Кафедра экономики и менеджмента
КОНТРОЛЬНАЯ РАБОТА
по дисциплине: Эконометрика
на тему: Парная линейная регрессия, парная нелинейная регрессия, множественная регрессия, временные ряды
Выполнил (а) студент (ка):
4
курса заочного
отделения
Специальность: 080105.65
Финансы и кредит
Проверил (а):
Руза 2010
Содержание
1. Моделирование и идентификация парной линейной регрессии 4
1.1. План работы 4
1.2. Модель Монте-Карло линейной регрессии 4
1.2.1. Уравнение парной линейной регрессии 4
1.2.2. Последовательность выполнения работы по моделированию. 4
1.3. Идентификация модели парной линейной регрессии 9
1.3.1. Основные положения процедуры идентификации 9
1.3.2. Последовательность выполнения 10
1.4. Оценка существенности параметров линейной регрессии
и корреляции 11
1.4.1. Основные положения 11
1.4.2. Порядок выполнения проверки нулевой гипотезы 12
1.5. Оценка доверительных интервалов линии регрессии
и прогноза зависимой переменной 14
1.5.1. Основные положения 14
1.5.2. Последовательность выполнения процедуры оценки
доверительных интервалов 14
1.6. Идентификация с помощью функции «Линейн» («LINEST»)
ППП Excel 17
1.7. Идентификация с помощью «Пакета анализа - Регрессия»
ППП Excel 18
1.8. Анализ регрессии для реальных экономических показателей. 20
2. Моделирование и идентификация парной нелинейной
регрессии 22
2.1. План работы 22
2.2. Модель Монте-Карло нелинейной регрессии 22
2.2.1. Последовательность выполнения работы по моделированию 23
2.3. Идентификация модели парной нелинейной регрессии 25
2.3.1. Основные положения 25
2.3.2. Последовательность выполнения 25
2.4. Анализ нелинейной регрессии для реальных
экономических показателей 28
3. Моделирование и идентификация множественной
линейной регрессии 30
3.1. План работы 30
3.2. Модель Монте-Карло множественной линейной регрессии 30
3.2.1. Последовательность выполнения работы по моделированию 30
3.3. Идентификация модели множественной линейной регрессии 32
3.3.1. Основные положения процедуры идентификации
параметров множественной линейной регрессии 32
3.3.2. Последовательность выполнения работы 33
3.4. Идентификация с помощью «Пакета анализа - Регрессия»
ППП Excel 36
3.5. Анализ множественной регрессии для реальных
экономических показателей 38
4. Моделирование и идентификация временных рядов 41
4.1. План работы 41
4.2. Модель Монте-Карло временного ряда 41
4.2.1. Последовательность выполнения работы по моделированию 44
4.3. Идентификация модели временного ряда методом
наименьших квадратов 46
4.3.1. Основные положения идентификации 46
4.3.2. Последовательность выполнения 46
4.4. Идентификация временного ряда методом Юла-Уокера 50
4.4.1. Основные положения идентификации 50
4.4.2. Последовательность выполнения 52
4.5. Анализ временных рядов для реальных экономических
показателей. 53
Список использованной литературы 55
1. Моделирование и идентификация парной линейной регрессии
1.1. План работы
:
- синтез модели Монте-Карло парной линейной регрессии (прямая задача).
- вычисление параметров парной линейной регрессии (обратная задача идентификации.
- оценка существенности параметров линейной регрессии и доверительные интервалы линии регрессии.
- оценка доверительных интервалов прогноза.
- идентификация модели реальных экономических наблюдений (в соответствии с заданным вариантом).
1.2. Модель Монте-Карло линейной регрессии
1.2.1. Уравнение парной линейной регрессии
Парное линейное регрессионное уравнение имеет вид
 , где
(1.1) , где
(1.1)
x
- независимая переменная (признак-фактор),
y
- зависимая переменная (результативный признак),
a
, b
- параметры модели.
Данное уравнение определяет зависимость признак-фактора y
от результативного признака x
.
В реальности на данную связь оказывает влияние множество других неконтролируемых факторов, в связи, с чем данная связь представляется как:
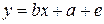 , где
(1.2) , где
(1.2)
e
- случайное отклонение наблюдаемой зависимой переменной, вызванное влиянием других факторов. Данная величина распределена по центрированному нормальному закону со средним квадратическим отклонением σе
. Задачей идентификации регрессионной модели является по данным реальных наблюдений зависимой (y
) и независимой (x
) переменным при наличии случайных отклонений (e
) оценить параметры регрессионной модели a
и b
.
Именно уравнение (1.2) является основой статистического моделирования уравнения регрессии.
1.2.2. Последовательность выполнения работы по моделированию
:
1.2.2.1. Открываем новую книгу. Cохраняем книгу в папке под именем ПЛР. Xls (Парная Линейная Регрессия). Озаглавим лист «Модель».
1.2.2.2. Формируем заголовки для исходных данных модели (Рисунок 1.1):
- коэффициенты модели a
, b
;
- объем наблюдений n
;
- среднее квадратическое отклонение погрешности СКОе
;
- математическое ожидание независимой переменной Мх
;
-среднее квадратическое отклонение независимой переменной СКОх
.
- коэффициент корреляции r
;
- коэффициент детерминации D
.
Вводим n =100
и значения а
, b
, CKOe
(σе
), Mx
, CKOx
.
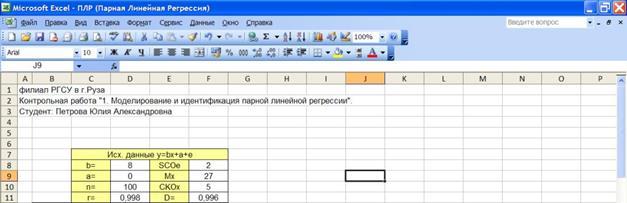
Рисунок 1.
1
1.2.2.3. Сформируем заголовки таблицы модели (Рисунок 1.2).
Выделим ячейки для:
- номера наблюдения i
;
- независимой переменной x
;
- факторного значения зависимой переменной y
, определяемой независимой переменной x
;
- ошибки регрессии (отклонение наблюдаемой независимой величины от фактического значения зависимой переменной y
, определяемой независимой переменной x
) e
;
- наблюдаемого значения зависимой переменной (с учетом ошибки регрессии e
) y
;

