Любогощинский А.А. Анализ работы многопроцессорных систем Содержание.
Содержание. 1 Общие сведения о многопроцессорных системах. 2 Перспективные многопроцессорные системы. 8 Систолические и волновые матрицы. 8 Матричные процессоры. 10 Вычислительная поверхность Meiko. 11 Гиперкуб, или двоичный N-куб. 15 Базовый элемент мультипроцессорных систем 18 с однотипными процессорами. 18 Достигаемая производительность. 21 Обоснованность применения многопроцессорных 24 систем в АСУ. 24 Список использованной литературы. 28 Общие сведения о многопроцессорных системах. Традиционные архитектурные принципы построения ЭВМ, сформулированные фон Нейманом, использовались в неизменном виде свыше 40 лет. Основные из этих принципов следующие: Наличие единого вычислительного устройства, включающего процессор, средства передачи информации и память; Линейная структура адресации памяти, состоящая из слов фиксированной длины; Низкий уровень машинного языка; Централизованное последовательное управление. Возможности повышения скорости обработки в рамках фон-Неймановской архитектуры оказались исчерпанными из-за ограничений, определяемых последовательной выборкой команд и данных через общий интерфейс памяти. Для повышения производительности ЭВМ их архитектурные принципы должны будут претерпеть изменения, которые с наибольшей вероятностью выразятся во введении тех или иных видов параллелизма, имеющего целью преодоление узких мест фон-Неймановской архитектуры. Известны четыре основных принципа реализации параллельной обработки, которые можно применить при проектировании новых систем. Потоковая архитектура, управляемая потоками данных, которые передаются от источников к потребителям, будучи обозначены маркерами данных. Обработка имеет место при наличии всех входных данных (в отличие от фон-Неймановской архитектуры, в которой последовательность управления обычно определяется командами программы). Потоковая архитектура ориентирована на распараллеливание обработки, особенно для машин баз данных, концепции построения которых соответствуют японскому проекту ЭВМ пятого поколения. Архитектура ОКМД, когда в ЭВМ одна и та же операция выполняется одновременно над различными данными. Большинство суперЭВМ представляют собой ОКМД-машины. Архитектура МКМД, в которой объединяется множество независимых ЭВМ, каждая со своей памятью, способных одновременно выполнять несколько различных операций. Архитектура МКМД, включающая множество подчиненных процессоров, которые могут быть по отдельности подключены к общей памяти с множественным доступом через коммутационную матрицу, управляемую ведущим процессором. Такая архитектура применена в экспериментальных мини-суперЭВМ. Параллелизм может быть использован для повышения производительности ЭВМ на нескольких уровнях: Между работами или фазами работы; Между частями программы или в пределах циклов типа DO; Между фазами выполнения команд; Между элементами векторной операции или на уровне арифметических логических систем. Категории a и b образуют рубрику, которая может быть названа классом параллельных ЭВМ, а разновидности c и d представляют собой более тонкие формы параллелизма, который иногда используется в блоках последовательной обработки и часто реализуется посредством конвейерных процессоров. Основные архитектурные формы параллельных мультипроцессоров, которые используются в настоящее время, представлены ниже: А
рхитектура с потоком управления, суть которой в том, что отдельный управляющий процессор служит для посылки команд множеству процессорных элементов, состоящих из процессора и связанной с ним памяти. Архитектура с потоком данным, которая децентрализована в высокой степени и в которой параллельные команды посылаются вместе с данными во многие одинаковые процессорные элементы. Архитектура с управлением по запросам, в которой задачи разбиваются на менее сложные подзадачи и результаты выполнения которых после обработки данных снова объединяются для формирования окончательного результата. Команда, которую следует выполнять, определяется, когда ее результат оказывается нужным для другой активной команды. Архитектура с управлением наборами условий, в которой задачи разбиваются на менее сложные подзадачи, результаты решения которых снова соединяются и дают окончательный результат. Команда, которую следует выполнять, определяется, когда имеет место некоторый набор условий. Типичное применение такой архитектуры – распознавание изображений с использованием клеточных матриц процессорных элементов. А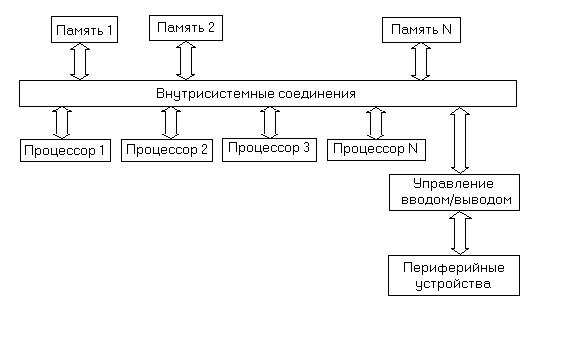
