|
1.Характеристика моделирования, понятия модели
Модель - это такой материальный или мысленно представляемый объект, который в процессе изучения замещает объект-оригинал, сохраняя некоторые важные для данного исследования типичные его черты.
Как мы уже говорили, человек применяет модели с незапамятных времен при изучении сложных явлений, процессов, конструировании новых сооружений. Хорошо построенная модель, как правило, доступнее для исследования, нежели реальный объект. Более того, некоторые объекты вообще не могут быть изучены непосредственным образом: недопустимы, например, эксперименты с экономикой страны в познавательных целях; принципиально неосуществимы эксперименты с прошлым или, скажем, с планетами Солнечной системы и т.п.
Модель позволяет научиться правильно управлять объектом, апробируя различные варианты управления на модели этого объекта. Экспериментировать в этих целях с реальным объектом в лучшем случае бывает неудобно, а зачастую просто вредно или вообще невозможно в силу ряда причин (большой продолжительности эксперимента во времени, риска привести объект в нежелательное и необратимое состояние и т.п.)
Процесс построения модели называется моделированием.
Другими словами, моделирование - это процесс изучения строения и свойств оригинала с помощью модели.
Различают материальное и идеальное моделирование.
Материальное моделирование, в свою очередь, делится на физическое и аналоговое моделирование.
Физическим принято называть моделирование, при котором реальному объекту противопоставляется его увеличенная или уменьшенная копия, допускающая исследование (как правило, в лабораторных условиях) с помощью последующего перенесения свойств изучаемых процессов и явлений с модели на объект на основе теории подобия.
От предметного моделирования принципиально отличается идеальное моделирование, которое основано не на материальной аналогии объекта и модели, а на аналогии идеальной, мыслимой.
Основным типом идеального моделирования является знаковое моделирование. Знаковым называется моделирование, использующее в качестве моделей знаковые преобразования какого-либо вида: схемы, графики, чертежи, формулы, наборы символов.
Важнейшим видом знакового моделирования является математическое моделирование, при котором исследование объекта осуществляется посредством модели, сформулированной на языке математики. Классическим примером математического моделирования является описание и исследование законов механики Ньютона средствами математики.
Процесс моделирования состоит из следующих этапов:
Объект - Модель - Изучение модели - Знания об объекте
Основной задачей процесса моделирования является выбор наиболее адекватной к оригиналу модели и перенос результатов исследования на оригинал. Существуют достаточно общие методы и способы моделирования.
2Типы и виды математических моделей применяемых в экономике недвижимости
При выполнении земельно-кадастровых и оценочных работ для решения экономических задач используются разнообразные виды экономико-математических моделей, эти модели позволяют делать анализ используемых объектов недвижимости и земельных ресурсов, выявлять определенные тенденции, находить оптимальные варианты устройства территории или использования объектов и других задач.
Существует несколько классификаций экономико-математических моделей, одна из них была предложена математиком-экономистом Кравченко:
1Корреляционные модели или производственные функции, которые позволяют определить степень влияния факторных признаков на результат.
2Балансовые модели, обеспечивают обоснование пропорций в производственном процессе
3Математической оптимизации, дающие возможность выбора наилучших вариантов развития
Брославец предложил следующую классификацию:
- экономико-статистические модели
- экономико-математические модели:
*детерминированные
*стохастические
В практической работе имеет смысл классифицировать модели в зависимости от лежащих в основе математических методов, поэтому модели можно разделить на:
1Аналитические, используется классический математический аппарат алгебры, геометрии, представленный в виде формул
2Экономико-статистические – основаны на методах математической статистики, теории вероятности, главное место среди них занимает производственная функция
3Оптимизационные - основана на методах математического программирования, позволяют находить экстремальные значения целевой функции по искомому значению переменной величины для определенных условий. Применяется когда из множества вариантов нужно выбрать наиболее оптимальный.
4Балансовая – обеспечивает обоснование и определение наилучших пропорций при организации производства, представлена в виде матриц и таблиц.
5Модель сетевого планирования.
3Условия применения экономико-математических методов и моделей.
- эмм могут быть полезны, если явления и процессы можно выразить количественно, существуют взаимосвязи и зависимости которые можно представить в виде уравнений или неравенств.
- при разработке модели должны быть учтены экономические, технологические и др. условия.
- количество исходной информации, ее достоверность должны соответствовать целям решаемых задач и задаваемой точности вычислений
- возможность анализа и корректировки результатов решения
- мах возможное упрощение модели, ее информации для более быстрого экономического решения задач
- комплексное применение математических моделей и методов.
4История развития математического моделирования
1898 Дмитриев предложил систему линейных уравнений для определения полных затрат ресурсов для производства товаров.
1928 Неймон доказал теорему о минимаксах, которая была положена в основу ряда важных принципов теории игр и линейного программирования.
1939 опубликована работа академика Кантаровича «Математические методы организации и планирования производства»
1941 Хичкок дал формальную постановку транспортной задачи и указал на некоторые подходы к ее решению
1947 Данциг предложил универсальный метод решения линейной экстремальной задачи, названный симплексный метод
50-е 60-е гг было опубликовано множество работ по линейному программированию. Значительный вклад в развитие эмм в России внесли Новожилов, Кравченко, Брославец.
5. Возможности применения ЭММ и моделирования при управлении земельными ресурсами, в оценочной деятельности
С помощью производственной функции в управлении земельными ресурсами и недвижимостью можно производить следующие действия:
- анализировать состояние и использовать ОН
- определять уровень результативного признака на перспективу, устанавливать его экономические оптимумы.
При проведении оценочных работ производственная функция позволяет рассчитать кадастровую или рыночную стоимость на перспективу с учетом изменений по ряду факторных признаков.
6.Характеристика экономико-статистического моделирования
В экономике и в с/х на формирование результатов производства оказывает влияние множество факторов.
Результаты производства могут быть значительно улучшены при применении экономико-статистических моделей, т.к данный тип моделирования позволяет выделить причинно-следственные связи, определить какие факторные признаки или показатели производства в большей степени влияют на конечный результат, т.е на результативный признак.
На основе экономико-статистических моделей рассчитывают ключевые показатели по проектам МХЗ и ВХЗ.
Также данный вид моделей используют при ведении оценочных работ при вычислении кадастровой и рыночной стоимости земельных участков.
Экономико-статистическая модель – функция, связывающая результативный и факторные показатели, выраженные в аналитическом, графическом или ином виде построенная на основе массовых данных и обладающая достоверностью.
7. Этапы экономико-статистического моделирования
1 Экономический анализ моделируемого объекта, сбор и обработка данных
2 Сбор статистических данных и их обработка
3 Определение математической формы связи, определение числовых параметров модели
4 Определение числовых параметров экономико-статистической модели
5 Оценка степени соответствия модели изучаемому процессу или явлению
6 Экономическая интерпретация модели, т.е анализ возможности ее использования для решения конкретных задач
8. Экономический анализ моделируемого объекта, сбор и обработка данных
На этой стадии важно правильно выбрать факторы, влияющие на результаты производства. При подборе независимых переменных, необходимо соблюдать следующие требования:
- точность производственной функции, она повышается при увеличении эмпирических данных
- при выборе независимых данных необходимо из множества переменных выбрать именно те, которые оказывают существенное влияние на результативный признак и они должны быть количественно измеримы.
- число отобранных факторов не должно быть большим
- включенные в модель факторные признаки не должны находиться между собой в функциональной связи, так как они будут характеризовать одну и ту же сторону изучаемого явления и дублировать друг друга.
За зависимую переменную принимается такой показатель, который исходя из поставленной цели исследования, наиболее полно характеризующий изучаемый процесс, это может быть прямой показатель, характеризующий результаты процесса или косвенный.
9. Определение математической формы связи, определение числовых параметров модели
Осуществляется путем логического анализа изучаемого процесса, выбора наиболее подходящего уравнения с последующим их построением и оценкой.
Содержательный анализ позволяет выбрать прямую или обратную связь, вид уравнения (линейное, нелинейной), форму связи (парная, множественная).
Подбор можно также осуществить путем применения стандартных программ на ЭВМ при этом исследуется достаточно большой объем статистических данных.
10. Оценка степени соответствия модели явлению. Критерий Фишера
Оценка производится с помощью специальных коэффициентов:
1корреляции 2детерминации 3Т-критерий Стьюдента 4F-критерий Фишера
Данные коэффициенты позволяют определить можно ли использовать полученную модель в производственных целях и с какой вероятностью ей можно доверять. Все коэффициенты производственной функции должны иметь экономический смысл и должны быть обоснованны.
Критерий Фишера применяется для проверки равенства дисперсий двух выборок. Его относят к критериям рассеяния.
При проверке гипотезы положения (гипотезы о равенстве средних значений в двух выборках) с использованием критерия Стьюдента имеет смысл предварительно проверить гипотезу о равенстве дисперсий. Если она верна, то для сравнения средних можно воспользоваться более мощным критерием.
В регрессионном анализе критерий Фишера позволяет оценивать значимость линейных регрессионных моделей. В частности, он используется в шаговой регрессии для проверки целесообразности включения или исключения независимых переменных (признаков) в регрессионную модель.
В дисперсионном анализе критерий Фишера позволяет оценивать значимость факторов и их взаимодействия.
Критерий Фишера основан на дополнительных предположениях о независимости и нормальности выборок данных. Перед его применением рекомендуется выполнить проверку нормальности.
11. Производственные функции.
Виды и способы представления
Математически выраженная зависимость результатов производства от производственных факторов. Формализованная символьная запись производственной функции имеет вид y= y(x1,x2….,xk)
Содержательно показатель у может быть, например, стоимостью валовой продукции, чистым доходом.
Величины (x1,x2….,xk) – могут выражать качественную оценку земель, фондообеспеченность хозяйств, нормы внесения удобрений в почву.
Существует несколько способов представления
производственной функции:
- табличный
– применяется при изучении зависимостей, полученных в результате непосредственных наблюдений.
- графический
– более нагляден, однако точность определения значений функции при заданных значениях фактора ограничена. Такой способ используется, когда важно не столько конкретное значение, сколько направление и характер изменения показателей.
