникнення переривань для організації наступного повернення.
Часто в машинах з невпорядкованим виконанням команд передбачені додаткові буферні схеми, які гарантують завершення команд у тому порядку, в якому вони знаходились у програмі. Такі схеми представляють собою деякій буфер "історії", тобто апаратну чергу, у яку заносяться команди та результати їх виконання у передбаченому програмою порядку.
На момент видачі команди вона поміщується в кінець цієї черги, організованої за принципом FIFO. Єдиний спосіб досягти початку цієї черги – завершення виконання всіх попередніх операцій. При невпорядкованому виконанні деяка команда може завершити своє виконання, але все ще буде знаходитись у середині черги. Команда звільняє чергу, коли вона досягне початку та її виконання завершиться у відповідному функціональному пристрої. Якщо команда знаходиться у початку черзі, але її виконання у функціональному пристрої ще не закінчено, вона залишається у черзі. Такий механізм дозволяє підтримувати модель точних переривань, оскільки вся необхідна інформація міститься у буфері і дозволяє скоректувати стан процесора у будь-який момент часу.
Цей же буфер історії дозволяє виконувати умовне виконання команд що слідують за командою умовного переходу. Це особливо важливо для підвищення швидкодії суперскалярних архітектур. Якщо затримувати виконання всіх наступних за командою переходу команд, втрати можуть виявитись дуже високими. Якщо команди переходів складають 15-20% всіх команд, то у архітектурі що обробляє 4 команди одночасно в середньому у кожному другому такті виконується команда переходу. Механізм умовного виконання команд, що слідують за командою переходу, дозволяє вирішити цю проблему. Це умовне виконання пов‘язано з виконанням команд із заздалегідь передбаченої гілки переходу. Пристрій керування видає команду умовного переходу, прогнозує напрямок переходу та продовжує виконувати команди з цієї передбаченої гілки переходу.
Якщо прогнозування було вдалим, видача команд буде продовжуватися без зупинок. У противному випадку виконання умовних команд зупиняється та очищується буфер історії. Після цього починається обробка команд з правильної гілки переходу. Таким чином, буфер історії не тільки дозволяє вирішити проблему точного переривання, а ще й дозволяє суттєво покращити швидкодію суперскалярного процесора.
Архітектура машин із довгим командним словом (VLIW) дозволяє скоротити об‘єм обладнання, що потрібне для одночасної видачі декількох команд і потенційно чим більша кількість таких команд, тим більша економія апаратних засобів процесора. Наприклад, суперскалярна машина що забезпечує паралельну видачу 2 команд повинна паралельно аналізувати 2 коду операцій, 6 полів номерів регістрів. Хоча для виконання 2 паралельних команд потреби в апаратурі порівняно невеликі, у сучасних моделях процесорів використовується навіть можливість одночасної видачі 4 команд, при подальшому нарощенні кількості конвеєрів складність апаратури дуже сильно зростає.
Архітектура VLIW базується на багатьох незалежних функціональних пристроях. Замість того, щоб намагатися паралельно видавати у ці пристрой незалежні команди, у таких машинах декілька операцій компонуються в одну дуже довгу команду. При цьому відповідальність на вірно вибрані паралельні команди повністю перекладається на компілятор, а апаратні засоби необхідні для суперскалярної обробки відсутні.
VLIW-команда може включати, наприклад, 2 цілочисельні операції, 2 операції з ПК, 2 операції звернення до пам‘яті та операцію переходу. Така команда може мати довжину від 112 до 168 біт.
Розглянемо роботу циклу інкрементації елементів вектора на подібній машині, при цьому одночасно можуть виконуватись 2 операції звернення до пам‘яті, дві операції з плаваючою комою та одна цілочисельна операція чи команда переходу. Цикл було розгорнуто сім разів, що дозволило уникнути всі можливі зупинки конвеєра. Один прохід по циклу відбувається за 9 тактів та виробляє 7 результатів. Таким чином, на обчислення кожного результату витрачається 1.28 тактів.
| Звернення до пам‘яті 1 |
Звернення до пам‘яті 2 |
Операція ПК 1 |
Операція ПК 2 |
Цілочисельна операція/перехід |
| LD F0, 0(R1) |
| LD F10,-16(R1) |
LD F6,-8(R1) |
| LD F18,-32(R1) |
LD F14,-24(R1) |
ADD F4,F0,F2 |
| LD F26,-48(R1) |
LD F22,-40(R1) |
ADD F12,F10,F2 |
ADD F8,F6,F2 |
| SD 0(R1),F4 |
SD –8(R1),F8 |
ADD F20,F18,F2 |
ADD F16,F14,F2 |
SUB R1,R1,#48 |
| SD –16(R1),F12 |
SD –24(R1),F16 |
ADD F28,F26,F2 |
ADD F24,F22,F2 |
BNEZ R1,LOOP |
| SD –32(R1),F20 |
SD –40(R1),F24 |
| SD 0(R1),F28 |
Для машин з VLIW – архітектурою був розроблений новий метод планування видачі команд, так зване "трасировочне планування". При використанні цього метода з послідовності вихідної програми генеруються довгі команди шляхом перегляду програми за межами базових блоків.
