Введение
Основные идеи современной информационной технологии базируются на концепции баз данных (БД). Согласно данной концепции основой информационной технологии являются данные, организованные в БД, адекватно отражающие реалии действительности в той или иной предметной области и обеспечивающие пользователя актуальной информацией в соответствующей предметной области. В широком смысле слова база данных — это совокупность описаний объектов реального мира и связей между ними, актуальных для конкретной прикладной области.
Как сущности, атрибуты и связи отображаются на структуры данных - определяется моделью данных.
Традиционно все СУБД классифицируются в зависимости от модели данных, которая лежит в их основе. Принято выделять иерархическую, сетевую и реляционную модели данных. Иногда к ним добавляют модель данных на основе инвертированных списков. Соответственно говорят об иерархических, сетевых, реляционных СУБД или о СУБД на базе инвертированных списков.
По распространенности и популярности реляционные СУБД сегодня — вне конкуренции. Они стали фактическим промышленным стандартом, и поэтому отечественному пользователю придется столкнуться в своей практике именно с реляционной СУБД.
Основы реляционной модели данных были впервые изложены в статье Е.Кодда в 1970 г. Эта работа послужила стимулом для большого количества статей и книг, в которых реляционная модель получила дальнейшее развитие. Наиболее распространенная трактовка реляционной модели данных принадлежит К.Дейту[1]
. Согласно Дейту, реляционная модель состоит из трех частей:
Структурной части.
Целостной части.
Манипуляционной части.
Структурная часть описывает, какие объекты рассматриваются реляционной моделью. Постулируется, что единственной структурой данных, используемой в реляционной модели, являются нормализованные n-арные отношения.
Целостная часть описывает ограничения специального вида, которые должны выполняться для любых отношений в любых реляционных базах данных. Это целостность сущностей и целостность внешних ключей.
Манипуляционная часть описывает два эквивалентных способа манипулирования реляционными данными - реляционную алгебру и реляционное исчисление.
Цель данной работы рассмотреть структурную и целостную часть реляционной модели базы данных.
1. Структурная часть реляционной модели
1.1 Типы данных
Любые данные, используемые в программировании, имеют свои типы данных.
Реляционная модель требует, чтобы типы используемых данных были простыми.
Для уточнения этого утверждения рассмотрим, какие вообще типы данных обычно рассматриваются в программировании. Как правило, типы данных делятся на три группы:
Простые типы данных.
Структурированные типы данных.
Ссылочные типы данных.
Простые, или атомарные, типы данных не обладают внутренней структурой. Данные такого типа называют скалярами. К простым типам данных относятся следующие типы: Логический, Строковый, Численный[2]
.
Различные языки программирования могут расширять и уточнять этот список, добавляя такие типы как:
Целый.
Вещественный.
Дата.
Время.
Денежный.
Перечислимый.
Интервальный.
И т.д.…
Конечно, понятие атомарности довольно относительно. Так, строковый тип данных можно рассматривать как одномерный массив символов, а целый тип данных - как набор битов. Важно лишь то, что при переходе на такой низкий уровень теряется семантика (смысл) данных. Если строку, выражающую, например, фамилию сотрудника, разложить в массив символов, то при этом теряется смысл такой строки как единого целого.
Структурированные типы данных предназначены для задания сложных структур данных. Структурированные типы данных конструируются из составляющих элементов, называемых компонентами, которые, в свою очередь, могут обладать структурой. В качестве структурированных типов данных можно привести следующие типы данных:
Массивы
Записи (Структуры)
С математической точки зрения массив представляет собой функцию с конечной областью определения. Например, рассмотрим конечное множество натуральных чисел

называемое множеством индексов. Отображение

из множества 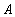 во множество вещественных чисел во множество вещественных чисел 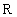 задает одномерный вещественный массив. Значение этой функции для некоторого значения индекса задает одномерный вещественный массив. Значение этой функции для некоторого значения индекса 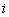 называется элементом массива, соответствующим . Аналогично можно задавать многомерные массивы. называется элементом массива, соответствующим . Аналогично можно задавать многомерные массивы.
Запись (или структура) представляет собой кортеж из некоторого декартового произведения множеств. Действительно, запись представляет собой именованный упорядоченный набор элементов 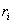 , каждый из которых принадлежит типу , каждый из которых принадлежит типу 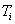 . Таким образом, запись . Таким образом, запись  есть элемент множества есть элемент множества  . Объявляя новые типы записей на основе уже имеющихся типов, пользователь может конструировать сколь угодно сложные типы данных[3]
. . Объявляя новые типы записей на основе уже имеющихся типов, пользователь может конструировать сколь угодно сложные типы данных[3]
.
Общим для структурированных типов данных является то, что они имеют внутреннюю структуру, используемую на том же уровне абстракции, что и сами типы данных.
При работе с массивами или записями можно манипулировать массивом или записью и как с единым целым (создавать, удалять, копировать целые массивы или записи), так и поэлементно. Для структурированных типов данных есть специальные функции - конструкторы типов, позволяющие создавать массивы или записи из элементов более простых типов.
Работая же с простыми типами данных, например с числовыми, мы манипулируем ими как неделимыми целыми объектами. Чтобы "увидеть", что числовой тип данных на самом деле сложен (является набором битов), нужно перейти на более низкий уровень абстракции. На уровне программного кода это будет выглядеть как ассемблерные вставки в код на языке высокого уровня или использование специальных побитных операций.
Ссылочный тип данных (указатели) предназначен для обеспечения возможности указания на другие данные. Указатели характерны для языков процедурного типа, в которых есть понятие области памяти для хранения данных. Ссылочный тип данных предназначен для обработки сложных изменяющихся структур, например деревьев, графов, рекурсивных структур.
Для реляционной модели данных тип используемых данных не важен. Требование, чтобы тип данных был простым, нужно понимать так, что в реляционных операциях не должна учитываться внутренняя структура данных. Конечно, должны быть описаны действия, которые можно производить с данными как с единым целым, например, данные числового типа можно складывать, для строк возможна операция конкатенации и т.д.