-аналитический
(основной) – это уравнение, показывающее порядок вычисления результативного показателя при заданных факторах производства.
-номографический
– применяется для быстрого определения значений производственной функции и реализации аналитических форм связи между переменными когда не требуется высокой точности результаты. Он предполагает построение номограмм, отражающих ту или иную математическую зависимость.
Виды производственной функции:
- ПФ Леонтьева , используется для описания мелкомасштабных или полностью автоматизированных производственных объектов.
- ПФ Кобба-Дугласа  , используется для описания среднемасштабных объектов, характеризующихся устойчивым, стабильным функционированием. , используется для описания среднемасштабных объектов, характеризующихся устойчивым, стабильным функционированием.
- Линейная ПФ  , применяется для моделирования крупномасштабных систем, в которых выпуск продукции является результатом одновременного функционирования множества различных технологий. , применяется для моделирования крупномасштабных систем, в которых выпуск продукции является результатом одновременного функционирования множества различных технологий.
- ПФ Аллена 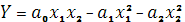 , используется для описания мелкомасштабных производств с ограниченными возможностями переработки ресурсов. , используется для описания мелкомасштабных производств с ограниченными возможностями переработки ресурсов.
- ПФ постоянной эластичности замены факторов 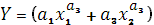 ^a4
, применяется в случаях, когда отсутствует точная информация об уровне взаимозаменяемых производственных факторов и есть основание предполагать, что этот уровень существенно не изменился при изменении V вовлекаемых рес-ов ^a4
, применяется в случаях, когда отсутствует точная информация об уровне взаимозаменяемых производственных факторов и есть основание предполагать, что этот уровень существенно не изменился при изменении V вовлекаемых рес-ов
- ПФ с линейной эластичностью замены факторов 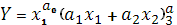 , используется для описания производственных процессов, у которых возможность замещения вовлекаемых факторов существенно зависит от их пропорций. , используется для описания производственных процессов, у которых возможность замещения вовлекаемых факторов существенно зависит от их пропорций.
- ПФ Солоу  , используется, когда предположение об однородности представляется неоправданным. , используется, когда предположение об однородности представляется неоправданным.
- ограниченная функция постоянной эластичности замены факторов 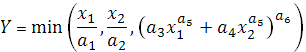 , для описания 2-х режимных производственных процессов, в котором один из режимов характеризуется отсутствием заменяемости факторов, другой – ненулевой постоянной. , для описания 2-х режимных производственных процессов, в котором один из режимов характеризуется отсутствием заменяемости факторов, другой – ненулевой постоянной.
- многорежимная ПФ  , используется при описании процессов, в которых уровень отдачи каждой новой единицы ресурса скачкообразно меняется в зависимости от соотношения факторов. , используется при описании процессов, в которых уровень отдачи каждой новой единицы ресурса скачкообразно меняется в зависимости от соотношения факторов.
- ПФ ЛП 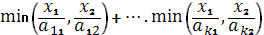 , используется, когда выпуск продукции является результатом одновременного функционирования коэффициента фиксированных технологий, использует одни и те же ресурсы. , используется, когда выпуск продукции является результатом одновременного функционирования коэффициента фиксированных технологий, использует одни и те же ресурсы.
12. Производственные функции. Применение на практике.
Математически выраженная зависимость результатов производства от производственных факторов. Формализованная символьная запись производственной функции имеет вид y= y(x1,x2….,xk)
Содержательно показатель у может быть, например, стоимостью валовой продукции, чистым доходом.
Величины (x1,x2….,xk) – могут выражать качественную оценку земель, фондообеспеченность хозяйств, нормы внесения удобрений в почву.
С помощью ПФ в ЗУ можно производить следующие действия:
- анализировать состояние и использование земельных угодий.
- готовить исходную информацию для экономико-математических задач по оптимизации различных решений, входящих в проекты ЗУ.
- определить уровень результативного признака на перспективу при планировании и прогнозировании использования земель в схемах и проектах ЗУ.
- установление экономического оптимума , k эластичности, эффективности и взаимозаменяемости факторов, т.е рассчитывать экономические характеристики ПФ и использовать их при принятии решений.
13. Понятие о статистической и корреляционной связях
В ходе статистического исследования объективно существующих связей между явлениями необходимо выявить причинно-следственные зависимости между показателями, т.е на сколько изменение одних показателей зависит от изменения других.
Статистическая
: не имеет ограничения в условиях присущих функциональной связи, при статистической связи разным значениям одной переменной соответствует разное распределение значений другой переменной.
Корреляционной называют связь
состоящую в том, что разным значениям одной переменной соответствуют различные средние значения другой переменной с изменением значений признака Х закономерным образом изменяется среднее значение признака У.
Корреляционная связь
– связь, где воздействие отдельных факторов проявляется только как тенденция при массовом наблюдении фактических данных.
В исследовании встречаются различные ситуации корреляционной зависимости:
1)Когда факторный признак Х определенным образом влияет на результативный признак У и четко прослеживается эта логическая зависимость.
2)Корреляция между признаками присутствует, однако оба признака являются действием общей причины.
Возникновение корреляционной зависимости при взаимосвязи признаков, каждый из которых является причиной и следствием.
15. Регрессия. Форма корреляционной связи
Корреляция и регрессия тесно связаны между собой, корреляция оценивает силу связи, т.е ее тесноту, регрессия – форму связи.
Для определения аналитического выражения связи применяют регрессионный метод.
Регрессия может быть однофакторной (парная) и многофакторной (множественной).
Парная – функциональная зависимость результативного признака от одного факторного.
Множественная – функциональная зависимость результативного признака от 2-х и более факторных признаков.
Под формой корреляционной связи понимают тип аналитической формы или уравнения, выражающего зависимость между изучаемыми признаками (уравнение регрессии).
Различают линейную и нелинейную регрессию (уравнение параболы, гиперболы).
Аналитическое уравнение корреляционной связи между 2-мя признаками можно найти с помощью выравнивания по способу наименьших квадратов, сглаживание средних и др. способов и приемов.
Уравнение регрессии является достаточно адекватным реальному моделированию явлений, если выполняются следующие требования:
1 совокупность исходных данных должна быть однородна
2 все факторные признаки должны иметь количественное выражение
3 V исследуемой выборочной совокупности должен быть достаточно большим
4 параметры модели не должны иметь количественных ограничений5 число факторных признаков должно быть оптимальным, практически установлено, что число признаков должно быть в 5 раз меньше изучаемой совокупности.
14. Установление тесноты связи. Коэффициент корреляции. Критерий Стьюдента.
Корреляционную связь можно выделить только в виде общей тенденции при массовом сопоставлении факторов, при этом каждому значению факторного признака будет соответствовать не одно определенное значение результата, а целая их совокупность.
Для выявления связи необходимо установить ее тесноту, которая выражается величиной k корреляции.
Для установления тесноты связи рассчитывается линейный k корреляции:
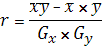 , ,
Где х –факторный признак
У – результативный признаку
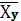 – среднее произведение признаков – среднее произведение признаков
 – среднее значение факторного признака – среднее значение факторного признака
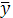 - среднее значение результативного признака - среднее значение результативного признака
Gx
– стандартное отклонение Х
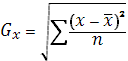 , n- количество наблюдений , n- количество наблюдений
k корреляции дает возможность определить полезность факторных признаков. Изменяется 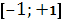 , положительное значение свидетельствует о прямой связи, т.е с увеличением факторного признака происходит увеличение результативного; отрицательный знак свидетельствует об обратной связи, т.е с увеличением факторного признака происходит уменьшение результативного. , положительное значение свидетельствует о прямой связи, т.е с увеличением факторного признака происходит увеличение результативного; отрицательный знак свидетельствует об обратной связи, т.е с увеличением факторного признака происходит уменьшение результативного.
k корреляции = 1 – абсолютная связь.
Сущность линейного k корреляции рассчитывают на основе критерия Стьюдента, при этом проверяется гипотеза равенства k корреляции = 0, для этого рассчитывается t-расчетное, которое должно быть > t-табличного:
, mr
– среднеквадратическая ошибка, которая рассчитывается 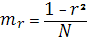 (при большом V выборки), и (при большом V выборки), и 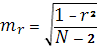 (при малом V выборки). (при малом V выборки).
Если t-расчетное > t-табличного – существенность k корреляции, V выборки достаточен.
Если t-расчетное < t-табличного – V выборки необходимо увеличить.
16. Оценка существенности связи
Точность или надежность изучения результатов корреляционной связи зависит от количества сопоставимых данных, число которых очень часто бывает ограниченно, поэтому полезно рассчитать погрешность вычисленного k корреляции или его сущность.
Сущность линейного k корреляции рассчитывают на основе критерия Стьюдента, при этом проверяется гипотеза равенства k корреляции = 0, для этого рассчитывается t-расчетное, которое должно быть > t-табличного:
, mr
– среднеквадратическая ошибка, которая рассчитывается (при большом V выборки), и (при малом V выборки).
Если t-расчетное > t-табличного – существенность k корреляции, V выборки достаточен.
Если t-расчетное < t-табличного – V выборки необходимо увеличить.
17. Построение модели множественной регрессии
Построение модели множественной регрессии включает в себя несколько этапов:
1)Выбор формы связи
2)Отбор факторных признаков
3)Обеспечение достаточного V совокупности для получения несмещенных оценок.
1 этап: сущность метода связана с выбором функции, заключается в том, что из большого числа уравнения регрессии, которая предлагается ПО на ЭВМ необходимо отобрать ту, которая описывает связи соц-экономических явлений.
Выбор функции сопровождается проверкой через показатели t-критерий Стьюдента и F-критерий Фишера.
Для описания соц-эконом. явлений более всего подходят 5 основных моделей:
- линейное уравнение y=a0
+a1
x1
+…+an
xn
- степенное уравнение
- гиперболическое
- параболическое
- экспонециональное
2 этап: важным этапом построения уже выбранного уравнения является отбор факторных признаков, т.е определение размерности моделей.
