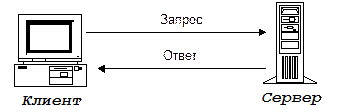ТЕМА 4. Основы сетевых информационных технологий
4.1. Модель взаимосвязи открытых систем
4.1.1. Сетевой режим обработки информации
4.2. Технология клиент-сервер
4.2.1. Модель файлового сервера. (FS)
4.2.2. Модель доступа к удаленным данным (RDA)
4.2.3. Модель сервера баз данных (DBS)
4.2.4. Модель сервера приложений (AS)
4.3. Многоуровневые системы клиент-сервер
4.4. Системы технологической почты
4.5.Технология работы в среде распределенной обработки данных
4.6.Базовые технологии обработки запросов в архитектурах
файл-сервера и клиент-сервера
4.7. Корпоративные технологии
4.7.1. СППР
4.1. Модель взаимосвязи открытых систем
Развитие средств вычислительной техники, а особенно появление персональных компьютеров привело к созданию нового типа информационно-вычислительных систем под названием локальная вычислительная сеть
(ЛВС).
ЛВС нашли широкое применение в системах автоматизированного проектирования и технологической подготовки производства, системах управления производством и технологическими комплексами, в конторских системах, бортовых системах управления и т.д. ЛВС является эффективным способом построения сложных систем управления различными производственными подразделениями. ЛВС интенсивно внедряются в медицину, сельское хозяйство, образование, науку и др.
Локальная сеть - (LAN - Local Area Network), данное название соответствует объединению компьютеров, расположенных на сравнительно небольшой территории (одного предприятия, офиса, одной комнаты). Существующие стандарты для ЛВС обеспечивают связь между компьютерами на расстоянии от 2,5 км до 6 км (Ethernet и ARCNET, соответственно).
ЛВС - набор аппаратных средств и алгоритмов, обеспечивающих соединение компьютеров, других периферийных устройств (принтеров, дисковых контроллеров и т.п.) и позволяющих им совместно использовать общую дисковую память, периферийные устройства, обмениваться данными.
В настоящее время информационно-вычислительные системы принято делить на 3 основных типа:
- LAN
(Lokal Area Network) - локальная сеть в пределах предприятия, учреждения, одной организации;
- MAN
(Metropolitan Area Network) - городская или региональная сеть, т.е. сеть в пределах города, области и т.п.;
- WAN
(Wide Area Network) - глобальная сеть, соединяющая абонентов страны, континента, всего мира.
Информационные системы, в которых средства передачи данных принадлежат одной компании и используются только для нужд этой компании , принято называть Сеть Масштаба Предприятия
или Корпоративная Сеть (Enterprise Network).
Для автоматизации работы производственных предприятий часто используются системы на базе протоколов MAP/TOP:
MAP (Manufacturing Automation Protocol) - сеть для производственных предприятий, заводов (выполняется автоматизация работы конструкторских отделов и производственных, технологических цехов). МАР позволяет создать единую технологическую цепочку от конструктора, разработавшего деталь, до оборудования, на котором изготавливают эту деталь.
TOP (Technical and Office Protocol) - протокол автоматизации технического и административного учреждения.
МАР/ТОР системы, полностью автоматизирующие работу производственного предприятия.
Основное назначение ЛВС - в распределении ресурсов ЭВМ: программ, совместимости периферийных устройств, терминалов, памяти. Следовательно, ЛВС должна иметь надежную и быструю систему передачи данных, стоимость которой должна быть меньше по сравнению со стоимостью подключаемых рабочих станций. Иными словами, стоимость передаваемой единицы информации должна быть значительно ниже стоимости обработки информации в рабочих станциях. Исходя из этого ЛВС, как система распределенных ресурсов, должна основываться на следующих принципах:
- единой передающей среды;
- единого метода управления;
- единых протоколов;
- гибкой модульной организации;
- информационной и программной совместимости.
Международная организация по стандартизации (ISO), основываясь на опыте многомашинных систем, который был накоплен в разных странах, выдвинула концепцию архитектуры открытых систем - эталонную модель, используемую при разработке международных стандартов.
На основе этой модели вычислительная сеть предстает как распределенная вычислительная среда, включающая в себя большое число разнообразных аппаратных и программных средств. По вертикали
данная среда представляется рядом логических уровней, на каждый из которых возложена одна из задач сети. По горизонтали
информационно-вычислительная среда делится на локальные части (открытые системы), отвечающие требованиям и стандартам структуры открытых систем.
Часть открытой системы, выполняющая некоторую функцию и входящая в состав того или иного уровня, называется объектом
.
Правила, по которым осуществляется взаимодействие объектов одного и того же уровня, называются протоколом
(методика связи).
Протоколы определяют порядок обмена информацией между сетевыми объектами. Они позволяют взаимодействующим рабочим станциям посылать друг другу вызовы, интерпретировать данные, обрабатывать ошибочные ситуации и выполнять множество других различных функций. Суть протоколов заключается в регламентированных обменах точно специфицированными командами и ответами на них (например, назначение физического уровня связи - передача блоков данных между двумя устройствами, подключенными к одной физической среде).
Каждый уровень подразделяется на две части:
- спецификацию услуг;
- спецификацию протокола.
Спецификация услуг определяет, что
делает уровень
, а спецификация протокола -как
он это делает
.
Причем, каждый конкретный уровень может иметь более одного протокола.
Большое число уровней, используемых в модели, обеспечивает декомпозицию информационно-вычислительного процесса на простые составляющие. В свою очередь, увеличение числа уровней вызывает необходимость включения дополнительных связей в соответствии с дополнительными протоколами и интерфейсами. Интерфейсы (макрокоманды, программы) зависят от возможностей используемой ОС.
Международная организация по стандартизации предложила семиуровневую модель
, которой соответствует и программная структура (рис.4.1.).

Рассмотрим функции, выполняемые каждым уровнем программного обеспечения:
1.Физический
- осуществляет как соединения с физическим каналом, так и расторжение, управление каналом, а также определяется скорость передачи данных и топология сети.
2.Канальный
- осуществляет обрамление передаваемых массивов информации вспомогательными символами и контроль передаваемых данных. В ЛВС передаваемая информация разбивается на несколько пакетов или кадров. Каждый пакет содержит адреса источника и места назначения, а также средства обнаружения ошибок.
3.Сетевой
- определяет маршрут передачи информации между сетями (ПЭВМ), обеспечивает обработку ошибок, а так же управление потоками данных.
Основная задача сетевого уровня - маршрутизация данных (передача данных между сетями). Специальные устройства - Маршрутизаторы (Router)
определяют для какой сети предназначено то или другое сообщение, и направляет эту посылку в заданную сеть. Для определения абонента внутри сети используется Адрес Узла (Node Address).
Для определения пути передачи данных между сетями на маршрутизаторах строятся Таблицы Маршрутов (Routing Tables)
, содержащие последовательность передачи данных через маршрутизаторы. Каждый маршрут содержит адрес конечной сети, адрес следующего маршрутизатора и стоимость передачи данных по этому маршруту. При оценке стоимости могут учитываться количество промежуточных маршрутизаторов, время, необходимое на передачу данных, просто денежная стоимость передачи данных по линии связи. Для построения таблиц маршрутов наиболее часто используют либо Метод Векторов
либо Статический Метод
. При выборе оптимального маршрута применяют динамические или статические методы. На сетевом уровне возможно применение одной из двух процедур передачи пакетов:
- датаграмм
- т.е., когда часть сообщения или пакет независимо доставляется адресату по различным маршрутам, определяемым сложившейся динамикой в сети. При этом каждый пакет включает в себя полный заголовок с адресом получателя. Процедуры управления передачей таких пакетов по сети называются датаграммной службой;
- виртуальных соединений
- когда установление маршрута передачи всего сообщения от отправителя до получателя осуществляется с помощью специального служебного пакета - запроса на соединение. В таком случае для этого пакета выбирается маршрут и, при положительном ответе получателя на соединение закрепляется для всего последующего трафика (потока сообщений в сети передачи данных) и получает номер соответствующего виртуального канала (соединения) для дальнейшего использования его другими пакетами того же сообщения. Пакеты, которые передаются по одному виртуальному каналу, не являются независимыми
и поэтому включают сокращенный заголовок, включающий порядковый номер пакета, принадлежащему одному сообщению.
Недостатки:
значительная по сравнению с датаграммой сложность в реализации, увеличение накладных расходов, вызванных установлением и разъединением сообщений.
ВЫВОД.
Датаграммный режим предпочтительнее использовать для сетей сложной конфигурации, где значительное число ЭВМ в сети, иерархическая структура сети, надежность, достоверность передачи данных по каналам связи, длина пакета более 512 байт.
4.Транспортный
- связывает нижние уровни (физический, канальный, сетевой) с верхними уровнями, которые реализуются программными средствами. Этот уровень как бы разделяет средства формирования данных в сети от средств их передачи. Здесь осуществляется разделение информации по определенной длине и уточняется адрес назначения. Транспортный уровень позволяет мультиплексировать передаваемые сообщения или соединения. Мультиплексирование сообщений позволяет передавать сообщения одновременно по нескольким линиям связи, а мультиплексирование соединений - передает в одной посылке несколько сообщений для различных соединений.
5.Сеансовый
- на данном уровне осуществляется управление сеансами связи между двумя взаимодействующими пользователями (определяет начало и окончание сеанса связи: нормальное или аварийное; определяет время, длительность и режим сеанса связи; определяет точки синхронизации для промежуточного контроля и восстановления при передаче данных; восстанавливает соединение после ошибок во время сеанса связи без потери данных.
6.Представительский
- управляет представлением данных в необходимой для программы пользователя форме, генерацию и интерпретацию взаимодействия процессов, кодирование/декодирование данных, в том числе компрессию и декомпрессию данных. На рабочих станциях могут использоваться различные операционные системы : DOS, UNIX, OS/2. Каждая из них имеет свою файловую систему, свои форматы хранения и обработки данных. Задачей данного уровня является преобразование данных при передаче информации в формат, который используется в информационной системе. При приеме данных данный уровень представления данных выполняет обратное преобразование. Таким образом появляется возможность организовать обмен данными между станциями, на которых используются различные операционные системы.
Форматы представления данных могут различаться по следующим признакам:
- порядок следования битов и размерность символа в битах;
- порядок следования байтов;
- представление и кодировка символов;
- структура и синтаксис файлов.
Компрессия или упаковка данных сокращает время передачи данных. Кодирование передаваемой информации обеспечивает защиту ее от перехвата.
7.Прикладной
- в его ведении находятся прикладные сетевые программы, обслуживающие файлы, а также выполняет вычислительные, информационно-поисковые работы, логические преобразования информации, передачу почтовых сообщений и т.п. Главная задача этого уровня - обеспечить удобный интерфейс для пользователя.
На разных уровнях обмен происходит различными единицами информации: биты, кадры, пакеты, сеансовые сообщения, пользовательские сообщения.
Сетевой режим автоматизированной обработки информации
Сеть – это совокупность программных, технических и коммуникационных средств, обеспечивающих эффективное распределение вычислительных ресурсов.
Сеть, являясь одновременно продуктом и мощным стимулом развития человека, позволяет:
построить распределенные хранилища информации (базы данных);
расширить перечень решаемых задач по обработке информации;
повысить надежность информационной системы за счет дублирования работы ПК;
создать новые виды сервисного обслуживания (электронная почта);
снизить стоимость обработки информации.
Архитектура сетей обладает следующими характеристиками:
 Открытость
– обеспечение возможности подключения к сети любых типов ПК. Открытость
– обеспечение возможности подключения к сети любых типов ПК.
Ресурсы.
Ценность и значимость сети должны определяться набором хранимых в ней знаний, данных и способностью технических средств оперативно представлять их или обрабатывать.
Надежность
– обеспечение высокого показателя «наработки на отказ» за счет оперативных сообщений об аварийном режиме, тестирования, программно-логического контроля и дублирования техники.
Динамичность
– минимизация времени отклика сети на запрос пользователя.
Интерфейс
– обеспечение сетью широкого набора сервисных функций по обслуживанию пользователя и предоставлению запрашиваемой информации.
