| Огляд комп’ютерних систем
(курсова робота)
Содержание
Функціонально розподілені системи
Паралельні комп’ютери
Продуктивність паралельних комп’ютерів
Методи розподілення доступу до спільної пам’яті в багатопроцесорних системах
Системи з розподіленою пам’яттю
Класичні матричні системи
Архітектура NUMA
Використання в комп’ютерах Cray T3D/T3D. Система „Еврика"
Обчислювальні кластери
Комунікаційні середовища кластерних систем
Метакомп’ютери
Класифікація Флінна та Хонні. Класи обчислювальних систем
Класифікація Флінна
Пам’ять з чергуванням адрес
Асоціативна пам’ять (безадресна пам’ять)
Обчислювальні системи з структурою, що перебудовується
Трансп’ютери
В ЕОМ перших трьох поколінь всі обчислювальні функції реалізовувались одним процесором і інтерпретувалися ним, як арифметичні та логічні операції. Висока продуктивність системи утворилась на основі багатопроцесорних комплексів.
Використання в таких комплексах однотипних процесорів є економічно невигідним, оскільки в кожному процесорі використовується лише та частина ресурсів, яка необхідна для виконання певної операції в певний момент часу. Найбільш економічний спосіб побудови багатопроцесорних систем - це використання спеціалізованих процесорів, орієнтованих на реалізацію певних функцій: обробка скалярних величин, текстів, матрична обробка, ввід-вивід даних.
Система складається із сукупності процесорів, що мають індивідуальну та основну пам’ять.

Ядро системи забезпечує інформаційне спряження усіх пристроїв. Воно може бути реалізоване у вигляді системної шини комутаційного поля або комутатора основної пам’яті. Управляючий процесор виконує супервізорні функції, обробляючий - обробку числових і символьних даних, матричний - матричну і векторну обробку.
Склад процесора конкретної системи залежить від складу конкретної задачі. Обробка кожної задачі розподіляється між процесорами. Різні кроки завдань, програми і гілки програм виконуються обробляючим, матричним і мовним процесорами. Розподіл задач здійснюється управляючим процесором.
За останній час архітектура паралельних комп’ютерів зросла досить великими темпами. В даний час налічується дуже багато архітектурних рішень, проте всіх їх можна поділити на два класи:
1. Комп’ютери з спільною пам’яттю (мультипроцесорні системи). В даних комп’ютерах декілька процесорів мають доступ до спільної оперативної пам’яті одночасно. Всі процесори працюють в одному адресному просторі.

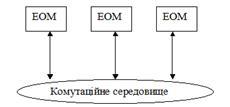
2. Комп’ютери з розподіленою пам’яттю. Складаються з декількох ЕОМ, кожна з яких має свою власну оперативну пам'ять, окрему операційну систему, свої пристрої введення / виведення. Об’єднання цих комп’ютерів відбувається через єдине комутаційне середовище.
Векторно-конвеєрні комп’ютери
Класичним прикладом комп’ютерів даного типу є комп’ютери Cray C90, що був випущений на початку 90-х років. Даний комп’ютер містить 16 рівноцінних процесорів, з часом такту 4,1нс, тобто тактова частота складає 250 МГц. Всі процесори однакові, як по характеристиках, так і по відношенню по розділенню ресурсів.
Структура ОЗП.
Кожне слово в пам’яті складається з 80 біт, 64 з них - біти даних, 16 біт - для корекції помилок. Для реалізації паралельного доступу вся пам'ять розбита на банки. При максимальній конфігурації вся пам'ять розбивається на 1024 банки, які в свою чергу об’єднуються в секції та підсекції. Кожна з восьми секцій включає в себе 8 підсекцій, кожна з яких включає 64 банки. При одночасному зверненні до однієї підсекції, конфлікт вони вирішують за 6 тактів. Якщо вибірка відбувається з кроком, то час вирішення конфлікта збільшується із збільшенням значення стеку. Кожен процесор має доступ до ОЗП через чотири порти, що працюють зі швидкістю два слова за такт. З цих чотирьох портів обов’язково один виділяється для операції вводу/виводу. Ще один обов’язково виділяється для проведення запису.