Проблема отбора факторных признаков для построения моделей связи может быть решена на основе эвристических методов (метод экспертных оценок) или с использованием многомерных статистических методов анализа.
Наиболее распространенный метод пошаговой регрессии. Сущность метода пошаговой регресс заключается в последовательном включении факторных признаков в уравнение регрессии и последующей проверки их значений.
При проверке значимости введенного фактора определяется на сколько уменьшается сумма квадратов остатков и растет величина множественного коэффициента корреляции [R].
Фактор является не значимым, если его включают в уравнение регрессии только изменяет значение k регрессии не уменьшая при этом сумму квадратов остатков и не увеличивая R.
18. Отбор факторных признаков для включения в модель множественной регрессии
Важным этапом построения уже выбранного уравнения является отбор факторных признаков, т.е определение размерности моделей.
Проблема отбора факторных признаков для построения моделей связи может быть решена на основе эвристических методов (метод экспертных оценок) или с использованием многомерных статистических методов анализа.
Наиболее распространенный метод пошаговой регрессии. Сущность метода пошаговой регресс заключается в последовательном включении факторных признаков в уравнение регрессии и последующей проверки их значений.
При проверке значимости введенного фактора определяется на сколько уменьшается сумма квадратов остатков и растет величина множественного коэффициента корреляции [R].
Фактор является не значимым, если его включают в уравнение регрессии только изменяет значение k регрессии не уменьшая при этом сумму квадратов остатков и не увеличивая R.
Если при включении в модель факторного признака величина R увеличивается, а k регрессии не меняются или меняются не значительно, то данный признак существенен и его включают в уравнение регрессии и наоборот.
19. Понятие мультиколлинеарности. Причины возникновения и способы устранения.
Под мультиколлинеарностью понимают тесноту зависимости между факторными признаками включенными в модель.
Наличие мультиколлинеарности между признаками приводит к следующему:
1)Искажается величина, параметров модели которые имеют тенденцию к завышению
2)Изменяется смысл экономической интерпретации k регрессии (коэффициенты при х – а1
, а2
)
3)Усложняется процесс определения наиболее существенных факторных признаков, поэтому при решении проблем мультиколлинеарности выдерживаются несколько этапов:
- установление наличия М
- определение причин возникновения М
- разработка мер по ее устранению
Возникновение М вызвано следующими причинами:
-Факторные признаки отображают одну и ту же сторону процесса
-В качестве факторного признака используются показатели, суммарное значение которых представляет собой постоянную величину
-Факторные признаки являются составными элементами друг друга
-Факторные признаки по экономическому смыслу дублируют друг друга
Индикатором определения наличия М между факторными признаками является парный коэффициент корреляции
между 2-мя факторными признаками.
Если он превышает величину 0,8, то М присутствует.
Для устранения М необходимо из корреляционной модели исключить один из признаков или преобразовать факторный признак в новый.
Выбор какой из факторных признаков необходимо исключить осуществляется на основе логического анализа.
Для этого сравнивается линейный k корреляции данных факторных признаков с результативным, исключают тот факторный признак, у которого линейный k корреляции с результативным признаком меньше.
21. Меры тесноты связей в многофакторной системе
Многофакторная система требует не одного, а несколько показателей тесноты связи. Основой изменения связи является матрица парных коэффициентов корреляции.
На основе этой матрицы можно судить о тесноте связи факторов с результативным фактором при включении их в уравнение регрессии.
При множественной регрессии тесноту связи характеризует множественный коэффициент корреляции [R]. Помимо R мерой тесноты связи является коэффициент детерминации [R2
]. Также нормируемый коэффициент регрессии [β].
22. Множественный коэффициент корреляции, проверка значимости
При множественной регрессии тесноту связи характеризует множественный коэффициент корреляции [R]. Рассчитывается при наличии линейной связи между результативным признаком и несколькими факторами.
R всегда положителен, изменяется [0;+1]. Приближение R к 1 свидетельствует о сильной зависимости между признаками.
Проверка значимости R осуществляется по F-критерию Фишера.
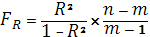 , ,
Где R2
– k детерминации, n – количество наблюдений, m – количество факторных признаков.
23. Коэффициент детерминации. Коэффициент эластичности
Помимо множественного коэффициента корреляции мерой тесноты связи является и коэффициент детерминации [R2
]. Коэффициент детерминации характеризует какая доля вариации результативного признака обусловлена изменением факторных признаков включенных в модель (уравнение множественной регрессии).
Для анализа также используется частный коэффициент эластичности рассчитывается по формуле:
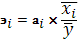
Где эi
– k эластичности
аi
– k регрессии при соответствующем факторном признаке
– среднее значение факторного признака
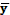 - среднее значение результативного признака - среднее значение результативного признака
Коэффициент эластичности показывает на сколько % в среднем изменится значение результативного признака при изменении факторного признака на 1 %.
24. Коэффициенты регрессии. Нормированные коэффициенты регрессии
Для экономического анализа используют коэффициенты регрессии, поэтому подбирают уравнение множественной регрессии. Регрессионная модель позволяет количественно оценить действия факторов, k регрессии позволяют судить об относительном вкладе факторного признака в регрессию.
Значимость коэффициента регрессии определяется также нормированным коэффициентом регрессии [β].
Существует простая связь между нормированным и ненормированным коэффициентами регрессии:
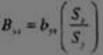
25. Корреляционно-регрессионная модель
Корреляционно-регрессионной моделью в системах взаимосвязанных признаков является такое уравнение регрессии, которые включают основные факторы, влияющие на вариацию результативного признака и обладает высоким коэффициентом детерминации (не менее 0,5) и значимыми k регрессии.
Коэффициент детерминации >0,5 означает, что результативный признак У должен зависеть более чем на 50% от совокупности факторов включенных в модель из этого следовательно не любое уравнение регрессии можно считать моделью.
Существует ряд рекомендаций для построения корреляционно-регрессионной модели:
1)Признаки-факторы должны находится в причинной связи с результативным признаком, т.е должна быть в наличии корреляционная связь.
2)Признаки не должны быть составными частями результативного признака или его функции
3)Признаки-факторы не должны дублировать друг друга, т.е быть коллинеарными.
Использование корреляционно-регрессионной модели для прогноза состоит в подстановке уравнения регрессии, ожидаемых значений факторных признаков для расчета точечного прогноза результативного признака.
26. Стадии оптимизационного моделирования
1- изучение экономического процесса или объекта моделирования
2- постановка э-м задачи с четким определением цели
3- определение переменных и ограничений задачи
4- математическая запись модели через буквенные символы
5- сбор информации и разработка технико-экономических коэффициентов
6- разработка числовой развернутой эм модели
7- решение задач на ПК, анализ результатов, корректировка модели, решение с учетом корректировки
8- экономический анализ выполненных расчетов и выбор оптимального варианта решения задач
1Отвечает на вопрос что мы могли получить
2Постановка задачи имеет решающее значение, от этого зависит в каком виде будет представлена модель. При подстановке выявляются не известные параметры, а также вся совокупность факторов, влияющих на размер тех параметров, которые представлены в качестве неизвестных. Очень важный момент – выбор функции цели (критерия opt) Критерий opt выступает как признак, по которому осуществляется выбор наилучшего варианта.
3После начального анализа и выбора критерия opt устанавливается, что же будет неизвестной величиной. Неизвестное обозначается xj
, при этом j (1;n). Переменные могут быть как основными так и дополнительными. Основные переменные могут отображать искомые площади по видам использования, видам угодий, площади под с/х культурами, V производства того или иного вида продукции, V производства в стоимостном выражении. Состав и количество переменных зависят от продуктивного планового периода, степенью детализации, размера объекта. Одновременно с определением переменных устанавливается их единица измерения, при выборе единицы измерения следует руководствоваться некоторыми принципами:
- размерность переменных должна быть удобной для получения необходимой информации, для расчета ТЭК
- принятая размерность не должна требовать дополнительной сложности расчетов
- следует избирать однотипные единицы измерения, они должны быть такими чтобы одноименные показатели не отличались между собой
После установления переменных определяется состав ограничений. Состав ограничений охватывает следующие группы условий:
1По использованию ресурсов (производственные, земельные)
2По обязательному производству продукции
3Устанавливающие пропорции между используемыми ресурсами, между отраслями
4По гарантируемому производству специфической продукции
5Взаимосвязи между отдельными переменными
Ограничения, которые накладываются на все или большинство переменных, выражают основные условия задачи.
Дополнительные ограничения накладываются на отдельные переменные или на небольшое количество переменных, эти ограничения обычно учитывают особенности процесса, отдельные требования по производству продукции.
Вспомогательные ограничения не имеют особого экономического смысла, используются для правильного оформления экономических требований.
1)Тот состав ограничений, который был выделен, записывается с помощью буквенных символов, т.е оформление в виде математической записи с помощью различных k. k при переменных обозначаются через английские буквы с соответствующими индексами.
Общий вид целевой функции: 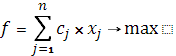 min min
2)Исходной информацией для составления э-м задачи являются годовые отчеты, производственные планы, текущая информация. Достоверность и устойчивость результатов решения зависит от качества использования информации и ТЭК
3)После подбора информации необходимых ТЭК для каждой группы ограничений, которые записаны через буквенные символы, составляется развернутая численная модель или уравнение (неравенство), где вместо aij
будет стоять конкретный числовой параметр
4)Специальная программа, в которую вводится матрица выдает opt или не opt решение. Если решение не opt, это значит:
-Допущена ошибка при введении информации в программу
-Не правильно сформулировано ограничение
-Не сбалансированы ресурсы
27. Матрица экономико-математической модели
Матрица – это специальная таблица, содержащая основную информацию о моделируемом объекте – смысловые или кодовые обозначения функции цели, переменных и ограничений, их численное выражение в виде конкретных коэффициентов и ограничений.
В э-м задаче применяются 2 наиболее общих способа расположения элементов в матричной модели – прямоугольный и блочный.
Прямоугольная матричная модель представляет собой обычную таблицу с различным соотношением значащих и нулевых элементов (разной заполненности).