Рисунок 1.2
1.2.2.4. Сформируем заголовки строк для расчета (Рисунок 1.3) среднего, суммы, СКО
соответствующих столбцов.
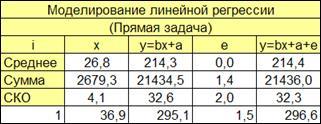
Рисунок 1.3
1.2.2.5. Вводим первый номер наблюдения (i=1
) (Рисунок 1.3).
1.2.2.6. Смоделируем первое значение независимой переменной.
Случайное значение независимой переменной x
моделируется нормальным законом распределения с заданными математическим ожиданием и средним квадратическим отклонением по формуле:
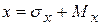 , где
(1.3) , где
(1.3)
Z
- центрированная и нормированная случайная величина, распределенная по нормальному закону (MZ=0
, σZ=1
),
Mx
, σx
- математическое ожидание и среднее квадратическое отклонение независимой переменной.
Центрированная и нормированная случайная величина моделируется на основании центральной предельной теоремы путем 12-ти кратного сложения равномерно распределенных случайных чисел Ri
в диапазоне (0,1].
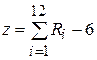 (1.4) (1.4)
Синтаксис функцией, возвращаемой случайное число, равномерно распределенное в диапазоне (0,1], имеет вид: R=
слчис().
Таким образом, для моделирования независимой переменной необходимо в ячейку, где моделируется переменная x
необходимо ввести формулу:
«=((слчис()+слчис()+слчис()+слчис()+слчис()+слчис()+слчис()+слчис()+слчис()+слчис()+слчис()+слчис()-6))*[ σx
]
+ [Mx
]
», где
[Mx
]
и [σx
]
- соответственно адреса ячеек, где заданы математическое ожидание и среднее квадратическое отклонение независимой переменной.
Поскольку при копировании данные адреса, где заданы математическое ожидание и среднее квадратическое отклонение не должны изменяться, ссылки на них должны быть абсолютными.
1.2.2.7. Рассчитаем теоретическое значение зависимой переменной. Теоретическое значение зависимой переменной определяется формулой:
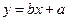 , (1.5) , (1.5)
1.2.2.8. Смоделируем ошибку модели.
Ошибка модели моделируется центрированным нормальным законом распределения аналогично моделированию независимой переменной по формуле: «=(слчис()+слчис()+слчис()+слчис()+слчис()+слчис()+слчис()+слчис()+слчис()+слчис()+слчис()+слчис()-6)*[
σe
]
», где
[σe
]
- абсолютная ссылка на ячейку, где задано среднее квадратическое отклонение ошибки регрессионной модели.
1.2.2.9. Рассчитаем фактическое значение зависимой переменной. Фактическое значение зависимой переменной рассчитывается как сумма теоретического значения и ошибки.
1.2.2.10. Моделируем сто наблюдений.
Пользуясь средствами копирования содержимого ячеек в Excel получаем 100 наблюдений независимой и зависимой переменной. В ячейку количества наблюдений n
ввести 100.
1.2.2.11. Рассчитаем коэффициенты корреляции и детерминации.
В ячейку для коэффициента корреляции вводим функцию «коррел» из категории «статистические» для массивов зависимой и наблюдаемой независимой (с учетом ошибки) переменных.
Коэффициент детерминации равен:
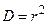 , (1.6) , (1.6)
1.2.2.12. Рассчитаем средние, суммы и СКО
:
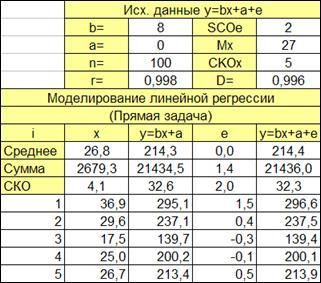
Рисунок 1.
4
В соответствующие ячейки независимой переменной вводим формулы расчета среднего значения, суммы и среднего квадратического отклонения.
Скопируем данные формулы для значений зависимой (факторной, наблюдаемой) переменных и ошибки регрессии (Рисунок 1.4).
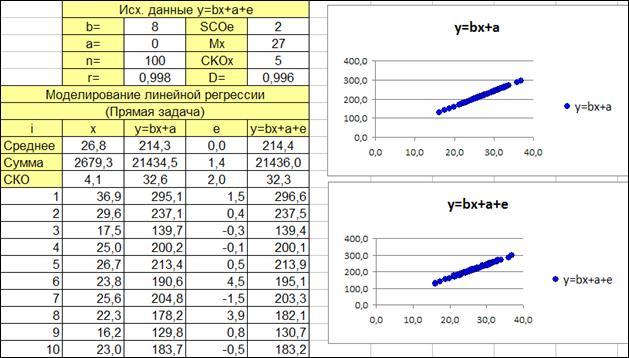
Рисунок 1.
5
Представим копию интерфейса с таблицей из первых 10-ти наблюдений и двух зависимостей (Рисунок 1.5).
1.2.2.13. Исследуем влияние параметров регрессионной модели на связь y(x)
Исследуем влияние СКО
ошибки регрессионной модели на коэффициент корреляции и детерминации. Изменяя СКО
ошибки модели получаем моделируемые значения наблюдений (Рисунок 1.6, в верхней части приведены значения коэффициентов корреляции и детерминации).
 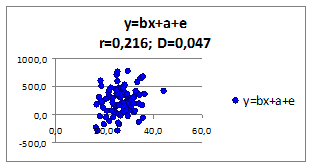 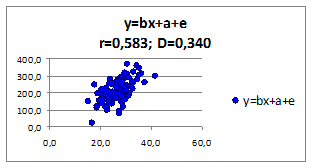 
Рисунок 1.
6
Исследуем влияние коэффициента регрессии b
на связь зависимой переменной от независимой. Построим графики для различных коэффициентов регрессии. Значения коэффициента регрессии b
приведены в верхней части рисунка:
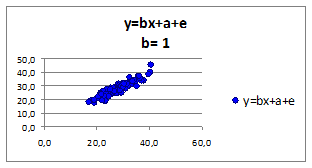 
Рисунок 1.7
Исследуем влияние коэффициента а
на связь зависимой переменной от независимой. Построим графики для различных коэффициентов а
(а>0
, а<0
). Значения коэффициента регрессии a
приведены в верхней части рисунка:
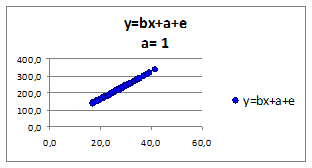 
Рисунок 1.8
1.2.2.14. Сделаем выводы из полученных данных:
- знак коэффициента регрессии b
имеет прямую связь со знаком коэффициента корреляции r
. При изменении знака коэффициента регрессии b
, меняется и знак коэффициента корреляции r
.
- при уменьшении среднего квадратического отклонения σe
, коэффициенты корреляции r
и детерминации D
увеличиваются.
- при изменении параметра a
коэффициент эластичности не меняется.
- примеры регрессионных зависимостей в экономике с параметрами:
b>0
- зависимость средней заработной платы от среднедушевого прожиточного минимума в день одного трудоспособного человека.
b<0
- зависимость расходов на покупку продовольственных товаров (в общих расходах %) от среднедневной заработной платы одного работающего.
a>0
– зависимость расходов предприятия от объема производства.
a<0
-
1.3. Идентификация модели парной линейной регрессии
1.3.1. Основные положения процедуры идентификации
:
Идентификация параметров модели основана на минимизации суммы квадратов отклонений наблюдаемой переменной от теоретической зависимости
 (1.7) (1.7)
т.е. необходимо найти такие коэффициенты a
и b
, которые позволяют получить наименьшее значение суммы квадратов отклонений в данном выражении. Дифференцирование данного выражения по коэффициентам a
и b
, приравнивание производных нулю:
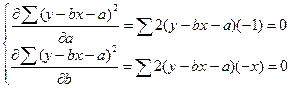 (1.8) (1.8)
позволяет получить систему нормальных уравнений:
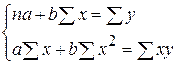 (1.9) (1.9)
Поделив, левые и правые части на n
получаем:
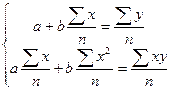 (1.10) (1.10)
Данный метод вычисления коэффициентов называется методом наименьших квадратов (МНК). Выражая средние значения через оператор среднего:
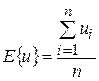 (1.11) (1.11)
Система нормальных уравнений имеет вид:
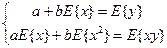 (1.12) (1.12)
Решение данной системы уравнений относительно a
и b
на основе формулы Крамера имеет вид:
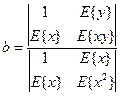 (1.13) (1.13)
Коэффициент a
может быть получен как:
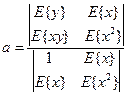 (1.14) (1.14)
Данный коэффициент может быть получен также по формуле, вытекающей из теоретического уравнения линейной регрессии:
 , т.е. (1.15) , т.е. (1.15)
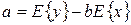 (1.16) (1.16)
1.3.2. Последовательность выполнения
:
1.3.2.1. Создаем копию листа «Модель» помещаем его перед листом «Лист2» и переименуем его назвав «Идентификация».
1.3.2.2. Выделяем ячейки (Рисунок 1.9) для расчета:
- коэффициентов a
и b
,
- значений xy
, x2
.
- значений y
, полученных по рассчитанным коэффициентам a
и b
.
Колонки y=bx+a
и e
в расчете коэффициентов a
и b
участия не принимают, поскольку теоретическая зависимость и погрешность нам не известна. Именно их мы оцениваем по моделируемому фактическому значению y=bx+a+e
.
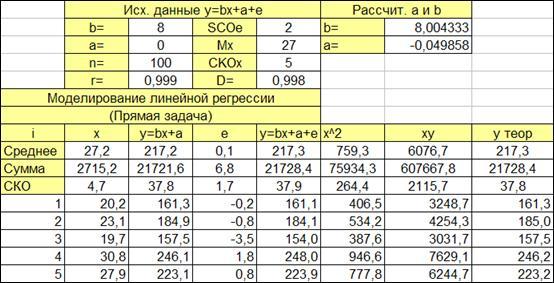
Рисунок 1.9
1.3.2.3. Рассчитаем значения xy
, x2
.
1.3.2.4. Получим средние значения, входящие в формулы расчета коэффициентов a
и b
.
1.3.2.5. Рассчитаем коэффициенты a
и b
по формулам (1.15) и (1.16).
1.3.2.6. Сопоставим заданные коэффициенты a
и b
с рассчитанными.
1.3.2.7. Получим столбец идентифицированной (с рассчитанными коэффициентами линии регрессии a
и b
) (Рисунок 1.9).
1.3.2.8. Добавим к графику факторной линии регрессии график идентифицируемой линии (с рассчитанными коэффициентами).
1.3.2.9. Увеличивая СКО
случайного отклонения σе
получаем два графика факторной и идентифицируемой линии регрессии (Рисунок 1.10).
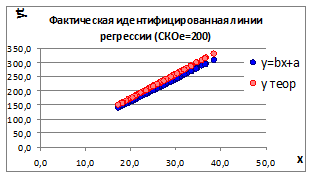 
Рисунок 1.10
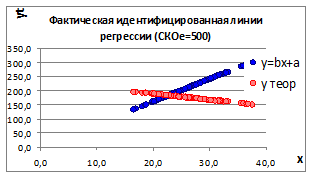 
Рисунок 1.
11
1.3.2.10. При увеличении СКОе
уменьшаются коэффициенты корреляции r
и детерминации D
, а, следовательно, уменьшается связь между изучаемыми параметрами. И это наглядно видно на графиках - несовпадение факторной и идентифицируемой линии регрессии.
1.3.2.11. Получим два наблюдения за процессом при одном и том же относительно большом СКОе
и построим графики (Рисунок 1.11).
Изменение параметров линии регрессии происходит потому, что происходит изменение влияния случайных факторов на связь между изучаемыми параметрами.
1.4. Оценка существенности параметров линейной регрессии и корреляции.
1.4.1. Основные положения
:
Общая сумма квадратов отклонения независимой переменой y
может быть представлена суммой квадратов отклонения y
и остаточной суммы квадратов переменной
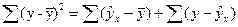 (1.17) (1.17)
Scom
Общая сумма квадратов отклонений
|
Sfact
Сумма квадратов отклонений, обусловленная регрессией
|
Srem
Остаточная сумма квадратов отклонений
|
Средние квадраты данных отклонений вычисляется как:
 (1.18) (1.18)
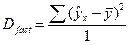 (1.19) (1.19)
 (1.20) (1.20)
F
-отношение определяется как:
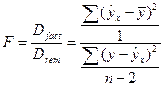 (1.21) (1.21)
Нулевая гипотеза (об отсутствии связи между y
и x
) принимается если:
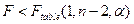 , где
(1.22) , где
(1.22)
Ftable
(1,n-2,α)
- табличное значение F
-критерия для степеней свободы 1
(числитель), n-2
(знаменатель),α
- уровень значимости.
Гипотеза о наличии связи между y
и x
принимается если
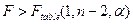 (1.23) (1.23)
1.4.2. Порядок выполнения проверки нулевой гипотезы
:
1.4.2.1. Сделаем копию листа и озаглавим его «Существенность параметров».
1.4.2.2. Сформируем заголовки таблицы модели (Рисунок 1.12).
1.4.2.3. Выделим ячейки для расчета:
- средних квадратов отклонений на одну степень свободы (Dcom
, Dfact
, Drem
),
- коэффициента детерминации D
через суммы квадратов отклонений,
- средних квадратов отклонений,
- F
-отношения, через средние квадратов отклонений на одну степень свободы,
- F
-отношения, через коэффициент детерминации,
- табличного значения F
-критерия,
1.4.2.4. Сформируем заголовки строк для расчета сумм квадратов отклонений.
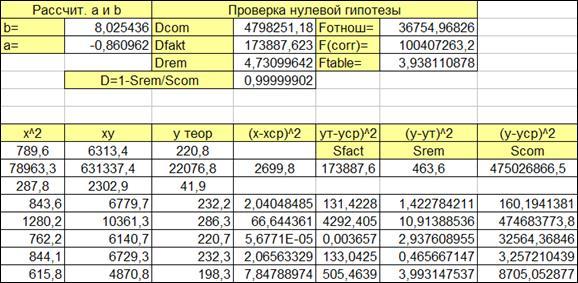
Рисунок 1.12
1.4.2.5. Рассчитаем суммы квадратов отклонений (Sfact
, Srem
, Scom
).
1.4.2.6. Рассчитаем средние квадраты отклонений на одну степень свободы (1.20, 1.21, 1.22).
1.4.2.7. Рассчитаем коэффициент детерминации D
через суммы квадратов отклонений:
 (1.24) (1.24)
1.4.2.8. Вычислим F
-отношение через средние квадратов отклонений на одну степень свободы (1.23),
1.4.2.9. Вычислим F
-отношения, через коэффициент детерминации:
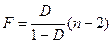
1.4.2.10. Вычислим табличное значение F
-критерия,
Введем табличное значение F
-критерия для уровня значимости а = 0,05
, воспользовавшись стандартной функцией из статистической категории Fобр
(FINV) с тремя аргументами: (уровень значимости; степень свободы числителя F
-отношения; степень свободы знаменателя F
-отношения). Для нашего случая в ячейку табличного значения F
-критерия заносится формула «=FINV(0,05;1;98)»
1.4.2.11. Из данных вычислений получили:
Так как Ftable
< F
, то гипотеза Но
о наличии связи между x
и y
принимается.
1.4.2.12. При увеличении ошибки регрессионной модели е
, F
-отношение уменьшается, что говорит об ослаблении связи между x
и y
, что, в конце концов, приводит к разрыву этой связи. Тогда гипотеза Но
о наличии связи между x
и y
отвергается. (Рисунок 1.12а, Рисунок 1.12б)

