Содержание
СПИСОК ИСПОЛЬЗУЕМЫХ ИСТОЧНИКОВ……………………….…………….…….……..35. Ошибка! Закладка не определена.
Введение.. 3
Глава 1 Корреляционный анализ. 4
1.1 Функциональная, статистическая и корреляционная зависимости.. 4
1.2 Линейная парная регрессия. 4
1.3 Коэффициент корреляции.. 4
1.4 Основные положения корреляционного анализа.4
1.5 Корреляционное отношение и индекс корреляции.. 4
1.6 Понятие о многомерном корреляционном анализе.4
Множественный и частный коэффициенты корреляции.. 4
1.7 Ранговая корреляция. 4
Глава 2 Регрессионный анализ. 4
2.1. Основные положения регрессионного анализа. Парная регрессионная модель. 4
2.2. Интервальная оценка функции регрессии.. 4
2.3. Проверка значимости уравнения регрессии. Интервальная оценка параметров парной модели.. 4
2.4. Нелинейная регрессия. 4
2.5. Определение доверительных интервалов. 4
для коэффициентов и функции регрессии.. 4
2.6. Мультиколлинеарность. 4
2.7. Понятие о других методах многомерного статистического анализа.. 4
Заключение.. 4
Список используемых источников.. 4
Приложение 1. 4
Приложение 2. 4
Диалектический подход к изучению природы и общества требует рассмотрения явлений в их взаимосвязи и непрестанном изменении. Понятия корреляции и регрессии появились в середине XIX в. благодаря работам английских статистиков Ф. Гальтона и К. Пирсона. Первый термин произошел от латинского «correlatio» – соотношение, взаимосвязь. Второй термин (от лат. «regressio» - движение назад) введен Ф. Гальтоном, который, изучая зависимость между ростом родителей и их детей, обнаружил явление «регрессии к среднему» – у детей, родившихся у очень высоких родителей, рост имел тенденцию быть ближе к средней величине.
В практике экономических исследований очень часто имеющиеся данные нельзя считать выборкой из многомерной нормальной совокупности, например, когда одна из рассматриваемых переменных не является случайной или когда линия регрессии явно не прямая и т.п. В этих случаях пытаются определить кривую (поверхность), которая дает наилучшее (в смысле метода наименьших квадратов) приближение к исходным данным. Соответствующие методы приближения получили название регрессионного анализа. Задачами регрессионного анализа являются установление формы зависимости между переменными, оценка функции регрессии, оценка неизвестных значений (прогноз значений) зависимой переменной.
Выше сказанным обусловлена актуальность выбора темы курсовой работы. Цель данной работы – исследовать функциональную зависимость между случайными величинами методами корреляционного и регрессионного анализов.
В естественных науках часто речь идет о функциональной зависимости (связи), когда каждому значению одной переменной соответствует вполне определенное значение другой. Функциональная зависимость может иметь место как между детерминированными (неслучайными) переменными (например, зависимость скорости падения в вакууме от времени и т.п.), так и между случайными величинами (например, зависимость стоимости проданных изделий от их числа и т.п.).В экономике в большинстве случаев между переменными величинами существуют зависимости, когда каждому значению одной переменной соответствует не какое-то определенное, а множество возможных значений другой переменной. Иначе говоря, каждому значению одной переменной соответствует определенное (условное) распределение другой переменной. Такая зависимость (связь) получила название статистической (или стохастической, вероятностной).
Возникновение понятия статистической связи обусловливается тем, что зависимая переменная подвержена влиянию ряда неконтролируемых или неучтенных факторов, а также тем, что измерение значений переменных неизбежно сопровождается некоторыми случайными ошибками. Примером статистической связи является зависимость урожайности от количества внесенных удобрений, производительности труда на предприятии от его энерговооруженности и т.п.
В силу неоднозначности статистической зависимости между Yи Х для исследователя, в частности, представляет интерес усредненная по х схема зависимости, т.е. закономерность в изменении среднего значения - условного математического ожидания  (Y) (математического ожидания случайной переменной Y, найденного при условии, что переменная Х приняла значение х ) в зависимости от х. (Y) (математического ожидания случайной переменной Y, найденного при условии, что переменная Х приняла значение х ) в зависимости от х.
Определение
: Статистическая зависимость между двумя переменными, при которой каждому значению одной переменной соответствует определенное среднее значение, т.е. условное математическое ожидание другой, называется корреляционной. Иначе, корреляционной зависимостью между двумя переменными величинами называется функциональная зависимость между значениями одной из них и условным математическим ожиданием другой.
Корреляционная зависимость может быть представлена в виде:
(Y)= (1.1) (1.1)
 (X)=ψ(x) (1.2) (X)=ψ(x) (1.2)
 Предполагается, что φ(x)≠const и ψ(x)≠const, т.е. если при изменении х или у уcловные математические ожидания Предполагается, что φ(x)≠const и ψ(x)≠const, т.е. если при изменении х или у уcловные математические ожидания (Y) и (Y) и  не изменяются, то говорят, что корреляционная зависимость между переменными Х и У отсутствует. Сравнивая различные виды зависимости между Х иY, можно сказать, что с изменением значений переменной Х при функциональной зависимости однозначно изменяется определенное значение переменной у, при корреляционной – определенное среднее значение (условное математическое ожидание) Y, а при статистической- определенное (условное) распределение переменной Y (Рис.1.1) не изменяются, то говорят, что корреляционная зависимость между переменными Х и У отсутствует. Сравнивая различные виды зависимости между Х иY, можно сказать, что с изменением значений переменной Х при функциональной зависимости однозначно изменяется определенное значение переменной у, при корреляционной – определенное среднее значение (условное математическое ожидание) Y, а при статистической- определенное (условное) распределение переменной Y (Рис.1.1)
рис. 1.1
Таким образом, из рассмотренных зависимостей наиболее общей выступает статистическая зависимость. Каждая корреляционная зависимость является статистической, но не каждая статистическая зависимость является корреляционной. Функциональная зависимость представляет частный случай корреляционной.
Уравнения (1.1) и (1.2) называются модельными уравнениями регрессии (или просто уравнениями регрессии) соответственно Yпо Х и Х по Y, функции ψ(x) и φ(у) – модельными функциями регрессии (или функциями регрессии), а их графики - модельными линиями регрессии (или линиями регрессии).
Для отыскания модельных уравнений регрессии, вообще говоря, необходимо знать закон распределения двумерной случайной величины (Х,Y). На практике исследователь, как правило, располагает лишь выборкой пар значений ( , , ) ограниченного объема. В этом случае речь может идти об оценке (приближенном выражении) по выборке функции регрессии. Такой наилучшей (в смысле метода наименьших квадратов) оценкой является выборочная линия (кривая) регрессии Yпо Х ) ограниченного объема. В этом случае речь может идти об оценке (приближенном выражении) по выборке функции регрессии. Такой наилучшей (в смысле метода наименьших квадратов) оценкой является выборочная линия (кривая) регрессии Yпо Х
 ) (1.3) ) (1.3)
где – условная (групповая) средняя переменной Yпри фиксированном значении переменной Х = х; – условная (групповая) средняя переменной Yпри фиксированном значении переменной Х = х;  , , ,…, ,…, - параметры кривой. - параметры кривой.
Аналогично определяется выборочная линия (кривая) регрессии Х по Y:
 (1.4) (1.4)
где  – условная (групповая) средняя переменной Х при фиксированном значении переменной Y= у; – условная (групповая) средняя переменной Х при фиксированном значении переменной Y= у;  -параметры кривой. -параметры кривой.
Уравнения (1.3), (1.4) называют также выборочными уравнениями регрессии соответственно Yпо Х и Х по Y.
При правильно определенных аппроксимирующих функциях  ) и ) и 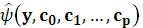 с увеличением объема выборки(n с увеличением объема выборки(n ) они будуг сходиться по вероятности соответственно к функциям регрессии ψ(x) и φ(у). ) они будуг сходиться по вероятности соответственно к функциям регрессии ψ(x) и φ(у).
Статистические связи между переменными можно изучать методами корреляционного и регрессионного анализа. Основной задачей регрессионного анализа является установление формы и изучение зависимости между переменными. Основной задачей корреляционного анализа – выявление связи между случайными переменными и оценка ее тесноты.
Данные о статистической зависимости удобно задавать в виде корреляционной таблицы.
Рассмотрим в качестве примера зависимость между суточной выработкой продукции Y(т) и величиной основных производственных фондов Х (млн руб.) для совокупности 50 однотипных предприятий (табл. 1).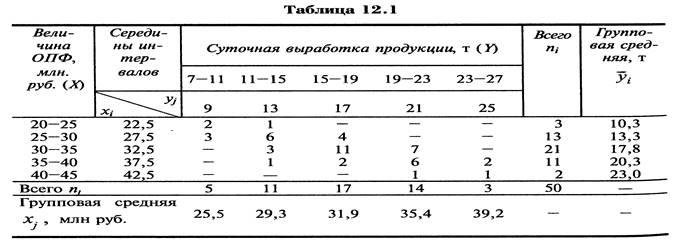 (В таблице через (В таблице через и и обозначены середины соответствующих интервалов, а через обозначены середины соответствующих интервалов, а через , и , и  – соответственно их частоты.) – соответственно их частоты.)