Автономность
– возможность независимой работы сетей различных уровней.
Коммуникации –
обеспечение по любой принятой пользователем конфигурации сети четкого взаимодействия ПК, защиты данных от НСД, автоматического восстановления работоспособности при аварийных сбоях, высокой достоверности передаваемой информации.
Для взаимодействия компонентов в сети используются протоколы и интерфейсы.
Протокол
– документ, определяющий правила взаимодействия одноименных уровней работающих друг с другом абонентов. Наиболее важными функциями протоколов на всех уровнях сети являются: защита от ошибок, управление потоками данных в сети, защита от ошибок, управление потоками данных в сети, защита ее от перегрузок, выполнение операций по маршрутизации сообщений и оптимизации использования ресурсов в сети, обеспечивающее большую степень доступности услуг сети путем образования нескольких маршрутов между двумя абонентами.
Интерфейс
– свод правил по взаимодействию (стыковке) между функциональными компонентами, расположенными в смежных уровнях и входящими в одну и ту же систему.
Многообразие сетевых технологий вызывает необходимость их классификации по каким-либо ключевым признакам (табл. 1).
Таблица 1
Классификация сетевых технологий
| Признаки классификации
|
| Специализация
|
Способ
организации
|
Способ связи
|
Состав ПК
|
Охват территории
|
Универсальные
Специализиро-
ванные
|
Одноранговые
(одноуровневые)
Двухуровневые
|
Проводные
Беспроводные
Спутниковые
|
Однородные
Неоднородные
|
Локальные
Территориальные
(региональные)
Федеральные
Глобальные
|
По признаку специализации сетевые технологии подразделяются на универсальные, предназначенные для решения всех задач пользователей (например, Академсеть РФ - для решения разнообразных информационных задач), и специализированные – для решения небольшого количества специальных
задач (например, технология резервирования мест на авиационные рейсы).
Одноранговая технология (одноуровневая) – функции рабочей станции и сервера совмещены, т.е. ПК может быть одновременно и сервером и рабочей станцией. Запрос информации осуществляется друг к другу.
Двухуровневые технологии – связь осуществляется между ПК (рабочими станциями) и серверами (специальные компьютеры). Задачей сервера – обслуживание рабочих станций с предоставлением им своих ресурсов, которые существенно выше чем ресурсы рабочей станции.
Беспроводные сетевые технологии – частотные каналы передачи данных (средой является эфир). Преимущество беспроводных технологий – работа с портативными компьютерами.
Однако скорость передачи данных не может сравниться с пропускной способностью кабеля, хотя в последнее время заметен ее рост.
Спутниковые технологии- физической средой передачи данных также является эфир. Использование спутников оправдано в случае значительного удаления абонентов друг от друга при чрезмерном ослаблении посылаемых электромагнитных сигналов с большими посторонними шумами. Чтобы сигналы, направленные отправителем, не смешивались с аналогичными к получателю, при работе со спутником прокладываются два частотных канала – один для отправителя, другой для получателя. Это позволяет избежать ошибки при передаче информации.
Протоколы в ЛВС
Организация ЛВС базируется на принципе многоуровневого управления процессами, включающими в себя иерархию протоколов и интерфейсов.
Протокол УФК определяет форму представления и порядок передачи данных через физический канал связи, фиксирует начало и конец кадра, который несет в себе данные, формирует и принимает сигнал со скоростью, присущей пропускной способности канала.
Второй уровень (канальный) можно разделить на два подуровня: управление доступом к каналу (УДК) и управление информационным каналом (УИК).
Протокол УДК устанавливает порядок передачи данных через канал, выборку данных.
Протокол УИК обеспечивает достоверность данных, т.е. формируются проверочные коды при передаче данных.
Во многих ЛВС отпадает необходимость в сетевом уровне. К нему прибегают при комплексировании нескольких ЛВС, содержащих моноканалы.
Протокол УП обеспечивает транспортный интерфейс, ликвидирующий различия между потребностями процессов в обмене данными и ограничениями информационного канала, организуемого нижними уровнями управления. Протоколы высоких уровней - УС, УПД, УПП - по своим функциям аналогичны соответствующим протоколам глобальных сетей, т.е. реализуется доступ терминалов к процессам, программ к удаленным файлам, передача файлов, удаленный ввод заданий, обмен графической информацией и др.

Сетевой протокол.
Он предписывает правила работы компьютерам, которые подключены к сети. Стандартные протоколы заставляют разные компьютеры говорить на одном языке. Таким образом, осуществляется возможность подключения к Интернет разнотипных компьютеров, работающих под управлением различных операционных систем.
На нижних (2-м и 3-м) уровнях используются два основных протокола: IP -протокол Интернет и ТСР - протокол управления передачей.
Так как ЭТИ два протокола тесно взаимосвязаны, то часто их объединяют и говорят , что в Интернет базовым протоколом является TCP/IP: все остальные протоколы строятся на их основе.
Конечными пользователями глобальной сети являются host-компьютеры (или устройства), имеющие 32-битный адрес, разбитый на 4 байта и представленный в десятичном формате (256.256.256.256), так как в двоичном виде он плохо воспринимается людьми.
Именно на их основе и функционирует Интернет. Протокол ТСР разбивает информацию на порции, нумерует все порции, чтобы при получении можно было правильно собрать информацию. Каждый пакет получает заголовок ТСР, где, кроме адреса получателя, содержится информация об исправлении ошибок и о последовательности передачи пакетов. Затем пакеты ТСР разделяются на еще более мелкие пакеты IP .
Пакеты состоят из трех различных уровней, каждый из которых содержит: данные приложения, информацию ТСР, информацию IP .
Перед отправкой пакета протокол ТСР вычисляет контрольную сумму. При поступлении снова рассчитывается контрольная сумма, если пакет поврежден, то запрашивается повторная передача.
Затем принимающая программа объединяет пакеты IP в пакеты ТСР, из которых реконструируются исходные данные. Протоколы TCP/IP обеспечивают передачу информации между компьютерами. Все остальные протоколы сих помощью реализуют самые разные услуги Интернет.
Стандартная модель сетевого взаимодействия
ISO/
OSI
| Номер
|
Название уровня
|
Примеры
|
| 7 |
Приложения |
MS Word, Netscape Communicator |
| 6 |
Представления |
ASCII, EBCDIC |
| 5 |
Сеансовый |
NCP, РТР, НТТР, NetBEUI |
| 4 |
Транспортный |
TCP, SPX |
| 3 |
Сетевой |
IP, IPX, Apple Talk |
| 2 |
Канальный |
Х.25, РРР, CSMA/CD, Frame Relay, ISDN, АТМ |
| 1 |
Физический |
RS-232, 10BaseT |
| Протоколы Х.25, Frame Relay в определенных условиях могут рассматриваться как |
| протоколы третьего уровня модели ISO/OSI, но на практике они обычно используются для |
| образования каналов при построении сетей IP или IPX . |
Наиболее перспективным в настоящее время является протокол АТМ. Он чрезвычайно гибко масштабируется от локальных до глобальных сетей, предполагает высокие скорости передачи данных (до 655 Мбит/сек), включает в себя средства управления качеством обслуживания (QoS), что особенно актуально при передаче мультимедийного трафика. Однако высокая стоимость оборудования А ТМ пока ограничивает его применение.
ТСР - (транспортный протокол), протокол высокого уровня имеет собственные средства контроля (целостность кадра, ошибки), средства оповещения о перегрузке сети (для контроля потока);
IP- межсетевой протокол;
ТСР/IР- основной протокол связи по INTERNET;
НТТР - транспортный протокол передачи гипертекста (в основе лежит система обработки запросов и ответов).
Модели клиент-сервер
- это технология взаимодействия компьютеров в сети. Каждый из компьютеров имеет свое назначение и выполняет свою определенную роль. Одни компьютеры в сети владеют и распоряжаются информационно-вычислительными ресурсами (процессоры, файловая система, почтовая служба, служба печати, база данных), другие имеют возможность обращаться к этим службам, пользуясь их услугами.
Компьютер, управляющий тем или иным ресурсом называют сервером
этого ресурса, а компьютер, пользующийся им - клиентом
.
Каждый конкретный сервер определяется видом того ресурса, которым он владеет. Например, назначением сервера баз данных является обслуживание запросов клиентов, связанных с обработкой данных; файловый сервер, или файл-сервер,
распоряжается файловой системой и т.д.
Этот принцип распространяется и на взаимодействие программ. Программа, выполняющая предоставление соответствующего набора услуг, рассматривается в качестве сервера, а программы пользующиеся этими услугами, принято называть клиентами.
Программы имеют распределенный характер, т.е. одна часть функций прикладной программы реализуется в программе-клиенте, а другая - в программе-сервере, а для их взаимодействия определяется некоторый протокол.
Рассмотрим эти функции. Один из основных принципов технологии клиент-сервер заключается в разделении функций стандартного интерактивного приложения на четыре группы, имеющие различную природу.
Первая группа
. Это функции ввода и отображения данных.
Вторая группа
- объединяет чисто прикладные функции, характерные для данной предметной области (для банковской системы - открытие счета, перевод денег с одного счета на другой и т.д.).
Третья группа
- фундаментальные функции хранения и управления информационно-вычислительными ресурсами (базами данных, файловыми системами и т.д.).
Четвертая группа
- служебные функции, осуществляющие связь между функциями первых трех групп.
В соответствии с этим в любом приложении выделяются следующие логические компоненты:
- компонент представления (presentation), реализующий функции первой группы;
- прикладной компонент (business application), поддерживающий функции второй группы;
- компонент доступа к информационным ресурсам (resource manager), поддерживающий функции третьей группы, а также вводятся и уточняются соглашения о способах их взаимодействия (протокол взаимодействия).
Различия в реализации технологии клиент-сервер
определяются следующими факторами:
- видами программного обеспечения, в которые интегрирован каждый из этих компонентов;
- механизмами программного обеспечения, используемыми для реализации функций всех трех групп;
- способом распределения логических компонентов между компьютерами в сети;
- механизмами, используемыми для связи компонентов между собой.
Выделяются четыре подхода, реализованные в следующих моделях:
1. модель файлового сервера (File Server - FS);
2. модель доступа к удаленным данным (Remote Data Access - RDA);
3. модель сервера баз данных (Data Base Server - DBS);
4. модель сервера приложений (Application Server - AS).
4.3.1. Модель файлового сервера. (FS) -
является базовой для локальных сетей ПК. До недавнего времени была популярна среди отечественных разработчиков, использовавших такие системы, как FoxPro, Clipper, Clarion, Paradox и т.д.
Одним из компьютеров в сети считается файловым сервером и предоставляет другим компьютерам услуги по обработке файлов. Файловый сервер работает под управлением сетевой операционной системы (Novell NetWare) и играет роль компонента доступа к информационным ресурсам (т.е. к файлам). На других ПК в сети функционирует приложение, в кодах которого совмещены компонент представления и прикладной компонент (рис.4.7.).
 
Клиент Сервер
 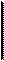   Запросы Запросы
 Компонент Прикладной Компонент доступа к Компонент Прикладной Компонент доступа к
 представления компонент ресурсам представления компонент ресурсам
файлы
Рис.4.7. Модель файлового сервера
Протокол обмена представляет собой набор вызовов, обеспечивающих приложению доступ к файловой системе на файл-сервере.
К недостаткам технологии данной модели относят низкий сетевой трафик (передача множества файлов, необходимых приложению), небольшое количество операций манипуляции с данными (файлами), отсутствие адекватных средств безопасности доступа к данным ( защита только на уровне файловой системы) и т.д.
4.3.2. Модель доступа к удаленным данным (RDA) –
существенно отличается от FS-модели методом доступа к информационным ресурсам. В RDA-модели коды компонента представления и прикладного компонента совмещены и выполняются на компьютере-клиенте. Доступ к информационным ресурсам обеспечивается операторами специального языка (SQL, если речь идет о базах данных) или вызовами функций специальной библиотеки (если имеется специальный интерфейс прикладного программирования - API).
