| ВСЕРОССИЙСКИЙ ЗАОЧНЫЙ ФИНАНСОГО-ЭКОНОМИЧЕСКИЙ
ИНСТИТУТ
КАФЕДРА СТАТИСТИКИ
КУРСОВАЯ РАБОТА
по дисциплине «Статистика»
на тему «Выборочный метод изучения производственных и финансовых показателей»
Исполнитель:
Москва- 2009
Оглавление
Введение................................................................................................. 3
Теоретическая часть.................................................................... 5
Расчетная часть............................................................................ 20
Аналитическая часть.................................................................... 37
Заключение............................................................................................ 39
Литература............................................................................................ 41
Введение.
Наиболее корректный статистический анализ общественного процесса обеспечивают сведения о каждом его проявлении. Или, говоря статистическим языком, полный анализ всей совокупности возможен только при учете значения признака у каждой единицы совокупности. В качестве примера такого анализа можно привести всеобщие переписи населения.
Однако, массовый характер общественного явления часто влечет за собой невозможность исследования его в полном объеме, т.е. во всех его проявлениях. В статистической науке разработан специальный метод, позволяющей исследовать лишь часть явления, а результаты и выводы транспонировать на все явление в целом. Такой метод называется «выборочное наблюдение». Основой метода выборочного наблюдения служит взаимосвязь между единичным и общим, между частью и целым, которая существует в общественных явлениях.
Исследуемая часть статистической совокупности называется выборочной, а количество единиц, составляющих ее объем принято обозначать n. Вся совокупность называется генеральной, объем генеральной совокупности обычно обозначают N.
Можно выделить ряд причин применения выборочного наблюдения:
· недостаток временных ресурсов (как для проведения обследования, так и для анализа полученного большого объема данных);
· недостаток кадровых ресурсов, т.е. квалифицированных специалистов для проведения наблюдения и анализа;
· недостаток материальных ресурсов, т.е. слишком дорогостоящее наблюдение;
· практическая невозможность учета всех единиц совокупности в связи с их уничтожением в результате наблюдения (например, в случае обследования всхожести партии семян, продолжительности горения электроламп и т.д.);
· практическая нецелесообразность наблюдения каждой единицы совокупности (например, определения уровня потребления продукта питания населением региона и т.д.)
Основным принципом выборочного наблюдения является принцип рэндомизации (от англ. random – случай), т.е. принцип случайности отбора единиц совокупности, определяющий равенство единиц по возможности быть отобранными в выборочную совокупность. Данный принцип должен выполняться даже в случае планомерного отбора единиц.
В результате неполного обследования генеральной совокупности могут возникнуть ошибки наблюдения – ошибки репрезентативности. Поэтому, основной задачей исследователя является, во-первых, обеспечение представительности (репрезентативности) выборки, и, во-вторых, определение степени уверенности в соответствии параметров выборочной и генеральной совокупностей.
Задачи работы: описать теоретические основы выборочного метода
Теоретическая часть.
Множество всех единиц совокупности, обладающих определенным признаком и подлежащих изучению, носит в статистике название генеральной совокупности
.
На практике по тем или иным причинам не всегда возможно или же нецелесообразно рассматривать всю генеральную совокупность. Тогда ограничиваются изучением лишь некоторой части ее, конечной целью которого является распространение полученных результатов на всю генеральную совокупность, т. е. применяют выборочный метод.
Выборочный метод
, статистический метод исследования общих свойств совокупности каких-либо объектов на основе изучения свойств лишь части этих объектов, взятых на выборку. Для этого из генеральной совокупности особым образом отбирается часть элементов, так называемая выборка, и результаты обработки выборочных данных (например, средние арифметические значения) обобщаются на всю совокупность. Основой выборочного метода является закон больших чисел.
В силу этого закона при ограниченном рассеивании признака в генеральной совокупности и достаточно большой выборке с вероятностью, близкой к полной достоверности, выборочная средняя может быть сколь угодно близка к генеральной средней. Таким образом, средняя арифметическая, рассчитанная по выборке, может с достаточным основанием рассматриваться как показатель, характеризующий генеральную совокупность в целом.
При составлении выборки можно поступать двумя способами: после того как объект отобран и над ним произведено наблюдение, он может быть возвращен или не возвращен в генеральную совокупность. В связи с этим выборки подразделяют на повторные и бесповторные. Для того, что бы по данным выборки можно было достаточно уверенно судить об интересующем признаке генеральной совокупности, необходимо, что бы объекты выборки правильно его представляли. Другими словами, выборка должна правильно представлять пропорции генеральной совокупности. Это требование формулируют так: выборка должна быть репрезентативной (представительной). Репрезентативная выборка
- это такая выборка, в которой все основные признаки генеральной совокупности, из которой извлечена данная выборка, представлены приблизительно в той же пропорции или с той же частотой, с которой данный признак выступает в этой генеральной совокупности. Существуют способы, позволяющие гарантировать достаточную репрезентативность выборки. Как доказано в ряде теорем математической статистики, таким способом при условии достаточно большой выборки является метод случайного отбора элементов генеральной совокупности, такого отбора, когда каждый элемент генеральной совокупности имеет равный с другими элементами шанс попасть в выборку. Выборки, полученные таким способом, называются случайными выборками. Случайность выборки является, таким образом, существенным условием применения выборочного метода.
Статистическое наблюдение можно организовать сплошное и несплошное. Сплошное наблюдение представляет собой обследование всех без исключения элементов изучаемой совокупности и, следовательно, получение исчерпывающей статистической информации. Несплошное наблюдение представляет собой учёт только подмножества элементов общей совокупности, на основе которого можно получить обобщающие характеристики всей совокупности с некоторой степенью точности.
В статистической практике самым распространенным является выборочное наблюдение.
Выборочное наблюдение, статистическое наблюдение, при котором исследованию подвергают не все элементы изучаемой совокупности (называемой при этом «генеральной»), а только некоторую, определённым образом отобранную их часть. Отобранная часть элементов совокупности (выборка) будет представлять всю совокупность с приемлемой точностью при двух условиях: она должна быть достаточно многочисленной, чтобы в ней могли проявиться закономерности, существующие в генеральной совокупности; элементы выборки должны быть отобраны объективно, независимо от воли исследователя, так чтобы каждый из них имел одинаковые шансы быть отобранным или же чтобы шансы эти были известны исследователю.
Совокупность, из которой производится отбор, называется генеральной, и все ее обобщающие показатели - генеральными.
Совокупность отобранных единиц именуют выборочной совокупностью, и все ее обобщающие показатели - выборочными.
При любых статистических исследованиях возникают ошибки двух видов: регистрации и репрезентативности.
Ошибка выборки
расхождение между характеристиками выборочной и генеральной совокупности. Ошибки регистрации могут иметь случайную (непреднамеренную) и систематическую (тенденциозную) ошибку, возникающую вследствие нарушения правил отбора (или из-за смещений при отборе). При определении случайной ошибки предполагается, что ошибка регистрации равна нулю. Систематическую ошибку часто называют ошибкой, вызванной смещением. Общая ошибка выборки складывается из случайной ошибки (вследствие случайных различий между элементами совокупности, включенными в выборку и не попавшими в нее) и из смещения (систематической ошибки), если оно существует.
Случайные ошибки обычно уравновешивают друг друга, поскольку не имеют преимущественного направления в сторону преувеличения или преуменьшения значения изучаемого показателя. Систематические ошибки направлены в одну сторону вследствие преднамеренного нарушения правил отбора (предвзятые цели). Их можно избежать при правильной организации и проведении наблюдения.
Ошибки репрезентативности присущи только выборочному наблюдению и возникают в силу того, что выборочная совокупность не полностью воспроизводит генеральную. Они представляют собой расхождение между значениями показателей, полученных по выборке, и значениями показателей этих же величин, которые были бы получены при проведенном с одинаковой степенью точности сплошном наблюдении, т.е. между величинами выборных и соответствующих генеральных показателей.
Виды выборок.
В зависимости от того, как осуществляется отбор элементов совокупности в выборку, различают несколько видов выборочного обследования. Отбор может быть случайным, механическим, типическим и серийным.
В зависимости от конкретных условий для выборки единиц применяются различные приемы отбора:
1. собственно случайный отбор
–состоит в отборе случайно попавших единиц совокупности. Выборка называется собственно случайной, если при извлечении выборки объема n
все возможные комбинации из n
элементов, которые могут быть получены из генеральной совокупности объема N
, имеют равную вероятность быть извлеченными. По определению, при собственно случайной выборке выполняется принцип случайности.
Отбор производится с помощью жеребьевки, таблицы (либо генератора) случайных чисел. Главный принцип – случайность, т.е. все единицы генеральной совокупности, имеют равную вероятность попасть в выборочную совокупность.