Матричная модель с блочным расположением информации – таблица, составленная из прямоугольной матрицы, обычно расположена по диагонали каждому из блоков в э-м задаче соответствуют свои значения правой части и строки содержащие k целевой функции. Объединение блоков в единую модель обеспечивается связующим блоком.
В матричной модели э-м задач k каждого ограничения (условие) записывается отдельной строкой, при этом k aij
указывается в столбце соответствующей переменной xj
=> aij
одинокого относится как к строке (ограничение) так и к столбцу (переменной).
28. Понятие и виды технико-экономических коэффициентов
ТЭК в зависимости от назначения подразделяют на нормативные, пропорциональности и связи.
- нормативные k по экономическому содержанию делятся на k по уровню затрат и уровню производства. При получении нормативного k могут быть использованы специально разработанные нормативные данные для определения природных и экономических условий.
- k пропорциональности вводятся в матрицу по дополнительным и вспомогательным ограничениям с целью обеспечения пропорционального развития взаимосвязи отраслей или пропорциональной зависимости между отдельными переменными.
- k связи обозначающий связь между получаемым значением переменной и V ограничения. В большинстве случаев все k связи = 1.
29. Приемы моделирования
- запись ограничений по использованию ресурсов
а) V ресурсов известен и постоянен 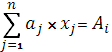
б) V ресурсов известен но может меняться 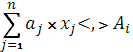
в) если предполагается увеличение или уменьшение ресурса, то через вспомогательные переменные можно установить V, например, необходимо определить V привлеченных трудовых ресурсов 
г) V ресурсов неизвестен  Объем неизвестных ресурсов можно определить через вспомогательные переменные (отраженную величину) Объем неизвестных ресурсов можно определить через вспомогательные переменные (отраженную величину) 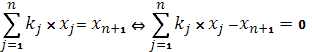
д) при ограничении используют двойные пределы, т.е переменная может менять численные показатели в определенных границах
- ограничения могут отображать технологические связи, например, удельный вес жилой застройки по этажности – многоэтажные 85%, 2-х этажные 10%, 1-этажные 5%
30. Определение переменных и ограничений экономико-математической задачи
Переменные делятся на основные и вспомогательные.
Основные переменные – это размеры площадей сельскохозяйственных площадей сельскохозяйственных культур, многолетних насаждений, естественных кормовых угодий, а так же поголовье скота.
Вспомогательными являются переменные, характеризующие формирование оптимальных рационов кормления, размеры капиталовложений по отраслям и дополнительную потребность в производственных ресурсах.
При постановке задач математического программирования обычно предполагается ограниченность ресурсов, которые необходимо распределить на производство продукции. Поэтому очень важно определить, какие ресурсы являются для изучаемого процесса решающими и в то же время лимитирующими, каков их запас. Если все виды производственных ресурсов, к которым относятся сырье, трудовые ресурсы, мощность оборудования и др., используются для выпуска продукции, то необходимо знать расход каждого вида ресурса на единицу продукции.
Все ограничения, отражающие экономический процесс, должны быть непротиворечивыми, т.е. должно существовать хотя бы одно решение задачи, удовлетворяющее всем ограничениям.
В качестве ограничений при построении экономико-математической модели выступает система неравенств, имеющая следующий вид: 
где aij — норма расхода i-го производственного ресурса на производство единицы j-го вида продукции;
wi — запасы i-го вида производственного ресурса на рассматриваемый период времени.
31. Виды информации, информационное обеспечение моделирования
При разработке э-м модели существенное значение имеет информационное обеспечение. Решение любой задачи связано с большим количеством информации, если для ее решения имеется необходимая информация то можно сказать, что задача информационно обеспечена.
Земельно-кадастровая информация – особый вид данных характеризующих состояние системы.
Информационное обеспечение процесса моделирования проходит следующие этапы:
-Получение исходной информации
-Обработка информации, ее анализ и оценка
-Подготовка информации для решения э-м задачи
-Переработка информации в процессе решения задач
Получение исходной информации происходит на основе детального изучения объекта в процессе подготовительных работ.
2 этап: производится в камеральных и полевых условиях, информация приводится к виду пригодному для дальнейшего использования.
3 этап: в процессе подготовки определенные показатели используются при ЗУ проектировании, кадастровых работах, осуществление экономических процессов, такие как затраты на производство продукции, V имеющихся ресурсов, стоимостные показатели.
4 этап: в результате переработки могут изменятся ТЭпоказатели, отображающие норму затрат на единицу продукции на площади с учетом времени разработанной модели.
Требования к информации:
- полная
- достоверная
- современная и оперативная
- должна быть представлена в удобной форме
- экономичная
Требования к системе информационного обеспечения:
- достаточность
- информационная совместимость с внешними системами.
- гибкость и возможность развития систем информационного обеспечения с учетом изменения в системе управления.
- возможность реализации принципиально безбумажность технологии, при одноразовом вводе и многоразовом использовании информации.
33. Статистические методы в управлении
Эффективность управления производственными, социальными и экономическими процессами во многом зависит от умения пользоваться всем спектром аналитических и статистических методов. Корректное их использование позволяет глубже понимать сущность происходящих процессов, а также вести осознанный поиск оптимальных решений локальных и условно глобальных задач.
Статистические методы изучения информации применимы для анализа экономического состояния предприятия, его конкурентоспособности на рынке, социально-производственной привлекательности, территориальной общности и производства, а также для решения множества других задач, стоящих перед управленцами всех направлений и рангов.
Для принятия решений немаловажное значение имеет, в каком виде будет представлена информация: необработанном и хаотичном или классифицированном, ранжированном и структурированном. Причем речь идет не только об информации, полученной в результате наблюдений, но и о таких данных, которые являются паспортными для исходных объектов. Не имеет значения, что представляют собой объекты изучения, в каждом случае они будут характеризоваться набором показателей: обобщенных и детальных, описывающих сходные явления и специфические черты объектов.
Очевидно, неклассифицированная и неструктурированная информация неудобна в плане принятия решений, управления, а обилие характеристик мешает анализу. Поэтому на первом этапе изучения информацию необходимо классифицировать и структурировать. Наиболее удобной формой классификации информации является представление ее в виде неких однородных образов, которые объединяют объекты по принципу схожести - близости характеристик. Это позволяет дифференцированно подходить к принятию решений, и, кроме того, однородность образов дает возможность прогнозировать их реакцию (обратную связь) на управляющие воздействия.
Таким образом, первым этапом исследования информации должны стать ее классификация, фильтрация и представление в упорядоченном и компактном виде. Этап классификации во многом определяет результаты всего исследования. От того, насколько удачно разделены объекты, удалось ли на первом этапе отфильтровать недостоверную информацию, не потеряна ли объективность при группировке детализированных характеристик, зависят точность принимаемых решений и управление.
34. Классификация объектов
Классификация - основа интеллектуальной деятельности человека. Встречаясь с новым явлением, человек сопоставляет его с уже известными ему явлениями, пытаясь найти аналог в известной ему области. Рассматривая группу каких-либо объектов, человек непроизвольно производит их разделение на подгруппы близких друг другу элементов. Классификация присутствует при упорядочении известных нам фактов, явлений, предметов.
Таким образом, методы классификации (распознавания образов) являются вполне естественной областью повседневной и повсеместной деятельности человека при систематизации и оценке явлений и предметов.
Для рассмотрения задач классификации лучше всего подходят многомерные статистические исследования.
Среди возможных методов классификации несомненный практический интерес вызывают методы распознавания образов, которые изучают числовые и нечисловые переменные и постоянные величины, используют методы математической, статистической и логической их обработки. Одной из ведущих теорий в области распознавания образов является кластерный анализ, благодаря которому решение задач классификации было осуществлено несложными компьютерными методами, а также были получены легко интерпретируемые результаты.
Одной из основополагающих задач классификации является формализация отличия одного объекта от другого - поиск совпадения или различия нечетко обрисованных объектов, сложноструктурированных множеств, выявление неявного течения процесса.
В практике встречаются два основных типа классификации. Простейший случай включает в себя заранее классифицированное пространство (млекопитающие, множество натуральных чисел, элементарные частицы) с известными характеристиками, определяющими принадлежность классу. В этом случае любой новый объект (предмет) можно по совпадению характеристик или причислить к какому-либо классу, или нет.
Более сложная ситуация возникает при необходимости объективной классификации множества объектов без предварительных подсказок о числе классов, наиболее существенных характеристиках и принципах разделения. Такая классификация является основной задачей кластерного анализа. Однако и в этом случае необходимо выделить, сформулировать или синтезировать достаточно общее свойство классифицируемых совокупностей. И уже это свойство позволит решить, сходны объекты или различны. Разумность выбора общего свойства должна быть подкреплена практическими результатами - это позволит утверждать, что выполненная классификация объективна.
В истории целенаправленной деятельности человека классификация осуществлялась методами, тесно связанными с предметом классификации. Интуитивно-эвристические подходы к классификации были доступны только выдающимся ученым и были результатом их озарения. И основной сложностью при этом был выбор наиболее важной характеристики или нескольких характеристик, по которым и определялось сходство или различие объектов.
35. Общие сведения о кластерном анализе. Понятие, преимущества
Кластерный анализ
- совокупность математических методов, предназначенных для формирования относительно "отдаленных" друг от друга групп "близких" между собой объектов по информации о расстояниях или связях (мерах близости) между ними.
Термин кластерный анализ, впервые был введен Трионом в 1939 году. Фактически, кластерный анализ является не столько обычным статистическим методом, сколько "набором" различных алгоритмов "распределения объектов по кластерам", т.е. включает в себя более 100 различных алгоритмов классификации.
Во многих отраслях науки перед исследователями постоянно встает вопрос о том, как организовать наблюдаемые данные в наглядные структуры, т.е. развернуть таксономии (группы, классы). Таким образом, в многомерном статистическом анализе кластерный анализ занимает особое место.