З точки зору архітектурних ідей, машину з дуже довгим командним словом можна розглядати як розширення RISK- архітектури. Апаратні ресурси надані компілятору, та ресурси плануються статичною. В машинах з дуже довгим командним словом до цих ресурсів належать конвеєрні функціональні пристрої, шини та банки пам‘яті. Для підтримки високої пропускної здатності між функціональними пристроями та регістрами необхідно використовувати декілька наборів регістрів. Апаратне усунення конфліктів виключається і перевага надається простій логіці керування. На відміну від традиційних машин, регістри і шини не резервуються, а їх використання повністю визначається під час компіляції.
В машинах типу VLIW, крім того, цей принцип заміни керування під час виконання програми плануванням під час компіляції розповсюджений на планування використання пам‘яті. Для підтримки зайнятості конвеєрних функціональних пристроїв повинна бути забезпечена висока пропускна здатність пам‘яті. Одним із сучасних підходів до збільшення пропускної здатності пам‘яті є розшарування пам‘яті. Але у системі із розшарованою пам’яттю виникає конфлікт пам‘яті, якщо іде звернення до вже зайнятого шару пам‘яті. У звичайних машинах стан шарів пам‘яті керується апаратним чином. У машинах VLIW ця функція передана апаратним засобам. Можливі конфлікти банків перевіряє спеціальний модуль компілятора – модуль усунення конфліктів.
Виявлення конфліктів не є задачею оптимізації, це скоріше функція контролю коректності виконання операцій. Компілятор має визначати, що конфлікти неможливі, або у противному випадку припускати що може виникнути найгірша ситуація. У певних випадках, наприклад коли іде звернення до динамічного масиву і індекси обчислюються під час виконання програми, простого рішення немає. Якщо компілятор не може виявити конфлікти, операції доводиться виконувати та планувати послідовно, що веде до зменшення продуктивності.
Компілятор з трасіровочним плануванням виявляє ділянки програми без звернених дуг (переходів назад), які стають кандидатами для створення розкладу. Зверненні дуги наявні в програмах з циклами. Для збільшення тіла циклу широко використовується розгортання циклів, що веде до виникнення великих ділянок без зворотних дуг. Якщо дана програма, що має напрямки переходу тільки вперед, компілятор робить евристичне передбачення вибору умовних гілок. Шлях, що має найбільшу імовірність виконання називається трасою та використовується для оптимізації з урахуванням залежностей між даними та командами. Під час планування генерується довге командне слово. Всі операції довгого командного слова видаються одночасно та виконуються паралельно.
Після обробки першої траси планується наступний шлях, що має найбільшу імовірність виконання. Процес компонування команд продовжується до тих пір, доки не буде оптимізована вся програма.
Основною умовою досягнення ефективності VLIW-машини є коректне передбачення вибору умовних гілок. Відмічено, наприклад, що прогноз умовних гілок для наукових програм часто буває точним. Повернення назад присутні у всіх ітераціях циклу за виключенням останньої. Таким чином, прогноз, який дається вже самими командами переходу назад, у більшості випадків буде точним.
В основі реалізації ієрархії пам‘яті сучасних комп‘ютерів полягають 2 принципи: принцип локальності звернень та співвідношення вартість / швидкодія. Принцип локальності звернень говорить про те, що більшість програм не виконують звернень до всіх команд та даних рівноімовірно, а найчастіше звертаються до певної частини свого адресного простору.
Ієрархія пам‘яті сучасних комп‘ютерів будується на декількох рівнях, причому більш високий рівень менший по об‘єму, більш швидкий та має більшу вартість в перерахунку на один байт, ніж нижчий рівень. Усі рівні ієрархії взаємопов‘язані: дані на певному рівні можуть бути знайдені на більш низькому рівні та всі дані на більш низькому рівні можуть бути знайдені на ще нижчому і так далі, доки не буде досягнута основа ієрархії.
Архітектура пам‘яті складається з багатьох рівнів, але у кожний момент часу ми маємо справу тільки з двома сусідніми рівнями. Мінімальна одиниця інформації яка може бути присутня або відсутня у дворівневій ієрархії називається блоком. Розмір такого блоку може бути або фіксованим, або змінним. Якщо об‘єм фіксований, то об‘єм пам‘яті має бути кратним об‘єму блока.
Вдале чи невдале звернення до більш високого рівня називається відповідно попаданням (hit) або промахом (miss). Попадання це звернення до об‘єкта пам‘яті, який знайдено на даному рівні. Якщо об‘єкт не знайдено на даному рівні, така ситуація називається промахом. Коефіцієнт попадань (hit ratio) обчислюється як відносна кількість вдалого звернення до блока від загальної кількості звернень. Коефіцієнт промахів (miss ratio) – це відносна кількість промахів при зверненні до пам‘яті. Зрозуміло, сума цих коефіцієнтів повинна в результаті давати 1 або 100% якщо обчислення ведеться у процентах.
Оскільки підвищення швидкодії є головною причиною появи ієрархії пам‘яті, коефіцієнти попадань та промахів є важливими характеристиками. Час звернення при попаданні (hit time) є час звернення до більш високого рівня ієрархії, яке включає до себе час, необхідний для з‘ясування того, наявний блок у даному рівні ієрархії чи ні. Втрати при промаху (miss penalty) є час для заміщення блоків у більш високому рівні на блок з нижчого рівня + час для пересилки цього блока в пристрій (як правило, процесор). Втрати на промах також включають у себе дві компоненти: час доступу (access tine) – час звернення до першого слова при промаху, та час пересилки (transfer tine) – додатковий час для пересилки решти слів блоку. Час доступу пов‘язаний з затримкою пам‘яті більш низького рівня, у той час як час для пересилки пов’язаний зі смугою пропускання каналу між двома рівнями ієрархії.
