БЕЛОРУССКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ КУЛЬТУРЫ И ИСКУССТВ
Кафедра информационных ресурсов
Диплом:
«Лингвистическое обеспечение автоматизированных систем библиотек сельскохозяйственного профиля»
Выполнила:
студентка 5 курса ФИДК (537 гр.)
Евстигнеева А. Г.
Научный руководитель:
профессор
Яцевич Н. А.
Допущен к защите________________________
зав. кафедрой инф. ресурсов. профессор
Нешитой В. В.
число_________месяц_________год_________
Минск 2010
Содержание:
Введение- 3 -
Глава 1. Теоретические аспекты лингвистического обеспечения автоматизированных библиотечно-информационных систем.- 9 -
1.1. Понятие, состав и требования к современному лингвистическому обеспечению.. - 9 -
1. 2. Обзор лингвистического обеспечения сельскохозяйственных библиотек России и Украины.. - 17 -
1.2.2. Средства лингвистического обеспечения Государственной научной сельскохозяйственной библиотеки Украинской академии сельскохозяйственных наук. - 22 -
Глава 2. Структура лингвистических средств Белорусской сельскохозяйственной библиотеки им. И. С. Лупиновича Национальной академии наук Беларуси. - 28 -
2.1. База данных УДК и ее применение в качестве информационно-поискового языка
. - 30 -
2.2. Тезаурус по сельскому хозяйству и продовольствию
.. - 39 -
2.2.1. Назначение и структура тезауруса
. - 39 -
2.2.2. Парадигматические отношения
. - 45 -
2.2.3. Использование тезаурусов
. - 54 -
2.3. Проблема выбора средств лингвистического обеспечения и их интеграции в библиотеках АПК.- 58 -
Заключение. - 62 -
Приложение №1………………………………………………………………………………………. - 71 -
Введение
Лингвистическое обеспечение
- это комплекс средств, используемых в библиотеке для формирования, обработки, хранения и поиска информации, а также средств и методов их создания, ведения, использования и контроля. Лингвистическое обеспечение (ЛО) требуется на всех направлениях деятельности библиотеки. Состав и структура лингвистического обеспечения зависят от того, в какой области библиотечной деятельности оно используется. Можно выделить несколько функций, возложенных на лингвистическое обеспечение и отсюда несколько видов ЛО:
1. лингвистическое обеспечение подготовки баз данных (обработка, ввод информации, формирование баз данных);
2. лингвистическое обеспечение подготовки информационных изданий;
3. лингвистическое обеспечение процессов распределения потоков информации между ее потребителями.
Лингвистическое обеспечение включает в себя лингвистические средства и средства манипулирования с данными и информационными массивами. Лингвистические средства — это совокупность информационно-поисковых языков (ИПЯ), используемых в информационно-поисковой системе (ИПС), правил перевода информации с естественного языка на ИПЯ и критерия выдачи информации, обеспечивающих представление смыслового содержания документов информационных массивов в виде, удобном для машинной обработки и обеспечивающем автоматизированный поиск информации. информационно-поисковые языкои являются основным элементом ЛО, поскольку от них зависит эффективность поиска. Они предназначены для выражения основного содержания документов и информационных запросов с целью последующего хранения и поиска информации в ИПС. информационно-поисковые языки по сути считаются главной характеристикой ИПС, поскольку от их качества (терминологической наполненности, терминологической однозначности лексических единиц, наличия логической связи между элементами, справочного аппарата, удобства пользования и т. д.) зависит эффективность поиска, его полнота и точность. [44, C. 13]
В начале 50-х годов в США начали создаваться информационно-поисковые языки, получившие название дескрипторных (от англ. слова to
describe
- описывать). В основе дескрипторных информационно-поисковых языков лежит алфавитный перечень слов или словосочетаний.
Одной из первых информационно-поисковой системой, в которой использовался такой информационно-поисковый язык, была система "Унитерм", разработанная в 1952 г. известным американским логиком и документалистом Мортимером Таубе. В этой системе реализован предложенный им принцип координатного индексирования. В системе "Унитерм" в качестве индексов, описывающих содержание документов и запросов и координируемых при поиске, использовались ключевые слова, выбранные из их текстов, названные унитермами. (Слово "унитерм" означает в переводе с английского "единичный термин"). Выбранные из текста унитермы располагались в алфавитном порядке в специальной картотеке. [1, С. 5]
Сейчас прогресс шагнул далеко вперед и мы стоим на пороге информационного общества. И, казалось бы, повсеместная автоматизация - это новый вектор развития библиотек, который позволит создать максимально комфортные условия для работы читателей. Но на практике, изучив данную проблему более детально, я столкнулась с цифрами, которые составляют далеко не самую безоблачную статистическую картину. Автоматизация библиотечно-библиографических процессов идет в библиотеках АПК медленно: только 30% библиотек оснащены компьютерами; 2% библиотек имеют выход в Интернет и менее 0,5% библиотек имеют свои сайты в Интернете. На первом этапе автоматизации библиотеки создают свои электронные каталоги и в качестве ИПЯ используют УДК и/или ББК, язык ключевых слов и язык библиографического описания.
Лингвистическое обеспечение в Центральной научной сельскохозяйственной библиотеке Российской Академии Наук, например, включает семь ИПЯ:
- схему комплексно-системного каталога (КСК),
-УДК,
-ББК,
- язык библиографического описания,
- Отраслевой Рубрикатор, разработанный на основе ГРНТИ,
- Информационно-поисковый тезаурус,
- язык ключевых слов.
И это действительно хорошая работа! Это результат труда многих людей на протяжении долгих лет.
Но ЦНСХБ - это самая крупная из библиотек АПК на территории бывшего СНГ. Другие же библиотеки не могут похвастаться подобными достижениями. С целью анализа данной проблемы и поиска выхода из нее и было проведено исследование, положенное в основу данной дипломной работы.
Актуальность исследования. Обеспеченность информационными ресурсами является необходимым условием функционирования и раз вития агропромышленного комплекса (АПК) России. Научно-технические библиотеки (НТБ) занимают важное место в государственной системе научно-технической информации (ГСНТИ), которая призвана создавать и развивать информационные ресурсы и информационное обеспечение науки и производства. Современный период развития НТБ рассматривается как новый этан компьютеризации, связанный с переходом на сетевые информационные технологии, широкое использование электронных документов и БД. Научные сельскохозяйственные библиотеки (НСХБ), обеспечивающие информационное сопровождение деятельности ученых и специалистов АПК, активно формируют сего дня собственные электронные документные ресурсы, используют доступные по телекоммуникационным каналам машиночитаемые ресурсы других библиотек и информационных служб, разрабатывают и совершенствуют методы и средства информационного поиска. При этом они вынуждены использовать традиционные и автоматизированные информационно-поисковые системы (ИПС).
Если под ИПС мы понимаем совокупность информационно поисковых массивов, их носителей, информационно-поискового языка, правил его использования, критериев выдачи, программных и технических средств, то традиционные ИПС представлены системой карточных каталогов и картотек, где информационно-поисковыми языками являются элементы библиографического описания (автор индивидуальный или коллективный, тин документа, язык документа и т.д.), классификации отраслей знания (УДК, ББК, десятичная классификация Дьюи и т.п.), схемы предметных рубрик и т.п.
Информационно-поисковый язык (ИПЯ) - формализованный искусственный язык для индексирования документов, информационных запросов и описания фактов с целью но следующего их хранения и поиска. ИПЯ и дополняющие их методики систематизации документов, инструкций по ведению каталогов и т.п. составляют лингвистическое обеспечение традиционных ИПС. В автоматизированных ИПС используются специально разработанные ИПЯ (рубрикаторы, словари ключевых слов, тезаурусы и т.д.). Информационными массивами являются электронные каталоги и базы данных на машиночитаемых носителях; организация и использование информационных массивов определяются соответствующими стандартами и обеспечиваются программными и техническими средствами. Эффективность информационного поиска в автоматизированных ИПС в значительной степени зависит от ее лингвистического обеспечения: ИПЯ и средств их ведения и поддержки.
От выбора лингвистического обеспечения зависит совместимость языковых средств данной ИПС с другими, а значит и возможности информационного поиска в них, поскольку совместимость лингвистического обеспечения - это возможность использования в ИПС поисковых образов документов на одном ИПЯ, а поисковых предписаний на другом, а также возможность автоматического или ручного перевода поискового образа документа с одного ИПЯ на другой. Создание единого информационного пространства АПК подразумевает возможность использования любых ИПС для получения нужной информации с любого, подключенного в единую информационную сеть терминала. Для того, чтобы поиск в этих информационных ресурсах был возможен, прост и оперативен, необходимо разработать в каждой НСХБ оптимальное лингвистическое обеспечение, позволяющее осуществлять переход из одной ИПС в другую легко и комфортно для пользователя. Теоретические разработки по лингвистическому обеспечению НСХБ отсутствуют.
По статистике 2002 г. только 30% научных СХБ находились на разных стадиях внедрения автоматизации в библиотечно-библиографические процессы. Наиболее передовые позиции в этом занимает Центральная научная сельскохозяйственная библиотека Россельхозакадемии (ЦНСХБ), которая является федеральным учреждением ГСНТИ в области АПК, крупнейшей научных СХБ РФ, осуществляющей функции отраслевого информационного центра, в т.ч. генерацию документографических БД, создание реферативной и обзорной информации, выпуск реферативных изданий. В ЦНСХБ автоматизированы основные библиотечно-библиографические процессы в рамках интегрированной автоматизированной библиотечно-информационной системы (АБИС), созданы электронные ресурсы по проблематике АПК федерального значения, в т.ч. крупнейшая в мире русскоязычная БД по АПК «АГРОС». ЦНСХБ является головным методическим центром для 688 научно-технических библиотек АПК, которые используют ее разработки и информационные продукты в своей практической деятельности. Как
методический центр ЦНСХБ проводит работы, направленные на формирование единого информационного пространства отрасли. Она имеет самую сложную из всех библиотек АПК структуру лингвистических средств и систему методических пособий по работе с ними. Лингвистическое обеспечение ИПС ЦНСХБ складывалось исторически, в условиях автоматизации назрела необходимость его оптимизации. К объектам оптимизации следует отнести состав используемых ИПЯ, их совместимость и гармонизацию в рамках ИПС, совершенствование самих ИПЯ и средств их ведения и поддержки. Разработка оптимальной структуры лингвистического обеспечения ИПС ЦНСХБ будет способствовать ее эффективному функционированию в рамках единого информационного пространства АПК РФ. Такая структура лингвистического обеспечения ИПС может служить моделью для других НСХБ. Все это обусловливает актуальность выбранной темы для исследования.
Целью исследования является обоснование структуры лингвистического обеспечения научных сельскохозяйственных библиотек, способствующей максимально полному удовлетворению информационных потребностей ученых и практиков в релевантной информации по вопросам АПК.
Разработка данного исследования ставит перед собой следующие задачи
:
1. Теоретическое изучение понятия «лингвистическое обеспечение» и его эволюции.
2. Характеристика основных подходов к лингвистическому обеспечению АБИС.
3. Изучение опыта внедрения лингвистического обеспечения в АБИС библиотек сельскохозяйственного профиля.
4. Анализ состояния лингвистического обеспечения в Белорусской сельскохозяйственной библиотеке.
5. Обоснование проблемы выбора лингвистического обеспечения.
Теоретическая и методологическая основа исследования
Проблемы лингвистического обеспечения библиотек АПК ранее углубленно изучались только Л. Н. Пирумовой, на основе работ которой и строилось данное исследование. Отдельные вопросы разработки лингвистического обеспечения также рассматривались в контексте решения общих проблем развития ИПС, электронных каталогов по АПК. Эти вопросы затрагивались в работах М. А. Аветисова, Г. К. Быстровой, С. А. Дубинской, Л. М. Фрида. В работах В. Г. Позднякова подчеркивается роль лингвистического обеспечения в информационном обслуживании ученых и практиков АПК, а также необходимость сотрудничества библиотек АПК в решении ряда проблем.
Однако эти работы носят общий характер, трактующий лингвистическое обеспечение как неотъемлемую часть ИПС, но не касаются детального рассмотрения методики построения, ведения, использования и назначения лингвистических средств. Разработка теоретических и методологических проблем лингвистического обеспечения началась в 60-х годах, когда пришло понимание того, что без информационно-поисковых языков вычислительные машины остаются только машинами, и начался вслед за этапом «механическим» новый «логико-лингвистический», по определению А.В. Соколова, этап в развитии ИПС.
Вопросы лингвистического обеспечения поднимаются, с разной степенью детализации, во всех трудах, касающихся ИПС, поскольку лингвистическое обеспечение является ее неотъемлемой частью. Это подчеркивают в своих работах Ю. М. Арский, Г. Г. Белоногов, В. А. Глинский, Б. А. Кузнецов, А. И. Михайлов, В. А. Мишин, В. В. Морозов, В. В. Попов, Я. Л. Шрайберг и др.
Ранние разработки в области ИПЯ касались лингвистического обеспечения больших электронно-вычислительных машин и отражены в работах М. Г. Гаазе-Рапопорта, Р. Г. Котова, Б. В. Якушина, Л. Н. Пирумовой. Работы последних лет относятся к ИПС, работающим в диалоговых режимах на персональных компьютерах. Теоретические разработки проблемы лингвистического обеспечения автоматизированных ИПС касались в 60-70-х годах только информационных центров, что объясняется отсутствием автоматизации в библиотеках и библиотечно-библиографических процессах. Работы А. Б. Антопольского, Г. Г. Артаманова, Б. Р. Певзнера, А. В. Соколова, А. И. Черного послужили основой для дальнейшего развития теории лингвистического обеспечения ИПС. С развитием автоматизации библиотечно-библиографических процессов появились работы, посвященные развитию ИПЯ библиотечных ИПС. Проблемы лингвистических
средств для библиотечных технологий рассматриваются в трудах Л.И. Беневоленской, Е. М. Зайцевой, О. А. Фуралева, М. В. Экстрем и др.
В работах Н. И. Гендиной обобщены и развиты принципы лингвистического обеспечения, описанные в трудах отечественных исследователей, в приложении к библиотечным технологиям, рассматривается широкий спектр вопросов, относящихся к лингвистическому обеспечению, в т.ч. индексированию, информационному поиску и т.д. Ряд научных разработок посвящен отдельным аспектам лингвистического обеспечения. Вопросы классификационных ИПЯ исследовались такими учеными, как Л. Н. Пирумова, М. А. Довбенко, Е. Н. Пименов, Ю. А. Шрейдер и др. Развитию Библиотечно-библиографической классификации (ББК) посвящен ряд работ Э. Р. Сукиасяна. Проблемы ведения, разработки, актуализации Универсальной десятичной классификации (УДК) отражены в работах О. А. Антошковой, Н. Д. Борисовой, А. В. Владимировой, О. В. Караджи, Б. В. Кристального, Л. В. Лобовой, Б.И. Маршака, Т. В. Тужилковой и др.
Рубрикатору ГСНТИ посвящены работы В. Н. Белоозерова, И. Е. Гендлиной, Б.В. Кристального, Н. В. Лукашевич, В. М. Полонского, Ю.Ф. Тарасюк, З.М. Храпкина и др. С развитием и совершенствованием автоматизированных баз данных все большее внимание уделяется дескрипторным языкам. Методика создания информационно-поискового тезауруса содержится в работах О.А. Лавреновой, А.В. Соколова. Выявлению и обоснованию оптимальных путей развития дескрипторных языков посвящены труды Л. Н. Пирумовой, Л. П. Алексеевой, Д. Н. Бакун, С. А. Белькова, П. И. Браславского, С. Л. Гольдштейн, С. В. Еринева, В. М. Лейчик, С. А. Мамонтова, В. М. Масляковой, Л. И. Оранской, Т. Я. Ткаченко и др.
ИПЯ непосредственно связаны с аналитико-синтетической обработкой информации, поскольку именно на этом этапе осуществляется перевод информации с естественного на искусственные языки и создается поисковый образ документа. Исследованиями в области аналитико-синтетической обработки информации занимаются теоретики и практики библиотековедения и информационной деятельности: Ф. С. Воройский, А. Ф. Еареев, В. В. Корнеев и др. В работах последних лет поднимаются проблемы автоматизированного индексирования, о них пишут Л. В. Кнорина, Н. Н. Литвинова, П.В. Лукашевич. Важное место в разработке лингвистического обеспечения ИПС отводится проблеме совместимости информационно-поисковых языков. Особенно важной и актуальной проблема совместимости ИПЯ становится в наши дни с развитием сетевых технологий, глобальной сети Интернет. Большой интерес, в этой связи, представляют груды А. В. Бобко, Р. С.Еиляревского, Т. Б. Грищенко, А. Ю. Евсюкова, Л. А. Жариковой, А. С. Калиновского. К). В. Ланграф, Н. В. Рябовой, Г. А. Скарук и др.
В отличие от информационных центров, где информация хранится преимущественно в электронной форме, в библиотеке информация часто существует на бумажных носителях и наряду с электронными формами обслуживания применяются традиционные формы. Поэтому особый интерес представляет перевод карточных каталогов в электронные (конверсия каталогов), и в связи с этим - концепции объединения традиционных и электронных каталогов в единую информационно-поисковую систему с единым лингвистическим обеспечением. Эти проблемы освещены в работах С. К. Вилснской, Н. А. Еалюк, М. Н.Захаровой, М. Н.Романовой, Е. М. Ручимской, О. А. Фуралева, И. Ю. Черкасовой и др.
Проблемы лингвистического обеспечения постоянно обсуждаются на страницах библиотечной печати, ею занимаются видные теоретики библиотековедения и информатики, но эти разработки чаще носят теоретический характер и могут служить базой для дальнейших разработок прикладного характера. Практически отсутствуют работы о структуре лингвистического обеспечения НСХБ. Однако необходимость в этом назрела поскольку актуальной стала задача создания единой сетевой ИПС по вопросам АПК с единым или совместимым лингвистическим обеспечением. В этой ситуации с новых позиций следует рассматривать традиционные ИПЯ, которые используются в НСХБ и могут быть использованы в автоматизированной библиотечной ИПС. Поэтому необходимо глубокое и всестороннее исследование лингвистических средств НСХБ с целью разработки структуры ее лингвистического обеспечения, выработки рекомендаций по его совершенствованию. Недостаточная разработанность проблемы применительно к сельскохозяйственной ИПС явилась еще одним основанием для выбора темы исследования.
Практическая значимость данного исследования
– это усовершенствование модели лингвистического обеспечения в Белорусской сельскохозяйственной библиотеке, а также разработка путей внедрения средств лингвистического обеспечения в процессы поиска документов.
Дипломная работа выполнена на базе Белорусской сельскохозяйственной библиотеки им. И. С. Лупиновича Национальной академии наук Беларуси.
Глава 1. Теоретические аспекты лингвистического обеспечения автоматизированных библиотечно-информационных систем.
1.1. Понятие, состав и требования к современному лингвистическому обеспечению.
Создать условия, при которых читатель может получить доступ к информационно-поисковым системам библиотек различной удаленности и вести эффективный поиск в них, помогают лингвистическое обеспечение (ЛО) и его основная составляющая - информационно-поисковые языки (ИПС). Задача библиотек состоит не только в том, чтобы собрать в своих фондах возможно полно документы, но сделать их доступными для пользователя, дать информацию о них и раскрыть информацию, содержащуюся в них. Всему этому способствуют каталоги, базы данных, библиографические и реферативные издания. Информация в них должна быть систематизирована и представлена в таком виде, который позволяет осуществлять быстрый поиск в данных ИПС, БД, электронном каталоге.
Любая ИПК включает следующие элементы:
1. информационный массив;
2. ИПЯ, на которой переводится входная информация и запросы; правила этого перевода (индексирование);
3. критерии выдачи, то есть правила сравнения перевода запроса на ИПЯ с результатами перевода на ИПЯ входной информации, определяющие отбор информации, подлежащей выдаче на запрос.
Понятие ЛО шире понятия информационно-поискового языка, поскольку включает их в себя. Лингвистическое обеспечение автоматизированных систем включает ИПЯ, методики индексирования документов и запросов на них, инструкции и методики их ведения и использования, а также средства поддержания ИПЯ в автоматизированной системе.
Средством свертывания информации и смысловой обработки документов является информационно-поисковый язык (ИПЯ) - формализованный искусственный язык, предназначенный для индексирования документов, информационных запросов. Искусственный язык, специально разработанный для автоматизированного поиска, лишен недостатков естественного языка (многозначность, избыточность) и лучше приспособлен для информационного иска, увеличивая полноту и точность выдачи информации. При создании ИПЯ учитываются требования, которые отвечают его задаче - полноте и точности поиска:
- однозначность - каждая запись на ИПЯ должна иметь только один смысл, то есть искусственный ИПЯ должен устранять такие недостатки, с точки зрения поиска естественного языка, как полисемия и омонимия;
- явное выражение полезных для поиска семантических (смысловых) отношений между словами (логических отношений и психологических ассоциаций) ИПЯ;
- возможность корректировки и дополнения ИПЯ;
удобство пользования, ИПЯ должен обладать компактностью записей, способствующих его запоминанию;
- способность точно идентифицировать предмет, отличить его особенности и описать его с необходимой степенью детализации и глубины.
Семантическое богатство ИПЯ зависит от его терминологической наполненности, структуры построения и от взаимоотношений лексических единиц, составляющих лексику, словарный состав ИПЯ, Лексическая единица (ЛЕ) информационно-поискового языка - это обозначение отдельного понятия, принятое в нем. Лексические единицы каждого ИПЯ называются по-разному: в классифицированных системах - это индексы, в языке предметных рубрик это - рубрики, в дескрипторных языках - дескрипторы, в языке
ключевых слов - ключевое слово. По тому, какие лексические единицы используются в ИПЯ, различают словарные и кодированные ИПЯ. В словарных ИПЯ (тезаурус) используются элементы естественного языка, и перевод на естественный язык не требуется. В кодированных ИПЯ (УДК, ББК) индексы или рубрики сопровождаются таблицей соответствия, то есть каждой лексической единице на искусственном языке дается словесное ее выражение на естественном языке. Основу лексики любого ИПЯ составляют термины, являющиеся носителями научной информации в текстах документов. Любой ИПЯ создается на основе терминологии определенной области знаний.
Разработка ИПЯ проходит несколько этапов: отбор лексических единиц; процесс нормализации лексики; систематизация и группировка лексики; построение классификационных схем; оформление лексики ИПЯ.