Секція вводу виводу.
Підтримує три типи каналів для роботи із зовнішніми пристроями:
1. Low-speed channels (LOSP) 6 Мбіт/с
2. High-speed channels (HISP) 200Мбіт/с
3. Very high-speed channels (VHISP) 1800 Мбіт/с
Секція міжпроцесорної взаємодії.
Основне завдання - це передача даних та керуючої інформації між процесорами та синхронізація їх взаємної роботи. Містить розділені регістри та семафори, які об’єднуються в групи, що називаються кластерами. Кожен кластер містить вісім 32-розрядних регістрів, вісім 64-розрядних регістра і 32 однобітних семафори. Кількість кластерів визначається конфігурацією комп’ютера.
Регістрова структура процесора.
Так як всі процесори даного комп’ютера є однакові, то розглянемо структуру одного процесора. Кожен процесор вміє обробляти три типи даних:
адреси
скаляри
вектори.
Кожен процесор має набір основних та проміжних регістрів. До основних відносяться: А-регістри, що призначені для роботи з адресами, S-регістри, що призначені для роботи із скалярними даними. Проміжні регістри В та Т, призначені для запису проміжних результатів обміну процесора з пам’яттю. Адресні регістри містять вісім регістрів у основному наборі та 64 в проміжному. Всі регістри 64-розрядні і призначені для виконання скалярних операцій. Кожен з векторних регістрів містить 128 64-розрядних елементів. Призначені для збереження елементів вектора. Кількість таких регістрів - 8. для виконання векторних операцій є два додаткових регістра - 8-розрядний VL, в якому зберігається довжина вектора та регістр 128-бітний VM - регістр маски. Якщо і-тий розряд даного регістра рівний 1, то процесор буде виконувати операції над і-тим елементом вектора.
Необхідність оцінювання продуктивності комп’ютерів виникла з початку їх виникнення. Основна задача оцінювання - знайти оптимальний критерій для визначення ефективності роботи, що буде універсальним для вибору комп’ютера.
Однією з одиниць оцінки продуктивності є пікова продуктивність, тобто кількість операцій, що виконує комп’ютер у найбільш сприятливих умовах (конвеєри заповнені, дані в регістрах, немає конфліктів з пам’яттю). Проте пікова продуктивність - це лише теоретичний показник. На одних задачах продуктивність може досягати до пікової продуктивності, а на інших задачах буде досягати лише 2% пікової продуктивності.
Користувача цікавить, наскільки продуктивно комп’ютер буде працювати на його програмах, тому показник пікової продуктивності не є універсальним при виборі комп’ютера.
Ще один спосіб оцінки продуктивності - це обрахунок кількості операцій за секунду. Вимірюється в МІРS-ах. Для визначення цього показника достатньо порахувати кількість операцій процесора за одиницю часу. Цей показник також не є універсальним, так як кожний процесор має свій власний набір інструкцій і програма користувача може на різних процесорах утворювати різну кількість операцій. Наприклад, операція а+b на процесорах Intel буде потребувати 3 мікрооперації, 2 з яких - зчитування значень з пам’яті, а третя - безпосередньо додавання. На інших процесорах ця операція може мати іншу кількість мікрооперацій.
Інший приклад - комп’ютер ILLIAC IV. Продуктивність комп’ютера - 10 мільярдів операцій/с. проте продуктивність досягалась тільки при роботі з даними розмірності "байт". На більших розмінностях продуктивність різко падала. Ще один недолік використання даного показника - це неможливість точного вимірювання продуктивності з використанням співпроцесора. Якщо співпроцесор існує, то всі операції з плаваючою комою покладаються на нього, тобто головний процесор виконує меншу кількість операцій. Якщо ж співпроцесора немає, то головний процесор регулює його роботу, тобто починає виконувати велику кількість операцій для виконання дій з плаваючою комою, тобто фактично кількість збільшується. Виникає протиріччя: з використанням співпроцесора кількість інструкцій зменшується, а отже, продуктивність зменшується, проте операції з плаваючою комою виконуються швидко; а коли співпроцесора немає, кількість інструкцій за секунду велика, а отже, продуктивність велика, проте реально операції над числами з плаваючою комою виконуються повільніше.
Отже, при оцінці продуктивності комп’ютерних систем не варто користуватися лише апаратними показниками, потрібно також враховувати програмно-апаратне середовище. На основі деяких критеріїв формуються еталонні тестові програми, які при запуску на кожній комп’ютерній системі показують продуктивність даної системи. Ці програми називають benchmark.
Однією з найпопулярніших тестових програм є тест LINPACK, який для тестового завдання розв’язує систему рівнянь із щільною матрицею. Спочатку в цьому тесті розв’язується система із ста рівнянь. Проте продуктивність сучасних систем є настільки великою, що дана система рівнянь вирішується надзвичайно швидко і оцінити продуктивність стає неможливо. Тому дана програма поставляється з відкритим кодом і кожен користувач може змінювати розмірність матриці.
Також існує ще ряд тестових програм, наприклад STREAM для тестування векторних операцій, LFK, PERFECT та багато інших. Проте жоден з цих тестів не покаже реальну продуктивність системи. Тому потрібно проводити комплексне тестування системи, також потрібно чітко розуміти призначення комп’ютерної системи та які задачі вона буде вирішувати.
Системи із спільною пам’яттю
Паралельні ПК із спільною пам’яттю
Комп’ютери даного класу відповідно мають переваги та недоліки.
Переваги:
простота програмування;
спільний адресний простір;
простота роботи;
Недоліки:
невелика кількість процесорів;
дуже велика вартість;
Щоб збільшити кількість процесорів, але при цьому залишити єдиний адресний простір, пропонується декілька архітектур. Найпопулярніша з них - СС VNUMA.
В даній архітектурі фізична пам’ять є фізично розподіленою, але на логічному рівні - це її єдиний адресний простір. Також дана архітектура вирішує проблему когерентності кешів і забезпечує повну сумісність з комп’ютерами SMP.
Приклад архітектури СС VNUMA будемо розглядати на комп’ютері ИP Saperdome. Він випущений в 2000 році. Максимальна конфігурація може включати до 64 процесорів, максимальна кількість оперативної пам’яті - 256Гб, розширення - до 1Тб.
Основу архітектури складають обчислювальні коди, зв’язані між собою ієрархічною системою перемикачів. Кожна комірка - це мультипроцесор, на якому розміщені всі необхідні компоненти. Кожна комірка може містити до 4 процесорів, оперативна пам’ять - до 16Мб.
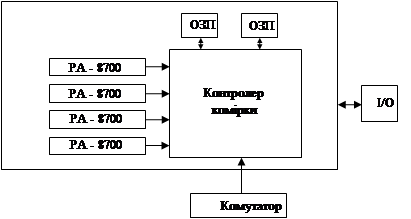
Центральне місце в комірці займає контролер комірки. Це дуже складний пристрій, який складається з 24 млн транзисторів. Контролер зв’язаний з кожним процесором через окремий порт. Швидкість обміну даних - 2Гбіт/с. Також контролер слідкує за когерентністю кеш - пам’яті процесора. Пам’ять комірки може мати ємність від 2Гб і конструкцію поділено на 2 банки, що зв’язані з контролером комірки через окремі порти з швидкістю передачі інформації - 2Гбіт/с. Система введення/виведення включає в себе PCI - слоти. Окремий порт комірки зв’язаний з комутатором, через який відбувається зв’язок з іншими комірками.
При повній конфігурації ПК HP Superdome складається з двох стійок:

Самі комутатори зв’язані між собою, а також мають по одному порту для розширення системи. Швидкість обміну даними - 8Гб/с.
Одним з центральних питань використання архітектури СС VNUMA є різниця в часі звернення. В комп’ютерах HP Superdome є 3 види затримки:
процесор і пам’ять знаходяться в одній комірці - затримка мінімальна;
процесор і пам’ять знаходяться в різних комірках, під’єднані до одного комутатора - затримка середня;
процесор і пам’ять розміщені в різних комірках, комірки під’єднані до різних комутаторів - затримка максимальна.
Тому при написанні програми для даного комп’ютера потрібно уникати можливості розпорідного звернення до пам’яті. Також даний комп’ютер має ряд особливостей:
він може працювати як єдиний класичний ПК, а можна його скорегувати так, щоб розбити на декілька частин, кожна з яких називається n Portition, вона може працювати під окремою операційною системою;
"гаряча" заміна усіх компонентів системи;
ефективна робота з великою кількістю периферійних пристроїв;
резервування;
моніторинг всіх параметрів системи.
Розглянемо процесор РА-8700. його тактова частота - 750МГц., володіє суперскалярною архітектурою і витрачає 4 такти на виконання однієї операції. Іншими словами, пікова продуктивність даного процесора - 3 ГФлопс, а всієї 64-процесорної системи - 192 ГФл. Процесор РІ 8700 на кожному такті виконує стільки операцій, скільки йому дозволяє інформаційна структура коду, а також кількість вільних функціональних пристроїв. Всього пристроїв в процесорі є 10.4 з них - для виконання арифметичних операцій над цілими числами; 4 - над дробовими і 2 функціональні пристрої - для проведення запису/читання. Починаючи з процесорів РІ 8500, кеш І рівня розміщується на кристалі процесора і досягає об’єму 2,25 Мб. При складанні програм для комп’ютерів даного класу можуть виникнути проблеми, що характерні для усіх типів паралельних комп’ютерів. А саме, неможливість розпаралелення фрагментів коду, тобто, якщо 25% коду - це послідовні операції, то збільшення швидкодії більш ніж у 5 разів досягнути нереально. Також потрібно звертати увагу на неоднорідність звернень до пам’яті.
Дані системи ще називають SMP - системами. Даний тип систем не має таких недоліків, як у випадку систем з розділеною пам’яттю. Проте основна проблема при розробці таких систем - це складність комутації процесорів з пам’яттю та організація одночасного доступу процесорів до спільних пристроїв. Є декілька архітектурних методів для вирішення даної проблеми:
1. Використання загальної шини.

Всі процесори та ОП під’єднуються до однієї шини, що являє собою набір провідників. Коли процесор "хоче" працювати з пам’яттю, він монополізує доступ до шини. Інші пристрої в даний час не можуть працювати з ОЗП, їм доводиться "чекати" коли відкриється доступ до шини. В таких системах можна максимум об’єднати 4-5 процесорів.
2. Іншим методом використання єдиної пам’яті є створення декількох окремих блоків, кожен з яких може працювати з одним процесором. Одною з таких реалізацій є система матричних комутаторів.

На вузлах сітки провідників ставиться комутатор, який відкриває або забороняє процесору доступ до даного блоку пам’яті. В системі, в якій є n процесорів та n блоків пам’яті потрібно  комутаторів, що при значних n є дуже великим числом. комутаторів, що при значних n є дуже великим числом.
3. Ще одним способом організації спільного доступу до пам’яті є використання омега мережі.

В даній системі кожен з процесорів зв’язаний з комутатором, кожен комутатор може з’єднати будь який свій вхід з будь яким виходом. Зв'язок процесорів з пам’яттю відбувається через комутатори. Перевага даного методу - значно менша кількість комутаторів. Недолік - досить великий час затримки через досить великий час перемикання комутаторів.
Обчислювальні системи з розподіленою пам’яттю.
Ідея побудови таких обчислювальних систем є дуже простою. Береться деяка кількість обчислювальних вузлів, кожен з яких складається з процесорного елемента та оперативної пам’яті, доступ до якої має тільки цей процесорний елемент. Доступ до віддаленої пам’яті відбувається іншим, більш складнішим шляхом. В наш час в ролі обчислювальних вузлів все частіше використовуються повноцінні комп’ютери. Комунікаційне середовище може спеціально розроблятися для певної системи, або бути стандартною мережевою технологією, вільно доступною на ринку. Переваги в таких системах наступні:
Користувач може довільно конфігурувати систему, в залежності від своїх бажань та можливостей.
Дана система може практично необмежено розростатись і вартість такої системи значно менша ніж інші паралельні системи.
Дані системи отримали назву - комп’ютери з масовим розпаралелюванням або масово паралельні комп’ютери. Найбільшого розповсюдження дані системи набули з 90-х років. Серед найпопулярніших систем можна виявити Intel Paragon IBM SP1 SP2. Всі вони різняться тільки процесорами, що входять до їхнього складу та комунікаційним середовищем.
Перевагами цих систем є можливість розв’язку декількох паралельних незалежних або слабозв’язаних задач. Також перевагою можна вказати відносну простоту та дешевизну створення. Недоліками є складна організація роботи такої системи (синхронізація даних, реалізація механізму повідомлень між комп’ютерами) та великі накладні витрати при передачі даних по мережі. По характеру зв’язків між ЕОМ даної системи можна виділити наступні типи:
1. Непрямі або слабозв’язані. В слабозв’язаних системах комп’ютери обмінюються даними через спільний зовнішній запам’ятовуючий пристрій. Цей пристрій працює по принципу "поштової скриньки", тобто один комп’ютер записує дані в спільну пам'ять, а інший звідти її зчитує.