Для того щоб описати деякий рівень ієрархії пам‘яті треба відповісти на такі питання:
1.Де може розміщуватися блок на вищому рівні ієрархії (розміщення блока);
2.Як знайти блок, коли він знаходиться на верхньому рівні (ідентифікація блока);
3.Який блок повинен бути замінений у випадку промаху (заміщення блоків);
4.Що відбувається під час запису (стратегія запису).
Концепція кеш-пам‘яті виникла раніше ніж архітектура IBM/360, та сьогодні присутня практично у всіх типах комп‘ютерів.
Всі визначення, які було визначено раніше можуть бути використані і для кеш-пам‘яті, хоча слово "рядок" (line) часто вживається замість слова "блок".
Як правило, для опису кеш-пам‘яті використовуються такі характеристики:
| Розмір блока (рядка) |
4-128 КБайт |
Втрати при промаху
Час доступу
Час пересилки
|
8-32 такти синхронізації
6-10 тактів синхронізації
2-22 такти синхронізації
|
| Коефіцієнт промахів |
1%-20% |
| Час попадання |
1-4 тактів синхронізації |
| Розмір кеш-пам‘яті |
4КБайт-16МБайт |
У таблиці наведені типові значення параметрів сучасних систем кеш-пам‘яті для різних моделей комп‘ютерів. Розглянемо організацію кеш-пам‘яті більш докладно, відповідаючи на 4 раніше поставлені питання
Принципи розміщення блоків в кеш-пам‘яті визначають три основних типи їх організації:
- Якщо кожний блок основної пам‘яті має тільки одне фіксоване місце, на якому він може з‘явитися в кеш-пам‘яті, то така кеш-пам‘ять називається кешем з прямим відображенням (direct mapping). Це найпростіша організація кеш-пам‘яті, при якій для відображення адрес блоків основної пам‘яті на адреси кеш-пам‘яті просто використовуються молодші розряди адреси блока. Таким чином, всі блоки основної пам‘яті що мають однакові молодші розряди адреси опиняються в одному блоку кеш-пам‘яті, тобто (адреса блоку в кеш-пам‘яті) = (адреса блоку основної пам‘яті)%(число блоків в кеш-пам‘яті);
- Якщо деякий блок основної пам‘яті може розташовуватись у будь-якому місці кешу, то кеш називається повністю асоціативним;
- Якщо деякий блок основної пам‘яті може розташовуватися на обмеженій множині місць кешу, то кеш називається множинно-асоціативним. Часто множина представляє собою групу з двох або більшого числа блоків в кеші. Якщо множина складається з n блоків, то таке розміщення називається множинно-асоціативним з n каналами. Для розміщення блока перш за все необхідно з‘ясувати номер множини. Множина визначаються молодшими розрядами адреси пам‘яті: (адреса множини кешу) = (адреса блоку основної пам‘яті) % (кількість множин в кеш-пам‘яті). Далі, блок може розміщуватись у довільному місці множини.
Діапазон можливих реалізацій кеш-пам‘яті охоплює багато рішень: кеш з прямим відображенням представляє собою просто одноканальну множинно-асоціативну кеш-пам‘ять, а повністю асоціативна кеш-пам‘ять з m блоками може бути названа m-канальною множино-асоціативною. У сучасних процесорах як правило використовується кеш-пам‘ять з прямим відображенням або чотирьох-(двух-)канальна множинно-асоціативна кеш-пам‘ять.
У кожного блока в кеш-пам‘яті присутній адресний тег, що вказує, який блок з основної пам‘яті даний блок в кеш-пам‘яті представляє. Ці теги часто одночасно порівнюються з адресою пам‘яті, виставленою процесором.
Крім того, необхідний спосіб визначення того, що блок у кеш-пам‘яті містить актуальну та придатну для використання інформацію. Найбільш загальним способом визначення того, що блок у кеш-пам‘яті містить актуальну інформацію є додавання до тега так званого біта актуальності (valid bit).
Адресація у множинно-асоціативній кеш-пам‘яті відбувається шляхом ділення адреси отриманої від процесора на три частини: поле зміщення використовується для вибору байта у середині блока кеш-пам‘яті, поле індексу визначає номер множини, а поле тега використовується для порівняння. Якщо загальний розмір кешу зафіксувати, то збільшення ступеню асоціативності веде до збільшення кількості блоків у множині, при цьому зменшується розмір індексу та збільшується розмір тега.
При виникненні промаху, контролер кеш-пам‘яті повинен вибрати блок для заміни. Користь від використання організації з прямим відображенням полягає у тому, що апаратні засоби при ньому дуже прості. Обирати просто нема чого: на попадання перевіряється тільки один блок і тільки цей блок може бути замінений. При повністю асоціативній чи множинно-асоціативній організації кешу маємо декілька блоків, з яких потрібно обирати кандидата у випадку промаху. Як правило для заміщення блоків застосовується дві основні стратегії: випадкова та LRU. У першому випадку, щоб мати рівномірний розподіл, блоки-кандидати обираються випадково. У деяких системах, для того щоб отримати відновлювальну поведінку яка корисна при налагодженні апаратури, використовують псевдовипадковий генератор випадкових чисел.