Этап отбора лексических единиц особенно важен в процессе создания информационно-поискового языка, поскольку от него зависят возможности данного ИПЯ: терминологическая наполненность, соответствие уровню развития науки, отражаемой в нем, а значит, и поисковые возможности данного ИПЯ. Отбор лексических единиц происходит в процессе аналитико-синтетической обработки документов на этапе аннотирования, систематизации индексирования.
ИПЯ неразрывно связан с процессом аналитико-синтетической обработки информации, поскольку на этом этапе раскрывается тематическое содержание документа, происходят свертывание информации, представленной в нем, и ее перевод на формализованный язык, позволяющий внести информацию в ЭК, а затем вести в нем поиск. Прежде чем информация предстанет в виде элементов ИПЯ, она проходит семантическую, то есть смысловую обработку. Текст, представленный на естественном языке, анализируется с точки зрения его содержания. В ходе осмысления содержания текста документа человеком (семантической обработки) происходит отбор наиболее значимых, основных тем документа, а затем их перевод с естественного на искусственный язык. При этом точность и полнота перевода зависят от возможностей ИПЯ, От уровня разработки его лексического и терминологического аппарата, наличия правил этого перевода.
Таким образом, именно ИПЯ является основным компонентом любой ИПС, без которой она превращается только в беспорядочный «сундук» информации. В традиционной ИПС использовались ИПЯ, разработанные для карточных каталогов; наибольшее распространение получили Универсальная десятичная классификация (УДК) и Библиотечно-библиографическая классификация (ББК). Однако использование их в автоматизированных системах пока не обеспечивает эффективного поиска. Вместе с тем существуют ИПЯ, специально разработанные для автоматизированных ИПС и для автоматизированного поиска: рубрикаторы, тезаурусы. При создании электронных каталогов, автоматизированных ИПС перед библиотеками встает задача выбора ЛО и ИПЯ, которые будут использоваться в них.
Как правило, в одной информационно-поисковой системе используются несколько ИПЯ, поэтому встает вопрос об их совместимости. В условиях одной ИПС эта проблема решается, если все документы, входящие в ее документный поток, индексируются на всех ИПЯ, используемых в данной поисковой системе. Для достижения совместимости в одной ИПС следует обеспечить единую методику индексирования на всех ИПЯ этой системы, а также добиться унификации и стандартизации языковых средств и поддерживающих компонентов ЛО.
Использование нескольких ИПЯ в одной ИПС объясняется тем, что каждый из языков предназначен для выполнения определенных функций в ней, а также осознанием того, что не может быть создан единый ИПЯ, выполняющий одновременно все функции лингвистических средств и все задачи, стоящие перед информационно-поисковой системой. Одновременное использование нескольких информационно-поисковых языков обеспечивает быстрый и разнообразный доступ потребителя к информационным ресурсам
в зависимости от его знания какого-либо из ИПЯ и от того, какого рода информация ему нужна и для каких целей. Все это относится к решению проблемы узкой совместимости в рамках одной ИПС. [51, C. 58]
Проблема совместимости средств ЛО различных ИПС стала особенно актуальна с развитием информационных сетей. Поскольку каждая ИПС использует свои ИПЯ, то обмен информацией между информационно-поисковыми системами затруднен из-за несовместимости этих ИПЯ. Различают средства и методы достижения лингвистической совместимости. К средствам ее обеспечения относятся рубрикаторы, классификаторы, библиотечные форматы записи, тезаурусы и нормативные словари, конверторы, необходимые для перевода информации из одной формы ее предоставления в другую. К основным методам совместимости лингвистических средств относят: методологическую совместимость; стандартизацию и унификацию языковых средств; создание общесетевых универсальных ИПЯ; сопряжение языковых средств; методы конверсии языковых средств; сосуществование разных ИПЯ в сети.
Методическая совместимость - это разработка единых принципов создания и ведения ЛО отдельных ИПС, входящих в одну информационную сеть; разработка нормативных документов, определяющих структуру и состав ЛО участников сети. Стандартизация - это разработка единых стандартов, позволяющих произвести унификацию отдельных элементов БО, ИПЯ, терминологии.
Универсальные (общесистемные) языки должны обеспечить единообразие формирования информационных массивов. Примером создания универсальных языковых средств является разработка Государственного рубрикатора научно-технической информации (ГРНТИ).
Метод конверсии, то есть преобразование записей на одном информационно-поисковом языке в записи на другом ИПЯ автоматизированными средствами, реализуется созданием таблиц соответствия. Например, в отраслевом рубрикаторе Центральной научной сельскохозяйственной библиотеки (ЦНСХБ) каждой рубрике Рубрикатора приписан индекс УДК.
Сосуществование языковых средств предполагает параллельное использование нескольких ИПЯ в одной ИПС. Анализ 10 важнейших библиотечных процессов (комплектование, учет библиотечных фондов; библиографическое описание произведений печати, систематизация (или предметизация), организация библиотечного каталога, техническая обработка документов, работа с фондом, обслуживание читателей, работа МБА, справочно-библиографическая и информационная работа) показывает, что ИПЯ в той или иной степени используются в каждом из перечисленных процессов, кроме того, существует прямая зависимость между качеством лингвистических средств и эффективностью используемой библиотечно-библиографической технологии. Следовательно, изменение или расширение функций автоматизированной библиотечной системы связано в первую очередь с реальным выбором комплекса ИПЯ, усилением семантической силы используемых информационно-поисковых языков. Исследователи отмечают, что, несмотря на существенные достижения в области интерактивных систем (генерация БД, возрастание скорости передачи информации), совершенствование и упрощение поисковой процедуры достигнуто лишь в части автоматизации механических, рутинных процессов интерактивного поиска. Что касается связанных с ним интеллектуальных процессов, то они автоматизацией охвачены слабо или фактически не охвачены. Другими словами, интерактивный поиск дает быстрые результаты по поиску по простейшим элементам базы обслуживания (БО): автору, названию, но тематический поиск, который является интеллектуальным, остается слабым звеном. В исследованиях по анализу эффективности работы интерактивных систем отмечено, что наибольшее влияние на результаты поиска оказывают именно интеллектуальные операции: определение предмета, области поиска, выбор базы данных, выбор стратегии поиска и оценка его результатов. Причем основная сложность заключается в
выборе стратегии поиска, что напрямую связано с использованием лингвистических средств. В интерактивном режиме существует задача оптимизации методов поиска, его полноты, релевантности и скорости создания поискового предписания.
Это гарантирует формализованное описание содержания документов в ЭК и информационных запросов, что достигается при помощи комплекса ИПЯ. Классификационные и дескрипторные языки служат инструментом более тонкого анализа для проведения тематического поиска. Сочетание нескольких ИПЯ дает возможность проведения поиска по тематическим признакам, что обеспечивает его полноту и точность.
В Центральной научной сельскохозяйственной библиотеке Российской Академии наук используются для автоматизированного поиска:
• язык библиографического описания (ЯБО);
• язык ключевых слов (ЯКЛ);
• информационно-поисковый тезаурус (ИПТ);
• отраслевой рубрикатор, разработанный на основе ГРНТИ (ОР).
Результативность поиска в ЭК во многом зависит от выбора стратегии поиска; от лингвистических средств, используемых в данном ЭК; от качества индексирования документов на используемых в электронных каталогах ИПЯ. Семантическая обработка документа подразумевает полноту и точность перевода с естественного языка на ИПЯ, которые зависят от структуры, лексической наполненности и других возможностей информационно-поискового языка, разработанности правил этого перевода, от соответствия единиц естественного языка лексическим единицам ИПЯ. Именно от точности и единообразия описания исходной информации языковыми средствами зависит релевантность (степень соответствия содержания документа, найденного при поиске, содержанию информационного запроса) и полнота поиска. Если известны источники и реквизиты документа, то поиск ведется по языку библиографического описания, если нужен тематический поиск, то используются отраслевой рубрикатор, информационно-поисковый тезаурус, язык ключевых слов. В ИПС данной библиотеки используется, коммуникативный формат К118МАКС, Структура языка библиографического описания богата поисковыми возможностями, заложенными в этом формате на БО, состоящем из 229 элементов данных. Эти данные позволяют идентифицировать и разыскать документ по каждому из этих -элементов. Чём полнее используются возможности коммуникативного формата, тем шире возможности поиска по формальным признакам документа.
Установлено, что поиск только по БО может быть достаточно эффективен, так как заглавия пригодны для автоматизированного поиска. Эффективность поиска возрастает, когда к БО добавляются рубрики или индексы ИПЯ. Точность поиска в этом случае составляет 70 процентов, а полнота - 50 процентов. Точность поиска возрастает еще на 3-5 процентов, если к этому добавляются ключевые слова и дескрипторы. БД с рефератами и/или аннотациями дает максимально эффективный поиск в автоматизированном режиме, поскольку возможен поиск по всем полям, то есть по всему тексту документа. Использование всех текстов документа (БО, аннотаций, рефератов) в качестве ПОД расширяет возможности поиска, так как в них выражены синтаксические связи между ключевыми словами.
Результативность тематических запросов зависит от ИПЯ, на котором они сформулированы. Запрос может быть сделан на естественном языке, то есть выражен известными пользователю терминами - научными или общеупотребительными, и какое-то количество нужных пользователю документов может быть найдено. Однако, как показал опыт, это будут не все документы по заданной теме и, возможно, в выборку не войдут самые ценные из них, о чем пользователь может и не подозревать. Может показаться, что поисковые возможности естественного языка и ключевых слов одинаковы, но это не так.
К примеру:
• в документе № 1 препарат А упоминается в качестве стандарта при оценке свойств препарата Б;
• в документе № 2 описаны свойства, формы, назначения, способы применения и т. п. препарата. На запрос «препарат А» и при поиске по текстовым полям (естественней язык) пользователь получит оба документа, так как в их текстовых полях, например, в аннотации, в реферате, поисковая система найдет термин «препарат А». Однако документ № 1 не релевантен запросу и не нужен пользователю (это «информационный шум»). Документ № 1 релевантен только запросу о «препарате Б». На запрос «препарат А» и при поиске по терминам поля «ключевые слова» поисковая система выдаст только релевантный запросу документ № 2, поскольку индексатор заиндексировал документ ключевым словом «препарат А», так как в нем содержится существенная информация об этом препарате, в отличие от документа № 1.
Но следует иметь в виду, что поиск по терминам текста и ключевым словам не может обеспечить удовлетворительной полноты нахождения нужных источников информации. К примеру, если «препарат А» в документах № 1 и № 2 имеет разные наименования, что очень распространено в научных текстах. При этом версии написания термина, использованные в документе и, следовательно, индексатором в качестве текста ключевых слов могут отличаться от версии термина, использованной пользователем в запросе. Очевидно, что в таких случаях поисковая система не найдет значительное количество документов. В числе недополученных пользователем могут быть особенно ценные и релевантные его запросу документы.
В качестве ключевых слов (КС) могут выступать отобранные из текста документа слова или словосочетания естественного языка, раскрывающие наиболее важные смысловые аспекты документа. Для пользователя поиск будет наиболее эффективным, если формулировка его запроса совпадет с дескрипторами ИПТ.
ИПТ представляет собой алфавитный перечень отраслевой терминологии, где отражены иерархические, синонимические и ассоциативные отношения между терминами (дескрипторами).
Использование дескрипторов ИПТ позволяет систематизатору преодолеть такую особенность естественного языка, как неоднозначность (одно и то же понятие может быть сформулировано по-разному), а всем специалистам в данной области — единообразно переводить слова естественного языка на ИПЯ. Это повышает вероятность того, что пользователь сможет найти данный документ. Благодаря тезаурусу, при поиске пользователь может использовать в запросе синонимы, в то же время в тезаурусе есть отсылка от синонима к основному термину, то есть документ все равно будет найден по основному термину.
При индексировании документов КС индексатор в целях обеспечения полноты отражения понятий и релевантности поиска выбирает именно дескрипторы ИПТ, однако бывает, что используемый автором исходного документа термин является очень узким и специфичным либо редко встречающимся в специальной литературе, и поэтому, естественно, что он еще не нашел отражения в ИПТ. В этом случае индексатор может отразить понятие в виде ключевого слова, которое считает оптимальным. Понятно, что термины ИПТ все индексаторы напишут одинаково, а формулировки прочих ключевых слов теоретически могут оказаться не совпадающими, и тогда пользователь не сможет найти часть документов. Для предотвращения подобных ситуаций в ЦНСХБ Россельхозакадемии например, постоянно ведется работа по унификации написания ключевых слов, составляется картотека ключевых слов, фиксирующая согласованные формулировки, принимаются методические решения, которые заносятся в специальные рекомендации по индексированию на языке ключевых слов. Данную работу выполняет так называемый Лингвистический отдел ЦНСХБ. Тезаурус и ключевые слова дают эффективный узкотематический поиск. Важное значение имеет использование методик индексирования на ИПЯ, используемых в ИПС. Методики способствуют унификации индексирования документов, препятствуют проявлению субъективизма индексатора в определении места документа, обеспечивают точность, полноту и однозначность отображения информации в БД. Индексирование — это основное средство раскрытия содержания документа и соответственно всего текущего документного потока, который составляет фонд библиотеки. От качества индексирования зависит не только эффективность тематического поиска в информационных ресурсах, но и эффективность использования ее фондов.
Независимо от типа ИПЯ основными требованиями, которые предъявляются к процессу индексирования документа, являются: а) полнота и точность раскрытия содержания; б) объективность его раскрытия; в) единообразие отображения средствами данного ИПЯ сходных по содержанию документов (другими словами все документы по одному вопросу должны получить одинаковые индексы, рубрики, дескрипторы и т. д. и попасть в одно место в информационно-поисковой системе).
Процесс индексирования включает несколько этапов: анализ содержания документа; выявление и отбор понятий, тем, отражающих основное содержание документа; выбор терминов индексирования (рубрик, кодов, индексов, дескрипторов, ключевых слов) и принятие решений о составе ПОД; перевод содержания документа с естественного языка на ИПЯ; добавление любой необходимой информации к названию документа (расширение названия, создание аннотации); редактирование терминов индексирования на ИПЯ. Как для классификационных (УДК, ББК), так и для дескрипторных (тезаурус) ИПЯ полнота и детальность индексирования связаны с обеспечением полноты и релевантности тематического поиска.
Полнота и детальность индексирования зависят от семантической наполненности ИПЯ, его способности описать документ в характеристиках, присущих индексируемому документу. Повышение глубины (детальности) индексирования увеличивает точность информационного поиска, его эффективность за счет возможности предоставления информации по самым «узким», специальным вопросам.
Поэтому при создании автоматизированной ИПС, электронного каталога библиотека стоит перед выбором лингвистического обеспечения, которое будет в них использоваться. Состав и структура лингвистического обеспечения автоматизированной системы связаны с функциями библиотеки. От выбора ИПЯ и лингвистических средств зависит эффективность работы ИПС.
При выборе ЛО необходимо учитывать тематический диапазон фонда, отрасль знаний, представленную в фонде и информационных ресурсах, структуру и объем входного документного потока, тип и особенности ИПС, информационные запросы пользователей. Именно задачи, стоящие перед ИПС, определяют выбор и состав лингвистических средств, совокупность которых должна обеспечить ее эффективную работу. Оптимизация структуры лингвистического обеспечения автоматизированной ИПС заключается в формировании структуры, которая включает информационно-поисковые языки, обеспечивающие все ее библиотечно-библиографические процессы и функции как на внутрибиблиотечном, так и на межбиблиотечном уровне. Лингвистические средства ИПС должны обеспечивать эффективный информационный поиск. Это могут быть ИПЯ, специально разработанные для автоматизированных ИПС, либо приспособленные для работы в них.
Методика формирования структуры лингвистического обеспечения ИПС включает несколько этапов:
1) анализ задач, стоящих перед библиотекой, ее функций и библиотечно-библиографических процессов. Задачи определяют функции, которые реализуются технологиями. Выявление библиотечно-библиографических процессов позволяет определить лингвистические средства, требуемые для их обеспечения;
2) изучение роли и функций ИПЯ в ИПС. Ознакомление с теорией лингвистического обеспечения позволяет понять назначение и роль ИПЯ в формировании и структурировании информационных массивов, в аналитико-синтетической обработке информации, информационном поиске и т. д.
3)анализ эффективности использования собственных ИПЯ позволяет понять, как уже используемые в библиотеке информационно-поисковые языки обеспечивают автоматизированные библиотечно-библиографические процессы, наметить пути совершенствования и адаптации их к автоматизированной ИПС;
4)изучение существующих отраслевых ИПЯ. В случае, если собственные ИПЯ не обеспечивают эффективное функционирование ИПС (эффективный информационный поиск), изучение структуры и поисковых возможностей, методических пособий отраслевых и м других ИПЯ позволит определить, подходят ли они данной ИПС;
5)создание структуры лингвистического обеспечения: подбор ИПЯ, определение: функций каждого ИПЯ в структуре с учетом внутрибиблиотечных процессов и существования библиотеки в едином информационном пространстве отрасли;
6)адаптация выбранных лингвистических средств к условиям ИПС; проведение работ, обеспечивающих использование ИПЯ в ИПС и выполнение правил работы с ними, усовершенствование ИПЯ с целью повышения эффективности их использования, разработка методических пособий.
Модель структуры ЛО должна основываться на практической значимости и научной обоснованности ценности каждого ИПЯ в ИПС. Применение ИПЯ, которые не используются в автоматизированной системе, может быть оправдано только их использованием для другого рода тематического поиска.
Структура лингвистических средств ЦНСХБ в соответствии с ее оптимизированной моделью выглядит так:
Внутрибиблиотечный уровень:
• язык библиографического описания (для идентификации документов и информационного поиска по полям коммуникативного формата):
• УДК (для индексирования входного документного потока);
• Отраслевые рубрикаторы (для индексирования входного документного потока и тематического поиска в БД; структурирования информационных массивов; формирования текущих библиографических и реферативных изданий; определения тематического диапазона библиотечных фондов ЦНСХБ);
• Информационно-поисковый тезаурус (используется для индексирования входного документного потока и тематического поискав БД; создания терминологической базы по сельскому хозяйству и продовольствию);
• Язык ключевых слов (для индексирования входного документного потока и тематического поиска в БД; отбора лексики в информационно-поисковый тезаурус по сельскому хозяйству и продовольствию);
Межбиблиотечный уровень:
• УДК (в корпоративной каталогизации и АСОД, а также в качестве международного информационного языка);
• Язык ключевых слов (в корпоративной каталогизации и АСОД и для идентификационного поиска информации в БД страны);
• Отраслевые рубрикаторы (как язык-посредник межотраслевого информационного общения, для обмена информацией и ее поиска в ИПС РФ и других стран СНГ, а также в качестве общеотраслевого ИПЯ АПК);
• Информационно-поисковый тезаурус (как терминообраза АПК, а также в качестве
общеотраслевого ИПЯ АПК).
На примере оптимизации структуры лингвистических средств Центральной научной сельскохозяйственной библиотеки видно, что составе ее лингвистических средств целесообразно оставлять только те информационно-поисковые языки, которые будут использоваться в автоматизированном поиске.
1. 2.
Обзор лингвистического обеспечения сельскохозяйственных библиотек России и Украины.
1.2.1. Средства лингвистического обеспечения Центральной научной сельскохозяйственной библиотеки Российской сельскохозяйственной академии.
Задача лингвистических средств — обеспечить не только быстрый, но эффективный поиск, предоставляющий максимально полно релевантную информацию по запросу пользователя. Автоматизированные системы обычно обеспечивают поиск текущей информации, в то время ретроспективную информацию пользователю приходится искать традиционным способом в карточных каталогах. Таким образом , ИПС библиотек сегодня включают электронные каталоги, базы данных и карточные каталоги. Эффективное использование информационно-библиотечной системы предполагает взаимосвязи составляющих ее компонентов, тесного взаимодействия всех библиотечных процессов. Нельзя забывать, что значительная часть библиотечных документов отражена только в карточных каталогах. В ЦНСХБ Россельхозакадемии в карточном комплексно-системном каталоге свыше 6 млн. карточек, а в электронном — около 1 млн. записей. Структура лингвистических средств ЦНСХБ включает ИПЯ, используемые, как при автоматизированном, так и при традиционном поиске. В состав лингвистических средств входят классификационные и дескрипторные ИПЯ. Вот основные.
Классификационные языки
:
1. Схема комплексно-системного каталога (КСК)
2. Отраслевой рубрикатор по сельскому хозяйству и продовольствию (ОР),
3. Универсальная десятичная классификация (УДК).
Дескрипторные языки
:
1. Информационно-поисковый тезаурус по сельскому хозяйству и продовольствию (ИПТ),
2. язык ключевых слов.
Ретроспективный поиск традиционным путем ведется по карточному комплексно-системному каталогу (КСК), строящемуся по классификационной схеме КСК, текущий поиск ведется по электронному каталогу (ЭК) и БД «AGROS». В процессе аналитико-синтетической обработки, на все документы, поступающие в фонд библиотеки, проставляются: систематизация КСК, индексы УДК, рубрики Отраслевого рубрикатора, дескрипторы ИПТ и ключевые слова. Т. е. в ЭК и БД «AGROS» вводится информация на всех ИПЯ, используемых в ЦНСХБ. От индексаторов, создающих поисковый образ документа (ПОД), требуется знание всех ИПЯ, что создает повышенную нагрузку на них. Ведение, поддержка и разработка ИПЯ требуют огромных трудозатрат. Использование нескольких ИПЯ объясняется, с одной стороны, тем, что каждый из них выполняет свою функцию в ИПС, а с другой стороны, аксиомой, гласящей, что не существует идеального единого ИПЯ, выполняющего одновременно все функции лингвистических средств и обеспечивающего все информационные задачи, решаемые ИПС.
Каждый ИПЯ предназначен для удовлетворения определенных информационных нужд и поисковых задач. Кроме того, использование нескольких ИПЯ помогает в некоторой степени решить проблему совместимости ЛО разных ИПС, поскольку предполагает, что один из используемых в ИПС ИПЯ знаком пользователю, что значительно облегчает для него поиск в ней. Этим объясняется, что некоторые библиотеки не только не сокращают, а наоборот расширяют состав своих лингвистических средств. Примером этому служит ГПНТБ, которая ввела в состав своих лингвистических средств Классификацию Дьюи, поскольку она используется во многих американских библиотеках. Но все ли ИПЯ используются при поиске текущей информации в автоматизированной системе ЦНСХБ?