1. Принцип жеребьевки. Каждый элемент генеральной совокупности заносится на бумажку (это могут быть фамилии, адреса, просто номера (в этом случае выпавшие номера ставят в соответствие с людьми в списках) и т.д.), затем бумажки помещаются в барабан, перемешиваются и не глядя вытаскиваются.
2. Принцип таблицы случайных чисел. Начиная с любого места таблицы, берем четыре следующих друг за другом числа. Эти числа и будут номерами людей в списке, которых следует отобрать в выборку (числа, превышающие численность генеральной совокупности, опускаются) [1, 101].
3. Принцип генератора случайных чисел. Это то же самое, что и таблицы случайных чисел, только числа вырабатываются компьютером (для этого существует специальная программа).
Различают повторную и бесповторную выборку. При повторном отборе каждый выбранный элемент возвращается в ГС. При бесповторном отборе выбранный элемент не возвращается в ГС.
2. Наиболее близкой к собственно случайной выборке является механическая выборка. механический отбор
– когда все единицы наблюдаемой совокупности располагают в определенной последовательности (по номерам, по алфавиту и т.д.), единицы выбирают через определенный промежуток;
Механическая выборка всегда бесповторная, так как объем генеральной совокупности задан (или его можно рассчитать, используя имеющиеся данные о пропорции единиц генеральной т выборочной совокупностей). Проведение механической выборки требует список характеристик респондентов (фамилии, адреса, телефоны и т.д.). Из этого списка через равные промежутки люди отбираются в выборку. Этот промежуток называется шагом выборки
.
 [3, 19], где [3, 19], где
N – объем генеральной совокупности
n – объем выборочной совокупности.
Начало отбора выбирается случайным образом в пределах шага выборки. Например, если шаг выборки равен 20, то начинать отбор надо с любого числа от 1 до 20.
Поэтому на практике систематический отбор считают эквивалентным случайному, если порядок расположения элементов в списке никак не связан с исследуемыми переменными. По сравнению со случайной выборкой систематический отбор часто позволяет с большей точностью оценивать средние значения исходной совокупности. Однако следует иметь в виду, что систематический отбор дает удовлетворительные результаты только в том случае, если в списках отсутствует цикличность, связанная с интервалом отбора, или др. тенденции, способные оказывать систематическое влияние на результат.
3. гнездовой отбор
– производится в том случае, если для изучения берут не отдельные единицы совокупности, а отдельные группы единиц или гнезда.
Вид выбора, при котором отбираемые объекты представляют собой группы или гнезда (кластеры) более мелких единиц. Раньше понятие гнезда распространялось только на двухступенчатую выборку, отобранные на первой ступени объекты рассматривались как серии элементарных единиц, которые подвергались сплошному обследованию. Сейчас этот вид отбора сохранил за собой название серийного, а понятие гнезда расширилось на случаи выборки многоступенчатой. Гнездом называют единицу отбора высшей ступени, состоящую из более мелких единиц низшей ступени. В выборку могут быть включены как все единицы низшего уровня, так и их часть. Число единиц образующих гнездо, называют его размером. Гнездовой отбор обладает большими организационными преимуществами перед отбором единиц. Значительно проще осуществить отбор и обследование нескольких компактных групп, чем десятков или сотен отдельных единиц. Технические преимущества гнездового отбора особенно ощутимы при построении территориальной выборки. Отбор небольшого числа территориальных сегментов (населенных пунктов, районов, жилых кварталов и т. д.), затем выборочный или сплошной опрос проживающего в них населения существенно уменьшают стоимость исследования и сроки его проведения. Основные рекомендации при выборе гнезд сводятся к тому, чтобы различия между гнездами были минимальными, а составляющие их единицы были бы по возможности более неоднородными. Это правило прямо противоположно основному принципу расслоения, в соответствии с которым выигрыш в точности тем больше, чем более однородными будут выделенные слои. Другая рекомендация касается выбора размера гнезд: большое число малых гнезд предпочтительнее малого числа крупных. Гнездовая выборка являясь удобной и экономичной формой отбора, не означает отступления от принципа случайности. Для отбора равноразмерных гнезд применима любая схема простого случайного отбора или систематичного отбора. Если гнезда сильно различаются по размеру, то выполняют предварительное расслоение совокупности гнезд по размеру с последующим извлечением выборки из каждого слоя. Другая распространенная форма выбора гнезд - отбор с вероятностью, пропорциональной размеру. Особенно он эффективен в случаях, когда из большого числа гнезд самого разного размера необходимо отобрать незначительное число при наличии других факторов расслоения.
4. типический отбор
– это вероятностная выборка, обеспечивающая равномерное представительство в выборочной совокупности различных частей (типов) явлений. Существует несколько этапов в проведении типической выборки:
- первоначальная (или генеральная) совокупность разбивается на 2 и более подгруппы по какому-либо признаку (например, по полу);
- определяется число подлежащих наблюдению единиц в каждой группе. При этом используется пропорциональное и непропорциональное размещение. При пропорциональном размещении количество отбираемых в каждую группу единиц пропорционально удельному весу данной группы в генеральной совокупности. При непропорциональном размещении из каждой группы отбирают одинаковое число единиц.
5. комбинированный отбор
– на практике часто применяют комбинированный отбор, при котором сочетаются указанные выше способы. Например, разбивают генеральную совокупность на серии одинакового объема, затем простым случайным отбором выбирают несколько серий и, наконец, из каждой серии простым случайным отбором извлекают отдельные объекты.
В экономико-статистических исследованиях используют следующие способы отбора единиц из генеральной совокупности:
1. индивидуальный отбор – в выборку отбираются отдельные единицы;
2. групповой отбор – в выборку попадаются качественно однородные группы или серии изучаемых явлений;
3. комбинированный отбор – как комбинация индивидуального и группового отбора.
В зависимости от способа отбора единиц различают:
1. повторная выборка. При повторном отборе вероятность попадания каждой отдельной единицы в выборку остается постоянной, так как после отбора какой-то единицы, она снова возвращается в совокупность и снова может быть выбранной. Повторная выборка в социально-экономической жизни встречается редко. Обычно выборку организуют по схеме бесповторной выборки.
2. бесповторная выборка. В этом случае каждая отобранная единица не возвращается обратно, и вероятность попадания отдельных единиц в выборку все время изменяется (для оставшихся единиц она возрастает).
Основные характеристики параметров генеральной и выборочной совокупностей обозначаются символами:
N - объем генеральной совокупности (число входящих в нее единиц);
n - объем выборки (число обследованных единиц);
 - генеральная средняя (среднее значение признака в генеральной совокупности); - генеральная средняя (среднее значение признака в генеральной совокупности);
 - выборочная средняя; - выборочная средняя;
р - генеральная доля (доля единиц, обладающих данным значением признака в общем числе единиц генеральной совокупности);
w - выборочная доля;
s2
- генеральная дисперсия (дисперсия признака в генеральной совокупности);
S2
- выборочная дисперсия того же признака;
s - среднее квадратическое отклонение в генеральной совокупности;
S - среднее квадратическое отклонение в выборке.
Ошибки наблюдения
При большом числе единиц исследуемой совокупности ошибки и неточности могут погашаться, однако, если применяется выборочное наблюдение, тогда ошибки могут существенно повлиять на результаты исследования.
В ходе наблюдения могут возникнуть следующие ошибки:
1. Ошибки регистрации – ошибочные результаты наблюдения, полученные в результате недостаточной квалификации исследователя, неточности измерительных приборов, некорректности подсчетов и т.д.
2. Ошибки могут быть случайными и систематическими [12].
· Систематические ошибки репрезентативности – ошибки, вызванные нарушением правил выбора единиц совокупности для наблюдения;
· Ошибки репрезентативности (случайные) – ошибки, отражающие несовпадение выводов о части явления с выводами о явлении в целом. Такие ошибки возникают при применении несплошного метода наблюдения, случайные ошибки репрезентативности – ошибки, отражающие неравномерное распределение единиц в совокупности, в связи с чем, выборочная совокупность не корректно характеризует генеральную совокупность.
Средняя и предельная ошибка для показателей средней величины
Обобщающей характеристикой совокупности по изучаемому признаку является средняя величина признака. Поэтому, как правило, сначала рассчитывают среднее значение признака для выборочной совокупности (  ), а затем, исходя из меры соответствия между генеральной и выборочной совокупностями, определяют пределы, в которых может колебаться среднее значение признака в генеральной совокупности ( ), а затем, исходя из меры соответствия между генеральной и выборочной совокупностями, определяют пределы, в которых может колебаться среднее значение признака в генеральной совокупности (  ). ).
Поскольку точные характеристики генеральной совокупности не определены, то указать единичное значение расхождения между средними для выборочной и генеральной совокупностей невозможно. В связи с этим, определяют средний размер всех возможных ошибок ( ) выборочного наблюдения. Другими словами, показатель ) выборочного наблюдения. Другими словами, показатель  называется средняя ошибка выборочной средней. Для повторного отбора [8]: называется средняя ошибка выборочной средней. Для повторного отбора [8]:

 – дисперсия выборочной совокупности; – дисперсия выборочной совокупности;
n – численность единиц выборочной совокупности [13].
С применением поправочного коэффициента на бесповторность средняя ошибка выборочной средней для бесповторного отбора будет определяться следующим образом:

– дисперсия выборочной совокупности;
N – численность единиц генеральной совокупности.
То есть, средняя в генеральной совокупности может отклониться от средней в выборочной совокупности в сторону увеличения или уменьшения на величину .
Предельная ошибка выборочной средней (  ) определяет границы, в пределах которых может колебаться среднее значение генеральной совокупности относительно среднего значения выборки. Различия между средней и предельной ошибкой обусловлены величиной коэффициента доверия t. ) определяет границы, в пределах которых может колебаться среднее значение генеральной совокупности относительно среднего значения выборки. Различия между средней и предельной ошибкой обусловлены величиной коэффициента доверия t.
Суть этого коэффициента можно определить как ряд следующих заключений:
· предполагается наличие расхождения между параметрами выборки и параметрами генеральной совокупности, которое называется ошибкой;
· предполагается, что вместо полученных определенных результатов выборки, могли быть другие, несколько отличные результаты, и, следовательно, могли быть другие характеристики выборочной совокупности и другие ошибки [15];
· предполагается образование ряда распределения из возможных ошибок, причем, в таком ряду рассчитывается среднее значение – средняя ошибка выборки ( );
· предполагается наличие степени вероятности Р у каждой ошибки в этом ряду распределения;
· предполагается формирование распределения вероятностей ошибок Р(t), т.е. определение плотности вероятности ошибок (графическое изображение см. рис 2.);
· предполагается более высокая вероятность появления ошибок определенного размера (среднего размера ошибки) (графически отображается в виде возвышения «волны», характеризующей вероятность, см. рис. 2.);
· по оси абсцисс на графике откладывается значение t; тогда, чем ближе вероятность ошибки расположена к оси ординат (соответственно, к вероятности появления средней ошибки), тем меньше значение t.
· в зависимости от степени репрезентативности («доверия») выборочных данных, определяется значение t, от величины которого зависит вероятность появления ошибок других размеров, отличных от средней ошибки, следовательно, зависят границы колебания значения параметров генеральной совокупности относительно выборки [6].
Таким образом, количественное выражение t, в конечном итоге, является мерой «доверия» к реальности выборочных данных. Тогда предельная ошибка выборочной средней ( ) будет определяться следующим образом:
 . .
Отсюда, среднее значение генеральной совокупности имеет вид:

В статистике существуют наиболее распространенные уровни вероятностей, например: 0,954; 0,997 и др. Это означает, что, соответственно, в 6 случаях из 1000 и в 3 случаях из 1000 ошибка выборки может превысить пределы, определенные выборочным наблюдением.
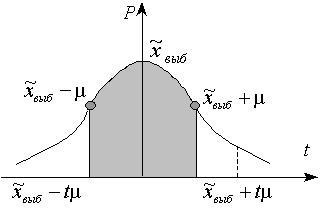
Рис. 2.
На рисунке 2. затемненная площадь под кривой показывает вероятность появления средней ошибки выборочной средней. Площадь фигуры, образованной перпендикулярами, опущенными на ось абсцисс[1]
, и кривой плотности вероятности определяет вероятность появления предельной ошибки выборочной средней [17].
Средняя и предельная ошибка для показателей доли
Анализ генеральной совокупности не ограничивается расчетом средних величин. Для характеристики распространенности единиц совокупности с тем или иным значением изучаемого признака рассчитываются показатели структуры (доли).
Принцип транспонирования выводов о выборке на генеральную совокупность, принятый для средних величин, сохраняется и при определении показателей доли:
1. Средняя ошибка выборки ( )для доли (w) единиц, обладающих изучаемым признаком, при повторном отборе: )для доли (w) единиц, обладающих изучаемым признаком, при повторном отборе:

w – удельный вес единиц, обладающих изучаемым признаком;
 – дисперсия для показателя доли; – дисперсия для показателя доли;
n – численность единиц выборочной совокупности.
2. Средняя ошибка выборки ( )для доли (w) единиц, при бесповторном отборе:

N – численность единиц генеральной совокупности.
3. Предельная ошибка выборочной доли (  ): ):

Тогда, удельный вес единиц, обладающих изучаемым признаком, в генеральной совокупности будет находиться в пределах: 
Определение необходимого объема выборки
Прежде чем приступить к осуществлению выборочного наблюдения необходимо определить количество единиц выборочной совокупности, обеспечивающее репрезентативность, и, следовательно, надежность результатов исследования [4].
На практике для реализации выборочного наблюдения исследователем задаются:
· степень точности исследования (вероятность);
· предельная ошибка, т.е. интервал отклонения, определяемый целями исследования.
Исходя из этих критериев, рассчитывается необходимая численность выборочной совокупности (n) на основе формулы предельной ошибки выборки. Как указывалось выше, предельная ошибка выборки определяется для средней величины (  ) и для доли (w), то, соответственно, имеем два варианта определения необходимой численности выборочной совокупности: ) и для доли (w), то, соответственно, имеем два варианта определения необходимой численности выборочной совокупности:
а) для повторного отбора:
 
б) для бесповторного отбора:
 