С этой точки зрения, если рассматривать массив, например, как единое целое и не использовать поэлементных операций, то массив можно считать простым типом данных. Более того, можно создать свой, сколь угодно сложных тип данных, описать возможные действия с этим типом данных, и, если в операциях не требуется знание внутренней структуры данных, то такой тип данных также будет простым с точки зрения реляционной теории. Например, можно создать новый тип - комплексные числа как запись вида  , где , где  . Можно описать функции сложения, умножения, вычитания и деления, и все действия с компонентами . Можно описать функции сложения, умножения, вычитания и деления, и все действия с компонентами  и и 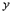 выполнять только внутри этих операций. Тогда, если в действиях с этим типом использовать только описанные операции, то внутренняя структура не играет роли, и тип данных извне выглядит как атомарный. выполнять только внутри этих операций. Тогда, если в действиях с этим типом использовать только описанные операции, то внутренняя структура не играет роли, и тип данных извне выглядит как атомарный.
Именно так в некоторых пост-реляционных СУБД реализована работа со сколь угодно сложными типами данных, создаваемых пользователями.
1.2 Домены
В реляционной модели данных с понятием тип данных тесно связано понятие домена, которое можно считать уточнением типа данных.
Домен - это семантическое понятие. Домен можно рассматривать как подмножество значений некоторого типа данных имеющих определенный смысл. Домен характеризуется следующими свойствами:
Домен имеет уникальное имя (в пределах базы данных).
Домен определен на некотором простом типе данных или на другом домене.
Домен может иметь некоторое логическое условие, позволяющее описать подмножество данных, допустимых для данного домена.
Домен несет определенную смысловую нагрузку.
Например, домен  , имеющий смысл "возраст сотрудника" можно описать как следующее подмножество множества натуральных чисел: , имеющий смысл "возраст сотрудника" можно описать как следующее подмножество множества натуральных чисел:

Если тип данных можно считать множеством всех возможных значений данного типа, то домен напоминает подмножество в этом множестве.
Отличие домена от понятия подмножества состоит именно в том, что домен отражает семантику, определенную предметной областью. Может быть несколько доменов, совпадающих как подмножества, но несущие различный смысл. Например, домены "Вес детали" и "Имеющееся количество" можно одинаково описать как множество неотрицательных целых чисел, но смысл этих доменов будет различным, и это будут различные домены[4]
.
Основное значение доменов состоит в том, что домены ограничивают сравнения. Некорректно, с логической точки зрения, сравнивать значения из различных доменов, даже если они имеют одинаковый тип. В этом проявляется смысловое ограничение доменов. Синтаксически правильный запрос "выдать список всех деталей, у которых вес детали больше имеющегося количества" не соответствует смыслу понятий "количество" и "вес".
Понятие домена помогает правильно моделировать предметную область. При работе с реальной системой в принципе возможна ситуация когда требуется ответить на запрос, приведенный выше. Система даст ответ, но, вероятно, он будет бессмысленным.
Не все домены обладают логическим условием, ограничивающим возможные значения домена. В таком случае множество возможных значений домена совпадает с множеством возможных значений типа данных.
1.3 Отношения, атрибуты, кортежи отношения
Фундаментальным понятием реляционной модели данных является понятие отношения. В определении понятия отношения будем следовать книге К. Дейта.
Атрибут отношения есть пара вида <Имя_атрибута : Имя_домена>.
Имена атрибутов должны быть уникальны в пределах отношения. Часто имена атрибутов отношения совпадают с именами соответствующих доменов.
Отношение 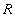 , определенное на множестве доменов , определенное на множестве доменов  (не обязательно различных), содержит две части: заголовок и тело. (не обязательно различных), содержит две части: заголовок и тело.
Заголовок отношения содержит фиксированное количество атрибутов отношения:

Тело отношения содержит множество кортежей отношения. Каждый кортеж отношения представляет собой множество пар вида <Имя_атрибута : Значение_атрибута>:

таких что значение 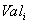 атрибута атрибута 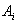 принадлежит домену принадлежит домену 
Отношение обычно записывается в виде:
 , ,
или короче
 , ,
или просто
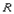 . .
Число атрибутов в отношении называют степенью (или -арностью) отношения. Мощность множества кортежей отношения называют мощностью отношения.
Заголовок отношения описывает декартово произведение доменов, на котором задано отношение. Заголовок статичен, он не меняется во время работы с базой данных. Если в отношении изменены, добавлены или удалены атрибуты, то в результате получим уже другое отношение (пусть даже с прежним именем).
Тело отношения представляет собой набор кортежей, т.е. подмножество декартового произведения доменов. Таким образом, тело отношения собственно и является отношением в математическом смысле слова. Тело отношения может изменяться во время работы с базой данных - кортежи могут изменяться, добавляться и удаляться.
Рассмотрим отношение "Сотрудники" заданное на доменах "Номер_сотрудника", "Фамилия", "Зарплата", "Номер_отдела". Т.к. все домены различны, то имена атрибутов отношения удобно назвать так же, как и соответствующие домены. Заголовок отношения имеет вид:
Сотрудники (Номер_сотрудника, Фамилия, Зарплата, Номер_отдела)
Пусть в данный момент отношение содержит три кортежа:
(1,Иванов, 1000, 1)
(2, Петров, 2000, 2)
(3, Сидоров, 3000, 1)
такое отношение естественным образом представляется в виде таблицы[5]
:
Таблица 1 Отношение "Сотрудники"
| Номер_сотрудника |
Фамилия |
Зарплата |
Номер_отдела |
| 1 |
Иванов |
1000 |
1 |
| 2 |
Петров |
2000 |
2 |
| 3 |
Сидоров |
3000 |
1 |
Реляционной базой данных называется набор отношений.
Схемой реляционной базы данных называется набор заголовков отношений, входящих в базу данных.
Хотя любое отношение можно изобразить в виде таблицы, нужно четко понимать, что отношения не являются таблицами. Это близкие, но не совпадающие понятия. Различия между отношениями и таблицами будут рассмотрены ниже.
Термины, которыми оперирует реляционная модель данных, имеют соответствующие "табличные" синонимы:
| Реляционный термин |
Соответствующий "табличный" термин |
| База данных |
Набор таблиц |
| Схема базы данных |
Набор заголовков таблиц |
| Отношение |
Таблица |
| Заголовок отношения |
Заголовок таблицы |
| Тело отношения |
Тело таблицы |
| Атрибут отношения |
Наименование столбца таблицы |
| Кортеж отношения |
Строка таблицы |
| Степень (-арность) отношения |
Количество столбцов таблицы |
| Мощность отношения |
Количество строк таблицы |
| Домены и типы данных |
Типы данные в ячейках таблицы |
Свойства отношений непосредственно следуют из приведенного выше определения отношения. В этих свойствах в основном и состоят различия между отношениями и таблицами.