Кластерный анализ, в отличие от других статистических методов, имеет несколько преимуществ
:
1. с помощью кластерного анализа задачи распознавания образов решаются простыми и логичными методами, причем алгоритмы этих решений легко формализуются в компьютерные программы;
2. в кластерном анализе существуют методы комплексного изучения показателей различных типов данных (интервальных данных, частот, бинарных данных), при этом, не накладываются ограничения на представление исследуемых объектов;
3. простота и доступность процедур кластерных методов распознавания образов позволяет сосредоточить внимание исследователя на содержании сложных многофакторных объектов;
4. методы кластерного анализа позволяют накапливать знания с помощью информации, полученной в результате каждого эксперимента (измерения), выполненного в ходе использования кластерной модели. При этом характеристики кластеров могут корректироваться этими новыми знаниями, благодаря чему идет их накопление на каждой итерации (повторении).
Помимо всего этого, кластерный анализ позволяет сокращать размерность данных, делать ее наглядной; так же может применяться к совокупностям временных рядов, здесь могут выделяться периоды схожести некоторых показателей и определяться группы временных рядов со схожей динамикой.
Сочетание таких характеристик делает аппарат кластерного анализа незаменимым инструментом в задачах управления, классификации, оптимизации и прогноза промышленных, экономических и социальных систем.
Существенно затрудняет работу при использовании кластерного анализа лишь то, что развивался он параллельно сразу в нескольких направлениях, таких как психология, биология и др., поэтому у большинства методов существует по два и более названий.
Техника кластеризации применяется в самых разнообразных областях. Например, в области медицины кластеризация заболеваний, лечения заболеваний или симптомов заболеваний - широко используемые таксономии. В археологии с помощью кластерного анализа исследователи пытаются установить таксономии каменных орудий, похоронных объектов и т.д. Так же широкое применение кластерного анализа присутствует в маркетинговых исследованиях в истории, географии, экономике, филологии, искусствоведении,
36. Задача кластеризации
Задача кластерного анализа состоит в разбиении неоднородного множества, состоящего из каких-либо элементов, имеющих сходные измерения, на группу подмножеств, каждое из которых признается условно однородным. При этом основополагающую роль играет изучение различий между элементами множества, разными объектами, подмножествами, множествами.
На основе функций близости (схожести) элементов возможно несколько способов решения задач
классификации:
1. Исследователь может задать заранее известные ему характеристики исследуемых множеств или кластеров и после этого сформировать граничные условия этих кластеров, обозначив их контуры и целевые функции. Далее каждый элемент исходного неоднородного множества проверяется на близость каждому кластеру и в результате присоединяется к одному из них. Однако интуитивное определение кластеров не совсем корректно, так как объекты зачастую имеют большое количество взаимозависимых функций, в результате чего часть обозначенных первоначально кластеров может оказаться пустыми или же возможна неоднородность большинства характеристик внутри кластера.
2. Кластеры могут быть определены в автоматическом режиме в процессе нейтрального изучения функций расстояния. В этом случае рассматриваются некоторые сгущения объектов, проводятся границы между получившимися сгущениями, и, таким образом, определяются кластеры. Полученные в автоматическом режиме кластеры анонимны, не изучены и требуют определения наиболее существенных характеристик кластеров в процессе разделения исходного множества.
3. Исследователь может задать определенные критерии оптимальности, исходя из которых, решением задачи кластерного анализа может быть некоторая структура групп. Эти критерии, заданные целевыми функциями, определяют содержание кластеров, их характеристики, количество групп и факторов управления. В качестве целевой функции можно принять максимальную плотность элементов внутри групп или минимум отклонений от ядра группы, т. е. наименьшее расхождение характеристик.
Для решения задач кластерного анализа необходимо количественно определить меру сходства, подобия и различия объектов исследования. Эта мера в кластерном анализе называется функцией расстояния и определяется не только для объектов, имеющих естественные количественные характеристики, но и для тех объектов, параметры которых носят качественный характер.
37. Понятие кластера
Само название метода – кластерный анализ – этимологически берет начало от слов «класс», «классификация». Английское слово «the cluster» имеет значения: группа, пучок, куст, гроздь, т.е. объединение каких-то однородных явлений. В данном контексте оно близко к математическом понятию «множество». Кластер
представляет собой множество условно однородных (схожих) элементов (объектов). Степень однородности (сходства) может быть различной и определяется целями классификации.
Кластер имеет следующие математические характеристики: центр, радиус, среднеквадратическое отклонение, размер кластера.
Центр кластера - это среднее геометрическое место точек в пространстве переменных. Кластеры могут быть перекрывающимися. В этом случае невозможно при помощи математических процедур однозначно отнести объект к одному из двух кластеров. Такие объекты называют спорными. Спорный объект - это объект, который по мере сходства может быть отнесен к нескольким кластерам.
Радиус кластера - максимальное расстояние точек от центра кластера.
Размер кластера может быть определен либо по радиусу кластера, либо по среднеквадратичному отклонению объектов для этого кластера. Объект относится к кластеру, если расстояние от объекта до центра кластера меньше радиуса кластера. Если это условие выполняется для двух и более кластеров, объект является спорным. Неоднозначность данной задачи может быть устранена экспертом или аналитиком.
Каждая единица совокупности в кластерном анализе рассматривается как точка в заданном признаковом пространстве. Значение каждого из признаков у данной единицы служит ее координатой в этом пространстве по аналогии с координатами точки в нашем реальном трехмерном пространстве. Таким образом, признаковое пространство – это область варьирования всех признаков совокупности изучаемых явлений.
38. Функции расстояния (различия, несходства)
Если уподобить признаковое пространство обычному пространству, имеющему евклидову метрику, то тем самым можно получить возможность измерять «расстояния» между точками признакового пространства.
Наиболее распространенной функцией расстояния между двумя объектами по некоторому признаку является расстояние в метрике Евклида или евклидово расстояние.
Метрика Евклида позволяет не учитывать знаковые различия, пропорционально увеличивает расстояние между объектами в случае разных абсолютных значений показателей. В результате увеличивается размерность кластерного поля, объекты искусственно отдаляются друг от друга, в результате чего границы между кластерами становятся более четкими и точными.
Второй по значимости функцией расстояния принято считать метрику несхожести Хемминга.
Метрика Хемминга может использоваться в тех случаях, когда знаковые различия характеристик объектов имеют принципиальное значение. За счет нивелирования знаковых различий показателей объекты оказываются сконцентрированными к области ядра кластера, но при этом утрачиваются важные знаковые характеристики различий.
Так же существуют следующие функции расстояния:
1. L
-норма
2. норма – верхняя граница
3. функция Махаланобиса
Независимые переменные в уравнении регрессии можно представлять точками в многомерном пространстве (каждое наблюдение изображается точкой). В этом пространстве можно построить точку центра. Эта "средняя точка" в многомерном пространстве называется центроидом, т.е. центром тяжести. Расстояние Махаланобиса определяется как расстояние от наблюдаемой точки до центра тяжести в многомерном пространстве, определяемом коррелированными (неортогональными) независимыми переменными (если независимые переменные некоррелированы, расстояние Махаланобиса совпадает с обычным евклидовым расстоянием). Эта мера позволяет, в частности, определить является ли данное наблюдение выбросом по отношению к остальным значениям независимых переменных.
4. функция Джеффриса-Сатуситы
5. коэффициент дивергенции.
39. Дистанционный коэффициент (Эвклидово расстояние)
Оно попросту является геометрическим расстоянием в многомерном пространстве и вычисляется следующим образом:
расстояние(x,y) = {∑i (xi - yi)2
}1/2
Заметим, что евклидово расстояние (и его квадрат) вычисляется по исходным, а не по стандартизованным данным. Это обычный способ его вычисления, который имеет определенные преимущества (например, расстояние между двумя объектами не изменяется при введении в анализ нового объекта, который может оказаться выбросом). Тем не менее, на расстояния могут сильно влиять различия между осями, по координатам которых вычисляются эти расстояния. К примеру, если одна из осей измерена в сантиметрах, а вы потом переведете ее в миллиметры (умножая значения на 10), то окончательное евклидово расстояние (или квадрат евклидова расстояния), вычисляемое по координатам, сильно изменится,
40. Информационные признаки, используемые при кластеризации
Особенностью информационного сопровождения задач, решаемых методами кластеризации, является возможность использования практически любой информации об объектах исследования: формализованной и записанной в произвольной форме, объективной и субъективной, непосредственно измеренной или полученной косвенными путями, систематизированной и хаотичной - причем любая информация представляет определенную ценность для исследования. Такую разнородную и неструктурированную информацию об изучаемых объектах правомерно считать сложным множеством, требующим декомпозиции, шкалирования и нормирования для последующей кластеризации, структурного и содержательного анализа.
Выделяется три типа информации, используемой в кластерном анализе:
1многомерные данные - первичная информация.
2данные о близости (метрические и иные расстояния между объектами).
3данные о кластерах: координаты в признаковом пространстве, характеристики и свойства, границы кластеров.
Качество результатов обработки сложного множества, в первую очередь, зависит от обоснованности выбора признакового пространства. Эта задача состоит из двух взаимосвязанных подзадач: выбора наиболее информативных признаков и исключения взаимно корелируемых характеристик объектов. При этом определяется информативность признака, т. е. его «важность» для классификации. Признаки, имеющие максимальный «вес», используются в качестве описательных элементов (дескрипторов) при поиске нужных групп. Поскольку признаки являются главной характеристикой объектов, по которой определяется сходство или различие, их выбор и дает ту или иную систему разделения на однородные группы.
Существенную сложность в выборе правил разделения для классификации представляет ранжирование признаков. Процедура установления рангов изучаемых характеристик требует определения «полезности» каждого признака. В тех случаях, когда все признаки объявляются «равнополезными», т. е. их «весовые» коэффициенты принимают равные значения, это приводит к избыточности размерности признакового пространства, лишние характеристики не только усложняют вычислительные процедуры, но и размывают границы между кластерами, нивелируют характеристики объектов.
Таким образом, классификация во многом зависит от количества и качества выбора информационных показателей.