Отраслевой Рубрикатор по сельскому хозяйству и продовольствию
(ОР), разработан на основе Государственного Рубрикатора научно-технической информации (ГРНТИ). Его назначение: структурировать информационные массивы, полно и точно отражать политематический поток документов, поступающих на ввод в ЭК и БД «AGROS», обеспечить полноту и точность информационного поиска, удовлетворять требованиям сортировки массивов документов при создании различных информационных продуктов, выполнять формально-логический контроль рубрик вводимых документов. ОР выполняет функции ЛО информационных изданий: текущих библиографических и реферативных журналов. ОР используется при тематическом поиске и формировании больших информационных массивов, комплектовании фонда, определяя его тематический диапазон, при индексировании документов. Пять уровней иерархии обеспечивают достаточно глубокий тематический поиск.
Использование ГРНТИ во всех информационных центрах РФ позволяет использовать ОР в качестве межсистемного языкового средства, обеспечивающего взаимодействие как на отраслевом, так и на межотраслевом уровне. С его помощью возможен обмен информацией, поиск в различных ИПС.
Информационно-поисковый тезаурус
по сельскому хозяйству и продовольствию (ИПТ) разрабатывается в ЦНСХБ с 1992 г., за основу взят тезаурус ВНИИТЭИагропром. Терминологическая база содержит свыше 20 тыс. терминов, включающих все отрасли АПК и смежные с ним области, охрану окружающей среды и т. д. Используется при индексировании документов в ходе аналитико-синтетической обработки документов и при поиске информации в ЭК и БД «AGROS». В автоматизированной ИПС ЦНСХБ осуществляется процедура автоматического приписывания вышестоящих терминов, что обеспечивает полноту тематического поиска. Назначение ИПТ — отражение терминологической лексики отрасли, отражении парадигматических отношений, существующих между лексическими единицами-терминами, используемыми в сельскохозяйственной науке и практике, в обеспечении контроля и нормализации отраслевой лексики и единообразном, формализованном ее представлении в БД «AGROS» и ЭК ЦНСХБ. ИПТ выполняет функцию терминологического справочника АПК.
Язык ключевых слов
используется в ЦНСХБ с 1992 г. при индексировании документов и информационном тематическом поиске. Ключевые слова — слово или словосочетание из текста документа, несущие наибольшую смысловую нагрузку в нем. Язык ключевых слов — это нормализованная лексика; ключевые слова записываются индексатором в процессе аналитико-синтетической обработки документа в соответствии с правилами, разработанными в библиотеке. Язык ключевых слов дополняет ИПТ, позволяя осуществлять максимально полный тематический поиск. Ключевые слова являются терминологическим резервом лексики ИПТ, из которой после соответствующей лексической обработки в ИПТ вводятся новые дескрипторы и создаются новые словарные статьи.
Универсальная десятичная классификация (УДК)
— используется в ЦНСХБ с 1963 г. УДК является международной классификацией, используемой более чем в 60 странах мира. Все документы, поступающие в фонд ЦНСХБ, сопровождаются систематизацией по УДК, которая вводится в ЭК и БД «AGROS». Однако в качестве ИПЯ используется только для фонда открытого доступа книг и справочного фонда. До 1992 г. систематизация УДК печаталась на каталожных карточках ЦНСХБ, которые распространялись по системе Централизованной библиографической информации (ЦБИ) по библиотекам отрасли. Большинство библиотек отрасли строят карточные систематические каталоги по отраслевым таблицам УДК. Карточки ЦБИ выполняли функции централизованной каталогизации и систематизации; готовые каталожные карточки использовались для пополнения каталогов и картотек. Далеко не все сельскохозяйственные библиотеки уже оснащены компьютерами, карточные каталоги остаются для них единственным средством тематического поиска, а те, кто автоматизировал уже обработку документов и создает ЭК, продолжают использовать УДК наряду с ключевыми словами в качестве ИПЯ. Пока поиск по УДК не очень эффективен, но создаются авторитетные файлы УДК, электронные таблицы классификации, разрабатываются технологии приспособления этого ИПЯ для автоматизированного поиска. Вопрос о централизованной обработке документов актуален, возможно его решение на качественно новом уровне: информацию можно получать по запросу в электронной форме на дискете или по электронной почте, а затем использовать либо в ЭК, либо, распечатав в виде карточек, в карточных каталогах. Принимая во внимание, что УДК используется не только во многих зарубежных странах, странах СНГ, но и во всех технических библиотеках РФ, этот ИПЯ остается перспективным с точки зрения использования его в автоматизированном поиске, поэтому ЦНСХБ продолжает использовать его в своей ИПС.
Комплексно-системный каталог (КСК)
существует с 1935 г., долгое время он был единственным средством тематического поиска в ЦНСХБ. Его схема сочетает в себе принципы предметного и систематического каталогов. Разделы КСК включают предметные рубрики, расположенные в алфавитном порядке, внутри рубрик материал размещен в систематическом порядке. Отличительной чертой КСК от прочих каталогов является то, что он собирает в комплексе всю (книжную и статейную) информацию по какому-либо вопросу. В этом смысле он приближен к базам данных. Расположение документов в подрубриках в обратнохронологическом порядке делает его удобным для пользователя, предпочитающего в первую очередь знакомиться с последними документами, вышедшими по интересующему его предмету. Объем КСК составляет свыше 6 млн. карточек. В 1999 г. каталог законсервирован, это означает, что в него сегодня вливаются карточки на документы, изданные до 1999 г., которые продолжают поступать в фонд библиотеки. Таким образом, для текущего тематического поиска каталог закрыт.
С 1992 г. в ЦНСХБ создается электронный каталог и с 1992 по 1998 гг. в библиотеке параллельно велись карточный и электронный каталоги, что требовало больших трудозатрат. Это объясняется необходимостью адаптировать пользователя к автоматизированной ИПС, научить его работать с ЭК и БД «AGROS». Кроме того, требовалось оснастить читательскую зону необходимым количеством ПЭВМ. Решение о консервации КСК было принято на основе того, что пользователь уже приобрел необходимые навыки работы с ЭК и БД «AGROS», может самостоятельно, либо с помощью посредника (дежурного библиографа) формировать тематический запрос и вести поиск в автоматизированном режиме. С консервацией КСК встает вопрос об использовании схемы КСК в качестве ИПЯ автоматизированной ИПС, о необходимости систематизации по КСК текущего входного документального потока и ввода ее в ЭК и БД «AGROS». КСК остается основным средством тематического ретроспективного поиска и, в этом смысле он должен и будет поддерживаться (редактироваться и т. д.). Однако в библиотеке начался процесс ретроконверсии карточных каталогов, который пока идет медленно, но работа началась и, главное, будет продолжаться. Это, вероятно, сократит количество обращений пользователей к карточному каталогу. В ходе ретроконверсии систематизация КСК используется как важный источник раскрытия содержания документа, но она трансформируется и термины из систематизации записываются в поля “дескрипторы” и “ключевые слова”. [59, C. 25-26]
Проведенные в библиотеке исследования по эффективности тематического поиска показали, что поиск по систематизации КСК, записанной в традиционном виде, невозможен, поскольку запись систематизации содержит точки, тире, цифры, которые автоматизированная система не может распознать и идентифицировать из-за отсутствия схемы КСК в электронном виде.
Рассматривалась возможность создания алгоритма распознавания записи систематизации КСК; выяснилось, что этот процесс потребует больших финансовых и трудовых затрат, поскольку запись каждого из 8 разделов каталога имеет свою специфику и за годы существования ИПЯ видоизменялась много раз. Кроме того, потребуется перевести в электронную форму АПУ КСК и сами схемы, которые насчитывают 8 томов. Задача — дорогостоящая, но выполнимая, если бы этот ИПЯ был единственным лингвистическим средством тематического поиска в ЦНСХБ. Если рассматривать термины (рубрики и подрубрики), использованные в систематизации, как ключевые слова и составить поисковое предписание по ним, то поиск возможен. Но из этого следует, что необходимо преобразовать запись одного ИПЯ в другой ИПЯ — язык ключевых слов, который самостоятельно используется в автоматизированной ИПС. В таком виде поиск по предметным рубрикам КСК будет дублировать поиск по дескрипторам тезауруса и ключевым словам. КСК как ИПЯ, существующий 65 лет, накопил богатую терминологическую базу — около 45 тыс. понятий, включенных в алфавитно-предметный указатель (АПУ) и представляющих собой алфавитный список предметных рубрик и подрубрик, а также “скрытых” терминов, отраженных в документах фонда ЦНСХБ. АПУ долгое время являлся единственным терминологическим справочником отрасли, но ИПТ также отражает в алфавитном порядке терминологию отрасли и является терминологическим словарем по АПК. При этом ИПТ уже существует в электронной форме, разработано программное обеспечение его ведения и поддержки. Однако ИПТ собирает отраслевую лексику с 1975 г. и насчитывает свыше 20 тыс. терминов, что меньше объема АПУ КСК. Было проведено изучение областей терминологического покрытия ИПЯ КСК и ИПТ, которое показало, что словарный состав ИПТ позволяет адекватно отображать большую часть понятий КСК и очевидно, что с каждым годом тенденция к совместимости будет усиливаться.
Предполагается, что через несколько лет термины ИПТ полностью повторят термины АПУ КСК. Степень покрытия и совпадения терминологии двух ИПЯ имеет несущественные различия. Причинами отсутствия терминов КСК в ИПТ следует считать либо “привычку” индексатора отражать какое-либо понятие уже имеющимися ,возможно менее специфическим, более широким термином ИПТ и по этой причине не поступающими от них предложениями на ввод термина в тезаурус в качестве дескриптора, либо уже принятым для ИПТ решением не включать данный термин из-за появления новой формулировки, из-за решения не вводить узкие термины в статус дескрипторов, а использовать их в качестве ключевых слов. Выявленные в ходе исследования отсутствующие в ИПТ термины включены в лексическую обработку, но выявлен ряд устаревших терминов, введение которых в ИПТ из КСК не будет осуществлено. Это позволяет сделать вывод, что хотя КСК более богатая терминологическая система, но в ней присутствует некоторый процент терминов неиспользуемых в аграрной науке, несовременных, забытых или неактуальных, в то время как ИПТ включает таких терминов значительно меньше. Это объясняется, в частности, тем, что автоматизированное ведение ИПТ позволяет отслеживать частоту встречаемости терминов, что делает работу более эффективной.
С карточным АПУ КСК этот процесс требует значительно больших временных затрат. Термины, используемые в качестве ключевых слов, значительно сокращают разницу в объемах терминологических баз ИПТ и КСК, что позволяет говорить о значительном отражении терминологического состава ИПЯ КСК лингвистическими средствами автоматизированной ИПС. Кроме того, ИПТ является контролируемым автоматизированным путем лингвистическим средством обработки документов, а КСК не контролируется автоматически. Таким образом, в целях оптимизации структуры лингвистических средств автоматизированной ИПС ЦНСХБ целесообразна консервация КСК в качестве ИПЯ обработки входного документального потока, прекращение терминологического наполнения, ведения справочно-поискового аппарата и дальнейшей разработки его схемы. [44, C. 14-18].
1.2.2.
С
редства лингвистического обеспечения Государственной научной сельскохозяйственной библиотеки Украинской академии сельскохозяйственных наук.
Лингвистическое обеспечение - это комплекс языковых средств, необходимых для обработки документов и запросов, проведения эффективного поиска в электронном каталоге (ЭК) по тематическим запросам, осуществления языковой совместимости ЭК разных библиотек для обмена данными. Вопрос ЛС - пожалуй, наиболее проблемная и трудоемкая часть работы по ЭК, который является визитной карточкой библиотеки. Предоставление пользователю максимально благоприятных условий для поиска и распространения ресурсов библиотеки с целью информационно-библиотечного обеспечения агропромышленного производства, расширение их доступности для всех категорий пользователей - эта задача может быть решена при наличии развитой системы лингвистического обеспечения ЭК.
Для раскрытия содержания документов есть три основных вида информационно-поисковых языков: классификационный, предметизационный и дескрипторный.
Классификационный язык предназначен для индексирования документов и информационных запросов посредством понятий и кодов определенной классификационной системы (ББК, УДК, Десятичная классификация Дьюи и др.). [66, C. 35].
Универсальная десятичная классификация (УДК) является одной из самых распространенных классификационных систем в мире. Она постоянно развивается и совершенствуется, хорошо приспособлена для автоматизированных технологий и дает возможность осуществлять отраслевой поиск информации в АБИС "ИРБИС".Это позволяет сохранить в ЭК все положительные характеристики традиционных каталогов, которые вобрали в себя многолетний опыт библиотекарей и библиографов и привнести новые возможности поиска информации посредством использования информационно-коммуникационных технологий.
Для систематизации документов в ГНСХБ УААН частично используются таблицы ББК (для расстановки документов общественно-политического и гуманитарного направления) и украиноязычные таблицы УДК, подготовленные Книжной палатой Украины им. Ивана Федорова (К., 2000, с изменениями и дополнениями). [69]
В основе классификационных языков лежит систематическая классификация понятий, то есть такая, которая фиксирует смысловые отношения между понятиями. Классификационные языки предназначены, прежде всего, для формализации логических связей слов естественного языка.
Все ИПМ классификационного типа характеризуются определенными свойствами, прежде всего, невысокой эффективностью и некоторыми трудностями при информационном поиске, особенно с применением технических средств. К этим недостаткам относятся: предварительная координация (связь) слов и словосочетаний в рубрике, практическая невозможность полного и детального разработки схемы классификации и подключение ее к АБИС, сложность обновления и дополнения, трудоемкость использования при индексировании.
Все эти недостатки побудили к созданию языков вербального типа. Их используют для представления лексических единиц слова и выражения естественного языка в орфографические форме. В отличие от классификационных языков, используемых для систематизации документов, они ориентированы на обозначение в поисковом образе документа (ПОД) или в поисковом образе запроса (ПОЗ) конкретных объектов или предметов содержания этих документов.
К языкам вербального типа относятся предметизационный дескрипторный языки, которые используют предметные рубрики и ключевые слова при наличии неконтролируемой лексики.
Язык предметизации предназначен для индексирования документов и информационных запросов с помощью рубрикаторов (словарей предметных рубрик), а в случае их отсутствия - по методике предметизации. В основе лежит алфавитный перечень предметных рубрик (ПР), который является краткой формулировкой темы на естественном языке. Важнейшим этапом предметизации является идентификация признаков содержания документа с предметными рубриками. Предметная рубрика выполняет информационную, эвристическую, комплектующую и терминологическую функции.
Основными требованиями к формированию ПР являются лаконичность вместе с полным и точным раскрытием содержания документа, а также простота, которая способствует поиску необходимых документов. Особенностью формулировки предметных рубрик является то, что лексика ИПМ предметных рубрик должна быть максимально приближенной к языку автора документа. Однако, с развитием науки, практической деятельности людей, с изменениями информационных потребностей пользователей и т.д. она может изменяться, дополняться новыми и избавляться от устаревших лексических единиц, изменять свою структуру.
Как искусственная система язык предметизации должен быть построен стандартно, предельно однообразно. Это помогает читателю сэкономить время и силы при поиске. Практика работы ГНСХБ УААН доказывает, что пользователи чаще заинтересованы вести поиск не по классификационным системами, а по запросам тематического, предметного характера. При этом предметные рубрики менее популярны, чем ключевые слова, потому что в библиотеках нет единой системы предметизации, отсутствует универсальный словарь предметных рубрик, пользователи не владеют методикой предметизации, что усложняет формулировку ПОЗ, адекватного поисковом образа документа. Не во всех ЭК реализуется доступ пользователей к внутренним словарям предметных рубрик. Вместе предметные рубрики непригодны для глубокого, достоверного поиска по теме в машиночитаемых библиографических базах данных.
Некоторые темы документа могут не охватываться ПР. Особенно это касается научных сборников, материалы конференций, симпозиумов и т.п., где встречаются статьи и доклады, которые лишь отдаленно пересекаются с основной тематикой сборника, но представляют интерес для пользователей конкретной библиотеки. Вероятнее всего, такие побочные (непрофильные) темы не будут отражены ни классификационными индексами, ни ПР, но могут быть описаны ключевые слова (КС).
Ключевые слова - это нормализованный ИПЯ; слова записываются в соответствии с правилами, разработанных для ИПС. При выборе сроков и обработки их для введения в усовершенствованный информационный документ разрабатываются и принимаются решения по методике индексирования документов различной тематики.
Ключевые слова целесообразно использовать для дополнительного раскрытия содержания документа на более глубоком уровне, то есть использовать ПР для описания основных предметов документа и их аспектов, а КС - для дальнейшей детализации, а также описания побочных тем документа. Тогда в ПОД будут содержаться ПР (нормализованная лексика) и КС в редакции автора. Такой подход удобен для всех категорий пользователей: как для тех, кто примерно знает, что хочет найти (для этого удобно использовать ПР), так и для тех, кого может заинтересовать очень специфическое (поиск происходит при КС).Особую ценность список КС может приобрести на последнем этапе поиска, когда по запросу найдено определенный массив документов. Просмотрев списки КС, можно, даже не просматривая источники, сразу определить нужную информацию. Таким образом, использование КС увеличивает поисковые возможности ЭК.
Ключевые слова следует рассматривать как дополнительное средство увеличения полноты индексирования и представления разных по значимости тем документа, не описанных другими ИПМ. Вот почему целесообразно расширить возможности тематического поиска с помощью подключения к КС, которые для пользователей является наиболее понятным средством розыска большого количества релевантных документов.
Дескрипторный язык служит для координатного индексирования документов и запросов с помощью тезауруса (словаря дескрипторов) или определением ключевых слов с использованием естественного языка. В основу дескрипторных ИПМ положен алфавитный перечень лексических единиц. Комплекс ключевых слов является своего рода лексической моделью научного текста. Функциональная значимость КС определяется тем, что они являются одним из наиболее оптимальных способов классификации, хранения и передачи информации. Отражая развитие и терминодинамику определенной научной отрасли, комплекс КС является еще и системой отбора и распространения современной терминологии.
Следовательно, каждая из указанных ИПМ имеет свои преимущества и недостатки.
Любая из указанных выше ИПМ обязательно функционирует в определенной информационно-поисковой системе, представленной как в традиционном, так и в автоматизированном режимах.
Традиционная ИПС - это совокупность каталогов и картотек на бумажных носителях, автоматизированная - электронный каталог. Собственно каталоги и картотеки и являются теми навигационными "ступеньками", с помощью которых читатель открывает все богатство библиотечных фондов, ориентируется в тематическом разнообразии документального потока в разные исторические периоды существования библиотеки.
На сегодня все больше библиотек сельскохозяйственной сети создают электронные каталоги, базы данных (БД) и перед ними встает вопрос о выборе лингвистического обеспечения для них. Во многом выбор ЛС зависит от того, какие информационно-поисковые языки использовались в этих библиотеках для карточных каталогов. Как правило, именно их приспосабливают для электронных каталогов и БД. Это обусловлено тем, что новые ИПМ требуют обучения индексаторов, а также трудоемкостью создания ИПМ и желанием сохранить пользовательские связь традиционных и электронных каталогов. В основном в сельскохозяйственных библиотеках для карточных каталогов используются ИПМ классификационного типа: УДК и ББК. [65, C. 14-15].
С 2000 г. в ГНСХБ УААН наряду с традиционными каталогами и картотеками ведется электронный каталог. Как для карточного каталога, так для ЭК используются своя собственная классификация - Отраслевой предметный рубрикатор по сельскому и лесному хозяйству (ГПР), разработанный на основе списка рубрик предметного каталога ГНСХБ. Он создавался на протяжении многих лет и сейчас является основным методическим и рабочим инструментом систематизаторов сектора.
Выбор лингвистического обеспечения библиотеки определяется задачами ее информационно-поисковой системы и информационными ресурсами, а также запросами ее пользователей. Именно их разнообразные потребности необходимо учитывать, планируя и создавая ЛС. ГНСХБ УААН использует как лингвистические средства несколько ИПМ параллельно. Это способствует быстрому и широкому доступу пользователей к информации наиболее известной им на информационно-поисковом языке.
Для расширения возможностей поиска в ЭК библиотеки применяется предметный поиск, который является междисциплинарным, межотраслевым и комплексным. По такому запросу пользователи получают комплекс всех документов по предмету, проблемы, темы независимо от отраслей знаний, к которым относятся все эти документы. Основой для создания языка предметных рубрик стал перечень рубрик алфавитно-предметного указателя (АПП) в Список рубрик предметного каталога ГНСХБ УААН и Государственный стандарт Украины ГСТУ 25395-2000 (ISO 5963:1985) «Информация и документация. Обследование документа, установление его предмета и отбор терминов индексирования. Общая методика». [68]
Разнообразие информационно-поисковых языков, которые составляют структуру лингвистических средств, объясняется типо-видовым разнообразием и тематической сложностью входного документного потока, традициями и особенностями Государственной научной сельскохозяйственной библиотеки, навыками работников и запросами пользователей библиотеки, а также тем, что ни одна из современных ИПМ не может в полном объеме обеспечить полноту и эффективность поиска релевантной информации.
Комплексное применение ИПМ позволяет:
• наиболее полно осуществлять обработку политематической входного документного потока библиотеки для ввода его в БД;
• обеспечить точность информационного поиска;
• удовлетворять требованиям сортировки массивов документов при создании различной исходной продукции, в т ч. текущих изданий;
• выполнять формально-логический контроль рубрик документов, которые вводятся.
Для этого выявляются дублирующие или избыточные (неработающие) рубрики; проводится сравнительный анализ части рубрик ГПР с целью устранения многоаспектности, дублирование рубрик, унификации наименований; уточняется справочно-ссылочный аппарат, редактируются наименования рубрик, примечания.
С включением в фонд и аналитико-синтетическую обработку документов новой тематики (например, "Нанотехнологии", "Интеллектуальная собственность", "Экономические нормативы") создаются новые ПР, для которых разрабатываются схемы, создается ссылочной-справочный аппарат, приписываются комментарии и примечания. Затем этот раздел включается в машинный ГПР ЭК.