Такий підхід використовується, коли треба підвищити надійність системи. Тобто одна ЕОМ є основною, вона проводить всі операції контролю обрахунків, введення / виведення інформації, і з певною періодичністю передає їх на резервну ЕОМ. У випадку відмови основної ЕОМ резервна її заміняє.
2. Прямозв’язані. В прямозв’язаних системах є три види зв’язків:
зв'язок через загальний оперативний пристрій;
пряме управління або зв'язок "процесор-процесор";
зв'язок через адаптери.
Зв'язок через загальний оперативний пристрій значно сильніший ніж зв'язок через зовнішній запам’ятовуючий пристрій. Обмін інформацією відбувається також за принципом "поштової скриньки".
Прямий зв'язок може бути не тільки інформаційним, але і командним, тобто один процесор може управляти іншим.
Зв'язок через адаптери - це зв'язок через комп’ютерну мережу.
3. Сателітний зв'язок. Сателітний зв'язок використовується для зменшення навантаження на певну ЕОМ. До комп’ютера підключається інший комп’ютер значно меншої потужності. Цей комп’ютер називається сателітом. Комп’ютер - сателіт виконує наступні операції:
організацію роботи основної ЕОМ з периферійними пристроями, зовнішньою пам’яттю, віддаленими абонентами;
попереднє сортування даних, перетворення їх у форму, зручну для основної ЕОМ;
перетворення вихідної інформації у вигляд, зручний для користувача.
Методом використання єдиної пам’яті є створення декількох окремих блоків, кожен з яких може працювати з одним процесором. Одною з таких реалізацій є система матричних комутаторів.

На вузлах сітки провідників ставиться комутатор, який відкриває або забороняє процесору доступ до даного блоку пам’яті. В системі, в якій є n процесорів та n блоків пам’яті потрібно  комутаторів, що при значних n є дуже великим числом. комутаторів, що при значних n є дуже великим числом.
Об’єднання переваг систем SMP знайшло своє відображення в архітектурі NUMA (Non Uniform Memory Access).
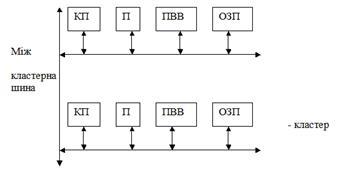
Розглянемо дану архітектуру на прикладі комп’ютера СМ*. Даний комп’ютер складається з системи кластерів, кожен з яких містить власний процесор, власну ОП, власний пристрій вводу/виводу, власний контролер пам’яті. Кластери з’єднані між собою єдиною міжкластерною шиною. Ця ОП даної системи є єдиною для користувача. Коли процесор звертається до оперативної пам’яті, контролер пам’яті аналізує адресу, і якщо дані знаходяться у власному кластері, то звертається до них через локальну шину. Якщо дані знаходяться в іншому кластері, то використовується міжкластерна шина.
Іншим прикладом комп’ютера з архітектурою NUMA є комп’ютер BBN Butterfly. Кожен вузол даного комп’ютера містить процесор, ОП, контролер пам’яті і власний пристрій вводу/виводу. Зв'язок з іншими вузлами відбувається через спеціальний комутатор Butterfly. Основною проблемою є узгодження кеш-памяті процесорів. Для вирішення цієї проблеми було розроблено архітектуру СС NUMA. Це дуже складна архітектура, що містить велику кількість протоколів для узгодження кеш-памяті. Така ж проблема узгодження кешу притаманна сучасним SMP системам. Технологія вирішення цієї проблеми досить складна. Сучасні SMP системи можуть містити 16-64 процесорів, тоді як архітектура NUMA дозволяє об’єднувати декілька тисяч процесорів в одну систему.
Розглянемо, як приклад, комп’ютери класу Cray T3E/T3D. Ці комп’ютери є масово паралельними комп’ютерами, які можуть містити до 2000 процесорів. Як і всі комп’ютери даного класу, він складається з вузлів та комунікаційного середовища. Всі вузли комп’ютера діляться на 3 групи: вузли користувачів, вузли операційної системи та обчислювальні вузли. Користувач має доступ тільки до вузлів користувачів, які можуть працювати в багатозадачному середовищі. Доступу до вузлів операційної системи користувач не має. На цих вузлах виконуються файли операційної системи і служать для підтримки багатьох сервісних функцій.
Обчислювальні вузли призначені для виконання програм користувача в монопольному режимі. При запуску програми користувача, для її виконання виділяється потрібна кількість вузлів і забезпечується монопольний режим використання цих вузлів. Кількість вузлів кожного типу залежить від системи. Наприклад, реально працююча система має таку конфігурацію - 24/16/576 (24 - вузли користувача; 16 - вузли операційної системи; 576 - обчислювальні вузли). Кожен вузол системи складається з процесорного елементу та мережного інтерфейсу. Процесорний елемент складається з процесора Dec Alpha, локальної пам’яті і допоміжних підсистем. В системі Т3Е-1200Е використовуються процесори Alpha-21164 з частотою 600МГц. Мережний інтерфейс зв’язаний з мережним комутатором, що являється частиною комунікаційного середовища.