В отношении нет одинаковых кортежей. Действительно, тело отношения есть множество кортежей и, как всякое множество, не может содержать неразличимые элементы. Таблицы в отличие от отношений могут содержать одинаковые строки.
Кортежи не упорядочены (сверху вниз). Действительно, несмотря на то, что мы изобразили отношение "Сотрудники" в виде таблицы, нельзя сказать, что сотрудник Иванов "предшествует" сотруднику Петрову. Причина та же - тело отношения есть множество, а множество не упорядочено. Это вторая причина, по которой нельзя отождествить отношения и таблицы - строки в таблицах упорядочены. Одно и то же отношение может быть изображено разными таблицами, в которых строки идут в различном порядке.
Атрибуты не упорядочены (слева направо). Т.к. каждый атрибут имеет уникальное имя в пределах отношения, то порядок атрибутов не имеет значения. Это свойство несколько отличает отношение от математического определения отношения. Это также третья причина, по которой нельзя отождествить отношения и таблицы - столбцы в таблице упорядочены. Одно и то же отношение может быть изображено разными таблицами, в которых столбцы идут в различном порядке.
Все значения атрибутов атомарны. Это следует из того, что лежащие в их основе атрибуты имеют атомарные значения. Это четвертое отличие отношений от таблиц - в ячейки таблиц можно поместить что угодно - массивы, структуры, и даже другие таблицы[6]
.
Из свойств отношения следует, что не каждая таблица может задавать отношение. Для того, чтобы некоторая таблица задавала отношение, необходимо, чтобы таблица имела простую структуру (содержала бы только строки и столбцы, причем, в каждой строке было бы одинаковое количество полей), в таблице не должно быть одинаковых строк, любой столбец таблицы должен содержать данные только одного типа, все используемые типы данных должны быть простыми.
Каждое отношение можно считать классом эквивалентности таблиц, для которых выполняются следующие условия:
Таблицы имеют одинаковое количество столбцов.
Таблицы содержат столбцы с одинаковыми наименованиями.
Столбцы с одинаковыми наименованиями содержат данные из одних и тех же доменов.
Таблицы имеют одинаковые строки с учетом того, что порядок столбцов может различаться.
Все такие таблицы есть различные изображения одного и того же отношения.
Труднее всего дать определение вещей, которые всем понятны. Если давать не строгое, описательное определение, то всегда остается возможность неправильной его трактовки. Если дать строгое формальное определение, то оно, как правило, или тривиально, или слишком громоздко. Именно такая ситуация с определением отношения в Первой Нормальной Форме (1НФ). Дать определение 1НФ сложно ввиду его тривиальности. Поэтому, приведем несколько объяснений.
1. Говорят, что отношение 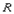 находится в 1НФ, если оно удовлетворяет определению 2. находится в 1НФ, если оно удовлетворяет определению 2.
Это, собственно, тавтология, ведь из определения 2 следует, что других отношений не бывает. Действительно, определение 2 описывает, что является отношением, а что - нет, следовательно, отношений в непервой нормальной форме просто нет.
2. Говорят, что отношение находится в 1НФ, если его атрибуты содержат только скалярные (атомарные) значения.
Опять же, второе определение опирается на понятие домена, а домены определены на простых типах данных.
Не первую нормальную форму можно получить, если допустить, что атрибуты отношения могут быть определены на сложных типах данных - массивах, структурах, или даже на других отношениях. Легко себе представить таблицу, у которой в некоторых ячейках содержатся массивы, в других ячейках - определенные пользователями сложные структуры, а в третьих ячейках - целые реляционные таблицы, которые в свою очередь могут содержать такие же сложные объекты. Именно такие возможности предоставляются некоторыми современными пост-реляционными и объектными СУБД.
Требование, что отношения должны содержать только данные простых типов, объясняет, почему отношения иногда называют плоскими таблицами (plain table). Действительно, таблицы, задающие отношения двумерны. Одно измерение задается списком столбцов, второе измерение задается списком строк. Пара координат (Номер строки, Номер столбца) однозначно идентифицирует ячейку таблицы и содержащееся в ней значение. Если же допустить, что в ячейке таблицы могут содержаться данные сложных типов (массивы, структуры, другие таблицы), то такая таблица будет уже не плоской. Например, если в ячейке таблицы содержится массив, то для обращения к элементу массива нужно знать три параметра (Номер строки, Номер столбца, номер элемента в массиве). Таким образом появляется третье объяснение Первой Нормальной Формы: Отношение находится в 1НФ, если оно является плоской таблицей[7]
.
В данной главе была рассмотрена только классическая реляционная теория, в которой все отношения имеют только атомарные атрибуты и заведомо находятся в 1НФ.
2. Целостность реляционных данных
Во второй части реляционной модели данных определяются два ограничения, которые должны выполняться в любой реляционной базе данных. Это:
Целостность сущностей.
Целостность внешних ключей.
Прежде, чем описывать целостность сущностей, необходимо описать использование null-значений в реляционных базах данных.
2.1 Null-значения
Основное назначение баз данных состоит в том, чтобы хранить и предоставлять информацию о реальном мире. Для представления этой информации в базе данных используются привычные для программистов типы данных - строковые, численные, логические и т.п. Однако в реальном мире часто встречается ситуация, когда данные неизвестны или не полны. Например, место жительства или дата рождения человека могут быть неизвестны (база данных разыскиваемых преступников). Если вместо неизвестного адреса уместно было бы вводить пустую строку, то что вводить вместо неизвестной даты? Ответ - пустую дату - не вполне удовлетворителен, т.к. простейший запрос "выдать список людей в порядке возрастания дат рождения" даст заведомо неправильных ответ.
Для того чтобы обойти проблему неполных или неизвестных данных, в базах данных могут использоваться типы данных, пополненные так называемым null-значением. Null-значение - это, собственно, не значение, а некий маркер, показывающий, что значение неизвестно.
Таким образом, в ситуации, когда возможно появление неизвестных или неполных данных, разработчик имеет на выбор два варианта.