Запросы к информационным ресурсам направляются по сети удаленному компьютеру, который обрабатывает и выполняет их, возвращая клиенту блоки данных (рис.4.8).
 
Клиент Сервер
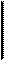  SQL SQL
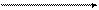 Компонент Прикладной Компонент доступа к Компонент Прикладной Компонент доступа к
 представления компонент ресурсам представления компонент ресурсам
данные
Рис.4.8. Модель доступа к удаленным данным
Говоря об архитектуре клиент-сервер, подразумевают данную модель. Основное достоинство RDA-модели заключается в унификации интерфейса клиент-сервер в виде языка SQL и широком выборе средств разработки приложений. К недостаткам можно отнести существенную загрузку сети при взаимодействии клиента и сервера посредством SQL-запросов; невозможность администрирования приложений в RDA, т.к. в одной программе совмещаются различные по своей природе функции (представления и прикладные).
4.3.3. Модель сервера баз данных (DBS) -
реализована в некоторых реляционных СУБД (Informix, Ingres, Sybase, Oracle), (рис.4.9).
Ее основу составляет механизм хранимых процедур - средство программирования SQL-сервера. Процедуры хранятся в словаре баз данных, разделяются между несколькими клиентами и выполняются на том же компьютере, где функционирует SQL-сервер. В DBS-модели компонент представления выполняется на компьютере-клиенте, в то время как, прикладной компонент оформлен как набор хранимых процедур и функционирует на компьютере-сервере БД. Там же выполняется компонент доступа к данным, т.е. ядро СУБД.
 
  Клиент Вызов
Сервер Клиент Вызов
Сервер
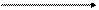 Компонент Прикладной Компонент доступа к Компонент Прикладной Компонент доступа к
 представления компонент SQL ресурсам представления компонент SQL ресурсам

Рис.4.9. Модель сервера баз данных
Понятие информационного ресурса сужено до баз данных, поскольку механизм хранимых процедур - отличительная характеристика DBS-модели - имеется пока только в СУБД.
Достоинства DBS-модели:
- возможность централизованного администрирования прикладных функций;
- снижение трафика (вместо SQL-запросов по сети направляются вызовы хранимых процедур);
- возможность разделения процедуры между несколькими приложениями;
- экономия ресурсов компьютера за счет использования единожды созданного плана выполнения процедуры.
К недостаткам относится:
- ограниченность средств написания хранимых процедур, представляющих собой разнообразные процедурные расширения SQL, которые уступают по изобразительным средствам и функциональным возможностям в сравнении с языками С или Pascal. Сфера их использована ограничена конкретной СУБД из-за отсутствия возможности отладки и тестирования разнообразных хранимых процедур.
На практике чаще используются смешанные модели, когда целостность базы данных и некоторые простейшие прикладные функции обеспечиваются хранимыми процедурами (DBS-модель), а более сложные функции реализуются непосредственно в прикладной программе, которая выполняется на компьютере-клиенте (RDA-модель).
4.3.4. Модель сервера приложений (AS) -
представляет собой процесс, выполняемый на компьютере-клиенте, отвечающий за интерфейс с пользователем (т.е. реализует функции первой группы). (рис.4.10).
  
   Клиент Сервер Сервер Клиент Сервер Сервер
Компонент API
Прикладной SQL
Компонент доступа
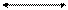  представления компонент к ресурсам представления компонент к ресурсам
Рис.4.10. Модель сервера приложений
Прикладной компонент реализован как группа процессов, выполняющих прикладные функции, и называется сервером приложения
(Application Server - AS).
Доступ к информационным ресурсам осуществляет менеджер ресурсов (например, SQL-сервер). Из прикладных компонентов доступны такие ресурсы как, базы данных, очереди, почтовые службы и др. AS, размещенная на компьютере, где функционирует менеджер ресурсов, избавляет от необходимости направления SQL-запросов по сети, что повышает производительность системы.
Модели RDA и DBS опираются на двухзвенную схему разделения функций:
- в RDA-модели прикладные функции отданы программе-клиенту (прикладной компонент сливается с компонентом представления);
- в DBS-модели ответственность за их выполнение берет на себя ядро СУБД (прикладной компонент интегрируется в компонент доступа к информационным ресурсам).
В AS-модели реализована трехзвенная схема разделения функций. Здесь прикладной компонент выделен как важнейший изолированный элемент приложения. Сравнивая модели, AS обладает наибольшей гибкостью и имеет универсальный характер.
Принципы перехода к новой информационной системе.
При переходе к новой информационной системе (ИС) необходимо решить такие вопросы как выбор одной из четырех моделей, компоненты архитектуры ИС и инструментарий перехода.
Наиболее распространенной ИС является FS-модель (примем ее за исходную), а в качестве целевой - RDA-модель (наиболее распространена и относительно проста). На практике наблюдаются и другие схемы перехода ( FS-->DBS, RDA--->DBS, RDA-->AS, FS-->AS). Наиболее типичный случай это FS-->RDA, это переход от локальных сетей ПК к архитектуре систем с сервером баз данных.
Следующий шаг - определение компонентов архитектуры системы, имеющей в своей основе RDA-модель - компьютер-клиент и сервер баз данных
. Проблема заключается в выборе аппаратного и базового программного обеспечения этих компонентов.
На сегодняшний день используются ПК на базе процессоров Pentium под управлением ОС/2 MS Windows (распространенность, популярность, большое число приложений, широкий набор активно используемых русифицированных продуктов). Самое важное достоинство MS Windows - множество средств быстрой разработки приложений, работающих с SQL-ориентированными СУБД, и доступность этих средств для отечественных пользователей.
Говоря о сервере БД, необходимо упомянуть, что это должен быть мощный компьютер, снабженный высокоскоростными надежными механизмами дисковой памяти большой емкости и системой архивирования на магнитных лентах. Его работа должна осуществляться под управлением многозадачной многопользовательской ОС, поддерживающей промышленные стандарты.
Сервер
– процесс, обслуживающий информационную потребность клиента: поиск или обновление БД, в этом случае сервер носит название – сервер БД
, обработку данных – сервер приложения
.
Клиент
– приложение, посылающее запрос на обслуживание сервера. Задача сервера – инициирование связи с сервером, определение вида запроса на обслуживание, получение от сервера результата обслуживания, подтверждение окончания обслуживания.
Клиент-серверная архитектура реализует многопользовательский режим работы и является распределенной, когда клиенты и серверы располагаются на разных узлах локальной или глобальной сети.
Схема клиент-серверной архитектуры включает три уровня представления: уровень представления (презентации) данных пользователем; уровень обработки данных приложением и уровень взаимосвязи с БД. Согласно схемы пользователь (клиент) в одном случае вводит данные, которые после контроля и преобразования некоторым приложением попадают в БД, а в другом случае запрашивает обработку данных приложением, которое обращается за необходимыми данными к БД. Получив необходимые данные сервер их обрабатывает, а результаты помещает либо в БД, либо выдает пользователю в удобной для него форме (текст.док-т, электронная таблица, график), или делает то и другое вместе.
Выбор конкретной схемы определяется различными вариантами территориального распределения удаленных подразделений предприятия, требованиями эксплуатационной надежности, быстродействием, простотой обслуживания. На рис.2. представлены различные схемы клиент-серверной архитектуры.
Файл-серверная
архитектура – самый простой вариант распределенной обработки данных, когда на сервере располагаются только файлы данных, а на клиентской части находятся приложения пользователей вместе с СУБД. Использование файл-серверов предполагает, что вся обработка данных выполняется на рабочей станции, а файл-сервер лишь выполняет функции накопителя данных и средств доступа.
Двухуровневая клиент-серверная
архитектура основана на использовании только сервера базы-данных (DB-сервера), когда клиентская часть содержит уровень представления данных, а на сервере находится БД вместе с СУБД и прикладными программами.
DB-сервер отличается от файл-сервера тем, что в его оперативной памяти, помимо сетевой ОС, функционирует централизованная СУБД, которая обеспечивает совместное использование рабочими станциями базы данных, размещенной во внешней памяти этого
DB-сервера. DB-сервер дает возможность отказаться от пересылки по сети файлов данных целиком и передавать только ту выборку из БД, которая удовлетворяет запросу пользователя. При этом возможно разделение пользовательского приложения на две части:
одна выполняется на сервере и связана с выборкой и агрегированием данных из БД, а вторая часть по представлению данных для анализа и принятия решения выполняется на клиентской машине. Таким образом, увеличивается общая производительность информационной системы в результате объединения выч.ресурсов сервера и клиентской рабочей станции.
Обращение к БД осуществляется на языке SQL, который стал стандартом для реляционных БД. Поэтому сервер БД называют SQL-сервером, который поддерживается всеми реляционными СУБД: Oracle, Informix, MSSQL, ADABASD, InterBase, SyBase и др.
Клиентское приложение может быть реализовано на языке настольных СУБД (MSAccess, FoxPro, Paradox, Clipper и др.). При этом взаимодействие клиентского приложения с SQL-сервером осуществляется через ODBC-драйвер (OpenDataBaseConnectivity), который обеспечивает возможность пересылки и преобразования данных из глобальной БД в структуру БД клиентского приложения.
Представление
данных пользователя Приложение База данных
 Централизованная Централизованная
Система
  Архитектура Архитектура
   «Файл-сервер» «Файл-сервер»
Двухуровневая
архитектура
«клиент-сервер»
         Трехуровневая Трехуровневая
Архитектура
«клиент-сервер»
Многоуровневая
Архитектура
«клиент-сервер»
Рис.2. Варианты клиент-серверной архитектуры КЭИС
Трехуровневая клиент-серверная
архитектура позволяет помещать прикладные программы на отдельные серверы приложений, с которыми через API-интерфейс (ApplicationProgramInterface) устанавливается связь клиентских рабочих станций. Клиентская часть приложения вызывает необходимые функции сервера приложения, называемые «сервисами». Прикладные программы в свою очередь обращаются к серверу БД с помощью SQL запросов. Такая организация позволяет повысить производительность и эффективность КЭИС за счет:
- многократности повторного использования общих функций обработки данных в множестве клиентских приложений при существенной экономии системных ресурсов;
- параллельности в работе сервера приложений и сервера БД, причем сервер приложений может быть менее мощным по сравнению с сервером БД;
- оптимизации доступа к БД через сервер приложений из клиентских мест путем диспетчеризации выполнения запросов в сети;
- повышение скорости и надежности обработки данных в результате дублирования ПО на нескольких серверах приложений, которые могут заменять друг друга в сети в случае перегрузки или выхода из строя одного из них;
- переноса функций администрирования системы по проверке полномочий доступа пользователей с сервера БД на сервер приложений.
Многоуровневая архитектура «клиент-сервер»
создается для территориально-распределенных предприятий. Здесь наблюдаются отношения «многие ко многим» между клиентскими рабочими станциями и серверами приложений, между серверами приложений и серверами БД. Такая организация позволяет более рационально организовать информационные потоки между структурными подразделениями. Каждый сервер приложений обслуживает потребности какой-либо одной функциональной подсистемы и сосредоточивается в головном для подсистемы структурном подразделении (сервер приложения по управлению сбытом – в отделе сбыта, сервер приложения по управлению снабжением – в отделе закупок и т.д.). Интегрированная БД находится на отдельном сервере, на котором обеспечиваются централизованное ведение и администрирование общих данных для всех приложений.
Ведение нескольких серверов БД особенно актуально для предприятий с филиальной структурой , когда в центральном офисе используется общая БД, содержащая общую
нормативно-справочную (НС), планово-бюджетную информацию и консолидированную отчетность, а в территориально—удаленных филиалах поддерживается оперативна
я информация о деловых процессах. При обработке данных в филиалах для контроля используется плановая и НС информация из центральной БД, а в центральном офисе получение консолидированной отчетности сопряжено с оперативной информацией филиалов.
4.3. Многоуровневые системы клиент-сервер
Технология клиент-сервер считается одним из "китов" современного мира компьютерных сетей. Но задачи, для решения которых она была разработана, уходят в прошлое. Новые задачи и технологии требуют переосмысления принципов клиент-серверных систем. Одна из таких технологий World Wide Web. Web-технология является развитием архитектуры клиент-серверы, т.е. с помощью одного клиента можно подключиться ко многим серверам. Информационная система, кроме интерфейса, должна иметь уровни обработки данных и их хранения. Проблема разработчиков интерсетей в согласовании работы Web с другими элементами системы, например базами данных. Одним из перспективных способов решения этой проблемы - многоуровневые системы клиент-сервер.