У другому випадку, щоб замінити імовірність викидання інформації, що може скоро знадобитися, всі звернення до блоків фіксуються. Замінюється блок, який не було використано довший період часу.
Перевага випадкового метода полягає у тому, що його простіше реалізувати в апаратурі. Коли кількість блоків для підтримки траси збільшується, алгоритм LRU стає все більш дорогим та часто тільки наближеним. У таблиці наведені відміни у промахах при використанні алгоритму LRU та випадкового алгоритму:
| Асоціативність |
2-канальна |
4-канальна |
8-канальна |
| Розмір кеш-пам‘яті |
LRURandom |
LRURandom |
LRURandom |
| 16КБ |
5.18%5.69% |
4.67%5.29% |
4.39%4.96% |
| 64КБ |
1.88%2.01% |
1.54%1.66% |
1.39%1.53% |
| 256КБ |
1.15%1.17% |
1.13%1.13% |
1.12%1.12% |
При зверненні до кешу на реальних програмах переважають операції читання. Всі звернення за командами є зверненнями по читанню та більшість команд не записують в пам‘ять. Як правило, операції запису складають 10% загального числа операцій з пам’яттю. Бажання зробити загальний випадок більш швидким означає оптимізацію кешу для виконання операцій по читанню, але при реалізації високопродуктивної обробки даних не можна нехтувати швидкістю операцій запису.
Загальний випадок є більш простим. Блок з кеш-пам‘яті може бути прочитаний у той самий час, коли читається та порівнюється його тег. Таким чином, читання блоку починається відразу як тільки стає доступною адреса блока. Якщо читання проходить з попаданням, блок надходить до процесора без затримок. Якщо виникає промах, то від заздалегідь прочитаного блоку нема ніякого ефекту затримки або прискорення.
Але при виконанні операції запису ситуація повністю змінюється. Саме процесор визначає розмір запису (часто від 1 до 8 байт) та тільки ця частина блоку може бути змінена. У загальному випадку це передбачає виконання над блоком послідовності операцій читання-модифікація-запис: читання оригіналу блока, модифікація його частини та запис нового значення блоку. Більш того, модифікація блоку не може починатись до тих пір, доки перевіряється тег, щоб впевнитись у тому, що звернення є попаданням. Оскільки перевірка тегів не може виконуватись паралельно з іншою роботою, операції запису займають більше часу, ніж операції читання.
Дуже часто організація кешу на різних машинах відрізняється саме стратегією виконання запису. Коли виконується запис до кешу, маємо 2 базові можливості:
- наскрізна запис (write through) – інформація записується у два місця: у блок кеш-пам‘яті та у блок більш низького рівня пам‘яті;
- запис із зворотнім копіюванням (write back) – інформація записується тільки у блок кеш-пам‘яті. Модифікований блок кешу записується в основну пам‘ять тільки коли він заміщується. Для скорочення частоти копіювання блоків при заміні часто з кожним блоком кешу пов‘язується так званий біт модифікації. Цей біт стану показує чи був змінений блок, що знаходиться в кеш-пам‘яті. Якщо він не модифікувався, то зворотне копіювання відміняється, оскільки більш низький рівень пам‘яті містить ту саму інформацію що і блок в кеші.
Обидва підходи до організації запису мають свої переваги та недоліки. При запису із зворотним копіюванням операції запису виконуються із швидкістю кеш-пам‘яті, та декілька операцій запису в один і той самий блок кешу потребують тільки однієї операції запису блока у нижчій рівень. Оскільки у цьому випадку звернення до основної пам‘яті відбуваються рідше, потрібна менша смуга пропускання пам‘яті, що добре для мультипроцесорних систем. При наскрізному запису промахи по читанню не впливають на запис до більш низького рівня, та крім того, наскрізна запис простіша для реалізації ніж запис із зверненим копіюванням. Наскрізний запис має також перевагу у тому, що основна пам‘ять має найновішу копію даних. Це також важливо для мультипроцесорних систем, а також для організації вводу/виводу.
Коли процесор очікує завершення запису при виконання наскрізного запису, то кажуть що він призупиняється для запису (write stall). Загальний метод мінімізації по запису пов‘язаний з використанням буфера запису (write buffer), який дозволяє процесору продовжити виконання команд під час оновлення вмісту пам‘яті. Але зупинки по запису можуть виникати навіть при наявності буфера запису.
При промаху під час запису маємо дві додаткові можливості:
- розмістити запис у кеш-пам‘яті (вибірка при записі (fetch on write)). Блок завантажується у кеш, після чого виконуються дії аналогічні до виконання запису з попаданням. Це схоже на промах при читанні.
- Не розміщувати запис у кеш-пам‘яті (називається також записом в оточення (write around)). Блок модифікується на більш низьком рівні та не завантажується в пам‘ять.