Для каждого значения, т.е. для каждой строки корреляционной таблицы вычислим групповые средние
 (1.5) (1.5)
где  - частоты пар ( - частоты пар ( ) и ) и  ; m – число интервалов по переменной Y. ; m – число интервалов по переменной Y.
Вычисленные групповые средние поместим в последнем столбце корреляционной таблицы и изобразим графически в виде ломаной, называемой эмпирической линией регрессии Y по X поместим в последнем столбце корреляционной таблицы и изобразим графически в виде ломаной, называемой эмпирической линией регрессии Y по X
Аналогично для каждого значения  по формуле по формуле
 (1.6) (1.6)
вычислим групповые средние  , где , где  , l – число интервалов по переменной X. , l – число интервалов по переменной X.
По виду ломанной можно определить наличие линейной корреляционной зависимости Y по X между двумя рассматриваемыми переменными, которая выражается тем точнее чем больше объем выборки n:
n= (1.7) (1.7)
Поэтому уравнение регрессии(1.3) будем искать в виде:
 (1.8) (1.8)
Отвлечемся на время от рассматриваемого примера и найдем формулы расчета неизвестных параметров уравнения линейной регрессии.
С этой целью применим метод наименьших квадратов, согласно которому неизвестные параметры и выбираются таким образом, чтобы сумма квадратов отклонений эмпирических групповых средних и выбираются таким образом, чтобы сумма квадратов отклонений эмпирических групповых средних  , вычисленных по формуле (1.5), от значений , вычисленных по формуле (1.5), от значений  , найденных по уравнению регрессии (1.8), была минимальной: , найденных по уравнению регрессии (1.8), была минимальной:
S= (1.9) (1.9)
На основании необходимого условия экстремума функции двух переменных S=S( ) приравниваем к нулю ее частные производные, т.е. ) приравниваем к нулю ее частные производные, т.е.

Откуда после преобразования получим систему нормальных уравнений для определения параметров линейной регрессии:
 (1.10) (1.10)
Учитывая (1.5) преобразуем выражение и с учетом (1.7), разделив обе части уравнений (1.10) на n, получим систему нормальных уравнений в виде:
 (1.11) (1.11)
где соответствующие средние определяются по формулам:
 , ,  (1.12) (1.12)
 (1.13) (1.13)
 (1.14) (1.14)
Подставляя значение  из первого уравнения системы(1.11) в уравнение регрессии (1.8), получаем из первого уравнения системы(1.11) в уравнение регрессии (1.8), получаем
 (1.15) (1.15)
Коэффициент b1
в уравнении регрессии, называемый выборочным коэффициентом регрессии (или просто коэффициентом регрессии) Yпо Х, будем обозначать символом . Теперь уравнение регрессии Yпо Х запишется так: . Теперь уравнение регрессии Yпо Х запишется так:
(1.15)
Коэффициент регрессии Yпо Х показывает, на сколько единиц в среднем изменяется переменная Y при увеличении переменной Х на одну единицу.
Решая систему (1.11), найдем
 , (1.16) , (1.16)
где  - выборочная дисперсия переменной X - выборочная дисперсия переменной X
 = = – ( – ( (1.17) (1.17)
µ - выборочный корреляционный момент:
µ= (1.18) (1.18)
Рассуждая аналогично и полагая уравнение регрессии (1.4) линейным, можно привести его к виду:

где
 (1.21) (1.21)
выборочный коэффициент регрессии (или просто коэффициент регрессии) Х по Y, показывающий, на сколько единиц в среднем изменяется переменная Х при увеличении переменной Y на одну единицу = = – ( – ( –выборочная дисперсия переменной Y. –выборочная дисперсия переменной Y.
Так как числители в формулах (1.16) и (1.20) для  и и  совпадают, а знаменатели – положительные величины, то коэффициент регрессии и имеют одинаковые знаки, определяемые знаком совпадают, а знаменатели – положительные величины, то коэффициент регрессии и имеют одинаковые знаки, определяемые знаком  . Из уравнений регрессии (1.15) и (1.19) следует, что коэффициенты и определяют угловые коэффициенты (тангенсы углов наклона) к оси Ох соответствующих линий регрессии, пересекающихся в точке ( . Из уравнений регрессии (1.15) и (1.19) следует, что коэффициенты и определяют угловые коэффициенты (тангенсы углов наклона) к оси Ох соответствующих линий регрессии, пересекающихся в точке ( ). ).
Перейдем к оценке тесноты корреляционной зависимости. Рассмотрим наиболее важный для практики и теории случай линейной зависимости вида (1.15).На первый взгляд подходящим измерителем тесноты связи Yот Х является коэффициент регрессии ибо, как уже отмечено, он показывает, на сколько единиц в среднем изменяетсяY, когда Х увеличивается на одну единицу. Однако зависит от единиц измерения переменных. Например, в полученной ранее зависимости он увеличится в 1000 раз, если величину основных производственных фондов Х выразить не в млн руб., а в тыс. руб.
Очевидно, что для «исправления» как показателя тесноты связи нужна такая стандартная система единиц измерения, в которой данные по различным характеристикам оказались бы сравнимы между собой. Статистика знает такую систему единиц. Эта система использует в качестве единицы измерения переменной ее среднее квадратическое отклонение s.
Представим уравнение (1.15) в эквивалентном виде:
 (1.22) (1.22)
В этой системе величина
r = (1.23) (1.23)
показывает, на сколько величин  изменится в среднем Y, когда X увеличится на одно изменится в среднем Y, когда X увеличится на одно  .Величина r является показателем тесноты линейной связи и называется выборочным коэффициентом корреляции (или просто коэффициентом корреляции). .Величина r является показателем тесноты линейной связи и называется выборочным коэффициентом корреляции (или просто коэффициентом корреляции).
  На рис. 1.2 приведены две корреляционные зависимости переменной Yпо Х. В случае а) зависимость между переменными менее тесная и коэффициент корреляции должен быть меньше, чем в случае б), так как точки корреляционного поля а) дальше отстоят от линии регрессии, чем точки поля б). На рис. 1.2 приведены две корреляционные зависимости переменной Yпо Х. В случае а) зависимость между переменными менее тесная и коэффициент корреляции должен быть меньше, чем в случае б), так как точки корреляционного поля а) дальше отстоят от линии регрессии, чем точки поля б).
Нетрудно видеть, что r совпадает по знаку с (а значит, и с )
Если r > 0 ( > 0, > 0), то корреляционная связь между переменными называется прямой, если r < 0 (< 0, < 0) – обратной . При прямой (обратной) связи увеличение одной из переменных ведет к увеличению (уменьшению) условной (групповой) средней другой.
Учитывая равенство (1.16), формулу для r представим в виде:
 (1.24) (1.24)
Отсюда видно, что формула для r симметрична относительно двух переменных, т.е. переменные Х и Yможно менять местами. Тогда аналогично формуле (1.24) можно записать:
 (1.25) (1.25)
Найдя произведение обеих частей равенств(1.24) и (1,25), получим:
 (1.26) (1.26)
или
 (1.27) (1.27)
т.е. коэффициент корреляции r переменных Х и Y есть средняя геометрическая коэффициентов регрессии, имеющая их знак.
Отметим основные свойства коэффициента корреляции
(при достаточно большом объеме выборки n), аналогичные свойствам коэффициента корреляции двух случайных величин .
1. Коэффициент корреляции принимает значения на отрезке
[-1; 1], т.е.
 (1.28) (1.28)
В зависимости от того, насколько  приближается к 1, различают связь слабую, умеренную, заметную, достаточно тесную, тесную и весьма тесную, т.е. чем ближе к 1, тем теснее связь. приближается к 1, различают связь слабую, умеренную, заметную, достаточно тесную, тесную и весьма тесную, т.е. чем ближе к 1, тем теснее связь.
2. Если все значения переменных увеличить (уменьшить) на одно и то же число или в одно и то же число раз, то величина коэффициента корреляции не изменится.
3. При r
= ± 1 корреляционная связь представляет линейную функциональную зависимость. При этом линии регрессии
Y
по Х и Х по
Y
совnадают и все наблюдаемые значения располагаются на общей прямой.
4. При r
= 0 линейная корреляционная связь отсутствует. При этом групповые средние переменных совпадают
с их общими средними, а линии регрессии
Y
по
X
и
X
по
Y
параллельны осям координат. Равенство r
= 0 говорит лишь об отсутствии линейной корреляционной зависимости (некоррелированности переменных), но не вообще отсутствии корреляционной, а тем более статистической зависимости.
Выборочный коэффициент корреляции r
является оценкой генерального коэффициента корреляции
ρ (о котором речь пойдет дальше), тем более точной, чем больше объем выборки п.
И указанные выше свойства, строго говоря, справедливы для ρ. Однако при достаточнобольшом nих можно распространить и на r.
Корреляционный анализ (корреляционная модель)– метод, применяемый тогда, когда данные наблюдений или эксперимента можно считать случайными и выбранными из совокупности, распределенной по многомерному нормальному закону.