Классическая система клиент-сервер работает по схеме "запрос-ответ" (двухуровневая архитектура). Клиент выполняет активную функцию (запросы), сервер пассивно на них отвечает.
Любая информационная система должна иметь минимум три функциональные части - модули хранения данных, их обработки и интерфейса с пользователем.
Каждая из этих частей может быть реализована независимо от двух других.
Например
. Не изменяя программ, используемых для хранения и обработки данных, можно изменить интерфейс с пользователем таким образом, что одни и те же данные будут отображаться в виде таблиц, графиков или гистограмм. Не меняя программ представления данных и их хранения, можно изменить программы обработки, изменив алгоритм полнотекстового поиска. Не меняя программ представления и обработки данных, можно изменить программное обеспечение для хранения данных, перейдя на другую файловую систему.
В классической архитектуре клиент-сервер три основные части приложения распределяются по двум физическим модулям. Обычно ПО хранения данных располагается на сервере (/: сервере базы данных), интерфейс с пользователем - на стороне клиента, а вот обработку данных приходится распределять между клиентской и серверной частями. В этом основной недостаток данной архитектуры. Разбиение алгоритмов обработки данных требует синхронизации действий обеих частей системы. Чтобы избежать несогласованности различных элементов архитектуры, пытаются выполнять обработку данных на одной из двух частей - либо на стороне клиента ("толстый" клиент), либо на сервере ("тонкий" клиент, или "2,5-уровневый клиент-сервер"). Каждый подход имеет свой недостаток: в первом случае
неоправданно перегружается сеть, т.к. по ней передаются необработанные (избыточные) данные, усложняется поддержка и изменение системы, так как замена алгоритма вычислений или исправление ошибки требует одновременной полной замены всех интерфейсных программ, иначе последует несогласованность данных; во втором случае
, когда вся обработка информации выполняется на сервере, возникает проблема описания встроенных процедур и их отладки (описание является декларативным и не допускает пошаговой отладки). Кроме того, систему с обработкой информации на сервере абсолютно невозможно перенести на другую платформу.
Большинство современных средств быстрой разработки приложений (RAD), которые работают с различными БД, реализует первую модель ("толстый" клиент), обеспечивающую интерфейс с сервером БД через язык SQL.. Этот вариант, кроме выше перечисленных недостатков, имеет низкий уровень безопасности.
Например. В банковских системах все операционисты имеют права на запись в основную таблицу учетной системы. Кроме того, данную систему почти невозможно перевести на Web-технологи., так как для доступа к серверу БД используется специализированное клиентское ПО.
Недостатки рассмотренных выше моделей:
1.
"Толстый" клиент
· сложность администрирования;
· сложность в обновлении ПО, т.к. его замену необходимо производить одновременно по всей системе;
· сложность в распределении полномочий, так как разграничение доступа происходит не по действиям, а по таблицам;
· перегрузка сети из-за передачи по ней необработанных данных;
· слабая защита данных.
2.
"Толстый" сервер
· усложняется реализация, так как языки PL/SQL не приспособлены для разработки подобного ПО и нет средств отладки;
· производительность программ на языках PL/SQL ниже, чем на других языках, что важно для сложных систем;
· программы, написанные на СУБД-языках, работают ненадежно, что может привести к выходу из строя всего сервера БД;
· созданные таким образом программы полностью непереносимы на другие системы и платформы.
Для решения перечисленных проблем используются многоуровневые (три и более) модели клиент-сервер.Многоуровневые архитектуры клиент-сервер - более разумно распределяют модули обработки данных, которые выполняются на одном или нескольких отдельных серверах.
Эти программные модули выполняют функции сервера
для интерфейсов с пользователями и клиента
- для серверов БД. Кроме того, различные серверы приложений могут взаимодействовать между собой для более точного разделения системы на функциональные блоки, выполняющие определенные роли.
Например. Можно выделить сервер управления персоналом, который будет выполнять все необходимые для управления персоналом функции. Связав с ним отдельную БД, можно скрыть от пользователей все детали реализации этого сервера, разрешив обращаться только к его общедоступным функциям. Такая система проще адаптируется к Web, т.к. легче разработать html-формы для доступа пользователей к определенным функциям БД, чем ко всем данным.
В трехуровневой модели "тонкий" клиент не перегружен функциями обработки данных, а выполняет основную роль системы представления информации, поступающей с сервера приложений. (Такой интерфейс реализуется с помощью стандартных средств Web-технологии - браузера, CGI и Java). Это уменьшает объем данных, передаваемых между клиентом и сервером приложений, позволяя подключать клиентов с медленными телефонными каналами.
Трехуровневая модель клиент-сервер позволяет более точно назначать полномочия пользователей, так как они получают права не к самой БД, а к определенным функциям сервера приложений, что повышает защищенность системы.
Многоуровневые клиент-серверные системы легко можно перевести на Web-технологию - для этого достаточно заменить клиентскую часть универсальным браузером, а сервер приложений дополнить Web-сервером и небольшими программами вызова процедур сервера. В трехуровневой системе по каналу связи между сервером приложений и БД передается много информации, при этом не замедляются вычисления, так как для связи указанных элементов используются более скоростные линии. Это требует меньших затрат, так как оба сервера находятся в одном помещении. Но при этом встает проблема согласованности совместных вычислений, которую призваны решать менеджеры транзакций - новые элементы многоуровневых систем.
Менеджеры транзакций
МТ -
позволяют одному серверу приложений одновременно обмениваться данными с несколькими серверами БД. Хотя серверы Oracle имеют механизм выполнения распределенных транзакций, но если пользователь хранит часть информации в БД Oracle, часть в БД Informix, а часть в текстовых файлах, то без МТ не обойтись. МТ используется для управления распределенными разнородными операциями и согласования действий различных компонентов информационной системы. Любое сложное ПО требует использования МТ.
Например.
Банковские системы должны осуществлять различные преобразования представлений документов, т.е. работать одновременно с данными, хранящимися как в БД, так и в обычных файлах, - именно эти функции и помогает выполнять МТ.
МТ - это программа или комплекс программ, с помощью которых можно согласовать работу различных компонентов инф-ой системы.
Логически МТ делится на несколько частей:
· коммуникационный менеджер (контролирует обмен сообщениями между компонентами инф-ой системы;
· менеджер авторизации (обеспечивает аутентификацию пользователей и проверку их прав доступа);
· менеджер транзакций (управляет распределенными операциями);
· менеджер ведения журнальных записей (следит за восстановлением и откатом распределенных операций);
· менеджер блокировок (обеспечивает правильный доступ к совместно используемым данным).
Обычно М-коммуникационный объединен с М-авторизации, а М-транзакций с М-блокировок и системных записей. Причем такой М редко входит в комплект поставки, поскольку его функции (ведение записей, распределение ресурсов и контроль операций), как правило, выполняет сама БД (например, Oracle).
Наибольшие изменения произошли в М-коммуникации, так как в этой области появились новые объектно-ориентированные технологии (CORBA, DCOM и т.д.). Многоуровневая модель клиент-сервер позволяет существенно упростить распределенные вычисления, делая их не только более надежными, но и более доступными.
4.4. Системы технологической почты
-
это гарантированная доставка информации и средство для интеграции приложений
Проектирование информационных систем ставит перед системными аналитиками решения следующих проблем:
распределенность системы;
интеграция различных приложений;
удобство администрирования.
Современные ВС в основном являются распределенными, поэтому встает задача выбора способа взаимодействия между отдельными частями таких систем. Слияние нескольких информационных систем требует решения интеграции большого количества разнородных приложений. Такая (интегрированная) система должна обладать всей функциональностью объединяемых подсистем и сохранить простоту и удобство использования. Решение данной проблемы возможно осуществить с помощью систем технологической почты
(СТП).
Термин «технологическая почта» используется для обозначения взаимодействия между приложениями ("электронная почта" - взаимодействие между людьми), передаваемая информация является технологической ее формирование и передача могут осуществляться без/или с минимальным участием человека.
Система технологической почты включает в себя два различных способа взаимодействия, используемых в современных распределенных системах.
Один из них основывается на концепции соединения (рис.1), а другой - на идее обмена сообщениями.

   1 1
 2 2
3
Рис.1. Механизм взаимодействия с установлением соединения
Процесс взаимодействия приложений и использованием установления соединения можно разделить на три фазы:
1. установление соединения;
2. передача информации;
3. закрытие соединения.
Такое взаимодействие требует наличие соединения всех трех фаз и одновременной работы приложений, что не всегда возможно.
Системы, построенные на принципе обмена сообщениями, используют при взаимодействии технологию очередей сообщений (рис.2).
Рис.2. Взаимодействие приложений с использованием технологии очередей сообщений
Приложения, которые обмениваются информацией, адресуют ее не напрямую друг другу, а в ассоциированные с приложениями очереди сообщений. Соединение между приложением и очередью происходит, как правило, в режиме on-line, что позволяет избежать затраты времени на установление соединения. Управляющее ПО может находиться как на одной машине с приложениями, так и на выделенном сервере. Системы, использующие технологию очередей сообщений, в Отличие от систем установления соединений, не требуют ни постоянного соединения в процессе взаимодействия, ни одновременной работы взаимодействующих приложений. Эти свойства обеспечивают им гибкость и приемлемость в различных областях применения.
Универсальность систем технологической почты позволяет им работать на гетерогенных
(многообразие программно-аппаратных платформ, на которых работают отдельные компоненты СТП, а также многообразие способов соединения и протоколов взаимодействия, применяемых в системе) структурах. Гетерогенность достигается за счет разделения серверной и клиентских частей СТП. Клиентские части обладают небольшой функциональностью и могут быть перенесены на различные платформы. Т.о., для функционирования СТП не нужны затраты на дополнительное оборудование - система адаптируется к существующим средствам (как аппаратным и программным, так и к существующим каналам передачи данных) и не требует их замены.
Преимvшecтвa использования СТП:
- Гарантированность доставки сообщения. Серверы очередей сообщений
сами определяют, каким образом обеспечить гарантированность доставки при отказе отдельных частей системы: произвести повторную пересылку, найти альтернативный маршрут или применить другие способы. Так как СТП обеспечивают обмен информацией между приложениями, то факт недоставки сообщения должен быть отслежен и обработан (в отличие о электронной почты, где в случае недоставки сообщения, пользователь должен сам выполнить какие-либо корректирующие действия);
- Отсутствие блокировки приложения на время передачи информации, т.к. действует технология очередей сообщений, и выделение серверной части системы ТП, отвечающей за доставку сообщения. Отсутствие блокировки позволяет уменьшить время простоя приложений;
- Возможность установки приоритетов сообщений и опций при отправке. Приоритеты позволяют реализовать -несколько параллельных систем передачи сообщений. При этом сообщения с более низким приоритетом не будут оказывать никакого влияния на процесс доставки сообщений с более высоким приоритетом. Это имеет положительное свойство при проектировании и настройке больших систем, а также при администрировании систем;
- Возможность обмена информацией в гетерогенной среде, где возможна модернизация как технических, так и программных средств.
4.5. Технология работы в среде распределенной обработки данных
Одной из важнейших сетевых технологий является распределенная обработка данных, позволяющая повысить эффективность удовлетворения информационной потребности пользователя и, обеспечить гибкость и оперативность принимаемых им решений.
Достоинствами распределенной обработки информации является:
- большое число взаимодействующих между собой пользователей;
- устранение пиковых нагрузок с централизованной базы данных за счет распределения обработки и хранения локальных баз данных на разных ЭВМ;
- возможность доступа пользователя к вычислительным ресурсам сети ЭВМ;
- обеспечение обмена данными между удаленными пользователями.