рхитектура, содержащая ЭВМ с общей памятью, в которой используется та или иная система межсоединений для объединения процессоров с памятью. Системы межсоединений могут быть конструктивно оформлены в виде шин, колей, кубов, кэшей (быстродействующих буферных ЗУ большой емкости) или матриц переключателей. Архитектура с параллельными процессорами, в которой используется высокая степень параллелизма, допускающая возможность независимого выполнения нескольких процессов на нескольких процессорах. Широко используемой формой структур параллельной обработки являются гиперкубы или двоичные n-кубы, в которых между вычислительными узлами имеют место двухпунктовые связи для передачи сообщений между обрабатывающими узлами. В 16-вершинном кубе каждый узел соединен с четырьмя ближайшими соседями. В мультипроцессорных системах используют несколько процессоров, каждый из которых работает под управлением своих собственных команд и которые обычно обмениваются информацией через общую память. Одним из способов классификации мультипроцессорных систем является проявляющаяся в них степень связности составных частей. На рисунке проиллюстрировано четыре уровня связности, которые могут иметь место м
ежду процессорами. В системах с сильными связями процессоры объединены посредством системной шины, накладывающей ограничения на производительность системы. Взаимодействие через общую память является менее сильным видом связности, а для уменьшения ограничений, вносимых общей шиной, могут быть применены многопортовые запоминающие устройства. В случае использования нескольких автономных ЭВМ, снабженных каждая собственной операционной системой, объединенных в так называемый кластер и взаимодействующих с помощью коммуникационного программного обеспечения через сеть межсоединений, имеет место наиболее слабый уровень связности. По виду взаимоотношений процессоров мультипроцессоры могут быть, кроме того, подразделены на системы с аутократическим управлением, с одной стороны, и системы с равноправными процессорами – с другой. В системах первого типа между процессорами имеют место отношения ''хозяев'' и ''подчиненных''. В системах с равноправными процессорами все они имеют одинаковые возможности доступа к общей шине. С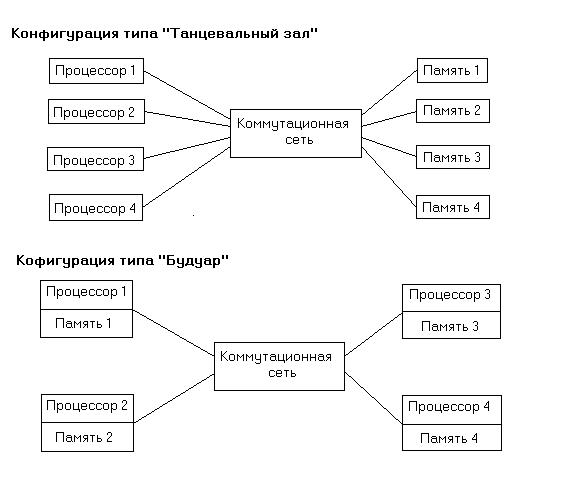
реди мультипроцессорных систем, состоящих из отдельных процессорных и запоминающих устройств, можно выделить системы с конфигурацией типа ''танцевальный зал'', в которых процессоры размещены в одном ряду, а запоминающие устройства, обращенные в их сторону, - в другом; соединение `процессоров с запоминающими устройствами осуществляется при этом посредством коммутационной сети (см. рис). Другим крайним случаем организации мультипроцессоров является конфигурация типа ''будуар'', при которой каждый процессор тесно связан со своей собственной памятью, а коммутационная сеть служит для соединения между собой пар процессор-память (см. рис.). Для описания способа организации параллельных вычислений используется также понятие одновременность, котороеозначаетнезависимое, асинхронное функционирование параллельно работающих вычислительных устройств в противоположность их синхронному (или жесткому) взаимодействию в составе мультипроцессорной системы. Перспективные многопроцессорные системы. Систолические и волновые матрицы. Для цифровой обработки сигналов используются матричные вычислительные структуры двух следующих видов. Систолический процессор, представляющий собой регулярную матрицу процессорных элементов, каждый из которых обменивается информацией со своими ближайшими соседями, причем все процессоры работают синхронно под управлением общего источника синхронизации, частота которой ограничивается быстродействием самого медленного процессора матрицы. Происхождением термина систолический является аналогия между ритмическими сокращениями сердечной мышцы и синхронной прокачкой данных через матрицу процессорных элементов. Волновой процессор, также представляющий собой матрицу процессорных элементов, которые обмениваются информацией с ближайшими соседями, но функционирует в условиях отсутствия единого источника синхронизации. В таком процессоре имеют место одновременность работы элементов и управление данными. Управление каждым процессорным элементом осуществляется локально, причем выполнение операции инициируется поступлением входных данных после того, как результат предыдущей операции выведен в соответствующий соседний процессор. ''Волны'' обработки распространяются по матрице по мере того, как процессорные элементы передают выходные данные своим соседям. П