Основная задача корреляционного анализа
,
как отмечено выше, состоит в выявлении связи между случайными переменными путем точечной и интервальной оценок различных (парных, множественных, частных) коэффициентов корреляции.
Дополнительная задача корреляционного анализа (являющаяся основной в регрессионном анализе) заключается в оценке уравнений регрессии одной переменной по другой.
Рассмотрим простейшую модель корреляционного анализа – двумерную. Плотность совместного нормального распределения двух переменных X
и Y
имеет вид:
 (1.28) (1.28)
ρ- коэффициент корреляции между переменными X и Y, определяемый через кореляционный момент (ковариацию)  по формуле: по формуле: или или
ρ= (1.30) (1.30)
Величина ρ характеризует тесноту связи между случайными переменными X и Y. Указанные параметры  ρ дают исчерпывающие сведения о корреляционной зависимости между переменными. ρ является показателем тесноты связи лишь в случае линейной зависимости между двумя переменными, получаемой, в частности при их совместном нормальном распределении. ρ дают исчерпывающие сведения о корреляционной зависимости между переменными. ρ является показателем тесноты связи лишь в случае линейной зависимости между двумя переменными, получаемой, в частности при их совместном нормальном распределении.
Введенный выше коэффициент корреляции, как уже отмечено, является полноценным показателем тесноты связи лишь в случае линейной зависимости между переменными. Однако часто возникает необходимость в достоверном показателе интенсивности связи при любой форме зависимости.
Для получения такого показателя воспользуемся правилом сложения дисперсий:
 (1.31) (1.31)
где  общая дисперсия переменной общая дисперсия переменной
 (1.32) (1.32)
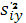 средняя групповых дисперсий средняя групповых дисперсий  , или остаточная дисперсия , или остаточная дисперсия
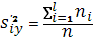 (1.33) (1.33)
  (1.34) (1.34)
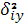 межгрупповая дисперсия межгрупповая дисперсия
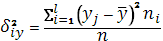 (1.35). (1.35).
Остаточной дисперсией измеряют ту часть колеблемости Y, которая возникает из-за изменчивости неучтенных факторов, не зависящих от Х.
Межгрупповая дисперсия выражает ту часть вариации Y, которая обусловлена изменчивостью Х.
Величина
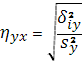 (1.36) (1.36)
получила название эмпирического корреляционного отношения
Yпо Х.
Чем теснее связь, тем большее влияние на вариацию переменной Y
оказывает изменчивость Х
по сравнению с неучтенными факторами, тем выше  .Величина .Величина  ,называемая эмпирическим коэффициентом детерминации,
показывает, какая часть общей вариации Y
обусловлена вариацией Х.
Аналогично вводится эмпирическое корреляционное отношение Х по
Y: ,называемая эмпирическим коэффициентом детерминации,
показывает, какая часть общей вариации Y
обусловлена вариацией Х.
Аналогично вводится эмпирическое корреляционное отношение Х по
Y:
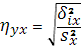 (1.37). (1.37).
Отметимосновные свойства корреляционных отношений:
1.
Корреляционное отношение есть неотрицательная величина, не превосходящая единицу: 0 . .
2.
Если η=0, то корреляционная связь отсутствует.
3.
Если η=1, то между переменными существует функциональная зависимость.
4.
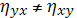 , т.е. в отличие от коэффициента корреляции r при вычислении корреляционного отношения существенно, какую переменную считать независимой, а какую– зависимой. , т.е. в отличие от коэффициента корреляции r при вычислении корреляционного отношения существенно, какую переменную считать независимой, а какую– зависимой.
Эмпирическое корреляционное отношение  является показателем рассеяния точек корреляционного поля относительно эмпирической линии регрессии, выражаемой ломаной, соединяющей значения является показателем рассеяния точек корреляционного поля относительно эмпирической линии регрессии, выражаемой ломаной, соединяющей значения  Однако в связи с тем, что закономерное изменение Однако в связи с тем, что закономерное изменение  нарушается случайными зигзагами ломаной, возникающими вследствие остаточного действия неучтенных факторов, преувеличивает тесноту связи. По- этому наряду с рассматривается показатель тесноты связи нарушается случайными зигзагами ломаной, возникающими вследствие остаточного действия неучтенных факторов, преувеличивает тесноту связи. По- этому наряду с рассматривается показатель тесноты связи 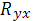 , характеризующий рассеяние точек корреляционного поля относительно линии регрессии , характеризующий рассеяние точек корреляционного поля относительно линии регрессии 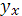 (1.3). Показатель получил название теоретического корреляционного отношения или индекса
корреляции Y по X: (1.3). Показатель получил название теоретического корреляционного отношения или индекса
корреляции Y по X:
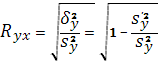 (1.38). (1.38).
Подобно вводится и индекс корреляции X по Y:
 (1.39). (1.39).
Достоинством рассмотренных показателей η и R
является то, что они могут быть вычислены при любой форме связи между переменными. Хотя η и завышает тесноту связи по сравнению с R,
но для его вычисления не нужно знать уравнение регрессии. Корреляционные отношения η и R
связаны с коэффициентом корреляции r
следующим образом: 0
В случае линейной модели т.е. зависимости  индекс корреляции равен коэффициенту корреляции r(по абсолютной величине): индекс корреляции равен коэффициенту корреляции r(по абсолютной величине):  . .
Коэффициент детерминации  , равный квадрату индекса корреляции (для парной линейной модели - r2
), показывает долю общей вариации зависимой переменной, обусловленной регрессией или изменчивостью объясняющей переменной.. , равный квадрату индекса корреляции (для парной линейной модели - r2
), показывает долю общей вариации зависимой переменной, обусловленной регрессией или изменчивостью объясняющей переменной..
Чем ближе к единице, тем лучше регрессия аппроксимирует эмпирические данные, тем теснее наблюдения примыкают к линии регрессии. Если = 1, то эмпирические точки (
x
, у)
лежат на линии регрессии (см. рис. 12.4) и между переменными Y
и Х
существует линейная функциональная зависимость. Если =0, то вариация зависимой переменной полностью обусловлена воздействием неучтенных в модели переменных, и линия регрессии параллельна оси абсцисс .
Экономические явления чаще всего адекватно описываются многофакторными моделями. Поэтому возникает необходимость обобщить рассмотренную выше двумерную корреляционную модель на случай нескольких переменных.
Пусть имеется совокупность случайных переменных 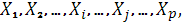 имеющих совместное нормальное распределение. В этом случае матрицу составленную из парных коэффициентов корреляции имеющих совместное нормальное распределение. В этом случае матрицу составленную из парных коэффициентов корреляции 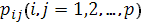 ,будем называть корреляционной. Основная задача многомерного корреляционного анализа состоит в оценке корреляционной матрицы ,будем называть корреляционной. Основная задача многомерного корреляционного анализа состоит в оценке корреляционной матрицы 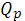 по выборке. Эта задача решается определением матрицы выборочных коэффициентов корреляции. по выборке. Эта задача решается определением матрицы выборочных коэффициентов корреляции.
В многомерном корреляционном анализе рассматривают две типовые задачи:
а) определение тесноты связи одной из переменных с совокупностью остальных
(р – 1) переменных, включенных в анализ;
б) определение тесноты связи между переменными при фиксировании или исключении влияния остальных q
переменных, где q
 (p-2). (p-2).
Эти задачи решаются с помощью множественных и частных коэффициентов корреляции.
Множественный коэффициент корреляции.
Теснота линейной взаимосвязи одной переменной с совокупностью других (p с совокупностью других (p переменных переменных  рассматриваемой в целом, измеряется с помощью множественного (или совокупного) коэффициента корреляции рассматриваемой в целом, измеряется с помощью множественного (или совокупного) коэффициента корреляции  , который является обобщением парного коэффициента корреляции , который является обобщением парного коэффициента корреляции 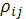 Выборочный множественный, или совокупный, коэффициент корреляции Выборочный множественный, или совокупный, коэффициент корреляции  , являющийся оценкой , может быть вычислен по формуле: , являющийся оценкой , может быть вычислен по формуле:
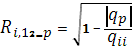 (1.40) (1.40)
Где  определитель матрицы определитель матрицы  ; ;  алгебраическое дополнение элемента алгебраическое дополнение элемента 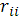 той же матрицы. той же матрицы.
Множественный коэффициент корреляции заключен в пределах 0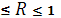 . Он не меньше, чем абсолютная величина любого парного или частного коэффициента корреляции с таким же первичным индексом. . Он не меньше, чем абсолютная величина любого парного или частного коэффициента корреляции с таким же первичным индексом.
С помощью множественного коэффициента корреляции (по мере приближения R к 1) делается вывод о тесноте взаимосвязи, но не о ее направлении. Величина , называемая выборочным множественным (или совокупным) коэффициентом детерминации, показывает, какую долю вариации исследуемой переменной объясняет вариация остальных переменных.
Частный коэффициент корреляции.
Если переменные коррелируют друг с другом, то на величине парного коэффициента корреляции частично сказывается влияние других переменных. В связи с этим часто возникает необходимость исследовать частную корреляцию между переменными при исключении (элиминировании) влияния одной или нескольких других переменных.