2.2
Принципи організації основної пам’яті у сучасних комп‘ютерах
Основна пам‘ять представляє собою наступний рівень ієрархії пам‘яті. Основна пам‘ять задовольняє запити з кешу ту служить в якості інтерфейсу вводу-виводу, оскільки є місцем призначення для вводу та джерелом для виводу. Для оцінки швидкодії основної пам‘яті використовують 2 основні параметри: затримка та смуга пропускання. Традиційно затримка основної пам‘яті має відношення до кешу, а смуга пропускання чи пропускна здатність відноситься до вводу/виводу. У зв‘язку із зростанням популярності кеш-пам‘яті другого рівня та збільшенням розміру блоків у такій кеш-пам‘яті, смуга пропускання основної пам‘яті стає важливою також і для кеш-пам‘яті.
Затримка пам‘яті традиційно оцінюється двома параметрами: часом доступу та тривалістю циклу пам‘яті. Час доступу представляє собою проміжок між видачею запиту на читання та моментом надходження замовленого слова з пам‘яті. Тривалість циклу пам‘яті визначається мінімальним часом між двома послідовними зверненнями до пам‘яті.
Основна пам‘ять сучасних комп‘ютерів реалізується на мікросхемах статичних да динамічних ЗПДВ (Запам‘ятовуючий пристрій з довільною вибіркою). Мікросхеми статичних ЗПДВ (СЗПДВ) мають менший час доступу та не потребують циклів регенерації. Мікросхеми динамічних ЗПДВ (ДЗПДВ) характеризується більшою ємністю та меншою вартістю, але потребує схем регенерації та мають значно більший час доступу.
У процесі розвитку ДЗПДВ із зростанням їх ємності основним питанням вартості таких мікросхем було питання о кількості адресних ліній та вартості відповідного корпусу. У ті роки було прийнято рішення про необхідність мультиплексування адресних ліній, що дозволило скоротити наполовину кількість контактів корпусу, необхідних для передачі адреси. Тому звернення до ДЗПДВ відбувається за два етапи: перший етап починається з видачі сигналу RAS (RowAccessStrobe), який фіксує у мікросхемі адресу рядка, другий етап включає перемикання адреси для надання адреси стовбчика та подання сигналу CAS. Назви цих сигналів пов‘язані із внутрішньою організацією мікросхеми, яка як правило представляє собою прямокутну матрицю.
Додатковою вимогою організації ДЗПДВ є необхідність періодичної регенерації її стану. При цьому всі біти в рядку можуть регенеруватися одночасно, наприклад шляхом читання цього рядка. Тому до всіх рядків ДЗПДВ періодично повинно бути звернення, причому з періодичністю приблизно 8 мілісекунд.
Ця вимога означає що система основної пам‘яті іноді буває недоступною процесору, тому що вона очікує сигнали регенерації. Розробники ДЗПДВ намагаються підтримувати такий час не більший ніж 5% загального часу. Часто контролери ДЗПДВ включають апаратуру для періодичного оновлення ДЗПДВ.
На відміну від динамічних, статичні ЗПДВ не потребують регенерації та час доступу до них співпадає з тривалістю циклу. Для мікросхем що використовують приблизно одну і ту саму технологію, ємність ДЗПДВ у 4-8 разів перевищує ємність СЗПДВ, але останні мають у 8-16 разів меншу тривалість циклу та більшу вартість. Тому в основної пам‘яті практично кожного комп‘ютера зараз використовується ДЗПДВ. Але існують і виключенні, наприклад суперкомп‘ютери Cray Research мають СЗПДВ у якості основної пам‘яті.
Для забезпечення збалансування системи зі зростанням швидкості процесорів повинна лінійно зростати і швидкість пам‘яті. У останні роки ємність мікросхем динамічної пам‘яті почетверялася кожні 3 роки, збільшуючись приблизно на 60% кожного року. Нажаль швидкість цих мікросхем зростає тільки на 7% у рік. У той же час швидкість процесорів збільшувалась на 50% за рік починаючи з 1987 року. У таблиці наведені основні характеристики мікросхем пам‘яті різних поколінь:
| Рік появи |
Ємність кристала |
Тривалість RAS |
Тривалість СAS |
Час циклу |
Оптимізований режим |
| max |
min |
| 1982 |
64КБіт |
180нс |
150 |
75нс |
250нс |
150нс |
| 1985 |
256КБіт |
150 |
120 |
50 |
220 |
100 |
| 1988 |
1 МБіт |
120 |
100 |
25 |
190 |
50 |
| 1991 |
4 МБіт |
100 |
80 |
20 |
165 |
40 |
| 1994 |
16 МБіт |
80 |
60 |
15 |
120 |
30 |
| 1997 |
64 МБіт |
65 |
45 |
10 |
100 |
20 |
Ясно, що узгодження продуктивності сучасних процесорів із швидкодією основної пам‘яті залишається однією з основних проблем. Наведені вище рішення підвищення швидкодії системи за рахунок введення великої кеш-пам‘яті або введення багаторівневої кеш-пам‘яті можуть бути непридатні з точки зору вартості. Тому важливим напрямком сучасних розробок є методи підвищення смуги пропускання при пропускній здатності пам‘яті за рахунок її організації, включаючи спеціальні методи організації ДЗПДВ.
Основними методами збільшення смуги пропускання пам‘яті є збільшення розрядності, або "ширини" пам‘яті, використання розшарування пам‘яті, використання незалежних банків пам‘яті, використання спеціальних режимів роботи схем ДЗПДВ.