Понятие о малой выборке
В практике статистического исследования иногда необходимо сделать выводы по малому числу наблюдений. Это может быть связано с ограниченностью ресурсов на проведение выборки, или с ограниченным доступом к объекту исследования. Если число наблюдений (единиц выборочной совокупности) не превышает 30, то выборка называется малой. Расчет показателей для малой выборки осуществляется с применением специальной методики, учитывающей распределение вероятностей появления ошибок определенных размеров. Напротив, в выборочной совокупности с большим количеством единиц распределение ошибок предполагается нормальным или близким к нормальному.
Расчетная часть
Задача:
Имеются следующие выборочные данные по предприятиям одной из отраслей промышленности региона в отчетном году (выборка 20% - ная механическая), млн. руб.:
Таблица 1
| № предприятия
п /п
|
Выручка от продажи продукции
|
Затраты на производство и реализацию продукции
|
| 1
|
36,45
|
30,255
|
| 2
|
23,4
|
20,124
|
| 3
|
46,54
|
38,163
|
| 4
|
59,752
|
47,204
|
| 5
|
41,415
|
33,546
|
| 6
|
26,86
|
22,831
|
| 7
|
79,2
|
60,984
|
| 8
|
54,72
|
43,776
|
| 9
|
40,424
|
33,148
|
| 10
|
30,21
|
25,376
|
| 11
|
42,418
|
34,359
|
| 12
|
64,575
|
51,014
|
| 13
|
51,612
|
41,806
|
| 14
|
35,42
|
29,753
|
| 15
|
14,4
|
12,528
|
| 16
|
36,936
|
31,026
|
| 17
|
53,392
|
42,714
|
| 18
|
41
|
33,62
|
| 19
|
55,68
|
43,987
|
| 20
|
18,2
|
15,652
|
| 21
|
31,8
|
26,394
|
| 22
|
39,1204
|
32,539
|
| 23
|
57,128
|
45,702
|
| 24
|
28,44
|
23,89
|
| 25
|
43,344
|
35,542
|
| 26
|
70,72
|
54,454
|
| 27
|
41,832
|
34,302
|
| 28
|
69,345
|
54,089
|
| 29
|
35,903
|
30,159
|
| 30
|
50,22
|
40,678
|
Задание 1
Признак – уровень рентабельности продукции
(рассчитайте путем деления прибыли от продаж, т.е. разности между выручкой от продажи продукции и затратами на ее производство и реализацию, на затраты на производство и реализацию продукции).
Число групп – пять
.
Задание 2
Связь между признаками – затраты на производство
и реализацию продукции
и уровень рентабельности продукции
.
Задание 3
По результатам выполнения задания 1 с вероятностью 0,997 определите:
1. Ошибку выборки среднего уровня рентабельности организации и границы, в которых будет находиться средний уровень рентабельности в генеральной совокупности;
2. Ошибку выборки доли организаций с уровнем рентабельности продукции 23,9% и более и границы, в которых будет находиться генеральная доля.
Задание 4
Выпуск продукции и удельный расход стали по региону, в текущем периоде характеризуется следующими данными:
Таблица 2
| Вид продукции
|
Фактический выпуск продукции, шт.
|
Расход стали на единицу продукции, кг
|
| по норме
|
фактически
|
| А
|
320
|
36
|
38
|
| Б
|
250
|
15
|
12
|
| В
|
400
|
10
|
9
|
Определите:
1. Индивидуальные индексы выполнения норм расхода стали.
2. Общий индекс выполнения норм расхода стали на весь выпуск продукции.
3. Абсолютную экономию (перерасход) стали.
Решение здания №1:
1. Рассчитываем уровень рентабельности по формуле, данной в условии задачи:
Уровень рентабельности =
 *1000 *1000
Таблица 3
| № предприятия
п/п
|
Выручка от продажи продукции
|
Затраты на производство и реализацию продукции
|
Уровень рентабельности продукции
|
| 1
|
36,45
|
30,255
|
204,7
|
| 2
|
23,4
|
20,124
|
162,8
|
| 3
|
46,540
|
38,163
|
219,5
|
| 4
|
59,752
|
47,204
|
265,8
|
| 5
|
41,415
|
33,546
|
234,6
|
| 6
|
26,86
|
22,831
|
176,5
|
| 7
|
79,2
|
60,984
|
298,7
|
| 8
|
54,720
|
43,776
|
250
|
| 9
|
40,424
|
33,148
|
219,5
|
| 10
|
30,21
|
25,376
|
190,5
|
| 11
|
42,418
|
34,359
|
234,5
|
| 12
|
64,575
|
51,014
|
265,8
|
| 13
|
51,612
|
41,806
|
234,5
|
| 14
|
35,42
|
29,753
|
190,5
|
| 15
|
14,4
|
12,528
|
149,4
|
| 16
|
36,936
|
31,026
|
190,5
|
| 17
|
53,392
|
42,714
|
250
|
| 18
|
41,0
|
33,62
|
219,5
|
| 19
|
55,680
|
43,987
|
265,8
|
| 20
|
18,2
|
15,652
|
162,8
|
| 21
|
31,8
|
26,394
|
204,8
|
| 22
|
39,204
|
32,539
|
204,8
|
| 23
|
57,128
|
45,702
|
250
|
| 24
|
28,44
|
23,89
|
190,5
|
| 25
|
43,344
|
35,542
|
219,5
|
| 26
|
70,720
|
54,454
|
298,7
|
| 27
|
41,832
|
34,302
|
219,5
|
| 28
|
69,345
|
54,089
|
282,1
|
| 29
|
35,903
|
30,159
|
190,5
|
| 30
|
50,220
|
40,678
|
234,6
|
2.
Строим ранжированный ряд данных по уровню рентабельности продукции и сортируем по возрастанию
Таблица 4
| № предприятия
п/п
|
Выручка от продажи продукции
|
Затраты на производство и реализацию продукции
|
Уровень рентабельности продукции
|
| 15
|
14,4
|
12,528
|
149,4
|
| 2
|
23,4
|
20,124
|
162,8
|
| 20
|
18,2
|
15,652
|
162,8
|
| 6
|
26,86
|
22,831
|
176,5
|
| 24
|
28,44
|
23,89
|
190,5
|
| 29
|
35,903
|
30,159
|
190,5
|
| 14
|
35,42
|
29,753
|
190,5
|
| 16
|
36,936
|
31,026
|
190,5
|
| 10
|
30,21
|
25,376
|
190,5
|
| 22
|
39,204
|
32,539
|
204,8
|
| 1
|
36,45
|
30,255
|
204,7
|
| 21
|
31,8
|
26,394
|
204,8
|
| 9
|
40,424
|
33,148
|
219,5
|
| 3
|
46,54
|
38,163
|
219,5
|
| 18
|
41
|
33,62
|
219,5
|
| 25
|
43,344
|
35,542
|
219,5
|
| 27
|
41,832
|
34,302
|
219,5
|
| 11
|
42,418
|
34,359
|
234,5
|
| 13
|
51,612
|
41,806
|
234,5
|
| 5
|
41,415
|
33,546
|
234,6
|
| 30
|
50,22
|
40,678
|
234,6
|
| 17
|
53,392
|
42,714
|
250
|
| 8
|
54,72
|
43,776
|
250
|
| 23
|
57,128
|
45,702
|
250
|
| 4
|
59,752
|
47,204
|
265,8
|
| 19
|
55,68
|
43,987
|
265,8
|
| 12
|
64,575
|
51,014
|
265,8
|
| 28
|
69,345
|
54,089
|
282,1
|
| 7
|
79,2
|
60,984
|
298,7
|
| 26
|
70,72
|
54,454
|
298,7
|
3.Расчитаем количество интервалов по формуле Стерджеса:
k =1+3.32 lg n ,где n-d нашем случае 30
k = 1+3.32 lg 30=1+3.32*1.4771=5.9
4. Рассчитаем длину интервала и шаг интервала по следующей формуле:
h
=