Рисунок 1.12а

Рисунок 1.12б
1.4.2.13. При ошибке регрессионной модели, при которой нулевая гипотеза отвергается идентифицированная линия регрессии намного отклоняется от заданной.
1.5.
Оценка доверительных интервалов линии регрессии и прогноза зависимой переменной.
1.5.1. Основные положения
:
Стандартная ошибка в оценках параметров а
и b
определяется как:
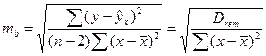 (1.25) (1.25)
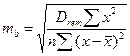 (1.26) (1.26)
Соответственно, доверительные интервалы для фактических коэффициентов bf
и af
будут:
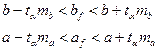 (1.27) (1.27)
Стандартное отклонение для линии регрессии определяется как:
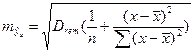 (1.28) (1.28)
Соответственно, доверительные интервалы для линии регрессии определяются как:
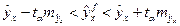 (1.29)
(1.29)
Стандартная ошибка прогноза определяется формулой по полученной линии регрессии определяется как:
 (1.30) (1.30)
Доверительные границы прогноза определяются как:
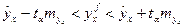 (1.31) (1.31)
1.5.2. Последовательность выполнения процедуры оценки доверительных интервалов
:
1.5.2.1. Скопируем лист и озаглавим его «Доверительные интервалы».
1.5.2.2. Сформируем заголовки таблицы модели:

Рисунок 1.13
1.5.2.3. Выделим ячейки (Рисунок 1.13) для расчета:
- стандартных ошибок оценки коэффициента b
и a
(CKOb
, CKOa
),
- значения t
-критерия Стьюдента для коэффициентов b
и a
(tb
, ta
),
- табличного значения t
-критерия (tinv
),
- верхних и нижних доверительных интервалов (Дов.инт. НГ, ВГ
).
1.5.2.4. Рассчитаем стандартные ошибки в оценке коэффициентов линии регрессии mb
, ma
(1.27, 1.28).
1.5.2.5. Рассчитаем фактические значения t
-критерия Стьюдента по формулам:
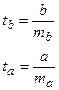 (1.32) (1.32)
1.5.2.6. Введем функцию расчета табличного значения t
-критерия.
Аргументы функции: доверительная вероятность (α
) и число степеней свободы (n-2
).
1.5.2.7. Сопоставляя фактические и табличные значения t
-критерия Стьюдента модели b
и a
и выдвинув гипотезу Но
(о статистической незначимости параметров, т.е. a=b=rxy=0
), делаем вывод:
т.к. ta
>tтабл
, tb
< tтабл
, то b
-незначим, а
не случайно отличается от нуля, а сформировалось под влиянием систематически действующей произвольной.
1.5.2.8. Рассчитаем верхние и нижние значения коэффициентов b
и a
для уровня значимости α=0,05
(1.29).
1.5.2.9. Добавим колонки с расчетом нижней и верхней границы линии регрессии (Рисунок 1.14).
Расчет производится по формулам (1.30, 1.31).
(При вводе формул обращаем особое внимание, на то, какие ссылки должны быть абсолютными, а какие - относительными).
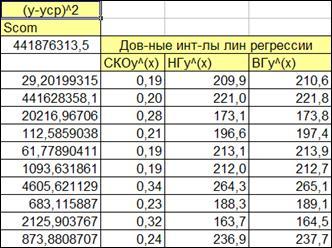
Рисунок 1.14
1.5.2.10. Построим точечные графики зависимости полученной линии регрессии и доверительных интервалов для различных значений ошибки σе
(Рисунок 1.15).
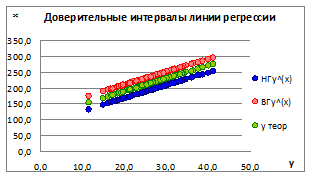 
Рисунок 1.15
1.5.2.11. Как видно на графике, при увеличении значений ошибки σе
границы доверительных интервалов увеличиваются и наоборот, что говорит об ослаблении связи между x
и y
.
1.5.2.12. Добавим колонки с расчетом нижней и верхней границы линии прогноза зависимой переменной для уровня значимости α=0,05
(Рисунок 1.16). Доверительные границы прогноза зависимой переменной вычисляются по формулам (1.32, 1.33).
Вначале получим столбец значений СКО
(1.32). После этого получить значения нижней и верхней границ (1.33). Данные интервалы учитывают статистический характер оценок коэффициентов b
и a
. Однако для больших объемов наблюдений значение в формуле (1.30).
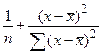
относительно малы по сравнению с единицей. В этой связи оценка стандартной ошибка прогноза может быть определена как:
 (1.33) (1.33)
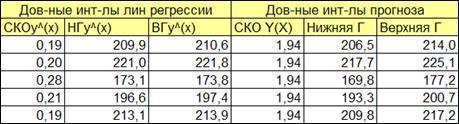
Рисунок 1.16
Доверительные интервалы в этом случае будут строиться аналогично. Однако следует учесть, что они справедливы лишь для конкретного набора зависимой и независимой переменных, т.е. для конкретных идентифицированных значений коэффициентов b
и a
.
1.5.2.13. Изменяя ошибку модели получим несколько доверительных границ прогноза.
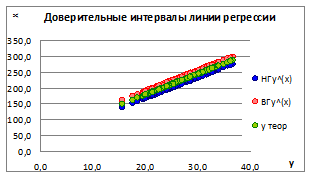 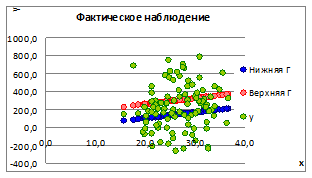 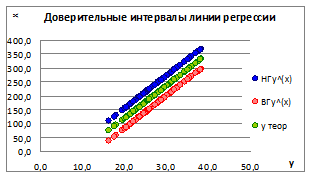 
Рисунок 1.17
1.5.2.14. Из рисунка видно, что с увеличением границ прогноза связь между x
и y
ослабевает под влиянием ошибки σе
. на линии регрессии.
1.6. Идентификация с помощью функции «Линейн» («LINEST») ППП Excel
. Для идентификации с помощью функции «Линейн» («LINEST») ППП Excel необходимо:
-выделим массив ячеек 2х5 (Рисунок 1.18).
-вызовем функцию «линейн».
-введем 4 аргумента:
-массив y
-массив x
-константа а
– ИСТИНА
-статистические характеристики – ИСТИНА
Введем данную формулу, как формулу массива для этого нажмем на клавишу F2 или активизируем строку формул. После ввода формулы массива удерживая клавиши <Shift> и <Ctrl> жмем на клавишу<Enter>.
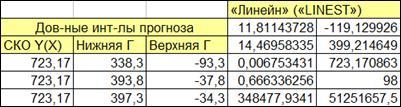
Рисунок 1.18
Таблица 1.1 представляет возвращаемые переменные в ячейках формулы массива (Рисунок 1.18).
Таблица 1.
1
| Коэффициент регрессии, b
|
Свободный член, a
|
| СКО
коэффициент регрессии b
, mb
|
СКО
коэффициента а
, ma
|
| Коэффициент детерминации, D
|
Стандартное отклонение наблюдаемых значений независимой переменной от линии регрессии, σrem
(корень из Drem
) |
| F
-отношение |
Число степеней свободы n-2
в F
-критерии (1
, n-2, α
) |
| Сумма квадратов отклонений, объясняемой регрессией |
Остаточная сумма квадратов |
При повторе моделирования (путем нажатия клавиши F9) полученные с данной функцией результаты совпадают с ранее вычисленными «вручную».
1.7. Идентификация с помощью «Пакета анализа - Регрессия» ППП Excel. После вызова команды «Анализ данных» в меню «Сервис» выберем инструмент анализа «Регрессия». В диалоговом окне (Рисунок 1.19) введем интервалы для независимой и зависимой переменных x
y
.
Введем значение уровень надежности равный (1-α
)100%, где α
- уровень значимости. Например, для уровня значимости α =0,05
, «Уровень значимости» будет составлять 95%.
Установим флажок на «выходном интервале» и в соседнюю ссылку вставим адрес левой верхней ячейки, с которой будут выводиться результаты анализа.
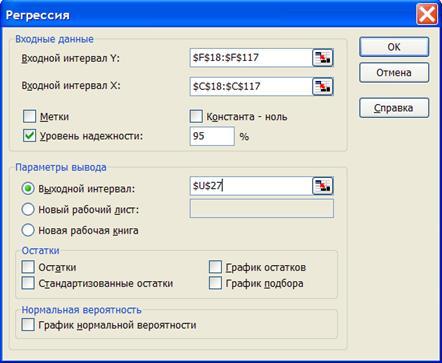
Рисунок 1.19
Рисунок 1.20 представляет результат анализа.
Заголовки таблицы «ВЫВОД ИТОГОВ».
Регрессионная статистика.
Множественный R
– коэффициент корреляции, Данный пакет может быть использован для идентификации множественной регрессии (что будет рассмотрено далее), чем и объясняется определение данного коэффициента.
R-квадрат
– коэффициент детерминации.
Стандартная ошибка
– корень квадратный из среднего квадрата отклонений Drem
.
Наблюдения
– число наблюдений.
Дисперсионный анализ
Регрессия df
– число степеней свободы (degree of freedom) для Sfact
(сумма квадратов отклонений, обусловленная регрессией).
Остаток - df
– число степеней свободы для Srem
(остаточная сумма квадратов отклонений).
Итого - df
– число степеней свободы для Scom
(общая сумма квадратов отклонений).
Регрессия - SS
–сумма квадратов отклонений, обусловленная регрессией (Sfact
).
Остаток - SS
–остаточная сумма квадратов отклонений (Srem
).
Итого SS
–общая сумма квадратов отклонений (Scom
).
Регрессия - MS
– cредний квадрат отклонений на одну степень свободы, обусловленный регрессией (Dfact
).
Остаток - MS
– cредний квадрат отклонений на одну степень свободы, обусловленный регрессией (Drem
).
Итого - MS
– cредний квадрат отклонений на одну степень свободы, обусловленный регрессией (Dcom
).
F
– F
-отношение.
Значимость F
- вероятность принятия нулевой гипотезы (гипотезы об отсутствии связи).
Y-пересечение – Коэффициенты – оценка коэффициента а
.
Переменная х1
- Коэффициенты - оценка коэффициента b
.
Y-пересечение (Переменная х1
, х2
) – Стандартная ошибка – СКО
оценки коэффициентов а
и b
.
Y-пересечение (Переменная х1
, х2
) – t-статистика
– фактические значения t
-критерия Стьюдента для коэффициентов а
и b
.
Y-пересечение (Переменная х1
, х2
) - Р-значения
- вероятность принятия нулевой гипотезы относительно коэффициентов регрессии а
и b
.
Y-пересечение (Переменная х1
, х2
) – Нижние (Верхние) 95%
- Нижние и верхние доверительные границы для коэффициентов регрессии а
и b
для доверительной вероятности 0,95 (а=0,05
).
(Экспоненциальная форма представления числа 1Е-44 эквивалентна записи 1*10-44).
1.7.1. Сопоставим значения таблицы «ВЫВОД ИТОГОВ» с рассчитанными вручную и с использованием функции «ЛИНЕЙН».
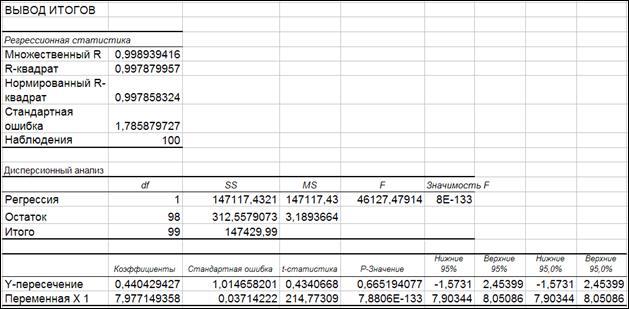
Рисунок 1.20
1.8 Анализ регрессии для реальных экономических показателей
По статистическим данным за n
-ый год сформирована таблица. Проведем идентификацию и анализ парной линейной регрессии, используя функцию «Линейн» ППП Excel (Рисунок 1.21).
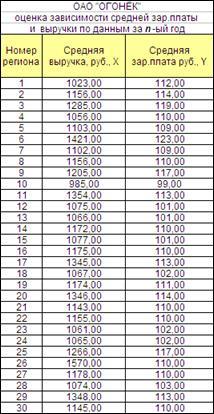
Рисунок 1.21
На основе данной таблицы и с помощью функции «Линейн» ППП Excel получаем следующие данные (Рисунок 1.22):
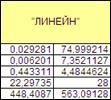
Рисунок 1.22
Из полученных данных можем вывести линейное уравнение зависимости y
от x
. Оно имеет вид: y
=74,999214+0,029281x
, т.е. с увеличением выручки на 1 руб., зар.плата будет увеличиваться на 0,029281 в среднем.
Судя по значению D=0,443311- связь переменных регрессии умеренная. Причем, 44%- это доля вариации y, объясненная вариацией фактора x, включенного в уравнение, а остальные 56% вариаций приходятся на долю других факторов, не учтенных в уравнении.
Выдвинем гипотезу Но
о статистически незначимом отличии показателей от нуля: a=b=r
xy
=0
. С помощью таблицы Стьюдента определили, что t
табл
для числа степеней свободы df
=n-2
=30-2=28 и а=0,05
составляет 2,0484.
t
a
=74,999214/7,3521127=10,2> t
табл
t
b
=0,029281/0,006201=4,72> t
табл
Исходя из этого, гипотеза Но
отклоняется т.е. a
и b
неслучайно отличаются от нуля, а статистически значимы.
2. Моделирование и идентификация парной нелинейной регресси
и
2.1. План работы
В процессе выполнения данной работы необходимо:
-синтезировать модель Монте-Карло парной нелинейной регрессии (прямая задача).
-вычислить параметры парной нелинейной регрессии (обратная задача идентификации.
-оценить существенность параметров линейной регрессии и доверительные интервалы линии регрессии.
-оценить доверительные интервалы прогноза.
-составить отчет по работе.
2.2. Модель Монте-Карло нелинейной регрессии
Парная нелинейная регрессия подразделяется на два вида
-нелинейная относительно независимой переменной x
,
-нелинейная относительно оцениваемых параметров a
и b
.
Примером первого вида являются уравнения:
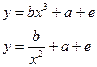 (
2.1) (
2.1)
Примером второго вида являются степенная и экспоненциальная функции:
 , где
(2.2) , где
(2.2)
x
- независимая переменная (признак-фактор),
y
- зависимая переменная (результативный признак),
a
, b
- параметры модели.
e
- случайное отклонение наблюдаемой зависимой переменной, вызванное влиянием других факторов. Аналогично линейным моделям данная величина распределена по центрированному нормальному закону со средним квадратическим отклонением σе
. Задачей идентификации регрессионной модели является по данным реальных наблюдений зависимой (y
) и независимой (x
) переменной при наличии случайных отклонений (e
) оценить параметры регрессионной модели a
и b
.
Парная нелинейная регрессия относительно независимой переменной x
легко приводится к линеному виду путем замены переменной (z=x3
– для первого уравнения и z=1/x2
– для второго).
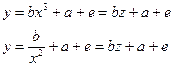 (2.3) (2.3)
Уравнения парной нелинейной регрессия относительно оцениваемых параметров a
и b
не все приводятся к линейному виду. В данной работе рассматриваются модели, которые могут быть приведены к линейному виду (такие нелинейные модели называются внутренне линейными).
Степенная и экспоненциальная модели внутренне линейны, поскольку они могут быть приведены в линейному виду.
Так, для степенного уравнения логарифмирование позволяет получить линейную модель в виде:
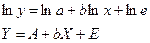 (2.4) (2.4)
Аналогично экспоненциальная модель приводится как:
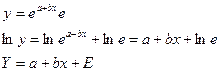 (2.5) (2.5)
Данные уравнения являются основой статистического моделирования нелинейной регрессии.
Значения параметров для выполнения работы определяется вариантом. Ниже представлена методика выполнения работы для уравнения
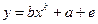 (2.6) (2.6)
2.2.1. Последовательность выполнения работы по моделированию.
2.2.1.1. Откроем новую книгу и сохраним ее в своей папке под именем ПНР.xls (Парная Нелинейная Регрессия). Озаглавим лист «Модель».
2.2.1.2. Сформируем заголовки для исходных данных модели (Рисунок 2.1)
- коэффициенты модели a
, b
;
- объем наблюдений n
;
- среднее квадратическое отклонение погрешности СКОе
;
- математическое ожидание независимой переменной Мх
;
- среднее квадратическое отклонение независимой переменной СКОх
.
- значение степени k
2.2.1.3. Введем значения а
, b
, k
, CKOe
(σе
), Mx
, CKOx
.
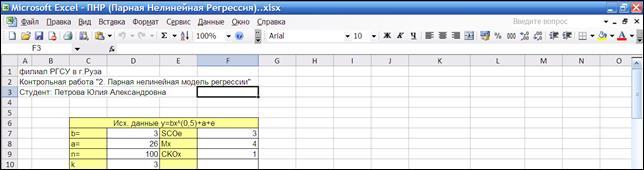
Рисунок 2.1
2.2.1.4. Сформируем заголовки таблицы модели (Рисунок 2.2).
2.2.1.5. Выделим ячейки для:
-расчета коэффициента корреляции r
;
-индекса корреляции R
.
-номера наблюдения i
;
-независимой переменной x
;
-факторного значения зависимой переменной y
, определяемой независимой переменной x
;
-ошибки регрессии (отклонение наблюдаемой независимой величины от фактического значения зависимой переменной y
, определяемой независимой переменной x
) e
;
-наблюдаемого значения зависимой переменной (с учетом ошибки регрессии e
) y
;
Рисунок
2.2
2.2.1.6. Введем первый номер наблюдения (i=1
).
2.2.1.7. Смоделируем первое значение независимой переменной.
Случайное значение независимой переменной x
моделируется аналогично линейной модели.
2.2.1.8. Рассчитаем теоретическое значение зависимой переменной.
Теоретическое значение зависимой переменной определяется формулой:
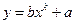 (2.7) (2.7)
2.2.1.9. Смоделируем ошибку модели.
Ошибка модели моделируется аналогично линейной модели.
2.2.1.10. Рассчитаем фактическое значение зависимой переменной. Фактическое значение зависимой переменной рассчитывается как сумма теоретического значения и ошибки.
2.2.1.11. Смоделируем сто наблюдений.
Пользуясь средствами копирования содержимого ячеек в Excel получим 100 наблюдений независимой и зависимой переменной. В ячейку количества наблюдений n
введем 100.
В отчете представить 10 первых значений (Рисунок 2.3) и построить точечные графики теоретической зависимости и смоделированных фактических наблюдений (Рисунок 2.4).
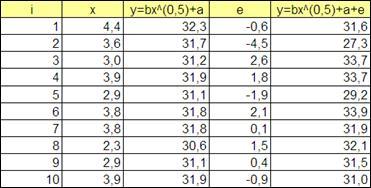
Рисунок 2.3