Ведутся подготовительные работы по организации Отраслевого тезауруса (ГТ): проводится отбор массива лексических единиц (ЛЕ) по всему диапазону входного потока БД, формируется словарь ОТ. Отбор ЛЕ осуществляется специалистами в ходе аналитико-синтетического обработки документов. ЛЕ поступают сначала в карточную картотеку и используются некоторое время как ключевые слова. Работа над ними состоит из нескольких этапов:
1. мониторинг на частотность появления терминов в документах;
2. согласование со специалистами,
3. проверка в справочниках и тезаурусах, а также в зарубежных БД.
Впоследствии:
1. проводится лингвистическая обработка;
2. редакция;
3. происходит построение статьи термина-дескриптора;
4. проводится сверка с электронной рубрикой.
Все эти процессы позволяют выявлять ошибки индексирования и ввода информации в Отраслевой тезаурус. [70, C. 55-57]
В связи с отсутствием в Украине единого научно-исследовательского, научно-методического и информационного центра по разработке и ведению лингвистических средств, библиотеки на практике сталкиваются с рядом сложных проблем не решенных на теоретическом уровне. Это, например, выбор ИПЯ. При организации электронного каталога неизбежно возникает вопрос: каким ИПЯ воспользоваться для раскрытия предметного содержания документа: языком предметных рубрик, языком ключевых слов или их сочетанием?
Несмотря на принципиальные различия этих языков, практика их применения осложняется из-за нерешенных проблем. Ни в теории предметизации, ни в теории координатного индексирования нет четких рекомендаций относительно выбора таких параметров, как длина лексической единицы (слово или словосочетание), постоянство словосочетаний, прямой или инверсированный порядок приведения ЛЕ в словосочетаниях т.д. На практике это влечет за собой невозможность сравнения результатов семантической обработки документов и запросов, снижает показатели полноты и точности информационного поиска.
Проблема нормализации лексических единиц усиливается из-за того, что на практике нет средств контроля лексики, в равной мере доступных всем библиотекам. Отсутствие информационно-поискового тезауруса, который бы поддерживался в рабочем состоянии, был пригоден для пополнения и внесения изменений, причем учитывал отраслевую специфику, существенно осложняет процесс координатного индексирования, а отдельные попытки их создания не решают этих проблем.
Таким образом, определенность в подходах при решении проблем, первые шаги к координации усилий библиотек разных систем и ведомств дают надежду на более активные действия. Надо понимать, что каждая идея интеграции предусматривает необходимость строгого соблюдения стандартов. Стандарты при интеграции библиотечно-информационных ресурсов содержат правила предъявления библиографических записей и правил взаимодействия библиотек при обмене записями.
При создании единой информационно-библиографической среды следует учитывать ряд условий, а именно:
• полная совместимость с международными форматами UNIMARC и UKRMARC на основе использования средств импорта / экспорта данных;
• разработка технологии доступа с использованием WEB-технологий в объединенных ресурсов библиотек - участниц корпоративной системы каталогизации;
• разработка технологии доступа с использованием протокола Z39.50 к объединенным ресурсам библиотек;
• разработка технологии пополнения объединенных ресурсов библиотек-участниц корпоративной системы каталогизации;
• создание возможности для совместной работы библиотек - участниц региональной системы с библиотекой государственного уровня;
• вопросы обеспечения форматной и лингвистической совместимости библиографических записей партнеров.
Кроме того, необходимо решать вопросы технического обеспечения (приобретение, тестирование и установка оборудования; поддержка системы связи между участниками проекта), а также вопросы подготовки кадров в виде мероприятий по обучению разработанным новым технологиям персонала библиотек-участниц, проведения оперативного консультирования. [67, C. 32-35].
Единое ЛО сельскохозяйственных БД позволит создать единое информационное пространство отрасли. Наличие предметного рубрикатора, разработанного на основе Государственного рубрикатора научно-технической информации, который используется в отраслевых библиотеках, УДК и в дальнейшем Отраслевого тезауруса позволит улучшить качество индексирования документов, облегчит поиск в отраслевых БД.
Согласно плану научной работы сектора и фундаментальной научной темы исследования библиотеки "Научные основы совершенствования информационно-библиотечного обеспечения аграрной отрасли" (№ гос. Регистрации 107U003106), утвержденной Экспертным советом при УААН (решение № 3 от 20.03.08 г.) ГНСХБ УААН проводит информационную научно-методическую работу с библиотеками области, организует семинары, курсы повышения квалификации по вопросам индексирования и работы с ИПЯ. В рамках этих мероприятий была разработана Инструкция "О порядке формирования предметных рубрик ЭК ДНСХБ УААН". В системе повышения квалификации работников сети все большую актуальность приобретает проблема расширения общей лингвистической (относительно информационно-поисковых языков) культуры библиотекарей, в том числе путем привлечения специалистов для проведения занятий по УДК. Это способствует профессиональному становлению библиотекаря качественно новой формации, для которого свободная ориентация в ресурсах глобальных сетей является неотъемлемым элементом профессиональной квалификации.
Это сложная и трудоемкая работа может быть решена только коллективными усилиями. Только объединение библиотек сделает возможным создание библиотеки нового типа, которая бы соответствовала международному модельному стандарту деятельности и формировала новый взгляд общества на современное культурно-информационное учреждение.
Работники ГНСХБ надеются что библиотеки области также примут участие в разработке статей тезауруса или в отборе лексики для него. Такая кооперация поможет не только созданию единого ЛО, единого информационного пространства, не только сократит финансовые затраты библиотек на разработку собственного ЛО, но и поможет повысить уровень индексирования документов по сельскому и лесному хозяйству.
Глава 2. Структура лингвистических средств Белорусской сельскохозяйственной библиотеки им. И. С. Лупиновича Национальной академии наук Беларуси.
Успешное функционирование современной научной библиотеки во многом зависит от автоматизации библиотечных процессов. Для БелСХБ внедрение системы автоматизации библиотек ИРБИС в 1995 году предоставило огромные возможности для эффективной работы библиотеки и качественного обслуживания пользователей.
До внедрения ИРБИС в библиотеке использовалась АИБС МАРК, в которой были созданы два электронных каталога: книг и статей. Одновременно поддерживались все традиционные библиотечные технологии: читательские формуляры, ручные каталоги и картотеки и т. п.
Внедрив ИРБИС, библиотека прекратила вести карточные каталоги и картотеки и был создан единый электронный каталог, в котором представлены сведения о книгах, журналах, статьях, БД и др. Встроенные в ИРБИС внутренние словари и меню-справочники, формально-логический контроль части данных, а также автоматическая сверка на дублетность повысили качество электронного каталога. Т. к. система предложила большой выбор полей при описании документа, библиографическая запись стала более информативной. Автоматическое формирование словарей по мере ввода записей позволило реализовать быстрый поиск по всем элементам описания и их сочетаниям.
Работа в ИРБИС повлекла изменения и в обслуживании пользователей: была создана БД читателей, внедрена технология автоматического формирования заказа на выдачу документов в электронном каталоге и технология автоматического учета выдачи/возврата документов. АРМ «Читатель» обеспечил свободный доступ пользователя к электронному каталогу без участия библиотекаря.
Внедрение системы создало предпосылки для организации открытого доступа пользователей к наиболее ценной и часто спрашиваемой части фонда БелСХБ с пометкой в электронном каталоге о местонахождении документа.
Внедрение системы автоматизации библиотек «ИРБИС» позволило расширить набор лингвистических средств в БелСХБ.
Библиотека одной из первых приобрела БД УДК, которая используется как автономно, так и встроенной в АРМ Каталогизатор в виде АПУ к УДК и БД УДК. В связи с тем, что в электронном каталоге поиск по линейному индексу невозможен, принято решение поисковый образ документа записывать простыми индексами УДК без знаков присоединения, т. е. координатами. В этом случае поиск записей по УДК ведется аналогично поиску по ключевым словам с использованием возможностей автоматизированной системы (логические операторы, усечение индексов справа и т. д.).
В библиотеке используется БД УДК на CD-ROM. Она является полным электронным изданием таблиц УДК и распространяется ГПНТБ России на основании лицензии ВИНИТИ. БД представлена в поисковом интерфейсе системы автоматизации библиотек ИРБИС. Каждая запись БД содержит индекс, наименование рубрики, ссылки и методические указания. Поиск в БД может быть осуществлен как по графу на полную глубину, так и по индексам отдельных таблиц и по ключевым словам. Интерфейс снабжен удобными средствами отбора индексов и построения конкретных индексов с последующим их переносом в библиографическую запись, созданную при помощи любой АБИС.
Крупным шагом в совершенствовании поискового образа документа ЭК БелСХБ стало внедрение в процесс индексирования Информационно-поискового тезауруса по сельскому хозяйству и продовольствию, созданного ЦНСХБ в 2002 г. Основным назначением электронной версии информационно-поискового тезауруса (ИПТ) научно-технических терминов по сельскому хозяйству является смысловая обработка документов и запросов для машинного поиска информации. ИПТ является отраслевым тезаурусом, в котором достаточно полно представлена лексика всех тематических разделов рубрики 68 (сельское и лесное хозяйство) Рубрикатора ГРНТИ, 65 (пищевая промышленность), а также с разной степенью охвата другие тематические разделы в части сельского хозяйства, пищевой и перерабатывающей промышленности.
ИПТ постоянно обновляется и корректируется. Выявление и отбор терминологии проводится при индексировании документов по сельскохозяйственной тематике. В основу отбора терминов положены следующие критерии:
– частота появления термина в индексируемых документах и информационных запросах,
– полезность его для поиска информации,
– наличие в терминологических стандартах,
– точность и однозначность термина,
– краткость и понятность его.
Отобранная терминология редактируется и дополняется терминами из различных справочных изданий (сельскохозяйственной энциклопедии, ветеринарной энциклопедии, ветеринарного энциклопедического словаря, терминологических словарей, учебников, монографий, справочников, ГОСТов).
Отобранные и отредактированные термины (лексические единицы) объединяются в классы условной эквивалентности с последующим делением на дескрипторы и аскрипторы.
Далее описываются средства лингвистического обеспечения БелСХБ (Информационно-поисковый тезаурус по сельскому хозяйству и продовольствию
и БД УДК
), т. к. они наиболее широко используются в библиотеках АПК.
2.1. База данных УДК и ее применение в качестве информационно-поискового языка.
Универсальная десятичная классификация
(УДК) – наиболее разработанная международная комбинационная иерархическая классификационная система, которая широко используется во всем мире для индексирования различных видов документов, организации как традиционных, так и электронных каталогов, для поиска документов в информационно-поисковых системах.
УДК отвечает наиболее существенным требованиям, предъявляемым к классификационным системам: международности, универсальности, мнемоничности, возможности отражения новых достижений науки и техники без каких-либо серьезных изменений в ее структуре. В УДК весь универсум информации (все зарегистрированные знания) рассматривается в качестве целостной системы, все разделы которой органично связаны между собой.
Универсальная десятичная классификация является весьма гибкой и эффективной системой для организации библиографических записей на все виды информации на любых носителях. УДК построена таким образом, что новые события и новые области знания могут быть легко в ней учтены. Сам код не зависит от какого-либо конкретного языка (он состоит из арабских цифр и часто используемых знаков препинания).
Широкое использование УДК в качестве международной классификационной системы определяется ее технологическими свойствами: комбинационной структурой, развитой системой типизации, удобной индексацией. Возможности УДК как комбинационной системы заключаются в том, что она имеет развитую систему общих и специальных определителей.
Универсальная десятичная классификация является основой систематизации накопленных человечеством знаний в библиотеках, базах данных и других хранилищах информации. Она принята для индексирования научно-технических документов в большинстве стран мира и была опубликована в целом или частично на 39 различных языках. На английском языке она широко используется как в англоязычных странах, так и в тех, где английский является одним из официальных и рабочих языков (Британские острова, Канада, Австралия, Новая Зеландия, Индия, ряд африканских стран). Печатные издания существуют в размере карманных изданий (например, французское, английское издания), в стандартной версии (например, испанское, французское, английское издания) или расширенной версии (например, русское издание). Существуют и электронные версии, также доступные на разных языках и в различных форматах.
В России УДК является обязательным реквизитом всей книжной продукции и информации по естественным и техническим наукам.
В нашей стране Универсальная десятичная классификация используется в качестве классификационной системы при организации справочно-информационных фондов и каталогов в органах научно-технической информации, научных, специальных и технических библиотеках, Национальной книжной палате, издательствах, в библиотеках высших учебных заведений технического, сельскохозяйственного и медицинского профиля.
Машиночитаемый эталон УДК
Одним из первых мероприятий Консорциума УДК, созданного для развития и совершенствования Универсальной десятичной классификации на современном этапе, стало создание международной базы данных, которая могла стать основой для всех изданий УДК – это машиночитаемый эталон УДК (Master Reference File – MRF).
MRF представляет собой базу данных, которая содержит таблицы УДК вместе с отчетами, необходимыми для управления, обслуживания и архивирования. Он содержит окончательную утвержденную версию УДК и функционирует в качестве рабочего инструмента для Консорциума УДК (УДКК), который создал и ведет базу данных для управления содержанием УДК, для определения потребностей и приоритетов для изменений, а также для того, чтобы отслеживать все изменения во времени.
Дубликат базы данных используется для регулярного технического обслуживания и обновления в течение года. После завершения он используется для создания нового MRF каждый год (в период декабрь / январь). Новая версия MRF, содержащая изменения за этот год, используется для распространения среди членов Консорциума и держателей лицензии.
Пользователи – не издатели – могут также воспользоваться прямым доступом к MRF, независимо от того, для каких целей им это необходимо: классификации, научных исследований или для других целей.
Консорциум УДК разрешает доступ (по лицензии) к базе данных MRF, с тем чтобы способствовать созданию различных программных приложений, направленных на отображения и обработку таблиц УДК, или использовать их в других приложениях. УДКК всегда готов обсудить такие случаи и готов вести переговоры для активного сотрудничества.
База данных MRF была разработана с помощью программного пакета ЮНЕСКО CDS/ISIS, который поддерживает международные стандарты обмена библиографическими данными в формате ИСО-2709. CDS/ISIS является международно-признанной информационно-поисковой программой, очень популярной из-за ее низкой стоимости, стабильности и адаптивности. Хотя у нее нет особых требований, когда дело доходит до компьютерной обработки и памяти, она способна обработать большое количество данных и имеет очень надежный поиск и сортировку объектов. Кроме того, программа доступна для разных платформ (DOS, Windows, UNIX) и постоянно совершенствуется.
Данные из MRF могут быть экспортированы как в формате ИСО-2709, так и в формате обычного текста, а также могут быть использованы в любом другом ИСО-2709-совместимом приложении или дополнительно отформатированы для печати, издательских целей и др.
По соображениям эффективности (с точки зрения затрат и времени) размер MRF-базы ограничивается приблизительно размером средних изданий УДК, какими они были известны до начала 1990-х годов.
База данных MRF потенциально может быть многоязычной, но в настоящее время распространяется только на английском языке, хотя с конца 1980-х годов существуют неполные версии на немецком и французском языках. Английский остается рабочим языком Консорциума.
Каждый индекс УДК в базе данных MRF, включая основные и вспомогательные определители, проходит в отдельном отчете. Каждый кусок данных, имеющих отношение к индексу УДК, его значению, регистрации, отображения, источнику или применению, вводится в отдельном поле (поля в CDS/ISIS не ограничены, и длина каждой области может составлять, где это необходимо, несколько подполей). Одна запись в MRF состоит из 30 областей, сгруппированных в две категории. Первые двадцать полей носят описательный характер и отражают фактическое содержание этих индексов УДК, остальные десять – это административные данные, которые содержат информацию, имеющую отношение к обслуживанию базы данных.
Есть три базы данных, содержащие записи MRF:
1) MRF - содержит наиболее актуальную версию машиночитаемого эталона, включая самые последние официально разрешенные дополнения и другие изменения, за исключением аннулирований. Эта база данных постоянно обновляется, но не распространяются, за исключением особых случаев. MRF является основной базой данных и используется для поддержания текущего состояния.
2) MRFCAN – содержит аннулированные индексы. В настоящее время эта база содержит все официально санкционированные отмененные после 1993 года индексы. Каждая запись содержит административные данные с указанием даты и источника списания (например, номер «Дополнений и исправлений к УДК», в которых публикуются аннулирования).
UMRF – распределенная версия MRF, которая состоит из записей, экспортируемых из главных базы данных без административных областей. Каждый год, вскоре после публикации «Дополнений и исправлений к УДК» и обновления MRF, версии UMRF «замораживается» и распространяется среди подписчиков. Эти «замороженные» версии существуют за каждый год с 1993 года.
Master Reference File
Master Reference File сохраняется в штаб-квартире Консорциума УДК в Королевской библиотеке в Гааге. Он обновляется один раз в год в декабре/январе, включая изменения и поправки, опубликованные в «Дополнениях и исправлениях к УДК», как правило, опубликованных в ноябре прошлого года в печатном виде (и в электронной форме, начиная с 2002 года). В дополнение к обновленной базе данных MRF каждому пользователю предоставляются отдельные файлы (как текстовые, так и ИСО), содержащие новые индексы, изменения и замены, которые уже включены в текущую версию на этот год. Инструкции по редактированию и управлению базой данных также включены. Руководство по применению Master Reference File, называемое «Руководство к MRF», является бесплатным для всех членов Консорциума и держателей лицензии.
База данных в своей последней модификации в 2007 году содержит 67770 индексов УДК и имеет размер около 15000 килобайт. Распределение записей в соответствии с разделом и предметными областями выглядит следующим образом (обновлено в июле 2008 года):
Индекс Описание (сокращенное) Количество в УДК
Ia/к Общие вспомогательные 12993
в том числе:
Ic Язык 1364
Id Форма 362
Ie Место 9384
If Этнические 33
Ig Время 284
Ik Свойства 805
Ik Материалы 152
Ik Процессы 333
Ik Лица 267
Основная таблица 54777
в том числе:
0 Общий отдел ... 1800
1 Философия. Психология 824
2 Религия 2419
3 Общественные науки 6813
в том числе:
30/32 Общественные науки в целом. Статистика.
Социология. Демография. Политика 962
33 Экономика 2004
34 Право 1826
35 Государственное управление… 1010
36 Общественное благосостояние 581
37 Образование 234
39 Фольклор. Этнографии 194
5 Математика. Естественные науки 11176
в том числе:
50 Науки об окружающей среде 49
51 Математика 1033
52 Астрономия 625
53 Физика 1846
54 Химия. Минералогические науки 3305
55 Науки о Земле 1497
56/59 Палеонтологии. Биологические науки 2820
6 Прикладные науки. Медицина. Техника 27486
в том числе:
61 Медицинские науки 3170
62/621.2 Техника в целом. Тепловые двигатели.
Гидравлика 1575
621.3 Электротехника 1698
621.4/.6 Тепловые двигатели. Пневмоэнергетика.
Обработка жидкостей 477
621.7/.9 Механическая техника 1486
622 Горное дело 679
623 Военная техника 618
624/627 Строительная техника 1522
628 Санитарная техника 628
629 Техника транспортных средств 1779
63 Сельскохозяйственные науки 2273
64 Экономика 718
65 Управление и организация промышленности 1387
66 Химические науки 4455
67/68 Различные отрасли промышленности и ремесел 4576
69 Строительство 705
7 Искусство. Отдых. Развлечения. Спорт 2596
8 Языки. Языкознание. Литература 616
9 География. Биографии. История 435 [56, 60, html]
Всероссийский институт научной и технической информации Российской академии наук поддерживает электронную базу данных УДК на русском языке, основанную на полной печатной версии УДК на русском языке (4-е полное издание в 10-ти томах). Она создана Ассоциацией ЭБНИТ на основании договора с ВИНИТИ РАН.
Преимущества БД УДК.
База данных УДК обладает несколькими явными преимуществами перед печатными таблицами:
1. БД является полным электронным изданием таблиц УДК. Благодаря этому решилась проблема, связанная с приобретением печатных таблиц – в них отпала необходимость. БД ежегодно актуализируется. Кроме этого, опечатки и ошибки, которые встречаются в классификации, оперативно исправляются, чего не скажешь о печатных таблицах, в которых ошибки будут исправлены в последующих изданиях
2. БД УДК – автономный продукт, который устанавливается на рабочий стол неограниченного количества компьютеров.
3. Поскольку Международный Консорциум УДК старается поддерживать состав классификационных таблиц в актуальном состоянии, в УДК постоянно вносятся изменения и дополнения, отследить которые сложно. На сегодняшний день ВИНИТИ издано 9 томов основных таблиц и к ним уже 4 выпуска «Изменений и дополнений». База данных предлагает новое решение - поиск по всем исключенным индексам, где представлены не только год и причина исключения индекса, но и заменяющие индексы. Отсутствие указания причины означает «исключен как излишний». Этим обеспечивается существенное упрощение процессов реклассификации систематических каталогов и переиндексирования документов, отраженных в ЭК.
4. БД снабжена удобными средствами отбора и построения конкретных индексов с последующим их переносом в библиографическое описание любой автоматизированной системы.
5. И, наконец, использование БД УДК произвольно: ее можно выставить в подразделениях библиотеки, на кафедры, в пользовательскую зону. Одновременно с ней может работать неограниченное количество пользователей.
База данных УДК представлена в поисковом интерфейсе Системы автоматизации библиотек ИРБИС. Поиск в базе данных может быть осуществлен как по графу на полную глубину с возможностью использования ссылочного аппарата, так и по индексам отдельных таблиц и по ключевым словам. Интерфейс снабжен удобными средствами отбора индексов и построения конкретных индексов с последующим их переносом в библиографическое описание, создаваемое при помощи любой автоматизированной библиотечно-информационной системы.
Представляемая БД УДК в настоящее время соответствует Российскому эталону таблиц УДК по его состоянию на 2008г. (учтены «Изменения и дополнения», вып. 1-4):
- переведены в состояние пассивных записи словарных статей (ЗСС) общих определителей .00 (как исключенных из таблиц), а также тех ЗСС, заглавные индексы которых включали .00;
- ликвидированы соответствующие элементы справочно-ссылочного аппарата;
- включены записи словарных статей новых общих определителей -02 Свойства, -04 Отношения, процессы и операции;
- дан в новой редакции раздел 2 Религия;
- в значительной мере переработаны ЗСС разделов 0, 1, 3, 5, 61, 6/621, 622/629, 63/65, 66, 67/69, а также записи общих определителей.
Следует обратить внимание, что в базе данных УДК представлены два типа записей словарных статей - активные (действующие) ЗСС и пассивные ЗСС, т.е. записи тех словарных статей, которые исключены из таблиц УДК и, следовательно, не подлежат применению при индексировании документов.