ри различии времени обработки в разных элементах волновые матричные процессоры оказываются более эффективными, чем систолические. Рис. иллюстрирует различие между систолическими и волновыми матрицами процессорных элементов. Для реализации и систолических, и волновых мультипроцессоров, в которых каждый элемент представляет собой 32-разрядный микропроцессор, могут быть применены транспьютеры Т414. Возможен и другой подход, при котором матрица строится из одноразрядных микропроцессоров, причем множество таких элементарных процессоров размещается конструктивно в одной интегральной схеме. Геометрически-арифметический параллельный процессор (GAPP) фирмы NCR представляет собой двумерную однокристальную матрицу, содержащую 72 одноразрядных процессора, каждый из которых имеет ЗУПВ емкостью 128 бит. Из нескольких GAPP могут быть построены матрицы большой размерности, предназначенные для обработки изображений и сигналов, а также для работы с базами данных. Обработка слов данных с помощью GAPP осуществляется параллельно, причем действия над словами переменной длины выполняются путем последовательной обработки их разрядов (параллельная обработка слов – последовательная обработка битов). GAPP представляет собой скорее матричный процессор класса ОМКД, нежели систолическую матрицу, так как в нем имеется возможность подачи данных на все ячейки. Однако эта способность GAPP реализуется с помощью протяженных межсоединений, которые снижают скорость. В то же время GAPP может служить основой для построения систолических матриц. Процессоры CLIP фирмы Stonefield (разработанный в Лондонском университетском колледже в 70-х годах) и DAP фирмы ICL являются матричными процессорами, представляющими собой БИС, содержащие одноразрядные процессорные элементы. CLIP применяется главным образом для обработки изображений, а ICL DAP в основном используется для реализации алгоритмов быстрой обработки сигналов и числовых расчетов. Интегральный систолический матричный процессор был разработан в исследовательском центре GEC Hirst. МА717 представляет собой систолическую матрицу, в которую данные вводятся через периферийные элементы, а движение их по матрице происходит в виде протоков от элемента к элементу. Рабочая частота устройств, реализуемых на принципах этой систолической архитектуры, может почти в два раза превышать рабочую частоту процессоров GAPP. Матричные процессоры. Для реализации обработки сигналов матрицы МКМД могут быть организованы в виде систолических или волновых матриц. Систолическая матрица состоит из отдельных процессорных узлов, каждый из которых соединен с соседними посредством упорядоченной решетки. Большая часть процессорных элементов располагает одинаковыми наборами базовых операций, и задача обработки сигнала распределяется в матричном пространстве по конвейерному принципу. Процессоры работают синхронно, используя общий задающий генератор тактовых сигналов, поступающих на все элементы. В волновой матрице происходит распределение функции между процессорными элементами, как в систолической матрице, но в данном случае не имеет места общая синхронизация от задающего генератора. Управление каждым процессором организуется локально в соответствии с поступлением необходимых входных данных от соответствующих соседних процессоров. Результирующая обрабатывающая волна распространяется по матрице по мере того, как обрабатываются входные данные, и затем результаты этой обработки передаются другим процессорам в матрице. Вычислительная поверхность Meiko. Вычислительная поверхность Meiko была разработана инженерами и программистами, работавшими над проектированием транспьютера Inmos; они поставили перед собой задачу построить на основе транспьютеров гибкую, наращиваемую мини-суперЭВМ, характеризующуюся отношением стоимость/производительность около 250 долл./(млн. операций/с) и максимальной производительностью свыше 1000 млн. операций/с. Фирма Meiko отказалась от использования жестких фиксированных топологий вычислительной поверхности, так как оценила эти топологии как компромисс, не позволяющий достичь абсолютной гибкости. Для различных областей применения требуются