Рисунок 2.4
2.3. Идентификация модели парной нелинейной регрессии
.
2.3.1. Основные положения
:
Рассматриваемая нелинейная регрессионная модель приводится к линейной путем введения новой переменной
 . .
Процедура идентификации и анализа полученной линейной модели y
(z
) аналогичена процедуре идентификации и анализа для линейной модели.
2.3.2. Последовательность выполнения.
2.3.2.1. Вводим новую переменную.
2.3.2.2. Получим столбец 100 значений новой переменной (Рисунок 2.5).
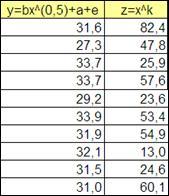
Рисунок 2.5
Таким образом, задача свелась к линейной модели
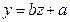
2.3.2.3. Для определения параметров a
и b
применить функцию «Линейн» («LINEST») ППП Excel, для чего выделить массив ячеек 2х5 (Рисунок 2.6).
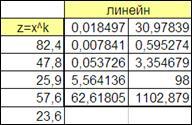
Рисунок 2.6
2.3.2.4. Аналогично, как это делалось для линейной модели вводим формулу массива.
В ячейках формулы массива (Рисунок 2.6) возвращаемые переменные расположены в соответствии с таблицей, представленной в разделе парной линейной регрессии.
2.3.2.5. Сопоставим идентифицированные значения коэффициентов модели с заданными.
Посредством нажатия на клавишу F9 (при нажатии которой происходит новая генерация случайных чисел) пронаблюдать за изменением идентифицируемой линий регрессии из-за вариации рассчитанных коэффициентов a
и b
.
2.3.2.6. Видно, что при увеличении коэффициента a
, коэффициент b
уменьшается. Идентификационная линия регрессии с уменьшением коэффициента a
приближается к теоретической линий данной регрессии.
Заключение о принятии нулевой гипотезы, построение доверительных интервалов линии регрессии y
(z
) и прогноза строятся аналогично, как это делалось выше для линейной модели (в рамках данной работы это разрешается не проводить).
2.3.2.7. Построим точечные графики зависимости теоретической и идентифицируемой линий регрессии.
Для этого необходимо преобразовать полученные зависимости от z
в зависимости от x
и получить столбец значений y
(Рисунок 2.7).

Рисунок 2.7
В качестве параметров a
и b
используются идентифицированные с помощью функции «Линейн» значения.
2.3.2.8. С помощью мастера диаграмм построим теоретическую и идентифицированную линии регрессии (Рисунок 2.10).
2.3.2.9. Построим доверительные интервалы прогноза.
Доверительные интервалы прогноза определяются как:
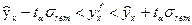 , где , где
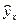 - теоретическое идентифицированная нелинейная линия регрессии (на странице Excel – yт
), - теоретическое идентифицированная нелинейная линия регрессии (на странице Excel – yт
),
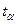 - табличное значение коэффициента Стъюдента для доверительной вероятности α=0,05
, - табличное значение коэффициента Стъюдента для доверительной вероятности α=0,05
,
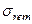 - Стандартное отклонение наблюдаемых значений независимой переменной от линии регрессии (2-й столбец,3-я строка возвращаемой таблицы функции «ЛИНЕЙН»). - Стандартное отклонение наблюдаемых значений независимой переменной от линии регрессии (2-й столбец,3-я строка возвращаемой таблицы функции «ЛИНЕЙН»).
Табличное значение коэффициента Стъюдента (tinv
) для рассматриваемого примера (Рисунок 2.8):
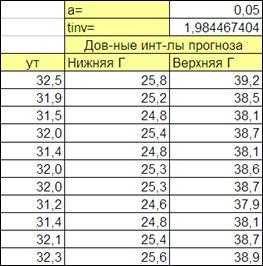
Рисунок 2.8
Получим график с нелинейной регрессией и доверительными интервалами прогноза (Рисунок 2.9).