С ростом количества признаков снижается устойчивость классификации, размываются границы между группами. При неограниченном росте количества признаков усложняется содержательная интерпретация изучаемых процессов из-за необходимости учета второстепенных деталей, не существенных с точки зрения основного содержания исследования, что, в свою очередь, приводит к расплывчатости в описании объектов. Однако излишнее сокращение количества признаков может привести к примитивному описанию объектов при интерпретации содержания кластеров и отсутствию познавательной ценности результатов классификации.
Признаковые пространства
могут иметь природу двух типов. К первому типу относятся признаки, имеющие «непосредственное содержательное отношение к изучаемой проблеме». Эти признаки каким-либо способом фиксируются в ходе исследования или получаются с помощью расчетов исходных факторов. Второй тип признакового пространства получается в результате преобразования кластерной матрицы, в основном за счет трансформации строк, столбцов и самой системы координат.
Практика разделения неоднородного множества на некоторое количество однородных подмножеств указывает на возможность рационального подбора переменных, с помощью которых выделяются или сглаживаются различия между объектами. Выбор признаков, определяющих объекты, является основой формулировки решающих правил разделения исходного множества на подмножества.
Выбор признаков для классификации во многом зависит от целей исследования. Поэтому одно и то же множество может быть разделено на принципиально различные группы, отличающиеся не только количеством входящих в них элементов, но и их смешением в подгруппах. К примеру, классификация бригад по производственным признакам (производительность труда, фондовооруженность, трудовая дисциплина и т. п.), скорее всего, не совпадет с классификацией по обобщенным социально-демографическим признакам их членов (возраст, семейное положение, обеспеченность жильем и т. п.). Следовательно, нельзя классифицировать группу социально-экономических объектов один раз для любых случаев - процесс этот должен повторяться при изменении целей исследования или управления.
Теоретически классифицировать методами кластерного анализа можно неограниченное количество объектов с любым набором признаков. Однако практически существуют довольно жесткие ограничения, связанные со сложностью процедур, возможностями быстродействия и объема памяти компьютера. Поэтому в начале исследования определяется желательная размерность признакового пространства и ориентировочное количество групп, на которые следует разделить исходное множество. Последнее ограничение связано с возможностями восприятия информации при исследовании и управлении.
С увеличением количества распознанных объектов растет точность управления и достоверность знаний об их специфике, и было бы идеальным рассмотрение каждого элемента множества в отдельности (в этом случае и классификация не нужна). Но такая детальная группировка не воспринимается человеком, и поэтому в реальных классификациях количество групп, как правило, не превышает десяти. Размерность признакового пространства не является столь жестким условием и варьируется от одного показателя до пятидесяти, но может быть и больше. Если жё исследователи не ограничены вычислительными мощностями, то количество признаков может быть весьма значительным.
Дать формальный ответ на вопрос о качестве выбора размерности признакового пространства классификации до окончания процедуры кластеризации практически невозможно. Оценка размерности осуществляется на стадии интерпретации полученных результатов и в тех случаях, когда эти результаты не удовлетворяют условиям или анализа, приходится возвращаться к исходным процедурам обработки начальных массивов информации, но с использованием нового набора информационных признаков. В отдельных случаях, при нехватке характеристик, ведется дополнительная работа по сбору данных.
41. Схемы использования информации, предназначенной для кластеризации
Сильной стороной кластерного анализа можно считать его «всеядность»: какой бы вид информации ни предложить, кластерной матрице он оказывается полезен. Тем не менее в необработанном виде многие виды информации использовать практически невозможно. Необработанная информация разнопланова еще и потому, что зачастую принадлежит разным содержательным группам и поэтому ее нельзя систематизировать в общем поле измерения. В таких условиях постановщик исследования вынужден находить способ преобразования исходных данных, чтобы они отвечали единой аксиоматике кластерной модели классификации. Некоторые типы исходной информации, а также возможные способы придания им удобного для классификации вида приведены в табл. 1.
| Тип информации и ее основные характеристики
|
Преобразования, необходимые для использования информации в кластерной модели
|
| Прямая числовая информация, полученная непосредственно от объектов
|
Можно использовать в виде абсолютных или относительных (проценты, приведенные затраты) чисел. Расстояния между объектами вычисляются в кластерной модели
|
| Косвенная числовая информация о признаках, влияющих на поведение объектов, вторичных признаках, аналогичных объектах, условиях среды и т.п.
|
Можно использовать с учетом коэффициентов корреляции зависимостей или подобия объектов
|
| Альтернативная числовая информация опросных листов или паспортных данных. Нечисловая информация легко кодируется и переводится в числовую
|
Возможно прямое использование в относительном виде. Каждый параметр требует разработки собственной шкалы
|
| Нечисловая информация типа «меню», полученная в результате анкетирования респондентов или опроса экспертов
|
Требует разработки числовых аналогов текстовым характеристикам, недопустимо использование евклидовой аксиоматики. Расстояния, как правило, не вычисляются. Сравнение идет по совпадению предпочтений
|
| Историческая, генетическая, этимологическая информация о предыдущем развитии объекта исследования
|
Может быть представлена в виде уравнений регрессии, коэффициентов эластичности, начальных координат, рядов динамики
|
| Априорная числовая и нечисловая информация
|
Формируется экспертами до проведения расчетов кластерной матрицы. С ее помощью определяются предварительные характеристики кластеров, граничные функции, содержание кластеров
|
| Теоретическая информация, являющаяся следствием каких либо закономерностей, теоретических положений
|
Преобразования этого типа информации зависят от ее содержания и формального представления
|
| Гипотетическая информация о возможных результатах классификации, мотивах деятельности, гипотезах развития и т.п.
|
то же
|
| Эвристическая информация, основанная на предыдущем опыте, творческих способностях, образовании, интуиции
|
то же
|
| Экспериментальная информация, полученная в результате проверки гипотез или эксперимента
|
то же
|
| Случайная информация, полученная в результате незапланированных мероприятий, неожиданных результатов поиска
|
то же
|
42. Измерение характеристик объектов и их представление в задачах кластеризации
В прикладных задачах кластеризации встречаются два вида характеристик объектов: объективные показатели, которые могут быть оценены непосредственным измерением, и такие показатели, которые нельзя измерить в первоначальном виде (удовлетворенность работой, управленческие предпочтения, выбор рационального пути развития). Второй вид параметров требует введения опосредованных единиц измерения, экспертных оценок, проведения опросов общественного мнения и т. п. Очевидно, первая группа объективных показателей может быть непосредственно измерена с заданной точностью, а для второй группы характерна не только неопределенность, но и формально немотивированная изменчивость показателей.
Числовые характеристики первой группы, как правило, соответствуют аксиоматике Евклида. Для субъективных показателей возникает задача выбора приемлемой метрики, а в дальнейшем - сопоставимости показателей обеих групп. Для этого существуют различные искусственные методы включающие нормирование показателей, т. е. представление чисел в относительных единицах, как правило, на отрезке [0; 1].
Несмотря на «всеядность» кластерного анализа относительно исходной информации, в предварительно обработанном виде эмпирические данные должны отвечать следующим требованиям:
-содержательной репрезентативности, т. е. информация должна отражать существенные для исследования свойства объектов классификации;
-полноте объема информации, достаточной для объяснения явлений;
-достоверности;
-существованию формальных правил, по которым можно объективно интерпретировать данные, упорядоченные матрицы и т. п. Если это невозможно сделать в автоматическом режиме, то должны существовать эксперты, способные по приведенной информации дать оценку явлениям;
релевантности (степень соответствия запроса и найденного, то есть уместность результата или адекватность)
экспертных оценок.
43. Целевые функции кластеризации
В качестве критерия правильности классификации методами кластерного анализа можно использовать такие функции, которые содержат в себе содержательную логику основных задач, понимание постановщиком исследования того, как должно выглядеть разделенное множество объектов. И это было бы самым разумным решением.
Но чаще всего постановщик задачи не знает, какие могут быть результаты классификации, и тем более не может априори определить, какое разбиение следует признать оптимальным. В этом случае на помощь приходят целевые функции, сформулированные на основе изучения кластерной матрицы или промежуточных результатов кластеризации. Как правило, эти целевые функции корреспондируют с основными содержательными закономерностями, но обнаружить и обосновать эту связь нужно отдельно.
Использование целевых функций позволяет разрабатывать алгоритмы оптимизации кластерной задачи и формального выбора наиболее эффективного разбиения. В практических задачах трудно сформулировать единственную целевую функцию для поиска оптимального решения. Обычно постановщику хочется добиться соблюдения нескольких условий оптимизации. Несложный алгоритм последовательной фильтрации позволяет использовать любое число целевых функций, но для этого необходимо, чтобы в зону оптимального решения кластерной задачи попали несколько решений, иначе уже на второй итерации выбирать будет не из чего.
Сформулируем некоторые целевые функции, способные оценить качество классификации и выбрать оптимальные варианты.
А. Минимум объектов, не попавших ни в один кластер (потери классификации)
Несмотря на то, что потери объектов при классификации - процесс неизбежный, постановщик задачи, желающий сделать исследование репрезентативным, старается свести эти потери к минимуму:
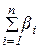
где: 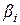 - объект, который после окончания расчетов не попал ни в один кластер. - объект, который после окончания расчетов не попал ни в один кластер.
Причины потерь объектов классификации могут состоять как в объективной невозможности создания однородных групп, так и в ошибках специалистов, выполняющих исследование.
Если количество объектов, не вошедших ни в один кластер после завершения всех вариантов классификации, достаточно велико, разумно провести специальное исследование причин подобных результатов.
В.Максимально возможная компактность каждого кластера
Компактность кластера можно определить следующим образом:
• разделить исходное множество на кластеры;
• у каждого кластера вычислить условный «центр массы».
С. Максимальное суммарное расстояние между границами (оболочками) кластеров
Этот критерий оценивает расстояние между образами (кластерами), что, в свою очередь, характеризует степень их отличия друг от друга и то, насколько методически объективно разделены объекты изучения.