 , где n
=5 групп , где n
=5 групп
Тогда шаг интервала:
h
= =2,986 =2,986
Формируем группы:
1 группа: 14,94- 17,926
2 группа: 17,926- 20,912
3 группа: 20,912- 23,898
4 группа: 23,898 – 26,884
5 группа: 26,884 – 29,87
Для удобства проставим номера групп в таблицу относительно уровня рентабельности.
Таблица 5
| № предприятия
п/п
|
Выручка от продажи продукции
|
Затраты на производство и реализацию продукции
|
Уровень рентабельности продукции
|
№ групп
|
| 15
|
14,4
|
12,528
|
14,94
|
1
|
| 2
|
23,4
|
20,124
|
16,28
|
1
|
| 20
|
18,2
|
15,652
|
16,28
|
1
|
| 6
|
26,86
|
22,831
|
17,65
|
1
|
| 24
|
28,44
|
23,89
|
19,05
|
2
|
| 29
|
35,903
|
30,159
|
19,05
|
2
|
| 14
|
35,42
|
29,753
|
19,05
|
2
|
| 16
|
36,936
|
31,026
|
19,05
|
2
|
| 10
|
30,21
|
25,376
|
19,05
|
2
|
| 22
|
39,1204
|
32,539
|
20,23
|
2
|
| 1
|
36,45
|
30,255
|
20,48
|
2
|
| 21
|
31,8
|
26,394
|
20,48
|
2
|
| 9
|
40,424
|
33,148
|
21,95
|
3
|
| 3
|
46,54
|
38,163
|
21,95
|
3
|
| 18
|
41
|
33,62
|
21,95
|
3
|
| 25
|
43,344
|
35,542
|
21,95
|
3
|
| 27
|
41,832
|
34,302
|
21,95
|
3
|
| 11
|
42,418
|
34,359
|
23,46
|
3
|
| 13
|
51,612
|
41,806
|
23,46
|
3
|
| 5
|
41,415
|
33,546
|
23,46
|
3
|
| 30
|
50,22
|
40,678
|
23,46
|
3
|
| 17
|
53,392
|
42,714
|
25,00
|
4
|
| 8
|
54,72
|
43,776
|
25,00
|
4
|
| 23
|
57,128
|
45,702
|
25,00
|
4
|
| 4
|
59,752
|
47,204
|
26,58
|
4
|
| 19
|
55,68
|
43,987
|
26,58
|
4
|
| 12
|
64,575
|
51,014
|
26,58
|
4
|
| 28
|
69,345
|
54,089
|
28,21
|
5
|
| 7
|
79,2
|
60,984
|
29,87
|
5
|
| 26
|
70,72
|
54,454
|
29,87
|
5
|
Таблица 6
Интервальный ряд распределения предприятий по уровню рентабельности продукции
| №
гр.
|
Вариант признака (
xj
)
Уровень рентабельности продукции
|
Частота (
fj
)
ЧИСЛО
ПРЕДПРИЯТИЙ,
ед.
|
Частость (
wj
)
ДОЛЯ ПРЕДПРИЯТИЙ В ОБЩЕМ ИТОГЕ
|
| 1
|
14,94 – 17,926
|
4
|
0,13
|
| 2
|
17,926 – 20,912
|
8
|
0,27
|
| 3
|
20,912 – 23,898
|
9
|
0,3
|
| 4
|
23,898 – 26,884
|
6
|
0,2
|
| 5
|
26,884 – 29,87
|
3
|
0,1
|
| Итого
|
30
|
1,00
|
6. Определим моду.
Для вычисления моды в интервальном ряду сначала находится модальный интервал (в данном случае этот интервал 209.12– 23,898), имеющий наибольшую частоту, а значение моды определяется линейной интерполяцией:
Mo
=
x
о
+( х1
- хо
) *
 ,
,
,
где хо
– нижняя граница модального интервала;
х1
– верхняя граница модального интервала;
 , ,  , ,  – частота ni
модального, до и послемодального интервала. – частота ni
модального, до и послемодального интервала.
хо
= 20,912
; хо
- х1
=2,986
;  - частота модального интервала = 9
; - частота модального интервала = 9
;  - частота домодального интервала = 8
; -частота послемодального интервала= 6 - частота домодального интервала = 8
; -частота послемодального интервала= 6
Получаем:
Mo
=20,912+2,986* =
21,66 =
21,66
7. Определим медиану.
Таблица 7
Вспомогательная таблица для расчёта медианы
| №
гр.
|
Уровень рентабельности продукции
|
Число предприятий,
ед.
|
Накопленное число предприятий,
ед.
|
| 1
|
14,94-17,926
|
4
|
4< 15
|
| 2
|
17,926-20,912
|
8
|
12<15
|
| 3
|
20,912-23,898
|
9
|
21>15
|
| 4
|
23,898-26,884
|
6
|
27
|
| 5
|
26,884-29,87
|
3
|
30
|
| Итого
|
30
|
 , ,
где хо
– нижняя граница модального интервала;
х1
– верхняя граница модального интервала;
fMe
– частота медианного интервала;
S
ме-1
- накопленная частота интервала предшествующего медианному.
 - половина от общего числа наблюдений; - половина от общего числа наблюдений;
Получаем:


Задание 2.
1. Строим аналитическую группировку.
Таблица 8
Таблица для построения аналитической группировки
| № группы
|
Уровень рентабельности продукции
|
№ п/п
|
Затраты на производство и реализацию продукции одним предприятием,млн.руб.
|
| 1
|
14,94-17,926
|
15
|
12,528
|
| 2
|
20,124
|
| 20
|
15,652
|
| 6
|
22,831
|
| Итого
|
4
|

|
| 2
|
17,926-20,912
|
24
|
23,89
|
| 29
|
30,159
|
| 14
|
29,753
|
| 16
|
31,026
|
| 10
|
25,376
|
| 22
|
32,539
|
| 1
|
30,255
|
| 21
|
26,394
|
| Итого
|
8
|

|
| 3
|
20,912-23,898
|
9
|
33,148
|
| 3
|
38,163
|
| 18
|
33,62
|
| 25
|
35,542
|
| 27
|
34,302
|
| 11
|
34,359
|
| 13
|
41,806
|
| 5
|
33,546
|
| 30
|
40,678
|
| Итого
|
9
|

|
| 4
|
23,898-26,884
|
17
|
42,714
|
| 8
|
43,776
|
| 23
|
45,702
|
| 4
|
47,204
|
| 19
|
43,987
|
| 12
|
51,014
|
| Итого
|
6
|

|
| 5
|
26,884-29,87
|
28
|
54,089
|
| 7
|
60,984
|
| 26
|
54,454
|
| Итого
|
3
|

|
| Всего
|
30
|

|
Таблица 9
Зависимость уровня рентабельности продукции
от затрат на производство и реализацию продукции
| №
гр.
|
Уровень рентабельности продукции
|
Число предприятий, ед.
|
Средние в группе затраты на производство и реализацию продукции одним предприятием,
млн. руб.
|
| 1
|
14,94 – 17,926
|
4
|
17,784
|
| 2
|
17,926 – 20,912
|
8
|
28,764
|
| 3
|
20,912 – 23,898
|
9
|
36,129
|
| 4
|
23,898 – 26,884
|
6
|
45,733
|
| 5
|
26,884 – 29,87
|
3
|
56,509
|
| Итого
|
30
|
35,6
|
2. Строим корреляционную таблицу.
Таблица 10
Интервальный ряд распределения предприятий
по затратам на производство и реализацию продукции
| Затраты на производство и реализацию продукции, млн. руб.,
yj
|
Число предприятий, ед.,
fj
|
| 12,528 - 22,2192
|
3
|
| 22,2192 - 31,9104
|
8
|
| 31,9104 - 41,6016
|
9
|
| 41,6016 - 51,2928
|
7
|
| 51,2928 - 60,984
|
3
|
| Итого
|
30
|
 млн.руб. млн.руб.
1) 12,528 – 22,2192
2) 22,2192 – 31,9104
3) 31,9104 – 41,6016
4) 41,6016 – 51,2928
5) 51,2928 – 60,984
Корреляционная таблица, характеризующая наличие связи между уровнем рентабельности продукции
и затратами на производство и реализацию продукции
Таблица 11
| Уровень рентабельности продукции
|
Затраты на производство и реализацию продукции, млн. руб.
|
Итого
|
| 12,528 - 22,2192
|
22,2192 - 31,9104
|
31,9104 - 41,6016
|
41,6016 - 51,2928
|
51,2928 - 60,984
|
| 14,94 – 17,926
|
3
|
3
|
| 17,926 – 20,912
|
8
|
1
|
9
|
| 20,912 – 23,898
|
8
|
1
|
9
|
| 23,898 – 26,884
|
6
|
6
|
| 26,884 – 29,87
|
3
|
3
|
| Итого
|
3
|
8
|
9
|
7
|
3
|
30
|
3. Рассчитываем характеристики интервального ряда распределения
Таблица 12
Расчетная таблица для нахождения характеристик ряда распределения.
| х
|
хц
|
f
|