Рисунок 2.9
2.3.2.10. Генерируя различные случайные последовательности и изменяя СКОe
получим различные теоретические и идентифицированные линии регрессии (Рисунок 2.10, Рисунок 2.11).

Рисунок 2.10
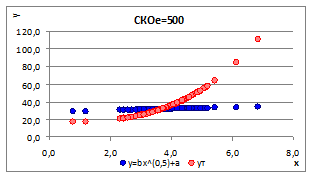 
Рисунок 2.11
2.3.2.11. Из полученных линий регрессии видим, что в нашем случае (при первоначально заданной CKOe
=3) связь параметров a
иb
была достаточно сильной. Поэтому при генерации различных случайных последовательностей теоретические и идентифицированные линии регрессии практически не отличаются друг от друга. При увеличении CKOe
(CKOe
=500) появляются значимые различия между линиями, а в некоторых случаях связь близка к разрыву.
2.4.
Анализ нелинейной регрессии для реальных экономических показателей.
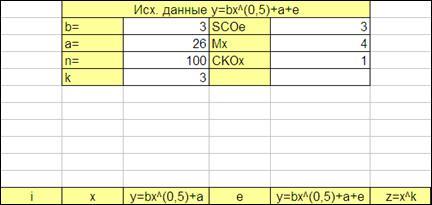
Исследуем зависимость общих расходов предприятия от объема производства.
Дана таблица наблюдений:
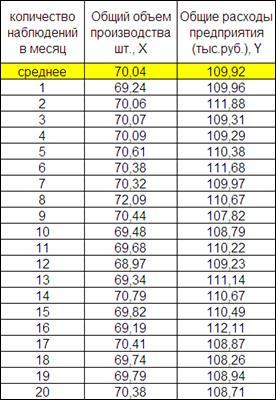
Рисунок 2.12
Исследуем данную зависимость при заданном уравнении y
=
bxk
+
a
+
e
и k
=0.5.
Получим средние значения по столбцам, а так же значения X
Y
и X
^2
.
Вычислим значения a
и b
:
b
= (ср
XY
-ср
X
*ср
Y
)/(ср
X
^2-(ср
X
)^2))
a
=ср
Y
-
b
*ср
X
.
Формула для вычисления Yтеор
имеет вид: Yтеор
=b*x+a
.
Рассчитаем средний квадрат отклонения (Y-Yтеор
)^2
, а так же для приведения нелинейного уравнения к линейному введем и рассчитаем новую переменную Z=X^k
.
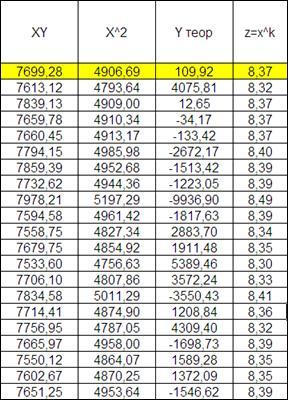
Рисунок 2.13
При помощи функции «Линейн» проведем анализ полученных данных:
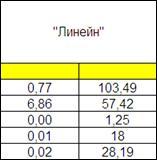
Рисунок 2.14
Графически данная зависимость имеет вид:

Рисунок 2.15
3. Моделирование и идентификация множественной линейной регресси
и
3.1. План работы
-в процессе выполнения данной работы необходимо
-синтезировать модель Монте-Карло множественной линейной регрессии (прямая задача).
-вычислить параметры множественной линейной регрессии (обратная задача идентификации).
-составить отчет по работе.
3.2. Модель Монте-Карло множественной линейной регрессии (прямая задача)
Уравнение множественной линейной регрессии.
Множественная линейная регрессия имеет вид
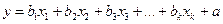 , где
(3.1) , где
(3.1)
x1
,
x2
,
x3
,
…, x
k
,
- независимые переменные,
y
- зависимая переменная,
a,b1
, b2
, b3
,…, b
k
- параметры модели.
В реальности на данную связь оказывает влияние множество других неконтролируемых факторов, в связи с чем данная связь представляется как:
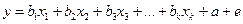 ,где
(3.2
) ,где
(3.2
)
e
- случайное отклонение наблюдаемой зависимой переменной, вызванное влиянием других факторов. Уравнение (3.1) является основой статистического моделирования уравнения регрессии.
В рамках данной работы будет моделироваться и идентифицироваться модель третьего порядка:

3.2.1. Последовательность выполнения работы по моделированию.
Откроем новую книгу. Cохраним книгу в своей папке под именем МЛР. Xls (Множественная Линейная Регрессия).
Для данной задачи рекомендуется отменить режим автоматического пересчета листа. Для этого необходимо в «Сервис»\ «Параметры»\ «Вычисления» установить режим «вручную».
3.2.1.2. Сформируем заголовки для исходных данных модели (Рисунок 1.1):
- коэффициенты модели,
a,b1
, b2
, b3
,…, b
k
;
- среднее квадратическое отклонение погрешности СКОе
;
- математическое ожидание независимых переменных Мх1
, Мх2
, Мх3
,
;
- среднее квадратическое отклонение независимых переменных СКОх1
,
СКОх2
,
СКОх3
,
Ввести значения а
, b1
, b2
, b3
, CKOe
(σ
е
), Мх1
, Мх2
, Мх3
,СКОх1
, СКОх2
, СКОх3
, согласно варианту контрольной работы.
3.2.1.3. СКОе
задать равным нулю.
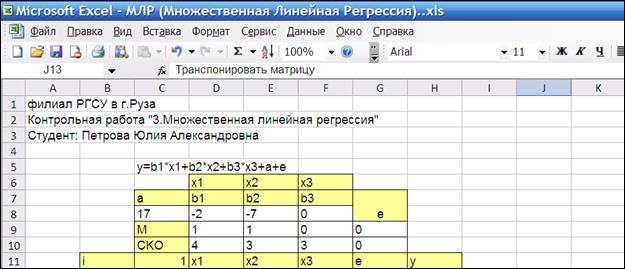
Рисунок 3.1
3.2.1.4. Сформируем заголовки таблицы модели (Рисунок 3.1).
Выделим ячейки для:
i
– номер наблюдения,
1
– единичный вектор (будет рассмотрен ниже),
х1
, х2
, х3
- значения переменных x1
, x2
, x3
,
е
– значение ошибки в текущем наблюдении e
,
y
– моделируемое факторное значения зависимой переменной y
, определяемое независимыми переменными x
1
, x
2
, x
3
и ошибкой e
.
3.2.1.5. Моделирование двадцати наблюдения (Рисунок 3.2 (показаны первые 4 наблюдения))
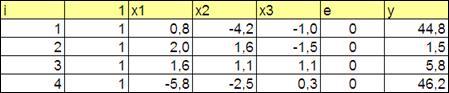
Рисунок 3.2
Колонка единичного вектора заполняется единицами.
Случайные значения независимых переменных x
1
, x
2
, x
3
– моделируются аналогично предыдущему по формуле
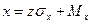 , где
(3.3) , где
(3.3)
Z
- центрированная и нормированная случайная величина, распределенная по нормальному закону (MZ
=0, σZ
=1),
Mx
, σx
- математическое ожидание и среднее квадратическое отклонение независимой переменной.
Центрированная и нормированная случайная величина моделируется на основании центральной предельной теоремы путем 12-ти кратного сложения равномерно распределенных случайных чисел R
i
в диапазоне (0,1].
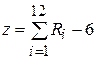 (3.4) (3.4)
Синтаксис функцией, возвращаемой случайное число, равномерно распределенное в диапазоне (0,1], имеет вид:
R=
слчис().
Для моделирования независимой переменной необходимо в ячейку, где моделируется переменная x
необходимо ввести формулу:
«=(слчис()+слчис()+слчис()+слчис()+слчис()+слчис()+слчис()+слчис()+слчис()+слчис()+слчис()+слчис()-6)*[ σx
]+ [Mx
]», где
[Mx
] и [σx
] - соответственно адреса ячеек, где заданы математическое ожидание и среднее квадратическое отклонение независимой переменной (ссылки на данные ячейки должны быть абсолютными).
Аналогично моделируется ошибка в текущем наблюдении e
,
Факторное значения зависимой переменной y
, определяемое независимыми переменными x
1
, x
2
, x
3
и ошибкой e
вычисляется по формуле (3.2).
3.2.1.6. Задав СКОе
=0 (Ме
=0) построим точечные графики зависимости у(х1
), у(х2
), у(х3
)
(Рисунок 3.3).
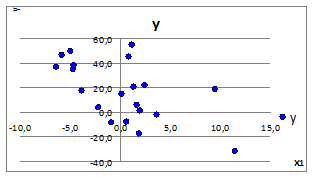 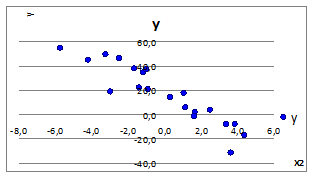 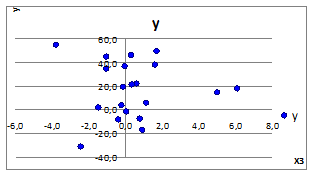
Рисунок 3.3
3.2.1.7. При СКОе
=0 имеем отсутствие линейной связи y
(x
). Это объясняется тем, что внутри рассматриваемых случаев случайная природа образования зависимости имеет место существовать.
3.3. Идентификация модели множественной линейной регрессии
3.3.1. Основные положения процедуры идентификации параметров множественной линейной регрессии
Задачей идентификации и является нахождение таких значений a, b1
, b2
, b3
, при которых сумма квадратов ошибки будет минимальна
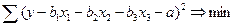 (3.5) (3.5)
На основании смоделированных значений наблюдений мы имеем следующую систему уравнений:
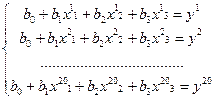 (3.6) (3.6)
Где верхний индекс обозначает номер моделируемого наблюдения.
Если ввести следующие векторы и матрицу как:
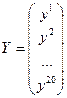 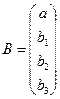 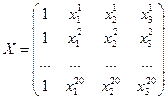 , (3.7) , (3.7)
то система уравнений может быть записана в векторной форме:
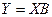 (3.8) (3.8)
Условие минимума квадрата ошибки в векторной форме будет иметь вид:
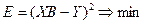 (3.9) (3.9)
Данный минимум обеспечивается при условии равенства нулю производной:
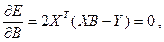 где
(3.10) где
(3.10)
ХТ
- транспонированная матрица Х
.
Раскрывая скобки получаем:
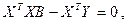 (3.11) (3.11)
Откуда вектор параметров модели будет определяться как:
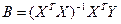 (3.12) (3.12)
3.3.2. Последовательность выполнения работы
:
Для расчета элементов вектора В
(состоящего из значений коэффициентов регрессионной модели) необходимо последовательно получим:
- транспонированную матрицу - ХТ
,
- произведение - ХХТ
,
- обратную матрицу – (ХХТ
)-1
,
- произведение - (ХХТ
)-1
ХТ
,
- произведение - (ХХТ
)-1
ХТ
Y
,
3.3.2.1. Получим транспонированную матрицу ХТ
.
Транспонированная матрица получается путем замены срок на столбцы,

Для получения транспонированной матрицы необходимо:
-выделим исходную матрицу
-кликнем по кнопке «Копирование
»,
-кликнем на ячейку, в которой необходимо разместить транспонированную матрицу (20 столбов вправо и 5 строк вниз от нее ячейки должны быть свободными),
-выполним команду «Правка>Специальная вставк
a
».Поставим флажок «Транспонирование
» и нажмем на клавишу ОК.
На рабочем поле появилась транспонированная матрица (Рисунок 3.4 - приводим лишь первые столбцы).