Первый вариант состоит в том, чтобы ограничиться использованием обычных типов данных и не использовать null-значения, а вместо неизвестных данных вводить либо нулевые значения, либо значения специального вида - например, договориться, что строка "АДРЕС НЕИЗВЕСТЕН" и есть те данные, которые нужно вводить вместо неизвестного адреса. В любом случае на пользователя (или на разработчика) ложится ответственность на правильную трактовку таких данных. В частности, может потребоваться написание специального программного кода, который в нужных случаях "вылавливал" бы такие данные. Проблемы, возникающие при этом очевидны - не все данные становятся равноправны, требуется дополнительный программный код, "отслеживающий" эту неравноправность, в результате чего усложняется разработка и сопровождение приложений.
Второй вариант состоит в использовании null-значений вместо неизвестных данных. За кажущейся естественностью такого подхода скрываются менее очевидные и более глубокие проблемы. Наиболее бросающейся в глаза проблемой является необходимость использования трехзначной логики при оперировании с данными, которые могут содержать null-значения. В этом случае при неаккуратном формулировании запросов, даже самые естественные запросы могут давать неправильные ответы. Есть более фундаментальные проблемы, связанные с теоретическим обоснованием корректности введения null-значений, например, непонятно вообще, входят ли null-значения в домены или нет.
Вопрос о проблемах использования null-значений в теории реляционных баз данных окончательно не решен. Основоположник реляционного подхода Кодд считал null-значения неотъемлемой частью реляционной модели, хотя К. Дейт выступает против null-значений[8]
.
2.2 Потенциальные ключи и целостность сущностей
По определению, тело отношения есть множество кортежей, поэтому отношения не могут содержать одинаковые кортежи. Это значит, что каждый кортеж должен обладать свойством уникальности. На самом деле, свойством уникальности в пределах отношения могут обладать отдельные атрибуты кортежей или группы атрибутов. Такие уникальные атрибуты удобно использовать для идентификации кортежей.
Пусть дано отношение . Подмножество атрибутов 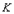 отношения будем называть потенциальным ключом, если обладает следующими свойствами: отношения будем называть потенциальным ключом, если обладает следующими свойствами:
Свойством уникальности - в отношении не может быть двух различных кортежей, с одинаковым значением .
Свойством неизбыточности - никакое подмножество в не обладает свойством уникальности.
Любое отношение имеет по крайней мере один потенциальный ключ. Действительно, если никакой атрибут или группа атрибутов не являются потенциальным ключом, то, в силу уникальности кортежей, все атрибуты вместе образуют потенциальный ключ. Потенциальный ключ, состоящий из одного атрибута, называется простым. Потенциальный ключ, состоящий из нескольких атрибутов, называется составным. Отношение может иметь несколько потенциальных ключей. Традиционно, один из потенциальных ключей объявляется первичным, а остальные - альтернативными. Различия между первичным и альтернативными ключами могут быть важны в конкретной реализации реляционной СУБД, но с точки зрения реляционной модели данных, нет оснований выделять таким образом один из потенциальных ключей. Понятие потенциального ключа является семантическим понятием и отражает некоторый смысл (трактовку) понятий из конкретной предметной области. Для того чтобы проиллюстрировать этот факт, рассмотрим отношение "Сотрудники" (Приложение 1).
При первом взгляде на таблицу, изображающую это отношение, может показаться, что в таблице имеется три потенциальных ключа - в каждой колонке таблицы содержатся уникальные данные. Однако среди сотрудников могут быть однофамильцы и сотрудники с одинаковой зарплатой. Табельный же номер по сути свой уникален для каждого сотрудника. Какие же соображения привели нас к пониманию того, что в данном отношении только один потенциальный ключ - "Табельный номер"? Именно понимание смысла данных, содержащихся в отношении.
Попробуем представить это отношение в другом виде, изменив наименования атрибутов:
| A |
B |
C |
| 1 |
Иванов |
1000 |
| 2 |
Петров |
2000 |
| 3 |
Сидоров |
3000 |
Предъявим кому-нибудь эту таблицу и не сообщим смысл наименований атрибутов. Очевидно, что невозможно судить, не понимая смысла данных, может или не может в этом отношении появиться, например, кортеж (1, Петров, 3000). Если бы, кстати, такой кортеж появился (что, на первый взгляд, вполне возможно, т.к. не нарушается уникальность кортежей), то мы точно смогли бы сказать, что не является альтернативным ключом - ни один из атрибутов по отдельности. Но мы не сможем сказать, что же является первичным ключом[9]
.
Потенциальные ключи служат средством идентификации объектов предметной области, данные о которых хранятся в отношении. Объекты предметной области должны быть различимы.
Потенциальные ключи служат единственным средством адресации на уровне кортежей в отношении. Точно указать какой-нибудь кортеж можно только зная значение его потенциального ключа.
Т.к. потенциальные ключи фактически служат идентификаторами объектов предметной области (т.е. предназначены для различения объектов), то значения этих идентификаторов не могут содержать неизвестные значения. Действительно, если бы идентификаторы могли содержать null-значения, то мы не могли бы дать ответ "да" или "нет" на вопрос, совпадают или нет два идентификатора.
Это определяет следующее правило целостности сущностей:
Атрибуты, входящие в состав некоторого потенциального ключа не могут принимать null-значений.
2.3 Внешние ключи и их целостность
Различные объекты предметной области, информация о которых хранится в базе данных, всегда взаимосвязаны друг с другом. Например, накладная на поставку товара содержит список товаров с количествами и ценами, сотрудник предприятия имеет детей, числится в подразделении и т.д. Термины "содержит", "имеет", "числится" отражают взаимосвязи между понятиями "накладная" и "список товаров", "сотрудник" и "дети", "сотрудник" и "подразделение". Такие взаимосвязи отражаются в реляционных базах данных при помощи внешних ключей, связывающих несколько отношений.
Рассмотрим пример с поставщиками и поставками деталей. Предположим, что нам требуется хранить информацию о наименовании поставщиков, наименовании и количестве поставляемых ими деталей, причем каждый поставщик может поставлять несколько деталей и каждая деталь может поставляться несколькими поставщиками. Можно предложить хранить данные в следующем отношение ( Приложение 2).
Потенциальным ключом этого отношения может выступать пара атрибутов {"Номер поставщика", "Номер детали"} - в таблице они выделены курсивом.
Приведенный способ хранения данных обладает рядом недостатков.
Что произойдет, если изменилось наименование поставщика? Т.к. наименование поставщика повторяется во многих кортежах отношения, то это наименование нужно одновременно изменить во всех кортежах, где оно встречается, иначе данные станут противоречивыми. То же самое с наименованиями деталей. Значит, данные хранятся в нашем отношении с большой избыточностью.