При распределенной обработке производится работа с базой, т.е. представление данных, их обработка, работа с базой на логическом уровне осуществляется на компьютере клиента, а поддержание базы в актуальном состоянии - на сервере. При наличии распределенной базы данных база размещается на нескольких серверах. В настоящее время созданы базы данных по всем направлениям человеческой деятельности: экономической, финансовой, кредитной, статистической, научно-технической, маркетинга, патентной информации, электронной документации и т.д.
Создание распределенных баз данных (РБД) было вызвано двумя тенденциями обработки данных, с одной стороны - интеграцией, а с другой - децентрализацией.
Интеграция подразумевает централизованное управление и ведение баз данных. Децентрализация обеспечивает хранение данных в местах их возникновения или обработки, при этом скорость обработки повышается, стоимость снижается, увеличивается степень надежности системы.
Распределенная база данных
- база данных, части которой размещены на отдельных ЭВМ, входящих в сеть. При этом некоторые данные могут дублироваться.
При проектировании РБД осуществляется разбиение объекта на несколько частей (фрагментов) и размещение каждого фрагмента на один или несколько компьютеров. Размещение фрагментов может быть избыточным
или безызбыточным.
При избыточном размещении необходимо определить степень дублирования фрагментов. Выгоды, получаемые от дублирования, пропорциональны соотношению объемов выборки данных и их обновления. Для поддержания целостности базы данных требуется корректировка всех копий. Преимущества дублирования уменьшаются с увеличением стоимости хранения фрагментов и, увеличиваются, так как повышается устойчивость системы против отказов. Эффективность работы пользователей с РБД зависит от обеспеченности их информацией о содержащихся в РБД данных, их структуре и размещении. Эту задачу решает сетевой словарь-справочник данных, находящийся в одной ЭВМ сети или дублирующийся на нескольких ЭВМ. При этом, словарь-справочник может иметь распределенную структуру, т.е. когда его отдельные фрагменты распределены по рабочим станциям сети.
К организации баз данных предъявляются такие общие требования как, обеспечение высокой скоростью обработки запросов, секретности, независимости (физической и логической) данных, безопасности и т.д. Кроме перечисленных требований, к РБД выдвигаются требования "прозрачности": распределенной структуры БД; совместного доступа к данным; распределенной обработки.
Распределенная структура БД предполагает независимость конечных пользователей и программ от способа размещения информации на рабочих станциях сети, т.е. формулирование запросов к РБД производится аналогично запросам к централизованной БД.
Совместный доступ к данным подразумевает модификацию одних и тех же данных несколькими пользователями не нарушая целостности РБД.
"Прозрачность" распределенной обработки означает независимость пользователей и программ от типа локальной вычислительной сети и применяемого сетевого программного обеспечения. Обработка запроса пользователя может производиться на нескольких ЭВМ.
Доступ пользователей к РБД и администрирование осуществляется с помощью системы управления распределенной базой данных (СУРБД), которая обеспечивает выполнение следующих функций:
- автоматическое определение ЭВМ, хранящей требуемые в запросе данные;
- декомпозицию распределенных запросов на частные подзапросы к БД отдельных ЭВМ;
- планирование обработки запросов;
- передачу частных подзапросов и их исполнение на удаленных ЭВМ;
- прием результатов выполнения частных подзапросов;
- поддержание в согласованном состоянии копий дублированных данных на различных ЭВМ сети;
- управление параллельным доступом пользователей к РБД;
- обеспечение целостности РБД.
4.6. Базовые технологии обработки запросов в архитектурах
файл-сервера и клиент-сервера
Прикладные программы управления данными представляют собой необходимый инструмент для распределенной обработки.
Архитектура клиент-сервера сети позволяет различным прикладным программам одновременно использовать общую базу данных. Совершенно очевидно, что перенос программ управления данными с рабочих станций на сервер способствует высвобождению ресурсов рабочих станций, предоставляет возможность увеличить число частных, локально решаемых задач. Данная архитектура позволяет также централизовать ряд самых важных функций управления данными, такие, как защита информации баз данных, обеспечение целостности данных, управление совместным использованием ресурсов.
Одним из важных преимуществ архитектуры клиент-сервера в сетевой обработке данных является возможность сокращения времени реализации запроса. В подтверждение этому рассмотрим две базовые
технологии обработки информации в архитектуре клиент-сервера сети и технологии использования традиционного файлового сервера.
Допустим, что прикладная программа базы данных загружена на рабочую станцию и пользователю необходимо получить все записи, удовлетворяющие некоторым поисковым условиям. В среде традиционного файлового сервера
программа управления данными, которая выполняется на рабочей станции, должна осуществить запрос к серверу каждой записи базы данных (рис.4.11,а). Программа управления данными на рабочей станции может определить, удовлетворяет ли запись поисковым условиям, лишь после того, как она будет передана на рабочую станцию.
Очевидно, что данный технологический вариант обработки информации имеет наибольшее суммарное время передачи данных по каналам сети.
В среде клиент-сервера
, напротив, рабочая станция посылает запрос высокого уровня серверу базы данных
. Сервер базы данных осуществляет поиск записей на диске и анализирует их. Записи, удовлетворяющие условиям, могут быть накоплены на сервере. После того, как запрос целиком обработан, пользователю на рабочую станцию передаются все записи, которые удовлетворяют поисковым условиям (рис. 4.11,б).
Данная технология позволяет снизить сетевой трафик и повысить пропускную способность сети. Более того, за счет выполнения операции доступа к диску и обработки данных в одной системе сервер может осуществить поиск и обрабатывать запросы быстрее, чем если бы эти запросы обрабатывались на рабочей станции.
Прикладные программы баз данных клиент-сервера поддерживаются программными продуктами:
- NetWare Btrieve- программой управления записями с индексацией по ключу (выполняется на сервере);
- NetWare SQL - ядром реляционных баз данных, предназначенным для обеспечения системы защиты и целостности данных.
Службы баз данных NetWare Btrieve и NetWare SQL фирмы Novell позволяют разработчикам создавать надежные прикладные программы баз данных без необходимости написания собственных программ управления записями, что обеспечивает удобный перенос прикладных программ в среду клиент-сервера.
В настоящее время разработаны десятки тысяч прикладных автономных и многозадачных программ, ориентированных на клиента версий NetWare Btrieve, NetWare SQL, которые могут быть использованы организациями, создающими или имеющими сеть ЭВМ. Более того, версии NetWare Btrieve и NetWare SQL фирмы Novell для клиентов имеют согласованные API, что упрощает перенос программ из среды одного клиента в среду другого.

| Файл-сервер |
Рабочая станция |
a) Типовая среда обработки запросов в сетях ЭВМ.

б) Распределенная среда обработки запросов в сетях ЭВМ.
Рис. 4.11. (а,б).Технологии обработки запросов по базовым вариантам
По степени изменчивости все базы данных (БД) можно разделить на два класса:
А - условно-постоянные (в основном для справочных систем);
Б - сильно динамичные (для банковских, биржевых систем и т.п.).
Для ведения баз данных первого и второго классов используются системы управления базами данных (СУБД), которые в значительной степени отличаются друг от друга как по функциональным возможностям, так и по эксплуатационным характеристикам.
Например,
- для условно-постоянных БД
наиболее важными показателями являются показатели скорости отработки запросов и скорости формирования выходных отчетов по БД
, а такие показатели, как скорость отработки транзакций и контроль целостности БД при отработке транзакций не столь критичны;
- для сильно-динамичных БД
, на первый план выходят такие показатели, как скорость отработки транзакций, возможность контроля целостности, скорость формирования отчетов, согласованность по чтению и транзакциям. Менее критичны здесь скорости отработки запросов.
Поэтому любая СУБД не может одинаково успешно применяться при работе с БД разных классов. Такие системы, как CLIPPER, FOXPRO ориентированы на первый класс БД-(А), и здесь имеются неплохие результаты, а такие СУБД ,как Informix, Ingres, SyBase создавались для второго класса-(Б).
Исходя из вышесказанного напрашивается вывод: найти "золотую середину", которая удовлетворяла бы требованиям обоих классов (А) и (Б). Решением этой противоречивой задачи является использование дифференциальной организации файлов базы данных, или дифференциальных файлов (ДФ)
.
В последнее время разработчики СУБД ведущих фирм подошли к использованию идеи ДФ. Причинами явились следующие факты:
- значительно расширился класс решаемых на IBM PC задач, так, что термин "персональный компьютер" уже не соответствует действительности;
- широкое распространение локальных вычислительных систем (ЛВС);
- разработка многопользовательских и многозадачных систем;
- стремительное развитие технической базы ЭВМ (в большей степени дисковой памяти).
Остановимся на сути ДФ применительно к БД в ЛВС. Реализация идеи ЛВС в различных СУБД значительно отличается.
Идея ДФ включает три положения:
- основной файл БД остается неизменным при любых обновлениях базы данных, т.е., любые изменения БД последовательно накапливаются в специальном файле изменений
(не путать с журналом транзакций) - ДФ
;
- никакие индексы для него не создаются и не поддерживаются.
Когда ДФ достигнет значительных размеров (примерно 25-40% от размеров БД), администратор вносит все изменения в основной файл БД в удобный момент времени в пакетном режиме.
В качестве примера возьмем сравнение книги, где наблюдаются опечатки в страницах и, базы данных с ДФ. Нет необходимости переиздания книги из-за нескольких опечаток или незначительных изменений. Если это количество имеет тенденцию к значительному росту и достигло предельного значения, то становятся оправданными затраты на переиздание книги, куда должны быть включены все накопленные изменения.
Достоинства ДФ относятся к обеспечению высокой надежности, целостности БД и скорости отработки транзакций.
Вопрос, какие скорости отработки транзакций можно обеспечить при использовании ДФ, является довольно важным. Очевидно, что скорость отработки транзакций при такой организации БД возрастет в десятки раз. При этом сервер базы данных практически напоминает обычный файл-сервер.
Что касается индексов, то проблемы их поддержания не существует (скорости добавления, удаления и модификации записей БД находятся на самом высоком уровне). Внесение добавлений в БД не отличается от добавлений в обычный последовательный файл. Время обновления записей БД не зависит ни от размеров БД, ни от длины ключей, ни от их числа. Временные затраты на блокировку (как одно из узких мест для БД и ЛВС) сведены к минимуму.
Для того, чтобы обеспечить согласованность данных по чтению нет необходимости блокировать целиком таблицу, что имеет место в ряде СУБД, т.е., когда запрос (или формируемый отчет) начинает выполняться, СУБД "запоминает" старший адрес в ДФ (моментальный снимок). При этом пользователь, инициализирующий свой запрос, не обязан ждать "своего момента". Он "не видит" никого из пользователей и получает снимок БД именно в этот момент времени. Далее, по мере выполнения запроса (даже очень быстрого) часть записей-целей могла быть или изменена или удалена. Это отразится только на старших адресах ДФ, а поэтому СУБД просто проигнорирует любые изменения данных, случившиеся после начала выполнения запроса. Гарантируется корректировка сложных и длительных запросов к БД, т.е. обеспечение согласованности по чтению и транзакциям.
Становится интересным вопрос, как в этом случае ведется поиск в БД. В этом случае по ассоциатору находится множество записей-целей: число и список их адресов в основной БД, после чего производится считывание "ассоциатора" ДФ и производится корректировка этого списка. За счет этой корректировки время поиска увеличивается, причем величина этого увеличения зависит от размеров ДФ. Своевременность обновления БД должна быть в компетенции администратора БД. Чтобы исключить существенные издержки, связанные с ДФ, можно накапливать изменения БД для их пакетной обработки и при поиске ДФ не учитывать. В ряде систем, таких как банковские, допускается потеря некоторой точности в период между циклами обновления - "контролируемое запаздывание".
Помимо всего прочего использование ДФ обеспечивает:
- возможность администратору восстанавливать случайно удаленные записи;
- возможность (при необходимости) хранить индексные файлы на самих рабочих станциях;
- возможность создания распределенных БД;
- одновременное выполнение транзакций.
Непротиворечивость данных может обеспечиваться механизмом захвата на уровне записи - откат транзакций любой доступной вложенности.