Рисунок
3.4
Убедимся, что процедура транспонирования произведена правильно.
3.3.2.2. Получим произведение матриц ХХТ
.
Произведение матрицы Х
размерностью (20х4) на матрицу ХТ
размерностью (4х20) будет матрица размерностью (4х4).
В этой связи выделим область ячеек 4х4 и введем в них формулу массива умножения матриц «Мунож» (категория «математические»).
В раскрывшемся диалоговом окне (Рисунок 3.5) введем адреса умножаемых массивов.
После чего кликнем по кнопке «ОК», нажмем на клавишу F2 или активизируем строку формул и удерживая клавиши <Shift> и <Ctrl> нажмем на клавишу<Enter>.
В выделенных ячейках появится результат умножения (Рисунок 3.6).
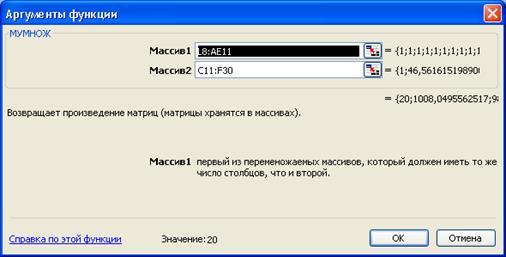
Рисунок
3.5
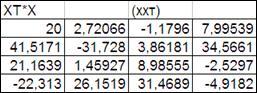
Рисунок 3.6.
3.3.2.3. Получим обратную матрицу (ХХТ
)-1
.
Выделим ячейки (4х4) для обратной матрицы и ввести в них формулу массива вычисления обратной матрицы «Мобр» (в той же категории). В диалоговом окне ввести адреса исходной обращаемой матрицы и аналогично получить значения ее элементов (Рисунок 3.7)
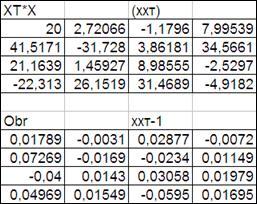
Рисунок 3.7
3.3.2.4. Получим произведение матриц (ХХТ
)-1
ХТ
.
Произведение матрицы (ХХТ
)-1
ХТ
размерностью (4х4) на матрицу размерностью (4х20) будет матрица размерностью (4х20).
Следовательно, для ввода формулы массива необходимо выделить ячейки для матрицы размером (4х20). После чего аналогично получить результат умножения (Рисунок 3.8 – приведены первые столбцы результата умножения).
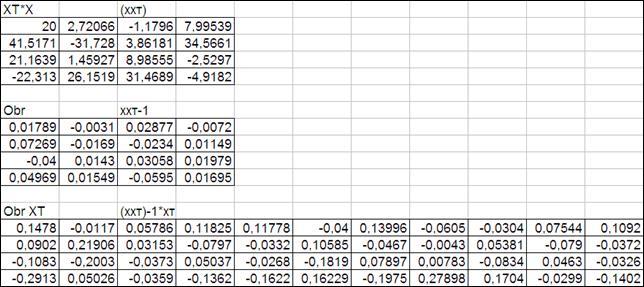
Рисунок
3.8
3.3.2.5. Получим произведение матриц (ХХТ
)-1
ХТ
Y
, т.е. вектор коэффициентов В
.
Произведение матрицы (ХХТ
)-1
ХТ
Y
размерностью (4х20) вектор Y
размерностью (20х1) будет вектор размерностью (4х1).
Следовательно, необходимо выделить 4 ячейки на поле и ввести в них аналогично формулу умножения матриц.
Озаглавим слева данные ячейки (a
, b1
, b2
, b3
) (Рисунок 3.9)
Значения в этих ячейках должны совпадать с заданными значениями a, b1
, b2
, b3
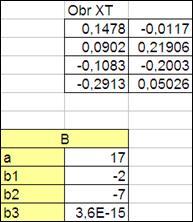
Рисунок 3.9
3.4. Идентификация с помощью «Пакета анализа - Регрессия» ППП Excel
Идентификация с помощью «Пакета анализа - Регрессия» ППП Excel аналогична процедуре идентификации линейной парной регерессии. Отличие заключается в задании входного интервала Х.
Для идентификации множественной регрессии необходимо задавать адреса ячеек не одного столбца, а нескольких столбцов (для нашего примера 3), в которых размещены значения независимых переменных x1
, x2
, x3
(Рисунок 3.10).
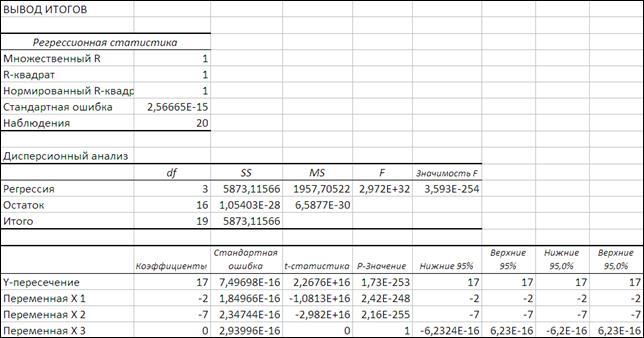
Рисунок 3.10
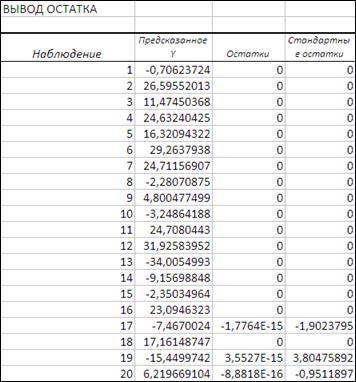
Рисунок 3.11
  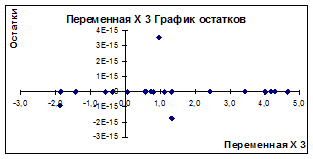
Рисунок 3.12
Уравнение регрессии имеет вид: y
=17-2x1
-7x2
Значимость критерия F
показывает, что полученное значение не случайно, оно сформировалось под влиянием существенных факторов, т.е. подтверждается значимость всего уравнения и показателя тесноты связи (индекса множественной детерминации) R
-квадрат оценивает долю вариаций результата за счет представленных в уравнении факторов в общей вариации результата. 100% указывает на полную связь между результативными и факторными признаками. Стандартная ошибка определяет тесноту связи с учетом степени свободы общей и остаточной дисперсии. Она дает тесноту связи, которая не зависит от числа факторов.
3.5.
Пример анализа экономических показателей на предприятии.
Исследуем зависимость денежной выручки за несколько месяцев (y
) от поступления денежных средств за пребывание льготных категорий граждан (x1
) и среднего возраста льготных категорий.
Дана таблица наблюдений.
Анализ зависимости выручки (y
тыс.руб.) санатория "Огонёк" от средней суммы поступлений денежных средствот льготных путевок (x1
тыс. руб.) и среднего возраста льготной категории (x2
лет).
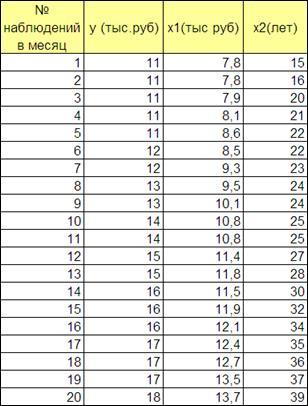
Рисунок 3.13
Проведем анализ с помощью «Пакета анализа - Регрессия» ППП Excel.
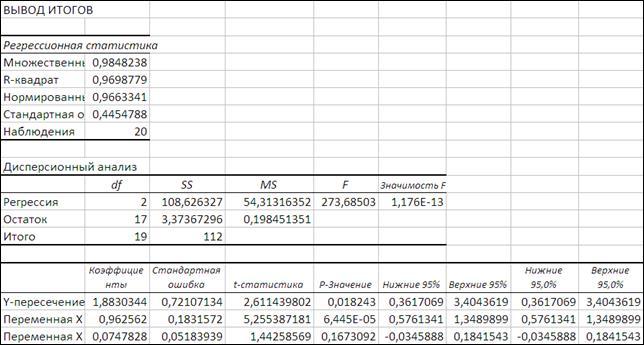
Рисунок 3.14