различные конфигурации; оптимальные топологии оказываются неодинаковыми для разных задач, решение которых может потребовать использования различных ресурсов. Так, например, для одних применений может понадобиться большая доля вычислительных ресурсов, а для других – наличие быстрых методов обращения к базам данных. Гибкость вычислительной поверхности обеспечивается за счет наличия набор модульных подсистем, которым может быть придана любая топологическая конфигурация, соответствующая конкретному применению. Вычислительную поверхность можно рассматривать как целое процессорное хозяйство, работающее в многозадачном окружении, в котором на каждый вычислительный элемент приходится отдельная независимая задача. В этой ситуации многие реальные прикладные задачи могут решаться практически без каких-либо модификаций. С другой стороны, параллельность, внутренне присущая машине, может быть эффективно реализована в таких ситуациях, когда машина рассматривается со стороны задачи как однородный обрабатывающий ресурс. Для того чтобы главная ЭВМ имела возможность создавать физическое отображение всей физической поверхности, предусмотрена поддерживающая инфраструктура. Пользуясь отображением и конфигурацией электронных средств, эта инфраструктура обеспечивает соединение топологических элементов в соответствии с высокоуровневым описанием, полученным из прикладной программы, которая должна быть загружена. Программные средства определяют как описание, выводимое на основе прикладной программы, так и машину, на которой эта программ будет выполняться. Программы могут быть написаны на языке Оккам или на других языках, таких, как Фортран, Си, Паскаль и т.д. Эти программы, выполняемые в соответствии с закономерностями языка Оккам, обеспечивают связь процессора с другими процессорами, которые, возможно, осуществляют копии той же программы. Процесс формирования топологии обеспечивает иерархическое управление исходной программой, автоматическую рекомпиляцию, выдачу сообщений об ошибках в процессе выполнения, загрузку и прогонку программ в распределенном мультипроцессоре с использованием однофункциональных ключевых команд. Производительность малой настольной вычислительной поверхности М10 может достигать 250 млн. операций/с; она ориентирована на использование ее в качестве персонального вычислительного ресурса, рабочей станции или системы проектирования. В более крупных системах используются модули типа М40, каждый из которых является основой для построения вычислительных средств в диапазоне от вычислительных установок, имеющих суммарную производительность 1100 млн. операций/с и одновременно адресуемую динамическую память с произвольной выборкой объемом 42 Мбайт, до машин баз данных с памятью 315 Мбайт, производительностью 400 млн. операций/с и пропускной способностью дисковой памяти более 75 Мбайт/с. модуль М40 имеет компактное конструктивное оформление размерами 40 дюйм 20 дюйм 20 дюйм и, обладая неограниченными соединительными возможностями, может быть включен в состав системы аналогичных модулей, имеющей необходимые масштабы. Для создания заказных модулей вычислительные поверхности предусмотрен ряд плат и подсистем. Чтобы поверхность представляла логически оформленное вычислительное средство с точки зрения прикладного программиста, все вычислительные элементы соответствуют одной и той же обобщенной модели (см. рис. ниже). Каждый элемент построен на основе транспьютера и имеет наряду со специализированными функциональными блоками свой собственный интерфейс с глобальной супервизорной шиной и собственную локальную память. Каждый элемент снабжен восемью о
днонаправленными последовательными коммуникационными каналами, имеющими быстродействие 10 или 20 Мбит/с. В число специализированных функциональных плат входят следующие: Счетверенное вычислительное устройство, включающее четыре элемента, каждый из которых содержит транспьютер Т414, ЗУПВ емкостью 256 Кбайт с обнаружением ошибок, восемь однонаправленных последовательных каналов связи и интерфейс супервизорной шины; Запоминающее устройство большой емкости, содержащее транспьютер Т414, ЗУПВ емкостью 8 Мбайт с обнаружением ошибок, восемь однонаправленных последовательных каналов связи, интерфейс супервизорной шины и периферийный интерфейс SCSI с ЦДП-управлением и быстродействием 2 Мбайт/с. Для подключения к этому интерфейсу имеются винчестерские диски емкостью 500 Мбайт и лазерные