4.7. Корпоративные технологии
Корпоративные системы (системы управления) -
это автоматизированная система управления достаточно крупным предприятием, имеющим сложную организационно-производственную структуру. К предприятиям или организациям такого типа можно отнести, например, промышленные предприятия с разветвленной цеховой структурой производства, предприятия энергоснабжения и связи, торговые оптово-закупочные предприятия, базы, администрации округов.
Корпоративные системы должны работать в сети и включать в себя все функциональные комплексы задач, обеспечивать автоматизированное управление предприятиями, организациями, ведомствами.
Корпоративные системы (системы автоматизации и управления корпорацией, компанией, финансовой группой и т.п.) включают в себя значительно больше функций, чем просто управление предприятием. Корпорация может объединять различные управленческие, производственные, финансовые и другие структуры, иметь несколько территориально удаленных филиалов, предприятий, торговых фирм, занимающихся самыми разнообразными видами деятельности (производственной, строительной, добывающей, банковской, страховой и пр.). Здесь на первый план выходят скорее проблемы правильной организации информационного обеспечения: уровней иерархии, агрегирования информации, ее оперативности и достоверности, консолидации данных и отчетов в центральном офисе, организации доступа к данным и их защиты, технологии согласованного обновления единой информации общего доступа. В качестве компонентов системы присутствуют: функционально полная подсистема бухгалтерского учета с возможностью использования различных международных стандартов; подсистемы оперативного, производственного учета, учета кадров, различные подсистемы управления, делопроизводства и планирования, анализа и поддержки принятия решений и пр. Причем, бухгалтерская составляющая в такой системе не является главенствующей, т.к. подобные разработки ориентированы больше на руководителей компаний и управляющих разных уровней. В такой системе важнее взаимосвязь и согласованность всех составных частей, непротиворечивость их данных, а также активность применения системы для управления компанией в целом.
В настоящее время весьма актуален переход от небольших локальных сетей персональных компьютеров к промышленным корпоративным информационным системам. Большинство средних и крупных государственных и коммерческих организаций постепенно отказываются от использования только ПК, задачей сегодняшнего дня - создание открытых и распределенных информационных систем.
На сегодняшний день развитие информационных технологий - создание единых сетей предприятий и корпораций, объединяющих удаленные компьютеры и локальные сети, часто использующие разные платформы, в единую информационную систему. Т.е. необходимо объединить пользователей компьютеров в единое информационное пространство и предоставить им совместный доступ к ресурсам. Однако здесь возникает множество трудностей, связанных с решением задачи по организации каналов связи (кабель Ethernet не протянешь по городу, а тем более до другого конца планеты). При построении корпоративных сетей иногда используются телефонные каналы, но связь по таким коммутируемым линиям ненадежна, аренда выделенных линий связи дорога, а эффективность такого канала невысокая. Проблема возникает и при интегрировании в корпоративную сеть разнородных ЛВС, а также в подключении больших компьютеров, например, IBM mainframe или VAX. Сложности возникают и при объединении в одну локальную сеть компьютеров с разными ОС. Поэтому построение корпоративной сети задача не из легких.
Проблема первая - это каналы связи. Самым оптимальным вариантом является использование уже существующих глобальных сетей передачи данных общего пользования, чтобы коммуникационный протокол в корпоративной сети совпадал с принятым в существующих глобальных сетях. Наиболее рациональным выбором здесь следует считать протокол Х.25. Данный протокол позволяет работать даже на низкокачественных линиях связи, так как разрабатывался он для подключения удаленных терминалов к большим ЭВМ и соответственно включает в себя мощные средства коррекции ошибок, освобождая от этой работы пользователя.
Дальнейшее развитие Х.25 - Frame Relay, а также новые протоколы типа АТМ, хотя и обещают значительно большие скорости, требуют практически идеальных линий связи и, возможно, не скоро будут широко применяться в ближайшем будущем. Существующие в нашей стране глобальные сети общего доступа - SprintNet, Infotel, Pochet и прочие - построены на базе Х.25
Протокол Х.25 позволяет организовать в одной линии до 4096 виртуальных каналов связи. Если протянуть к офису одну выделенную линию, то ее можно использовать для объединения нескольких удаленных офисов, подключения корпоративных информационных ресурсов, доступа к системам электронной почты, базам данным - одновременно.
Выделенная линия - это обычная телефонная линия, с которой можно работать на скоростях 9600-28800 бит/с. Более скоростные линии (64 Кбит/с и >) стоят значительно дороже.
Обычно сети Х.25 строятся на двух типах оборудования - Switch или центр коммутации пакетов (ЦКП) и PAD (packet assembler/disassembler - сборщик/разработчик пакетов), называемый также пакетным адаптером данных (ПАД), или терминальным концентратором. ПАД служит для подключения к сети Х.25 оконечных устройств через порты. Примером использования ПАД в корпоративной сети - подключение банкоматов к центральному компьютеру банка.
ЦКП
(центр коммутации пакетов) - его задача состоит в определении маршрута, т.е. в выборе физических линий и виртуальных каналов в них, по которым будет пересылаться информация.
Информационные технологии служат основной цели – построению информационных систем, которые могут существенно различаться как по масштабам, так и по классу решаемых задач. В стандартный набор при создании информационных технологий входят стоимость, производительность и надежность.
Но при этом необходимо заметить, что это характеристики не самих технологий, а продукции, полученной на их основе. Сюда же следует включить стоимость сопровождения, стоимость подготовки обслуживающего персонала, удобство использования и т.д. Естественно, требования, выдвигаемые к стоимости, производительности и надежности вытекают из задач, для решения которых и создаются эти продукции.
Сложно дать точное определение корпоративным или некорпоративным (персональным) технологиям. Рассматривая такой атрибут как надежность
, можно сказать, что здесь кроется основное отличие систем коллективного пользования от систем персональных. При выходе из строя персональной системы страдает один пользователь, а при отказе системы, обслуживающей сотни и тысячи человек, последствия несоизмеримо тяжелее. Проблема обеспечения максимальной надежности очень строго стоит на всех уровнях корпоративных технологий, будь то аппаратные, программные или организационные уровни.
Что касается производительности
или «пропускной
способности»
, то для пользователя она (производительность) неинтересна, если его запросы выполняются в пределах ограничений на время отклика. Иначе обстоит дело для системы коллективного пользования. Пропускная способность является одной из основных задач администратора системы, так как именно он отвечает за то, чтобы система обслуживала бы заданное количество пользователей, обеспечивая при этом приемлемые характеристики для каждого конкретного пользователя. Иначе говоря, корпоративные системы предназначены для коллективного обслуживания и любой корпоративный сервер мощнее персонального компьютера.
Перед корпоративными и персональными технологиями стоят задачи увеличения производительности систем, и только принципы определения этой производительности могут различаться. Для одних – это выходная мощность
, для других – пропускная способность
. Рассматривая последний фактор, приходим к выводу, что он является общим понятием, так как для обеспечения пропускной способности системы в целом, необходимо чтобы некоторые ее подсистемы имели высокую выходную мощность.
Следствием надежности и производительности является стоимость.
Она также распространяется и на количество построенных на определенной технологии систем. В пересчете на количество операций в секунду стоимость мэйнфрейма или корпоративного сервера выше, чем персонального компьютера. Это разные устройства и предназначены они для решения разных, хотя и в чем-то схожих задач. При производстве таких устройств необходимы дополнительные затраты, идущие на исследовательские работы, двойное (тройное) резервирование всех критических подсистем, на тестирование и доводку и т.д. Не маловажное значение для сложных систем имеет стоимость их эксплуатации и сопровождения, модернизации и обучения персонала.
При минимизации стоимости системы, подход, применяемый в корпоративных технологиях, существенно отличается от подхода персональных технологий. Корпоративные технологии на всех уровнях системы предназначены для уменьшения стоимости эксплуатации системы за определенный период времени. Из этого следует, что при построении разных классов систем необходимо применение различных технологий, или, иначе говоря, корпоративным системам – корпоративные технологии.
В ближайшем будущем Internet станет основной платформой, на которой будут поставляться системы поддержки и принятия решений (СППР) для внутри- и межкорпоративных приложений. Прикладные коммерческие СППР, использующие Web, должны обладать следующими свойствами:
· доступам к данным по принципу самообслуживания;
· высоким уровнем доступности;
· высокой производительностью;
· возможностью использования, не требующего администрирования программного обеспечения клиентов
(Ориентированные на работу через Web клиенты должны поддерживать автоматическую загрузку из сети и обеспечивать отказ от выполняемой в обход браузера инсталляции какого-либо программного обеспечения);
· продуманной системой безопасности;
· унифицированными метаданными;
· поддержкой неструктурированных данных
Полноценный доступ пользователей к неструктурированным данным, как и к тому, которым они располагают по отношению к структурированным или реляционным базам.
Создание систем поддержки принятия решений (СППР)
на основе хранилищ данных
В любой информационной системе в той или иной степени присутствуют СППР. Поэтому, сразу после приобретения техники и установки программного обеспечения, перед организацией встает задача создания системы поддержки принятия решений. По мере развития бизнеса, упорядочения структуры организации и налаживания межкорпоративных связей, проблема разработки и внедрения СППР становится особенно актуальной. Одним из подходов таких систем стало использование хранилищ данных.
В зависимости от данных, с которыми работают СППР
, их можно разделить на оперативные
, предназначенные для немедленного реагирования на текущую ситуацию, и стратегические
– основанные на анализе большого количества информации из разных источников с привлечением сведений, содержащихся в системах, аккумулирующих опыт решения проблем.
Оперативные СППР
получили название Информационных Систем Руководства (ИСР). Они представляют собой наборы отчетов, построенные на основании данных из транзакционной информационной системы предприятия или системы, отражающей в режиме реального времени все аспекты производственного цикла предприятия. Для ИСР характерны следующие основные черты:
· отчеты, как правило, базируются на стандартных для организации запросах; число последних относительно невелико;
· ИСР представляет отчеты в максимально удобном виде (таблицы, деловая графика, мультимедийные возможности и т.п.);
· ИСР, как правило, ориентированы на конкретный вертикальный рынок (финансы, маркетинг, управление ресурсами).
Примером СППР может служить разработанная корпорацией ORACLE программа Discoverer
. Это простое в использовании средство для создания нерегламентированных запросов, анализа информации, генерации отчетов и их публикации на Web, которое дает бизнес-пользователям всех уровней возможность получать непосредственный доступ к информации, содержащейся в реляционных Хранилищах Данных, Витринах Данных и системах оперативной обработки транзакций (OLTP), поддерживающих бизнес-процессы в их организациях. Discoverer позволяет производить исследование данных посредством их детализации, «вращения» отчетов и создания диаграмм и графиков.
В Хранилищах Данных для улучшения производительности обычно производится предварительное агрегирование – огромные количества хранящихся данных суммируются в тех разрезах, которые могут представлять интерес для конечных пользователей. При запросе информации из детальной таблицы очень большого объема, Discoverer автоматически (прозрачно для пользователя) переадресовывает запросы к таблицам, в которых хранятся предварительно просуммированные итоги.
При работе с Discoverer не требуется точного совпадения запроса пользователя с имеющимися суммарными таблицами. Программа выбирает итоговые таблицы, наиболее близкие к требующимся, и (прозрачно для пользователя) производит все необходимые операции агрегирования по иерархии.
Открытый доступ.
Чтобы обеспечить возможность интеграции данных из отчетов пользователя с другими приложениями для настольных систем, можно экспортировать отчеты в большое число форматов файлов, например, HTML, XLS, TXT. Доступ к другим базам данных (Informix, MSSQLServer, Sybase, DB2 и др.) можно осуществить с помощью ODBC. Можно посылать отчеты другим пользователям, используя для этого электронную почту с соответствующим MAPI.
Для обеспечения доступа к корпоративным данным максимальному числу пользователей и минимизации при этом затрат на администрирование организации используют DiscovererViewer. Это Java–версия пользовательского варианта Discoverer, который позволяет анализировать данные, имея на компьютере только стандартный браузер Web. Вся логика Discoverer выполняется на сервере приложений, что позволяет добиться масштабируемости и простоты администрирования.