Всі маршрутизатори розміщуються у вузлах трьохвимірної решітки і з’єднані між собою. Мережевий інтерфейс зв’язаний з маршрутизатором. Всі вузли зв’язані між собою топологією трьохвимірногопростору, тобто ті вузли, що знаходяться на межах куба мають зв’язок з протилежними вузлами.
Кожен вузол безпосередньо зв’язаний з 6-ма сусідніми вузлами, в незалежності від того, де розміщується вузол: чи на грані, чи на ребрі, чи на його вершині. Два вузли зв’язані між собою двома однонаправленими каналами у різних напрямках. В комп’ютерах Cray T3E-1200E швидкість передачі даних по цих каналах досягла 480Мб/с, а час затримки на рівні апаратури - 1мс. Пошук вузла в трьохвимірній решітці відбувається наступним чином: спочатку відбувається зміщення по вісі х
до того моменту, поки поточна координата х
не буде рівна координаті х
шуканого вузла. Аналогічний пошук відбувається по осях y
, z
. Також кожен маршрутизатор може паралельно передавати дані в трьох напрямках. Цікавою особливістю даного комп’ютера є апаратна підтримка бар’єрної синхронізації. Бар’єр - це таке місце в програмі, доходячи до якого процес зупиняє своє виконання до тих пір, поки решта процесів не дойдуть до цієї точки.
Цей вид синхронізації досить часто використовується при написанні програм, проте програмна реалізація бар’єру є досить складною і вимагає витрат ресурсів. Апаратна реалізація значно скорочує витратність ресурсів.