Далее, как отразить факт, что некоторый поставщик, например Петров, временно прекратил поставки деталей? Если мы удалим все кортежи, в которых хранится информация о поставках этого поставщика, то мы потеряем данные о самом Петрове как потенциальном поставщике. Выйти из этого положения, оставив в отношении кортеж типа (2, Петров, NULL, NULL, NULL) мы не можем, т.к. атрибут "Номер детали" входит в состав потенциального ключа и не может содержать null-значений. То же самое произойдет, если некоторая деталь временно не поставляется никаким поставщиком. Получается, что мы не можем хранить информацию о том, что есть некий поставщик, если он не поставляет хотя бы одну деталь, и не можем хранить информацию о том, что есть некоторая деталь, если она никем не поставляется.
Подобные проблемы возникают потому, что мы смешали в одном отношении различные объекты предметной области - и данные о поставщиках, и данные о деталях, и данные о поставках деталей. Говорят, что это отношение плохо нормализовано (просто нормализованным оно является хотя бы потому, что оно есть отношение и, следовательно, автоматически находится в 1НФ).
О том, как правильно нормализовать отношения, будет сказано в следующих главах, сейчас же предложим разнести данные по трем отношениям - "Поставщики", "Детали", "Поставки". Для нас важно выяснить, каким образом данные, хранящиеся в этих отношениях взаимосвязаны друг с другом. Эта связь определяется семантикой предметной области и описывается фразами: "Поставщики выполняют Поставки", "Детали поставляются через Поставки". Эти две взаимосвязи косвенно определяют новую взаимосвязь между "Поставщиками" и "Деталями": "Детали поставляются Поставщиками".
Эти фразы отражают различные типы взаимосвязей. Чтобы более точно отразить предметную область, можно иначе переформулировать фразы: "Один Поставщик может выполнять несколько Поставок", "Одна Деталь может поставляться несколькими Поставками". Это пример взаимосвязи типа "один-ко-многим". Взаимосвязь между "Поставщиками" и "Деталями" можно переформулировать так: "Несколько Деталей может поставляться несколькими Поставщиками". Это пример взаимосвязи типа "много-ко-многим".
В реляционных базах данных основными являются взаимосвязи типа "один-ко-многим". Взаимосвязи типа "много-ко-многим" реализуются использованием нескольких взаимосвязей типа "один-ко-многим". Отношение, входящее в связь со стороны "один" (например, "Поставщики"), называют родительским отношением. Отношение, входящее в связь со стороны "много" (например, "Поставки"), называется дочернем отношением.
Механизм реализации взаимосвязи "один-ко-многим" состоит в том, что в дочернее отношение добавляются атрибуты, являющиеся ссылками на ключевые атрибуты родительского отношения. Эти атрибуты и являются внешними ключами, определяющими, с какими кортежами родительского отношения связаны кортежи дочернего отношения. Такие атрибуты еще называют мигрирующими из родительского отношения.
Таким образом, наш пример с поставщиками и поставляемыми деталями должен выглядеть следующим образом:
Таблица 2 Отношение "Поставщики"
| Номер поставщика |
Наименование поставщика |
| 1 |
Иванов |
| 2 |
Петров |
| 3 |
Сидоров |
Таблица 3 Отношение "Детали"
| Номер детали |
Наименование детали |
| 1 |
Болт |
| 2 |
Гайка |
| 3 |
Винт |
Таблица 4 Отношение "Поставки"
| Номер поставщика |
Номер детали |
Поставляемое количество |
| 1 |
1 |
100 |
| 1 |
2 |
200 |
| 1 |
3 |
300 |
| 2 |
1 |
150 |
| 2 |
2 |
250 |
| 3 |
3 |
1000 |
В отношении "Поставки" атрибуты "Номер поставщика" и "Номер детали" являются ссылками на ключевые атрибуты отношений "Поставщики" и "Детали", и, следовательно, являются внешними ключами. Заметим, что данные отношения свободны от недостатков, описанных выше, когда все данные предлагалось хранить в одном отношении. Действительно, при изменении наименования поставщика или детали, это изменение происходит только в одном месте. Если поставщик прекратил поставки всех деталей, то удаляются соответствующие кортежи в отношении "Поставки", данные же о самом поставщике остаются без изменений.
Пусть дано отношение 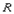 . Подмножество атрибутов . Подмножество атрибутов  отношения будем называть внешним ключом, если: отношения будем называть внешним ключом, если:
Существует отношение  ( и не обязательно различны) с потенциальным ключом ( и не обязательно различны) с потенциальным ключом 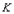 . .
Каждое значение в отношении всегда совпадает со значением для некоторого кортежа из , либо является null-значением.
Отношение называется родительским отношением, отношение называется дочерним отношением.
Внешний ключ, также как и потенциальный, может быть простым и составным.
Внешний ключ должен быть определен на тех же доменах, что и соответствующий первичный ключ родительского отношения.
Внешний ключ, как правило, не обладает свойством уникальности. Так и должно быть, т.к. в дочернем отношении может быть несколько кортежей, ссылающихся на один и тот же кортеж родительского отношения. Это, собственно, и дает тип отношения "один-ко-многим".
Если внешний ключ все-таки обладает свойством уникальности, то связь между отношениями имеет тип "один-к-одному". Чаще всего такие отношения объединяются в одно отношение, хотя это и не обязательно.
Хотя каждое значение внешнего ключа обязано совпадать со значениями потенциального ключа в некотором кортеже родительского отношения, то обратное, вообще говоря, неверно. Например, могут существовать поставщики, не поставляющие никаких деталей. Для внешнего ключа не требуется, чтобы он был компонентом некоторого потенциального ключа (как получилось в примере с поставщиками и деталями).
Null-значения для атрибутов внешнего ключа допустимы только в том случае, когда атрибуты внешнего ключа не входят в состав никакого потенциального ключа. Т.к. внешние ключи фактически служат ссылками на кортежи в другом (или в том же самом) отношении, то эти ссылки не должны указывать на несуществующие объекты. Это определяет следующее правило целостности внешних ключей:
Правило целостности внешних ключей. Внешние ключи не должны быть несогласованными, т.е. для каждого значения внешнего ключа должно существовать соответствующее значение первичного ключа в родительском отношении.