Кеш першого рівня у багатьох випадках має фізичну ширину шин даних відповідну до кількості розрядів у слові, оскільки більшість комп‘ютерів звертаються саме до такої одиниці інформації. У системах без кешу другого рівня ширина шин даних основної пам‘яті комп‘ютера часто відповідає ширині шин даних кеша. Подвоєння або почетверення ширини шин кешу та основної пам‘яті подвоює або почетверює відповідну смугу пропускання системи пам‘яті.
Реалізація більш широких шин викликає необхідність мультиплексування між кешем та процесором, оскільки основною одиницею обробки інформації залишається слово. Кеш другого рівня дещо пом‘якшує цю проблему тому що мультиплексори можуть знаходитися між двома рівнями кешу, тобто затримка не така велика. Інша проблема, пов‘язана із збільшенням розрядності пам‘яті, визначається необхідністю визначення мінімального об‘єму для поступового нарощення пам‘яті яке виконується вже користувачем у процесі експлуатації системи. Подвоєння ширини шини веде до подвоєння цього мінімального інкременту. Також присутні проблеми корекції помилок у системах з широкою пам’яттю.
Прикладом може служити система Alpha AXP 21064, у якій кеш другого рівня, шина пам‘яті та сама пам‘ять мають розрядність 256 біт.
Наявність в системі багатьох мікросхем пам‘яті дозволяє використовувати потенційний паралелізм, закладений у такій організації. Для цього мікросхеми пам‘яті часто об‘єднуються у модулі або банки, що містять фіксоване число слів, причому тільки до одного слова у банку можлива звернення в кожний момент часу. У реальних системах швидкість доступу до цих банків рідко буває достатньою. Тому для підвищення швидкості треба забезпечити одночасний доступ до декількох банків пам‘яті. Одна з загальних методик називається розшаренням пам‘яті. При розшаренні банки впорядковуються таким чином, щоб N послідовних адресів i, i+1, i+2,….i+N-1 припадали б на N послідовних банків. В і-м банку пам’яті знаходяться тільки адреси kN+i, 0<= k <=M, де M – кількість слів у одному банку. Таким чином можна досягти підвищення швидкодії у N разів. Існують різні способи розшарення пам‘яті. Більшість з них нагадує конвеєри, що забезпечують посилку адресів у різні банки. Якщо потрібне звернення до непослідовних адресів у пам‘яті, швидкодія такого рішення зменшується.
Узагальненням ідеї розшарення пам‘яті є можливість реалізації декількох незалежних звернень, коли декілька контролерів пам‘яті дозволяють банкам пам‘яті (або групам розшарених банків пам‘яті) працювати незалежно.
Якщо система пам‘яті розроблена для підтримки багатьох незалежних запитів (як це має місце при роботі з кеш-пам'яттю, при реалізації багатопроцесорної та векторної обробки), ефективність системи буде в значній мірі залежати від частоти надходження незалежних запитів до різних банків. Звернення до послідовних адрес, або у більш загальному випадок звернення по адресах що відрізняються на непарне число, добре обробляється традиційними схемами розшарення пам‘яті. Проблеми виникають, коли різниця у послідовних зверненнях парна. Одне з рішень, запропоноване у великих комп’ютерах, полягає у тому, щоб статистично зменшити імовірність подібного звернення шляхом значного збільшення кількості банків пам‘яті. Наприклад, в суперкомп‘ютері NEC SX/3 використовуються 128 банків пам‘яті.
Подібні проблеми можуть бути вирішені як програмними, так і апаратними засобами.
У мікросхемах ДЗПДВ розмір рядка як правило є квадратним коренем від її загальної ємності: 1024 біт для 1МБіт, 2048 біт для 4МБІТ і т.д. З метою збільшення швидкодії всі сучасні мікросхеми пам‘яті забезпечують можливість подачі сигналів синхронізації, які дозволяють виконувати послідовні операції звернення до буферу без додаткового часу звертання до рядка. Маємо 3 способи такої оптимізації:
- блоковий режим – ДЗПДВ може забезпечити видачу чотирьох послідовних комірок для кожного сигналу RAS.
- Сторінковий режим – буфер працює як статичне ЗПДВ; при зміненні адреси стовпця можливий доступ до довільних бітів до тих пар, доки не настане нове звернення до рядка чи не настане час регенерації.
- Режим статичного стовпця – Дуже схожий на сторінковий режим за виключенням того, що не обов‘язково переключати строб адреси стовпця кожен раз для зміни адреси стовпця.
Починаючи з мікросхем ДЗПДВ ємністю 1МБіт, більшість допускає будь-який з цих трьох режимів, причому вибір режиму виконується на стадії встановлення кристалу в корпус шляхом вибору відповідних з‘єднань. Ці операції змінили традиційний час циклу пам‘яті для ДЗПДВ (див. попередню таблицю).