Каждая пассивная словарная статья содержит свой заглавный индекс, год исключения и его причины (отсутствие указания причины означает "исключен как излишний"), заменяющие индексы (при их наличии), а также может содержать данные ее бывшего активного состояния.
Особенности поиска.
В настоящей редакции базы данных (в отличие от предыдущих редакций) объектами поиска могут быть не только активные записи словарных статей, но и пассивные ЗСС (этим обеспечивается существенное упрощение процессов реклассификации рабочих систематических каталогов и переиндексирования документов, отраженных в электронных каталогах).
Активная ЗСС, кроме своих обязательных элементов данных - заглавного индекса и рубрики, может содержать:
- расширение заглавной рубрики;
- надрубрику (в случае десемантизированности заглавной рубрики);
- ссылки (См. также), отсылки (См.), обратные отсылки (Отс. от), смежные области, области применения и методические указания.
При индексировании документов и запросов предусмотрен поиск по базе данных УДК.
Цель поиска - найти совокупность табличных индексов (заглавных индексов активных записей словарных статей), каждый из которых необходим, а все они вместе достаточны для составления на языке УДК полного и точного поискового образа данного сообщения.
В случае документа итогом индексирования является поисковый образ документа (ПОД), в случае запроса - поисковое предписание (ПП).
Так как в общем случае содержание сообщения является тематически сложно-составным, то для упрощения общей задачи индексирования рекомендуется предварительно разбить исходное политематическое сообщение на монотематические части.
При работе с политематическим документом получается несколько тематических блоков, из которых затем формируется полный ПОД (как цепочка тематических блоков).
При работе с политематическим запросом получается несколько монотематических поисковых предписаний. При этом поиск в документальной БД может быть произведен по каждому из этих ПП в отдельности либо по их логической сумме.
Предусмотрены 2 стратегии поиска - стратегия «сверху-вниз» (на плоскости «Граф УДК») и стратегия «прямого доступа» («Плоскость поиска»).
Первая основывается на представимости иерархических классификаций ориентированными (вниз от корневой вершины) графами типа «сеть», на возможности экранной индикации таких графов и на возможности перемещения от вершины к вершине по ориентированным ребрам (и обратно).

Для реализации ссылочно-отсылочного аппарата пары соответствующих вершин сети связываются дополнительными ребрами:
- обоюдонаправленными в случае ссылок (См. также) и
- односторонне направленными в случае отсылок (См.) и обратных отсылок (Отс. от).
Поисковое движение по такому графу начинается сверху, т.е. от корневой вершины и продолжается вниз (в соответствии с принятыми делениями классов и с результатами смысловой идентификации классов на очередных уровнях графа с рассматриваемой темой сообщения) с возможным переключением по ссылкам и отсылкам на другие ветви графа. Раскрытие того или иного раздела - на кнопке «Содержание записи»
По мере достижения классов, которые достаточно полно и точно соответствуют данной теме, производится их отмечание с целью отбора индексов этих классов и построения по ним соответствующего поискового образа документов или поискового предписания (экранное окно "Конструктор").
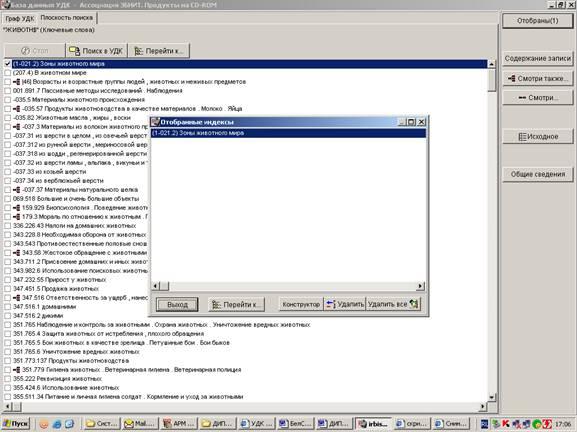
Затем отобранный индекс копируется и вставляется в библиографическое описание документа в АРМе «Каталогизатор» САБ ИРБИС.

Т.е. интерфейс снабжен удобными средствами отбора и построения конкретных индексов с последующим их переносом в библиографическое описание, создаваемое при помощи любой автоматизированной системы.
Подробная инструкция о структуре БД УДК и ее текущем состоянии размещена на кнопке «Общие сведения». Здесь же даны подробные методические указания по применению общих и специальных определителей, знаков УДК и примеры.
Кнопка «Исходное» - возвращает нас в исходное положение на плоскости Граф УДК.
Стратегия «прямого доступа» ориентирована главным образом на использование ключевых словоформ в качестве элементов логических формул поиска в БД требуемых записей словарных статей.
На этой плоскости предоставляется возможность использования логических операторов, возможность проведения поиска с усечением и без него, возможность комбинирования отработанных и новых запросов.
Здесь обеспечен ключевой режим поиска – по ключевым словам, по индексам основных и вспомогательных таблиц, по исключенным индексам.
Словарь ключевых слов формируется из отдельных слов предметных рубрик УДК:
1) словарь «Основные таблицы» – из индексов УДК основных таблиц;
2) девять словарей общих определителей – из индексов УДК вспомогательных таблиц общих определителей;
3) словарь «Исключенные индексы» представляет данные об исключенных индексах. Поиск пассивных записей словарных статей (данных об исключенных индексах) может производиться только по индексам, выбираемым из словаря.
2.2. Тезаурус по сельскому хозяйству и продовольствию.
2.2.1. Назначение и структура тезауруса.
Слово «тезаурус»
в переводе с греческого означает «сокровищница». Первые тезаурусы были разработаны в начале 60-х годов. Тезаурусы, используемые для информационного поиска, называют информационно-поисковыми (ИПТ).
Тезаурус является лексическим инструментом ИПС и представляет собой контролируемый, но изменяемый словарь терминов-дескрипторов и недескрипторов (аскрипторов), упорядоченных по систематическому и алфавитному принципам с указанием на смысловые связи между ними иерархического и неиерархического чипа (парадигматические отношения). Разработанный ИПТ должен исчерпывающим образом покрывать определенную область знаний, отражаемую входным потоком документов.
Сложность построения ИПТ общеизвестна. Несмотря на существование методических разработок отдельных его аспектов, каждый случай в целом требует особого решения. Это обусловлено разнообразием тематических областей и задачами поиска в конкретной БД.
БД ЛГРОС не является узкоспециализированной, она включает документальные массивы широкого тематического диапазона и ориентирована при этом на обслуживание достаточно детальных запросов пользователей. Это предопределяет состав и объем лексики ИПТ, его парадигматический аппарат, широту и глубину смыслового анализа и описания документов, т. е. методические принципы индексирования. В частности, использование в ИПС ЦНСХБ дескрипторного языка без грамматики требует достаточно высокой координации лексики. Отчасти это достигается включением в тезаурус значительного количества сложных терминов в виде словосочетаний. Однако, чтобы избежать ложной координации с другими терминами терминов типа КАЧЕСТВО, пришлось бы включить в тезаурус очень большое количество соответствующих словосочетаний (КАЧЕСТВО МЕДА, КАЧЕСТВО СКОРЛУПЫ, КАЧЕСТВО ТАБАКА и т. п.).
Принимая то или другое решение в отношении построения тезауруса и, следовательно, логики индексирования, следует учитывать все возможности поисковой системы, в том числе, поиск по текстовым полям и по ключевым словам. Термины, отвечающие задачам узкого детального поиска, индексатор может ввести в ПОД в качестве ключевых слов (КАЧЕСТВО ЯИЦ, КАЧЕСТВО МЕХА и т. п.), кроме того, они могут присутствовать в тексте заглавия, аннотации, реферата. В тезаурус же вводятся частотные термины-словосочетания - КАЧЕСТВО ПРОДУКТОВ ПИТАНИЯ; КАЧЕСТВО ЗЕРНА; КАЧЕСТВО СЕМЯН; КАЧЕСТВО С-Х ПРОДУКЦИИ и общий термин КАЧЕСТВО для индексирования других понятий.
Системный подход к построению ИНГ предъявляет определенные требования к составу и квалификации группы разработчиков тезауруса, действия которых должны быть четко координированными. В идеале, каждый разработчик должен быть не только специалистом в данной области, но и как создатель информационного языка специалистом по документальному поиску. Другими словами, разработчик тезауруса должен уметь не только отразить в ПОД содержание документа, но и сформулировать поисковое предписание, чтобы найти этот документ в БД.
ИПТ создается для повышения качества поиска в ИПС 11,11СХБ. В его функции входит:
- обеспечение индексирования документов и запросов средствами дескрипториого языка;
- отражение парадигматических отношений (отношения общности или противопоставления значений и использования), существующих между ЛЕ;
- контроль и нормализация лексики по сельскому хозяйству и продовольствию;
- обеспечение единого и формализованного представления информации в ИПС;
- функция терминологического справочного пособия в области сельского хозяйства и продовольствия;
- формально-логический контроль терминов индексирования;
- автоматизированное расширение ПОД (избыточное индексирование).
Разработка исходной версии ИПТ в соответствии с ГОСТ 7.25-80 складывается из следующих основных этапов:
- определение тематического охвата ИПТ;
- сбор массива лексических единиц:
- формирование словника ИПТ;
- построение словарных статей:
- оформление ИПТ;
- экспертиза и регистрация ИПТ.
После создания исходной версии осуществляется развитие, ведение и отладка ИПТ.
Состав лексики ИПТ определяется тематическим диапазоном Рубрикатора но сельскому хозяйству и продовольствию, на основе рубрик которою осуществляется отбор и формирование основного входного потока документов БД АГРОС. Для более полного охвата каждой тематической области и описания фондов ЦНСХБ используются также рубрики Рубрикатора ГРНТИ.
Отбор лексики для тезауруса осуществляется в процессе индексирования документов. Термины, выделенные из текста документа, значимые для данной предметной области заносятся в картотеку терминов, предлагаемых для включения в тезаурус*. Основным поводом для включения термина в тезаурус является отсутствие в нем дескриптора, отражающего данное понятие, или возможности точно отразить его комбинацией дескрипторов. Чтобы убедиться в этом, индексатор должен ознакомиться со статьями дескрипторов, близкими но смыслу к предлагаемому. Окончательная экспертиза термина на предмет включения его в ИПТ проводится службой ведения тезауруса. До включения термина в состав тезауруса он имеет статус ключевого слова и по результатам ФЛК выделяется в поле КЛС. Критерии отбора ЛЕ:
- частота появления в индексируемых документах и запросах;
- полезность для поиска информации;
- наличие в авторитетных справочниках, терминологических стандартах и т. п.;
- наличие в тезаурусах международных систем по сельскому хозяйству и продовольствию.
При выборе лексической формы записи термина-кандидата в дескрипторы предпочтение следует отдавать форме, наиболее часто встречающейся в отечественной литературе и отвечающей требованиям краткости, точности, однозначности, удобству запоминания и записи. Другие лексические формы, отражающие данное понятие, следует использовать для формирования класса условной эквивалентности, т. е. предлагать для включения в тезаурус в качестве аскрипторов.
В качестве ЛЕ тезауруса используются одиночные слова (имена существительные), словосочетания, аббревиатуры и сокращения. Ввод в тезаурус одиночных прилагательных, причастий и т. п. не допускается.
ЛЕ могут быть представлены на кириллице, латинице, включать химические символы, цифры, отдельные знаки пунктуации. Знак «точка» не допускается.
Ввод ЛЕ, обозначающих общие понятия (вопросы, задачи, проблемы, описание, условия и т. п.), нежелателен вследствие их неинформативности.
Имена существительные приводятся в форме именительного падежа: исчисляемые существительные, предпочтительно, во множественном числе, неисчисляемые (процесс, действие, состояние) - в единственном.
Например:
Исчисляемые существительные: Неисчисляемые существительные:
телята
ткани растений
родентициды
устойчивость
вспашка
эрозия почвы
Для преодоления языковой неоднозначности (полисемия, омонимия) в тезаурусе используются релятор краткое уточнение термина, заключенное в круглые скобки. Дескриптор с релятором следует рассматривать и использовать как словосочетание. Реляторы могут быть у дескрипторов и аскрипторов.
Например:
1. бычки (рыбы)бычки
В1 рыбы В1 телята
Кроме релятора, для устранения языковой неоднозначности используются разные формы грамматического числа и лексические примечания методического характера.
Лексическое примечание - это свободный текст, размещенный в словарной статье непосредственно под заглавным дескриптором или аскриптором и заключенный в круглые скобки. Основное назначение примечания - уточнение каким-либо способом понятия, отражаемого дескриптором, в целях облегчения правильного выбора индексатором термина индексирования в затруднительных случаях.
Лексическое примечание может содержать:
- определение понятия:
разнотравье
(Группа кормовых растений из разных бот. семейств, кроме злаковых, бобовых, осоковых)
- разграничение значений термина, который может использоваться для отражения разных понятий:
кофе (зерна)
(Кофе-продукт; для растения исп. кофейное дерево)
- определение области использования дескриптора:
баланс (В экономике)
- раскрытие аббревиатуры или иного сокращения:
фао
(Международная организация по сельскому хозяйству и продовольствию при ООН)
- другие уточнения, отсылки, характеристики:
Loliumhybridum(L.PerennexL. multiflorum)
Словосочетания вводятся в тезаурус, если они отвечают следующим условиям:
- словосочетание является лексически нерасторжимым, при разбиении его на отдельные компоненты теряется первоначальный смысл:
запуск коров носовая раковина
- словосочетание является географическим названием:
восточная сибирь алтайский край
- в словосочетание входит имя собственное:
метод кьельдаля болезнь тиззера
- значение словосочетания не выводится из значения его компонентов:
альтернативные источники энергии зеленая революция
- словосочетание является устойчивым, часто встречается и необходимо для разграничения предметных категорий:
болезни растений болезни животных
- отдельные компоненты словосочетания имеют слишком широкий смысл:
нарушения обмена веществ
- словосочетание обозначает наименование химического вещества:
сульфат натрия
нафталанская нефть
- словосочетание является наименованием с.-х. культур, животных, пород т. п.:
технические культуры пьемонтская порода
- словосочетание является частотным для какой-либо области знаний или практики: выращивание молодняка трансплантация эмбрионов
В словосочетаниях используется естественный (прямой) порядок слов. Словосочетания, содержащие прилагательное, как правило, начинаются с прилагательного:
лекарственные растения
свеклоуборочные комбайны В названиях ботанических видов на первое место ставится существительное в форме именительного падежа, на второе место - прилагательное:
овсяница луговая
пырей ползучий Это правило не распространяется на устойчивые словосочетания:
конский каштан
водный гиацинт Использование аббревиатур[1]
в качестве дескрипторов допускается:
- для наименований организаций и стран
РФ
юнеско
- для длинных и сложных названий методов, явлений, процессов и т.п.
пдрф
пдк
После отбора ЛЕ и формирования словника (в виде картотеки) осуществляется построение тезаурусных (словарных статей) посредством установления между терминами отношений синонимии (подчинения, условной эквивалентности), выбора дескрипторов из класса условной эквивалентности, установления иерархических ассоциативных отношений.
Тезаурус представляет собой сложную терминологическую систему, между элементами которой – Тезаурус представляет собой сложную терминологическую систему, между элементами которой - лексическими единицами - существуют различные виды связи - отношения. ЛЕ тезауруса разбиваются на два основные множества:
- дескрипторы - термины, используемые при индексировании;
- аскрипторы - термины, которые в данной ИПС запрещены для использования при индексировании, хотя они встречаются в текстах документов, включены в какие-либо словари, справочники и т. п. Другие названия аскрипторов: синонимы, омонимы, недескрипторы, запрещенные термины.
Смысловые (парадигматические отношения) между дескрипторами и между дескрипторами и аскрипторами определяют структуру тезауруса. Основными методологическими принципами формирования парадигматической структуры дескрипториого тезауруса являются:
- категоризация лексического состава:
- построение классификационных схем основных понятий, соответствующих его тематическому диапазону.
В состав Тезауруса по сельскому хозяйству и продовольствию входит лексика разных отраслей и областей знаний. Вопросы категоризации ЛЕ в политематическом тезаурусе имеют определенные трудности, особенно если терминология специфических областей включается в его состав на заключительных этапах построения классификационных схем ИПТ.
Категоризация лексики - это разбиение ЛЕ на определенные тематические группы, представленные общими терминами этих групп. Основой категоризации лексики являются рубрики Рубрикатора по сельскому хозяйству и продовольствию. Важное условие категоризации -непересекаемость понятий, отнесенных к разным категориям. Например, для отрасли «Животноводство» выделены непересекающиеся категории, отражаемые общими терминами ЖИВОТНЫЕ (полезные, дикие животные и др.); РАЗВЕДЕНИЕ ЖИВОТНЫХ (методы и способы создания новых пород, их разведение и т. п.); КОРМЛЕНИЕ и др.. Кроме категорий, специфичных для каждой отрасли или области знаний. в тезаурусе выделены категории общезначимой лексики, например, ОБОРУДОВАНИЕ; СВОЙСТВА; ТЕХНОЛОГИЧЕСКИЕ ПРОЦЕССЫ и др. (учреждения; страны; науки и т. п.).
Построение классификационных схем это установление парадигматических, т. е. внеконтекстных логических связей для ЛЕ, относящихся преимущественно, но необязательно, к одной категории. Если ЛЕ имеет признаки нескольких категорий (многозначность или полисемия) необходимо либо заменять ее другими более специфичными терминами либо присоединять к ней особую помету - релятор. Так ЛЕ ГОРЧИЦА
отнесена к тематической области «Растениеводство», а ГОРЧИЦА
(ПРИПРАВА) как продукт питания - к области "Пищевая промышленность". Словарная (тезаурусная) статья дескриптора является наглядным изображением классификационной схемы понятия, отображаемого данной ЛЕ, и может содержать:
- лексическое примечание;
- аскрипторы;
- вышестоящие термины с указанием уровня иерархии;
- нижестоящие термины с указанием уровня иерархии;
- ассоциативные термины.
Словарная статья аскриптора включает только сам аскриптор и ссылку на дескриптор, который следует использовать вместо него.
Место каждой ЛЕ в структуре отношений тезауруса определяется специальными метками или ссылками. В разработанном и отлаженном ИПТ не должно быть одиночных терминов, не имеющих связей.
Общим правилом при построении тезауруса является строгая взаимность ссылок (контролируется программными средствами), определяющих вид парадигматических отношений.
В таблице 1 представлены метки, используемые в словарных статьях для обозначения парадигматических связей между терминами, и другие элементы структуры статей.
Значения меток в словарных статьях дескрипторов и аскрипторов
| Метка |
Значение метки |
Статус заглавного термина словарной статьи |
Вид связи |
В
|
вышестоящий термин |
дескриптор
|
иерархическая
|
| Н |
нижестоящий термин |
дескриптор |
иерархическая |
а
|
ассоциативный термин |
дескриптор
|
ассоциативная
|
| см |
отсылка к дескриптору |
аскриптор-синоним |
синонимия |
| с |
аскриптор-синоним |
дескриптор |
синонимия |
| рус |
аскриптор на русском языке |
дескриптор-латынь |
синонимия |
исп
|
отсылка к дескриптору |
аскриптор-омоним |
синонимия |
| О |
аскриптор-омоним |
дескриптор |
синонимия |
()
|
лексическое примечание |
дескриптор
|
расшифровка,
уточнение,
тематическая
«привязка»
термина
|
Классификационная схема отдельного понятия складывается из иерархии дескрипторов, отношений синонимии и ассоциативных связей.
2.2.2. Парадигматические отношения.
При построении словарных статей иерархические отношения устанавливаю гея между понятиями, объем одного из которых составляет часть объема другого. К ним относятся, например, отношения типа «род-вид», «часть-целое»; «шире-уже» и т. п. Более широкое понятие (подчиняющее, вышестоящее) имеет больший объем, оно выражает существенные признаки класса предметов, процессов и т. п., которые являются частью этого широкого понятия, подчиненными ему или нижестоящими.
При построении тезауруса все основные понятия его тематического диапазона рассматриваются с точки зрения выделения наиболее существенных признаков этих понятий. Выделенные признаки используются в качестве основания деления широких понятий на более узкие. Эти узкие понятия по какому-либо существенному признаку делятся на еще более узкие. Таким образом строится классификационная схема какого-либо понятия с иерархической структурой - так называемое иерархическое дерево.
Например, одним из основных понятий тематической области «Ветеринария» является понятие БОЛЕЗНИ ЖИВОТНЫХ. Основанием деления одного из них -ИНФЕКЦИОННЫЕ БОЛЕЗНИ ЖИВОТНЫХ - является этиология заболеваний (по возбудителям). По этому принципу выделены нижестоящие понятия: БАКТЕРИАЛЬНЫЕ БОЛЕЗНИ, ВИРУСНЫЕ БОЛЕЗНИ, МИКОПЛАЗМЕННЫЕ БОЛЕЗНИ и др. Рассмотрим формирование дерева понятия БАКТЕРИАЛЬНЫЕ БОЛЕЗНИ ЖИВОТНЫХ. Известно, что бактериальные болезни животных вызывают бактерии из разных таксономических групп. Однако классификация заболеваний только но таксономической принадлежности возбудителей явно недостаточна. Она не отвечает, например, интересам специалистов по анаэробным инфекциям: чтобы найти нужные документы, пользователь должен перечислить в запросе все заболевания, относящиеся к этой группе, искать ее по терминам текста или ключевым словам, что, как правило, не дает удовлетворительного результата. Задача решается, если классификацию бактериальных болезней проводить еще по одному специфическому признаку (основанию деления), например, АНАЭРОБНЫЕ ИНФЕКЦИИ. В результате иерархическое дерево понятия БАКТЕРИАЛЬНЫЕ БОЛЕЗНИ ЖИВОТНЫХ приобретает вид:
БАКТЕРИАЛЬНЫЕ БОЛЕЗНИ ЖИВОТНЫХ
с бактериозы животных
В1 инфекционные болезни животных
Н1 анаэробные инфекции
Н2 клостридиозы
НЗ ботулизм
Н1 бруцеллез
Н1 вибриоз
Н1 гемофильные инфекции
В приведенной иерархической классификации дескриптор ИНФЕКЦИОННЫЕ БОЛЕЗНИ ЖИВОТНЫХ является вышестоящим (метка В) по отношению к дескриптору БАКТЕРИАЛЬНЫЕ БОЛЕЗНИ ЖИВОТНЫХ, а термины с меткой Н - нижестоящими по отношению к нему. Цифры при метках отражают все уровни иерархических отношений между заглавным дескриптором словарной статьи и дескрипторами более широкими (вышестоящими) и узкими (нижестоящими).