диски емкостью 2 Гбайт; Локальное главное устройство (стандарт IEEE 488), содержащее транспьютер Т414, ЗУПВ емкостью 3 Мбайт с обнаружением ошибок, ЭППЗУ емкостью 128 Кбайт, восемь однонаправленных последовательных каналов, интерфейс супервизорной шины, параллельный интерфейс IEEE 488 и сдвоенный последовательный интерфейс RS-232; Элемент индикации, содержащий транспьютер Т414, внутреннее статическое ЗУПВ емкостью 128 Кбайт, двупортовая память индикации емкостью 1,5 Мбайт, восемь однонаправленных последовательных каналов связи, интерфейс супервизорной шины, внешний тракт элементов изображения с рабочей частотой 70 МГц (200 Мбайт/с) и генератор цветовых видеосигналов в соответствии со стандартами CCIR/RS-343. Множество элементов индикации может быть объединено для формирования увеличенной памяти кадра и расширения пропускной способности при формировании изображений. Существуют вычислительные элементы повышенной производительности, построенные на базе транспьютера Т800, который имеет расширенные возможности для выполнения операций с плавающей запятой и внутреннее ЗУПВ емкостью 4 Кбайт. Гиперкуб, или двоичный N-куб. Гиперкубическая архитектура впервые была разработана в Калифорнийском технологическом институте; основной ее принцип состоит в использовании множества микропроцессоров, каждый из которых снабжен локальной памятью, для формирования вычислительных узлов, соединенных между собой двухпунктовыми связями. Гиперкуб размерности n объединяет N=2n узлов, которые независимо работают над выполнением отдельных частей полной программы. Так, куб размерности 6 содержит 64 узла, каждый из которых связан с шестью ближайшими соседями в пределах 6-размерного куба. Данные могут вводиться в узлы посредством сообщений, посылаемых по каналам связи от процессоров, выполняемых в других узлах, или от управляющего процессора куба. Для управления посылкой и получением сообщений служат специальные примитивы операционной системы. Ширина полосы пропускания сигналов связи гиперкуба растет с увеличением числа узлов пропорционально N log2N, задержка в худшем случае составляет log2N. Гиперкуб можно определить индуктивно; гиперкуб порядка N+1 может быть построен путем удвоения гиперкуба порядка N и соединения двух наборов узлов. Такой подход позволяет создавать программное обеспечение для гиперкубов любых размерностей; необходимо лишь определить размерность на время выполнения программы. Возможно также разделить большую гуперкубическую машину на субкубы, отвести каждой программе узлы в количестве, обеспечивающем максимально эффективное ее выполнение, и использовать узлы, являющиеся в данный момент избыточными, для других программ вместо того, чтобы оставлять их без применения. Гиперкуб представляет собой сеть с максимально возможной плотностью соединений; его объем может охватывать тысячи процессоров, потому что для удвоения количества процессоров к каждому узлу должен быть добавлен всего один коммуникационный канал. Плотность взаимосвязи узлов определяет практичность использования всей системы соединений, представляющей собой принципиально важную аппроксимацию параллельной вычислительной системы, так как конкретная конфигурация связей зачастую непредсказуема. Если узлы пронумированы от 0 до 2n-1, каждый процессор непосредственно связан со всеми теми, номера которых отличаются от его номера одной двоичной цифрой. Отбрасывая некоторые связи гиперкуба, можно отобразить в него многие другие виды сетевой топологии, к числу которых относятся следующие: Решетки, или сетки размерностью до N; Кольца; Цилиндры; Тороиды; Топология ''бабочка'' для БПФ. В гиперкубах используется высокоуровневая форма параллелизма, которую называют параллельной обработкой, обеспечивающей асинхронное выполнение операций в мультипроцессорной системе. Для увеличения производительности отдельных узлов, в работе которых имеет место значительная доля векторной обработки, может быть применен этот вид обработки. Максимальная производительность, которая может быть достигнута в подобной вычислительной системе, определяется как произведение производительности параллельной, векторной и скалярной обработки для данного применения. Для обеспечения максимальной производительности, достижимой с учетом ограничений, налагаемых степенью параллельности, которая присутствует в решаемой прикладной задаче, необходимо использовать языки параллельного программирования, такие, как Оккам.