D. Максимальное совпадение признаков (однородность) в каждом кластере
Соединение объектов в кластеры может происходить не только за счет однородности характеристик, но и в результате искусственных манипуляций: произвольного изменения масштаба расстояний, исключения из рассмотрения отдельных характеристик, субъективизма в постановке задач и многих других действий.
Поэтому важно найти объективную целевую функцию кластеризации, которая могла бы оценить схожесть характеристик объектов и на основании близости наибольшего количества показателей сформировать однородные кластеры. Впрочем, подобная целевая функция скрывает в себе немало трудноразрешимых задач: ведь не все показатели необходимы для точной характеристики объектов. Более того, «лишние» признаки способны дезориентировать исследователя, нивелируя интегральные (обобщающие) характеристики объектов изучения.
Вообще целевая функция однородности может быть сформулирована скорее в неформальном виде, чем задана алгоритмически. Учитывая неопределенность задачи выбора наиболее информативных характеристик, эффективнее эту процедуру поручить экспертам, причем не останавливаться на одном варианте показателей, а провести расчеты с несколькими вариантами. Сравнение результатов поможет оценить уровень доверия к экспертам.
Е. Максимальное приближение реального числа кластеров к теоретически идеальному.
F. Максимальная концентрация объектов в каждом кластере около расчетного ядра.
G. Максимальное приближение расположения объектов в кластерах к теоретически обоснованным законам распределения случайных величин.
H. Максимальное приближение дискриминантных линий, ограничивающих кластеры, к заранее заданным идеальным функциям.
44. Методы кластеризации
-K-средних (K-means)
-Графовые алгоритмы кластеризации
-Статистические алгоритмы кластеризации
-Алгоритм ФОРЕЛЬ
-Иерархическая кластеризация или таксономия
-Нейронная сеть Кохонена
-Ансамбль кластеризаторов
45. Кластеризация полным перебором объектов
Методически этот способ кластеризации наиболее прост, но довольно трудоемок. Применяется при небольшом числе объектов и обычно дает до 5-6 кластеров.
При полном переборе непреодолимые сложности составляют не только большой объем вычислений, но и невозможность интерпретации огромного количества вариантов кластеризации, многие из которых не имеют практического смысла, совпадают друг с другом или не удовлетворяют каким-либо формальным критериям кластеризации. Поэтому полный перебор должен сопровождаться алгоритмом исключения ненужных вычислительных процедур, изъятия из рассмотрения большого числа вариантов группировки, не удовлетворяющих целям исследования.
Для использования метода полного перебора и сокращения вычислений используются алгоритмы динамического программирования
46. Алгоритм «форель»
Существует последовательность действий, характерная для большинства известных процедур алгоритма «Форель»:
1. Случайно-интуитивным способом выбирается точка (объект классификации) в некотором метрическом пространстве.
2. Вычисляются расстояния от выбранной точки до всех остальных объектов. Затем эти расстояния заносятся в матрицу в упорядоченном виде. Полученная матрица нужна только для установления фиксированного радиуса сферы, являющейся границей кластера.
3. Радиус сферы выбирается произвольно. При выборе радиуса удобно придерживаться принципа попадания в сферу определенного количества объектов, вычисленных в предыдущей итерации. К примеру, это может быть одна треть от общего числа объектов.
4. Все объекты, попавшие в построенную сферу, становятся элементами кластера. Далее выбирается какой-либо новый элемент из сферы, который становится центром новой сферы того же радиуса.
5. Для выбора координат нового центра предпочтительно иметь какой-либо формальный критерий. Одним из логичных критериев может быть минимум расстояния от выбранного объекта до оболочки сферы.
6. Вновь построенная сфера включает в себя как объекты из первой сферы, так и новые. Старые объекты исключаются из рассмотрения, затем процедура построения сфер постоянного радиуса повторяется до тех пор, пока в сферу не попадет ни один новый объект. Это произойдет обязательно, потому что или в кластер войдут все рассматриваемые объекты, или расстояние между какими-либо объектами окажется больше радиуса сферы.
7. Кластером в этом алгоритме будут называться все объекты, которые вошли хотя бы в одну из построенных сфер. Очевидно, независимо от количества попаданий объекта в разные сферы в кластере он учитывается только один раз.
В алгоритме «Форель» качество классификации во многом зависит от рациональности выбора объектов - центров сфер и радиуса поиска. Если фазовое пространство метрики имеет три, два или одно измерение, то оценить исходные данные алгоритма можно визуально, а в случае неудачи изменить их. В многомерном пространстве исходные параметры выбираются вслепую, и при неудачах приходится рассматривать все новые и новые варианты, количество которых может быть весьма значительно.
Исследователь может менять параметры алгоритма «Форель». В зависимости от правильности выбора начальной точки - центра сферы конфигурация кластера и число кластеров существенно меняются. Поэтому имеет смысл провести кластеризацию несколько раз, меняя начальную точку и сравнивая полученные варианты. В том случае, если исследователя не удовлетворяет количество объектов, вошедших в кластер, или число сфер, то для измерения этих параметров можно варьировать значения радиуса сферы. Очевидно, увеличение радиуса приведет к расширению состава кластера, и наоборот.
Алгоритм «Форель» имеет существенные недостатки:
-отсутствуют автоматические критерии качества кластеризации
-границы между кластерами могут не иметь явно выраженных функций «водораздела».
-нет возможностей изменения правил выбора граничных значений кластеров, как следствие - ограниченные возможности для практического использования.
47. Сферический метод двухступенчатой кластеризации
Метод разработан на основе алгоритма «Форель», устраняя некоторые его недостатки. Сферический принцип построения кластеров более жесткий и предполагает минимальное вмешательство исследователя в классификацию на стадии вычисления и группировки кластеров. Множество объектов в сфере (гиперсфере) разделяется на ядро (наибольшее сгущение) и менее плотную часть.
Сферический метод кластеризации позволяет строго очертить границы между кластерами и однозначно присваивать каждому объекту принадлежность к какой-либо сфере. Но такие строгие границы оставляют достаточно много объектов (до 60 %) за пределами классифицированных множеств. Повышение качества кластеризации требует значительного уменьшения диаметра сфер, что приводит к увеличению кластеров, вплоть до числа, сопоставимого с числом объектов. Но в этом случае кластеризация не упрощает, а усложняет систему управления и теряет практический смысл.
Поэтому метод сферической кластеризации применим для такого расположения множества объектов, при котором существуют плотные ядра с малыми расстояниями между элементами и значительные межгрупповые расстояния, позволяющие пренебречь теми объектами, которые неизбежно окажутся вне сформированных кластеров. Сферический метод предполагает равноудаленность объектов от зоны сгущения с постепенным разрежением по мере удаления от центра сферы или зоны ядра.
48. Метод определения центра кластера с помощью вычисления среднеарифметических расстояний между объектами
Рассматриваемый метод предполагает наличие определенных сведений о содержании кластеров до начала вычислительных процедур. Естественно, априорные предположения могут быть достаточно приближенными. Во избежание ошибочных предположений исследователь может рассмотреть несколько вариантов начальной группировки объектов. Этот метод кластеризации не предполагает каких-либо ограничений геометрической формы кластера.
Предлагаемый алгоритм кластеризации состоит из следующих блоков:
1. Некоторой точке, принадлежащей множеству изучаемых объектов, присваивается геометрический признак центра координатной системы, причем первый объект в этой системе является началом отсчета.
2. Выбирается определенное число объектов (только количество), которые будут участвовать в расчетах условного центра кластера.
3. Далее необходимо задать какой-либо критерий, ограничивающий содержание кластера. В качестве примера ограничений может быть использовано предельное количество объектов в кластере или максимально допустимое расстояние от условного центра до наиболее удаленного объекта, или максимально возможный «водораздел» между наиболее близкими объектами. Исследователь, как правило, самостоятельно решает, какому критерию отдать предпочтение или выработать собственное ограничение на процесс формирования кластера.
4. В зависимости от выбранного алгоритма определения критерия, необходимого для завершения формирования кластера, вычисляется максимально допустимое расстояние между объектами d
. Расстояние может задаваться исследователем, исходя из анализа содержательного образа кластера или из соображений насыщенности кластера.
5. Методом перебора определяется объект АК
, наиболее близкий к объекту-центру Ац
. Далее проверяется выполнение неравенства: |АК
- АЦ
|
£
d
и, в случае безусловного выполнения этого неравенства, объект АК
заносится в матрицу данного кластера. Из дальнейшего рассмотрения объект АЦ
исключается.
6. В дальнейшем операции перебора повторяются, причем объект АК
становится центром рассматриваемой композиции. Итерации предыдущего блока выполняются до тех пор, пока не останется ни одного объекта вблизи любой из рассматриваемых точек, т. е. будет превышено пороговое значение d
.
Варианты классификации предлагаемым методом определяются перебором значений d
и начального объекта Ац
. При этом достаточно проблематично найти «водораздел» между кластерами из-за случайных помех на поле, в промежутках между сгустками объектов информации. Поскольку метод уравнивает значимость в замкнутом кластере сгущений и одиночных объектов, качество классификации случайно и требует специального изучения. Кроме того, в ряде случаев возможно объединение всех объектов информационного поля в один-два кластера. И наоборот, жестко заданные граничные условия способны вытеснить за пределы кластеров значительное число объектов.
В связи с последовательным включением объектов в кластеры разница между характеристиками начальных и конечных объектов может быть весьма существенной.
49. Метод постоянных кластеров и характеристик
Этот метод удобен в тех случаях, когда классифицируемая система хорошо изучена, и у исследователя существует определенная ясность относительно наиболее значимых характеристик кластеров. При этом исследователь может установить рациональные границы количества кластеров и их характеристики, не производя сложных вычислений. Тогда распределение объектов по кластерам происходит в результате простых арифметических расчетов, без циклических повторений, а в результате одной-двух итераций.
Алгоритм предлагаемого метода основан на содержательном анализе информационного поля до начала процедур кластеризации. На этом этапе исследователь должен определить рациональное число кластеров. исходя из физических возможностей оценки поля объектов, полезности для управления и возможности получения нетривиальных результатов. Введем обозначения: л - рациональное количество кластеров; Аш
(1с, I, т) ~ центр «массы» /-го кластера, имеющий координаты ^, /, т.