Перевагою такого метода оптимізації є те, що вона базується на внутрішніх схемах ДЗПДВ та не суттєво збільшує вартість системи, дозволяючи у 4 рази збільшити пропускну здатність підсистеми пам‘яті. Наприклад, блоковий режим був розроблений для підтримки режимів таких, як розшарення пам‘яті. Кристал за один раз читає значення 4 біт та передає їх за 4 оптимізовані цикли. Якщо час пересилки по шині не перевищує час оптимізованого циклу, єдине ускладнення для організації пам‘яті з чотириканальним розшаренням полягає у дещо ускладненій схемі керування синхросигналами. Сторінковий режим та режим статичного стовпця також можуть використовуватися, забезпечуючи навіть великий ступень розшарення при більш складному керуванні. Однією з тенденцій у розробці ДЗПДВ є наявність в них буферів сигналів з трьома станами. Це передбачає, що для реалізації традиційного розшарення з великою кількістю кристалів пам‘яті в системі повинні бути передбачені буферні мікросхеми для кожного банку пам‘яті.
Нові покоління ДЗПДВ розроблені з урахуванням можливостей подальшої оптимізації інтерфейсу між пам’яттю та процесором. У якості прикладу можна привести вироби компанії RAMBUS. Ця компанія бере стандартне наповнення ДЗПДВ та забезпечує новий інтерфейс, що робить роботу окремої мікросхеми більш схожою на роботу системи пам‘яті, а не на роботу окремої компоненти. RAMBUS відкинула сигнали RAS/CAS, замінивши їх шиною, яка припускає виконання інших звернень в інтервалі між посилкою адреси та надходженням даних. Кристал може повернути змінну кількість даних за одне звернення, і крім того може самостійно виконати регенерацію. RAMBUS пропонує байтовий інтерфейс та сигнал синхронізації, таким чином мікросхема може тісно синхронізуватися з тактовою частотою процесора.
Більшість систем основної пам‘яті використовують методи, подібні до сторінкового режиму ДЗПДВ для зменшення розбіжностей у швидкодії процесора та мікросхем пам‘яті.
2.6Концепція віртуальної пам‘яті
Загальновідома у теперішній час концепція віртуальної пам‘яті з‘явилася відносно давно. Вона дозволила вирішити цілу низку актуальних питань організації обчислень. Перш за все до числа таких питань відноситься надійне функціювання мультипрограмних систем.
У будь-який момент часу комп’ютер виконує множину процесів або задач, кожна з яких має свій адресний простір. Було б нераціонально віддавати всю фізичну пам‘ять одній програмі тим більше, що реальні програми використовують тільки малу частину їх адресного простору. Тому необхідний механізм розділення невеликої фізичної пам‘яті між декількома програмами. При цьому передбачений також певний рівень захисту, який обмежує задачу тими блоками, що їй належать. Більшість типів віртуальної пам‘яті скорочують також час початкового запуску програми оскільки не весь програмний код та дані потрібні задачі щоб почати виконання.
Інше питання, тісно пов‘язане з реалізацією концепції віртуальної пам‘яті, стосується організації обчислень задач дуже великого об‘єму. Якщо програма ставали занадто великою, частину її доводилось зберігати на диску та завантажувати до пам‘яті при потребі. Програмісти поділяли програми на частини і потім виявляли, котрі з них можна було виконати незалежно. Віртуальна пам‘ять звільнила програмістів від цієї задачі. Вона автоматично керує двома рівнями ієрархії пам‘яті: основною пам’яттю та зовнішньою (дисковою) пам’яттю.
Крім того, віртуальна пам‘ять спрощує завантаження програм, забезпечуючи механізм автоматичного переміщення програм, що дозволяє виконувати одну і ту ж саму програму у довільному місці оперативної пам‘яті.
2.7Сторінкова організація пам‘яті
У системах із сторінковою організацією основна та зовнішня пам‘ять діляться на блоки або на сторінки фіксованої довжини. Кожному користувачу надана деяка частина адресного простору, що може перевищувати розмір основної пам‘яті комп‘ютера та обмежена шириною адреси у конкретній машині. Ця частина називається віртуальною пам’яттю користувача. Кожне слово у віртуальній пам‘яті користувача описується віртуальною адресою, що складається з 2 частин: номером сторінки та номером байта у цій сторінці.
Керування різними рівнями пам‘яті відбувається програмою ядра операційної системи, які слідкують за розподілом сторінок та оптимізують обміни між цими рівнями. При сторінковій організації пам‘яті сусідні віртуальні сторінки не зобов’язані розміщуватись на сусідніх місцях фізичної оперативної пам‘яті. Для вказання відповідності між віртуальними сторінками та сторінками основної пам‘яті операційна система повинна сформувати таблицю сторінок для кожної програми та розмістити її в основній пам‘яті машини. При цьому кожній сторінці програми незалежно від того знаходиться вона в основній пам‘яті чи ні, ставиться у відповідність деякий елемент таблиці сторінок. Кожний елемент таблиці сторінок містить номер фізичної сторінки основної пам‘яті та спеціальний індикатор. Одиничний стан цього індикатора свідчить про те, що сторінка знаходиться у основній пам‘яті, нульовий – про відсутність.
Для підвищення ефективності такого методу у процесорах використовується спеціальна повністю асоціативна кеш-пам‘ять., яка також називається буфером перетворення адрес (БПА). Хоча наявність БПА не змінює принципу побудови схеми сторінкової організації, з точки зору захисту пам‘яті необхідно передбачити можливість його очищення при переключення з однієї програми на іншу.