Базовый элемент мультипроцессорных систем с однотипными процессорами. Транспьютеры представляют собой микропроцессоры, рассчитанные на работу в мультипроцессорных системах с однотипными процессорами. Особенностью транспьютеров является наличие коммуникационных быстрых каналов связи, каждый из которых может одновременно передавать по одной магистрали данные в процессор, а по другой – данные из него. В составе команд транспьютеров имеются команды управления процессами, поддержки языков высокого уровня, встроенная память емкостью 2 Кбайт. Н
а основе транспьютеров строятся структуры МКМД (множественный поток команд, множественный поток данных). На рисунке показана тороидальная матрица транспьютеров. Разрядность местной памяти каждого транспьютера наращивает разрядность памяти системы. Таким образом, полная разрядность памяти пропорциональна количеству транспьютеров в системе. Суммарная производительность также возрастает прямо пропорционально числу транспьютеров, входящих в систему. В дополнение к параллельной обработке, реализуемой транспьютерами, предусмотрены специальные команды для разделения процессорного времени между одновременными процессорами и обмена информацией между процессами. Хотя программирование транспьютеров может выполняться на различных языках высокого уровня, для повышения эффективности параллельной обработки был разработан специальный язык Оккам. Типичными представителями транспьютеров являются модели Т212, Т414, Т800 фирмы Inmos. Их основные характеристики приведены в таблице: | Характеристика | Т212 | Т414 | Т800 | | Разрядность | 16 | 32 | 32 | | Адресное пространство | 64 Кбайт | 4 Гбайт | 4 Гбайт | | Емкость встроенной памяти | 2 Кбайт | 2 Кбайт | 4Кбайт | | Скорость обработки данных, Мбайт/с |
20 |
40 |
40 | | Каналы связи: организация (число каналов число портов) |
4 2 |
4 2 |
4 2 | | Скорость обмена, Мбит/с | 10 | 10 или 20 | 20 |
В качестве объекта более подробного рассмотрения остановимся на транспьютере Т414, так как он стал первым 32-разрядным микропроцессором, который сделал реальностью параллельную обработку.
С
хема транспьютера представлена на рисунке. Транспьютер является 32-разрядным устройством с архитектурой RISC. Т414 имеет 32-разрядную шину внешней памяти с диапазоном физических адресов 4 Гбайт. Дополнительная память (пространство ввода/вывода) может иметь различную конфигурацию, причем возможно включение в ее состав одновременно быстродействующих и медленных устройств. Предусмотрены сигналы регенерации динамических ЗУПВ. Скорость пересылки данных по шине внешней памяти может достигать 25 Мбайт/с. Взаимодействие каждого транспьютера с другими транспьютерами и периферийными устройствами осуществляется посредством четырех коммуникационных каналов последовательной связи. Использование прямых последовательных каналов делает ненужным арбитраж приоритетов, необходимый для предоставления системной магистрали в мультипроцессорных системах, и исключает проблемы, связанные с пропускной способностью шин и их перегрузкой при введении в систему новых процессоров. Каждый последовательный канал является двунапрвленным. Пересылки производятся в виде последовательностей байтов. Обмен производится в асинхронном режиме. Система прерываний в традиционном смысле этого понятия отсутствует, но имеют место аналогичные средства, реализованные в виде двух уровней приоритета, присваиваемых процессам, ожидающим приема по последовательным каналам. Для упрощения обнаружения и анализа отказов к выходному контакту сигнала ошибки подключается схема установок флага ошибки. Информация о состоянии системы может быть сохранена для последующего анализа путем соединения контакта сигнала анализа (входного) с контактом сигнала ошибки (выходного). Достигаемая производительность. Достигаемая производительность в многопроцессорных системах равна:  , ,