Кожен процесорний елемент має вхідний і вихідний регістри синхронізації. Кожен з цих регістрів зв’язаний зі своїм власним ланцюгом синхронізації. Сам же ланцюг синхронізації складається з елементів двох типів - це реалізація логічного множення (операція And) і пристрій, що дублює значення свого одного входу на свої два виходи (елемент 1-2). Вихід останнього елемента And є входом для першого елемента 1-2. Самі елементи зв’язані один з одним структурою бінарного дерева. Пояснимо принцип його роботи. Якщо деякий процес дійшов до бар’єру, то у відповідному процесорному елементі у вхідний регістр синхронізації записується 1. Процесор не продовжить роботу даних до тих пір, поки у його вихідному регістрі синхронізації не буде 1. Якщо уважно переглянути структуру бар’єру, то можна помітити, що якщо хоча б на одному процесорному елементі у вхідному регістрі синхронізації буде 0, тобто процес ще не дійшов до бар’єру, то у всіх вихідних регістрах всіх процесорних елементів також будуть нулі і всі процеси будуть очікувати моменту, коли даний процес дійде до бар’єру.
Ці ж ланцюги в комп’ютерах даного сімейства можна використовувати і в наступних цілях. Наприклад, якщо замінити оператор множення на оператор логічного додавання, то ми отримаємо так звану "систему еврика". Тобто коли певний процес дійшов до точки бар’єру, то одиниця, записана у вхідний регістр синхронізації перейде на всі регістри всіх процесорних елементів. Тобто всі решта процесів "дізнаються" про те, що деякий процес уже завершив роботу. Такий метод використовується у різних задачах, наприклад, в задачах пошуку.
В комп’ютерній термінології поняття кластер може мати декілька значень. Наприклад, кластерна технологія використовується для покращення швидкодії та надійності серверів баз даних та веб-серверів. Ми ж надалі будемо мати на увазі тільки обчислювальні кластери, тобто кластери, що використовуються для проведення обчислень.
Поштовхом для розвитку обчислювальних кластерів є велика наявність на ринку не дорогої комп’ютерної техніки, ресурси якої можна об’єднати для вирішення конкретної задачі, в той же час, як суперкомп’ютери є дорогими і малодоступними.
Взагалі кажучи, обчислювальний кластер - це є об’єднання декількох комп’ютерів в рамках єдиної мережі для вирішення конкретної задачі. Кожен комп’ютер може працювати під своєю власною операційною системою: Windows-NT, Linux, Unix, тощо.
Склад і потужність вузлів може змінюватися в рамках єдиного кластера. Кожен вузол може бути як однопроцесорною машиною, так і багатопроцесорною SMP.
Існує багато варіантів створення та побудови кластерних систем. Всі вони відрізняються між собою комунікаційним середовищем, що використовується для передачі даних між вузлами. Спочатку використовувався стандарт Ethernet зі швидкістю 10Мбіт/с.
В наш час досить поширеною є технологія Fast Ethernet зі швидкістю 10Мбіт/с. Проте великі накладні витрати даної технології при передачі даних не дозволяють створити універсальні обчислювальні кластери. Як альтернативу розробники можуть використовувати технології Gigabit Ethernet, Clan, Myrinet, Servernet та інші.
При передачі даних основні характеристики, що впливають на продуктивність це - латентність та пропускна здатність мережі. Латентність - це час, який потрібен, щоб повідомлення було підготовлене до відправки. Пропускна здатність мережі - це кількість інформації, що може бути передана за одиницю часу. Якщо обмін інформацією між вузлами складається з великої кількості невеликих повідомлень, то визначну роль в обміні даними буде грати латентність. Якщо повідомлення одне і велике, то визначну роль в обміні даними буде грати пропускна здатність.
Коли програмний додаток відправляє дані, вони спочатку проходять декілька шарів програмної та апаратної підтримки. Кожен з цих шарів може вносити власні корективи у процес передачі повідомлення. Наприклад, неякісний мережевий адаптер може з затримкою передавати дані, а неякісно встановлений драйвер може значно спотворити потік бітів.
Розглянемо параметри, які впливають на продуктивність комп’ютерів даного класу:
Наявність фрагментів програми, які можна розпаралелювати. Якщо в програмі досить великі фрагменти послідовного коду, то розраховувати на збільшення продуктивності не варто.
Так як фізична пам’ять є розподіленою між вузлами системи, то для доступу процесора до віддалених фрагментів пам’яті використовується система повідомлень, а отже визначну роль будуть грати або латентність або пропускна здатність. Тому для створення додатків для таких кластерних систем потрібно розробити систему повідомлень та розглянути, як ці повідомлення будуть передаватися мережею, і які чинники будуть основними.
Якщо апаратура і програмне забезпечення не підтримує асинхронної передачі даних, то може виникнути ситуація, що деякі процесори очікують коли решта процесорів закінчить роботу. Така ситуація призводить до невеликих накладних витрат в роботі.
Для досягнення найбільш ефективної роботи потрібно досягнути максимально рівномірної навантаженості кожного вузла. Якщо такої рівномірності не буде, то деякі процесори будуть простоювати, а решта - перенавантажені. Рівномірність навантаження досить легко досягнути на рівномірних однорідних системах (системи, в яких всі вузли однакової конфігурації, що з’єднані однаковою мережею). На неоднорідних системах досить важко досягнути рівномірної навантаженості.
Ще один фактор, що впливає на продуктивність - це реальна продуктивність кожного вузла. Різні моделі процесорів можуть мати різну характеристику, а саме: кількість рівнів кеш пам’яті, різні кількості функціональних пристроїв, тощо.
На початку розвитку масово паралельні комп’ютери були досить дорогими та рідкісними. В наш час завдяки розвитку мережених технологій кластер можна створювати в будь-яких умовах.
Програміст може розділяти задачу між декількома комп’ютерами в мережі і отримувати результати. В такому розумінні можна використовувати глобальну мережу Internet. Взагалі кажучи, Інтернет можна розглядати як надпотужний єдиний паралельний комп’ютер з найбільшою в світі піковою продуктивністю та іншими характеристиками.
Комп’ютер, що складається з великої кількості інших комп’ютерів, називається метакомп’ютером.
Звідси і походить назва процесу вирішення задач на таких комп’ютерах. Не обов’язково в якості комунікаційного середовища обирати Інтернет. Це може бути довільна мережева технологія. Основне не спосіб передачі даних, а принцип створення системи. Конструктивні ідеї використання розподілених обчислень ресурсів з’явилися на початку 90-х років. Деякі системи були універсальними, а деякі створювалися для вирішення певної задачі. В деяких системах використовувалися високопродуктивні мережі та спеціальні протоколи, а деякі системи використовували звичайні канали зв’язку і звичайні протоколи.
Прогрес в мережених технологіях останнім часом дуже великий. Гігабітні канали зв’язку є досить звичайним явищем у наш час.
Об’єднавши різні обчислювальні системи в рамках єдиної мережі можна сформувати спеціальну обчислювальну систему. Деякі комп’ютери будуть від’єднуватись, деякі приєднуватись, проте для зовнішнього користувача все це має бути прозорим. Користувач задає тільки задачу, а система сама визначає, які вузли підключати, як перетворювати дані тощо. Для користувача все одно, як працює всередині метакомп’ютер. Можна провести аналогію з електричною мережею. Коли користувач вмикає електричний пристрій, йому байдуже, яка електростанція виробляє енергію. По цій аналогії обчислювальні мережі називають в англомовній літературі Creed.
При взаємодії метакомп’ютера з користувачем виникають наступні особливості:
Метакомп’ютер володіє дуже великими ресурсами, які навіть не йдуть у порівняння із звичайними комп’ютерами. Це пікова продуктивність, об’єм пам’яті, число доступних процесорів.
Метакомп’ютер є розподіленим по своїй природі. Складові метакомп’ютера можуть бути віддалені один від одного на сотні кілометрів, що впливає на швидкість їх взаємодії.
Метакомп’ютер може міняти конфігурацію. Деякі вузли можуть від’єднуватись, деякі приєднуватись, проте на роботу метакомп’ютера це впливати не повинно.
Метакомп’ютер не є однорідним. Він може включати в себе сотні, тисячі вузлів різної конфігурації з різними операційними системами. Все це повинно враховуватись при створенні метакомп’ютера.
Метакомп’ютер об’єднує комп’ютери багатьох організацій, в кожній з яких є своя власна політика доступу до ресурсів, адміністрування політики захисту.
Метакомп’ютер не належить нікому і тому його адміністрування проводиться в загальних рисах.
Говорячи про метакомп’ютер, мається на увазі не реалізація його апаратної частини, а принцип взаємодії його компонентів між собою.
При роботі з метакомп’ютером необхідно враховувати такі питання як: моделі програмування, розподілення і керування задачами, технологія організації доступу, інтерфейс з користувачем, безпека, надійність тощо.
Не дивлячись на здавалось би велику складність створення метакомп’ютера, на проблематику його роботи, вони здобули широке застосування у наш час. Метакомп’ютер дозволяє вирішити такі задачі, вирішення яких колись було нереальне. Наприклад, для побудови однієї макромолекули одному комп’ютеру потрібно було би декілька днів. І кількість числових експериментів для даної молекули може перевищити сотні тисяч. Жоден традиційний комп’ютер не володіє потужністю для вирішення даної задачі, проте спільні ресурси метакомп’ютера можуть допомогти.
Також до особливостей метакомп’ютерів можна віднести задачу розподіленого зберігання даних. В багатьох задачах об’єми даних, з якими працює дана задача, можуть перевищувати 1015
байт. Немає традиційного комп’ютера, який міг би зберігати таку інформацію. В метакомп’ютері всі ці дані розподілені на географічно віддалених між собою вузлах. Характерною задачею даної області є задача створення інформаційної системи для підтримки експерименту в фізиці високих технологій.
Існує багато різних засобів організації паралельно-обчислювальних систем. Серед них можна виділити:
векторно-конвеєрні комп’ютери
масивно-паралельні комп’ютери.
Тобто виникає необхідність певним чином класифікувати всі ці архітектури для того, щоб краще розуміти їх та вивчати. Існує понад 10 різних способів класифікації, в основі яких лежить той чи інший чинник, по якому буде відбуватись класифікація.
В основі даної класифікації лежить поняття потоку, а саме, потоків даних і потоку команд. Потоком називається деяка послідовність даних або команд. Флінн виділив 4 наступних класи:
1. SISD (Single Instruction Single Data stream). В даній архітектурі процесорний пристрій обробляє один потік команд і один потік даних. Це прості комп’ютери Фоннеймовського типу.