В словарной статье дескриптора его вышестоящие дескрипторы являются вершинами, с которыми он входит в соответствующие иерархические деревья. Один и тот же дескриптор может входить в разные деревья (пример 1), и находиться на разных вершинах иерархии одного и того же дерева (пример 2). Понятия, состоящие в родовидовых отношениях, не должны находиться на одном уровне иерархии. Максимальная глубина иерархии в тезаурусе БД АГРОС - 6 уровней.
Пример 1
ЛЮПИН
В1 алкалоидные культуры
В2 технические культуры
В1 бобовые травы
В2 кормовые травы
ВЗ кормовые культуры
В1 зернобобовые культуры
В1 ядовитые растения
а сидераты
Пример 2
ГОРНОАЛТАЙСКИЕ ОВЦЫ
В1 тонкорунные овцы
В2 породы овец
В1 мясо-шерстные овцы
В2 породы овец
Иерархическая связь имеет двунаправленный характер. Это значит, что если между двумя ЛЕ установлены отношения типа «род-вид», «выше-ниже» и т. п., то обратной ссылкой для отношения «вид» будет «род» и наоборот:
ягодные культурыклубника
Н1 клубника В1 ягодные культуры
Непротиворечивость связей отслеживается в компьютерной форме тезауруса программными средствами.
Отметим, что иерархические отношения, устанавливаемые между дескрипторами тезауруса, не претендуют на всеобщую применимость, их реализация отвечает задачам поиска информации конкретных областей знания. В связи с такой концепцией тезауруса, признано нецелесообразным строить иерархические деревья очень широких понятий как, например, СЕЛЬСКОЕ ХОЗЯЙСТВО, БОЛЕЗНИ ЖИВОТНЫХ и др., т. к. очевидна практическая узкая специализация пользователей или по отраслям сельского хозяйства, или по видам заболеваний животных и т. п. В тезаурусе такие широкие понятия связаны с более узкими терминами не иерархическими, а другими логическими отношениями - ассоциативными.
Пример:
болезни животных
а акушерские болезни
а аллергические болезни
а бесплодие животных
а болезни внутренних органов и систем

а хирургические болезни
а экзотические болезни
Такие широкие дескрипторы как БОЛЕЗНИ ЖИВОТНЫХ следует использовать только для индексирования документов общего характера, например, монографий, учебников, справочников и т. п., поиск по этому дескриптору из-за отсутствия иерархической связи с более узкими дескрипторами не будет эффективным - пользователь получит только часть документов.
При разработке тезауруса не ставятся чисто классификационные цели - иерархические деревья в нем формируются с целью создания средств для автоматизированного расширения ПОД или запроса.
Наличие в ИПС функции автоматизированного расширения ПОД имеет важное значения для методических принципов индексирования, стратегии поиска и оказывает существенное влияние на выбор логики тезауруса. Расширение ПОД - это включение в него более широких (вышестоящих) терминов тезауруса по отношению к использованным индексатором. Такое избыточное индексирование поисковая система осуществляет посредством реализации иерархических отношений, установленных между дескрипторами тезауруса.
В документе БД в поле ТЕР (термины тезауруса) находятся дескрипторы, используемые индексатором, а в ноле РТЗ (расширение по тезаурусу) - их вышестоящие дескрипторы, приписанные документу поисковой системой. При поиске но запросу <торговля зерном всех зерновых культур странами мира> документ об экспорте зерна пшеницы Канадой будет найден и выдан пользователю как релевантный запросу, благодаря процедуре избыточного индексирования за счет иерархических связей тезауруса:
зерновые культуры
Н1 гречиха
Н1 ежовник
Н1 кукуруза
Н1 овес
Н1 просо
Н1 пшеница

Н1 овес
Н1 просо
Н1 рис
Н1 рожь

Н1 ячмень
торговля
Н1 внешняя торговля
Н1 импорт

Н1 экспорт
страны мира
Н1 австрия
Н1 албания
Н1 алжир

Н1 канада

Установление иерархических связей между терминами тезауруса устраняет необходимость вручную индексировать документы всеми широкими понятиями, необходимыми для обеспечения полноты поиска., Например, по запросу <зерновые культуры> этот прием обеспечивает поиск в БД как документов, заиндексированных дескриптором ЗЕРНОВЫЕ КУЛЬТУРЫ, так и дескрипторами ПШЕНИЦА, РОЖЬ, ЯЧМЕНЬ и др., благодаря тому, что поисковая система расширяет ПОД последних термином ЗЕРНОВЫЕ КУЛЬТУРЫ. Поиск по общим терминам, стоящим над заданными в запросе, задается формулой запроса и выполняется, если между терминами в тезаурусе действительно установлены иерархические отношения.
При индексировании документов и формулировании темы запроса иерархическое построение словарных статей позволяет легко найти наиболее применимый специфический дескриптор. Поиск в тезаурусе нужного термина нужно проводить в следующей последовательности:
- обращение к известному дескриптору (одному или нескольким), отражающему более широкое понятие, к классу которого может относиться индексируемое понятие;
- обязательный просмотр статей выбранных дескрипторов, анализ их семантического «обрамления», т. е. примечания, синонимов, ассоциативных дескрипторов и, конечно, иерархически связанных с ними дескрипторов;
- выбор одного или нескольких дескрипторов, позволяющих точно отразить индексируемое понятие.
Иерархическая классификация позволяет быстро подбирать дескрипторы, необходимые для индексирования таких понятий, смысл которых в тезаурусе еще не отражен конкретными терминами.
Из-за определенной противоречивости концепций построения тезауруса, реализованных на разных этапах его развития, широкого тематического диапазона лексики, большого объема работ не все иерархические связи между дескрипторами существующей версии ИПТ установлены достаточно полно и корректно с точки зрения смысловых отношений между понятиями и задач поиска. Перечисленные недостатки устраняются в процессе отладки тезауруса.
При построении тезауруса необходимо стремиться к максимальному отражению семантических связей, однако, как показывает опыт, усложнение структуры ИПТ затрудняет его использование в самой ИПС и поэтому естественно искать разумный компромисс между объективностью ИПТ как структуры знаний и его практичностью - как информационно-поискового средства конкретной ИПС.
Многие дескрипторы тезауруса могут быть связаны отношениями подчинения более чем с одним дескриптором. Вслучае множественной иолииерархии, при
автоматизированном расширении ПОД в него включаются дескрипторы, отвечающие смысловым требованиям разных запросов, что порождает нежелательный информационный шум при поиске по конкретному запросу. Для ограничения поиска и получения релевантных документов пользователь должен средствами поисковой системы устранить нежелательные последствия полииерархии, поэтому можно сказать, что «нагрузка» на пользователя по корректировке запроса обратно пропорциональна «нагрузке» на индексатора. Напомним, что иерархические связи освобождают индексатора от необходимости вручную приписывать документу наряду со специфическими терминами и широкие (вышестоящие) дескрипторы.
Примером разного подхода к реализации иерархических отношений между понятиями являются два англоязычных тезауруса международных систем по сельскому хозяйству - тезаурус CABI* и тезаурус AGRIS (AGROVOC)**.
Некоторые иерархические связи, будучи правильными с точки зрения классификации знаний, могут быть маловажными или избыточными с точки зрения поиска. В таких случаях логично понятие подчинить наиболее важному термину (и с точки зрения поиска и с точки зрения естественности, органичности такой связи), а отношения с остальными выразить с помощью ассоциативных ссылок, которые индексатор примет во внимание при отражении того или другого аспекта. Этот подход и реализован в структуре отношений дескриптора LUPINUSLUTEUS в тезаурусе БД АГРОС: иерархически он подчиняется термину LUPINUS (истинная родовидовая связь), другие возможные аспекты его рассмотрения представлены ассоциативно связанными терминами, которые индексатор обязан использовать, если растение рассматривается в документе именно с этих точек зрения.
Кроме того, в силу принятой логики индексирования документов по растениеводству, ПОД должен содержать и общеупотребительное название с.-х. культуры, и научное (латинское) название конкретного вида используемого растения, например, ЛЮПИН и LUPINUSLUTEUS. Расширение ПОД в таком случае происходит за счет иерархических связей дескриптора ЛЮПИН как с.-х. культуры.
* САВ
I
- Международное бюро по с.-х. информации стран британского содружества
**
AGRIS
– Международная информационная система по сельскому хозяйству при ФАО
|
Современные поисковые системы располагают большим набором средств, используя которые грамотный пользователь добьется высокой релевантности поиска. Однако при разработке тезауруса следует предусматривать простые и эффективные стратегии поиска, учитывая, что пользователь, как правило, недостаточно осведомлен о возможностях ИПС. Индексатор должен знать все об особенностях ИПЯ, как инструментах индексирования документов и запросов, а также об особенностях поиска в данной ИПС.
Частичная замена иерархических отношений ассоциативными дает возможность заметно упростить структуру тезауруса, уменьшает риск информационного шума при поиске, упрощает его стратегию. Следует отметить также, что построение строго «научного» тезауруса требует неоправданно больших интеллектуальных и временных ресурсов, что неприемлемо в реальных условиях.
Отношения предпочтения
устанавливаются между дескриптором и другими ЛЕ класса условной эквивалентности, т. е. его синонимами, омонимами или ЛЕ, которые обладают многозначностью. В целях единообразия индексирования документов и формулирования запросов, из множества ЛЕ класса условной эквивалентности только одной ЛЕ придается статус дескриптора, другие ЛЕ класса условной эквивалентности запрещены для использования в ПОД.
Среди них:
- синонимы - ЛЕ, абсолютно или относительно совпадающие по значению и употреблению, но отличающиеся друг от друга по звуковому составу и написанию;
- омонимы - ЛЕ, значение которых не связано друг с другом ни по смыслу, ни ассоциативно, но совпадающие по звуковому составу и написанию, например, бор - химический элемент и бор – хвойный лес;
- ЛЕ, обладающие свойством обозначать разные понятия (предметы, явления и т. п.), т. е. обладающие многозначностью - лексической полисемией. В отличие от омонимов, между ними может существовать определенная семантическая связь.
Например, сыворотка в зависимости от контекста может обозначать сыворотку молока, сыворотку крови или препарат - сыворотка жеребой кобылы. Разграничение значений омонимов и многозначных ЛЕ достигается вводом в тезаурус в качестве дескрипторов более специфических терминов или присоединением к ЛЕ реляторов, уточняющих их значение. Сами же омонимы и многозначные ЛЕ, как и синонимы, имеют в ИПТ статус аскрипторов.
Аскрипторы размещаются в тезаурусе в общем порядке алфавита, они выделяются знаком «-» (черточка) и шрифтом «курсив». Синонимы имеют ссылку «см», омонимы и многозначные ЛЕ - «исп» к дескрипторам, которые следует использовать вместо них при индексировании.
В словарной статье дескриптора его синоним(ы), омоним или частично совпадающий по значению аскриптор (условный синоним) размещаются по алфавиту после дескриптора или лексическою латыни (научные наименования растений, животных, микроорганизмов и т. п.). Омонимы выделяются меткой <о>.
В тезаурусе взаимность ссылок между дескрипторами и аскрипторами контролируется программными средствами.
Аскрипторы составляют семантическое окружение дескриптора, уточняя понятие, которое он отражает в тезаурусе.
При отладке тезауруса для разграничения значений омонимов в случае наименований организмов в дальнейшем будут использоваться в качестве реляторов их таксономическая принадлежность, для других омонимов - уточнения в круглых скобках.
Просматривая статью многозначного аскриптора, индексатор должен сделать альтернативный выбор специфического термина (терминов).
Установлением отношений синонимии, омонимии, полисемии обеспечивается единообразная замена терминов, встречающихся в индексируемых документах, нормализованными ЛЕ тезауруса - дескрипторами. В результате согласованного отражения содержания документов индексаторами закладывается основа для эффективного поиска нужной информации пользователями БД, т. к. при составлении поисковых предписаний они также будут руководствоваться связями терминов тезауруса.
Все термины словарной статьи дескриптора так или иначе уточняют значение и объем понятия, отражаемого данным дескриптором. Так, например, в него включаются и аспекты, передаваемые некоторыми синонимами. В связи с этим, прорабатывая тот или другой дескриптор, следует обращать внимание не только на иерархические и ассоциативно связанные с ним дескрипторы, но и на ЛЕ, по отношению к которым использование данного дескриптора является предпочтительным. Только анализируя все связи дескриптора, можно быть уверенным в правильности выбора термина индексирования.
Наличие у каждого дескриптора большого количества синонимов, встречающихся в литературе, имеет ряд преимуществ. Зафиксированные отношения синонимии обеспечивают:
- поиск нужных дескрипторов в тезаурусе;
- автоматизированную замену ошибочно использованных индексатором аскрипторов соответствующим и дескрипторами;
поиск информации в БД по известным пользователю синонимам (конечно, если они есть в тезаурусе): в запросах также происходит автоматизированная замена их дескрипторами;
- удобство восприятия ПОД с латинскими дескрипторами, благодаря визуализации их русских эквивалентов (синонимы с меткой <рус>).
Ассоциативные отношения
- это любой вид смысловых отношений между понятиями, возможный в данной предметной области, кроме отношений синонимии.
Одним из критериев установления ассоциативных отношений между терминами является достаточно частая совместная встречаемость их в литературе, однако решающим является полезность такой связи для индексатора при подборе им нужных терминов для индексирования какого-либо понятия. Ассоциативную связь (метка а) следует воспринимать как рекомендацию обратить внимание на термины, имеющие какое-либо отношение к индексируемому понятию, т. е. пересекающиеся с ним но какому-либо аспекту отображения.
Ассоциативные отношения устанавливаются в основном:
- между дескрипторами разных иерархических деревьев одной категории (например, между дескрипторами тематической области «Ветеринария»);
- между дескрипторами разных категорий (например «Животноводство. Кормление животных. Корма» и «Пищевая промышленность. Продукты питания»);
- между дескрипторами, содержательно относящимся к одному иерархическому дереву (как правило, с развитым «ветвлением»), для устранения неоправданного возрастания объема тезауруса, а также информационного шума за счет маловажных для поиска терминов. В тезаурусе зафиксированы следующие распространенные логические связи между терминами, а также отношения, полезные с точки зрения индексирования и поиска:
- причина - следствие:
ветровая эрозия
а пыльные бури
- часть - целое:
крс
а породы крс
- предмет-процесс:
плуги
а вспашка
- вещество - его производные:
фенол
а карболовая кислота
- сходство или общность некоторых признаков:
биотипы
а генотипы
- организм (растения, животные, микроорганизмы и т. п.) -вид использования:
acertataricum
а декоративные деревья
- предмет, явление - аспекты рассмотрения:
паразито-хозяинные отношения
а круг хозяев
- используемые растения, животные, микроорганизмы -научное наименование рода или вида:
пшеница
а triticum
Приведенные примеры, конечно, не исчерпывают всех видов логических отношений между понятиями. По мере появления новых знаний, ввода новых дескрипторов количество и разнообразие ассоциативных связей в тезаурусе возрастает. Гак несомненно полезным для поиска является фиксация ассоциативных отношений типа «сырье-продукт», «свойство-носитель свойства», антонимия и др.
Ранее отмечалось, что в определенных случаях ассоциативные отношения устанавливаются между понятиями, которые фактически находятся в родовидовых, т. с. иерархических отношениях, но эти отношения нецелесообразны с точки зрения поиска. Иерархические деревья таких широких понятий, как, например, РАСТЕНИЯ или ЖИВОТНЫЕ имели бы слишком большое количество нижестоящих терминов, сложную структуру, большую глубину иерархии, что нецелесообразно, т. к. поиск по таким дескрипторам вряд ли возможен. Поэтому словарные статьи таких дескрипторов включают, как правило, только термины с меткой ассоциативной связи.
Пример:
растения
а вечнозеленые растения
а декоративные растения
а с-х культуры
а ядовитые растения
Разрыв иерархической цепочки в «безвредной» для поиска точке и установление в этом месте ассоциативной связи часто используется в тезаурусе в научных классификациях организмов. Именно так предполагается связать, например, ботанические семейства с верхними таксонами.
Ассоциативные отношения не следует устанавливать между дескрипторами, связь между которыми очевидна:
Пример:
болезни зубовзубы
В1 хирургические болезни В1 ротовая полость
Н1 пародонтоз В2 пищевой тракт
Ассоциативно связанные с дескриптором термины с меткой а размещаются в конце словарной статьи дескриптора. Метка является симметричной (двунаправленной) и контролируется программными средствами.
Пример:
несовместимостьконкуренция
а конкуренция а несовместимость
Изучив словарные статьи ассоциативных терминов, индексатор может найти в них дескрипторы, которые уточняют выбранное понятие или отражают какие-либо аспекты его рассмотрения, важные с точки зрения поиска. Кроме того, возможно, в словарных статьях ассоциативных терминов, будет найден дескриптор, более точно отражающий тему документа, чем ранее выбранный.
2.2.3. Использование тезаурусов
Индексирование - это перевод содержания документа и запроса с естественного на информационно-поисковый язык. В зависимости от типа ИПЯ (иерархическая классификация, дескрипторный ИПЯ) индексирование реализуется в процессах:
- предметизации (индексирование на языке предметных рубрик, алфавитно-предметной классификации):
- систематизации литературы на языке классификационных иерархических ИПЯ;
- координатного индексирования на языке дескрипторного ИПЯ или языка ключевых слов.
В зависимости от ИПЯ результатом индексирования, т. е. элементом ПОД на соответствующем ИПЯ, будет либо предметная рубрика, либо индекс классификации, либо набор дескрипторов или ключевых слов.
Отметим некоторые общие положения индексирования с помощью ИПТ.
При выборе аспектов индексирования содержания документа индексатор должен принимать во внимание:
- аспекты, которые выделяет автор работы - это видно из заглавия, определения целей и задач работы, самого исследования, заключения и выводов;
- темы, к которым данная работа имеет непосредственное отношение, хотя сам автор это не подчеркивает (такой анализ документа требует большой компетентности индексатора как специалиста):
- как положительные, так и отрицательные результаты работы.
Качество индексирования и эффективность поиска зависят от соблюдения следующих правил индексирования:
- максимально полно использовать лексический состав тезауруса, его структуру и связи между терминами;
- подбирать дескрипторы с учетом возможного использования их пользователем в поисковых предписаниях (ПОЗ);
- отражать разные аспекты содержания документа достаточным количеством дескрипторов, с тем чтобы
документ был найден по запросам пользователей разных специальностей.
Каждый выделенный аспект содержания документа следует индексировать как можно более специфичными дескрипторами и не использовать дополнительно более широких понятий. Однако если в содержании документа затрагивается и широкий аспект, и один или два узких, следует использовать и общий дескриптор, и один или два специфичных. Например, для индексирования статьи о породах овец, разводимых в Алтайском крае, следует использовать общий термин ПОРОДЫ ОВЕЦ и ГОРНОАЛТАЙСКИЕ ОВЦЫ, если этой породе уделено особое внимание.
Если для отражения понятия индексатор в тезаурусе не находит точного эквивалента, необходимо подобрать дескрипторы, близкие по смыслу.
В словарной статье дескриптора нужно принимать во внимание все элементы ее структуры:
- лексическое примечание и аскрипторы дают представление об объеме понятия, уточняют его содержание, область применения;
- ассоциативные термины - это дополнительный список дескрипторов, имеющих какое-либо отношение к данному понятию, среди них могут оказаться полезные для индексирования его аспектов. В случае растений, микроорганизмов, насекомых, рыб, диких животных и т.п. обращение к статьям ассоциативных дескрипторов обязательно для уточнения латинского наименования семейства рода или вида.
- иерархические отношения дают возможность легко подобрать наиболее специфичный дескриптор.
Например, для индексирования из алфавитного списка вначале был отобран дескриптор КУЛЬТИВИРУЕМЫЕ ГРИБЫ. В словарной статье этого дескриптора имеются вышестоящие термины (две ветви), т. е. дескриптор входит в иерархическое дерево с двумя вершинами: НИЗШИЕ РАСТЕНИЯ и ОВОЩНЫЕ КУЛЬТУРЫ. Двигаясь по иерархическому дереву вниз, т. е. просматривая нижестоящие термины, можно найти среди них более специфичный термин, чем выбранный вначале, например, ВЕШЕНКА, более точно отражающий индексируемое понятие. Движение вверх по иерархическому дереву приведет к более широким понятиям, использование которых при наличии более специфичных дескрипторов, конечно, недопустимо.
Если специфичный термин еще не введен в тезаурус, но включен в картотеку кандидатов в дескрипторы, он может быть использован для индексирования, но при этом индексатор должен выбрать из тезауруса еще и близкий по смыслу дескриптор или более широкое понятие. Так же следует поступать и с новыми понятиями, для отражения которых в картотеке нет терминов, при этом индексатор должен внести в картотеку использованное ключевое слово. На его карточке должны быть приведены известные индексатору сведения о термине, необходимые для включения его в тезаурус: вышестоящие и нижестоящие термины, синонимы, ассоциативные термины, лексическое примечание, если оно необходимо. Если термин не рекомендуется вводить в тезаурус, на карточке ставится помета «КЛ» (ключевое слово).
Компьютерная база данных ИПТ позволяет выводить его на печать автоматизированным способом в различных формах. Используемые в настоящее время печатные формы -дескрипторный словарь и лексико-семантический указатель (ЛСУ) имеют следующую последовательность знаков:
- цифры (0-9);
- латинский алфавит (А-2);
- русский алфавит (А-Я).
В пределах одной записи пробел предшествует знаку «дефис».
Дескрипторный словарь представляет собой алфавитный список дескрипторов и аскрипторов - терминов, запрещенных для использования при индексировании, со ссылкой на соответствующий дескриптор.
В ЛСУ термины даны в алфавитном порядке со своим семантическим окружением, составляющим словарную статью термина. Словарная статья дескриптора может включать лексическое примечание, синонимы, вышестоящие и нижестоящие дескрипторы и ассоциативные термины. Один и тот же дескриптор может присутствовать в словарных статьях нескольких других терминов - в зависимости от парадигматических отношений, установленных с ними в основной классификационной схеме понятия. Словарную статью аскриптора составляет сам аскриптор и дескриптор, который следует использовать вместо него. [43, C. 62-66].