где К – коэффициент эффективности; n – число процессоров; р1 – производительность одного процессора. Так как коэффициент эффективности постоянная величина, то производительность системы можно увеличить за счет увеличения производительности каждого процессора или увеличения числа процессоров. Повышение того или другого возможно до определенных границ, так как после них производительность многопроцессорных систем возрастает незначительно или уменьшается. Коэффициент эффективности зависит от параметров системы и его увеличение есть одна из главных задач. Он равняется: 
где T – время решения некоторой усредненной задачи на одном процессоре; T/n – время решения этой задачи на условном процессоре с производительностью в n раз большей или чистое время решения задачи на n процессорах; T(n) – затраты времени на взаимодействие n параллельно работающих процессоров. Коэффициент эффективности всегда меньше единицы. Его можно увеличить за счет уменьшения затрат времени на взаимодействие n параллельно работающих процессоров. Система будет самой эффективной, если t(n)→0. 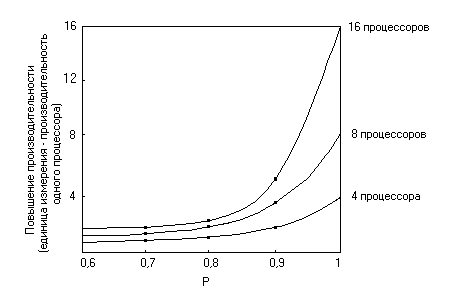
Маловероятно, чтобы один процессор смог достичь быстродействия более чем 2·109 флопс до того, как наступит перегрузка общей шины в ЦПУ. Поэтому в высокопроизводительной ЭВМ должна быть использована та или иная форма параллелизма. Повышение производительности, которое может быть достигнуто за счет использования параллельной обработки, зависит от доли вычислений, которые могут выполняться параллельно. Рисунок (см. выше) иллюстрирует повышение производительности, которое может быть достигнуто при использовании различного количества процессоров, работающих параллельно, по сравнению с долей P вычислений, которые могут выполняться параллельно. 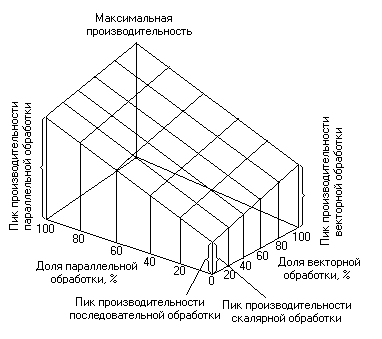
Соотношение между возможностями ЭВМ по выполнению векторной, параллельной и скалярной обработки иллюстрируется рисунком. Увеличение производительности, которое достигается за счет использования векторной и параллельной обработки данных, является весьма существенным, поэтому скорость реализации алгоритмов, в которых заложены обе этих формы параллелизма, возрастает. Обработка научных данных часто содержит значительную долю векторных и чисто параллельных вычислений, поэтому применение для этой обработки параллельных систем с возможностью действий над векторами, позволяющей поднять быстродействие каждого процессора, создает предпосылки для достижения уровней производительности, гораздо более высоких, чем производительность 2·109 флопс, являющаяся теоретическим пределом для одиночного процессора. С другой стороны, обработка коммерческих данных носит в основном скалярный характер и предоставляет меньшие возможности для увеличения эффективности универсальных и мегауниверсальных ЭВМ путем использования параллельной обработки данных. Обоснованность применения многопроцессорных систем в АСУ. В настоящее время управление различными техническими, организационными и социальными системами осуществляется с использованием компьютеров, без которых невозможно быстро обрабатывать большое количество информации и решать сложные задачи. Система управления, в которой все операции выполняются без участия человека, называются автоматической. Информация в автоматических системах обрабатывается с помощью микропроцессоров, размещенных в блоках управления, или центральной ЭВМ. Если активная и решающая роль в процессе управления принадлежит людям, то такие системы называются не автоматическими, а автоматизированными. Организованное, организационно-техническое управление и управление в социальной сфере осуществляются автоматизированными системами управления (АСУ). АСУ – система, в которой управленческая информация обрабатывается с помощью компьютера, а утверждение управленческих решений производится людьми. Задачи АСУ являются важными в плане обеспечения эффективного принятия решения и поэтому занимают особое место среди основных применений микроЭВМ. Комплексный характер АСУ обусловливает необходимость использования различных типов АРМ (специализированные конфигурации ПЭВМ) на различных