В цей клас входять наступні комп’ютери: РDР-11, VAX-11/780,CDC-6600,CDC-7600. В цей клас можуть також відноситись комп’ютери в яких існує конвеєрна обробка.

2. SIMD (Single Instruction Multiple Data). В архітектурах даного класу множинний потік даних обробляється єдиним потоком команд.
Сюди відносять комп’ютери, які мають векторні команди. Спосіб реалізації векторної команди ролі не грає. До цього класу відносяться: ILLIAC-4, ICL DAP, Cyber 205.

3. MISD (Multiple Instruction Single Data). В архітектурі даного класу єдиний потік даних обробляється множинним потоком інформації.
На даний час клас цих архітектур був порожній.
4. MIMD (Multiple Instruction Multiple Data). В даний клас входять обчислювальні системи, які мають декілька пристроїв обробки даних, кожен з яких працює з своїм власним потоком даних.
В даний клас входять всі можливі багатопроцесорні системи. Сюди також входять комп’ютери, в яких є один процесорний пристрій, що може працювати у багатозадачному середовищі.
Останній клас архітектури включає в себе дуже велику кількість обчислювальних систем, що також потребують класифікації. Дана класифікація була запропонована Р. Хонні. Весь клас MIMD архітектур він поділив на два підкласи:
1. З конвеєрною обробкою команд. Мається на увазі, що існує один конвеєрний пристрій, що працює в режимі розділеного часу для окремих потоків.
2. Кожен потік обробляється своїм власним пристроєм.
Другий підклас можна поділити на класи:
з перемикачами
мережі.
З перемикачами - це коли кожен процесор зв’язаний з кожним іншим через складний комутатор. Існують 2 види:
з спільною пам’яттю
з розподіленою пам’яттю
Мережі - це системи із розподіленою пам’яттю, коли кожен із процесорних пристроїв безпосередньо зв’язаний тільки з сусідніми пристроями, а зв'язок з віддаленими пристроями відбувається шляхом складної маршрутизації. Відповідно подальша класифікація залежить від типу мережі, а саме:
решітка
гіперкуб
ієрархія
змінна структура

Аналіз звернень в пам’ять особливо при обробці масивів показує, що доля звернень з послідовним збільшенням адреси достатньо велика. Для узгодження з конвеєром необхідно, щоб відбувалося випереджаюче зчитування у швидку регістрову пам’ять для послідовних адрес.
Таке випереджаюче зчитування і реалізовано у архітектурі з чергуванням адрес. Основна ідея полягає в тому, що адресний простір розподілений між банками пам’яті, так щоб сусідні слова розміщувалися в різних банках. При зверненні по деякій адресі всі еквівалентно адресовані слова всіх банків зчитуються у спеціальну швидку пам’ять, що називається фіксатором. При зверненні до наступного слова зчитування відбувається з фіксатора, а не з ОЗП.
Розглянемо більш детально архітектуру даної пам’яті. Коли відбувається зчитування з комірки за адресою 1, її значення зчитується фіксатором, причому у фіксатори зчитуються відповідні адреси з банку 2, 3, 0, тобто у фіксатори заносяться наступні m комірок, де m - кількість банків.
Розподілення адрес між m банками називають m-кратним чергуванням, звичайно m використовують як 2m
. таким чином ефект пам’яті залежить від кількості банків.
 
Асоціативна пам’ять являє собою сховище даних, в якому звернення до даних проходить полю ключа, що зберігається разом з даними. Схема порівняння (компаратор) виконує побітове порівняння вхідного із значенням ключів в словах асоціативної пам’яті. В результаті вибраними з пам’яті будуть ті слова, які мають аналогічний ключ.
Схема асоціативної пам’яті:
Для виконання операції пошуку вільних слів та пошуку по декількох бітах ключа персонального комп’ютера асоціативною пам’яттю вводиться регістр маски, біти якого вказують, які біти регістра ключа треба порівнювати.