Рисунок 3.15
 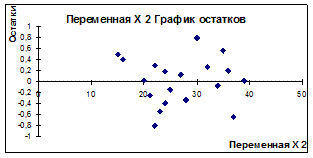 
Рисунок 3.16
Уравнение регрессии имеет вид y=1,883+0.9626x1
+0.0748x2
По множественному R
= 0,9699 видим, что связь коэффициентов регрессии тесная. Критерий Fчастн
х2
= 2 показывает статическую зависимость включения второго фактора после первого. Прирост факторной дисперсии за счет дополнительного признака х
2
незначительный. Вероятность х
2
случайного формирования много ниже уровня значимости. Прирост факторной дисперсии за счет признак х1
существенный. Поэтому фактор х2
можно исключить из рассмотрения и ограничиться парной регрессией y
=1,883+0,9626х1
. Уравнение более простое для анализа и прогноза.
4. Моделирование и идентификация временных рядов
4.1. План работы
В процессе выполнения данной работы необходимо:
-синтезировать модель Монте-Карло временного ряда (прямая задача).
-вычислить параметры временного ряда (обратная задача идентификации) на основе метода наименьших квадратов и получить уравнение прогноза.
-вычислить параметры временного ряда (обратная задача идентификации) на основе процедуры Юла-Уокера и получить уравнение прогноза.
-составить отчет по работе.
4.2. Модель Монте-Карло временного ряда
.
В общем виде модель авторегрессии-скользящего среднего АРСС(p,q) имеет вид:
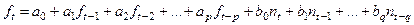 , где
(4.1) , где
(4.1)
ft
–значение временного ряда в момент времени t
,
ft
– значение временного ряда в момент времени t-1, t-2,…,t-k
,
ai
bi
– коэффициенты модели,
nt
, nt-1
,…, nt-k
– значения случайного центрированного (математическое ожидание равно нулю) и нормированного (среднее квадратическое отклонение равно единице) импульса типа «белый шум» в моменты времени t,
t-1,
t-2,…,
t-
k
.
Коэффициент a0
определяет (но не равен ему) среднее значение ряда (но не равен ему).
Анализ временных рядов удобно производить с помощью дискретного преобразования Лапласа или z
-преобразования (основанным на гармоническом разложении Фурье и преобразовании Фурье). Таблица 4.1 представляет весьма простые формулы для преобразования временного ряда, представленного во временной области, в ряд в терминах z
-преобразования и обратно.
Таблица 4.1.
| Основная теорема z
-преобразования |
| Описание процесса во временной области |
Описание процесса во области z
-преобразования |
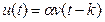 |
 |
Преимущество рассмотрения временных рядов в области z
-преобразования по сравнению с их анализом во временной области заключается в понижении «сложности» математических действий. Так операции дифференцирования, интегрирования, умножения, деления во временной области в z
-пространстве заменяются на операции умножения, деления, сложения, вычитания, соответственно.
Значительным преимуществом представления временных рядов в z
-пространстве является то, что это позволяет проводить математические действия над ними (складывать, вычитать, умножать, делить).
Без нарушения общности для простоты положим, что коэффициент a0
равен нулю.
На основании формул в данной таблице временной ряд (4.1) в терминах z-преобразования (с учетом равенства нулю коэффициента a0
) будет выглядеть как:
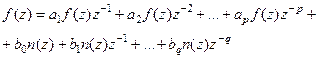 (4.2) (4.2)
Преобразуя данное выражение (вынося за скобки) f(
z)
и n(
z)
получаем;
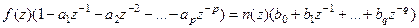 , ,
Откуда:
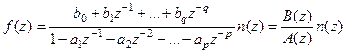
Полином:
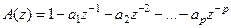 (4.3) (4.3)
определяет «авторегрессионную» составляющую модели.
Полином:
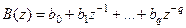 (4.4) (4.4)
представляет собой составляющую «скользящее среднее».
Уравнение:
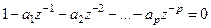 (4.5) (4.5)
называется характеристическим уравнением.
Корни данного уравнения полностью описывают поведение временного ряда. Для стационарных процессов все корни характеристического уравнения должны быть по модулю меньше единицы
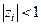
Если корни характеристического уравнения комплексно-сопряженными, то во временном ряду имеет место гармоническая составляющая.
В данной контрольной работе рассматривается модель авторегрессии 2-го порядка АРСС(2,0) или АР (2).
Соответственно модель авторегрессии 2-го порядка во временной области будет иметь вид
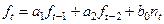 , (4.6
) , (4.6
)
а в z
-преобразовании:
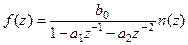 (4.7) (4.7)
Характер временного ряда определяется корнями характеристического уравнения:
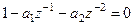 (4.8) (4.8)
Домножим левую и правую части на z2
и получим квадратное уравнение:
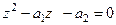 (4.9) (4.9)
Корни характеристического уравнения определяются как:
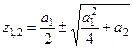 (4.10) (4.10)
По определению корней уравнения имеем:
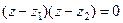 (4.11) (4.11)
или:
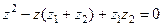 (4.12) (4.12)
Сопоставляя данное уравнение с (4.9) находим коэффициенты модели:
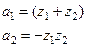 (4.13) (4.13)
Пусть корни характеристического уравнения комплексно-сопряженные:
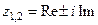 , где
(4.14) , где
(4.14)
Re
, Im
– действительная и мнимая части корней характеристического уравнения, соответственно.
Тогда на основании уравнения (4.13) получаем:
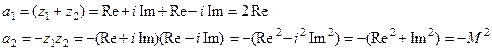 , где
(4.15) , где
(4.15)
М
– модуль корней характеристического уравнения
Рисунок 4.1 представляет единичный круг с комплексно-сопряженными корнями.
Для стационарного временного ряда все корни характеристического уравнения находятся внутри единичного круга (Рисунок 4.1).
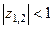 (4.16) (4.16)

Рисунок 4.1
Из этого условия вытекают ограничения на коэффициенты а1
, а2
:
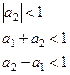 (4.17) (4.17)
Аргумент φ
определяется как:
 (4.18) (4.18)
Период временного ряда определяется отношением:
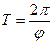 (4.19) (4.19)
При a0
=0 среднее значение ряда равно нулю. При a0
≠0 среднее значение временного ряда определяется как:
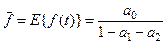 (4.20) (4.20)
Дисперсия ряда определяется как:
 (4.21) (4.21)
Уравнение (4.6) является основой статистического моделирования временного ряда.
4.2.1. Последовательность выполнения работы по моделированию.
4.2.1.1. Откроем новую книгу и сохраним ее в своей папке под именем ВР. xls (Временной ряд). Озаглавим лист «Модель».
4.2.1.2. Сформируем заголовки для исходных данных модели (Рисунок 4.2):
-действительные, мнимые части, модуль и аргумент корней характеристического уравнения Re,
Im,
M,
arctg
φ
;
-период Т
;
-коэффициенты модели a0, a1, a2, b0
;
-среднего значения и среднего квадратического отклонение ряда;
4.2.1.3. Введем значения Re,
Im, a0, b0
, соответствующие варианту контрольной работы.
4.2.1.4. Вычислим значения a1, a2,
M2
,
M,
arctg
φ,
T
(Рисунок 4.2).
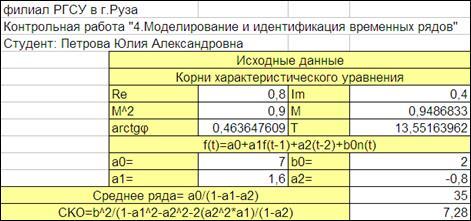
Рисунок 4.2
4.2.1.5. Сформируем заголовки таблицы модели временного ряда (Рисунок 4.3).
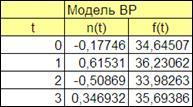
Рисунок 4.3
4.2.1.6. Введем первые 4 номера наблюдений (t
=1,2,3).
4.2.1.7. Смоделируем 4 значения случайного центрированного импульса n(t).
(математическое ожидание случайного импульса Mn=0
и среднее квадратическое отклонение случайного импульса СКО
n=1
)
Для этого аналогично, как моделировалась погрешность в предыдущих работах, в соответствующие ячейки необходимо ввести формулу:
«=(слчис()+слчис()+слчис()+слчис()+слчис()+слчис()+слчис()+слчис()+слчис()+слчис()+слчис()+слчис()-6»
4.2.1.8. Смоделируем первые 4 значения временного ряда от математического ожидания.
В момент времени t=0
значения f(
t-1)
и f(
t-2)
не определены, а для момента времени t=1
не определено значение f(
t-2)
. Поэтому данные значения ряда могут быть определены через средние значения (математические ожидания ряда).
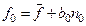
 (4.22) (4.22)
Для момента времени t=2,3,4,…
предыдущие значения временного ряда определены и, следовательно, в момент времени t=2
вводится формула, которая с учетом необходимости абсолютных ссылок на коэффициенты модели имеет вид (для данного расположения таблицы и исходных данных на листе Excel): «=$D$9*D16+$D$10*D15+$D$11*C17».
Выделяя последние 2 строки (для автоматического изменения значения времени) полученной таблице копировать моделируемое значения временного ряда до момента времени t=400
(Рисунок 4.3 представляет лишь первые 4 значения).
4.2.1.9. Построить графики временного ряда f(
t)
(Рисунок 4.4).
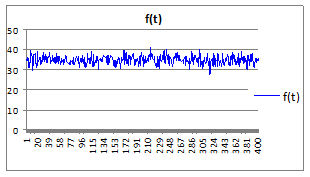 
Рисунок 4.4
4.3. Идентификация модели временного ряда методом наименьших квадратов.
4.3.1. Основные положения
:
Целью идентификации является оценка параметров a0, a1, a2, b0
по наблюдаемым (смоделированным) значениям, т.е. уравнению ряда:
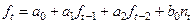 (4.23) (4.23)
можно поставить в соответствие уравнение множественной регрессии:
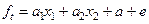 , где
(4.24) , где
(4.24)
x1
=ft-1
, x1
=ft-1
, e=b0
nt
В этом случае параметры a0, a1, a2
могут быть определены методом наименьших квадратов, как это проводилось при идентификации множественной регрессии.
Параметр b0
определяется на основе дисперсии временного ряда (4.21),
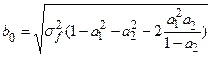 (4.25) (4.25)
4.3.2. Последовательность выполнения
:
4.3.2.1. Сделаем копию листа и озаглавим его «Идентификация МНК».
4.3.2.2. Добавим столбцы со значениями f(
t-1)
и f(
t-2)
(Рисунок 4.5).
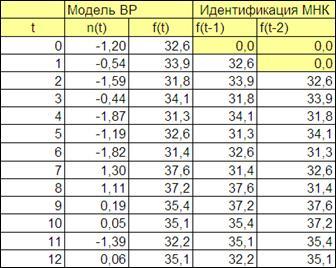
Рисунок 4.5
4.3.2.3. Проведем идентификацию методом наименьших квадратов (с помощью «Пакета анализа - Регрессия» ППП Excel)
Идентификация с помощью «Пакета анализа - Регрессия» ППП Excel аналогична процедуре идентификации множественной регрессии. В качестве входного интервала
Y
вводим столбец f(
t)
, входного интервала Х
– два столбца f(
t-1)
и f(
t-2)
.
Установим «флаг» на выходной интервал,
зададим адрес пустой ячейки справа оставив 3 пустых столбца от столбца f(
t-2)
и нажав на клавишу ОК
получим результаты идентификации(Рисунок 4.6).
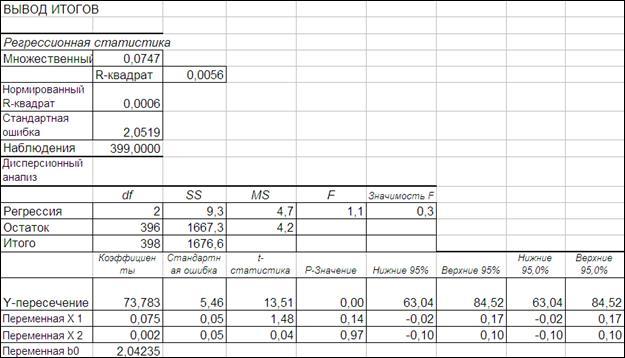
Рисунок 4.6
4.3.2.4. Оценим значение b0
по формуле 4.25.
Для этого рассчитаем среднее значение ряда и его среднее квадратическое отклонение (функции СРЗНАЧ и СТАНДОТКЛОН).
Пользуясь свойством копирования ячеек рассчитаем данные параметры для всех полученных столбцов в конце таблицы. Для удобства скопируем заголовок таблицы, и, разместить его в последней строке. Рисунок 4.7).
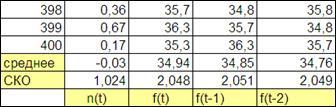
Рисунок 4.7
Под ячейкой переменная х1 таблицы ВЫВОД ИТОГОВ сформируем заголовок переменнаяb0
(Рисунок 4.8). В соседнюю ячейку введем формулу расчета b0
.
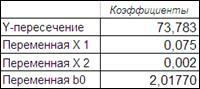
Рисунок 4.8
4.3.2.5. Оценим сущность полученной модели a0, a1, a2.
-дадим заключение о нулевой гипотезе,
-построим доверительные интервалы для коэффициентов модели a0, a1, a2
4.3.2.6. Сопоставим идентифицированные значения коэффициентов модели с заданными.
4.3.2.7. Введем столбец прогноза ряда (Рисунок 2.6
), в котором прогнозируемые значения ряда в момент времени t
+1 вычисляются в момент времени t
по формуле:
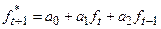 , где , где
a0,
a1,
a2
- идентифицированные значения коэффициентов модели, соответственно, «Y-пересечение», «Переменная Х1», «Переменная Х2».
Для этого в ячейку f
(2) введем данную формулу. При этом ссылки на ячейки со значениями a0,
a1,
a2
(«Y-пересечение», «Переменная Х1»,«Переменная Х2») должны быть абсолютными.
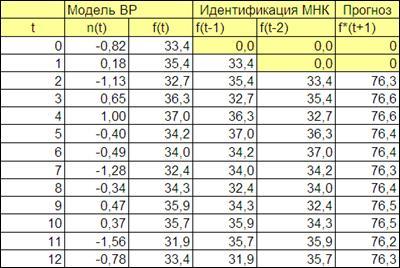
Рисунок 4.9
4.3.2.8. Построим график изменения временного ряда и прогноза для первых (начиная с момента времениt
=2) 25-35 значений (Рисунок 4.10).