рабочих участках, объектах, в соответствии с их функциональным назначением. Целью функционирования любой АСУ является повышение полноты, оперативности, точности и достоверности информации, используемых в задачах управления объектом. Каждую АСУ нужно рассматривать прежде всего как сложную систему, с одной стороны, состоящую из ряда подсистем, а с другой стороны, входящую в АСУ более высокого уровня. Такой системный подход обеспечивает взаимодействие как элементов АСУ, так и смежных АСУ различных уровней управления. МикроЭВМ в настоящее время применяются на нижних уровнях автоматизации (контроль, регулирование и управление). В более сложных системах микроЭВМ – это вычислительные блоки отдельных устройств управления, терминальных станций, т.е. элементы интеллектуальной периферии, коммутационных и узлов и т.п. На базе малых ЭВМ строится средний уровень автоматизации (управление, оптимизационное управление). На верхнем уровне автоматизации (оптимизационное, ситуационное управление) основой являются мега-, мини- и многопроцессорные системы повышенной производительности. Важным компонентом систем на верхних границах эффективности каждого уровня управления являются спецпроцессоры, аппаратно реализующие определенные функции или алгоритмы обработки информации. Приведенные данные свидетельствуют о том, что при создании комплексных систем управления необходима интеграция большого числа совместимых вычислительных систем различного класса (от микроЭВМ до мега-миниЭВМ). Невозможность использования какого-либо подкласса ЭВМ в системе управления в значительной мере снижает эффективность, не обеспечивает комплектности автоматизации управления. Совместная работа большого числа процессоров обеспечивается в результате оперативного анализа состояния сложной системы, решения задач перераспределения ресурсов, организации потоков заданий и данных, синхронизации режимов обмена информацией и заданиями, эффективного согласования рабочих циклов отдельных элементов системы. Большое значение имеет проблема обмена информацией. Предположим, что в системе, включающей процессоры, необходимо организовать связь процессоров по схеме ''каждый с каждым''. В этом случае число двунаправленных связей Q может определяться произведением: Q=(n-1)! Для пяти процессоров число связей Q=120, для десяти оно приближается к 40000 (Q=362880). Ясно, что и большая часть времени должна тратиться на обмен информацией при таком большом числе связей. Предположим, что в подобной системе в каждом из процессоров на обмен информацией с другим процессором тратится доля времени К. если учесть, что при этом может осуществляться обмен информацией с остальными (n-1) процессорами, то на обработку информации в процессоре останется доля времени Δq=1-K(n-1) от общего времени его работы. Следовательно, на всех n процессорах можно обрабатывать информацию в течение  Из анализа этой зависимости следует, что для каждого параметра К существует предельное число процессоров n*, превышение которого уже не приведет к увеличению вычислительной мощности системы. Так, при К=0,05, n*=10, при К=0,01, n*=50. Если только один процент времени тратится на обмен информацией между каждой парой процессоров, то включать в систему более 50 процессоров не имеет смысла, а на 50 процессорах можно обрабатывать информацию, затрачивая только примерно 50% времени. Поэтому необходимо совершенствовать структуру мультипроцессорных и мультимашинных систем для повышения эффективности их функционирования. Необходимо достаточно полно учитывать конкретные задачи, стоящие перед разработчиками таких систем. Применение иерархических структур на несколько порядков уменьшает количество связей, сокращает затраты времени на передачу информации между элементами системы. Список использованной литературы. Г.Б.Коробкин, Ю.И.Синещук, А.Г.Чирков ''Вычислительные системы АСУ'' (часть II) Петродворец 2000; Дж.Фрир ''Построение вычислительных систем на базе перспективных микропроцессоров'' Москва ''Мир'' 1999 1 |