На самом деле приведенные правила целостности сущностей и внешних ключей прямо следуют из определений понятий "потенциальный ключ" и "внешний ключ".
Действительно, в определении потенциального ключа требуется, чтобы потенциальный ключ обладал свойством уникальности. Это фактически означает, что мы должны уметь различать значения потенциальных ключей, т.е. при сравнении двух значений потенциального ключа мы всегда должны получать значения либо ИСТИНА, либо ЛОЖЬ. Но любое сравнение, в которое входит null-значение, принимает значение U - НЕИЗВЕСТНО, откуда следует, что атрибуты потенциального ключа не могут содержать null-значений.
Для внешних ключей правило целостности фактически входит в определение. Таким образом, с точки зрения реляционной теории, явная формулировка правил целостности является излишней - они автоматически вытекают из определений понятий ключа и внешнего ключа.
Тем не менее, явная формулировка правил целостности имеет определенный практический смысл. В большинстве серьезных СУБД за выполнением этих ограничений следит сама СУБД, если, конечно, пользователь явно объявил потенциальные и внешние ключи. Но, во-первых, для некоторых систем можно допустить, чтобы эти ограничения не выполнялись, а во-вторых, некоторые системы просто не поддерживают понятия целостности, например, некоторые "настольные" СУБД типа FoxPro 2.5. В этих случаях за целостностью данных должен следить сам пользователь, или программист, разрабатывающий приложение для пользователя.
Явная формулировка правил целостности помогает четко понять, какие опасности несет в себе пренебрежение этими правилами.
2.4 Операции, могущие нарушить ссылочную целостность
Ссылочная целостность может нарушиться в результате операций, изменяющих состояние базы данных. Таких операций три - вставка, обновление и удаление кортежей в отношениях. Т.к. в определении ссылочной целостности участвуют два отношения - родительское и дочернее, а в каждом из них возможны три операции - вставка, обновление, удаление, то нужно рассмотреть шесть различных вариантов.
Для родительского отношения
Вставка кортежа в родительском отношении. При вставке кортежа в родительское отношение возникает новое значение потенциального ключа. Т.к. допустимо существование кортежей в родительском отношении, на которые нет ссылок из дочернего отношения, то вставка кортежей в родительское отношение не нарушает ссылочной целостности.
Обновление кортежа в родительском отношении. При обновлении кортежа в родительском отношении может измениться значение потенциального ключа. Если есть кортежи в дочернем отношении, ссылающиеся на обновляемый кортеж, то значения их внешних ключей станут некорректными. Обновление кортежа в родительском отношении может привести к нарушению ссылочной целостности, если это обновление затрагивает значение потенциального ключа.
Удаление кортежа в родительском отношении. При удалении кортежа в родительском отношении удаляется значение потенциального ключа. Если есть кортежи в дочернем отношении, ссылающиеся на удаляемый кортеж, то значения их внешних ключей станут некорректными. Удаление кортежей в родительском отношении может привести к нарушению ссылочной целостности.
Для дочернего отношения
Вставка кортежа в дочернее отношение. Нельзя вставить кортеж в дочернее отношение, если вставляемое значение внешнего ключа некорректно. Вставка кортежа в дочернее отношение привести к нарушению ссылочной целостности.
Обновление кортежа в дочернем отношении. При обновлении кортежа в дочернем отношении можно попытаться некорректно изменить значение внешнего ключа. Обновление кортежа в дочернем отношении может привести к нарушению ссылочной целостности.
Удаление кортежа в дочернем отношении. При удалении кортежа в дочернем отношении ссылочная целостность не нарушается.
Таким образом, ссылочная целостность в принципе может быть нарушена при выполнении одной из четырех операций:
Обновление кортежа в родительском отношении.
Удаление кортежа в родительском отношении.
Вставка кортежа в дочернее отношение.
Обновление кортежа в дочернем отношении.
Стратегии поддержания ссылочной целостности
Существуют две основные стратегии поддержания ссылочной целостности:
RESTRICT (ОГРАНИЧИТЬ)- не разрешать выполнение операции, приводящей к нарушению ссылочной целостности. Это самая простая стратегия, требующая только проверки, имеются ли кортежи в дочернем отношении, связанные с некоторым кортежем в родительском отношении.
CASCADE (КАСКАДИРОВАТЬ)- разрешить выполнение требуемой операции, но внести при этом необходимые поправки в других отношениях так, чтобы не допустить нарушения ссылочной целостности и сохранить все имеющиеся связи. Изменение начинается в родительском отношении и каскадно выполняется в дочернем отношении. В реализации этой стратегии имеется одна тонкость, заключающаяся в том, что дочернее отношение само может быть родительским для некоторого третьего отношения. При этом может дополнительно потребоваться выполнение какой-либо стратегии и для этой связи и т.д. Если при этом какая-либо из каскадных операций (любого уровня) не может быть выполнена, то необходимо отказаться от первоначальной операции и вернуть базу данных в исходное состояние. Это самая сложная стратегия, но она хороша тем, что при этом не нарушается связь между кортежами родительского и дочернего отношений. Эти стратегии являются стандартными и присутствуют во всех СУБД, в которых имеется поддержка ссылочной целостности.
Можно рассмотреть дополнительные стратегии поддержания ссылочной целостности:
SET NULL (УСТАНОВИТЬ В NULL) - разрешить выполнение требуемой операции, но все возникающие некорректные значения внешних ключей изменять на null-значения. Эта стратегия имеет два недостатка. Во-первых, для нее требуется допустить использование null-значений. Во-вторых, кортежи дочернего отношения теряют всякую связь с кортежами родительского отношения. Установить, с каким кортежем родительского отношения были связаны измененные кортежи дочернего отношения, после выполнения операции уже нельзя.
SET DEFAULT (УСТАНОВИТЬ ПО УМОЛЧАНИЮ) - разрешить выполнение требуемой операции, но все возникающие некорректные значения внешних ключей изменять на некоторое значение, принятое по умолчанию. Достоинство этой стратегии по сравнению с предыдущей в том, что она позволяет не пользоваться null-значеними. Недостатки заключаются в следующем. Во-первых, в родительском отношении должен быть некий кортеж, потенциальный ключ которого принят как значение по умолчанию для внешних ключей. В качестве такого "кортежа по умолчанию" обычно принимают специальный кортеж, заполненный нулевыми значениями (не null-значениями!). Этот кортеж нельзя удалять из родительского отношения, и в этом кортеже нельзя изменять значение потенциального ключа. Таким образом, не все кортежи родительского отношения становятся равнозначными, поэтому приходится прилагать дополнительные усилия для отслеживания этой неравнозначности. Это плата за отказ от использования null-значений. Во-вторых, как и в предыдущем случае, кортежи дочернего отношения теряют всякую связь с кортежами родительского отношения.