Стратегические СППР
предполагают достаточно глубокую проработку данных, специально преобразованных так, чтобы их было удобно использовать в ходе процесса принятия решений. Неотъемлемым компонентом СППР этого уровня являются правила принятия решений, которые на основе агрегированных данных подсказывают менеджерскому составу выводы и придают системе черты искусственного интеллекта. Такие системы создаются только в том случае, если структура бизнеса уже достаточно определена и имеются основания для обобщения и анализа не только данных, но и процессов их обработки. Если ИСР (информац.системы руководства) - системы оперативного управления производственными процессами, то СППР – это механизм развития бизнеса, который включает в себя некоторую часть управляющей информационной системы, обширную систему внешних связей предприятия, а также технологические и маркетинговые процессы развития производства.
1.
Концепции хранилища данных (ХД)
Хранилища данных
представляют собой предметно ориентированные, интегрированные, неизменные, поддерживающие хронологию данных системы, организованные для целей поддержки управления.
В основе технологии Хранилищ данных лежат две идеи:
1. интеграция ранее разъединенных детализированных данных, т.е. исторических архивов, данных из традиционных СОД, данных из внешних источников, в едином ХД, их согласование, и, возможно, агрегация;
2. разделение набора данных, используемых для операционной обработки, и набора данных, используемых для решения задач анализа.
Чем больше информации вовлечено в процесс принятия решений, тем более обоснованное решение может быть принято. Информация, на основе которой принимается то или иное решение, должна обладать такими качествами, как достоверность, полнота, непротиворечивость и адекватность. Поэтому при проектировании СППР возникает вопрос, на каких данных эти системы будут работать. В ИСР качество оперативных решений обеспечивается тем, что данные выбираются непосредственно из информационной системы управления предприятием (или из БД предприятия), которая адекватно отражает состояние бизнеса на данный момент времени. Ранние версии стратегических СППР в качестве исходных использовали относительно небольшой объем агрегированных*
данных, поддающихся проверке на достоверность, полноту, непротиворечивость и адекватность.
По мере роста и развития ИСР, а также совершенствования алгоритмов принятия решений на основе агрегированных данных, системы принятия решений столкнулись с проблемами, вызванными необходимостью обеспечить растущие потребности бизнеса. В ИСР накопился объем данных, замедляющий процесс построения отчетов настолько, что менеджерский состав не успевал готовить на их основе соответствующие решения. Кроме того, с развитием межкорпоративных связей потребовалось вовлечь в процесс анализа данные из внешних источников, не связанных напрямую с производственными процессами и потому не входящих в систему управления предприятием.
В стратегических СППР
традиционная технология подготовки интегрированной информации на основе запросов и отчетов стала неэффективной из-за резкого увеличения количества и разнообразия исходных данных. Произошла задержка менеджмента, требующего быстрого принятия решений. Помимо этого, постепенное накопление в БД
предприятия данных для принятия решений и последующий их анализ стали отрицательно сказываться на оперативной работе с данными. Решение было найдено и сформулировано в виде концепции Хранилища Данных (DataWarehouse, ХД), которое выполняло бы функции предварительной подготовки и хранения данных для СППР на основе информации из сторонних источников, которые в достаточном количестве стали доступны на рынке информации (рис.1.).
    
 Внешние Объе- Витрины Отчеты Внешние Объе- Витрины Отчеты
Источники дине- данных
   Ние Ние
 Прикладные и Опера- СППР/ Прикладные и Опера- СППР/
  Системы очистка цион- ИСР Системы очистка цион- ИСР
  данных ная системы данных ная системы
   Накоплен. БД Корпора- Накоплен. БД Корпора-
 Данные тивное Данные тивное
 ХД Средства ХД Средства
 Internet ИАД Internet ИАД
Intranet
Исходные данные Преобразование Хранилища
данных
Рис.1. Информационная структура хранилища данных
Цель концепции Хранилищ данных:
▪ зафиксировать отличия в характеристиках данных в оперативных и аналитических системах (табл.1);
▪ определить требования к данным, помещаемым в целевую БД Хранилища данных;
▪ определить общие принципы и этапы ее построения, основные источники данных;
▪ предложить рекомендации по решению потенциальных проблем возникающих при выгрузке, очистке, согласовании, транспортировке и загрузке данных в целевую БД.
Таблица 1
Сравнение характеристик данных в информационных системах ориентированных на операционную и аналитическую обработку данных
| Характеристика
|
Операционные
|
Аналитические
|
Частота
Обновления
Источники данных
Объемы хранимых данных
Возраст данных
Назначение
|
Высокая частота, маленькими порциями
В основном – внутренние
Сотни мегабайт, гигабайты
Текущие (за период от нескольких месяцев до одного года)
Фиксация, оперативный поиск и преобразование данных
|
Малая частота, большими порциями
В основном – внешние
Гигабайты и терабайты
Текущие и исторические (за пеиод в несколько лет, десятки лет)
Хранение детализированных и агрегированных исторических данных, аналитическая обработка, прогнозирование и моделирование
|
Предметом концепции ХД являются сами данные.
После того как традиционная система обработки данных реализована и начинает функционировать, она становится таким же самостоятельным объектом, как и любой производственный процесс. В этом смысле данные обладают теми же свойствами и характеристиками, что и любой промышленный продукт: сроком годности, местом складирования (хранения), совместимостью с данными с других производств, рыночной стоимостью, транспортабельностью, компактностью, ремонтопригодностью и т.д. Предметом рассмотрения являются не способы описания и отображения объектов предметной области, а собственно данные, как самостоятельный объект предметной области, порожденной в результате функционирования ранее созданных систем оперативной обработки данных. Для понимания данной концепции необходимо выделить следующие моменты:
- концепция Хранилищ данных – это концепция подготовки данных для анализа;
- концепция Хранилищ данных не предопределяет архитектуру целевой СППР. Она указывает на то, какие процессы должны выполняться в системе, но не на то, где конкретно и как эти процессы должны выполняться.
Концепция ХД предполагает реализацию единого интегрированного источника данных.
Аналитические системы предъявляют более высокие требования к аппаратному и программному обеспечению, чем традиционные СОД. Реализация аналитической системы невозможна без разрешения таких вопросов, как:
 Неоднородность программной среды; Неоднородность программной среды;
Распределенность;
Защита данных от НСД;
Построение и ведение многоуровневых справочников метаданных;
Эффективное хранение и обработка очень больших объемов данных.
Таблица
Основные характеристики Хранилища данных
Неоднородность программной среды
|
Основным отличием систем ХД от традиционных СОД является то, что они создаются не на пустом месте. Решение будет опираться на неоднородную среду (сточки зрения производителей программных средств, принципов построения, операционных систем) |
Распределенность
|
ХД является распределенным решением. Это связано с тем, что в его основе лежит не просто концепция физического разделения наборов данных (для операционной и аналитической обработки). В основу положено физическое разделение узлов, в которых выполняется анализ данных. И хотя при реализации такой системы редко возникает необходимость в строгой синхронизации данных в различных узлах, средства репликации данных являются неотъемлемой частью такого решения. |
| Большие объемы хранимых данных |
Неизбежность работы с очень большими объемами данных (среднестатистические размеры БД в СППР превышают сотни гигабайт). |
| Значимость вопросов защиты данных |
Для предотвращения НСД к ХД, должны быть предусмотрены соответствующие средства защиты информации.
|
Значимость метаданных и высокоуровневых средств
проектирования
|
Наличие метаданных и средств их представления конечным пользователям является одним из основных факторов успешной реализации ХД. Без актуальных, максимально полных и легко понимаемых пользователем описаний данных ХД превращается в обычный, но очень дорогостоящий электронный архив. |
2.
Технология разработки и внедрения Хранилищ Данных
Первым этапом разработки ХД является бизнес-анализ процессов и данных предприятия. Несмотря на широкое распространение CASE-технологии, в России к бизнес-анализу и проектированию данных на концептуальном уровне не всегда относятся достаточно серьезно. Однако разработка СППР на основе ХД без подробного анализа обречена на неудачу. Разработчикам необходимо понимать цели бизнеса, способы их достижения, возникающие при этом проблемы и методы их решения, ресурсы, необходимые для разработки ХД. Самым критичным из ресурсов является время
. Разработка СППР, в которой не определены заранее кто, когда, зачем и как будет принимать решения, какое влияние то или иное решение оказывает на бизнес, какие решения отнести к оперативным, а какие к стратегическим и т.д., обречена на провал в конкурентной борьбе.
Особое назначение модели предприятия – определение и формализация данных, необходимых в процессе принятия решения. Существуют два подхода к бизнес-анализу:
1. описание бизнес
-процессов
, протекающих на предприятии, которое моделируется набором взаимосвязанных функциональных элементов. Такой подход эффективен, если бизнес стабилен и внешние факторы не играют в нем решающей роли.
анализ бизнес-событий.
Он используется при проектировании СППР на основе ХД и обеспечивает наибольшую эффективность:
· позволяет гибко модифицировать бизнес-процессы, ставя их в зависимость от бизнес-событий;
· интегрирует данные, которые при анализе бизнес-процессов остаются скрытыми в алгоритмах обработки данных;
· объединяет управляющие и информационные потоки;
· наглядно показывает, какая именно информация нужна при обработке бизнес-события и в каком виде она представляется.
Т.е., бизнес-событие имеет более тесную связь с информационными и управляющими потоками, чем бизнес-процесс.
Через анализ бизнес-событий необходимо перейти к анализу данных, используемых предприятием. Для этого нужна информация об используемых внешних данных и их источниках; о форматах данных, периодичности и форме их поступления; о внутренних информационных системах предприятия, их функциях и алгоритмах обработки данных, используемых при наступлении бизнес-событий. Особенность анализа данных при проектировании СППР на основе ИХ состоит в необходимости создания модели представления информации (состав и форма отображения данных), которая является организационно-функциональным ядром модели системы. При ее разработке последовательно рассматриваются:
· распределение пользователей системы: географическое, организационное, функциональное;
· доступ к данным: объем данных, необходимый для анализа, уровень агрегированности данных, источники данных (внешние или внутренние), описание информации, используемой совместно различными функциональными группами предприятия;
· аналитические характеристики системы: измерения данных, основные отчеты, последовательность преобразования аналитической информации и т.д.
При проектировании транзакционной системы обычно строго выдерживается последовательность процессов: бизнес-анализ, концептуальная модель данных, физическая модель данных, структура интерфейса и т.п. Возврат на предыдущий уровень считается отклонением от нормального хода выполнения проекта. В случае СППР на основе ХД нормальным считается итерационный, а иногда и параллельный, характер моделирования, при котором возврат на предыдущую стадию – обычное явление. Это связано с необходимостью выделения всех требуемых данных для произвольных запросов, для чего следует составить исчерпывающий перечень необходимых данных и построить схему их связей через бизнес-события. При этом из общего массива выделяется значимая информация и выясняется потребность в дополнительных источниках данных для принятия решений. Следующий шаг связан с решением в каком виде и на каких аппаратных и программных платформах размещать структуру данных СППР на основе ХД.
3.
Витрины Данных
Идея Витрины Данных (DataMart) возникла сравнительно недавно, когда стало очевидно, что разработка корпоративного хранилища – долгий процесс. Это обусловлено как организационными, так и техническими причинами:
· информационная структура реальной компании, как правило, очень сложна, и руководство зачастую плохо понимает суть происходящих в компании бизнес-процессов;
· технология принятия решений ориентирована на существующие технические возможности;
· может возникнуть необходимость в частичном изменении организационной структуры компании;
· требуются значительные инвестиции до того, как проект начнет окупаться;
· как правило, требуется значительная модификация существующей технической базы;
· значительные затраты времени специалистами компании на освоение новых технологий и программных продуктов.
Разработка и внедрение корпоративного хранилища требуют значительных усилий по анализу деятельности компании, и переориентации ее на новые технологии. Витрины Данных возникли в результате попыток смягчить трудности разработки и внедрения Хранилищ.