Выборочным частным коэффициентом корреляции
между переменными 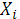 и при фиксированных значениях остальных (р и при фиксированных значениях остальных (р 2) переменных называется выражение 2) переменных называется выражение
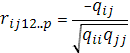 (1.41) (1.41)
Где  и и  алгебраические дополнения элементов матрицы . алгебраические дополнения элементов матрицы .
Частный коэффициент корреляции  , как и парный коэффициент корреляции r, может принимать значения от -1 до 1. Кроме того, , вычисленный на основе выборки объема n, имеет такое же распределение, что иY, вычисленный по (n–р + 2) наблюдениям. Поэтому значимость частного коэффициента корреляции оценивают так же, как и коэффициента корреляции, но при этом полагают , как и парный коэффициент корреляции r, может принимать значения от -1 до 1. Кроме того, , вычисленный на основе выборки объема n, имеет такое же распределение, что иY, вычисленный по (n–р + 2) наблюдениям. Поэтому значимость частного коэффициента корреляции оценивают так же, как и коэффициента корреляции, но при этом полагают
n' = n–р + 2.
Заканчивая краткое изложение, корреляционного анализа количественных признаков, остановимся на двух моментах.
1. Задача научного исследования состоит в отыскании причинных зависимостей. Только знание истинных причин явлений позволяет правильно истолковывать наблюдаемые закономерности. Однако корреляция как формальное статистическое понятие сама по себе не вскрывает причинного характера связи. С помощью корреляционного анализа нельзя указать, какую переменную принимать в качестве причины, а какую – в качестве следствия.
Иногда при наличии корреляционной связи ни одна из переменных не может рассматриваться причиной другой (например, зависимость между весом и ростом человека). Наконец, возможна ложная корреляция (нонсенс-корреляция), т.е. Чисто формальная связь между переменными, не находящая никакого объяснения и основанная лишь на количественном соотношении между ними (таких примеров в статистической литературе приводится немало). Поэтому при логических переходах от корреляциионной связи между переменными к их причинной взаимообусловленности необходимо глубокое проникновение в сущность анализируемых явлений.
2. Не существует общеупотребительного критерия проверки определяющего требования корреляционного анализа - нормальности многомерного распределения переменных. Учитывая свойства теоретической модели, .обычно полагают, что отнесение к совместному нормальному закону возможно, если частные одномерные распределения переменных не противоречат нормальным распределениям (в этом можно убедиться, например, с помощью критериев согласия); если совокупность точек корреляционного поля частных двумерных распределений имеет вид более или менее вытянутого «облака» с выраженной линейной тенденцией.
До сих пор мы анализировали зависимости между количественными переменными, измеренными в так называемых количественных шкалах, Т.е. в шкалах с непрерывным множеством значений, позволяющих выявить, насколько (или во сколько раз) проявление признака у одного объекта больше (меньше), чем у другого.
Вместе с тем на практике часто встречаются с необходимостью изучения связи между ординальными (порядковыми) переменными, измеренными в так называемой порядковой шкале. В этой шкале можно установить лишь порядок, в котором объекты выстраиваются по степени проявления признака (например, качество жилищных условий, тестовые баллы, экзаменационные оценки и т.п.). Если, скажем, по некоторой дисциплине два студента имеют оценки «отлично» И «удовлетворительно», то можно лишь утверждать, что уровень подготовки по этой дисциплине первого студента выше (больше), чем второго, но нельзя сказать, на сколько или во сколько раз больше.
Оказывается, что таких случаях проблема оценки тесноты связи разрешима, если упорядочить, или ранжировать, объекты анализа по степени выраженности измеряемых признаков. При этом каждому объекту присваивается определенный номер, называемый рангом. Например, объекту с наименьшим проявлением (значением) признака присваивается ранг 1, следующему за ним – ранг 2 и т.д. Объекты можно располагать и в порядке убывания проявления (значений) признака. Если объекты ранжированы по двум признакам, то имеется возможность оценить. тесноту связи между признаками, основываясь на рангах, Т.е. тесноту ранговой корреляции.
Коэффициент ранговой корреляции Спирмена
находится по формуле:
 (1.42) (1.42)
где  и и  ранги i-го объекта по переменным X и Y, n число пар наблюдений. ранги i-го объекта по переменным X и Y, n число пар наблюдений.
Если ранги всех объектов равны, то ρ=1, т.е. при полной прямой связи ρ=1. При полной обратной связи, когда ранги объектов по двум переменным расположены в обратном порядке ρ=- . Во всех остальных случаях . Во всех остальных случаях  . .
При ранжировании иногда сталкиваются со случаями, когда невозможно найти существенные различия между объектами по величине проявления рассматриваемого признака. Объекты, как говорят, оказываются связанными
. Связанным объектам приписывают одинаковые средние ранги, такие, чтобы сумма всех рангов оставалась такой же, как и при отсутствии связанных рангов.
При наличии связанных рангов ранговый коэффициент корреляции Спирмена вычисляется по формуле:
 (1.43) (1.43)
где  ; ;  ; ;
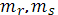 число групп неразличимых рангов у переменных X и Y; число групп неразличимых рангов у переменных X и Y;
 число рангов, входящих в группу неразличимых рангов переменных X и Y. число рангов, входящих в группу неразличимых рангов переменных X и Y.
Коэффициент ранговой корреляции Кендалла
находится по формуле:
 (1.44), (1.44),
где K статистика Кендалла.
Для определения Kнеобходимо ранжировать объекты по одной переменной в порядке возрастания рангов (1, 2, ... , n) и определить соответствующие их ранги ( ) по другой переменной. Статистика Kравна общему числу инверсий (нарушений порядка, когда большее число стоит слева от меньшего) в ранговой последовательности (ранжировке) . При полном совпадении двух ранжировок имеем K= 0 и τ= 1; при полной противоположности можно показать, что и ) по другой переменной. Статистика Kравна общему числу инверсий (нарушений порядка, когда большее число стоит слева от меньшего) в ранговой последовательности (ранжировке) . При полном совпадении двух ранжировок имеем K= 0 и τ= 1; при полной противоположности можно показать, что и  . Во всех остальных случаях . Во всех остальных случаях  . .
Коэффициент конкордации (согласованности) рангов Кендалла W,
определяемый по формуле:
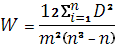 (1.45) (1.45)
где n число объектов;
m число анализируемых порядковых переменных;
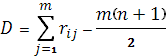 (1.46) (1.46)
отклонение суммы рангов объекта от средней их суммы для всех объектов, равной m(n+1)/2.
Значения коэффициента W заключены на отрезке т.е. , причем W=1 при совпадении всех ранжировок.
Корреляционный анализ может быть использован и при оценке взаимосвязи качественных (категоризованных) признаков (переменных), представленных в так называемой номинальной шкале, в которой возможно лишь различение объектов по возможным состояниям, градациям (например, пол, социальное положение, профессия и т.п.). Здесь в качестве соответствующих показателей могут быть использованы коэффициенты ассоциации, контингеници (сопряженности), бисериальной корреляции.
Глава 2
Регрессионный анализ
В регрессионном анализе рассматривается односторонняя зависимость случайной зависимой переменной Y от одной (или нескольких) неслучайной независимой переменной Х, называемой часто объясняющей переменной. Такая зависимость может возникнуть, например, в случае, когда при каждом фиксированном значении X соответствующие значения Y подвержены случайному разбросу за счет действия неконтролируемых факторов. Указанная зависимость Y от X (иногда ее называют регрессионной) может быть представлена также в виде модельного уравнения регрессии (1.1). В силу воздействия неучтенных случайных факторов и причин отдельные наблюдения y будут в большей или меньшей мере отклоняться от функции регрессии  . В этом случае уравнение взаимосвязи двух переменных (парная регрессионная модель) может быть представлено в виде: . В этом случае уравнение взаимосвязи двух переменных (парная регрессионная модель) может быть представлено в виде:  , где , где  — случайная переменная, характеризующая отклонение от функции регрессии. Эту переменную будем называть возмущающей или просто возмущением. Таким образом, в регрессионной модели зависимая переменная Y есть некоторая функция — случайная переменная, характеризующая отклонение от функции регрессии. Эту переменную будем называть возмущающей или просто возмущением. Таким образом, в регрессионной модели зависимая переменная Y есть некоторая функция  (Х) с точностью до случайного возмущения . (Х) с точностью до случайного возмущения .
Рассмотрим линейный регрессионный анализ, для которого функция (Х) линейная относительно оцениваемых параметров:
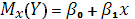 . (2.1) . (2.1)
Предположим, что для оценки параметров линейной функции регрессии (2.1) взята выборка, содержащая n пар значений переменных ( ), где i=1,2,..., ), где i=1,2,...,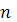 . В этом случае линейная парная регрессионная модель имеет вид: . В этом случае линейная парная регрессионная модель имеет вид:
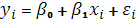 (2.2) (2.2)
Отметим основные предпосылки регрессионного анализа
:
1. В модели (2.2) возмущение 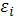 (или зависимая переменная (или зависимая переменная  ) есть величина случайная, а объясняющая переменная ) есть величина случайная, а объясняющая переменная  — величина неслучайная. — величина неслучайная.