Развитие тезауруса БД АГРОС носит динамический характер, что обусловлено появлением новых областей знаний, тематическим расширением документального совершенствованием дескрипторного языка и структуры тезауруса, задачами совместимости его с другими ИПЯ числе с тезаурусами международных ИПС, совпадающими по тематическому охвату с БД АГРОС. Такими тезаурусами являются Тезаурус САВI (САВ Thesaurus)* и тезаурус (AGROVOC). Для решения проблемы полной совместимости необходимо:
- провести сопоставительный анализ англоязычных тезаурусов и выбрать наиболее развитый соответствующий задачам поиска в БД AGROS в качестве базисного для создания его русской версии;
- осуществить сопряжение русской терминов лексикой базисного тезауруса;
- перенести структуру всех отношений базисного тезауруса на национальную терминологию;
- разработать технологию, программные и лингвистические средства для формирования и ведения динамического двуязычного ИПТ.
Сопоставительный анализ показал, что ни один из англоязычных тезаурусов в полном объеме не может служить в качестве базисного. Перенос их структуры отношений в отечественный ИПТ на данной стадии его развития сложен по многим причинам: особенности языка, развития отраслей; традиции и т. п. Кроме того, создание русской в целесообразно рассматривать но отношению к единому международному тезаурусу, вопрос о котором решается на международном уровне.
Тем не менее вопросы сопряжения термина решаются уже сейчас с целью облегчения вхождения, пользователя в "чужую" БД с помощью терминов национального тезауруса. Сближение терминологическою состава отечественного ИПТ с тезаурусами международных систем САВI, NAL, AGRIS происходит в процессе отбора лексики: одним из оснований для включения термина в состав ИПТ является наличие его английского эквивалента в тезаурусах международных систем. Классификационные схемы отдельных понятий, например, систематика растений, рыб, насекомых. вирусов, микроорганизмов и др., классификация ферментов, химических соединений и т. п. включаются в отечественный тезаурус в версии тезауруса САВI.
| * Тезаурус САВ
I
используется также Национальной библиотекой по сельскому хозяйству США (NAL) для индексирования документов БД AGRICOLA. |
2.3. Проблема выбора средств лингвистического обеспечения и их интеграции в библиотеках АПК.
Все больше сельскохозяйственных библиотек создают электронные каталоги (ЭК), базы данных (БД) и перед ними встает вопрос о выборе лингвистического обеспечения (ЛО) для них. Во многом выбор ЛО для ЭК и БД зависит от того какие информационно-поисковые языки (ИПЯ) использовались в этих библиотеках для карточных каталогов. Как правило, именно их приспосабливают для электронных каталогов и БД. Это продиктовано тем, что новый ИПЯ требует обучения индексаторов, а также трудоемкостью создания ИПЯ и желанием сохранить для потребителя связь традиционных и электронных каталогов.
В основном в научных сельскохозяйственных библиотеках для карточных каталогов используются ИПЯ классификационного типа: Универсальная десятичная классификация (УДК) и Библиотечно-библиографическая классификация (ББК). В Центральной научной сельскохозяйственной библиотеке РАСХН (ЦНСХБ), которая является информационным центром, наряду с этими ИПЯ, используются своя собственная классификация для карточного комплексно-системного каталога, Отраслевой рубрикатор, разработанный на основе ГРНТИ (ОР), а также дескрипторные ИПЯ: Отраслевой тезаурус по сельскому хозяйству и продовольствию (ОТ) и ИПЯ ключевых слов. [50, C. 170].
Выбор ЛО библиотеки определяется ее информационно-поисковыми задачами (ИПС), информационными ресурсами библиотеки, а также информационными потребностями и запросами ее пользователей. По такому же принципу построено ЛО крупнейших зарубежных БД по сельскому хозяйству, таких как CABabstract – БД CABI (Международное бюро сельскохозяйственной информации стран Британского содружества), Agricola – БД NAL (Национальной сельскохозяйственной библиотеки США), Agris – БД FАО (Продовольственная и сельскохозяйственная организация ООН), включает CODES (Рубрикатор) и тезаурус. В NAL используются также своя собственная классификация карточного каталога и классификация Дьюи.
Рубрикатор используется для формирования печатных и электронных версий изданий, а также для работы с большими массивами информации в БД. Тезаурус используется для тематического поиска различной глубины и детализации.
Любые классификации, ИПЯ требуют постоянной поддержки: терминологического наполнения и введения новых лексических единиц. Это под силу только крупным библиотекам и информационным центрам, где в штате есть специалисты-отраслевики и лингвисты. Кроме того, эта работа требует больших финансовых затрат. Поэтому необходима кооперация в этой работе и информационные центры и библиотеки ищут ее. Проблема совместимости ЛО сельскохозяйственных библиотек сейчас весьма актуальна, поскольку единое ЛО не только позволит потребителю комфортно чувствовать себя в различных ЭК и БД и переходить из одной ИПС в другую, но и облегчит тематический поиск в них. Единые принципы индексирования позволят создавать более точные поисковые предписания, успешнее вести поиск и получать максимум релевантной информации. Финансовые и кадровые проблемы также способствуют тому, что специалисты стремятся к объединению усилий в этой работе. [15, C. 61-62].
Редко говорится о совместимости или разработке единого Рубрикатора нескольких стран, поскольку чаще всего они используются для получения издательской продукции. Обычно речь идет о совместимости или создании единого международного тезауруса как основного инструмента при индексировании, создании поискового образа документа и поиска в ЭК и БД.
CABI и NAL решили эту проблему используя один тезаурус. За основу был взят англоязычный тезаурус CABInternational и с 1985 года ведутся совместные работы по его поддержанию и наполнению. Американские термины, которые не используются в Европе имеют соответствующую пометку. Тезаурус AGRIS – “Agrovoc” – трехязычный (английский, французский, испанский), есть также немецкая, итальянская и арабская версии. БД AGRIS – международная, в ее создании принимают участие многие страны мира, наличие версий тезауруса на нескольких языках позволяет использовать его для БД в разных странах. Несмотря на то, что тезаурус CABabstracts и “Agrovoc” англоязычные, в их основе лежат разные идеологии. Эти тезаурусы 2-х международных информационных систем по сельскому хозяйству имеют большое сходство по тематическому охвату, лексическому составу, построению и элементам словарных блоков, отношениям между терминами, но имеющиеся расхождения в этих же областях не позволяют считать их совместимыми в существующем виде. Давно обсуждается вопрос о создании единого тезауруса, но из-за финансовых трудностей он пока отложен. Эта работа не может быть механической из-за разницы в их построении. Равно как нельзя просто перевести, к примеру, тезаурус CABabstracts или Agrovoc на русский язык и считать его российским тезаурусом по сельскому хозяйству.
ЦНСХБ провела сравнительный анализ тезаурусов, их структуры, который показал, что разница и в терминологии очень велика. Анализ показал, что в каждом из тезаурусов есть свои преимущества, которые хотелось бы объединить. Предполагается, что объединенный тезаурус позволит взять от каждого тезауруса его лучшие качества. ЦНСХБ предполагает принять участие в этой работе с тем, чтобы в многоязычном тезаурусе была русская версия. Создание русскоязычной версии одного тезауруса позволит для каждой лексической единицы найти соответствующий эквивалент на русском языке. Это будет один тезаурус с единой идеологией, выверенными связями и т.д.
В ЦНСХБ работы по поддержанию ИПЯ, ведутся постоянно в соответствии с тем какие задачи эти ИПЯ призваны решать.
Отраслевой Рубрикатор (ОР) должен отвечать следующим требованиям:
- полно и точно отражать политематический поток документов, поступающих на ввод в БД
- обеспечить точность информационного поиска
- удовлетворять требованиям сортировки массивов документов при создании различной выходной продукции, в т.ч. текущих изданий
- выполнять формально-логический контроль рубрик вводимых документов.
С этой целью выявляются дублирующие или избыточные (неработающие) рубрики; проводится сопоставительный анализ части рубрик ОР и ГРНТИ с целью устранения многоаспектности, дублирования рубрик, унификации наименований; уточняется справочно-ссылочный аппарат, редактируются наименования рубрик, примечания. С включением в фонд и аналитико-синтетическую обработку документов новой тематики (например пищевой промышленности) создаются новые разделы ОР, для которых разрабатываются схемы, создается ссылочно-справочный аппарат, приписываются комментарии и примечания. Затем этот раздел включается в машинный ОР БД. Разрабатывается формат вывода машинного ОР на печать. Все изменения вносятся в электронную и печатную версию ОР. Программное обеспечение ведения и актуализации машинных ОР и ОТ разработано во ВНИИТЭИагропром. [49, C. 90-92].
Работы по совершенствованию Отраслевого тезауруса (ОТ) включают: отбор массива лексических единиц (ЛЕ) по всему диапазону входного потока БД, формирование словника ОТ, построение словарных статей. Отбор ЛЕ ОТ осуществляется специалистами в ходе одноразовой аналитико-синтетической обработки документов. ЛЕ поступают сначала в карточную картотеку и используются некоторое время в качестве ключевых слов. Работа над ними состоит из этапов: мониторинг на частотность появления терминов в документах; согласование со специалистами; проверка в справочниках и тезаурусах зарубежных БД; создание лингвистического обрамления; редактирование; построение статьи термина-дескриптора; сверка с машинным ОТ. После подготовки машинного ввода и корректировки связей ЛЕ вводится в ОТ.
Машинный ОТ осуществляет формально-логический контроль терминов в поле индексирования, что позволяет выявлять ошибки индексирования и ввода информации в БД. Ключевые слова, не отнесенные в ранг дескрипторов, выделяются в отдельное подполе, по ним возможен поиск. Ключевые слова – это нормализованный ИПЯ; они записываются в соответствии с правилами, разработанными для ИПС ЦНСХБ. По мере отбора терминов и обработки их для ввода в ОТ разрабатываются и принимаются решения по методике индексирования документов разной тематики.
Единое ЛО сельскохозяйственных библиотек позволит создать единое информационное пространство отрасли. В России уже существует единый Рубрикатор – Государственный рубрикатор научно-технической информации; на его основе разработан Отраслевой рубрикатор по сельскому хозяйству и продовольствию, который пока практически не используется в сельскохозяйственных библиотеках отрасли. Использование в отраслевых библиотеках УДК также способствует созданию единого ЛО. Тем более, что есть возможность централизованного индексирования по УДК в современных условиях и на новом уровне.
В течение многих лет ЦНСХБ являлась центром каталогизационной обработки, выпускала и рассылала по подписке каталожные карточки на книги и статьи по сельскому хозяйству, включаемые в ее фонд. Эти карточки получали индекс темы Централизованной библиографической информации (ЦБИ), отражающей основные проблемы сельского хозяйства. Библиотеки заказывали те из них, которые соответствовали тематике их фондов и каталогов. На карточках проставлялись (и сейчас проставляются) индексы УДК, соответствующие содержанию документа. Таким образом библиотеки получали готовую карточку с готовой систематизацией и оставалось лишь поставить ее в каталог или в картотеку статей. С удорожанием полиграфии и в связи с тяжелым финансовым положением библиотек, система ЦБИ перестала функционировать. Однако в последние годы проблема централизованной обработки документов вновь становится актуальной, не только потому, что там, где есть ЭК, как правило, продолжают функционировать карточные каталоги. А потому, что снят вопрос о дорогой полиграфии: теперь информацию можно получать по электронной почте по тем же темам ЦБИ, а затем, уже на месте, ее можно распечатать в виде карточки и использовать в традиционных и электронных каталогах. ЦНСХБ продолжает использовать УДК, которая стала одним из ИПЯ ее ЭК и БД “AGROS”.
Использование в библиотеках отрасли наряду с УДК, Отраслевого Рубрикатора и Отраслевого Тезауруса позволит улучшить качество индексирования документов, облегчит поиск в отраслевых БД.
Библиотека проводит методическую работу с библиотеками отрасли, организуя семинары, Дни повышения квалификации по вопросам индексирования и работы с ИПЯ. В течение многих лет разрабатывались отраслевые рабочие таблицы УДК по сельскому хозяйству, которые являлись основным методическим и рабочим инструментом систематизаторов в библиотеках отрасли. В настоящее время регулярно проводятся занятия и консультации по вопросам систематизации по таблицам УДК.
ОТ и ОР может быть использован в электронной форме, готовятся к переизданию их печатные версии. ЦНСХБ подготовлен в печатной форме словник дескрипторов ОТ, который может существенно облегчить работу индексатора. Предполагается провести ряд консультаций и семинаров по индексированию и работе с ОР и ОТ для библиотек отрасли.
ЦНСХБ надеется что библиотеки отрасли примут также участие в разработке статей тезауруса или в отборе лексики для него. Такая кооперация поможет не только созданию единого ЛО, единого информационного пространства, не только сократит финансовые затраты библиотек на разработку собственного ЛО, но и поможет повысить уровень индексирования документов по сельскому хозяйству.
Заключение
На современном этапе развития общества, вопреки расхожему мнению о неактуальности и бессмысленности существования библиотеки, ее роль, как центра генерации знаний, неуклонно возрастает. Но наряду с этим, процессы формирования нового информационного общества поставили перед современными библиотекаминовые задачи, обусловили необходимость пересмотра ее традиционных функций с точки зрения новых информационных технологий. Постепенно меняется статус традиционной библиотеки: происходит эволюция в направлении от пассивного «бумажного» книгохранилища к активному распространителя электронных информационных ресурсов. Существование информационных источников в электронном виде и наличие развитых сетевых систем коммуникации дает возможность развивать и совершенствовать информационную деятельность библиотек. Однако это требует пересмотра технологического статуса и средств поддержки информационно-лингвистического обеспечения библиотечной технологии.
Сейчас на страницах профессиональных периодических изданий, где освещается значительный практический опыт и прогнозы на будущее, значительное внимание уделяется новой политике каталогизации.
Современная информационная технология развивается в направлении разработки средств интеллектуализации и создания баз знаний, использования методов искусственного интеллекта. И без развитого лингвистического обеспечения, как одного из основных компонентов интеллектуального инструментария системы, невозможно обеспечить высокий уровень представления, обработки и раскрытия накопленных знаний.
Традиционным лингвистическим средством упорядочения и раскрытие знаний являются библиотечные классификации, поэтому репрезентация их на новой технологической основе - в гипертекстовом виде с реализацией механизма семантической сети - является перспективным направлением деятельности библиотек.
Перманентность развития информационно-технологической среды ставит перед библиотеками сельскохозяйственной сети важные и сложные задачи, а именно:
- формирование распределительных информационных ресурсов,
- формирование единого информационного пространства,
- выход на новый технологический и более качественный уровень процессов обработки и взаимообмена создаваемых информационных ресурсов.
Библиотеки перерастают из хранителя в разработчика информационных ресурсов и проводника в мировом информационном среде. При этом автоматизация всех процессов библиотечной деятельности должна обеспечить доступ пользователя к электронному каталогу и другим базам данных библиотеки с максимально адекватностью полученной информации до читательских запросов. Книга проходит сложный путь обработки, прежде чем информация дойдет до пользователя. Между ними стоит ряд невидимых широкой общественности технологических процессов, с помощью которых создается поисковый образ документа, который представляет собой совокупность характеристик этого документа, выраженных на информационно-поисковой языке.
Известно, что обеспечение доступа к информационным массивам осуществляется благодаря средствам лингвистического обеспечения, от качества которых зависит и эффективность поиска, и имидж библиотеки. Для того, чтобы пользователи могли оперативно, с достаточной полнотой, точностью и достоверностью находить информацию по узкоспециальных вопросов, работники сектора научной обработки документов разрабатывают новые и совершенствуют старые способы работы. Становление и развитие информационно-поисковых систем - как традиционных, так и автоматизированных - неразрывно связано с качеством лингвистического обеспечения, что является их неотъемлемой частью.
Для удовлетворения потребностей пользователей различных уровней доступа к информации необходимо решить определенные задачи:
• осуществлять аналитико-синтетическую обработку всех видов документов и запросов с необходимой полнотой и точностью;
• распределять информационные потоки по тематике;
• проводить документный поиск в режимах текущего и ретроспективного поиска по запросам;
• разрабатывать удобную для читателя рубрикацию документов в информационных изданиях.
В последнее время появилось немало работ, посвященных лингвистическому обеспечению автоматизированных библиотечно-информационных систем (Е. М. Зайцева, Э. Р. Сукиасян, И. Л. Скипор, Н. В. Богуславская, И. А. Милевская, Л. Н. Пирумова). Вместе с тем, отсутствуют комплексные исследования в области лингвистического обеспечения электронных библиотек.
В этой среде намечается тенденция сближения лингвистического и программного обеспечения, находящихся в тесном взаимодействии с текстовой информацией, хранящейся в электронных библиотеках, что позволяет говорить о формировании целостного гипертекстового лингвистического пространства в условиях электронных библиотек.
Создание и использование распределенных совокупностей электронных ресурсов, объединенных общей идеологией доступа и составляющих основу технологии электронных библиотек, позволит библиотекам решить проблему обслуживания локальных и удаленных пользователей и обмена информацией на международном уровне.
На современном этапе появляется понятие «гипертекстовое лингвистическое пространство
», которое применяется в отношении электронных библиотек.
Гипертекстовое лингвистическое пространство ЭБ представляет собой многоуровневую самоорганизующуюся систему. Самоорганизация данной системы достигается за счет реализации основных принципов формирования гипертекстового лингвистического пространства:
a. структурность,
b. интегрированность,
c. кооперативное действие системы,
d. открытость,
e. учет обратной связи,
f. альтернативность сценариев поиска (нелинейность),
g. возрастание уровня организации объекта во времени.
Результативность информационного поиска в гипертекстовом лингвистическом пространстве достигается за счет соблюдения принципов системности и целостности при его формировании. [64, С. 12-14].
Это новый этап в процессе разработки средств лингвистического обеспечения автоматизированных систем.
Это новая ступень в развитии библиотек.
На современном этапе, я все чаще слышу следующий вопрос: «Каково будущее библиотек? И есть ли вообще у традиционных библиотек в эпоху Интернета будущее?»
Мой ответ: «ДА!»
У библиотек есть будущее! Но это будут уже совсем другие библиотеки… с полнотекстовым доступом к фондам в on-line режиме, с гипертекстовым лингвистическим обеспечением и с огромными объемами бесценной информации.
Это то, к чему сегодня должна стремиться каждая библиотека, чтобы в будущем не исчезнуть, не устареть и не стать неактуальной.
Список литературы:
1. Пирумова, Л. Н. Лингвистическое обеспечение информационно-поисковых систем библиотек АПК: методика формирования и пути совершенствования [Текст]: автореферат диссертации кандидата педагогических наук / Л. Н. Пирумова; Московский государственный университет культуры и искусств. - М., 2003. -19 с.
2. Пирумова, Л.Н. Применение УДК в научных сельскохозяйственных библиотеках [Текст]: история и современность / Л. Н. Пирумова // Научно-техническая информация. Сер.1. - 2008. -№ 8. - С. 10-13.
3. Заболеева-Зотова, А. В. Лингвистическое обеспечение автоматизированных систем [Текст]: учебное пособие для студентов вузов / А. В. Заболеева-Зотова, Камаев В. А. - М.: Высшая школа, 2008. - 245 с. - (Для высших учебных заведений. Информатика и вычислительная техника).
4. Сизых, И. Лингвистическое обеспечение электронного каталога / И. Сизых // Библиотека. - 2009. - № 6. - С. 35-38.
5. Пирумова, Л. Н. Информационно-поисковые языки ЦНСХБ и развитие сельского хозяйства / Л. Н. Пирумова // Тезисы докладов Международной Научной Конференции, г. Краснодар. - Краснодар, 2000. - С. 200-202.
6. Методические рекомендации по применению лингвистических средств для обработки, формирования и ввода национального документного потока в Международную БД А ОК.18 и предоставления его международному сообществу [Текст]: Государственный контракт N 1245-А/13 от 13 ноября 2007 г.: "Провести научные исследования и разработать перечень русскоязычной научной лексики тезауруса АGROVOC ФАО ООН" этап 3. Разработка методических рекомендаций для обработки, формирования и ввода национального документного потока в Международную БД АОК18 и предоставления его международному сообществу / Исполн.: Поздняков В. Г. и др.; Российская академия сельскохозяйственных наук, Государственное научное учреждение «Центральная научная сельскохозяйственная библиотека. -Москва, 2008 -70 с. - Библиогр.: С. 70 (9 назв.).
7. Пирумова, Л. Н. Особенности посткоординатного индексирования документов по сельскому хозяйству и пищевой промышленности [Текст] / Л. Н. Пирумова, Ж. В. Соколова // Библиотечное дело - 2007: современные технологии и ресурсы.- 2007. -4.2.-С. 150-156.
8. Москаленко, Т. А. Информационно-поисковый тезаурус Парламентской библиотеки [Текст]: этапы разработки, ведение, применение и дальнейшие перспективы / Т. А. Москаленко, Н. А. Мякова // Научные и технические библиотеки. - 2009. - № 3. - С. 18-22.
9. Пирумова, Л. Н. Совместимость лингвистических средств ИПС по сельскому хозяйству [Текст] : проблемы и решения (на примере ЦНСХБ Россельхозакадемии) / Л. Н. Пирумова // Библиотечное дело-2003: гуманитарные и технологические аспекты развития. - 2003. - С. 122-123.
10. Зайцев, Е. М. Что нужно современной библиотеке: гипертекстовое лингвистическое пространство или автоматизированные лингвистические системы [Текст] / Е. М. Зайцев // Научные и технические библиотеки. - 2005. - № 4.- С. 5-13.
11. Сукиасян, Э. Р. Школа индексирования [Текст]: практическое пособие / Э.Р. Сукиасян. - Москва : Либерея-Бибинформ, 2005. -143 с. (Серия "Библиотекарь и время. XXI век").- ISBN 5-85129-175-3.
12.ГОСТ 7.59-2003. Индексирование документов. Общие требования к систематизации и предметизации [Текст]. - Москва. : Межгосударственный совет по стандартизации, метрологии и сертификации. - 6 с. - (Система стандартов по информации, библиотечному и издательскому делу).