|

|

|

|

|
| 14,94-17,926
|
16,433
|
4
|
65,732
|
5,574
|
22,296
|
31,069
|
124,276
|
| 17,926-20,912
|
19,419
|
8
|
155,352
|
2,588
|
20,704
|
6,698
|
53,584
|
| 20,912– 23,898
|
22,405
|
9
|
201,645
|
0,398
|
3,582
|
0,158
|
1,422
|
| 23,898– 26,884
|
25,391
|
6
|
152,346
|
3,384
|
20,304
|
11,451
|
68,706
|
| 26,884– 29,87
|
28,377
|
3
|
85,131
|
6,37
|
19,11
|
40,577
|
121,731
|
| Итого
|

|
30
|
660,206
|
|
85,996
|
|
369,719
|
Средняя арифметическая -  % %
Дисперсия - 
Среднее квадратическое отклонение - Размах вариации R= Xmax
- Xmin
= 29,87 – 14,94=14,93 Размах вариации R= Xmax
- Xmin
= 29,87 – 14,94=14,93
Среднее линейное отклонение - 
Коэффициент вариации -  % %
Так как V=15,9%, а 15,9% < 33%,то статистическая совокупность однородна, вариация признака невелика и найденная величина  =
22,% является надежной и типичной характеристикой всей совокупности.
=
22,% является надежной и типичной характеристикой всей совокупности.
4. Строим таблицу для расчета общей дисперсии.
Таблица 13
Вспомогательная таблица для расчёта общей дисперсии
| № п/п
|
Затраты на производство и реализацию продукции, млн. руб.
yi
|
yi
2
|
| 15
|
12,528
|
156,951
|
| 20
|
15,652
|
244,985
|
| 2
|
20,124
|
404,975
|
| 6
|
22,831
|
521,255
|
| 24
|
23,890
|
570,732
|
| 10
|
25,376
|
643,941
|
| 21
|
26,394
|
696,643
|
| 14
|
29,753
|
885,241
|
| 29
|
30,159
|
909,565
|
| 1
|
30,255
|
915,365
|
| 16
|
31,026
|
962,613
|
| 22
|
32,539
|
1058,787
|
| 9
|
33,148
|
1098,790
|
| 18
|
33,620
|
1130,304
|
| 5
|
33,546
|
1125,334
|
| 27
|
34,302
|
1176,627
|
| 11
|
34,359
|
1180,541
|
| 25
|
35,542
|
1263,234
|
| 3
|
38,163
|
1456,415
|
| 30
|
40,678
|
1654,700
|
| 13
|
41,806
|
1747,742
|
| 17
|
42,714
|
1824,486
|
| 8
|
43,776
|
1916,338
|
| 19
|
43,987
|
1934,856
|
| 23
|
45,702
|
2088,673
|
| 4
|
47,204
|
2228,218
|
| 12
|
51,014
|
2602,428
|
| 28
|
54,089
|
2925,620
|
| 26
|
54,454
|
2965,238
|
| 7
|
60,984
|
3719,048
|
| Итого
|
1069,615
|
42009,644
|
 =1271,196 =1271,196
 =1400,321 =1400,321
 1400,321 – 1271,196=129,125 – общая дисперсия. 1400,321 – 1271,196=129,125 – общая дисперсия.
Таблица 14
Вспомогательная таблица для расчёта межгрупповой и внутригрупповых дисперсий
| xj
|
fj
|
yj
|

|

|
| 14,94-17,926
|
4
|
12,528; 20,124; 15,652; 22,831.
|
17,784
|
1269,64
|
| 17,926-20,912
|
8
|
23,89; 30,159; 29,753; 31,026; 25,376; 32,539; 30,255; 26,394.
|
28,674
|
383,76
|
| 20,912– 23,898
|
9
|
33,148; 38,163; 33,62; 35,542; 34,302; 34,359; 41,806; 33,546; 40,678.
|
36,129
|
2,52
|
| 23,898– 26,884
|
6
|
42,714; 43,776; 45,702; 47,204; 43,987; 51,014.
|
45,733
|
616,07
|
| 26,884– 29,87
|
3
|
54,089; 60,984; 54,454.
|
56,509
|
1311,56
|
| Итого
|
30
|
-
|
35,6
|
3583,55
|
 =119,45 =119,45
7.Находим эмпирический коэффициент детерминации.
 = 0,925 (или 92,5%) = 0,925 (или 92,5%)
8. Находим эмпирическое корреляционное отношение.
 =0,96 =0,96
Таблица 15
Шкала Чеддока
| 
|
0,1 – 0,3
|
0,3 – 0,5
|
0,5 – 0,7
|
0,7 – 0,9
|
0,9 – 0,99
|
| Характеристика
тесноты связи
|
Слабая
|
Умеренная
|
Заметная
|
Тесная
|
Весьма тесная
|
Рассчитываем линейный коэффициент корреляции:

Т.к. r=0,989, она близка к 1, а, следовательно, связь весьма тесная.
Задание 3
1. По заданным условиям ошибку выборки среднего уровня рентабельности организации и границы, в которых будет находиться средний уровень рентабельности в генеральной совокупности, определим
по формуле  . Для расчета предельной ошибки выборки для средней, то есть . Для расчета предельной ошибки выборки для средней, то есть  , используем формулу для бесповторного отбора: , используем формулу для бесповторного отбора:  . Так как у нас выборка механическая 20% - ая . Так как у нас выборка механическая 20% - ая
Ф(t)= 0,997,то t=3.
 и и 

Следовательно,  или или 
Вывод:
Таким образом, с вероятностью 0,997 можно утверждать, что средний уровень рентабельности в генеральной совокупности будет не менее 20,289 и не более 23,725.
2. Находим ошибку выборки доли организаций с уровнем рентабельности продукции 23,9% и более и границы, в которых будет находиться генеральная доля, по формуле . Для этого сначала определяем долю предприятий в выборочной совокупности, имеющих уровень рентабельности продукции 23,9% и более. Для расчета предельной ошибки выборки по доле, то есть . Для этого сначала определяем долю предприятий в выборочной совокупности, имеющих уровень рентабельности продукции 23,9% и более. Для расчета предельной ошибки выборки по доле, то есть  , используем формулу для бесповторного отбора: , используем формулу для бесповторного отбора:  , так как у нас выборка механическая 20%-ая. , так как у нас выборка механическая 20%-ая.
 =0,3 =0,3
 , ,
Следовательно,  или или 
Вывод:
Таким образом, с вероятностью 0,997 можно утверждать, что доля предприятий в генеральной совокупности, имеющих уровень рентабельности 23,9%, будет не менее 0,076 и не более 0,524.
Задание 4.
Дана таблица:
Таблица 16
| Вид продукции
|
Фактический выпуск продукции, шт.
|
Расход стали на единицу продукции, кг
|
| по норме
|
фактически
|
| А
|
320
|
36
|
38
|
| Б
|
250
|
15
|
12
|
| В
|
400
|
10
|
9
|
1. Находим индивидуальные индексы выполнения норм расхода стали по формуле:
 ,где q – расходы, q0
, q1
- по норме и фактически ,где q – расходы, q0
, q1
- по норме и фактически
для продукции А =  = 1,056; = 1,056;
для продукции Б =  = 0,8; = 0,8;
для продукции В =  = 0,9. = 0,9.
2. Находим общий индекс выполнения норм расхода стали на весь выпуск продукции по формуле:

 (или 97,35%) (или 97,35%)
Вывод: То есть, объем продаж исключительно под влиянием изменения физического объема.
3. Абсолютная экономия стали
Таблица 17
| Вид продукции
|
Фактический выпуск продукции, шт.
ро
|
Расход стали на ед. продукции, кг.
|

|
| 
|

|
| А
|
320
|
36
|
38
|
1,056
|
| Б
|
250
|
15
|
12
|
0,8
|
| В
|
400
|
10
|
9
|
0,9
|
Абсолютная экономия составляет:
 тыс. руб. тыс. руб.
Вывод: То есть, предприятие фактически расходует сталь на 510 тыс. руб. меньше, чем положено по норме.
Аналитическая часть
В этой части работы мы рассмотрим задачу, составленную по данным предприятия ООО НПП «Курай».
Имеются выборочные данные о стаже работников.
| Стаж, лет
|
Среднесписочная численность работников, чел.
|
| До 3
|
7
|
| 3-5
|
15
|
| 5-7
|
10
|
| 7-9
|
22
|
| Свыше 9
|
46
|
| Итого
|
100
|
Нужно определить:
1) средний стаж работников;
2) дисперсию;
3) среднее квадратическое отклонение;
4) коэффициент вариации.
Решение:
1. Находим средний стаж работников. Для этого необходимо построить таблицу, в которой находим середину интервала.
Таблица 1
| Стаж, лет
|
Среднесписочная численность работников, чел.
|
xi
|
xi
f
|
| От 1 до 3
|
7
|
2
|
14
|
| От 3 до 5
|
15
|
4
|
60
|
| От 5 до 7
|
10
|
6
|
60
|
| От 7 до 9
|
22
|
8
|
176
|
| Свыше 9
|
46
|
10
|
460
|
| Итого
|
100
|
770
|
1. Средний стаж работников
хср
= лет. лет.
Для нахождения других признаков, мы достраиваем таблицу до следующего вида:
Таблица 2
| Стаж, лет
|
Среднесписочная численность работников, чел.
|
xi
|
xi
f
|
xi
-хср
|
(xi
-хср)2
|
(xi
-хср)2*f
|
| от 1 до 3
|
7
|
2
|
14
|
-5,7
|
32,49
|
227,43
|
| от 3 до 5
|
15
|
4
|
60
|
-3,7
|
13,69
|
205,35
|
| от 5 до 7
|
10
|
6
|
60
|
-1,7
|
2,89
|
28,9
|
| от 7 до 9
|
22
|
8
|
176
|
0,3
|
0,09
|
1,98
|
| Свыше 9
|
46
|
10
|
460
|
2,3
|
5,29
|
243,34
|
| Итого
|
100
|
770
|
707
|
Теперь находим:
2. Дисперсию:

3. Среднее квадратическое отклонение:

4. Коэффициент вариации:
 %. %.
Заключение
Одной из задач, которые стоят перед исследователем при проведении исследования, является сбор необходимых эмпирических данных об объекте исследования. Множество элементов, составляющих объект исследования, называют генеральной совокупностью (ГС). Наиболее простым, на первый взгляд, способом сбора данных является сплошное обследование ГС. Однако применение сплошного обследования не всегда представляется возможным. В этом случае применяется выборочное обследование. Суть выборочного метода заключена в том, что обследованию подвергается только часть элементов ГС, которая называется выборочной совокупностью (ВС). Изобретателем выборочного метода была сама жизнь. Действительно, еще до теоретического обоснования возможностей применения выборочного метода, статистики были вынуждены проводить выборочные обследования. Основными причинами для этого были отсутствие времени и средств [2].
Выборочный метод позволяет не только сократить временные и материальные затраты на проведения исследования, но и повысить достоверность результатов исследования. Это утверждение может вызвать недоумение: как можно получить более достоверные данные, обследовав меньшую часть ГС? Однако практика показывает, что достоверность полученной информации при использовании выборочного метода может быть не только не ниже, чем при сплошном обследовании, но и выше вследствие возможности привлечения персонала более высокого класса и применения различных процедур контроля качества получаемой информации.
Кроме того, выборочный метод имеет более широкую область применения. Широта области применения выборочного метода объясняется тем, что небольшой (по сравнению с ГС) объем выборки позволяет использовать более сложные методы обследования, включая использование различных технических средств (например, видео- и аудиосредства, персональные компьютеры и Интернет, а также сложную измерительную технику).
Выборочные обследования широко применяются в работе органов государственной статистики. Чаще всего крупные и средние предприятия охватываются сплошным; наблюдением, а наблюдение за деятельностью малых предприятий производится с помощью выборочных обследований. В ряде случаев выборочные наблюдения применяются в сочетании со сплошными переписями и учетами. Например, программа Всероссийской переписи населения 2002г. содержит как вопросы сплошного наблюдения, относящиеся ко всему населению, так и вопросы выборочного наблюдения 25% населения для характеристики основного занятия, занимаемого положения, места работы, а также вопросы 5%-ного выборочного обследования с целью изучения брачности и рождаемости.
Литература
1. Голуб Л. А. Социально-экономическая статистика. 2003
2. Бурцева С. А. Статистика финансов. 2004
3. Громыко Г.Л. Теория статистики. 2007
4. Елисеева И. И., Силаева С. А., Щирина А. Н. Практикум по макроэкономической статистике. 2007
5. Елисеева И.И. Общая теория статистики: Учебник для ВУЗов. – М.: Финансы и статистика, 2004.
6. Ефимова М.Р., Петрова Е.В., Румянцев В.Н. Общая теория статистики: Учебник. - М.: ИНФРА-М, 2002.
7. Ефимова М. Р., Бычкова С. Г. Практикум по социальной статистике. 2005
8. Теория статистики: Учебник. / Под ред. Р.А. Шмойловой. - М.: Финансы и статистика, 2002.
9. Назаров М. Г. Курс социально-экономической статистики. 2003
[1]
на рисунке изображены штрих-линиями
|