2. Математическое ожидание возмущения равно нулю: 
(или математическое ожидание зависимой переменной равно линейной функции регрессии:
M()= (2.3) (2.3)
3. Дисперсия возмущения (или зависимой переменной ) постоянна для любого i:
 (2.4) (2.4)
(или D() =  — условие гомоскедастичности или равноизменчивости возмущения (зависимой переменной)). — условие гомоскедастичности или равноизменчивости возмущения (зависимой переменной)).
4. Возмущения (или переменные и) не коррелированы.
 (i (i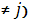 (2.5) (2.5)
5. Возмущение , (или зависимая переменная 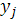 ) есть нормально распределенная случайная величина. ) есть нормально распределенная случайная величина.
Для получения уравнения регрессии достаточно первых четырех предпосылок. Требование выполнения пятой предпосылки (т.е. рассмотрение «нормальной регрессии») необходимо для оценки точности уравнения регрессии и его параметров.
Оценкой модели (2.2) по выборке является уравнение регрессии:
 (1.8). Параметры этого уравнения (1.8). Параметры этого уравнения  и и 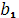 определяются на основе метода наименьших квадратов. определяются на основе метода наименьших квадратов.
Теорема Гауса-Маркова
.
Если регрессионная модель удовлетворяет предпосылкам 1-4, то оценки и имеют наименьшую дисперсию в классе линейных несмещенных оценок, т.е. являются эффективными оценками параметров и .
Воздействие неучтенных случайных факторов и ошибок наблюдений в модели (2.2) определяется с помощью дисперсии возмущений (ошибок) или остаточной дисперсии . Несмещенной оценкой этой дисперсии является выборочная остаточная дисперсия
 (2.6) (2.6)
где 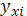 — групповая средняя, найденная по уравнению регрессии; — групповая средняя, найденная по уравнению регрессии;
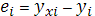 — выборочная оценка возмущения , или остаток регрессии. — выборочная оценка возмущения , или остаток регрессии.
В знаменателе выражения (2.6) стоит число степеней свободы n—2, а не n, так как две степени свободы теряются при определении двух параметров прямой и .
Построим доверительный интервал для функции регрессии, т.е. для условного математического ожидания  , который с заданной надежностью (доверительной вероятностью) , который с заданной надежностью (доверительной вероятностью)  =1— =1— накрывает неизвестное значение накрывает неизвестное значение
Найдем дисперсию групповой средней 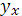 , представляющей выборочную оценку , представляющей выборочную оценку 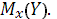 С этой целью уравнение регрессии (1.15) представим в виде: С этой целью уравнение регрессии (1.15) представим в виде:
 (2.7) (2.7)
На рис. 2.1 линия регрессии (2.7) изображена графически. Для произвольного наблюдаемого значения , выделены его составляющие: средняя 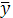 , приращение , приращение  , образующие расчетное значение , и возмущение , образующие расчетное значение , и возмущение  ,. ,.
  Дисперсия групповой средней равна сумме дисперсий двух независимых слагаемых выражения (2.7) : Дисперсия групповой средней равна сумме дисперсий двух независимых слагаемых выражения (2.7) :
 (2.8) (2.8)
Дисперсия выборочной средней
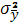 = = (2.9) (2.9)
Для нахождения дисперсии  представим коэффициент регрессии в виде: представим коэффициент регрессии в виде:
 (2.10) (2.10)
тогда
 (2.11) (2.11)
Найдем оценку дисперсии групповых средних (2.8), учитывая (2.9) и (2.11) и заменяя ее оценкой  : :
 (2.12) (2.12)
Исходя из того, что статистика t =  имеет имеет  -распределение Стьюдента с k=n—2 степенями свободы, можно построить доверительный интервал для условного математического ожидания -распределение Стьюдента с k=n—2 степенями свободы, можно построить доверительный интервал для условного математического ожидания
 (2.13) (2.13)
 
где  — стандартная ошибка групповой средней . — стандартная ошибка групповой средней .
Из формул (2,12) и (2,13) видно, что величина доверительного интервала зависит от значения объясняющей переменной х: при х =  она минимальна, а по мере удаления х от она минимальна, а по мере удаления х от  величина доверительного интервала увеличивается (рис. 2.2). Таким образом, прогноз значений (определение неизвестных значений) зависимой переменной у по уравнению регрессии оправдан, если значение объясняющей переменной не выходит за диапазон ее значений по выборке (причем тем более точный, чем ближе х к ). Другими словами, экстраполяция кривой регрессии, т.е. ее использование вне пределов обследованного диапазона значений объясняющей переменной (даже если она оправдана для рассматриваемой переменной исходя из смысла решаемой задачи) может привести к значительным погрешностям. величина доверительного интервала увеличивается (рис. 2.2). Таким образом, прогноз значений (определение неизвестных значений) зависимой переменной у по уравнению регрессии оправдан, если значение объясняющей переменной не выходит за диапазон ее значений по выборке (причем тем более точный, чем ближе х к ). Другими словами, экстраполяция кривой регрессии, т.е. ее использование вне пределов обследованного диапазона значений объясняющей переменной (даже если она оправдана для рассматриваемой переменной исходя из смысла решаемой задачи) может привести к значительным погрешностям.
Построенная доверительная область для (см. рис. 2.2) определяет местоположение модельной линии регрессии (т.е. условного математического ожидания), но не отдельных возможных значений зависимой переменной, которые отклоняются от средней. Поэтому при определении доверительного интервала для индивидуальных значений  зависимой переменной необходимо учитывать еще один источник вариации — рассеяние вокруг линии регрессии, т.е. в оценку суммарной дисперсии зависимой переменной необходимо учитывать еще один источник вариации — рассеяние вокруг линии регрессии, т.е. в оценку суммарной дисперсии  следует включить величину . В результате оценка дисперсии индивидуальных значений следует включить величину . В результате оценка дисперсии индивидуальных значений  при х = при х =  равна: равна:
 (2.14) (2.14)
а соответствующий доверительный интервал для прогнозов индивидуальных значений будет определяться по формуле:
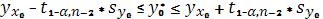 (2.15) (2.15)
Проверить значимость уравнения регрессии — значит установить, соответствует ли математическая модель, выражающая зависимость между переменными, экспериментальным данным и достаточно ли включенных в уравнение объясняющих переменных (одной или нескольких) для описания зависимой переменной.
Проверка значимости уравнения регрессии производится на основе дисперсионного анализа. Дисперсионный анализ применяется как вспомогательное средство для изучения качества регрессионной модели.
Согласно основной идее дисперсионного анализа
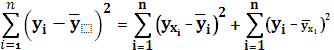 (2.16) (2.16)
или
 , (2.17) , (2.17)
Где Q — общая сумма квадратов отклонений зависимой переменной от средней, a и и 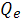 — соответственно сумма квадратов, обусловленная регрессией, и остаточная сумма квадратов, характеризующая влияние неучтенных факторов. — соответственно сумма квадратов, обусловленная регрессией, и остаточная сумма квадратов, характеризующая влияние неучтенных факторов.
Убедимся в том, что пропущенное в (2.17) третье слагаемое
 равно нулю. Учитывая (2.7) и первое уравнение системы (1.11), имеем: равно нулю. Учитывая (2.7) и первое уравнение системы (1.11), имеем:
 . .
Теперь

Схема дисперсионного анализа имеет вид, представленный в табл. 2.1
Таблица 2.1

Средние квадраты  и и  (табл. 2.1) представляют собой несмещенные оценки дисперсий зависимой переменной, обусловленной соответственно регрессией или объясняющей(ими) переменной(ыми) X и воздействием неучтенных случайных факторов и ошибок; m— число оцениваемых параметров уравнения регрессии; n — число наблюдений. (табл. 2.1) представляют собой несмещенные оценки дисперсий зависимой переменной, обусловленной соответственно регрессией или объясняющей(ими) переменной(ыми) X и воздействием неучтенных случайных факторов и ошибок; m— число оцениваемых параметров уравнения регрессии; n — число наблюдений.
Замечание
. При расчете общей суммы квадратов полезно иметь в виду, что
 ( (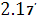 ) )
(формула (2.17') следует из разложения

При отсутствии линейной зависимости между зависимой и объясняющей(ими) переменной(ыми) случайные величины 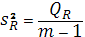 и и  имеют имеют  -распределение соответственно с m-1 и n-m степенями свободы, а их отношение -распределение соответственно с m-1 и n-m степенями свободы, а их отношение
F-распределение с теми же степенями свободы . Поэтому уравнение регрессии значимо на уровне , если фактически наблюдаемое значение статистики
 (2.18) (2.18)
где 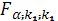 — табличное значение F-критерия Фишера—Снедекора, определенное на уровне значимости при — табличное значение F-критерия Фишера—Снедекора, определенное на уровне значимости при  =m-1 и =m-1 и  n-m степенях свободы. n-m степенях свободы.