Потокові машини.
На сучасному етапі можна виділити наступні три підходи до організації обчислювального процесу:
Процедурне програмування
Даний підхід реалізовується майже в усіх машинах Фон-Неймановського типу. Дані машини повинні містити пристрій управління в процесорі, що містить вказівник на поточну команду, яка виконується, щоб команди послідовно зчитувалися і виконувалися на операційному пристрої, а результат записувався в запам’ятовуючий пристрій. Особливості принципів роботи машини даного типу наступні:
Послідовне виконання команд
Обробка даних з перезаписом в пам’яті та регістрі
При послідовній обробці швидкість визначається швидкодією елементів, що обмежує продуктивність ЕОМ. Ці обмеження обумовлені елементною базою кожного компонента.
Функціональне програмування
Обчислювальна модель, в якій програма розглядається як множина визначених функцій, називається функціональною моделлю. Для опису функціональних моделей використовують два типи мов програмування:
Використання аплікативних мов
Використання мов з однократним присвоєнням
Відмінною рисою цих моделей є те, що в їх основу покладена чітка і зрозуміла математична модель λ-перетворень.
Потокове програмування
Основна ідея потокового програмування або моделі обчислювального процесу по потоку даних заснована на операції обробки даних, яка активується цими даними.
Реальне виконання деякої операції можливе тільки тоді, коли дані для цієї операції будуть готові, тим самим дані, що передаються від однієї операції до іншої активізують дану операцію. В цьому принцип керування потоком даних наступний: всі операції виконуються тільки при наявності всіх операндів для її виконання.
Основні відмінності від машин Фон-Неймановського типу наступні:
Операції з готовими операндами можна виконувати одночасно
Обмін даними між операціями чітко визначений, тому відношення залежності між операціями легко виявити
Оскільки управління операціями виконується шляхом передачі даних між ними, то немає необхідності в управлінні ходом виконання операцій, а отже, немає необхідності в централізованому управлінні даних. Опис обчислювального процесу в машинних потоках даних може бути представлений у вигляді графа, в якому вершини - суть операції, а дуги - це напрямок передачі даних між операціями. Реалізація такої ідеї приводить до появи поняття командної комірки, яка повинна зберігати код операції, безпосередньо операнди операції та їх біти готовності та адресні поля, в яких вказуються поля операндів других командних комірок, в які відправляються результати даних операцій.
Схематично командну комірку можна зобразити наступним чином:
 
В загальному вигляді машина потоків даних повинна містити пам’ять командних комірок. Процесор, що виконує активовані команди та два спеціальні пристрої - арбітражна та розподільна мережа. Призначення арбітражної мережі - знаходження командних комірок, готових до виконання. Призначення розподільної мережі - розміщення отриманого результату в полях операндів інших командних комірок.
Структура машини потоків даних:

Обчислювальні системи з структурою, що перебудовується будуються на основі мікропроцесорних модулів. Модуль повинен реалізовувати наступні функції:
обробку даних, що зводиться до обробки логічних значень, числових значень і рядків-значень
управління обчислювальним процесом, що забезпечує взаємодію модуля з групою модулів та з системою в цілому
встановлення з’єднання з іншими модулями і передачу даних між ними для забезпечення обчислювального процесу
З урахуванням усіх цих функцій модуль обчислювальної системи розглядається як сукупність трьох процесорів - обробляючого, управляючого та комунікаційного.
Комунікаційний пристрій забезпечує обслуговування кількох каналів передачі даних. Фізично модуль може реалізуватися на основі однієї мікро ЕОМ, яка виконує в мультипрограмному режимі функції обробки управління процесорами та передачі даних.
В системах, що перебудовуються модулі об’єднуються в найпростіші структури, які дозволяють достатньо легко визначити шляхи з’єднань між взаємодіючими модулями. Найбільш зручними структурами для побудови розглядуваних систем є матричні, пірамідальні та кубічні.
Організація обчислювальних процесів забезпечується наступними засобами: після вводу завдання в систему, модуль, що прийняв завдання, посилає через комунікаційне середовище запит на пошук вільного модуля. Коли він знайдений, йому посилається завдання, що визначає:
імена наборів даних, в яких розміщується програма,
вихідні дані,
дані, в яких будуть розміщені результати обчислень.
Із завдання та програми модуль дізнається про необхідні ресурси, закріплює їх за собою і після цього ініціює виконання завдання. Після завершення роботи ресурси звільняються і відбувається очікування наступного завдання.
Паралельні програми будуються традиційним способом: виділення під задач та гілок програми, операції над векторами і матрицями та організація конвеєрної обробки даних.
В обчислювальній системі, що перебудовується повинно бути реалізовано децентралізоване управління ресурсами. Це означає, що в системі не повинно існувати окремого модуля, що відповідає за централізований розподіл ресурсів. Розподілене управління засноване на узгодженій роботі всіх модулів системи. Кожний з модулів реалізує однаковий набір правил управління, що забезпечує ефективне використання всіх ресурсів системи. Розподілене управління підвищує надійність системи, так як кожний модуль здатний реалізувати управління ресурсами. Як і в будь-якій багатопроцесорній системі, механізм управління повинен включати взаємне блокування процесів при запитах ресурсів. Для усунення блокування використовуються різні механізми управління ресурсами:
одночасне формування запитів на всі необхідні ресурси
розподіл ресурсів по типах
ієрархічний порядок виділення ресурсів
Трансп’ютер
являє собою 32-бітний мікропроцесор, в склад якого входять:
Центральний процесор з RISC-архітектурою.
64-розрядний співпроцесор для роботи з числами з плаваючою комою.
Внутрішній ОЗП ємністю 4Кб і зі швидкістю обміну 120Мбіт/с.
32-розрядна шина пам’яті, що дозволяє адресувати 4Гб зовнішньої пам’яті і має швидкодію 40Мбіт/с.
Чотири послідовні лінії зв’язку, які можуть працювати в двох напрямках зі швидкістю передачі 5, 10 або 20Мбіт/с.
Інтерфейс зовнішніх подій для зв’язку процесора та зовнішніх подій.
Трансп’ютери розміщуються на трансп’ютерних модулях - TRAM-модулях. Це дочірні плати, які містять сам трансп’ютер, ОЗП, інтерфейс, що включає інтерфейс живлення та ін.
В залежності від складу TRAM можуть мати різні розміри, які є стандартизовані та пронумеровані. TRAM розміщується на окремих платах, які або безпосередньо підключаються до комп’ютера або об’єднуються в мережу, як єдиний розподільний комп’ютер.
|