В некоторых реализация СУБД рассматривается еще одна стратегия поддержания ссылочной целостности:
IGNORE (ИГНОРИРОВАТЬ) - выполнять операции, не обращая внимания на нарушения ссылочной целостности.
Конечно, это не стратегия, а отказ от поддержки ссылочной целостности. В этом случае в дочернем отношении могут появляться некорректные значения внешних ключей, и вся ответственность за целостность базы данных ложится на пользователя. В дополнение к приведенным стратегиям пользователь может придумать свою уникальную стратегию поддержания ссылочной целостности.
Рассмотрим, как применяются стратегии поддержания ссылочной целостности при выполнении операций модификации базы данных.
При обновлении кортежа в родительском отношении допустимые стратегии:
RESTRICT (ОГРАНИЧИТЬ) - не разрешать обновление, если имеется хотя бы один кортеж в дочернем отношении, ссылающийся на обновляемый кортеж.
CASCADE (КАСКАДИРОВАТЬ) - выполнить обновление и каскадно изменить значения внешних ключей во всех кортежах дочернего отношения, ссылающихся на обновляемый кортеж.
SET NULL (УСТАНОВИТЬ В NULL) - выполнить обновление и во всех кортежах дочернего отношения, ссылающихся на обновляемый кортеж, изменить значения внешних ключей на null-значение.
SET DEFAULT (УСТАНОВИТЬ ПО УМОЛЧАНИЮ) - выполнить обновление и во всех кортежах дочернего отношения, ссылающихся на обновляемый кортеж, изменить значения внешних ключей на некоторое значение, принятое по умолчанию.
IGNORE (ИГНОРИРОВАТЬ) - выполнить обновление, не обращая внимания на нарушения ссылочной целостности.
При удалении кортежа в родительском отношении допустимые стратегии:
RESTRICT (ОГРАНИЧИТЬ) - не разрешать удаление, если имеется хотя бы один кортеж в дочернем отношении, ссылающийся на удаляемый кортеж.
CASCADE (КАСКАДИРОВАТЬ) - выполнить удаление и каскадно удалить кортежи в дочернем отношении, ссылающиеся на удаляемый кортеж.
SET NULL (УСТАНОВИТЬ В NULL) - выполнить удаление и во всех кортежах дочернего отношения, ссылающихся на удаляемый кортеж, изменить значения внешних ключей на null-значение.
SET DEFAULT (УСТАНОВИТЬ ПО УМОЛЧАНИЮ) - выполнить удаление и во всех кортежах дочернего отношения, ссылающихся на удаляемый кортеж, изменить значения внешних ключей на некоторое значение, принятое по умолчанию.
IGNORE (ИГНОРИРОВАТЬ) - выполнить удаление, не обращая внимания на нарушения ссылочной целостности.
При вставке кортежа в дочернее отношение допустимые стратегии:
RESTRICT (ОГРАНИЧИТЬ) - не разрешать вставку, если внешний ключ во вставляемом кортеже не соответствует ни одному значению потенциального ключа родительского отношения.
SET NULL (УСТАНОВИТЬ В NULL) - вставить кортеж, но в качестве значения внешнего ключа занести не предлагаемое пользователем некорректное значение, а null-значение.
SET DEFAULT (УСТАНОВИТЬ ПО УМОЛЧАНИЮ) - вставить кортеж, но в качестве значения внешнего ключа занести не предлагаемое пользователем некорректное значение, а некоторое значение, принятое по умолчанию.
IGNORE (ИГНОРИРОВАТЬ) - вставить кортеж, не обращая внимания на нарушения ссылочной целостности.
При обновлении кортежа в дочернем отношении допустимые стратегии:
RESTRICT (ОГРАНИЧИТЬ) - не разрешать обновление, если внешний ключ в обновляемом кортеже становится не соответствующим ни одному значению потенциального ключа родительского отношения.
SET NULL (УСТАНОВИТЬ В NULL) - обновить кортеж, но в качестве значения внешнего ключа занести не предлагаемое пользователем некорректное значение, а null-значение.
SET DEFAULT (УСТАНОВИТЬ ПО УМОЛЧАНИЮ) - обновить кортеж, но в качестве значения внешнего ключа занести не предлагаемое пользователем некорректное значение, а некоторое значение, принятое по умолчанию.
IGNORE (ИГНОРИРОВАТЬ) - обновить кортеж, не обращая внимания на нарушения ссылочной целостности.
Заключение
В заключении необходимо сделать основные выводы по работе.
Реляционная модель данных состоит из трех частей:
Структурной части.
Целостной части.
Манипуляционной части.
В классической реляционной модели используются только простые (атомарные) типы данных. Простые типы данных не обладают внутренней структурой.
Домены - это типы данных, имеющие некоторый смысл (семантику). Домены ограничивают сравнения - некорректно, хотя и возможно, сравнивать значения из различных доменов.
Отношение состоит из двух частей - заголовка отношения и тела отношения. Заголовок отношения - это аналог заголовка таблицы. Заголовок отношения состоит из атрибутов. Количество атрибутов называется степенью отношения. Тело отношения - это аналог тела таблицы. Тело отношения состоит из кортежей. Кортеж отношения является аналогом строки таблицы. Количество кортежей отношения называется мощностью отношения.
Отношение обладает следующими свойствами:
В отношении нет одинаковых кортежей.
Кортежи не упорядочены (сверху вниз).
Атрибуты не упорядочены (слева направо).
Все значения атрибутов атомарны.
Реляционной базой данных называется набор отношений.
Схемой реляционной базы данных называется набор заголовков отношений, входящих в базу данных.
Отношение находится в Первой Нормальной Форме (1НФ), если оно содержит только скалярные (атомарные) значения.
Современные СУБД допускают использование null-значений, т.к. данные часто бывают неполными или неизвестными.
Средством, позволяющим однозначно идентифицировать кортежи отношения, являются потенциальные ключи отношения.