Учитывая смысл величин  и , можно сказать, что значение F показывает, в какой мере регрессия лучше оценивает значение зависимой переменной по сравнению с ее средней. В случае линейной парной регрессии m=2 и уравнение регрессии значимо на уровне , если и , можно сказать, что значение F показывает, в какой мере регрессия лучше оценивает значение зависимой переменной по сравнению с ее средней. В случае линейной парной регрессии m=2 и уравнение регрессии значимо на уровне , если 
В 1 главе данной работы введен индекс корреляции R (для парной линейной модели — коэффициент корреляции r), выраженный через дисперсии .Тот же коэффициент в терминах «сумм квадратов» примет вид:
 (2.19) (2.19)
Следует отметить, что значимость уравнения парной линейной регрессии может быть проверена и другим способом, если оценить значимость коэффициента регрессии ,что означает проверку нулевой гипотезы о равенстве параметра 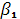 парной модели нулю. парной модели нулю.
Можно показать, что при выполнении предпосылки 5 регрессионного анализа
статистика t = имеет стандартный нормальный закон распределения N(0;l), а если в выражении (2.11) для имеет стандартный нормальный закон распределения N(0;l), а если в выражении (2.11) для 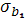 заменить параметр его оценкой , то статистика заменить параметр его оценкой , то статистика
t = (2.19) (2.19)
имеет t-распределение с k= n— 2 степенями свободы. По этому коэффициент регрессии значим на уровне , если 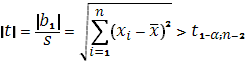 , a доверительный интервал для имеет вид: , a доверительный интервал для имеет вид:

Для парной регрессионной модели оценка значимости уравнения регрессии по F-критерию равносильна оценке значимости коэффициента регрессии либо коэффициента корреляции r по t-критерию , ибо эти критерии связаны соотношением F=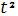 . А интервальные оценки для параметра — при нормальном законе распределения зависимой переменной и . А интервальные оценки для параметра — при нормальном законе распределения зависимой переменной и  = совпадают. = совпадают.
При построении доверительного интервала для дисперсии возмущении исходят из того, что статистика  имеет -распределение с k = n — 2 степенями свободы. Поэтому интервальная оценка дляна уровне значимости имеет вид имеет -распределение с k = n — 2 степенями свободы. Поэтому интервальная оценка дляна уровне значимости имеет вид
 (2.20) (2.20)
Соотношения между социально-экономическими явлениями и процессами далеко не всегда можно выразить линейными функциями, так как при этом могут возникать неоправданно большие ошибки. В таких случаях используют нелинейную (по объясняющей переменной) регрессию. Выбор вида уравнения регрессии (8.3) (этот важный этап анализа называется спецификацией или этапом параметризации модели) производится на основании опыта предыдущих исследований, литературных источников, других соображений профессионально-теоретического характера, а также визуального наблюдения расположения точек корреляционного поля. Наиболее часто встречаются следующие виды уравнений нелинейной регрессии: полиномиальное
 , гиперболическое , гиперболическое
 , степенное , степенное
 . .
Например, если исследуемый экономический показатель у при росте объема производства х состоит из двух частей — постоянной (не зависящей от х) и переменной (уменьшающейся с ростом х), то зависимость у от х можно представить в виде гиперболы  . Если же показатель у отражает экономический процесс, который под влиянием фактора х происходит с постоянным ускорением или замедлением, то применяются полиномы. В ряде случаев для описания экономических процессов используются более сложные функции. Например, если процесс вначале ускоренно развивается, а затем, после достижения некоторого уровня, затухает и приближается к некоторому пределу, то могут оказаться полезными логистические функции типа у = . Если же показатель у отражает экономический процесс, который под влиянием фактора х происходит с постоянным ускорением или замедлением, то применяются полиномы. В ряде случаев для описания экономических процессов используются более сложные функции. Например, если процесс вначале ускоренно развивается, а затем, после достижения некоторого уровня, затухает и приближается к некоторому пределу, то могут оказаться полезными логистические функции типа у =  . .
При исследовании степенного уравнения регрессии следует иметь в виду, что оно нелинейно относительно параметров  ,однако путем логарифмирования может быть преобразовано в линейное:ln= ln ,однако путем логарифмирования может быть преобразовано в линейное:ln= ln ln ln +…+ +…+ ln ln
Для определения неизвестных параметров ,  ,как и ранее, используется метод наименьших квадратов.В некоторых случаях нелинейность связей является следствием качественной неоднородности совокупности, к которой применяют регрессионный анализ. Например, объединение в одной совокупности предприятий различной специализации или предприятий, существенно различающихся по природным условиям, и т.д. В этих случаях нелинейность может являться следствием механического объединения разнородных единиц. Регрессионный анализ таких совокупностей не может быть эффективным. Поэтому любая нелинейность связей должна критически анализироваться. По расположению точек корреляционного поля далеко не всегда можно принять окончательное решение о виде уравнения регрессии. Если теоретические соображения или опыт предыдущих исследований не могут подсказать точного решения, то необходимо сделать расчеты по двум или нескольким уравнениям. Предпочтение отдается уравнению, для которого меньше величина остаточной дисперсии. Однако при незначительных расхождениях в остаточных дисперсиях следует всегда останавливаться на более простом уравнении, интерпретация показателей которого не представляется сложной. Весьма заманчивым представляется увеличение порядка выравнивающей параболической кривой, ибо известно, что всякую функцию на любом интервале можно как угодно точно приблизить полиномом .
Так, можно подобрать такой показатель k, что соответствующий полином пройдет через все вершины эмпирической линии регрессии. Однако повышение порядка гипотетической параболической кривой может привести к неоправданному усложнению вида искомой функции регрессии, когда случайные отклонения осредненных точек неправильно истолковываются как определенные закономерности в поведении кривой регрессии. Кроме того, за счет увеличения числа параметров снижается точность кривой регрессии (особенно в случае малой по объему выборки) и увеличивается объем вычислительных работ. В связи с этим в практике регрессионного анализа для выравнивания крайне редко используются полиномы выше третьей степени. ,как и ранее, используется метод наименьших квадратов.В некоторых случаях нелинейность связей является следствием качественной неоднородности совокупности, к которой применяют регрессионный анализ. Например, объединение в одной совокупности предприятий различной специализации или предприятий, существенно различающихся по природным условиям, и т.д. В этих случаях нелинейность может являться следствием механического объединения разнородных единиц. Регрессионный анализ таких совокупностей не может быть эффективным. Поэтому любая нелинейность связей должна критически анализироваться. По расположению точек корреляционного поля далеко не всегда можно принять окончательное решение о виде уравнения регрессии. Если теоретические соображения или опыт предыдущих исследований не могут подсказать точного решения, то необходимо сделать расчеты по двум или нескольким уравнениям. Предпочтение отдается уравнению, для которого меньше величина остаточной дисперсии. Однако при незначительных расхождениях в остаточных дисперсиях следует всегда останавливаться на более простом уравнении, интерпретация показателей которого не представляется сложной. Весьма заманчивым представляется увеличение порядка выравнивающей параболической кривой, ибо известно, что всякую функцию на любом интервале можно как угодно точно приблизить полиномом .
Так, можно подобрать такой показатель k, что соответствующий полином пройдет через все вершины эмпирической линии регрессии. Однако повышение порядка гипотетической параболической кривой может привести к неоправданному усложнению вида искомой функции регрессии, когда случайные отклонения осредненных точек неправильно истолковываются как определенные закономерности в поведении кривой регрессии. Кроме того, за счет увеличения числа параметров снижается точность кривой регрессии (особенно в случае малой по объему выборки) и увеличивается объем вычислительных работ. В связи с этим в практике регрессионного анализа для выравнивания крайне редко используются полиномы выше третьей степени.
Весьма важным для оценки точности определения зависимой переменной (прогноза) является построение доверительного интервала для функции регрессии
или для условного математического ожидания зависимой переменной 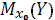 , найденного в предположении, что объясняющие переменные , найденного в предположении, что объясняющие переменные  приняли значения, задаваемые вектором приняли значения, задаваемые вектором 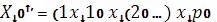 ). ).
Обобщая соответствующие выражения на случай множественной регрессии, можно получить доверительный интервал для :

где 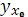 — групповая средняя, определяемая по уравнению регрессии, — групповая средняя, определяемая по уравнению регрессии,

ее стандартная ошибка.
При обобщении формул (2.15) и (2.14) аналогичный доверительный интервал для индивидуальных значений зависимой переменной примет вид:

где  . .
Доверительный интервал для дисперсии возмущений в множественной регрессии с надежностью 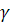 = 1 — строится аналогично парной модели по формуле (2.20) с соответствующим изменением числа степеней свободы критерия : = 1 — строится аналогично парной модели по формуле (2.20) с соответствующим изменением числа степеней свободы критерия :
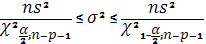 . .
Формально переменные, имеющие незначимые коэффициенты регрессии, могут быть исключены из рассмотрения. В экономических исследованиях исключению переменных из регрессии должен предшествовать тщательный качественный анализ. Поэтому может оказаться целесообразным все же оставить в регрессионной модели одну или несколько объясняющих переменных, не оказывающих существенного (значимого) влияния на зависимую переменную.