Пошук в таблицях сторінок, розташованих у пам‘яті комп‘ютера, та завантаження БПА може здійснюватися або програмним способом, або спеціальними апаратними засобами. У останньому випадку для того, щоб запобігти можливості звернення програми користувача до таблиці сторінок, з якими вони не пов‘язані, передбачені спеціальні заходи. З цією метою в процесорі реалізується спеціальний додатковий регістр захисту, що містить дескриптор таблиці сторінок для даної програми (базово-граничну пару). База з‘ясовує початок таблиці сторінок в основній пам‘яті, а границя – довжину таблиці сторінок відповідної програми. Завантаження цього регістру захисту дозволено тільки у привілейованому режимі. Для кожної програми операційна система зберігає дескриптор таблиці сторінок та встановлює його в регістр захисту процесора перед запуском відповідної програми.
Відмітимо деякі особливості, притаманні простим схемам із сторінковою організацією пам‘яті. Найбільш важливою з них є те, що всі програми, які повинні безпосередньо зв‘язуватись одна з одною без втручання операційної системи, повинні використовувати загальний простір віртуальних адрес. Це відноситься і до самої операційної системи, яка повинна працювати в режимі динамічного розподілу пам‘яті. Тому у деяких системах простір віртуальних адрес користувача скорочується на розмір загальних процедур, до яких програми користувача повинні мати доступ. Спільним процедурам повинен бути виділений певний об‘єм віртуального адресного простору всіх користувачів, щоб вони мали постійне місце в таблицях сторінок всіх користувачів. У цьому випадку для забезпечення цілісності, секретності та взаємної ізоляції повинні бути передбачені різні режими доступу до сторінок, які реалізуються за допомогою спеціальних індикаторів доступу в елементах таблиць сторінок.
Наслідком такого використання є значне зростання таблиць кожного користувача. Одне з рішень проблеми скорочення довжини таблиць базується на введенні багаторівневої організації таблиць. Окремим випадком багаторівневої організації таблиць є сегментація при сторінковій організації пам‘яті. Необхідність збільшення адресного простору користувача пояснюється бажанням уникнути необхідності переміщення частин програм та даних в межах адресного простору, які часто ведуть до проблем перейменування та значним ускладненням у розділенні загальної інформації між багатьма задачами.
2.
8Сегментація пам‘яті
Інший підхід до організації пам‘яті спирається на той факт, що програми часто ділаться на окремі частини-сегменти. Кожний сегмент представляє собою окрему логічну одиницю інформації, що містить сукупність даних або програм та розташовану у адресному просторі користувача. Сегменти створюються користувачами, які можуть звертатися до них по символічному імені. У кожному сегменті встановлюється своя власна нумерація слів, починаючи з нуля.
Часто у подібних системах обмін інформацією між користувачами будується на базі сегментів. Тому сегменти є різними логічними одиницями інформації, які необхідно захищати, а саме на цьому рівні вводяться різні режими доступу до сегментів. Можна виділити 2 основні типи сегментів: програмні сегменти та сегменти даних (сегменти стека є частковим випадком сегментів даних). Оскільки спільні програми повинні мати властивість реєнтерабельності, то з програмних сегментів допускається тільки вибірка та читання констант. Запис у програмні сегменти може розглядатися як недопустима операція. Вибірка команд з сегментів даних також може вважатися недопустимою операцією та будь-який сегмент може бути захищеним від операцій по запису або по читанню.
Для реалізації сегментації було запропоновано декілька схем, котрі відрізняються деталями реалізації, але засновані на тих самих принципах.
У системах з сегментацією пам‘яті кожне слово у адресному просторі користувача визначається віртуальною адресою, що складається з 3 частин: старші розряди розглядаються як номер сегменту, середні як номер сторінки у сегменті, молодші – номер слова у сторінці.
Як і у випадку сторінкової організації, необхідно забезпечити перетворення віртуальної адреси у реальну фізичну адресу основної пам‘яті. З цією метою для кожного користувача операційна система повинна сформувати таблицю сегментів. Кожний елемент таблиці сегментів містить вказівник (дескриптор) сегменту. При відсутності сторінкової організації поле бази визначає адресу сегмента в основній пам‘яті, а границя – довжину сегмента. При наявності сторінкової організації поле бази визначає адресу початку таблиці сторінок даного сегменту, а границя – кількість сторінок у сегменті. Поле індикаторів доступу являє собою деяку комбінацію ознак блокування читання, запису та виконання.
Таблиці сегментів різних користувачів операційна система зберігає у основній пам‘яті. Для визначення розподілу таблиці сегментів виконуваної програми використовується спеціальний регістр захисту, який завантажується операційною системою перед початком її виконання. Цей регістр містить дескриптор таблиці сегментів ((базу і границю), причому база містить адресу початку таблиці сегментів виконуваної програми, а границя – довжину цієї таблиці сегментів. Розряди номера сегмента віртуальної адреси використовуються в якості індексу для пошуку у таблиці сегментів. Таким чином, наявність базово-граничних пар у дескрипторі таблиці сегментів та у елементах таблиці сегментів запобігає можливості звернення програми користувача до таблиць сегментів та сторінок, з якими вона не пов‘язана. Наявність у елементах таблиці сегментів індикаторів режиму доступу дозволяє реалізувати необхідний режим доступу з боку даної програми. Для підвищення ефективності схеми використовується асоціативна кеш-пам‘ять.
|