13.Воройский, Ф. С. Аналитическая обработка документов для обеспечения научных исследований и разработок [Текст] / Ф. С. Воройский // Научные и технические библиотеки. - 2006. - № 2. - С. 23-32.
14.Пирумова, Л. Н. ИПЯ - язык, который надо знать [Текст]: о роли лингвистического обеспечения в развитии информационно-поисковых систем библиотек / Л. Н. Пирумова // Библиотека. - 2006. - № 10. - С. 61-65.
15.Пирумова, Л.Н. Роль ЦНСХБ Россельхозакадемии в развитии лингвистического обеспечения информационно-поисковых систем АПК / Л. Н. Пирумова, В. Е. Поздняков // Доклады РАСХН. - 2006. - № 1. - С. 61-64.
16.Аветисов, М. А. Автоматическое индексирование статей из научных сельскохозяйственных журналов [Текст] / М. С. Аветисов, В. И. Стеллецкий // Библиотечное дело - 2006: Скворцовские чтения. - Москва, 2006. - Ч. 2. - С. 54-60.
17.Качалина, В. В. Современное состояние и возможности совершенствования научной обработки потока новых документов в библиотеке [Текст]: аналитический обзор отечественных источников 2001-2005 гг. / В. В. Качалина // Библиотечное дело - XXI век. - Москва, 2006. - № 2. - С. 112-145.
18.Гендина, Н. И. Лингвистическое обеспечение АРБИКОН [Текст]: результаты социологического анализа / Н. И. Гендина, Т. А. Лигун // Научные и технические библиотеки. - 2007. - № 4. - С. 29-31.
19.Белозеров, В. Н. Термины и определения основных понятий теории УДК [Текст] / В. Н. Белозеров // НТИ. Сер.1. - 2007. - № 10. - С. 9-15.
20.Астахова, Т. С. Современная структура Универсальной десятичной классификации [Текст] / Т. С. Астахова // НТИ. Сер.1. - 2007. - № 10. - С. 15-20.
21.Словарь нормализованных научных терминов, эквивалентных терминам английской версии тезауруса AGROVOCФАО, на русском языке [Текст]: Государственный контракт N 1245-А/13 от 13 ноября 2007 г. этап N 1. Создание словаря нормализованных научных терминов, эквивалентных терминам английской версии тезауруса, на русском языке объемом 7100 терминов по ветеринарии, животноводству и биологии растений / Рос. акад. с.-х. наук, Государственное научное учреждение «Центральная научная сельскохозяйственная библиотека». - Москва, 2007. - 344 с.
22.Пирумова, Л. Н. Роль отраслевых микротезаурусов в совершенствовании лингвистического обеспечения информационно-поисковой системы [Текст] / Л. Н. Пирумова и др. // Библиотечное дело - 2008: библиотеки и профессиональное образование в информационном обществе. - Москва, 2008. - Ч. 2. - С. 33-37.
23.Пирумова, Л. Н. Микротезаурус по ветеринарии как элемент ЛО ЦНСХБ Россельхозакадемии [Текст] / Л. Н. Пирумова // Библиотечное дело - 2008: библиотеки и профессиональное образование в информационном обществе. -Москва, 2008. - Ч. 2. - С. 38-40.
24.Зайцева, Е. М. Лингвистическое обеспечение автоматизированных библиотечно-информационных систем [Текст]: современные требования и направления развития / Научные и технические библиотеки. - 2000. - № 3. -С. 54-57
25.Стандарты по библиотечному делу [Текст]: сборник / Сост.: Захарчук Т. В. и др. -СПб.: Профессия, 2000. -511 с. - (Серия "Библиотека"). - 18ВЫ 5-86457-186-5.
26.Глухов, В. А. Электронные библиотеки. Организация, технология и средства доступа [Текст] / В. А. Глухов, О. Л. Голицына, Н. В. Максимов // НТИ. Сер. 1. -2000. -№ 10. - С. 1-8.
27.Щербинина, Г. С. Философия координатного индексирования [Текст] / Г. С. Щербинина // Научные и технические библиотеки. - 2000. - № 9. - С. 67-78.
28.Сукиасян, Э. Р. Электронный каталог и читатель [Текст] / Э. Р. Сукиасян // Научные и технические библиотеки. 2000. - № 9. - С. 79-85.
29.Пирумова, Л. Н. К вопросу о совместимости средств лингвистического обеспечения баз данных по сельскому хозяйству [Текст] / Л. П. Пирумова // Библиотеки и ассоциации в меняющемся мире: новые технологии и новые формы сотрудничества. - Симферополь, 2000. - Т. 1. - С. 397-401.
30.Галюк, Н. А. Предметизация и индексация в контексте ретроспективной конверсии во ВГБИЛ [Текст] / Н. А. Галюк, М. Н. Романова // Библиотеки и ассоциации в меняющемся мире: новые технологии и новые формы сотрудничества. - Симферополь, 2000. - Т. 1. - С. 395-397.
31.Аветисов, М. А. Перспективы развития библиотечно-информационной системы и информационного обслуживания в области АПК [Текст] / М. А. Аветисов, Л. М. Фрид // Библиотеки и ассоциации в меняющемся мире: новые технологии и новые формы сотрудничества. - М., 1996. - Т. 1. - С. 60-62.
32.Информационное общество. Информационные ресурсы и технологии. Телекоммуникации [Текст]: материалы 5-ой международной конференции "НТИ-2000", Москва, 22-24 ноября 2000 г. / ВИНИТИ. - М., 2000. - 414 с.
33.Лавренова, О. А. Методика разработки информационно-поискового тезауруса [Текст] / О. А. Лавренова // Библиотековедение. - 2000. - № 6. - С. 39-42.
34.Скарук, Г. А. Тематический поиск в электронном каталоге: проблемы лингвистического обеспечения [Текст] / Г. А. Скарук // Библиотековедение. - 2001. - № 3. - С. 48-57.
36.Маршак, Б. И. Как из птицы ИБИС получить дикую кошку ИРБИС, а затем ее приручить [Текст] / Б. И. Маршак, А. И. Бродовский // Электронные изображения и визуальные искусства (ЕУА' 2000, Москва): материалы конференции. - М., 2000. -С.153-157.
37.Пименов, Е. О тезаурусе замолвим слово [Текст] / Е. Пименов // Библиотека. -2001. - № 7. - С. 42-45.
38.Шрайберг, Я. Л. Электронные библиотеки России: программная стратегия и проектная тактика [Текст] / Я. Л. Шрайберг // Научные и технические библиотеки. -2001. -№ 2. -С. 69-74
39.Скарук, Е. А. Лингвистическое обеспечение тематического поиска в электронном каталоге [Текст] / Е. А. Скарук // Библиография. - 2001. - № 2. - С. 75-77.
40.Казаков, Е. Н. Способы описания информационных потребностей пользователей при взаимодействии с электронными библиотеками через посредник с тезаурусом и рубрикатором [Текст] / Е. Н. Казаков // Сборник трудов Третьей всероссийской конференции по электронным библиотекам "Электронные библиотеки: перспективные методы и технологии, электронные коллекции". - Петрозаводск, 2001. - С. 68-72.
41.САВThesaurus.- 1995 ed. / CAB International. – 1315 c.
42.AGROVOC. Multilinqual agricultultural thesaurus / FAO. Third ed. English version. – Rome, 1997. – 602 c.
43.Пирумова, Л. Н. Тезаурус по сельскому хозяйству и продовольствию: индексирование документов и поиск информации в БД АGRОS [Текст]: методические материалы / Л. Н. Пирумова, Л. Т. Харченко; ЦНСХБ Россельхозакадемии. - М., 2001. - 69 с.
44.Сукиасян, Э. Р. Библиотечные каталоги: методические материалы [Текст] / Э. Р. Сукиасян. - М.: ИПО Профиздат, 2001. - 187 с. - ISBN5-88283-047-8. -(Современная библиотека, Вып. 19).
45.Пирумова, Л. Н. О совершенствовании структуры лингвистических средств ЦНСХБ Россельхозакадемии [Текст] / Л. Н. Пирумова, В. Е. Поздняков // Библиотеки и ассоциации в меняющемся мире: новые технологии и новые формы сотрудничества. - М., 2000. - Т. 1.
46.Алешин, Л. И. Поиск документов [Текст]: анализ и новые возможности / Л. И. Алешин // Библиография. - 2002. - № 4. - С. 14-22.
47.ЕnVoc. Многоязычный тезаурус терминов по окружающей среде [Текст]: информационный продукт системы ИНФОТЕРРА - Глобальные сети ЮНЕП по обмену информации по окружающей среде. - 4. изд.. - М. : ИНФОТЕРРА, 1999.
48.Ханжин, А. Г. Теоретические проблемы развития автоматического индексирования и поиска документов [Текст] / А. Г. Ханжин // Информационное общество. Интеллектуальная обработка информации. Информационные технологии. - М., 2002. - С. 365-367.
49.Пирумова, Л. Н. Лингвистическое обеспечение баз данных по сельскому хозяйству: проблемы кооперации [Текст] / Л.Н. Пирумова // Библиотеки и ассоциации в меняющемся мире: новые технологии и новые формы сотрудничества: материалы конференции, Судак, Украина, 51-13 июня 1999 г. / ГПНТБ России. - Судак, 1999. - Т. 2. - С. 90-92.
50.Пирумова, Л. Н. Лингвистическое обеспечение производства текущих изданий ЦНСХБ Россельхозакадемии [Текст] / Л. Н. Пирумова // Библиотечное Дело-2000. Проблемы формирования открытого информационного общества: тезисы докладов 5-ой международной научной конференции (Москва, 25-26 апреля, 2000 г.). - М., 2000.-С. 170-171.
51.Пирумова, Л. Н. Новый этап в информационном обслуживании потребителей ЦНСХБ [Текст] / Л.Н. Пирумова // Аграрная наука. - 1998. - № 3. -С. 28-29.
52.Пирумова, Л. Н. Об информативности пристатейных резюме в отечественных изданиях по вопросам АПК [Текст] / Л.Н. Пирумова // Библиотечное Дело-2001. Российские Библиотеки в мировом информационно и интеллектуальном пространстве: тезисы докладов 6-й международной научной конференции (Москва, 26-27 апреля, 2001 г.).- М., 2001. - С. 176-178.
53.Пирумова, Л. Н. Проблемы адаптации читателей к новым формам информационных услуг [Текст] / Л. Н. Пирумова // Тезисы докладов международной научной конференции «Информационное общество: культурологические аспекты и проблемы», Краснодар, 9 сентября, 1997 г. - Краснодар, 1997. - С. 293-295.
54.Пирумова, Л. Н. Совершенствование лингвистического обеспечения БД ЦНСХБ «АГРОС» [Текст] / Л.Н. Пирумова // Тезисы докладов и сообщения научной конференции «Библиотечное дело и демократия», 8-10 апреля, 1997 г. - М., 1997. -С. 62-65.
55.Пирумова, Л. Н. Аналитическая деятельность ЦНСХБ [Текст] / Л.Н. Пирумова, О. Б. Сладкова // Информационные ресурсы России. - 1998. - № 1. - С. 34-37.
56.Пирумова, Л. Н. Проблемы лингвистического обеспечения в БД «АГРОС» документального потока по пищевой промышленности [Текст] / Л. Н. Пирумова // Библиотечное дело и проблемы информатизации общества: тезисы докладов международной научной конференции, Москва, 27-28 апреля, 1999 г. / МГУК. - М., 1999.-Ч. 1.-С. 175-177.
57.
Пирумова, Л. Н. Роль и место ЦНСХБ в формировании современной отраслевой информационной среды [Текст] / Л. Н. Пирумова // НТИ. Сер. 1. - 1995. - №2. - С. 36-38.
58.
Пирумова, Л. Н. О совершенствовании структуры лингвистических средств ЦНСХБ Россельхозакадемии [Текст] / Л. Н. Пирумова, В. Г. Поздняков // Библиотеки и ассоциации в меняющемся мире: новые технологии и новые формы сотрудничества: труды конференции Судак, Украина, 9-17 июня 2001 г. / ГПНТБ России. - Судак, 2001. - Т. 1.-С. 528-531.
59.
Пирумова, Л. Н. Индексирование документов базы данных ЦНСХБ [Текст] / Л. Н. Пирумова, Л. Т. Харченко. - М., 1995. - 35 с.
60.
Master Reference File (MRF) [Электронныйресурс] /
UDC Consortium // http://www.udcc.org/mrf.htm
61.
Strachan, P.D.The UDC MRF Database Development and Design – a historical review [Электронныйресурс] /
P.D. Strachan, M. H. Oomes;UDC Consortium // http://www.udcc.org/mrf2.htm
62.
UDC-Online[Электронныйресурс] /
UDC Consortium // http://www.udconline.net/
63.
Яшина Н. Г. Гипертекстовое лингвистическое обеспечение электронной библиотеки: автореферат диссертации на соискание ученой степени кандидата педагогических наук: 05.25.03. – Казань, 2004. – 24 с.
64.Закон України «Про Національну програму інформатизації» .- К., 1998. - 10 с.
65.
Лавренова, О. А. Лингвистика информационных систем и межбиблиотечное сотрудничество / О. А. Лавренева // Библиотеки и ассоциации в меняющемся мире: новые технологии и новые формы сотрудничества. – 1997 – Т. 2.- С. 12-18.
66.
Митчелл, Д. Десятичная классификация Дьюи: средство организации знанийдля XXI века / Д.
Митчел // Научные и технические библиотеки , 1999.- № 4, C. 35-36.
67.
Про порядок формування предметних рубрик электронного каталогу ДНСГБ УААН: інструкція /Л. М. Татарчук // Бюлетень ДНСГБ УААН.- Вип.1.- 2009.- С. 32-36.
68.
Державний стандарт України ДСТУ 25395-2000 (ISO 5963:1985) Інформація та документація. Обстеження документа, встановлення його предмета та відбір термінів індексування. Загальна методика. - К., 2001.
69.
Універсальна десяткова класифікація (УДК): у 2 - х кн. / Книжкова палата України, - К., 2000. - 929 с.
70.
Бардієр К. Структура лінгвістичного забезпечення сучасних інформаційних сервісів / К. Бардієр // Бібліотечний вісник . - 2002 .- № 1, - С. 55 – 61.
71.
Вергунов, В.А. Державна наукова сільськогосподарська бібліотека УААН: історія і сьогодення / В.А. Вергунов; УААН. ДНСГБ. – К., 2007 [2008]. – 480 с. – (Іст.-бібліогр. сер. «Аграр. наука України в особах, документах, бібліографії; Кн. 20).
72.
Малицкий, Н. А.Функциональные возможности современных библиографических ИПС на Web [Электронный ресурс] /
Н. А.Малицкий, Б. С. Елепов// http://www.nbuv.gov.ua/Articles/crimea/2004/doc/258.pdf
73.
http://www.dnsgb.kiev.ua/
74.
http://irbis.gpntb.ru/
Приложение № 1
Основные понятия применяющиеся в среде лингвистического обеспечения АБИС СЛОВАРЬ
1. Упорядоченный перечень слов, словосочетаний, терминов, символических имен или наименований, знаков с указанием их значений или толкований или без них. Важным требованием к словарям, используемым в автоматизированных системах, является устранение синонимии и омонимии для обеспечения точности и полноты поиска.
2. В автоматизированных информационных системах - это структура данных, обеспечивающая доступ к БД и отдельным записям по их текстовому имени.
Виды словарей
Машинный словарь - словарь, находящийся в памяти ЭВМ и использующийся для автоматического и/или контролируемого индексирования.
Рубрикатор - разновидность словаря, содержанием которого является перечень предметных рубрик и их классификационных индексов. Одним из наиболее распространенных видов рубоикаторов являются иерархические тематические рубрикаторы (УДК, ГРНТИ, ББК, МКИ и др.).
Тезаурус (информационно-поисковый) - словарь, содержащий разрешенные для использования при индексировании лексические единицы ИПЯ, а также парадигматические отношения между этими лексическими единицами. Тезаурусы различают по принципу их организации (например, алфавитный, иерархический, фасетный), способу использования (например, машинный тезаурус, т.е. находящийся в памяти ЭВМ), тематике и полноте охвата его лексикой определенной предметной области (например, базовый тезаурус, рабочий тезаурус, многоотраслевой тезаурус, узкотематический тезаурус и т.п.) В некоторых автоматизированных информационых системах словари, выполняющие функции тезауруса, носят иные названия, например Базовый терминологический словарь (БТС) ВИМИ.
Предметная рубрика - краткое наименование классификационного признака однородных объектов (узко) библиографической или (широко) информационной деятельности.
Классификационный индекс - условное обозначение цифровыми или буквенно-цифровыми символами деления какой-либо системы классификации.
Синонимия - совпадение или близость значений различных слов (синонимов).
Омономия - внешнее совпадение слов, одинаковых по написанию и звучанию (омонимов).
Лексическая единица - обозначение отдельного понятия в естественном или специально созданном искусственном языке, например ИПЯ. Лексическая единица может иметь вид слова, устойчивого словосочетания, аббревиатуры, символьного кода и т.п.
Виды отношений и связанные с ними термины Ассоциативные отношения
1.Разновидность парадигматических отношений, отражающих представление пользователя о взаимосвязи понятий, которые они отображают. Часто под ассоциативными отношениями понимаются все виды парадигматических отношений, кроме отношений типа "вид-род" и "часть-целое". Так же как и парадигматические отношения, они являются внетекстовыми и служат для реализации конкретных задач пользователей.
2.Отношения между данными в структурах данных.
Парадигматические отношения, аналитические отношения, ассоциативные отношения - вид логических отношений между лексическими единицами ИПЯ (дескрипторами, ключевыми словами и т.п.), не зависящими от конкретного контекста, в котором соответствующие им понятия употребляются. Парадигматические отношения позволяют осуществлять избыточное индексирование текстов путем включения в поисковый образ документа и поисковое предписание близких по смыслу лексических единиц ИПЯ для повышения полноты поиска.
Семантические отношения - отношения между понятиями в "семантических сетях". Различают лингвистические (соответствующие и взаимоотношению слов в предложении), теоретико-множественные и логические отношения.
Синтагматические отношения, текстуальные отношения, синтаксические отношения - отношения между лексическими единицами ИПЯ (дескрипторами, ключевыми словами и т.п.), которые выражают логические связи между соответствующими понятиями в тексте документа. Синтагматические отношения являются разновидностью семантических отношений.
Синтагма - группа лексических единиц, связанных синтагматическими отношениями и представляющих собой законченное предложение на информационно-поисковом языке.
Фасет - группа однородных терминов, связанных общностью какого-либо признака (характеристики, основания деления). Служит средством построения ИПЯ фасетной структуры.
Индексирование - это процесс перевода содержания документов и запросов с естественного на информационно-поисковый язык, в результате чего создаются поисковые образы документов (ПОД) и поисковые предписания (ПП).
Индексирование, наряду с составлением библиографического описания, реферированием, аннотированием , составлением обзоров, является разновидностью аналитико-синтетической обработки или свертывания информации.
В зависимости от ИПЯ (иерархическая классификация, алфавитно-предметная классификация, дескрипторный ИПЯ) индексирование может воплощаться в следующих процессах:
-предметизация, т.е. индексирование на основе языка предметных рубрик, алфавитно-предметной классификации
-систематизация литературы, осуществляемая на базе классификационных иерархических ИПЯ
-координатное индексирование, реализуемое на основе дескрипторного ИПЯ или языка ключевых слов.
Соответственно, в зависимости от используемого ИПЯ, результатом индексирования т.е. ПОД и ПП, могут быть либо индекс классификации, либо перечень дескрипторов или
ключевых слов.
Информационно-поисковый язык (ИПЯ) - это искусственный язык, предназначенный для выражения содержания документов или запросов или описания фактов с целью последующего поиска.
Дескрипторный ИПЯ - это ИПЯ, лексическими единицами которого являются дескрипторы и использование которого основано на принципе координатного индексирования.
Координатное индексирование - это индексирование путем перечисления ключевых слов и/или дескрипторов.
Принцип координатного индексирования заключается в том, что центральная тема документа или информационного запроса выражается в виде перечня наиболее значимых слов или словосочетаний, которые являются как бы координатами документа или запроса.
В состав лексики отбирают не любые слова вообще, а "ключевые слова", т.е. слова, несущие в тексте наибольшую смысловую нагрузку.
Ключевое слово - это полнозначное слово или словосочетание, являющееся носителем существенной в данном тексте (документе или запросе) информации с точки зрения информационного поиска.
Нормативный словарь, в котором в едином алфавитном ряду приведены все важнейшие ключевые слова и дескрипторы отрасли или области знаний с соответствующими пометами, называется дескрипторным словарем.
Нормативный словарь дескрипторов и ключевых слов с зафиксированными парадигматическими отношениями, предназначенный для координатного индексирования документов и запросов, называется информационно-поисковым тезаурусом. Слово "тезаурус" происходит от греческого слова 'ЧЬезаип" - сокровище. Лексика дескрипторного ИПЯ в качестве основных лексических единиц включает дескрипторы и аскрипторы.
Дескриптор - это нормализованное слово, или словосочетание, выбранное из группы синонимичных или близких по значению, ключевых слов (класса условной эквивалентности) и предназначенное для индексирования документов и запросов, др. словами - нормализованное слово, которому искусственным путем придана смысловая однозначность.
Аскрипторы (недескрипторы) - это лексические единицы, подлежащие замене на дескрипторы в поисковых образах документов (запросов) при поиске и обработке информации.
Аскрипторы всегда сопровождаются ссылками на заменяющие их дескрипторы, включая такие, как - «см» или «исп».
Дескрипторная статья состоит из заглавного дескриптора, списка дескрипторов и аскрипторов, семантически связанных с ним, с указанием вида связи. В рамках дескрипторной статьи термины располагаются в сл. порядке:
-дескриптор - обозначение класса условной эквивалентности, т.е. совокупности всех лексических единиц (лингвистических и информационных синонимов), описывающих класс условной эквивалентности
-индексы (цифровые нотации) рубрик соответствующего рубрикатора, к которому относится этот дескриптор
- обозначение предметных полей, к которым относится дескриптор
- пометы, определяющие или уточняющие значение дескриптора в рамках системы
- перечень простых недескрипторов, заменяемых данным дескриптором при индексировании. Они являются простыми синонимами к дескриптору и приводят после символа "с" - синонимы
- перечень вышестоящих дескрипторов
- перечень нижестоящих дескрипторов
- перечень ассоциативных дескрипторов
|