Под мултиколлинеарностью
понимается высокая взаимная коррелированностъ объясняющих переменных. Мультиколлинеарность может проявляться в функциональной (явной) стохастической (скрытой) формах. При функциональной форме мультиколлинеарности по крайней мере одна из парных связей между объясняющими переменными является линейной функциональной зависимостью. В этом случае матрица Х'Х особенная, так как содержит линейно зависимые векторы-столбцы и ее определитель равен нулю, т.е. нарушается предпосылка 6 регрессионного анализа. Это приводит к невозможности решения соответствующей системы нормальных уравнений и получения оценок параметров регрессионной модели.
Однако в экономических исследованиях мультиколлинеарность чаще проявляется в стохастической форме, когда между хотя бы двумя объясняющими переменными существует тесная корреляционная связь. Матрица Х'Х в этом случае является неособенной, но ее определитель очень мал. В то же время вектор оценок b и его ковариационная матрица К в соответствии с формулами пропорциональны обратной матрице  а значит, их элементы обратно пропорциональны величине определителя а значит, их элементы обратно пропорциональны величине определителя  . В результате получаются значительные средние квадратические отклонения (стандартные ошибки) коэффициентов регрессии . В результате получаются значительные средние квадратические отклонения (стандартные ошибки) коэффициентов регрессии и оценка их значимости по t-критерию не имеет смысла, хотя в целом регрессионная модель может оказаться значимой по F-критерию. и оценка их значимости по t-критерию не имеет смысла, хотя в целом регрессионная модель может оказаться значимой по F-критерию.
Оценки 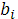 становятся очень чувствительными к незначительному изменению результатов наблюдений и объема выборки. Уравнения регрессии в этом случае, как правило, не имеют реального смысла, так как некоторые из его коэффициентов могут иметь неправильные с точки зрения экономической теории знаки и неоправданно большие значения. Один из методов выявления мультиколлинеарности заключается в анализе корреляционной матрицы между объясняющими переменными становятся очень чувствительными к незначительному изменению результатов наблюдений и объема выборки. Уравнения регрессии в этом случае, как правило, не имеют реального смысла, так как некоторые из его коэффициентов могут иметь неправильные с точки зрения экономической теории знаки и неоправданно большие значения. Один из методов выявления мультиколлинеарности заключается в анализе корреляционной матрицы между объясняющими переменными  и выявлении пар переменных, имеющих высокие коэффициенты корреляции (обычно больше 0,8).Если такие переменные существуют, то говорят о мультиколлинеарности между ними. Полезно также находить множественные коэффициенты корреляции между одной из объясняющих переменных и некоторой группой из них. Наличие высокого множественного коэффициента корреляции (обычно принимают больше 0,8) свидетельствует о мультиколлинеарности. Другой подход состоит в исследовании матрицы Х'Х. Если определитель матрицы Х'Х близок к нулю (например, одного порядка с накапливающимися ошибками вычислений), то это говорит о наличии мультиколлинеарности. Для устранения или уменьшения мультиколлинеарности используется рад методов. Один из них заключается в том, что из двух объясняющих переменных, имеющих высокий коэффициент корреляции (больше 0,8), одну переменную исключают из рассмотрения. При этом, какую переменную оставить, а какую удалить из анализа, решают в первую очередь на основании экономических соображений. Если с экономической точки зрения ни одной из переменной.Нельзя отдать предпочтение, то оставляют ту из двух переменных, которая имеет больший коэффициент корреляции с зависимой переменной. Другим из возможных методов устранения или уменьшения мультиколлинеарности является использование пошаговых процедур отбора наиболее информативных переменных. Например, вначале рассматривается линейная регрессия зависимой переменной Y объясняющей переменной, имеющей с ней наиболее высокий коэффициент корреляции (или индекс корреляции при нелинейной форме связи). На втором шаге включается в рассмотрение та объясняющая переменная, которая имеет наиболее высокий частный коэффициент корреляции с Y и вычисляется множественный коэффициент (индекс) корреляции. На третьем шаге вводится новая объясняющая переменная, которая имеет наибольший частный коэффициент корреляции с Y, и вновь вычисляется множественный коэффициент корреляции и т.д. Процедура введения новых переменных продолжается до тех пор, пока добавление следующей объясняющей переменной существенно не увеличивает множественный коэффициент корреляции. и выявлении пар переменных, имеющих высокие коэффициенты корреляции (обычно больше 0,8).Если такие переменные существуют, то говорят о мультиколлинеарности между ними. Полезно также находить множественные коэффициенты корреляции между одной из объясняющих переменных и некоторой группой из них. Наличие высокого множественного коэффициента корреляции (обычно принимают больше 0,8) свидетельствует о мультиколлинеарности. Другой подход состоит в исследовании матрицы Х'Х. Если определитель матрицы Х'Х близок к нулю (например, одного порядка с накапливающимися ошибками вычислений), то это говорит о наличии мультиколлинеарности. Для устранения или уменьшения мультиколлинеарности используется рад методов. Один из них заключается в том, что из двух объясняющих переменных, имеющих высокий коэффициент корреляции (больше 0,8), одну переменную исключают из рассмотрения. При этом, какую переменную оставить, а какую удалить из анализа, решают в первую очередь на основании экономических соображений. Если с экономической точки зрения ни одной из переменной.Нельзя отдать предпочтение, то оставляют ту из двух переменных, которая имеет больший коэффициент корреляции с зависимой переменной. Другим из возможных методов устранения или уменьшения мультиколлинеарности является использование пошаговых процедур отбора наиболее информативных переменных. Например, вначале рассматривается линейная регрессия зависимой переменной Y объясняющей переменной, имеющей с ней наиболее высокий коэффициент корреляции (или индекс корреляции при нелинейной форме связи). На втором шаге включается в рассмотрение та объясняющая переменная, которая имеет наиболее высокий частный коэффициент корреляции с Y и вычисляется множественный коэффициент (индекс) корреляции. На третьем шаге вводится новая объясняющая переменная, которая имеет наибольший частный коэффициент корреляции с Y, и вновь вычисляется множественный коэффициент корреляции и т.д. Процедура введения новых переменных продолжается до тех пор, пока добавление следующей объясняющей переменной существенно не увеличивает множественный коэффициент корреляции.
Многомерный статистический анализ определяется
как раздел математической статистики, посвященный математическим методам построения оптимальных планов сбора, систематизации и обработки многомерных статистических данных, направленных на выявление характера и структуры взаимосвязей между компонентами исследуемого признака и предназначенных для получения научных и практических выводов. Многомерные статистические методы среди множества возможных вероятностно-статистических моделей позволяют обоснованно выбрать ту, которая наилучшим образом соответствует исходным статистическим данным, характеризующим реальное поведение исследуемой совокупности объектов, оценить надежность и точность выводов, сделанных на основании ограниченного статистического материала. С некоторыми разделами многомерного статистического анализа, такими, как многомерный корреляционный анализ, множественная регрессия, многомерный дисперсионный анализ. Приведем теперь краткий обзор ряда других методов многомерного статистического анализа, которые уже нашли отражение в статистических пакетах прикладных программ. В первую очередь следует выделить методы, позволяющие выявить общие (скрытые или латентные) факторы, определяющие вариацию первоначальных факторов. К ним относятся факторный анализ и метод главных компонент.
Факторный анализ
. Основной задачей факторного анализа является переход от первоначальной системы большого числа взаимосвязанных факторов  к относительно малому числу скрытых (латентных) факторов к относительно малому числу скрытых (латентных) факторов  . Скажем, производительность труда на предприятиях зависит от множества факторов из которых многие связаны между собой. Используя факторный анализ, можно установить влияние на рост производительности труда лишь нескольких обобщенных факторов непосредственно не наблюдавшихся. . Скажем, производительность труда на предприятиях зависит от множества факторов из которых многие связаны между собой. Используя факторный анализ, можно установить влияние на рост производительности труда лишь нескольких обобщенных факторов непосредственно не наблюдавшихся.
Модель факторного анализа записывается в виде:
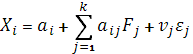 , i=1,2,…,m, k , i=1,2,…,m, k , ,
где  = M( = M( ) — математическое ожидание первоначального фактора ) — математическое ожидание первоначального фактора
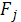 — общие (скрытые или латентные) факторы (J = 1,2,...,k); — общие (скрытые или латентные) факторы (J = 1,2,...,k);
 — нагрузки первоначальных факторов на общие факторы; — нагрузки первоначальных факторов на общие факторы;
 — характерные факторы (i = 1,2,...,/я); — характерные факторы (i = 1,2,...,/я);
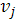 — нагрузки первоначальных факторов на характерные факторы. — нагрузки первоначальных факторов на характерные факторы.
Первое слагаемое в модели — неслучайная составляющая, другие два слагаемых случайные составляющие. Особенностью факторного анализа является неоднозначность определения общих факторов.
Метод главных компонент (компонентный анализ).
В отличие от рассматриваемых в факторном анализе общих факторов, которые обусловливают большую (но не всю) часть вариации первоначальных факторов, главные компоненты объясняют всю вариацию и определяются однозначно. Модель главных компонент имеет вид:
 ,
i=1,2,…m. ,
i=1,2,…m.