Витрина Данных
– специализированное хранилище, которое обслуживает одно из направлений деятельности компании (например: учет запасов или маркетинг). Происходящие здесь бизнес-процессы, во-первых, относительно изучены, а во-вторых, не столь сложны, как процессы в масштабах всей компании. Количество сотрудников, занимающихся конкретной деятельностью невелико (рекомендуется, чтобы Витрина обслуживала не более 10-15 человек). Стоимость такого проекта значительно ниже стоимости разработки корпоративного Хранилища. Необходимо заметить, что разработка такого проекта способствует продвижению новой технологии и приводит к быстрой окупаемости затрат. Следовательно, необходимо запараллелить процессы разработки корпоративного Хранилища и разработку, и внедрение Витрин Данных.
Витрины Данных дешевле и проще в построении и базируются на более дешевых серверах MicrosoftWindowsNT, а не мультипроцессорных UNIX-комплексах. Но рост числа Витрин вызывает сложность их взаимодействия, так как не удается сделать витрины полностью независимыми. Витрины Данных нацелены на специфические нужды определенной службы, занимающейся либо закупками, либо произведенными товарами, либо планированием. Преимущество Витрин данных, по сравнению с Хранилищем, состоит в возможности быстрого получения сведений для поддержки решений в нужном месте
, не задействуя при этом информационную систему всей корпорации. В то же время витрины данных могут быть и частью хранилища. Из хранилищ данных информация «перетекает» в различные отделы, отфильтровываясь в соответствии с заданными настройками СППР. Витрины хранят обобщенную информацию
, тогда как более подробные данные можно найти в Хранилище. Пользователи имеют доступ к подмножествам хранилищ (т.е. к витринам данных), что улучшает обработку отдельных запросов, а к хранилищам обращаются лишь в случае необходимости. Такая стратегия обеспечивает важное преимущество, – реализуется единый подход к корпоративным данным. В витрины данных направляются копии информации из единого хранилища, и сотрудники разных подразделений на свои вопросы не рискуют получить разные ответы.
Одна из основных задач развития корпоративных Хранилищ/Витрин данных состоит в объединении корпоративных данных, рассеянных по системам обработки транзакций. Поэтому создавать анклавы данных из множества независимых витрин данных может оказаться выгоднее, чем строить единую корпоративную СППР.
Сочетание взаимосвязанных хранилищ и витрин данных увеличивает производительность: в витрины данных в стиле OLAP (On-lineAnalyticalProcessing – оперативный анализ
данных
) помещаются заранее агрегированные данные из хранилища, что ускоряет обработку запроса, т.к. обрабатывается меньший объем данных, разбитых уже на категории. Это эффективно в том случае, если данные не подвержены частым изменениям. В противном случае придется часто проводить реорганизацию базы данных. Что целесообразнее применять: единое хранилище; самостоятельные витрины данных; витрины, связанные с хранилищем; витрины, соединенные с неким промежуточным программным обеспечением? На этот вопрос однозначного ответа нет, т.к. оптимальный вариант вытекает из требований бизнеса, интенсивности запросов, сетевой архитектуры и необходимости быстрой реакции.
Хранилище Метаданных (Репозиторий)
Принципиальное отличие СППР на основе ХД от интегрированной системы управления предприятием состоит в обязательном наличии в СППР метаданных. В общем случае метаданные помещаются в централизованно управляемый Репозиторий, в который включается информация о структуре данных Хранилища, структурах данных, импортируемых из различных источников, о самих источниках, методах загрузки и агрегирования данных, сведения о средствах доступа, а также бизнес-правилах оценки и представления информации. Там же содержится информация о структуре бизнес-понятий. Например, клиенты могут подразделяться на кредитоспособных и некредитоспособных, на имеющих или не имеющих льготы, они могут быть сгруппированы по возрастному признаку, по местам проживания и т.п. Отсюда появляются новые понятия: постоянный клиент
, перспективный клиент
и т.п. Некоторые бизнес-понятия (соответствующие измерениям в ХД) образуют иерархии, например, товар
может включать продукты питания
и лекарственные препараты
, которые, в свою очередь, подразделяются на группы продуктов и лекарств и т.д.
Широко известны Репозитории, входящие в состав популярных САSE-средств (PowerDesigner (Sybase), Designer 2000 (Oracle), Silverrun (CSAResearch)), систем разработки приложений (Developer 2000 (Oracle), PowerBuilder (Sybase)), администрирования и поддержки информационных систем (Platinum, MSP). Все они, однако, решают частные задачи, работая с ограниченным набором метаданных, и предназначены, и основном, для облегчения труда профессионалов — проектировщиков, разработчиков и администраторов информационных систем.
Репозиторий метаданных СППР на основе ХД предназначен не только для профессионалов, но и для пользователей, которым он служит в качестве поддержки при формировании бизнес-запросов. Более того, развитая система управления метаданными должна обеспечивать возможность управления бизнес-понятиями со стороны пользователей, которые могут изменять содержание метаданных и образовывать новые понятия по мере развития бизнеса. Тем самым Репозиторий
превращается из факультативного инструмента в обязательный компонент СППР и ХД
.
Разработка системы управления метаданными сходна с разработкой распределенной транзакционной системы. При ее создании необходимо решать следующие задачи:
• анализ процессов возникновения, изменения и использования метаданных;
• проектирование структуры хранения метаданных (например, в составе реляционной базы данных);
• организация прав доступа к метаданным;
• блокировка и разрешение конфликтов при совместном использовании метаданных (что очень часто возникает при изменении общих бизнес-понятий в рампах структурного подразделения);
• разделение метаданных между Витринами Данных;
• согласование метаданных ХД с Репозиториями САSE-средств, применяемых при проектировании и разработке Хранилищ;
• реализации пользовательского интерфейса с Репозиторием.
Опыт реализации управления метаданными показывает, что основная трудность состоит не в программной реализации, а в определении содержания конкретных метаданных и методики работы с ними, в практическом внедрении Репозитория. Кроме того, если подходить к проектированию итерационно, последовательно переходя от разработки соответствующих бумажных форм и методик к созданию CASE-модели метаданных, от централизованной к распределенной модели, используя в качестве системы для хранения метаданных промышленную реляционную СУБД, можно значительно упростить задачу.
Поскольку большинство СASE-средств использует различные форматы метаданных, поставщики систем управления метаданными выработали стандарт обмена MDIS, обеспечивающий возможность интеграции CASE-средств в СППР на основе ХД. К сожалению, не все предлагаемые сегодня на российском рынке продукты соответствуют этому стандарту, поэтому преобразование форматов метаданных представляют собой достаточно сложный процесс, упростить который призваны специализированные программные продукты, в том числе, например, средства фирмы EvolutionaryTechnologiesInternational или PrismSolutions (DataWarehouseDirectory).
По завершении разработки структуры метаданных и системы управления ими, решается задача заполнения и обновления данных в ХД.
Загрузка Хранилища
При заполнении ХД необходимо определить спектр задач, которые будут решаться с его помощью и круг пользователей.
При описании технологии заполнения Хранилища различают три взаимосвязанные задачи:
- СборДанных (Data Acquisition),
- Очистка Данных (DataCleansing) и
- Агрегирование Данных (DataConsolidation).
Под Сбором Данных
будем понимать процесс, который состоит в организации передачи данных из внешних источников в Хранилище. Лишь некоторые аспекты этого процесса полностью или частично автоматизированы в имеющихся продуктах. Прежде всего, это относится к интерфейсам с существующими БД. Как правило, здесь, имеется несколько возможностей:
1. поддерживаются интерфейсы всех крупных производителей серверов баз данных (Oracle, Informix, ADABAS и т. д.);
2. практически всегда имеется ODBC-интерфейс;
3. можно извлекать данные из текстовых файлов в формате CSV (commaseparatedvalues) и из некоторых структурированных файлов, например файлов dBase.
Набор имеющихся интерфейсов — важнейшая характеристика, которая часто позволяет оценить, для каких задач проектировался продукт. Так, если среди поддерживаемых интерфейсов имеются AS/400, 052/400, IMS, VSAM (как в популярном продукте PASSPORT фирмы Carleton), то он предназначен скорее для использования в системах, работающих на больших мэйнфреймах, чем в сети из ПК. Несколько иной набор интерфейсов предлагает, например, хорошо известный продукт InfoPump фирмы PLATINUMTechnology, который обеспечивает поддержку LotusNotes, MicrosoftAccess, dBase и работу с текстовыми файлами. Крупные производители серверов либо имеют собственные средства сбора данных, либо устанавливают партнерские отношения с производителями таких средств и разрабатывают инструментарий промежуточного уровня для тиражирования «чужих» данных (таков, например, ReplicationServer фирмы Sybase).
 



Рис. 1.8. Склад данных с простой архитектурой клиент-сервер
Второй аспект процесса сбора данных, который автоматизирован в некоторых продуктах, - это организация процесса пополнения Хранилища. В том же InfoPump, например, имеется возможность строить расписание пополнения Хранилища данными либо на временной основе, либо с использованием механизма событий. Имеются и более сложные программные комбинации, например корпорация SoftwareAG разработала собственное решение для сбора и очистки данных, называемое, SourcePoint,, которое на нижнем уровне использует PASSPORT, а функции организации расписаний реализует как надстройку над этим нижним уровнем. Помимо этого SourcePoint реализует параллельные извлечение, передачу данных и заполнение Хранилища.
Под очисткой данных
обычно понимается процесс модификации данных по ходу наполнения Хранилища: исключение нежелательных дубликатов, восстановление пропущенных данных, приведение данных к единому формату, удаление нежелательных символов (например, управляющих) и унификация типов данных, проверка на целостность, и фактически все продукты располагают тем им иным набором средств очистки данных и соответствующими средствами диагностики.
При заполнении Хранилища агрегированными данными
мы должны обеспечить выборку данных из транзакционной базы данных и других источников в соответствии с метаданными, поскольку агрегирование происходит в терминах бизнес-понятий. Так, например, агрегированная величина «объем продаж продукта Х в регионе Y за последний квартал» содержит понятия «продукт» и «регион», которые являются бизнес-понятиями данного предприятия. Следует подчеркнуть, что задача выборки необходимых данных не может быть решена полностью автоматически: возможны коллизии (отсутствие необходимых данных, ошибки в данных и т. п.), когда вмешательство человека окажется необходимым. Далее, предполагая, что объектом анализа являются числовые показатели, связанные с бизнес-понятиями, такие как ОБЪЕМ ПРОДАЖ или ПРИБЫЛЬ, когда необходимо определить правила вычисления этих показателей для составных бизнес-понятий, исходя из их значений для более простых бизнес-понятий. Это и есть правила агрегирования.
Простейшей архитектурой системы на основе ХД является архитектура клиент-сервер.
Традиционно само хранилище размещается на сервере (или на серверах), а анализ данных выполняется на клиентах. Некоторое усложнение в эту схему вносят Витрины Данных. Они также размещаются на серверах, но, учитывая взаимодействия между Витринами, приходится вводить так называемые переходники
(HubServers), через которые идет обмен данными между Витринами.
Переход к базам данных клиент-сервер – относительно небольшой скачок в развитии хранилища данных. На рис. 1.8 и 1.9 показаны две альтернативные архитектуры хранилища данных, основанные на современной модели клиент-сервер.
На рис. 1.8 приложение EIS, написанное на языке Xbase осуществляет доступ к централизованному SQL-хранилищу данных посредством прикладного программного интерфейса ODBC. В такой среде довольно легко реализовать простейшую модель клиент-сервер, где один сервер обслуживает несколько клиентов.
На рис. 1.9 представлен более сложный вариант архитектуры клиент-сервер.
Доступ к логически централизованному на множестве платформ, осуществляется так же, как и в примере на рис. 1.8. Однако внутри хранилища данных для доступа к его распределенным компонентам применяется комбинация интерфейсов IDAPI и DRDAAPI. В таком случае приложение, выполняющееся над хранилищем данных, выступает в двоякой роли: как сервер для комплекса приложений EIS и как клиент, запрашивающий информацию у других серверов хранилища данных.



 IDAPI IDAPI
 IDAPI IDAPI
DRDA


Рис.1.9. Распределенный склад данных со сложной архитектурой клиент-сервер
*
Агрегирование – объединение данных по функциональным признакам
|