Рисунок 4.10
4.3.2.9. Получим столбец ошибок прогноза (начиная с момента времени t
=2) f*
(
t)-
f(
t).
4.3.2.10. Получим автокорреляционную функцию ошибки прогноза.
Для этого выделим ячейки для аргумента k
автокорреляционной функции и самой функции r(
k)
.
Замечание:
при включенном режиме (Сервис\параметры\вычисления) Автоматически или в режиме Вручную и при нажатии клавиши F9
весь лист пересчитывается заново. В этой связи все моделируемые, а следовательно и рассчитываемые по формулам переменные изменяются.
Введем значения аргумента k
(от 0 до 30) (Рисунок 2.7).
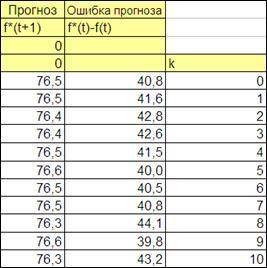
Рисунок 4.11
Для получения автокорреляционной функции в ячейку, соответствующей r(0)
вставить формулу расчета коэффициента корреляции (категория статистические, функция КОРРЕЛ):
«=КОРРЕЛ(I22:I389;I22:I389)»
В качестве массива 1 и массива 2 используется один и тот же массив ошибок. Обратим внимание на то, что вводимые массивы ошибок на 30 (от t=0
до t=370
) данных меньше чем полный массив моделирования (от t=0
до t=400
).
Это связано с тем, что нам необходимо получить значения коэффициента корреляции между массивами f(
t)
и f(
t+
k),
где k
изменяется от 0 до 30. Значения же f
(371+30) не существует.
После нажатия на клавишу «Ввод» получаем значение автокорреляционной функции для k=0
, равное единице.
Для получения автокорреляционной функции для k=1.2,3,…30
необходимо изменять адреса второго массива последовательно на единицу,
Для этого необходимо в формуле расчета коэффициента корреляции r(0)
ссылки на первый массив сделаем абсолютными, т.е. с помощью клавиши «F4» запишем как: «=КОРРЕЛ($I$22:$I$389;I22:I389)»
После этого скопируем данную формулу для всех k=1.2,3,…30
(Рисунок 4.12).
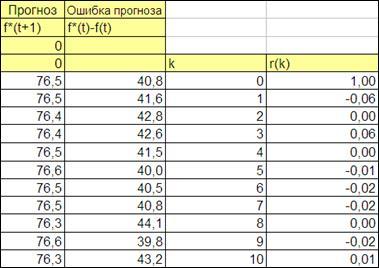
Рисунок 4.12
Получим график автокоррелфяционной функции и сделаем заключение о качестве полученной модели прогноза (Рисунок 4.13).

Рисунок 4.13
4.4. Идентификация временного ряда методом Юла-Уокера
.
4.4.1. Основные положения идентификации
:
Как было показано, модель авторегрессии АР (p) имеет вид:
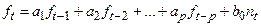 (4.26) (4.26)
Домножим левую и правую части на f(t-k)
:
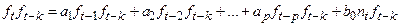
Применим оператор среднего к левой и правой частям:
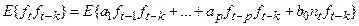 . .
Учитывая свойство линейности оператора среднего (оператор от суммы равен сумме оператором и оператор от постоянной, умноженной на случайную величину равен постоянной, умноженной на оператор от случайной величины) получаем:
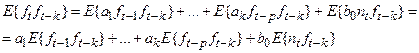
Разделив левую и правую части на дисперсию временного ряда получаем:
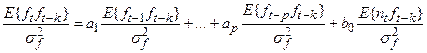
Исходя из определения коэффициента автокорреляции центрированной случайной величины:
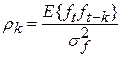
и учитывая, что коэффициент корреляции временного ряда ft-k
с белым шумом nt
равен нулю получаем:
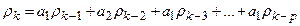 (4.27) (4.27)
Подставив в данное выражение последовательно k
=1,2,3,…,p
получаем систему уравнений:
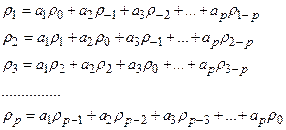
Учитывая, что
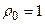
и то, что автокорреляционная функция четная
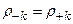
получаем:
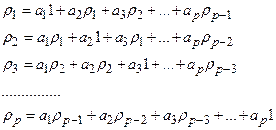
Данная система уравнений в векторной форме имеет вид:
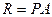 , где
(2.28
) , где
(2.28
)
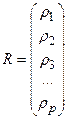 , , 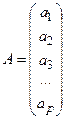 , ,
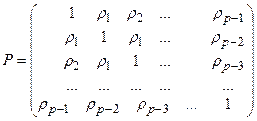
Вектор R
и матрица P
состоят из коэффициентов автокорреляции, которые вычисляются известным значениям временного ряда.
Вектор А
, представляющий неизвестные коэффициенты модели (которые и подлежат идентификации) может быть определен из уравнения (4.28) как:
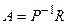
Данное уравнение носит название уравнения Юла-Уокера
4.4.2. Последовательность выполнения
:
4.4.2.1. Сделаем копию листа и озаглавим его «Идентификация Юл-Уокер».
4.4.2.2. Удалим промежуточные и выходные результаты идентификации методом наименьших квадратов.
Для этого очистить ячейки с результатами идентификации МНК с помощью Пакета анализа Регрессия и восстановить свойства их границ.
Удалим четыре столбца нового листа: «прогноз f
*(t
+1)», «ошибка прогноза - f
*(t)-
f
(t)
», «k
», «автокорреляционную функцию ошибки прогноза - r(
k)
».
4.4.2.3. Получим необходимые значения коэффициентов корреляции.
Вектор R
и матрица R
уравнения Юла-Уокера:
для авторегрессионной модели 2-го порядка имеют вид:
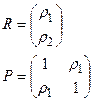
Следовательно, получим значения коэффициентов автокорреляции временного ряда ρ
1
, ρ
2
. Аналогично, как вычислялась выше автокорреляционная функция для ошибки прогнозирования, получим значения автокорреляционного ряда f(
t)
(Рисунок 4.14).
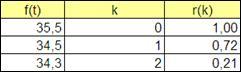
Рисунок 4.14
4.4.2.4. Сформируем вектор R
и матрицу P
уравнения Юла-Уокера (Рисунок 4.15)
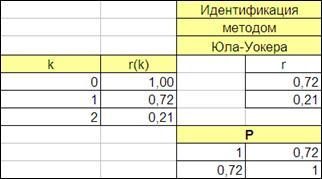
Рисунок
4.15
4.4.2.5. Получим обратную матрицу P-1
(функция МОБР) (Рисунок 4.16).
4.4.2.6. Получим вектор А
(функция МУМНОЖ) (Рисунок 4.16).
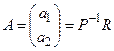
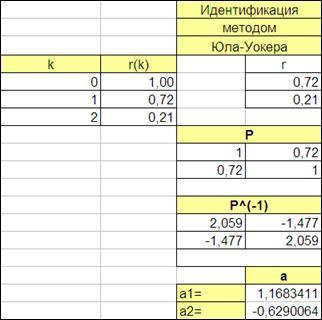
Рисунок 4.16
4.4.2.7. Сопоставим идентифицированные параметры временного ряда с заданными:
| Заданные: |
Идентифицированные: |
| a1
= 1,6 |
а1
= 1,16 |
| а2
= -0,8 |
а2
= -0,62 |
4.5. Анализ временных рядов для реальных экономических показателей.
Установлена зависимость прибыли предприятия у
(млн.руб.) от цен на сырье х1
(тыс. руб. за 1т) и производительности труда х2
(ед. продукции на 1 рабочее место). На основании наблюдений составлена таблица:
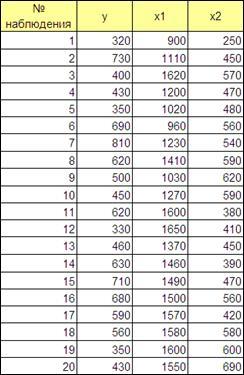
Рисунок 4.17
Проведем идентификацию с помощью «Пакета анализа - Регрессия» ППП Excel.
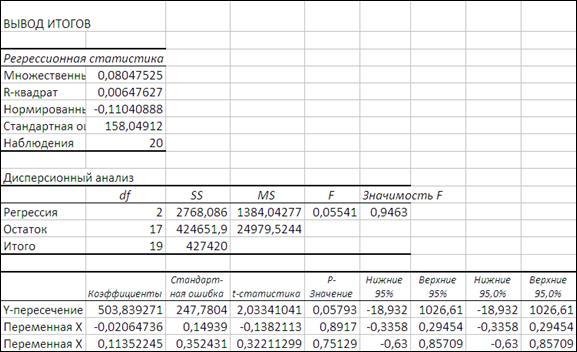
Рисунок 4.18
Из полученных данных видим, R
-квадрат свидетельствует о невысокой точности данной модели. Хотя множественный R
говорит о существовании слабой связи между показателями. Причем х2
является более значимым для данной зависимости у
от х1
и х2
. На тесноту связей могут также оказывать другие факторы, которые не внесены в таблицу наблюдений. Поэтому требуется провести дополнительные наблюдения и проанализировать модель.
Список использованЫХ ИСТОЧНИКОВ
1. Эконометрика: Учебник / Под ред. И.И.Елисеевой. - М: Финансы и статистика, 2004. - 344 с.: ил.
2. Практикум по эконометрике: Учеб. пособие / И.И.Елисеева, С.В.Курышева, Н.М.Гордеенко и др. Под ред. И.И.Елисеевой. - М: Финансы и статистика, 2004. - 192 с.: ил.
3. Горшков В.А. Временные ряды. Моделирование, идентификация, прогноз. - М:, Спутник-плюс, 2006.-145 с.: ил.
|