Как видим, в модели отсутствуют характерные факторы, так как главные компоненты полностью обусловливают всю вариацию первоначальных факторов. Для углубления анализа изучаемого явления после выявления главных компонент рассматривают регрессию на главных компонентах, в которых последние выступают в качестве обобщенных объясняющих переменных. Среди других методов многомерного статистического анализа отметим методы, позволяющие осуществить классификацию экономических объектов, т.е. отнесение их к определенным классам. Это методы дискриминантного и кластерного анализа.
Дискриминантный анализ
позволяет отнести объект, характеризующийся значениями m признаков, к одной из l совокупностей (классов, групп), заданных своими распределениями. Предполагается, что l совокупностей заданы выборками (называемыми обучаемыми), которые содержат информацию о статистических распределениях совокупностей в m-мерном пространстве признаков.
При отсутствии обучающих выборок могут быть использованы методы кластерного анализа
, позволяющие разбить исследуемую совокупность объектов на группы «схожих» объектов, называемых кластерами, таким образом, чтобы объекты одного класса находились на «близких» расстояниях между собой, а объекты разных классов — на относительно «отдаленных» расстояниях друг от друга. При этом каждый объект  (j = l,2,...,m) рассматривается как точка в m-мерном пространстве, и выбор способа вычисления расстояний или близости между объектами и признаками является узловым моментом исследования, от которого в основном зависит окончательный вариант разбиения объектов на классы. (j = l,2,...,m) рассматривается как точка в m-мерном пространстве, и выбор способа вычисления расстояний или близости между объектами и признаками является узловым моментом исследования, от которого в основном зависит окончательный вариант разбиения объектов на классы.
В 1 главе данной работы были введены понятия функциональной, статистической и корреляционной зависимости. Разобраны методы определения линейной парной регрессии, коэффициента корреляции. Установлены основные свойства коэффициента корреляции, также сформулирована основная задача корреляционного анализа и основные свойства корреляционных отношений.
Во 2 главе настоящей работы приводятся основные положения регрессионного анализа. Указываются методы нахождения интервальной оценки функции регрессии и характеров парной модели.
Методы корреляционного и регрессионного анализа не действуют изолированно. При решении практических задач используют их совместно. В приложении 1 эти методы применяются для установления линейной зависимости между ценообразованием однотипных продуктов в магазинах юго-западных районов Брянщины. В результате исследования между ценами на продукты (яблоки, апельсины) линейной зависимости установлено не было (коэффициент r=-0.03).
1. Кремер, Н.Ш. Теория вероятностей и математическая статистика [Текст] / Н.Ш.Кремер. – 3-е изд., перераб. и. доп. – М.:ЮНИТИ-ДАНА, 2009. – 551 с. – (Серия «золотой фонд российских учебников»). ISBN 978–5–238–01270–4
2. Шамолин, М.В. Высшая математика [Текст] / М.В.Шамолин –М.: Издательство «Экзамен», 2008. – 909,[3] с. (Серия «Учебник для вузов») ISBN 978–5–377–01452–2
3. Бочаров,П.П. Теория вероятности. Математическая статистика. [Текст] / П.П.Бочаров, А.В.Печинкин – М.:Гардарика, 1998. – 328 с. ISBN 5–7762–0035–0
4. Гмурман, В.Е. Теория вероятностей и математическая статистика [Текст]: учеб. пособие для вузов / В.Е. Гмурман. – изд. 6-е, стер. – М.: Высшая школа, 1998–479 с. ISBN 5–06–003464–X
5. Солодовников, А.С. Теория вероятностей [Текст]: учеб. пособие для студ. пед. ин-тов по матемюспец. / А.С.Солодовников. – М.: Просвещение, 1983. – 207 с.
В данном приложении выявлялась существования линейной зависимости между ценами на фрукты (апельсины яблоки) в магазинах г. Новозыбков, г. Клинцы, г. Злынка. В результате были собраны сведения о ценах на указанные продукты в 30 магазинах.
Собранные сведения содержатся в таблице1
 |
555 |
557 |
59 |
61 |
63 |
 |
| 40 |
1 |
3 |
4 |
| 42 |
2 |
5 |
2 |
9 |
| 44 |
2 |
3 |
2 |
7 |
| 46 |
4 |
3 |
1 |
8 |
| 48 |
1 |
1 |
2 |
 |
1 |
8 |
12 |
8 |
1 |
В которой:
x(руб.) – цена за 1 кг яблок,
y(руб.) – цена за 1 кг апельсин,
 , , – частота. – частота.
Для каждого значения, т.е. для каждой строки корреляционной таблицы вычислим групповые средние по формуле: 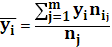 , где , где  - частоты пар ( - частоты пар (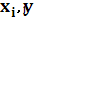 ) и ) и 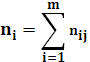 ; m – число интервалов по переменной Y ; m – число интервалов по переменной Y
Вычисленные групповые средние  поместим в последнем столбце корреляционной таблицы и изобразим графически в виде ломаной, называемой эмпирической линией регрессии Y по X (рис.1) поместим в последнем столбце корреляционной таблицы и изобразим графически в виде ломаной, называемой эмпирической линией регрессии Y по X (рис.1)
Аналогично для каждого значения  по формуле: по формуле:  вычислим групповые средние вычислим групповые средние  , где , где  , l – число интервалов по переменной X. Вычисленные групповые средние , l – число интервалов по переменной X. Вычисленные групповые средние  и поместим в последнюю строку корреляционной таблицы и изобразим графически в виде ломаной. По виду ломанной можно определить наличие линейной корреляционной зависимости Y по X между двумя рассматриваемыми переменными. Поэтому уравнение регрессии будем искать в виде: и поместим в последнюю строку корреляционной таблицы и изобразим графически в виде ломаной. По виду ломанной можно определить наличие линейной корреляционной зависимости Y по X между двумя рассматриваемыми переменными. Поэтому уравнение регрессии будем искать в виде: 
Строим кривые по точкам  (, (, ) и ) и  (, (, ) )

Находим  и и для это строим таблицу: для это строим таблицу:
|
|
 |
 |
 |
| 40 |
4 |
-4 |
-2 |
-8 |
16 |
| 42 |
9 |
-2 |
-1 |
-9 |
9 |
| 44 |
7 |
0 |
0 |
0 |
0 |
| 46 |
8 |
2 |
1 |
8 |
8 |
| 48 |
2 |
4 |
2 |
4 |
8 |
 |
-5 |
41 |
 =44; =44;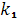 =2;n=30 =2;n=30
Находим среднее значение переменной X по формуле
 =43.67 =43.67
Находим выборочную дисперсию переменной X по формуле:
 5.36 5.36
Аналогично находим 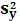 и и 
 |
 |
 |
 |
 |
| 55 |
1 |
-4 |
-2 |
-2 |
4 |
| 57 |
8 |
-2 |
-1 |
-8 |
8 |
| 59 |
12 |
0 |
0 |
0 |
0 |
| 61 |
8 |
2 |
1 |
8 |
8 |
| 63 |
1 |
4 |
2 |
2 |
4 |
|
0 |
24 |
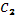 =59; =59;  =2; n=30. =2; n=30.
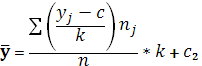 =59, =59,
 3.2 3.2
Считаем коэффициент ковариации для переменных X и Y для этого составляем таблицу:
 |
55 |
57 |
59 |
61 |
63 |
|
 |
-2 |
-1 |
0 |
1 |
2 |
| 40 |
-2 |
4 |
-6 |
-2 |
| 45 |
-1 |
2 |
-2 |
0 |
| 44 |
0 |
0 |
| 46 |
1 |
-4 |
1 |
-3 |
| 48 |
2 |
4 |
4 |
|
4 |
-2 |
-7 |
4 |
-1 |
Cov(x,y)=
Определяем коэффициенты регрессии Yна Xи Xна Yпо формулам:
 -0.02 -0.02
 -0.04 -0.04
Прямая регрессии Yна X имеет уравнение: 
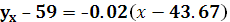
Прямая регрессии Xна Y имеет уравнение: 
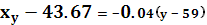
Построим прямые регрессии совместно с эмпирической линией регрессии Y по Xи с линией регрессии Xна Y.

Определим коэффициента корреляции формуле:
Если r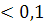 то цены на данную пару продуктов не зависят друг от друга т.е. цена на один вид продукта не влияет на ценообразование другого вида. то цены на данную пару продуктов не зависят друг от друга т.е. цена на один вид продукта не влияет на ценообразование другого вида.
РОССИЙСКАЯ ФЕДЕРАЦИЯ
МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ
Государственное образовательное учреждение
высшего профессионального образования
БРЯНСКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ
имени академика И.Г.Петровского
филиал БГУ в г. Новозыбкове
Кафедра математики, физики и информатики
Курсовая работа на тему:
«Функциональная зависимость и регрессия»
Выполнил:
студент 402 группы
Иволга Василий Анатольевич
Научный руководитель:
кандидат физико-математических наук, доцент кафедры МФИ
Савичева Галина Владимировна
Новозыбков 2010
|