Рассматриваемый метод позволяет включить все объекты в кластеры. Это серьезный недостаток метода, потому что содержательный анализ информационного поля классификации свидетельствует о существовании достаточно большого количества объектов, которые не могут быть без искажения свойств причислены ни к одному из существующих кластеров. Вообще говоря, этот недостаток можно устранить введением вспомогательных функций максимально допустимых расстояний от центра кластера до наиболее удаленного объекта. Эта функция не может быть постоянной величиной, а должна вычисляться для каждого кластера в зависимости от плотности ядра кластера, количества объектов, дисперсии характеристик и других признаков. Впрочем, это отдельная научная задача.
Вторым недостатком рассматриваемого метода является необходимость предварительного определения количества кластеров и их типовых характеристик. Класс подобных задач чрезвычайно узок и, скорее всего, может быть вторым этапом классификации. То есть вначале каким-либо методом классификация уже проведена, а предлагаемый метод используется для подтверждения или опровержения полученных результатов.
Ограниченный объем вычислений и простота логических процедур позволяют менять количество кластеров при решении одной задачи и выбирать наиболее удобный для интерпретации вариант классификации.
50. Алгоритм метода постоянных кластеров и их характеристик
Рассмотрим алгоритм метода постоянных кластеров и их характеристик:
1-й шаг. Изучение содержательных характеристик информационного поля, анализ данных и определение количества кластеров, их основных характеристик - граничных условий.
2-й шаг. Распределение объектов по кластерам в зависимости от включения координат объекта в граничные условия кластера.
3-й шаг. Вычисление координат центров «массы» кластеров Аш
как средних арифметических координат объектов, входящих в рассматриваемый кластер.
4-й шаг. Замена априорных характеристик - границ кластеров на новые критерии кластеризации.
5-й шаг. Принимая точки Ащ,А,а, •••, Ац„ за центры «масс» кластеров (их количество сохранилось), начинаем формирование кластеров заново. При этом используем принцип наибольшей близости объекта к какому-либо центру кластера.
6-й шаг. Пересчитав все расстояния от объектов до каждого из центров и присоединив их к ближайшему, получим новое поле кластеров, при котором все объекты будут принадлежать какому-либо кластеру из определенных заранее.
7-й шаг. Для вновь сформированных кластеров производится перерасчет центров «массы», вычисляются типовые характеристики.
51. Алгоритм «краб»
В алгоритме «Краб» предусмотрена процедура фильтрации при заданной целевой функции отбора лучшего варианта. Оптимальный набор кластеров имеет жесткую, единственно возможную форму поля, причем контуры отдельных кластеров необязательно должны иметь сферическую оболочку.
Положительные стороны алгоритма «Краб» заключаются в возможности реализации поставленных целей кластеризации. В результате использования целевых функций удается ограничить количество рассматриваемых вариантов кластеризации до числа, определяемого целевыми функциями. Алгоритмом предусматривается формулировка суперцели, включающей в себя определенное число целевых функций. В этом случае результатом классификации будет единственный, наилучший вариант распределения объектов по кластерам.
Обозначим: М=åm - суммарное количество объектов, рассматриваемых в условиях данной задачи классификации; n - количество кластеров, полученных в результате классификации объектов; F - критерий оптимальности классификации, причем Fmax
- суперцель.
Последовательность процедур алгоритма «Краб»:
1. Построение информационного поля m-объектов кластеризации, вычисление характеристик объектов и евклидовых расстояний между ними.
2. Формирование матрицы минимальных расстояний между объектами. Размерность симметричной матрицы (m - 1).
3. Построение контура минимальных расстояний между объектами и нанесение граничной линии на кластерное поле. Проверка замкнутости граничной линии.
4. Разделение информационного массива на возможные кластеры, количество которых находится на отрезке [1; m - 1].
5. Сравнение качества кластеризации по заданным критериям F. Формирование информационных массивов кластеров и значений F.
6. Фильтрация вариантов кластеризации по локальным критериям F1
, F2
, F3
, …, Fk
, а также по комплексным критериям F1,2
и так далее.
7. Определение наилучшего варианта кластеризации по критерию суперцели Fmax
.
8. Описание характеристик объектов, содержащихся в кластерах при наилучшем варианте Fmax
или соответствующих локальным критериям оптимальной кластеризации.
В результате вычислительных процедур алгоритма «Краб» исходные объекты распределяются по кластерам достаточно простым способом и соответствуют сформулированным критериям оптимальности разбиения. Но, несмотря на простоту вычислительных процедур, количество вариантов кластеризации чрезвычайно велико. Кроме того, при расчете каждого варианта приходится рассматривать множество значений расстояний между объектами внутри кластера для расчета критериев F. Поэтому исследователи обычно вводят промежуточные ограничения для сокращения числа рассматриваемых вариантов.
52. Кластеризация с помощью экспертных оценок. Задачи
Прямое использование коллективного опыта специалистов при классификации объектов нашло решение в задачах кластерного анализа с участием мнений экспертов. Этот метод применяется при начальном разделении множества объектов, когда ведется поиск принципов распределения элементов по кластерам, или в случае необходимости поиска нетривиальных, но предсказуемых решений, или в простейших формулировках исследования, при дефиците ресурсов для сбора и обработки материалов. Бывает также, что формальная кластеризация дает разбиение, малопригодное в реальных условиях управления.
Экспертные оценки при кластеризации применяются в чистом виде или в комбинации с формальными процедурами, обеспечивая последним содержательный контроль за результатами классификации и способствуя углубленному пониманию постановочных задач. Таким образом, применение экспертных оценок в задачах кластеризации повышает эффективность работы в отношении как качества классификации, так и упрощения вычислительных процедур.
С помощью экспертных оценок возможно решение следующих задач кластерного анализа:
• установление границ кластеров и определение дискриминантных функций;
• поименное отнесение каждого объекта к определенному кластеру в соответствии с субъективным мнением экспертов;
• целевой отбор признаков (характеристик) для формирования кластеров и последующего изучения пространства объектов или придания признакам «весовых» оценок;
• разработка правил коллективной выработки функций формирования кластеров, установка формальных процедур классификации.
На этапе предварительного отбора параметров экспертиза необходима для того, чтобы какая-либо характеристика не оказалась неучтенной. На этом этапе эксперт достигает полноты учета характеристик за счет понимания содержания исследования с одновременным использованием фактографического материала кластерной матрицы. При этом эксперты, как правило, игнорируют формализованные правила выбора признаков, а придают решающее значение опыту и интуиции. Очевидно, руководитель исследования имеет возможность сделать поправку на компетентность эксперта в рассматриваемом вопросе.
Практически в задачах кластерного анализа компетентность экспертов измеряется как отклонение заявленных ими образов от установившихся и обоснованных кластеров.
Компетентность экспертов может быть вычислена как метрическая мера вероятности ошибки распознавания уже классифицированных объектов. Исследователем устанавливаются границы допустимых погрешностей экспертов, причем далеко уклонившиеся от нормы эксперты признаются нерелевантными источниками информации, использование мнений которых неэффективно.
53. Кластеризация с помощью экспертных оценок. Алгоритм.
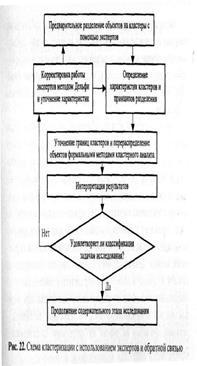
54. Кластеризация методом определения «ближайших соседей».
Этот универсальный метод классификации может использовать критерий близости объектов в метрической системе мер, или критерий подобия объектов. Исходные данные об элементах рассматриваемого множества должны быть представлены в матричной форме. Обязательной характеристикой исходных данных должна быть возможность их сравнения для определения иерархических уровней.
Метод «ближайших соседей» основан на иерархической агломеративной модели обработки матрицы, содержащей данные обо всех парах объектов классификации, расстояниях между ними или коэффициентах подобия. Таким образом, возможна классификация исходного множества малыми кластерами с очень близкими характеристиками. С увеличением радиусов кластеров сходство будет уменьшаться, а количество объектов в каждом кластере увеличиваться.
Метод «ближайших соседей» ставит задачу выбора первого объекта классификации, которая в предыдущих методах решалась случайным образом. В предлагаемой постановке подобный подход не может быть реализован, потому что содержание классификации зависит от того, какой элемент будет назван первым. В связи с этим предлагается до начала кластеризации сформулировать критерий значимости характеристик объектов и в соответствии с этим критерием выбрать первый объект.
Очевидно, при жестких граничных условиях первоначально каждый объект образует единственный собственный кластер, куда другие объекты не могут входить, затем постепенно кластер включает в себя и другие объекты из наиболее близких по схожести или подобию. Это включение происходит путем парных сравнений.
Алгоритм кластеризации методом «ближайшего соседа» по эффективности не уступает более сложным методам, а по доступности расчетов превосходит их. К ограничениям метода можно отнести требование минимальной изменчивости во времени исходного множества объектов. Поэтому динамично развивающиеся системы не могут быть объективно классифицированы методом «ближайшего соседа».
В иерархической системе, которая должна быть разделена на условно однородные группы объектов, выделяется или один признак, или группа признаков, определяющая значимость объектов. Таким образом, выстраивается цепочка ранжированных объектов, пригодных для последующей кластеризации.
Метод «ближайших соседей» предусматривает последовательную сортировку объектов исследования (элементов классифицируемого множества). Таким образом, выстроив иерархическую последовательность кластеров, можно определить, какой минимально допустимый уровень сходства объекта и кластера достаточен для получения приемлемого уровня их объединения. Все коэффициенты сходства или подобия должны быть определены заранее и занесены в матрицу. По этим коэффициентам выполняется идентификация априорных совокупностей (подмножеств) с «ближайшими соседями». Алгоритмом предусматривается, что все значения коэффициентов (элементов матрицы) после идентификации и включения в кластерную модель должны быть исключены из дальнейшего рассмотрения.
|