Потенциальный ключ отношения - это набор атрибутов отношения, обладающий свойствами уникальности и неизбыточности. Доступ к конкретному кортежу можно получить, лишь зная значение потенциального ключа для этого кортежа.
Традиционно один из потенциальных ключей объявляется первичным ключом, остальные - альтернативными ключами.
Потенциальный ключ, состоящий из одного атрибута, называется простым. Потенциальный ключ, состоящий из нескольких атрибутов, называется составным.
Отношения связываются друг с другом при помощи внешних ключей.
Внешний ключ отношения - это набор атрибутов отношения, содержащий ссылки на потенциальный ключ другого (или того же самого) отношения. Отношение, содержащее потенциальный ключ, на который ссылается некоторый внешний ключ, называется родительским отношением. Отношение, содержащее внешний ключ, называется дочерним отношением.
Внешний ключ не обязан обладать свойством уникальности. Поэтому, одному кортежу родительского отношения может соответствовать несколько кортежей дочернего отношения. Такой тип связи между отношениями называется "один-ко-многим". Связи типа "много-ко-многим" реализуются использованием нескольких отношений типа "один-ко-многим".
В любой реляционной базе данных должны выполняться два ограничения:
Целостность сущностей
Целостность внешних ключей
Правило целостности сущностей состоит в том, что атрибуты, входящие в состав некоторого потенциального ключа не могут принимать null-значений.
Правило целостности внешних ключей состоит в том, что внешние ключи не должны ссылаться на отсутствующие в родительском отношении кортежи, т.е. внешние ключи должны быть корректны.
Ссылочную целостность могут нарушить операции, изменяющие состояние базы данных. Такими операциями являются операции вставки, обновления и удаления кортежей.
Для поддержания ссылочной целостности обычно используются две основные стратегии:
RESTRICT (ОГРАНИЧИТЬ) - не разрешать выполнение операции, приводящей к нарушению ссылочной целостности.
CASCADE (КАСКАДИРОВАТЬ) - разрешить выполнение требуемой операции, но внести каскадные изменения в другие отношения так, чтобы не допустить нарушения ссылочной целостности.
Дополнительными стратегиями поддержания ссылочной целостности являются:
SET NULL (УСТАНОВИТЬ В NULL) - все некорректные значения внешних ключей изменять на null-значения.
SET DEFAULT (УСТАНОВИТЬ ПО УМОЛЧАНИЮ) - все некорректные значения внешних ключей изменять на некоторое значение, принятое по умолчанию.
В реальных СУБД можно также отказаться от использования какой-либо стратегии поддержания ссылочной целостности:
IGNORE (ИГНОРИРОВАТЬ) - выполнять операции, не обращая внимания на нарушения ссылочной целостности.
Пользователь может разработать свою уникальную стратегию поддержания ссылочной целостности.
Список литературы
Атре Ш. Структурный подход к организации баз данных. - М.: Финансы и статистика, 1983. - 320 с.
Беренсон Х., Бернштейн Ф., Грэй Д., Мелтон Д., О"Нил Э., О"Нил П. Критика уровней изолированности в стандарте ANSI SQL //СУБД. - 1996. - №2. - С. 45-60.
Бойко В.В., Савинков В.М. Проектирование баз данных информационных систем. - М.: Финансы и статистика, 1989. - 351 с.
Гилуа М.М. Множественная модель данных в информационных системах. - М.: Наука, 1992. – 40 с.
Голосов А.О. Аномалии в реляционных базах данных //СУБД. - 1986. - №3. - С. 23-28.
Дейт К. Введение в системы баз данных . 6-издание. - Киев: Диалектика, 1998. - 784 с.
Джексон Г. Проектирование реляционных баз данных для использования с микроЭВМ. - М.: Мир, 1991. - 252 с.
Диго С.М. Проектирование и использование баз данных. - М.: Финансы и статистика, 1995. - 208 с.
Пушников А.Ю. Введение в системы управления базами данных. Часть 1. Реляционная модель данных: Учебное пособие/Изд-е Башкирского ун-та. - Уфа, 1999. - 108 с.
Савельев В.А. Персональный компьютер для всех. Создание и использование баз данных. - М.: Просвещение, 1991. – 248 c.
Симонович С.В. Информатика. Базовый курс. - М.: Дрофа, 2000. – 388 c.
Тиори Т., Фрай Д. Проектирование структур баз данных. В 2 кн., - М.: Мир, 1985. Кн. 1. – С. 287 с., Кн. 2. – 320 с.
Приложение 1
Таблица Отношение "Сотрудники"
| Табельный номер |
Фамилия |
Зарплата |
| 1 |
Иванов |
1000 |
| 2 |
Петров |
2000 |
| 3 |
Сидоров |
3000 |
Приложение 2
Таблица Отношение "Поставщики и поставляемые детали"
| Номер поставщика |
Наименование поставщика |
Номер детали |
Наименование детали |
Поставляемое количество |
| 1 |
Иванов |
1 |
Болт |
100 |
| 1 |
Иванов |
2 |
Гайка |
200 |
| 1 |
Иванов |
3 |
Винт |
300 |
| 2 |
Петров |
1 |
Болт |
150 |
| 2 |
Петров |
2 |
Гайка |
250 |
| 3 |
Сидоров |
3 |
Винт |
1000 |
[1]
Дейт К. Введение в системы баз данных . 6-издание. - Киев: Диалектика, 1998. – С. 74.
[2]
Бойко В.В., Савинков В.М. Проектирование баз данных информационных систем. - М.: Финансы и статистика, 1989. –С. 24.
[3]
Диго С.М. Проектирование и использование баз данных. - М.: Финансы и статистика, 1995. - С.71.
[4]
Гилуа М.М. Множественная модель данных в информационных системах. - М.: Наука, 1992, с.37
[5]
Пушников А.Ю. Введение в системы управления базами данных. Часть 1. Реляционная модель данных: Учебное пособие / Изд-е Башкирского ун-та. - Уфа, 1999. - С. 29.
[6]
Там же. - С. 30-31.
[7]
Там же. - С. 33.
[8]
Дейт К. Введение в системы баз данных . 6-издание. - Киев: Диалектика, 1998. - С. 109.
[9]
Пушников А.Ю. Введение в системы управления базами данных. Часть 1. Реляционная модель данных: Учебное пособие/Изд-е Башкирского ун-та. – Уфа, 1999. – С. 34.
|